On the Coherence of Large-Scale Networks with Distributed PI and PD Control
Emma Tegling, Henrik Sandberg

TL;DR
This paper introduces distributed PI and PD controllers for large-scale double-integrator networks, significantly improving coherence by bounding state variance in the presence of stochastic disturbances, especially when agents have access to absolute measurements.
Contribution
It proposes novel distributed PI and PD control schemes that overcome known limitations of standard consensus protocols, ensuring bounded network coherence with limited sensing capabilities.
Findings
Controllers achieve bounded variance in network states
Optimal tuning improves network coherence
Simulation results validate theoretical improvements
Abstract
We consider distributed control of double-integrator networks, where agents are subject to stochastic disturbances. We study performance of such networks in terms of coherence, defined through an H2 norm metric that represents the variance of nodal state fluctuations. Specifically, we address known performance limitations of the standard consensus protocol, which cause this variance to scale unboundedly with network size for a large class of networks. We propose distributed proportional integral (PI) and proportional derivative (PD) controllers that relax these limitations and achieve bounded variance, in cases where agents can access an absolute measurement of one of their states. This case applies to, for example, frequency control of power networks and vehicular formation control with limited sensing. We discuss optimal tuning of the controllers with respect to network coherence and…
Click any figure to enlarge with its caption.
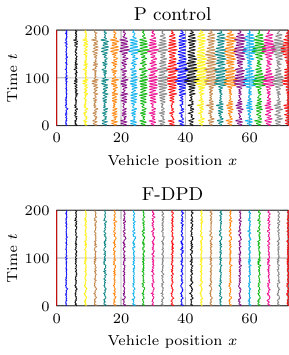 Figure 1
Figure 1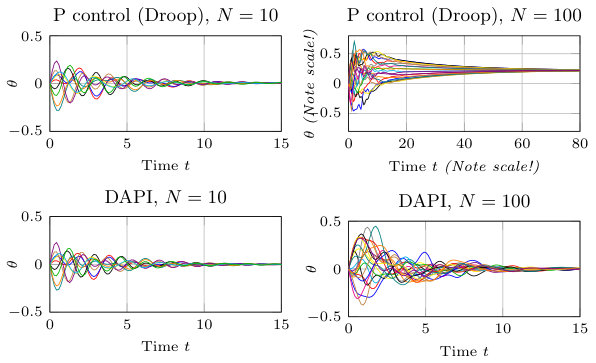 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
On the Coherence of Large-Scale Networks
with Distributed PI and PD Control
Emma Tegling and Henrik Sandberg The authors are with the School of Electrical Engineering and the ACCESS Linnaeus Center, KTH Royal Institute of Technology, SE-100 44 Stockholm, Sweden (tegling, [email protected]). This work was supported in part by the Swedish Research Council through grants 2013-5523 and 2016-00861.
Abstract
We consider distributed control of double-integrator networks, where agents are subject to stochastic disturbances. We study performance of such networks in terms of coherence, defined through an norm metric that represents the variance of nodal state fluctuations. Specifically, we address known performance limitations of the standard consensus protocol, which cause this variance to scale unboundedly with network size for a large class of networks. We propose distributed proportional integral (PI) and proportional derivative (PD) controllers that relax these limitations and achieve bounded variance, in cases where agents can access an absolute measurement of one of their states. This case applies to, for example, frequency control of power networks and vehicular formation control with limited sensing. We discuss optimal tuning of the controllers with respect to network coherence and demonstrate our results in simulations.
I Introduction
The problem of distributed control of networked systems has been extensively studied over the past decades [1, 2, 3]. A well-studied subproblem in this context is that of consensus, that is, to drive the network of agents to the same state. When the system is subject to external disturbances or uncertainties, there are, however, limitations to the performance achievable through distributed control. In particular, there are limits on how close the agents of a large-scale network can come to a state of consensus, or what is often called the coherence of the network. Such fundamental limitations were studied in [4], where scalings of measures of network coherence with network size were established for first- and second-order consensus networks. It was shown that reasonable performance in sparse networks, such as vehicle platoons, requires that each agent can access measurements of its own states with respect to a global reference frame; what we refer to as absolute feedback.
