On the Probe Complexity of Local Computation Algorithms
Uriel Feige, Boaz Patt-Shamir, Shai Vardi

TL;DR
This paper investigates the probe complexity of local computation algorithms (LCAs) for graph problems, establishing bounds and separations for different coloring and matching problems, and designing efficient algorithms for approximating maximum matching.
Contribution
It provides new bounds on probe complexity for weak coloring and matching problems, including a separation between 2- and 3-coloring, and introduces an efficient randomized LCA for approximate maximum matching.
Findings
Log-star probes suffice for weak 3-coloring.
Omega(log n / log log n) probes are needed for weak 2-coloring.
A new randomized LCA approximates maximum matching with degree-independent probes.
Abstract
The Local Computation Algorithms (LCA) model is a computational model aimed at problem instances with huge inputs and output. For graph problems, the input graph is accessed using probes: strong probes (SP) specify a vertex and receive as a reply a list of 's neighbors, and weak probes (WP) specify a vertex and a port number and receive as a reply 's neighbor. Given a local query (e.g., "is a certain vertex in the vertex cover of the input graph?"), an LCA should compute the corresponding local output (e.g., "yes" or "no") while making only a small number of probes, with the requirement that all local outputs form a single global solution (e.g., a legal vertex cover). We study the probe complexity of LCAs that are required to work on graphs that may have arbitrarily large degrees. In particular, such LCAs are expected to probe the graph a number of times that…
Click any figure to enlarge with its caption.
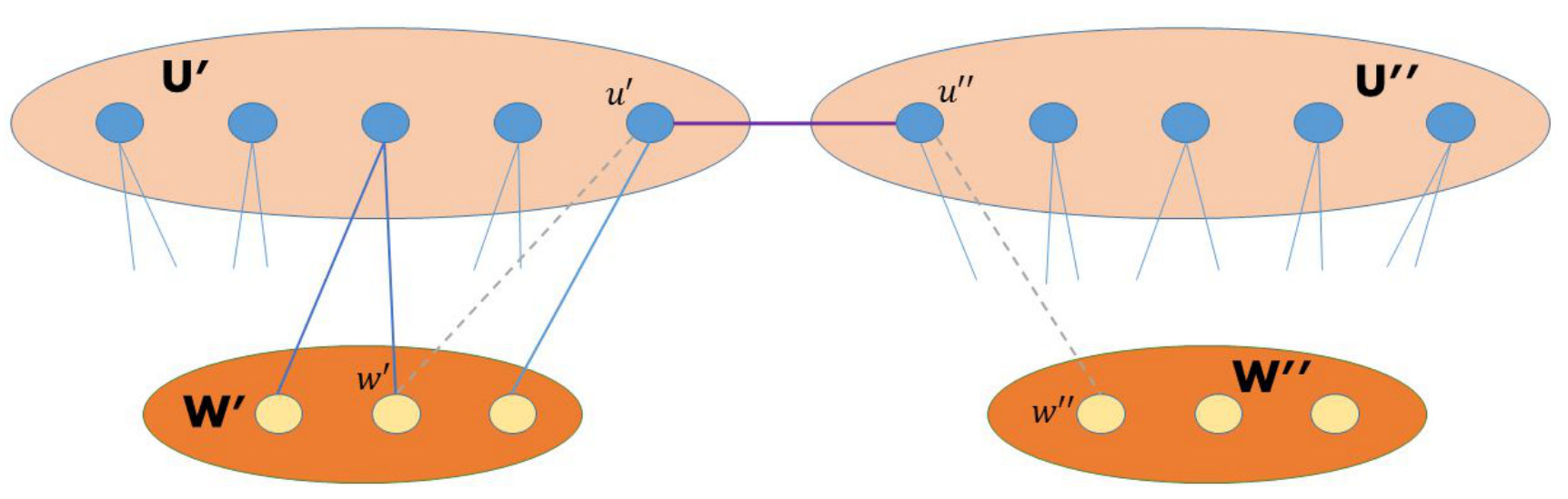 Figure 1
Figure 1Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
On the Probe Complexity of Local Computation Algorithms
Uriel Feige Weizmann Institute of Science, Rehovot, Israel. E-mail: [email protected]. Supported in part by the Israel Science Foundation (grant No. 1388/16). Work partly done in Microsoft Research, Herzeliya, Israel.
Boaz Patt-Shamir Tel Aviv University, Tel Aviv, Israel. E-mail: [email protected]. Supported in part by the Israel Science Foundation (grant No. 1444/14).
Shai Vardi California Institute of Technology, Pasadena, CA, USA. E-mail: [email protected]. Part of the research was carried out when Shai was a postdoctoral researcher at the Weizmann Institute of Science. Supported in part by the I-CORE in Algorithms Postdoctoral Fellowship.
Abstract
The Local Computation Algorithms (LCA) model is a computational model aimed at problem instances with huge inputs and output. For graph problems, the input graph is accessed using probes: strong probes (SP) specify a vertex and receive as a reply a list of ’s neighbors, and weak probes (WP) specify a vertex and a port number and receive as a reply ’s neighbor. Given a local query (e.g., “is a certain vertex in the vertex cover of the input graph?”), an LCA should compute the corresponding local output (e.g., “yes” or “no”) while making only a small number of probes, with the requirement that all local outputs form a single global solution (e.g., a legal vertex cover). We study the probe complexity of LCAs that are required to work on graphs that may have arbitrarily large degrees. In particular, such LCAs are expected to probe the graph a number of times that is significantly smaller than the maximum, average, or even minimum degree.
For weak probes, we focus on the weak coloring problem [40]. Among our results we show a separation between weak 3-coloring and weak 2-coloring for deterministic LCAs: weak probes suffice for weak 3-coloring, but weak probes are required for weak 2-coloring.
For strong probes, we consider randomized LCAs for vertex cover and maximal/maximum matching. Our negative results include showing that there are graphs for which finding a maximal matching requires strong probes. On the positive side, we design a randomized LCA that finds a approximation to maximum matching in regular graphs, and uses probes, independently of the number of vertices and of their degrees.
1 Introduction
In classical algorithmic models, an algorithm is given an input and is required to compute an output. When dealing with truly massive data, such as the Internet, just reading the entire input may turn out to be impossible or impractical. The model of local computation algorithms (LCAs), as studied by Rubinfeld et al. [46], proposes the following idea. An algorithm in the LCA model is required to produce only a specified part of the output, and is expected to access only a “small” part of the input (without any pre-processing). For example, an LCA for maximal independent set (MIS) is given a vertex ID as a query, and is expected to return a “yes/no” answer, indicating whether or not the queried vertex is in the MIS; all replies to queries must be consistent with the same MIS.
The focus of this paper is LCAs for graph problems; the input is a graph, which the LCA is allowed to probe. For the purpose of understanding our notions of probes, it helps to think of the graph as being represented as a two dimensional by array (where is the maximum degree). Rows are labeled from to by the vertex names. In a given row , the cell specifies the degree of , the cell for specifies the ID of the neighbor connected to ’s th port (the order of these neighbors is arbitrary, not necessarily from smallest to largest), and cells for contain [math]. A strong probe (SP) specifies a row number and gets the entire row in response. A weak probe (WP) specifies a single cell and gets its content in response. Weak probes are identical to the graph probing characterization of Goldreich and Ron [21]. Previous work typically considered graphs of constant bounded degree, and did not differentiate between strong and weak probes; as we consider graphs with unbounded degrees, it is natural to distinguish between them.
LCAs are useful in scenarios when the input is so large that we may not even be able to compute the entire solution, yet there is a global function that we wish to query small parts of. Well known examples include locally-decodable codes (LDCs) (e.g., [27, 53]) and local reconstruction (e.g., [24, 47]). LDCs are error-correcting codes that allow a single bit of the original message to be decoded with high probability by querying a small number of bits of a codeword. Local reconstruction involves recovering the value of a function for a particular input given oracle access to a closely related function . LCAs have recently been applied to solving convex problems in a distributed fashion [34]. Traditional methods for solving distributed optimization, such as iterative descent methods (e.g., [36]) and consensus methods (e.g., [7]) require global communication, and any edge failure or lag in the system immediately affects the entire solution, by delaying computation or causing it not to be computed at all; furthermore, if the network changes in a small way, the entire solution needs to be recomputed. If an LCA is used, most of the system remains unaffected by local changes or failures. Hence LCAs can be used to make systems more robust to edge failures, lag, and dynamic changes. There are other situations when LCAs may be useful - say we wish to perform some computation on each of the vertices of an MIS of some huge graph. LCAs allow us to be able to begin work on some vertices before the entire MIS is computed, and guarantee that the local replies to the queries will be consistent with the same global solution, that will be available at some point in the future. See [50] for more on the applications of LCAs.
One of the main challenges of designing LCAs is bounding their probe complexity - the worst-case number of probes the LCA needs to make to the graph in order to reply to a single query. Although there are other complexity measures for LCAs (see the related work section), in this work we primarily focus on probe complexity, and only briefly remark upon other measures.
Noting that in many real-world applications, graphs have vertices of high degree (see, e.g., [26]), it is natural to ask whether one can design LCAs with low probe complexity for graphs in which the maximal, average, or even minimal degree is large. Another natural question is more “local” in nature: can we design an LCA that, for vertex with degree , uses probes? There are known LCAs for MIS, maximal matching, approximate maximum matching, coloring and other problems, e.g., [2, 12, 32, 38, 39, 45]: the probe complexity in these results is typically exponential in the maximal degree ([32] gives an LCA for approximate maximum matching with probe complexity polynomial in ). None of the above results appears to be useful for graphs of high degree; for example, if we would like to have a -probe LCA, the above results only hold when the maximal (or average) degree is at most . A notable exception is the algorithm of Levi et al. [32], whose complexity is roughly , and therefore gives a -probe LCA for .
In this work, we consider LCAs for graph problems when the degrees are large. We focus on the number of probes that a vertex needs to make in order to compute its value in the solution: Can we even hope for an LCA whose probe complexity is polylogarithmic in if the minimal degree is ? From the algorithmic perspective, the main challenge is that in high-degree graphs, we cannot afford to obtain information about all the neighbors of a vertex: using strong probes, we can only know their IDs; using weak probes - not even that. In many cases, this is sufficient reason to preclude (even SP) LCAs with sub-degree probe complexity altogether. Consider, for example, a problem that is considered easy in most natural computational models: given a tree, mark all nodes that have a leaf as a neighbor. In the closely related distributed LOCAL model (e.g., [44]), each vertex can send an unbounded message to all of its neighbors and do unlimited computation in each round. The complexity of algorithms in the LOCAL model is measured by the number of rounds required for every vertex to compute its own value in the solution. For this problem (the leaf-neighbor-marking problem), a single round suffices, but it is easy to see that an LCA requires (weak or strong) probes per query (where is the degree of the queried vertex).
1.1 Our Contributions
Since we do not want to probe all neighbors, we need to carefully choose a small set of neighbors that we do probe. In Section 3, we discuss several natural methods of sampling a single neighbor, a “parent”. In subsequent sections, these parent sampling techniques are used in LCAs that we design for the problem of weak-coloring (a coloring in which every non-isolated vertex has at least one neighbor colored differently than ).
In Section 4, we give tight upper and lower bounds for weak -coloring. Our algorithm is deterministic and uses weak probes, whereas our lower bound holds also for randomized LCAs that may use strong probes.
Theorem 1.1**.**
There exists a deterministic WP LCA for weak -coloring that uses probes.
Theorem 1.2**.**
Every (randomized or deterministic) SP LCA for weak -coloring of the cycle graph requires probes.
In Section 5 we show how to augment the algorithm of Section 4 in order to reduce the number of colors to :
Theorem 1.3**.**
There exists a deterministic WP LCA for weak -coloring that uses weak probes, where is the degree of the queried vertex.
