On the Reconstruction of Face Images from Deep Face Templates
Guangcan Mai, Kai Cao, Pong C. Yuen, Anil K. Jain

TL;DR
This paper demonstrates that deep face templates can be inverted to reconstruct face images using a novel neural network, revealing vulnerabilities in face recognition systems and emphasizing the need for template security.
Contribution
We introduce NbNet, a neighborly de-convolutional neural network, to reconstruct face images from deep templates without prior knowledge of the target or network.
Findings
Achieved 95.20% TAR on LFW under type-I attack
Reconstructed images can be identified with over 92% accuracy in FERET
Reconstruction demonstrates significant vulnerability in face templates
Abstract
State-of-the-art face recognition systems are based on deep (convolutional) neural networks. Therefore, it is imperative to determine to what extent face templates derived from deep networks can be inverted to obtain the original face image. In this paper, we study the vulnerabilities of a state-of-the-art face recognition system based on template reconstruction attack. We propose a neighborly de-convolutional neural network (\textit{NbNet}) to reconstruct face images from their deep templates. In our experiments, we assumed that no knowledge about the target subject and the deep network are available. To train the \textit{NbNet} reconstruction models, we augmented two benchmark face datasets (VGG-Face and Multi-PIE) with a large collection of images synthesized using a face generator. The proposed reconstruction was evaluated using type-I (comparing the reconstructed images against the…
Click any figure to enlarge with its caption.
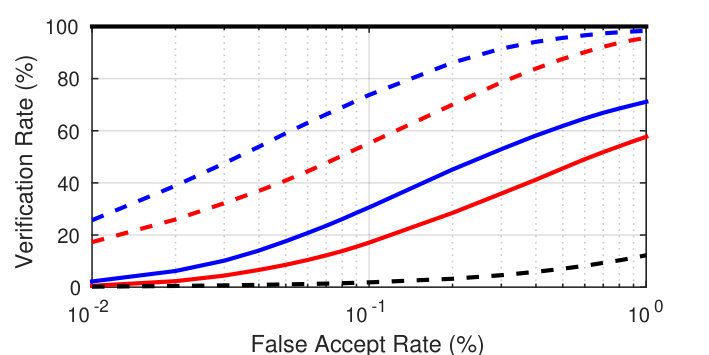 Figure 1
Figure 1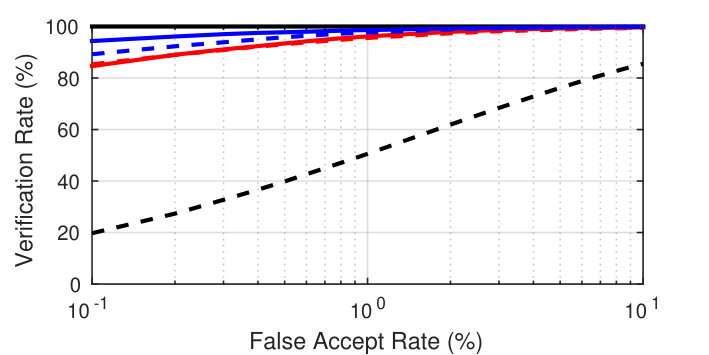 Figure 2
Figure 2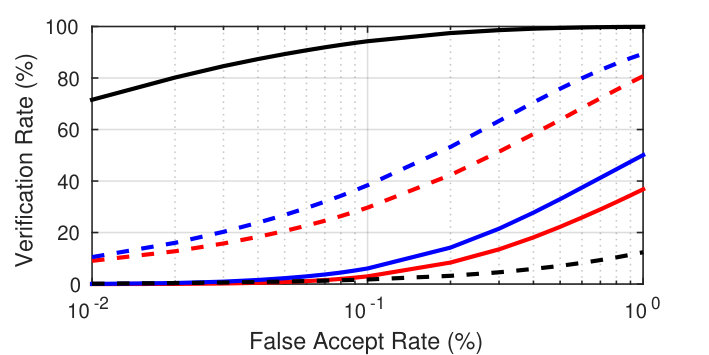 Figure 3
Figure 3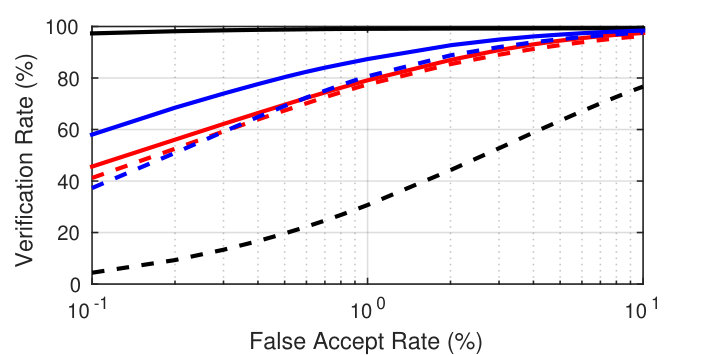 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8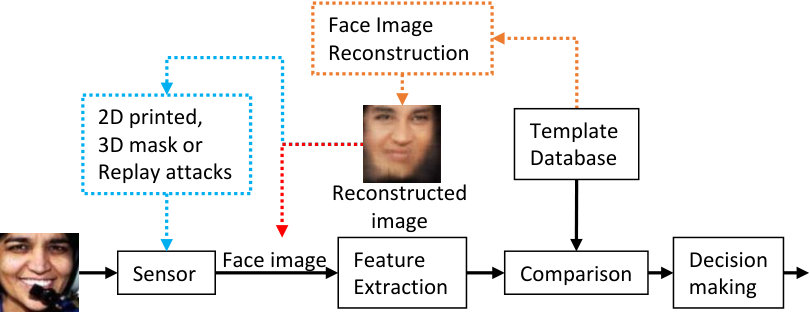 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11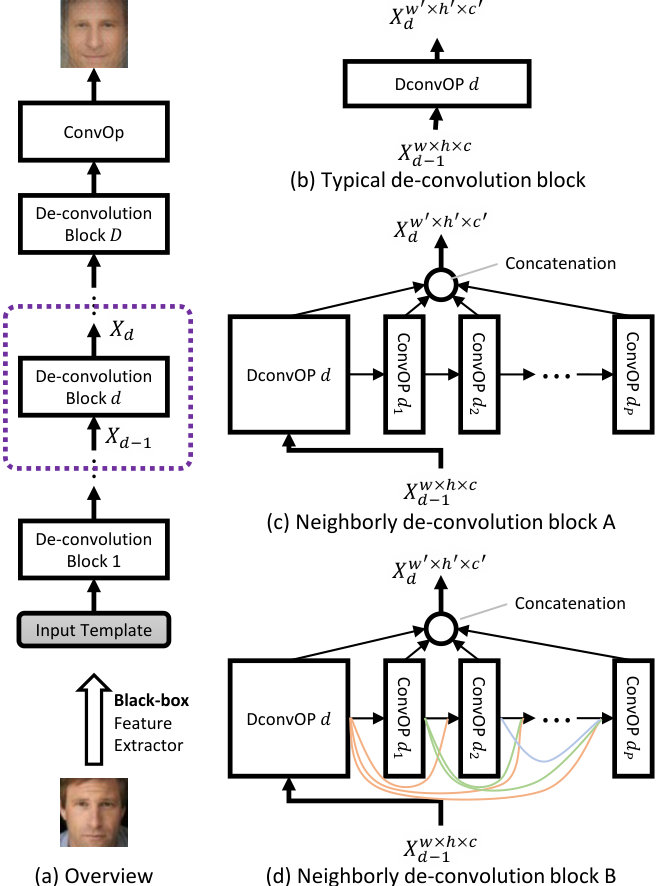 Figure 12
Figure 12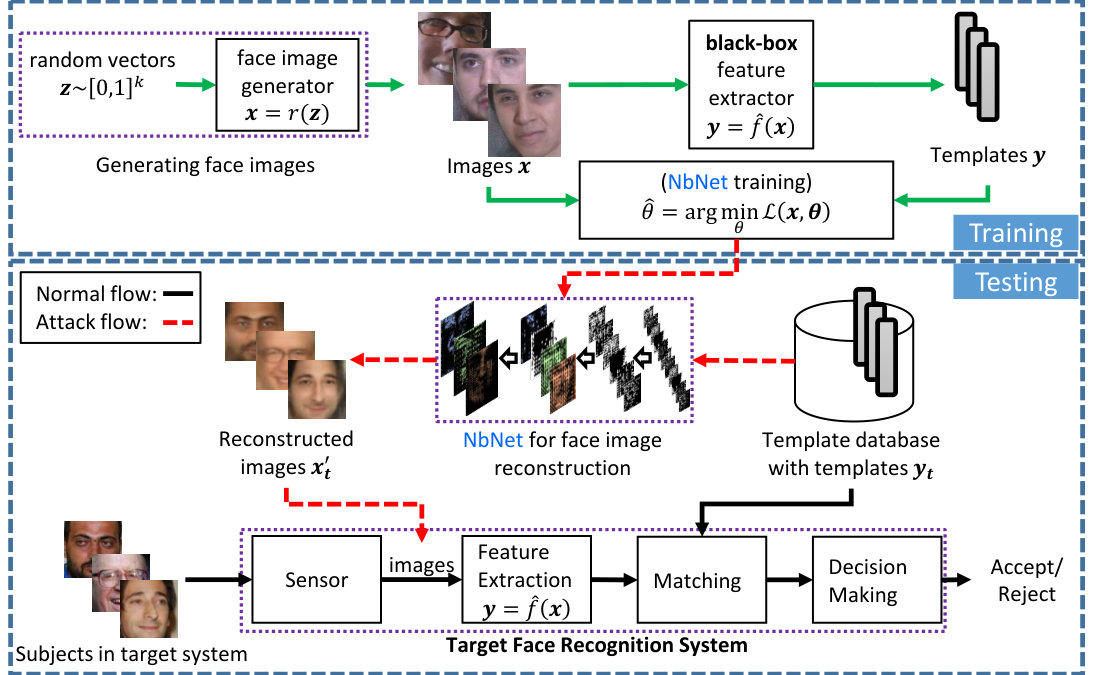 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35 Figure 36
Figure 36 Figure 37
Figure 37 Figure 38
Figure 38 Figure 39
Figure 39 Figure 40
Figure 40| Algorithm | Template features | Evaluation | Remarks |
|---|---|---|---|
| MDS [11] | PCA, BIC, COTS | Type-I attacka: TAR of 72% using BICb and 73% using COTSc at an FAR of 1.0% on FERET | Linear model with limited capacity |
| RBF regression [9] | LQP [12] | Type-II attackd: 20% rank-1 identification error rate on FERET; EER = 29% on LFW; | RBF model may have limited generative capacity |
| CNN [13] | Final feature of FaceNet [14] | Reported results were mainly based on visualizations and no comparable statistical results was reported | White-box template extractor was assumed |
| Cole et. al., [15] | Intermediate feature of FaceNet [14]e | High-quality images (e.g., front-facing, neutral-pose) are required for training. | |
| This paper | Final feature of FaceNet [14] |
Type-I attack: TARf of 95.20% (LFW) and 73.76% (FRGC v2.0) at an FAR of 0.1%; rank-1 identification rate 95.57% on color FERET
