TL;DR
This paper presents a novel 3D model-aided particle filter approach for markerless visual tracking of a robot's end-effector, enabling robust, closed-loop control using only visual data from cameras.
Contribution
It introduces a 3D model-aided particle filter with HOG features for end-effector tracking, integrating CAD models and rendering for improved robustness and accuracy.
Findings
Robust end-effector tracking in cluttered environments
Effective compensation for kinematic errors
Successful closed-loop arm control using vision
Abstract
This paper addresses recursive markerless estimation of a robot's end-effector using visual observations from its cameras. The problem is formulated into the Bayesian framework and addressed using Sequential Monte Carlo (SMC) filtering. We use a 3D rendering engine and Computer Aided Design (CAD) schematics of the robot to virtually create images from the robot's camera viewpoints. These images are then used to extract information and estimate the pose of the end-effector. To this aim, we developed a particle filter for estimating the position and orientation of the robot's end-effector using the Histogram of Oriented Gradient (HOG) descriptors to capture robust characteristic features of shapes in both cameras and rendered images. We implemented the algorithm on the iCub humanoid robot and employed it in a closed-loop reaching scenario. We demonstrate that the tracking is robust to…
Click any figure to enlarge with its caption.
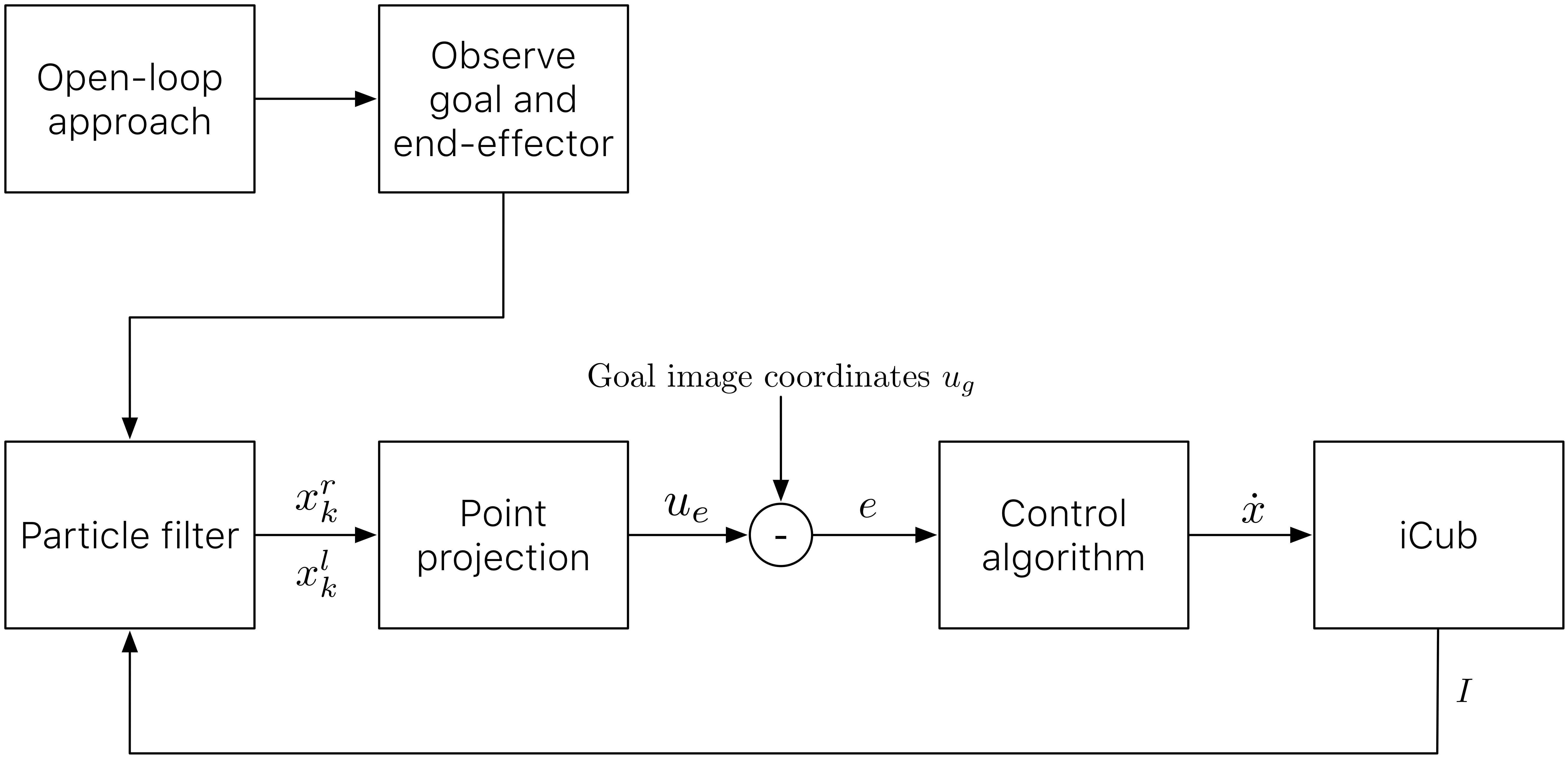 Figure 1
Figure 1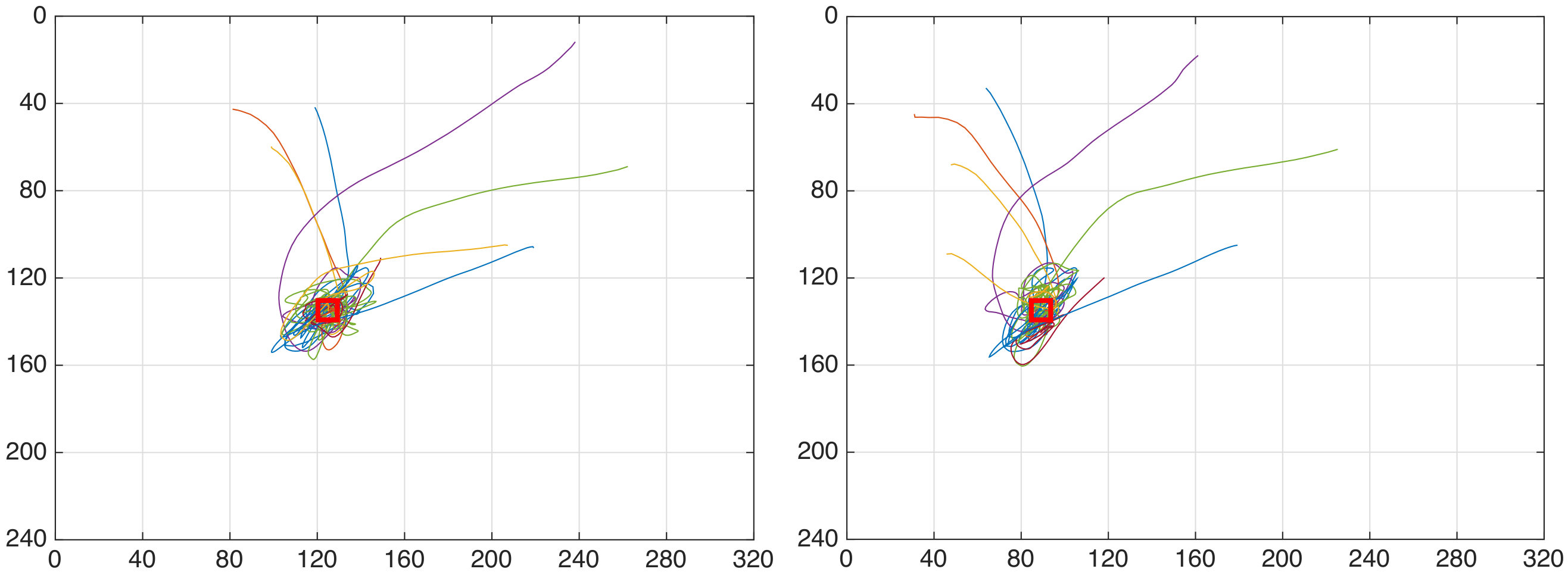 Figure 2
Figure 2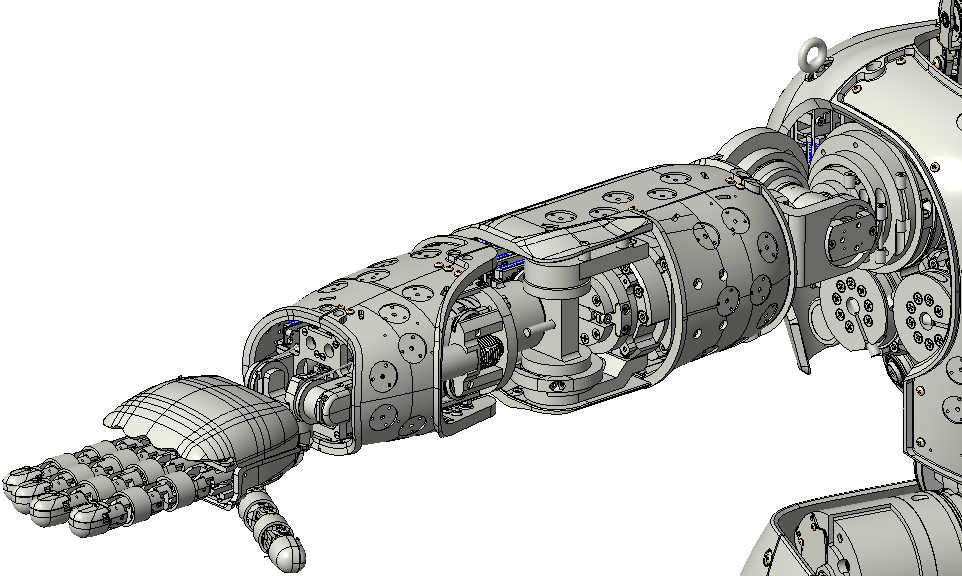 Figure 3
Figure 3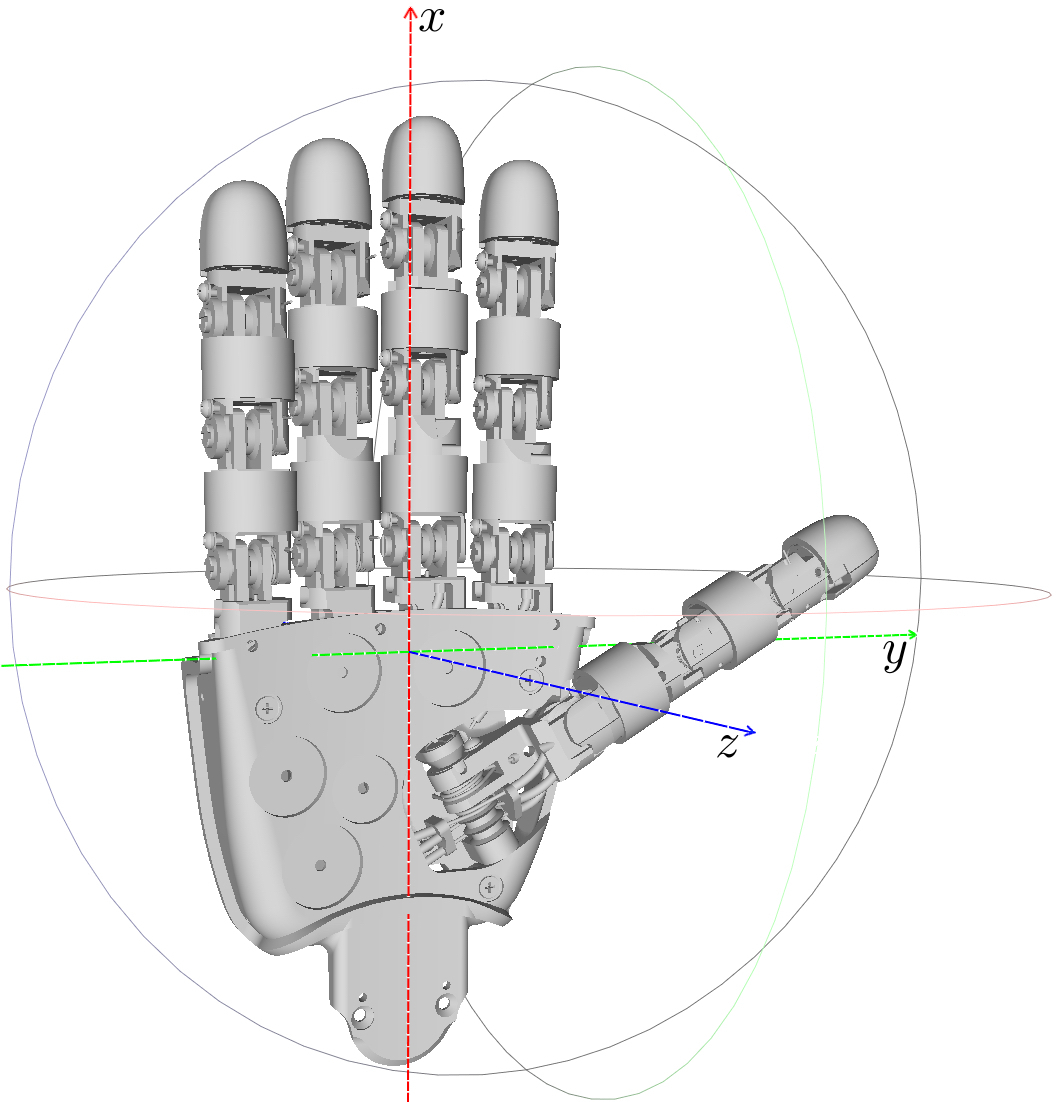 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6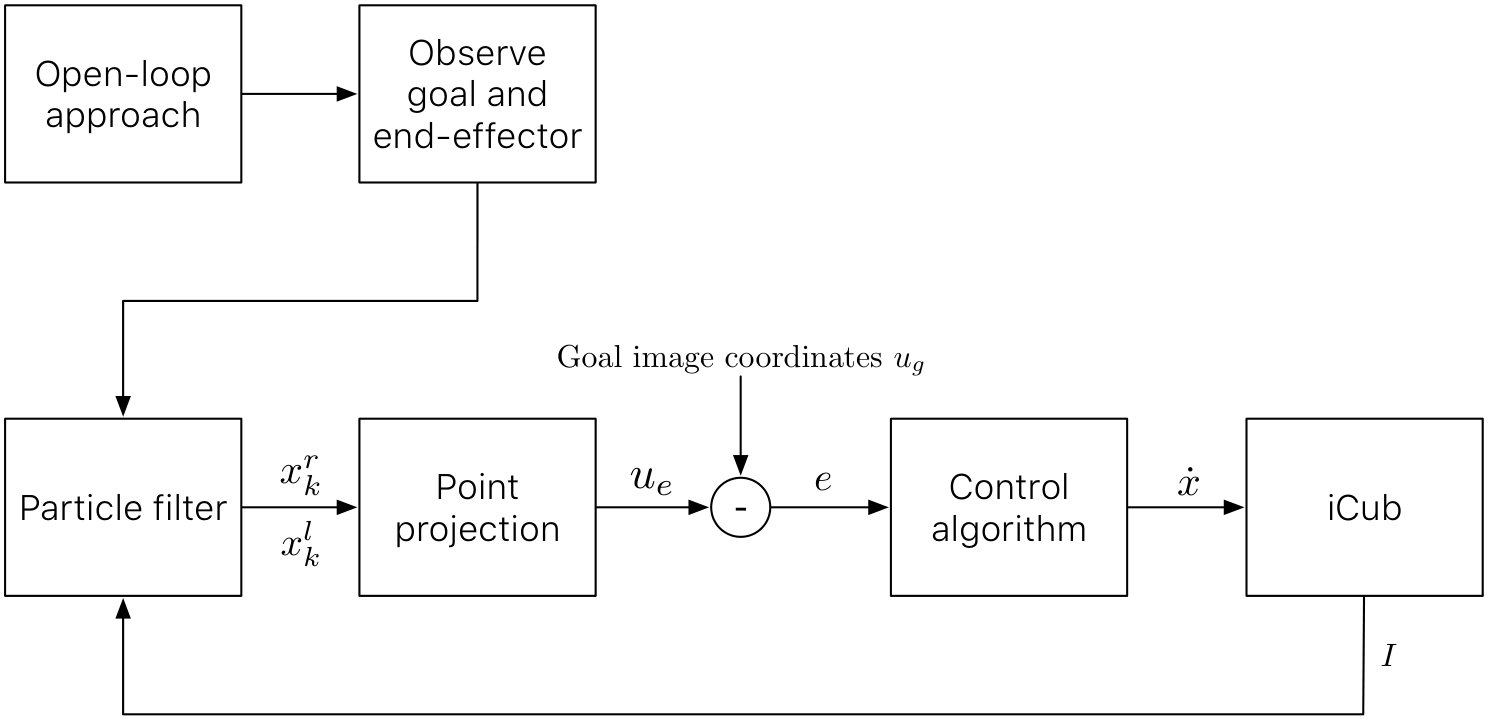 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10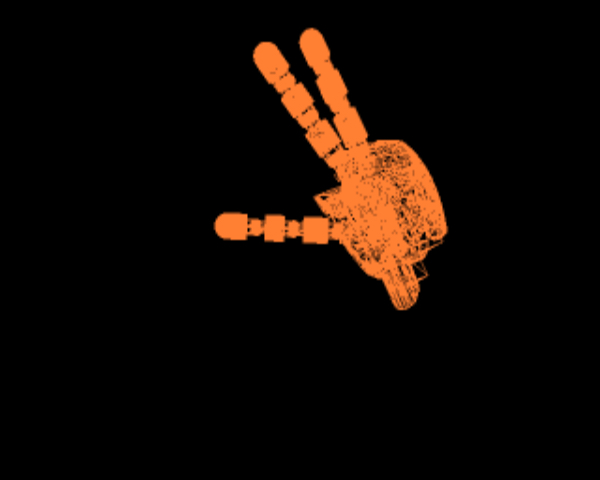 Figure 11
