Multilevel linear models, Gibbs samplers and multigrid decompositions
Giacomo Zanella, Gareth Roberts

TL;DR
This paper analyzes the convergence of Gibbs samplers in multilevel Bayesian models, providing explicit formulas and guidelines for optimizing their implementation across various hierarchical structures.
Contribution
It introduces a multigrid approach to derive convergence rates for Gibbs samplers in complex multilevel models, extending analysis beyond two-level hierarchies.
Findings
Explicit convergence rate formulas for multilevel models
Guidelines for parametrization and identifiability in Gibbs sampling
Simulation results indicating broader applicability to non-Gaussian and gradient-based MCMC
Abstract
We study the convergence properties of the Gibbs Sampler in the context of posterior distributions arising from Bayesian analysis of conditionally Gaussian hierarchical models. We develop a multigrid approach to derive analytic expressions for the convergence rates of the algorithm for various widely used model structures, including nested and crossed random effects. Our results apply to multilevel models with an arbitrary number of layers in the hierarchy, while most previous work was limited to the two-level nested case. The theoretical results provide explicit and easy-to-implement guidelines to optimize practical implementations of the Gibbs Sampler, such as indications on which parametrization to choose (e.g. centred and non-centred), which constraint to impose to guarantee statistical identifiability, and which parameters to monitor in the diagnostic process. Simulations suggest…
Click any figure to enlarge with its caption.
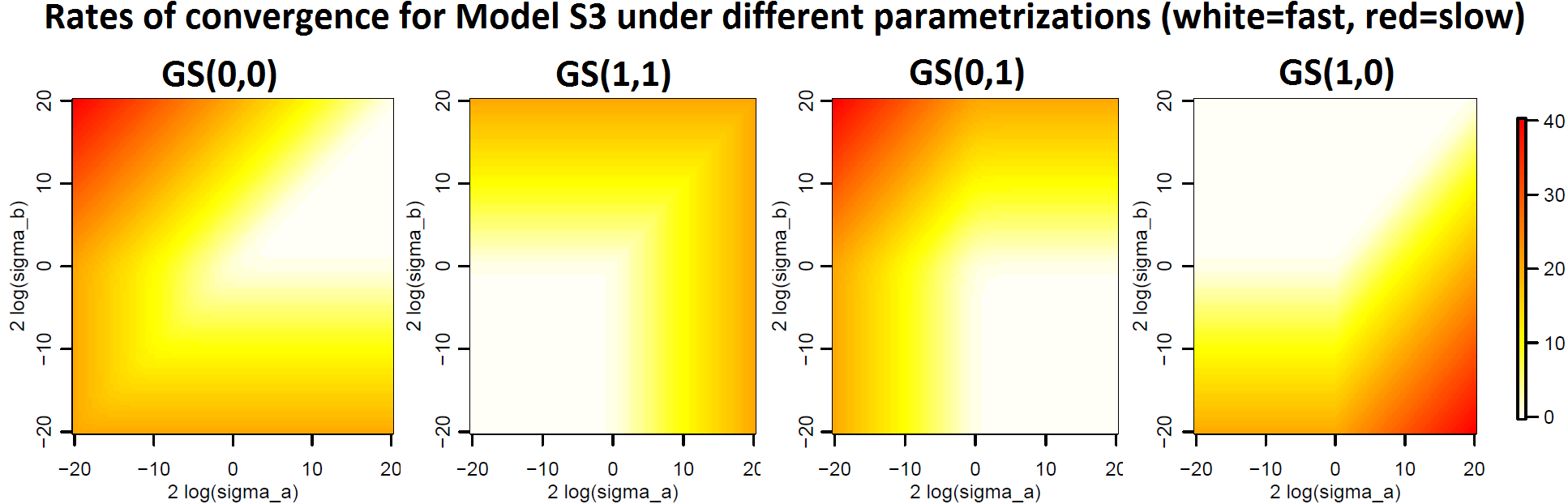 Figure 1
Figure 1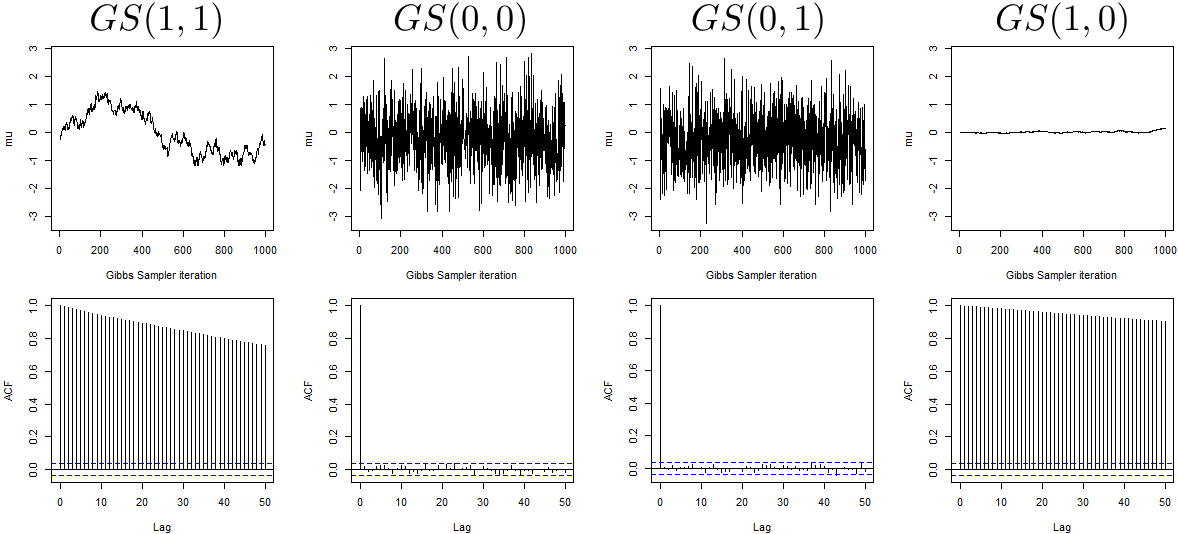 Figure 2
Figure 2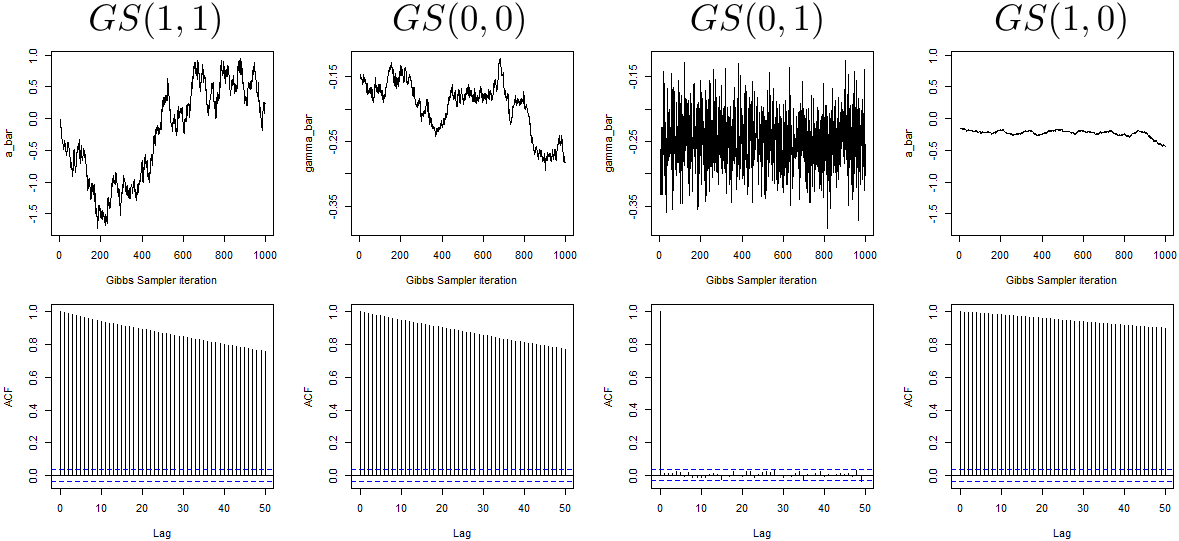 Figure 3
Figure 3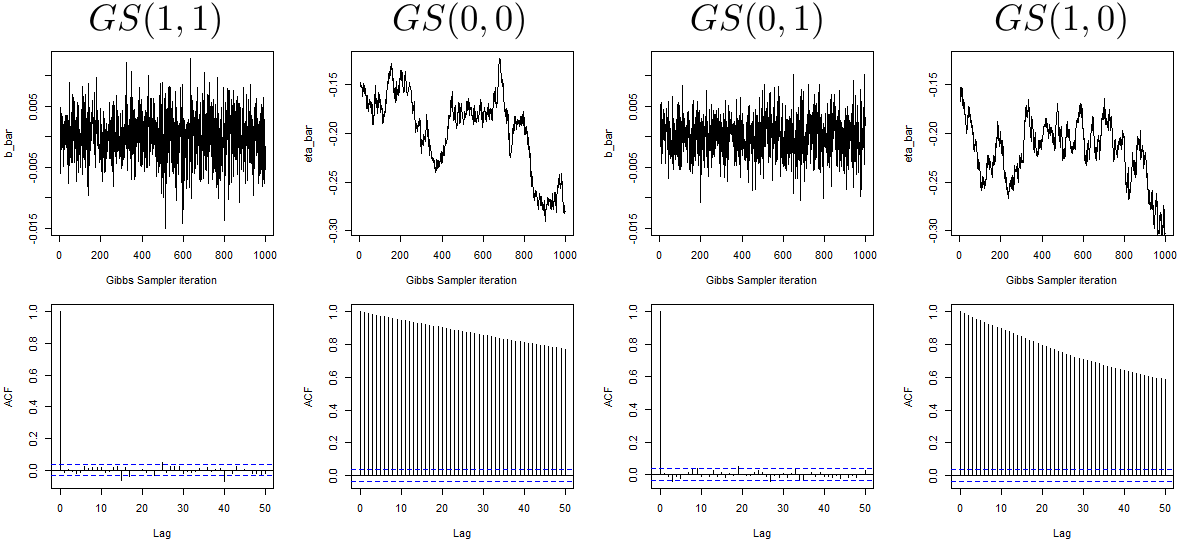 Figure 4
Figure 4| , | , | , | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Unconstrained | 273 | 287 | 268 | 273 | 314 | 280 | 287 | 351 | 255 |
| 1483 | 2741 | 1656 | 506 | 33614 | 507 | 372 | 553 | 300 | |
| 52405 | 52537 | 49847 | 46404 | 49634 | 50134 | 43869 | 50682 | 51259 | |
| Effective Sample Size (ESS) | Runtime | ESS/time [1/s] | |||||
| HMC (unconstrained) | 530 | 545 | 518 | 5697s | 0.09 | 0.10 | 0.09 |
| HMC () | 1661 | 1611 | 3907 | 1737s | 0.96 | 0.93 | 2.2 |
| HMC () | 1369 | 1263 | 1897 | 1459s | 0.94 | 0.87 | 1.3 |
| NUTS (unconstrained) | 30 | 18 | 28 | 906s | 0.03 | 0.02 | 0.03 |
| NUTS () | 108 | 176 | 696 | 312s | 0.35 | 0.57 | 2.2 |
| NUTS () | 8000 | 19914 | 20062 | 134s | 60 | 149 | 150 |
| Gibbs (unconstrained) | 21 | 27 | 4.3 | 0.91s | 24 | 30 | 4.7 |
| Gibbs () | 27 | 27 | 5.6 | 0.92s | 29 | 30 | 6.1 |
| Gibbs () | 8000 | 7992 | 8037 | 1.00s | 8000 | 7992 | 8037 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods and Bayesian Inference · Bayesian Methods and Mixture Models · Statistical Methods and Inference
Multilevel linear models, Gibbs samplers and multigrid decompositions
Giacomo Zanella111 Department of Decision Sciences, BIDSA and IGIER, Bocconi University, via Roentgen 1, 20136 Milan, Italy. [email protected]
and Gareth Roberts222 Department of Statistics, University of Warwick, Coventry, CV4 7AL, UK. [email protected]
Abstract
We study the convergence properties of the Gibbs Sampler in the context of posterior distributions arising from Bayesian analysis of conditionally Gaussian hierarchical models. We develop a multigrid approach to derive analytic expressions for the convergence rates of the algorithm for various widely used model structures, including nested and crossed random effects. Our results apply to multilevel models with an arbitrary number of layers in the hierarchy, while most previous work was limited to the two-level nested case. The theoretical results provide explicit and easy-to-implement guidelines to optimize practical implementations of the Gibbs Sampler, such as indications on which parametrization to choose (e.g. centred and non-centred), which constraint to impose to guarantee statistical identifiability, and which parameters to monitor in the diagnostic process. Simulations suggest that the results are informative also in the context of non-Gaussian distributions and more general MCMC schemes, such as gradient-based ones.