Type-II attack: TAR of 58.05% (LFW) and 38.39% (FRGC v2.0) at an FAR of 0.1%; rank-1 identification rate 92.84% on color FERET |
Requires a large number of images for network training |
| Layer name | Output size () | D-CNN | NbNet-A, NbNet-B |
| input layer | |||
| De-convolution Block (1) | DconvOP, stride 2 | DconvOP, stride 2 { ConvOP, stride 1} | |
| De-convolution Block (2) | DconvOP, stride 2 | DconvOP, stride 2 { ConvOP, stride 1} | |
| De-convolution Block (3) | DconvOP, stride 2 | DconvOP, stride 2 { ConvOP, stride 1} | |
| De-convolution Block (4) | DconvOP, stride 2 | DconvOP, stride 2 { ConvOP, stride 1} | |
| De-convolution Block (5) | DconvOP, stride 2 | DconvOP, stride 2 { ConvOP, stride 1} | |
| De-convolution Block (6) | DconvOP, stride 2 | DconvOP, stride 2 { ConvOP, stride 1} | |
| ConvOP | ConvOP, stride 1 | ||
| Loss layer | Pixel difference or perceptual loss [38] | ||
| Modela | Training Dataset | Training Loss | Testing Dataset | Training and Testing Process |
|---|---|---|---|---|
| VGG-Dn-P | VGG-Face | Perceptual Loss | LFW FRGC v2.0 color FERET | Train a DCGAN using the training dataset, and then use face images generated from the pretrained DCGAN for training the target D-CNN. Test the trained D-CNN using testing datasets. |
| VGG-NbA-P | ||||
| VGG-NbB-P | ||||
| VGG-Dn-M | Pixel Difference (MAEb ) | |||
| VGG-NbA-M | ||||
| VGG-NbB-M | ||||
| VGGr-NbB-M | Directly train the target D-CNN using face images from the training dataset, and then test the trained D-CNN using testing datasets. | |||
| MPIE-Dn-P | Multi-PIE | Perceptual Loss | Train a DCGAN using the training dataset, and then use face images generated from the pretrained DCGAN for training the target D-CNN. Test the trained D-CNN using testing datasets. | |
| MPIE-NbA-P | ||||
| MPIE-NbB-P | ||||
| MPIE-Dn-M | Pixel Difference (MAE) | |||
| MPIE-NbA-M | ||||
| MPIE-NbB-M | ||||
| MPIEr-NbB-M | Directly train the target D-CNN using face images from the training dataset, and then test the trained D-CNN using testing datasets. | |||
| Mixedr-NbB-M | VGG-Face CASIA-Webface Multi-PIE | |||
| RBF[9] | LFW | N/A | LFW | Train and test the RBF regression based method using the training and testing images specified in the evaluation protocol. |
| FRGC v2.0 | N/A | FRGC v2.0 |
| Attack | Type-I | Type-II | ||
| FAR | 0.1% | 1.0% | 0.1% | 1.0% |
| Original | 100.00 | 100.00 | 97.33 | 99.11 |
| VGG-Dn-P | 84.65 | 96.18 | 45.63 | 79.13 |
| VGG-NbA-P | 95.20 | 99.14 | 53.91 | 87.06 |
| VGG-NbB-P | 94.37 | 98.63 | 58.05 | 87.37 |
| VGG-Dn-M | 70.22 | 88.35 | 26.22 | 64.88 |
| VGG-NbA-M | 79.52 | 94.94 | 30.97 | 68.14 |
| VGG-NbB-M | 89.52 | 97.75 | 37.09 | 79.19 |
| VGGr-NbB-M | 72.53 | 93.21 | 27.38 | 70.72 |
| MPIE-Dn-P | 85.34 | 95.57 | 41.21 | 77.51 |
| MPIE-NbA-P | 80.33 | 95.46 | 21.75 | 63.05 |
| MPIE-NbB-P | 89.25 | 97.69 | 37.30 | 80.67 |
| MPIE-Dn-M | 37.11 | 63.01 | 3.23 | 13.26 |
| MPIE-NbA-M | 50.54 | 78.91 | 6.11 | 33.26 |
| MPIE-NbB-M | 67.86 | 88.56 | 24.00 | 57.98 |
| MPIEr-NbB-M | 34.87 | 65.56 | 3.67 | 21.24 |
| Mixedr-NbB-M | 71.62 | 92.98 | 19.29 | 65.63 |
