Decorrelated Jet Substructure Tagging using Adversarial Neural Networks
Chase Shimmin, Peter Sadowski, Pierre Baldi, Edison Weik, Daniel, Whiteson, Edward Goul, Andreas S{\o}gaard

TL;DR
This paper introduces an adversarial neural network-based jet substructure tagger that effectively discriminates signals while remaining decorrelated from jet mass, reducing systematic uncertainties and improving discovery potential.
Contribution
It presents a novel adversarial training approach for decorrelated jet tagging, including a parametric method for continuous resonance mass interpolation.
Findings
Outperforms traditional neural networks under systematic uncertainties.
Maintains high discrimination power while reducing mass correlation.
Enables continuous mass hypothesis testing with a single trained model.
Abstract
We describe a strategy for constructing a neural network jet substructure tagger which powerfully discriminates boosted decay signals while remaining largely uncorrelated with the jet mass. This reduces the impact of systematic uncertainties in background modeling while enhancing signal purity, resulting in improved discovery significance relative to existing taggers. The network is trained using an adversarial strategy, resulting in a tagger that learns to balance classification accuracy with decorrelation. As a benchmark scenario, we consider the case where large-radius jets originating from a boosted resonance decay are discriminated from a background of nonresonant quark and gluon jets. We show that in the presence of systematic uncertainties on the background rate, our adversarially-trained, decorrelated tagger considerably outperforms a conventionally trained neural network,…
Click any figure to enlarge with its caption.
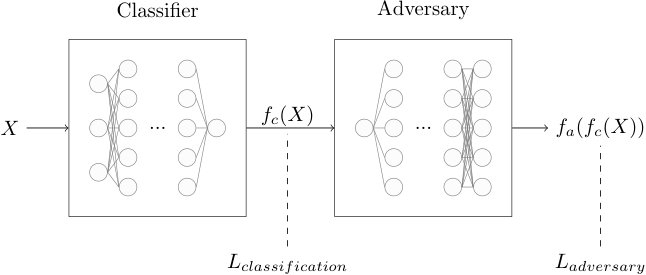 Figure 1
Figure 1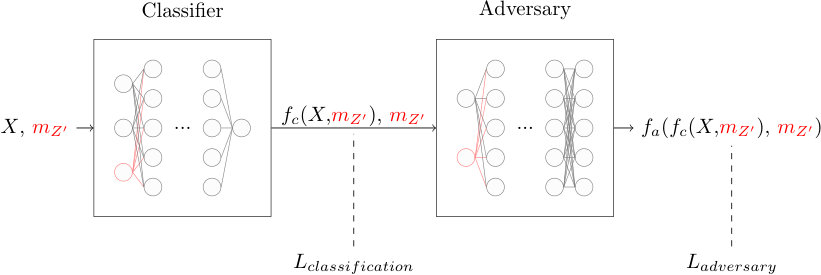 Figure 2
Figure 2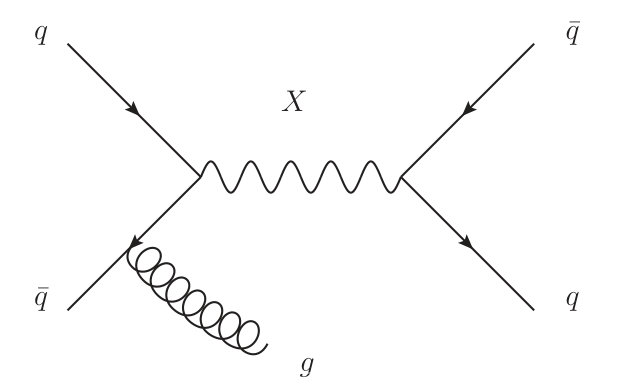 Figure 3
Figure 3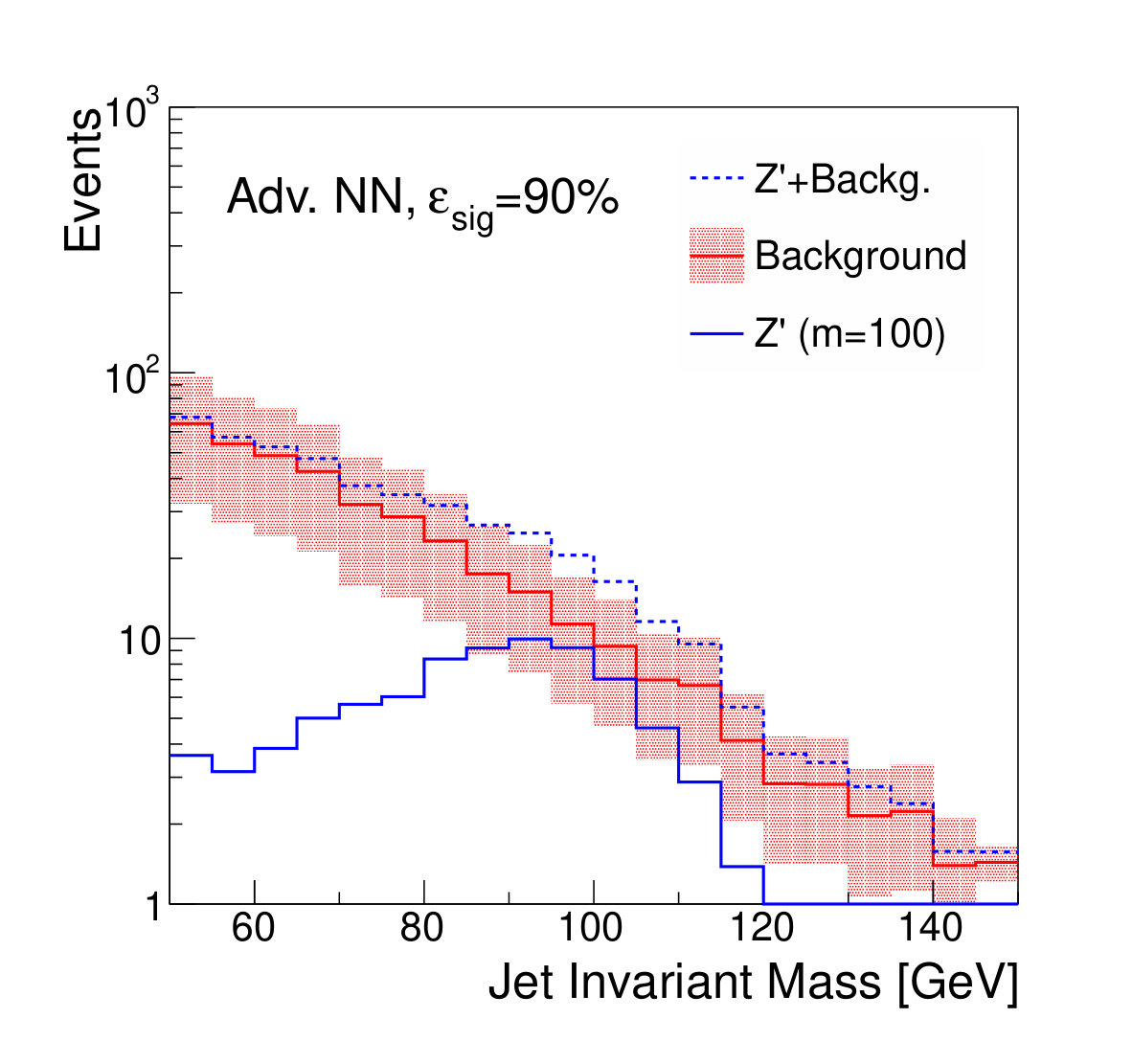 Figure 4
Figure 4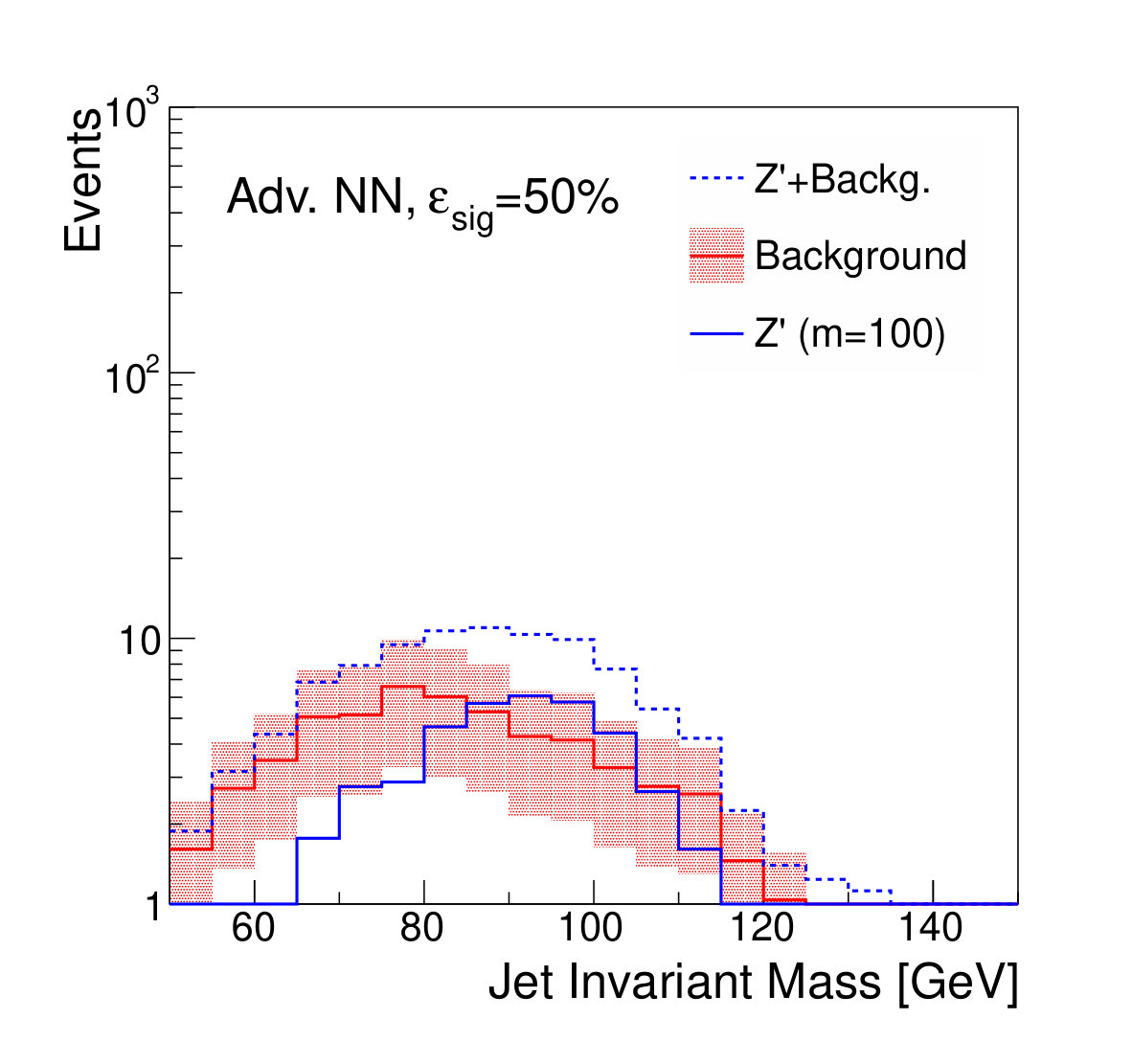 Figure 5
Figure 5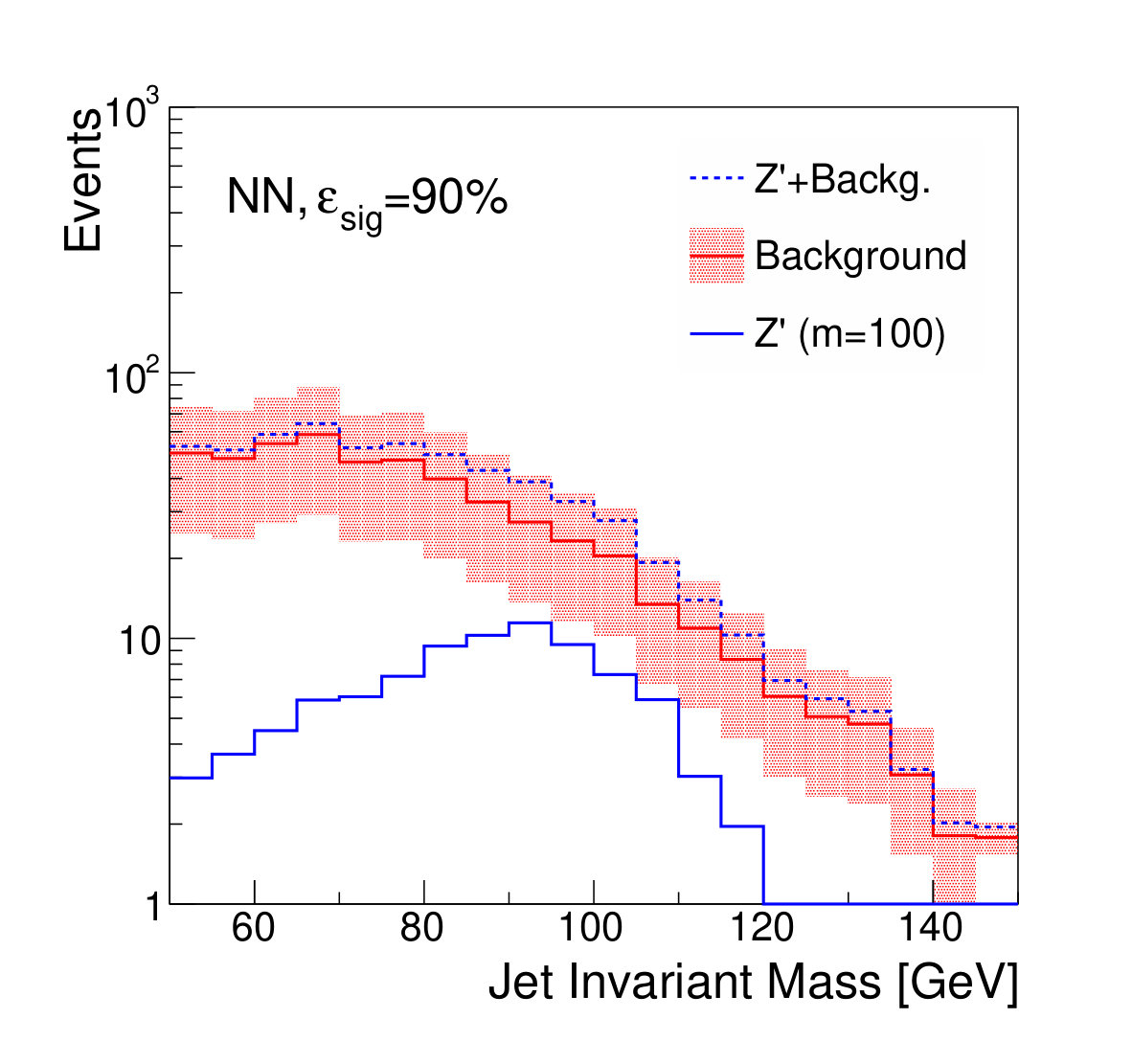 Figure 6
Figure 6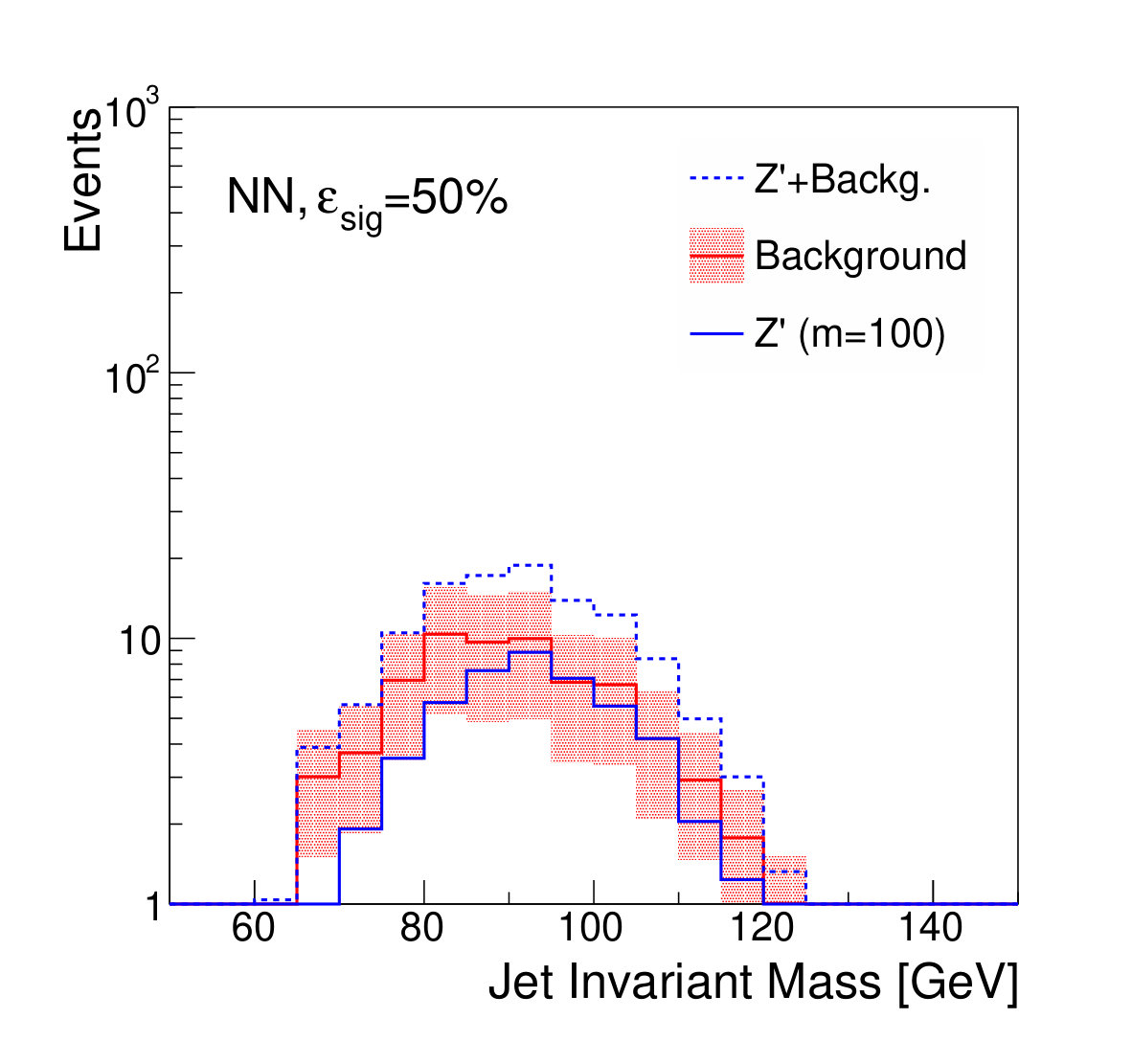 Figure 7
Figure 7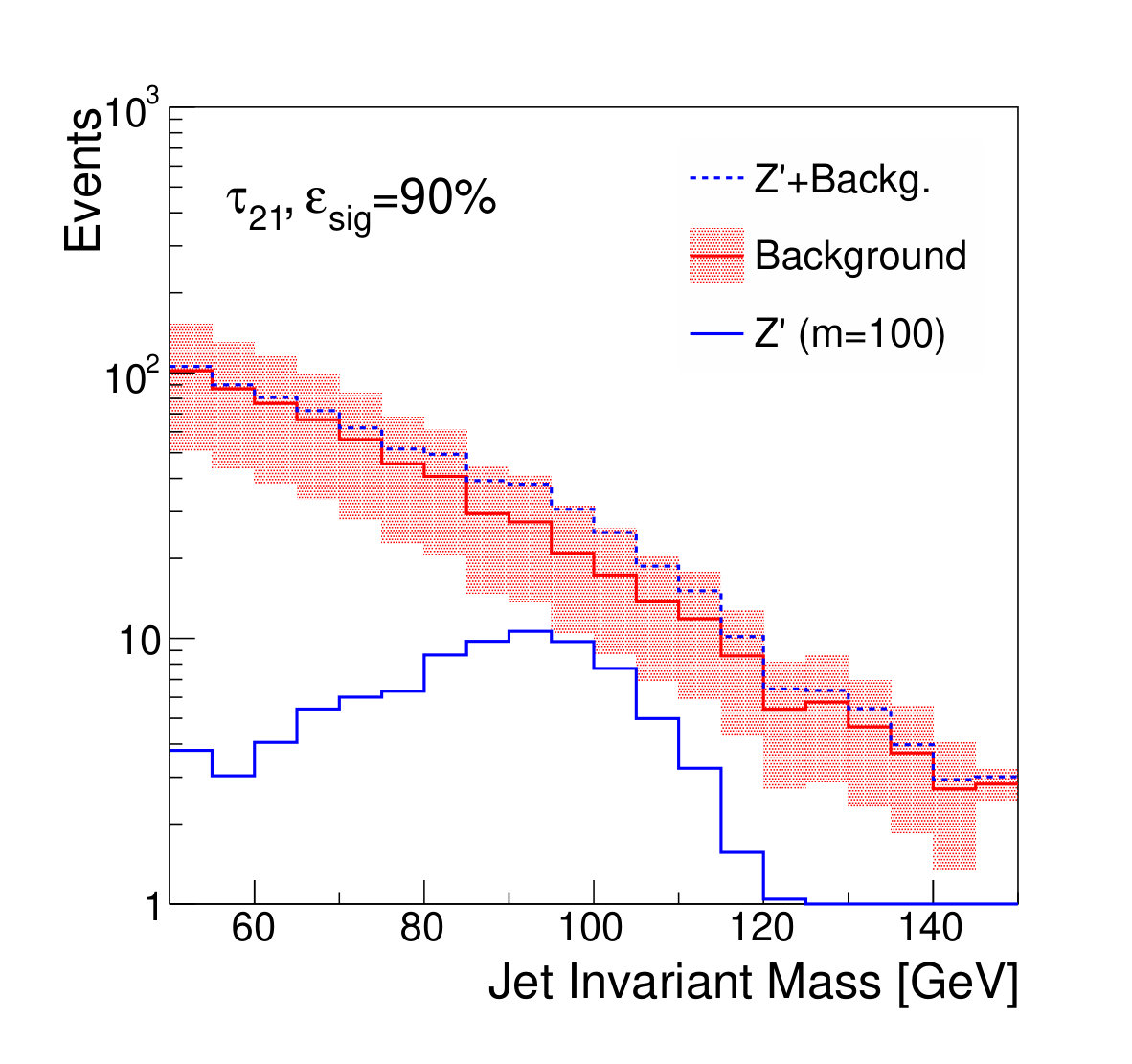 Figure 8
