Optimal probabilistic dense coding schemes
Roger Alfredo K\"ogler, Leonardo Neves

TL;DR
This paper introduces optimal probabilistic decoding schemes for dense coding with non-maximally entangled states, balancing success probability and confidence, and enhancing information transfer in quantum communication.
Contribution
It proposes novel optimal probabilistic decoding schemes, including quantum-state separation and multistage decoding, improving upon existing methods for dense coding with non-maximally entangled states.
Findings
Quantum-state separation increases message distinguishability with optimal success probability.
Multistage decoding enhances mutual information for qudits.
The schemes interpolate between error-prone and error-free decoding approaches.
Abstract
Dense coding with non-maximally entangled states has been investigated in many different scenarios. We revisit this problem for protocols adopting the standard encoding scheme. In this case, the set of possible classical messages cannot be perfectly distinguished due to the non-orthogonality of the quantum states carrying them. So far, the decoding process has been approached in two ways: (i) The message is always inferred, but with an associated (minimum) error; (ii) the message is inferred without error, but only sometimes; in case of failure, nothing else is done. Here, we generalize on these approaches and propose novel optimal probabilistic decoding schemes. The first uses quantum-state separation to increase the distinguishability of the messages with an optimal success probability. This scheme is shown to include (i) and (ii) as special cases and continuously interpolate between…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1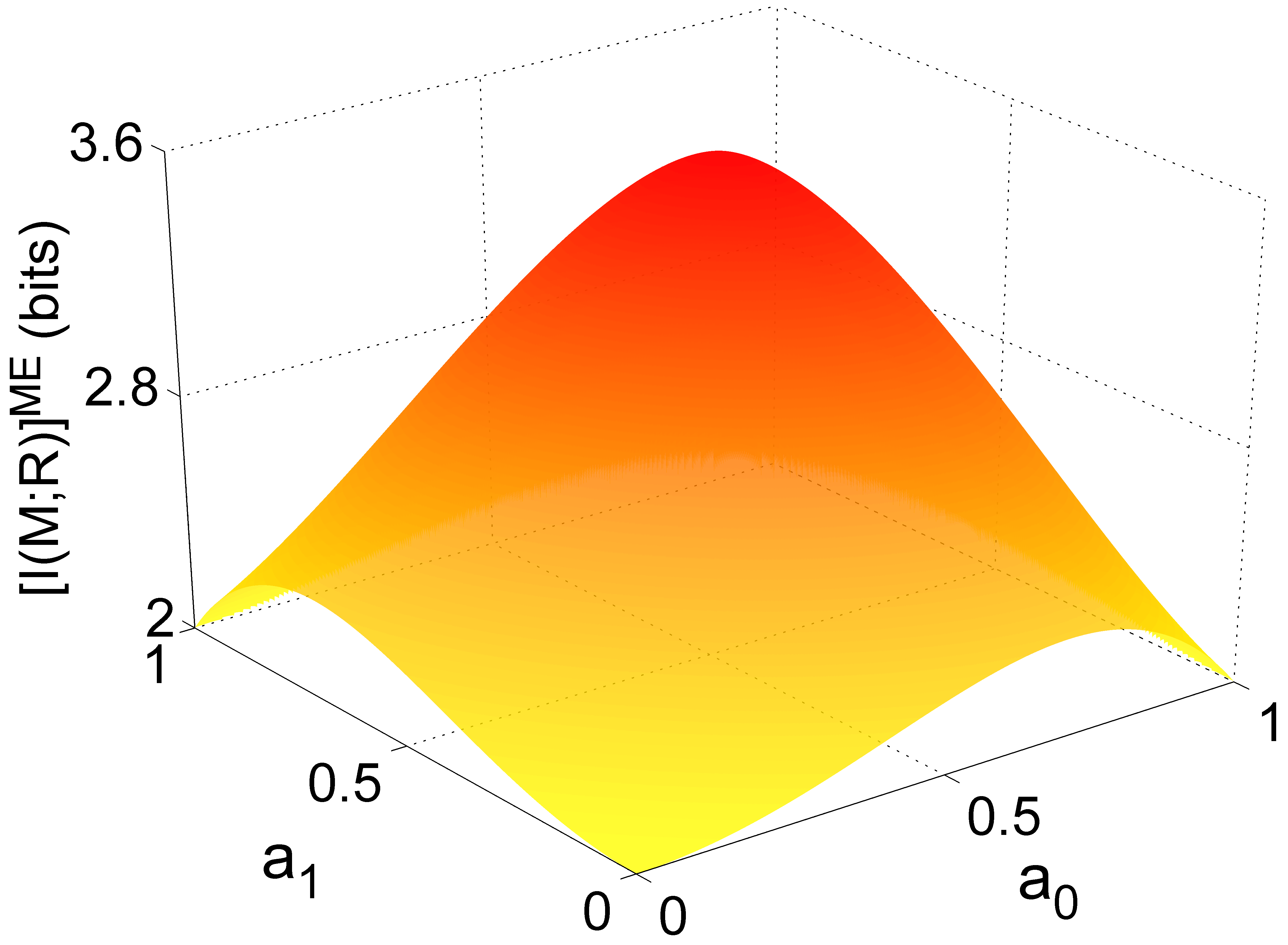 Figure 2
Figure 2 Figure 3
Figure 3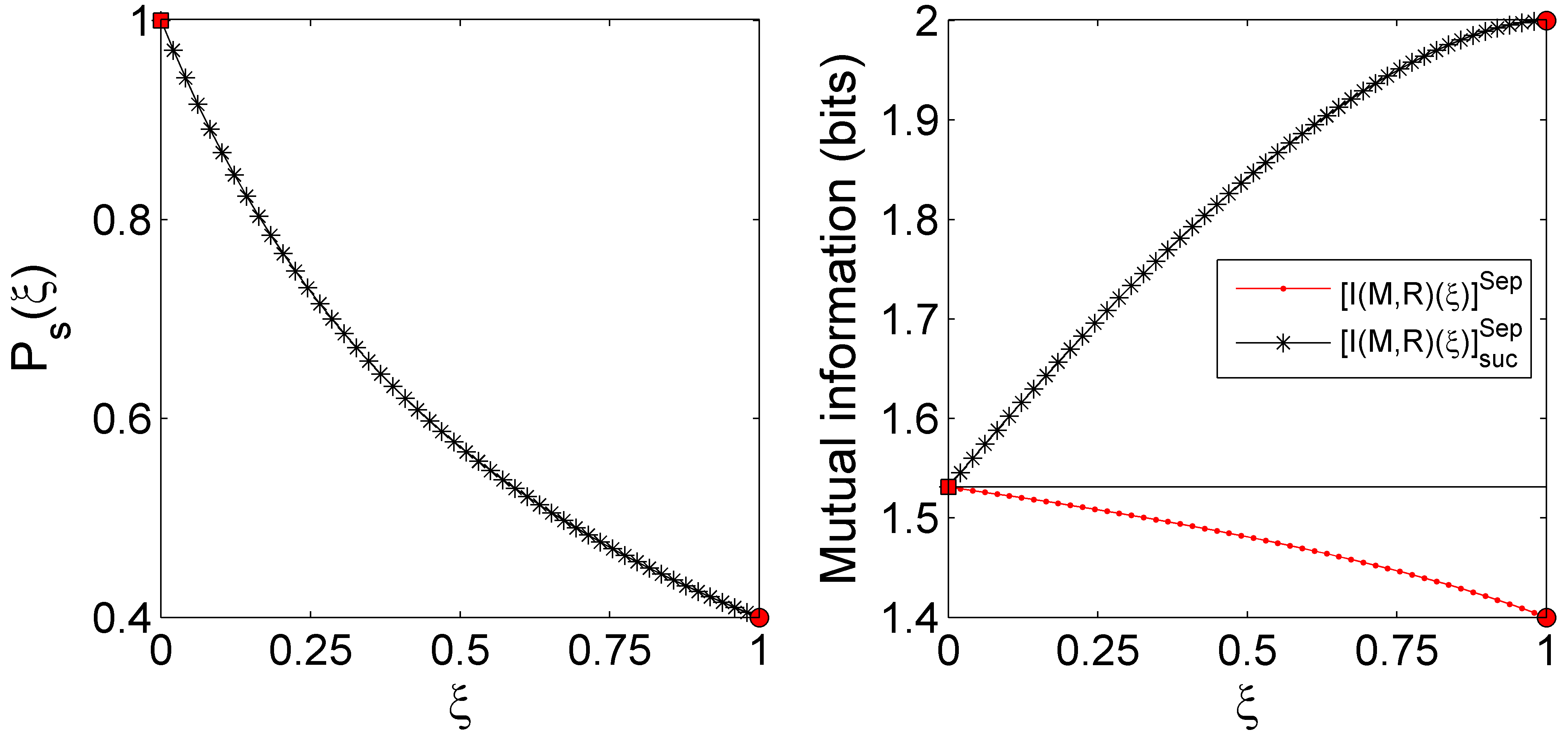 Figure 4
