The Effect of Unresolved Contaminant Stars on the Cross-Matching of Photometric Catalogues
Tom J. Wilson, Tim Naylor

TL;DR
This paper investigates how unresolved contaminant stars affect the accuracy of cross-matching photometric catalogues, revealing significant flux contamination issues that impact the reliability of astrophysical data integration.
Contribution
It demonstrates that flux contamination from blended stars causes deviations in source matching, providing linear relations and quantifying contamination effects in crowded fields.
Findings
At least one in three faint stars suffers >1% flux contamination.
Contamination causes up to 50% reduction in matched counterparts.
Flux contamination impacts probability-based matching accuracy.
Abstract
A fundamental process in astrophysics is the matching of two photometric catalogues. It is crucial that the correct objects be paired, and that their photometry does not suffer from any spurious additional flux. We compare the positions of sources in WISE, IPHAS, 2MASS, and APASS with Gaia DR1 astrometric positions. We find that the separations are described by a combination of a Gaussian distribution, wider than naively assumed based on their quoted uncertainties, and a large wing, which some authors ascribe to proper motions. We show that this is caused by flux contamination from blended stars not treated separately. We provide linear fits between the quoted Gaussian uncertainty and the core fit to the separation distributions. We show that at least one in three of the stars in the faint half of a given catalogue will suffer from flux contamination above the 1% level when the…
Click any figure to enlarge with its caption.
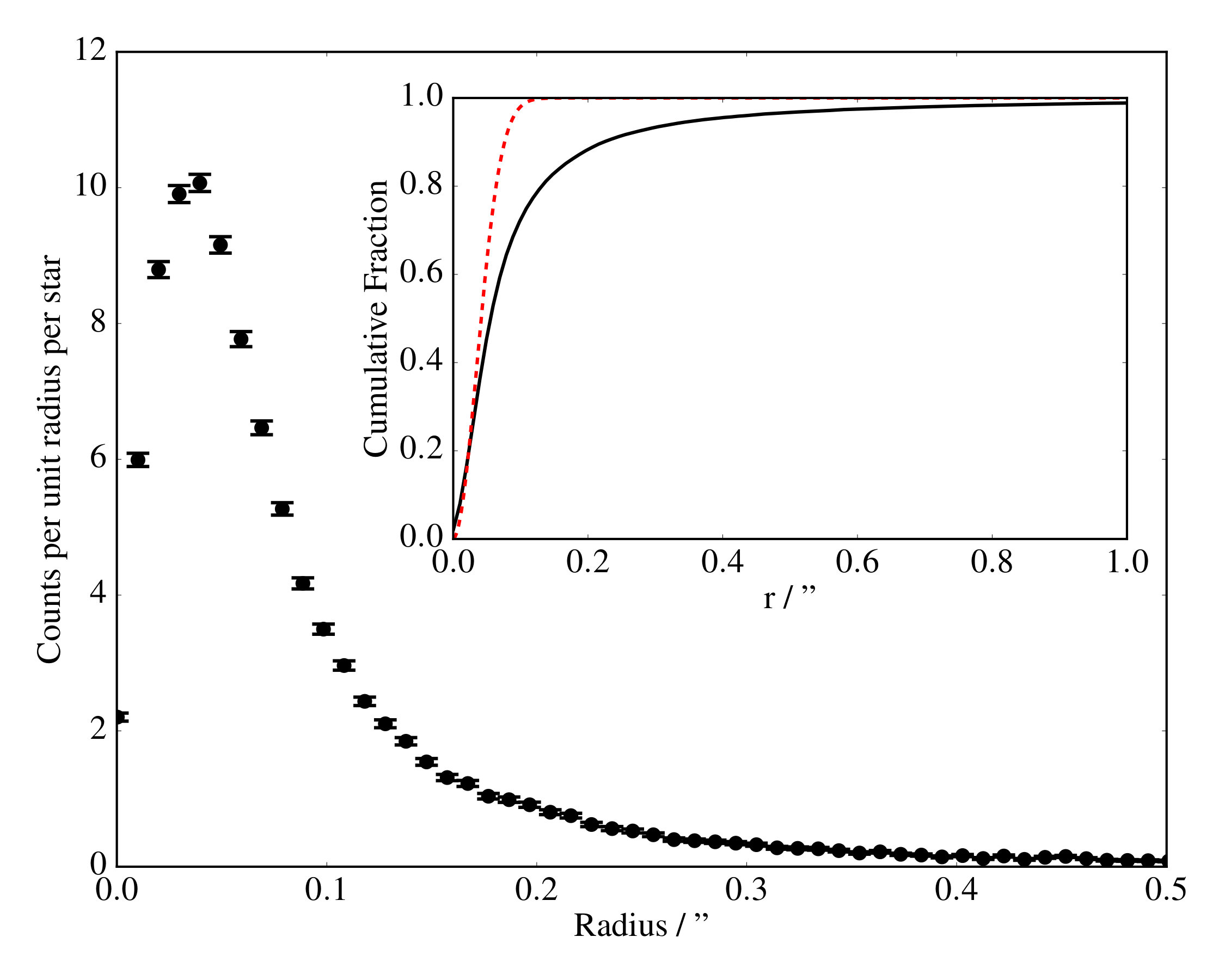 Figure 1
Figure 1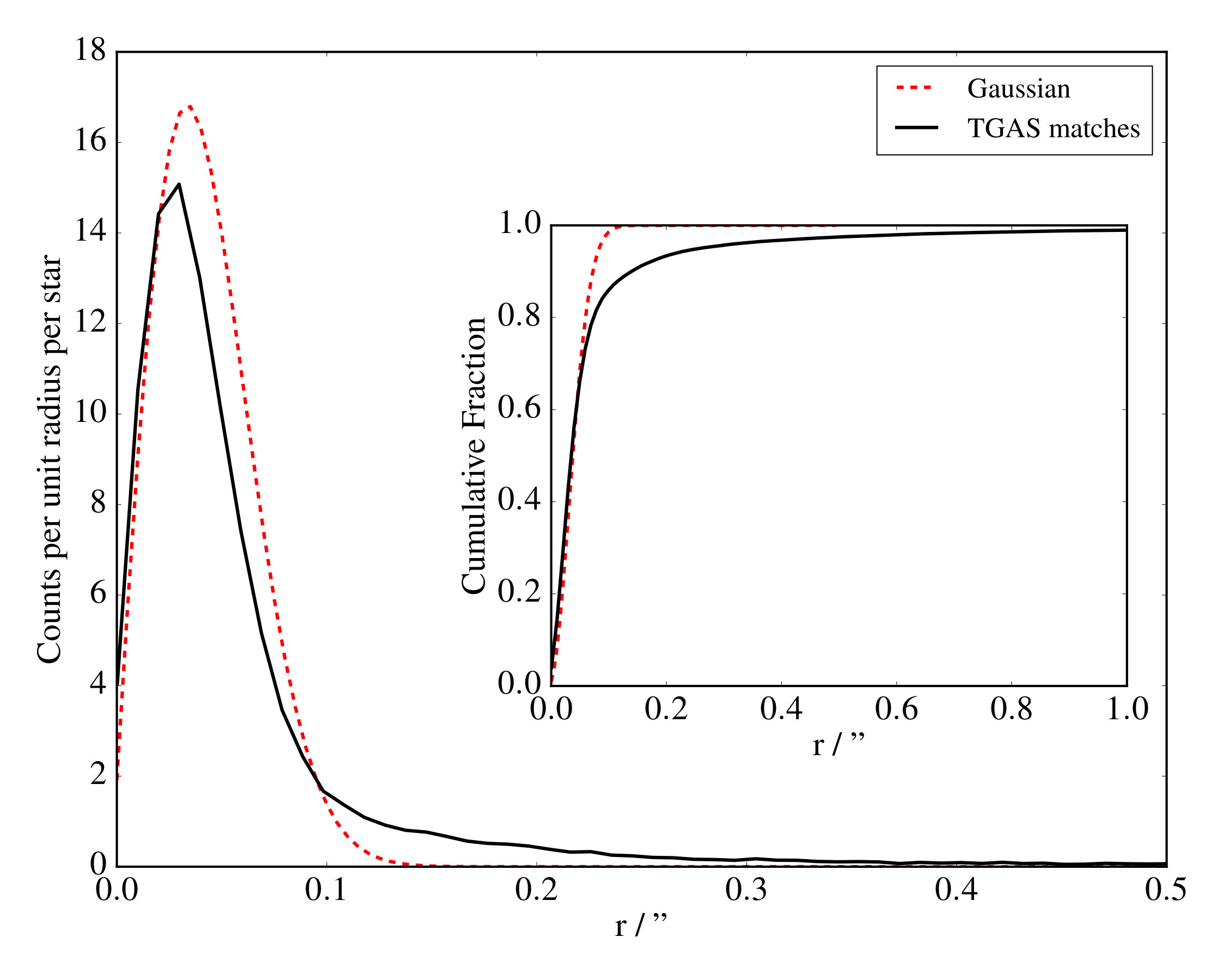 Figure 2
Figure 2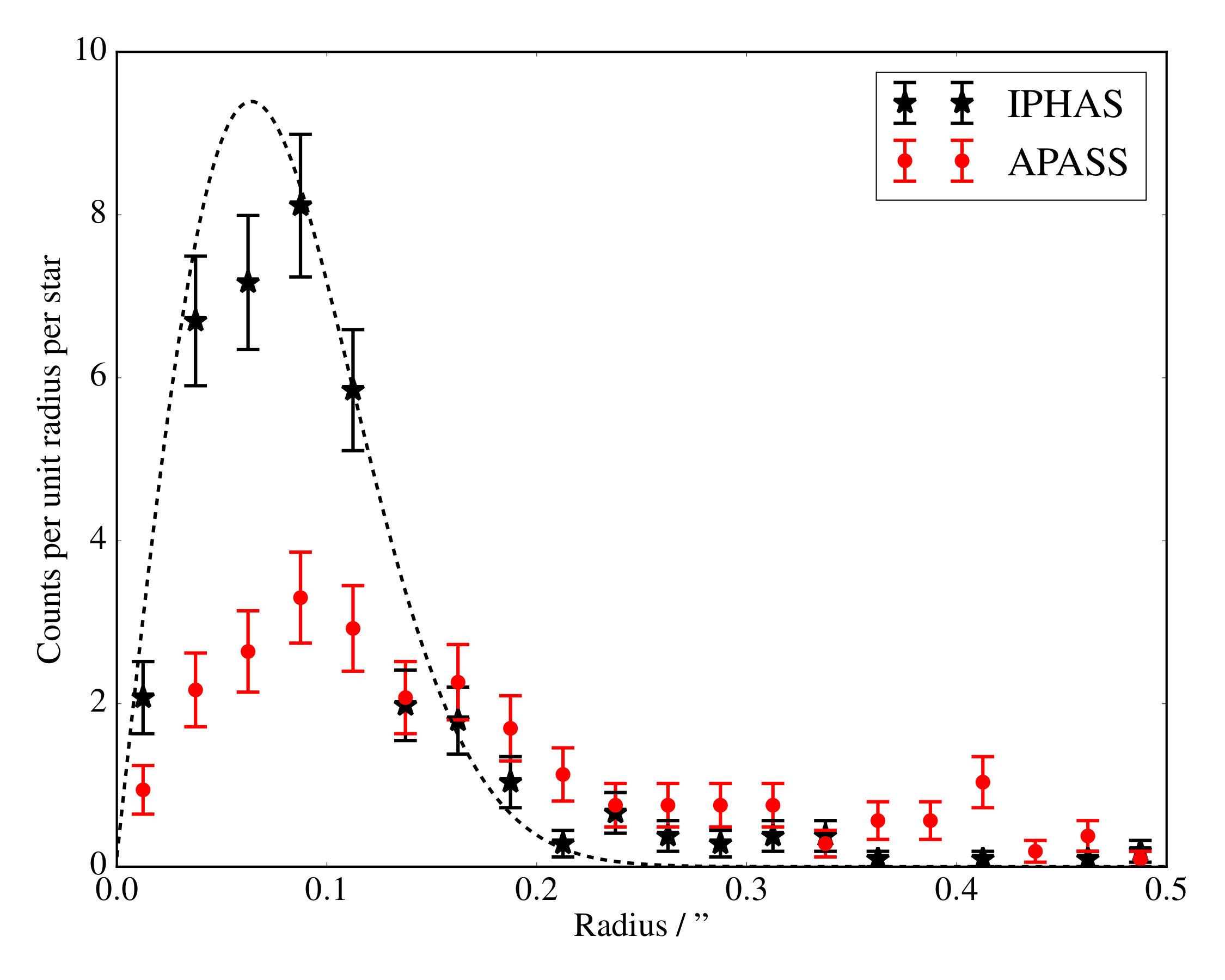 Figure 3
Figure 3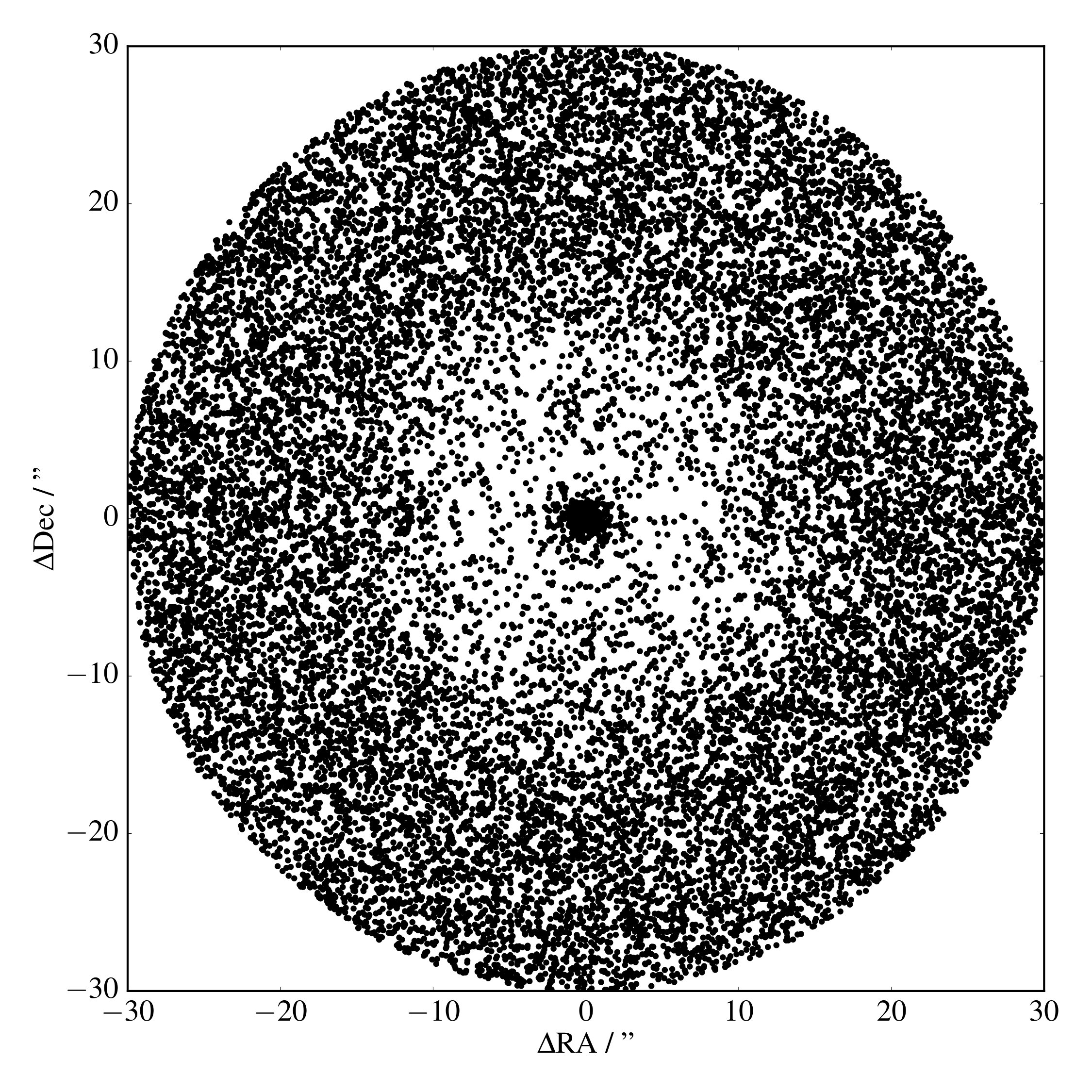 Figure 4
Figure 4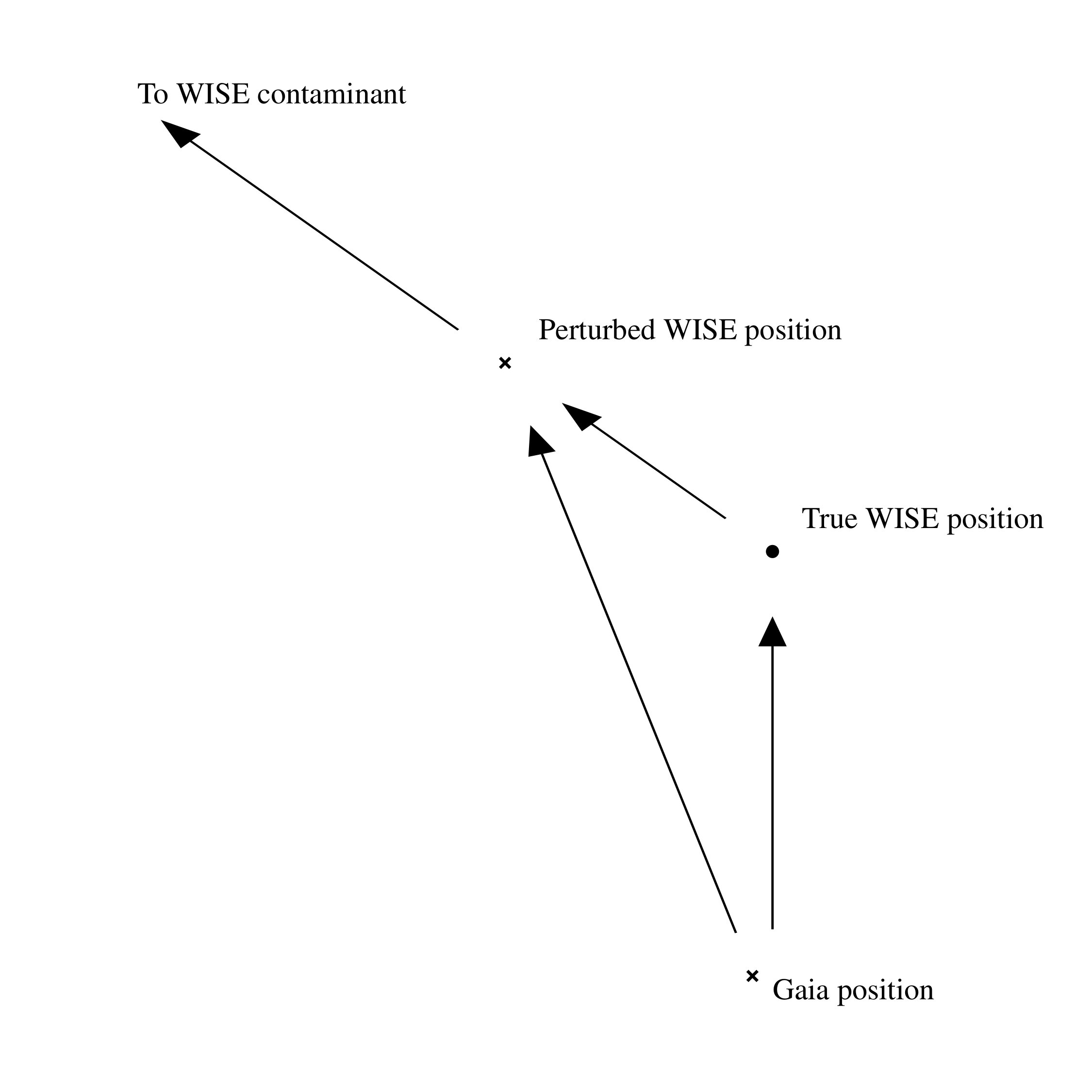 Figure 5
Figure 5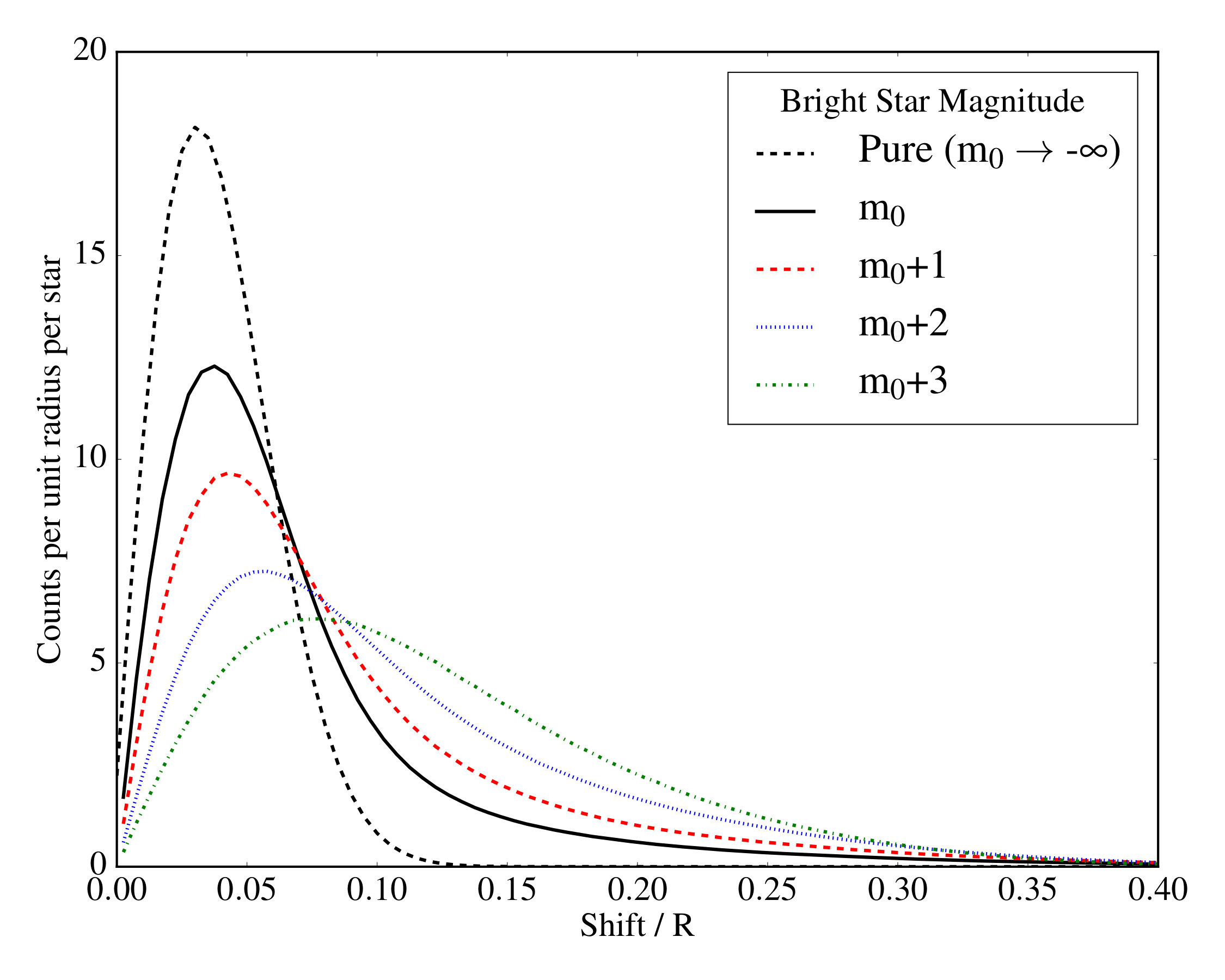 Figure 6
Figure 6| Symbol | Definition |
|---|---|
| Area | |
| Flux ratio of bright and faint objects | |
| Probability density of matches at given distance | |
| , | Galactic sky coordinates |
| Total number of counterparts | |