1 Introduction
Markov chain Monte Carlo (MCMC) is established as the computational workhorse of most Bayesian statistical analyses for complex models. For hierarchical models with conditionally conjugate priors, the Gibbs sampler (Gelfand and Smith, 1990; Smith and Roberts, 1993) remains one of the most natural algorithm of choice, thanks to its simplicity of implementation and low computational cost per iteration (thanks to conjugacy and conditional independence). Nonetheless, speed of convergence of the resulting Markov chain can be a major issue and can be highly sensitive to the model structure and the implementation details, such choice of parametrization (Hills and Smith, 1992; Gelfand et al., 1995) or identifiability constraints (Vines et al., 1996; Gelfand and Sahu, 1999; Xie and Carlin, 2006). This work provides a contribution towards gaining a quantitative understanding of the interaction between Bayesian hierarchical structures and the behaviour of MCMC algorithms, which lies at the heart of the practical success of Bayesian statistics.
While there is some previous work in the area (Roberts and Sahu, 1997; Meng and Van Dyk, 1997; Papaspiliopoulos et al., 2003; Jones and Hobert, 2004; Papaspiliopoulos et al., 2007; Yu and Meng, 2011), current theoretical understanding of the interaction between Bayesian hierarchical models and MCMC convergence is still very limited, and almost nothing is known for models of hierarchical depth greater than two. The present paper offers a contribution towards such an understanding, focusing on theory for Gaussian hierarchical models and seeking quantitative results. In particular, we derive analytic expressions for the convergence rates of the Gibbs Sampler for various multilevel linear models and explore the dependence of these rates on the model structure, the choice of parametrization and the introduction of identifiability constraints. The theoretical results given in this paper extend and improve substantially on existing literature (Roberts and Sahu, 1997; Yu and Meng, 2011; Bass and Sahu, 2016b; Gao and Owen, 2017) both in terms of generality of hierarchical structure and the availability of explicit rates. We also show by simulations that the understanding gained from the Gaussian case can be extrapolated to more general settings.
In general, the Gibbs sampler can be elegantly described in terms of orthogonal projections (Amit, 1991, 1996; Diaconis et al., 2010). While in principle this theory provides the tools to extract practical convergence information for Gibbs samplers in the context of multivariate Gaussian distributions, in order to apply it to practically used Bayesian multilevel models one needs detailed knowledge of the spectrum of non-trivial high-dimensional matrices, which has drastically limited its applicability to derive analytic results. In this paper we combine this general framework with a novel multigrid decomposition approach that allows us to focus on low-dimensional Markov chains and derive explicit analytic results concerning Gibbs sampler rates of convergence for multilevel linear models, such as nested and crossed random effect models with an arbitrary number of layers and/or factors.
Our results have various practical implications. First they can be readily used in the popular context of conditionally Gaussian models, where there exist unknown variances at various levels of the hierarchy (Gelman and Hill, 2006). In that case our results describe, for example, the optimal updating strategies for the hierarchical mean structure conditional on the variances, allowing to optimize the mean parametrization on the fly (Section 3.2), or the computationally optimal way of imposing statistically identifiability (Sections 4.2), and provide theoretically grounded indication of which parameters to monitor in the convergence diagnostic process (Section 2.1). Also, our results can be used as a building block to derive computational complexity statements about the Gibbs Sampler in the context of multilevel linear model (see e.g. Papaspiliopoulos et al. (2019) for work in that direction). Note that in the context of conditionally Gaussian models the entire Gaussian mean component could be updated in a single block, thus avoiding convergence issues related to single-site updates. However these block updates can in principle be computationally expensive (up to cost in the dimension () of the Gaussian to be updated), while single-site updating schemes with provably bounded convergence rate can offer a more scalable alternative. For some class of models, sparse linear algebra methods can reduce the cost of the block update by exploiting sparsity in the posterior precision matrix, but the resulting computational cost depends on the model structure and can still be super-linear (see e.g. Section 4 for models leading to dense precision matrices and Papaspiliopoulos et al. (2019) for more discussion).
While impressive results are being obtained with black-box software implementation of Hamiltonian Monte Carlo (HMC) such as STAN (Carpenter et al., 2017), our results suggest that Gibbs Sampling schemes built on our methodological guidance can be substantially cheaper than gradient-based ones in the context of hierarchical models, leading to improved performances (Section 5). Moreover, our simulations show that the methodological results we develop in this paper are also helpful when fitting multilevel models with gradient-based schemes (Section 5.1) and allow to obtain drastic improvements in efficiency also when using generic software, such as STAN.
Throughout the paper, we shall couch all our results in terms of rates of convergence. Specifically, let be a Markov chain with stationary distribution and transition operator defined by . The rate of convergence associated to is defined as the smallest number such that for all
[TABLE]
where denotes the space of square -integrable functions, is its associated -norm and is the expectation of with respect to . The rate of convergence characterizes the speed at which converges to its stationary distribution , with a simple argument giving that if
[TABLE]
then .
1.1 Paper overview and structure
Section 2 carefully introduces the 3-level hierarchical models we shall consider, and provides motivating simulations. Then in Section 3 we shall give a complete analysis for 3-level symmetric models (i.e. homogeneous variances and symmetric data structure). At the heart of the analysis is a multigrid decomposition of the Gibbs sampler into completely independent Markov chains describing different levels of hierarchical granularity, Theorem 1. Such multigrid decomposition simultaneously applies to every Gibbs sampler induced by all centred/non-centred parametrizations and is fundamentally a statistical property of the hierarchical models under consideration. Although multigrid ideas have already been used in methodological contexts to design improved MCMC schemes (Goodman and Sokal, 1989; Liu and Sabatti, 2000), to our knowledge they had never been used in theoretical contexts to study convergence rates. We demonstrate that the slowest of these independent chains is always that corresponding to the coarsest level, regardless of the value of the variance components and on the number of branches in the hierarchy, and thus derive explicit expressions for the rates of convergence in symmetric contexts.
In Section 4 we focus on crossed effect models, using again a multigrid decomposition approach to derive explicit convergence rates. The results show that in the context of crossed models, centred/non-centred reparametrizations are not sufficient to guarantee fast convergence of the resulting Gibbs Sampler. On the other hand, we show that the latter can be achieved by imposing stronger statistical identifiability through additional linear constraints and our theory provides indications on which constraints lead to faster convergence. Finally, a simulation study reported in Section 5 suggests that the analysis of the Gaussian case leads to useful guidance also in the case of non-Gaussian models for both the Gibbs Sampler and Hamiltonian Monte Carlo algorithms (Neal et al., 2011).
Section 6 considers 3-level non-symmetric hierarchical models, providing bounds on convergence rates based on comparisons with related symmetric models and discussing the use use of bespoke parametrizations, where the choice of centred or non-centred parametrization in each branch of the hierarchy depends on the branch-specific parameter.
Section 7 considers hierarchical models with arbitrary depth (). Using an appropriate auxiliary random walk, whose evolution through the hierarchical tree is governed by the parameters’ squared partial correlations, we are able to extend the multigrid analysis to general tree structures and some non-symmetric cases. We again demonstrate a fundamental multigrid decomposition in Theorem 9 where the coarsest level chain converges the slowest, and we give explicit formulae for optimal partial non-centering strategies.
2 Three level hierarchical linear models
The theoretical innovation in this paper is centred around an important case in which we can obtain explicit Gibbs sampler rates of convergence, and as a result study explicitly the effects of particular models, parametrization schemes and blocking strategies. Therefore we shall begin with a detailed study of the following three-level Gaussian linear model, giving a fairly complete understanding of the interaction between model structure and parametrization and the Gibbs Sampler convergence behaviour.
Model S3** (Symmetric 3-levels hierarchical model).**
Suppose
[TABLE]
where , and run from 1 to , and respectively and are iid normal random variables with mean 0 and variance . We employ the standard Bayesian model specification assuming , and a flat prior on .
For the theoretical analysis, we will consider the variance terms , and to be known, while in the simulations we will assume them to be unknown and give them a prior distribution. Defining , and , the Gibbs Sampler explores the posterior distribution by iteratively sampling from the full conditional distributions of , a and b as follows (see below for motivation of denoting such sampler as GS()).
Sampler GS()****.
Initialize , and and then iterate
Sample from ; 2. 2.
Sample from for all ; 3. 3.
Sample from for all and ,
where , and are the full conditionals of Model S3 (see supplementary material for explicit expressions).
Given the conditional independence structure of the model, Sampler GS(1,1) is equivalent to a blocked Gibbs sampler with components , a and b, i.e. a scheme performing consecutive updates of , and at each iteration.
The parametrization induced by (2) is often referred to as non-centred parametrization (NCP) and it is contrasted with the centred parametrization (CP) obtained by replacing and with and respectively. Under the centred parametrization the model formulation becomes
[TABLE]
Figures 1(b) and 1(a) provides a graphical representation of the two parametrizations. In the case refers to the fact that both levels 1 and 2 use a non-centred parametrization, while in the case indicates that both levels use a centred parametrization. The resulting Gibbs sampler for the centred parametrization is as follows.
Sampler GS()****.
Initialize , and and then iterate
Sample from ; 2. 2.
Sample from for all ; 3. 3.
Sample from for all and ,
where , and are the full conditionals induced by (3) (see supplementary material for explicit expressions).
Together with the fully non-centred parametrization and the fully centred parametrization , one can also consider the mixed parametrizations given by and and the corresponding Gibbs Sampler schemes and . See Figures 1(c) and 1(d) for graphical representations.
2.1 Illustrative example
As an illustrative example, we simulated data from Model S3 with , , , and . This correspond to a scenario of high level of noise in the measurements. We fit model S3 assuming the standard deviations to be unknown and placing weakly informative priors, namely , and a priori distributed according to an Inverse Gamma distribution with shape and rate parameters equal to . We compare the efficiency of the Gibbs sampling schemes corresponding to the four different parametrizations, denoting them by , , and . For this simple example we initialized the chains at true values of the parameters and , which we know because we are in a simulated dataset example. The more realistic case of starting the chains from randomly chosen states led to the same conclusions of this illustrative examples. Note that all the four schemes have the same starting states (modulo re-parametrization) to have a fair comparison.