Figure 4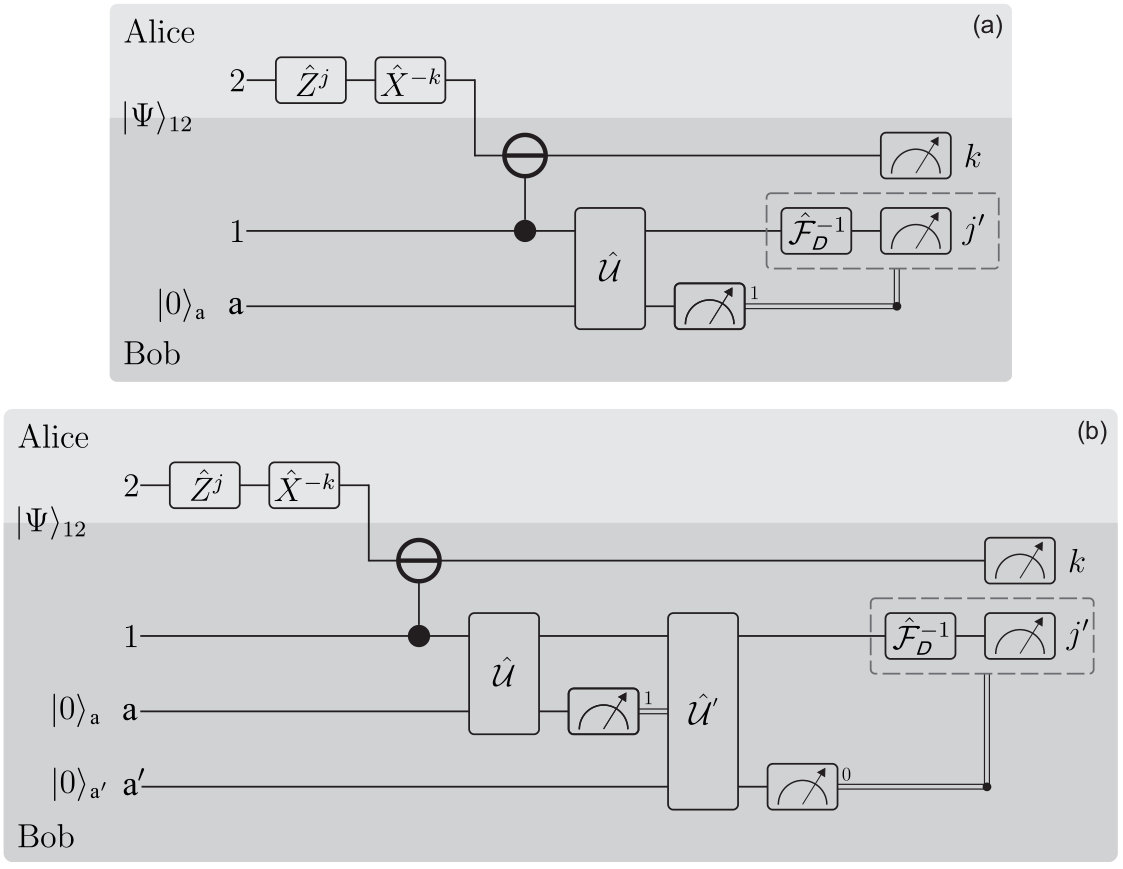 Figure 5
Figure 5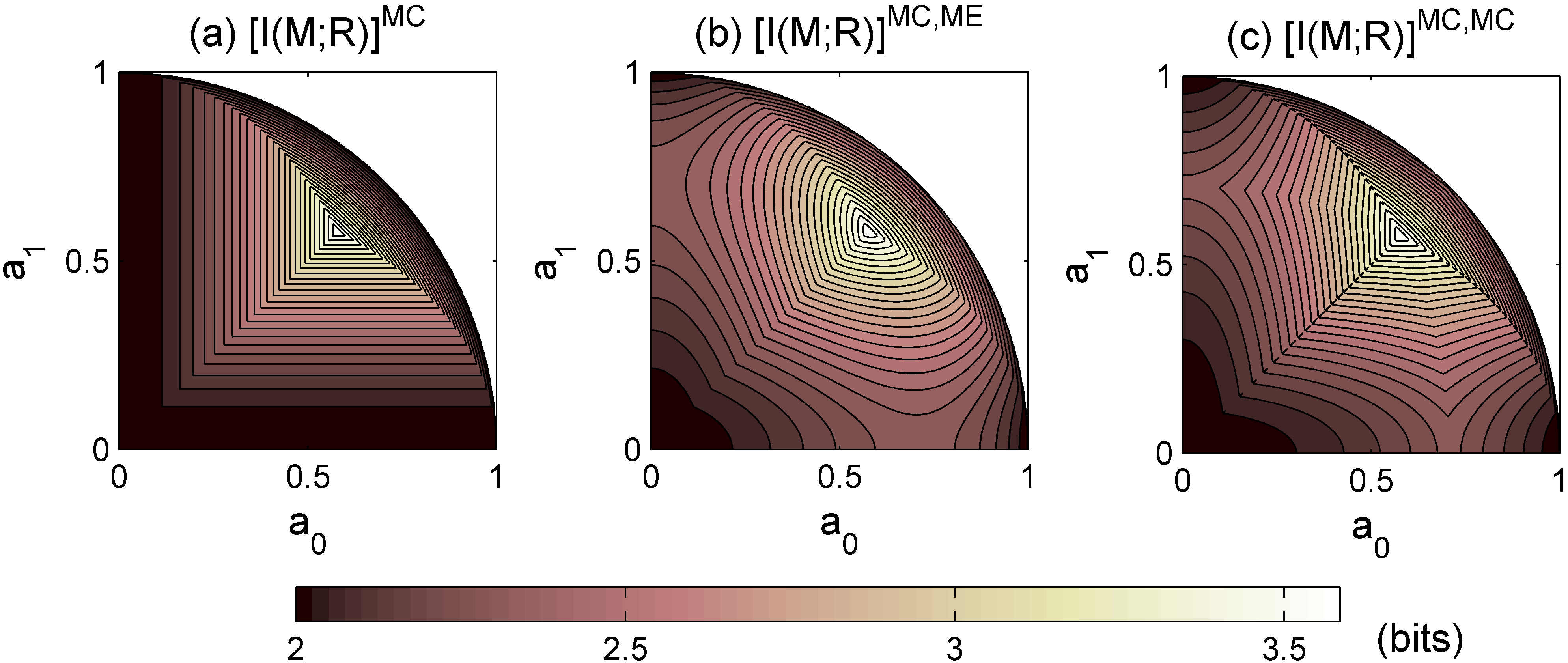 Figure 6
Figure 6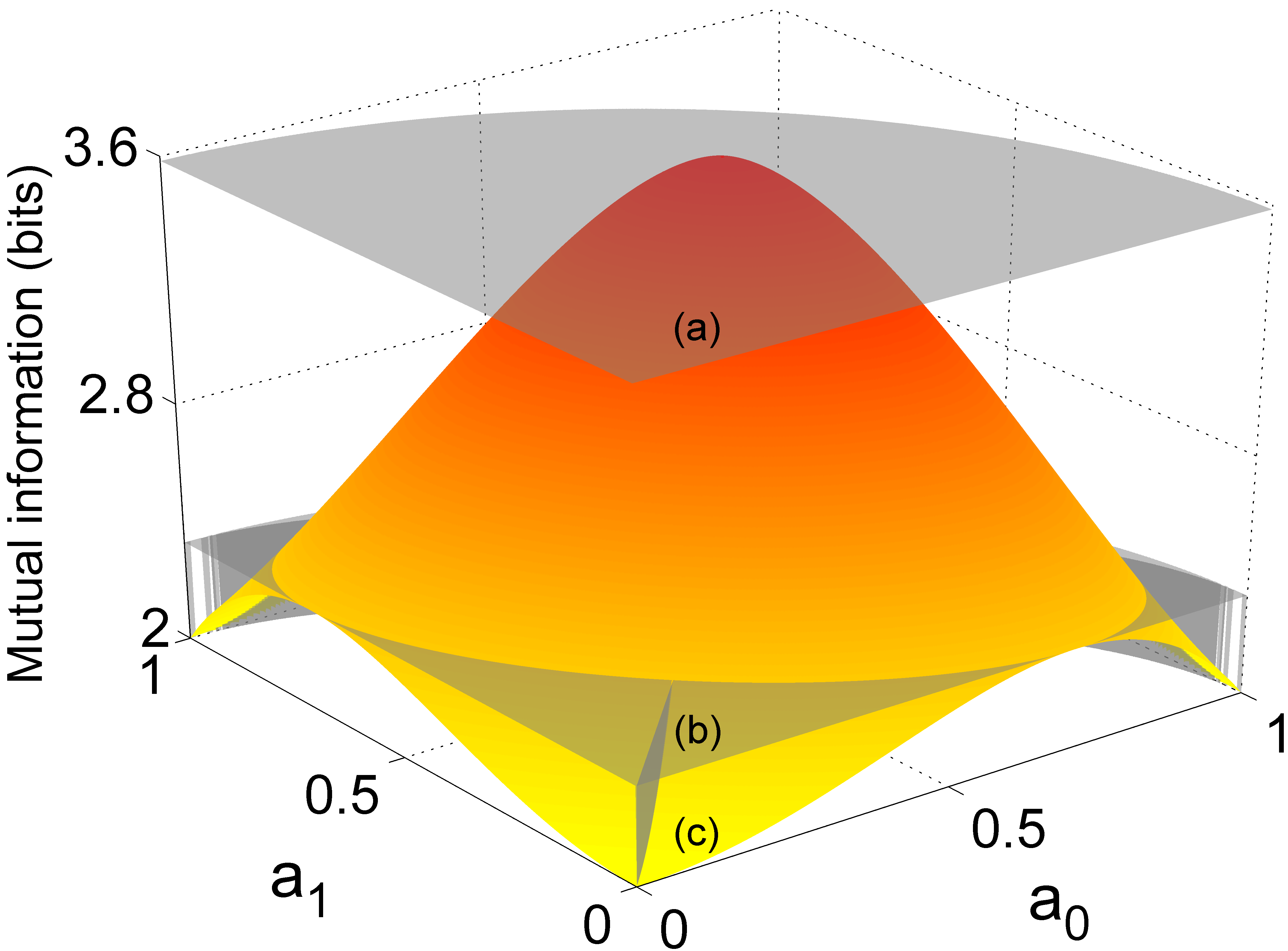 Figure 7
Figure 7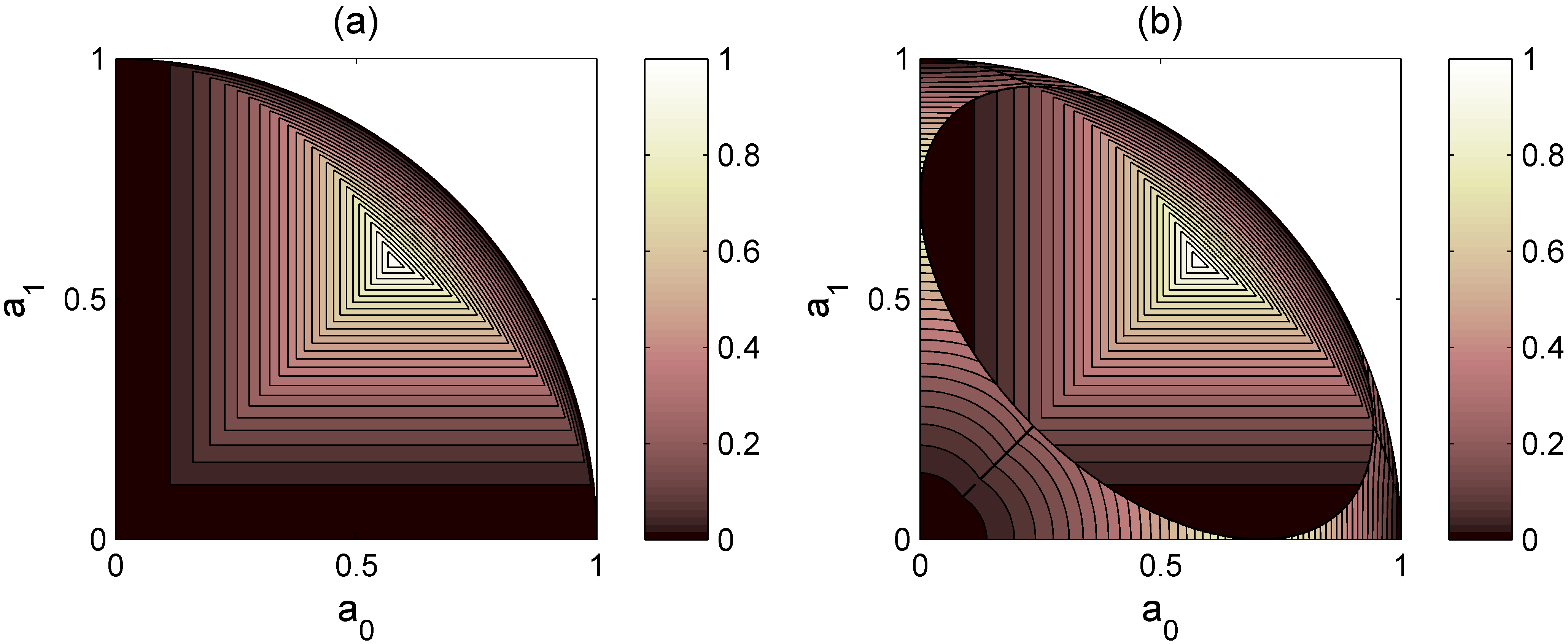 Figure 8
Figure 8| Schmidt rank |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Optimal probabilistic dense coding schemes
Roger A. Kögler111E-mail: [email protected] and Leonardo Neves
- Departamento de Física, Universidade Federal de Minas Gerais*
Belo Horizonte, MG 31270-901, Brazil
Abstract
Dense coding with non-maximally entangled states has been investigated in many different scenarios. We revisit this problem for protocols adopting the standard encoding scheme. In this case, the set of possible classical messages cannot be perfectly distinguished due to the non-orthogonality of the quantum states carrying them. So far, the decoding process has been approached in two ways: (i) The message is always inferred, but with an associated (minimum) error; (ii) the message is inferred without error, but only sometimes; in case of failure, nothing else is done. Here, we generalize on these approaches and propose novel optimal probabilistic decoding schemes. The first uses quantum-state separation to increase the distinguishability of the messages with an optimal success probability. This scheme is shown to include (i) and (ii) as special cases and continuously interpolate between them, which enables the decoder to trade-off between the level of confidence desired to identify the received messages and the success probability for doing so. The second scheme, called multistage decoding, applies only for qudits (-level quantum systems with ) and consists of further attempts in the state identification process in case of failure in the first one. We show that this scheme is advantageous over (ii) as it increases the mutual information between the sender and receiver.