We show that some dependence on the degree is unavoidable, at least when using weak probes.
Theorem 1.4**.**
Any WP LCA for weak -coloring -regular graphs with requires at least probes.
In Section 6, we design a randomized LCA for weak -coloring, whose probe complexity is independent of the maximal degree and show how it can be implemented in both the strong and weak probe models.
Theorem 1.5**.**
There exists a randomized WP LCA for weak -coloring that uses probes, and a randomized SP LCA for weak -coloring that uses probes.
In Section 7, we give a lower bound for vertex cover in the strong probe model. Specifically, we show that for high degree graphs, many strong probes are necessary to approximate a minimal vertex cover to any interesting precision.
Theorem 1.6**.**
For any , any randomized SP LCA that computes a vertex cover whose size is a -approximation to the size of the minimal vertex cover requires at least probes.
A corollary of Theorem 1.6 is the following.
Corollary 1.7**.**
Any SP LCA for maximal matching on arbitrary graphs requires probes.
In Section 8, we describe an LCA that finds a matching that is a -approximation to the maximum matching, for regular (and approximately-regular, see Section 8 for a definition) graphs, using a constant number of probes.
Theorem 1.8**.**
There exists an SP LCA that finds a -approximate maximum matching in expectation on -regular graphs that uses probes per query.
In Section 9, we show that for graphs with sufficiently high girth and degree, polynomially (in ) many strong probes suffice.
Theorem 1.9**.**
There exists an SP LCA that finds a -approximate maximum matching in expectation on -regular graphs of girth , with and , that uses probes per query.
1.2 Overview of our Techniques
In Section 3 we discuss deterministic and randomized methods of sampling a “parent” for each vertex. No matter how the parents are chosen, the resulting graph is a disjoint set of directed subgraphs, each one containing exactly one cycle. The main technical content of Section 3 is the analysis of the diameter of these subgraphs, depending on the choice of parent selecting scheme.
In Section 4 we address the problem of weak -coloring. Our LCA (the proof of Theorem 1.1) is based on the following approach. Given an arbitrary graph, the directed subgraphs formed by the parent relation (as above) span all vertices, and each of their connected components has at least two vertices. Hence any weak 3-coloring of every component separately induces a weak 3-coloring of the whole graph. Each component has one cycle, but it turns out that the -coloring algorithm for rooted trees of Goldberg, Plotkin and Shannon [20] can be adapted in order to legally 3-color (and hence also weakly 3-color) such a component. When implemented as an LCA, the upper bound of on the number of probes follows from a similar upper bound on the number of rounds of the (modified) algorithm of [20]. To prove a nearly matching lower bound (Theorem 1.2) we use a reduction to the lower bound of Linial [33] for distributed algorithms that legally 6-color a cycle. Adapting lower bounds from the distributed setting to the LCA setting also involves an argument of Göös et al. [22].
In Section 5 we show how to augment the algorithm of Section 4 in order to reduce the number of colors to , thus proving Theorem 1.3. It takes only one more probe to transform the weak 3-coloring to a weak -coloring that is legal for all vertices except for those vertices that do not serve as parents (which we refer to as leaves). The final step involves changing the colors of (some) leaves. In order to determine whether a vertex is a leaf, we probe all of its neighbors, making the probe complexity linear in the degree of the queried vertex.
One natural method of proving lower bounds for LCAs is by reduction to the distributed LOCAL model, as was done in [22] (and as we do in the proof of Theorem 1.2). The relationship between LCAs and distributed algorithms has been studied before (e.g., [12, 43, 45, 46]) – given a distributed algorithm to a problem that takes rounds, one immediately obtains an LCA that uses probes (where is the maximal degree), by probing all nodes within radius . The inverse reduction doesn’t work, as an LCA may probe remote (disconnected) nodes. Consider, for example, the following artificial problem: each vertex has to color itself blue if the node with ID has an odd number of neighbors, and red otherwise. An LCA for this problem needs a single probe, while a distributed algorithm requires time proportional to the graph’s diameter. Göös et al. [22] show that for many natural problems, probing undiscovered vertices does not help. But even if we consider only local probes, the best lower bound we can hope for using such a reduction is the distributed time lower bound: a lower bound of rounds in the distributed model implies a lower bound of probes in the LCA model (recall that an upper bound of rounds in the distributed model implies an upper bound of probes!). This suggests that we may need new tools to obtain stronger lower bounds. In the proof of Theorem 1.4, we iteratively construct families of -regular graphs, where graphs in family (for ) contain roughly vertices, and we show that weak 2-coloring of graphs in family requires at least deterministic weak probes. Every graph in family is composed of disjoint copies of graphs from family and two auxiliary vertices and . From each graph a single edge is removed, and instead one of its endpoints is connected to and the other to . Intuitively, it is reasonable to expect that cannot decide on a color before it knows the color of at least one of its neighbors. Likewise, it is reasonable to expect that each neighbor, being a member of a graph in , requires (by an induction hypothesis) probes. The combination of these two non-rigorous claims would imply that requires at least probes (one to determine the name of one of its neighbors, and probes so as to determine the color of that neighbor). Turning this informal intuition into a rigorous proof is nontrivial, and this is the main content of our proof of Theorem 1.4.
In Section 6, we design a randomized LCA for weak -coloring. A key aspect in our randomized LCA is that each vertex first chooses a random temporary color. This induces a weak 2-coloring for most vertices of the graph: each vertex whose temporary color differs from the temporary color of a neighbor can keep its color. Extending this weak 2-coloring to the remaining vertices is done by associating a parent with each vertex, with the intended goal that the color of the vertex will differ from the color of the parent (determining the color of the parent uses an inductive process). This aspect has several different implementations, leading to different probe complexities. Namely, for an arbitrary parent choice, the number of strong probes is . If we implement the arbitrary choice using weak probes, the probe complexity is . For a more clever randomized choice of parent, we get that the strong probe complexity is , and the weak probe complexity is . All these bounds on probe complexity hold with high probability.
We note that our results do not prove a separation between the complexities of deterministic and randomized WP LCAs for weak -coloring (although we conjecture that there is one), as our lower bound that is linear in the degree is proved only for regular graphs of degree at most , and our upper bound for randomized WP LCAs for weak -coloring is .
Randomized LCAs generally use a pseudo-random generator in order to limit the number of bits that they use, while ensuring consistency (e.g., [2, 32, 45]). In order to explore the theoretical limitations of the probe complexity of LCAs, we assume that our randomized LCAs have unbounded access to random bits. Nevertheless, we show in Section 6 that one can implement the randomized WP LCA for weak 2-coloring (the one using the arbitrary parent choice scheme) using a pseudo-random generator with a seed of length .
In the proof of Theorem 1.6 (Section 7) we construct a family of bipartite graphs in which a large subset of vertices have “almost” the same view at distance . Exactly one of these vertices, , needs to be added to the vertex cover; however, there are many vertices for which a small number of strong probes does not suffice in order to verify that they are not , and hence they must add themselves to the vertex cover. In our construction we use vertex naming schemes based on low degree polynomials in order to ensure that certain vertices do not share many neighbors.
In Section 8 we give an LCA for approximate maximum matching in regular graphs. We first describe an LCA for matching on graphs of degree bounded by , that uses at most probes per query. (Alternatively, if we wish to have a better dependency on and are willing to have a dependency on , then an LCA of Even, Medina and Ron [12] has probe complexity .) Our LCA is a simple variation on a randomized LCA of Yoshida, Yamamoto and Ito [54]: whereas [54] do not limit the number of probes used by their LCA but instead analyse and provide upper bounds on the expected number of probes used by their LCA (expectation taken both other choice of random edge and randomness of the LCA), we run essentially the same LCA, but with a strict upper bound on the number of probes. This upper bound is a factor of larger than the expectation. Markov’s inequality implies that this gives a -approximation to the maximum matching in expectation.
To obtain an LCA for a -regular graph , if we use LCA . If , we sparsify the graph: for some universal constant (independent of ), each edge remains in the graph with probability , and then all vertices that still have degree higher than are removed from the graph. This results in a graph of degree bounded by . Every matching in is a matching in . Moreover, we show that the expected size of a maximum matching in (expectation taken over choice of random sparsification) is at least times the size of the maximum matching in . Hence it suffices to find a -approximate maximum matching in the bounded degree graph , and it will serve as a -approximate maximum matching in . A sufficiently large matching in can be found by , using probes to per query. To implement on , but using only probes to , we show that each strong probe to can be simulated by strong probes to .
In Section 9, we show that we can find a -approximation to the maximum matching for regular graphs with sufficiently high degree and girth using polynomially (in ) many probes. Gamarnik and Goldberg [16] show that the randomized greedy algorithm finds a approximation to the maximum matching on regular graphs with sufficiently high degree and girth. Similarly to Section 8, if the vertex degrees are sufficiently small (say, below ), we can use an LCA of [54] (an implementation of the randomized greedy algorithm that uses in expectation probes in graphs of maximum degree ), while placing a strict upper bound on the number of probes (this upper bound is a factor of larger than the expectation). If the degrees are large, our approach is once again to sparsify the graph prior to using the LCA of [54] (modified to have a strict upper bound on the number of probes). Unfortunately, the resulting graph is only nearly regular but not actually regular. This requires us to extend the result of [16] from regular graphs to nearly regular graphs. We do so without need to refer to the proofs of [16], by the following approach. We add imaginary edges to , making it regular (while maintaining high girth). The LCA now runs on a regular graph, and hence the bounds of [16] apply. The new problem that arises is that the matching that is output by the LCA might contain imaginary edges. However, we prove that the expected fraction of imaginary edges in that matching is similar to their fraction within the input graph (our proof uses both the high girth assumption and the fact that the randomized greedy algorithm is local in nature). This, combined with the fact that the fraction of imaginary edges in the input graph was small (because is nearly regular), implies that the imaginary edges can be discarded from the solution without significantly affecting the approximation ratio.
1.3 Related Work
In this work, we focus on the probe complexity of LCAs; however, there are several criteria by which one can measure the performance of LCAs. Rubinfeld et al. [46] focus on the time complexity of LCAs: how long it takes to reply to a query; Alon et al. [2] emphasize the space complexity, in particular, the length of the random seed used (randomized LCAs need a global random seed to ensure consistency). Expanding upon this, Mansour et al. [38] describe LCAs for maximal matching and other problems that use polylogarithmic (in the size of the graph; exponential in the degree) time and space when the degrees of the graph are bounded by a constant. Even, Medina and Ron [12], focusing on probe complexity, give deterministic LCAs for MIS, maximal matching and -coloring for graphs of degree bounded by a constant , which use probes. Fraigniauld, Heinrich and Kosowski [15] investigate local conflict coloring, a general distributed labeling problem, and use their results to improve the probe complexity of -vertex coloring to approximately probes. Mansour, Patt-Shamir and Vardi [37] introduce a unified model, that takes into account all four complexity measures: probe complexity, time complexity (per query) and space complexity, divided into enduring memory (in all known LCAs, this includes only the random seed) and transient space (the computational space used per query). They show that it is possible to obtain LCAs for which all of these are independent of for certain problems, such as a approximation to a maximal acyclic subgraph, using probes. Few papers address super-constant degrees: Levi, Rubinfeld and Yodpinyanee [32] give LCAs for MIS and maximal matching for graphs of degree , using an improvement of Ghaffari [17]. Reingold and Vardi [45] give LCAs for MIS, maximal matching and other problems that apply to graphs that are sampled from some distribution. This limitation allows them to address graphs with higher maximal degree, as long as the average degree is , and the tail of the distribution is sufficiently light. If we restrict ourselves to LCAs that use polylogarithmic time and space, the approximate maximum matching LCA of [32] accommodates graphs of polylogarithmic degree. Levi, Ron and Rubinfeld [31] describe an LCA that constructs spanners using a number of probes polynomial in .
