Development and Evaluation of Two Learning-Based Personalized Driver Models for Car-Following Behaviors
Wenshuo Wang, Ding Zhao, Junqiang Xi, David J. LeBlanc, J. Karl, Hedrick

TL;DR
This paper presents two novel learning-based personalized driver models for car-following behaviors, utilizing naturalistic driving data to improve flexibility and accuracy over traditional physical-based models.
Contribution
The paper introduces two new learning-based models combining GMM with HMM and GMM with PDF, demonstrating their effectiveness in modeling driver behaviors.
Findings
Both models fit driver data well.
GMM-PDF model shows higher accuracy with more data.
Models outperform traditional physical-based approaches.
Abstract
Personalized driver models play a key role in the development of advanced driver assistance systems and automated driving systems. Traditionally, physical-based driver models with fixed structures usually lack the flexibility to describe the uncertainties and high non-linearity of driver behaviors. In this paper, two kinds of learning-based car-following personalized driver models were developed using naturalistic driving data collected from the University of Michigan Safety Pilot Model Deployment program. One model is developed by combining the Gaussian Mixture Model (GMM) and the Hidden Markov Model (HMM), and the other one is developed by combining the Gaussian Mixture Model (GMM) and Probability Density Functions (PDF). Fitting results between the two approaches were analyzed with different model inputs and numbers of GMM components. Statistical analyses show that both models…