| RBF [9] | 19.76 | 50.55 | 4.41 | 30.70 |
| Attack | Type-I | Type-II | ||
| FAR | 0.1% | 1.0% | 0.1% | 1.0% |
| Original | 100.00 | 100.00 | 94.30 | 99.90 |
| VGG-Dn-P | 17.10 | 57.71 | 3.00 | 36.81 |
| VGG-NbA-P | 32.66 | 71.54 | 8.65 | 51.87 |
| VGG-NbB-P | 30.62 | 71.14 | 6.06 | 50.09 |
| VGG-Dn-M | 3.52 | 35.94 | 0.68 | 20.40 |
| VGG-NbA-M | 8.95 | 55.84 | 2.39 | 33.40 |
| VGG-NbB-M | 16.44 | 67.57 | 3.60 | 44.19 |
| VGGr-NbB-M | 6.75 | 55.51 | 4.05 | 36.18 |
| MPIE-Dn-P | 55.22 | 95.65 | 29.70 | 80.72 |
| MPIE-NbA-P | 49.75 | 94.41 | 28.46 | 78.71 |
| MPIE-NbB-P | 73.76 | 98.35 | 38.39 | 89.41 |
| MPIE-Dn-M | 12.82 | 47.84 | 10.47 | 38.39 |
| MPIE-NbA-M | 15.58 | 61.44 | 13.42 | 48.46 |
| MPIE-NbB-M | 28.48 | 80.67 | 19.85 | 63.04 |
| MPIEr-NbB-M | 12.72 | 49.53 | 11.75 | 40.59 |
| Mixedr-NbB-M | 9.65 | 63.82 | 8.15 | 45.10 |
| RBF [9] | 1.86 | 12.29 | 1.78 | 12.37 |
| Attack | Type-I | Type-II | ||
|---|---|---|---|---|
| Probe | fa | fb | dup1 | dup2 |
| VGG-Dn-P | 89.03 | 86.59 | 76.77 | 78.51 |
| VGG-NbA-P | 94.87 | 90.93 | 80.30 | 81.58 |
| VGG-NbB-P | 95.57 | 92.84 | 84.78 | 84.65 |
| VGG-Dn-M | 80.68 | 74.40 | 62.91 | 65.35 |
| VGG-NbA-M | 86.62 | 80.44 | 64.95 | 66.67 |
| VGG-NbB-M | 92.15 | 87.00 | 75 | 75.44 |
| VGGr-NbB-M | 81.09 | 74.29 | 61.28 | 62.28 |
| MPIE-Dn-P | 96.07 | 91.73 | 84.38 | 85.53 |
| MPIE-NbA-P | 93.86 | 90.22 | 79.89 | 79.82 |
| MPIE-NbB-P | 96.58 | 92.84 | 86.01 | 87.72 |
| MPIE-Dn-M | 73.54 | 64.11 | 53.26 | 49.12 |
| MPIE-NbA-M | 72.23 | 64.01 | 51.09 | 44.74 |
| MPIE-NbB-M | 85.61 | 78.22 | 71.06 | 68.42 |
| MPIEr-NbB-M | 63.88 | 54.54 | 44.57 | 35.96 |
| Mixedr-NbB-M | 82.19 | 76.11 | 62.09 | 58.77 |
| Original | 100.00 | 98.89 | 97.96 | 99.12 |
| CPU | GPU | #Params | |
|---|---|---|---|
| D-CNN | 84.1 | 0.268 | 4,432,304 |
| NbNet-A | 62.6 | 0.258 | 2,289,040 |
| NbNet-B | 137.1 | 0.477 | 3,411,472 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
On the Reconstruction of Face Images from Deep Face Templates
Guangcan Mai, Kai Cao, Pong C. Yuen∗, and Anil K. Jain
Guangcan Mai and Pong C. Yuen are with the Department of Computer Science, Hong Kong Baptist University, Hong Kong SAR, CHINA.
E-mail:{csgcmai,pcyuen}@comp.hkbu.edu.hk; Kai Cao and Anil K. Jain are with the Department of Computer Science and Engineering, Michigan State University, MI, 48824, USA.
E-mail: {kaicao,jain}@cse.msu.edu∗ Corresponding author
Abstract
State-of-the-art face recognition systems are based on deep (convolutional) neural networks. Therefore, it is imperative to determine to what extent face templates derived from deep networks can be inverted to obtain the original face image. In this paper, we study the vulnerabilities of a state-of-the-art face recognition system based on template reconstruction attack. We propose a neighborly de-convolutional neural network (NbNet) to reconstruct face images from their deep templates. In our experiments, we assumed that no knowledge about the target subject and the deep network are available. To train the NbNet reconstruction models, we augmented two benchmark face datasets (VGG-Face and Multi-PIE) with a large collection of images synthesized