There are few explicit impossibility results LCAs. Göös et al. [22] show that any LCA for MIS requires probes, by showing that probing vertices that have not yet been discovered is not useful. This implies that, on a ring, the number of probes that an LCA needs to make is “roughly the same” as the number of rounds required by a distributed LOCAL algorithm, implying that the lower bounds of Linial [33] holds for LCAs as well. Levi, Ron and Rubinfeld [31] show that an LCA that determines whether an edge belongs to a sparse spanning subgraph requires probes. Feige, Mansour and Schapire [13], adapting a lower bound from the property testing literature [21], show that approximating the minimum vertex cover in bounded degree bipartite graphs within a ratio of (for some explicit fixed ) cannot be done with probes.
The distributed lower bound for vertex cover by Kuhn, Moscibroda and Wattenhofer [29, 30] shows that no -round distributed algorithm for Vertex Cover has an approximation ratio better than or for positive constants and . The main idea behind the lower bound of [29, 30] is that two vertices, one of which should clearly be in the vertex cover, and the other of which should not, have the same view at any distance up to . Compare this with our lower bound construction for the proof of Theorem 1.6: by requiring that two vertices only have almost the same view, we are able to leverage the difference between distributed algorithms and LCAs to obtain a stronger lower bound.
Weak coloring was introduced by Naor and Stockmeyer [41]. They show that there exists a LOCAL distributed algorithm that requires rounds for weak -coloring graphs of maximal degree , assuming the degree of every vertex is odd. In contrast, they show that there is no constant time LOCAL algorithm for weak -coloring all graphs with vertices with even degrees, for constant . Our deterministic weak 2-coloring LCA (Theorem 1.3) uses probes, but when cast within the LOCAL model it takes rounds (independently of ).
LCAs can be used as subroutines in approximation algorithms e.g., [10, 43, 42, 54]. The goal of such algorithms is to output an approximation to the size of the solution to some combinatorial problem (such as Vertex Cover, Maximum Matching, Minimum Spanning Tree), in time sublinear in the input size. In particular, if one has an LCA whose running time is that solves some problem, one can obtain an approximation to the size of the solution (with some constant probability) by executing this LCA on a sufficiently large (but constant) number of vertices chosen uniformly at random, to obtain an approximation algorithm whose running time is (see e.g., [42, 50] for more details).
Sampling techniques similar to the one we use in Section 8 for sparsifying regular graphs are used by Goel, Kapralov and Khanna [18] – each edge of a regular bipartite graph is kept independently with some probability, and the remaining graph still has a perfect matching w.h.p. The same authors also use an adaptive sampling technique to further reduce the running time of finding a perfect matching in a regular bipartite graph to [19].
The concept of LCAs is related to but should not be confused with local algorithms as in [4, 5, 48]. The difference is that these local algorithms do not require the output for different probes to satisfy a global consistency property, but rather to satisfy some local criteria. For example, the goal might be for each vertex to output a small dense subgraph that contains it, without requiring two different vertices to agree on whether they share the same dense subgraph or not.
2 Preliminaries
We denote the set of integers by . All logarithms are base . Our input is a simple undirected graph , in which every vertex has an ID and all IDs are distinct, . The neighborhood of a vertex , denoted , is the set of vertices that share an edge with : . The degree of a vertex , is . The girth of , denoted is the length of the shortest cycle in .
LCAs.
Our definition of LCAs is slightly different from previous definitions in that it focuses on probe complexity. We do this so as not to introduce unnecessary notation. See [37, 50] for definitions that also take into account other complexity measures.
Definition 2.1** (Probe).**
We assume that the input graph is represented as a two dimensional by array, where is the maximum degree. Rows are labeled from to by the vertex names. For any , the cell specifies the degree of , the cell for specifies the name of the neighbor connected to ’s th port. Cells for contain [math]. We define strong and weak probes as follows.
- •
A strong probe (SP) specifies the ID of a vertex ; the reply to the probe is the entire row corresponding to (namely, the list of all neighbors of ).
- •
A weak probe (WP) specifies a single cell and receives its content (namely, only the neighbor of ).
We note that knowing that is ’s neighbor does not give us information regarding which one of ’s ports is connected to. This property is crucial for the proof of Theorem 1.4.
Definition 2.2** (Local computation algorithm).**
A deterministic -probe local computation algorithm for a computational problem is an algorithm that receives an input of size . Given a query , makes at most probes to the input in order to reply. must be consistent; that is, the algorithm’s replies to all of the possible queries combine to a single feasible solution to the problem.
A randomized -local computation algorithm differs from a deterministic one in the following aspects. Before receiving its input, it is allowed to write random bits (referred to as the random seed) to memory.111In this work, we generally allow the random seed to be unbounded. In Section 6 we remark upon the seed length/probe tradeoff that we can achieve for the algorithm described therein. Thereafter, it must behave like a deterministic LCA, except that when answering queries it may also read and use the random seed. For any input , , the probability (over the choice of random seed) that there exists a query in for which uses more than probes is at most , which is called ’s failure probability.
When LCA is given input graph and queried on vertex , we denote this by .
An LCA is said to require probes on a graph , if there is at least one query for which uses probes. We say that an LCA requires probes for a family of graphs, if for some graph , requires probes.
Graph Problems.
We examine several well-studied graph problems:
- •
Weak -Coloring: Given a graph and an integer , find an assignment , such that for each non-isolated vertex there exists a vertex such that . Weak -coloring can be viewed also as a domatic partition – partitioning the vertices of the graph into (at least) two sets such that each one of them is a dominating set. Weak 3-coloring is a natural weakening of weak 2-coloring, but no longer gives a domatic partition.
To avoid confusion, we refer to the problem of assigning each vertex a color from such that no two neighbors have the same color (usually simply called -coloring) by proper -coloring.
- •
(Minimum) Vertex Cover (VC): Given a graph , find a set of vertices of minimum cardinality, such that for every edge , at least one of is in .
- •
Maximal Matching: Given a graph , find an edge set such that no two edges in share a vertex, and there is no edge such that has no neighbors in .
- •
Maximum Matching: Given a graph , find an edge set of maximum cardinality such that no two edges in share a vertex.
Definition 2.3** (Approximation algorithm).**
Given a maximization problem over graphs and a real number , a (possibly randomized) -approximation algorithm is guaranteed, for any input graph , to output a feasible solution whose expected value is at least an fraction of the value of an optimal solution (in expectation over the random bits used by ).222The definition of approximation algorithms to minimization problems is analogous, with .
Definition 2.4** (Unicyclic tree, unicyclic forest).**
A set of vertices and directed edges such that each vertex has one outgoing edge is called a unicyclic tree. A disjoint set of unicyclic trees is called a unicyclic forest.
Observe that in a unicyclic tree, there is a single cycle, and there are no edges from a vertex on the cycle to a vertex not on the cycle. Furthermore, unless self-loops are allowed, there are no isolated vertices in a unicyclic forest.
3 Local Exploration
We analyze classes of directed graphs with out-degree one that result from procedures by which local algorithms explore the neighborhood of a given vertex in a graph . We assume that vertices have IDs, which might be adversarial. For randomized algorithms, we allow the algorithm to replace the original IDs by random IDs, chosen from a large enough range so that collisions are unlikely. (If collisions do occur, they can be resolved by appending the original ID to the random ID, with negligible effect on our bounds, because collisions are so unlikely.) Let denote the open neighborhood of and the closed neighborhood (including itself).
We consider several ways by which a vertex chooses an outgoing edge to a parent vertex . The three deterministic schemes are:
Arbitrary. A neighbor is chosen arbitrarily, and becomes . 2. 2.
Lowest neighbor. The vertex of smallest ID () becomes . 3. 3.
Lowest ID. The vertex of smallest ID becomes . Here, if has a lower ID that any of its neighbors then is its own parent (), and the directed graph has a self-loop.
For randomized schemes, we have:
Random. A neighbor is chosen uniformly at random. 2. 2.
Random lowest neighbor. Same as lowest neighbor, but with random IDs. 3. 3.
Random lowest ID. Same as lowest ID, but with random IDs.
We note that it is possible to implement all schemes in the strong probe model using a single probe. In the weak probe model, the arbitrary and random schemes can be implemented using a single probe, but the rest use a number of probes that can be as large as the degree of .
Proposition 3.1**.**
In any of the above schemes, the graph decomposes into unicyclic trees.
Proof.
Every vertex has one outgoing edge. Hence the number of edges equals the number of vertices in each connected component.∎
The following two lemmas are useful for understanding the lowest neighbor and lowest ID schemes. In the following, “directed path” refers to the path implied by the directed edges created by the parent operation.
Lemma 3.2**.**
In the lowest ID scheme, every directed path has non-increasing IDs (decreasing, except for self loops). Moreover, no neighbor (in ) of a path vertex has lower ID than any of the vertices reachable from via this directed path.
Proof.
Every directed path is non-decreasing from the definition of the scheme, and the fact that the IDs are unique implies that, except for self-loops, the paths are decreasing. Consider any vertex that is a neighbor of , and any vertex , reachable from via the directed path. Then it must hold that , where the first inequality is due to the first part of the lemma, and the second due to the choice of . ∎
Lemma 3.3**.**
In the lowest neighbor scheme, the vertices at odd locations (or even locations) of any directed path have non-increasing IDs. Moreover, no neighbor (in ) of a path vertex has lower ID than any of the vertices reachable from via the directed path at an odd distance from .
Proof.
The proof of the first part of the lemma is the following: consider vertices on a path - (possibly ). As , . The proof of the second part of the lemma is identical to the proof of the second part of Lemma 3.2. ∎
Proposition 3.4**.**
For the arbitrary parent scheme, the cycle in each component may be of arbitrary length (but greater than one), for the lowest neighbor scheme the cycle is of length two, and for lowest ID scheme the cycle is of length one (self loop).
Proof.
For the arbitrary and lowest neighbor schemes, as a vertex cannot choose itself as its parent, the cycle must be of length at least two. In the lowest neighbor scheme, the vertex with the smallest ID in the connected component, has an outgoing edge to some vertex , who in turn must have an outgoing edge to (otherwise would not have the lowest ID in the connected component). In the lowest ID scheme, the cycle must be of length one, as it is a self loop at the vertex with the lowest ID in the connected component. ∎
We refer to the vertex of lowest ID on the unique cycle of a component as the root of the component. (When random IDs are used, the root can be the cycle vertex of either lowest original ID or lowest random ID – both options work.)
We analyze how long it takes a vertex to discover the root of its own component by the following procedure: follow the directed path that starts at until a cycle is completed. We refer to this as the longest directed path from .
Proposition 3.5**.**
There are graphs of diameter for which the longest directed path in the lowest ID scheme is of length .
Proof.
Let be a graph composed of a path with vertices with IDs from to 1. The longest directed path is then of length . To make the diameter equal to 2, add one vertex with ID connected to all other vertices. ∎
Proposition 3.6**.**
There are graphs for which the longest directed path in the random lowest ID scheme has length with constant probability, where the probability is taken over the choice of random IDs.
Proof.
Let be such that is a power of . Consider a graph composed of disjoint copies of the following graph . The graph is composed of a sequence of layers, with vertices in layer , for ; every two successive layers comprise a complete bipartite graph. In any such , the lowest random ID vertex has probability (greater than) of being in layer . Conditioned on this, the probability that the lowest random ID vertex in layers is at level is (greater than) , and so on. Hence, the probability that the directed path from the root has length is at least . By the union bound, the probability that the length of the longest directed path in is at most is at most ∎
Theorem 3.7**.**
For any graph , the longest directed path has length at most with high probability (over the random choice of IDs) in the random lowest neighbor scheme. Moreover, if is of bounded degree , then with high probability the longest directed path has length at most ( signifies that the constant in the notation depends on ).
Proof.