Figure 2 shows the mixing behaviour of the global mean and displays the potentially dramatic difference among mixing properties of the Gibbs Sampler under different parametrizations.
Based on Figure 2 one would certainly exclude using and to fit the model under consideration and may be tempted to deduce that both and lead to good mixing properties of the resulting chain. However, as an additional check, a cautious practitioner may also explore the mixing of the parameters at the first level, namely a and . Figure 3 displays the behaviour of the global averages of such parameters, namely and , in the first 1000 iterations.
Again, we see a dramatic difference induced by different parametrizations and, somehow surprisingly, we see that, despite having good mixing behaviour at level 0 (i.e. ), displays very poor mixing behaviour at level 1 (i.e. ). It is then natural to explores also the mixing behaviour at level 2 and Figure 4 does so again by plotting the global averages and .
In this case and are the only one achieving good mixing. Based on Figures 2, 3 and 4 it is natural to choose to fit the model using the sampler corresponding to the mixed parametrization , as it is the only one providing a good mixing across all three levels.
This simple example shows many typical issues arising when fitting Bayesian multi-level models and raises many questions. For example, one would like to know what are good parameters to use to diagnose convergence, in order to avoid misleading conclusions like the one suggested by Figure 2. In fact, while in two level model good mixing of the global hyperparameters such as typically indicates good global mixing, this is not true in other multi-level models. Indeed, it is legitimate to wonder whether diagnoses based only on the global means, like in Figures 2-4, are enough to deduce good mixing of the whole Markov chain, which in our example has more than dimensions ( mean components and precision components). Below we will show that for Model S3, mixing of the global means ensures mixing of the whole -dimensional mean components of the chain given the variances (see e.g. Corollary 1). Therefore it is enough to monitor the three global means and the three variances to ensure a reliable check of the chain mixing properties.
Even more crucially, it is desirable to have simple and theoretically grounded guidance in choosing a computationally efficient parametrization, given the huge impact it can have on computational performances. The theoretical analysis developed in the next section will provide useful guidance in this respect.
3 Multigrid decomposition for the three level hierarchical model
The basic ingredient of our analysis is the following multigrid decomposition. Consider the four possible parametrization of Model S3: , and the mixed parametrizations and . In order to provide a unified treatment, regardless of the chosen parametrization, we denote the parameters used by and the resulting Gibbs Sampler by . For example, in the NCP case , , and coincides with GS(1,1). First consider the map sending to
[TABLE]
where, loosely speaking, represent the increments of at the -th coarseness level. More precisely
[TABLE]
where
[TABLE]
It is easy to see that the map is a bijection between and , where . The dimensionality of equals the one of , which is , because has parameters and constraints. The following theorem shows that the Markov chain induced by factorizes under the transformation .
Theorem 1** (Multigrid Decomposition).**
Let be a Markov chain on evolving according to . Then the timewise transformations , and are each a Markov chain and evolve independently.
While the posterior independence of , and is well-known, the remarkable fact following from Theorem 1 is that also the Markov chains induced by the Gibbs Sampler are independent (note that the independence of the random vector under the target measure is a necessary but not sufficient condition for the independence of a corresponding MCMC scheme).
Remark 1**.**
It is worth noting that the three subspaces of spanned by the vectors , and , respectively, do not depend on the choice of parametrization . Thus the multigrid decomposition is intrinsic to the model, and not dependent on the particular parametrization being considered.
Theorem 1 provides a useful tool to analyze the Markov chain of interest, . In fact the factorization into independent Markov chains implies that the rate of convergence of is simply given by the worst rate of convergence among , and . Interestingly, the slowest chain is always the chain at the highest level , regardless of the choice of parametrization and the values of .
Theorem 2** (Hierarchical ordering of convergence rates).**
Let , and be the Markov chains defined in Theorem 1. Then the associated convergence rates satisfy
[TABLE]
Theorems 1 and 2 imply that the rate of convergence of the global chain coincides with the one of the sub-chain sampling the global means .
Corollary 1**.**
(Rate of convergence of ) Given the notation of Theorem 1,
[TABLE]
3.1 Explicit rates of convergence under different parametrizations
The multigrid decomposition developed in Section 3 allows to perform a direct analysis on the convergence properties of the Markov chain of interest . The latter is a Gibbs Sampler targeting a multivariate Gaussian distributions and thus, in principle, could be analyzed using, for example, the tools developed in Amit (1996); Roberts and Sahu (1997); Khare et al. (2009). However, these results require to have a full characterization of the spectrum of a matrix, where is the number of dimensions in the Markov chain under consideration. Given the high-dimensionality of , which has parameters, it is hard to apply directly such results and in fact the convergence properties of have been studied heuristically or numerically in the literature (see e.g. (Gelfand et al., 1995, Sec.4) and (Roberts and Sahu, 1997, Sec.4.2)). Corollary 1, however implies that it suffices to study the skeleton chain , which is a low-dimensional chain (namely 3-dimensional) amenable to direct analysis. Therefore, using Corollary 1, we can derive analytic expressions for the rates of convergence for the Gibbs Sampler under different parametrizations.
Theorem 3**.**
Given an instance of Model S3, the rate of convergence of the four Gibbs Sampler schemes , , and are given by
[TABLE]
where , and .
Theorem 3 provides explicit and informative formulas regarding the interaction between choice of parametrization and resulting efficiency of the Gibbs Sampler for Model S3.
Figure 6 summarizes graphically the dependence of the converge rates of different parametrizations from the values of the variances of various levels. Roughly speaking, the figure suggests that there is a partition of the hyperparameter space (corresponding to the white regions in each plot) such that in each region one and only one of the four parametrizations performs well.
Consider for example the illustrative example of Section 2.1. Applying Theorem 3 to such context we obtain that the rates of convergence (up to the third decimal digit) of the various Gibbs Samplers under consideration given are
[TABLE]
Recall that values of close to 1 mean slow convergence, see (1) and discussion thereof. These numbers provide a quantitative and theoretically grounded description of the behaviour heuristically observed in Section 2.1 and can be easily used to optimize performances (see e.g. Section 3.2 below).
3.2 Conditionally optimal parametrization
A natural and practically relevant question is what is the optimal parametrization (among the four possible choices , , and ) as a function of the normalized variance components . Using the formulas of Theorem 3 we can obtain the following explicit answers.
Corollary 2** (Optimal parametrization for Model S3).**
The rate of convergence of the Gibbs Sampler targeting Model S3 is minimized by the following choice of parametrization:
- •
use a centred parametrization at the lowest level if and only if ,
- •
use a centred parametrization at the middle level if and only if .
The resulting Gibbs Sampler has a rate of convergence upper bounded by , with the equality holding if and only if and (in which case all parametrizations are equivalent).
Table 1 provides a graphical representation of the decision process. This simple rule guarantees that the resulting Gibbs Sampler has a rate of converges smaller than , thus guaranteeing a high sampling efficiency for fixed variances.
Table 1 implies that the choice of parametrization of a given level (i.e. whether it is computationally convenient to use a centred or non-centred parametrization) depends on the ratio between the normalized variance at the level under consideration and the sum of the normalized variances of the levels below. This results extend previous intuition for the two-level case (e.g. Papaspiliopoulos et al. (2003)) to deeper hierarchical levels (in this case three levels).
Corollary 2 allows for simple and effective strategies to ensure high sampling efficiency in practical implementations of Gibbs Sampling for Model S3 in the case of unknown variances. Common implementations choose a parametrization of the Gaussian component (for example the fully centred parametrization ) and alternate updating with and with direct sampling (which is straightforward using the conditional independence of , and given ). Given Corollary 2, instead, one can choose the optimal parametrization given on-the-fly according to Table 1. This ensures that the sampling step will have a high efficiency, regardless of the values of . Note that the additional computational cost required by choosing the optimal parametrization according to Table 1 at each step is negligible compared to the cost of a Gibbs Sampling iteration.
Figure 7 compares the resulting autocorrelation functions in the context of the illustrative example of Section 2.1, with unknown variances .
We compare the Gibbs Sampler with optimal parametrization (updating with , where is the optimal parametrization chosen according to Table 1, and exactly) with the centred Gibbs Sampler (updating with and exactly) and a blocked Gibbs Sampler (updating and exactly), which can be implemented because the distribution of is multivariate Gaussian. All schemes are then combined with the parameter expansion methodology of Meng and Van Dyk (1999); Liu and Wu (1999). The results in Figure 7 show that using the optimal parametrization reduces significantly the autocorrelation compared to, e.g., the fully centred one, and achieves a mixing that is basically equivalent to the one obtained by the exact blocked Gibbs Sampler. In all cases parameter expansion helps to reduce the autocorrelation in the samples of the standard deviations .
The similarity of performances between the Gibbs Sampler with optimal parametrization and the blocked one is interesting because the Gibbs update of only requires univariate updates and has a potentially lower computational cost compared to a full multivariate block update of , which requires large matrix operations. While these matrix operations can be performed efficiently in the context of nested linear models (see e.g. Papaspiliopoulos and Zanella, 2017), their cost becomes significantly larger for example in the context of crossed random effect models (see Section 4 below and Papaspiliopoulos et al., 2019). Note that such a similarity of performances is not surprising given our theoretical results above. In fact Corollary 2 guarantees that the sampler used in the Gibbs update have a rate of convergence upper bounded by , which is well separated from 1. When such updates are nested within a larger sampler (e.g the one updating and ) the difference between and exact update of and a Gibbs one with good rate of convergence can easily become negligible.
4 Multigrid decomposition for crossed effect models
Interestingly, the multigrid decomposition can be used to analyze non-nested models. In this section we focus on the following crossed effect model.
Model Ck** (k-factors crossed-effects model).**
[TABLE]
with for , and . We denote the number of observed datapoints by .
Similarly to Sections 2 and 3, we use bold letters to denote the following vectors: , , and . The standard Gibbs Sampler to sample from the posterior distribution of Model Ck is defined as follows.
Sampler GS-crossed**.**
At each iteration
sample from , 2. 2.
sample from with going from to .
Model Ck and Sampler GS-crossed have recently been analysed in Papaspiliopoulos et al. (2019) using the multigrid decomposition approach developed in Section 3 of this paper to derive expressions for the convergence rate of Sampler GS-crossed. In particular, Papaspiliopoulos et al. (2019) considered the following linear functions of
[TABLE]
for each and proved the following result.
Theorem 4** (Papaspiliopoulos et al. (2019)).**
Let
[TABLE]
be the Markov chain generated by Sampler GS-crossed. Then the time-wise transformations and , …, are independent Markov chains. Moreover, the rate of convergence of is
[TABLE]
Theorem 4 implies that the convergence properties of Sampler GS-crossed deteriorate as increases because goes to 1 as . Motivated by this consideration, Papaspiliopoulos et al. (2019) propose a collapsed Gibbs Sampler that avoids such slowdown for increasing data size while preserving the same computational cost per iteration of Sampler GS-crossed. In the following two sections we extend the analysis of Model Ck performed in Papaspiliopoulos et al. (2019), focusing on the role of, respectively, reparametrizations and statistical identifiability.
4.1 Reparametrizations and crossed effects models
In the context of nested models, reparametrization techniques based on hierarchical centering offers a way to make the Gibbs Sampler robust to large datasets (see e.g. Corollary 2). We now show that this is not the case in the crossed effects context of Model Ck. In this section we focus on the case , which is a case often studied theoretically in the literature (see e.g Gao and Owen (2017); Brown et al. (2018) for recent examples). In this case, hierarchical centering leads to four possible parametrizations defined as
[TABLE]
Each parametrization corresponds to a different Gibbs Sampler, which at each iteration updates from , from \mathcal{L}\big{(}{\bm{\beta}}^{(1)}|\mu,{\bm{\beta}}^{(2)},\bm{y}\big{)}, and from \mathcal{L}\big{(}{\bm{\beta}}^{(2)}|\mu,{\bm{\beta}}^{(1)},\bm{y}\big{)}. The following result characterizes the rate of convergence of such Gibbs Samplers for all combinations .