using a face generator. The proposed reconstruction was evaluated using type-I (comparing the reconstructed images against the original face images used to generate the deep template) and type-II (comparing the reconstructed images against a different face image of the same subject) attacks. Given the images reconstructed from NbNets, we show that for verification, we achieve TAR of 95.20% (58.05%) on LFW under type-I (type-II) attacks @ FAR of 0.1%. Besides, 96.58% (92.84%) of the images reconstructed from templates of partition fa (fb) can be identified from partition fa in color FERET. Our study demonstrates the need to secure deep templates in face recognition systems.
Index Terms:
Face recognition, template security, deep networks, deep templates, template reconstruction, neighborly de-convolutional neural network.
1 Introduction
Face recognition systems are being increasingly used for secure access in applications ranging from personal devices (e.g., iPhone X111https://www.apple.com/iphone-x/#face-id and Samsung S8222http://www.samsung.com/uk/smartphones/galaxy-s8/) to access control (e.g., banking333https://goo.gl/6TGcrr and border control444https://goo.gl/ViVdDY). In critical applications, face recognition needs to meet stringent performance requirements, including low error rates and strong system security. In particular, the face recognition system must be resistant to spoofing (presentation) attacks and template invertivility. Therefore, it is critical to evaluate the vulnerabilities of a face recognition system to these attacks and devise necessary countermeasures. To this end, several attack mechanisms (such as hill climbing [1, 2, 3], spoofing [4, 5, 6, 7, 8], and template reconstruction (template invertibility) [9]) have been proposed to determine the vulnerabilities of face recognition systems.
In this paper, we focus on the vulnerability of a face recognition system to template invertibility or reconstruction attacks. In a template reconstruction attack (Fig. 1), we want to determine if face images can be successfully reconstructed from the face templates of target subjects and then used as input to the system to access privileges. Fig. 2 shows examples of face images reconstructed from their deep templates by the proposed method. Some of these reconstructions are successful in that they match well with the original images (Fig. 2 (a)), while others are not successful (Fig. 2 (b)). Template reconstruction attacks generally assume that templates of target subjects and the corresponding black-box template extractor can be accessed. These are reasonable assumptions because: (a) templates of target users can be exposed in hacked databases555https://goo.gl/QUMHpv,666https://goo.gl/KdxzqT, and (b) the corresponding black-box template extractor can potentially be obtained by purchasing the face recognition SDK. To our knowledge, almost all of the face recognition vendors store templates without template protection, while some of them protect templates with specific hardware (e.g., Secure Enclave on A11 of iPhone X [10], TrustZone on ARM777https://www.arm.com/products/security-on-arm/trustzone).