Keywords Dense coding Quantum-state separation Maximum-confidence measurements Multistage decoding
1 Introduction
Quantum information theory has impacted in many ways our knowledge on how information may be stored, manipulated, and transmitted [1]. Much of its achievements were consequence of a unique type of correlation among physical systems exhibited only by the quantum systems, namely the entanglement. This is, for instance, the resource that enables information to be transmitted in an unparalleled and secure fashion as shown in quantum teleportation [2] and quantum cryptography [3], respectively. Another remarkable application of entanglement is the quantum communication protocol called dense coding, proposed by Bennett and Wiesner [4]. They have shown that if two parts share this resource, one part can send more information to another than would be possible without entanglement. The simplest example of this protocol works as follows: Alice, the sender, and Bob, the receiver, share a pair of qubits (two-level systems) in a known maximally entangled Bell state. She performs, on her qubit, one of the four unitaries , , , and given by the identity and the Pauli operators, respectively. Each of these local unitary operations maps the initial two-qubit state into one of the four orthogonal Bell states, which then can be used to encode two bits of information. After this encoding, Alice sends her qubit to Bob who can extract these two bits of information by performing a Bell-state measurement on both qubits in his possession. Therefore, by sending a single qubit, part of a shared maximally entangled pair, Alice is able to communicate two bits of classical information to Bob. If there was no entanglement, a single qubit would enable just one bit of information to be transmitted between them.
Likewise any other quantum information protocol that relies on maximally entangled states to work perfectly, dense coding is also affected when the entanglement shared between Alice and Bob is not maximal. In this scenario, many schemes have been proposed to optimize the protocol [5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17]. We can divide these schemes into two main lines of investigation. In the first, one optimizes the encoding/decoding processes while trying to transmit the same amount of information that would be possible with a maximally entangled state [5, 6, 7, 8, 9, 10, 11, 12]. In the second, one seeks to maximize the number of perfectly distinguishable messages that can be encoded and transmitted through the shared entangled state [13, 14, 15, 16, 17].222For qudits (-level systems), this number will be intermediate between the one achieved by a maximally entangled and a non-entangled state. For qubits, this number would be 3, but as shown in [13], it is impossible to encode three perfectly distinguishable messages in any partially entangled two-qubit state. Our work follows the first line of investigation and, in this context, we assume that Alice’s encoding scheme will be the standard one presented in the original dense coding proposal [4]. This encoding, performed with a set of orthogonal unitary operators333To be defined in Sect. 2. applied with equal a priori probabilities, maximizes the information transmission capacity of the protocol, as shown in Refs. [7, 10, 18].
Within the framework established above, the set of possible classical messages encoded by Alice will not be perfectly distinguishable due to the non-orthogonality of the quantum states carrying them. What remains is to optimize Bob’s decoding process, i.e., to find the measurement strategy which optimally discriminates among these non-orthogonal states. So far, this problem has been approached in two ways:
- (i)
Bob implements a measurement which always infers Alice’s message and minimizes the inevitable error in doing so. This strategy admits no failure probability and, as shown in [5, 6], it maximizes the mutual information between them in the dense coding.
- (ii)
Bob implements a measurement that infers Alice’s message without error, but only with a certain success probability, which must be maximized in order to optimize the process. In case of failure, nothing else is done. As shown in [8, 12], this strategy provides full confidence in identifying the non-perfectly distinguishable messages at the cost of reducing the mutual information between them in comparison with the case (i).
The decoding processes (i) and (ii) are implemented via minimum-error (ME) and maximum-confidence (MC) measurements, respectively. Reviews on these discrimination strategies may be found in Refs. [19, 20, 21]. The field of quantum-state discrimination has rapidly evolved in the last years, becoming a fundamental tool in quantum information theory. Many new optimized measurement strategies have been proposed [22, 23, 24, 25, 26] and applied in protocols like, for instance, quantum teleportation [27] and entanglement swapping [28].
Here, we propose the application of the probabilistic discrimination strategies introduced in Refs. [23, 26] by one of us and co-workers, in the decoding process of the dense coding protocol. Firstly, we present a family of probabilistic decoding schemes which include (i) and (ii) described above as special cases and continuously interpolate between them. It is implemented via quantum-state separation, namely a map that transforms the states carrying part of Alice’s message into more distinguishable states, with an optimal success probability [26]. After a successful event, the decoding is accomplished with a ME measurement. This scheme allows Bob to trade-off between the level of confidence he wishes to identify Alice’s messages and the success probability for this task. The second group of probabilistic decoding schemes applies only for dense coding with qudits. It relies on the following fact: After a failed discrimination attempt in a probabilistic strategy, the qudit states, in general, still carry information about the input states. Thus, they can be subjected to further discrimination attempts and the process may be iterated [23]. We call this process multistage decoding and show that it improves over scheme (ii) increasing the mutual information between Alice and Bob.
This paper is organized as follows. In Sect. 2 we describe the encoding/decoding processes in the dense coding studied here and provide a simple expression for the mutual information, the figure of merit to be optimized in our protocols. In Sect. 3 we briefly review the decoding scheme (i), which is used as the final step in our protocols. In Sect. 4 we introduce the family of probabilistic protocols assisted by quantum-state separation. The multistage decoding is presented and discussed in Sect. 5. In Sect. 6 we present a qualitative analysis of the application of these decoding schemes in quantum key distribution. Finally, we conclude the paper in Sect. 7.
2 Dense coding
2.1 Encoding
Let us consider Alice and Bob sharing a known bipartite entangled state where system 1 (2) lives in a -dimensional Hilbert space, (), and it is in Bob’s (Alice’s) hands. Using the Schmidt decomposition [1], this state can be written as
[TABLE]
where ’s are strictly positive real numbers satisfying and, hence, is the Schmidt rank of the state, which satisfies (see Table 1 for a prompt reference on these quantities). The Schmidt bases are assumed to coincide with the computational basis spanning (). If that is not the case in the beginning, they can apply local unitary rotations to align them.
In the dense coding protocol studied here, Alice encodes one of messages with the same a priori probability (), by performing a local unitary operation (for and ) on her system. Thus, the classical message encoded in the quantum state will be defined by the ordered pair . This is illustrated in the circuits of Fig. 1. The unitaries and are the generalized Pauli operators acting on a - and -dimensional Hilbert space, respectively. They are defined by their action on the computational basis as
[TABLE]
and
[TABLE]
where denotes addition modulo . With this encoding process, the state shared between Alice and Bob in Eq. (1) is transformed into
[TABLE]
The unitary and hermitian operator is a generalization of the controlled-not gate for arbitrary dimensions [29]. Having system 1 (2) as the control (target), its action on the computational basis is defined by444Even if the bases and have different cardinalities, the gate can still be defined, as pointed out in [30].