| Magnitude difference between faint and bright object | |
| Magnitude of bright object | |
| Number of stars per unit area per magnitude | |
| Radial distance | |
| Contamination figure of merit | |
| Cutoff radius | |
| RA, Dec | Celestial coordinates |
| Number of objects in circle of given radius | |
| , | Cartesian coordinates |
| Scaling for increase in star counts with magnitude | |
| Width of radial annulus | |
| , | Proper motion in sky coordinates |
| Astrometric Gaussian uncertainty | |
| Astrometric uncertainty given in catalogue | |
| Uncertainty fit to the inner radius of an AUF | |
| Number of separations per unit distance | |
| Number of stars per unit area | |
| Number of detected sources per unit area |
| Catalogue | Criteria |
|---|---|
| Gaia | astrometric_excess_noise 0.865mas; or matched_observations 8 or |
| astrometric_n_good_obs_al + astrometric_n_good_obs_ac 60 | |
| WISE | “Contam” flag is either “D”, “P”, “H”, or “O”; or “ext” flag is 2, 3, 4, or 5; or |
| “Phqual” flag is “X” or “Z”; “detbit” == 0; Mag == NaN; “sat” flag 0; or == NaN | |
| APASS | Mag 20 or Mag 10 |
| 2MASS | “Galcontam” or “Mpflag” flags set; or “Blend” flag == 0; “Read” flag == 0 or 3; Mag == NaN; or == NaN |
| IPHAS | ; or Mag == NaN, “Saturated” flag set, or == NaN |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
The Effect of Unresolved Contaminant Stars on the Cross-Matching of Photometric Catalogues
Tom J. Wilson,1 and Tim Naylor1
1School of Physics, University of Exeter, Stocker Road, Exeter EX4 4QL, UK E-mail: [email protected]
(Accepted 2017 March 10. Received 2017 March 10; in original form 2017 February 6)
Abstract
A fundamental process in astrophysics is the matching of two photometric catalogues. It is crucial that the correct objects be paired, and that their photometry does not suffer from any spurious additional flux. We compare the positions of sources in WISE, IPHAS, 2MASS, and APASS with Gaia DR1 astrometric positions. We find that the separations are described by a combination of a Gaussian distribution, wider than naively assumed based on their quoted uncertainties, and a large wing, which some authors ascribe to proper motions. We show that this is caused by flux contamination from blended stars not treated separately. We provide linear fits between the quoted Gaussian uncertainty and the core fit to the separation distributions.
