Online Sequential Monte Carlo smoother for partially observed stochastic differential equations
Pierre Gloaguen (MIA-Paris), Marie-Pierre Etienne (MIA-Paris), Sylvain, Le Corff

TL;DR
This paper presents an online Monte Carlo smoothing algorithm for partially observed stochastic differential equations, using unbiased estimators to handle unknown transition densities, enabling real-time data processing with linear complexity.
Contribution
Introduces a novel online smoothing algorithm for SDEs that employs unbiased estimators to manage unknown transition densities, extending previous methods.
Findings
Algorithm is consistent and effective.
Performance demonstrated on two models.
Computational complexity grows linearly with samples.
Abstract
This paper introduces a new algorithm to approximate smoothed additive functionals for partially observed stochastic differential equations. This method relies on a recent procedure which allows to compute such approximations online, i.e. as the observations are received, and with a computational complexity growing linearly with the number of Monte Carlo samples. This online smoother cannot be used directly in the case of partially observed stochastic differential equations since the transition density of the latent data is usually unknown. We prove that a similar algorithm may still be defined for partially observed continuous processes by replacing this unknown quantity by an unbiased estimator obtained for instance using general Poisson estimators. We prove that this estimator is consistent and its performance are illustrated using data from two models.
Click any figure to enlarge with its caption.
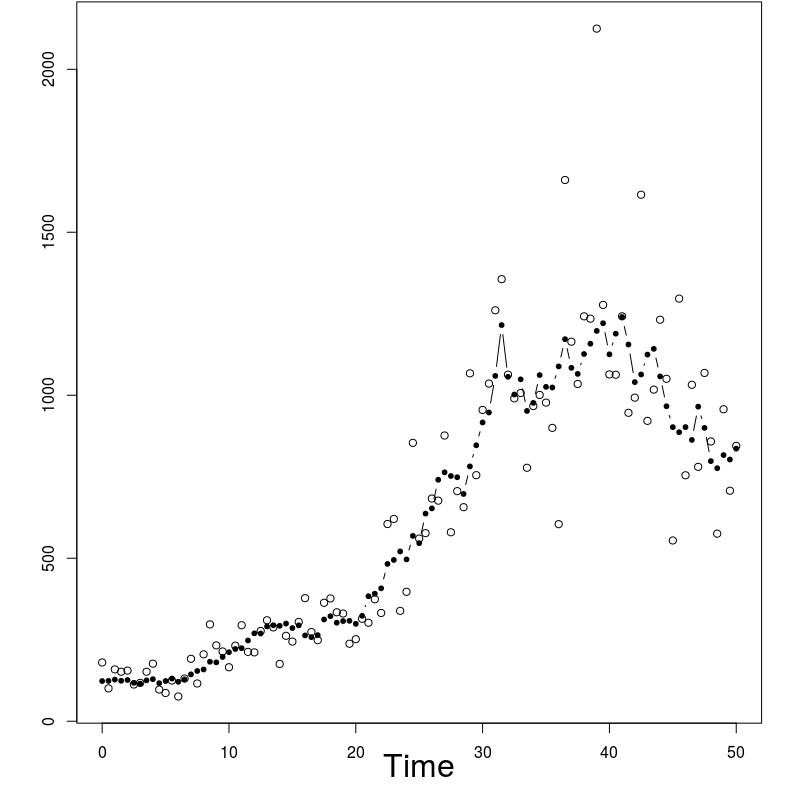 Figure 1
Figure 1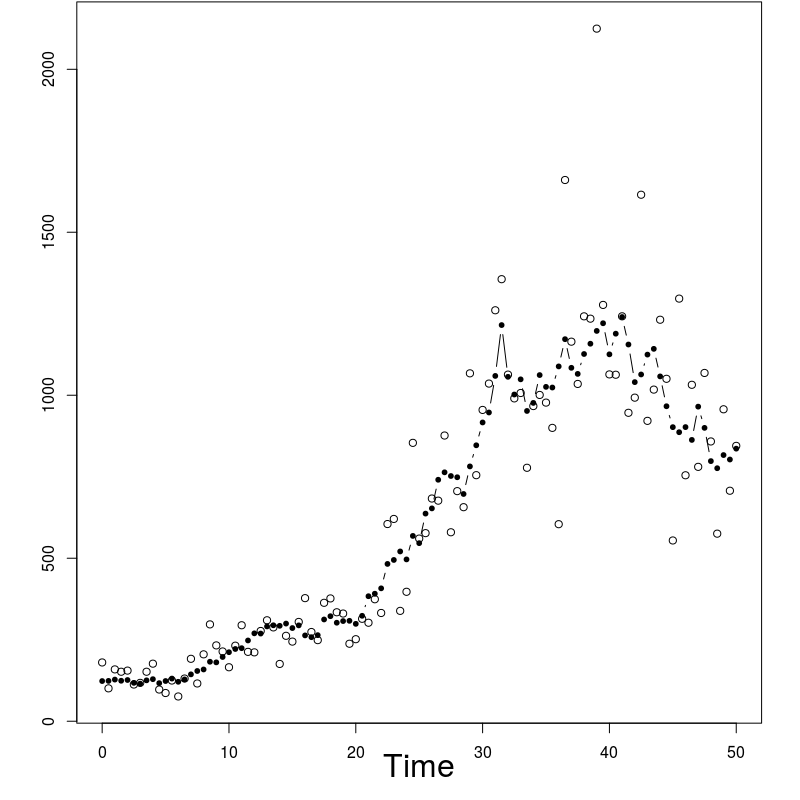 Figure 2
Figure 2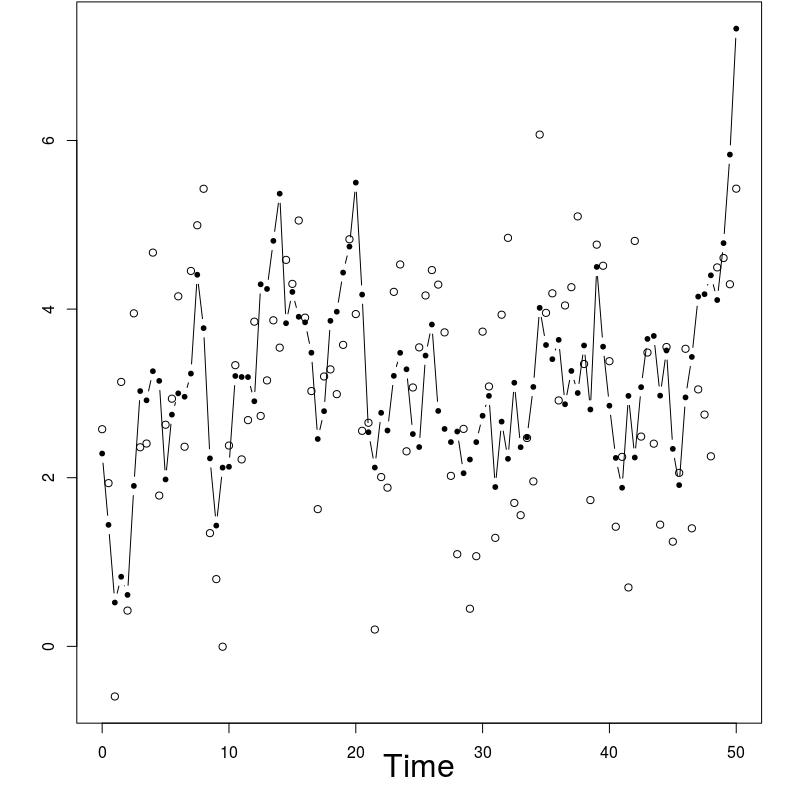 Figure 3
Figure 3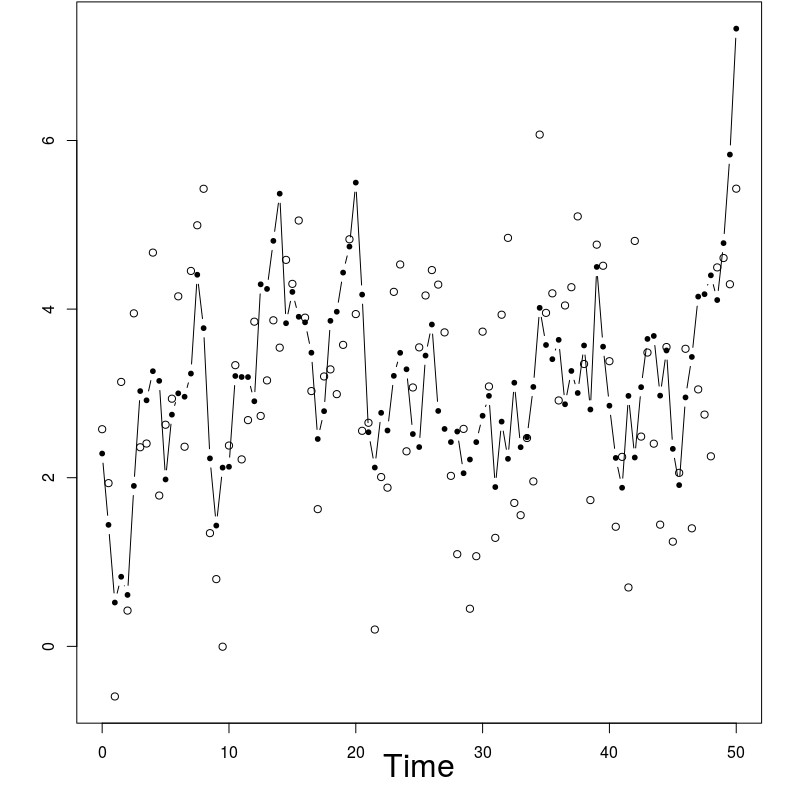 Figure 4
Figure 4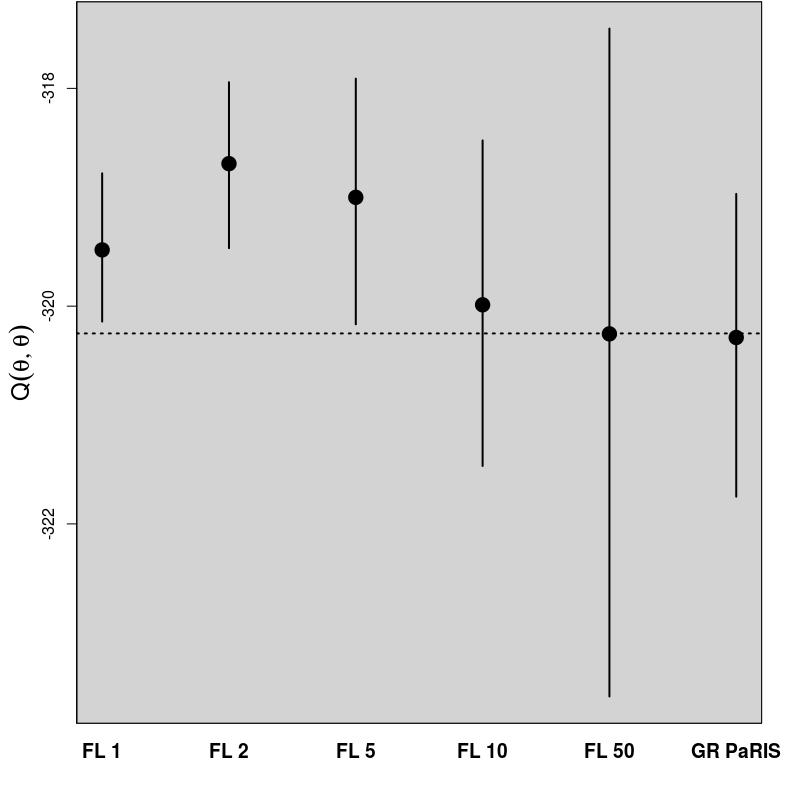 Figure 5
Figure 5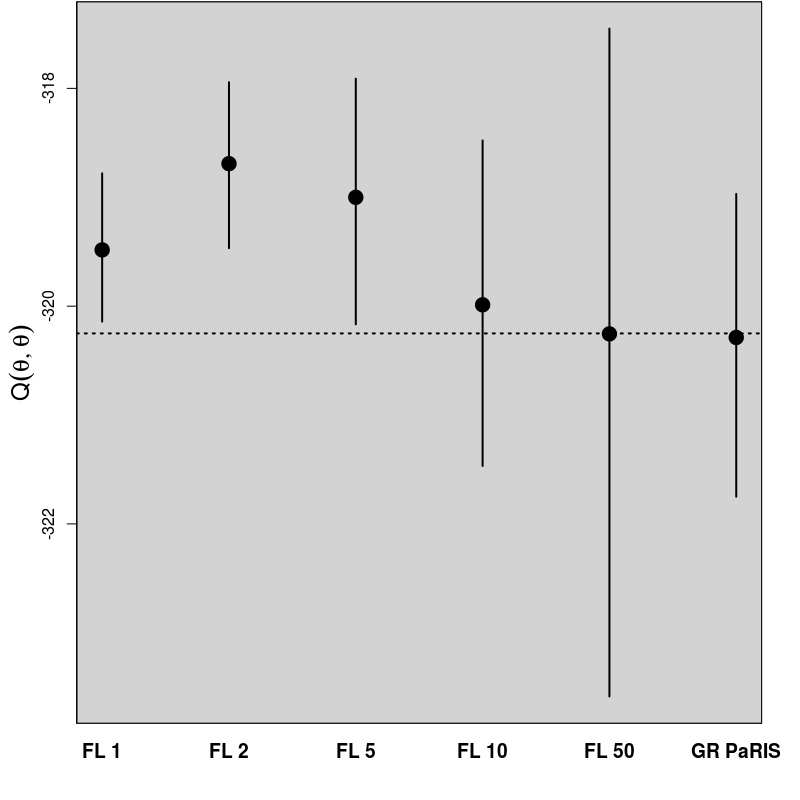 Figure 6
Figure 6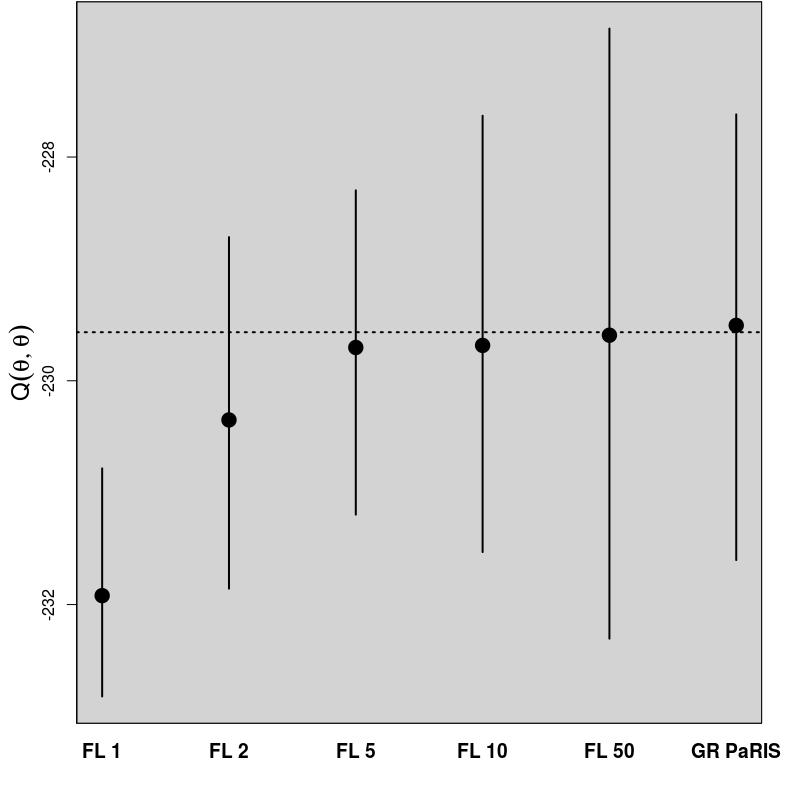 Figure 7
Figure 7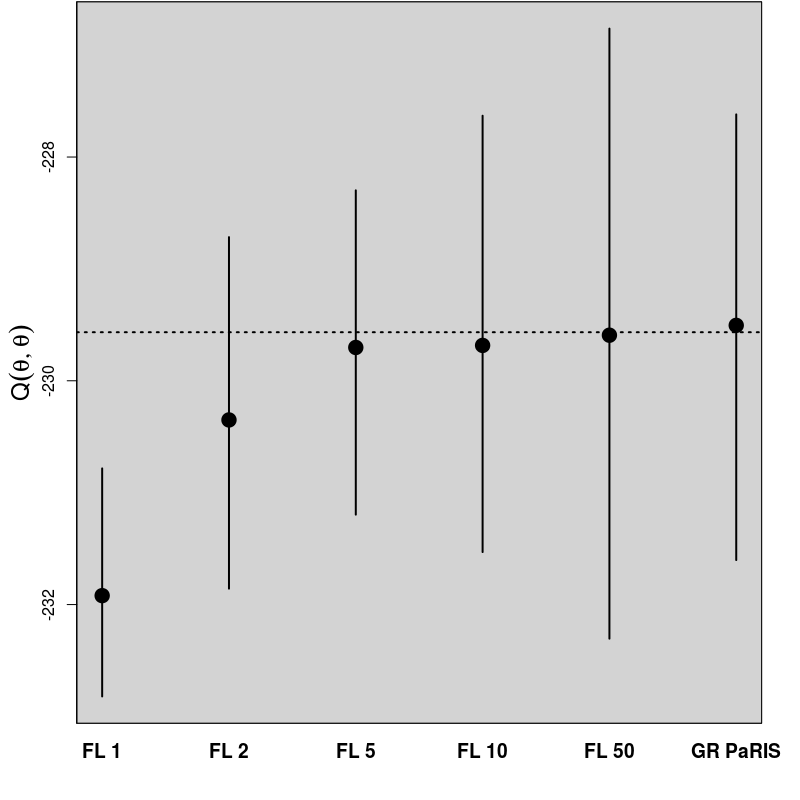 Figure 8
Figure 8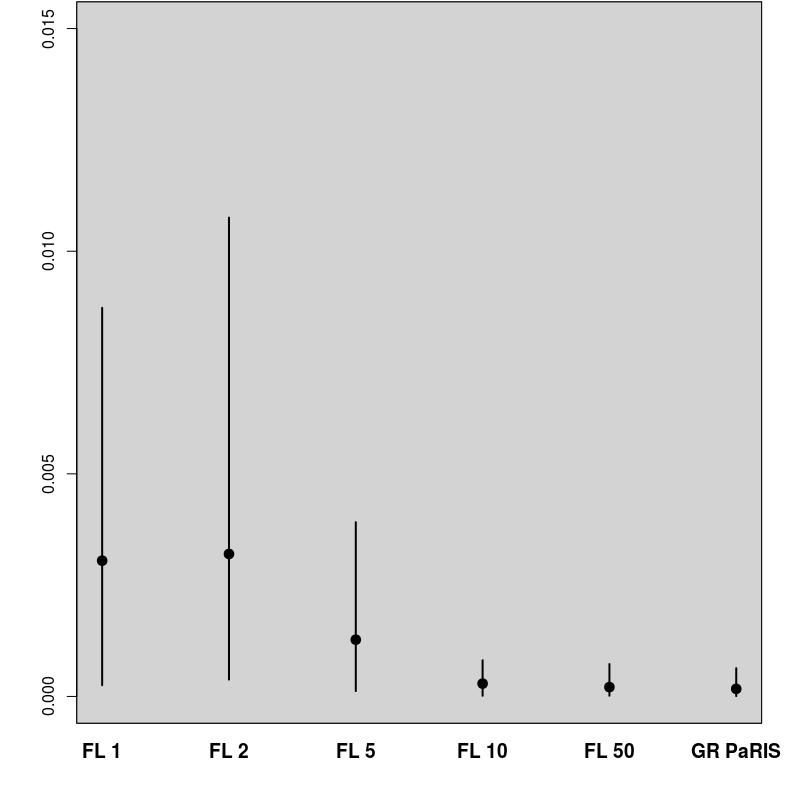 Figure 9
Figure 9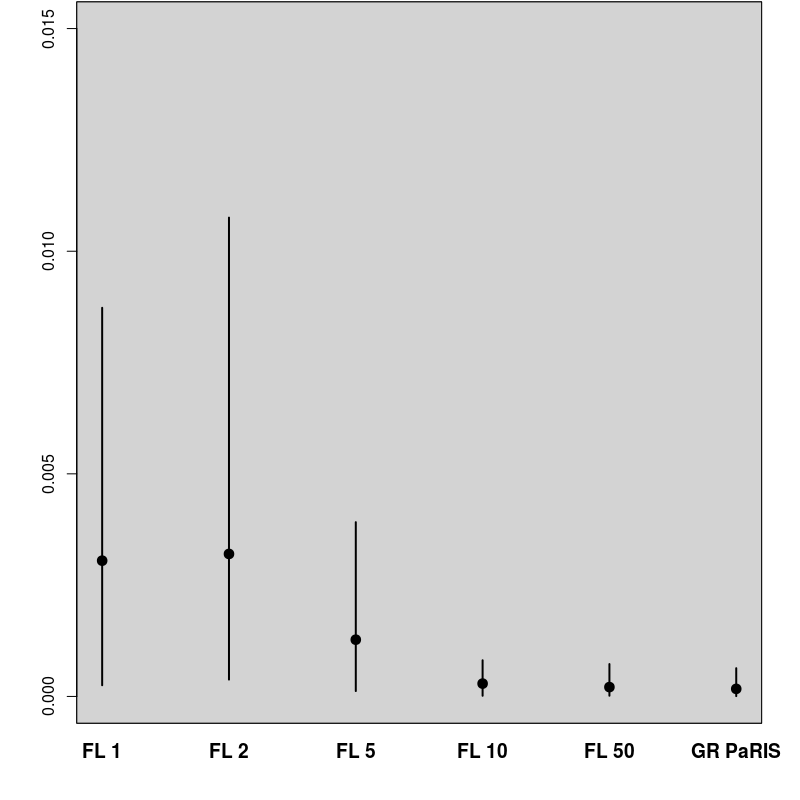 Figure 10
Figure 10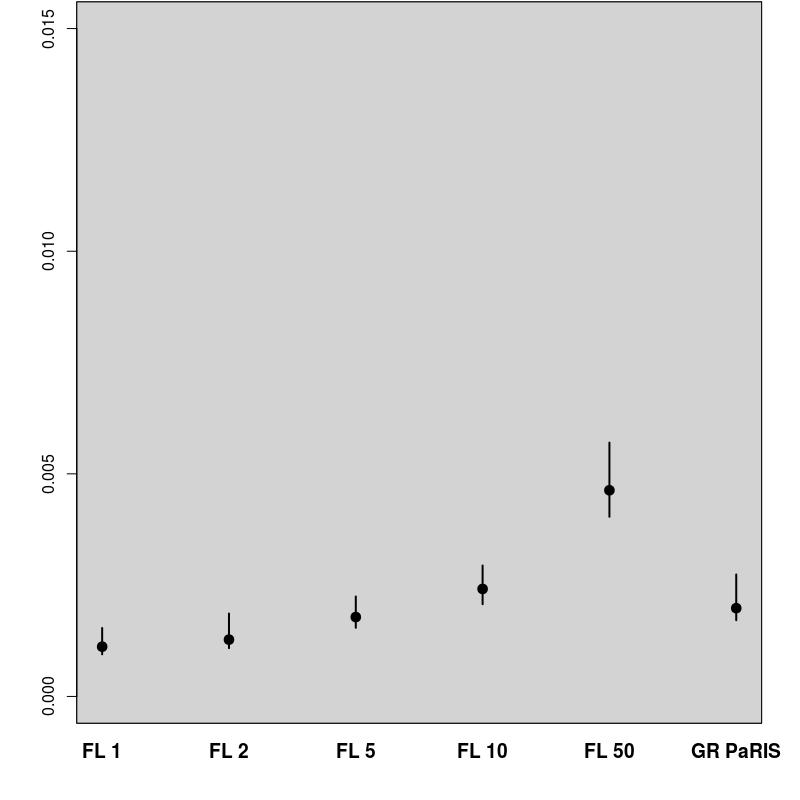 Figure 11
Figure 11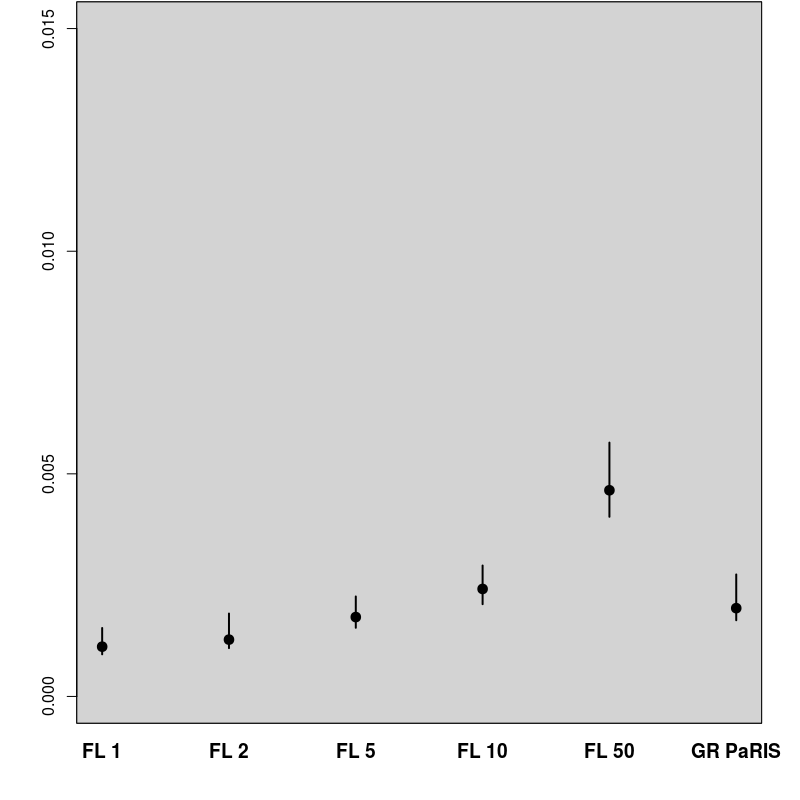 Figure 12