Figure 11 Figure 12
Figure 12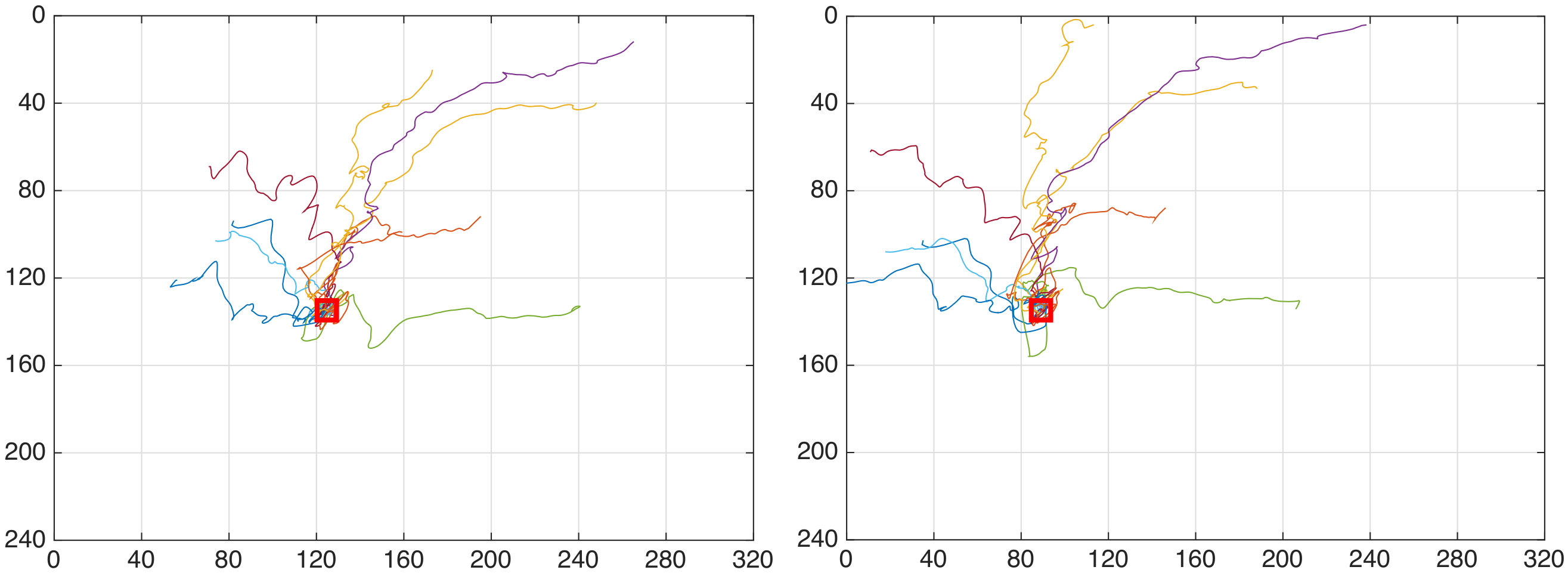 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15| 100 | |
| Velocity | Success/Trials | Mean square error |
|---|---|---|
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Visual end-effector tracking using a 3D model-aided particle filter
for humanoid robot platforms
Claudio Fantacci1, Ugo Pattacini1, Vadim Tikhanoff1 and Lorenzo Natale1 1Claudio Fantacci, Ugo Pattacini, Vadim Tikhanoff and Lorenzo Natale are with Istituto Italiano di Tecnologia, iCub Facility, Humanoid Sensing and Perception, Via Morego 30, Genova, Italy [email protected], [email protected], [email protected], [email protected]
Abstract
This paper addresses recursive markerless estimation of a robot’s end-effector using visual observations from its cameras. The problem is formulated into the Bayesian framework and addressed using Sequential Monte Carlo (SMC) filtering. We use a 3D rendering engine and Computer Aided Design (CAD) schematics of the robot to virtually create images from the robot’s camera viewpoints. These images are then used to extract information and estimate the pose of the end-effector. To this aim, we developed a particle filter for estimating the position and orientation of the robot’s end-effector using the Histogram of Oriented Gradient (HOG) descriptors to capture robust characteristic features of shapes in both cameras and rendered images. We implemented the algorithm on the iCub humanoid robot and employed it in a closed-loop reaching scenario. We demonstrate that the tracking is robust to clutter, allows compensating for errors in the robot kinematics and servoing the arm in closed loop using vision.