We show that at least one in three of the stars in the faint half of a given catalogue will suffer from flux contamination above the 1% level when the density of catalogue objects per PSF area is above approximately 0.005. This has important implications for the creation of composite catalogues. It is important for any closest neighbour matches as there will be a given fraction of matches that are flux contaminated, while some matches will be missed due to significant astrometric perturbation by faint contaminants. In the case of probability-based matching, this contamination affects the probability density function of matches as a function of distance. This effect results in up to 50% fewer counterparts being returned as matches, assuming Gaussian astrometric uncertainties for WISE-Gaia matching in crowded Galactic plane regions, compared with a closest neighbour match.
keywords:
surveys – astrometry – stars: general – catalogues – techniques: photometric
††pubyear: 2017††pagerange: The Effect of Unresolved Contaminant Stars on the Cross-Matching of Photometric Catalogues–The Effect of Unresolved Contaminant Stars on the Cross-Matching of Photometric Catalogues
1 Introduction
Broadband photometry is a staple of astrophysics, able to provide a wealth of information on a plethora of objects of interest without the time requirements of spectroscopy. To break degeneracies in theoretical models and gain as much understanding as possible, oftentimes multi-wavelength coverage is required. This means combining the efforts of several surveys, where teams and collaborations have independently taken photometric images of the sky in various wavelength regimes. It is therefore of vital import that we correctly identify the same stars in separate catalogues.
Traditionally, the method for matching two catalogues together uses the smallest distance between a given star in one catalogue and stars in the opposing catalogue, pairing those stars that both have the other star as their closest corresponding star. Additionally there is a cutoff radius beyond which no pairs can be matched, typically 2" or 3". Due to the nearest-neighbour nature of the matching, this is typically referred to as proximity matching.