Figure 12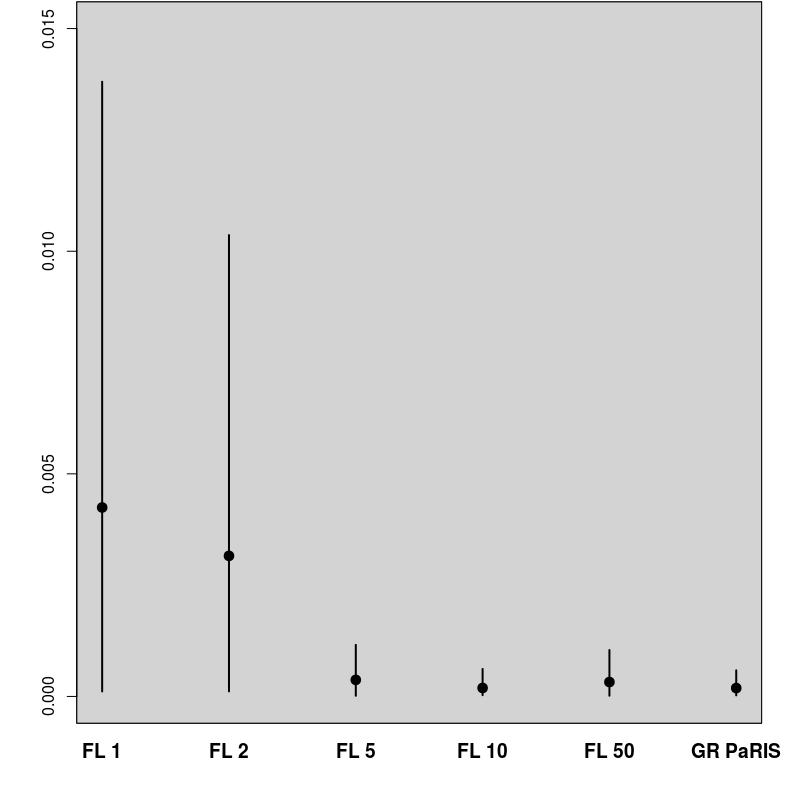 Figure 13
Figure 13 Figure 14
Figure 14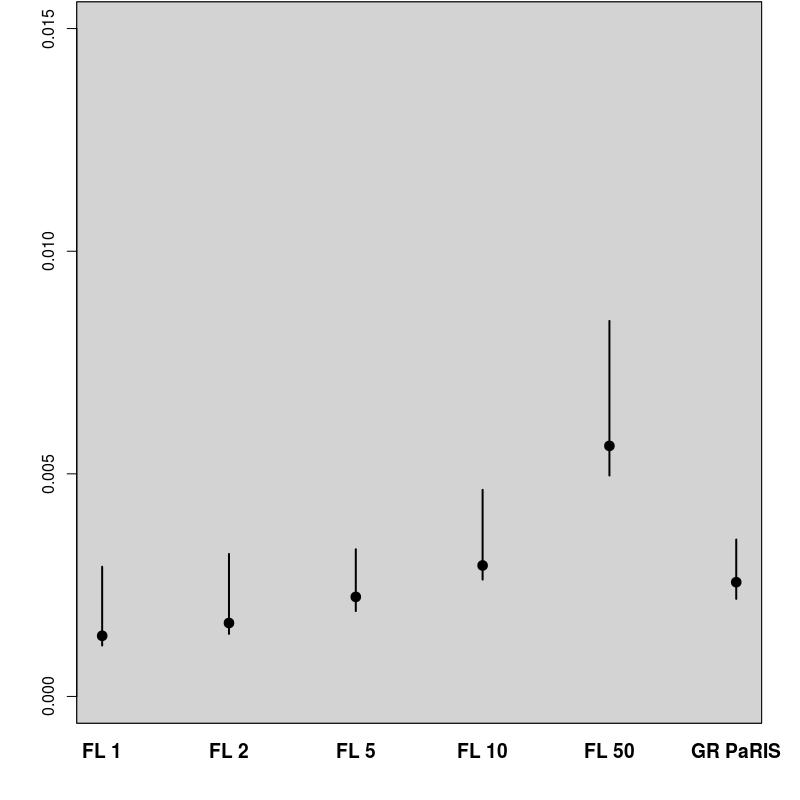 Figure 15
Figure 15 Figure 16
Figure 16Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStochastic processes and financial applications · Target Tracking and Data Fusion in Sensor Networks · Statistical Methods and Inference
Online Sequential Monte Carlo smoother for partially observed stochastic differential equations
Pierre Gloaguen111AgroParistech, UMR MIA 518, F-75231 Paris, France.
Marie-Pierre Etienne11footnotemark: 1
Sylvain Le Corff222Laboratoire de Mathématiques d’Orsay, Univ. Paris-Sud, CNRS, Université Paris-Saclay.
Abstract
This paper introduces a new algorithm to approximate smoothed additive functionals for partially observed stochastic differential equations. This method relies on the recent procedure introduced in [24] which allows to compute such approximations online, i.e. as the observations are received, and with a computational complexity growing linearly with the number of Monte Carlo samples. The algorithm of [24] cannot be used in the case of partially observed stochastic differential equations since the transition density of the latent data is usually unknown. We prove that a similar algorithm may still be defined for partially observed continuous processes by replacing this unknown quantity by an unbiased estimator obtained for instance using general Poisson estimators. We prove that this estimator is consistent and its performance are illustrated using data from two models.