[TABLE]
where denotes subtraction modulo . The state of system 1 in Eq. (4) is given by
[TABLE]
and the set is composed by equally likely symmetric states. They are equally likely because the encoding is performed with the same a priori probability. In addition, they are symmetric under the action of because the conditions and apply [31].
As pointed out in Ref. [13], in the encoding given by Eq. (4), the unitary [Eq. (2)] is the “classical” part of the process since it enables one to encode one of perfectly distinguishable (PD) messages in a -level qudit. This is no better than using a “-state” classical communication channel. On the other hand, [Eq. (3)] is the quantum enhancement, as it introduces, locally, relative phases on the shared entangled state allowing one to encode (in combination with ) one of messages, which may or may not be PD, thus increasing the information capacity over any -state classical channel. The extent of this enhancement, however, depends on the initial entangled state shared between Alice and Bob. If it is uniform, i.e., if in Eq. (1), the states in Eq. (4) become
[TABLE]
where is the discrete Fourier transform acting on the -dimensional (sub)space555The Fourier transform is defined as . Along the paper, the (sub)space where it acts depends on the relationship between , , and (see Table 1). If , then so that acts, necessarily, on a -dimensional subspace of . If , then so that acts on a subspace of , for , or the entire space, for . of system 1. In this case is easy to check that
[TABLE]
and , which means that Alice can encode PD messages. In addition, if , the entanglement of (1) is maximal and the number of possible PD messages is the maximum allowed for the quantum channel, that is, if , and if . However, if the shared entangled state is not uniform (which implies partial entanglement), the overlap between the states in Eq. (4) will be
[TABLE]
meaning that the possible messages Alice can encode will not be PD, as a consequence of the non-orthogonality of the symmetric states defined in (6).
2.2 Decoding
After receiving system 1 from Alice, Bob performs a joint measurement on 1 and 2 to determine the corresponding state and, hence, decode her message. First, he applies the unitary and hermitian gate. From Eq. (4), this yields
[TABLE]
Now, the state of system 2 can be perfectly determined by a projective measurement onto the computational basis. To finish the decoding, Bob must identify the state of system 1 [Eq. (6)] through a proper measurement, which is the problem we will address here. The process described so far is sketched in the circuit of Fig. 1a, where the operation in the black box will take different forms according to Bob’s measurement strategy.
As shown in Eq. (7), if the state shared between Alice and Bob is uniform, the symmetric state in (6) reduces to . Therefore, the set is composed by mutually orthogonal states which can be perfectly discriminated by applying an inverse Fourier transform followed by a projective measurement onto the computational basis, as sketched in Fig. 1b. This is the standard dense coding protocol devised by Bennett and Wiesner in Ref. [4].
For a non-maximally and non-uniform entangled state, the set is composed by non-orthogonal states, for which there is no measurement able to identify among them deterministically and with full confidence. Therefore, the optimal decoding process requires optimal discrimination among those states. In the next sections we shall present measurement strategies applied to this problem, focusing our attention on the probabilistic ones.
2.3 Mutual information in the dense coding
Before addressing the optimal decoding strategies, we briefly describe the mutual information between Alice and Bob in the dense coding discussed above. This will be our figure of merit to analyze the performance of the protocols.
The mutual information between two random variables and quantifies the amount of information about acquired by determining the value of [32]. In the present context, take values in the set of possible messages encoded by Alice and in the measurement results of Bob’s decoding. As shown in Appendix, this quantity can be written in a simplified and more instructive form as
[TABLE]
where
[TABLE]
In these expressions, denotes the discrimination strategy to be adopted by Bob to identify the state of system 1. is the conditional entropy which quantifies the uncertainty about the random variable when we know the value of . Both variables now are associated with the encoding/decoding process for the part of the message encoded in system 1, i.e., take values in the set of symmetric states (6), and in the set of outcomes corresponding to the generalized measurement . In (12), gives the probability of obtaining the outcome given that the prepared state was . Note that the number of measurement operators, , is arbitrary, as long as they form a physically realizable measurement. Here, we shall consider only .
The conditional entropy in Eq. (12) is associated with the uncertainties in the discrimination of the symmetric states (6). It obeys , where 0 and indicates no uncertainty (orthogonal states) and maximum uncertainty (identical states), respectively. Thus, from Eq. (11), the mutual information in the dense coding satisfies
[TABLE]
where the minimum corresponds to a state with no entanglement and the maximum to a uniform entangled state. For non-uniform entangled states, we must find optimal discrimination strategies which minimize , as will be shown next.
3 Decoding with minimum-error quantum measurements
Dense coding with non-maximally entangled states, using the encoding scheme discussed in Sect. 2.1, has been first studied by Barenco and Ekert [5]. Restricting to the case of qubits, they have shown that the standard decoding process [see Fig. 1b] presented in Ref. [4] was already the optimal one, maximizing the mutual information between Alice and Bob. Later, this result was generalized for arbitrary dimensions [6]. In the standard process, Bob determines the state of system 1 with the projective measurement
[TABLE]
for . This is exactly the optimal measurement that discriminates among equally likely symmetric states with minimum error [33]. Therefore, by applying the ME strategy in the decoding, Bob performs the standard protocol which is the optimal one when no failure probability is admitted in the process. Using Eqs. (6), (11), (12), and (14), the mutual information between Alice and Bob will be
[TABLE]
where
[TABLE]
is the probability of obtaining an outcome if the state of system 1 is . It is easy to see that if the entangled state is uniform, and . Also, if there is no entanglement, and , as expected. For any other entangled state , showing that even partial entanglement is always better than no entanglement at all.
As an example, consider an entangled state with and . Using Eqs. (15) and (16) we plot the corresponding maximal mutual information as a function of the Schmidt coefficients and () in Fig. 2. The maximum, , is reached for a maximally entangled state; the minimum values, 2 bits, correspond to product states (, , and ). The curves in the axes , , and , correspond to entangled states with non-maximal Schmidt rank (), but with Alice encoding the same number of messages of a full rank state. Obviously, these messages will be even less distinguishable as the states carrying them are also linearly dependent, thus reducing the mutual information. This situation differs from the one presented in Sect. 2 and will not be addressed here.
