Permutation Generators Based on Unbalanced Feistel Network: Analysis of the Conditions of Pseudorandomness
Kwangsu Lee

TL;DR
This paper analyzes the minimal rounds needed for unbalanced Feistel network-based permutation generators to achieve pseudorandomness and proposes a new unbalanced Feistel structure to extend block cipher sizes.
Contribution
It provides a theoretical analysis of round requirements for unbalanced Feistel networks and introduces a new structure for large input-output size block ciphers.
Findings
Minimal rounds for source-heavy structures determined
Minimal rounds for target-heavy structures determined
Proposed new unbalanced Feistel network extends small to large block sizes
Abstract
A block cipher is a bijective function that transforms a plaintext to a ciphertext. A block cipher is a principle component in a cryptosystem because the security of a cryptosystem depends on the security of a block cipher. A Feistel network is the most widely used method to construct a block cipher. This structure has a property such that it can transform a function to a bijective function. But the previous Feistel network is unsuitable to construct block ciphers that have large input-output size. One way to construct block ciphers with large input-output size is to use an unbalanced Feistel network that is the generalization of a previous Feistel network. There have been little research on unbalanced Feistel networks and previous work was about some particular structures of unbalanced Feistel networks. So previous work didn't provide a theoretical base to construct block ciphers that…
Click any figure to enlarge with its caption.
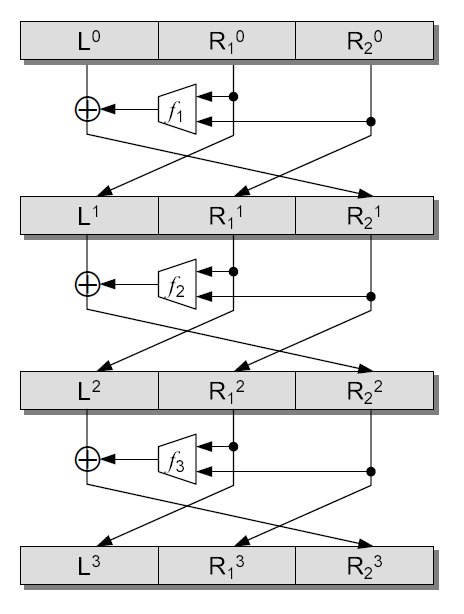 Figure 3
Figure 3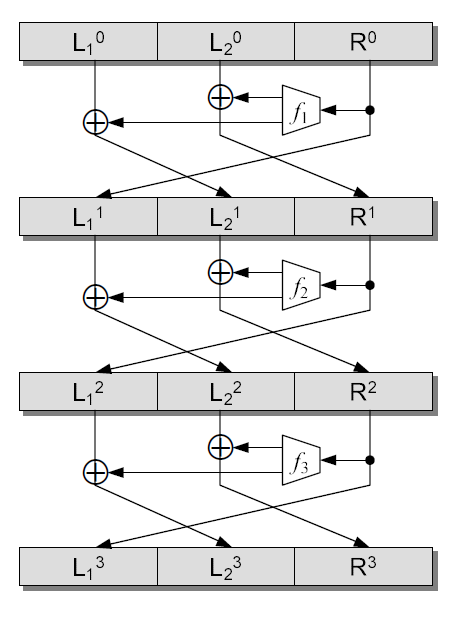 Figure 3
Figure 3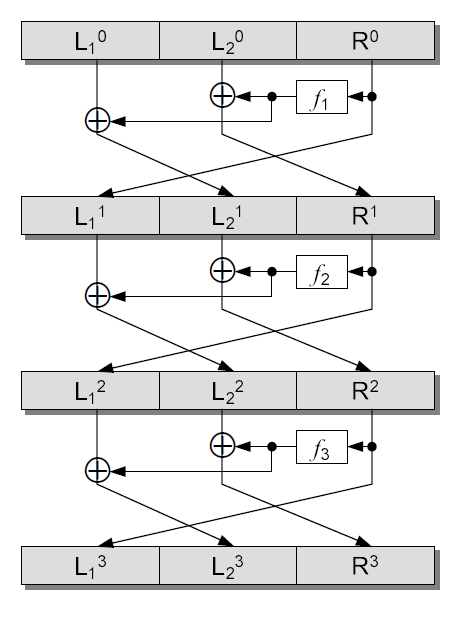 Figure 3
Figure 3 Figure 4
Figure 4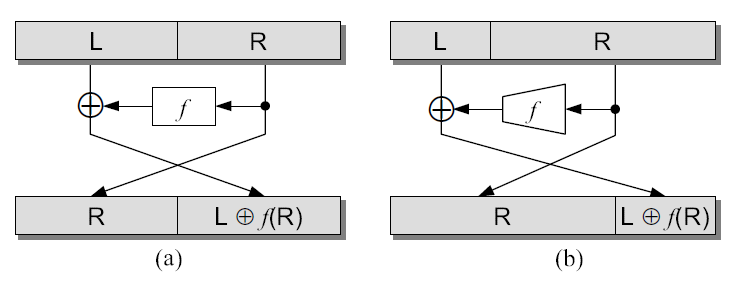 Figure 5
Figure 5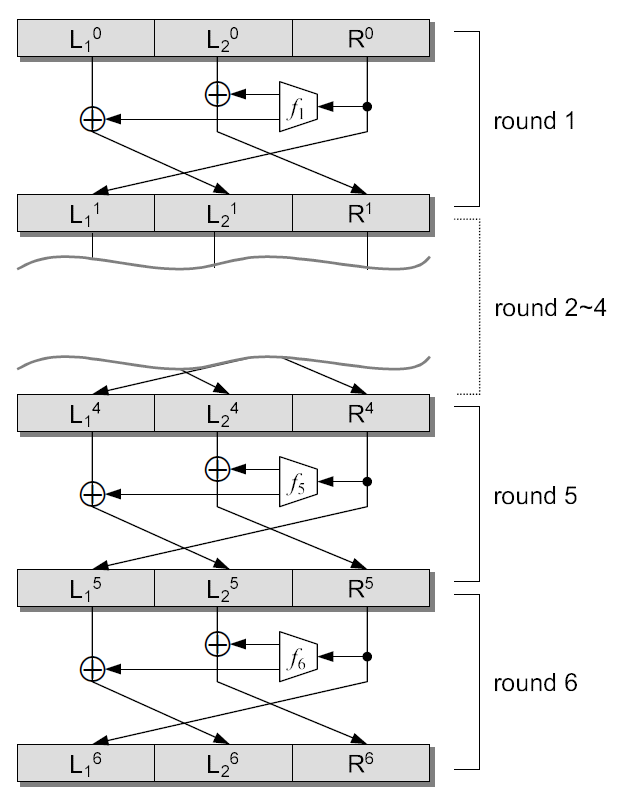 Figure 6
Figure 6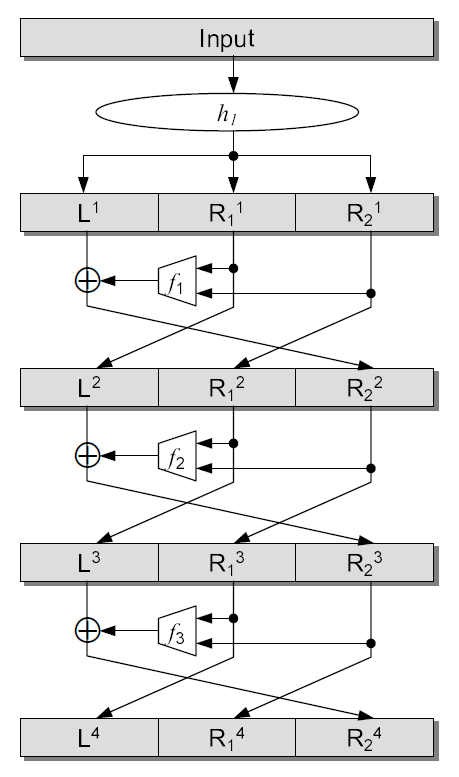 Figure 7
Figure 7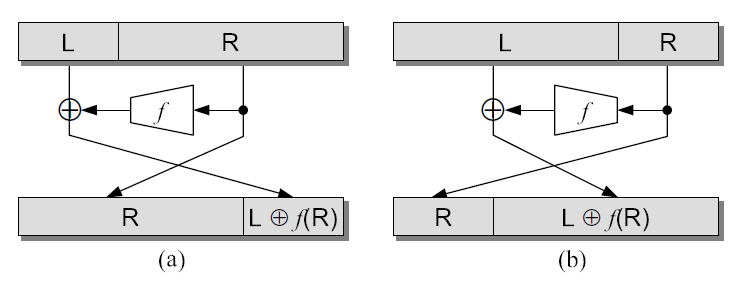 Figure 8
Figure 8| Balanced | Unbalanced Feistel network | Proposed structure | ||
| Feistel network | :-UFN | :-UFN | :-UFN2 | |
| Number of rounds | 3 | |||
| Memory size | ||||
| Relative ratio | ||||
| Running time | ||||
| Relative ratio | ||||
| Balanced | Unbalanced Feistel network | Proposed structure | ||
| Feistel network | :-UFN | :-UFN | :-UFN2 | |
| Number of rounds | 3 | |||
| Memory size | - | - | - | - |
| Relative ratio | - | - | - | - |
| Running time | ||||
| Relative ratio | ||||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsCryptographic Implementations and Security · Coding theory and cryptography · Chaos-based Image/Signal Encryption
Permutation Generators Based on Unbalanced Feistel Network: Analysis of the Conditions of Pseudorandomness111 Advisor: Kwang-Hyung Lee. This is an English translation of the MS Thesis written in Korean.