Recently, the idea of matching between catalogues following a probabilistic approach (starting with Sutherland & Saunders, 1992; more recently, e.g., Budavári & Szalay, 2008, Fleuren et al., 2012, Naylor et al., 2013, and Line et al., 2017) has become common. Instead of merely assigning a maximum match radius, the methods calculate the probability of finding a star’s counterpart in a second catalogue at a given separation. These probabilities are based on the uncertainty in the position of the star in each catalogue. This we will refer to as probability-based matching. It gives a more flexible approach by adjusting the size scale over which matches are considered likely to match the precision of the detections. High quality, precise astrometric data only allow matches between stars close to one another, while less precise data are allowed to have counterparts beyond the 2-3" typical proximity cutoff.
Proximity matching is equivalent to carrying out probability-based matching using a “top-hat” function with the cutoff radius, inside which a star is equally likely to exist at any distance from another detection and outside which it is impossible to be matched. Astrometrically the full probability-based method is favourable because the top-hat is unphysical. To improve upon this “top-hat”, we require a more complete description of the probability of detecting the counterpart in the opposing catalogue at a given separation. These probabilities of star pairs being counterparts to one another as a function of separation are themselves a function of what we shall refer to as the astrometric uncertainty functions (AUFs). Usually, these distributions are assumed to be purely Gaussian. This does not account for any wings to the distributions themselves, yet these are known to exist (see, e.g., Krawczyk et al., 2013 Figure 4 or Munari et al., 2014 Figure 2). The assumption that the AUF is Gaussian could lead to a significant mis-identification of a large number of counterparts. In the probability-based matching case this incorrect matching is due to the assumed shape of the distributions not being a good description. In the proximity matching case it is caused by the accepted cutoff radius being too small.