Keywords: Stochastic differential equations, Smoothing, Sequential Monte Carlo Methods.
1 Introduction
This paper introduces a new algorithm to solve the smoothing problem for partially observed continuous time stochastic processes. In this setting, the hidden state process is assumed to be a solution to a stochastic differential equation (SDE) and the only information available is given by noisy observations of the states at some discrete time points . The bivariate stochastic process is a state space model such that conditional on the state sequence the observations are independent and for all the conditional distribution of given depends on only.
Statistical inference for partially observed state sequences often requires to solve bayesian filtering and smoothing problems, i.e. the computation of the posterior distributions of sequences of hidden states given observations. The filtering problem refers to the estimation, for each , of the distributions of the hidden state given the observations . Smoothing stands for the estimation of the distributions of the sequence of states given observations with . These posterior distributions are crucial to compute maximum likelihood estimators of unknown parameters using the observations only. For instance, the E-step of the EM algorithm introduced in [7] boils down to the computation of a conditional expectation of an additive functional of the hidden states given all the observations up to time . Similarly, by Fisher’s identity, recursive maximum likelihood estimates may be computed using the gradient of the loglikelihood which can be written as the conditional expectation of an additive functional of the hidden states. See [5, Chapter and ], [15, 19, 20, 27] for further references on the use of these smoothed expectations of additive functionals applied to maximum likelihood parameter inference in latent data models.
The exact computation of these expectations is usually not possible in the case of partially observed diffusions. In this paper, we propose to use Sequential Monte Carlo (SMC) methods to approximate smoothing distributions with random particles associated with importance weights. [13, 18] introduced the first particle filters and smoothers for state space models by combining importance sampling steps to propagate particles with resampling steps to duplicate or discard particles according to their importance weights. Unfortunately, these methods cannot be applied directly to partially observed stochastic differential equations since some elementary quantities, such as transition densities of the hidden states, are not available explicitly. Discretization procedures may be used to approximate transition densities, for instance the Euler-Maruyama method, the Ozaki discretization which proposes a linear approximation of the drift coefficient between two observations [25, 28], or Gaussian based approximations using Taylor expansions of the posterior mean and variance of an observation given the observation at the previous time step, [16, 17, 29]. Other approaches based on Hermite polynomials expansion were also introduced by [1, 2, 3] and extended in several directions recently, see [21] and all the references on the approximation of transition densities therein. However, even the most recent discretization based approximations of the transition densities induce a systematic bias of particle based approximations of posterior distributions, see for instance [6]. To overcome this difficulty, [11] proposed to solve the filtering problem by combining SMC methods with an unbiased estimate of the transition densities based on the generalized Poisson estimator (GPE). In this case, only the Monte Carlo error has to be controlled as there is no Taylor expansion to approximate unknown transition densities.
The only solution to solve the smoothing problem for partially observed SDE using SMC methods has been proposed in [23] and extends the fixed-lag smoother of [22]. Using forgetting properties of the hidden chain, the algorithm improves the performance of [11] to approximate smoothing distributions but at the cost of a bias that does not vanish as the number of particles grows to infinity. In the case of discrete time state space models, approximations of the smoothing distributions may also be obtained using the Forward Filtering Backward Smoothing algorithm (FFBS) and the Forward Filtering Backward Simulation algorithm (FFBSi) developed respectively in [18, 14, 9] and [12]. Both algorithms require first a forward pass which produces a set of particles and weights approximating the sequence of filtering distributions up to time . Then, a backward pass is performed to compute new weights (FFBS) or sample trajectories (FFBSi) in order to approximate the smoothing distributions. Recently, [24] proposed a new SMC algorithm, the particle-based rapid incremental smoother (PaRIS), to approximate on-the-fly (i.e. using the observations as they are received) smoothed expectations of additive functionals. Unlike the FFBS algorithm, the complexity of this algorithm grows only linearly with the number of particles and contrary to the FFBSi algorithm, no backward pass is required.
In this paper, we extend the use of PaRIS algorithm to partially observed SDE. The proposed algorithm allows to approximate smoothed expectations of additive functionals online and with a complexity growing only linearly with the number of particles. The crucial and simple result (Lemma 1) of the application of PaRIS algorithm to SDE is that the accept reject mechanism introduced in [8] ensuring the linear complexity of the procedure is still correct when the transition densities are replaced by unbiased estimates. The usual FFBS and FFBSi algorithms may not be extended this easily since they both require the computation of weights defined as ratios involving the transition densities, thus replacing these unknown quantities by unbiased estimates does not lead to unbiased estimators of the weights. The proposed Generalized Random version of PaRIS algorithm, hereafter named GRand PaRIS algorithm, may be applied to general hidden Markov models whose Markovian dynamics is ruled by a stochastic differential equation (one of the first two domains defined in [4]) but also to any general state space model where the transition density of the hidden chain may be estimated unbiasedly.
Section 2 describes the proposed algorithm to approximate smoothed additive functionals using unbiased estimates of the transition density of the hidden states and details the application of this algorithm when the transition density may be approximated using a GPE. In Section 3, classical convergence results for SMC smoothers are extended to the setting of this paper and illustrated with numerical experiments in Section 4. All proofs are postponed to Appendix A.
2 The Generalized Random PaRIS algorithm
is defined as a weak solution to the following SDE in :
[TABLE]
where is a standard Brownian motion. It is assumed that is of the form where is a twice continuously differentiable function. The solution to (1) is supposed to be partially observed at times through an observation process in . For all , the distribution of given has a density with respect to a reference measure on given by . The distribution of has a density with respect to a reference measure on given by . For all , the conditional distribution of given has a density with respect to .
Let , the joint smoothing distributions of the hidden states are defined, for all measurable function on , by:
[TABLE]
For all , denote the filtering distributions. The aim of this section is to detail the extension of PaRIS algorithm to approximate expectations of the form
[TABLE]
when the transition density of the hidden states is not available explicitly and where are given functions on . The algorithm is based on the following link between the filtering and smoothing distributions for additive functionals, see [24]:
[TABLE]
The approximation of (3) requires first to approximate the sequence of filtering distributions. Sequential Monte Carlo methods provide an efficient and simple solution to obtain these approximations using sets of particles associated with weights , .
