From Odometers to Circular Systems: A global structure theorem
Matthew Foreman, Benjamin Weiss

TL;DR
This paper establishes a structural equivalence between two large classes of ergodic measure-preserving systems, revealing deep connections and implications for classifying complex dynamical systems like toral diffeomorphisms.
Contribution
It proves a canonical isomorphism between Odometer Based and Circular Systems, linking their structures and extensions, with implications for classifying diffeomorphisms.
Findings
Both classes have the same global structure with respect to joinings.
The classes are canonically isomorphic via a continuous map.
Implications include the unclassifiability of torus diffeomorphisms up to measure-isomorphism.
Abstract
The main result of this paper is that two large collections of ergodic measure preserving systems, the Odometer Based and the Circular Systems have the same global structure with respect to joinings. The classes are canonically isomorphic by a continuous map that takes factor maps to factor maps, measure-isomorphisms to measure-isomorphisms, weakly mixing extensions to weakly mixing extensions and compact extensions to compact extensions. The first class includes all finite entropy ergodic transformations with an odometer factor. By results in a previous paper, the second class contains all transformations realizable as diffeomorphisms using the strongly uniform untwisted Anosov-Katok method. An application of the main result will appear in a forthcoming paper that shows that the diffeomorphisms of the torus are inherently unclassifiable up to measure-isomorphism. Other consequences…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3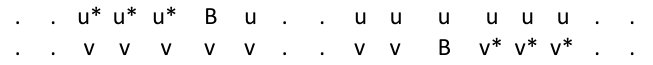 Figure 4
Figure 4 Figure 5
Figure 5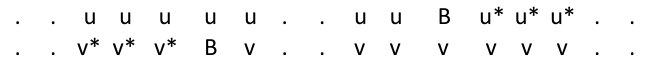 Figure 6
Figure 6Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
From Odometers to Circular Systems:
A Global Structure Theorem
Matthew Foreman, Benjamin Weiss
Abstract
The main result of this paper is that two large collections of ergodic measure preserving systems, the Odometer Based and the Circular Systems have the same global structure with respect to joinings. The classes are canonically isomorphic by a continuous map that takes factor maps to factor maps, measure-isomorphisms to measure-isomorphisms, weakly mixing extensions to weakly mixing extensions and compact extensions to compact extensions. The first class includes all finite entropy ergodic transformations with an odometer factor. By results in [5], the second class contains all transformations realizable as diffeomorphisms using the untwisted Anosov-Katok method. An application of the main result will appear in a forthcoming paper that shows that the diffeomorphisms of the torus are inherently unclassifiable up to measure-isomorphism. Other consequences include the existence measure distal diffeomorphisms of arbitrary countable distal height.
Contents
1 Introduction
The isomorphism problem in ergodic theory was formulated by von Neumann in 1932 in his pioneering paper [19]. Simply put it asks to determine when two measure preserving actions are isomorphic, in the sense that there is a measure isomorphism between the underlying measure space that intertwines the actions. It has been solved completely only for some special classes of transformations. Halmos and von Neumann [13] used the unitary operators defined by Koopman to completely characterize ergodic measure preserving transformations with pure point spectrum, these transformations can be concretely realized (in a Borel way) as translations on compact groups. Another notable success was the use of the Kolmogorov entropy to distinguish between measure preserving systems. Ornstein’s work showed that entropy completely classifies a large class of highly random systems, such as independent processes, mixing Markov chains and certain smooth systems such as geodesic flows on surfaces of negative curvature.
Closely related to the isomorphism problem is the study of structural properties of measure preserving systems. These including mixing properties and compactness. A famous example is the Furstenberg-Zimmer structure theorem for ergodic measure preserving transformations, which characterizes every ergodic transformation as an inverse limit system of compact extensions followed by a weakly mixing extension. This result is fundamental for studying recurrence properties of measure preserving systems and the related proofs of Szemeredi-type combinatorial theorems ([9]).
In this paper we present a new phenomenon, Global Structure Theory. Most structure theorems in ergodic theory consider a single transformation in vitro. The approach here is study whole, intact ecosystems of transformations with their inherent relationships.
Our main result shows that two large collections of measure preserving transformations have exactly the same structure with respect to factors and isomorphisms (and more generally, joinings). More concretely, define the odometer based transformations to be those finite entropy transformations that contain a non-trivial odometer factor. Spectrally, this is equivalent to the associated unitary operator having infinitely many finite period eigenvalues. To each odometer, we can associate a class of symbolic systems, the circular systems. In [5], it is shown that the circular systems coincide exactly with the ergodic transformations realizable as diffeomorphisms of the torus using the untwisted method of Approximation-by-Conjugacy, due to Anosov-Katok ([1]).
We can make two categories by taking the objects to be these two classes of systems and by taking morphisms to be factor maps (or more generally joinings) that preserve the underlying timing structure. The main theorem of this paper says that these two categories are isomorphic by a map that takes measure-isomorphisms to measure-isomorphisms, weakly mixing extensions to weakly mixing extensions and compact extensions to compact extensions. It follows that it takes distal towers to distal towers. Moreover the map preserves the simplex of non-atomic invariant measures, takes rank one transformations to rank one transformations and much more. (This will be discussed further in the forthcoming [8].) In other words the global structure of these two categories is identical.
We can get more detail by considering systems based on a fixed odometer map and circular systems based on that odometer map and an arbitrary fast growing coefficient sequence. Doing so gives us collections of pairwise isomorphic categories that can be amalgamated to yield the statement above. The main theorem is framed in this more granular setting.
Our result might be a mere curiosity, were it not for an application which we now describe.
Foreshadowed by a remarkable early result by Feldman [4], in the late 1990’s a different type of result began to appear: anti-classification results that demonstrate in a rigorous way that classification is not possible. This type of theorem requires a precise definition of what a classification is. Informally a classification is a method of determining isomorphism between transformations perhaps by computing (in a liberal sense) other invariants for which equivalence is easy to determine.
The key words here are method and computing. For negative theorems, the more liberal a notion one takes the stronger the theorem. One natural notion is the Borel/non-Borel distinction. Saying a set or function is Borel is a loose way of saying that membership in or the computation of can be done using a countable (possibly transfinite) protocol whose basic input is membership in open sets. Say that or is not Borel is saying that determining membership in or computing cannot be done with any amount of countable resources.
In the context of classification problems, saying that an equivalence relation on a space is not Borel is saying that there is no countable amount of information and no countable transfinite protocol for determining, for arbitrary whether . Any such method must inherently use uncountable resources.111Many well known classification theorems have as immediate corollaries that the resulting equivalence relation is Borel. An example of this is the Spectral Theorem, which has a consequence that the relation of Unitary Conjugacy for normal operators is a Borel equivalence relation.
In considering the isomorphism relation as a collection of pairs of measure preserving transformations, Hjorth showed that is not a Borel set. However the pairs of transformations he used to demonstrate this were inherently non-ergodic222The ergodic components of the pairs were rotations of the circle., leaving open the essential problem:
Is isomorphism of ergodic measure preserving transformations Borel?
This question was answered by Foreman, Rudolph and Weiss in [6], where they gave a negative answer. This answer can be interpreted as saying that determining isomorphism between ergodic transformations is inaccessible to countable methods that use countable amounts of information.
In the same foundational paper from 1932 where von Neumann formulated the isomorphism problem he expressed the likelihood that any abstract measure preserving transformation is isomorphic to a continuous measure preserving transformation and perhaps even to a differentiable one. This brief remark eventually gave rise to one of the outstanding problems in smooth dynamics, namely:
Does every ergodic MPT have a smooth model?
By a smooth model is meant an isomorphic copy of the transformation which is given by smooth diffeomorphism of a compact manifold preserving a measure equivalent to the volume element. Soon after entropy was introduced, A. G. Kushnirenko showed that such a diffeomorphism must have finite entropy, and up to now this is the only restriction that is known.
This paper is the second in a series of papers whose original purpose was to show that the variety of ergodic transformations that have smooth models is rich enough so that the abstract isomorphism relation, when restricted to these smooth systems, is as complicated as it is in general. We show this to be the case even when restricting to diffeomorphisms of the 2-torus that preserve Lebesgue measure this is the case. In the third paper we will complete the proof of the following theorem:
Theorem** (Anti-classification of Diffeomorphisms).**
If is either the torus , the disk or the annulus then the measure-isomorphism relation among pairs of measure preserving -diffeomorphisms of is not a Borel set with respect to the -topology.
It was natural for us to try to adapt our earlier work to establish this result. However we were faced at first with the following difficulty. The transformations built in [6] were based on odometers (in the sense that the Kronecker factor was an odometer). It is a well known open problem whether it is possible to have any smooth transformation on a compact manifold that has a non-trivial odometer factor. Thus proving the anti-classification theorem in the smooth context required constructing a different collection of hard-to-classify transformations and then showing that this collection could be realized smoothly. This is our application of the main result of this paper.
The paper ([5]) constructed a new collection of systems, the Circular Systems, which are defined as symbolic systems constructed using the Circular Operator, a formal operation on words. The main result in [5] has as a consequence that uniform circular systems can be realized as smooth models using the method developed by Anosov and Katok.
The primary theorem of this paper allows us to transfer the general isomorphism structure for odometer based systems to the isomorphism structure for circular systems, at least up to automorphisms of the underlying odometer or rotation. Namely there remains the issue of preserving the timing mechanism. In the forthcoming [7] it is shown how to construct odometers so that for the resulting circular systems, up to a small correction factor, all isomorphisms preserve the underlying timing structure. This allows us to conclude the proof of the anti-classification theorem for diffeomorphisms.
Here is a more concrete description of the results in the paper. In the present paper we are concerned with the entire class of systems based on a fixed odometer and the relations between them. The odometer is determined by a sequence of positive integers greater than one, . The the circular operator is determined by an additional sequence of integers . For this paper, the sequence of ’s can be arbitrary subject to the requirement that . However for realizing circular systems as diffeomorphisms there is a fixed growth rate, determined by the size of the alphabet of the odometer based system and , that the sequence of ’s must eventually exceed.
We describe symbolically here, but show in a forthcoming paper that consists of representations of arbitrary ergodic systems with finite entropy that have the specific odometer as a factor. In the language of “cutting and stacking” constructions these are those constructions where no spacers are introduced. We fix , and hence a sequence of circular operators. Applying these to each of the elements of we obtain a second class, , of circular systems. This class consists of some of the extensions of a fixed irrational rotation which is determined by the circular operator. As remarked above, for suitably chosen coefficient sequences, this class can be characterized as those transformations realizable as diffeomorphisms using the Anosov-Katok technique. We consider the two classes as categories where the morphisms are graph joinings which are either the identity of the base or reverse it. These are called synchronous and anti-synchronous joinings respectively. Our main theorem then takes the form:
Theorem 1**.**
For a fixed circular coefficient sequence the categories and are isomorphic by a functor that takes synchronous joinings to synchronous joinings, anti-synchronous joinings to anti-synchronous joinings, isomorphisms to isomorphisms and weakly mixing extensions to weakly mixing extensions.333E. Glasner showed that the functor takes compact extensions to compact extensions.
It is natural to extend the collections of morphisms of and to general synchronous and non-synchronous joinings. Because the ergodic joinings are not closed under composition, in extending Theorem 1 one is forced to consider at least some non-ergodic joinings. At the end of the paper we discuss how to extend Theorem 1 to expanded categories that have as morphisms arbitrary synchronous and anti-synchronous joinings. This involve expanding our analysis of generic sequences to non-ergodic joinings. We also describe some detailed analysis of the combinatorics behind the isomorphism .
We have provided a detailed table of contents which enumerates the contents of the paper. Here is a brief summary. Much of the section following this one is standard, with the exception §2.6, which is exposes generic sequences for transformations and extends that notion to joinings. In §3, the reader will find an explanation of our two categories and a proof that circular systems contain a canonical rotation factor. Section 4 is primarily concerned with defining a map that is a symbolic analogue of complex conjugation on the unit circle. In sections 5 and 6 the mapping is defined on morphisms, while contains the proof of the main result. In there is a more detailed analysis of of the dynamical properties of our mapping which may prove useful in the future, and in the final section we collect some problems that are left open.
1.1 Acknowledgements
This work was inspired by the pioneering work of our co-author Dan Rudolph, who passed away before this portion of the grand project was undertaken. We owe an inestimable debt to J.P. Thouvenot who suggested using the Anosov-Katok technique to produce our badly behaved transformations rather than directly attacking the “odometer obstacle.” We would like to thank E. Glasner for showing that preserves compact extensions. Finally the first author would like to thank Christian Rosendal for asking very useful questions about how general our results were.
2 Preliminaries
This section establishes some of the conventions we follow in this paper. There are many sources of background information on this including any standard text or [20], [15]. A small portion of the material in this section was presented in [5], but is repeated here in an attempt to be self-contained. The reader is referred to [5] for any missing definitions.
2.1 Measure Spaces
We will call separable non-atomic probability spaces measure spaces and denote them where is the Boolean algebra of measurable subsets of and is a countably additive, non-atomic measure defined on .444We will occasionally make an exception to this by calling discrete probability measures on a finite set measures; we hope that context makes the difference clear. We will often identify two members of that differ by a set of -measure [math] and seldom distinguish between and the -algebra of classes of measurable sets modulo measure zero unless we are making a pointwise definition and need to claim it is well defined on equivalence classes.
We will frequently use without explicit mention the Maharam-von Neumann result that every standard measure space is isomorphic to where is Lebesgue measure and is the algebra of Lebesgue measurable sets.
If and are measure spaces, an isomorphism between and is a bijection such that is measure preserving and both and are measurable. We will ignore sets of measure zero when discussing isomorphisms; i.e. we allow the domain and range of to be subsets of and (resp.) of measure one. A measure preserving system is an object where is a measure isomorphism. A factor map between two measure preserving systems and is a measurable, measure preserving function such that . A factor map is an isomorphism or conjugacy between systems iff is a measure isomorphism. Following common practice, we will use the word conjugacy interchangeably with isomorphism in this context.
For a fixed measure space we can consider the collection of measure preserving transformations . These form a group that can be endowed with a Polish topology that has basic open sets described as follows. We fix a finite measurable partition of and an and take as a neighborhood of
[TABLE]
Details about this topology can be found in many sources including [12], [20].
2.2 Joinings
We remind the readers of the definitions. Extensive treatments of joinings can be found in [11] or [16]. All of the definitions and basic results about joinings necessary for this paper occur in Chapter 6 of the latter reference.
Definition 2**.**
A joining between two measure preserving systems and is a measure on defined on the product -algebra such that
* is invariant,* 2. 2.
for each set , , 3. 3.
for each set , .
The graphs of factor maps provide natural examples of joinings. We characterize these with a definition.
Definition 3**.**
A joining is a graph joining between and if and only if for all and all , there is a such that
[TABLE]
A joining between and is an invertible graph joining if and only for all there is a such that
[TABLE]
and vice versa: for all , there is a such that equation 1 holds.
Here are some standard facts (see [11]):
Proposition 4**.**
Let and . Then
There is a canonical one-to-one correspondence between the collection of graph joinings of and and the collection of factor maps from to . A graph joining concentrates on the graph of the factor map. We can represent the graph joining corresponding to a measure preserving map by
[TABLE] 2. 2.
There is a canonical one-to-one correspondence between the collection of invertible graph joinings of and and the collection of conjugacies between and . 3. 3.
Suppose that and are Boolean algebras that generate and respectively as -algebras. Let be a joining of with such that for all and all there are such that we have , then is a graph joining.
We note that perhaps a more proper term for an invertible graph joining is the earlier usage diagonal joining. In view of the results of this section we will often be careless and say that is a factor map or is a conjugacy/isomorphism to mean that is a graph joining or is an invertible graph joining.
To each joining of and we can associate its adjoint , the joining of with defined for and as:
[TABLE]
If is a graph joining corresponding to a factor map , then concentrates on .
The following is immediate:
Proposition 5**.**
* is an invertible graph joining if and only if both and are graph joinings.*
Thus we can apply Proposition 4, item 3 to both and to get a criterion for being the joining associated with a conjugacy.