Figure 8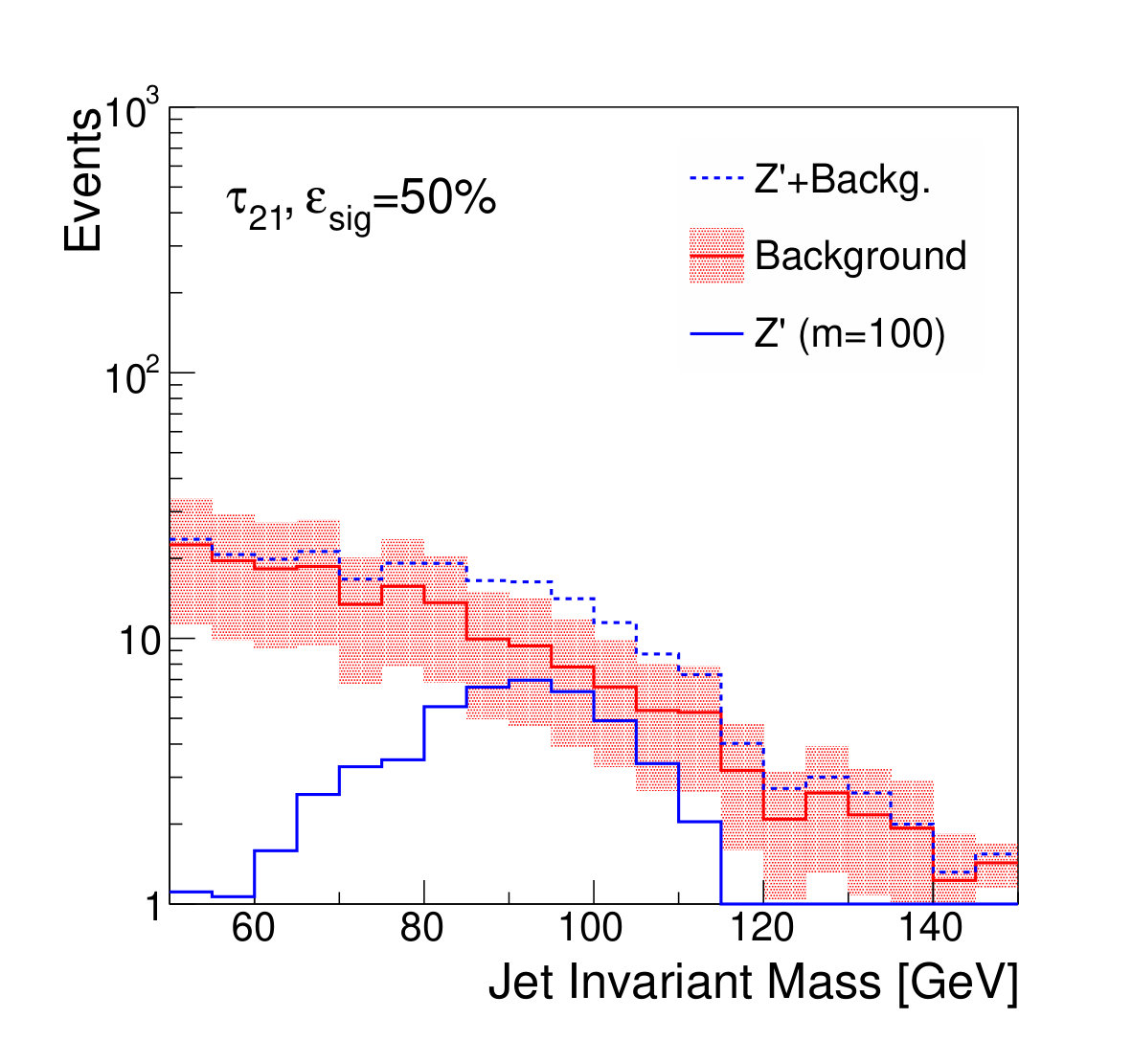 Figure 9
Figure 9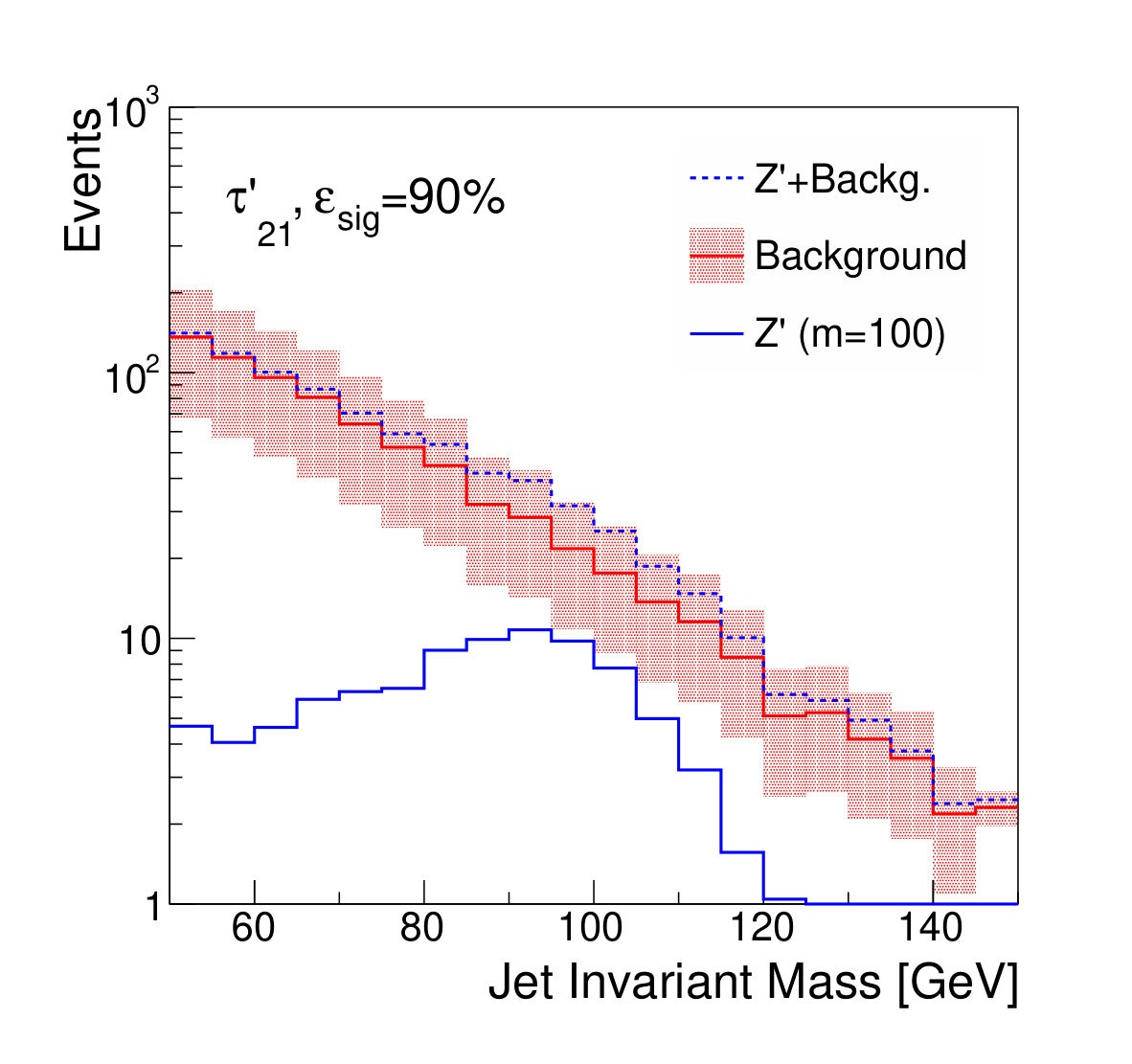 Figure 10
Figure 10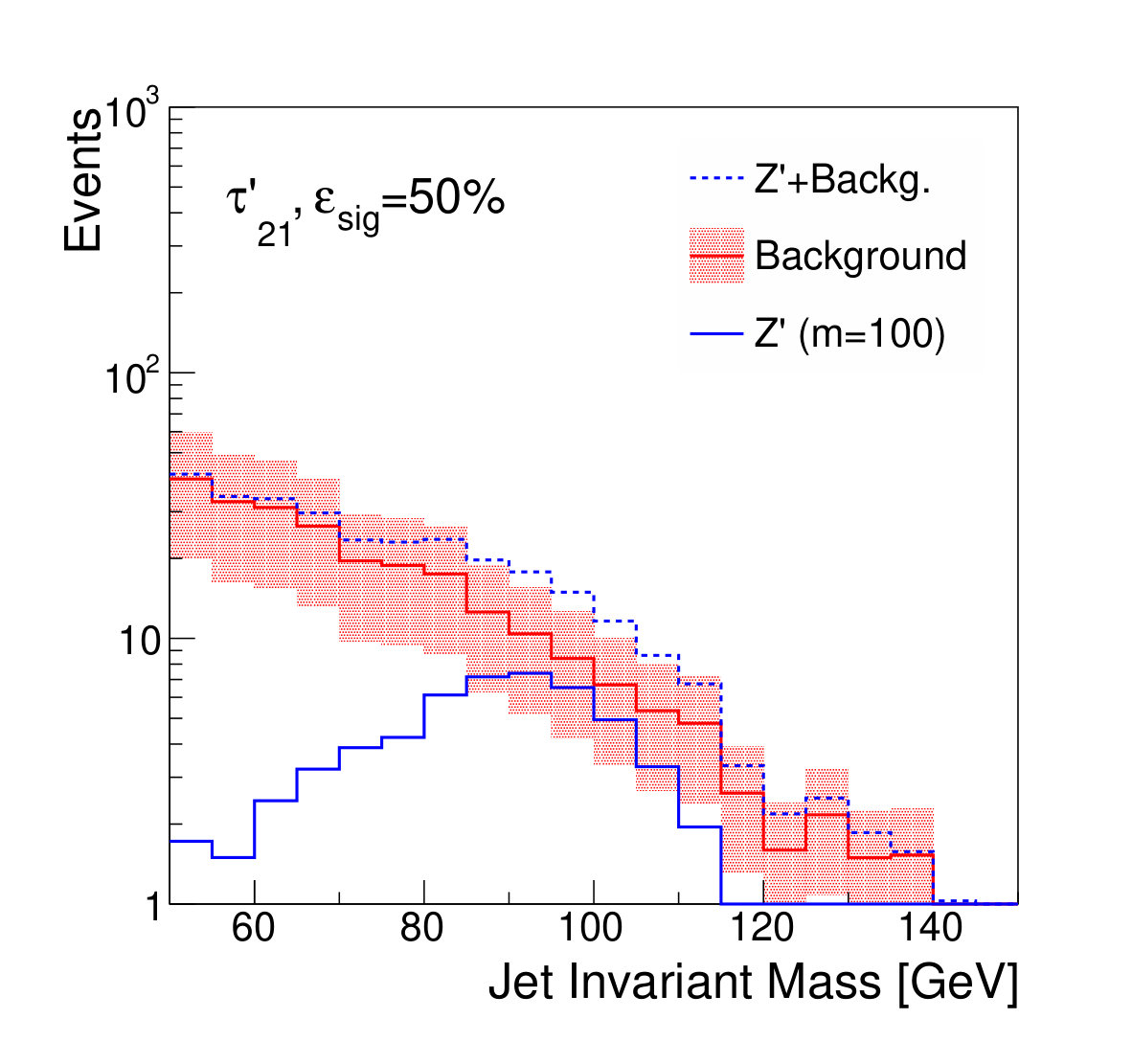 Figure 11
Figure 11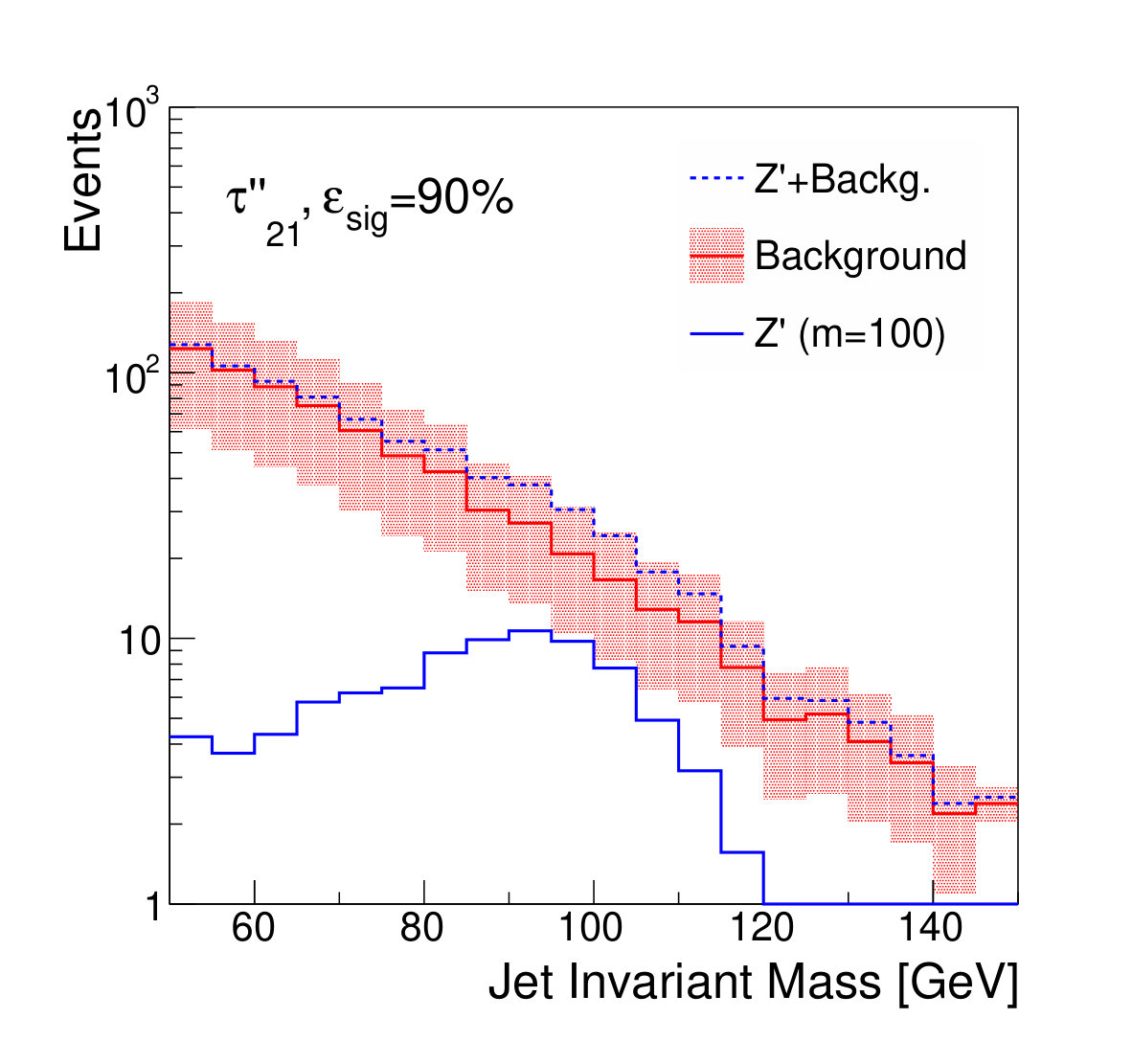 Figure 12
Figure 12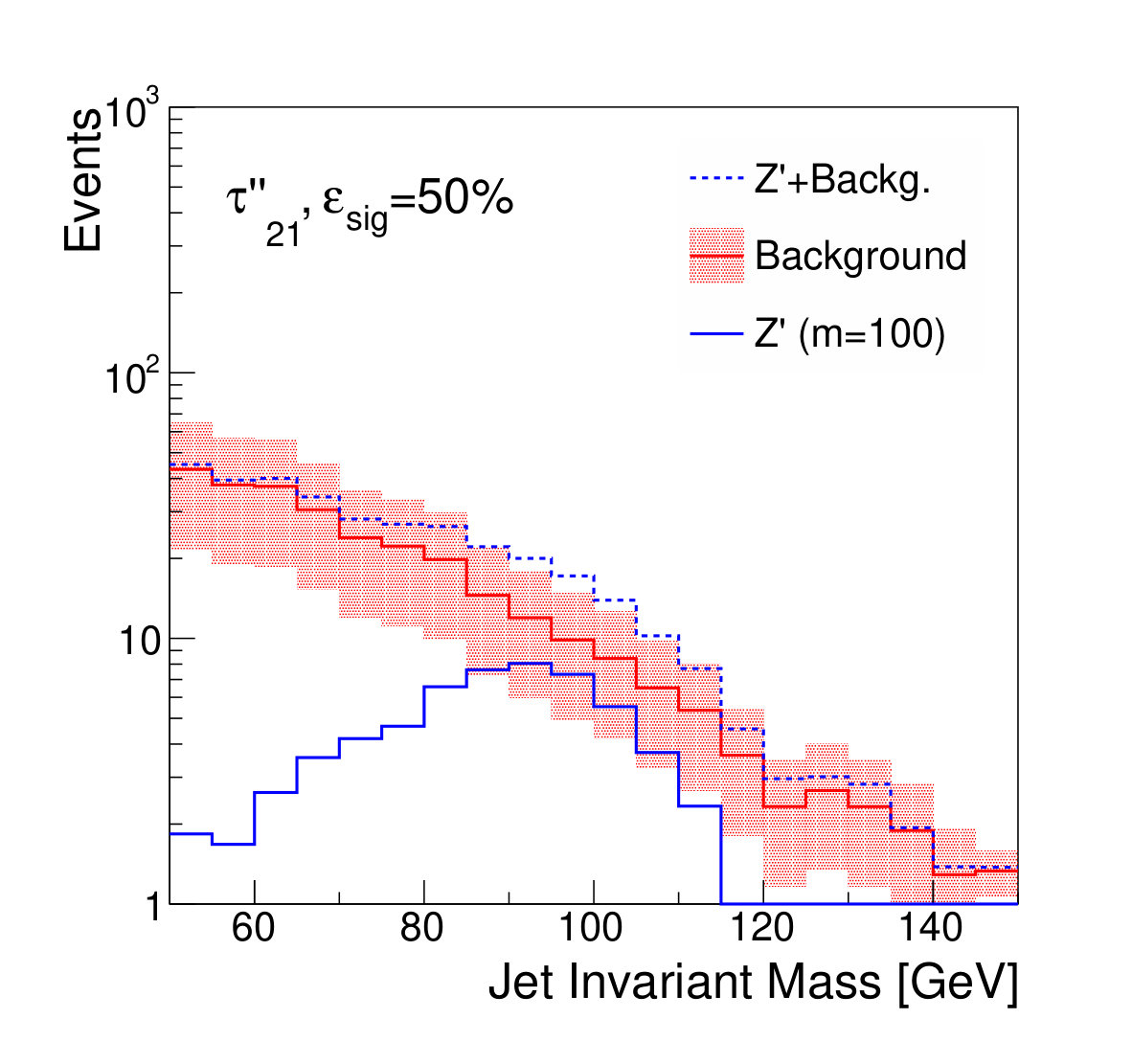 Figure 13
Figure 13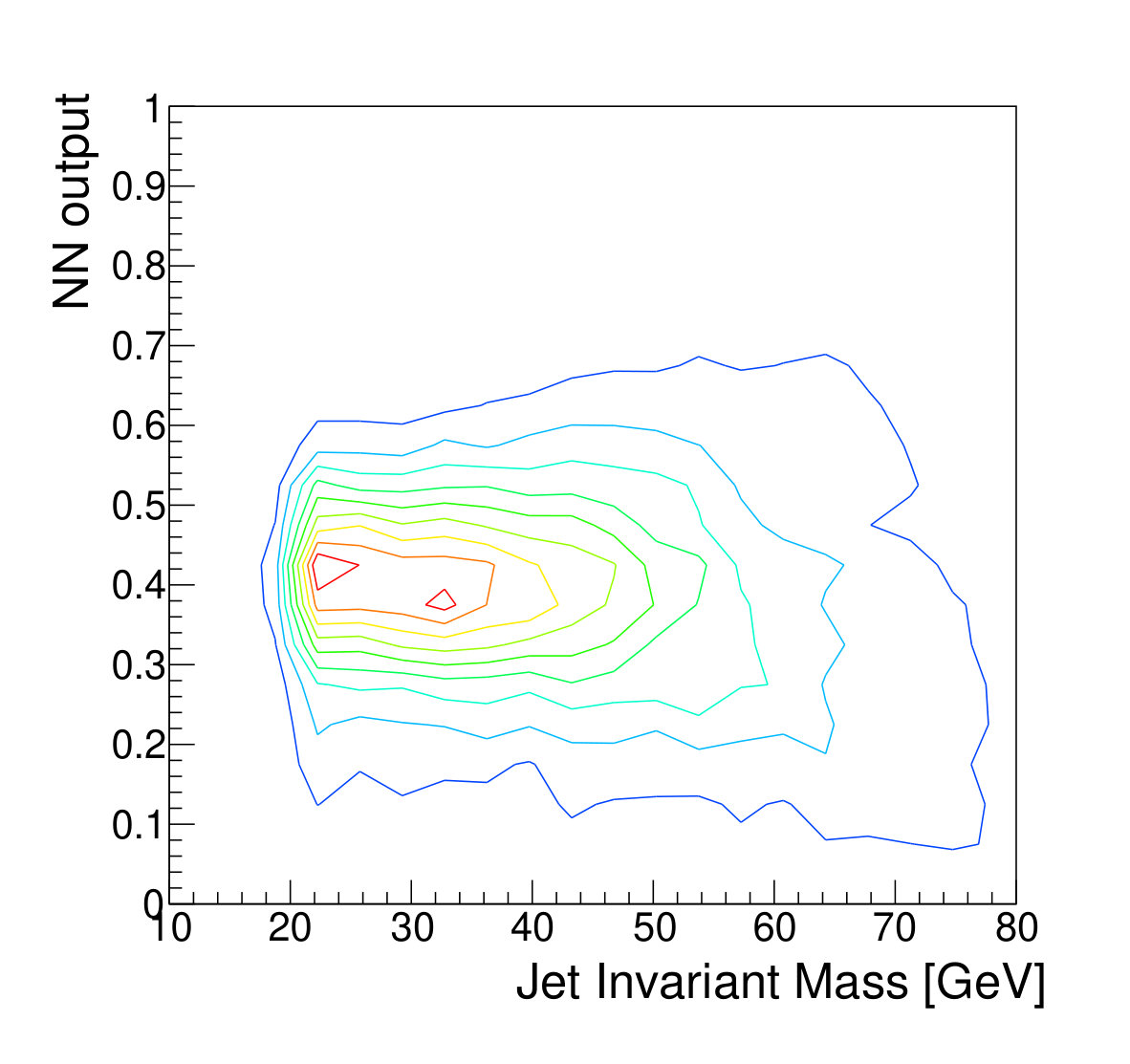 Figure 14
Figure 14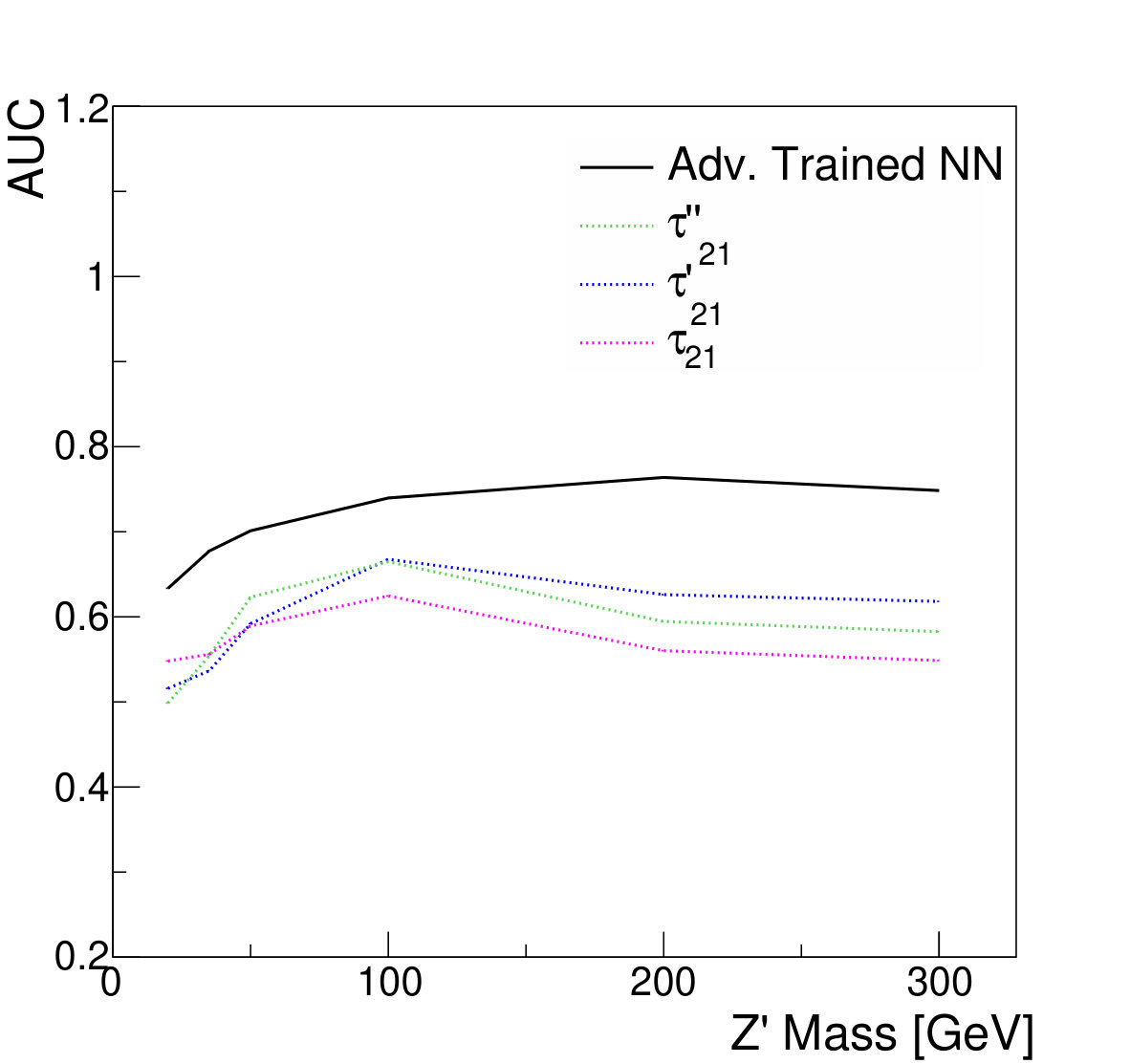 Figure 15
Figure 15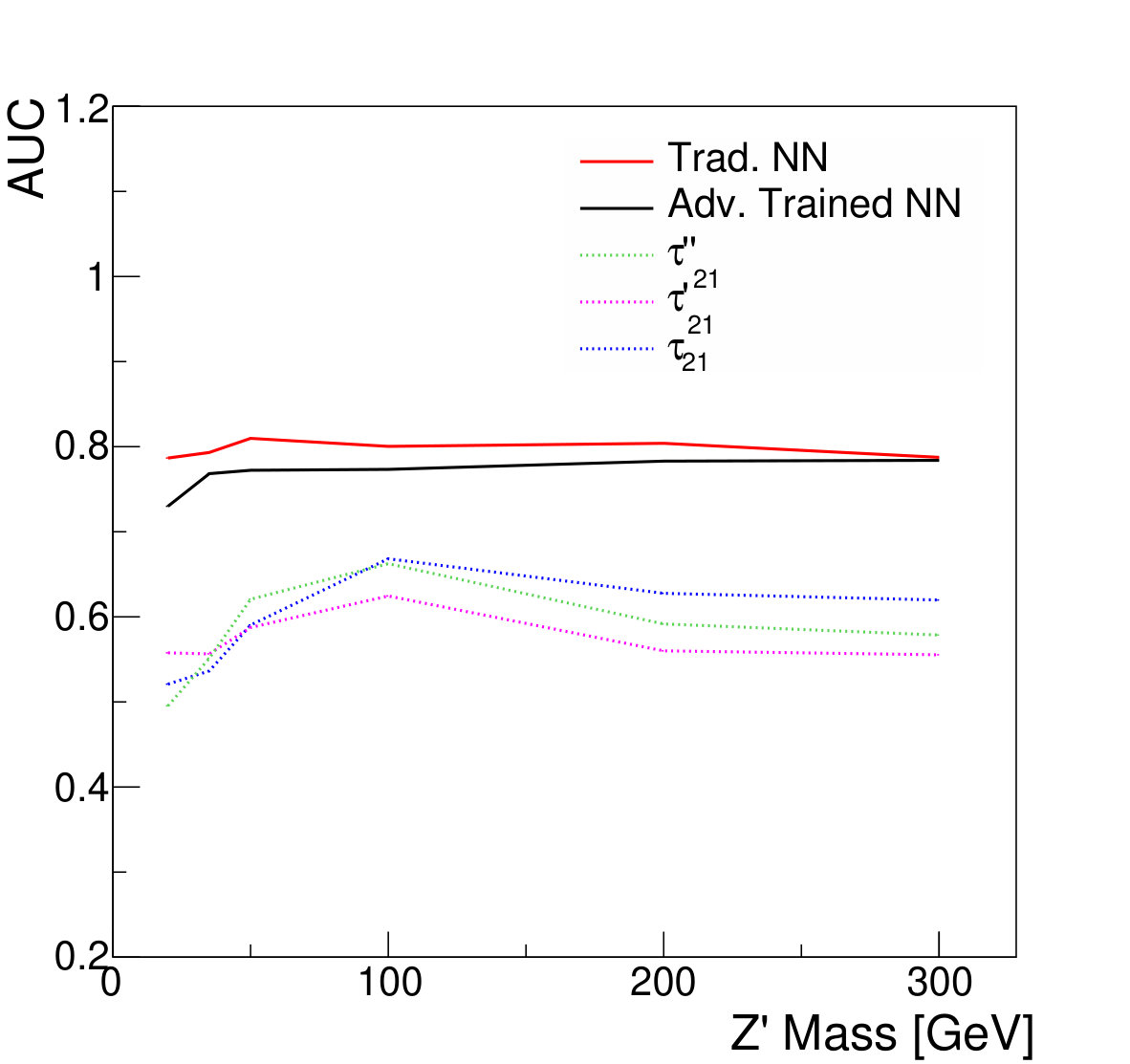 Figure 16
Figure 16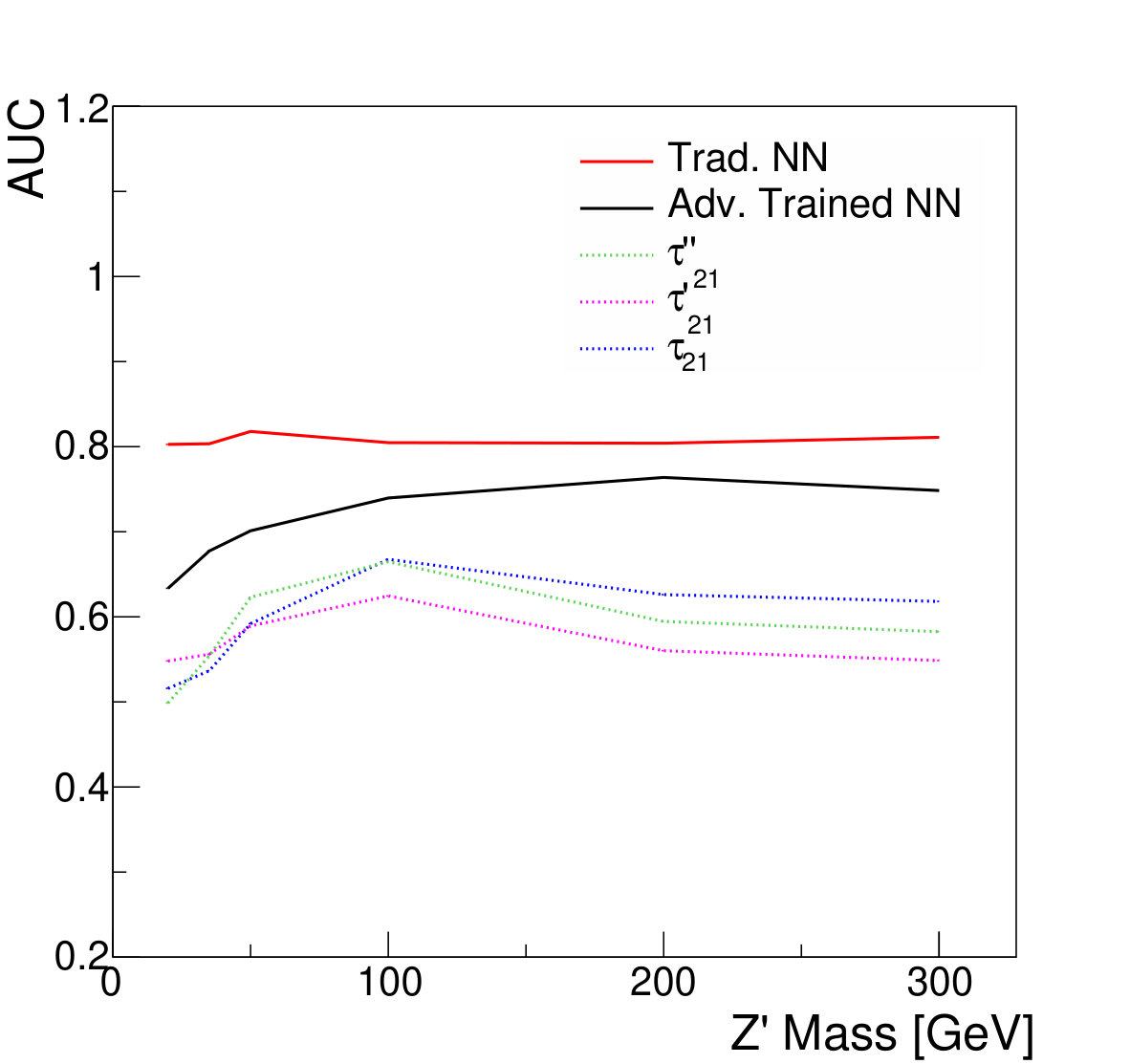 Figure 17
Figure 17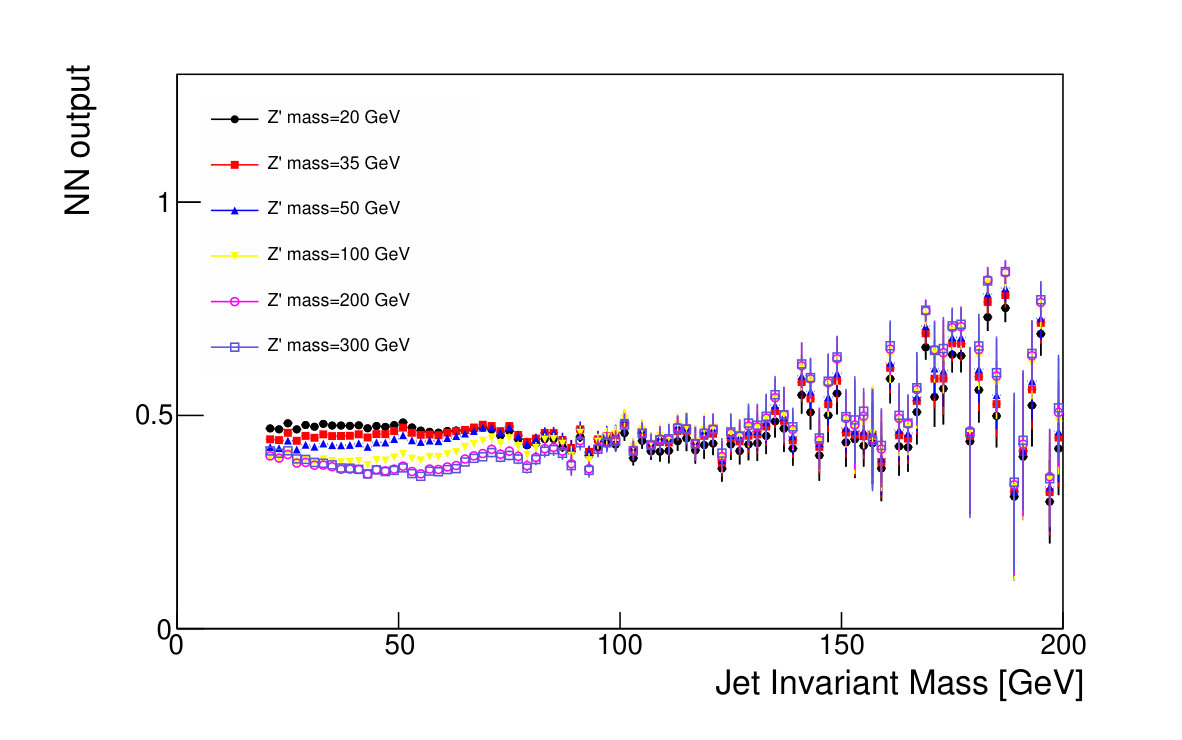 Figure 18
Figure 18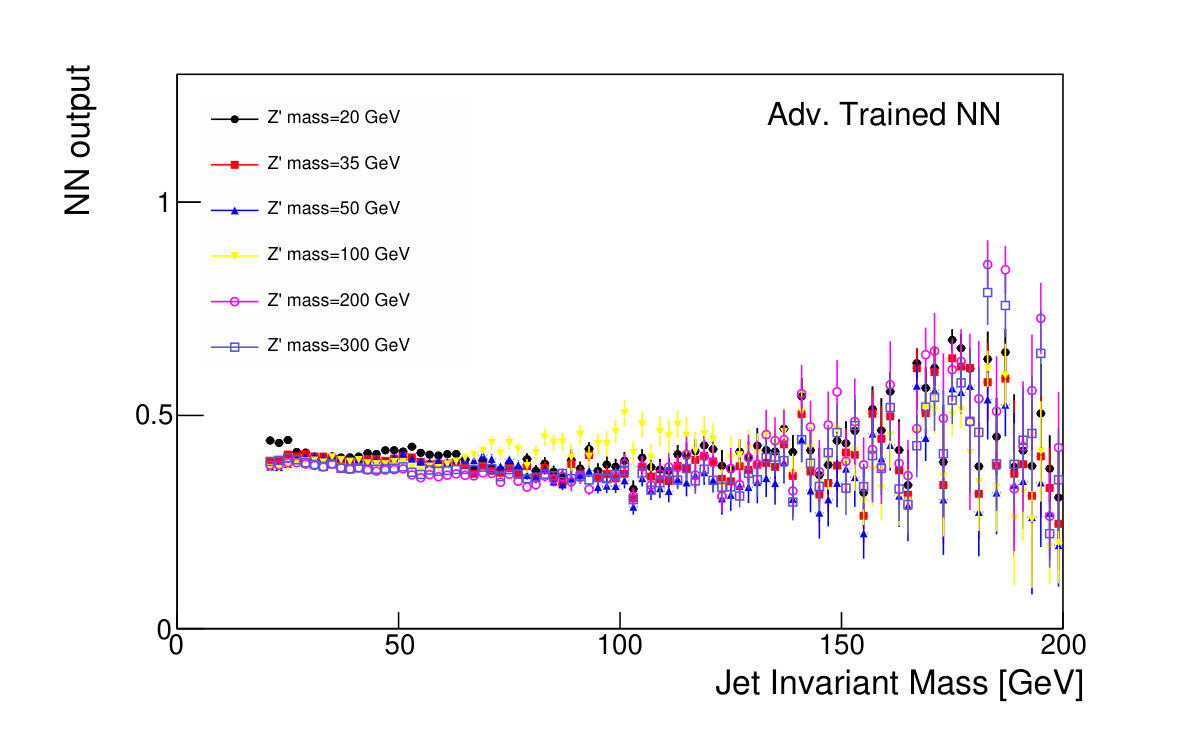 Figure 19
Figure 19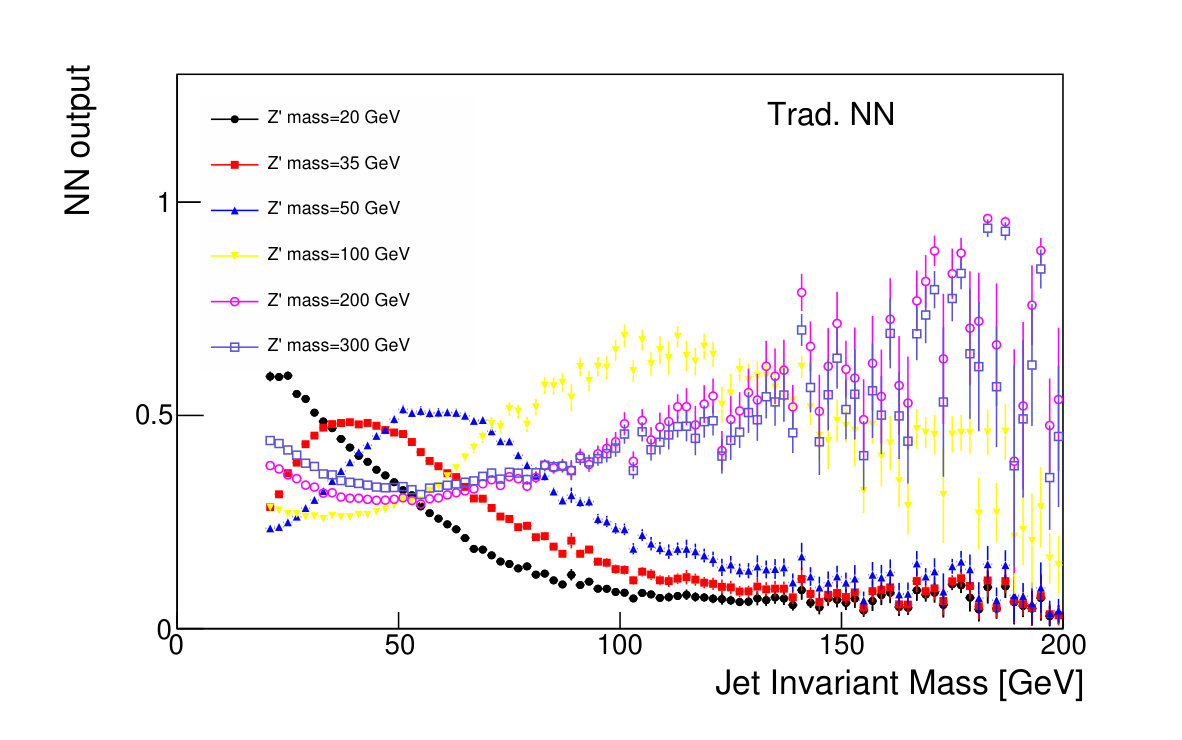 Figure 20
Figure 20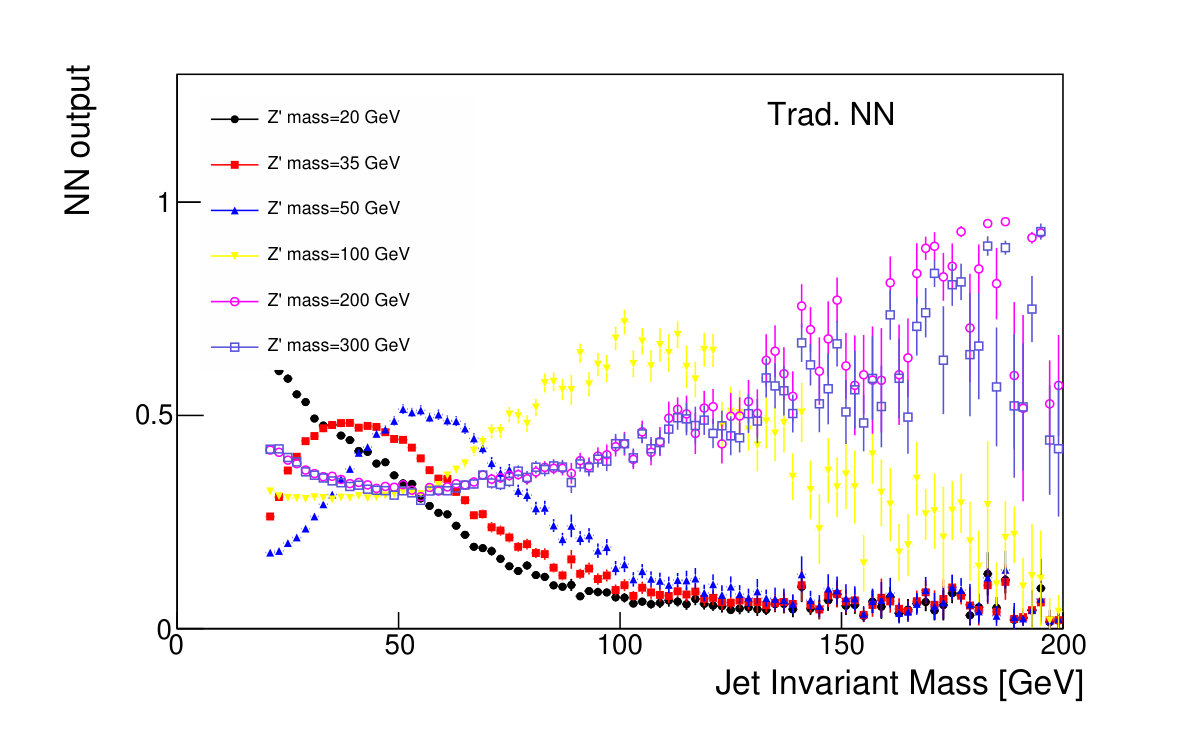 Figure 21
Figure 21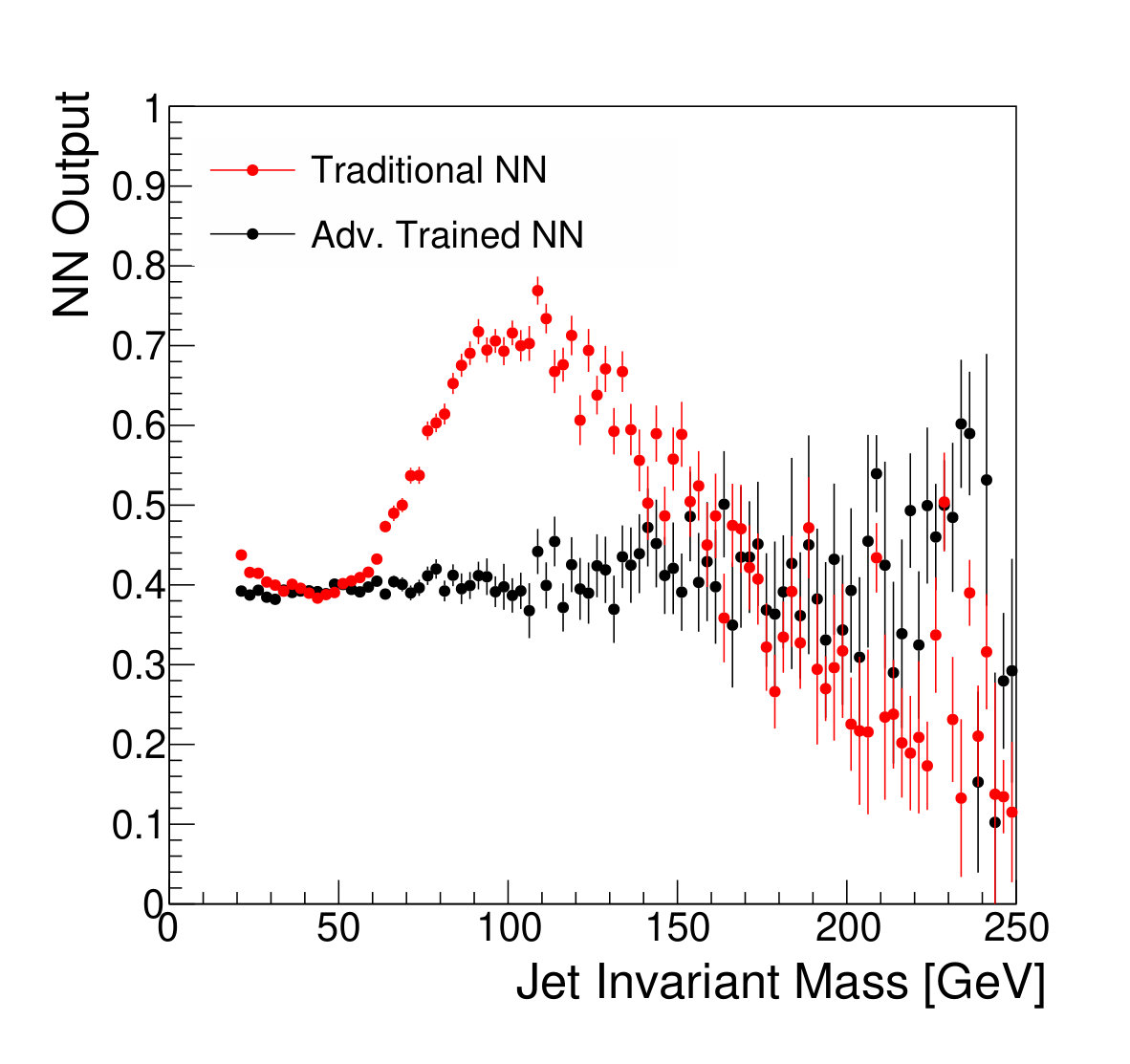 Figure 22
Figure 22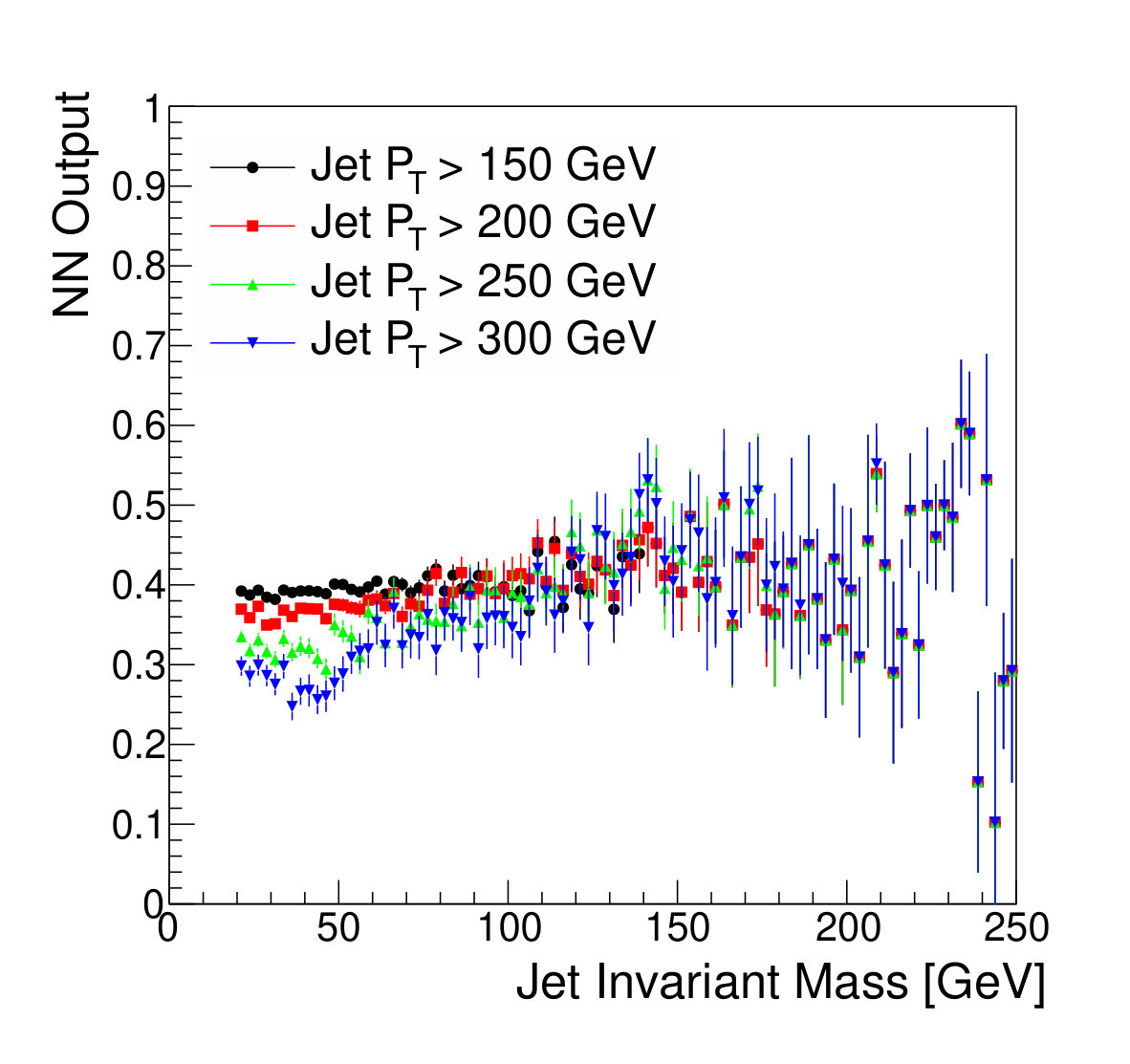 Figure 23
Figure 23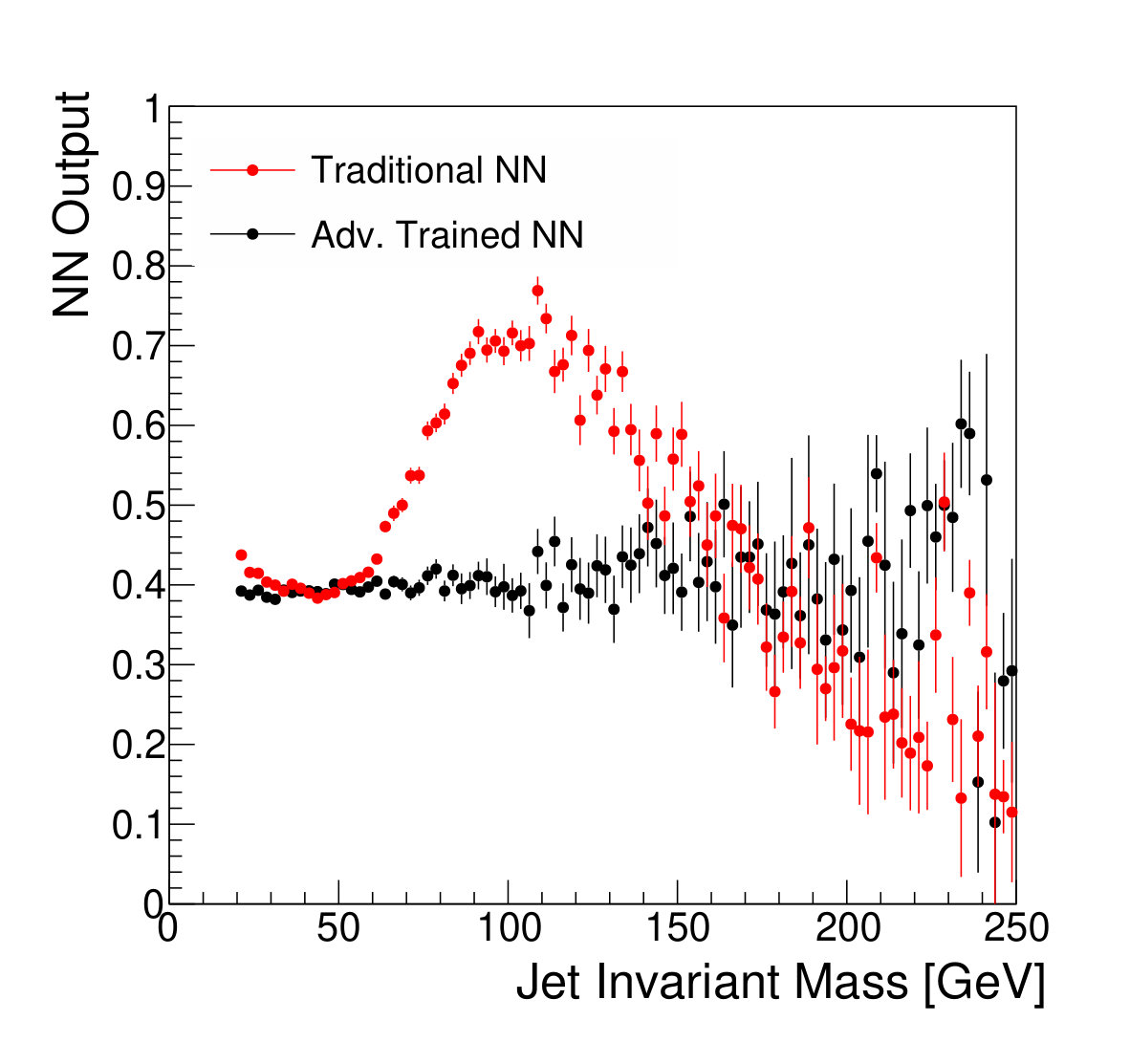 Figure 24
Figure 24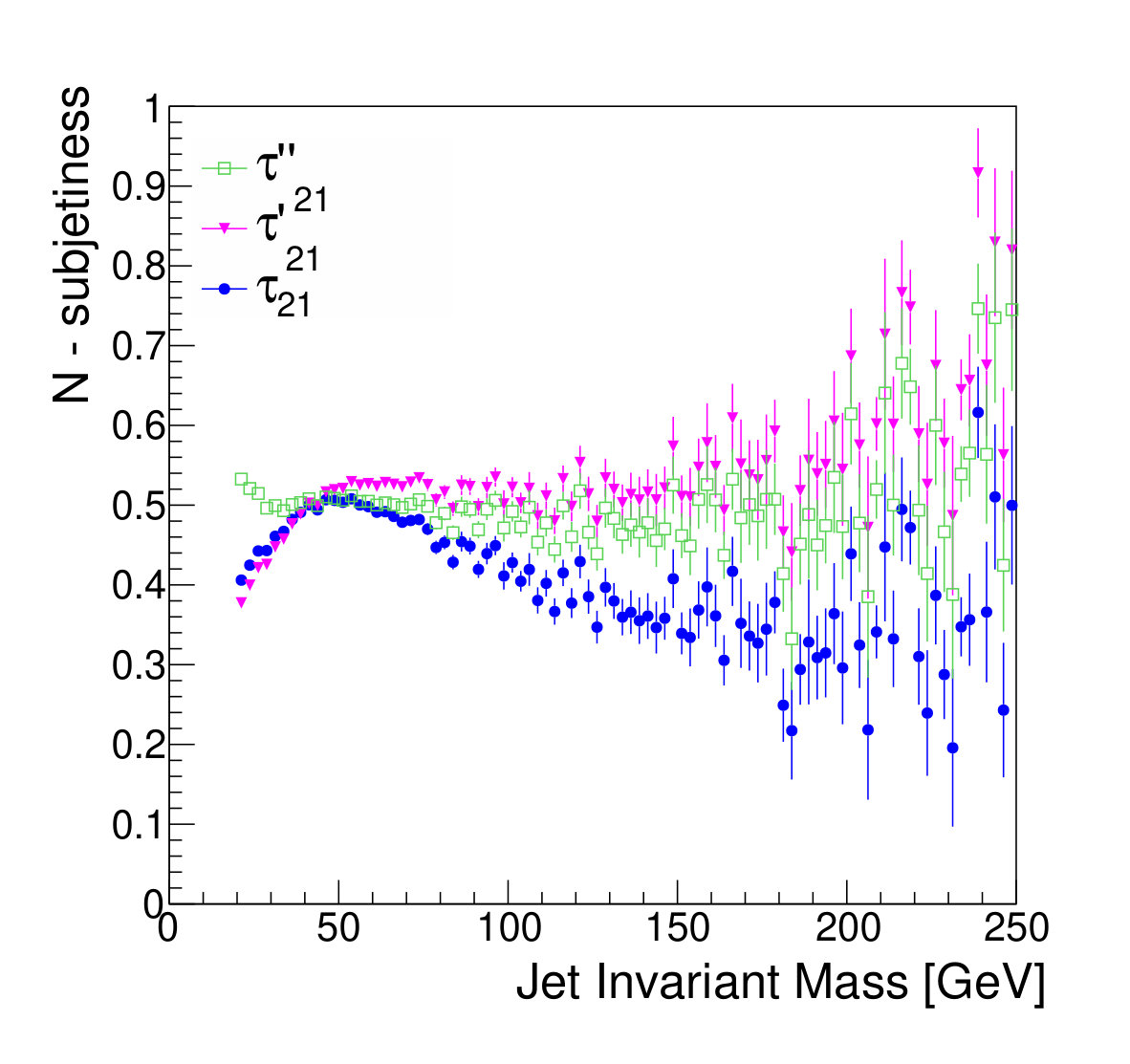 Figure 25
Figure 25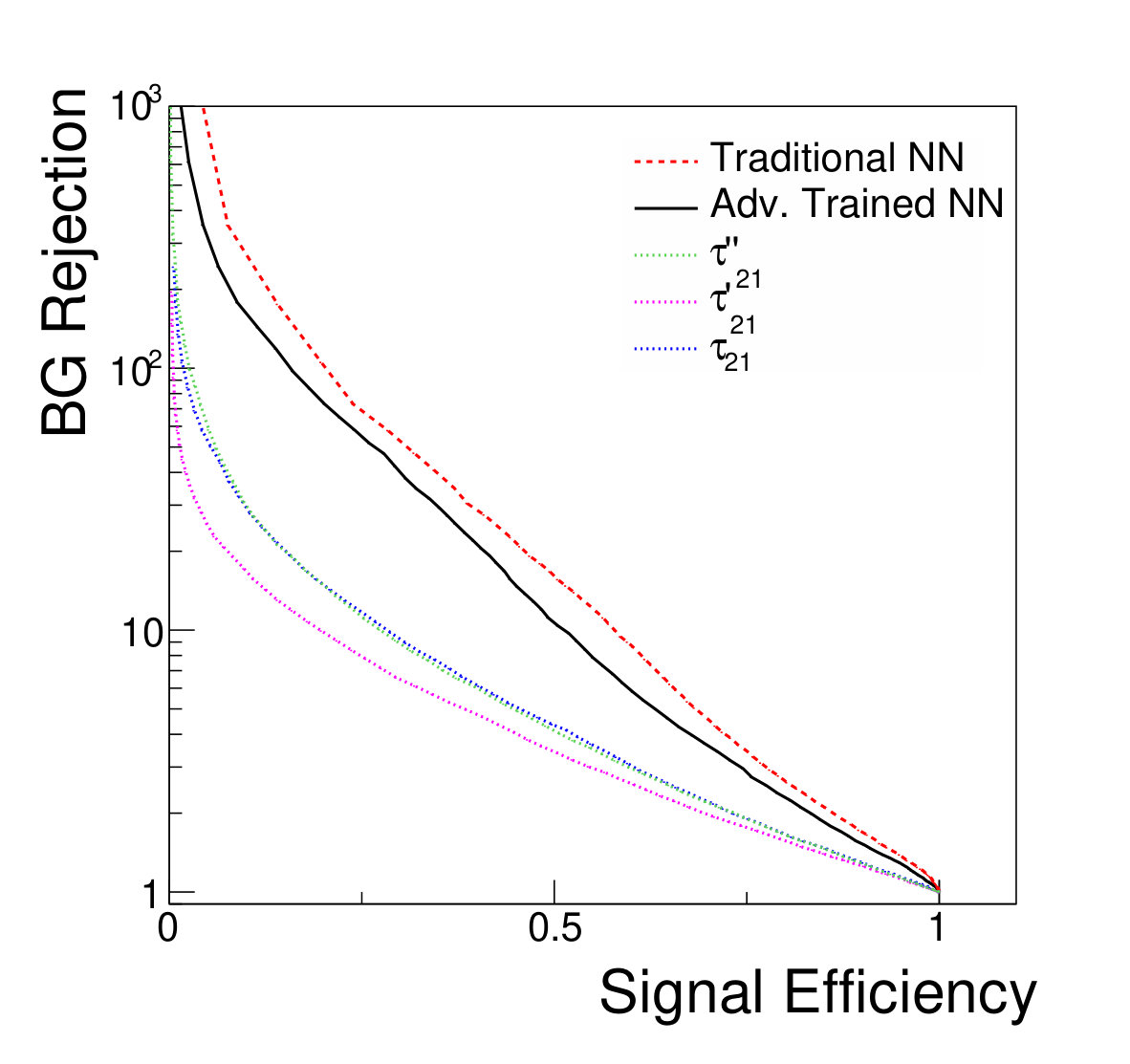 Figure 26
Figure 26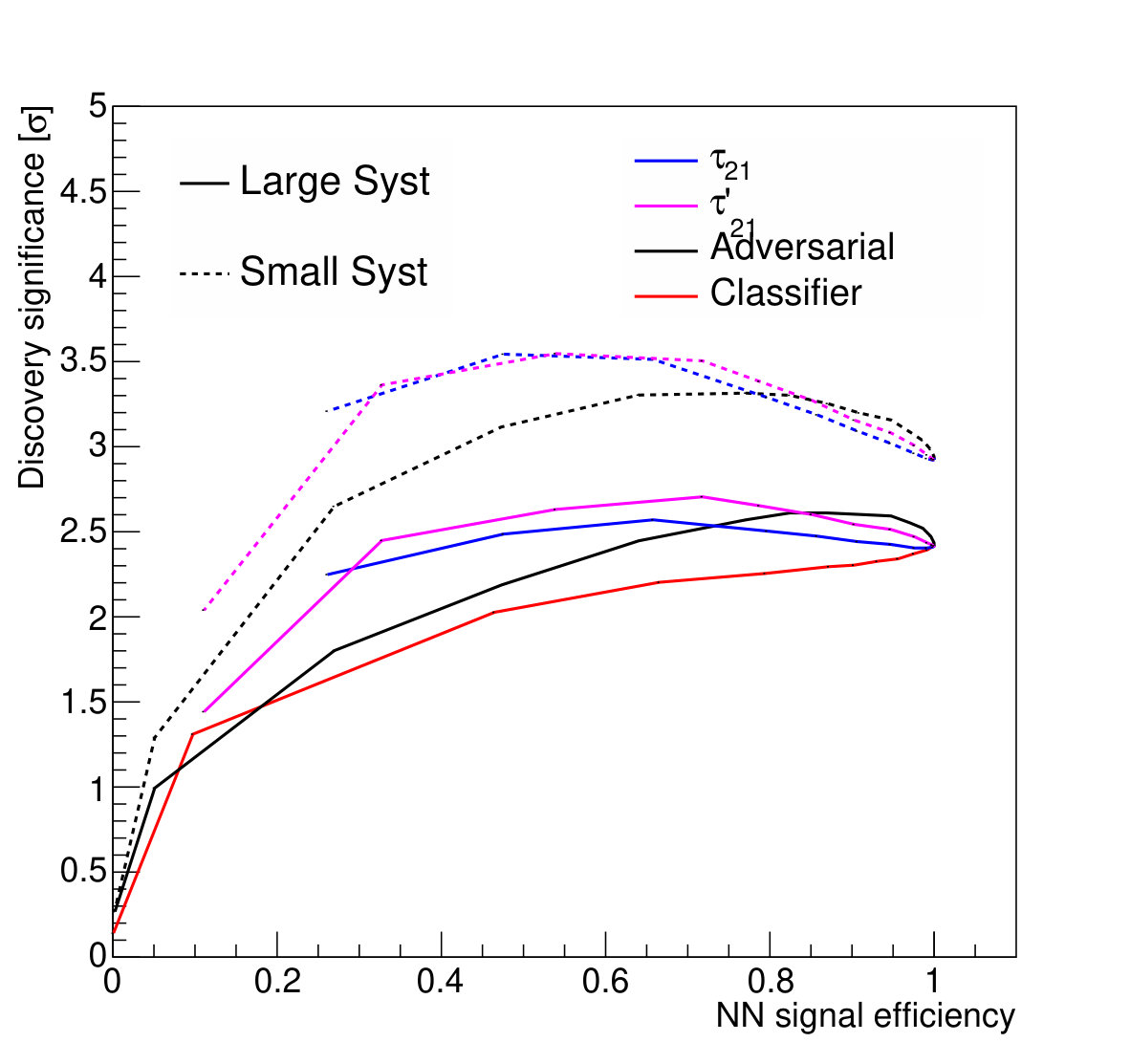 Figure 27