Denote the random ID of vertex by . Assume w.l.o.g. that the random ID are drawn uniformly at random from . We show that with high probability, any directed path that has length has a vertex with ID at most . This suffices, as the probability that any vertex has ID less than is at most , by the union bound. Label the even vertices on a directed path that begins at (i.e., has no incoming edges) by , where is the length of the path (we assume the path has even length for simplicity). Let be the random variable denoting the ID of . If has neighbors whose IDs are lower than , the expected value of is , as the IDs are chosen uniformly at random, and the marginal distribution of the IDs is uniform over ; hence
[TABLE]
Let denote the event that . Notice that these events are independent, conditioned on there being a path of length (it is easy to see that they are independent if one thinks of computing the random IDs of vertices only when they are encountered). By the Chernoff bound,
[TABLE]
Hence, setting to be large enough, it holds that with probability at least , there will be at least indices such that , hence is at most . Taking a union bound over all possible paths (there are at most such paths, one from each vertex), completes the proof of the first part.
For graphs of maximum degree , there are at most paths of length . The probability of a decreasing sequence in the even locations is . A simple union bound gives that the probability that there is at least one directed -path of length exactly is at most (by Stirling’s inequality)
[TABLE]
As every path of length at least contains a path of length exactly , this bound holds for paths of length at least . Setting completes the proof. ∎
4 Weak -Coloring
An LCA for weak -coloring receives as a query a vertex and is required to return ’s color in a legal weak -coloring. In this section, we describe a deterministic WP LCA for weak -coloring that uses probes, independent of the maximal degree. In Section 5 we use this LCA as a subroutine in a deterministic LCAs for weak -coloring, that uses probes, where is the degree of the queried vertex.
Recall the proper -coloring algorithm of Goldberg, Plotkin and Shannon [20] (which we denote by GPS) for rooted forests. The GPS algorithm has two parts; in the first, a proper -coloring is found in rounds, (using the symmetry breaking technique of Cole and Vishkin [11]), and in the second, the number of colors is reduced to in three more rounds. Let be the number of rounds by which the GPS algorithm is guaranteed to terminate for graph . Set ; that is, is the maximal round complexity of the GPS algorithm on graphs of size . By [20], .333In [20] the bound is stated as . It is easy to verify (see also [6]) that .
We would like to create a directed spanning forest that does not have isolated vertices, and simulate the GPS algorithm on it. This would guarantee a proper -coloring of the forest, implying a weak -coloring of the graph. Unfortunately, it is not clear how to build such a forest using weak probes.444With strong probes, we could use the smallest neighbor scheme (the smaller ID vertex of the -cycle would be the root). Instead, we do the following: Each vertex chooses an arbitrary parent, creating a spanning unicyclic forest (see Proposition 3.1). We then simulate a modified version of the GPS algorithm on this graph, which we call MGPS. The modifications are minor - first, as unicyclic forests do not have roots, we do not concern ourselves with them. The second is simply a change in the stopping condition - the GPS algorithm stops when the number of colors is ; as this is a global property that cannot be verified locally, we run the algorithm for rounds. One can verify that the proofs of [20] hold for MGPS on unicyclic forests; see Appendix A for more details.
Our weak -coloring LCA is the following (Algorithm 1). Given a graph , we first probe the graph in order to discover a (subgraph of a) spanning unicyclic forest: For each vertex , let denote an arbitrary neighbor of . Our subgraph is and all of its ancestors up to distance (at most) . The MGPS algorithm is then simulated for (we expand on how below), and the color of is returned.
Claim 4.1**.**
Given a graph and query , the color returned for a vertex by Algorithm 1 is the same as that of the MGPS algorithm.
Proof.
We need to show that at the end of the while loop of Algorithm 1, the color of is identical to the color it would have been assigned by running MGPS on . To this end, we show that (1) the probes give us sufficient information to perform the necessary computations and (2) it suffices to execute round of the MGPS algorithm on vertices at distance at most from . We prove (2) by “reverse” induction. For the base case, , clearly it suffices to simulate the MGPS algorithm for rounds on vertex . For the inductive step, assume that it suffices to simulate MGPS for rounds on vertices at distance at most from . In order to do this, we only need to know the color of the vertices at distance at most from at time .
To prove (1), we note that in order to simulate MGPS on these vertices, we need the initial color of the vertices as well as the parent of the furthest vertex from - a total of vertices, hence we require probes. ∎
Theorem 1.1.
Given a graph , and query , Algorithm 1 returns a color for that is consistent with some valid weak -coloring using weak probes.
Proof.
From Claim 4.1, every vertex has at least one neighbor with a different color (its parent); hence the resulting coloring is a valid weak -coloring. The probe complexity is immediate, as we only probe the graph in the initialization phase, in which we perform probes. ∎
This result is asymptotically optimal:
Theorem 1.2.
Every SP LCA for weak -coloring a ring requires probes.
Proof.
From [33], every distributed, possibly randomized, LOCAL algorithm for -coloring a ring requires rounds, for any constant . Using the reduction of [22], this implies that every LCA for -coloring a ring requires probes. Suppose that there exists a weak -coloring LCA that uses probes. Then we can convert it to a proper -coloring LCA on a ring using more probes, as follows. Each vertex discovers the color of its neighbors, using one query (and hence at most probes) per neighbor. If two adjacent vertices have the same color, the one with the lower ID adds to its color. The new coloring is a proper -coloring: if two adjacent vertices have the same color after this step, it must hold that they had the same color before and either both or neither changed their color. In either case, it means that at least one of them, , had another neighbor with the same color. But then had the same color as both of its neighbors, a contradiction. ∎
5 Deterministic WP Weak -Coloring
In Subsection 5.1, We describe a WP LCA for weak -coloring an arbitrary graph in probes, where is the degree of the queried vertex. In Subsection 5.2 we show that some dependence on the degree cannot be avoided. Combined with Theorem 1.2, this implies that the LCA of Subsection 5.1 is asymptotically optimal.
5.1 Upper Bound
We extend Algorithm 1 to a weak -coloring LCA, Algorithm 2. The high level description of the algorithm is the following: we use Algorithm 1 to generate a spanning unicyclic forest and color it with the colors (recall that although the output of Algorithm 1 is a weak coloring, on every unicyclic tree it is in fact a proper coloring). We then recolor all vertices that have the color with the complement of their parent’s color; this ensures that all non-leaf vertices are colored legally (a leaf is a vertex that is not the parent of any other vertex). Finally, we recolor all leaves with the complement of their parent’s color.
Claim 5.1**.**
Step of Algorithm 2 guarantees that every non-leaf has a different color from either its parent or child.
Proof.
In Step , every vertex that has the color recolors itself if the color of is [math], and [math] otherwise. Hence has a different color than its parent, and both and its parent obey the weak coloring rule. We need to verify that ’s child, denoted , also has a different color than its parent or child (assuming is not a leaf). Assume w.l.o.g. that was recolored [math]. Vertex was not colored at the end of Step , as the output of Algorithm 1 is a legal (not weak) -coloring of the subgraph. If was colored , we are done. Otherwise, was colored [math], but its child was colored a different color. If its child was colored , it is now colored . ∎
Step guarantees that leaves have a different color from their parents, and does not create any new color conflicts; hence Algorithm 2 yields a legal weak -coloring. Step uses probes: to discover all of ’s neighbors (the parent had already been discovered), and more probe per neighbor, to check if is its parent. This gives
Theorem 1.3.
Algorithm 2* is a deterministic weak -coloring WP LCA that uses weak probes, where is the degree of the queried vertex.*
From Theorem 1.2 we know that every LCA for deterministic weak -coloring requires probes. We now show that some dependence on the degree is unavoidable.
5.2 Lower Bound
We prove the following.
Theorem 1.4.
Let be an arbitrary integer and let be the largest integer satisfying . Then there is some such that every weak 2-coloring WP LCA that works on all -regular graphs of size requires at least weak probes. In particular, there exists a constant such that every WP LCA for weak 2-coloring requires at least probes whenever .
Before proving the theorem we present some useful principles.
Proposition 5.2**.**
For given positive integers and a family of graphs with vertices, suppose that every weak 2-coloring algorithm for requires at least probes. Then the same holds also if the name space is changed from to .
Proof.
Suppose for the sake of contradiction that on name space there is a weak 2-coloring algorithm that uses fewer than probes. Then run the same algorithm on name space , adding to each name. ∎
Lemma 5.3**.**
For given positive integers and a family of graphs with vertices, suppose that every weak 2-coloring algorithm for requires at least probes. Then for every algorithm for weak 2-coloring of that uses at most probes, there is an adversary that does the following:
Selects a query vertex , . 2. 2.
Adaptively answers any legal sequence of probes, where the answer to probe for may depend on all probes up to and including probe . 3. 3.
Exhibits two graphs from (or possibly, the same graph but with different naming of the vertices) that are consistent with all probe answers, and such that in one graph leads to an inconsistent weak coloring and in the other leads to an inconsistent weak coloring. (Namely, the information provided by the answers to the probes is insufficient in order to determine whether would color with color 0 or with color 1.)
Proof.
Given and consider a two player game between a player who makes probes, and a player who answers the probes. The game starts with player announcing a vertex name . It then continues for rounds, where in each round makes a legal probe and provides an answer. Player wins if at the end of the game there are two graphs from (or possibly, the same graph but with different naming of the vertices) that are consistent with all probe answers, and such that in one graph must be [math] and in the other must be . Being a finite full information sequential game, either or have a winning strategy. Suppose that has a winning strategy. Then this strategy gives rise to a weak 2-coloring algorithm for with probes (because at that point can be the same for all namings for graphs of that are consistent with the probe answers), contradicting the premise of the lemma. Hence has a winning strategy, and this can serve as , proving the lemma. ∎
We are now ready to prove Theorem 1.4.
Proof.
We shall construct by induction a sequence of families of graphs, such that every graph (for ) is -regular and has vertices, and every algorithm for weak 2-coloring that works on the entire family requires at least weak probes.
The base case of the induction. The family contains a single graph – the complete bipartite graph on vertices , minus a perfect matching. As required by the induction invariant, it indeed is -regular, has at most vertices, and weak -coloring it requires at least one probe. (If there are zero probes, then for some color, say 0, there are at least named vertices that always have this color. If we name the vertices of such that these 0-colored vertices correspond to one vertex and its neighbors, the resulting coloring is not a legal weak 2-coloring.)
The inductive step. Suppose that we have family that satisfies the inductive hypothesis, for some . We now explain how to derive family from it. A graph in will be composed of graphs from and two special vertices and . In each of the graphs we remove one edge, and connect to one of its endpoints and to its other endpoint. Thus the graph obtained has vertices and is regular. Doing so in all possible ways (namely, every graph from can serve as each , and every edge in can be removed) gives the set of graphs that constitute .
Let be smallest integer such that there is a weak 2-coloring for that uses at most probes, and let be a weak 2-coloring algorithm for that uses at most probes. It remains to prove that . For the sake of contradiction, suppose that .
By definition, specifies for each queried vertex a probing algorithm. Let be the algorithm for in which each queried vertex in uses its algorithm from .
Lemma 5.4**.**
Algorithm as defined above is a weak 2-coloring algorithm for .
Proof.
Suppose for the sake of contradiction that there is some graph which fails to weakly 2-color. Let be a vertex colored by in the same color as its neighbors. We now show that there is an input in which is colored by in the same color as its neighbors, contradicting the fact that be a weak 2-coloring algorithm for .