A potential source of confusion. Proposition 4 allows us to identify graph joinings with factor maps and invertible graph joinings with conjugacies. These joinings are always ergodic as joinings. However, there are non-ergodic conjugacies between ergodic measure preserving transformations. More explicitly: there are ergodic systems and and non-ergodic isomorphisms .555The second author has given examples of of isomorphic ergodic transformations where every conjugacy is non-ergodic. The associated joining is, however, ergodic as a -invariant measure.
Let and be measure spaces and and be factor maps. We can define a canonical joining of and that reflects the factor structure as follows. We let and be the disintegrations of and over respectively. The relatively independent joining of and over is the joining :
[TABLE]
We will sometimes write this as .
We will be concerned about categories of measure preserving systems where the morphisms are joinings. For this we must describe the composition operation. Suppose we are given joinings between and and between and . Then is a common factor of both and and we can consider the relatively independent joining .
We define the composition of and to be the projection of the relatively independent joining of and to a measure on . Formally, if and is the relatively independent joining, then:
[TABLE]
Example 6**.**
Suppose that and are factor maps. If is the joining associated with and is the joining associated with , then is the joining associated with the factor map .666In the following, in the context of factor maps we will be sloppy about whether this is associated with a joining of with or a joining of with .
The following are standard facts (e.g. in §6.2 of [11]):
Proposition 7**.**
The operation of composition of joinings is associative: if and are joinings, then
[TABLE] 2. 2.
Suppose that and are factor maps Let and be joinings of and respectively. Let be the projection of to a joining of and via and be defined similarly. Finally let be the projection of the composition of and to a joining of with . Then:
[TABLE]
2.3 Symbolic Systems
Let be a countable or finite alphabet endowed with the discrete topology. Then can be given the product topology, which makes it into a separable, totally disconnected space that is compact if is finite.
Notation: If is a finite sequence of elements of , then we denote the cylinder set based at in by writing . If we abbreviate this and write . Explicitly: . The collection of cylinder sets form a base for the product topology on .
Notation: For a word we will write for the length of . We will write for the characteristic function of the interval in .
The shift map:
[TABLE]
defined by setting is a homeomorphism. If is a shift invariant Borel measure then the resulting measure preserving system is called a symbolic system. The closed support of is a shift invariant closed subset of called a symbolic shift or sub-shift.
Symbolic shifts are often described intrinsically by giving a collection of words that constitute a clopen basis for the support of an invariant measure. Fix a language , and a sequence of collections of words with the properties that:
for each all of the words in have the same length , 2. 2.
each occurs at least once as a subword of each , 3. 3.
there is a summable sequence of positive numbers such that for each , every word can be uniquely parsed into segments
[TABLE]
such that each , and for this parsing
[TABLE]
The segments in condition 2 are called the spacer or boundary portions of .
Definition 8**.**
A sequence satisfying properties 1.)-3.) will be called a construction sequence.
Associated with a construction sequence is a symbolic shift defined as follows. Let be the collection of such that every finite contiguous subword of occurs inside some . Then is a closed shift invariant subset of that is compact if is finite.777 The symbolic shifts built from construction sequences coincide with transformations built by cut-and-stack constructions.
Formally, we have constructed a symbolic shift. To get a measure preserving system we find a shift invariant measure concentrating on and write . In [5] we define the notion of a uniform construction sequence and show that the resulting are uniquely ergodic.
We want to be able to unambiguously parse elements of . For this we will use construction sequences consisting of uniquely readable words.
Definition 9**.**
Let be a language and be a collection of finite words in . Then is uniquely readable iff whenever and then either or is the empty word.
In our constructions we will restrict our measures to a natural set:
Definition 10**.**
Suppose that is a construction sequence for a symbolic system with each uniquely readable. Let be the collection such that there are sequences of natural numbers , going to infinity such that for all there is an .
Note that is a dense shift invariant set. The following lemma is routine:
Lemma 11**.**
Fix a construction sequence for a symbolic system in a finite language. Then:
* is the smallest shift invariant closed subset of such that for all , and , has non-empty intersection with the basic open interval .* 2. 2.
Suppose that there is a unique invariant measure on , then is ergodic.
Item 1 is clear from the definitions. If is a Polish space, is a Borel automorphism and is a -invariant Borel set with a unique -invariant measure on , then that measure must be ergodic.
Let be a uniquely readable construction sequence, and . By the unique readability, for each either lies in a well-defined subword of belonging to or in a spacer of a subword of belonging to some .
Lemma 12**.**
Suppose that is built from and is a shift invariant measure on concentrating on . Then for -almost every there is an for all , there are such that .
Let be the collection of such that for some , but is in a boundary portion of . By the Ergodic Theorem and clause 3.) of the definition of a construction sequence .
It follows from the Borel-Cantelli Lemma that for almost all there is an such that for all , . Fix an and such an . From the definition of there are arbitrarily large and such that . Using backwards induction from to and the definition of , this also holds for all .
2.4 Locations
By Lemma 12 for -almost all and for all large enough there is a unique with such that .
Definition 13**.**
Let and suppose that for some . We define to be the unique with with this property. We will call the interval the principal -block of , and its principal -subword. The sequence of ’s will be called the location sequence of .
We interpret as saying that is the symbol in the principal -subword of containing [math]. We can view the principal -subword of as being located on an interval inside the principal -subword. Counting from the beginning of the principal -subword, the position is located at the position in .
Remark 14**.**
Suppose that has a principal -block for all . Let . It follows immediately from the definitions that and are well defined and the position of the principal -block of is in the position inside the principal -block of .
The next lemma tells us that an element of is determined by knowing any tail of the sequence together with a tail of the principal subwords of .
Lemma 15**.**
Suppose that and and for all , and have the same principal -subwords. Then .
Since there are sequences tending to infinity such that and . Since we know that and . Since and have the same principal subwords, . The lemma follows.
Remark 16**.**
We record some consequences of Lemma 15:
Suppose that we are given a sequence with . If we specify which occurrence of in is the principal occurrence, and the distances of the principle occurrence to the beginning of go to infinity, then determines an completely up to a shift with . 2. 2.
A sequence and sequence of words comes from an infinite word if both and go to infinity and that the position in is in the position in a subword of identical to .
Caveat*: just because is the location sequence of some and is the sequence of principal subwords of some , it does not follow that there is an with location sequence and sequence of subwords .* 3. 3.
If have the same principal -subwords and for all large enough , then .
2.5 A note on inverses of symbolic shifts
We define operators we label , and apply them in several contexts
Definition 17**.**
If is in , we define the reverse of by setting . For , define:
[TABLE]
If is a word, we define to be the reverse of . If we are viewing as sitting on an interval, we take to sit on the same interval. Similarly, if is a collection of words, is the collection of reverses of the words in .
If is an arbitrary symbolic shift then its inverse is . It will be convenient to have all of our shifts go in the same direction, thus:
Proposition 18**.**
The map sending to is a canonical isomorphism between and .
We will use the notation for the system and for the system .
We can say more. For a fixed symbolic shift , the canonical isomorphism gives rise to a canonical correspondence
[TABLE]
between joinings of with and joinings of with .
We will also use the following remark.
Remark 19**.**
Assume that there is a unique non-atomic measure on a shift invariant set . Then there is also a unique non-atomic shift invariant measure on and for this measure, which we denote , we have .
2.6 Generic points and sequences
Let be a measure preserving transformation from to , where is a compact metric space. Let be the space of all real valued complex functions. Then a point is generic for if and only if for all ,
[TABLE]
The Ergodic Theorem tells us that for a given and ergodic equation above holds for a set of -measure one. Intersecting over a countable dense set of gives a set of -measure one of generic points. For symbolic systems we can describe generic points as being those such that the -measure of all basic open intervals is equal to the density of such that occurs in at .
The symbolic systems we consider will be built from construction sequences and are characterized by the limiting properties of finite information. We now describe how this works in greater detail. A more complete discussion of this can be found in [21].
Let be a shift invariant measure on a symbolic system defined by a uniquely readable construction sequence in a finite language . Assume that is the length of the words in . By we will denote the discrete measure on the finite set given by . By we will denote the discrete probability measure on defined by
[TABLE]
Thus is the relative measure of among all . The denominator is a normalizing constant to account for spacers at stages and for shifts of size less than .
Explicitly, if is the start of a word in , then the sets are disjoint and their union has a measure that tends to one as grows to infinity. The set is partitioned into many sets by the words and gives their relative size in . Since the measure of an arbitrary finite cylinder set can be calculated along the individual columns represented by a fixed , it is clear that the determine uniquely the measure .
Using the unique readability of words in a word in determines a unique sequence of words in such that ,
[TABLE]
When , each is in the region of spacers added in , . We will denote the empirical distribution of -words in by EmpDist. Formally:
[TABLE]
Then extends to a measure on in the obvious way.
To finitize the idea of a generic point in we introduce the notion of a generic sequence of words.
Definition 20**.**
A sequence is a generic sequence of words* if and only if for all and there is an for all ,*
[TABLE]
The sequence is generic for a measure if for all :
[TABLE]
where is the variation norm on probability distributions.
It follows that if is a generic sequence of words then it is generic for a unique measure . Even though Definition 20 involves only the measures it is easy to see (using the Ergodic Theorem) that for any , if is generic then the density of the occurrences of in the will converge to .
We can summarize the exact relationship between the empirical distributions and the by saying that the empirical distribution is the proportion of occurrences of among the -words that appear in , whereas is approximately the density of the locations of the start of -words in . Letting , be the density of the positions where an occurrence of begins in , and be the density of locations of letters in some spacer we see that these are related by:
[TABLE]
We record the following consequence of the Ergodic Theorem for future reference:
Proposition 21**.**
Let be an ergodic symbolic system with construction sequence and measure . Then for any generic the sequence of principal subwords of s, , is generic for . In particular, generic sequences for exist.
We will need a characterization of when a generic sequence of words determines an ergodic measure.
Definition 22**.**
A sequence with is an ergodic sequence* if for any and there are , and such that for all , if*
[TABLE]
is the parsing of into words and spacers then there is a subset with and for all
[TABLE]
Notice that in the definition of an ergodic sequence we are not assuming that it is a generic sequence for a measure. This follow easily (see Lemma 24), but we have not made it part of the definition to emphasize its finitary nature. In the next lemma we use the fact that the language is finite.
Lemma 23**.**
Any generic sequence for an ergodic measure is an ergodic sequence.
Suppose we are given and . For all we can apply the Ergodic Theorem to find an much bigger than and a set with such that for all and all :
[TABLE]
Fix a generic point for . Let , and define an infinite sequence of disjoint intervals of length that cover by inductively letting , and . We take the intervals to be the sequence
[TABLE]
Notice that the complement of these intervals in has density less than since their union clearly covers .
Though this is an infinite sequence of intervals, the fact our language is finite implies that only finitely many distinct words of length occur as subwords of on these intervals. For each such word , the density of those in the domain of such that an occurrence of a starts at is within of .888By taking , we can account for negligible “end effects” so that . We ignore end effects in the rest of the proof.
Next take large enough that , and parse into words from and the sections of corresponding to spacers in words in for some . By taking large enough we can take the density of locations in occurring in spacers to be arbitrarily small. Let be this density.
The words from have length much larger than , and we can collect all those words that are -covered by the -intervals we chose above into a set .
The proportion of not covered by words in can be split into the spacer section and the portion inside words in . For the complement of the -intervals has density at least . It follows that the density of sections of covered by elements of is less than .
Thus the fraction of not covered by words in is at most . It is now clear that if are chosen to be sufficiently small then
[TABLE]
and all will have the property that
[TABLE]
which implies inequality 3 for pairs of words in . Using inequality 4 and the fact that is generic for gives an so that for all when is parsed into words a -fraction will lie in and this concludes the proof.
We will also need the converse to Lemma 23, namely that the limiting measure defined by an ergodic sequence is, in fact, ergodic.
Lemma 24**.**
An ergodic sequence is generic and the measure defined by an ergodic sequence is ergodic.
Inequality 3 implies that for each and , the limit of the density of occurrences of in exists as goes to infinity. It follows (since is finite) that is a generic sequence and hence it defines a unique measure .
The ergodicity of is equivalent to the fact that the ergodic averages of all functions converge almost everywhere to a constant. Functions of the form where and their shifts linearly span a dense set in from which it easily follows that if were not ergodic there would be some , and with converging -a.e. to a non-constant function. This means that there is a and disjoint sets of positive measure in such that for all large enough for all
[TABLE]
Take small compared to and . Find as in the definition of ergodic sequence for this and . Choose large enough that inequality 5 holds and so that is negligible. Finally take so that is negligible.
The inequality 5 depends only on the initial -block of and . Thus for large enough we can compute and by the empirical distributions of the -blocks in .
Since is large compared to the frequency of occurrence of in a block of length is determined by its frequencies in the words in in the -parsing of . We now get a contradiction to inequality 5, since except for an -fraction, these -words have their -words distributed very close to .
If and are symbolic systems then a joining of and will be a symbolic system, but may not have well-defined construction sequence, even if and do.999We run into this problem when considering joinings of circular systems and their inverses that project to the -map on the canonical factors; these notions are defined in future sections. Accordingly we must generalize our definition of empirical distribution to take into account the relative locations of words in typical . We express this by shifting one of the basic open sets and considering words , which we view as starting at the locations .
Let and be uniquely readable construction sequences for and in the languages respectively. Assume for simplicity that all words in and have the same length.
Let . Then we can uniquely parse a word as
[TABLE]
where each and each is in the region of spacers for words in , . The similar statement holds for , and :
[TABLE]
The definition must take into account the relative shifts of and , the shifts of allow spacers to occur in different places and for the possibility that .
Let be natural numbers, , and and . Write and in terms of and -words as above. For , define an occurrence of in to be a such that and if is the location of in , then occurs at in . We note the bijection between occurrences of in and occurrences of in .
In defining empirical distributions for joinings we generalize Definition 20. The empirical distribution of a shifted pair is defined to be the proportion of times it occurs, relative to the proportion of times arbitrary pairs with the same shift occur.
Definition 25**.**
Fix Let be the collection
[TABLE]
Assume that . For and , we define:
[TABLE]
As before, extends uniquely to a probability measure on . Definition 25 facilitates a notion of a generic sequence for a joining.
Definition 26**.**
A sequence of is called generic iff
* and* 2. 2.
for all and there is an for all ,
[TABLE]
The definition of an ergodic sequence of pairs is done analogously.
It is easy to check that is generic/ergodic if and only if is generic/ergodic. For ergodic joinings the analogues of Proposition 21, and Lemmas 23 and 24 hold and are proved in exactly the same way.
We have given these definitions in the case of a product of two symbolic shifts, but they generalize immediately to products of three or more shifts. For example, to consider three shifts with construction sequences , we would consider a sequence of the form:
[TABLE]
where the words belong to the respective construction sequences and the ’s and ’s give the shifts relative to the first coordinate.
We will be concerned with compositions of joinings, which involves products of three shifts. To prepare for this we need the notion of a conditional empirical distribution.
Definition 27**.**
Let . Given a fixed and a pair and we define the conditional empirical distribution* to be:*
[TABLE]
[TABLE]
for
Using the same ideas we can define the empirical distribution conditioned on a by looking at and counting occurrences of for the .
This definition generalizes to products of three or more systems. When working in three or more systems, there will be multiple ’s playing the role of in Definition 27. They will refer to the position of the sequences being counted, relative to the conditioning sequence. So for example, if have construction sequences and is a generic sequence for a joining of and , then
[TABLE]
counts pairs , where have been shifted by and *relative to *.
Let be a -invariant measure on and a -invariant measure on . Recall from Section 2.2 that the composition of and is defined to be projection of the relative independent joining of and over the common factor to a measure on . We now describe a method for detecting generic sequences for relatively independent joinings.
Suppose that systems and have a common factor .