Click any figure to enlarge with its caption.
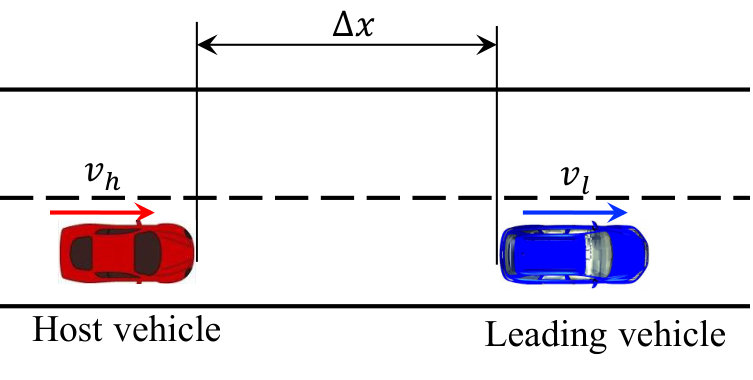 Figure 1
Figure 1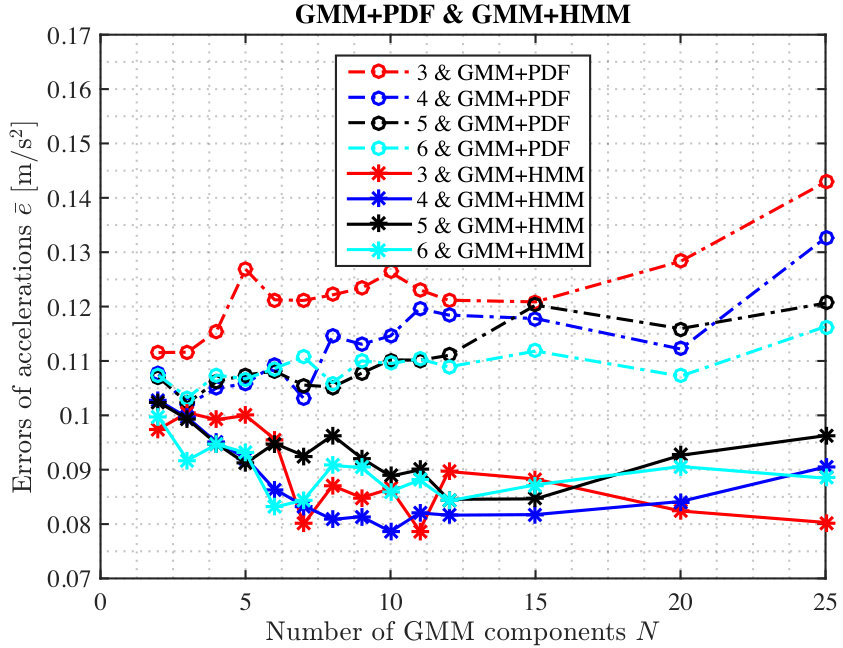 Figure 2
Figure 2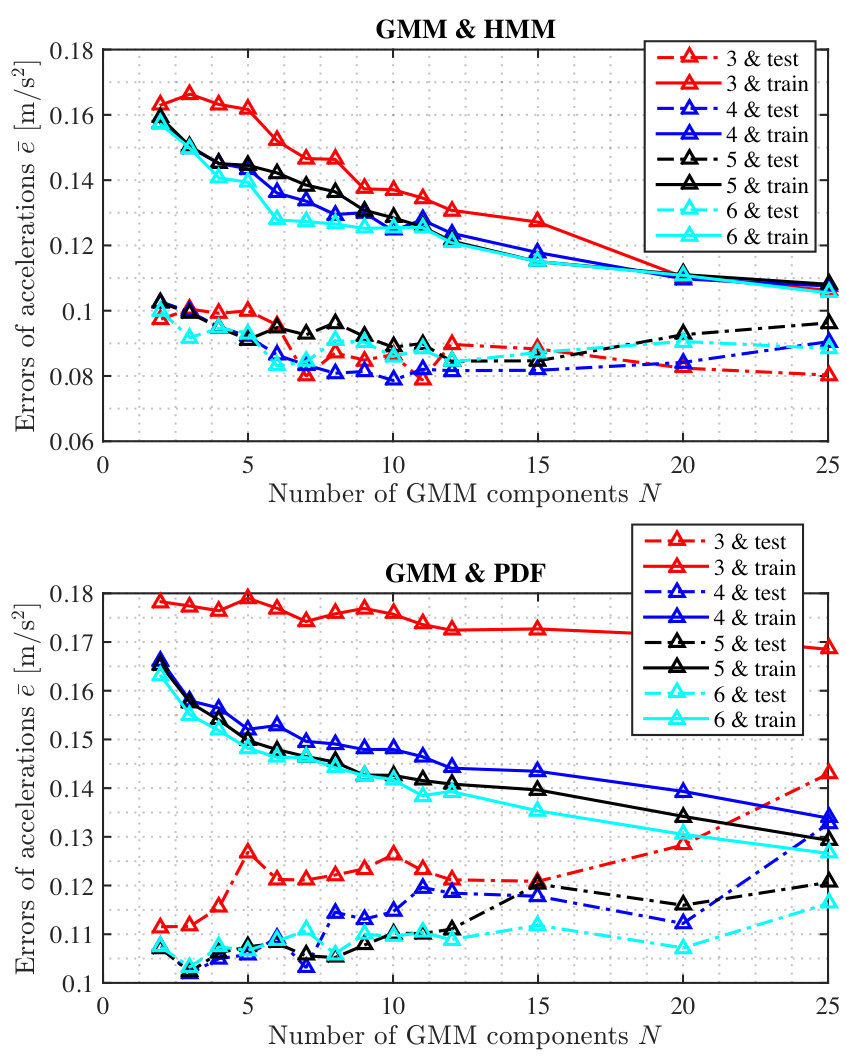 Figure 3
Figure 3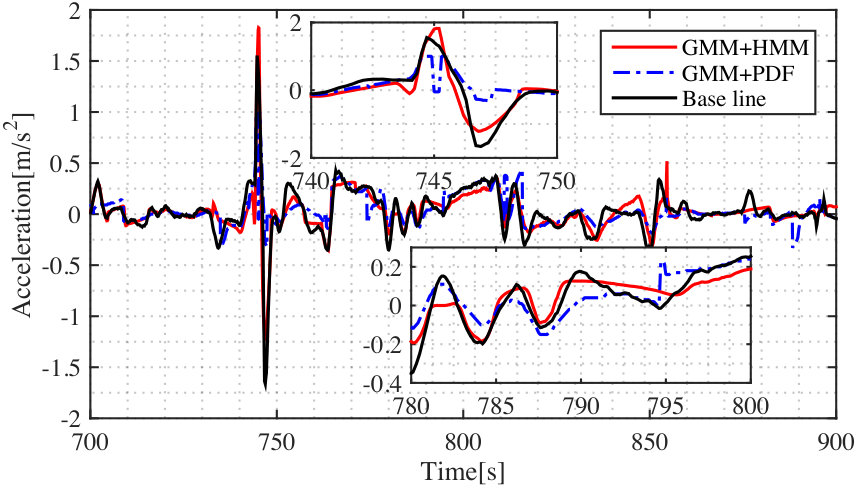 Figure 4
Figure 4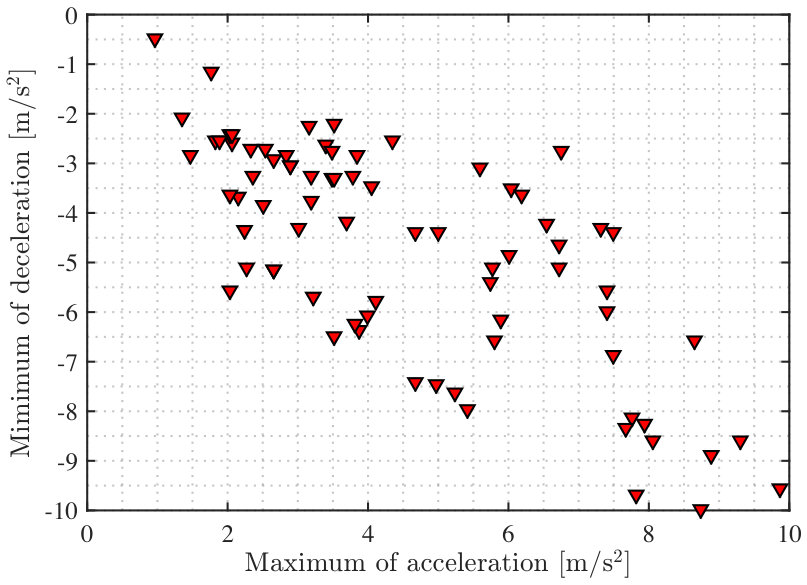 Figure 5
Figure 5Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAutonomous Vehicle Technology and Safety · Vehicle emissions and performance · Traffic control and management
Development and Evaluation of Two Learning-Based Personalized Driver Models for Car-Following Behaviors
Wenshuo Wang1, Student Member, IEEE, Ding Zhao2, Junqiang Xi3, David J. LeBlanc2, and J. Karl Hedrick4 This work was supported by China Scholarship Council.1Wenshuo Wang is with the School of Mechanical Engineering, Beijing Institute of Technology, Beijing, China, 100081, and with the Department of Mechanical Engineering, University of California Berkeley, CA, 94720 USA. [email protected]2Ding Zhao and David J. LeBlanc are with the University of Michigan Transportation Research Institute, Ann Arbor, MI 48109 [email protected]3Junqiang Xi is with the Department of Mechanical Engineering, Beijing Institute of Technology, Beijing, China, 100081. [email protected]4*J. Karl Hedrick is with the Department of Mechanical Engineering, University of California at Berkeley, Berkeley, CA 94720 USA. [email protected]
Abstract
Personalized driver models play a key role in the development of advanced driver assistance systems and automated driving systems. Traditionally, physical-based driver models with fixed structures usually lack the flexibility to describe the uncertainties and high non-linearity of driver behaviors. In this paper, two kinds of learning-based car-following personalized driver models were developed using naturalistic driving data collected from the University of Michigan Safety Pilot Model Deployment program. One model is developed by combining the Gaussian Mixture Model (GMM) and the Hidden Markov Model (HMM), and the other one is developed by combining the Gaussian Mixture Model (GMM) and Probability Density Functions (PDF). Fitting results between the two approaches were analyzed with different model inputs and numbers of GMM components. Statistical analyses show that both models provide good performance of fitting while the GMM–PDF approach shows a higher potential to increase the model accuracy given a higher dimension of training data.
Index Terms:
Personalized model, Learning-based driver model, Gaussian mixture model, Hidden Markov model, Car-following behavior.