Kwangsu Lee
A Thesis for the Degree of Master of Science
Division of Computer Science,
Department of Electrical Engineering and Computer Science,
Korea Advanced Institute of Science and Technology
February 2000
Abstract
A block cipher is a bijective function that transforms a plaintext to a ciphertext. A block cipher is a principle component in a cryptosystem because the security of a cryptosystem depends on the security of a block cipher. A Feistel network is the most widely used method to construct a block cipher. This structure has a property such that it can transform a function to a bijective function. But the previous Feistel network is unsuitable to construct block ciphers that have large input-output size. One way to construct block ciphers with large input-output size is to use an unbalanced Feistel network that is the generalization of a previous Feistel network. There have been little research on unbalanced Feistel networks and previous work was about some particular structures of unbalanced Feistel networks. So previous work didn’t provide a theoretical base to construct block ciphers that are secure and efficient using unbalanced Feistel networks.
In this thesis, we analyze the minimal number of rounds of pseudo-random permutation generators that use unbalanced Feistel networks. That is, after categorizing unbalanced Feistel networks as source-heavy structures and target-heavy structures, we analyze the minimal number of rounds of pseudo-random permutation generators that use each structure. Therefore, in order to construct a block cipher that is secure and efficient using unbalanced Feistel networks, we should follow the results of this thesis. Additionally, we propose a new unbalanced Feistel network that has some advantages such that it can extend a previous block cipher with small input-output size to a new block cipher with large input-output size. We also analyze the minimum number of rounds of a pseudo-random permutation generator that uses this structure.
Contents
Chapter 1 Introduction
A block cipher is a symmetric key cryptosystem that encrypts a plaintext into a ciphertext block by block [20]. The block cipher should have the one-to-one correspondence between plaintexts and ciphertexts. The block cipher is the most important element in most cryptographic systems. In particular, it is the essential element used in the implementation of other cryptographic primitives such as pseudo-random number generators, stream ciphers, and hash functions [20, 33]. Since the security of most cryptographic systems depends on the security of block ciphers, a secure block cipher must be implemented to build a secure cryptosystem. A secure block cipher is a block cipher where the output value of the block cipher becomes a random value. That is, when the output value of the block cipher is random, the block cipher becomes a secure one since it is very hard for an attacker to guess the plaintext or the secret key of the cipher from the ciphertext. Mathematically, a block cipher is a secure block cipher if it is a pseudo-random permutation (PRP) generator [16].
The biggest problem of implementing a block cipher is that it is difficult to implement a function that has the one-to-one correspondence property and the output randomness property at the same time. The way to solve this problem is to use a Feistel network structure. A Feistel network structure is a method that converts an arbitrary function into a one-to-one correspondence function. This structure was designed by H. Feistel in designing the Lucifer cipher [8, 9]. That is, if a block cipher is implemented using a Feistel network, a secure block cipher can be easily implemented by simply implementing an arbitrary function whose output value is random. This is because if the output value of an arbitrary function is random, the Feistel network structure automatically converts it to a one-to-one correspondence function.
Therefore, most block ciphers are constructed by using a Feistel network structure or a slightly modified structure of the Feistel network structure [23, 38, 33, 29]. In addition, some research has been done on the security of block ciphers using the Feistel network structure [3, 20, 18, 32]. In particular, there have been numerous studies on pseudo-random permutation generators after the work of Luby and Rackoff [16, 36, 40, 28, 31, 32, 26, 25, 1, 7, 27]. However, the problem of the previous (balanced) Feistel network is that it is difficult to construct a block cipher with a large input/output size. That is, when a block cipher that can process a large size of data at one time is implemented, the input size of a round function used in the Feistel network structure also increases as the input/output size of the block cipher increases. In practice, however, the cost of implementing a round function is proportional to the input size of the round function. Therefore, the previous (balanced) Feistel network structure is inappropriate when constructing a block cipher with large input/output size.
One of the ways to solve this problem is to use an unbalanced Feistel network structure which is a modification of the previous balanced Feistel network. An unbalanced Feistel network is a Feistel network structure in which the size of a target-block combined with the output of a round function and the size of a source-block which is the input of the round function are different [2, 17, 35]. Therefore, the round function in an unbalanced Feistel network structure can be implemented at a lower cost than a balanced Feistel network since it is possible to control the input size of the round function in the unbalanced Feistel network structure. Especially, as the information processing capability of the computer increases, a block cipher with a large input-output size that is capable of processing a large amount of information will be needed. Therefore, much research is needed on unbalanced Feistel networks suitable for implementing block ciphers with large input-output size. However, there are not many studies on unbalanced Feistel networks.
There are some studies to implement a pseudo-random permutation generator, which is a secure block cipher using an unbalanced Feistel network [14, 21]. However, these studies failed to show the minimum number of rounds for a block cipher using an unbalanced Feistel network to become a secure and efficient block cipher. In fact, the minimum number of rounds is important when constructing a block cipher because the number of rounds greatly affects the speed and cost of the block cipher. That is, when constructing a block cipher, a small number of rounds must be used to implement a fast block cipher at low cost. It is therefore very important to determine the minimum number of rounds to be a secure block cipher.
Therefore, in this thesis, we first find the minimum number of rounds for a pseudo-random permutation generator, which is a secure block cipher using a Feistel network. Next, we propose a scalable new unbalanced Feistel network structure and find the minimum number of rounds for this structure to become a secure block cipher. The advantage of a newly proposed structure is that it can easily construct a block cipher with a large input-output size using a previously designed secure block cipher with fixed input-output size. In other words, there is a lot of analysis and research on a new block cipher in order to newly design a block cipher with a large input-output size. However, by using this newly proposed structure, a new block cipher with a large input-output size can be implemented using the previously analyzed secure block cipher. So we do not have to do another analysis and research.
The structure of this thesis is as follows. In Chapter 2, we first define a block cipher, a Feistel network, and a pseudo-random number generator. Then we summarize the existing studies on pseudo-random permutation generators. In Chapter 3, we investigate the condition of the number of rounds for a block cipher using an unbalanced Feistel network to be a pseudo-random permutation generator. In Chapter 4, we propose a scalable unbalanced Feistel network structure, and analyze the conditions for a secure block cipher using this new structure to be a pseudo-random permutation generator. In Chapter 5, we compare a balanced Feistel network structure, an unbalanced Feistel network structure, and the newly proposed structure. Finally, in Chapter 6, we conclude the thesis and present the direction of future research.
Chapter 2 Preliminaries
In this chapter, we define the terms used in the thesis and summarize the studies related to a pseudo-random permutation generator. A block cipher is a secret-key cryptosystem that processes messages using the same key when encrypting and decrypting messages. A block cipher is the basis of cryptographic systems for message authentication, data integrity verification, and digital signature. Mathematically, a block cipher is a one-to-one function (permutation) since it must be able to encrypt and decrypt messages using a secret key. A Feistel network structure is most commonly used to build block ciphers because it has the advantage of converting arbitrary functions to permutations. In order for a block cipher to be a secure block cipher, the output value of the block cipher must be a random value. That is, when a block cipher becomes a pseudo-random permutation generator, it becomes a secure block cipher. In this case, the permutation generator is pseudo-random, meaning that any efficient algorithm can not distinguish between an ideal permutation generator and .
This chapter is organized as follows. In Section 2.1, we first define symbols used in this paper. In Section 2.2, we define a block cipher, which is a secret-key cryptosystem, and investigate the characteristics of the block cipher and attack methods for block ciphers. In Section 2.3, we define the most commonly used Feistel networks for building block ciphers and discuss the advantages and disadvantages of them. In Section 2.4, we define the pseudorandomness. In Section 2.5, we finally summarize existing studies on pseudo-random permutation generators
2.1 Notation
The symbols used in this paper are defined as follows.