[TABLE]
Let be the relatively independent joining of and . Let be the distintegrations of and respectively. Then the relatively independent joining is characterized by the fact that for -a.e ,
[TABLE]
Let be sequences of refining partitions that generate and respectively. Since the sequence of partitions generates , equation 6 is equivalent to the property that for all and -a.e. ,
[TABLE]
To finitize this we approximate by for large , where is the atom of to which belongs. We let be shorthand for the distribution , and stands for the conditional distribution . (We use similar notation in Lemma 28 for the conditional distribution given by and on various partitions.)
By Martingale convergence,101010See (e.g.) [11], Theorem 14.26, page 261. for and fixed if sufficiently large, then for proportion of the in the same atom as :
[TABLE]
but for a collection of of whose union has -measure less than .
One can deal similarly with and . We have shown:
Lemma 28**.**
In the notation above, is the relatively independent joining of and if and only if for all , for all large enough , there is a collection of atoms of total measure at least for which:
[TABLE]
We now express Lemma 28 in terms of sequences of finite words. Suppose that , and are the uniquely readable construction sequences for , and .
Proposition 29**.**
Let be a sequence of words. Suppose that:
* is generic for ,* 2. 2.
* is generic for .* 3. 3.
for all and for all sufficiently large there is an and a set and for each a set of indices that satisfies such that for all :
- (a)
**
and 2. (b)
for all and ,
[TABLE]
is less than .
If is the relatively independent joining of , then is a generic sequence for .
Observe that the hypothesis 3b implies a similar equation for any while the other parameters are fixed. Now use hypothesis 3a with a summable sequence of ’s and we can conclude by the Borel-Cantelli lemma that for -almost every for sufficiently large, if is the principal -block of with location , then the inequality in 3b will hold for and .
Now by hypotheses 1 and 2, the single empirical distributions are converging to and respectively (where is the disintegration of over ).
It then follows by integration that the sequence of ’s is generic for a measure on , which is the relatively independent joining.
Remark 30**.**
It follows immediately from hypothesis 3 of Proposition 29 that if we are given a finite set of natural numbers then for all sufficiently large we can find an , and as in hypothesis 3 so that (a) and (b) hold simultaneously for all .
An immediate corollary of this is:
Corollary 31**.**
Suppose that satisfies the hypotheses of Proposition 29. Then is generic for .
There is a converse to Proposition 29, namely that a generic sequence for the relatively independent joining of two odometer based system satisfies the conditions 1-3 of the Proposition. The first two are immediate while the third simply expresses the fact that the generic sequence sequence is actually representing the relatively independent joining. For later use we record this as:
Lemma 32**.**
Given joinings of and of if is generic for the relatively independent joining then it satisfies the hypotheses of Proposition 29.
2.7 Unitary Operators
We will use spectral tools introduced by Koopman and studied by Halmos and von Neumann. We reprise the basic facts we will use. Readers unfamiliar with this material can find it in [20] or [11]. Let and be measure preserving systems.
If is a measure preserving transformation then induces a unitary isometry by setting
[TABLE]
If is an isomorphism then is invertible. Moreover if is multiplicative on bounded functions then there is a measure preserving transformation such that .
If is a factor map, then the map gives an injection of into , whose range is a closed invariant subspace. Conversely if is a closed invariant subspace containing 1 that is closed under taking complex conjugates, truncation and multiplication by elements of , then there is a factor such that .
For the rest of this discussion assume that is ergodic. Then the eigenvalues of all have multiplicity one and form a subgroup . The group is an isomorphism invariant.
The collection of eigenfunctions generate a closed subspace of corresponding to a factor of . This factor is called the Kronecker factor. If is any subgroup of then there is a further factor of that is canonically determined by the eigenfunctions coming from eigenvalues in .
Assume that is an isomorphism from to . Then and if are the factors of and determined by then determines an unique isomorphism between and .
It follows from this that if is an eigenvalue of then there are factors of and isomorphic to rotation of by . Moreover there is a unique isomorphism that intertwines and the projection maps of and to .
The analogous statement holds for odometers. If consists of finite order eigenvalues and is the corresponding odometer transformation, then there is a unique isomorphism that intertwines and the projection maps of and to .
2.8 Stationary Codes and -Distance
In this section we briefly describe a standard idea, that of a stationary code that we will use to understand the existence of factor maps and isomorphisms. We review some standard facts here. A reader unfamiliar with this material who wants to see proofs should see [17].
Definition 33**.**
Suppose that is a countable language. A code of length is a function , where is the interval of integers starting at and ending at .
Given a code and an we define the stationary code determined by to be where:
[TABLE]
Let be a symbolic system. Suppose we have two codes and that are not necessarily of the same length. Define and . Then is a semi-metric on the collection of codes. The following is a consequence of the Borel-Cantelli lemma.
Lemma 34**.**
Let Suppose that is a sequence of codes such that . Then there is a shift invariant Borel map such that for -almost all ,
A shift invariant Borel map , determines a factor of by setting (i.e. ). Hence a convergent sequence of stationary codes determines a factor of .
Let and be codes. Define to be
[TABLE]
More generally we can define the metric on by setting
[TABLE]
For , we set
[TABLE]
provided this limit exists.
To compute distances between codes we will use the following application of the Ergodic Theorem.
Lemma 35**.**
Suppose that is ergodic and that and be codes. Then for almost all :
[TABLE]
We finish with a useful remark:
Remark 36**.**
If and are words in a language defined on an interval and with , then .
3 Odometer based and Circular Symbolic Systems
Two types of symbolic shifts play central roles for the proofs of our main theorem. We dub them odometer based and circular systems. In this section we give some general facts about symbolic systems with uniquely readable construction sequences, define odometer and circular systems, and show that every circular system has a canonical rotation factor.
3.1 Odometer Based Systems
We recall the definition of an odometer transformation. Let be a sequence of natural numbers greater than or equal to 2. Let
[TABLE]
be the -adic integers. Then naturally has a compact abelian group structure and hence carries a Haar measure . We make into a measure preserving system by defining to be addition by 1 in the -adic integers. Concretely, this is the map that “adds one to and carries right”. Then is an invertible transformation that preserves the Haar measure on . Let .
The following results are standard:
Lemma 37**.**
Let be an odometer system. Then:
* is ergodic.* 2. 2.
The map is an isomorphism between and . 3. 3.
Odometer maps are transformations with discrete spectrum and the eigenvalues of the associated linear operator are the roots of unity ().
Any natural number can be uniquely written as:
[TABLE]
for some sequence of natural numbers with .
Lemma 38**.**
Suppose that is a sequence of natural numbers with and . Then there is a unique element such that for each .
We now define the collection of symbolic systems that have odometer maps as their timing mechanism. This timing mechanism can be used to parse typical elements of the symbolic system.
Definition 39**.**
Let be a uniquely readable construction sequence with the properties that and for all for some . The associated symbolic system will be called an odometer based system.
Thus odometer based systems are those built from construction sequences such that the words in are concatenations of words in of a fixed length . The words in all have length and the words in equation 2 are all the empty words.
Equivalently, an odometer based transformation is one that can be built by a cut-and-stack construction using no spacers. An easy consequence of the definition is that for odometer based systems , for all and for all , exists.
Proposition 40**.**
Let be an odometer based system and suppose that is a shift invariant measure. Then concentrates on .
Let . Then is shift invariant. Suppose that gives positive measure. For let be the left and right endpoints of the principal -block of . Then for all there is an such that:
for all or 2. 2.
for all .
We assume that gives the collection of such that there is an for all positive measure, the other case is similar.
Define by setting least satisfying item 1. Then is a Borel function. Let . Then the ’s are disjoint, and . Hence for all , a contradiction.
The next lemma justifies our terminology.
Lemma 41**.**
Let be an odometer based system with each . Then there is a canonical factor map
[TABLE]
where is the odometer system determined by .
For each , we know that for all is defined and both and go to infinity. By Lemma 38, the sequence defines a unique element in . It is easily checked that intertwines and .
In the forthcoming paper [8] we show a strong converse to this result: if has finite entropy and an odometer factor then can be presented by an odometer based system.
Heuristically, the odometer transformation parses the sequences in by indicating where the words constituting begin and end. Shifting by one unit shifts this parsing by one. We can understand elements of as being an element of the odometer with words in filled in inductively.
We will use the following remark about the canonical factor of the inverse of an odometer based system.
Remark 42**.**
If is the canonical factor map, then the function is also factor map from to (i.e. with the operation “”). If is the construction sequence for , then is a construction sequence for . If is the canonical isomorphism given by Proposition 18, then Lemma 37 tells us that the projection of to a map is given by .
From this remark we immediately see:
Lemma 43**.**
Let be the canonical correspondence between joinings of and and joinings of and given after Proposition 18. Then the joining concentrates on the set of pairs such that if and only if concentrates on the collection of such that .
3.2 Circular systems
We now define and discuss circular systems. The paper [5] showed that the circular systems give symbolic characterizations of the smooth diffeomorphisms defined by the Anosov-Katok method of conjugacies. The construction sequences of circular systems have quite specific combinatorial properties that will be important to our understanding of the Anosov-Katok systems and their centralizers in the third paper in this series.
We call these systems circular because they are closely tied to the behavior of rotations by a convergent sequence of rationals . The rational rotation by permutes the intervals of the circle cyclically along a sequence determined by some numbers (mod ): the interval is the interval in the sequence.111111We assume that and are relatively prime and the exponent is the multiplicative inverse of mod . The operation which we are about to describe models the relationship between rotations by and when is very close to .
Let be positive natural numbers with relatively prime. Set
[TABLE]
with . It is easy to verify that:
[TABLE]
Let be a non-empty set. We define an operation , which depends on , an integer , and on sequences of words in a language by setting:121212We use for repeated concatenation of words.
[TABLE]
To start our construction we frequently take and . In this case we adopt the convention that . Hence
[TABLE]
Remark 44**.**
We remark:
- •
Suppose that each has length , then the length of is .
- •
Every occurrence of an in has an occurrence of a to the left of it. If then every occurrence of a has an to the right of it.
- •
Suppose that and occurs at position in and occurs at and neither occurrence is in a . Then there must be some occurring between and .
The operator automatically creates uniquely readable words, as the next lemma shows, however we will need a stronger unique readability assumption for our definition of circular systems.
Lemma 45**.**
Suppose that is a language, , and that , and are words in the language of some fixed length . Let
[TABLE]
Suppose that is written as where and are words in . Then either is the empty word and or is the empty word and .
The map is one-to-one. Hence each location in the word of length is uniquely determined by the lengths of nearby sequences of ’s and ’s.
In fact something stronger is true: if occurs at place in then is uniquely determined by the knowing the and the letters on either side of .
We now describe how to use the operation to build a collection of symbolic shifts. Our systems will be defined using a sequence of natural number parameters and that is fundamental to the version of the Anosov-Katok construction presented in [14].
Fix an arbitrary sequence of positive natural numbers . Let be an increasing sequence of natural numbers such that . From the and we define sequences of numbers: . We begin by letting and and inductively set
[TABLE]
(thus ) and take
[TABLE]
Then clearly is relatively prime to .131313 and being relatively prime for , allows us to define the integer in equation 9. For , has one element, , so we set .
Definition 46**.**
A sequence of integers such that , will be called a circular coefficient sequence*.*
Let be a non-empty finite or countable alphabet. We will construct the systems we study by building collections of words in the alphabet by induction as follows:
- •
Fix a circular coefficient sequence .
- •
Set .
- •
Having built we choose a set and form by taking all words of the form with .141414Passing from to we use with parameters and and take modulo . By Remark 44, the length of each of the words in is .
We will call the elements of prewords.
Strong Unique Readability Assumption: Let , and view as a collection of letters. Then each element of can be viewed as a word with letters in . We assume that in the alphabet , each is uniquely readable.
Definition 47**.**
A construction sequence will be called circular if it is built in this manner using the -operators, a circular coefficient sequence and each satisfies the strong unique readability assumption.
It follows from Lemma 45 that each in a circular construction sequence is uniquely readable.
Definition 48**.**
A symbolic shift built from a circular construction sequence will be called a circular system.
For emphasis we will often write circular construction sequences as and the associated circular shift . We sometimes write to emphasize that a word is a circular word.
We will need to analyze the words constructed by in detail. We start by describing the boundary and interior portions of the words.
Definition 49**.**
Suppose that . Then consists of blocks of repeated times, together with some ’s and ’s that are not in the ’s. The interior of is the portion of in the ’s. The remainder of consists of blocks of the form and . We call this portion the boundary of .
In a block of the form the first and last occurrences of will be called the boundary occurrences of the block . The other occurrences will be the interior occurrences.
While the boundary consists of sections of made up of ’s and ’s, not all ’s and ’s occurring in are in the boundary, as they may be part of a power .
The boundary of constitutes a small portion of the word:
Lemma 50**.**
The proportion of the word written in equation 11 that belongs to its boundary is . Moreover the proportion of the word that is within letters of boundary of is .
The next lemma was proved in [5] (Lemma 20).
Lemma 51**.**
Let be a circular system and be a shift invariant measure on . Then the following are equivalent:
* has no atoms.* 2. 2.
* concentrates on the collection of such that is unbounded in both and .* 3. 3.
* concentrates on .*
Remark 52**.**
Let be a circular system.
There are only two invariant atomic measures, one concentrates on the constant “” sequence, the other on the constant “” sequence. 2. 2.
for , Lemma 12 can be strengthened to say that for all for all large enough , the principal -block of exists. 3. 3.
The symbolic shift has zero topological entropy.
A direct inspection reveals that the only periodic points in are the two fixed points constant “” and “”.
The second item follows because if has a principal -block at then it has a principal -block at some for an with .
The fact that the topological entropy of is zero follows easily from the fact that the tend to infinity.
3.3 The structure of the words
The words used to form circular transformations have quite specific combinatorial properties. We begin with an important definition for our understanding of rotations; the three subscales at stage . Fix a sequence defining a circular system. Using equation 11 we define the subscales of a word :
- Subscale 0 is the scale of the individual powers of of the form ; we call each such occurrence of a a 0-subsection
- Subscale 1 is the scale of each term in the product that has the form ; We call these terms 1-subsections.
- Subscale 2 is the scale of each term of that has the form ; We call these terms 2-subsections.
Summary
[TABLE]
By contrast we will discuss -subwords of a word . These will be subwords that lie in , the stage of the construction sequence. We will use -block to mean the location of the -subword.
3.4 The canonical circle factor
We now define a canonical factor of a circular system and show that this factor is isomorphic to a rotation of the circle by , where is the limit of as goes to infinity.
Definition 53**.**
Let be a circular coefficient sequence. Let . We define a circular construction sequence such that each has a unique element as follows:
* and* 2. 2.
If then .
Let be the resulting circular system.
It is easy to check that has unique ergodic non-atomic measure, since every occurs exactly many times in .
Let be an arbitrary circular system with coefficients . Then has a canonical factor isomorphic to . This canonical factor plays a role for circular systems analogous to the role odometer transformations play for odometer based systems.
To see is a factor of , we define the following function:
[TABLE]
We record the following easy lemma that justifies the terminology of Definition 53:
Lemma 54**.**
Let be defined by equation 14. Then:
* is a Lipshitz map,* 2. 2.
* and thus* 3. 3.
* is a factor map of to and to *
A variant of item 3 is also true: can be interpreted as a function from to . With this interpretation is also a factor map. We will call the circle factor of any circular system with construction coefficients .
Fix a circular coefficient sequence , and let and be given in definition 53. Let and .
If , from we can determine the locations of the beginnings and ends of the words that contain . Since for all , for all the sequence uniquely determines .
Theorem 55**.**
Let be the unique non-atomic shift invariant measure on . Then
[TABLE]
where is the rotation of the unit circle by and are the -algebras of measurable sets.
A more involved geometric proof of this fact is given in [5]. Here present a simple algebraic proof. As usual we identify the unit circle with and use additive notation for the group operations.
By Lemma 12, the collection of such that for all large enough , the principal -block of exists, has measure one. We define a map by a limiting process. For such that exists, we let
[TABLE]
iff
[TABLE]
Claim 56**.**
If is defined, then .
From equation 11, we see that the position of in an -block is determined by the parameters and , which determine its location among the 2-subsections, 1-subsections, 0-subsections and inside the -words respectively. Explicitly:
[TABLE]
where is the position of in its principal -word.