Probability-based matching also has increased flexibility in allowing for comparisons between two detections in one catalogue by including additional information, such as magnitudes (e.g., Budavári & Szalay, 2008 and Naylor et al., 2013). If two stars are close enough to the same star in another catalogue to be considered likely matches, the extra parameter space allows for the possibility of rejecting an unfavourable match that is serendipitously nearer than the better match. However, this extra information can not be used if the AUFs are ill-defined, so it is vital that they are correct.
In this paper we will explain how crowding in high density regions causes long, non-Gaussian tails in the AUFs. We will begin by initially introducing the catalogues being used throughout the paper in Section 2, and in Section 3 defining the AUF more formally. We will then examine the spatial distribution of an examples of matches for a crowded region of the Galactic plane before discussing some possible reasons for the non-Gaussianity seen in the distributions, concluding that they cannot satisfactorily explain the results in Section 4. We introduce the effect of crowding seen in photometric catalogues in Section 5. This is used to explain how this effect causes the non-Gaussian tails, before we test the hypothesis with some simple approximations in Sections 6 and 7. We then put the effect into context for several additional large scale, commonly used surveys in Section 8. Finally, we offer some options to overcome the issue of contamination in Section 9. Here we give some cases where one can maximise the number of true matches at the expense of false positives, or, alternatively, minimise the number of false positives and contaminated matches. We define symbols used throughout the paper in Table 1.
2 Catalogues
The matching of photometric catalogues has significant problems in very crowded fields, and is at its worst in the Galactic plane, especially towards the Galactic centre. In addition, the crowding becomes more problematic with increasing seeing or larger point spread functions (PSFs). The crowding of stellar fields is then a function of both stellar density and PSF area, which is why we have chosen to focus on WISE (Wright et al., 2010) for most of our work. With a full-width at half maximum (FWHM) in bands and a relatively deep survey reaching , the WISE datset suffers from significant crowding. At the other extreme, the recently released Gaia DR1 (Gaia Collaboration et al., 2016) provides excellent and unprecedented astrometric precision, and with a FWHM should be effectively uncrowded.
Initially we will consider Gaia and WISE, but we will introduce APASS (Henden & Munari, 2014), IPHAS (Barentsen et al., 2014), and 2MASS (Skrutskie et al., 2006) in a later Section. To ensure minimal erroneous or poor data in the catalogues, we first clean them to remove either known non-stellar sources, or to remove spurious, low-quality, saturated, and upper flux limit objects, as detailed in Table 2.
3 The Astrometric Uncertainty Function
The probability that two stars in two photometric catalogues are counterparts to one another is the probability that the stars from the two catalogues are drawn from the same original sky position, involving the AUFs of both catalogues. However, the order-of-magnitude higher precision in the Gaia dataset simplifies the problem such that the probability of matches reflects only the uncertainties in the second catalogue. Thus, we only require the AUF of WISE detections in this instance.
This means we can model the probability of measuring a source, with “true” position at the origin, at position as a centered, circular, two-dimensional Gaussian (Quetelet, summarised by Herschel, 1857)
[TABLE]
where is the astrometric uncertainty in either of the orthogonal axis directions. The astrometric uncertainty can be approximately related to the photometric signal-to-noise ratio (SNR) and image PSF scale length. King (1983) quotes the relationship as the FWHM of the image divided by the SNR.
When considering a circular geometry, we can transform this to radial coordinates by integrating over , which changes the Gaussian distribution to a Rayleigh distribution, given by
[TABLE]
is a probability density function, the probability per unit area, that the WISE star will be detected at an offset from the Gaia source. Alternatively, is the probability per unit length that the WISE star is detected at a radial offset from the Gaia source. It is the function that we will compare to our data in Section 4.
4 Fitting the Distribution
To check the validity of , our AUF, we must test it against some example data. Consider a large sample of matches, i.e. pairs of stars, all of which have a similar astrometric uncertainty . The number of matches per unit distance in a narrow annulus to is
[TABLE]
where is the total number of matches. Assuming all stars in the sample are true matches (see Section 4.2 for further discussion), we can then compare our expected number of stars per unit distance with the number detected.
In this section we will consider matches between WISE and the Tycho-Gaia Astrometric Solution (TGAS; Michalik et al., 2015) for an 800 square degree region of the Galactic plane (, ). Although the TGAS is a relatively bright subset of the full Gaia dataset, limiting our match numbers, we will require the proper motions, which are only available for TGAS stars, in Section 4.2. We will discuss the effects of the full magnitude range in Section 8, and find the magnitude cut does not affect the conclusions drawn in this Section.
4.1 Uncertainties for WISE Data
Matching between our two catalogues, we take WISE stars in a narrow range of values (typically 0.01") and proximity match them in a nearest-neighbour scheme to the TGAS dataset. From this we find the number of stars in given radius bins, and plot the number of stars per unit radius within each annulus, along with the assumed astrometric distribution, based on the quoted uncertainties. Figure 1 shows the resulting distribution for one narrow range of uncertainties . We can see that the distribution is reasonably well described by a Rayleigh distribution in the inner region, below , but that there is a significant non-Gaussian tail to the distribution of match distances.
4.2 Common Sources of Additional Astrometric Sources
There are two obvious potential causes of non-Gaussian data: a population of uncorrelated false matches, and the effects of proper motion on the apparent match distance between two catalogues of different epochs. As we show below neither of them can adequately explain the effect entirely, requiring an alternative explanation.
4.2.1 Proper motions
Proper motions are often cited as being the cause of these “wings” at large separations (e.g., Section 6.4 Figure 2 of Cutri et al., 2012, Appendix A1 of Flesch & Hardcastle, 2004). As WISE operated in 2010 while Gaia records positions in epoch J2015 we must check to see if this is a significant cause of match offsets. We obtained the Gaia proper motions in the orthogonal axes for all stars in the 800 square degree region of the Galactic plane used to construct the distributions in Figure 1.
We calculated the new celestial coordinates for the Gaia positions, transformed from the J2015 epoch to WISE’s J2010 epoch as
[TABLE]
with an equivalent transformation for declination, where and are the projected proper motions in the two orthogonal sky axis directions. The new distribution of proper motion-corrected separations was compared to a Gaussian of the average uncertainty , shown in Figure 2. As can be seen, while the distribution tightens slightly towards smaller separations, the large, non-Gaussian tail remains beyond . This leads to an incompatible cumulative distribution shown inset to Figure 2. The non-Gaussian tail increases with decreasing brightness (see Section 7 for more details), and the average magnitude of stars in Figure 2 is bright, at W1. We therefore cannot explain most of the non-Gaussianity of the distributions with proper motions.
4.2.2 Uncorrelated False Matches
While we cannot explain the non-Gaussianity to the match distributions with proper motions, these are purely proximity matches. We expect some contamination from uncorrelated stars which could potentially explain the non-Gaussian wings. At its most dense, there are Gaia stars per square degree in the Galactic plane region in question. The expected number of randomly placed objects in a circle of a given radius, , is the multiple of the stellar density, , and the area, ,
[TABLE]
where we have limited ourselves to a circle of radius 0.5" as per Figure 1. We therefore expect 0.1% of the stars to be false matches. These numbers are upper limits, as the nearest-neighbour scheme employed reduces contamination beyond the radius of the true match separation for each star. We conclude that we cannot explain the distribution wings with uncorrelated star contamination.
5 Explaining the Distribution Wings
5.1 Star Spatial Distributions
To explain the distribution of matches between two catalogues, it is illuminating to consider a Gaia source of magnitude . We can find the offsets from this star to all WISE objects with radial offset <30". Repeating this calculation for all such stars in a 25 square degree region of the Galactic plane at , we build up a density of WISE sources astrometrically near Gaia sources in a narrow Gaia magnitude range as a function of radial distance, shown in Figure 3.