Run on vertices from , namely, on and on its neighbors. Altogether this involves at most probes. Observe that has edges. Hence at least of the edges of are not involved in any of these probes, and consequently there is an edge (not involving ) that is not probed. Now construct by including as one of the and the edge as the edge removed from this . Hence maintains in the same set of neighbors that it has in , and neither nor its neighbors change their color under , giving the desired contradiction. ∎
For every in the range , let be the algorithm for in which the name space is rather than , and each queried vertex uses its algorithm from . Under this notation, . The proof of Lemma 5.4 shows that algorithm is a weak 2-coloring algorithm for with name space ,
Lemma 5.4 together with the inductive hypothesis implies that . (In fact, it could be that by itself requires more than probes, and then we are done. But suppose that we are not yet done.) Together with our assumption (for the sake of contradiction) that we get that . This implies that satisfies the conditions of Lemma 5.3 with respect to the family . Likewise, using Proposition 5.2 we have that for every in the range , algorithm satisfies the conditions of Lemma 5.3 with respect to the family and the name space .
We now exhibit a graph on which makes at least probes, showing that . Recall that needs to be constructed from graphs (for ) each from , and two auxiliary vertices and . We use an adversary argument to construct . For every , the adversary uses the name space for graph . The adversary names as , and makes the th port of lead into . The adversary will use as subroutines the adversaries whose existence is guaranteed by Lemma 5.3.
The query that the adversary gives to is the vertex . First, assume that at least one probe is made to a port of , and assume w.l.o.g. that the first probe is such a probe. Upon a probe to port of vertex the adversary replies by the vertex that is the query provided by adversary . Likewise, given any probe in graph , the adversary relays the probe to the corresponding adversary , and relays the received answer back to .
Suppose for the sake of contradiction that stops after probes (rather than ), and suppose without loss of generality that it gives the color 0. As spent at least one probe on a port of , only probes are left for any of the graphs . By Lemma 5.3, in each the corresponding adversary can complete the graph is such a way that must be [math]. This gives the graphs .
To complete the description of , we need to select in each an edge incident with the corresponding that will be removed, so as to allow to connect to (and to connect to the other endpoint of the edge). To ensure that in we have that , the removed edge will be one that was not probed by in the adversarial process described above, and also not probed by upon query . Altogether this excludes at most ports of (the inequality holds because and ), and hence has an incident edge that can be removed. On constructed as above, and all its neighbors are all colored 0, contradicting that ends after probes. Hence uses at least probes.
Recall that we assumed that at least one probe is made to a port of . If no such probe is made, then the adversary can reply to all of the probes and complete the graphs arbitrarily. Then, for each , the adversary can remove some unprobed edge to a vertex that is colored [math] (there must be at least one such vertex and at least one such edge in each ), and connect to using this port, and the port in . ∎
6 Randomized Weak -Coloring
In this section we give a randomized LCA for weak -coloring, Algorithm 3. Each node is randomly assigned a color, and then the inconsistencies created by this coloring are corrected. We consider four possible implementations of the correction process: using strong probes with arbitrary parent selection, the probe complexity of Algorithm 3 is ; using strong probes with randomized selection, it is ; using weak probes with arbitrary parent selection, it is ; and using weak probes with randomized selection, it is .
Algorithm 3 is the following. First, each vertex is assigned a color uniformly at random from . We say that a vertex is good if it has a neighbor such that . Otherwise, is bad. Every good vertex ’s color is fixed to be . Bad vertices choose a parent independently of . When a vertex is queried, if it is good, it returns its color, otherwise, it probes its parent. If its parent is good, returns the complementary color of , otherwise it continues iteratively until it encounters either a good vertex or a vertex that it had already encountered. In the first case, we call the encountered vertex a (primary) root; in the second case, this necessarily closes a unique cycle and we call the lowest ID vertex on the cycle a (secondary) root and color it [math]. We then color the vertices on this cycle from the root using alternating colors. We differentiate between primary and secondary roots only for clarity; the algorithm treats them identically.
Lemma 6.1**.**
Algorithm 3* produces a weak 2-coloring.*
Proof.
Regardless of , for every query , the algorithm terminates (because can have at most distinct vertices). Hence every vertex indeed receives a color. We show that must have a neighbor with . If receives its color in Step then there is some neighbor for which . must also receive its color in its own Step and . If receives its color in Step or then there are two cases to consider.
Vertex is not the root of . In this case, consider the parent of . When is queried, it assigns to the color . When is queried, it assigns itself as well. This is because and are either identical (if is a cycle), or has an extra edge . As is not the root of , and have the same root. Hence . 2. 2.
Vertex is the root of . Then sits on the unique cycle of . Let be the vertex on that cycle such that is the parent of . Then necessarily is the same cycle with as its root, and hence .
∎
6.1 Strong Probes
Arbitrary choice of parent.
We first analyze Algorithm 3 for arbitrary strong probes.
Theorem 6.2**.**
For every vertex graph and every , the probability (over the random choice of ) that there is a vertex that uses more than strong probes, when executing Algorithm 3 with an arbitrary (but independent of ) choice of parent for each vertex, is at most . In particular, for this probability is at most .
Proof.
Denote the subgraph created by taking only edges from vertices to their parents by . For every , there are at most directed (simple) paths in of length : for every , there is at most one path of length from , as the out-degree of each vertex in is exactly . For any set of vertices , the probability that is monochromatic with respect to is . Applying the union bound over the possible paths of length completes the proof. ∎
The following proposition shows that the upper bound of Theorem 6.2 is tight, even for graphs of diameter .
Proposition 6.3**.**
There are graphs of diameter for which the longest monochromatic path in the lowest ID scheme is of length with probability over the random choice of .
Proof.
Let be a graph as in the proof of Proposition 3.5: a path with vertices with IDs from to and one vertex with ID connected to all other vertices. The probability that a path of length is monochromatic is . There are such disjoint paths. Therefore, the probability that none of these is monochromatic is at most , for . ∎
Random choice of parent.
We now show that the random lowest ID scheme for choosing parents does strictly better. We say that a vertex is boring if it has the same color as all its neighbors under . Namely, the boring vertices are those that are not secondary roots. Let denote the size of the largest boring connected subgraph in under a 2-coloring .
Lemma 6.4**.**
For every vertex graph , the probability (over the random choice of ) that is at most .
Proof.
Consider a connected subgraph of size and let denote the number of vertices not in but adjacent to . For to be boring all these vertices need to be of the same color, and this happens with probability . In any vertex graph , the number of ways of picking a connected subgraph of vertices that has exactly neighbors is at most (see Appendix B). Hence the expected number of boring connected subgraphs of size is as most .
Suppose that the size of the largest boring connected subgraph is . Then for every , this subgraph has subgraphs of its own that are boring. By Markov’s inequality, this event happens with probability at most (over the choice ). ∎
Theorem 6.5**.**
For every graph, the longest monochromatic path has length w.h.p. in the random lowest neighbor scheme.
Proof.
Fixing in Lemma 6.4 implies that after the random coloring, the size of the largest boring component is at most , with high probability. Moreover, there are at most components in the graph.
Consider now an arbitrary component of size (but still ). We bound from above the probability that under the random lowest neighbor scheme, contains a monochromatic path of length (for simplicity, assume divides ). Consider an arbitrary path in (not directed, prior to choosing parents) of length . For vertex () on let denote the number of fresh neighbors of in , where a neighbor of is fresh if it was not a neighbor of any vertex where is even. Hence and . By Lemma 3.3, in any directed (nonincreasing) path that agrees with up to vertex , vertex has only choices for a parent (if chooses as parent a non-fresh neighbor, some ancestor of would have already chosen it). Consequently, the number of candidate monochromatic paths of length is at most:
[TABLE]
where is the number of starting vertices, is the number of ways of choosing the sequence of in odd (or even) locations, and the number of choices of parents is maximized when all are the same.
The probability that a particular candidate of path is realized as a monochromatic path in the random neighbor scheme is at most . Therefore, the probability that there is at least one such path of length is at most . Setting for some gives that (as ) with high probability over the choice of random IDs the longest monochromatic path in has length . ∎
Proposition 6.6**.**
There are graphs for which the longest monochromatic path has length in the random lowest neighbor scheme with probability (over random IDs and random colors).
Proof.
Consider the cycle. The probability that a segment of length is both monochromatic and monotone decreasing is , and there are such disjoint segments. The probability that none of these segments satisfies both properties is at most . Setting completes the proof. ∎
6.2 Weak Probes
The only difference between using strong and weak probes in the implementation of Algorithm 3 is that one strong probe suffices for Step , but we may need weak probes to check whether a neighbor of is colored differently than .
Corollary 6.7** (to Theorem 6.2).**
Algorithm 3* uses weak probes w.h.p. when implemented with an arbitrary (but independent of ) choice of parent.*
Proof.
When implementing Algorithm 3 with weak probes, Step 1 can take as many probes as the degree of the current vertex (denoted in the pseudocode). Note, however, that the probability that none of the neighbors of have a different color decays exponentially with the degree. Hence, if the degree is , for some , then the probability that none of the neighbors is colored differently is . By Theorem 6.2, we know that the length of any monochromatic path is at most w.h.p. If any of the vertices on such a path has more than neighbors, we are done (for failure probability ). Otherwise, we need to make at most probes. ∎
Proposition 6.8**.**
There are graphs for which Algorithm 3 uses weak arbitrary probes with constant probability (over the random choice of ).
Proof.
Let be a constant, and let be a collection of disjoint cliques of size , denoted . The probability that at least one such clique is monochromatic is at least , for sufficiently large . (If we wish to have a connected graph as a lower bound, we can simply connect to by a single edge for , with minimal effect.) Let be the number of edges in each clique. For deterministic choice of parent, it is easy to guarantee that for all cliques, there is a particular query for which a cycle will be closed only after probes (i.e., only when the last vertex of the clique is reached). ∎
Corollary 6.9** (to Theorem 6.5).**
Algorithm 3* uses weak probes w.h.p. when implemented using the lowest random neighbor scheme. (The probability is over the random choices of parent and ).*
Proof.
The proof is similar to the proof of Corollary 6.7: By Theorem 6.5, we know that the length of any monochromatic path is at most , for some . If any of the vertices on such a path has more than neighbors, for an appropriately chosen , we are done. Otherwise, we need to make at most probes w.h.p. ∎
Proposition 6.10**.**
There are graphs for which Algorithm 3, when implemented using the random lowest neighbor scheme, uses weak probes with constant probability over the random choice of .
Proof.
Let be constants. Let be a collection of copies of the following graph : a path of length , , where all are connected to (all vertices of a) clique of size . The probability that is monochromatic is . The probability that for all , the parent of is , is . For and as above, the probability that both events happen is at least roughly (up to low order multiplicative terms) . Letting and setting to be appropriately small, the probability that none of the have this property is . ∎
6.3 Seed Length
Thus far in this section, we assumed that we have a perfectly random string of unlimited length, that we can use to generate . We show to to implement Algorithm 3 using a seed of logarithmic length. Our result, whose proof we defer to Appendix C, is the following.
Theorem 6.11**.**
Algorithm 3* is a randomized LCA for weak -coloring arbitrary graphs that can be implemented as*
an 2. 2.
an
6.4 Discussion
We showed that for , a linear dependence on the degree is necessary for deterministic weak -coloring LCAs. It would be interesting to resolve whether such a dependence is also necessary for higher degrees. We conjecture that this is indeed the case. If so, it would give a separation between deterministic and randomized LCAs for this problem.
7 Lower Bound for Vertex Cover
In this section we prove Theorem 1.6:
Theorem 1.6.
For any , any randomized SP LCA that computes a vertex cover whose size is a -approximation to the size of the minimal vertex cover requires at least probes.
In order to prove Theorem 1.6 , we use the minimax theorem of Yao [52], by showing a lower bound on the expected number of queries required by a deterministic LCA when the input is selected from a certain distribution. To this end we construct, for infinitely many values of , a family of graphs, parametrized by a constant .
Let be a prime number, and its associated field. Let be a bipartite graph, where , . Label each vertex in by a -tuple , and the vertices in by a pair , . Associate each vertex with the polynomial . Connect to iff .
Claim 7.1**.**
For every two different vertices , .
Proof.