I INTRODUCTION
Humanoid robots are designed to work in an unstructured and possibly complex environment where humans live [1, 2] and they rely on a wide variety of sensors to perceive and interact with it. The perception and interaction capabilities of a humanoid robot with such complexities depend on the available sensors. However, the proprioception of the robot might be affected by a number of impairments, including measurement noises, sensor biases, mechanical interplay of the links, frictions and so forth. This is particularly relevant for humanoid robots in which elastic elements (like tendon-driven actuators) introduce errors in the computation of the direct kinematics. Precise estimation of objects using vision is also affected by errors introduced by imprecise knowledge of the cameras extrinsic parameters, especially in case in which cameras are moving to simulate the human oculomotor system. As a consequence, tasks like reaching, grasping and, in general, manipulation with the end-effector can be problematic. Vision plays an important role in this respect, as it mimics the human sense of vision and provides contactless measurements of the environment. In this context, visual servoing [3, 4, 5, 6, 7, 8] can be profitably employed to compensate for errors in the visual domain resorting to a closed loop control of the robot’s end-effector by means of a visual feedback. To control the robot’s end-effector pose relative to a desired target, it is of central importance to have a precise knowledge of its pose over time.
Recursive Bayesian estimation is a well known tool for tracking an object/objects by fusing measurements from sensors [9, 10, 11, 12]. In particular, particle filters [13, 14, 15, 16] have proven to be effective in robotics [17] and in a wide variety of fields [18]. Object tracking using visual feedback turns out to be challenging in that it generally requires the development of suitable filtering techniques that need to account for the presence of cluttered background and to be sufficiently fast to cope with the real-time specifications of the task. To fulfill such requirements, Graphics Processing Unit (GPU) technologies, comprising their software development kit (e.g. CUDA [19], OpenCL [20]), enable real-time implementation of complex recursive filtering pipelines for visual object tracking.
In this paper we propose a novel particle filter that estimates the 6D pose (considering position and orientation) of the robot’s end-effector without the use of markers. To yield our estimates, we resort to Computer Aided Design (CAD) schematics in order to render 3D mesh models of the end-effector as they would appear from the robot’s viewpoints. Finally, we extract Histogram of Oriented Gradient (HOG) [21] descriptors from the camera images that we compare against the rendered images. We demonstrated that our approach is effective and robust in experimental visual servoing tests carried out in real settings using the iCub humanoid robot [1].
The rest of the paper is organized as follows. Section II provides an overview of visual hand tracking for both human and robotic hand. Section III briefly introduces recursive Bayesian filtering and the particle filter formulation, then details our contributions to 6D pose estimation of a robot’s end-effector using histogram of oriented gradient descriptors. In Section IV we report on the experiments to validate our framework. Finally, Section V provides concluding remarks and future work.
II RELATED WORK
The problem of hand tracking has been extensively addressed in computer vision, especially for building intuitive interfaces. Due to its similarity with the task we addressed in this paper we revise some of this work.
One of the first contribution on hand-shaped object tracking was in 1994 with DigitEyes [22], which tackled the problem with a disjoint hand model-based approach (i.e. each part of the hand was considered an independent entity to be estimated), using a combination of line and point features with a Gauss-Newton algorithm [23]. This method, however, does not perform well in complex scenario, such as cluttered background.
Later in 2000, another approach for hand tracking is presented under the name of Conditional Density Propagation (CONDENSATION) [24]. CONDENSATION is based on a joint hand model-based approach and Sequential Monte Carlo (SMC) methods to fit a B-spline around a single hand in images. This approach is capable of working in cluttered environment, although it does not provide 3D information about the pose as it can track only planar curves, and shows limitations when applied to rotating targets. It is evident from [24] that SMC methods provide a reliable approach for estimating the state of an object in a cluttered scene.
In 2004, the Smart Particle Filter [25, 26] was proposed to track a hand with depth sensors and skin color detection, by using a Stochastic Meta-Descent (SMD) optimization method (based on gradient descent) and a particle filter to form what the authors refer to as “smart particles”. The SMD optimization is used on each particle to explore the state space, then the new particles are combined together in a particle set by using importance sampling [16]. The method, although promising, makes use of depth sensors and skin color that can be unavailable on some humanoid robots; furthermore, the computational burden of using an optimization method and a particle filter may not fit well with the required time constraints.
More recently in 2006, the authors of [27] presented the Hierarchical Bayes Filter which is based on a tree-based filtering method that uses color and edge detectors. This framework relies upon a tree of template hierarchy of the hand poses, which is manually built [28], and uses skin color detectors which may lead to poor performance on a humanoid robotic platform.
In robotics the problem of hand localization has been often simplified using special markers. This approach requires to modify the robot, hardly scales to a cluttered environment and occlusions, but, more importantly, it does not allow to detect important parts of the hand like the tip of the hands or the torso. This is fundamental for grasping objects. The first breakthrough dealing with humanoid robots and specifically tracking of an anthropomorphic hand are relatively recent, dating back to 2006 [29, 30, 31, 32].