I Introduction
Understanding individual driver behaviors and development of personalized driver models are critical for active safety control systems [1, 2, 3], vehicle dynamic performance [4], and human-centered vehicle control systems [5, 6, 7], eco-driving systems [8], and automated vehicles [9]. For instance, a driver assistance system will be more effective if the individual characteristics or/and driving styles can be incorporated [2]. Personalized driver models can be referred to [9] “a driver model which can generate the output sequences being as close as possible to what the individual driver would have done in the same driving situation”. Lefevre et al. [1], Butakov and Ioannou [2, 3] developed a personalized driver model based on the Gaussian mixture model and then applied to the advanced driver assistance systems (ADASs), increasing the potential for more widespread acceptance and use of ADASs.
Generally, the ways to establish a personalized driver model can be grouped into two categories: physical-based model and learning-based model. For the physical-based model, formulations with unknown parameters are usually used to describe the structure of driver’s driving behaviors such as car following, path following, lane change, overtaking. The major benefit of the physical-based model is that most model parameters have their specific physical meanings, enabling them to be easily interpreted. For example, the intelligent driver model (IDM), optimal velocity model (OVM) [10], and control-oriented car-following model are popular physical-based models in the applications of vehicle control [11, 12, 13] and traffic flow analysis [14]. The model parameters can be identified using parameter estimation approaches [15, 16] such as least squares, Kalman filter, stochastic parameter estimation, etc. The physical-based approach can model driver’s basic behavior, however, it is hard to model uncertainties and non-linearity because of the uncertainty and diversity of individual driver’s behavior and driving environment. Fortunately, learning-based models can be developed to overcome these issues. Popular approaches have been developed to generate a learning-based driver model such as stochastic switched AutoRegressive eXogenous model (SS-ARX) [17, 18], hidden Markov model [19], neural network [20, 21], and Gaussian mixture model [21]. These models are believed to represent an individual driver’s driving characteristics and describe the underlying source after correctly training. However, it is difficult to explain the physical meaning of the model parameters when learning-based models are directly utilized to generate a highly nonlinear function for driver’s behavior (e.g., decision-making and control). Butakov and Ioannou [2] created a more explainable, flexible, and accurate driver lane change model by combining the learning-based and physical-based methods together, in which physical-based model was used to mimic the driving behavior and the learning-based model (i.e., GMM) was used to describe the parameter distribution of the physical model.
In the above mentioned learning-based approaches, the GMM method is usually chosen to establish driver model due to its effectiveness of modeling driving tasks [2, 22, 23, 10, 24, 25]. However, limited works studied the comparison between different learning-based approaches. In this paper, two learning-based approaches were shown, in which the influences of different combinations between parameters (e.g., vehicle speed, range, relative speed.) with different numbers of GMM component on model performance were analyzed and discussed. This paper provides the systematic re-examination, evaluation, and comparison of two learning-based approaches for modeling driver’s car-following behavior, and also helps researchers understand how many and what parameters are more suitable to model a driver’s car-following behavior.
The structure of this paper is organized as follows. Section II shows the problem formulation of driver’s car-following behavior. Section III presents the basic methods for personalized driver model. Section IV shows the data collection and data preprocessing. Section V discusses and analyzes the experiment results.
II Problem Formulation
II-A Personalized Driver Model
A specific definition of the personalized driver model is given as: A personalized driver model can be referred to a model that can generate or predict an individual driver’s operating parameter (e.g., steering angle, throttle opening, braking force.) or behavior (e.g., lane change, stop & go, overtaking, decision-making with traffic light.) with the same environment inputs, including traffic users (e.g., other vehicles, bicycles, and pedestrians.), weather conditions, and road conditions.
In this paper, we are going to investigate the personalized driver models for car-following behaviors, which can generate a personalized longitudinal control signal sequence (i.e., acceleration).
II-B Car-Following Scenario
The car-following behavior can be illustrated by Fig. 1. We define the following variables to represent the relative motion of the host vehicle and the vehicle located ahead in the same lane as leading vehicle.
- •
is the state of the host vehicle at time , where is the longitudinal position of the host vehicle, is the longitudinal speed of the host vehicle, and is the jerk of the host vehicle defined as .