- •
represents a set of all -bit strings. That is, .
- •
is a set of all functions whose inputs are -bits and whose outputs are -bits.
- •
is a set of functions whose input and output are both -bits in size. That is, is .
- •
is a set of permutations (one-to-one functions) whose input and output sizes are both -bits. That is,
- •
is the length of a bit string . That is, is if the bit size of is -bits.
- •
is an exclusive OR (XOR) per bit unit when the bit size of and is equal.
- •
is a concatenation of two bit strings and . In this case, we have .
- •
is the composition of two functions and when and are elements of the set . That is, .
2.2 Block Cipher
A block cipher can usually be a private-key cryptosystem or a public-key cryptosystem. However, in this paper, the secret-key cryptosystem is called a block cipher. The structure of a block cipher is given in Figure 2.1.
A block cipher is a function that sends an -bit plaintext to an -bit ciphertext [20, 37]. The function of the block cipher is specified by an -bit secret key. If a plaintext is encrypted and decrypted again, the original plaintext must be obtained. Therefore, the block cipher must be a one-to-one function (bijection) for -bit plaintexts and -bit ciphertexts when a secret key is specified. That is, each secret key defines a different permutation. The definition of the block cipher is as follows.
Definition 2.2.1** (Block Cipher).**
Let be the set of -bit secret keys. The -bit block cipher is defined as a function . We have that holds for an arbitrary plaintext and a random key ().
A true random block cipher is a block cipher that generates all permutations between the domain and the range [20]. In the -bit block cipher, the domain corresponds to the set of plaintexts and the number of plaintexts is , so the size of the domain is . The range corresponds to the set of ciphertexts and the number of ciphertexts is , so the size of the range is also . Therefore, the number of all permutations is . In the -bit block cipher, one key specifies one permutation, so we need number of secret keys to enumerate all permutations. That is, the size of a secret key of the ideal block cipher must be bits.
Definition 2.2.2** (Ideal Block Cipher).**
An ideal block cipher is a block cipher that implements all number of one-to-one functions that exist between number of elements. In this case, each secret key specifies each one-to-one function.
It is impossible to actually build an ideal block cipher because it requires bits for a secret key. Thus, in order for a block cipher using an -bit secret key to be secure, the permutations that are specified by -bit secret keys must appear randomly chosen from all permutations.
The security of a block cipher is measured by the security against the various attack methods of attackers. The attack on the block cipher is divided into four categories according to the information that the attacker can access:
Ciphertext-only attack: The attacker uses only ciphertexts to get the secret key of the block cipher. 2. 2.
Known-plaintext attack: The attacker uses known plaintexts and ciphertexts pairs to find the secret key of the block cipher. 3. 3.
Chosen-plaintext attack: The attacker finds the secret key of the block cipher by using the pairs of plaintexts and corresponding ciphertexts chosen by the attacker. 4. 4.
Chosen-ciphertext attack: The attacker finds the secret key using the chosen ciphertexts and its corresponding plaintexts.
Differential cryptanalysis and linear cryptanalysis are the most powerful methods of attacking block ciphers. Differential cryptanalysis is a chosen-plaintext attack developed by Biham and Shamir [3]. This attack method exploits the fact that the probability distribution of the difference between the input/output pair of a nonlinear function is not uniform. Linear cryptanalysis is a known-plaintext attack developed by Matsui [18]. This attack method extracts the information of a related key by using a linear approximation of a nonlinear function.
2.3 Feistel Network
A Feistel network is the most commonly used structure for designing a block cipher. This structure was first used when designing a Lucifer cipher by H. Feistel [8, 9]. After that, this was used to design block ciphers such as DES, FEAL, Blowfish, and RC5 [23, 38, 33, 29].
A Feistel network is a method that converts an arbitrary function to a permutation that is a one-to-one correspondence function. The definition of a Feistel network is as follows.
Definition 2.3.1** (Feistel Network).**
For any function belonging to , one round Feistel network is defined as a function . Similarly, for the functions , which belong to the set , an rounds Feistel network is defined as a function , where , , , and .
The above Feistel network can be seen as a permutation. To show that a function is a one-to-one correspondence function (bijection), we should show that it is a one-to-one function and an onto function. However, we only need to show that it is a one-to-one function since the input and output bits of the Feistel network are the same.
Theorem 2.3.1**.**
The function is a one-to-one function.
Proof.
If the function is a one-to-one function, then for and such that . If and , then and . Because of , we consider two cases.
- •
Case : by the definition of .
- •
Case and : since .
So the function is a one-to-one function. ∎
A Feistel network is divided into a balanced Feistel network and an unbalanced Feistel network [35]. A balanced Feistel network is a Feistel network in Definition 2.3.1 with the same and sizes. In contrast, an unbalanced Feistel network is a Feistel network in Definition 2.3.1 with different and sizes (). The balanced Feistel network and unbalanced Feistel network structures are given in Figure 2.2.
The DES algorithm that uses a Feistel network was invented in 1970s and it has been used as the standard block cipher for 20 years [23]. Many researchers have studied the security of the DES algorithm [3, 18, 34]. In addition, many other block ciphers that were invented after DES were also affected by the DES cipher.
Example 1** (DES).**
The DES algorithm is a 64-bit block cipher with a 56-bit secret key. This cipher has a 16 rounds balanced Feistel network structure. The th round is defined as
[TABLE]
where , , is an expansion function, is a substitution function, and is a permutation function.
An unbalanced Feistel network is divided into a source-heavy unbalanced Feistel network and a target-heavy unbalanced Feistel network [35]. The source-heavy unbalanced Feistel network is a Feistel network where the size of the block which is the input to the function, is greater than the size of the block which is combined with the output of the function (). Whereas the target-heavy Feistel network is a Feistel network where the size of the block is smaller than the size of the block (). The structures of source-heavy and target-heavy Feistel networks are given in Figure 2.3.
The MARS algorithm is a block cipher proposed for the advanced encryption standard (AES) to replace the DES block cipher [6]. This cipher uses a target-heavy unbalanced Feistel network.
Example 2** (MARS).**
The MARS algorithm is a 128-bit block cipher proposed for AES and it can have different size of secret keys. This cipher has a 32 rounds unbalanced Feistel network. The th round is defined as
[TABLE]
where is the addition operator in mod .
The main advantage of a block cipher using an unbalanced Feistel network is that it can select the input size of the function used in the Feistel network. In particular, as the amount of data that the computer has to process due to the development of the Internet, the amount of messages to be encrypted is also increasing. As the information throughput increases, an encryption scheme that can process large amounts of data becomes necessary. Therefore, a block cipher with a large input size is needed. The advanced encryption standard (AES) selected by National Institute of Standards and Technology (NIST) also requires a 128-bit block cipher to reflect this demand [22].
When implementing a block cipher with a large input value, it is difficult to implement the function of a Feistel network if a balanced Feistel network is used. This is because the cost of implementing the function is generally proportional to the size of the input value of the function. However, since the input size of the function can be selected in an unbalanced Feistel network, it is very effective to use an unbalanced Feistel network in implementing a large block cipher. In other words, a block cipher with a large input size using a target-heavy unbalanced Feistel network can be implemented at a lower cost than a cipher using other Feistel network structures.
2.4 Pseudo-Randomness
Before defining pseudo-randomness, we first review what two distributions are computationally equivalent. The computational equivalence of two distributions means that no effective algorithm can determine that two distributions are different. In other words, computational indistinguishability is a criterion for judging the equivalence of two distributions. Therefore, the pseudo-randomness distribution is a distribution that can not be distinguished from the truly random distribution by computation [11].
At this time, it is necessary to define an algorithm for determining whether two distributions are identical. The definition of an algorithm for determining identical distributions is defined by the following oracle machine.
Definition 2.4.1** (Oracle Machine ).**
An oracle machine is a Turing machine that has an oracle tape as an additional tape and has two special states called “oracle invocation” and “oracle appeared”. The oracle machine has an input value of and an output value of 1. The oracle machine that can access a function whose input value is bits in size is called and operates as follows: If the state of the oracle machine is not “oracle appeared”, then it operates as the same as a normal Turing machine. If the state of the oracle machine is “oracle origin”, then the oracle machine writes an oracle query which is bits string to the oracle tape. Then, the state of the oracle machine is changed to “oracle appeared”, and the content of the oracle tape is replaced by the oracle reply . This process repeats times. The 1-bit output of the oracle machine is calculated from the values .