Figure 27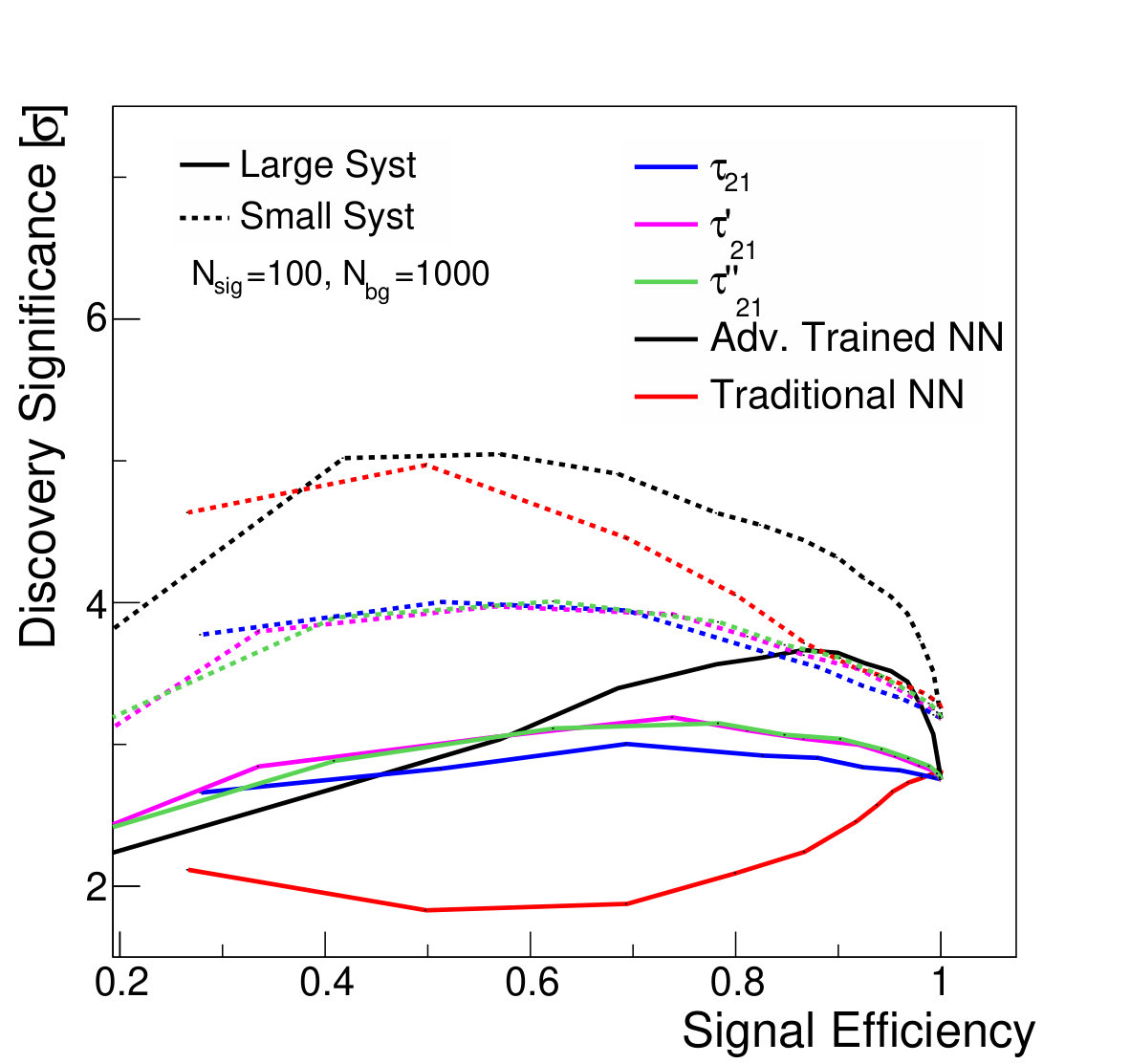 Figure 28
Figure 28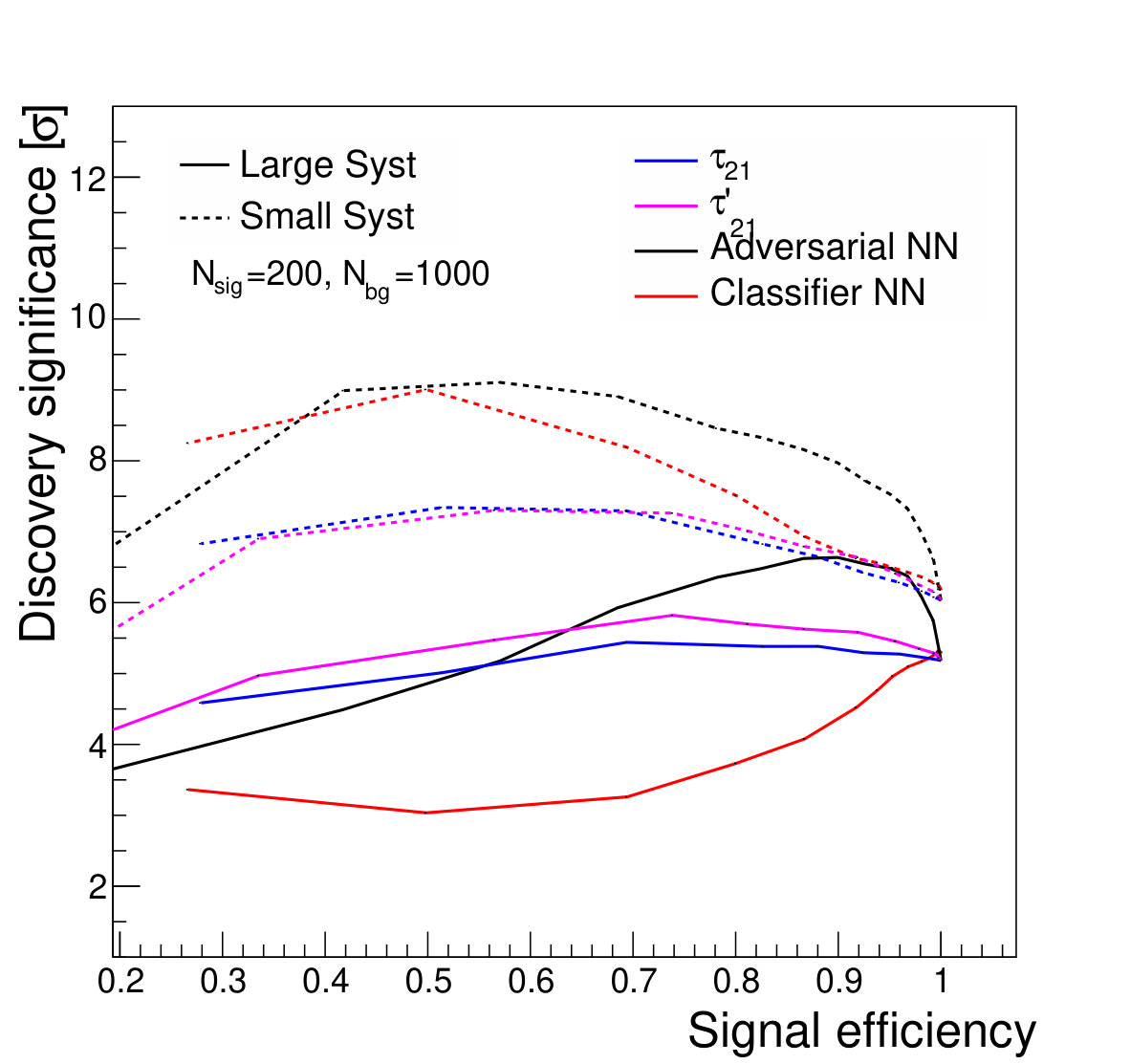 Figure 29
Figure 29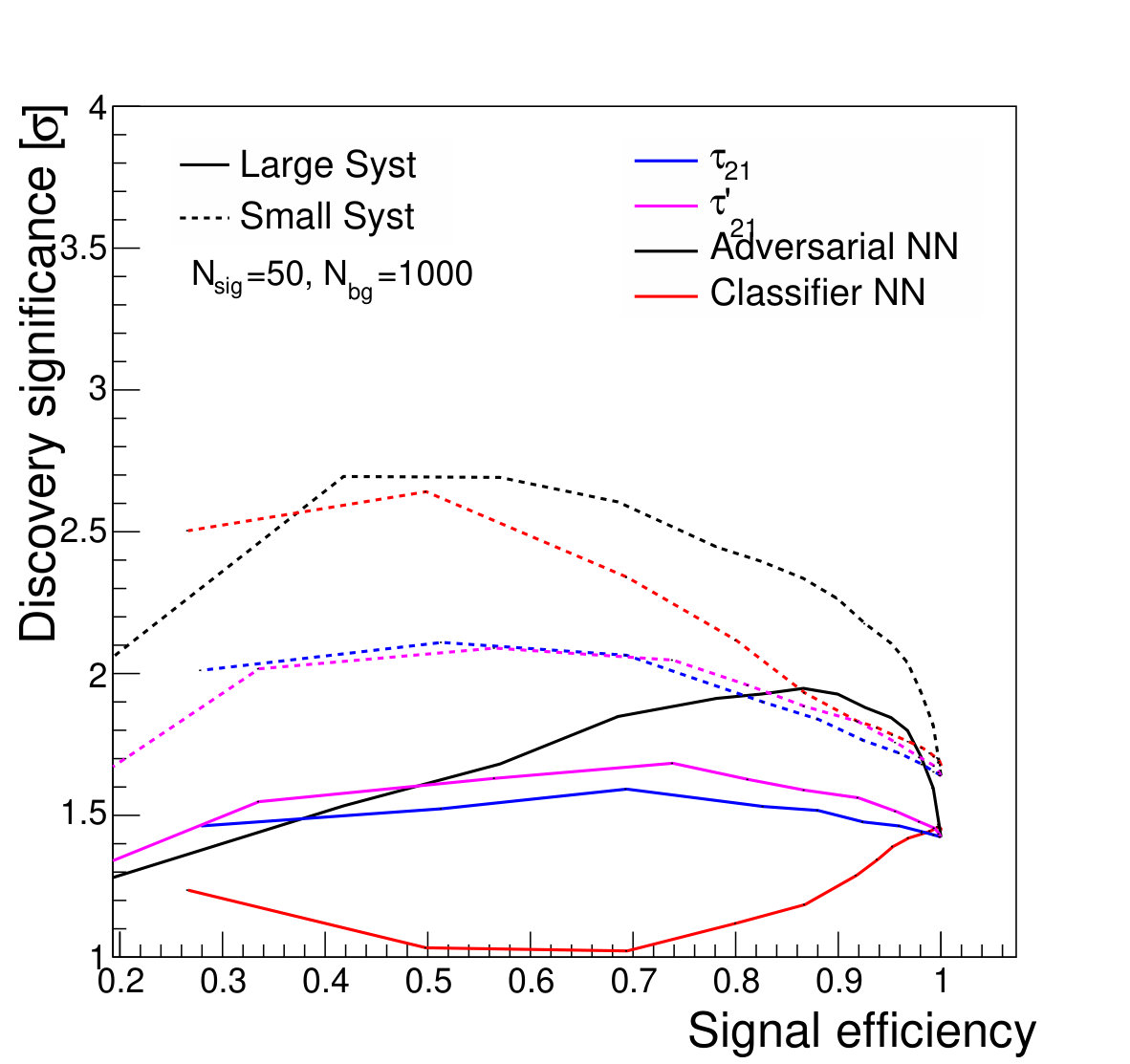 Figure 30
Figure 30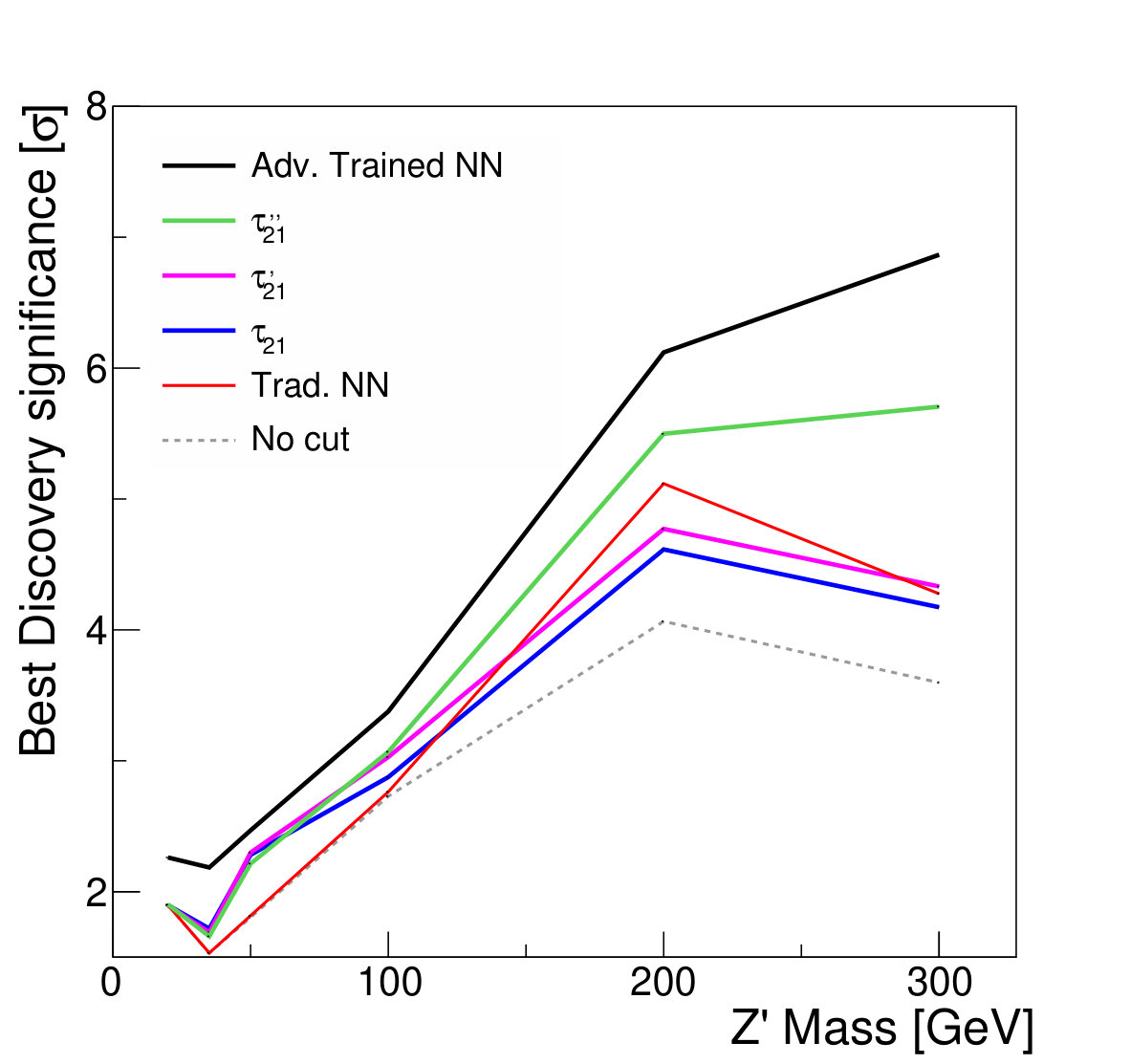 Figure 31
Figure 31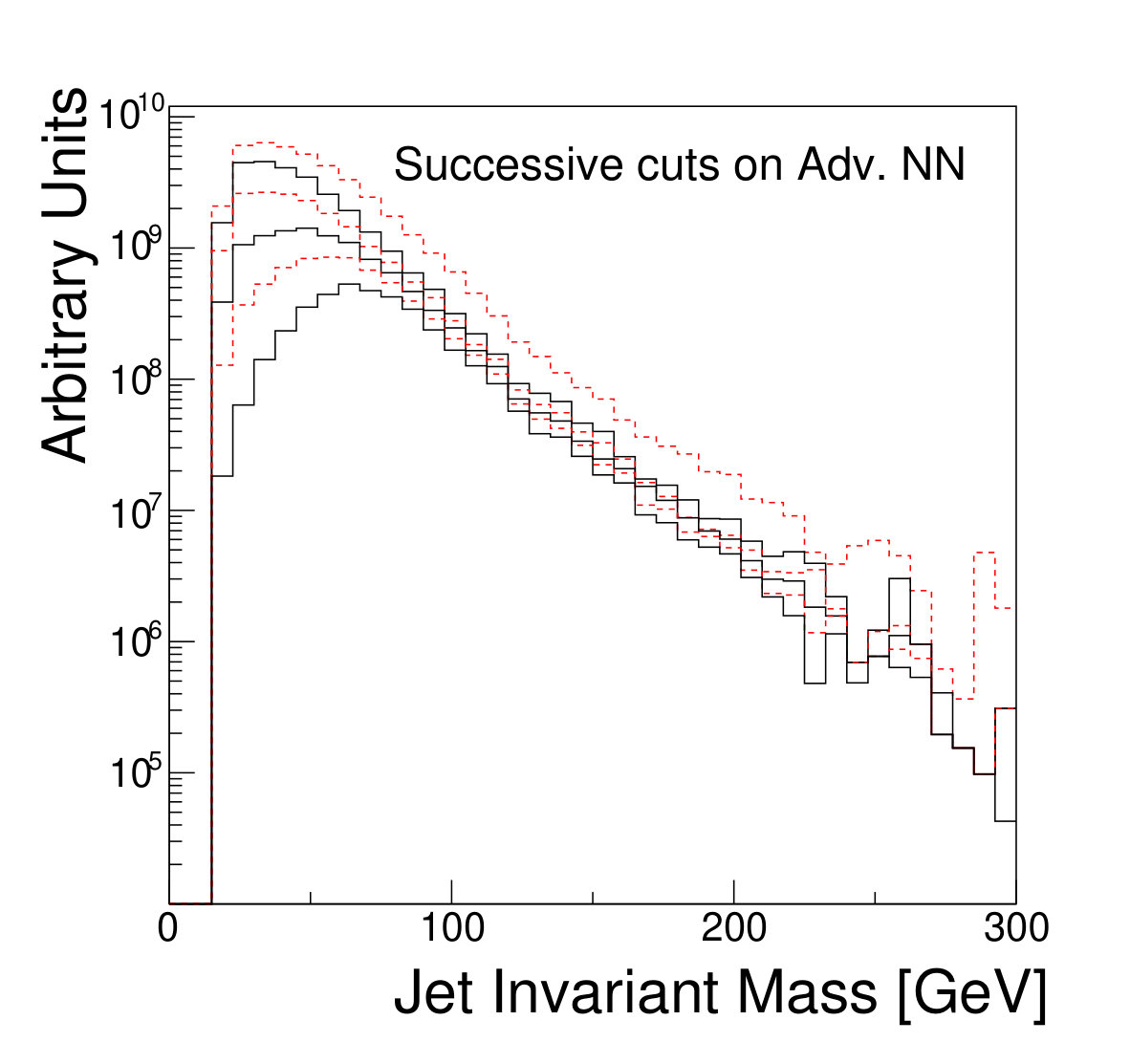 Figure 32
Figure 32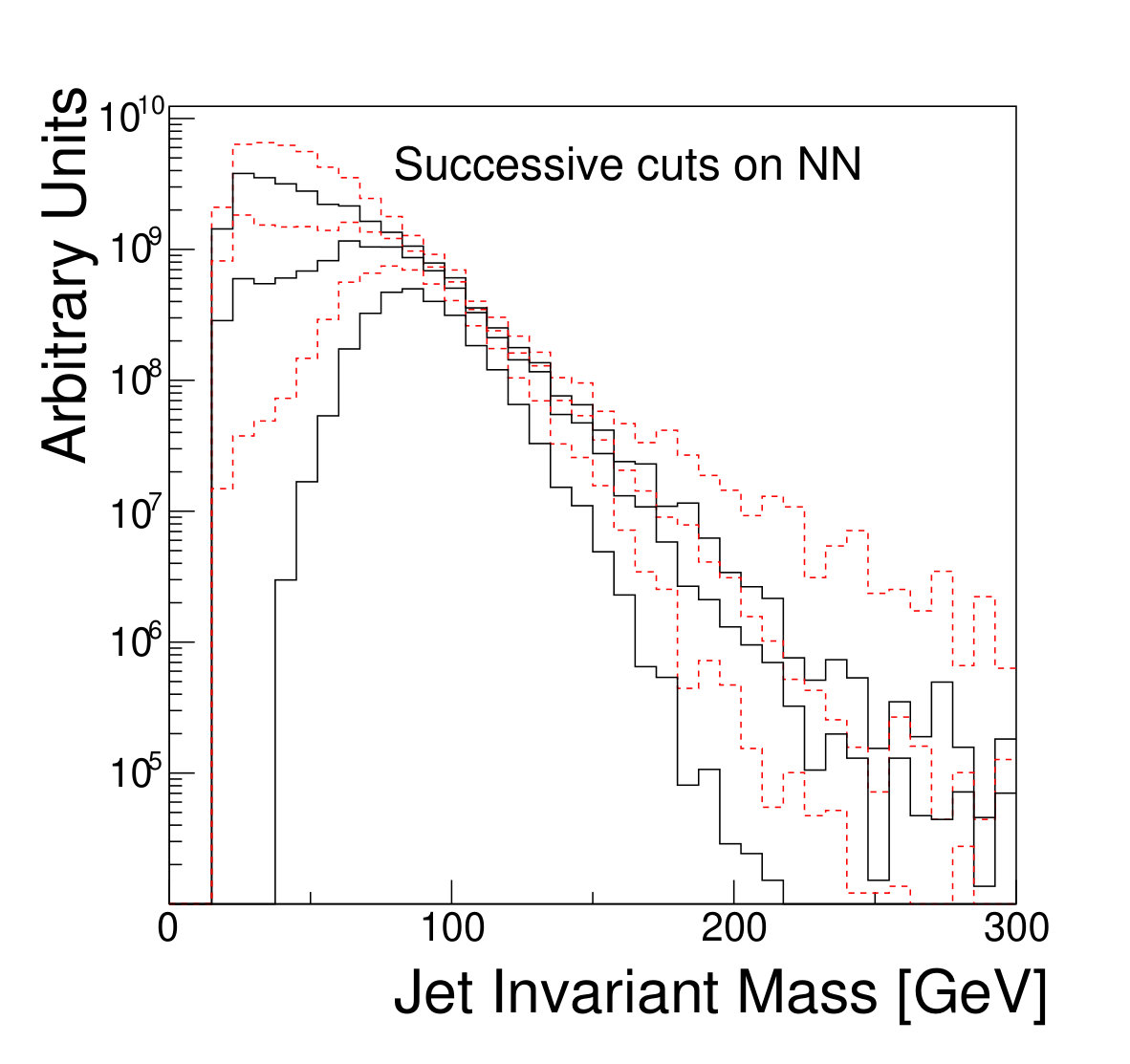 Figure 33
Figure 33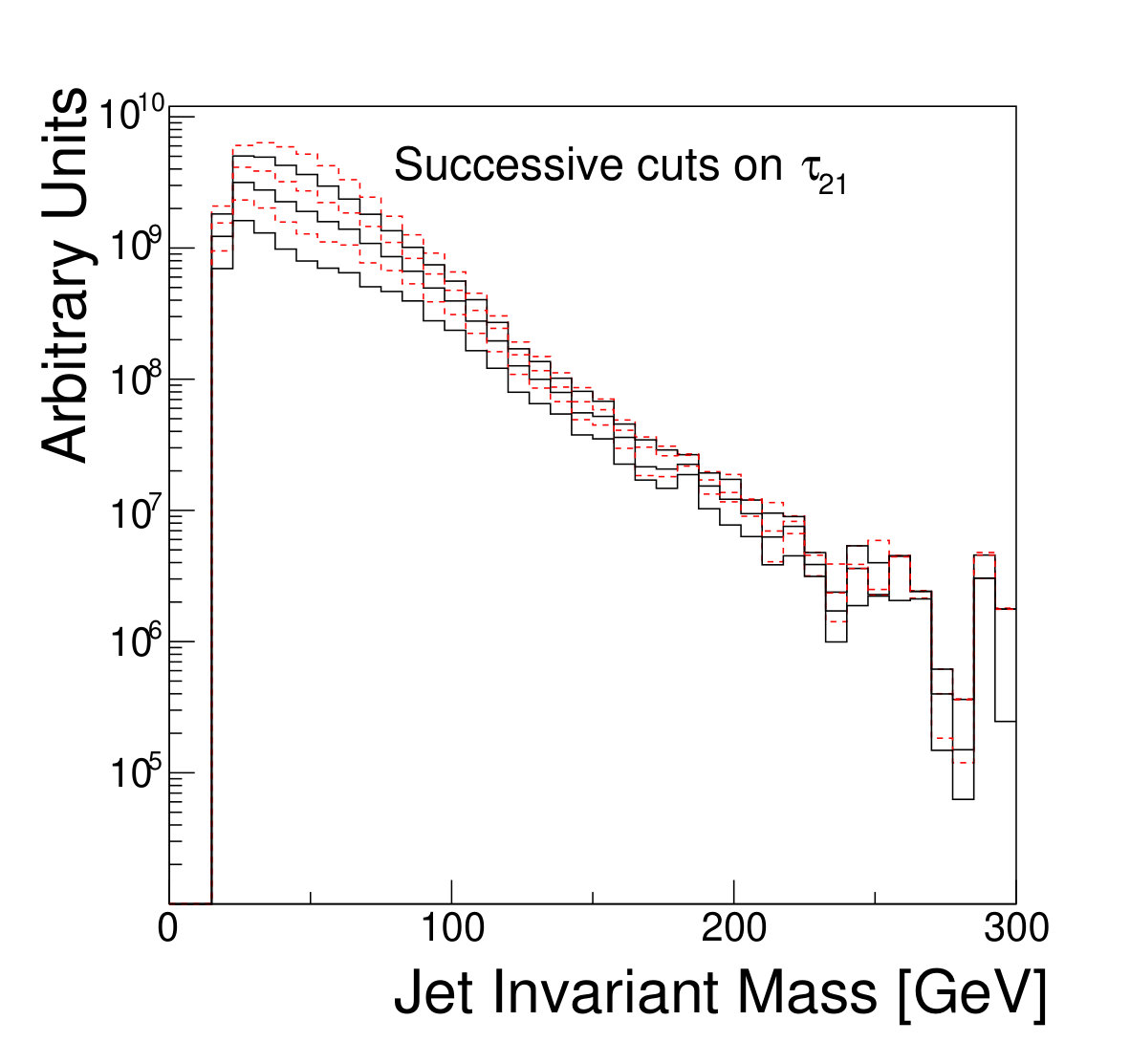 Figure 34
Figure 34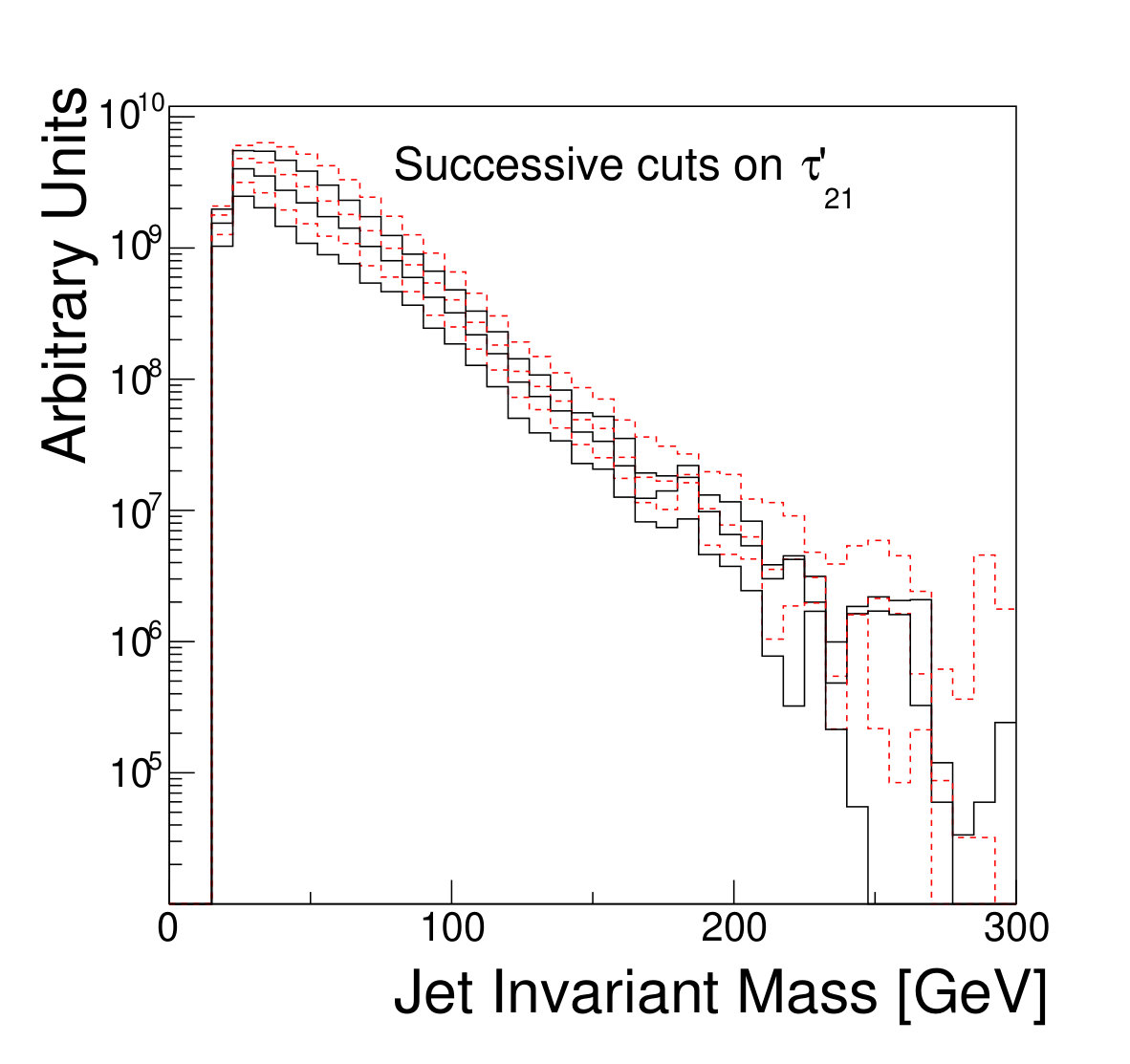 Figure 35
Figure 35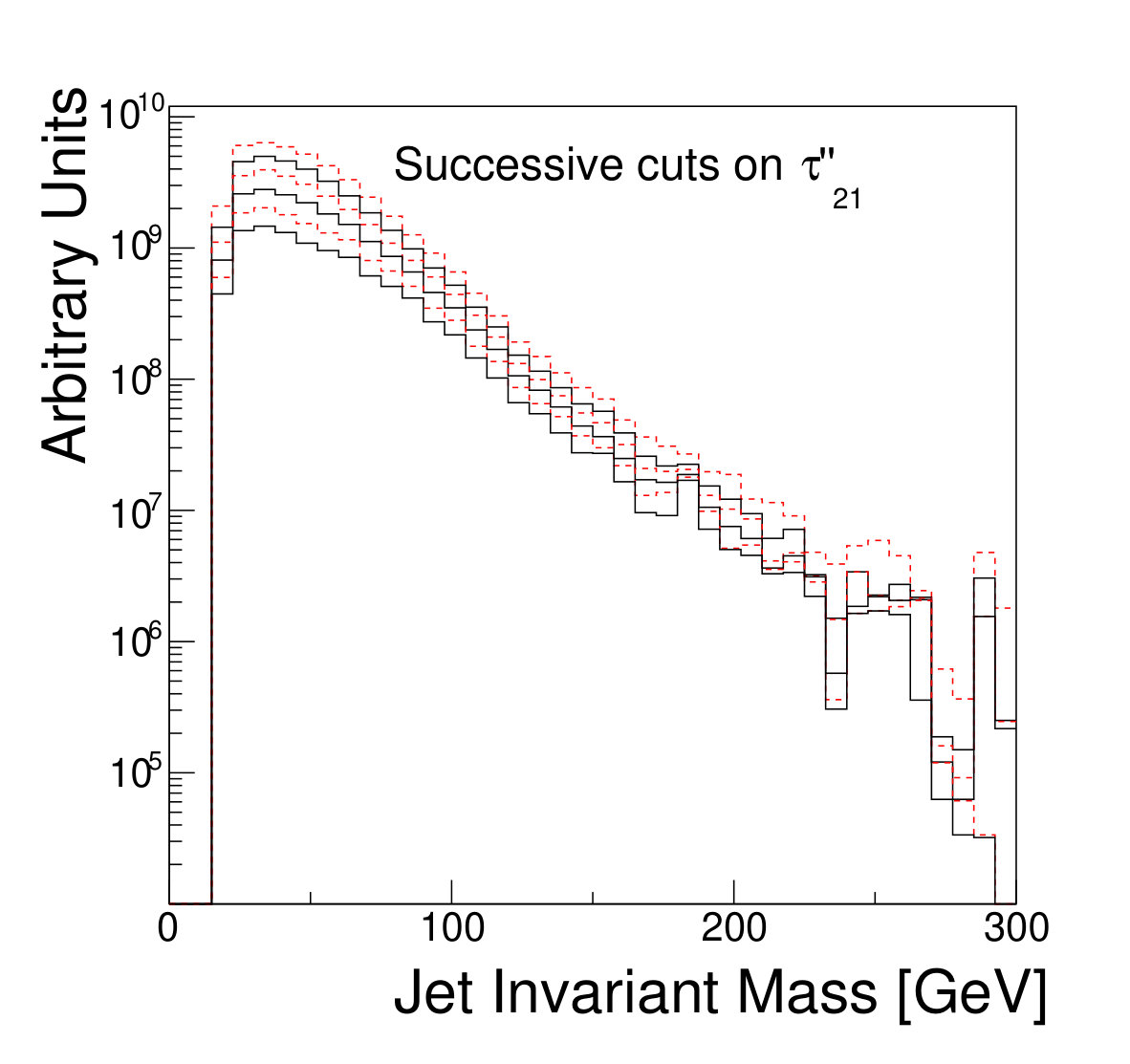 Figure 36
Figure 36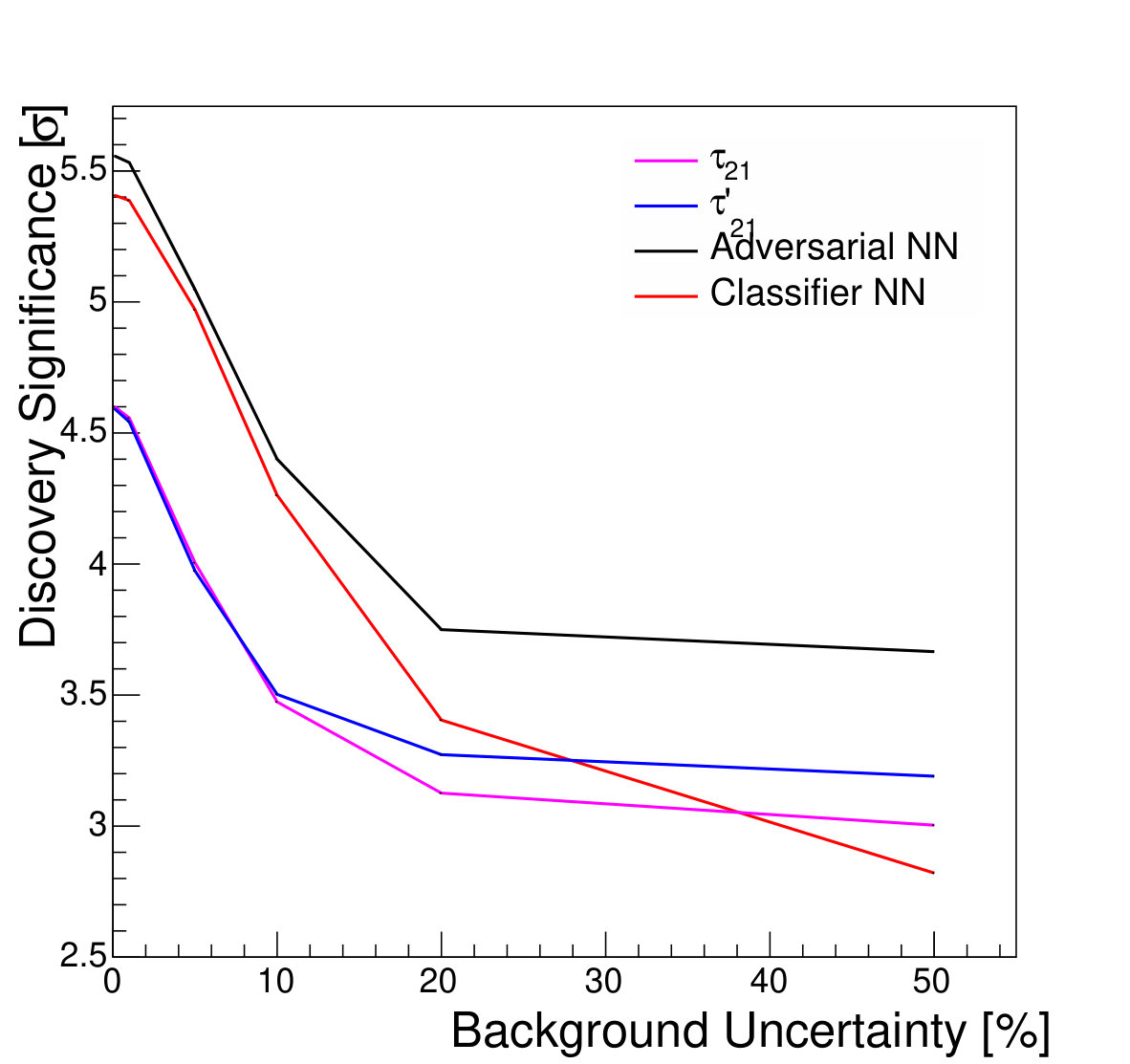 Figure 37
Figure 37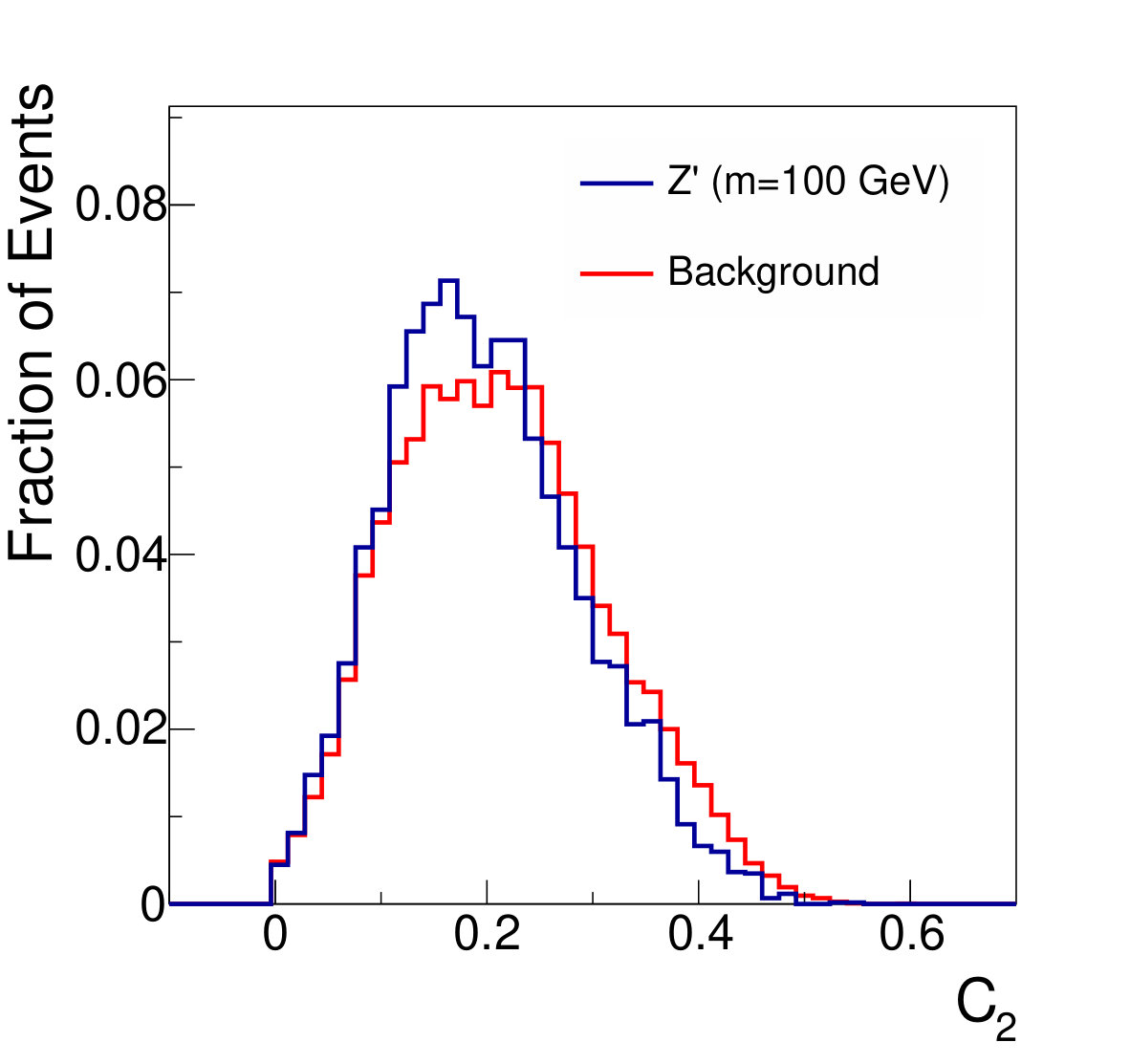 Figure 38
Figure 38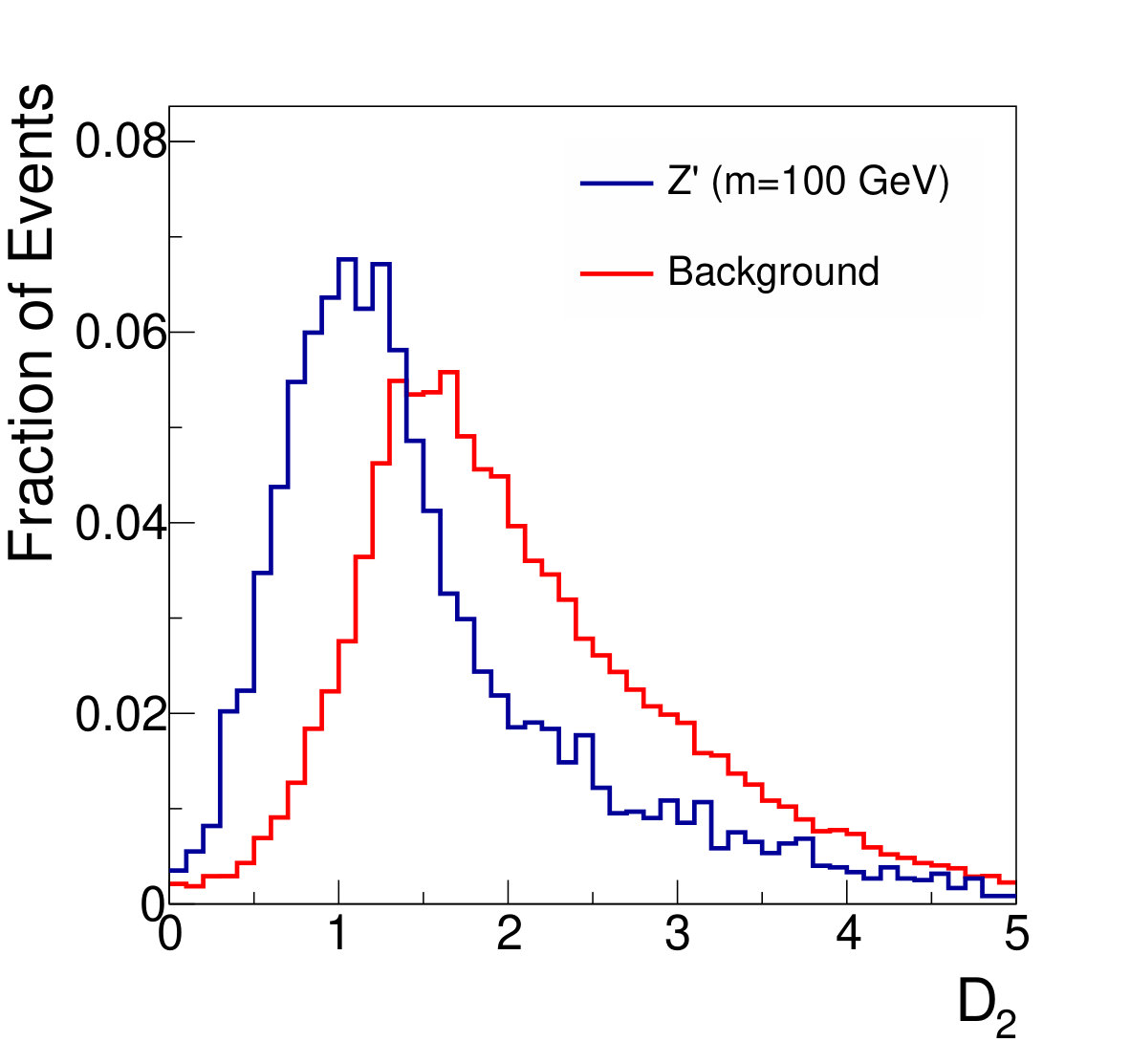 Figure 39
Figure 39 Figure 40
Figure 40| Method | Signal | Background | Discovery |
|---|---|---|---|
| Eff. | Eff. | Signif. () | |
| 5% background uncertainty | |||
| Adv. Trained NN | 0.44 | 0.06 | 5.05 |
| Traditional NN | 0.39 | 0.03 | 4.97 |
| 0.44 | 0.19 | 4.00 | |
| 0.50 | 0.29 | 3.97 | |
| 0.52 | 0.26 | 4.01 | |
| 50% background uncertainty | |||