At time , particles are sampled independently according to , where is a probability density with respect to . Then, is associated with the importance weights . For any bounded and measurable function defined on , the expectation is approximated by
[TABLE]
Then, for , using , the auxiliary particle filter of [26] samples pairs of indices and particles using an instrumental transition density on and an adjustment multiplier function on . Each new particle and weight at time are computing following these steps:
choose a particle index at time in with probabilities proportional to , for in ; 2. -
sample using this chosen particle according to ; 3. -
associate the particle with the importance weight:
[TABLE]
The expectation is approximated by
[TABLE]
PaRIS algorithm uses the same decomposition as the FFBS algorithm introduced in [10] and the FFBSi algorithm proposed by [12] to approximate smoothing distributions. It combines both the forward only version of the FFBS algorithm with the sampling mechanism of the FFBSi algorithm. It does not produce an approximation of the smoothing distributions but of the smoothed expectation of a fixed additive functional and thus may be used to approximate (2). Its crucial property is that it does not require a backward pass, the smoothed expectation is computed on-the-fly with the particle filter and no storage of the particles or weights is needed.
PaRIS algorithm relies on the following fundamental property of when is as in (2):
[TABLE]
Therefore, [24] introduces sufficient statistics (starting with , ), approximating , for and . First, replacing by in the last equation leads to the following approximation of :
[TABLE]
where
[TABLE]
Computing exactly these approximations would lead to a complexity growing quadratically with because of the normalizing constant in (6). Therefore, PaRIS algorithm samples particles in the set with probabilities to approximate the expectation (5) and produce . Choosing , at each time step these statistics are updated according to the following steps.
- (i)
Run one step of a particle filter to produce for . 2. (ii)
For all , sample independently in for with probabilities , given by (6). 3. (iii)
Set
[TABLE]
Then, (2) is approximated by
[TABLE]
As proved in [24], the algorithm is asymptotically consistent (as goes to infinity) for any precision parameter . However, there is a significant qualitative difference between the cases and . As for the FFBSi algorithm, when there exists such that , PaRIS algorithm may be implemented with complexity using the accept-reject mechanism of [8].
In general situations, PaRIS algorithm cannot be used for stochastic differential equations as is unknown. Therefore, the computation of the importance weights and of the acceptance ratio of [8] is not tractable. Following [11, 23], filtering weights can be approximated by replacing by an unbiased estimator , where is a random variable in such that:
[TABLE]
where, for all ,
[TABLE]
Practical choices for are discussed below, see for instance (9) which presents the choice made for the implementation of such estimators in our context. In the case where is unknown, the filtering weights in (4) then become:
[TABLE]
Therefore, to obtain a generalized random version of PaRIS algorithm, we only need to be able to sample from the discrete probability distribution in the case of SDE based HMM. Consider the following assumption: for all , there exists a random variable measurable with respect to such that,
[TABLE]
Lemma 1**.**
Assume that holds for some . For all , define the random variable as follows:
* repeat
* Sample independently , and with probabilities proportional to . *
* until . *
* Set . *
Then, the conditional probability distribution given of is .
Proof.
See Appendix A. ∎
Note that Lemma 1 still holds if assumption (A1) is relaxed and replaced by one of the two following assumptions:
[TABLE]
[TABLE]
It is worth noting that under assumptions (A1) or (A2), the linear complexity property of PaRIS algorithm still holds, whereas if only assumption (A3) holds, the algorithm has a quadratic complexity.
Bounded estimator of
For , by Girsanov and Ito’s formulas, the transition density of (1) satisfies, with ,
[TABLE]
where is the law of Brownian bridge starting at at 0 and hitting at , is such a Brownian bridge, is the p.d.f. of a normal distribution with mean and variance , evaluated at and is defined as:
[TABLE]
with the Laplace operator. Assume that there exist random variables and such that for all , . Let be a random variable taking values in with distribution and be independent uniform random variables on , and . As shown in [11], a positive unbiased estimator is given by
[TABLE]
Interesting choices of are discussed in [11] and we focus here on the so called GPE-1, where is a Poisson distribution with intensity . In that case, the estimator (8) becomes:
[TABLE]
On the r.h.s. of (9), the product over elements is bounded by 1, therefore, a sufficient condition to satisfy of the assumptions (A1)-(A3) is that the function:
[TABLE]
is upper bounded almost surely by . In particular, if is bounded almost surely, (10) always satisfies assumption (A3) and Algorithm 1 can be used. This condition is always satisfied for models in the domains and defined in [4], i.e. domains for which the exact algorithms EA1 and EA2 can be used.
When (A1) or (A2) holds, it can be nonetheless of practical interest to choose the bound corresponding to (A3). Indeed, this might increase significantly the acceptance rate of the algorithm, and therefore reduce the number of drawings of the random variable , which has a much higher cost than the computation of , as it requires simulations of Brownian Bridges. Moreover, this latter option can also avoid numerical optimization if no analytical expression of is available. In practice, we found this option more efficient in terms of computation time when has moderate values.
3 Convergence results
Consider the following assumptions.
- H1
- (i)
For all and all , . 2. (ii)
.
- H2
, and , where
[TABLE]
Lemma 2**.**
For all , the random variables are independent conditionally on and
[TABLE]
Proof.
See appendix A ∎
Proposition 1**.**
Assume that HH1 and HH2 hold and that for all , . For all and all , there exist such that for all and all ,
[TABLE]
Proof.
See appendix A ∎
4 Numerical experiments
This section investigates the performance of the proposed algorithm with the sine and log-growth models. In both cases, the proposal distribution is chosen as the following approximation of the optimal filter (or the fully adapted particle filter in the terminology of [26]):
[TABLE]
where is the p.d.f. of Gaussian distibution with mean and variance , i.e. the Euler approximation of equation (1). As the observation model is linear and Gaussian, the proposal distribution is therefore Gaussian with explicit mean and variance.
In order to evaluate the performance of the proposed algorithm, the following strategy has been chosen. We compare the estimation of the EM intermediate quantity with the one obtained by the fixed lag method of [23], for different values of the lag (namely, 1,2,5,10,50). The particle approximation of for each model is computed using each algorithm, see Figure 1 for the SINE model (and respectively Figure 3 for the log-growth model). This estimation is performed 200 times to obtain the estimates , using particles for PaRIS algorithm, and replications for the Monte Carlo approximation of each . Moreover, the E step requires the computation of a quantity such as (2) with . is not available explicitly and is approximated using the unbiased estimator proposed in [23, Appendix B] based on 30 independent Monte Carlo simulations. The intermediate quantity of the EM algorithm is also estimated with our algorithm 30 times using particles, the reference value is then computed as the arithmetic mean of these 30 estimations, and denoted by . Figure 1 (resp. 3 ) shows this estimate for an example on one simulated data set. The GRand Paris algorithm is performed using particles in both cases, the fixed lag technique using so that both estimations require similar computational times.