Because the oracle machine determines the equality of the two distributions, the pseudo-randomness is determined by the computational power of the oracle machine. An effective algorithm for determining the equality of two distributions is an oracle machine that calculates the output value within a probabilistic polynomial-time. Thus, the pseudo-random distribution refer to a distribution that can not be distinguished from the true random distribution using probabilistic polynomial-time oracle machines. At this time, the indistinguishability is defined as the following.
Definition 2.4.2** (Polynomial-Time Indistinguishability).**
If two distributions and are indistinguishable in polynomial-time, then the following equation holds for all probabilistic polynomial-time algorithms , all polynomials , and sufficiently large values
[TABLE]
where the output of algorithm is 1 bit.
A cryptographically secure pseudo-random bit generator was first introduced by Blum and Micali [5]. After that, a number of pseudo-random bit generators have been proposed based on number theoretic problems [4, 15, 39]. Håstard et al. have shown that a pseudo-random bit generator can be constructed using an arbitrary one-way function [13]. A pseudo random bit generator is defined as follows. In this case, an ideal random bit generator has a uniform distribution of all possible output values.
Definition 2.4.3** (Pseudo-Random Bit Generator).**
A pseudo-random bit generator is defined by a deterministic polynomial-time algorithm and satisfies the following two conditions:
Scalability: for all . 2. 2.
Pseudo-Randomness: The algorithm is indistinguishable from the ideal random bit generator in polynomial time.
Blum and Micali showed that it is possible to construct a pseudo-random bit generator using the difficulties of the discrete logarithm problem [5]. The pseudo-random bit generator of Blum and Micali is described in Example 3.
Example 3** (Blum-Micali Pseudo-Random Bit Generator).**
Let be a large prime, and be a generator of . The set is defined as . The function is defined as . The function is defined as for and for . The Blum-Micali pseudo-random bit generation algorithm is described as follows.
generate a large prime and a generator of .
select a random integer from .
for do
.
.
end for
output .
Blum, Blum, and Shub showed that it is possible to construct a pseudo-random bit generator using the difficulties of the quadratic residuacity problem [4]. The pseudo-random bit generator of Blum, Blum, and Shub is described in Example 4.
Example 4** (Blum-Blum-Shub Pseudo-Random Bit Generator).**
Let be a function that outputs the least significant bit of a binary string . The Blum-Blum-Shub pseudo-random bit generation algorithm is described as follows.
generate a large prime such that .
generate a large prime such that .
.
select a random integer such that .
.
for do
.
.
end for
output .
A pseudo-random function generator is a function generator that is indistinguishable from an ideal random function generator that generates all possible functions with a uniform probability distribution. Goldreich, Goldwasser, and Micali showed that a pseudo-random bit generator can be used to create a pseudo-random function generator [12]. A pseudo-random function generator is defined as follows.
Definition 2.4.4** (Pseudo-Random Function Generator).**
A pseudo-random function generator is defined as an algorithm that generates a set of functions. For all probabilistic polynomial-time oracle , all polynomials , and sufficiently large values, it satisfies
[TABLE]
where is an ideal random function generator that generates all possible functions as a uniform probability distribution.
Goldreich, Goldwasser and Micali proposed a pseudo-random function generator as follows.
Example 5** (GGM Pseudo-Random Function Generator).**
Let be a pseudo random bit generator whose input is bits and whose output is bits. That is, for the initial value . Let be the first bit string of and be the remaining bit string of . That is, and . For a -bit binary string , is defined as . For a given , a pseudo-random function is defined as
[TABLE]
where . For polynomials and and given , a pseudo-random function is defined as
[TABLE]
where and is a pseudo-random bit generator with bits input and bits output.
Let us look at the performance of the GGM pseudo-random function generator. A pseudo-random function generator must generate a pseudo-random string of approximately bits. Assuming that the size of the string is properly selected and that is not a value much larger than , then the size of pseudo-random bits that the pseudo-random function must generate is proportional to the input bit size . So the smaller the input bit size of the function, the faster the function can be generated.
A pseudo-random permutation generator was introduced by Luby and Rackoff [16]. The definition of pseudo-random permutation generator is given as follows.
Definition 2.4.5** (Pseudo-Random Permutation Generator).**
A pseudo-random permutation generator is defined as an algorithm which generates a set of permutations. For all probabilistic polynomial-time oracle , all polynomials , and sufficiently large values, it satisfies the following equation
[TABLE]
where is an ideal random permutation generator that produces all possible permutations with a uniform probability distribution.
Luby and Rackoff showed that a pseudo-random permutation generator could be constructed by using a pseudo-random function and a three rounds balanced Feistel network structure.
Example 6**.**
A three rounds balanced Feistel network that uses pseudo-random functions is a pseudo-random permutation generator and is defined as
[TABLE]
where and .
A super pseudo-random permutation generator is a permutation generator, which can not be distinguished from an ideal random permutation generator when an oracle machine is able to access both a permutation and the inverse of the permutation. The definition is given as follows.
Definition 2.4.6** (Super Pseudo-Random Permutation Generator).**
A super pseudo-random permutation generator is defined as an algorithm that generates the set of permutations. For all probabilistic polynomial-time oracle , all polynomials , and the large value, it satisfies the following equation
[TABLE]
where is the inverse of the permutation , is an ideal random permutation generator that produces a permutation with a uniform probability distribution, and is the inverse of .
Luby and Rackoff show that it is possible to build a super pseudo-random permutation generator by using a pseudo-random function and a four rounds balanced Feistel network structure.
Example 7**.**
A four rounds balanced Feistel network that uses pseudo-random functions is a super pseudo-random permutation generator and is defined as
[TABLE]
where and .
If a block cipher is a pseudo-random permutation generator, then it becomes a secure block cipher for a chosen-plaintext attack. If a block cipher is a super pseudo-random permutation generator, then it becomes a secure block cipher for a chosen-plaintext attack and a chosen-ciphertext attack.
2.5 Pseudo-Random Permutation Generator
The research on pseudo-random permutation generators has been started by Luby and Rackoff. They have proved that a three rounds balanced Feistel network that uses pseudo-random functions is a pseudo-random permutation generator [16]. The proof of pseudo-random permutation is largely divided into two parts. First, the proof show that a three rounds Feistel network that uses ideal random functions becomes a pseudo-random permutation generator. Next, the proof show that that a three rounds Feistel network that uses pseudo-random functions is pseudo-random by using contradiction. The proof that shows the pseudo-randomness of the three rounds Feistel network that uses ideal random functions looks like this. First, we define as an event that a machine can distinguish a balanced Feistel permutation generator from an ideal permutation generator . Next the proof show that is the same as if the event does not occur, and it also show that the probability of the event is very low. To prove that a three rounds Feistel network that uses pseudo-random functions is pseudo-random by using contradiction. In other words, if the three rounds Feistel network that uses ideal random functions is pseudo-random, but the three rounds Feistel network that uses pseudo-random functions is not pseudo-random, then it is possible to derive a contradiction on the assumption that pseudo-random functions are pseudo-random.
There have been some studies to simply prove the pseudo-randomness of permutation generators since the work of Luby and Rackoff. Maurer used a local random function instead of a pseudo-random function to show that a three rounds Feistel network is a pseudo-random permutation generator [19]. Naor and Reingold have proved that a three rounds structure that uses a pairwise independent permutation and a two rounds Feistel network is pseudo-random [21].
After the work of Luby and Rackoff, much research focused to build pseudo-random permutation generators by using balanced Feistel networks and pseudo-random functions with small number of rounds. That is, if we use pseudo-random functions with small number of rounds, then the size of keys used in the permutation can be decreased since the size of keys for pseudo-random functions is large. Let be pseudo-random functions, and be the composition of the function with times. The results are summarized as follows.
- •
and are not pseudo-random permutations [30].
- •
and are not pseudo-random permutations [24, 41].
- •
is not a super pseudo-random permutation [32].
- •
For all , is not a pseudo-random permutation [40].
- •
For all , is not a super pseudo-random permutation [32].
- •
is a pseudo-random permutation [28].
- •
If is an identity function, is a super pseudo-random permutation [32].
- •
If is a simple function like a shift operation, is a pseudo-random permutation and is a super pseudo-random permutation [25].
Although many studies are concerned with the use of a small number of pseudo-random functions, reducing the size of the secret key using fewer pseudo-random functions is not a huge benefit. This is because it is possible to increase a small key to a large key using a pseudo random bit generator.