There are three distinct regions. First, beyond 10" from the Gaia objects we have a constant density of sources, which are uncorrelated, additional WISE objects. Second, we have a tight clustering of detections inside , which are the WISE detections corresponding to our Gaia objects. Third, we have a region where we see randomly placed objects at a lower density than those at larger .
However, non-match stars - those in the WISE catalogue whose magnitude would lie outside of our 0.25 magnitude range - are not correlated with those stars that do lie in that small magnitude range. We therefore expect them to have a constant stellar density across the entire sky, meaning that between 2" and 10" radial distance we should see the same density of objects in some small area as we do beyond 10". This apparent reduction in stellar density is caused by crowding, a well known issue where bright sources dominate and cause non-detections of fainter objects inside their PSF, reducing the number of objects measured at these intermediate distances.
The important point to stress here is that these stars have not gone away - they are merely absorbed into the PSF of the bright star. This causes flux contamination, which will compromise the photometry. However, since the vast majority of the contaminating sources will be objects significantly fainter than the main detection, with a low relative flux ratio, the photometric effect is small.
5.2 Contaminant Stars
More crucial, however, is the effect these sources have on the derived positions. Figure 4 shows an example schematic. A Gaia source and its true WISE match are offset by some small distance - on the order of tenths of arcseconds - but there lies inside the WISE PSF a second, undetected source with a tenth of the flux of the primary source, at . This will tug on the position of the WISE primary by 0.3", changing the apparent separation between the WISE object(s) and the Gaia object. The distribution of separations - which we would wish to use for any probabilistic catalogue matching - is then a combination of two functions: the initial Gaussian-based statistics and the effects of undetected, embedded, contaminants.
6 Validation with Synthetic Distributions
To test the effect these embedded stars could have on the AUF, we created a synthetic dataset based on simple geometric arguments. First we require the distribution of shifts that result when stars are contaminated within their PSF.
To obtain the shift distribution, we placed test stars inside circles of a given sample bright star’s PSF at random. These drawings assumed that the number density of stars increases by a factor of with every step in magnitude. We then found the flux-weighted position of the stars in each PSF. Once all test contaminants had been drawn, the number of new positions in each given distance bin was recorded. Finally, the distribution was reduced to a probability density function by normalising.
We convolved the resultant function with a Rayleigh distribution of FWHM, representing a star with SNR=20. The results of this are shown in Figure 5, for several bright stars with increasing magnitudes, representing increasing number densities of sky objects. The convolved functions still resemble the “pure” AUF in the inner region of the PSF, albeit with a broadened equivalent astrometric uncertainty, but the contamination also introduces a very long tail of separations. These objects are flux contaminated enough to introduce offsets on the order of 0.3-0.4FWHM. This effect increases as the number density of objects increases, representing increased large separation contamination.
In summary, we suggest that the effect of astrometrically perturbed sources leading to large wings in distributions of counterpart distances, seen in the number of astrometric separations as a function of distance, is caused by the crowding out of fainter objects in the PSF. This leads to that fraction of stars - a very large fraction in regions of high stellar density, faint magnitudes, or large PSFs - with contaminant stars buried in their PSF exhibiting significantly non-Gaussian distributions in their detected positions. This will cause additional missed proximity matches if using a cutoff radius on the order of 1-2". It will also cause the resultant likelihoods derived from any probabilistic catalogue matching methods to fail in sampling the correct probability of matches and non-matches, also leading to a large fraction of false negative assignments.
7 Quantifying the Contamination Levels
We showed that simple arguments about the effects of faint embedded stars inside brighter PSFs can reproduce similar results to those seen in the data (Figure 5 cf. Figure 1) in Section 6. However, we must now quantify the contamination levels from those faint stars. At a given stellar magnitude there will be some fraction of stars containing unresolved stars and another fraction which do not have within them additional sources. These are contaminated and uncontaminated objects, respectively. The uncontaminated fraction will still obey traditional Gaussian-based probabilistic statistics, but the contaminated stars will exhibit large shifts to their apparent position. This leads to the significant wings in their AUFs, as seen in, e.g, Figure 1.
The average number of stars inside the circle of the PSF can be calculated in a similar way to Equation 5, but for the area we use the radius of the circle the PSF subtends on the sky - typically 1-1.5 times the FWHM. In addition the number density is now the number of stars per square degree up to magnitudes fainter than the star of magnitude . This then gives us a fraction of stars which are contaminated,
[TABLE]
with the PSF cutoff radius, a normalisation factor, and the increase in stellar density with each step in magnitude. The choice of is a reasonably arbitrary one, with stars technically being contaminated by faint stars with vanishingly small flux ratios, requiring an upper limit to the integral approaching infinity. However, the test data used in Section 6 show a convergence of the resulting AUFs for . This suggests that above , the distribution of contaminant shifts is dominated by the brighter contaminating stars, with very faint contaminants unable to affect the flux-weighted position. Thus we choose , giving a flux ratio . For WISE in the Galactic plane, , this gives a stellar density of deg*-2* for ; a factor of 3 increase over Equation 5. The contamination levels themselves use for the area in question , compared to the 0.5" used when calculating the false positive rate.
We find that inside one out of every four PSFs of stars of there will be a star of . This increases to approximately one star of inside the PSF of every 13th magnitude WISE star. Naturally some of these objects will be deblended during the reduction process, meaning that these numbers are upper limits, but as Figure 3 demonstrates, not all of them are successfully recovered, meaning they must be buried within the brighter detections.
7.1 The Contamination Figure of Merit, Q
The levels of contamination are dependent on the distribution of sources with magnitude and the size of the catalogue’s PSF. To compare the contamination levels between catalogues requires a consistent metric.
Formally quantifying the stellar density requires fitting the number of stars per unit magnitude as a function of magnitude for the sky area in question. However, for a large fraction of the objects in the catalogue the contaminants that are perturbing their astrometry would be below the completeness limit of the catalogue, even outside of the bright star’s PSF. This leads to the requirement that we extrapolate the number density of sources below the completeness limit. It is more straightforward to just consider the stellar density of the overall catalogue, and assume the extrapolation of the number density to faint magnitudes.
We must decide on both a magnitude for which we will assess the contamination () and a maximum acceptable contamination level, before we can compare the contamination levels between catalogues. For , we choose the median magnitude of the catalogue, which gives a lower bound to the contamination level of the fainter half of the catalogue. Additionally, we choose a contamination level of 33%, the point at which a significant number of objects will be pertubed. These values then provide a baseline value, which can then be compared to values calculated for specific catalogues.
The number of stars per unit area in the magnitude range from the median magnitude of the catalogue to five magnitudes fainter is approximately ten times that of the detected source density. We showed in Section 7 that contaminants more than five magnitudes fainter than the central object do not contribute to the overall perturbation, and we therefore limit ourselves to . If we also wish to limit ourselves to 33% of sources being contaminated, then
[TABLE]
Substituting FWHM and , where is the source catalogue density, we have
[TABLE]
This means that a 33% contamination level of stars of the median magnitude is achieved when the contamination figure of merit
[TABLE]
It may be surprising that a catalogue where only a fraction of a percent of the sources might contain as contamination another source detected in the catalogue suffers from 33% perturbation. Howevever, the 0.5% result is simply the chance that a star above the completeness limit of the survey falls within a box with side length equal to the FWHM of the survey. The PSF length scale and, more importantly, the fact that stars are astrometrically perturbed by objects below the sensitivity of the survey both contribute to a much more significant contamination level. However, the value is a useful tool for comparing surveys of different spatial resolutions and dynmical ranges.