Theorem 5**.**
Let and . Then we have
[TABLE]
Figure 8 summarizes graphically the results of Theorem 5, showing the dependence of the converge rates on the choice of parametrization. The rate displayed in Figure 8 for the fully centred parametrization is the lower bound given in (9).
Theorem 5 implies that centering both factors (i.e. setting ) is always computationally worse than any of the other parametrizations because . On the other hand, the optimal choice of among , and depends on the specific values of and . More precisely, the expressions in (9) imply that the convergence rate is minimized by centering the first factor (i.e. setting ) if and only if and centering the second factor (i.e. setting ) if and only if . These results are in agreement with, for example, the empirical results obtained in Gelfand et al. (1996, Sec.6) and Browne (2004).
More crucially, Theorem 5 implies that as . Therefore, regardless of the parametrizations chosen, the convergence of Gibbs Samplers targeting Model Ck deteriorate as the number of factors and increase. This is in contrast with the nested case analysed in Section 3, where reparametrization techniques are successful in providing samplers with good convergence properties for all choices of hyperparameter values. In the next section we show that a more effective way to achieve good convergence properties is to impose stronger identifiability constraints.
4.2 Connections to statistical identifiability
The parameters in Model Ck are not identifiable, in the sense that the mapping in not injective. While this is not strictly speaking an issue for Bayesian inferences, one may wonder whether imposing identifiability on model parameters results in avoiding the degradation of mixing described in previous sections (see e.g. Vines et al. (1996); Gelfand and Sahu (1999); Xie and Carlin (2006); Kaufman et al. (2010); Vallejos et al. (2015) for related discussion and some examples in applications). We consider imposing identifiability by conditioning on some linear constraints, such as the commonly used choices of or . More generally, one can obtain identifiability for Model Ck by imposing a linear constraint for each from to , where is a linear combination of weighted by some non-negative terms satisfying . Interestingly, one can exploit the multigrid decomposition to derive the convergence rates of the resulting Gibbs Samplers for all choices of weights .
Theorem 6**.**
The rate of convergence of Sampler GS-crossed conditioned on for is given by
[TABLE]
where .
Comparing (10) with (7) we can see that, since , the rate of convergence always decreases after imposing the identifiability constraints for . Thus, Theorem 6 implies that, in this context, imposing identifiability always improves the convergence properties of the Gibbs Sampler. To our knowledge, this is the first rigorous result of this kind in the Bayesian computation literature. On the other hand, the result also shows that imposing identifiability per se does not guarantee fast convergence. For example, Theorem 6 implies that the rate of convergence of Sampler GS-crossed conditioned on for each is given by
[TABLE]
while the rate of convergence of Sampler GS-crossed conditioned on for each equals 0, i.e. the sampler produces i.i.d. draws from the posterior distribution . While in both cases we observe an improvement over the original Gibbs Sampler in terms of convergence rates, the result shows that conditioning on for each leads to a convergence rate that can still go to 1 as the datasize increase. Interestingly (10) implies that the rate of convergence is minimized when is maximized, which happens when the weights in the linear constraints are constant, for example for all and .
5 Beyond the Gaussian case: a Poisson example
The results of Section 4.2 provide guidance on the choice of which linear constraint to use to impose identifiability for models also beyond the Gaussian case. As an example, we consider the following crossed random effect model with Poisson likelihood, which is the simplest analogue of Model Ck in the context of count data.
Model CkP** (Poisson crossed-effects model).**
[TABLE]
*with for and . *
We consider sampling from the posterior distribution of Model CkP using the standard Gibbs Sampler that, similarly to Sampler GS-crossed, at each iteration updates from and then from for . Here , and are defined as in the beginning of Section 4.
We explore the extent to which the conclusions drawn from Theorem 6 apply also to Model CkP by means of simulations. We consider the case with three different combinations of values of and , with data simulated from the model. For the prior hyperparameters we use and . We compare the standard Gibbs Sampler with no constraints, with the versions obtained by imposing the linear constraint and , respectively, where and are defined as in (6). Table 2 reports the resulting effective same sizes for various parameters (namely , the average effective sample size of for and similarly for over ).
The results in Table 2 are very much coherent with the theoretical results obtained in the Gaussian case in Theorem 6. In particular, imposing identifiability always improves mixing of the Gibbs Sampler, and imposing constraints on and leads to a sampler with faster convergence compared to imposing constraints on and . Moreover, the difference in resulting efficiency between the two set of linear constraints increases with and , as suggested by Theorem 6.
5.1 Comparison with Hamiltonian Monte Carlo
Finally, we also explore whether the results in Theorem 6 are useful also to guide the implementation of other MCMC schemes targeting Model CkP, such as Hamiltonian Monte Carlo (HMC) (Neal et al., 2011) and the No-U-Turn Sampler (NUTS) (Hoffman and Gelman, 2014) implemented in the widely used software STAN (Carpenter et al., 2017). We consider the same setting of the rightmost column of Table 2 where .
Table 3 reports effective sample sizes (ESS), runtime and ESS per unit of computation time for HMC and NUTS, and compare those to the Gibbs Sampler one (see also the supplementary material for traceplots and autocorrelation functions). Table 3 suggests that imposing identifiability through linear constraints as suggested by Theorem 6 helps significantly also gradient-based sampler such as HMC and NUTS, both by speeding up convergence (higher ESS) and by reducing the cost per iteration (lower runtime). We expect the reduction in runtime for HMC and NUTS to arise from the adaptation of the tuning parameters performed by STAN (e.g. step-size and number of leapfrog steps within each iteration) so that for better identified and less correlated targets (as the one with the linear constraints) the number of required leapfrog steps per iteration is lower, leading to a reduction in runtime. Overall, imposing identifiability results in a significantly higher sampling efficiency: for example, when the constraints is imposed, NUTS is over three orders of magnitude more efficient than in the unconstrained version. Also, especially for NUTS, the constraints lead to a more efficient sampler than the ones with , which is analogous to the results of Theorem 6. In general, Table 3 supports the fact that the results of Theorem 6 can also provide useful guidance to derive significantly more efficient implementations of gradient-based MCMC algorithms. Finally, note that the runtime of the Gibbs Sampler is orders of magnitude lower than the one HMC and NUTS, suggesting that for random effect models such as Model CkP gradient-based schemes can be much more costly than Gibbs-type schemes, which exploit more directly the conditional independence among random effects. We leave a more detailed investigation of these aspects in the context of more general and complex models to future work.
All simulations reported in Tables 2 and 3 were performed on the same desktop computer with 16GB of RAM and an Intel core i7-7700 @ 3.60 GHz processor, using the R programming language (R Core Team, 2018). Effective sample sizes are estimated using the mcmcse R package (Flegal et al., 2017). The supplementary material provides the R code used to implement the Gibbs Samplers and the Stan code used to specify the models.
Remark 2**.**
Interestingly, the multigrid decomposition can be applied also to Model CkP, with the appropriate modifications. In this case the Markov chain induced by the Gibbs Sampler can be decomposed into independent Markov chains and \big{(}\tilde{\delta}{\bm{a}}^{(1)}(t)\big{)}_{t=1}^{\infty}, …, \big{(}\tilde{\delta}{\bm{a}}^{(k)}(t)\big{)}_{t=1}^{\infty}, where and . In this case the rate of convergence of the original chain coincides with the one of , which evolves according to a -dimensional Gibbs Sampler with full conditionals given by:
[TABLE]
where . We expect such a -dimensional Gibbs Sampler to be potentially amenable to analysis using the framework of iterated random functions (Diaconis and Freedman, 1999), in order to obtain an upper bound on convergence rates (see e.g. Alsmeyer and Fuh, 2001, Theorem 2.1.(b)). We leave these extensions to future works and mention it in Section 8 as a possible avenue for future research directions.
6 Non-symmetric hierarchical models
Section 3 describes how to choose the optimal parametrization as a function of for Model S3. In general, both the variance terms and , and the number of branches and in the hierarchy could depend on and . In this section we consider such non-symmetric cases for two and three level hierarchical models. In these non-symmetric cases the computationally optimal strategy will involve centering some branches of the hierarchy and non-centering others: we will refer to these strategies as bespoke parametrizations.
Consider the following non-symmetric 2-levels model (which we describe in terms of precisions rather than variances for notational convenience).
Model NS2** (Non-symmetric 2-levels hierarchical model).**
*Consider the following 2-levels model with centred parametrization *
[TABLE]
where the precision components are assumed to be known.
Papaspiliopoulos et al. (2003) studied the symmetric version of Model NS2, where and for all and some fixed and . They showed that the rates of convergence induced by the centred and non-centred parametrizations are given respectively by
[TABLE]
where . The following Theorem provides an extension to the general non-symmetric case. We consider Model NS2 with a bespoke parametrization defined by indicators as , meaning that equals 0 if component is centred and 1 if it is non-centred.
Theorem 7**.**
The rate of convergence of the Gibbs Sampler targeting Model NS2 with bespoke parametrization given by is
[TABLE]
where .
Equation (14) shows that in the non-symmetric case, the GS rate of convergence is given by a weighted average of the precision ratios and depending on whether each component is centred or not. This has clear analogies with the symmetric case in (13). The weights in the average of (14) are themselves a function of , thus introducing dependence across components in terms of centering and the overall convergence rate. Nonetheless, the following corollary shows that even in the context of Model NS2, the choice of optimal parametrization in each branch of the three can be carried out independently following the same intuition of the symmetric case: for each in use centred parametrization if and only if , otherwise use a non-centred parametrization . Note that the optimal choice on each branch of the hierarchy can be taken independently of other branches, which make the implementation easy (compared to a scenario where the optimal decision on each branch was influenced by other branches).
Corollary 3**.**
Let for all from 1 to . Then
[TABLE]
By (14), the strategy described in Corollary 3 ensures that . This is the same upper bound one can obtain in the symmetric case (see (13) and Papaspiliopoulos et al. (2003)), meaning that in this case bespoke parametrizations are successful in dealing with the lack of symmetry.
Consider now the three-level non-symmetric case.
Model NS3** (Non-symmetric 3-levels hierarchical model).**
Consider a more general 3-levels model with centred parametrization
[TABLE]
where variance components are assumed to be known.
In this case the multigrid factorization of Theorem 1 does not apply directly to Model NS3, but nonetheless it can still be used to obtain upper bounds on the rates of convergence.
Theorem 8**.**
Given an instance of Model NS3 we define
[TABLE]
If for every , then the rate of convergence of the Gibbs Sampler with centred parametrization satisfies
[TABLE]
The results of Theorem 8 suggest that as the number of datapoints increase the efficiency of the Gibbs sampler with centred parametrization increases. In fact, as increases the assumptions of Theorem 8 are eventually satisfied and the bound on the convergence rate goes to [math] as and increase. Theorem 8 provides rigorous theoretical support and characterization of the well known fact that the centred parametrization is to be preferred in contexts of large and informative datasets (Gelfand et al., 1995; Papaspiliopoulos et al., 2003). We note that the convergence rate for the Gibbs Sampler targeting Model NS3 is not easily tractable, and that deriving analytic expressions for the optimal bespoke parametrization in this context is still an open problem.