The SINE model
The performance of the GRand PaRIS algorithm are first highlighted using the SINE model, where is supposed to be the solution to:
[TABLE]
This simple model has no explicit transition density, however GPE estimators may be computed by simulating Brownian bridges. The process solution to (11) is observed regularly at times through the observation process :
[TABLE]
where the are i.i.d. . In the example displayed on Figure 1, we set . In that case, the function defined in (10) can be upper bounded either on or only on , the GRand PaRIS algorithm has therefore a linear complexity.
This same experiment was reproduced on 100 different simulated data sets. For each simulation , the empirical absolute relative bias and the empirical absolute coefficient of variation are computed as
[TABLE]
where and are the empirical mean and standard deviation of the sample . For each estimation method, the resulting distributions of and are shown on Figure 2.
The GRand PaRIS algorithm outperforms the fixed lag methods for any value of the lag as the bias is the lowest (it is already negligible for ) and with a lower variance than fixed lag estimates with negligible bias (i.e., in this case, lags larger than 10). Small lags lead to strongly biased estimates for the fixed lag method, and unbiased estimates are at the cost of a large variance. It is worth noting here that the lag for which the bias is small is model dependent.
Log-growth model
Following [4] and [24], the performance of the proposed algorithm are also illustrated with the log-growth model defined by:
[TABLE]
In order to use the exact algorithms of [4] and the GPE of [11], we consider (15) after the Lamperti transform, i.e., the process defined by , with , which satisfies the following SDE:
[TABLE]
In this case, the conditions of the Exact Algorithm 2 defined in [4] are satisfied, as for any there exists such that for all , . Moreover, is lower bounded uniformly by . Then, GPE estimators may be computed by simulating the minimum of a Brownian bridge, and simulating Bessel bridges conditionally to this minimum, as proposed by [4].
The process solution to (16) is observed regularly at times through the observation process defined as:
[TABLE]
where the are i.i.d. . The parameters are given by
[TABLE]
In that case, the function defined in (10) can be upper bounded as a function of when , the GRand PaRIS algorithm has therefore a linear complexity. The intermediate quantity of the EM algorithm is evaluated as for the SINE model, see Figures 3 and 4.
The results for the fixed lag technique are similar to the ones presented in [23, Figure 1] on the same model. For small lags, the variance of the estimates is small, but the estimation is highly biased. The bias rapidly decreases as the lag increases, together with a great increase of variance. Again, the GRand PaRIS algorithm outperforms the fixed lag smoother as it shows a similar (vanishing) bias as the fixed lag for the largest lag and a smaller variance than the fixed lags estimates with negligible bias.
5 Conclusions
This paper presents a new online SMC smoother for partially observed differential equations. This algorithm relies on an accept-reject procedure inspired from the recent PaRIS algorithm. The main result of the article for practical applications is that the mechanism of this procedure remains valid when the transition density is approximated by a an unbiased positive estimator. The proposed procedure outperforms the existing fixed lag smoother for SDE of [23], as it does not introduce an intrinsic and non vanishing bias. In addition, numerical simulations highlight a better variance using data from two different models. It can be implemented for the class of models and defined in [4] with a linear complexity in .
Appendix A Proofs
Proof of Lemma 1.
Let be the first time draws are accepted in the accept-reject mechanism. For all , write
[TABLE]
Let be a function defined on ,
[TABLE]
which concludes the proof. ∎
Proof of Lemma 2.
The independence is ensured by the mechanism of SMC methods. By (7),
[TABLE]
Note that by Lemma 1,
[TABLE]
Since and are independent conditionally to :
[TABLE]
Moreover, conditionally to , the probability density function of is given by
[TABLE]
Therefore, this yields:
[TABLE]
which concludes the proof. ∎
Proof of Proposition 1.
The results is proved by induction. At time , the result holds using that for all , and the convention . In addition, is a standard importance sampler estimator of with so that for any bounded function on ,
[TABLE]
Assume the results holds for and that for simplicity. Write
[TABLE]
where and . By Lemma 2, the random variables are independent conditionally on and by HH2,
[TABLE]
Therefore, by Hoeffding inequality,
[TABLE]
On the other hand,
[TABLE]
where
[TABLE]
By [24, Lemma 11], which implies by the induction assumption that
[TABLE]
Then,
[TABLE]
Similarly, as , by Hoeffding inequality,
[TABLE]
Note that
[TABLE]
By the induction assumption,
[TABLE]
The proof is completed using Lemma 3. ∎
Lemma 3**.**
Assume that , , and are random variables defined on the same probability space such that there exist positive constants , , , and satisfying
- (i)
, -a.s. and , -a.s., 2. (ii)
For all and all , , 3. (iii)
For all and all , .
Then,
[TABLE]
Proof.
See [8]. ∎
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Y. Ait-Sahalia. Transition densities for interest rate and other nonlinear diffusions. Journal of Finance , 54:1361–1395, 1999.
- 2[2] Y. Ait-Sahalia. Maximum likelihood estimation of discretely sampled diffusions: a closed-form approximation approach. Econometrica , 70:223–262, 2002.
- 3[3] Y. Ait-Sahalia. Closed-form likelihood expansions for multivariate diffu- sions. The Annals of Statistics , 36:906–937, 2008.
- 4[4] A. Beskos, O. Papaspiliopoulos, G. Roberts, and P. Fearnhead. Exact and computationally efficient likelihood-based estimation for discretely observed diffusion processes (with discusion). J. Roy. Statist. Soc. Ser. B , 68(3):333–382, 2006.
- 5[5] O. Cappé, E. Moulines, and T. Rydén. Inference in Hidden Markov Models . Springer, 2005.
- 6[6] P. Del Moral, J. Jacod, and P. Protter. The Monte Carlo method for filtering with discrete-time observations. Probability Theory and Related Fields , 120:346 – 368, 2001.
- 7[7] A. P. Dempster, N. M. Laird, and D. B. Rubin. Maximum likelihood from incomplete data via the EM algorithm. J. Roy. Statist. Soc. B , 39(1):1–38 (with discussion), 1977.
- 8[8] R. Douc, A. Garivier, E. Moulines, and J. Olsson. Sequential Monte Carlo smoothing for general state space hidden Markov models. Ann. Appl. Probab. , 21(6):2109–2145, 2011.