Additionally, we can compare the number of objects affected both photometrically and astrometrically throughout the dynamical range of the catalogue. Towards the bright end of the catalogue, the number density of stars contaminating is relatively low. Here any stars affected will have accurate astrometric positions, and so the undetected contaminants will lead to large astrometric offsets compared to their uncertainties. However, the fraction of stars affected is sufficiently small that the contribution to the AUF from contaminated stars may be negligible. At the faint end of the catalogue the opposite is true, where the effective stellar density is very high and therefore the fraction of stars photometrically compromised is high. However, the SNR rapidly decreases towards the completeness limit of the survey and thus the influence of the contaminant stars is diminished, lost amidst the inherent uncertainty in measuring the position. Astrometrically the most affected part of the catalogue is between these two extremes, in the region where the stellar density is still high enough to have a large fraction of stars contaminated, but with accurate enough positions that the effects of contaminants are easily detectable.
8 Surveys in Context and the Quoted-Core Distribution Uncertainty Relationship
While we have focused mostly on the WISE AUF, it is salient at this point to mention how this effect changes the distributions of other catalogues. Here we will briefly discuss three additional, complementary, large-scale surveys: two optical surveys, APASS and IPHAS, and the near-IR survey 2MASS. These catalogues are especially useful as they allow us to directly probe the effect of increasing stellar density and decreasing PSF scale length. We will also put WISE into a wider context.
We have shown evidence of a broadening of the AUFs relative to their assumed Gaussian positional uncertainties in Section 6. As a consequence, we fit the AUFs for large sections of the Galaxy for each survey in one square degree divisions, giving relationships between the quoted and best-fit Rayleigh distribution uncertainties. The relationship between the quoted uncertainty and best fit Rayleigh distribution is
[TABLE]
with the core uncertainty such that the Rayleigh distribution best fits the smallest radial offsets of the given dataset, and the quoted uncertainty that as taken directly from their respective catalogues. We fit for some arbitrary offset , but as expected the best fits have intercepts on the order , resulting in effectively a scaling between the quoted and core uncertainties.
However, as detailed further in Section 9, while these broadened Gaussian uncertainties are useful, it must be cautioned that these empirical uncertainties do not necessarily allow for the selection of uncontaminated objects. Figure 5 shows that there is significant overlap between the contaminated and uncontaminated distributions.
8.1 APASS
As an all-sky survey bridging the gap between the Tycho2 and SDSS surveys (Henden & Munari, 2014), APASS is a very important survey. However, it has a relatively large PSF, using a diameter of 15-20" for its aperture photometry, and large detector pixels (/pixel), leading to a significant fraction of contaminated stars and large wings in the APASS-Gaia separation distribution. This is mitigated slightly by its reasonably bright completeness limit, effectively reducing the stellar density at its faint end, giving a contamination fraction on the order of tens of percent, or a value of .
APASS has very conservative astrometric uncertainties in DR9, requiring an empirical fit to any data being used in a probability-based matching process. In the Galactic plane (l 120, b 0) the core uncertainty is approximately 65% of the quoted uncertainty, decreasingly dramatically towards the Galactic pole () where the core uncertainty is 30% of the quoted uncertainty.
8.2 IPHAS
IPHAS used the Isaac Newton Telescope on La Palma to conduct a relatively large scale, deep survey of a section of the Galactic plane. The median PSF FWHM of combined with a 0.33" pixel scale (Barentsen et al., 2014) lead to a good ability to resolve sources even in crowded regions. In spite of this, IPHAS has a similar value as APASS, at , indicating a similar relative level of contamination at the two catalogues’ respective median magnitudes. This results in a contamination fraction of 10-15% at the faint end of the survey. Its much smaller PSF radius compared with APASS allows for a deeper survey at the same contamination level, or reduced contamination level at the same magnitude, as shown in Section 8.2.1.
While the survey does not provide astrometric uncertainties for individual stellar sources, the high quality of the photometry means that there is good agreement between empirical distribution uncertainties and astrometric uncertainties calculated as the image FWHM divided by the photometric SNR, as per King (1983).
8.2.1 APASS vs IPHAS
As was seen in Sections 8.1 and 8.2, both optical catalogues have a similar value - that is, the number of stars in an area the size of their PSF FWHM is similar. With the overlap in sky coverage and photometric bands, we can directly compare the separations of stars in common to both APASS and IPHAS with Gaia.
After matching both datasets to Gaia for , , IPHAS and APASS stars which matched to the same Gaia object were assumed to be themselves the same object. Stars were then selected with APASS astrometric uncertainties less than 0.15". Their separation distributions were then compared, as shown in Figure 6.
The theoretical AUF matches the IPHAS distribution relatively well, with a small wing on the order of several percent, consistent with density contamination arguments. However, those same stars’ positions are much more uncertain in APASS, caused in part by the differences in SNR, sky conditions etc., but additional broadening is caused by the vastly increased area subtended by stars on the sky in the APASS system.
As a consequence, we consider separately the magnitude at which a given catalogue will reach approximately 33% contamination within its PSF. This value highlights the differences between APASS and IPHAS. The magnitude at which contamination of APASS sources up to five magnitudes fainter reaches 33% is , which is approximately at the completeness limit of the survey in the uncrowded Galactic pole. However, the magnitude at which IPHAS suffers 33% five magnitude fainter contamination is , a few magnitudes fainter than its limiting magnitude of 20-21. This highlights the importance of spatial resolution on the contamination levels of photometric observations.
8.3 2MASS
2MASS is frequently used to define the reference sky positions of those catalogues that came after it due to its all-sky completeness level (WISE and IPHAS both use it, for example), and therefore it is very important to understand the contamination levels that it suffers. However, it has a reasonably large PSF (FWHM 2.5") and is a relatively faint (K 16-17) survey. The contamination level rapidly increases with increasing magnitude and there are stars in every 2MASS PSF at its limiting magnitude in the Galactic plane. This results in , or one in three contaminated stars with contaminants up to five magnitudes fainter at .
The quoted uncertainties match the core region of the distribution to within 10%.
8.4 WISE
With its large, 10" PSF and high SNR leading to faint limiting magnitudes, WISE is especially susceptible to crowding, leading to, on average, one faint star inside every PSF of stars with . WISE has an especially large value, . Its 33% contamination level at the 1% flux level is reached at a very bright magnitude as well, with one in three stars of suffering from a star inside its PSF.
In the Galactic plane, we find that the core uncertainty is twice the quoted uncertainty, explained by the large fraction of contaminated stars. However, the Galactic poles suffer much less from contamination with its reduced stellar density. We therefore find that at the quoted uncertainties fit the distributions with only minor broadening. Core uncertainties are only 10-15% larger at these larger uncertainties, but below 0.15" the core uncertainty plateaus requiring a constant to explain these brightest objects.
8.5 Gaia
As a survey dedicated to astrometry, Gaia has unparalleled precision in the positions of stars. Its PSF of 0.1" FWHM leads to a very small value of , 50 times better than any other catalogue used, or a limiting magnitude contamination of . The magnitude at which contamination from stars five magnitudes fainter reaches 33% is , far fainter than the completeness limit of the survey. From this we are confident in using Gaia as the reference catalogue for quantifying the effects of contamination.
9 How to Deal with Contaminated Astrometric Detections
While the effect of unresolved objects inside stellar PSFs causing large wings to the probability distributions is explicit qualitatively, it is much more difficult to utilise it quantitatively. However, there are several ways to improve the matching process, depending on the specific requirements of the final catalogue of matches.
Two extremes of catalogue matching are the case where we must only return sources we can trust to not be contaminated or be false positives, and the case where we do not necessarily care whether our sources are contaminated, and are also willing to accept a large number of false positives. The decision may also be motivated by whether it is acceptable that matches have detections with fluxes that are compromised by a second star in their PSFs in one or both of the respective catalogues.