Consider and , the polynomials associated with and respectively. Let . As is not the zero polynomial, it has at most roots in . ∎
Let to be a graph consisting of two identical copies of . We denote these two copies by and . Let ; let ; let .
We define the following operation on (see Figure 1). Let and be edges such that and . Remove and from , and add an edge . We call this operation , and call and the fusion vertices. Note that there are possible choices for and possible choices for .
Given a graph , the optimal size of the vertex cover of is at most , as and a fusion vertex constitute a vertex cover.
Note that a vertex can locally detect whether it is in or in just by looking at its own degree. However, to detect whether it is one of the fusion vertices, it needs to determine the degrees of its neighbors, which is impossible to do with number of probes significantly smaller than its degree.555Compare this with a distributed algorithm in the LOCAL model, for which one round suffices to determine this.
We now describe the graph family we use. Let be as above. Let be the set of all possible namings of by the ID set . Let . Given a naming and a pair of edges , the graph is defined as follows:
The topology of is given by . 2. 2.
The vertices of are named according to .
The family of graphs we consider is . We now analyze the behavior of a given deterministic LCA with proble complexity less than on a graph chosen uniformly at random from . We first make the following simplification. Suppose that running on some is given as a query. If probes or , it knows that is neither nor and hence need not include in the VC. For simplicity, we also assume that if probes or , it knows not to add to the VC. Note that this only strengthens , hence we can make this assumption without loss of generality.
We use the following definition.
Definition 7.2** (View).**
Let be a deterministic SP LCA. We denote by the subgraph that discovers when queried on vertex in graph , i.e., the set of all probed vertices and their neighbors.
Claim 7.3**.**
Let be an SP LCA with probe complexity less than . Let . Assume that is queried on with vertex . Then there is some vertex such that has no neighbors except in . (That is, neither nor any of its neighbors (except ) is probed in .)
Proof.
probes and, say, vertices from and vertices from , for some such that . From Claim 7.1, sees at most vertices from as a result of probing vertices in . Furthermore, sees at most vertices from as a result of probing vertices in . As , at least one vertex in is only seen once, while probing . ∎
Consider an input graph , where . We use the following notation.
- •
denotes the event that is given as a query. Note that is independent of and .
- •
denotes the event that none of is probed when is queried on .
Claim 7.4**.**
Fix and . Let be a vertex in . If and hold, there exist such that
Proof.
By Claim 7.3, there is some vertex that has no neighbors other than in . Let be identical to except that and are interchanged. Set . The claim follows. ∎
A symmetrical argument holds for .
Claim 7.5**.**
Fix , and let be the ID of the vertex given to a deterministic SP LCA as a query. If the probe complexity of is less than , then , where the probability is over the choice of and .
Proof.
Fix . If probes vertices in and vertices in , it will hit one of with probability at most , over the choice of . Since and , the probability is maximized for . As this bound holds for any , the result follows. ∎
Claim 7.4 and Claim 7.5 imply that when a deterministic SP LCA is queried on a vertex from a random graph in , it cannot discern in less than probes whether is a fusion vertex with probability greater than . Hence the LCA must add vertex to the VC, because at least one fusion vertex must be in the VC. Therefore, the size of the VC that computes is at least , whereas the optimal VC has size at most :
Theorem 7.6**.**
There does not exist a deterministic SP LCA that computes a VC that is an -approximation to the optimal VC and uses fewer than probes with probability greater than on a graph chosen uniformly at random from .
Proof.
Let . Recall that . We have shown that if the number of probes is less than , then the approximation ratio is at least . ∎
Applying Yao’s principle [52] to Theorem 7.6 completes the proof of Theorem 1.6.
Corollary 7.7**.**
Any SP LCA for maximal matching on arbitrary graphs requires probes.
Proof.
It is well known that, given any maximal matching, taking both end vertices of every edge gives a -approximation to the VC (e.g., [51]). Therefore, an LCA for maximal matching would immediately give a -approximation to the minimal vertex cover. Setting in Theorem 1.6 gives . The result follows. ∎
8 Almost Maximum Matching in Regular Graphs
Our goal in this section is the following: given a regular input graph , the LCA receives an edge as a query; for some almost maximum matching , if , the LCA outputs “yes”, otherwise it outputs “no”. All outputs must be consistent with the same .
8.1 Bounded Degree Graphs
We give an LCA for finding a approximation to maximum matching on bounded degree graphs whose probe complexity is independent of . We use the following result of [54] (rephrased), that can be found in the proof of Theorem 3.7 in [54].
Lemma 8.1** ([54]).**
Let be a graph whose degree is bounded by . There exists a randomized LCA for -approximate maximum matching, whose probe complexity is in expectation, where expectation is taken both other the choice of queried edge and over the randomness of the LCA.
For completeness, we summarize this algorithm in Appendix D.
Theorem 8.2**.**
There exists an SP LCA that finds a -approximate maximum matching (in expectation) on graphs with degree bounded by that uses probes per query.
(Note that in Theorem 8.2 the matching is a approximation in expectation, while the probe complexity is worst case; the opposite is true for Lemma 8.1.)
Proof of Theorem 8.2.
Set . Consider the LCA of Lemma 8.1 with parameter : For any edge , let be the random variable denoting the number of probes required to reply to the query for . By Lemma 8.1, , for some constant , where expectation is taken both other the choice of queried edge and over the randomness of the LCA. Let us use the notation .
Our algorithm is simply the algorithm of [54] (with parameter ), except that if the algorithm uses more than probes it returns “no”; i.e., the edge is not in the approximate maximum matching.
By Markov’s inequality, the expected fraction of edges for which is at most . Hence in expectation, the LCA will reply incorrectly on at most edges; the approximation ratio of the LCA is therefore . ∎
8.2 High Degree Regular Graphs
Let be a fixed constant. For some that may depend on , and for some (for our proofs suffices), let be a -regular graph on vertices. We wish to design a randomized SP LCA that outputs a matching of size in . As cannot have a matching larger than , this provides a -approximation. An -approximately--regular graph is one for which the average degree is and all vertex degrees lie within the range .
Theorem 1.8.
There exists an SP LCA that finds a -approximate maximum matching in expectation on -approximately--regular graphs that uses probes per query.
Our approach is based on sparsification of . Let be a parameter that depends on (in this section we shall take , but in Appendix F we show that also suffices). Construct from a random graph in two steps:
Initially , and every edge is included in independently with probability . We refer to these edges as surviving edges. 2. 2.
To obtain , (simultaneously) drop from every vertex that has more than surviving edges.
Proposition 8.3**.**
* has maximum degree .*
Proof.
By step 2 of the sparsification. ∎
Lemma 8.4**.**
Every strong probe in can be implemented by strong probes to .
Proof.
On a probe to vertex , the reply needs to be the list of its neighbors in . Probe in so as to get the list of its neighbors in , and hence of its surviving edges. If has more than surviving edges, then reply that is not in . If has at most surviving edges, probe each of their endpoints and include the respective vertex in the reply only if it is a member of (has at most surviving edges). ∎
The following lemma suffices for proving Theorem 1.8. Stronger bounds (of the form ) are provided by Theorem F.3 in Appendix F.
Lemma 8.5**.**
For every , the expected size of a maximum matching in graph is at least .
Proof.
Consider first only the first step of the sparsification. Let every vertex choose at random a color of either 0 or 1 uniformly and independently. Call an edge eligible only if it is a surviving edge whose endpoints have different colors. For a vertex , let denote the number of eligible edges incident with it. Consider a fractional matching in which the weight of every edge is .
Claim 8.6**.**
The expected weight contributed by any edge to the fractional matching is at least .
Proof.
Edge survives with probability , and, conditioned on surviving, is eligible with probability . The expected degree of a vertex in is , and its expected eligible degree is . As its degree is dominated by the binomial distribution, its variance is at most . Its standard deviation is therefore at most . From Claim E.1,
Hence the total expected fractional weight is
[TABLE]
∎
The fractional matching above is supported on edges of a bipartite graph, and hence it can be transformed into an integer matching of the same size.
Finally, some of the matched edges might be removed due to vertices that are removed in the second step of the sparsification. However, the total number of vertices removed it that step is of order ; is absorbed into Inequality (1). (This last statement requires to be at least some sufficiently large constant. Such a choice of can be enforced in our sparsification procedure. Its effect on the upper bound on the number of probes can be absorbed into the notation in Theorem 1.8.) ∎
The combination of Lemma 8.4 and Lemma 8.5 implies that we can randomly reduce the problem of approximating maximum matching in a -regular graph with arbitrarily large to that of approximating maximum matching in a graph of degree bounded by , with an expected additive loss of at most in the approximation factor, and a multiplicative loss of in the number of strong probes.
Theorem 8.7**.**
There is a randomized reduction from the problem of approximating maximum matching in a -regular graph with arbitrarily large to that of approximating maximum matching in a bipartite graph of degree at most , with an expected additive loss of at most in the approximation factor, and a multiplicative loss of in the number of strong probes.
Proof of Theorem 1.8.
Let be a -regular graph. Let . Set . If , combining Theorem 8.2 and Theorem 8.7 gives required algorithm: use the sparsification technique to obtain , run the LCA of Theorem 8.2 to obtain a -approximate maximum matching on , which is also a -approximate matching in . If , the LCA of Theorem 8.2 suffices.
This gives a probe complexity of . To obtain the actual bound of Theorem 1.8 , set and use Corollary F.4 in lieu of Theorem 8.7. ∎
9 Almost Maximum Matching in Regular Graphs with High Girth
In this section, we prove Theorem 1.9.
Theorem 1.9.
For any , let be an -vertex -regular graph of girth , with and . Then there is a randomized SP LCA that uses at most probes and finds a matching that matches at least vertices in expectation.
Our starting point is the following result of Gamarnik and Goldberg [16] (a restatement of their Theorem 5):
Theorem 9.1**.**
[16]** Let be a an -regular graph, of girth , where . Then the expected size of the matching found by the randomized greedy algorithm is at least
[TABLE]
We use the following corollary.
Corollary 9.2**.**
For every , if and then the expected size of the matching found by the randomized greedy algorithm on an -regular graph of girth at least is at least .
Corollary 9.2 implies that almost every vertex is matched by the randomized greedy algorithm. However, this guarantee is global in nature. For our purpose (e.g., for the proof of Lemma 9.8 that will follow), it is useful to change them into local guarantees, as in Corollary 9.4). The local guarantees follow from the fact that the randomized greedy algorithm can be implemented as a (randomized) LCA, which we refer to as RG-LCA, for randomized greedy LCA. The algorithm is essentially the maximal matching algorithm of [54]; similarly to Section 8, if the LCA performs more probes than the allotted number, we return “no”.
Proposition 9.3**.**
Let , and , and let be a -regular graph with girth . On a query to edge , the probability (over the random permutation over the edges) that RG-LCA probes extend to edges at distance greater than from is at most .
Proof.
There are exactly edges at distance (exactly) from any edge , as the graph is -regular. The probability that any specific edge at distance is probed is at most . For an edge at distance more than to be probed, at least one edge at distance exactly needs to be probed. Setting , gives that the probability that one such edge is probed is at most (using Stirling’s inequality),
[TABLE]
∎
Corollary 9.4**.**
Let , and , and let be a -regular graph with girth . For every vertex , the probability that is matched by RG-LCA is at least . For every edge, the probability that it is in this matching is at least and at most .
Proof.
The distance neighborhood of any two vertices or edges in is identical, due to the regularity and high girth. Therefore, by symmetry, every vertex and edge are equally likely to be in the matching. By Proposition 9.3 the probes do not extend beyond this neighborhood, except with negligible probability. This, combined with Corollary 9.2, gives the vertex probability. As is -regular, dividing by gives the edge probabilities. ∎
We now consider the number of probes made by RG-LCA. For this purpose we use the following theorem of [54] (an adaptation of their Theorem 2.1 to matching).666Their theorem (when viewed in the context of SP LCAs) states that the expected number of strong probes an LCA for maximal independent set needs to make is , where is the number of edges and is the number of vertices. A maximal matching in is a maximal independent set on the line graph of , . If has degree bounded by , has degree bounded by , we have .