From the definition of , and working mod 1:
[TABLE]
Expanding this, using our formula for and the fact that all but two terms of are divisible by , we get:
[TABLE]
where
[TABLE]
The first and third terms of equation 15 cancel, thus:
[TABLE]
Since , the claim follows.
Since the sequence is summable, for almost all is Cauchy. We define
[TABLE]
It is easy to check that is one-to-one. By the unique ergodicity of the rotation , Theorem 55 will be proved when we establish:
Claim 57**.**
The map satisfies:
[TABLE]
In particular, if is the unique invariant measure on
[TABLE]
Suppose that and both exist. Then . If follows that . Taking limits we see that .
This finishes the proof of Theorem 55.
3.5 Kronecker Factors
Both odometer transformations and irrational rotations of the circle are ergodic discrete spectrum transformations. Because the odometer transformation based on is a factor of any odometer based system and the rotation is a factor of any circular system , both are factors of the respective Kronecker factors of or . In general it is not the whole Kronecker factor in either case.
We make the following lemma explicit in the case of odometer based transformations. In the case of systems with a circle factor the exactly analogous results hold.
Lemma 58**.**
Let and be measure preserving systems. Suppose that has an odometer factor and that is an isomorphism. Then there is a unique odometer factor of with an isomorphism such that the following diagram commutes:
[TABLE]
If each finite order eigenvalue of has multiplicity 1 (e.g. if is ergodic), then is the unique odometer factor of isomorphic to .
Since the unitary operator takes eigenfunctions to eigenfunctions, we know that takes the subspaces of corresponding to to a subspace of corresponding to an isomorphic copy of . The lemma follows.
An immediate corollary of Lemma 58 is that if and are ergodic odometer based systems over the same odometer , with projections and , then is an isomorphism between the canonical odometer factors.
We record the following consequences for later use;
Proposition 59**.**
Suppose that and are both ergodic odometer based systems with coefficients . Then any isomorphism takes the canonical odometer factor of to the canonical odometer factor of .
Similarly if and are both ergodic circular systems with the same coefficient sequences , then any isomorphism between and takes the canonical rotation to the canonical rotation factor
In the first case there is a unique factor of and corresponding to the eigenvalues of and . Any isomorphism must preserve the factor corresponding to these eigenvalues. The same argument works for , as it is isomorphic to the rotation by .
3.6 Uniform Systems
In [5] it is established that the strongly uniform circular systems with sufficiently fast growing , are realizable as measure preserving diffeomorphisms of the torus. Strongly uniform systems are those for which each word in occurs the same number of times in each word in . These systems carry unique non-atomic invariant measures, simplifying much of what we do later in this paper. For example the correspondence between the measures on uniform odometer systems and on their uniform circular system counterparts given in equation 33, is automatic.
In the forthcoming [8] we show that arbitrary (i.e. non-uniform) circular systems are realizable as measure preserving diffeomorphisms of the torus, provided that the measures of the words in go to zero.
4 Details of Circular Systems
This section examines the circular systems defined in section 3.2 in more detail. Initially we are given a circular coefficient sequence and where satisfies the inductive definition in equation 12. When is fixed, we again let modulo and . Without significant loss of generality it is convenient to assume that .
To understand joinings of circular systems we will be comparing generic elements of circular and , and their parsings into subwords. We will use the following terminology:
Definition 60**.**
Let be finite sequences of elements of having length . Given intervals and in of length we can view and as functions having domain and respectively. We will say that is shifted by relative to iff is the shift of the interval by . We say that is the -shift of iff and are the same words and is the shift of the interval by .
4.1 Understanding the words
We elaborate on the descriptions given in Section 3.3. Our first combinatorial lemma is the following:
Lemma 61**.**
Let for some and . View as a word in the alphabet lying on the interval of integers .
If and are the locations of the beginnings of [math]-subsections in the same 2-subsection, then . 2. 2.
If and are such that is the location of the beginning of a [math]-subsection occurring in a -subsection and at the i beginning of a [math]-subsection occurring in the next 2-subsection then .
To see the first point, the indices of the beginnings of [math]-subsections in the same -subsection differ by multiples of coming from powers of a and intervals of of the form .
To see the second point, let and be consecutive -subsections. In view of the first point it suffices to consider the last [math]-subsection of and the first [math]-subsection of . But these sit on either side of an interval of the form . Since , we see that .
Assume that and and is shifted with respect to . On the overlap of and , the 2-subsections of split each 2-subsection of into either one or two pieces. Since all of the 2-subsections in both words have the same length, the number of pieces in the splitting and the size of each piece is constant across the overlap except perhaps at the two ends of the overlap. If splits a 2-subsection of into two pieces, then we call the left piece of the pair the even piece and the right piece the odd piece.
If is shifted only slightly, it can happen that either the even piece or the odd piece does not contain a -subsection. In this case we will say that split is trivial on the left or trivial on the right
Lemma 62**.**
Suppose that the -subsections of divide the -subsections of into two non-trivial pieces. Then
the boundary portion of occurring between each consecutive pair of 2-subsections of completely overlaps at most one [math]-subsection of 2. 2.
there are two numbers and such that the positions of the [math]-subsections of in even pieces are shifted relative to the [math]-subsections of by and the positions of the [math]-subsections of in odd pieces are shifted relative to the [math] subwords of by . Moreover .
This follows easily from Lemma 61
In the case where the split is trivial we get Lemma 62 with just one coefficient, or .
A special case Lemma 62 that we will use is:
Lemma 63**.**
Suppose that the -subsections of divide the -subsections of into two pieces and that for some occurrence of an -subword of in an even (resp. odd) piece is lined up with an occurrence of some -word in . Then every occurrence of an -word in an even (resp. odd) piece of is either:
- a.)
lined up with some -subword of or 2. b.)
lined up with a portion of a -subsection that has the form .
Moreover, no -subword in an odd (resp. even) piece of is lined up with a -subword in .
4.2 Full measure sets for circular systems
Fix a summable sequence of numbers in and a circular coefficient sequence . As we argued in the proof of Lemma 50, the proportion of boundaries that occur in words of is always summable, independently of the way we build . Recall the set given in Definition 10, where is the symbolic shift defined from a construction sequence.
Definition 64**.**
We define some sets that a typical generic point for a circular system eventually avoids. Let:
* be the collection of such that does not have a principal -block or is in the boundary of that -block,* 2. 2.
* is in the first or last copies of in a power of the form where ,* 3. 3.
* is in the first or last 1-subsections of the 2-subsection in which is located*, 4. 4.
* is in the first or last 2-subsections of the principal -block of*.
Lemma 65**.**
Assume that . Let be a shift invariant measure on , where is a circular system. Then:
[TABLE]
Assume that is a summable sequence, then for : 2. 2.
[TABLE]
This is an application of the Ergodic Theorem.
In particular we see:
Corollary 66**.**
For -almost all there is an such that for all ,
* is in the interior of its principal -block,* 2. 2.
.
In particular, for almost all and all large enough : 3. 3.
if , then
[TABLE] 4. 4.
* is not in a string of the form or .*
This follows from the Borel-Cantelli Lemma.
The elements of such that some shift fails one of the conclusions 1.)-4.) of Corollary 66 form a measure zero set. Consequently we work on those elements of whose whole orbit satisfies the conclusions of Corollary 66. Note, however that the depends on the shift .
Definition 67**.**
We will call mature for (or say that is mature at stage ) iff is so large that for all .
Thus if is mature at stage then for all the principal -block of exists and conclusions 1-4 of Corollary 66 hold.
Recall that in Section 3.2, we defined a canonical factor of a circular system which we called the circle factor. Since the notion of maturity only involves the punctuation of the words involved, it is an easy remark that for all , is mature for just in case is mature for , where is the canonical factor map.
For the following definition and lemma, we view as a function with domain , and as a function with domain or, sometimes, an interval . In each of these cases we use dom() to mean the domain of .
Definition 68**.**
We will use the symbol in multiple equivalent ways. If or we define to be the collection of such that is in the boundary portion of an -subword of . This is well-defined by our unique readability lemma. In the spatial context we will say that if is the boundary of an -subword of .
For
[TABLE]
An integer, iff , viewed as an element of , belongs to the -boundary, .
In what follows we will be considering a generic point and all of its shifts. We will use the fact if is mature at stage , then we can detect locally those for which the -shifts of are mature.
Lemma 69**.**
Suppose that , is mature for and .
Suppose that . Then is mature for iff
- (a)
* and* 2. (b)
. 2. 2.
For all but at most portion of the , the point is mature for .
In particular, if , and is mature for , the upper density of those for which the -shift of is not mature for is less than .
Similarly:
Lemma 70**.**
Suppose that and has a principal -block. Then is mature provided that . In particular, if is mature for and is not in a boundary portion of its principal -block or in , then is mature for .
4.3 The map
Proposition 59 implies that any isomorphism between an ergodic and induces an isomorphism between and , where is the canonical circle factor. Because is canonically isomorphic with (Proposition 18) and is isomorphic to the rotation of the circle, we see that is isomorphic to the rotation .
We use a specific isomorphism as a benchmark for understanding of potential maps . If we view as a rotation of the unit circle by radians one can view the transformation as a symbolic analogue of complex conjugation on the unit circle, which is an isomorphism between and . Copying over to a map on the unit circle gives an isomorphism between and . Such an isomorphism must be of the form
[TABLE]
for some . It follows immediately from this characterization that is an involution, however for completeness we prove this directly (and symbolically) in Proposition 79.
As usual we find it more convenient to work on the unit interval rather than the unit circle. The complex conjugacy map corresponds to the map on .
We begin by recalling from equation 11 the formula for a that is of the form :
[TABLE]
where and with . By examining this formula we see that
[TABLE]
Applying the identity in formula 10, we see that this can be rewritten as151515We take .
[TABLE]
We can reindex again and get another form of equation 17:
[TABLE]
We can now state the basic lemma about the way lines up with a shift of .
Lemma 71**.**
Let and view as sitting at location . Let and . Consider as being the word in location . For all but at most of the occurrences of an -subword of starting in a location , the reversed word occurs in starting at .
The word starts with a block of ’s and then a block of copies of , whereas starts with a block of ’s followed by copies of . Hence if we shift to the right by (to get ) the first copy of is aligned with the first copy of in . Hence all of the copies of in the first 1-subsection are aligned with the copies of in the first 1-subsection of . Because the consecutive blocks of ’s and ’s (or ’s and ’s) in the 2-subsections add up to we see that every copy of in the first 2-subsection of is aligned with with a copy of .
We now argue as in Section 4.1. At the end of each 2-subsection, has a block of ’s of length , followed at the beginning of the next 2-subsection, by a block of ’s of length . Together the ’s and ’s form a block of length , which is equivalent mod() to . Similarly the combined length of a block of ’s and ’s finishing and starting consecutive 2-subsections of is equal to mod().
Both the beginning of the block of ’s ending the 2-subsection and the end of the block of ’s starting the 2-subsection are of distance less than from the location of the end of the 2-subsection. It follows from this and the comments in the previous paragraph, that if and are consecutive 2-subsections of and and are the corresponding 2-subsections of then the beginning of the first occurrence of in is within of the first occurrence of is and their locations are equivalent mod(). Hence inside the first 1-subsection, the 0-subsections are lined up except for at most copies of . This pattern is continued through , giving at most locations of -blocks that are not aligned in .
Since there are less than 2-subsections with potential misalignments, the Lemma is proved.
The next proposition gives a somewhat more detailed view into situation of Lemma 71.
Proposition 72**.**
Let and suppose that
[TABLE]
We look at the relative positions of -words in and .
Each occurrence of in is either lined up with an occurrence of or entirely lined up with a section of inside . 2. 2.
There is a number such that for all the number of occurrences of lined up with an occurrence of is .
The first part is clear from the proof of Lemma 71. The second part follows because all of the 1-subsections in a given 2-subsection of have the same alignment relative to .
Since the total number of occurrences of -subwords in , the proportion of -subwords lined up with in is at most .
Suppose that is given by the canonical construction sequence . We define a sequence of functions and argue that they converge to an isomorphism from to .
We begin by defining an increasing sequence of natural numbers. Recall the definition of the Anosov-Katok coefficients and given in equations 13 and 12. Since and are relatively prime we can define in . For the following definition we will view as a natural number with .161616In the notation used to define , . However the notation is ambiguous (it depends on ), so we use in this context.
We let and
[TABLE]
Lemma 73**.**
If is defined as above, then .
This is proved inductively using the fact that .
Let be the circular system in the language , as given in Definition 53. We now define a stationary code with domain that approximates elements of by defining
[TABLE]
Since for all and all large enough , is defined, the default value is only obtained for finitely many .
Lemma 74**.**
* is given by a finite code.*
To check whether is defined one need only examine on the interval . The relevant portion of necessary to compute is contained in . Hence is determined by a finite code.
The formula in equation 20 can be understood as follows. Suppose that and has a principal -block. Then the element defined as belongs to , has a principal -block that is the reverse of the principal -block of and moreover, the principal -block of is exactly lined up with the principal -block of .
The reverse of the principal -block of begins with a block of many ’s, and hence if then the first -subword of the principal -block of is lined up with the first -subword of the principal -block of . The rest of the terms used to define (coming from ) are used for lower order adjustments inside this principal -block.
Thus, a qualitative description of can be given as follows:
It first reverses the principal -block of leaving it exactly lined up. 2. 2.
It then adjusts the result by shifting so that the first occurrence of a reverse -block lines up with the first -subword of the principal -block of . (So far we have described .) By Lemma 71, we get a sequence where the principal -block of has the vast majority of its -blocks lined up with the -blocks of : all of them except those that span a section of boundary at the juncture of two 2-subsections of the principal -word of . 3. 3.
Finally it shifts by which is the cumulative adjustment at earlier stages.
The next lemma follows from this description:
Lemma 75**.**
Let and suppose that has a principal -block. Let . Then at least
[TABLE]
proportion of the -blocks in the principal -block of are lined up with -blocks in .
We first consider . By Lemma 71, all but of the -blocks in are aligned with the -blocks in . This is proportion
[TABLE]
The general result follows by induction.
Theorem 76**.**
Suppose that is a circular coefficient sequence. Then the sequence of stationary codes converges to a shift invariant function that induces an isomorphism from to .
We first show that the sequence converges, which will follow if we show that the code distances between the and are summable. For notational simplicity, let and with .
Claim: There is a summable sequence of positive numbers such that for almost all , the -distance between and is bounded by , and and agree on all but at most proportion of the -blocks of .
We use Lemma 35, which tells us that for a typical , the code distance between and is , which is defined to be the density of
[TABLE]
Because for each , there is only one possible -subword at any location of any element of . Thus to compute -distance, it suffices count positions where the ’s disagree on the locations of the -subwords.
By Lemma 69 for a typical and all , is not mature for has density at most , hence we can neglect these when computing the density of .
This allows us to assume that is defined. We compute the density of the difference between and as they pass across an -block in . If this number is then the distance between and is bounded by the sum of and the density of .
As crosses an -block it produces the reverse -block shifted by . Explicitly, if is the -block of , as crosses it produces . As passes across this same section, each time it crosses an -block it produces . If starts at then the beginning of this copy of is .
We begin by rewriting as where . By Lemma 71, all but of the -blocks in are aligned with the -blocks in . Hence, relative to the complement of , the portion of the principal -block of that lies in an -block aligned with an -block of is
[TABLE]
Because there is only one possible -word, whenever is aligned with they are equal.
Putting this altogether, we see that and agree on all of the -subwords of the principal -block of that are aligned with . The disagreements are limited to the -subwords that are not aligned and the boundary. The total length of the disagreements is therefore bounded by
[TABLE]
This has proportion .
Thus the distance between and is bounded by . In particular the distances are summable and the sequence converges almost everywhere to a function .
We now show that is an isomorphism between and . Since takes an -block to a shift of the reverse -block, it makes sense to discuss the principal -block of . Since the ’s cohere as in Remark 14, for , is in the position of the principal -block of (provided both and are defined). An application of the Ergodic Theorem shows that if is defined to be the collection of such that:
[TABLE]
then . From the Borel-Cantelli Lemma, it follows that for almost every for all large enough the principal -blocks of and are the same, and thus that for .