4 Decoding assisted by quantum-state separation
The first probabilistic approach to the dense coding with non-maximally entangled states (considering the encoding presented in Sect. 2.1) was given by Hao et al. for the case of qubits [8] and later generalized by Pati et al. [12] for the case of qudits. These authors have shown that with this non-ideal resource Alice could communicate classical bits to Bob—the maximum achieved, deterministically, by a maximally entangled state—with a certain success probability.
Here, we introduce a new family of probabilistic dense coding schemes which have those in Refs. [8, 12] as special cases and interpolate continuously between them and the ones presented in [5, 6] (described in the previous section). Our approach is based on Bob’s ability of mapping the symmetric states given by Eq. (6) into the symmetric states given by
[TABLE]
where
[TABLE]
and . It is easy to see that and
[TABLE]
which is a uniform symmetric state. This map has been proposed by one of us and co-workers in Ref. [26] where it was shown that the states are more distinguishable (or more separated from a geometrical point of view) than those in the set for any , namely, for all . Also, the distinguishability increases with and reach its maximum for where the states become uniform. They will be orthogonal if the ’s are linearly independent and maximally separated for linearly dependent ’s.
4.1 Separation of symmetric states
The map described above is probabilistic. As demonstrated in [26], the optimal success probability, , for the transformation is
[TABLE]
, where is the smallest coefficient of the entangled state (1) and, consequently, of the symmetric state (6). The physical implementation of this transformation is as follows: First, one applies a unitary coupling, , between the original system (1 in our protocol) and a two-dimensional ancillary system (ancilla). Assuming their initial state to be , it will evolve as
[TABLE]
where is the computational basis in the ancilla space, and are the Kraus operators acting on (sub)space and responsible for the success and the failure in the mapping, respectively. They are given by [26]
[TABLE]
[TABLE]
and satisfy , where is the identity operator in this space. Finally, is the state which is transformed in case of a failed mapping and is given by
[TABLE]
These states are also symmetric but less distinguishable than the ’s, i.e., for all . This is because they are restricted to a subspace of the -dimensional space where the ’s live, as at least one of the coefficients in (24) vanishes. Note that there is no dependence of the failure states with the distinguishability parameter .
4.2 Bob’s decoding
Let us assume that Bob applies the map on system 1 to assist his decoding process of Alice’s message. After the unitary coupling (21), he performs a projective measurement on the ancilla. A projection onto (), with probability [], maps into () and the process is successful (unsuccessful). In this section we consider the following scenario: If Bob’s mapping succeeds, he accomplishes the decoding with a final measurement on system 1; otherwise, he does nothing in it, retrieving no information of its state. This is equivalent to the approach presented in Refs. [8, 12]. In the next section we also show an improvement on this.
After a successful event, Bob applies the ME measurement given by Eq. (14) in order to determine, in an optimal way, the state and thus infer the component of Alice’s message . The dense coding protocol with this whole decoding procedure is illustrated in the circuit of Fig. 3. From Eqs. (14) and (17), the probability of obtaining an outcome if the state of system 1 is will be
[TABLE]
where is given by (18). Using Eqs. (11) and (12) and taking into account both successful and failed events in Bob’s mapping, the mutual information between him and Alice, as a function of the distinguishability parameter , will be
[TABLE]
From this expression, we can obtain the boundary cases: If no transformation is performed, i.e., if , then and [see Eq. (15)], that corresponds to the results of Refs. [5, 6]. If , Bob performs the maximum separation [see Eq. (19)] and , so that recovers the results of Refs. [8, 12]. Finally, if there is no entanglement, then and , as expected.
The selected term in Eq. (26), , corresponds to the mutual information between Alice and Bob considering only successful events in his mapping. The descending ordering of the quantities shown in (15) and (26) reads as
[TABLE]
where the equality holds only for or . The first inequality can be easily perceived if one recalls that a successful mapping transforms the input states into the more distinguishable ones , thus reducing the conditional entropy (12) and, consequently, increasing the mutual information [see Eq. (11)]. The second inequality is a consequence that the ME measurement provides, on average, a larger probability of correctly identifying the states than any other probabilistic strategy [23], as the one described in this section. Therefore, it produces a larger mutual information between Alice and Bob. Despite that, the probabilistic strategies allow for Bob to identify—with a certain success probability—Alice’s non-PD messages more confidently than would be possible by applying the ME strategy.
The dense coding assisted by quantum-state separation introduced here enables Bob to trade-off between the level of confidence he wishes to identify Alice’s non-PD messages and the optimal success probability, [Eq. (20)], for doing so. This is done by fixing the distinguishability parameter , which sets the operations given by Eqs. (21)–(23) he must implement for achieving his goal. Let us illustrate the protocol with a simple example: Assume that Alice and Bob share a two-qubit non-maximally entangled state given by
[TABLE]
Using Eqs. (18), (20), (25), and (26), we plot in Fig. 4 the success probability and the mutual information as functions of . The solid line in the right panel corresponds to the mutual information , given by Eq. (15), reached when Bob applies the ME measurement. The whole discussion above can be appreciated from these graphs. In particular, the right panel demonstrates the relationship between the mutual informations established in Eq. (27). Also, the squares plotted for and the circles for correspond to the results of the dense coding protocols proposed in Refs. [5, 6] and [8, 12], respectively.
5 Multistage decoding
The second class of probabilistic dense coding we propose here is based on the following: After a failed attempt in the map described in the previous section, the state of system 1, , is transformed into [see Eq. (24) and subsequent discussion]. These failure states are restricted to a -dimensional subspace of , where , and denotes the multiplicity of the smallest Schmidt coefficient, namely . The case is not of interest because the entangled state is uniform and the protocol works perfectly. For , the failure states are identical (up to a global phase) for all and hence, retrieve no information about the ’s. On the other hand, for we have , and the failure states, although less distinguishable than the ’s, will still carry some information about them. Therefore, instead of simply doing nothing in case of failure in the mapping (as considered in Sect. 4.2 and also in Ref. [12]), Bob may try to identify the state (and hence ) to infer in Alice’s message . He can apply any strategy that discriminates, optimally, among the equally likely symmetric states in the set , having in mind that these states are now linearly dependent. Depending on the strategy he adopts and other features of the entangled state (e.g., and the multiplicity of the other Schmidt coefficients), Bob can iterate this process in as many stages as allowed by the quantum channel. This is the essence of the multistage decoding which, as we will see, increases the mutual information between Alice and Bob. Note that this scheme applies only when none of the systems are qubits and the condition holds.