In [29] the authors proposed a novel framework based on the Virtual Visual Servoing (VVS) paradigm, first introduced in [33, 34]. 3D CAD models are used within a rendering engine to virtually create the hand-effector as if it had been seen by a camera using information provided by the direct kinematics. The virtual end-effector is then compared against the real end-effector acquired by the camera images by means of the Chamfer distance transform [35] and its pose is refined via a classical visual servoing approach.
In [31, 32], a computer graphics simulator is exploited to create the body schema of the robot, including an appearance model of the hand shape with texture. The output of the simulator is used to generate predictions about hand appearance in the robot camera images, based on the sensorimotor proprioceptive information, i.e. the motor encoders. The predictions are then compared to the camera images using the Chamfer distance transform in a SMC algorithm to estimate the offset present in the robot’s encoders. It is worth pointing out that, in this framework, filtering is carried out on encoder biases which are then used to estimate the pose of the end-effector. This approach focuses on the estimation of robotic limb poses and may be problematic to be extended to other objects present in the field-of-view of the robot’s cameras.
In this work, we proposes a recursive Bayesian filter using the VVS approach. Our approach provides a novel particle filter architecture with the following contributions: 1 we render, for each particle, an image of the 3D mesh model of the end-effector as it would appear from the robot’s viewpoints (likewise in augmented reality contexts); 2 we then use this state representation to directly estimate the 6D pose (position and orientation) of the end-effector in the robot operative space using 2D image descriptors. In particular, we use HOG to compare the rendered images with the robot’s camera images and, as a result, the particles which are more likely to represent the end-effector will have higher weight. The main advantage of our approach is that, given proper 3D models, we can potentially track any other object in the robot operational space which is within the robot’s camera field-of-view. Visual servoing experiments with a real robotic platform show that our approach allows precise closed-loop control of the hand of the robot in cluttered environment and meets the time-constraints for a real-time implementation.
III 6D END-EFFECTOR TRACKER
In this section, we briefly provide background on particle filtering and we detail our implementation and contributions.
III-A Particle filtering
Filtering is the problem of recursively estimating over time of a dynamical system given the noisy measurement history , . In the Bayesian framework, the entity of interest is the posterior density that contains all the information about the state vector given all the measurements up to time . Such a Probability Density Function (PDF) can be recursively propagated in time resorting to the well known Chapman-Kolmogorov equation and the Bayes’ rule [36]
[TABLE]
given an initial density . The PDF is referred to as the predicted density, is the filtered density, is the Markov transition density representing the conditional probability that the state at time will take value given that the state at time is equal to , and is the measurement likelihood function denoting the probability that the measurement at time will take value given the state .
In many practical applications, such as navigation, tracking and localization, the transition and/or likelihood models are usually affected by nonlinearities and/or non-Gaussian noise distributions [15, 13], thus precluding analytical solutions of eqs. (1) and (2). In these cases, one must invariably resort to some approximations. Sequential Monte Carlo methods, also known as particle filters, can deal with arbitrary nonlinearities and distributions and supply a complete representation of the posterior state distributions.
The idea behind particle filtering is to approximate the posterior density at discrete-time by a set of random samples (particles) , where is the state of particle , is its weight, i.e.
[TABLE]
where is the Dirac delta function. This approximation of the posterior improves as [14]. In this way, the evaluation of the integrals of the Bayesian filtering equations (1) and (2) is performed via the Monte Carlo numerical integration method, i.e., by transforming the integrals into discrete sums.
Given and using the measurement at time , the key is how to form the particle approximation of the posterior at , i.e. denoted as . In principle, the particle approximation (3) can be computed by drawing a set of independent and identically distributed samples , , from the posterior . However, such a solution is not feasible because is not known, thus the computation of the weights and particles at time is based on the concept of importance sampling [37]. Let us introduce a proposal or importance density to draw (preliminary) particles at time :
[TABLE]
whose weights are computed as follows:
[TABLE]
for . This recursive procedure starts at time by sampling times from the initial PDF .
The described particle method, also known as Sequential Importance Sampling (SIS), inevitably fails after many iterations, because all particle weights, except a few, become zero (a poor approximation of the posterior PDF due to particle degeneracy). The collapse of the SIS scheme can be prevented by resampling the particles. The resampling step chooses particles from , where the selection of particles is based on their weights: the probability of particle being selected during resampling amounts to . After resampling, all particle weights are equal to . The simplest choice is to select as the transitional density, i.e. . In literature, this Particle Filter (PF) is also known as the bootstrap filter [13].
III-B Initialization and prediction step using direct kinematics
To initialize the PF at time , each particle is set equal to the pose of the end-effector evaluated by means of the direct kinematics map , where are the joint angles, with the total number of joints of the kinematic chain connecting the base frame to the end-effector frame [38, 39].
The direct kinematics map is also used to propagate particles over time: the joint angles are used to compute the motion of the end-effector , i.e.
[TABLE]
where is provided by the Denavit-Hartenberg (DH) convention [38, 39] and is the process noise modeling uncertainties and disturbances in the object motion model. As a result, the Markov transition density is the PDF
[TABLE]
III-C Filtering step using CAD models and HOG descriptors
We use a 3D rendering engine to virtually create images from the point of view of the robot camera depicting the mechanical model of the end-effector. We then make use of HOG descriptors to extract features from them. As a result, we can define a likelihood that compares the descriptors of the synthetic and real images. For the sake of simplicity the following subsections consider a single camera viewpoint.
III-C1 Exploitation of CAD models
the key idea is, at any time instant , to virtually create an image displaying the mechanical structure of the manipulator as if it had been seen by the robot’s camera. This goal is achieved by means of a 3D rendering engine such, e.g., OpenGL [40], Unity [41] or Unreal Engine [42], which are capable of carrying out multiple parallel rendering activities. In order to avoid introducing dependencies and to have a code that is tailored for our applications, we decided to adopt the OpenGL solution.