The importance of absolute feedback for network coherence was also recognized in [5, 6, 7], where the impact of leaders (select agents with access to absolute measurements) was studied in first-order consensus networks. In this work, we will focus on problems of second-order consensus, and do not consider adding absolute measurements to improve performance, which would require increasing the agents’ sensory capabilities. Instead, we propose the use of alternative controller structures, namely controllers with integral and derivative action in addition to standard proportional control.
Proportional-integral-derivative (PID) control has been studied for consensus networks in [8] and the role of integral action in disturbance rejection in both first- and second-order consensus networks was described in [9, 10, 11]. While these works have focused on proving convergence of the respective control strategies, we address the question of their performance and their scalability to large-scale networks. In particular, we show that for certain cases of second-order consensus considered in [4], distributed PI and PD control can relax the performance limitations found therein.
We study cases in which the agents have access to absolute measurements of only one of their states and evaluate performance in terms of an norm metric representing network coherence. For these cases, we compare proportional control, with which the norm metric scales unboundedly with network size for a large class of networks, to distributed PI and PD control, where the same metric can be shown to be bounded for any network. The apparent reason for this improved scalability is that integral or derivative action, when applied to the available absolute state measurement, emulates absolute feedback from the other state. For example, the derivative of a position measurement corresponds to a velocity measurement. While this may seem intuitive for ideal integral or derivative action, the controllers we consider here are modified to account for imperfections. In particular, we first consider a distributed averaging PI (DAPI) controller, in which the integral state is passed through a consensus filter to prevent destabilizing drift due to measurement noise (“dead-reckoning”). A version of this controller has previously been studied in the context of electric power networks in [12, 13, 14]. Second, we model low-pass filtering of the derivative action in the proposed filtered distributed PD (F-DPD) controller. Interestingly, the improved scalability is achieved with any design of these filters, yet this paper also provides insights into how their design impacts performance, as well as to their optimal tunings.
The remainder of this paper is organized as follows. We introduce the problem setup and the performance metric in Section II, where we also give examples from applications. In Section III, we discuss known limitations of proportional control. We introduce the DAPI and F-DPD controllers and evaluate their performance in Section IV, then discuss their tuning in Section V. We conclude in Section VI.
II Preliminaries
II-A Notation
Consider a network of identical agents modeled by the undirected graph , where is the set of nodes and is the set of edges. Denote by the neighbor set of agent in . Assume that each edge in has an associated weight and denote by the weighted graph Laplacian whose elements if and otherwise. Throughout this paper, the graph is assumed to be connected. The eigenvalues of can thus be written .
II-B Problem set-up
We consider a set of agents, each governed by double-integrator dynamics and subject to stochastic disturbances:
[TABLE]
Here, is a control input and is assumed to be a zero-mean Gaussian white noise process that is uncorrelated across nodes. Henceforth, we will often drop the time-dependence in the notation. Without loss of generality, we assume that the states for each agent represent deviations from a desired trajectory with common constant velocity , so that , where is a given setpoint. The states may carry different meanings depending on the application. We provide two examples at the end of this section.
The control objective is for all agents to follow the desired trajectory, in our case, to drive the states to zero. We model full state feedback control and first consider a standard linear consensus algorithm (see, for example, [3])
[TABLE]
where are nonnegative gains. We refer to (2) as proportional (P) control, since the feedback is proportional to state measurements at time .
Throughout this paper, we distinguish between two types of state measurements and feedback: relative and absolute. Relative measurements are taken with respect to neighbors, as in for , while absolute measurements imply that agent can access its own state or . In (2), we say that absolute feedback from the state () exists if (). In the following, we will consider cases in which absolute measurements are only available for either or , and let this apply to all agents. Regarding the assumption on uniform gains , see Remark 1.
By defining the state vectors and , we can write the system (1) with control (2) as
[TABLE]
where is the weighted graph Laplacian with edge weights for , and is the noise vector.
In order to provide tractable closed-form solutions in what follows, we will impose the following assumption:
Assumption A1** (Proportional gains)**
The ratio is uniform across all . We write and , so that and , with .