| Adv. Trained NN | 0.82 | 0.48 | 3.67 |
| Traditional NN | 1.00 | 1.00 | 2.82 |
| 0.60 | 0.32 | 3.00 | |
| 0.70 | 0.50 | 3.19 | |
| 0.70 | 0.45 | 3.15 | |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Decorrelated Jet Substructure Tagging using Adversarial Neural Networks
Chase Shimmin
Department of Physics and Astronomy, UC Irvine, Irvine, CA 92627
Department of Physics, Yale University, New Haven, CT
Peter Sadowski
Department of Computer Science, UC Irvine, Irvine, CA 92627
Pierre Baldi
Department of Computer Science, UC Irvine, Irvine, CA 92627
Edison Weik
Department of Physics and Astronomy, UC Irvine, Irvine, CA 92627
Edward Goul
Department of Physics, MIT, Cambridge, MA 02139
Daniel Whiteson
Department of Physics and Astronomy, UC Irvine, Irvine, CA 92627
Andreas Søgaard
Department of Physics and Astronomy, University of Edinburgh, Edinburgh UK
Abstract
We describe a strategy for constructing a neural network jet substructure tagger which powerfully discriminates boosted decay signals while remaining largely uncorrelated with the jet mass. This reduces the impact of systematic uncertainties