- •
is the state of the leading vehicle at time , where is the longitudinal position of the leading vehicle and is the longitudinal speed of the leading vehicle.
- •
are the current states representing current driving situation at time , where is the relative distance between the host vehicle and the leading vehicles, is the relative speed between the host vehicle and the leading vehicle, and is the relative acceleration between two vehicles.
The history of explanatory variables, , and acceleration sequences, , are taken as the model input. The predicted vehicle acceleration is taken as the model output. At each step , the learned driver model generates an acceleration . The general form of the proposed driver model is presented as
[TABLE]
The equation (1) is to generate an acceleration with the current input, , according to the history information, , with the prediction step s.
III Methods
In this section, two learning-based approaches of modeling a personalized driver car-following behavior are discussed, i.e., the Gaussian Mixture Regression with the Hidden Markov Model (GMR-HMM) and the Gaussian Mixture Model with Probability Density Functions (GMM-PDF). To understand the two approaches, the GMM, HMM, and PDF are separately discussed in the following sections.
III-A Gaussian Mixture Model
A set of -dimension sequence, with , can be encoded in a combination of Gaussian models. Assuming that the data in each component of GMM is subject to a Gaussian distribution:
[TABLE]
where and is mean and covariance of the th Gaussian distribution . For all data , it can be encoded by a Gaussian mixture model:
[TABLE]
where ; is the prior probability and .
For the car-following model, if we assign , the joint distribution between and can be rewritten as
[TABLE]
The parameter of (4) can be estimated by expectation maximization (EM) algorithm [2]. For the initial value at iteration step , we apply the -means clustering method to determine , and then calculate . Thus, we can obtain the estimated optimal parameter until the log-likelihood function is convergent or meets the maximum iteration steps , where the optimal objection for the log-likelihood function is formulated as:
[TABLE]
The number of GMM component can be determined by Bayesian information criterion (BIC). Further, we also discussed the influences of numbers of GMM component on training and tested the model performance.
Our goal is to generate a personalized acceleration sequence based on the learned driver model. With this purpose in mind, two basic approaches are employed and discussed as follows, i.e., HMM and PDF.
III-B Hidden Markov Model
The joint distribution is encoded to generate the output of the personalized driver model in a continuous HMM of states. Here, each component of GMM is treated as a state of HMM. The HMM can be presented by , where is the initial prior probability of being in state , is the transitional probability from state to ; and are the mean and the covariance matrix of the th Gaussian distribution of the HMM. Therefore, the input and output components in each state of the HMM are defined as:
[TABLE]
[TABLE]
As such, the acceleration at time can be estimated, given the history information, and the observed state at time , by using
[TABLE]
where is the HMM forward variable, computed as the probability of being in state at time , given by:
[TABLE]
Here, the initial value at time is computed by
[TABLE]
III-C Probability Density Function
The second approach to get the estimated output, is to compute the value that can maximize the probability based on the probability density function of the GMM, i.e.,
[TABLE]
where is the set of possible value that can reach and is the estimated parameter of the GMM using the collected driving data on the basis of (5).
IV Experiments for Data Collection
In this section, the data collection and the procedure of data training and test are presented.
IV-A Data Collection
The data used in this paper is from the Safety Pilot Model Deployment (SPMD) database [26]. It recorded naturalistic driving of 2,842 equipped vehicles in Ann Arbor, Michigan for more than two years. In the SPMD program, 98 sedans are equipped with data acquisition system and MobilEye® [13, 27], which provides: a) relative position to the lead vehicle (range), and b) lane tracking measures about the lane delineation both from the painted boundary lines and the road edge. The error of range measurement is around 10% at 90 m and 5% at 45 m [28]. Data in two separate months, October 2012 and April 2013, were downloaded from the U.S. Department of Transportation website [29]. To ensure consistency of the used dataset, we apply the following criteria to extracting the car-following events from the entire datasets:
- •
[0.1 m, 120 m]
- •
Longitude [−88.2, −82.0]
- •
Latitude [41.0, 44.5]
- •
Duration of car-following 50 s
All the car-following events were detected from 76 drivers. To the end, the number of entire purified car-following events is 5,294.