Example 1** (Vehicular formation)**
Consider a set of vehicles in a formation, where the control objective for each vehicle is to follow the trajectory , despite being subject to random forcings . Here, is a common cruising velocity and is the desired inter-vehicle spacing. Each vehicle controls its velocity according to (2), with nearest-neighbor interactions, so that for , and , resulting in a 1-D string formation. The closed-loop system becomes (3).
Consider a scenario in which the vehicles are not equipped with speedometers, but have radars to measure relative positions and velocities with respect to neighbors. Furthermore, the position of the lead vehicle is broadcast across the network, so each vehicle can calculate its own position. In this example, there is therefore absolute feedback from the position , but not from the velocity , so while in (2).
Example 2** (Frequency control in power network)**
Synchronization in power networks is typically studied through a system of coupled swing equations. Under some simplifying assumptions, the linearized swing equation can be written as:
[TABLE]
where is the phase angle deviation at node , is the frequency deviation, and and are, respectively, inertia and damping coefficients. The term can be seen as the net power injection at the node, and is the susceptance of the power line. In the absence of any additional control input, we also refer to (4) as frequency droop control.
The system (4) can be cast as the P-controlled system (3), with , , , , and . The power injection can be absorbed into the disturbance input , which we take to represent random fluctuations in generation and load. In this problem, there is absolute feedback from the frequency , but only relative feedback from the phase angles (absolute measurement of phase angles would require phasor measurement units (PMUs), which in general are not available).
II-C Performance metric
We evaluate performance of control laws in terms of measures of network coherence. Coherence can be understood as a measure of network disorder, or in other words, how well the control objective of consensus is achieved. Similar to **[4, 5]**, we define it as the steady-state variance of the agents’ deviation from the network average:
[TABLE]
The quantity can be evaluated analytically as the squared norm of an input-output system from the disturbance input in (1) to a performance output defined as
[TABLE]
where is the () vector of all ones.
To better analyze the scaling of (5) with the network size, we will normalize it by the total number of agents:
[TABLE]
It is the scaling of as increases that we can refer to as the level of coherence in the network. For a given control law to be scalable, should be uniformly bounded, in which case the system can also be regarded as fully coherent.
III Limitations of proportional control
We begin the discussion on limitations of the proportional control law (2) by stating the closed-form expression for its performance.
Lemma III.1
The scaled performance output variance (7) for the P-controlled system (3) is given by
[TABLE]
Proof:
See Appendix. ∎
Clearly, in the absence of absolute feedback (that is, if and/or ), the sum in (8) tends towards infinity if one or more of the Laplacian eigenvalues , approaches zero. Laplacian eigenvalues typically tend to zero as a network grows large, unless it is densely interconnected. If the sum increases faster than linearly in , the performance metric will scale badly and the network lacks coherence. This was the problem considered in [4], where asymptotic scalings of expressions like (8) were derived for networks built over -dimensional torical lattices . Their results for the most problematic 1-dimensional network (a ring graph) show that scales linearly in if one of is zero, and as if both are zero. The same scalings can be derived using arguments based on effective resistances for networks that can be embedded in lattice networks, see [15].
This points at a fundamental limitation to the performance of the P controller (3), as the variance (8) is only bounded for any network if there is absolute feedback from both the states and . That is, both measurements are required for P control to be scalable. An important question has therefore been whether alternative controller structures can alleviate these limitations. In the next section, we present linear controllers for which it suffices to have an absolute measurement of either or to achieve bounded scalings for any network.
Remark 1
*The assumption that the absolute feedback gains are uniform across the network is needed to derive the closed-form expression (8), but can be shown not to be important for the main conclusion that scales badly in the absence of absolute feedback. With non-uniform gains , bounds on on the form (8) can instead be stated in terms of the minimum and maximum available gains. *
IV Distributed PI and PD control
We now introduce the distributed PI and PD controllers with which we propose to address the limitations posed by proportional control. We show that these controllers achieve bounded output variances (7), and demonstrate the performance improvement through numerical examples.