Research to build pseudo-random permutation generators from unbalanced Feistel network structures has only recently begun [21, 14]. Naor and Reingold showed that an unbalanced Feistel network with total number of rounds is a pseudo-random permutation generator if it uses a pairwise independent permutation in the first round, a source-heavy unbalanced Feistel network where the size of a source block is times larger than a target-block in the remaining rounds, and the function of the Feistel network is a pseudo-random function [21]. The pairwise independent permutation is defined as a permutation in which the distribution of the function output values is uniform even if any two input values are selected. The pseudo-random permutation generator of Naor and Reingold is given in Figure 2.4 where is two, is a pairwise independent of permutation, and , and are pseudo-random functions.
Jutla showed that an unbalanced Feistel network with total number of rounds is a pseudo-random permutation generator if it uses a pseudo-random function for the -function of the Feistel network, and a target-heavy unbalanced Feistel network where a target-block size is larger than a source block by times [14]. At this time, the probability that an oracle machine that distinguishes between an ideal random permutation generator and a rounds target-heavy unbalanced Feistel network is less than . The pseudo-random permutation generator of Jutla is given in Figure 2.5 where is two and total rounds is six.
Chapter 3 Analysis of Unbalanced Feistel Networks
In this chapter, we analyze the conditions for permutation generators based on Feistel networks to be pseudo-random. This chapter is summarized as follows. An unbalanced Feistel network is a Feistel network with different sizes of source and target blocks. The unbalanced Feistel network is largely divided into a source-heavy unbalanced Feistel network and a target-heavy unbalanced Feistel network. For a source-heavy unbalanced Feistel network (:-UFN) where a source block is times larger than a target block, a rounds :-UFN using pseudo-random functions is a pseudo-random permutation generator. For a target-heavy unbalanced Feistel network (:-UFN) where a target-block is times larger than a source block, a rounds :-UFN using pseudo-random functions is a pseudo-random permutation generator. Therefore, the minimum number of rounds for a unbalanced Feistel network using pseudo-random functions to be pseudo-random is rounds.
The structure of this chapter is as follows. In Section 3.1, we divide unbalanced Feistel networks into two categories. In Section 3.2, we overview the proof method to prove the pseudorandomness of an unbalanced Feistel network. In Section 3.3, we analyze the conditions for a source-heavy unbalanced Feistel network to be pseudo-random. In Section 3.4, we analyze the conditions for a target-heavy unbalanced Feistel network to be pseudo-random.
3.1 Definition and Category
In a Feistel network, a block that is the input of a round function is called a source block, and a block that is combined with the output of a round function is called a target block. An unbalanced Feistel network is a Feistel network with different source and target block sizes. An unbalanced Feistel network with a source-block size of bits and a target block size of bits is denoted as :-UFN.
An unbalanced Feistel network is largely classified as a source-heavy unbalanced Feistel network or a target-heavy unbalanced Feistel network. A source-heavy unbalanced Feistel network is an unbalanced Feistel network where the size of a source block is larger than that of a target block. The source-heavy unbalanced Feistel network is denoted by :-UFN and it is defined as follows. For instance, a 3 rounds :-UFN structure is described in Figure 3.1.
Definition 3.1.1** (:-UFN).**
For any function belonging to the set of functions , one round :-UFN is defined by the following permutation
[TABLE]
Similarly, for any functions belonging to the set of functions , an rounds :-UFN is defined by the following permutation
[TABLE]
In this case, we have .
A target-heavy unbalanced Feistel network is an unbalanced Feistel network where the size of a target block is larger than that of a source block. The target-heavy unbalanced Feistel network is denoted by :-UFN and it is defined as follows. For instance, a 3 rounds :-UFN structure is described in Figure 3.2.
Definition 3.1.2** (:-UFN).**
For any function belonging to the set of functions , one round :-UFN is defined by the following permutation
[TABLE]
In this case, the function satisfies . Similarly, for any functions belonging to the set of functions , an rounds :-UFN is defined by the following permutation
[TABLE]
In this case, we have .
3.2 Overview of the Pseudo-Random Proof
We first overview the way to prove that an rounds unbalanced Feistel network using a pseudo-random function generator is a pseudo-random permutation generator. The overall method is similar to the method used by Luby and Rackoff [16].
First, we show that an rounds unbalanced Feistel network is not a pseudo-random permutation generator. For this, we show that there exists a linear relationship between the input and output values of the rounds unbalanced Feistel network. Then we use this linear relationship to build an oracle machine that distinguishes between an ideal random permutation generator and the rounds unbalanced Feistel network permutation generator.
Next, we show that if an rounds unbalanced Feistel network that uses ideal random functions is pseudo-random, then an rounds unbalanced Feistel network that uses pseudo-random functions is also pseudo-random. This is because if the rounds unbalanced Feistel network using ideal random functions is pseudo-random but the rounds unbalanced Feistel network using pseudo-random functions is not pseudo-random, then it is possible to show an contradiction that the pseudo-random function is pseudo-random.
The following is a proof strategy to showing that an rounds unbalanced Feistel network using ideal random functions is pseudo-random. We first define the case where the rounds unbalanced Feistel network is not a pseudo-random permutation generator as a BAD event. For the BAD event, we prove the following two things.
If the BAD event does not occur, the output of the rounds unbalanced Feistel network that uses ideal random functions is uniform. 2. 2.
The probability of the BAD event is very low.
By using these two things, we can prove that the rounds Feistel network using ideal random functions is a pseudo-random permutation generator.
3.3 The Pseudo-Random Proof of :-UFN
The following theorem show that a :-UFN is not pseudo-random if the number of rounds is less than or equal to .
Theorem 3.3.1**.**
A rounds :-UFN is not pseudo-random.
Proof.
For the proof, we first show that there is a linear relationship between the input and output values of the :-UFN, and that this linear relationship can be used to create an oracle machine that can distinguish between an ideal random permutation generator and the :-UFN. From the definition of a :-UFN, we first obtains the following equation
[TABLE]
We select two oracle queries and where and are indexes of two oracle queries with . Then, we have and . Therefore, if we choose two oracle queries and in which and are only different, then we can derive the following relation
[TABLE]
since .
This linear relation can be used to build an oracle machine that distinguishes between the :-UFN and an ideal random permutation generator. First, the oracle machine creates two oracle queries and that differ only in values and receives the responses . If the equation is satisfied from the responses of the queries, then the oracle machine outputs . Otherwise, the oracle machine outputs [math]. Thus, if the and values are generated by the :-UFN, then the output of the oracle machine is always . However, if the and values are generated by the ideal random permutation generator, then the probability that the equation is satisfied is . Therefore we have the following equation
[TABLE]
where is the :-UFN and is the ideal random permutation generator. From this equation, the rounds :-UFN is not pseudo-random. ∎
We now prove that a rounds :-UFN permutation generator using pseudo-random functions is pseudo-random. First, we define an event that can be used to distinguish a rounds :-UFN using ideal random functions from an ideal random permutation generator as the following BAD event.
Definition 3.3.1**.**
(The BAD event of a rounds :-UFN) A random variable is defined as an event in which and of two oracle queries with indexes and are equal where . The BAD event is a random variable defined as .
If an oracle machine is able to distinguish between a rounds :-UFN and an ideal random permutation generator, then the BAD event must occur. This means that if the BAD event does not occur, then the rounds :-UFN is equal to the ideal random permutation generator. In the following lemma, we prove it.
Lemma 3.3.2**.**
A rounds :-UFN permutation generator using an ideal random function generator is equal to an ideal random permutation generator if the BAD event does not occur. That is, for all possible , we have
[TABLE]
where is the output of the rounds :-UFN permutation generator.
Proof.
From the definition of a rounds :-UFN using ideal random functions, the reply of the th oracle machine query is described as
[TABLE]
where are functions generated by an ideal random function generator whose inputs are bits and whose outputs are bits, and the input values of are . By the definition of the BAD event , we obtain the following equation
[TABLE]
where and are the oracle indexes with .
Thus the output value of becomes a value with uniform distribution since the input values of are different for all oracle queries and is a function generated by the ideal random function generator. Therefore, the value of becomes a value with uniform distribution. ∎
Lemma 3.3.3**.**
The probability of the BAD event in a rounds :-UFN permutation generator is bounded by
[TABLE]
Proof.
By the definition of the BAD event, we have . We first calculate the probability of each event . A random variable represents an event that and are equal for the indexes and of the oracle queries with . By the definition of a :-UFN structure, we obtain the following equation
[TABLE]
where each is a function generated by an ideal random function generator.
Thus, the best choice for the event to occur is to select an oracle query with for . In this case, the probability of the event is . Therefore, we have . ∎
In Theorem 3.3.4, we prove that a rounds :-UFN that uses ideal random functions is pseudo-random from the above two lemmas, and we also prove that a rounds :-UFN that uses pseudo-random functions is also pseudo-random.
Theorem 3.3.4**.**
A rounds :-UFN permutation generator using pseudo-random functions is a pseudo-random permutation generator.