Note that unlike traditional passwords, biometric templates cannot be directly protected by standard ciphers such as AES and RSA since the matching of templates needs to allow small errors caused by intra-subject variations [17, 18]. Besides, state-of-the-art template protection schemes are still far from practical because of the severe trade-off between matching accuracy and system security [19, 20].
Face templates are typically compact binary or real-valued feature representations888As face templates refer to face representations stored in a face recognition system, these terms are used interchangeably in this paper. that are extracted from face images to increase the efficiency and accuracy of similarity computation. Over the past couple of decades, a large number of approaches have been proposed for face representations. These representations can be broadly categorized into (i) shallow [21, 22, 12], and (ii) deep (convolutional neural network or CNN) representations [23, 14, 24], according to the depth of their representational models999Some researchers [23] refer to shallow representations as those that are not extracted using deep networks.. Deep representations have shown their superior performances in face evaluation benchmarks (such as LFW [25], YouTube Faces [26, 14], and NIST IJB-A [27, 24]). Therefore, it is imperative to investigate the invertibility of deep templates to determine their vulnerability to template reconstruction attacks. However, to the best of our knowledge, no such work has been reported.
In our study of template reconstruction attacks, we made no assumptions about subjects used to train the target face recognition system. Therefore, only public domain face images were used to train our template reconstruction model. The available algorithms for face image reconstruction from templates [9, 11]101010MDS method in the context of template reconstructible was initially proposed for reconstructing templates by matching scores between the target subject and attacking queries. However, it can also be used for template reconstruction attacks [11].,[13, 15] are summarized in Table I. The generalizability of the published template reconstruction attacks [11, 9] is not known, as all of the training and testing images used in their evaluations were subsets of the same face dataset. No statistical study in terms of template reconstruction attack has been reported in [13, 15].
To determine to what extent face templates derived from deep networks can be inverted to obtain the original face images, a reconstruction model with sufficient capacity is needed to invert the complex mapping used in the deep template extraction model [28]. De-convolutional neural network (D-CNN)111111Some researchers refer to D-CNNs as CNNs. However, given that its purpose is the inverse of a CNN, we distinguish D-CNN and CNN. [29, 30, 31] is one of the straightforward deep models for reconstructing face images from deep templates. To design a D-CNN with sufficient model capacity121212The ability of a model to fit a wide variety of functions [28]. , one could increase the number of output channels (filters) in each de-convolution layer [32]. However, this often introduces noisy and repeated channels since they are treated equally during the training.
To address the issues of noisy (repeated) channels and insufficient channel details, inspired by DenseNet [33] and MemNet [34], we propose a neighborly de-convolutional network framework (NbNet) and its building block, neighborly de-convolution blocks (NbBlocks). The NbBlock produces the same number of channels as a de-convolution layer by (a) reducing the number of channels in de-convolution layers to avoid the noisy and repeated channels; and (b) then creating the reduced channels by learning from their neighboring channels which were previously created in the same block to increase the details in reconstructed face images. To train the NbNets, a large number of face images are required. Instead of following the time-consuming and expensive process of collecting a sufficiently large face dataset [35, 36], we trained a face image generator, DCGAN [37], to augment available public domain face datasets. To further enhance the quality of reconstructed images, we explore both pixel difference and perceptual loss [38] for training the NbNets. In summary, this paper makes following contributions:
An investigation of the invertibility of face templates generated by deep networks. To the best of our knowledge, this is the first such study on security and privacy of face recognition systems.
An NbNet with its building block, NbBlock, was developed for reconstructing face images from deep templates. The NbNets were trained by data augmentation and perceptual loss [38], resulting in maintaining discriminative information in deep templates.
Empirical results show that the proposed face image reconstruction from the corresponding templates is successful. We show that we can achieve the following, verification rates (security), TAR of 95.20% (58.05%) on LFW under type-I (type-II) attack @ FAR of 0.1%. For identification (privacy), we achieve 96.58% and 92.84% rank one accuracy (partition fa) in color FERET [39] as gallery and the images reconstructed from partition fa (type-I attack) and fb (type-II attack) as probe.
2 Related Work
In this section, we describe the current practice of storing face templates, the limitations of current methods for reconstructing face images from deep templates and introduce GANs for generating (synthesizing) face images.
2.1 Face Template Security
Unlike traditional passwords that can be matched in their encrypted or hash form with standard ciphers (e.g., AES, RSA, and SHA-3), face templates cannot be simply protected by standard ciphers because of the intra-subject variations in face images [17, 18]. Due to the avalanche effect131313https://en.wikipedia.org/wiki/Avalanche_effect [40] of standard ciphers, the face templates protected by standard ciphers need to be decrypted before matching. This introduces another challenge, (decryption) key management. In addition, decrypted face templates can also be gleaned by launching an authentication attempt.
Face template protection remains an open challenge. To our knowledge, either the vendors ignore the security and privacy issues of face templates, or secure the encrypted templates and the corresponding keys in specific hardware (e.g., Secure Enclave on A11 of iPhone X [10], TrustZone on ARM141414https://www.arm.com/products/security-on-arm/trustzone). Note that the requirement of specific hardware limits the range of biometric applications.
2.2 Reconstructing Face Images from Deep Templates
Face template reconstruction requires the determination of the inverse of deep models used to extract deep templates from face images. Most deep models are complex and are typically implemented by designing and training a network with sufficiently large capacity [28].
Shallow model based [11, 9]: There are two shallow model based methods for reconstructing face images from templates proposed in the literature: multidimensional scaling (MDS) [11] and radial basis function (RBF) regression [9]. However, these methods have only been evaluated using shallow templates. The MDS-based method [11] uses a set of face images to generate a similarity score matrix using the target face recognition system and then finds an affine space in which face images can approximate the original similarity matrix. Once the affine space has been found, a set of similarities is obtained from the target face recognition system by matching the target template and the test face images. The affine representation of the target template is estimated using these similarities, which is then mapped back to the target face image.