Theorem 9.5**.**
[54*]**
Let be a -regular graph. The expected number of strong probes made by RG-LCA is at most when querying a random edge, where the expectation is over the choice of edge and choice of random permutation.*
When the girth is large, we can remove the dependence on choice of edge in the expectation in Theorem 9.5:
Corollary 9.6**.**
Let be a -regular graph with girth . For every edge, the probability that RG-LCA uses more than strong probes when queried on any edge is at most , where the expectation is over the choice of random permutation.
Proof.
Using the same symmetry argument as in the proof of Corollary 9.4 gives that for every queried edge, the expected number of strong probes made by RG-LCA is at most roughly . Markov’s inequality completes the proof. ∎
Suppose now that graph is -regular, but . In this case Theorem 9.1 does not guarantee a large matching. Likewise, the expected number of probes (as stated in Theorem 9.5) might be too high, if is not bounded by a polynomial in . We handle both of these issues by the following sparsification procedure that creates an edge induced subgraph . Let , and let . (We will later also consider the case that ; we will need it when and are large. Note that Proposition 9.7 and Lemma 9.8 hold in this case as well.)
Keep each edge independently with probability . 2. 2.
Simultaneously, for every vertex of degree larger than , remove all of its edges.
In , for a vertex of degree , we define its deficit to be
Proposition 9.7**.**
* has maximum degree . The expected sum of deficits for vertices of is at most .*
Proof.
The maximality of the degree is due to the second stage of the sparsification. The expected degree of vertex in after the first stage is , hence the expected deficit of a vertex in is at most . ∎
We want to execute (a modified version of) RG-LCA on . To be able to apply Corollary 9.4 we need to be regular. For this we imagine that is embedded as part of a larger -regular graph . The graph need not be constructed explicitly. Rather, for the purpose of RG-LCA, each deficit edge of is imagined to lead into a fresh -regular tree of depth much larger than , and that the leaves of these trees are pairwise far away vertices in some huge large girth graph in which these leaves have degree and the remaining vertices have degree . (Queries are only to edges of . However, such queries might lead to probes to parts of . These are “virtual probes”. They are not actual probes to the input graph , but rather to the imaginary graph maintained by the LCA.)
Furthermore, we modify RG-LCA by enforcing the following: if a queried edge uses more than probes, the LCA terminates, and the edge is declared not to be in the matching. We refer to this LCA as bounded-RG-LCA.
Lemma 9.8**.**
After sparsification, bounded-RG-LCA uses probes and produces a matching of expected size at least .
Proof.
The bound on the number of probes is by design. It remains to lower bound the expected size of the matching. In the unbounded-RG-LCA, Corollary 9.4 implies that every vertex has probability at least of being matched. In bounded-RG-LCA, each edge might be declared unmatched with probability at most , by Corollary 9.6. We want to bound the expected number of edges that would be matched by RG-LCA but dropped by bounded-RG-LCA. There are two reasons this could happen: (1) bounded-RG-LCA exceeds the probe bound or (2) bounded-RG-LCA matches imaginary edges. We bound each of these separately:
- (1)
By Corollary 9.4, for any edge , the probability that is matched by RG-LCA is approximately . Conditioning on the event that an edge is matched, the probability of not being added by bounded-RG-LCA is . Hence the expected number of matched vertices that remain in is . 2. (2)
From Proposition 9.7, the expected number of deficit edges in is at most , hence by Corollary 9.4, the expected number of defective edges match is at most .
Overall, the total number of edges that would have been added by RG-LCA but are dropped by bounded-RG-LCA due to is . ∎
We are now ready to prove Theorem 1.9.
Proof of Theorem 1.9.
Recall that . We consider two possible setting of the parameters, and for each of them bound the number of probes.
and (here we do not require ). Run bounded-RG-LCA directly on , with a bound of (i.e., if bounded-RG-LCA performs more than probes, return that the queried edge is unmatched). If we had run (unbounded) RG-LCA, the resulting matching would have size , from Corollary 9.2. From Corollary 9.6, the number of edges from that would not be added by bounded-RG-LCA due to the bound is at most in expectation. Hence the expected size of the matching is at least . 2. 2.
(and ). Sparsify with , satisfying , to obtain a new graph . Execute bounded- RG-LCA on (or rather as explained above), enforcing an upper bound of on the number of probes (to ), where . By Lemma 9.8, the size of the matching found is at least .
One issue that still needs to be addressed is the number of probes to . By Lemma 8.4, every strong probe to can be implemented using strong probes to . However, for the LCA described above for , the multiplicative overhead in the number of probes can be avoided. The original reason for the multiplicative overhead was to check whether after the first step of the sparsification procedure, any of the (at most) neighboring vertices of a probed vertex has degree above (such vertices affect the reply to the strong probe). But in our LCA this check can be omitted. Observe that if at any point our LCA visits a vertex whose degree (after the first sparsification step) is above , this effectively means that the edge that led the LCA into this vertex should have been discarded (at the second sparsification step) and replaced by an imaginary edge in . Hence the LCA can simply replace the current vertex by an imaginary vertex and continue without interruption. (Further details omitted.)
∎
Acknowledgments.
We thank Noga Alon and Mika Göös for helpful discussions, and the anonymous referees for their useful comments.
APPENDIX
Appendix A The (Modified) Goldberg-Plotkin-Shannon Algorithm
We present the simplified version of the Golberg-Plotkin-Shannon algorithm [20] for unicyclic trees, which we call MGPS. The two modifications are the removal of the roots as a special case, and the execution of the algorithm for some possibly “redundant” rounds; the GPS algorithm terminates as soon as the number of colors is at most , while the MGPS algorithm may continue for several more rounds. This can cause the colors generated by the GPS and MGPS algorithms to be different, but it does not affect the correctness of the algorithm. The algorithm consists of two stages. In the first, shown as Algorithm 4, each unicyclic tree is colored with colors and in the second, the number of colors is reduced to , by shifting down: when there are colors, each vertex takes the color of its parent, and then vertices colored change their color to the smallest color in that is different than their parents’ and children’s current color (which is their previous color).
The following theorem asserts the correctness and running time of Algorithm 4.
Theorem A.1**.**
Algorithm 4* followed by the shifting-down phase produces a valid -coloring of a unicyclic tree in time on a CREW PRAM using a linear number of processors.*
Proof sketch.
We prove by induction that every vertex is colored differently than its parent. For the base of the induction, at the start of the algorithm, each vertex is colored with its ID, and the hypothesis holds. For the inductive step, assume that vertex is colored differently than its parent, at the start of a round. Denote ’s parent by (note that possibly ). If the first bit on which the colors of and differ is not the same as the first bit on which the colors of and differ, , and we are done. Otherwise, clearly . Similarly, shifting down preserves the coloring invariant.
Regarding the complexity: in each round of Algorithm 4, the number of bits needed to represent a vertex’s color decreases logarithmically, implying at most rounds are needed. Shifting down requires more rounds. ∎
Appendix B On the Number of Connected Subgraphs
Given a graph on vertices, a set of vertices is referred to as connected if its induced subgraph is connected. The neighborhood contains those vertices in that have at least one neighbor in . Let denote the maximum number of connected subsets of size that have precisely neighbors (namely, ) in an vertex graph.
Theorem B.1**.**
Using the notation above, .
Proofs for Theorem B.1 (sometimes with the term replaced by ) can be found in several places (e.g., [14] and [28]), but we do not know what the earliest reference to this theorem is. Alon [1] points out that Theorem B.1 is basically a special case of the following theorem of Bollobas [8].
Theorem B.2**.**
Let be a collection of items and let be a collection of sets such that:
* for every .* 2. 2.
* for every .* 3. 3.
* for every .* 4. 4.
* for every .*
Then holds. In particular, the upper bound on the number of sets is independent of the number of items.
For completeness, let us present a known short proof (that appears in Section 1.3 of [3] and in Section 9.2.2 of [25]) of Theorem B.2.
Proof.
Consider a uniformly random permutation of . For , let be an indicator random variable for the event that all items of precede all items of in this random permutation, and let . Then and consequently . However, the combination of the third and fourth conditions from Theorem B.2 imply that the events underlying and are disjoint for every , and consequently . Hence , as desired. ∎
We now prove Theorem B.1 using Theorem B.2.
Proof.
Fix an arbitrary vertex . A set will be referred to as eligible for if is connected, , and the neighborhood has size exactly . Let be the number of sets that are eligible for . Letting the sets serve as in Theorem B.2 and the sets serve as , it is not hard to see that all conditions of Theorem B.2 are satisfied, with and . It follows that .
To complete the proof, sum over all vertices of , and note that every eligible set is counted exactly times. ∎
Appendix C Random Weak -Coloring Seed Length
In order to prove Theorem 6.11, we need several definitions. A pseudorandom generator777We refer the reader to [49] for an excellent tutorial on pseudorandomness. is an algorithm that takes as input a short, perfectly random seed and returns a (much longer) sequence of bits that “looks” random. We clearly sacrifice some randomness when we do this: the bit sequence we get is defined by the random seed, and if the seed is of length , there are only possible distinct values of the sequence. The notions of -wise independent hash functions and almost -wise independent hash functions were introduced by Carter and Wegman [9]. To quantify what we mean by almost -wise independence, we use the notion of statistical distance.
Definition C.1** (Statistical distance).**
For random variables and taking values in , their statistical distance is
[TABLE]
For , we say that and are -close if .
Definition C.2** (-almost -wise independent hash functions).**
For such that , let be a random variable sampled uniformly at random from . For , a family of functions is -almost -wise independent if for all distinct , we have that and are -close, when is sampled uniformly from .
The following lemma is the main building block for the proof of Theorem 6.11.
Lemma C.3**.**
Let and let . Let be a function sampled uniformly at random from a family of -almost -wise independent hash functions. Then Algorithm 3 makes at most probes with probability at least .
Proof.
Fix and the queried vertex . Note that in any implementation of Algorithm 3, the algorithm stops making probes to when either (1) a primary root is found: a vertex ID is observed such that or (2) a secondary root is found. Denote by the algorithm that executes Algorithm 3, except that if it has observed the IDs of fewer than vertices before finding a root, it continues probing the graph until it has seen exactly IDs: If it finds a primary root, it continues making exactly the same probes as Algorithm 3 would have made if for every observed vertex , . If it encounters a secondary root, it continues making probes according to some (fixed) predetermined rule (e.g., probe all the neighbors of the vertex with the smallest ID out of all observed vertices, then the neighbors of the vertex with the second smallest ID, and so on).
Let be the first vertex IDs (other than ) that observes. We want to bound the probability that , an event we denote by . This is an upper bound on the probability that needs to make more than probes, hence also an upper bound on the probability that Algorithm 3 needs to make more than probes. Let be truly random independent assignment of to . The probability that for all is . As is an -almost -wise independent hash function, ; therefore . Taking a union bound over all possible queries gives that the probability that there exists a query for which Algorithm 3 needs to make more probes after it has observed vertex IDs is at most . ∎
We require the following theorem of Naor and Naor [40].
Theorem C.4** ([40]).**
For every and such that is a power of , and , there is a family of -almost -wise independent functions whose seed length is . In particular, for the seed length is .
Proof of Theorem 6.11.
Let be a function sampled uniformly at random from a family of hash functions as in Theorem C.4, setting and . The seed length for such a family is . From Lemma C.3, Algorithm 3 observes at most vertices with probability .