We now argue that if is typical and , then . It suffices to show that and .171717We are adopting the convention that in defining for we count from the left end of an -block. Thus the position in a word corresponds to the position in .
If is mature for and large enough that for and have the same principal -blocks, then unless . Assuming that , we know from Lemma 73 that
[TABLE]
Hence, and . Applying Lemma 69 (using the fact that , and hence ) we see that for large , and that . Since we have shown that .
As noted before Theorem 55, if then is determined by any tail of the sequence . In particular, if we know a tail of we can determine . Since for large , , is one-to-one on a set of measure one.
We can now conclude that is an isomorphism. It is shift invariant since it is a limit of stationary codes, it maps from to , and is one-to-one on a set of -measure one. If we define a measure on the Borel sets of by setting , then is a shift invariant, non-atomic measure on . Since is uniquely ergodic, is as well and thus must be equal to the unique invariant measure . We have shown that is an isomorphism between and .
Definition 77**.**
We denote the limit of by .
We describe the qualitative behavior of in a remark that we will use later:
Remark 78**.**
There is a summable sequence such that for all but measure of , there is an interval containing 0 in such that , and moreover and agree on this interval. It follows from the Borel-Cantelli Lemma that for almost all and large enough , agrees with on the principal -block of . Thus for a typical and large enough , the map reverses the principal -block while keeping its location and then shifts it by .
As noted at the beginning of this section, the next proposition follows immediately from Theorem 55, however we include a symbolic proof for completeness.
Proposition 79**.**
The map is an involution.
It is immediate from the qualitative description of given before Lemma 75, that each is an involution. To see that is the identity, let . We can choose an large enough that for all , and agree with on all but proportion of the -blocks and has measure . Then is equal to the identity on a set of density at least . Letting and completes the argument.
4.4 Synchronous and Anti-synchronous joinings
Every odometer based system has a built in metronome: its odometer factor defined in Lemma 41. Correspondingly circular systems can be timed by their canonical rotation factor defined in Lemma 54.
Joinings between odometer based and circular systems may induce non-trivial automorphisms of the underlying timing structure. To avoid this complication we restrict ourselves to synchronous and anti-synchronous joinings: those which preserve or exactly reverse the underlying timing. We now make this idea precise.
Both the odometer transformations and rotations of a circle have easily understood inverse transformations and the isomorphisms between transformations and their inverses are given by the maps and respectively. If and are either odometer based or circular systems let and be the corresponding odometer or rotation systems on which they are based.
Definition 80**.**
- •
Let and be odometer based systems with the same coefficient sequence, and a joining between and . Then is synchronous if joins and and the projection of to a joining on is the graph joining determined by the identity map (the diagonal joining of the odometer factors); is anti-synchronous if is a joining of with and its projection to is the graph joining determined by the map .
- •
Let and be circular systems with the same coefficient sequence and a joining between and . Then is synchronous if joins and and the projection to a joining of with is the graph joining determined by the identity map of with , the underlying rotations; is anti-synchronous if it is a joining of with and projects to the graph joining determined by on .
There is always a synchronous joining of odometer systems with the same underlying timing factor :
Definition 81**.**
Suppose that and are based on . Then the relatively independent joining of and over is a synchronous joining, which we will call the synchronous product joining. The relatively independent joining of and over the map we will call the anti-synchronous product joining. We will use the same terminology for the independent joinings of circular systems over the identity and .
5 Building the Functor
The main result of this paper concerns two categories whose objects are odometer based systems and circular systems respectively. The morphisms in these categories will be graph joinings. We will show that there is a functor taking odometer systems to circular systems that preserves the factor and conjugacy structure. In this section we focus on defining the function from odometer based systems to circular systems that underlies the functorial isomorphism between these categories.
We begin by defining a function from the odometer based symbolic shifts to the circular symbolic shifts . After having done so we define on the pairs where is an invariant measure on . Finally we define on synchronous and anti-synchronous graph joinings.
We will use the notation that . Then the ’s are the lengths of the odometer based words in and the ’s are the lengths of the circular words in .
Except where otherwise stated we will assume that we are working with a fixed circular coefficient sequence .
Let be a language and be a construction sequence for an odometer based system with coefficients . Then for each the operation is well-defined. We define a construction sequence and bijections by induction as follows:
Let and be the identity map. 2. 2.
Suppose that and have already been defined.
[TABLE]
Define the map by setting
[TABLE]
We note in case 2 the prewords are:
[TABLE]
Definition 82**.**
Define a map from the set of odometer based systems (viewed as subshifts) to circular systems (viewed as subshifts) as follows. Suppose that is built from a construction sequence . Define
[TABLE]
where has construction sequence .
Suppose that is a circular system with coefficients . We can recursively recursively build functions from words in to words in . The result is a odometer based system with coefficients .181818We are using the strong unique readability assumption on the ’s to see the unique readability of the words in the sequence .
If is the resulting odometer based system then . Thus we see:
Proposition 83**.**
The map is a bijection between odometer based symbolic systems with coefficients and circular symbolic systems with coefficients .
That is one-to-one follows from the unique readability of words occurring in the construction sequence .
Remark 84**.**
It is clear from Definition 82 that preserves uniformity and strong uniformity (see [5] for these notions). In fact it preserves much more: the simplex of non-atomic invariant measures, rank one transformations and so on. We verify much of this in this paper and more in the forthcoming [8].
To understand the correspondence between measures on and we will have to understand the structure of basic open intervals. Recall that we write to mean the basic open interval of determined by sitting on the interval . Without the subscript , is shorthand for . We adopt the same conventions for , that the subscripts correspond to the beginning of the sequence and without a subscript the sequence begins at zero.
5.1 Genetic Markers
To see that can be extended to a map from invariant measures on odometer based systems to invariant measures on circular systems, we begin by recalling how to identify elements of a symbolic system. Suppose that is a construction sequence for an odometer based transformation . Let be the corresponding circular construction sequence for . By Lemma 15 to specify a typical or , it suffices to give a tail of the sequence of principal -blocks or along with the locations or .
Definition 85**.**
Suppose that are words in and respectively and occurs as an -subword of in a particular location. Viewing as a concatenation of -subwords, there is a such that . Let and call the genetic marker of in .
Suppose that and and is an -subword of occurring at a particular location. Then there is a sequence of words such that is a -subword of at a definite location and the location of in is inside . Let be the genetic marker of inside . We call the sequence the genetic marker of in . If is the genetic marker of some -word inside and -word, we will call it an -genetic marker.
If occurs as a subword of then the genetic marker of that occurrence codes its location inside .
Suppose that has principal -blocks . Each is a concatenation of words . Let
[TABLE]
or equivalently
[TABLE]
Each is a concatenation of words , and we see that belongs to . In particular, the genetic marker of inside is the sequence .
Genetic markers for regions of words in : In circular words, genetic markers code regions rather than subwords. Given and as above, we can consider the construction of starting with the collection is an -subword of . Each of the genetic markers of a subword of determines a region of -subwords of . More explicitly, in the first step of the construction we put into the argument of . At the next step we put the result into the argument of and so on. Thus we see that there are bijections between
sequences with , 2. 2.
-subwords of , 3. 3.
the regions of occupied by the occurrences of powers where is the element of determined by .
Thus genetic markers give the correspondence between the regions of that are not in and particular occurrences of an -word in .
The next lemma computes the number of occurrences of a with a given genetic marker in .
Lemma 86**.**
Suppose that occurs in with genetic marker . Then the number of occurrences of in with the same genetic marker is
[TABLE]
Fix and . We prove equation 25 for by induction on . If then we have a single genetic marker . By formula 11 for we see that the argument occurs in exactly times.
Suppose now that we know that formula 25 holds for . We show it for . Let and be the -subword of with genetic marker. Let be the subword of with genetic marker . Then:
[TABLE]
is equal to
[TABLE]
[TABLE]
The lemma follows.
Since particular -genetic markers correspond to powers of ’s that occur with the same multiplicity in , independently of the marker, we see that for a given and :
[TABLE]
We can restate equation 26 in the language of section 2.6. It says that
[TABLE]
In particular, if we fix a set of genetic markers we can compare the number of occurrences of a word with genetic marker in in with the number of occurrences in the corresponding . Specifically, the number of occurrences of a word in at some genetic marker in is . The proportion of -words occurring with a genetic marker in relative to all -words occurring in is the same as the proportion of -words with genetic markers in occurring in relative to the total number of genetic markers. The number of -genetic markers is so this proportion is equal to
[TABLE]
This is simply a restatement of our discussion involving empirical distributions in Section 2.6.
We introduce some notation that allows us to compare densities of various sets between odometer based and circular words. For sets and we denote their densities by:
[TABLE]
Then and can be viewed as discrete probability measures on the sets and respectively.
Lemma 87**.**
Let , and . We view as sitting on the interval and as sitting on Let be a collection of -genetic markers, the total number of -genetic markers and .
If:
- •
* some with genetic marker in begins at in *
- •
* some with genetic marker in begins at in ,*
then the following equations hold:
[TABLE]
We prove equation 30. Equation 29 is similar but easier. The other two equations follow algebraically.
The union of the boundary regions for to consist exactly of the elements of that are not part of any -word. We denote the complement of by . The various are pairwise disjoint and for each , consists of the locations of entire -words. Starting with , iteratively deleting boundary sections as decreases to , and using Lemma 50 we see that the -measure of is .
Let is at the beginning of an -word. Then consists of a portion of the regions made up of -words; i.e. . We note that and is disjoint from .
By Lemma 86, the number of -words occurring in with a given genetic marker does not depend on the marker. Let be the total number of -words occurring in . Then:
[TABLE]
We compute conditional expectations to get equation 30:
[TABLE]
Equation 29 is similar and 31, 32 follow from the first two equations by substitution.
The following relationship between pairs of measures on and on
[TABLE]
is the limit of equation 32 as goes to infinity. This relationship will hold for a correspondence between measures that we build in forthcoming sections.
We note that since has a density that depends only on the circular coefficient sequence, the measures of is the same for all invariant measures. If we set be this density, then we can rewrite the previous equation as:
[TABLE]
A consequence of equation 33 is that for all basic open sets , determines and vice versa.
For counting arguments the following inequalities will be helpful.
Lemma 88**.**
Let be a number greater than [math]. Then there are constants between 0 and 1 such that for all and and all collections of -genetic markers,
if
[TABLE]
then
[TABLE]
By equation 25 there are
[TABLE]
many that occur at the beginning of occurrences of -subwords with genetic markers in . Since
[TABLE]
we have:
[TABLE]
Since the is a summable sequence, converges as goes to . The inequality 34 follows.
Since , inequality 34 can be rewritten as:
[TABLE]
Infinite genetic markers: Suppose that we are given a construction sequence for an odometer based or circular system , and an occurrence of an -word in . Then we can inductively define an infinite sequence of words , letting , and to be the -subword of that contains . For each we get a genetic marker , and these cohere as goes to infinity. We define the infinite genetic marker to be .
If an -word occurs inside an occurrence of an -word in , then . Thus their infinite genetic markers agree on the tail .
As in Remark 16, if we are given a sequence of words , with , and an infinite sequence such that the genetic marker denotes an instance of in then we can find an with as a tail of its principal subwords. If is odometer then is unique up to a shift of size less than or equal to . A similar statement holds for circular systems.
5.2 and .
To understand the relationships between and , we define maps and where and are as in definition 10. The map will be one-to-one but will not, in general it is continuum-to-one. Nevertheless will be the identity map.
We begin by considering a element . Let be the principal -subword of . The sequence determines a sequence of circular words which we assemble to define . Let be the infinite genetic marker of . To describe completely we need to define . Set , and inductively define to be the position in the first occurrence of an -word with genetic marker in . Set to be the element of with principal subwords and location sequence .
We define a map that associates an element of to each element of . Given such an , let be its sequence of principal -subwords. For each occurs as in the preword corresponding to . Let . Then the sequence of words and genetic markers determine an element of except for the location of 0 in the double ended sequence. (The sequence is double ended because .)
We determine this location arbitrarily in a manner that makes the sequence of ’s the principal -blocks of () and the the sequence of genetic markers of these -blocks. Let be a sequence of zeros of length . Then is a well-defined member of the odometer associated with . From equation 24, determines a sequence . Thus by Lemma 15, the pair and determines a unique element of which we will denote . It is easy to check that and that for each , there is a perfect set of with .
We can get more precise information about correspondences between and by noting that if we are given a sequence of principal subwords of an , the genetic markers define an element of up to a choices . Specifically, suppose that is such that the infinite genetic marker of is . Then there is an that has a sequence of principal -blocks .
The following lemma will be useful for understanding joinings.
Lemma 89**.**
Let . Then . If , and , then there is a canonical correspondence between occurrences of in and finite regions of where occurs. The occurrences of in these finite regions have the same infinite genetic marker in as does in .
Given an and a , the shift and have a tail of the principal -blocks in common. Moreover the genetic markers associated with this tail are the same for both and . It follows that is a shift of .
We can describe the correspondence as follows. If occurs in at , then is the principal -word of . Choose an so large that some -word is the principal -word of both and . Then is the principal -block of . Let be the genetic marker of the occurrence of (at ) in . The region of corresponding to this occurrence of is the collection of occurrences of with the genetic marker in the principal -block of .
5.3 Transferring measures up and down, I
In this section we develop the tool we need for lifting measures on to measures on . This will also allow us to establish a one-to-one correspondence between synchronous joinings on odometer systems and synchronous joinings on the corresponding circular systems. Throughout this section we will use to denote either the projection of an odometer based system to its canonical odometer factor or a circular system to its canonical circular factor.
We begin with a proposition relating sequences of words in a construction sequence for an odometer based system to sequences of words in a construction sequence for a circular system.
Proposition 90**.**
Let be a sequence with . Let . Then:
* is an ergodic sequence iff is an ergodic sequence.* 2. 2.
* is a generic sequence for a measure iff is a generic sequence for a measure . In case either sequence is generic, the measures and satisfy equation 33.*
Both parts follow immediately from the definitions using equations 27 and 28 to relate the frequencies of -words in -words , for to the frequencies of in the corresponding . Equation 33 follows from the Ergodic Theorem and Lemma 87.
We endow that collection of invariant measures on a symbolic system with the weak* topology.
Theorem 91**.**
Let be a uniquely readable construction sequence for an odometer based system and be the associated circular construction sequence for . Then there is a canonical affine homeomorphism between shift invariant measures concentrating on and non-atomic, shift invariant measures such that equation 33 holds between and .
By Proposition 40 and Lemma 51 we can assume that and concentrate on and respectively.
We begin by defining the correspondence for ergodic measures. Suppose that we are given an ergodic measure and we want to associate a measure . Let be a generic point for . Let be the sequence of principal -blocks of . By Proposition 21 this sequence is generic for . By Proposition 90, if we let , then is an ergodic sequence. Let be the measure associated with . Then is ergodic and equation 33 holds by Proposition 90.
The other direction is similar, let be generic for . Propositions 21 and 90 imply that if is the sequence of principal -blocks of and , then is ergodic and generic for a measure . Again equation 33 holds by Proposition 90.
Suppose now that is an arbitrary measure on . Write the ergodic decomposition of as:
[TABLE]
We define by
[TABLE]
which gives a corresponding measure on . Since equation 33 holds between corresponding ergodic components and , it holds between and .
By the ergodic decomposition theorem the map is a surjection. Since the map is invertible, it is a bijection. The map is affine by construction.
It remains to show that it is a homeomorphism. To see that is weak* continuous it suffices to show that for all and there is a and an such that for all invariant , if for all
[TABLE]
we know that for all we have
[TABLE]
But the equation 33 easily implies this taking and
[TABLE]
The argument that the inverse is continuous is the same.
Definition 92**.**
We will call a pair constructed as in Theorem 91 corresponding measures*.*
Remark 93**.**
It follows from Proposition 90 that if and are corresponding measures on and and is arbitrary then is generic for iff is generic for . The point is generic just in case its sequence of principal subwords is generic for . By item 2 of Proposition 90, this holds just in case the sequence of principal subwords of is generic; i.e. is generic.