in background modeling while enhancing signal purity, resulting in improved discovery significance relative to existing taggers. The network is trained using an adversarial strategy, resulting in a tagger that learns to balance classification accuracy with decorrelation. As a benchmark scenario, we consider the case where large-radius jets originating from a boosted resonance decay are discriminated from a background of nonresonant quark and gluon jets. We show that in the presence of systematic uncertainties on the background rate, our adversarially-trained, decorrelated tagger considerably outperforms a conventionally trained neural network, despite having a slightly worse signal-background separation power. We generalize the adversarial training technique to include a parametric dependence on the signal hypothesis, training a single network that provides optimized, interpolatable decorrelated jet tagging across a continuous range of hypothetical resonance masses, after training on discrete choices of the signal mass.
I Introduction
The enormous center-of-mass energy of the Large Hadron Collider (LHC) enables the production of particles at such extreme velocities that the decay products of even massive particles can become collimated. Rather than producing distinct deposits of energy in the calorimeter, hadronic decay products of such boosted objects can overlap, creating a single large jet. Distinguishing between jets originating from a single particle (such as a quark or gluon), and those which contain two or three hadronic decay products, is known as jet tagging, and has become an essential component of searches for new physics at the LHC Butterworth et al. (2008); Adams et al. (2015); Abdesselam et al. (2011); Altheimer et al. (2012, 2014).
However, optimizing the LHC discovery potential requires balancing the competing constraints of signal discrimination and systematic uncertainties. We consider the case posed in Ref. Shimmin and Whiteson (2016) in which a spectrum of jet masses is examined for the presence of a signal-like resonance peak. The background is dominated by QCD jets, while the hypothetical signal is produced via the hadronic decay of a boosted resonance.