7 Hierarchical linear models with arbitrary number of levels
In this section we consider Gaussian hierarchical models with an arbitrary number of levels, namely levels. We refer to the highest level of the hierarchy (i.e. the one furthest away from the data) as level 0, down to level being the lowest level (i.e. closest to the data). The 3 level model of Section 3 is a special case of the theory developed here where .
7.1 Model formulation
In order to allow for more generality and keep the notation concise, in this section we will use a graphical models notation. In particular will denote a finite tree with levels and root . For each node we will denote by the unique parent of and by the collection of children of . Moreover we write and if is respectively an ancestor or a descendant of (with and possibly being equal) while and denote the same notions with the additional condition of . For each node we denote by the level of node (i.e. its distance from ). For each we denote by the collection of nodes at level . For example we have and . Noisy observations will occur only at leaf nodes. The collection of leaf nodes is denoted as . For simplicity we assume that all leaf nodes are at level , i.e. , although this assumption could be easily relaxed allowing some branches to be longer than others.
Model NSk** (-levels hierarchical model).**
Suppose that we have a hierarchy described by a tree with observations occurring at leaf nodes . We assume the following hierarchical model
[TABLE]
where with being the number of observed data at leaf node , and are known precision components and all normal random variables are sampled independently. Following the standard Bayesian model specification we assume a flat prior on .
We are interested in sampling from the posterior distribution of given some observations . The centred parametrization of Model NSk leads to the following Gibbs Sampler.
Sampler GS()****.
*Initialize and then iterate the following kernel:
For , sample from for all , where is the full conditional distribution of given by Model NSk. When equals 0 or the levels and have to be replaced by empty sets in the conditioning.*
7.2 Non centering and hierararchical reparametrizations
Model NSk expresses Gaussian hierarchical models using a centred parametrization. The corresponding non-centred version is given by the following example.
Example 1** (Fully non-centred parametrization).**
Under the same setting as Model NSk, define
[TABLE]
and assume a flat prior on .
The non-centred parametrization can be obtained as a linear transformation of the centred version of Model NSk. More generally, we will consider the class of parametrizations that can be obtained by reparametrizing as follows.
Definition 1** (Hierarchical reparametrizations).**
Let be a random vector with elements indexed by a tree . We say that is a hierarchical (linear) reparametrization of if
[TABLE]
for some real-valued coefficients satisfying for all . We denote (17) by .
Using terminology from Papaspiliopoulos et al. (2003), we refer to the family of hierarchical reparametrizations of as partially non-centred parametrizations (PNCP) of Model NSk. Note that (17) does not span the space of all linear transformations of . In fact can be thought as a matrix inducing a linear transformation of with the additional sparsity constraint of being zero on all elements such that . The following Lemma shows that the definition of the class of PNCP does not depend on the starting parametrization used to formulate Model NSk. For example, one could equivalently define the class of PNCP of Model NSk as the collection of hierarchical reparametrization of the non-centred parametrization of Example 1.
Lemma 1**.**
If is a hierarchical reparametrization of , then also is a hierarchical reparametrization of .
As for the 3-levels case we are interested in assessing the computational efficiency of the different Gibbs Sampling schemes arising from different PNCP’s. For each PNCP the corresponding Gibbs Sampler scheme is defined analogously to .
Sampler GS()****.
*Initialize and then iterate the following kernel:
For , sample from for all , where is the full conditional distribution of given by Model NSk.*
Sampler GS() is easy to implement because the family of PNCP preserves the hierarchical structure of Model NSk. In fact, any PNCP of Model NSk exhibits the following conditional independence structure:
[TABLE]
Note that this is a weaker condition than the one holding for the centred parametrization . In the latter case, the conditional independence graph corresponds exactly to the tree , meaning that if
[TABLE]
Despite being weaker than (T), condition (H) still guarantees that all parameters at the same level are conditionally independent (thus simplifying the update of ) and that the full conditional distribution of each depends only on the descendants or ancestors of . The following Lemma and Corollary provide a simple way to check that any PNCP of Model NSk satisfies (H).
Lemma 2**.**
Property (H) is closed under hierarchical re-parametrizations, meaning that if satisfies (H) then any hierarchical re-parametrization of satisfies (H) too.
Corollary 4**.**
Any PNCP of Model NSk satisfies (H).
7.3 Symmetry assumption
To provide a full analysis of the convergence properties of Sampler GS() we need a symmetry assumption that we now define. Let denote the partial correlation Corr\left(\beta_{t},\beta_{r}\Big{|}{\bm{\beta}}_{T\backslash\{t,r\}}\right), namely
[TABLE]
and for all . Here is the precision matrix of . Let be a random walk going through from root to leaves as follows: almost surely and then, for
[TABLE]
Equation (18) implies that at each step the Markov chain X jumps from the current state to one of its children choosing proportionally to the squared partial correlation between and . Since almost surely for all we can use the following simplified notation: for any and in we use , and to denote respectively , and .
Given the above definitions, we define the following symmetry condition: there exist a symmetric matrix such that
[TABLE]
and if and . Note that is invariant to coordinate-wise rescaling of and therefore both property (S) and the transition kernel of X are invariant to rescalings. Therefore we can consider, without loss of generality, the following rescaled version of defined by
[TABLE]
Given (19), condition (S) can be written, in terms of the precision matrix of as
[TABLE]
The rescaled version will be helpful later to design an appropriate multigrid decomposition of . Also, it can be seen that property () is closed under symmetric hierarchical parametrizations.
Definition 2** (Symmetric hierarchical reparametrizations).**
We say that is a symmetric hierarchical reparametrization of if the coefficients of depend only on the levels of and in the hierarchy .
Lemma 3**.**
Property () is closed under symmetric hierarchical reparametrizations, meaning that if satisfies () then any symmetric hierarchical reparametrization of satisfies () too.
Various special cases of Model NSk satisfy assumption (S). For example, we now consider three cases: a fully symmetric case (both the tree and the variances are symmetric), a weakly symmetric case (non-symmetric tree and symmetric variances) and a non-symmetric case (both tree and variances non-symmetric).
Model Sk** (Symmetric -levels hierarchical model).**
Consider the -level Gaussian Hierarchical model where the observed data are generated from
[TABLE]
where for any positive integer . The parameters have the following hierarchical structure: for each level from to
[TABLE]
Here are known precisions and the root parameter is given a flat prior . For each the positive integer represents the number of branches from level to level .
It is easy to see that the posterior distribution of Model Sk, conditioned on the observed data , satisfies (S). In this case the random walk X defined by (18) coincides with the natural random walk going through .
Example 2** (Weakly symmetric case).**
Another special case of Model NSk satisfying (S) is given by the case of a general tree and precision terms defined as for all and , where are level-specific precision terms. This is an extension of Model Sk where the lack of symmetry of is compensated by appropriate variance terms. Condition (S) can be checked by evaluating the partial correlations of the resulting vector .
Example 3** (Non-symmetric cases).**
In both cases previously considered (Model Sk and Example 2) the auxiliary Markov chain X defined in (18) follows a natural random walk, in the sense that at each time the chain chooses the next state uniformly at random among children nodes. However, condition (S) is also satisfied by non-symmetric cases where X is not a natural random walk. In particular any instance of Model NSk such that
[TABLE]
for some -dimensional vector induces a posterior distribution satisfying (S). In fact, in the context of Model NSk conditions (S*) and (S) are equivalent (this can be derived from (T) and (18)).
The cases previously considered are expressed in terms of centred parametrization, meaning that as all the instances of Model NSk they satisfy (T). Nevertheless Lemma 3 shows that any symmetric hierarchical reparametrization of a vector satisfying () still satisfies (). This implies, for example, that the fully non-centred version of Model Sk and any mixed strategy where some level is centred and some is not centred, still satisfies () (after rescaling).
Moreover, note that the exact analysis we will now provide for the Gibbs sampler on models satisfying () can be used to provide bound on general cases that do not satisfy () (see for example Theorem 8).
7.4 Multigrid decomposition
We now show how to use the multigrid decomposition to analyze the Gibbs Sampler for random vectors satisfying (H) and (S). Our aim is to provide a transformation of that factorizes the Gibbs Sampler Markov Chain into independent and more tractable sub-chains. Similarly to Section 3 in the following we will often denote by . We proceed in two steps, first introducing the averaging operators and then the residual operators . For any the averaging operator is defined as
[TABLE]
where is the Markov chain defined by (18). Loosely speaking can be interpreted as the averages of at the coarseness corresponding to the -th level of the hierarchy. In particular and .
Example 4** (Averaging operators in the symmetric case).**
Let be given by Model Sk. Then
[TABLE]
Given , we define the residual operators as with defined as
[TABLE]
for and for . Analogously to the 3-level case of Section 3, under suitable assumptions the residual operators decompose the Markov chain generated by the Gibbs Sampler into independent sub-chains. To prove the result we first need the following lemma.
Lemma 4** (-residuals interact only with -residuals).**
Let be a Gaussian random vector satisfying (H) and (). Then for any and with , for all we have the identity
[TABLE]
Given Lemma 4 we can prove the following multigrid decomposition for hierarchical linear models.
Theorem 9** (Multigrid decomposition for levels).**
Let be a Markov chain evolving according to GS() with satisfying (H) and (). Then , …, are independent Markov chains. Moreover, each chain evolves according to the following blocked Gibbs sampler scheme with components: for going from to sample
[TABLE]
where denotes the conditional distribution of given .
Theorem 9 implies that running a Gibbs sampler targeting distributions satisfying (H) is equivalent to running independent blocked Gibbs Samplers, one for each level of coarseness from to .
Corollary 5**.**
Let satisfies (H) and (). Then the rate of convergence of GS() is given by where for each , is the rate of convergence of .
7.5 Hierarchical ordering of rates
Combining the results in Roberts and Sahu (1997, Sec.2.2) with the multigrid decomposition, we can characterize the rates of convergence of the independent Markov chains described above as follows.
Theorem 10**.**
The rate of convergence of is given by the largest modulus eigenvalue of . Here is the dimensional identity matrix, while and are, respectively, the strictly lower and strictly upper triangular part of , with given by ().
Theorem 10 implies that the convergence properties of the independent Markov chains are closely related. In particular, from the rates of convergence point of view, the Markov chains updating for behave as Gibbs samplers targeting a decreasing number of dimensions (from down to 1) of a single -dimensional Gaussian distribution with precision matrix given by , where is given by (). This suggests that the convergence properties of the sub-chains will typically improve from that of to that and that the rate of convergence of will typically determine the rate of the whole sampler GS(). In particular, in the centred parametrization case we can use the well-known Cauchy interlacing theorem (see e.g. Bhatia, 2013) to show that the rate of convergence is monotonically non-increasing from to .
Theorem 11**.**
(Ordering of rates for centred parametrization)* Let be a Gaussian vector satisfying (T) and () and let be the corresponding Markov chain evolving according to GS(). Then the convergence rates of the independent Markov chains , …, satisfy*
[TABLE]
In Theorem 11 we needed the additional assumption (T) to prove (23). The reason is that, while in most cases the convergence rates of a deterministic-scan Gibbs Sampler targeting a -th dimensional Gaussian distribution improves if one of the coordinates is conditioned to a fixed value and the sampler targets only the remaining coordinates, this is not true in general. Example 2 of Roberts and Sahu (1997) provides a counter-example (see also Whittaker, 1990, page 319). In Roberts and Sahu (1997), this example was used a counter-example regarding blocking strategies, it also works in the present context. We note that, if one were to consider a random scan version of the Gibbs Sampler, the reversibility of the induced Markov chains would allow to prove the ordering result in Theorem 11 with no need to assume (T). We leave this as a direction of future research and briefly mention it in Section 8.