Proof.
From Lemma 3.3.2 and Lemma 3.3.3, we can show that a :-UFN permutation generator using an ideal random function generator is a pseudo-random permutation generator. First, we have since is the same as an ideal random permutation generator when the BAD event does not occur by Lemma 3.3.2. We also have since the absolute value of the probability difference is less than 1. Therefore, we have the following equation
[TABLE]
We now show that a rounds :-UFN permutation generator using a pseudo-random function generator is a pseudo-random permutation generator. For this, we use the proof by contradiction. That is, if a rounds :-UFN using an ideal random function generator is pseudo-random but a rounds :-UFN using a pseudo-random function generator is not pseudo-random, then we can derive a contradiction to the pseudo-randomness of the pseudo-random function generator.
Suppose that a :-UFN permutation generator using a pseudo-random function generator is not pseudo-random. Then there exists an oracle machine which distinguishes an ideal random permutation generator and with a probability greater than for a constant .
First, we let be a permutation generator in which an ideal random function generator is used from the first round to the th round and a pseudo-random function generator is used from the th round to the th round in a :-UFN permutation generator for with . Let be the probability that an oracle machine that has access to this permutation generator will output . That is,
[TABLE]
where are functions generated by a pseudo-random function generator and are functions generated by an ideal random function generator. Let be the probability that an oracle machine that has access to the ideal random permutation generator will output . Since we supposed that the rounds :-UFN using a pseudo-random function generator is not pseudo-random, we get the following equation
[TABLE]
However, since the rounds :-UFN using an ideal random function generator has been shown to be a pseudo-random permutation generator, we have . Therefore, we have for some . By using this, an oracle machine that distinguishes an ideal random function generator and a pseudo-random function generator with a probability higher than can be constructed as follows.
In the oracle machine , we first change the part of that calculates the oracle query reply to . In this case, is a function whose input is bits and whose output is bits. If in is a function generated by a pseudo-random function generator , then we have . On the other hand, if in is a function generated by an ideal random function generator , then we have . However, it is possible to distinguish the ideal random function generator and the pseudo-random function generator with a probability greater than since . But this contradicts that the pseudo-random function generator is pseudo-random. Therefore, the rounds :-UFN using a pseudo-random function generator is a pseudo-random permutation generator. ∎
From Theorem 3.3.1 and Theorem 3.3.4, the minimum number of rounds of the :-UFN permutation generator using a pseudo-random function generator to be pseudo-random is .
3.4 The Pseudo-Random Proof of :-UFN
The following theorem show that a :-UFN permutation generator is not pseudo-random if the number of rounds is less than or equal to .
Theorem 3.4.1**.**
A rounds :-UFN permutation generator is not pseudo-random.
Proof.
From the definition of a :-UFN, we obtain the following equation
[TABLE]
If we choose two oracle queries and in which and are only different, then we have for all with . Therefore, from the oracle responses , we can derive the following relation
[TABLE]
By using this linear relation, we can build an oracle machine that distinguishes between an :-UFN permutation generator and an ideal random permutation generator. First, the oracle machine creates two oracle queries and that differ only in values and receives oracle responses . If the equation is satisfied from the responses of the queries, then the oracle machine outputs . Otherwise, the oracle machine outputs [math]. Thus, if the and values are generated by the :-UFN, then the output of the oracle machine is always . However, if the and values are generated by the ideal random permutation generator, then the probability that the relation is satisfied is . Therefore we have the following equation
[TABLE]
where is the :-UFN and is the ideal random permutation generator. Thus the rounds :-UFN permutation generator is not pseudo-random. ∎
We now prove that a rounds :-UFN permutation generator using pseudo-random functions is pseudo-random. First, we define an event that can be used to distinguish a rounds :-UFN using ideal random functions from an ideal random permutation generator as the following BAD event.
Definition 3.4.1**.**
(The BAD event of a rounds :-UFN) A random variable is defined as an event in which and of two oracle queries with indexes and are equal where . The BAD event is a random variable defined as .
Lemma 3.4.2**.**
A rounds :-UFN permutation generator using an ideal random function generator is equal to an ideal random permutation generator if the BAD event does not occur. That is, for all possible , we have
[TABLE]
where is the output of the rounds :-UFN permutation generator.
Proof.
From the definition of a rounds :-UFN, the reply of the th oracle machine query is described as
[TABLE]
where are functions generated by an ideal random function generator whose inputs are bits and whose outputs are bits.
By the definition of the BAD event , we obtain the following equation
[TABLE]
where and are the oracle indexes with . Thus the output values of become values with uniform distribution since the input values of are different for all oracle queries and are functions generated by the ideal random function generator. ∎
Lemma 3.4.3**.**
The probability of the BAD event in a rounds :-UFN permutation generator is bounded by
[TABLE]
Proof.
For the proof, we should show that and since by the definition of the BAD event .
First, we show that . By the definition of , we have for the oracle query indexes and with . Thus we obtain the following equation
[TABLE]
Similarly, we can obtain the following equation
[TABLE]
Since each oracle query should be different, we have for oracle query indexes and with . Thus, we have
[TABLE]
By using similar approach, we have . Therefore, we obtain . ∎
In Theorem 3.4.4, we prove that a rounds :-UFN that uses ideal random functions is pseudo-random from the above two lemmas, and we also prove that a rounds :-UFN that uses pseudo-random functions is also pseudo-random.
Theorem 3.4.4**.**
A rounds :-UFN permutation generator using a pseudo-random function generator is a pseudo-random permutation generator.
Proof.
From Lemma 3.4.2 and Lemma 3.4.3, we can show that an :-UFN permutation generator that uses an ideal random function generator is a pseudo-random permutation generator. First, we have since is the same as an ideal random permutation generator when the BAD event does not occur by Lemma 3.4.2. We also have since the absolute value of the probability difference is less than 1. Therefore, we have the following equation
[TABLE]
We now show that a rounds :-UFN permutation generator using a pseudo-random function generator is a pseudo-random permutation generator. For this, we use the proof by contradiction. That is, if a rounds :-UFN using an ideal random function generator is pseudo-random but a rounds :-UFN using a pseudo-random function generator is not pseudo-random, then we can derive a contradiction to the pseudo-randomness of the pseudo-random function generator.
Suppose that an :-UFN permutation generator using a pseudo-random function generator is not pseudo-random. Then there exists an oracle machine which distinguishes an ideal random permutation generator and with a probability greater than for a constant .
First, we let be a permutation generator in which an ideal random function generator is used from the first round to the th round and a pseudo-random function generator is used from the th round to the th round in the :-UFN permutation generator for with . Let be the probability that an oracle machine that has access to this permutation generator will output . That is,
[TABLE]
where are functions generated by a pseudo-random function generator and are functions generated by an ideal random function generator. Let be the probability that an oracle machine that has access to the ideal random permutation generator will output . Since we supposed that the rounds :-UFN using a pseudo-random function generator is not pseudo-random, we get the following equation
[TABLE]
However, since the rounds :-UFN using an ideal random function generator has been shown to be a pseudo-random permutation generator, we have . Therefore, we have for some . By using this, an oracle machine that distinguishes an ideal random function generator and a pseudo-random function generator with a probability higher than can be constructed as follows.
In the oracle machine , we first change the part of that calculates the oracle query reply to . In this case, is a function whose input is bits and whose output is bits. If in is a function generated by a pseudo-random function generator , then we have . On the other hand, if in is a function generated by an ideal random function generator , then we have . However, it is possible to distinguish the ideal random function generator and the pseudo-random function generator with a probability greater than since . But this contradicts that the pseudo-random function generator is pseudo-random. Therefore, the rounds :-UFN using the pseudo-random function generator is a pseudo-random permutation generator. ∎
From Theorem 3.4.1 and Theorem 3.4.4, the minimum number of rounds of the :-UFN permutation generator using a pseudo-random function generator to be pseudo-random is .
Chapter 4 Analysis of Modified Unbalanced Feistel Networks
In this section, we propose an unbalanced Feistel network structure that can extend an -bit block cipher to a -bit block cipher. Then we analyze the conditions for this modified Feistel structure to be pseudo-random. This chapter is summarized as follows.
An :-UFN2 structure, which can extend an -bit block cipher to a -bit block cipher, is a target-heavy unbalanced Feistel network where both the input and output of round functions are bits. The main advantage of the :-UFN2 structure is that it allows to build a new block cipher with large input size by using an existing block cipher with proven security. In order for an :-UFN2 permutation generator that uses pseudo-random functions to be pseudo-random, the round number must be odd and the total number of rounds must be at least .