The mechanical structure of the manipulator chain of a humanoid robot consists of an arm and a hand, e.g., see Fig. 1.
To render the mechanical structure of the manipulator with respect to the reference frame of the robot and project it to the camera plane given the pose of the end-effector , we need the joint angles , the joint angles of the camera kinematic chain and the camera calibration matrix accounting for the intrinsic camera parameters [43]. Formally, at any time instant , the rendered or predicted image is defined as
[TABLE]
where internally a roto-translation from a common reference frame to the camera image plane is performed by means of the projection matrix
[TABLE]
being the homogeneous transformation from the common reference frame to the camera frame. A pictorial representation of (10) is shown in Fig. 2.
III-C2 Likelihood evaluation using HOG descriptors
a measurement likelihood function needs to be defined to update the weights of the particles, using measurement extracted from the camera image and the information extracted from the rendered image given . The key idea is to extract image features characterizing the shape of the objects, so that the image , associated to particle , that is more similar to the image will be rewarded with a higher weight .
HOG descriptors capture robust characteristics of shape (gradient structure, edges) in a local representation with an easily controllable degree of invariance to local geometric and photometric transformations. The associated descriptors are computed on a dense grid of uniformly spaced cells, and provide robust information about shapes in the presence of a cluttered environment. The HOG is compared to assess whether a rendered image is more likely to represent the real manipulator configuration captured by the camera image .
Using the renderer and the HOG descriptors on both the camera and the predicted image allows defining the following likelihood function:
[TABLE]
where is a free tuning parameter.
The pseudo code of the overall PF algorithm is reported in Table I for a single processing cycle at time instant .
IV EXPERIMENTAL RESULTS
To evaluate the effectiveness and robustness of the proposed approach for estimating the pose of the end-effector, a C++ implementation of the PF algorithm has been tested on the iCub platform [1]. We ran our experiments on a laptop with an Intel i7 3.40 GHz processor and an NVIDIA GeForce GT 750M with 2048 MB VRAM. To implement (12), we use the CUDA HOG implementation available in OpenCV [44] as it provides a significant speed boost compared to the standard CPU implementation.
IV-A Experimental setup
The final goal of the experiments is twofold: 1 to assess the filtering capabilities of our approach and 2 to use it in visual servoing-aided reaching tasks.
The end-effectors of the iCub are defined as a point on the surface of the left and right palm, below the middle fingers (a pictorial representation is provided in Fig. 3).
However, we can freely move the end-effectors to ease the execution of the task. In the context of our experiments, we consider the right hand end-effector and we move it from the palm to the right index fingertip.
The state of the pose of the end-effector is denoted by , where: is the cartesian position of the end-effector with respect to the root reference frame which is positioned at the level of the waist in the center of the robot [1]; is the orientation of the end-effector expressed with a compact axis-angle notation having the unit vector axis multiplied by the rotation angle , i.e. , , . The motion of the particles is modeled according to eq. (9), with defined as follows: the position disturbances are modeled as a white Gaussian noise with standard deviation ; the orientation disturbances are modeled as a Gaussian noise on a spherical cap [45], with standard deviations and for, respectively, the rotation angle and the cap aperture. We use particles to balance the performance and the computational burden of the PF, and for the resampling threshold. All the PF parameters are summarised in Table II.
During each rendering call, we use the CAD models of the right palm, thumb, index and middle fingers. The iCub ring and little fingers are both coupled and underactuated by a single motor. Due to the lack of a proper modeling of their kinematics, we could only get imprecise information about their pose. As a consequence, we decided to disable these two fingers from being rendered.
We planned two different reaching tasks on the iCub with two different goals: with the former task we aimed to demonstrate that our PF provides reliable estimates of the end-effector for visual servoing, achieving sub-pixel precision; the latter task was to show that we can perform precise reaching in a cluttered scenario. The complete pipeline of our visual servoing loop is shown in Fig. 4.
Open-loop approach: before entering the visual servoing control loop, we use the iCub stereo vision to get a rough 3D localization of our target. In particular, we employ a Structure From Motion algorithm [30] to get such 3D point and then we move the right hand using an open loop control.
Observe goal and end effector: in order to carry out visual tracking and visual servoing the robot has to observe both the target object and its end-effector. We then use the gaze controller of the iCub [46] to focus the attention of the robot to these two targets. This configuration is also known in literature to as endpoint closed-loop system [4].
Particle Filter: the PF described in section III is initialized and run for each camera. The output are the poses and of the right hand fingertip, respectively, for the left and right camera. Estimates are evaluated using a weighted mean on the particle set, referred to as the Expected a Posterior (EAP) estimates [47].
Point projection: estimates carried out by the PF are projected, respectively for each camera, onto the camera plane. This amounts to multiplying the position of the right hand fingertip and (in homogeneous form) by the left and right camera version of eq. (11), which is equivalent to evaluate
[TABLE]
for the left camera and
[TABLE]
for the right camera. Note that functions , , are linear in , and . As a result, from eqs. (13)-(15) and (16)-(18), we collect the two coordinate pairs on the left and right image plane and . Finally, we define the goal image coordinate controlled by the visual servoing algorithm for the reaching task as .
Goal image coordinate: we manually provide the goal image coordinate , used to evaluate the reaching error .