Deep model based[13, 15]: Zhmoginov and Sandler [13] learn the reconstruction of face images from templates using a CNN by minimizing the template difference between original and reconstructed images. This requires the gradient information from target template extractor and cannot satisfy our assumption of black-box template extractor. Cole et. al. [15] first estimate the landmarks and textures of face images from the templates, and then combine the estimated landmarks and textures using the differentiable warping to yield the reconstructed images. High-quality face images (e.g., front-facing, neutral-pose) are required to be selected for generating landmarks and textures in [15] for training the reconstruction model. Note that both [13] and [15] does not aim to study vulnerability on deep templates and hence no comparable statistical results based template reconstruction attack were reported.
2.3 GAN for Face Image Generation
With adversarial training, GANs [41, 42, 37, 43, 44, 45, 46, 47, 48, 49] are able to generate photo-realistic (face) images from randomly sampled vectors. It has become one of the most popular methods for generating face images, compared to other methods such as data augmentation [50] and SREFI [51]. GANs typically consist of a generator which produces an image from a randomly sampled vector, and a discriminator which classifies an input image as real or synthesized. The basic idea for training a GAN is to prevent images output by the generator be mistakenly classified as real by co-training a discriminator.
DCGAN [37] is believed to be the first method that directly generates high-quality images () from randomly sampled vectors. PPGN [44] was proposed to conditionally generate high-resolution images with better image quality and sample diversity, but it is rather complicated. Wasserstein GAN [45, 46] was proposed to solve the model collapse problems in GAN [42]. Note that the images generated by Wasserstein GAN [45, 46] are comparable with those output by DCGAN. BEGAN [47] and LSGAN [48] have been proposed to attempt to address the model collapse, and non-convergence problems with GAN. A progressive strategy for training high-resolution GAN is described in [49].
In this work, we employed an efficient yet effective method, DCGAN to generate face images. The original DCGAN [37] is easy to collapse and outputs poor quality high-resolution images (e.g., in this work). We address the above problems with DCGAN (Section 3.6.2).
3 Proposed Template Security Study
An overview of our security study for deep template based face recognition systems under template reconstruction attack is shown in Fig. 3; the normal processing flow and template reconstruction attack flows are shown as black solid and red dotted lines, respectively. This section first describes the scenario of template reconstruction attack using an adversarial machine learning framework [52]. This is followed by the proposed NbNet for reconstructing face images from deep templates and the corresponding training strategy and implementation.
3.1 Template Reconstruction Attack
The adversarial machine learning framework [52, 54] categorizes biometric attack scenarios from four perspectives: an adversary’s goal and his/her knowledge, capability, and attack strategy. Given a deep template based face recognition system, our template reconstruction attack scenario using the adversarial machine learning framework is as follows.
Adversary’s goal: The attacker aims to impersonate a subject in the target face recognition system, compromising the system integrity.
Adversary’s knowledge: The attacker is assumed to have the following information. (a) The templates of the target subjects, which can be obtained via template database leakage or an insider attack. (b) The black-box feature extractor of the target face recognition system. This can potentially be obtained by purchasing the target face recognition system’s SDK. The attacker has neither information about target subjects nor their enrollment environments. Therefore, no face images enrolled in the target system can be utilized in the attack.
Adversary’s capability:(a) Ideally, the attacker should only be permitted to present fake faces (2D photographs or 3D face masks) to the face sensor during authentication. In this study, to simplify, the attacker is assumed to be able to inject face images directly into the feature extractor as if the images were captured by the face sensor. Note that the injected images could be used to create fake faces in actual attacks. (b) The identity decision for each query is available to the attacker. However, the similarity score of each query cannot be accessed. (c) Only a small number of trials (e.g., ) are permitted for the recognition of a target subject.
Attack strategy: Under these assumptions, the attacker can infer a face image from the target template using a reconstruction model and insert reconstructed image as a query to access the target face recognition system. The parameter of the reconstruction model can be learned using public domain face images.
3.2 NbNet for Face Image Reconstruction
3.2.1 Overview
An overview of the proposed NbNet is shown in Fig. 5 (a). The NbNet is a cascade of multiple stacked de-convolution blocks and a convolution operator, ConvOp. De-convolution blocks up-sample and expand the abstracted signals in the input channels to produce output channels with a larger size as well as more details about reconstructed images. With multiple () stacked de-convolution blocks, the NbNet is able to expand highly abstracted deep templates back to channels with high resolutions and sufficient details for generating the output face images. The ConvOp in Fig. 5 (a) aims to summarize multiple output channels of -th de-convolution block to the target number of channels (3 in this work for RGB images). It is a cascade of convolution, batch-normalization [53], and tanh activation layers.
3.2.2 Neighborly De-convolution Block
A typical design of the de-convolution block [29, 37], as shown in Fig. 5 (b), is to learn output channels with up-sampling from channels in previous blocks only. The number of output channels is often made large enough to ensure sufficient model capacity for template reconstruction [32]. However, the up-sampled output channels tend to suffer from the following two issues: (a) noisy and repeated channels; and (b) insufficient details. An example of these two issues is shown in Fig. 5 (a), which is a visualization of output channels in the fifth de-convolution block of a D-CNN that is built with typical de-convolution blocks. The corresponding input template was extracted from the bottom image of Fig. 5 (a).
To address these limitations, we propose NbBlock which produces the same number of output channels as typical de-convolution blocks for the face template reconstruction. One of the reasons for noisy and repeated output channels is that a large number of channels are treated equally in a typical de-convolution block; from the perspective of network architecture, these output channels were learned from the same set of input channels and became the input of the same forthcoming blocks. To mitigate this issue, we first reduce the number of output channels that is simultaneously learned from the previous blocks. We then create the reduced number of output channels with enhanced details by learning from neighbor channels in the same block.