The structure of this chapter is as follows. In Section 4.1, we define an :-UFN2 structure and examines the properties of this structure. In Section 4.2, we analyze the conditions for the :-UFN2 structure to be a pseudo-random permutation generator.
4.1 Definition and Property
As the information throughput increases, a block cipher with a large input is needed to process large amounts of data. In general, however, it is not easy to build a block cipher with a large input. It is also difficult to ensure the security of this new block cipher. However, if we can use a block cipher that is as secure as DES, we can trust the security of the new cipher. However, the DES cipher does not expand to a block cipher with a larger input because the input is fixed at 64 bits. Therefore, we propose an :-UFN2 permutation generator that can extend an -bit block cipher to a -bit block cipher. We also analyze the condition for this structure to be a pseudo-random permutation generator.
An :-UFN2 structure is a target-heavy unbalanced Feistel network in which the input and output of round functions are bits. It is defined as follows. For instance, a 3 rounds :-UFN2 structure is described in Figure 4.1.
Definition 4.1.1** (:-UFN2).**
For any function belonging to the set of functions , one round of :-UFN2 is defined by the following permutation
[TABLE]
Similarly, for any functions belonging to the set of functions , an rounds :-UFN2 is defined by the following permutation
[TABLE]
In this case, we have .
4.2 The Pseudo-Random Proof of :-UFN2
In Theorem 4.2.1, we show that an :-UFN2 permutation generator is not pseudo-random if is even. In Theorem 4.2.2, we show that an :-UFN2 permutation generator is not pseudo-random if is odd and the number of rounds is less than or equal to .
Theorem 4.2.1**.**
If is even, then an :-UFN2 permutation generator is not pseudo-random.
Proof.
If is even, then we obtain the following equation
[TABLE]
In this equation, is satisfied from the definition of an :-UFN2, is satisfied from the property of and the number of is even, and is satisfied from the recursive application of the above equation.
We can build an oracle machine that distinguishes between an :-UFN2 permutation generator and an ideal random permutation generator. First, the oracle machine queries and receives a response . If the equation is satisfied, then the oracle machine outputs . Otherwise, it outputs [math]. Thus, if the oracle response is generated by the :-UFN2, then the output of the oracle machine is always . However, if the oracle response is generated by the ideal random permutation generator, then the probability that the equation is satisfied is . Therefore the :-UFN2 permutation generator with even is not pseudo-random since the oracle machine exists. ∎
Theorem 4.2.2**.**
If is odd, then a rounds :-UFN2 permutation generator is not pseudo-random.
Proof.
To prove that a rounds :-UFN2 is not pseudo-random, we show that there is a relation between the input and output of oracle queries. Next, we build an oracle machine that can distinguish an :-UFN2 permutation generator and an ideal permutation generator by using this relation.
From the definition of an :-UFN2, we obtain the following equation
[TABLE]
In this case, is represented as
[TABLE]
where is defined as
[TABLE]
Thus, we obtain the following relation between the input and output of an :-UFN2 as
[TABLE]
If we choose two oracle queries with different and blocks for the indexes and with , then we obtain the following equations
[TABLE]
By using these two equations, we have the following relation for two oracle queries and their responses as
[TABLE]
An oracle machine that distinguishes between an :-UFN2 permutation generator and an ideal random permutation generator can be built as follows. First, the oracle machine queries and and receives responses and . If the equation is satisfied, then the oracle machine outputs . Otherwise, it outputs [math]. Thus, if the oracle response is generated by the :-UFN2, then the output of the oracle machine is always . However, if the oracle response is generated by the ideal random permutation generator, then the probability that the equation is satisfied is . Therefore the :-UFN2 permutation generator is not pseudo-random since the oracle machine can distinguish two permutation generators. ∎
We now prove that a rounds :-UFN2 permutation generator using pseudo-random functions is pseudo-random. First, we define an event that can be used to distinguish a rounds :-UFN2 using ideal random functions from an ideal random permutation generator as the following BAD event.
Definition 4.2.1**.**
(The BAD event of rounds :-UFN2) A random variable is defined as an event in which and of two oracle query indexes and are equal where . The BAD event is a random variable defined as .
If an oracle machine is able to distinguish between a rounds :-UFN2 and an ideal random permutation generator, then the BAD event must occur. This means that if the BAD event does not occur, then the rounds :-UFN2 is equal to an ideal random permutation generator. In the following lemma, we prove it.
Lemma 4.2.3**.**
A rounds :-UFN2 permutation generator using an ideal random function generator is equal to an ideal random permutation generator if is odd and the BAD event does not occur. That is, for all possible , we have
[TABLE]
where is the output of the rounds :-UFN2 permutation generator.
Proof.
If the response of the oracle query is generated by an :-UFN2 permutation generator, then the oracle response is calculated by the following algorithm. In this case, and .
[TABLE]
By using this algorithm, the oracle response can be represented by and the intermediate value that is used in the algorithm as follows.
[TABLE]
Let , , and be column vectors. Let be a matrix in which only the elements are [math] and the other elements are . Then the above equation can be represented as a linear relation . If we let , then the linear relation can be represented as . This is equal to a function such that .
Now, we show that the output of has a uniform probability distribution. The value has a uniform probability distribution since the :-UFN2 permutation generator uses ideal random functions. That is, the probability that is chosen in is . Therefore, if the function is a one-to-one correspondence function, then the output value of the function also has a probability value equal to . If the function is a one-to-one function, then is a one-to-one correspondence function since the domain and region of are the same.
If the function is a one-to-one correspondence, then the inverse of must exist. That is, the inverse matrix of the matrix must exist since . If the determinant of is not zero, then there exists an inverse matrix. So we should show that .
In order to show that the determinant of the square matrix is not zero, we convert to an echelon form . At this time, only row addition and row interchange are used. If the echelon form contains a row of zero, then , otherwise [10]. Thus, we should show that does not contain a row of zero.
First, we select an element in as the first pivot element and perform row addition. Then we have the following matrix. We also select an element in as th pivot element for .
[TABLE]
The above matrix contains pivot elements for all columns except the column. Therefore, the element at position should be selected as the th pivot. To do so, all values except the th element of the th row vector must be set to zero. Let be the th row vector of the above matrix. The th pivotal element is obtained by performing row addition . By the property of the XOR operation, the result of row addition is , where if is even and if is odd depending on the property of the XOR. An echelon form is obtained by performing row exchange so that each pivot is located diagonally in the matrix.
Thus, when is an odd number, the echelon form matrix does not include a row of zero. Therefore, if is odd, the output of rounds :-UFN2 has a uniform probability distribution. ∎
Lemma 4.2.4**.**
The probability of the BAD event in a rounds :-UFN2 permutation generator is bounded by
[TABLE]
Proof.
For the proof, we should show that since by the definition of the BAD event .
By the definition of , we have for the oracle query indexes and with . Thus we obtain the following equation
[TABLE]
Similarly, we can obtain the following equation
[TABLE]
Since each oracle query should be different, we have for oracle query indexes and with . Thus, we have
[TABLE]
Therefore, we have . ∎
In Theorem 4.2.5, we prove that a rounds :-UFN2 that uses ideal random functions is pseudo-random from the above two lemmas, and we also prove that a rounds :-UFN2 that uses pseudo-random functions is also pseudo-random.
Theorem 4.2.5**.**
A rounds :-UFN2 permutation generator using a pseudo-random function generator is a pseudo-random permutation generator.
Proof.
From Lemma 4.2.3 and Lemma 4.2.4, we can show that an :-UFN2 permutation generator that uses an ideal random function generator is a pseudo-random permutation generator. First, we have since is the same as an ideal random permutation generator when the BAD event does not occur by Lemma 4.2.3. We also have since the absolute value of the probability difference is less than
- Therefore, we have the following equation
[TABLE]
We now show that a rounds :-UFN2 permutation generator using a pseudo-random function generator is a pseudo-random permutation generator. For this, we use the proof by contradiction. That is, if a rounds :-UFN2 using an ideal random function generator is pseudo-random but a rounds :-UFN2 using a pseudo-random function generator is not pseudo-random, then we can derive a contradiction to the pseudo-randomness of the pseudo-random function generator.
Suppose that an :-UFN2 permutation generator using a pseudo-random function generator is not pseudo-random. Then there exists an oracle machine which distinguishes an ideal random permutation generator and with a probability greater than for a constant .