IV-A Absolute -feedback: Distributed PI control
Suppose that an absolute measurement of is available, while one of is not. For this case, we propose to use the following distributed averaging proportional-integral (DAPI) controller:
[TABLE]
where is the integral state, is a positive gain (integral gain), and we will discuss the averaging filter shortly. First, note that if for all , it ideally holds that and since, by definition, , the integral state would correspond to an absolute measurement of the state , modulo initial values. In this case, we would therefore expect that the controller (9) has a performance similar to (2) with absolute feedback from both and . However, as mentioned in the introduction, an averaging filter on the integral states with positive gains is required to ensure system stability [10]. We will show that also with this filter, the desired performance scaling can be achieved.
By inserting (9) into (1) we obtain, in vector form:
[TABLE]
In line with Assumption A1, we make the following assumption on the weighted Laplacian matrix :
Assumption A2
The gains are proportional to for all . We write , so that , with .
Under Assumptions A1–A2, the system (10) is input-output stable with respect to the output (6) [16] and its performance can be stated as follows:
Proposition IV.1
*The scaled performance output variance (7) for the DAPI-controlled system (10) is given by *
[TABLE]
Proof:
The result (11) is derived in the same manner as in the proof of Lemma III.1, and the details are omitted for the sake of brevity. ∎
While the expression (11) is convoluted, it allows for the following important conclusion:
Corollary IV.2
For any positive and finite gains and , in (11) is uniformly bounded in . It holds that
[TABLE]
Proof:
It is readily verified that the expression from the sum in (11) is monotonically decreasing in . Its supremum is therefore obtained as and is . Thus, the sum , which, inserted in (11), gives the upper bound in (12). The lower bound is obtained when for all . This is, e.g., the case when is the complete graph , as . ∎
Remark 2
If in (11), the output variance for P control with absolute feedback from both and is retrieved, substituting the integral gain for in (8). This is in line with the discussion at the beginning of this section. Interestingly though, letting (which is only possible in theory) does not necessarily minimize . We will discuss how to optimize performance for in Section V.
Example 2** (Continued)**
Applying DAPI control to the power system dynamics (4) yields the closed-loop system:
[TABLE]
In this case, the integral action is also referred to as secondary frequency control, the role of which is to eliminate any stationary frequency control errors that arise with just P control [12, 13]. As we have shown in this section, it also improves transient performance.
In Fig. 1a, we show a simulation of P control (4) and DAPI control (13) on a radial power network (here modeled by a path graph) with, respectively, 10 and 100 nodes. The figures show that P control does not scale well to the larger network, while DAPI control does.
IV-B Absolute -feedback: Distributed PD control
Suppose now that an absolute measurement of is available, while one of is not. In this case, distributed proportional derivative (PD) control can be used to improve performance compared to the P controller. With ideal derivative action, the controller would take the form:
[TABLE]
which, since , is identical to (2) with absolute feedback from both and , substituting the derivative gain for . Clearly, this controller would therefore also have the same performance. Ideal derivative action is, however, neither possible nor desirable to implement, partly due to the sensitivity to high frequency noise. We therefore consider a controller where the derivative action is low-pass filtered:
[TABLE]
Here, the state corresponds to the derivative action, and is the time constant of the filter. We will refer to the controller (15) as filtered distributed PD control (F-DPD). Note that the ideal PD controller is retrieved for .
Remark 3
An alternative approach would be to apply ideal derivative action and low-pass filter the entire control signal in (14). The resulting performance scaling is similar. We choose the controller (15) to enable a better comparison to the P controller (2), as the proportional action is modeled as unfiltered in both.