Control algorithm: the control algorithm takes the error as input and computes the cartesian velocities to be performed by the end-effector to achieve . To relate changes in point coordinates to changes in position of the robot, the image Jacobian is calculated from eqs. (13)-(18). We note that the Jacobian turns out to be a matrix relating to . The missing columns corresponding to the orientation of the end-effector are not considered because we make the simplifying assumption that the final desired orientation is the one provided by the open loop approaching phase. The cartesian velocities are finally evaluated inverting the Jacobian matrix [4, 30] with
[TABLE]
with a proportional gain, and are used by a cartesian controller [48] implemented on the iCub platform. The main advantage of using the cartesian controller is that it automatically deals with singularities and joint limits, and can find solutions in virtually any working conditions.
iCub: while motions are performed, new camera images are provided to the particle filter to re-iterate the pipeline.
IV-B Task 1
The goal of the first task is to assess whether we can perform visual servoing by using the estimates provided by our PF and achieve precise reaching of the goal. The iCub is required to reach the fixed point , from different starting points and with two different velocities, and . No objects are present in the path between the starting to the goal point. The termination condition is achieved when the -norm of falls below pixel.
Table III summarises the results of the first task. The robot achieved sub-pixel precision for all trials with a mean square error of and respectively for the slower and faster velocity.
A pictorial view of the trajectories are shown in Figs. 6 and 6.
It is worth noticing that faster velocities produce very smooth trajectories, but longer time lapses are required to reach the goal. On the other hand, slower velocities produce trajectories that are directed to the goal, but are more spiky. While the spiky trajectories are due to the slow motion of the end-effector, the slow convergence to the goal of the faster trajectories can be mitigated by employing a higher number of particles and by refining the control algorithm.
IV-C Task 2
For the second task, the iCub is presented with a table full of everyday objects and toys, as depicted in Fig. 7.
In this settings, it is possible to test the robustness and effectiveness of the our PF. The goal is to reach for the red nose of a ladybug plush, as highlighted in Fig. 8, for trials.
Reaching was successful during the attempts: the filter turns out to be capable of tracking the hand pose while performing the reaching motion in a cluttered scenario. Figs. 11, 11 and 11 show, respectively, a snapshot of the initial discrepancy between the end-effector pose provided by the direct kinematics and the real one, the precision of the estimated pose before starting the reaching motion and the final position of the end-effector with the associated estimated pose.
V CONCLUSIONS AND FUTURE WORK
This paper tackles the estimation of the pose of a humanoid robot end-effector by means of a recursive Bayesian algorithm. CAD models of the robot mechanical structure were used within a 3D rendering engine to virtually create images showing the manipulator as if they had been seen by the robot’s cameras. It was shown that 6D (position and orientation) estimation using dense Histogram of Oriented Gradient (HOG) descriptors on both camera and rendered images provide robust and reliable results. The tracking algorithm has been integrated in a closed-loop control, to demonstrate that it allows to servo the hand with pixel accuracy using visual feedback. This demonstrates that the algorithm can be effectively used in closed-loop to compensate for errors in the kinematic model of the robot and depth estimation.
The proposed approach paves the way to a number of possible future work comprising: I joint estimation of the pose of the end-effector and of the object to manipulate using, e.g., the random Random Finite Set (RFS) filtering approach [49, 50, 51, 52, 53, 54]; II use data fusion techniques to exploit multiple features to improve both performance and robustness of the recursive Bayesian filtering; III conduct tests on different robot platform like, e.g., WALK-MAN [2]; IV distribute a Free and Open Source Software (FOSS) implementation of the algorithms to the community.
ACKNOWLEDGMENT
This work was supported by the WALK-MAN project, funded under the European Community’s 7th Framework Programme No. 611832 (Cognitive Systems and Robotics FP7-ICT-2013-10).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] G. Metta, L. Natale, F. Nori, G. Sandini, D. Vernon, L. Fadiga, C. Von Hofsten, K. Rosander, M. Lopes, J. Santos-Victor, et al. , “The icub humanoid robot: An open-systems platform for research in cognitive development,” Neural Networks , vol. 23, no. 8, pp. 1125–1134, 2010.
- 2[2] N. G. Tsagarakis, D. G. Caldwell, A. Bicchi, F. Negrello, M. Garabini, W. Choi, L. Baccelliere, V. Loc, J. Noorden, M. Catalano, et al. , “WALK-MAN: A high performance humanoid platform for realistic environments,” Journal of Field Robotics , 2016.
- 3[3] B. Espiau, F. Chaumette, and P. Rives, “A new approach to visual servoing in robotics,” IEEE Transactions on Robotics and Automation , vol. 8, no. 3, pp. 313–326, 1992.
- 4[4] S. Hutchinson, G. D. Hager, and P. I. Corke, “A tutorial on visual servo control,” IEEE Transactions on Robotics and Automation , vol. 12, no. 5, pp. 651–670, 1996.
- 5[5] E. Malis, F. Chaumette, and S. Boudet, “2-1/2-D visual servoing,” IEEE Transactions on Robotics and Automation , vol. 15, no. 2, pp. 238–250, 1999.
- 6[6] D. Kragic and H. I. Christensen, “Survey on Visual Servoing for Manipulation,” Tech. Rep. ISRN KTH/NA/P–02/01–SE CVAP 259, 2002.
- 7[7] F. Chaumette and S. Hutchinson, “Visual servo control. I. Basic approaches,” IEEE Robotics & Automation Magazine , vol. 13, no. 4, pp. 82–90, 2006.
- 8[8] F. Chaumette and S. Hutchinson, “Visual servo control. II. Advanced approaches [Tutorial],” IEEE Robotics & Automation Magazine , vol. 14, no. 1, pp. 109–118, 2007.