IV-B Data Training Process
IV-B1 Preprocessing
For the th driver, all the raw data, , were smoothed by a moving average filter with a window size . The data for each single driver were evenly divided into groups and then groups were randomly selected as the training data and the remaining group was used to test the model, which is also called the leave-one-out cross-validation method. Here, all the divided data groups for each single driver meet the following conditions:
[TABLE]
where presents the group of data for the driver, and are union and intersection, respectively; is the empty set. In this paper, we set .
IV-B2 Dimension of Model Inputs
We will investigate the influence of different inputs on the model performance. For the personalized driver model, the different input variables are tested using the following combinations:
- •
; ;
- •
; ;
- •
; ;
- •
; .
where represents the th input. Here, we default that the host vehicle speed, , and relative range, , at current time are the basic parameters for describing a driver’s car-following behavior. In the training procedure, the training data are .
IV-B3 Number of the GMM Components
Different numbers of the GMM components will affect the model accuracy. More components will cause the over-fitting problem, and fewer components could not characterize the underlying sources of data and will increase the prediction error. Therefore, {2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 15, 20, 25} are selected to investigate the influences of the GMM components on model performance.
IV-C Data Testing Process
We will repeatedly run 10 times for each training dataset of a driver participant and the average errors of 10 runs is selected as the performance index to evaluate the model performance. We run 10 times for each training dataset is because the initial value used in (9) is generated by using -means cluster (-MC) method in which the initial value was randomly generated.
For the reachable region, in (10), we set . The and can be generated from the statistical information of each driver, as shown in Fig. 2. In Fig. 2, 75 driver participants are included and each point represents a driver. For most drivers, the and are located at m/s2. Therefore, in our work, for all drivers we set m/s2 and m/s2. Therefore, when inputing , we can obtain an locally optimal corresponding estimated output using (10).
IV-D Performance Index
The average errors, , between the real value () and the estimated value () are used as the performance index to evaluate the presented methods and computed by
[TABLE]
where is the length of time-indexed test data. A smaller (larger) value of indicates a better (undesirable) performance for the proposed approaches.
V Results Analysis
In this section, the training and test results with respect to different input variables and numbers of GMM component based on two approaches, i.e., GMM+HMM and GMM+PDF, are presented and discussed. To simplify the description and show more clear, we take one of 75 driver participants for example.
V-A Influence of the GMM Component
For the different number of GMM components, the training and test accuracy of the model will be different. More components will decrease the training errors, but can result in over-fitting problems and increase computational costs; inversely, fewer components can reduce computational efforts but may induce larger errors. For example, Fig. 3 shows the average errors of training and test results with different numbers of GMM components using different approaches for a driver. The horizontal and vertical axis are the number of GMM component and average errors of acceleration, respectively. The number represents the dimension of training data, as discussed in Section IV, B. For example, “5 & train” represents the dimension of training input is 5, i.e., , and, correspondingly, “5 & test” represents the input dimension of test data is 4, i.e., .
V-A1 GMM+HMM
Top plot in Fig. 3 shows the training and test average errors of acceleration using the GMM+HMM approach. It is obviously that the training errors are decreasing with the number of GMM components increasing. The test errors are decreasing with the number of GMM components increasing from 2 to 10; after that, the test errors are increasing slightly.
V-A2 GMM+PDF
Similarly, the bottom plot in Fig. 3 shows the training and test errors of acceleration using GMM-PDF approach. It can be concluded that the training errors decreases and the test errors of acceleration increases while the number of GMM increases.
V-B Influence of Model Inputs
V-B1 GMM+HMM
From the top plot of Fig. 3, we can know that for different kinds of input by using GMM+HMM approach, the training errors are decreasing with a higher dimension of input, but not for the test errors. In addition, for the test results using GMM+HMM approach while the dimension of training data is 4, i.e., , we found that the estimation accuracy is better than others.
V-B2 GMM+PDF
From the bottom plot of Fig. 3, it can be seen that for different dimensions of training data with the GMM+PDF approach, the training errors are decreasing with the dimension of training data increasing, and the same case occurs for the test errors. For the GMM+PDF approach, the estimation accuracy is the best when the 6-dimension of training data is chosen, i.e., .