Let denote the -th NbBlock, which is shown as the dashed line in Fig. 5 (a) and is the building component of our NbNet. Suppose that consists of one de-convolution operator (DconvOP) and convolution operators (ConvOPs) . Let and denote the output of DconvOP and -th ConvOP in -th NbBlock , then
[TABLE]
where denotes the output of the -th NbBlock, denotes a function of channel concatenation, and is the set of outputs of DconvOP and all ConvOPs in ,
[TABLE]
where and denotes the output of DconvOP and the -th ConvOP in -th block, resp., and satisfy
[TABLE]
where is a non-empty subset of .
Based on this idea, we built two NbBlocks, A and B, as shown in Figs. 5 (c) and (d), where the corresponding reconstructed networks are named NbNet-A and NbNet-B, respectively. In this study, the DconvOp (ConvOp) in Figs. 5 (b), (c), and (d) denotes a cascade of de-convolution (convolution), batch-normalization [53], and ReLU activation layers. The only difference between blocks A and B is the choice of ,
[TABLE]
In our current design of the NbBlocks, half of output channels ( for block ) are produced by a DconvOP, and the remaining channels are produced by ConvOPs, each of which gives, in this study, eight output channels (Table. II). Example of blocks A and B with 32 output channels are shown in Figs. 5 (b) and (c). The first two rows of channels are produced by DconvOp and the third and fourth rows of channels are produced by the first and second ConvOps, respectively. Compared with Fig. 5 (a), the first two rows in Figs. 5 (b) and (c) have small amount of noise and fewer repeated channels, where the third and fourth row provide channels with more details about the target face image (the reconstructed image in Fig. 5 (a)). The design of our NbBlocks is motivated by DenseNet [33] and MemNet [34].
3.3 Reconstruction Loss
Let us denote as the reconstruction loss between an input face image and its reconstruction , where denotes an NbNet with parameter and denotes a black-box deep template extractor.
Pixel Difference: A straightforward loss for learning reconstructed image is pixel-wise loss between and its original version . The Minkowski distance could then be used and mathematically expressed as
[TABLE]
where denotes number of pixels in and denotes the order of the metric.
Perceptual Loss [38]: Because of the high discriminability of deep templates, most of the intra-subject variations in a face image might have been eliminated in its corresponding deep template. The pixel difference based reconstruction leads to a difficult task of reconstructing these eliminated intra-subject variations, which, however, are not necessary for reconstruction. Besides, it does not consider holistic contents in an image as interpreted by machines and human visual perception. Therefore, instead of using pixel difference, we employ the perceptual loss [38] which guides the reconstructed images towards the same representation as the original images. Note that a good representation is robust to intra-subject variations in the input images. The representation used in this study is the feature map in the VGG-19 model [55]151515Provided by https://github.com/dmlc/mxnet-model-gallery. We empirically determine that using the output of ReLU3_2 activation layer as the feature map leads the best image reconstruction, in terms of face matching accuracy. Let denote feature mapping function of the ReLU3_2 activation layer of VGG-19 [55], then the perceptual loss can be expressed as
[TABLE]
3.4 Generating Face Images for Training
To successfully launch an template reconstruction attack on a face recognition system without knowledge of the target subject population, NbNets should be able to accurately reconstruct face images with input templates extracted from face images of different subjects. Let denote the probability density function (pdf) of image , the objective function for training a NbNet can be formulated as
[TABLE]
Since there are no explicit methods for estimating , we cannot sample face images from . The common approach is to collect a large-scale face dataset and approximate the loss function in Eq. (7) as:
[TABLE]
where denotes the number of face images and denotes the -th training image. This approximation is optimal if, and only if, is sufficiently large. In practice, this is not feasible because of the huge time and cost associated with collecting a large database of face images.
To train a generalizable NbNet for reconstructing face images from their deep templates, a large number of face images are required. Ideally, these face images should come from a large number of different subjects because deep face templates of the same subject are very similar and can be regarded as either single exemplar or under large intra-user variations, a small set of exemplars in the training of NbNet. However, current large-scale face datasets (such as VGG-Face [23], CASIA-Webface [56], and Multi-PIE [57]) were primarily collected for training or evaluating face recognition algorithms. Hence, they either contain an insufficient number of images (for example, 494K images in CASIA-Webface) or an insufficient number of subjects (for instance, 2,622 subjects in VGG-Face and 337 subjects in Multi-PIE) for training a reconstruction NbNet.
Instead of collecting a large face image dataset for training, we propose to augment current publicly available datasets. A straightforward way to augment a face dataset is to estimate the distribution of face images and then sample the estimated distribution. However, as face images generally consist of a very large number of pixels, there is no efficient method to model the joint distribution of these pixels. Therefore, we introduced a generator capable of generating a face image from a vector with a given distribution. Assuming that is one-to-one and smooth, the face images can be sampled by sampling . The loss function in Eq. (7) can then be approximated as follows:
[TABLE]
where denotes the pdf of variable . Using the change of variables method [58, 59], it is easy to show that and have the following connection,
[TABLE]
Suppose a face image of height , width , and with channels can be represented by a real vector in a manifold space with . It can then be shown that there exists a generator function that generates with a distribution identical to that of , where can be arbitrarily distributed and is uniformly distributed (see Appendix).
To train the NbNets in the present study, we used the generative model of a DCGAN [37] as our face generator . This model can generate face images from vectors that follow a uniform distribution. Specifically, DCGAN generates face images with a distribution that is an approximation to that of real face images . It can be shown empirically that a DCGAN can generate face images of unseen subjects with different intra-subject variations. By using adversarial learning, the DCGAN is able to generate face images that are classified as real face images by a co-trained real/fake face image discriminator. Besides, the intra-subject variations generated using a DCGAN can be controlled by performing arithmetic operations in the random input space [37].