First, we let be a permutation generator in which an ideal random function generator is used from the first round to the th round and a pseudo-random function generator is used from the th round to the th round in an :-UFN2 permutation generator for with . Let be the probability that an oracle machine that has access to this permutation generator will output . That is,
[TABLE]
where are functions generated by a pseudo-random function generator and are functions generated by an ideal random function generator. Let be the probability that an oracle machine that has access to the ideal random permutation generator will output . Since we supposed that the rounds :-UFN2 using a pseudo-random function generator is not pseudo-random, we get the following equation
[TABLE]
However, since the rounds :-UFN2 using an ideal random function generator has been shown to be a pseudo-random permutation generator, we have . Therefore, we have for some . By using this, an oracle machine that distinguishes an ideal random function generator and a pseudo-random function generator with a probability higher than can be constructed as follows.
In the oracle machine , we first change the part of that calculates the oracle query reply to . In this case, is a function whose input is bits and whose output is bits. If in is a function generated by a pseudo-random function generator , then we have . On the other hand, if in is a function generated by an ideal random function generator , then we have . However, it is possible to distinguish the ideal random function generator and the pseudo-random function generator with a probability greater than since . But this contradicts that the pseudo-random function generator is pseudo-random. Therefore, the rounds :-UFN2 using a pseudo-random function generator is a pseudo-random permutation generator. ∎
Chapter 5 Comparison of Unbalanced Feistel Networks
In this chapter, we compare the amount of memory required for implementation and the time of a pseudo-random permutation generator when implementing the pseudo-random permutation generator using a balanced Feistel network, unbalanced Feistel networks, and the newly proposed Feistel network.
To implement a pseudo-random permutation generator, we must implement a pseudo-random function used in a Feistel network. However, the implementation cost of the pseudo-random function and the speed of the pseudo-random function greatly affect the cost and speed of the Feistel network. Therefore, depending on how to implement the pseudo-random function, the comparison value can vary greatly. Therefore, in this chapter, we will compare the method that can most simply implement the pseudo-random function and the method that uses the GGM pseudo-random function generator. In other words, the cost and the execution speed of each pseudo-random permutation generator are investigated by using these two methods.
5.1 Using Memory and Pseudo-Random Bit Generator
The simplest way to implement a pseudo-random function is to use memory and a pseudo-random bit generator. That is, if the input value of a function is given, the output value is calculated by using a pseudo-random bit generator. At this time, the initial value of the pseudo-random bit generator uses an ideal random value such as coin tosses. However, a pseudo-random function must give the same output value for the same input value. Thus, the input value and the output value are stored in memory. That is, given the same input value as before, the output is obtained by referring to the memory instead of using the pseudo-random bit generator.
Before describing this algorithm, we assume that the size of the key that specifies a pseudo-random function used in the th round of a Feistel network is bits. We also assume that the input of a pseudo-random bit generator is bits and the output is bit. That is, . An algorithm that implements a pseudo-random function whose input is bits and output is bits is as follows.
Since the input of the pseudo-random function is bits and the output is bits, the amount of memory required to implement a pseudo-random function is bits. Therefore, an rounds Feistel network using pseudo-random functions requires bits memory. The time to calculate the output value of a pseudo-random function is proportional to the time to calculate the output of a pseudo-random bit generator. Thus, the execution time of a pseudo-random function whose output is bits is proportional to the value of the output size. Therefore, the execution time of the rounds Feistel network is proportional to value.
In case of implementing a pseudo-random function by using the algorithm 1, the memory size required for each pseudo-random permutation generator and the execution time of each Feistel network are shown in Table 5.1. In the total memory size, the pseudo-random permutation generator using a newly proposed structure (:-UFN2) requires the least memory and the pseudo-random permutation generator using a source-heavy unbalanced Feistel network (:-UFN) requires the most memory. In the execution time of the whole Feistel network, the pseudo-random permutation generator using a source-heavy unbalanced Feistel network (:-UFN) is the fastest and the pseudo-random permutation generator using a target-heavy unbalanced Feistel network (:-UFN) is the slowest.
5.2 Using the GGM Pseudo-Random Function
Another way to implement a pseudo-random function is to use the pseudo-random function generator of Goldreich, Goldwasser, and Micali. A major advantage of the GGM pseudo-random function generator is that it can implement a pseudo-random function without storing previously generated pseudo-random bits.
Let be the size of the entire key of a pseudo-random permutation generator. Then the th pseudo-random function of the pseudo-random permutation generator from an rounds Feistel network will use bits of the key. We first prepare two pseudo-random bit generators and . Let be the first bits of , and be the next bits of . A pseudo-random function whose the key size is is defined by the following algorithm.
Since the pseudo-random bits that are previously generated by the algorithm can not be stored, the amount of memory required is fixed. By analyzing the above algorithm, the number of pseudo-random bits that the algorithm must generate to compute one pseudo-random permutation is maximum bits. Therefore, the memory size and the time of each Feistel network are shown in Table 5.2.
It can be seen that the pseudo-random permutation generator using a target-heavy (:-UFN) and the proposed structure (:-UFN2) is the fastest in the execution time of the entire Feistel network. On the other hand, it can be seen that the pseudo-random permutation generator using a source-heavy (:-UFN) is the slowest.
Chapter 6 Conclusion
In this paper, we analyze the minimum number of rounds for a block cipher from unbalanced Feistel networks to be a pseudo-random permutation generator which is a safe and efficient block cipher. We also propose a new unbalanced Feistel network structure that can be extended and analyze the minimum number of rounds for this structure to be a pseudo-random permutation generator.
The minimum number of rounds for a permutation generator from unbalanced Feistel networks to be a pseudo-random permutation generator is as follows.
- •
In case of a source-heavy unbalanced Feistel network where the source block is bits and the target block is bits: If pseudo-random functions are used in round functions and the total number of rounds is or more, then a source-heavy unbalanced Feistel network is a pseudo-random permutation generator.
- •
In case of a target-heavy unbalanced Feistel network where the source-block is bits and the target block is bits: If pseudo-random functions are used in round functions and the total number of rounds is more than , then a target-heavy unbalanced Feistel network is a pseudo-random permutation generator.
A newly proposed architecture is an unbalanced Feistel network architecture that can extend an -bit block cipher to a -bit block cipher. The minimum number of rounds of a permutation generator from this structure to be pseudo-random is as follows.
- •
If is even, then a newly proposed structure is not a pseudo-random permutation generator.
- •
If is odd, pseudo-random functions are used, and the total number of rounds is or more, then a newly proposed structure is a pseudo-random permutation generator.
In all three structures, the probability that an arbitrary algorithm can distinguish between an ideal random permutation generator and a pseudo-random permutation generator is less than after obtaining plaintext and ciphertext pairs. Therefore, when a block cipher is implemented using an unbalanced Feistel network structure, it can be a safe and efficient block cipher only if the number of rounds shown in this paper is satisfied.
In this paper, we examined only the condition of the number of rounds for an unbalanced Feistel network using pseudo-random functions to be pseudo-random. If a permutation generator from an unbalanced Feistel network is a super pseudo-random permutation, it becomes a secure block cipher for both chosen plaintext and chosen ciphertext attacks. Therefore, in the future, it is necessary to analyze the condition of the round number for a block cipher from an unbalanced Feistel network to be the super pseudo-random permutation generator.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] William Aiello and Ramarathnam Venkatesan. Foiling birthday attacks in length-doubling transformations - benes: A non-reversible alternative to feistel. In Ueli M. Maurer, editor, Advances in Cryptology - EUROCRYPT ’96 , volume 1070 of Lecture Notes in Computer Science , pages 307–320. Springer, 1996.
- 2[2] Ross J. Anderson and Eli Biham. Two practical and provably secure block ciphers: BEARS and LION. In Dieter Gollmann, editor, Fast Software Encryption - FSE ’96 , volume 1039 of Lecture Notes in Computer Science , pages 113–120. Springer, 1996.
- 3[3] Eli Biham and Adi Shamir. Differential cryptanalysis of DES-like cryptosystems. J. Cryptology , 4(1):3–72, 1991.
- 4[4] Lenore Blum, Manuel Blum, and Mike Shub. A simple unpredictable pseudo-random number generator. SIAM J. Comput. , 15(2):364–383, 1986.
- 5[5] Manuel Blum and Silvio Micali. How to generate cryptographically strong sequences of pseudo-random bits. SIAM J. Comput. , 13(4):850–864, 1984.
- 6[6] Carolynn Burwick, Don Coppersmith, Edward D’Avignon, Rosario Gennaro, Shai Halevi, Charanjit Jutla, Stephen M. Matyas, Luke O’Connor, Mohammad Peyravian, David Safford, and N. Zunic. MARS - a candidate cipher for AES. NIST AES Proposal , 268, 1998.
- 7[7] Don Coppersmith. Luby-rackoff: Four rounds is not enough. Technical report, IBM Thomas J. Watson Research Division.
- 8[8] Horst Feistel. Cryptography and computer privacy. Scientific American , 228:15–23, 1973.