The system (1) with the controller (15) becomes:
[TABLE]
The performance of this system, under Assumption A1, is given by the following proposition:
Proposition IV.3
The scaled performance output variance (7) for the F-DPD-controlled system (16) is given by
[TABLE]
Proof:
This result is derived in the same manner as in the proof of Lemma III.1. The system’s stability can in this case be verified through the characteristic polynomial , which satisfies the Routh-Hurwitz criterion. ∎
Again, the expression is convoluted, but it reveals that the output variance is bounded for any network:
Corollary IV.4
For any positive and finite gains and , the variance in (17) is uniformly bounded in . It holds that
[TABLE]
Proof:
Similar to the proof of Corollary IV.2, it can be verified that from the sum in (17) is monotonically decreasing in . An upper bound is thus obtained as , which gives for all . Therefore, . ∎
Example 1** (Continued)**
Consider again the formation of vehicles. Since no absolute feedback from velocities was available, we implement the F-DPD controller (15). Fig. 1b shows a simulation of a 100 vehicle formation under a white noise disturbance input. While the spacings between neighbors seem well-regulated in both systems, the P-controlled system appears less coherent.
V Controller tuning for improved coherence
Neither the DAPI controller (9), nor the F-DPD controller (15) represents ideal integral or derivative action. In both cases, we have modeled filters to mitigate well-known issues related to noise and uncertainties. In this section, we discuss how the design of those filters impacts performance.
V-A Optimal distributed averaging in DAPI
As discussed in Section IV-A, robust stability of the DAPI controlled system (10) requires an alignment between the agents’ integral states through a distributed averaging filter. While the control objectives will be reached for any non-zero gains [13], an important control design question is how to choose these gains to optimize network performance. In our case, this choice is reflected through the constant (see Assumption A2). Consider the following proposition.
Proposition V.1
For a given DAPI controlled system (10), there is either a that minimizes in (11), or is minimized by and is monotonically increasing for . The case holds if for all and the case holds if for all . If none of these applies, must be evaluated case-by-case.
Proof:
See Appendix. ∎
Finding a closed form expression for is in general not tractable due to the many terms in the sum (11), and must be done on a case-by-case basis. However, it is possible in the special case of a complete network graph:
Corollary V.2
If the network graph is complete and the edge weights for all , then is given by
[TABLE]
if this is a positive number. Otherwise .
Proof:
In this case, the eigenvalues for , and (19) follows from the proof of Proposition V.1.∎
Remark 4
An explicit inclusion of measurement noise in the model increases the output variance , and shifts the optimal . Such a model reveals that is always suboptimal, since is then infinite.
It is interesting to note that in cases where , the performance of the DAPI controlled system at the optimum is better than with P control and absolute feedback from both and (as that performance is retrieved for , see Remark 2). Looking at e.g. (19), we note that this occurs in particular if is small relative to , so that there is little alignment in the state between agents. This is the case in power networks, where in general (see Example 2).
V-B Impact of low-pass filter in F-DPD
The low pass filter in the F-DPD controller (15) is included as a more realistic implementation of derivative action, which is otherwise well-known to be highly sensitive to high frequency variations and noise. While, by Corollary IV.4, F-DPD achieves bounded output variance for any finite filter constant , choosing a small value (corresponding to a high bandwidth) gives better performance:
Proposition V.3
For a given F-DPD controlled system (16), the output variance in (17) is minimized by and is monotonically increasing for .
Proof:
It holds that . Since , , for and for all . ∎
This is an intuitive result, as would give ideal derivative action and therefore the most accurate substitute for absolute feedback from . However, a greater value for would make the system less sensitive to noise. This trade-off must be done based on system-specific knowledge.
Remark 5
We have limited the analysis here to a first order filter, as higher order filters make the expressions for output variances even more convoluted. However, numerical results indicate that higher order filters increase , though it remains bounded.
VI Conclusions
In this paper, we have addressed limitations to the performance of the standard proportional consensus protocol in double-integrator networks. These limitations imply that the variance measure in (7), that characterizes lack of network coherence, scales unboundedly with network size in sparse networks, unless absolute feedback from both the system’s state is available. We addressed these shortcomings by proposing distributed proportional integral (PI) and proportional derivative (PD) controllers, which radically improve performance by making bounded if absolute measurements from one of the system’s states are available.