V-C Comparison Between Two Methods
The comparison results between two methods are shown in Fig. 4. It is obvious that for different dimensions of training data (i.e., , ), the GMM+HMM approach has a higher estimation accuracy than the GMM+PDF approach. For the GMM+HMM method, the mean estimation errors, , can be lower than 0.1, but for the GMM+PDF method, is always larger than 0.1, even for different numbers of the GMM components and dimensions of training data.
Fig. 5 shows the estimation results with two different methods when the dimension of training data is 4 and the number of components is 12. We note that the GMM + PDF method has a higher potential to increase the model accuracy given a higher dimension of training data.
VI Conclusions and Future Works
This paper proposed and compared two personalized driver models in car-following scenarios. The GMM+HMM method (Gaussian mixture model + hidden Markov model) and the GMM+PDF method (Gaussian mixture model + probability density function) were used to fit large-scale naturalistic driving data to describe the uncertainties and nonlinearities of the human behaviors. Different GMM components and training data dimensions was tested out and their influences on the model accuracy were analyzed. For training a personalized car-following driver model, we found that:
- •
For the GMM + HMM method, a higher dimension of the training data might not result in a higher estimation accuracy. The preferred number of the GMM components is 10 15 and the preferred dimension of training data is 4, including host vehicle speed, relative range, relative speed, and the acceleration of the host vehicle.
- •
For GMM + PDF methods, a higher dimension of the training data can slightly reduce the estimation errors of acceleration but will increase the computational cost.
- •
In the car-following case, the GMM + HMM method can catch the underlying sources of naturalistic driving data and shows a better prediction performance than GMM + PDF method by about 27.3%.
The Gaussian mixture model is a popular tool to generate a statistical model due to its flexibility and simplicity for learning, but it is sensitive to outliers especially with small numbers of data points. Also, due to the bounded nature of driving behaviors, tails of the Gaussian distributions might be shorter than required, which affects the fitting accuracy. In the future work, we will take the bounded feature of driver behaviors into consideration and develop a learning-based bounded driver model.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] S. Lefèvre, A. Carvalho, Y. Gao, H. E. Tseng, and F. Borrelli, “Driver models for personalised driving assistance,” Vehicle System Dynamics , vol. 53, no. 12, pp. 1705–1720, Oct. 2015.
- 2[2] V. A. Butakov and P. Ioannou, “Personalized driver/vehicle lane change models for ADAS,” IEEE Transaction on Intelligent Transportation Systems , vol. 64, no. 10, pp. 4422 – 4431, Oct. 2015.
- 3[3] V. A. Butakov and P. Ioannou, “Personalized driver assistance for signalized intersections using V 2I communication,” IEEE Transactions on Intelligent Transportation Systems , vol. 17, no. 7, pp. 1910 –1919, Jul. 2016.
- 4[4] X. Fu and D. Soeffker, “Modeling of individualized human driver model for automated personalized supervision,” SAE Technical Paper, Tech. Rep., 2010.
- 5[5] W. Wang, J. Xi, and J. Wang, “Human-centered feed-forward control of a vehicle steering system based on a driver’s steering model,” in 2015 American Control Conference (ACC) . IEEE, Jul. 2015, pp. 3361–3366.
- 6[6] W. Wang, J. Xi, and H. Chen, “Modeling and recognizing driver behavior based on driving data: a survey,” Mathematical Problems in Engineering , vol. 2014, 2014.
- 7[7] W. Wang, J. Xi, C. Liu, and X. Li, “Human-centered feed-forward control of a vehicle steering system based on a driver’s path-following characteristics,” IEEE Transactions on Intelligent Transportation Systems , DOI:10.1109/TITS.2016.26063.
- 8[8] X. Xiang, K. Zhou, W.-B. Zhang, W. Qin, and Q. Mao, “A closed-loop speed advisory model with driver’s behavior adaptability for eco-driving,” IEEE Transactions on Intelligent Transportation Systems , vol. 16, no. 6, pp. 3313–3324, Dec. 2015.