We can use Theorem 91 to characterize the possible simplexes of invariant measures for circular systems. By a theorem of Downarowicz ([3], Theorem 5), every non-empty compact metrizable Choquet simplex is affinely homeomorphic to the simplex of invariant probability measures for a dyadic Toeplitz flow. Note that the space of invariant probability measures is always a compact Choquet simplex, hence this theorem is optimal.
Since Toeplitz flows are special cases of odometer based systems it follows immediately that every non-empty compact metrizable Choquet simplex is affinely homeomorphic to the simplex of invariant measures of a 2-symbol odometer based system.
Let be a compact Choquet simplex and an odometer based system having its simplex of invariant probability measures affinely homeomorphic to . Let be a circular system corresponding to an odometer based system . Then the non-atomic measures on are a Choquet simplex isomorphic to . There are two additional ergodic measures, the atomic measures concentrating on the constant “” sequence and on the constant “” sequence. These two atomic measures are isolated among the ergodic measures.
In the forthcoming [8] we discuss the question of invariant measures further and show that preserves several other properties, such as being rank one.
6 , genetic markers and the -map
Our goal is to understand the structure of synchronous and anti-synchronous joinings between pairs of ergodic systems . We will use Theorem 91 to define a bijection between synchronous joinings of odometer based systems and synchronous joinings of circular systems. This is relatively easy: to a joining of with that projects to the identity we can directly associate an odometer system with a measure such that the corresponding measure on can be identified with a measure on that projects to the identity. We carry this construction out in detail in section 7 and show that the map given by Theorem 91 gives a bijection between synchronous joinings of the two kinds of systems.
The situation for anti-synchronous joinings of and is more complicated. In Lemma 43, we remarked that the anti-synchronous joinings of and can be identified with joinings of and that concentrate on . Similarly we can identify the anti-synchronous joinings of and with joinings of with that concentrate on . We give notation for these sets:
Let be the collection of anti-synchronous joinings of and . 2. 2.
Let be the collection of anti-synchronous joinings of and .
To understand the relationship between and we need an analogue of Lemma 87, and the corresponding analogue of equation 33. We now describe the tools we use to do this.
Fix construction sequences for and for and respectively based on and the corresponding circular systems based on .
Let be an arbitrary point in with and . Let and be the sequence of principal subwords of and respectively. If and , then and are the sequences of principal subwords of and .
Let . Then and set .
Definition 94**.**
Define by taking as its principal -subword sequence and as its location sequence.
We will study the relationship between and via the function taking to .
6.1 Genetic Markers revisited
To understand the relationship between joinings in and in we need to take into account the manner that shifts the reverse of the second coordinate of a the image of a generic pair for and the interplay between the map and genetic markers. Let . Suppose that is a pair of -words coming from that occur aligned inside -words . If and occur at the same location in , then determines in the following way:
for we must have
[TABLE]
(where ).
Definition 95**.**
Let and . Define the -genetic marker of an occurrence of the pair in to be where is the genetic marker of in and is the genetic marker of in .191919Note that the genetic marker denotes a different position inside then it does in . We call and a conjugate pair.
Being a conjugate pair is equivalent to satisfying the numerical relationship given in equation 36 and thus either element of a conjugate pair determines the other. Hence for purposes of counting conjugate pairs we need only use the first coordinates, .
Let be words that occur in a pair . Then the relative alignment of and in is determined by the -map. This is approximated with a high degree of accuracy by where the code sends intervals. Accordingly:
Definition 96**.**
Define the pair to be .
Thus determines a basic open interval in which we might also write as . Alternatively we could write this as:
[TABLE]
We now have a lemma extending Lemma 72 which says that if and belong to and then, relative to , all occurrences of in are either lined up with an occurrence of a for some or a boundary section of . The lemma also says that if are lined up then and form a conjugate pair.202020In this case both and are of length one.
Proposition 97**.**
Let and . Then for we consider occurrences of in .212121Since we are considering different shifts in and .
If occurs in , then and form a conjugate pair. 2. 2.
There is a constant such that all conjugate pairs occur times. 3. 3.
Fix a conjugate pair of genetic markers of . If is a location of an occurrence of in with genetic marker , but not a location of , then the section of in the interval is contained in .
Item 1 is immediate from the definitions.
The latter items are asking about pairs of the form occurring in . Such a pair occurs at if and only if the pair occurs aligned in at . Item 3 is equivalent to saying that is lined up with a portion of contained in .
We fix and prove 2 and 3 by induction on . The case that is the content of Lemma 72. Suppose that the proposition is true for and , we prove it for and .
A pair of -circular words lined up in the shifted pair must have conjugate genetic markers. Moreover any there is a number such that any pair with conjugate genetic markers occurs lined up many times.
Fix an occurrence of an -word so that no word in occurs at , i.e is not lined up with the reverse of an -word in . Then is lined up with a segment of that is a subset of in . To pass from to we shift by , where . Noting that each reversed -word ends with a string of ’s of length , we see that after the additional shift there can be no -subwords inside lined up with anything besides a portion of contained in .
Suppose that and are -words and we have an occurrence of and lined up in the pair . If and , we let be the occurrence of -subwords of with genetic markers and that contain and . It follows from the previous paragraph that the genetic markers of and are conjugate and are aligned in . By Lemma 72, and are conjugate and thus and are conjugate.
Further each conjugate pair occurs aligned the same number of times in the pair . The number is independent of and and . It follows now that given a conjugate pair of genetic markers , the number of occurrences of a pair of circular -words with genetic marker in aligned with an occurrence of a circular word with genetic marker is in is .
To finish we note that the unaligned -words are in two categories, those that are not aligned because the -words that contain them are not aligned, or those that are not aligned by the final shift . In each case, the unaligned -words in occur across from boundary sections in the word .
Thus, using the backwards -operation to wrap words around the circle in opposite directions introduces some slippage, but the slippage is uniform and predictable.
Definition 98**.**
Suppose that and are a conjugate pair of -genetic markers and . Let and have genetic markers and in respectively. Then the set of locations such that occurs in starting at with genetic marker but does not occur starting at in is called the -slippage of .
A location can belong to the slippage of for two mutually exclusive reasons. Either, for some proper tail segment of , is part of the slippage of the subword of with genetic marker or is part of the slippage of the inside the word containing caused by .
Let stand for the -slippage of -subwords of ; i.e. the locations in of some -word such that there there is no -word at position . Inside an -word we find multiple copies of corresponding the location of each word in . Denote the union of these copies as . Then it follows that:
[TABLE]
and moreover the union is disjoint.
The slippage is the portion of of the words that we have no control over when counting, so we want to be able to estimate the proportion of words in the slippage. Let
[TABLE]
The next proposition allows us to control the -slippage by controlling the successive -slippages.
Proposition 99**.**
[TABLE]
We begin by noting that for between and , all pairs of -words have the same proportion of slippage of -words in . Thus is equal to the proportion of slippage of all of the -words occuring in pairs of -subwords of .
The argument is similar to Lemma 87. Starting with and decreasing until , using that fact that the union in equation 37 is disjoint, one inductively demonstrates that:
[TABLE]
We can combine item 3 of Lemma 97 with equation 39 to see that if is in , then is a subset of . It thus follows from Lemma 75 that:
[TABLE]
Because the definition of was made entirely in terms of genetic markers, the whole discussion could have been carried out simply by considering . The numerics depend only on the circular coefficient sequence, not on particular construction sequences .
Viewing the operator as the limit of the codes , we can pass to infinity and define similarly and let be the proportion of locations of -subwords of a typical such that no -subword of occurs at .
Then:
[TABLE]
It follows that .
We now formulate and prove the version of Lemma 87 involving the map. One might expect that would require considering arbitrary pairs of genetic markers and . However, by Proposition 97, if occurs in with -genetic marker , then the only genetic marker it can occur lined up with in is its conjugate pair. Similarly either of the genetic markers of aligned words occurring in and occurring in determine the other member of the conjugate pair.
It follows that we need only consider pairs whose genetic markers are conjugate in . Since the map to is a bijection we will refer to either of or as the genetic marker of a pair or equivalently .
We are reduced to considering sets rather than sets of pairs of genetic markers. Let and let be a set of -genetic markers of pairs of -words in . Let
[TABLE]
and
[TABLE]
and define
[TABLE]
If occurs at in and occurs at in then occurs at in
Lemma 100**.**
Let and . Let be a collection of -genetic markers, the total number of -genetic markers222222As before it is easy to check that . and . Then (in the notation above):
[TABLE]
The proof is essentially the same as the proof of Lemma 87, indeed the proof of equation 42 is the same. Because all genetic markers occur with the same frequency, after allowing for the portions in boundary sections and in slippage (which are disjoint), is the density of locations of occurrences of words with genetic markers in . Once again equations 44 and 45 follow from 42 and 43 by substitution.
The equation relating and that corresponds to equation 33 is:
[TABLE]
Once again is independent of the choice of . Setting , we can write the previous equation as:
[TABLE]
Understanding empirical distributions of joinings along the natural map involves studying how the slippage affects each pair of -words. Fix and where . Let the conjugate pair be the genetic marker of in . Then, as remarked earlier is determined by , since they are a conjugate pair. Define to be the collection of locations of -subwords of that have genetic marker . Item 2 of Proposition 97 implies that is the same for all choices of . Since is the union over all possible pairs of , we see that
[TABLE]
From the definition:
[TABLE]
is equal to
[TABLE]
This in turn is equal to:
[TABLE]
which in turn is equal to
[TABLE]
For notational convenience we write:
[TABLE]
and
[TABLE]
[TABLE]
Summarizing:
[TABLE]
6.2 Transferring measures up and down, II
In this section we describe the correspondence between joinings in and . We do this by considering generic points for the joinings and transferring them up or down.
For the reader’s convenience we repeat a definition. Let be an arbitrary point in with and . Let and be the sequence of principal subwords of and respectively. Then and are the sequences of principal subwords of and . If , then and we can set . Recall that we defined by taking as its principal -subword sequence and as its location sequence.
The following follows immediately from equation 27:
Lemma 101**.**
The sequence is generic for an invariant measure on if and only if is generic for an invariant measure on .
We will study the relationship between and via the function taking to . If is the location of the principal -block of , we define to be the word (in the language ) where . Rephrasing this, if are the principal -subwords of then .
Proposition 102**.**
The sequence is a generic sequence (resp. an ergodic sequence) if and only if is a generic sequence (resp. an ergodic sequence).
This follows immediately from equation 48.
It is worth remarking that Proposition 102 can be restated in the language of Definition 26 as saying that is a generic sequence if and only if is a generic sequence.
The next theorem is the analogue of Theorem 91 adapted to lifting joinings of with to joining of with . In the theorem the notation and refer to pairs of corresponding measures. We assume that is built in the language and is built in the language .
Theorem 103**.**
Suppose that and are construction sequences for two ergodic odometer based systems and with the same sequence parameters . Let and be the associated ergodic circular systems built with a circular coefficient sequence . Then there is a canonical affine homeomorphism between the simplex of anti-synchronous joinings of and and the simplex of anti-synchronous joinings of and such that equation 46 holds between and .
Suppose that we are given an anti-synchronous ergodic joining between and . Let be generic for . By lemma 23, the sequence of principal -blocks, is ergodic. By Proposition 102 the sequence define an ergodic measure . Since the satisfy equation 45, the Ergodic Theorem implies that and satisfy equation 46. It is easy to check that the definition of is independent of the choice of the generic pair .
For the other direction we can assume that we are given a generic pair for an ergodic measure on that concentrates on pairs such that . Taking principal subwords gives us a generic sequence . Each is a well-defined word in .
As in the definition of the pair gives a pair of sequences of genetic markers for some . Letting and the sequences and determine a pair in up to finite translations. These sequences are defined independently of the exactly location of the zero of ; the small shifts used in the definition of do not change the two sequences.
If we let , making small adjustments if necessary to make anti-synchronous, we get an element of . Applying Proposition 102 again we see the theorem.
We can extend this correspondence to non-ergodic joinings on and on , exactly as in Theorem 91; to go up we take an ergodic decomposition of :
[TABLE]
and define
[TABLE]
To go down we use the ergodic decomposition theorem and the measure to reverse this process.
Clearly the map is an affine bijection. It remains to show that it is continous. However, just as in Theorem 91, we see from equation 46, that for each there is a constant , independent of such that for all ,
[TABLE]
This clearly implies that the map is a weak* homeomorphism.
The proof of Theorem 103 shows that is generic for if and only if the pair is generic for . Moreover, the proofs of Theorems 91 and 103 are quite robust. In particular the constructions of the corresponding measures are independent of the various choices of generic points or , or .
7 The Main Result
We now turn to the main results of this paper. Fix an arbitrary circular coefficient sequence for the rest of the section. Let be the category whose objects are ergodic odometer based systems with coefficients . The morphisms between objects and will be synchronous graph joinings of and or anti-synchronous graph joinings of and . We call this the category of odometer based systems.
Let be the category whose objects consists of all ergodic circular systems with coefficients . The morphisms between objects and will be synchronous graph joinings of and or anti-synchronous graph joinings of and . We call this the category of circular systems.
Remark 104**.**
Were we to be completely precise we would take objects in to be presentations of odometer based systems by construction sequences without spacers together with suitable generic sequences and the objects in to be presentations by circular construction sequences and their generic sequences. This subtlety does not cause problems in the applications so we ignore it.
The main theorem of this paper is the following:
Theorem 105**.**
For a fixed circular coefficient sequence the categories and are isomorphic by a function that takes synchronous joinings to synchronous joinings, anti-synchronous joinings to anti-synchronous joinings, isomorphisms to isomorphisms and weakly mixing extensions to weakly mixing extensions.
Elaborating on Example 6:
Corollary 106**.**
The map preserves systems of factor maps (or alternatively extensions). Explicitly: let be a partial ordering, be a family of odometer based systems and is a commuting family of factor maps with . Then is a commuting family of factor maps among . Moreover the analogous statement holds for circular systems , factor maps and .
Theorem 105 can be interpreted as saying that the whole isomorphism and factor structure of systems based on the odometer is canonically isomorphic to the isomorphism and factor structure of circular systems based on . We call this a Global Structure Theorem.
7.1 The proof of the main theorem
Before we prove theorem 105 we owe the following lemma:
Lemma 107**.**
Both and are categories, and the composition of synchronous joinings is synchronous, the composition of two anti-synchronous joinings is synchronous and the composition of a synchronous and an anti-synchronous joining (in either order) is anti-synchronous.
To see that and are categories we must see that the morphisms are closed under composition. This is equivalent to the statement that the composition of two synchronous or anti-synchronous joinings are synchronous or anti-synchronous. This, in turn follows from Proposition 7 (item 2) applied to joinings of odometers or rotations.
We now prove Theorem 105.
By Proposition 83 the map gives a bijection between the objects of and and hence it remains to define the functor on the morphisms (i.e. joinings between systems and ) and show that it preserves composition.
7.1.1 Defining on morphisms
We split the definition of into two cases according to whether is synchronous or anti-synchronous. In both cases we define for arbitrary joinings even though the only joinings we use as morphisms in the categories are graph joinings; in particular the morphisms in each category are ergodic.
Case 1: is synchronous:
Suppose that a synchronous joining of odometer based systems and with coefficient sequence that are constructed with symbols in and from construction sequences and . We define a new construction sequence with the symbol set .
Given , we put a sequence
[TABLE]
into if and only there are words and .
It is easy to check that is an odometer based construction sequence with coefficients . Let be the associated odometer based system. Since is synchronous, it concentrates on members of that correspond to elements of . We can canonically identify with a shift invariant measure on .
Let be the circular system associated with . We can apply Theorem 91 to find shift invariant measure on associated with that is ergodic just in case is ergodic. Shift invariant measures on can be canonically identified with synchronous joinings on . Let be the joining of corresponding to . We let .
Explicitly: A generic sequence for the joining , can be viewed as a generic sequence for and transformed into a generic sequence for . The latter corresponds to a generic sequence of the form for the joining . This process is clearly reversible so is a bijection between the synchronous joinings of and the synchronous joinings of .