Theorem 11 implies the following corollary.
Corollary 6**.**
Let be a Gaussian vector satisfying (T) and (). Then the rate of convergence of GS() is given by the largest squared eigenvalue of the -dimensional matrix , where is defined by () and is the -dimensional matrix.
In particular, considering the special case of Model Sk it is easy to deduce the following result.
Corollary 7**.**
The rate of convergence of targeting Model Sk is given by the largest squared eigenvalue of the -dimensional matrix
[TABLE]
*where with and given by Model Sk, , and . *
7.6 Example: rates of convergence for 4-level models
The results developed in Sections 7.4 and 7.5 allow to analyze hierarchical models with an arbitrary number of levels. For example we could consider 4-level extensions of Model S3.
Model S4**.**
(Symmetric 4-levels hierarchical model) Suppose
[TABLE]
where , , and run from 1 to , , and respectively and are iid normal random variables with mean 0 and variance . We employ a standard Bayesian model specification assuming , , and a flat prior on .
In order to fit Model S4 with a Gibbs Sampler like GS(), one could consider centering or non-centering each of the three levels , and . Let be the non-centering indicators associated to the resulting in combinations. Here indicates that the -th level is non-centred while indicates that it is centred. The corresponding rates of convergence can then be expressed in terms of the following normalized variance ratios
[TABLE]
where , , and . If (i.e. using the non-centred parametrization at level ) the rates are
[TABLE]
When the expressions for the convergence rates are still explicit, but slightly more involved and are reported in Section 3.1 of the supplementary material. These rates can be derived from Corollary 5 and Theorem 10. It is worth noting that also in this 4-level case the skeleton chain is always the slowest chain for all centred and non-centred parametrizations (which can be checked by computing the rates of convergence of , and using Theorem 10 and comparing those to the ones of ), even if for the general -level case we were able to prove this fact only for the fully-centred parametrization (Theorem 11). The expressions given here can be easily used to derive conditionally optimal parametrizations for Model S4 given the rescaled variance components . For example, choosing whether to center or not each level by comparing the level-specific rescaled variances with the sum of the rescaled variances of the lower levels like in Section 3.2 leads to rates of convergence upper bounded by .
8 Conclusions and future work
In this work we studied the convergence properties of the Gibbs Sampler algorithm in the context of Gaussian multilevel models. To do so we developed a novel analytic approach based on multigrid decompositions that allows to factorize the Markov chain of interest into independent and easier to analyze sub-chains. This decomposition enables us to evaluate explicitly the -rate of convergence in various models of interest. The results offer a detailed and valuable insight into the interaction between multilevel structures (e.g. nested and crossed) and the Gibbs Sampler and provide guidance on the choice of the computationally optimal parametrizations or linear constraints, which can potentially be relevant also beyond the Gaussian case (see e.g. Section 5), and indication of which parameters to monitor in the convergence diagnostic process (see Theorem 2 and discussion at the end of Section 2.1). Since the first preprint version of this paper, the multigrid decomposition developed in this paper has already found other practical applications. In particular Papaspiliopoulos et al. (2019) have successfully exploited it to analyze the computational complexity of the Gibbs Sampler in the context of crossed random effect models (see also Gao and Owen, 2017) and to design an algorithmic modification with linear computational complexity.
Together with explicit formulas for -rates of convergences, the multigrid decomposition we developed in this paper provides a simple and intuitive theoretical characterizations of practical behaviors commonly observed in practice when fitting hierarchical models with MCMC, such as slower mixing for hyper-parameters at higher levels (see Theorems 2 and 11), algorithmic scalability with width of the hierarchy but not with height (e.g. Theorem 3 and Corollary 7) and good performances of centred parametrization in data-rich contexts (Theorem 8). We hope that the results presented in this work will provide a first step towards providing quantitative understanding of the behavior of MCMC algorithms (even beyond the Gibbs Sampler) in the extremely popular context of Bayesian hierarchical and multilevel models.
The present work could be extended in many directions. For example, it would be interesting to extend the results for non-symmetric cases, either by generalizing the bounds of Theorem 8 or by weakening the symmetry assumption in (S). In terms of classes of models considered, a natural and important extension would be to consider the multivariate case (where each parameter is a multivariate random vector) and the regression case. We expect many results developed in this work to extend to the multivariate and regression case, even if in that context the role played by non-symmetric cases will be more crucial. Another important class of models that would be worth approaching with methodologies analogous to the ones developed here are models based on Gaussian processes commonly used, for example, in spatial statistics (see e.g. Bass and Sahu, 2016a).
An important and ambitious aim would be to extend the results to other tractable distributions within the exponential family beyond the Gaussian case. A starting point for this could be to analyze Model CkP as mentioned in Remark 2. Also, many non-Gaussian hierarchical models can be well-approximated by Gaussian ones for sufficiently large data sets, so that it is reasonable to conjecture that the qualitative conclusions (at least) of our study might remain valid when extrapolated to non-Gaussian models, rather like the analysis given in Sahu and Roberts (1999). A detailed study of this question is left for future work.
We have concentrated in this paper on deterministic samplers. However, explicit rates of convergence of random scan samplers are also available in the Gaussian case as described in Amit (1996) and extended in Roberts and Sahu (1997). deterministic and random scan samplers can sometimes differ substantially in their convergence properties, see for example Roberts and Rosenthal (2015), although no general theory for this phenomenon is well-understood, so that the insights of this work could be particularly useful in this direction. Also, in the random scan case the reversibility of the induced Markov chains would allow us to apply the Cauchy interlacing theorem under weaker assumptions than Theorem 11 and thus prove orderings results for general hierarchical parametrizations .
While this work is focused on -rates of convergence, the same approach could be used to derive bounds on the distance (e.g. total variation or Wasserstein) between the distribution of the Markov chain at a given iteration and the target distribution (see e.g. Amit (1996), Roberts and Sahu (1997, eq.(15)) and Khare et al., 2009, Sec.4.4). Such a formulation would be interesting to extend the recent growth in literature on providing rigorous characterizations of the computational complexity of Bayesian hierarchical linear models, see for example Rajaratnam and Sparks (2015); Roberts and Rosenthal (2016); Johndrow et al. (2015). In order to provide full characterizations, however, the case of unknown variances should be considered (see e.g. Jones and Hobert (2004) for the two level case).
Acknowledgments
The authors are grateful for stimulating discussions with Omiros Papaspiliopoulos and Art Owen. GZ supported in part by an EPSRC Doctoral Prize fellowship, by the European Research Council (ERC) through StG “N-BNP” 306406 and by MIUR through the PRIN Project 2015SNS29B. GOR acknowledges support from EPSRC through grants EP/K014463/1 (i-Like) and EP/D002060/1 (CRiSM).
1 Remarks on the results’ proofs
We list proofs following the mathematical chronology. This is different from the order of appearance in the paper because here we start from the results for -level models, namely the results from Lemma 1 to Corollary 7, and then move to the ones for -level models and crossed models, namely the results from Theorem 1 to Theorem 8.
The results developed here rely on classical theory for Gaussian Gibbs Samplers and their autoregression representations. The following theorem summarizes the most relevant facts for our purposes. See Lemma 1 and Theorem 1 of Roberts and Sahu [1997] for proofs and more detailed statements.
Theorem 1.1**.**
The Markov chain generated by a deterministic-scan Gibbs Sampler targeting a -dimensional Gaussian distribution with covariance matrix evolves as a multivariate Gaussian autoregressive process with transition kernel given by
[TABLE]
for some fixed -dimensional square matrix and -dimensional vector . The rate of convergence of equals the largest modulus eigenvalue of .
The autoregressive matrix , which we will sometimes refer to as -matrix of the Gibbs Sampler under consideration, can be explicitly derived from the target covariance , following the recipe in Section 2.2 of Roberts and Sahu [1997]. The latter involves computing an -dimensional square matrix and then exploiting the identity , where is the -dimensional identity matrix, is the lower triangular part of and . The specific form of , which we will sometimes refer to as -matrix, depends on the updating strategy of the Gibbs Sampler under consideration.
In principle, Theorem 1.1 provides a constructive way to compute the rates of convergence of Gaussian Gibbs Samplers. In realistic high-dimensional statistical scenarios, however, it is typically very challenging to compute analytically the largest modulus eigenvalue of , as the latter is a matrix with dimensionality equal to the number of parameters in the problem. In the following proofs, we will exploit the probabilistic structure of hierarchical models, and the multigrid decomposition in particular, to reduce the problem to studying low-dimensional Gaussian autoregressions, namely the skeleton chains , with more tractable -matrices.
2 Proofs of Lemmas
Proofs of Lemmas 1 and 2
In order to prove Lemmas 1 and 2 we need some preliminary results on matrices indexed by elements of a tree .
Lemma 5** (Triangular matrices on trees).**
Suppose that a matrix satisfies the following lower-triangularity condition
[TABLE]
Then is invertible and its inverse satisfies (Lm). Similarly, if satisfies the following upper-triangularity condition
[TABLE]
then is invertible and its inverse still satisfies (Um).
Proof.
Suppose that satisfies (Lm). Also without loss of generality suppose for all by rescaling. Then write where is the identity matrix and satisfies the following strict lower-triangularity condition
[TABLE]
Consider . From the last expression it follows that implies and , where denote the level of in the tree . Iterating the same argument we have that implies and . It follows that satisfies (L) for all and that for all where is the zero matrix. Here indicates the number of levels of , as in Section 7 of the paper. From for it follows that
[TABLE]
and therefore . Since satisfies (L) for all it follows that satisfies (Lm).
The analogous statement for (Um) can be deduced by observing that satisfies (Um) if and only if its transpose satisfies (Lm). ∎
Lemma 5 can be used to deduce Lemma 1 in a straightforward way.
Proof of Lemma 1.
Suppose that is a hierarchical reparametrization of . This is equivalent to say that is a matrix satisfying (Lm) and that for all , . Lemma 5 implies that is invertible and that satisfies (Lm). Therefore is a hierarchical reparametrization of . ∎
To prove Lemma 2 we need an additional preliminary result.
Lemma 6** (Closure of Hm).**
Suppose that satisfies the following condition
[TABLE]
Then if we multiply from the right with a matrix satisfying (Lm), the product still satisfy (Hm). Similarly if we multiply from the left with a matrix satisfying (Um), the product still satisfy (Hm).
Proof.
Consider . From (Hm) and (Um), the elements in the latter sum are non-zero only when belongs to the intersection of and . It is easy to see that the intersection of these two sets is non-empty only if or . Therefore satisfies (Hm). The argument to show that satisfies (Hm) is analogous. ∎
We now combine Lemmas 5 and 6 to prove Lemma 2.
Proof of Lemma 2.
Suppose that satisfies (H). This is equivalent to saying that its precision matrix satisfies (Hm). Consider a hierarchical reparametrization of denoted by . Then its precision matrix is given by where denote the transpose of . By definition of hierarchical reparametrizations, satisfies (Lm). Therefore Lemma 5 implies that satisfies (Lm) and, consequently, Lemma 6 implies that satisfies (Hm). Since satisfies (Lm), then satisfies (Um) and thus Lemma 5 implies that satisfies (Um). We can then apply Lemma 6 to and to deduce that satisfies (Hm) and thus satisfies (H). ∎
Corollary 4 follows easily from equation (T) and Lemma 2.
Proof of Lemma 3
The strategy to prove Lemma 3 is similar to the one used to prove Lemmas 1 and 2 above, with the difference that we have to check that the symmetry condition is preserved under the operations considered. To do so we first prove two auxiliary lemmas.