In order to observe IDs, Algorithm 3, with arbitrary parent choice, needs to make at most strong probes or weak probes. Therefore with probability at least , Algorithm 3 will make at most strong probes or weak probes. ∎
Appendix D Almost-Maximum Matching on Bounded Degree Graphs
Nguyen and Onak [42] give an algorithm that approximates the size of the maximum matching in graphs with degree bounded by to within using probes. The algorithm samples edges uniformly at random, and checks whether they are in some matching , using the algorithm detailed below (the ‘O’ notation hides a dependency on that is not analyzed). By the Hoeffding bound, this suffices to estimate with constant probability and additive error at most . Yoshida, Yamamoto and Ito [54] show how to improve the total number of probes to , by tweaking the algorithm of [42], and fixing the number of vertices queried to be . The algorithms build on the algorithm of Hopcroft and Karp [23], and we summarize them here for completeness. Note that others (e.g., [35, 39, 32]) have used similar algorithms in the context of approximation algorithms, distributed algorithms and LCAs. We first need some definitions.
An augmenting path with respect to a matching is a simple path whose endpoints are free (i.e., not part of any edge in the matching ), and whose edges alternate between and . A set of augmenting paths is independent if no two paths share a vertex.
For sets and , we denote . An important observation regarding augmenting paths and matchings is the following.
Observation D.1**.**
If is a matching and is an independent set of augmenting paths, then is a matching of size .
While the main result of Hopcroft and Karp [23] is an improved matching algorithm for bipartite graphs, they show the following useful lemmas for general graphs.
Lemma D.2**.**
[23]** Let be an undirected graph, and let be some matching in . If the shortest augmenting path with respect to has length and is a maximal set of independent augmenting paths of length , the shortest augmenting path with respect to has length strictly greater than .
Lemma D.3**.**
[23]** Let be an undirected graph. Let be some matching in , and let be a maximum matching in . If the shortest augmenting path with respect to has length then .
The high level of the approach is the folllwing: Start with an empty matching. In stage , add a maximal independent collection of augmenting paths of length , to obtain the matching . For , by Lemma D.3, we have that the matching is a -approximation to the maximum matching.
In order to find such a collection of augmenting paths of length , we need to define a conflict graph:
Definition D.4**.**
[35]** Let be an undirected graph, let be a matching, and let be an integer. The -conflict graph with respect to in , denoted , is defined as follows. The nodes of are all augmenting paths of length , with respect to , and two nodes in are connected by an edge if and only if their corresponding augmenting paths intersect at a vertex of .
The high level sequential (non-local) algorithm for computing a maximal matching used by [42, 54] (and others) is described as Algorithm 5.
The idea behind [42, 54] is to implement oracle access to the matchings in Algorithm 5. Recall that the goal is to output an approximate size of the maximum matching. To that end, query edges at random. For each one, find out if it is in . The proportion of edges that are in is an approximation to the size of the maximum matching. To find out whether an edge is in , , construct (note that is always odd) and use that to construct the conflict graph: Let be the graph constructed by associating every path of length with a vertex, and adding an edge between two vertices and only if there is some vertex that is in both and . We say that a vertex in is valid if is an augmenting path with respect to . The conflict graph is the subgraph of induced by the valid vertices of . In order to find all paths of length containing a vertex , it suffices to probe the graph times. The difficulty comes from finding a maximal independent set in each of these conflict graphs. Nguyen and Onak do the following: Let be a graph. For each vertex , generate a unique real number in , called its rank. Construct a query subgraph rooted at vertex , denoted , is constructed as follows. Initialize to contain , and add to all of the neighbors of whose rank is smaller than the rank of . Continue iteratively - for each vertex in , add all of its neighbors whose rank is at most the rank of : . Then, simulate the greedy online algorithm for MIS on this subgraph, such that lower ranked vertices arrive earlier. The size of the query subgraph888More precisely, the size of the query subgraph multiplied by , as it is necessary to probe the neighbors of the perimeter of the subgraph in order to determine its borders. rooted at is an upper bound on the number of probes made to the graph in order to compute whether is in the MIS. Nguyen and Onak use a “locality lemma” in order to bound the expected number of probes that need to be made. Markov’s inequality is used to show that if queries are made, the total number of probes will be at most with probability at least . If more probes are needed, the algorithm can be terminated and started again with new random bits.
[54] improve the subroutine for maximal independent set as follows: instead of computing the entire query subgraph up front, only as much of the subgraph as is needed is constructed. For example, assume that the queried vertex has rank , and its neighbors and have rank and respectively. is added to the query subgraph first, and checked recursively for membership in the independent set. If it is in the MIS, we can return “no”, as is certainly not in the MIS. If is not in the MIS, is added and checked, and so on. Clearly in many cases fewer probes are made than if the entire query subgraph was discovered in advance, but there is another advantage: lower ranked vertices are more likely to be in the independent set, and these are probed first. The algorithm uses calls to the MIS subroutine, which uses weak probes. We note that [54] use the weak probe model, and their MIS algorithm can be implemented using strong probes in expectation. Overall,
Lemma D.5** ([54]).**
Let be a graph whose degree is bounded by . The expected number of probes used to reply to a query is .
In [54], similarly to [42], if the algorithm (for approximating the size of the maximum matching) uses more probes than the allotted number, it can be terminated and started again with new randomness. With LCAs that is not the case. We overcome this issue by allowing the LCA to use times more probes, for some constant . If the process still hasn’t terminated, we return “no” as a reply to the query.
Appendix E Expectation of the Maximum of Two Random Variables
Claim E.1**.**
Let and be two (possibly correlated) non-negative random variables drawn from the same distribution, with mean and variance . Then .
Proof.
By Chebyshev’s inequality, it holds that . Set .
By the union bound, it holds that .
The expectation of is
[TABLE]
∎
Appendix F Almost Maximum Matching in Almost -Regular Graphs
Let be a graph with vertices and edges. Let denote its average degree, and let be such that the degree of every vertex is in the range . For the graph is regular, and otherwise is approximately regular.
The following procedure will be referred to as randomized bipartite sparsification (with parameter ). It constructs from a random bipartite graph in three steps:
The set of vertices is partitioned at random into two groups and . This is done by choosing a random function , where for each vertex independently it holds that with probability . Vertex belongs to . Edges in with one endpoint in each side are referred to as bipartite edges and remain in the graph. The other edges are referred to as monochromatic edges and are dropped from the graph. 2. 2.
Every bipartite edge is declared to be a surviving edge independently with probability . The other edges are dropped from the graph. Determining which edges are surviving is done by choosing a random function , where for each edge independently it holds that with probability . Edge survives if . 3. 3.
To obtain , (simultaneously) drop all those surviving edges that are incident with a vertex that has more than surviving edges.
Proposition F.1**.**
* is bipartite and has maximum degree .*
Proof.
Bipartiteness follows from Step 1 of the randomized bipartite sparsification. The bound on the maximum degree follows from Step 3, in which vertices with more than surviving edges lose all their edges. ∎
Lemma F.2**.**
Given and of the randomized bipartite sparsification procedure, every strong probe in can be implemented by strong probes to .
Proof.
On a probe to vertex (where ), the reply needs to be the list of its neighbors in . Probe in so as to get the list of its neighbors in , and hence also the list of its incident edges in . Apply to and each of its neighbors, and determine the bipartite edges. Apply to the bipartite edges, and determine which of them is surviving. If has more than surviving edges, then reply that has no neighbors in . If has at most surviving edges, probe each of their endpoints, determine as above how many surviving edges it has, and include the respective vertex in the reply only if it has at most surviving edges. ∎
Theorem F.3**.**
There are universal constants such that for every the following holds. Let be a graph on vertices, with average degree and degrees in the range where . Then the expected size of a maximum matching in graph (generated by randomized bipartite sparsification with degree bound ) is at least .
Proof.
We sketch the proof, omitting some of the computations, and without optimizing the constants involved. Also, we will consider expectations of various quantities, omitting the proofs that their realized value is w.h.p. close to their expectation.
Consider first the outcome of Step 1. Since every edge has probability exactly of being bipartite, the expected average degree of the bipartite graph is . Moreover, for some fixed constant and every constant , for every vertex, its degree will fall in the interval with probability at least . Hence:
The expected number of vertices of degree smaller than is at most . 2. 2.
The expected total number of edges incident with vertices of degree larger than is at most .
Now let us analyze the expected size of the maximum (bipartite) matching in after Step 2. Let be such that this maximum matching contains edges. Then vertices are unmatched. Without loss of generality, at least of the unmatched vertices are in . By Hall’s condition, this implies that for some , there is a set of size , and a set in of size , such that all surviving edges with one endpoint in have their other endpoint in . The probability that such an event happens can be upper bounded as follows. There are at most ways of choosing the partition of into . After Step 1 (and using item 1 above), the sum of degrees of vertices in is at least . Using item 2 above, the sum of degrees of vertices in is at most . Hence after Step 1, the number of edges with one endpoint in and no endpoint in is at least:
[TABLE]
For the last inequality we used the facts that and , and assumed that .
Let us now require that , and then the number of edges with one endpoint in and no endpoint in is at least . Consider Step 2. In that step every edge with one endpoint in and no endpoint in needs to be dropped. The probability of this happening is at most . Hence if , the probability is at most (for larger the probability is even smaller). This suffices for applying a union bound over all (at most) choices of and , and conclude that with overwhelming probability, after Step 2, has a matching of size at least .
Finally, some of the matched edges might be removed in Step 3, because one of their incident vertices had more than surviving edges. However, the expected number of surviving edges that a vertex has is at most (using our assumption that ). Hence the probability that a vertex has more than surviving edges is at most (for some universal constant ), and the expected number of matched edges that are lost due to such events is at most . Therefore the expected size of the maximum matching in is at least
Let us now show how to choose the parameters for our proof. To obtain the desired lower bound on the size of the maximum matching, we require that . Choosing for slightly above suffices for this. In addition, recall that we took and hence . In the course of the proof we required that:
. 2. 2.
.
For the second requirement, we may balance the three terms on the right hand side to each give a value of . For the first term setting suffices. For the third term we choose . Then the first requirement translates to . For the second term we need a stronger requirement on , namely, , and this governs the choice of . ∎
Corollary F.4**.**
There is a randomized reduction from the problem of approximating maximum matching in a graph with arbitrarily large average degree and all degrees in the range , to that of approximating maximum matching in a bipartite graph of degree at most , with an expected additive loss of at most in the approximation factor, and a multiplicative loss of in the number of strong probes.
Proof.
The bound on the number of probes follows from Lemma F.2, and the bound on the approximation error follows from Theorem F.3 ∎
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Noga Alon. Private communication, 2016.
- 2[2] Noga Alon, Ronitt Rubinfeld, Shai Vardi, and Ning Xie. Space-efficient local computation algorithms. In Proc. 22nd ACM-SIAM Symposium on Discrete Algorithms (SODA) , pages 1132–1139, 2012.
- 3[3] Noga Alon and Joel Spencer. The Probabilistic Method . John Wiley, 3rd edition, 2008.
- 4[4] Reid Andersen. A local algorithm for finding dense subgraphs. ACM Trans. Algorithms , 6(4), 2010.
- 5[5] Reid Andersen, Shayan Oveis Gharan, Yuval Peres, and Luca Trevisan. Almost optimal local graph clustering using evolving sets. J. ACM , 63(2):15, 2016.
- 6[6] Leonid Barenboim and Michael Elkin. Distributed Graph Coloring: Fundamentals and Recent Developments . Synthesis Lectures on Distributed Computing Theory. Morgan & Claypool Publishers, 2013.
- 7[7] Vincent D Blondel, Julien M Hendrickx, Alex Olshevsky, and John N Tsitsiklis. Convergence in multiagent coordination, consensus, and flocking. In Proceedings of IEEE Conference on Decision and Control , pages 2996–3000. IEEE, 2005.
- 8[8] Bela Bollobas. On generalized graphs. Acta Math. Acad. Sci. Hungar. , 16:447–452, 1965.