We must show that if is a graph joining then so is . Once this is established it follows by symmetry that if is an isomorphism then is an isomorphism. Namely if is the adjoint joining of with defined as , then . Hence is a graph joining iff is a graph joining.
Suppose that is a graph joining. We apply Proposition 4, part 3. It suffices to show that for all basic open sets in of the form where and all , there are words that belong to and locations such that:
[TABLE]
Consider such that . Because is a graph joining, for all we can find words and locations such that
[TABLE]
Without loss of generality we can assume that for some each is an -word and that each .
Let be generic for and considering the pair , . Then by Remark 93 is generic for . We will choose words and locations and compute the measure in inequality 49 by computing the density of locations representing points in the symmetric difference.
Let
[TABLE]
By inequality 50, can be taken to have density less than .
Given words and locations we can define two sets , as follows:
[TABLE]
We need to find the words and locations so that the density of is less than .
For each , if is not the location of the beginning of an -word in then dropping reduces the measure of the symmetric difference in inequality 50. Thus, without loss of generality we can assume that for all , there is an -genetic marker coding the location of the -word in that starts at . Since has density less than , the density of such that either:
occurs at but for each , is not the position of the beginning of an -word with genetic marker in an occurrence of or 2. 2.
for some , is the position of the beginning of an -word with genetic marker in an occurrence of , but does not occur at ,
has density less than .
We are in a position to define the and the . For each we define index sets and a collection . We arrange the ’s so that they are pairwise disjoint and for some , . For , all of the are the same and equal to . For a fixed , let be the collection of locations of the beginnings of -subwords of that have genetic marker .
To compute the density of , it suffices to consider an extremely large and compute the density of inside the principal -subword of . Let be the principal -subword of and and .
We now argue as in Lemma 87. Let be the density of in and be the density of in . Among all -words the proportion that begin with an element of is . The density of that start -words in is . Letting be the density of , we see that is bounded away from [math] and independently of . The proportion of circular -subwords of that begin with a is
[TABLE]
Since concentrates on and concentrates on , the -words with a particular genetic marker in occupy the position of the same genetic marker in and similarly for and . The -genetic markers set up a one-to-one correspondence between subwords of and regions of that consist of occurrences of that have the same genetic marker. Each of the regions of with the same genetic marker have the same number of -words in them.
Temporarily call an -subword of bad if it begins with a in and similarly for -subwords of and . Then the property of being bad is determined by the -genetic marker of the -word: if is the beginning of -subword of with genetic marker , and is the beginning of an -subword of with the same genetic marker in , then if and only iff .
It follows the proportion of bad -subwords of is the same as the proportion of bad subwords of . In otherwords:
[TABLE]
It follows that
[TABLE]
Thus by taking small enough and large enough we can make as small as we want, and thus arrange that as desired.
To finish showing that is a bijection between graph joinings in each category and isomorphisms in each category we must also show that if is a graph joining then so is . But this is very similar. Given a , and an we can find and locations so that inequality 49 holds. Again we can assume that for some , for all , . The numbers determine locations in of beginnings of -words. We can augment our collection of locations by adding more ’s so that if is the start of a location in that has the same -genetic marker as , then for some we have and . In doing this we do not increase the density of . Reversing the procedure above this gives words and locations such that the density of is less than . (Note the lack of boundary in makes the computation easier by reducing the density of .)
Case 2: is anti-synchronous
On the anti-synchronous joinings we take to be the bijection between anti-synchronous joinings of with and of the circular systems with defined in Theorem 103. We show that takes anti-synchronous graph joinings to anti-synchronous graph joinings and vice versa. Having done this it will follow by a symmetry argument that sends anti-synchronous isomorphisms to anti-synchronous isomorphisms.
Suppose that is an anti-synchronous graph joining; i.e. is a graph joining of with that concentrates on . The map projects to the odometer map ; in particular is based on the same odometer that is. By Lemma 43 we can view as a graph joining of with that concentrates on . Similarly we view as concentrating on .
We must show that for all basic open sets in of the form where and all , there are words that belong to and locations such that:
[TABLE]
Consider such that . Because is a graph joining for all and all large enough we can find words and locations such that
[TABLE]
Without loss of generality we can assume that each . We will take sufficiently large according to a restriction we define later.
Let be generic for and let be as in Definition 94. Then is generic for . We argue as before considering sets:
[TABLE]
Then inequality 52, shows that can be taken to have density less than any positive .
Given words and locations we consider , as follows:
[TABLE]
Given , we need to find the words and locations so that the density of is less than . As in the synchronous case, for each we build index sets so that the ’s to be disjoint and have union the interval for some . For all we take . We need to find a collection of locations .
Fix an . Without loss of generality we can assume that is the beginning of a reversed -block in , since otherwise, discarding makes inequality 52 sharper. If is an arbitrary member of
[TABLE]
with , then there is an -word such that . Let be the genetic marker of in . We note that does not depend on , since it is determined entirely by the location of in and must be aligned with .
The genetic marker defines a region of -words in inside an -word in . Let be the collection of that are at the beginning of an -word in with genetic marker in an -word in and set
[TABLE]
This determines the collection .
We now compute the density of in terms of the density of . To do this it suffices to consider a large enough that has a principal -block and compute densities inside this principal -block. If this is sufficiently small we can deduce that the density of is small in . By Remark 78, we can also assume that is so large that restricted to this principal -block is equal to along this -block; equivalently the principal -block of is .
From Proposition 97, we know that if is an -sub-block of then either:
the corresponding sub-block of is at or 2. 2.
is part of the -slippage.
By item 2 of Proposition 97, the number of -sublocks in each case that correspond to a given -genetic marker does not depend on the genetic marker. Further in the second case is entirely part of .
We compute the density of elements of by separating them into these two sources. Explicity, we divide into:
Slippage:
Those that begin an -subword of a location of an -subword of that is in the -slippage.
Mistakes:
those such that is the location of the beginning of a circular -subword inside and is the location of an -word in .
We compute the density of the Mistakes and the Slippage separately. Again we will call -subwords that begin with elements of or bad.
Both the Mistakes and the Slippage occur at the beginning of -subwords of . Define to be density of in . Then proportion of that begin -subwords is:
[TABLE]
Of these a proportion of the -subwords are in the Slippage. Thus the collection of that belong to the Slippage has density
[TABLE]
Since goes to zero as goes to infinity we can make this term as small as desired by taking large enough.
Let be the location of the principal -block of (and thus of ). Let be the density of in .
Suppose now that belongs to the Mistakes. Let be the -genetic marker of the word beginning with in . Then there is a unique in that is at the beginning of an -subword of and has genetic marker . By construction, for that are not in the Slippage:
[TABLE]
Let be the proportion of -subwords of that begin with a . Since every genetic marker is represented exactly the same number of times in the complement of the slippage (Proposition 97), the proportion of words that begin with in the Mistakes is
[TABLE]
If is the density of in and is the density of the Mistakes, then
[TABLE]
Putting together equations 57, 58 and 59, we see that if we make sufficiently small we can make as small as desired.
Summarizing: By taking large enough, the density of is well approximated by the density of inside . This is the sum of the density of the slippage and the density of the Mistakes. We can make the density of the Slippage arbitrarily small by taking large enough and the density of the Mistakes arbitrarily small by taking sufficiently small. This establishes the claim that if is a graph joining then so is .
We must show that if is a graph joining then so is . We suppose that we are given a , we must find so that equation 52 holds. Let and approximate using . Again, we can assume that the collection of locations is saturated in the sense that if is the start of a location in that has the same -genetic marker as , then for some we have and . In doing this we do not increase the density of . We can now use equations 57, 58 and 59 again to see that if is made sufficiently small then so is .
Our next claim is that is an isomorphism if and only if is an isomorphism. Recall from Proposition 5 that is an isomorphism iff both and are graph joinings. Thus if is an isomorphism, both and are graph joinings. Since is an involution:
[TABLE]
Thus if is an isomorphism, so is .
Reversing this line of reasoning shows that if is a graph joining then is.
7.1.2 preserves composition
To finish the proof that is a functor we must show that preserves composition. The argument splits into four natural cases: composing synchronous joinings, composing a synchronous joining with an anti-synchronous joining on either side and composing two anti-synchronous joinings. We will carefully work out the case for compositions of synchronous embeddings, and discuss the appropriate modification in the cases involving at least one anti-synchronous embedding after Lemma 108.
The cases differ only that the shifts involved in the generic sequences have different forms. For ergodic synchronous joinings generic sequences can be taken to be of the form , whereas for anti-synchronous joinings of and a natural generic sequence is of the form .232323i.e. .
Preparatory Remarks
In the characterization of the relatively independent joining of and given in Lemma 28 and Proposition 29, the partitions and are given by and for . Formally the partitions and and consist of all possible products of these basic open sets. However, in the situation we are considering we have synchronous and anti-synchronous joinings. For synchronous joinings we can build a generating family for the relatively independent joining of and by considering products of pairs of basic open intervals in the same locations; e.g. pairs of the form . As a consequence, for verifying the hypotheses of Proposition 29 we can restrict our attention to the case where .
In the case of anti-synchronous joinings we need to distinguish the odometer based from the circular systems. For anti-synchronous joinings of odometer based systems with we can consider only intervals of the form where . For anti-synchronous joinings of the circular systems with , asymptotically the Empirical Distances concentrate on words of the form (where is the amount of shift for at scale ). Moreover, translations of sets of this form generate the measure algebra of the anti-synchronous joining.
Thus in the proof of the next lemma, to verify the hypothesis 3 of Proposition 29 we can take or depending on whether is synchronous or anti-synchronous.
Fix odometer based systems , and with construction sequences , and respectively. Let and be synchronous graph joinings of and , and and respectively and their relatively independent joining over .
Since and are graph joinings so is their composition. Thus the relatively independent joining is ergodic. Hence by Lemma 32 we can find generic sequences for and that satisfy the hypothesis of Proposition 29.
Lemma 108**.**
Let be generic for . Then the sequence is generic for the relatively independent joining of with .
Assuming the lemma, we show that preserves compositions. Corollary 31 shows that is generic for . From the way that is constructed, if , then is generic for (viewed as a measure on a circular system). From Lemma 108 and Corollary 31, we know that is generic for . Hence as desired.
It remains to prove Lemma 108.
We claim that satisfies the hypotheses of Proposition 29 for the joinings and .
The first two hypotheses follow immediately: and are constructed by taking the generic sequences and determined by and respectively, and the measures did not depend on the precise generic sequence taken. Hypothesis 3 remains to be shown.
We are given , and and need to find and the ’s so that inequalitites 3a and 3b hold. Since and are synchronous, so is the relatively independent joining. By the preparatory remarks can take , the relative location of words in and to be 0. Since the sequence of ’s is generic for the relatively independent product of and , we can find and for each a set such that the conditions in hypothesis 3 hold in the odometer context.242424For odometer systems, the length of the words in and is , for circular systems the words at stage have length .
Choose so large that the density of the boundary portions of circular -words is less than and so that for each , there is an with
[TABLE]
Let , and . For each we define the set . Each and each has a genetic marker in . We let has the same genetic marker in as some does in . Equation 26 implies that
[TABLE]
and thus .
Equation 27 implies that for and all large ,
[TABLE]
from which hypothesis 3a follows immediately.
Fix a and an . Let correspond to , and correspond to . Let . To see hypothesis 3b, we need to compute the empirical distributions of and conditioned on .
Let be the collection of such that occurs at in and occurs at in . Let be the collection of all . Then:
[TABLE]
As in the definition of in Section 7.1.1, we can view the relatively independent joining on as concentrating on a single odometer system and , the relatively independent joining of as concentrating on , which is canonically isomorphic to .
In the odometer system , consider the set consisting of those -words such that and have and in position . Then . Similarly . Equation 27 implies that
[TABLE]
and
[TABLE]
Finally noting that
[TABLE]
and using equations 60 and 61 we see that
[TABLE]
Arguing in the same manner we see:
[TABLE]
Since for large ,
[TABLE]
from equations 64, 65 and 66 we get the desired conclusion that
[TABLE]
is less than .
Lemma 108 holds where one or both of the joinings and are anti-synchronous as well, however the shift coefficients for the circular systems are no longer all [math] but belong to depending on which joinings are anti-synchronous. Similarly . The argument follows the same path until it reaches equation 61. This equation relies, in turn on equation 27. The analogue of equation 27 for anti-synchronous joinings is equation 48, which in turn carries over to the relatively independent product. The upshot is that equations 64, 65 and 66 hold after applying the appropriate shifts of and relative to .
This finishes the proof of Theorem 105.
7.2 Weakly-Mixing and Compact Extensions
We now show that preserves weakly-mixing and compact extensions. The fact that compact extensions are preserved is due to E. Glasner and we reproduce the proof here with his kind permission.
Proposition 109**.**
Let and be ergodic and suppose that and are corresponding synchronous joinings determining factor maps
[TABLE]
Then is a weakly mixing extension of (via ) if and only if is a weakly mixing extension of (via ).
Recall that if is a factor map from to , then the extension is weakly-mixing if the relatively independent joining of with itself over is ergodic relative to . In case is ergodic, this simply means that the relatively independent joining is ergodic.
Suppose that and are odometer based systems with construction sequences and respectively. If is a synchronous factor joining of over , and the extension is weakly-mixing then we can find an ergodic sequence of words that is generic for the relatively independent joining of with itself over , i.e. . This sequence will satisfy the hypotheses of Proposition 29. It follows that the sequence of ’s is also generic for an ergodic measure . As we argued in Lemma 108, the ’s also satisfy the hypothesis of Proposition 29. It follows that is the relatively independent joining . Since is ergodic is weakly mixing.
If, on the other hand the sequence of is not ergodic, then the sequence is also not ergodic. Hence if is weakly-mixing, then is weakly mixing.
It is immediate from the Furstenberg-Zimmer structure theorem ([11], Chapter 10, Proposition 10.14) that is a relatively distal extension of if and only if there is no intermediate extension of , with being a non-trivial weakly-mixing extension of . Thus takes measure-distal extensions to measure-distal extensions.
What requires more effort to establish is the following:
Proposition 110**.**
(E. Glasner) The functor takes compact extensions to compact extensions.
Glasner’s proof uses a result proved in the forthcoming [8]: If is an ergodic odometer based system the is a compact group extension of then there is a representation of as an odometer based system with the same coefficients.
Since is a compact extension of if and only if is a factor of a compact group extension of ,252525See [10] for an explicit statement and proof. it suffices to show that takes compact group extensions to compact group extensions.
To prove that takes compact group extensions to compact group extensions we use a remarkable theorem of Veech that characterizes group extensions of ergodic systems. The criteria is that every ergodic joining of with itself that is the identity on (i.e. , as a measure, concentrates on those pairs such that ) comes from a graph joining which is an isomorphism of that projects to the identity map on .262626This first appears in [18].
Explicity, Theorem 6.18, on page 136 of [11] shows that if, in the ergodic decomposition of the relatively independent product , only graph joinings appear, then is a compact group extension. The converse follows from Proposition 6.15, part 2 in [11], that if is a compact group extension of then every ergodic self-joining of over which is the identity on is a graph joining.
The map takes ergodic joinings to ergodic joinings, and all graph joinings to graph joinings, and the identity joining to the identity joining. Thus we see it preserves group extensions.
Furstenberg [9] and Zimmer [22] independently showed that for every ergodic system there is an ordinal and a tower of extensions such that is the trivial system, and for all , is a compact extension of , unless where is either a compact or a weakly mixing extension of . If there is no compact extension at the end of the tower, then is measure-distal and is a distal tower approximating . The least ordinal such that can be represented this way is the distal height or distal order of .
Let be an odometer based system and consider the odometer factor . Let be the Kronecker factor of . Then we have
[TABLE]
where may or may not be a trivial factor map. This tower is carried by to
[TABLE]
If is a non-trivial extension of , then Glasner’s result tells us that is a compact extension of , but is silent on the issue of whether is discrete spectrum; i.e. we do not know whether takes the Kronecker factor of to the Kronecker factor of .