Lemma 7** (Symmetric triangular matrices on trees).**
Suppose that a matrix satisfies the following symmetric lower-triangularity condition
[TABLE]
where is a real valued matrix. Then is invertible and its inverse satisfies (SLm). Similarly, if satisfies the following symmetric upper-triangularity condition
[TABLE]
with being a real valued matrix, then is invertible and its inverse still satisfies (SUm).
Proof.
Suppose that satisfies (SLm). Also without loss of generality suppose for all by rescaling. Since also satisfies (Lm), arguing as in the proof of Lemma 5 we can write where and satisfies the following symmetric strict lower-triangularity condition
[TABLE]
From we deduce that still satisfies (SL) for some different . Iterating the same argument we have that satisfies (SL) for all . Since it follows that satisfies (SLm).
The analogous statement for (SUm) can be deduced by observing that satisfies (SUm) if and only if its transpose satisfies (SLm). ∎
Lemma 8**.**
Let and satisfy respectively () and (SLm). Then the product satisfies () for some different matrix . Similarly, if satisfies (SUm) then the product satisfy ().
Proof.
First consider the product . Lemma 6 implies that satisfies (Hm) and therefore unless or . Given or and using () and (SLm) we have
[TABLE]
where the sum from to equals 0 if . The latter equation implies that satisfies ().
To prove that the product satisfies () note that and satisfying () and (SUm) respectively is equivalent to and satisfying () and (SLm) respectively. Therefore, by the first part of this Lemma, satisfies (SLm) and thus satisfies (). ∎
We now combine Lemmas 7 and 8 to prove Lemma 3.
Proof of Lemma 3.
Suppose that the precision matrix of satisfies (). Consider a symmetric hierarchical reparametrization of denoted by . Then its precision matrix is given by where denote the transpose of . By definition of symmetric hierarchical reparametrizations, satisfies (SLm). Therefore Lemma 7 implies that satisfies (SLm) and, consequently, Lemma 8 implies that satisfies (). Since satisfies (SLm), then satisfies (SUm) and thus Lemma 5 implies that satisfies (SUm). We can then apply Lemma 8 to and to deduce that satisfies (). ∎
Proof of Lemma 4
Proof of Lemma 4.
Suppose has zero mean (otherwise replace by ). As in Section 7.4 of the paper, given any and in we denote by . Using (H), for any and , we can write the full conditional expectation of as
[TABLE]
where for any . Note that () implies
[TABLE]
It follows
[TABLE]
Since the last equation does not depend on we have For any , by definition of , we have
[TABLE]
From the latter equation and the definition of it follows
[TABLE]
∎
3 Proofs for hierarchical models with an arbitrary number of levels
Proof or Theorem 9
To prove Theorem 9 we first need the following lemma.
Lemma 9**.**
Given and with ,
[TABLE]
Proof.
Let , with and be fixed. To make the notation more compact we denote by , by and by for all and . By replacing with we can suppose without loss of generality that for all and therefore and for all and . By definition and therefore
[TABLE]
where we used for and , which follows from the conditional independence of and given . Note that in (3.1) could be 0. From for any and () we have and therefore
[TABLE]
Combining (3.1) and (3.2) we have if and
[TABLE]
From the last equality and the definition of in (21) we have
[TABLE]
where the last equality is trivial if and can be deduced from (3.3) otherwise. The desired conditional independence follows from for all and . ∎
Proof of Theorem 9.
Theorem 9 follows easily from Lemmas 4 and 9 as follows. For each the sampling step
[TABLE]
in Sampler GS() is equal in distribution to sampling jointly the (d+1) residuals
[TABLE]
From the conditional independence statement in Lemma 9 the latter is equivalent to sampling independently each residual from
[TABLE]
Moreover, from Lemma 4
[TABLE]
Therefore the original sampling step in (3.4) is equivalent to sampling independently
[TABLE]
for . The thesis follows from the equivalence between (3.4) and (3.5). ∎
Proofs of Corollary 5, Theorem 10 and Theorem 11
Proof of Corollary 5.
The map from to is an injective linear transformation. The injectivity holds because for any and we can reconstruct from
[TABLE]
It follows that is a Markov chain with the same rate of convergence of the original chain . Then the thesis follows from Theorem 9 and the fact that the rate of convergence of a collection of independent Markov chains equals the supremum of the rates of convergence of the single chains. ∎
Proof of Theorem 10.
We are interested in the rate of convergence of the blocked sampler targeting and evolving according to (22). Consider first the case . Note that has a singular variance-covariance matrix because for each and it follows from (7.4) and (21) that
[TABLE]
and therefore some elements of are linear combinations of the others. In order to use standard tools it is more convenient to work with non-singular Gaussian random vectors. To do so it is sufficient to consider a sub-vector of obtained by removing from one children node for each parent node in . More formally, let be an arbitrary map from to such that for all and then define the subset as . It is then easy to see that the resulting sub-vector with for all has an invertible variance-covariance matrix. Moreover, since each is a function of the corresponding via (3.6) it follows that the blocked sampler targeting and evolving according to (22) is equivalent in distribution to a blocked Gibbs Sampler targeting and evolving according to
[TABLE]
for . Let be the -matrix associated to the Gibbs sampler in (3.7), defined by
[TABLE]
See the discussion of Theorem 1.1 for some details and references on -matrices. Then Lemma 4 implies that if and and 0 otherwise. The latter is equivalent to the equation
[TABLE]
where is the square matrix , denotes the dimensional identity matrix, denotes the Kronecker product of matrices and is the cardinality of . Theorem 1.1 implies that the rate of convergence of the Gibbs sampler in (3.7) equals the largest modulus eigenvalue of , where is the lower triangular part of and . Using basic properties of the Kronecker product we can see that
[TABLE]
where is the lower triangular part of and . From , where , it follows that the unique eigenvalues of are the same as the unique eigenvalues of and thus the largest modulus eigenvalue of equals the one of . The case is analogous (with no need to consider a sub-vector of and being equal to itself) and trivial to check. ∎
Proof of Theorem 11.
Theorem 9 shows that for are independent Markov chains. Arguing as in the proof of Theorem 10 above for each we consider rather than to avoid working with singular Gaussian random vectors. For any from 0 to , (T) implies that the -matrix of is tridiagonal (with blocks corresponding to up to ). It follows by Theorem 5 of [Roberts and Sahu, 1997] that the largest modulus eigenvalue of the autoregressive matrix of the Gibbs Sampler in (3.7) coincides with the square of the largest eigenvalue of the corresponding -matrix. We denote the latter by , where is the function mapping a symmetric matrix to its largest eigenvalue. Then, using (3.9) from the proof of Theorem 10, it follows and thus the rate of convergence of is given by . Noting that is obtained from by removing the first row and column, the desired inequality follows by applying the Cauchy interlacing theorem (see e.g. Bhatia, 2013), which states that the eigenvalues of a principal submatrix of a symmetric matrix interlace the original eigenvalues. ∎
3.1 Convergence rates for the example in Section 7.6 of the paper
If instead (i.e. using with at level 1) we have four different parametrization with rates of convergence given by
[TABLE]
4 Proofs for hierarchical models with three levels
Proof of Theorems 1, 2 and 3
Theorems 1, 2 and 3 are substantially special cases of the analogous theorems for -levels. In particular Theorem 1 is a special case of Theorem 9 for and Theorems 2 and 3 can be directly verified as follows. Using Corollary 5 we can evaluate the rates of convergence of the three subchains , and for the four parametrizations under consideration in Section 3 and check by inspection that
[TABLE]
and that the rates of convergence are the ones given by Theorem 3. In particular the rates of convergence of , and under are given by the following Table. The inequality is trivial, while the one can be checked case by case using the expressions in Figure 1 and the fact that the ratio of variances lie between 0 and 1.
Proofs of Corollaries 1-3 and Theorems 7- 8
Proof of Corollary 1.
By Theorem 1 the rate of convergence of the whole chain coincides with the maximum of the rates of the subchains, meaning that equals the maximum of , and . By Theorem 2 the latter equals . ∎
Proof of Corollary 2.
Follows from Theorem 3 by checking that for both and , the inequality holds if and only if ; and for both and the inequality holds if and only if . ∎
Proof of Theorem 7.
The Markov chain under consideration is a Gibbs Sampler sweeping through for some observed data assuming Model NS2 and with . To compute the Gibbs Sampler rate of convergence we first need to compute the matrix indexed by and defined as for and [math] for , where is the precision matrix of . See the discussion of Theorem 1.1 for more details and references on the derivation of -matrices. By computing the precision matrix of it can be seen that is given by
[TABLE]
where for all
[TABLE]
From Theorem 1.1 the rate of convergence of the Gibbs sampler of interest equals the largest modulus eigenvalue of the autoregressive matrix , where is the -dimensional identity matrix, is the lower triangular part of and . In this case is given by
[TABLE]
Finally note that has eigenvalues equal to 0 and one equal to
[TABLE]
∎
Proof of Corollary 3.
Starting from (14) we can see that for any
[TABLE]
where . Equation (4.1) implies that if and only if , which in turn implies the statement in Corollary 3. ∎
Proof of Theorem 8.
Given an instance of Model NS3 with variance terms satisfying
[TABLE]
the proof will proceed by comparing the original Gibbs Sampler with an auxiliary Gibbs Sampler targeting a different instance of Model NS3 with variance terms satisfying (S*) and thus allowing direct analysis using Corollary 6. In the context of Model NS3, (S*) reduces to requiring to be constant over , where is the partial correlation as in Section 7.3 of the paper. By computing the partial correlations of Model NS3 it can be checked that , where and are defined in Theorem 8. For each we define auxiliary variance terms such that for all and
[TABLE]
Such exist because by (4.2) and the left hand side of (4.3) can take any value in for belonging to . (4.3) implies that the instance of Model NS3 with variance terms satisfies (S*) with and . As discussed in Example 3, for models with centred parametrization like Model NS3, (S*) implies (S) and, after rescaling, (). In this case the matrix is given by
[TABLE]
Therefore, by Corollary 6, the rate of convergence of the Gibbs Sampler targeting the posterior distribution of Model NS3 with variance terms is given by , which is the largest squared eigenvalue of , where is the 3-dimensional identity matrix.
Finally we show that the Gibbs Sampler rate of convergence induced by the auxiliary variance terms is greater or equal than the original one given by . Denote by the precision matrix of the original posterior distribution and by the auxiliary one. By deriving and from the definition of Model NS3, it is easy to see that the only terms of and affected by replacing with are and . Moreover implies . The result then follows from the fact that the convergence rate of a deterministic scan Gibbs Sampler with single-site update is a non-increasing function of the diagonal elements of the target precision matrix (when the off-diagonal terms are kept constant), see Theorem 7 of Roberts and Sahu [1997]. ∎
5 Proofs for crossed models
Proof of Theorem 5.
The case follows directly from Theorem 4. Consider an arbitrary in and, analogously to (6), define
[TABLE]
for . It can be checked that the first part of Theorem 4 extends to any , meaning that , and are three independent Markov chains. Also, and perform i.i.d. sampling from and respectively and thus have rate of convergence equal to 0. It follows that the rate of convergence of the original Gibbs Sampler coicides with the one of the (low dimensional) three component Gibbs sampler targeting . Denote by the -matrix of the Gibbs Sampler targeting , and by and its lower and upper triangular parts. Then it holds
[TABLE]
and it can be obtained with simple calculations that the 3 eigenvalues of are . It follows by Theorem 1.1 that and, by symmetry, . Consider now . We have
[TABLE]
The matrix has one zero eigenvalue and two eigenvalues given by and where
[TABLE]
It follows, again by Theorem 1.1, that . To conclude the proof we now check that the inequality holds for all . The latter is equivalent to
[TABLE]
Squaring both sides, rearranging and dividing by 4 one obtains
[TABLE]
Dividing by and using
[TABLE]
The left-hand side equals
[TABLE]
which can be easily seen to be non-negative as both terms in the product are non-negative due to . ∎
To prove Theorem 6 we first need the following lemma. Consider the linear mapping from to defined as
[TABLE]
where and for with
[TABLE]
if and if .