3.5 *Differences with DenseNet *
One of the related work to NbNet is DenseNet [33], from which the NbNet is inspired. Generally, DenseNet is based on convolution layers and designed for object recognition, while the proposed NbNet is based on de-convolution layers and aimed to reconstruct face images from deep templates. Besides, NbNet is a framework whose NbBlocks produce output channels learned from previous blocks and neighbor channels within the block. The output channels of NbBlocks consist of fewer repeated and noisy channels and contain more details for face image reconstruction than the typical de-convolution blocks. Under the framework of NbNet, one could build a skip-connection-like network [60], NbNet-A, and a DenseNet -like network, NbNet-B. Note that NbNet-A sometimes achieves a comparable performance to NbNet-B with roughly 67% of the parameters and 54% running time only (see model VGG-NbA-P and VGG-NbB-P in Section 4). We leave more efficient and accurate NbNets construction as a future work.
3.6 Implementation Details
3.6.1 Network Architecture
The detailed architecture of the D-CNN and the proposed NbNets is shown in Table. II. The NbNet-A and NbNet-B show the same structure in Table. II. However, the input of the ConvOP in the de-convolution blocks (1)-(6) are different (Fig. 5), where NbNet-A uses the nearest previous channels in the same block, and NbNet-B uses all the previous channels in the same block.
3.6.2 Revisiting DCGAN
To train our NbNet to reconstruct face images from deep templates, we first train a DCGAN to generate face images. These generated images are then used for training. The face images generated by the original DCGAN could be noisy and sometimes difficult to interpret. Besides, the training as described in [37] is often collapsed in generating high-resolution images. To address these issues, we revisit the DCGAN as below (as partially suggested in [42]):
- •
Network architecture: replace the batch normalization and ReLU activation layer in both generator and discriminator by the SeLU activation layer [61], which performs the normalization of each training sample.
- •
Training labels: replace the hard labels (‘1’ for real, and ‘0’ for generated images) by soft labels in the range [0.7, 1.2] for real, and in range [0, 0.3] for generated images. This helps smooth the discriminator and avoids model collapse.
- •
Learning rate: in the training of DCGAN, at each iteration, the generator is updated with one batch of samples, while the discriminator is updated with two batches of samples (1 batch of ‘real’ and 1 batch of ‘generated’). This often makes the discriminator always correctly classify the images output by the generator. To balance, we adjust the learning rate of the generator to , which is greater than the learning rate of the discriminator, .
Example generated images were shown in Fig. 7.
3.6.3 Training Details
With the pre-trained DCGAN, face images were first generated by randomly sampling vectors from a uniform distribution and the corresponding face templates were extracted. The NbNet was then updated with the generated face images as well as the corresponding templates using batch gradient descent optimization. This training strategy was used to minimize the loss function in Eq. (9), which is an approximation of the loss function in Eq. (7).
The face template extractor we used is based on FaceNet [14], one of the most accurate CNN models for face recognition currently available. To ensure that the face reconstruction scenario is realistic, we used an open-source implementation161616https://github.com/davidsandberg/facenet based on TensorFlow171717Version 1.4.0 from https://www.tensorflow.org without any modifications (model 20170512-110547).
We implemented the NbNets using MXNet181818Version 0.1.0 from http://mxnet.io. The networks were trained using a mini-batch based algorithm, Adam [64] with batch size of 64, and . The learning rate was initialized to and decayed by a factor of 0.94 every 5K batches. The pixel values in the output images were normalized to by first dividing 127.5 and then subtracting 1.0. For the networks trained with the pixel difference loss, we trained the network with 300K batches, where the weights are randomly initialized using a normal distribution with zero mean and a standard deviation of 0.02. For the networks trained with the perceptual loss [38], we trained the networks with extra 100K batches by refining from the corresponding networks trained with the pixel difference loss. The hardware specifications of the workstations for the training are the CPUs of dual Intel(R) Xeon E5-2630v4 @ 2.2 GHz, the RAM of 256GB with two sets of NVIDIA Tesla K80 Dual GPU. The software includes CentOS 7 and Anaconda2191919https://www.anaconda.com.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] A. Adler, “Sample images can be independently restored from face recognition templates,” in CCECE , 2003.
- 2[2] J. Galbally, C. Mc Cool, J. Fierrez, S. Marcel, and J. Ortega-Garcia, “On the vulnerability of face verification systems to hill-climbing attacks,” Pattern Recognition , 2010.
- 3[3] Y. C. Feng, M.-H. Lim, and P. C. Yuen, “Masquerade attack on transform-based binary-template protection based on perceptron learning,” Pattern Recognition , 2014.
- 4[4] D. Wen, H. Han, and A. K. Jain, “Face spoof detection with image distortion analysis,” IEEE Transactions on Information Forensics and Security , 2015.
- 5[5] K. Patel, H. Han, and A. K. Jain, “Secure face unlock: Spoof detection on smartphones,” IEEE Transactions on Information Forensics and Security , 2016.
- 6[6] S. Liu, P. C. Yuen, S. Zhang, and G. Zhao, “3d mask face anti-spoofing with remote photoplethysmography,” in ECCV , 2016.
- 7[7] R. Shao, X. Lan, and P. C. Yuen, “Deep convolutional dynamic texture learning with adaptive channel-discriminability for 3d mask face anti-spoofing,” in IJCB , 2017.
- 8[8] Y. Liu, A. Jourabloo, and X. Liu, “Learning deep models for face anti-spoofing: Binary or auxiliary supervision,” in CVPR , 2018.