Suppose now that is given by a finite tower of factors:
[TABLE]
where is the Kronecker factor of and for all is the maximal compact extension of in . Then is distal of height . The map carries this to a tower of compact extensions
[TABLE]
From this we see that the distal height of is either or .
We do not know an example whether the height of can be . However the ordinary skew product construction applied to odometers gives examples of distal height where is the Kronecker factor. Hence from our analysis we see that there are ergodic circular systems with distal height for all finite .
In [2], Beleznay and Foreman proved that for all countable ordinals there is an ergodic measure preserving transformation of distal height . In that construction there are no eigenvalues of the operator of finite order. Hence if we let be an odometer with coefficient sequence going to infinity, is an ergodic transformation with distal height and zero entropy. In the forthcoming [8] we see that this implies that can be presented as an odometer based transformation. By the analysis we just gave we see that is a circular system with height . In [8] we see that can be realized as a smooth transformation. For infinite , , hence we have:
Theorem 111**.**
Let be a finite or countable ordinal. Then there is an ergodic measure distal diffeomorphism of of distal height .
7.3 Continuity
Fix a measure space . As noted in Section 2.3, we can identify symbolic shifts built from construction sequences with cut-and-stack constructions (whose levels generate ). By fixing a countable generating set in advance, we can make this association canonical. The levels in the cut-and-stack construction give the relationship with arbitrary partitions of . In this way the usual weak topology on measure preserving transformation of described in Section 2.1 determines a topology on the presentations of symbolic shifts as limits of construction sequences.
The finitary nature of the maps that give bijections between words in and words in easily shows that the map is a continuous map from the presentations of odometer based systems to presentations of circular systems. Thus we have:
Corollary 112**.**
The functor is a homeomorphism from the objects in to .
For the purposes of the complexity of the isomorphism relation we note:
Corollary 113**.**
The map is a continuous reduction of conjugacy between odometer based systems and circular systems.
7.4 Extending the main result
In the main result we restricted the morphisms to graph joinings, largely because compositions of graph joinings are ergodic joinings. Unfortunately a composition of ergodic joinings is not necessarily ergodic, and non-ergodic joinings also arise naturally as relatively independent joinings of ergodic joinings. In this section we indicate how to extend our results to the broader categories that include non-ergodic joinings as morphisms. For convenience, we will continue to require that our objects are ergodic measure preserving systems.
Let and be the categories that have the same objects as and , but where the collections of morphisms are expanded to include all synchronous and anti-synchronous joinings (rather than just graph joinings).
In Section 7.1.1, the definition of included all such joinings ( for a non-ergodic was defined via an ergodic decomposition). Thus without modification we can view as a map:
[TABLE]
To show that is a morphism between these categories, i.e. to show preserves composition for arbitrary morphisms, we develop a more combinatorial approach to lifting morphisms that coincides with the original definition.
We start by generalizing the notion of a generic sequence of words to include non-ergodic measures. Suppose is a symbolic system with a construction sequence . Let be a shift invariant measure which we assume is supported on the set (where is given in definition 10). The ergodic decomposition theorem gives a representation of as , where each is a shift invariant ergodic measure and is a probability measure on a set parameterizing the ergodic components. For each , there is a generic sequence of words for the measure . The main observation is that the set of probability measures on words of a fixed length is compact. Thus for any fixed and , we can find a finite set of parameters so that for all , there is some with272727The notions of and are given in the beginning of Section 2.6.
[TABLE]
This gives a partition of the parameter space into sets such that inequality 67 holds for all .
Now let be sufficiently large such that for each , we can find an element with
[TABLE]
If we denote by , then and . It is clear that one can obtain up to a small error from the finite data , which is a weighted finite collection of words.
For the symbolic sequences that we are interested in, such as the circular systems, the measure of the spacers is independent of the invariant measure (see Section 5.1). This means that for all , the sum is the same. In this context using inequality 68 we can arrange the inequality:
[TABLE]
The measure is defined on the extreme points of the simplex of shift invariant probability measures and if we choose the finite sets to consist of points that lie in the closed support of then we an easily ensure that when we go from to a with that . Taking a sequence and with , we get a set of ergodic measures and finite sets of integers with probability measures on such that converges to in the weak* topology.
Definition 114**.**
Let go monotonically to infinity and be a weighted sequence of words as above. Suppose that for each and , , then we call a generic sequence for .
We note that for a fixed , as varies is a generic sequence for –which is one of the ergodic measures in the support of .
In a manner exactly analogous to the analysis in Section 2.6, Definition 114 can be extended to products of symbolic systems, allowing for shifting of words in construction sequences.
Restricting our objects to ergodic systems and allows us to deal with the non-ergodic analogue of the material discussed between Definition 25 and Lemma 32 in a relatively straightforward way which we now discuss.
For the analogue of Proposition 29 in the non-ergodic case let us make the following observation. Fix a non-ergodic joining of and that has ergodic decomposition , where, by the ergodicity of and , each is also a joining of with . Fix a and an and a cylinder set determined by a word , at location and let represent its indicator function. For large, by the Martingale convergence theorem, there is a subset of of measure close to one such that when we look at the conditional expectation of with respect to the partition induced by the principal -words of , for and compare it to , the error is small.
The element of that partition that contains is given by a word and a location parameter , and the conditional expectation is:
[TABLE]
This easily gives a set with and a such that for , formula 69 gives a good approximation to for most of the .
If we have a generic sequence of weighted words for , then we can use it to calculate the expression in 69. This observation makes it possible for us to formulate Proposition 29 for non-ergodic joinings.
We are given ergodic systems and are given construction sequences such that for each , the words in each have the same length. Two joinings of and and of and are given. The analogue of Proposition 29 is now:
Proposition 115**.**
Let
[TABLE]
be a sequence of weighted words and . Suppose that the following hypothesis are satisfied:
* is generic for ,* 2. 2.
* is generic for ,* 3. 3.
For all there are and a set and for each there is a set such that
- (a)
** 2. (b)
** 3. (c)
For all and , if ,
[TABLE]
Then the weighted sequence given in 70 is generic for the relatively independent joining .
The analogues of Corollary 31 and Lemma 32 are easily verified, giving us a characterization of compositions of non-ergodic joinings and the existence of generic sequences satisfying the hypothesis of Proposition 115.
Verifying that preserves composition is now straightforward in the manner of Section 7.1.2: the and are constructed in exactly the same way. Checking the conditional distributions of short words relative to longer words ( vs. ) involves counting -words, and these are counted using Equation 27 for each component separately. The weighted average is then preserved.
8 Lagend
In this section we explore the interplay of the geometric, arithmetic and combinatorial aspects of the manner in which wraps the odometer based words around the circle. The map does not preserve the dynamics of the odometer when transforming it into a rotation, indeed it can’t. The shift of the odometer corresponds to a shift of the rotation. The relationship between and is characterized combinatorially as an optimal wrapping property. The latter is defined in terms of the notion of a perfect match. The results in this section can be used to give an alternate proof of the fact that if is ergodic then so is that does not use the notion of a generic sequence of words.
Central to our understanding circular systems is the manner in which an had its -words aligned with -words in . A word occurs in lined up with a word in if and only if occurs at some location in and occurs at in .
Definition 116**.**
Let be strings in the language and be words of the same length. A -match of and in and is a location in the domain of such that occurs at in and occurs at in .
If are circular -words then a perfect match of in is a such that there are -genetic markers such that occurs in and occurs in with genetic markers and respectively and is a match between all occurrences of and with these genetic markers.
Thus is a perfect match of and if and only if the occurrences of in are exactly aligned with the occurrences of is .
We will say that is a match between and if there is a location such that such that is a match between and at , and that every -match is perfect when has the property that for every occurrence of a pair of words in , if is a match between then is a perfect match between . The astute reader will have already recognized that being a match or a perfect match only refers to the genetic markers and the underlying circular factor–thus the actual identities of and are not material–only the locations of the genetic markers.
The notion of a perfect match is vacuous for odometer words; for if are odometer -words and are odometer -words then are the unique pair with a genetic markers and . Moreover, if matches any pair of -subwords, matches every pair of corresponding -subwords in the overlap of and .
If , then the -subwords of in the overlap of and are split into two pieces by the -subwords of ; the left portion of each of the -subwords of in the overlap coincides with the right portion of the corresponding -subword of . Call the matches in the left portion of left-matches.
Discussion. Let have genetic marker in and suppose that sits inside the word with genetic marker . Then words with genetic marker sit inside every 2-subsection of . It follows that if and is a perfect match of with having genetic marker win , then . Thus the relative position of in the -subword of with genetic marker is to the right of the position of in ; i.e. the relative shift is to the left to match with . For this reason, when we need only consider left shifts.
It is also easy to see that perfect matches between -words with genetic markers and inside an -words are those that match the first occurrence of an -word with genetic marker in with the first occurrence of an -word with genetic marker in .
The next lemma says that perfect matches can be viewed as the locations of shifts of odometer based words wrapped around the circle.
Lemma 117**.**
Suppose that and . Let and and suppose that is a perfect match between some pair of -subwords of and . Then there is a unique such that for all genetic markers , ,
- •
* is a perfect match between the -subwords of the with genetic markers and iff*
- •
* is a left match between the -subwords of with genetic markers and .*
The Lemma has an obvious analogue for negative and right matches.
Suppose that is a perfect match between and . Call the subwords of with genetic markers and and . Then are perfectly matched by . Let be the distance between the locations of and . Since we have . From our discussion we seen that is a left match of . We claim that this satisfies the lemma.
Let be the -subwords of inside which occur. Suppose that and , so , . If are left matched by in , then the first occurrences of and are matched by , hence inside , is a perfect match of and .
The relative position of and is duplicated over all -words with genetic markers in and . It follows that is a perfect match of and inside .
From the uniformity of the relative positions of -words it also follows that any two -subwords of -subwords in positions that are matched in are -matched. Since these exactly coincide with the -subwords of that are left-matched by , we have proved the lemma.
Lemma 118**.**
Let . Let and .Then:
Let be the least such that . Let . Then if matches inside with then occur inside the same -subword of . 2. 2.
Let . Then is a perfect match of occurrences of , inside an -word iff is a perfect match inside the word in which they appear.
Item 2 means that we usually don’t have to refer to a long words when we are discussing perfect matches of and and fixes the scale of the potential perfect matches.
We can identify perfect matches numerically:
Lemma 119**.**
Let , . Then there is a -genetic marker such that is the location of the first occurrence of some word genetic marker if and only if
[TABLE]
where .
From Lemma 117, we see the correspondence between odometer translations and circular translation. We now address the question: given an arbitrary circular translation, how does one adjust it to get an odometer translation that gives the best fit among a given collection of -words?
Theorem 120**.**
Let and . Then if , () then there is a such that and:
all -matches of a in are perfect matches, 2. 2.
and
[TABLE]
Without loss of generality (otherwise we reverse the role of and ). Words in with start with a block of ’s of length at least . Hence if matches -words inside , they both must occur in some -subword of .
To see item 1, we need to show how to improve to a that is a perfect match. Changing will involve sacrificing some of the matches of pairs in , but this will be compensated by the additional multiplicity of the remaining matches.
We prove by induction on , that for all with and all collections of pairs of -words and all , all , all natural number weightings and all we can find a such that such that (a) holds and
[TABLE]
Suppose first that . Then successive -subsections of -words are separated by boundary sections of size
[TABLE]
Because does not divide , given a -subsection of there is a unique -subsection of within which can match -words. Moreover this does not depend on , but rather the underlying locations of the words.
We start by lining up blocks of the form with blocks of the form . To do this we classify the -matches of a pair into left block matches if and align as282828In both of these graphics the second row is a portion of and represents a boundary section. These pictures are independent of .:
and right block matches if and align as:
Note by taking to be for some we can turn all left block matches of all of the into matches of entire with , but doing so destroys completely some of the right block matches. Similarly if we can shift to make all right block matches into matches of with by destroying left block matches.
If we examine a particular left block match of a pair in some and a right block match of another pair in and we change to to make match with then the sum of -matches between and goes up by one: we lose the right block matches but we gain left block matches and we gain one more match from the boundary section.
Suppose that
[TABLE]
Then from the previous paragraph that if we take for some then we can make all left block matches have multiplicity (while removing right block matches) and have:
[TABLE]
If, on the other hand, the weighted sum of the right block matches is greater than weighted sum of the left block matches, we shift the other direction to fix all right block matches and destroy all left block matches.
Thus we can assume that we have a such that for all , matches -powers of with -powers of . This would be a perfect match except that it matches -words across 2-subsections. Writing each then matches blocks of the form in one -subsection of with a block of the form in a (potentially) different -subsection of . Moreover is constant on all of these matches, since the differences between starts of -blocks are of length . Fix such a pair . By changing so that it lines up with in the first 1-subsection we create a perfect match of -words and increase the total number of matches of the form . This establishes the case where .
We now do the induction step. Let and assume the result holds for . Suppose that we are given .
We can decompose a -match between -subwords of and as where and is a match of subwords of and .
Here is a picture of a pair comparing in the upper row with the -shift of in the lower row.
Here is a picture after the shift of :
Let be the collection of pairs from sitting inside a pair that contain -matches of words . Arguing as in the case we can adjust to a so that it is a perfect match of -words in and, summing over and , the weighted sum of -matches of pairs in does not decrease.292929We note that it is not enough to increase the weighted sum of the number of matches of pairs in , because various matches may contain different number of -matches. Nonetheless, arguing as in the case , one of the two possibilities for lining up the subwords does not decrease the weighted sum of the number of -matches of -words.
This is how the -words look after shifting by :
The offset of the copies of and is . Note that the boundary sections line up.
We now are in the position of having shifted by so that the powers of pairs are lined up. The additional shift has absolute value less than . Moreover all of the words are lined up the same way when shifted by .
We call an occurrence of a that is lined up in good. Let be the number of good occurrences of and
[TABLE]
Note that
[TABLE]
We now view the pairs as sitting on the intervals and then shifting by :
We are in a position to apply our induction hypothesis with playing the role of , the ’s being the ’s, and the shift being .
The result is a such that every -match of a in a is perfect and
[TABLE]
We note that every -match of a in a is perfect. Since
[TABLE]
we see that
[TABLE]
This completes the proof of Lemma 120.
9 Open Problems
We finish with two open problems that we find interesting and believe to be feasible. The first is to characterize the class of transformations isomorphic to circular systems in Ergodic-theoretic terms. All circular systems have common properties such that can be described in terms of rigidity sequences or zero entropy. The suggestions is to find a complete characterization in using this type of notion.
The second problem can be stated as follows. For the realization problem, the underlying rotation of a circular system must be Liouvillian; however realization is not necessary for the results in this paper. Can an arbitrary irrational be the underlying rotation of a circular system?
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] D. V. Anosov and A. B. Katok. New examples in smooth ergodic theory. Ergodic diffeomorphisms. Trudy Moskov. Mat. Obšč. , 23:3–36, 1970.
- 2[2] Ferenc Beleznay and Matthew Foreman. The complexity of the collection of measure-distal transformations. Ergodic Theory Dynam. Systems , 16(5):929–962, 1996.
- 3[3] Tomasz Downarowicz. The Choquet simplex of invariant measures for minimal flows. Israel J. Math. , 74(2-3):241–256, 1991.
- 4[4] Jacob Feldman. Borel structures and invariants for measurable transformations. Proc. Amer. Math. Soc. , 46:383–394, 1974.
- 5[5] M. Foreman and B. Weiss. A symbolic representation of Anosov-Katok systems. To appear in Journal d’Analyse Mathematique , pages 1–63, 2015.
- 6[6] Matthew Foreman, Daniel J. Rudolph, and Benjamin Weiss. The conjugacy problem in ergodic theory. Ann. of Math. (2) , 173(3):1529–1586, 2011.
- 7[7] Matthew Foreman and Benjamin Weiss. Measure preserving diffeomorphisms of the torus are unclassifiable. TO APPEAR , pages 1–102, 2018.
- 8[8] Matthew Foreman and Benjamin Weiss. Odometer based systems. TO APPEAR , 2019.