On one hand, there has been intense theoretical work to develop jet substructure tagging tools Thaler and Van Tilburg (2011); Larkoski et al. (2013) with powerful discrimination between these types of jets. On the other hand, the processes that produce backgrounds to these searches are often not well understood or are poorly modeled by simulation tools. As a result, experiments in practice rely on the assumption of a smooth background spectrum which can be interpolated under a signal peak from sidebands. Unfortunately, the jet-tagging quantities may be correlated with jet mass, resulting in a distortion of the background shape Dolen et al. (2016), leading to systematic uncertainties which cannot be simply characterized or controlled. The desire for optimal discrimination and reduced sensitivity to systematic uncertainties are naturally at tension with each other.
One solution, Designing Decorrelated Taggers (DDT) Dolen et al. (2016), uses a simple parametric function to construct a modified version of one tagging variable (e.g. ), adjusted specifically to avoid distorting the mass spectrum. This has been shown CMS Collaboration (2016) to effectively balance the issues of discrimination and systematic uncertainty for the quantity .
However, a multivariate classifier (such as a neural network) utilizing the full suite of tagging variables will have considerably greater discrimination power than any individual variable, or pair of variables Baldi et al. (2016a). In principle, the DDT approach could be generalized to handle multiple variables, or even the output of a machine-learning-based combination of these variables, but the more complex and non-linear response will require increasingly complex and non-linear corrections.
In this paper, we incorporate the decorrelation requirement directly into the machine learning strategy by modifying the learning rule to include a constraint which attempts to penalize solutions that distort the background mass spectrum. The training strategy is adversarial Schmidhuber (1991); Ganin et al. (2016); Edwards and Storkey (2016); Goodfellow et al. (2014), in which a pair of networks, a classifier and an adversary, are trained simultaneously with different objectives. The classifier is trained in the traditional manner to maximize classification accuracy. As proposed by Ref. Louppe et al. (2016), the adversary is trained to infer the value of one of the classifier inputs from the classifer response. In this scheme, the two networks together perform a constrained optimization which maximizes classification accuracy while minimizing the dependence of the classifier response on the selected input. Here, one network performs jet substruture classification, while the adversary attempts to infer the jet mass solely from the classifier response.
Lastly, we generalize the adversarial decorrelation technique to include the case where both the classifier and its adversary are parameterized by some external quantity, such as a theoretical hypothesis for the mass of a new particle or a field coupling strength. This is motivated by the fact that resonance searches, such as the one described here, are often performed as scan over a range of potential masses. Generally the optimal classifier for each hypothesis will differ. However, the signal simulations used for training can usually only be sampled for a small number of hypotheses values due to the computational expense of producing them.
Networks parameterized in this way Cranmer et al. (2015); Baldi et al. (2016b) can interpolate to provide optimal classification for hypotheses which were not included in the training, allowing sensitivity to be evaluated without generating simulations at those points. We show that a single adversarially-trained classifier, parameterized in the hypothesis signal mass, remains decorrelated over the range of values upon which it is trained.
II Benchmark Data
Simulated samples are used to model the kinematics of the signal and background processes. As a benchmark signal, we use the model from Ref. Shimmin and Whiteson (2016), which produces a hadronically-decaying resonance boosted by its recoil against an initial state photon (Fig. 1). The same model can be used to study recoil against initial-state gluons or bosons; we choose the photon channel due to the simpler event topology.
Signal events in which a hypothetical boson decays to quarks are simulated at parton level with madgraph5 Alwall et al. (2014) v2.2.3, with pythia Sjostrand et al. (2006) v6.4.28 for showering and hadronization, and with delphes de Favereau et al. (2014) v3.1.2 in the ATLAS-style configuration for primitive detector simulation. The primary background is due to jets production, which is generated with sherpa Gleisberg et al. (2009) v.2.2.0 requiring one photon and one to three additional hard partons.
The measurement of jet masses is sensitive to the presence of additional in-time interactions, referred to as pile-up events. We overlay such interactions in the simulation chain, with an average number of interactions per event of , which is comparable to the level observed in ATLAS 2015 data, with the LHC delivering collisions at a 25ns bunch crossing interval.
The impact of pile-up events on jet reconstruction can be mitigated using several techniques. First, we employ a jet-area-based pileup subtraction on narrow-radius jets, as implemented by fastjet Cacciari et al. (2012). Additionally, when reconstructing large-radius jets, we apply a jet-trimming algorithm Krohn et al. (2010) which is designed to remove pileup, while preserving the two-pronged jet substructure characteristic of boson decay. Jets are trimmed by reclustering into subjets, with , and dropping subjets with less than 3% of the original jet .
As the angular separation of the quarks may be quite small in the case of a high- , we reconstruct a single large-radius jet with distance parameter . To reflect the thresholds imposed by the ATLAS trigger, we require GeV and GeV. In the case of multiple large- jets, the one with greatest is selected.
For the large-radius jets, we calculate various jet substructure variables such as the -subjettiness ratio Thaler and Van Tilburg (2011, 2012), and the Energy Correlation Functions Larkoski et al. (2013, 2014). Recent studies have shown that deep neural networks applied to lower-level calorimeter information can match the performance of several of these higher-level variables in combination Baldi et al. (2016a), but these higher-level variables capture most of the discriminative information and are theoretically well understood.
Distributions of the various kinematic quantities for jets selected in signal and background processes are shown in Fig. 2. The neural networks described below use eleven variables:
- •
Jet pseudo-rapidity, azimuthal angle, transverse momentum, and invariant mass;
- •
Jet energy correlation variables, and Larkoski et al. (2013);
- •
Jet N-subjettiness () Thaler and Van Tilburg (2011); and
- •
Photon energy, pseudo-rapidity, azimuthal angle, transverse momentum.
For comparison with Ref. Dolen et al. (2016), we additionally apply the DDT procedure to produce a modified variable, , which has reduced correlation with jet mass. However, no simple linear relationship was seen between the profile of and the jet mass, and a linear correction does not remove the dependence; this may be due to the application of jet trimming, which differs from the treatment in Ref. Dolen et al. (2016). To provide a fair comparison, we extend the DDT-style approach to use a second-order correction, producing a variable , which demonstrates reasonable indepenence from the jet mass (Fig. 5).
III Neural Networks
The strategy outlined in Ref. Louppe et al. (2016) describes how to train a classifier which is uncorrelated with a nuisance parameter. Here, we apply this strategy to the closely-related problem of decorrelating the classifier with respect to the jet invariant mass, as the nuisance parameter is not well defined; further discussion of this issue is found below in Sec. V. In Sec. VII, we extend this strategy to a problem requiring a parameterized solution.
Two neural networks — a jet classifier and an adversary — constitute two distinct segments of the feedforward architecture shown in Fig. 3. The loss of the tagger is defined as
[TABLE]
where is a positive constant, and and are the standard classification-error loss functions for each segment. The two neural networks are trained concurrently; the tagger’s objective is to minimize , while adversary minimizes only . The hyperparameter represents a tradeoff between the two objective terms; we found that a value of was a good tradeoff for our task, but in general this hyperparameter can be optimized like any other.
The classifier network in this experiment consisted of eleven input features, three fully-connected hidden layers each with 300 nodes having hyperbolic tangent activation functions, and a single logistic output node with the binomial cross-entropy classification objective. The adversarial network consisted of a single input, 50 nodes with hyperbolic tangent activation functions, and a softmax output layer with 10 classes corresponding to binned values of the jet invariant mass (each bin representing one decile of the background), and the multi-class cross-entropy classification objective.
Because the adversary is challenged with adapting to an ever-changing input as the classifier is trained, and also because its task is relatively easy, two strategies were used to train the adversary faster than the classifier. First, the adversary was given a head start at the beginning of training with 100 updates while the classifier was fixed. Second, the adversary was trained with a larger learning rate of compared to for the tagger objective.
The data set used for experiments was divided into training (80%), validation (10%, used for hyperparameter tuning), and testing (10%) subsets. Each classifier input feature was log-scaled if the empirical skew estimate was greater than 1.0, then standardized to zero mean and unit variance. Model parameters were initialized from a scaled normal distribution Glorot and Bengio (2010).
Training was performed using stochastic gradient descent, applied to mini-batches of 100 examples from each class. During training, the event weights were scaled so that the average weight for each class was 1.0. However, in the adversarial loss function , the signal events were given zero weight, rendering them invisible to the adversary.
Updates were made using a training momentum term of 0.5; the learning rate decayed by a factor of after each update. Training was stopped after 100 epochs, where an epoch was defined as a single pass through the background samples (k training events). Models were implemented in Keras Chollet (2015) and Theano Theano Development Team (2016), and hyperparameters were optimized on a cluster of Nvidia Titan Black processors.
IV Performance
We compare the discrimination power of five candidate classifiers: the NN trained without an adversary, the adversarially-trained NN, the unmodified , and the two DDT-modified variables , and . The performance can be characterized by measuring the signal efficiency and background rejection of various thresholds on these discriminators (Fig. 4).
The variable , which is modified to reduce correlation with the mass, results in a modest decrease in its classification power relative to the unmodified at GeV, though note that these effects are mass-dependent for both and . Similarly, the adversarial network does not match the discrimination power of the traditional classification network, due to the additional constraint imposed in its optimization. However, both NNs are clearly able to take advantage of the combined power of the substructure variables, and offer a large improvement in background rejection for similar signal efficiencies compared to classification based on alone.
The focus of this study, however, is to look beyond the pure discriminatory power of these tools and study their effect on the jet mass spectrum. In Fig. 5, it can be seen that the adversarial network output for background events has a profile which is largely independent of jet mass, while the classifying network is strongly dependent on jet mass. Similarly, and have a lessened dependence on jet mass, compared to . Figure 6 shows the effect on the jet mass distribution of successively stricter requirements on these variables. Note that the adversarial network’s dependence on jet mass is diminished, but not eliminated, as can be seen in the contour plot of Fig. 5. This is a reflection of the trade-off inherent in balancing classification power with jet mass dependence.
In Fig. 5, we also show the profile of the neural network output versus jet mass, for various thresholds on the jet , which shows some small -dependent effects, but no large features. As an alternative strategy, we trained a network using an adversarial strategy with respect to log(), which more closely mimics the approach used in Ref. Dolen et al. (2016); the training succeeded in finding a network with a flat response in log(), but the distortion in jet mass was much more significant. In principle, it is possible to use the adversary to enforce a two-dimensional decorrelation, but since the -dependence is not severe here, we leave this for future study.
V Statistical Interpretation
The ability to discriminate jets due the hadronic decay of a boosted object from those due to a quark or gluon is an important feature of a jet substructure tagging tool, but as discussed above it is not the only requirement. Due to the necessity of accurately modeling the background, it is desirable that the jet tagger avoid distortion of the background distribution. Simpler background shapes are especially preferred because they allow for robust estimates that are constrained by the sidebands; backgrounds that can be modeled with fewer parameters and inflections avoid degeneracy with signal features, such as a peak.
Fig. 5 shows qualitatively that the adversarial network’s response is not strongly dependent on jet mass. But a quantitative assessment is more difficult. Mass-independence is not in itself the goal; instead, we seek reduced dependence on knowledge of the background shape and reduced sensitivity to the systematic uncertainties that tend to dilute the statistical significance of a discovery.
However, our lack of knowledge of the true background model in general also makes it non-trivial to rigorously define and estimate the background uncertainty. In practice, experimentalists use an assumed functional form, with parameters constrained by background-dominated sidebands to predict the background in the signal region. These assumptions may be validated by examining control regions in which the signal is not present, and the background processes are expected to exhibit physically similar properties. For example, the tagger selection may be inverted to yield a sample with high background purity which may be used as a template. If the tagger selection induces a distortion of the spectrum, these techniques are ineffective. Moreover, when tagger-induced distortion depletes data from the sidebands (as is typically the case), any background model becomes more difficult to constrain. To demonstrate these effects on the overall statistical performance of a search, we construct a simplified statistical test which has the desired behavior of penalizing discriminators which yield excessive distortion of the background shape.
A threshold is placed on the discriminator output, after which a likelihood fit is performed, binned in the distribution of reconstructed large-radius jet masses using signal and background templates from simulated samples111In principle, the most powerful approach is a likelihood directly on the output of the discriminator, but this requires a valid model of the background, which is lacking in this case.. An uncertainty on the rate of the background is included in order to model our lack of knowledge of the background. We calculate expected discovery significance using a profile likelihood ratio Cowan et al. (2011) with the CLs technique Read (2002); Junk (1999), marginalizing over the unknown background rate.
Though the background shape is fixed via the template, the uncertainty on the rate provides the statistical behavior we seek. Specifically, if the uncertainty in the rate of the background is large enough, then the discovery significance is sensitive also to the shape of the background distribution as follows. In the case that the background is fairly flat, there are background-dominated sidebands which can constrain the rate uncertainty. In the opposite case that the background is distorted to mimic the signal, these sideband constraints have reduced power, and the signal and background are more difficult to distinguish statistically. Hence, the presence of rate uncertainties penalizes a solution which distorts the background spectrum as desired. Although this simple approach likely underestimates the true impact of more realistic systematics, it is sufficient to illustrate the effect on sensitivity. In the following, we take for the small (large)-uncertainty case a relative uncertainty of 5% (50%) on the overall background rate.
Examples of the final jet mass distribution are shown in Figs. 7 and 8 for thresholds on the discriminants which result in signal efficiency of 90% and 50% respectively.
VI Results
The discovery significance is measured for varying thresholds on the discriminator outputs. While all of the discriminators exhibit some degree of classification power, this study explores the question of whether they provide additional discovery significance.
Figure 9 shows the discovery significance as a function of the signal efficiency of the discriminator threshold, for two choices of background uncertainty. In the case of the small uncertainty (5% relative), applying a tighter threshold on the discriminator improves the discovery significance, despite lowering the signal efficiency, due to the heightened background suppression. Even at fairly low signal efficiencies of 50%, where the background is sculpted to look like the signal (see Fig. 8), the discovery significance is improved. This is as expected; if the background rate and shape are well known, then the lack of constraining sidebands is not detrimental.
For the case of the larger background rate uncertainty, thresholds on provide a smaller boost to the significance. The large relative uncertainty on the background will penalize configurations in which the background is sculpted to resemble the signal, preventing the data from constraining the background rate in the sidebands. Thresholds on and are slightly stronger, as expected, due to their decreased correlation with jet mass. Thresholds on the output of the classifier network, which has the strongest discrimination power, only weakens the discovery significance, due to the background mass distortion. However, the adversarial network is still capable of powerful discrimination which improves the discovery power at high signal efficiency, around 90%. Table 1 shows the maximal discovery significance for each case. The qualitative results persist for other signal-to-background ratios.
VII Parameterized Neural Networks
The studies above demonstrate the application for the case of a single example value of the hypothetical mass. In this section, we show that the same approach can be generalized to solve a set of closely related problems, jet classification for different masses, using a single neural network parameterized in .
These parameterized neural networks Baldi et al. (2016b) address a common problem in physics: solving a classification task multiple times for different values of an unknown latent variable, like . Simulations used to train jet classifiers are generally performed for a small set of fixed mass values. In the traditional approach, a separate neural network classifier is trained for each mass value. However, by treating as just another input feature, a single parameterized neural network can learn to solve the related classification tasks all at once (Fig. 10). Furthermore, the classifier can interpolate to other values of if the function is smooth.
For this experiment, some hyperparameters were tuned to this more complex task. The classifier had three hidden layers of 300 nodes, with a learning rate of , a momentum of , and an L2 weight decay factor of in each layer. The adversary consisted of two hidden layers of 100 nodes each, with a learning rate of , a momentum of , and an L2 weight decay factor of in each layer. The parameter was set to .
The adversary was also parameterized by including the mass as an input along with the classifier output. The resulting classifier predictions for background events are mostly independent of mass when conditioned on each theory mass (Fig. 11). Without this parameterization of the adversary, the marginalized classifier predictions are independent of mass, but not the conditional classifier predictions.
As expected, the resulting classifier demonstrates better performance than the single input features , or at all signal mass hypotheses tested (Fig. 12). As in the non-parameterized case, the traditional NN trained to maximize classification accuracy achieves the best separation.
Moreover, the lack of background distortion by the adversarially-trained network preserves the ability to distinguish the background and signal mass distributions, leading to improved discovery significance; see Fig. 13. The statistical test is performed as for the previous case, fitting a binned likelihood on the jet mass distribution after applying a threshold on the discriminator output. As before, the improved separation of the traditional NN does not translate to improved discovery significance.
We note that while the performance shown here is evaluated on hypothesized mass values used for training, Ref. Baldi et al. (2016b) demonstrates this architecture is able to successfully interpolate to other values of .
VIII Discussion
We have demonstrated that an adversarial training strategy may yield a jet classification tagger which leverages the powerfully discriminating information obtained by combining several input features, while decorrelating its output from the variable of interest, the jet mass. This allows the classifier to enhance signal to noise ratio while minimizing the tendency of the background distribution to morph into a shape which is degenerate with the observable signal. When the background cannot be reliably predicted a priori, as is often the case, it is important to be able to constrain its rate in sidebands surrounding the signal region. Therefore, avoiding such degeneracy is critical to performing successful measurements.
We note that, from Fig. 8, it is clear that applying sufficiently tight cuts to the adversarial classifier causes significant background morphing, particularly when compared to the -based discriminants. However, the solid lines of Fig. 9 illustrate the case where the background rate is uncertain and hence benefits from sideband constraints. We see that the optimal significance is realized for the adversarial classifier at a relatively high signal efficiency of roughly 90%, where the background morphing is quite limited (Fig. 7). Hence, the adversarial classifier achieves its goal of optimizing the tradeoff between correlation and discrimination power.
We also note that the decorrelation could potentially be improved. The contour plot in Fig. 5 shows that while the average NN output is independent of mass, there is certainly still structure that results in the background sculpting still observed. The residual dependence could also be removed, possibly with a more sophisticated adversary that is trained to predict multiple variables simultaneously. These improvements we leave for future work.
Finally, we extend the strategy to the case of a parameterized network wherein the NN classifier is trained to tag specific signal hypotheses, useful for scanning a range of theoretical parameter space with a search. The resulting combined approach should be readily applicable to experimental measurements and searches, boosting their discovery significance or search sensitivity.
IX Acknowledgements
The authors acknowledge useful conversations with Kyle Cranmer, Jesse Thaler, Kevin Bauer, and Dan Guest, helpful comments from Sal Rappoccio, Derek Soeder and Michela Paganini, and are grateful to the Aspen Center for Physics, where much useful discussion occured.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Butterworth et al. (2008) J. M. Butterworth, A. R. Davison, M. Rubin, and G. P. Salam, Phys.Rev.Lett. 100 , 242001 (2008) , ar Xiv:0802.2470 [hep-ph] . · doi ↗
- 2Adams et al. (2015) D. Adams, A. Arce, L. Asquith, M. Backovic, T. Barillari, et al. , (2015), ar Xiv:1504.00679 [hep-ph] .
- 3Abdesselam et al. (2011) A. Abdesselam et al. , Boost 2010 Oxford, United Kingdom, June 22-25, 2010 , Eur. Phys. J. C 71 , 1661 (2011) , ar Xiv:1012.5412 [hep-ph] . · doi ↗
- 4Altheimer et al. (2012) A. Altheimer et al. , BOOST 2011 Princeton , NJ, USA, 22–26 May 2011 , J. Phys. G 39 , 063001 (2012) , ar Xiv:1201.0008 [hep-ph] . · doi ↗
- 5Altheimer et al. (2014) A. Altheimer et al. , BOOST 2012 Valencia, Spain, July 23-27, 2012 , Eur. Phys. J. C 74 , 2792 (2014) , ar Xiv:1311.2708 [hep-ex] . · doi ↗
- 6Shimmin and Whiteson (2016) C. Shimmin and D. Whiteson, Phys. Rev. D 94 , 055001 (2016) , ar Xiv:1602.07727 [hep-ph] . · doi ↗
- 7Thaler and Van Tilburg (2011) J. Thaler and K. Van Tilburg, JHEP 03 , 015 (2011) , ar Xiv:1011.2268 [hep-ph] . · doi ↗
- 8Larkoski et al. (2013) A. J. Larkoski, G. P. Salam, and J. Thaler, JHEP 06 , 108 (2013) , ar Xiv:1305.0007 [hep-ph] . · doi ↗