The second-order consensus problem considered herein can be used to model a variety of applications ranging from biological networks to coordination of robots, see, for example, [3]. In this paper, we have presented two examples from vehicular formations and power networks. Our results show that if agents have limited access to absolute feedback, the proposed PI and PD controllers are preferable to P control, in particular for large-scale networked systems. We remark that this conclusion holds even though the proposed controllers do not model ideal integral and derivative action, but have filters that mitigate the effect of noise that would arise in a practical setting. The impact of other practical network aspects, such as communication delays, non-reliability of the channels and non-symmetries, is an open and important research question that is left for future work.
VII Acknowledgements
We would like to thank Bassam Bamieh for many interesting discussions and insightful comments related to this work. We are also grateful to Martin Andreasson and Hendrik Flamme for a number of incisive discussions, as well as to anonymous reviewers for their valuable feedback.
Appendix
Proof of Lemma III.1
The output variance in (5) is obtained as the squared norm of the system from input in (3) to the output (6). norm calculations for the types of systems considered herein have been presented in detail in [16, Chapter 2], so we only give a summary proof here. We derive the norm through a unitary state transformation: , , where is the unitary matrix that diagonalizes the Laplacian matrix (and by Assumption A1 also ), so that with . Due to the unitary invariance of the norm, we can also transform the input and output according to .
This state transformation block-diagonalizes the system (3), which can now be described through decoupled subsystems :
[TABLE]
for . The mode corresponds to the average mode in , which is unobservable from the output (6), so . Therefore, even though this mode would be undamped if , the overall system remains input-output stable since is Hurwitz for (its characteristic polynomial is , which has only positive coefficients).
It holds that , where the last equality is due to the fact that and therefore . Each subsystem norm is obtained as , where is the solution to the Lyapunov equation . Straightforward calculations give that for each and the result (8) follows.
Proof of Proposition V.1
Clearly, , where was defined in the proof of Corollary IV.2. Each term can be written as a fraction . By the quotient rule, , where for all , and . Now, since , and for all if for all . In this case for all , and . Conversely, if for all then \frac{\mathrm{d}s_{n}}{\mathrm{d}c}\big{|}_{c=0}<0, and each is minimized by the positive root of the quadratic function above, and . Therefore, \frac{\mathrm{d}}{\mathrm{d}c}V_{N}^{\mathrm{DAPI}}\big{|}_{c=0}<0 and some minimizes . If for some, but not all , the existence of a positive minimizer depends on remaining system parameters.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] A. Jadbabaie, J. Lin, and A. S. Morse, “Coordination of groups of mobile autonomous agents using nearest neighbor rules,” IEEE Trans. Autom. Control , vol. 48, no. 6, pp. 988–1001, June 2003.
- 2[2] R. Olfati-Saber and R. M. Murray, “Consensus problems in networks of agents with switching topology and time-delays,” IEEE Trans. Autom. Control , vol. 49, no. 9, pp. 1520–1533, Sept 2004.
- 3[3] W. Ren and E. Atkins, “Second-order consensus protocols in multiple vehicle systems with local interactions,” in AIAA Guidance, Navigation, and Control Conference , San Francisco, CA, Aug. 2005.
- 4[4] B. Bamieh, M. R. Jovanović, P. Mitra, and S. Patterson, “Coherence in large-scale networks: Dimension-dependent limitations of local feedback,” IEEE Trans. Autom. Control , vol. 57, no. 9, pp. 2235 –2249, Sept. 2012.
- 5[5] S. Patterson and B. Bamieh, “Leader selection for optimal network coherence,” in 49th IEEE Conference on Decision and Control , Dec 2010, pp. 2692–2697.
- 6[6] F. Lin, M. Fardad, and M. R. Jovanović, “Algorithms for leader selection in stochastically forced consensus networks,” IEEE Transactions on Automatic Control , vol. 59, no. 7, pp. 1789–1802, July 2014.
- 7[7] M. Pirani, E. M. Shahrivar, and S. Sundaram, “Coherence and convergence rate in networked dynamical systems,” in 54th IEEE Conference on Decision and Control , Dec 2015, pp. 968–973.
- 8[8] D. A. B. Lombana and M. di Bernardo, “Distributed pid control for consensus of homogeneous and heterogeneous networks,” IEEE Trans. Control Netw. Syst. , vol. 2, no. 2, pp. 154–163, June 2015.