Lemma 10**.**
Denote the linear constraints by for brevity. Then and are conditionally independent given and , meaning that
[TABLE]
Moreover , …, are conditionally independent given and , meaning that
[TABLE]
Proof of Lemma 10.
Since the joint distribution is multivariate Gaussian it is sufficient to check that the conditional expectations and do not depend on and similarly that does not depend on , and in order to deduce (5.1). With standard (but tedious) calculations for conditioned multivariate Gaussian distributions one can explicitly compute
[TABLE]
where is defined as
[TABLE]
with . ∎
Proof of Theorem 6.
Using Lemma 10 and arguing as in the proof of Theorem 9 we can deduce that \big{(}(\mu,\bar{a})(t)\big{)}_{t=1}^{\infty}, \big{(}\tilde{\delta}{\bm{a}}^{(1)}(t)\big{)}_{t=1}^{\infty}, …, \big{(}\tilde{\delta}^{(k)}{\bm{a}}(t)\big{)}_{t=1}^{\infty} are Markov chains and they evolve independently. Thus the rate of convergence of of the original Markov chain coincides with the supremum of the rate of convergence of these Markov chains. Since \big{(}\tilde{\delta}^{(s)}{\bm{a}}(t)\big{)}_{t=1}^{\infty} performs i.i.d. sampling for all , its rate of convergence is 0 and thus the rate of convergence of coincides with the one of \big{(}(\mu,\bar{a})(t)\big{)}_{t=1}^{\infty}. The latter is a components Gaussian Gibbs Sampler with one dimensional components. Using (5.5) and arguing as in the proof of Proposition 3 of Papaspiliopoulos et al. [2019] one can show that the matrix (as denoted in Theorem 1.1) of such Gibbs Sampler scheme is
[TABLE]
where is a lower triangular matrix with diagonal elements equal to , and that the resulting rate of convergence of is , which is the desired thesis. ∎
6 Full conditionals and additional material on the simulations
6.1 Full conditional distributions of GS(1,1) and GS(0,0)
This section reports the full conditional distributions involved in Samplers GS(1,1) and GS(0,0) described in Section 2 of the paper.
Sampler GS()****.
Initialize , and and then iterate
[TABLE]
where we use the dot subscript to indicate averaging over one dimension, meaning that , , , , and .
Sampler GS()****.
Initialize , and and then iterate
[TABLE]
where as before the dot subscript indicates averaging over indices.
6.2 Traceplots and autocorrelation function for the simulations in Section 5 of the paper
Figures 2-4 provide traceplots and autocorrelation functions for , and for the Gibbs Samplers considered in Table 2 of the paper (NB: we consider and rather than and because the latter are constrained to be equal to 1 in one of the sampler implementation).
Similarly, Figures 5 and 6 provide traceplots and autocorrelation functions for , and for the HMC and NUTS algorithms considered in Table 3 of the paper. See Table 3 of the paper for corresponding runtimes and effective sample sizes.
6.3 R code for the simulations in Section 5 of the paper
In this section we provide the R and Stan code used to perform the simulations reported in Table 2 and 3 of the paper. First we provide the R code defining the functions for the three Gibbs Samplers implemented in Table 2 of the paper.
R CODE FOR THE GIBBS SAMPLERS IMPLEMENTED IN TABLE 2
Gibbs_CrossedPoisson_1<-function(y,num_iterations,n1,n2){
Gibbs Sampler for crossed random effect model with Poisson likelihood and Gamma prior
Version 1: unconstrained
y_bar<-mean(y)
samples<-matrix(NA,nrow = num_iterations,ncol = 1+n1+n2) # initialize empty matrix for posterior samples
mu<-1;a<-rep(1,n1);b<-rep(1,n2) # set starting parameters
for (t in 1:num_iterations){# Gibbs iterations
mu<-rgamma(1,shape = alpha_mu+y_bar,rate = beta_mu+mean(a)*mean(b))
a<-rgamma(n1,shape = alpha_a+rowMeans(y),rate =beta_a+ mu*mean(b))
b<-rgamma(n2,shape = alpha_b+colMeans(y),rate =beta_b+ mu*mean(a))
samples[t,]<-c(mu,a,b)
}
return(samples)
}
Gibbs_CrossedPoisson_2<-function(y,num_iterations,n1,n2){
Gibbs Sampler for crossed random effect model with Poisson likelihood and Gamma prior
Version 2: conditioning on a[1]=b[1]=1
y_bar<-mean(y)
samples<-matrix(NA,nrow = num_iterations,ncol = 1+n1+n2)# initialize empty matrix for posterior samples
mu<-1;a<-rep(1,n1);b<-rep(1,n2) # set starting parameters
for (t in 1:num_iterations){# Gibbs iterations
mu<-rgamma(1,shape = alpha_mu+y_bar,rate = beta_mu+mean(a)*mean(b))
a[-1]<-rgamma(n1,shape = alpha_a+rowMeans(y)[-1],rate =beta_a+ mu*mean(b))
b[-1]<-rgamma(n2,shape = alpha_b+colMeans(y)[-1],rate =beta_b+ mu*mean(a))
samples[t,]<-c(mu,a,b)
}
return(samples)
}
Gibbs_CrossedPoisson_3<-function(y,num_iterations,n1,n2){
Gibbs Sampler for crossed random effect model with Poisson likelihood and Gamma prior
Version 3: conditioning on mean(a)=mean(b)=1
y_bar<-mean(y)
samples<-matrix(NA,nrow = num_iterations,ncol = 1+n1+n2)# initialize empty matrix for posterior samples
mu<-1;a<-rep(1,n1);b<-rep(1,n2) # set starting parameters
for (t in 1:num_iterations){# Gibbs iterations
mu<-rgamma(1,shape = alpha_mu+y_bar,rate = beta_mu+mean(a)*mean(b))
a<-rgamma(n1,shape = alpha_a+rowMeans(y),rate =beta_a+ mu*mean(b))
a<-a/mean(a)
b<-rgamma(n2,shape = alpha_b+colMeans(y),rate =beta_b+ mu*mean(a))
b<-b/mean(b)
samples[t,]<-c(mu,a,b)
}
return(samples)
}
Second we provide the Stan code defining the models used for the HMC and NUTS simulations in Table 3 of the paper.
STAN CODE DEFINING THE MODELS USED FOR THE SIMULATIONS IN TABLE 3
/*
Crossed random effect model with Poisson likelihood and Gamma prior
Version 1: unconstrained
*/
data {
int<lower=0> N;
int<lower=0> n1;
int<lower=0> n2;
int<lower=1,upper=n1> blk1[N];
int<lower=1,upper=n2> blk2[N];
int<lower=0> y[N];
}
parameters {
vector<lower=0>[n1] a;
vector<lower=0>[n2] b;
real<lower=0> mu;
}
transformed parameters {
vector[N] lambda;
real<lower=0> abar;
real<lower=0> bbar;
for (n in 1:N){
lambda[n] = mu * a[blk1[n]]* b[blk2[n]];
}
abar = mean(a);
bbar = mean(b);
}
model {
a ~ gamma(2, 0.1);
b ~ gamma(2, 0.1);
mu ~ gamma(2, 0.1);
y ~ poisson(lambda);
}
/*
Crossed random effect model with Poisson likelihood and Gamma prior
Version 2: conditioning on a[1]=b[1]=1
*/
data {
int<lower=0> N;
int<lower=0> n1;
int<lower=0> n2;
int<lower=1,upper=n1> blk1[N];
int<lower=1,upper=n2> blk2[N];
int<lower=0> y[N];
}
parameters {
vector<lower=0>[n1-1] a;
vector<lower=0>[n2-1] b;
real<lower=0> mu;
}
transformed parameters {
vector[N] lambda;
vector<lower=0>[n1] a_all;
vector<lower=0>[n2] b_all;
real<lower=0> abar;
real<lower=0> bbar;
a_all[1]=1;
for (i in 2:n1){
a_all[i]=a[i-1];
}
bb[1]=1;
for (j in 2:n2){
bb[j]=b[j-1];
}
for (n in 1:N){
lambda[n] = mu * a_all[blk1[n]]* b_all[blk2[n]];
}
abar = mean(a);
bbar = mean(b);
}
model {
a ~ gamma(2, 0.1);
b ~ gamma(2, 0.1);
mu ~ gamma(2, 0.1);
y ~ poisson(lambda);
}
/*
Crossed random effect model with Poisson likelihood and Gamma prior
Version 3: conditioning on mean(a)=mean(b)=1
*/
data {
int<lower=0> N;
int<lower=0> n1;
int<lower=0> n2;
int<lower=1,upper=n1> blk1[N];
int<lower=1,upper=n2> blk2[N];
int<lower=0> y[N];
vector[n1] alpha_a;
vector[n2] alpha_b;
}
parameters {
simplex[n1] a_norm;
simplex[n2] b_norm;
real<lower=0> mu;
}
transformed parameters {
vector<lower=0>[n1] a;
vector<lower=0>[n2] b;
vector[N] lambda;
real<lower=0> abar;
real<lower=0> bbar;
a = a_norm * n1;
b = b_norm * n2;
for (n in 1:N){
lambda[n] = mu * a[blk1[n]]* b[blk2[n]];
}
abar = mean(a);
bbar = mean(b);
}
model {
a_norm ~ dirichlet(alpha_a);
b_norm ~ dirichlet(alpha_b);
mu ~ gamma(2, 0.1);
y ~ poisson(lambda);
}
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Alsmeyer and Fuh [2001] Gerold Alsmeyer and Cheng-Der Fuh. Limit theorems for iterated random functions by regenerative methods. Stochastic processes and their applications , 96(1):123–142, 2001.
- 2Amit [1991] Yali Amit. On rates of convergence of stochastic relaxation for Gaussian and non-Gaussian distributions. J. Multivariate Anal. , 38(1):82–99, 1991.
- 3Amit [1996] Yali Amit. Convergence properties of the Gibbs sampler for perturbations of Gaussians. Ann. Statist. , 24(1):122–140, 1996.
- 4Bass and Sahu [2016 a] Mark R Bass and Sujit K Sahu. A comparison of centring parameterisations of gaussian process-based models for bayesian computation using mcmc. Statistics and Computing , pages 1–22, 2016 a.
- 5Bass and Sahu [2016 b] Mark R Bass and Sujit K Sahu. A comparison of centring parameterisations of gaussian process-based models for bayesian computation using mcmc. Statistics and Computing , pages 1–22, 2016 b.
- 6Bhatia [2013] Rajendra Bhatia. Matrix analysis , volume 169. Springer Science & Business Media, 2013.
- 7Brown et al. [2018] Lawrence D Brown, Gourab Mukherjee, Asaf Weinstein, et al. Empirical bayes estimates for a two-way cross-classified model. The Annals of Statistics , 46(4):1693–1720, 2018.
- 8Browne [2004] William J Browne. An illustration of the use of reparameterisation methods for improving MCMC efficiency in crossed random effect models. Multilevel modelling newsletter , 16(1):13–25, 2004.