In either case, it should be noted that there will be some situations, such as with WISE-Gaia matches, where one catalogue has a large PSF and the other has good spatial resolution, which will lead to a significant number of missed matches. These will be matches where one star contains within it as contamination a second object which is a separate entry in the opposite catalogue, which will lead to confusion in interpreting any results obtained. This will suggest that the faint Gaia source has a corresponding WISE magnitude below WISE’s completeness limit, which may not be the case in reality.
We also stress again that the contamination levels quoted here are upper limits, as active and passive deblending can help to resolve out overlapping objects, but note that this does not remove the effect entirely, as seen in the crowding out of stars (Figure 3).
9.1 Non-Contaminated Matches
First, when the goal is to only match those stars which are definitely true matches, but now additionally are not significantly flux contaminated, it is advisable to cut proximity matches at a minimum of 3. Equivalently, should be used as the uncertainty in the AUF when considering probability-based matches.
We recommend examining sample distributions of proximity-matched separations. These should then be compared to their quoted uncertainty. If the quoted uncertainties are a good match to the empirical AUFs then use , but otherwise make empirical corrections to fit the slightly broadened distributions to match as required.
This will mostly capture the “clean” population, but will also increase the number of non-matches, as the AUF will not be sampling the extended tails of the contamination. This will potentially lead to the belief that the star was not detected in the opposing catalogue, with a cutoff radius that omits a large fraction of true matches. It will also still include some fraction of sources which are photometrically compromised, especially towards the fainter end of a given survey.
9.2 Full Coverage Matches
The other extreme is the case where the goal is to achieve a large catalogue with as many matches as possible, in which the effect of false positives or contaminated fluxes is unimportant.
In this case, the cutoff radius for a traditional nearest-neighbour match should be some multiple of the largest PSF FWHM between the two catalogues, typically 1.5-2 FWHMs. Alternatively, if a probability-based matching system is being used, then it is advisable to construct a set of empirical AUFs for each astrometric uncertainty slice in turn, which will include the wings of the distributions.
These empirical functions are then used in place of as described by Sutherland & Saunders (1992), as per Naylor et al. (2013), in Pineau et al. (2017), of Rutledge et al. (2000), etc. These will increase the effective size of the area over which you can match between the catalogues, but will in turn increase the false match probability. Care should be taken when substituting any empirical functions into these probability-based matching methods, however, as any assumptions involving the use of Gaussian statistics (e.g., convolutions, mean positions, etc.) will no longer hold.
We can take the WISE-Gaia case to demonstrate the effects of an empirical AUF. To do so, we matched the two catalogues using a probability-based matching process (Wilson & Naylor, in prep). The matching was done twice for two different astrometric PDFs. First, the AUFs used were purely Gaussian-based using , and second, the WISE AUF was empirically constructed. When comparing the number of returned crossmatches, the Gaussian-based AUFs returned approximately half the pairs that the empirically constructed AUFs matched. Therefore, in crowded regions where the contamination of sources is high, probability-based matching using Gaussian statistics could result in as many as one in two true (albeit contaminated) counterparts being rejected as uncorrelated field objects.
10 Conclusions
We have presented an analysis of the distribution of WISE object positions with relation to Gaia positions to determine their AUF, the probability density function of a catalogue’s detected positions as a function of distance. We have found that the core of the distribution of separations can be fit with Gaussian statistics, although they require broadening, which we fit for empirically. However, there is an additional, significant, non-Gaussian tail to the distributions which is explained by flux contamination from fainter stars lying undetected within the PSF of the brighter star. In addition, we have discussed the contamination levels of APASS, IPHAS, and 2MASS.
We note that while we have focussed on the effects the contamination has on the measuring of individual positions, large tails are also seen in the distributions of proper motions (e.g., Dong et al., 2011, Feltzing & Johnson, 2002, Theissen et al., 2016). We suggest that the large tails seen in contaminated star positions could also propagate to explain the wings of these distributions, as proper motions are simply repeated astrometric measurements over a given time frame.
We have focused on WISE in this work, as it is especially affected by this problem, because it reaches reasonably faint magnitudes in the infra-red and has a large PSF. However, it remains a problem for all catalogues, being an especially important consideration for the next generation of very deep ground-based surveys, such as LSST, with its predicted depth in the optical of 25 resulting in a theoretical value of approximately . This means that at fainter magnitudes most detected objects will be contaminated by one or more faint objects in their PSF. In comparion, Gaia has a contamination level on the order of 0.1%, due to its 0.1" FWHM PSF, meaning its positions should be robust against contamination.
Acknowledgements
TJW acknowledges support from an STFC Studentship. The authors wish to thank the reviewer for their general advice and specific help with clean Gaia flags. This work has made use of the SciPy (Jones et al., 2001), NumPy (van der Walt et al., 2011), Matplotlib (Hunter, 2007), and F2PY (Peterson, 2009) Python modules.
This research has made use of the APASS database, located at the AAVSO web site. Funding for APASS has been provided by the Robert Martin Ayers Sciences Fund. We would also like to thank the team personally for their support and feedback during the early stages of this work.
This paper makes use of data obtained as part of the INT Photometric H Survey of the Northern Galactic Plane (IPHAS, www.iphas.org) carried out at the Isaac Newton Telescope (INT). The INT is operated on the island of La Palma by the Isaac Newton Group in the Spanish Observatorio del Roque de los Muchachos of the Instituto de Astrofisica de Canarias. All IPHAS data are processed by the Cambridge Astronomical Survey Unit, at the Institute of Astronomy in Cambridge. The bandmerged DR2 catalogue was assembled at the Centre for Astrophysics Research, University of Hertfordshire, supported by STFC grant ST/J001333/1.
This publication makes use of data products from the Two Micron All Sky Survey, which is a joint project of the University of Massachusetts and the Infrared Processing and Analysis Center/California Institute of Technology, funded by the National Aeronautics and Space Administration and the National Science Foundation.
This publication makes use of data products from the Wide-field Infrared Survey Explorer, which is a joint project of the University of California, Los Angeles, and the Jet Propulsion Laboratory/California Institute of Technology, funded by the National Aeronautics and Space Administration.
This work has made use of data from the European Space Agency (ESA) mission Gaia (http://www.cosmos.esa.int/gaia), processed by the Gaia Data Processing and Analysis Consortium (DPAC, http://www.cosmos.esa.int/web/gaia/dpac/consortium). Funding for the DPAC has been provided by national institutions, in particular the institutions participating in the Gaia Multilateral Agreement.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Barentsen et al. (2014) Barentsen G., et al., 2014, MNRAS , 444, 3230 · doi ↗
- 2Budavári & Szalay (2008) Budavári T., Szalay A. S., 2008, Ap J , 679, 301 · doi ↗
- 3Cutri et al. (2012) Cutri R. M., et al., 2012, Technical report, Explanatory Supplement to the WISE All-Sky Data Release Products
- 4Dong et al. (2011) Dong R., Gunn J., Knapp G., Rockosi C., Blanton M., 2011, AJ , 142, 116 · doi ↗
- 5Feltzing & Johnson (2002) Feltzing S., Johnson R. A., 2002, A&A , 385, 67 · doi ↗
- 6Flesch & Hardcastle (2004) Flesch E., Hardcastle M. J., 2004, A&A , 427, 387 · doi ↗
- 7Fleuren et al. (2012) Fleuren S., et al., 2012, MNRAS , 423, 2407 · doi ↗
- 8Gaia Collaboration et al. (2016) Gaia Collaboration Brown A. G. A., Vallenari A., Prusti T., de Bruijne J., Mignard F., Drimmel R., co-authors ., 2016, A&A, Special Gaia Volume