5.1 Decoding with maximum-confidence quantum measurements
We will describe the multistage decoding considering that at any stage Bob implements quantumstate separation, he sets the distinguishability parameter at its maximum,666This is not a requirement for the process but will be adopted here in order to establish a comparison with previous results in the literature and also to make the whole discussion clearer. i.e., (thus, from now on we omit from the corresponding expressions). For equally likely symmetric states, this map followed by a ME measurement (14) on the successfully transformed states discriminate among them with the maximum confidence [23]. In the present context, the linearly independent states (6) are transformed in the uniform states (19) which will be orthogonal. Accordingly, they will be discriminated unambiguously (which means confidence 1) with the optimal success probability [31]
[TABLE]
calculated from Eq. (20), where the subindex denotes the first stage in the decoding process. This is the probability that Bob will identify perfectly the non-PD messages from Alice. Using Eqs. (11) and (12), the mutual information between them will be
[TABLE]
where is the mutual information when Bob applies a discrimination strategy to identify the state [Eq. (24)] resulting from a failure in the mapping . For instance, if he applies the ME measurement (14) one obtains
[TABLE]
This case is illustrated in the quantum circuit of Fig. 5a. On the other hand, by applying the MC measurement and a given strategy in case of failure, this mutual information will be
[TABLE]
where
[TABLE]
which is the product between the dimension of the subspace spanned by and the square of the smallest nonvanishing coefficient of these states [23]. Additionally,
[TABLE]
where is a set of uniform symmetric states in a -dimensional subspace of , resulting from a successful mapping in the second stage of the decoding process. They are maximally distinguishable but not orthogonal since the failure states are linearly dependent. Thus, and . Figure 5b shows the quantum circuit with a well succeeded MC measurement at the second stage of the decoding process.
The same reasoning for in (30) can be applied to in (32) as long as the failure states in the second stage still carry information about the ’s. This process may then be iterated under this latter condition. Bob’s discrimination strategy on a given stage will depend on what is advantageous for him to infer Alice’s message. For instance, if his concern is to infer this message more confidently, it might be possible (as we will see in the example below) that a successful MC measurement on that stage still provides higher confidence than a ME measurement at the first stage. In this scenario, the success probability for his task will increase by employing the multistage decoding.
Equation (30) tells us that whenever
[TABLE]
the mutual information will always be larger than the one achieved by discarding the failure outcome in the decoding, as can be seen by comparing it with Eq. (26) for . The condition (35) is fulfilled in both cases discussed above, either by applying the ME measurement [see Eq. (31)] or another round of the MC measurement [see Eqs. (32)–(34)]. Therefore, the multistage optimal discrimination strategies enable to increase the transmission rate of classical information in the probabilistic dense coding protocols as compared with previous schemes [15, 12] which did not explored this unique feature of qudit states.
5.2 Example
We return to the example of Sect. 3 to illustrate the main results presented in this section. For an entangled state with and , Bob can perform a two-stage decoding. Figure 6 shows the specified mutual informations as functions of the Schmidt coefficients and (). In Fig. 6a we plot which is obtained from Eq. (26) with . It corresponds to a single-stage decoding: Bob performs a MC measurement where nothing else is done in case of failure. The results of two-stage decodings are shown in Figs. 6b, c. The plot of Fig. 6b corresponds to the mutual information where a ME measurement is performed at the second stage. It is obtained from Eqs. (30) and (31). Finally, in Fig. 6c we plot the mutual information for a two-stage MC measurement, which is obtained from Eqs. (30) and (32)–(34). Clearly, both two-stage decodings increase the mutual information between Alice and Bob.
Another interesting feature of this process can be appreciated in the graphs of Fig. 7. Considering the decoding with a two-stage MC measurement, we plot the mutual informations considering only successful events in the first [surface (a)] and second [surface (b)] stages, obtained from the underbraced part of Eq. (26) (with ) and Eq. (34), respectively. For the sake of comparison, we also reproduce, in surface (c), the mutual information of Fig. 2, obtained from a single-stage decoding performed with a ME measurement. Surface (a) shows that the first inequality in Eq. (27) is fulfilled. In this case, the mutual information reaches the maximum value provided by a maximally entangled channel, since the non-PD messages are distinguished with full confidence, although only probabilistically. This is independent of the amount of entanglement shared between Alice and Bob. In case of failure in the first stage of the MC measurement and a well succeeded event in the second one, the corresponding mutual information is greatly reduced as seen from surface (b). However, aside few exceptions,777In surface (b), the curves that reach the lower bound of 2 bits correspond to entangled states whose minimum Schmidt coefficient has multiplicity two, so that the second stage of MC measurement would be useless. it is larger than the lower bound of 2 bits that would be achieved if Bob had simply given up of inferring this part of Alice’s message after a failure in the first stage. What is more interesting to observe is that the regions of surface (c) below of surface (b) indicate the range of entangled states for which a success in the second stage of the MC measurement leads Bob to infer Alice’s message still more confidently than would be with a single-stage decoding via ME measurement. Therefore, for such entangled states, Bob increases the success probability of identifying the received non-PD messages with more confidence. This is shown in the graphs of Fig. 8. Figure 8a shows the success probability in the first stage of the MC measurement, which is the probability of reaching the mutual information shown in the surface (a) of Fig. 7. Figure 8b shows the overall success probability of performing the decoding with a larger confidence than with ME measurement. The improvement in the region below surface (b) of Fig. 7 is clear.
6 Decoding schemes applied to quantum key distribution
The decoding schemes presented in Sects. 3, 4, and 5 may also have impact in high-dimensional quantum key distribution (QKD) protocols. Here, we will address, qualitatively, which would be such possible impacts—a thorough and quantitative analysis is beyond the scope of the present paper. Hopefully, this will open the doors for further investigations on the subject.
Let us consider a generalization to high dimensions of the two-state QKD protocol developed by Bennett [34] (the B92 protocol). In order to generate a secure shared key with Bob, Alice sends him a quantum system prepared with equal probability in one of the -dimensional symmetric states , given by Eq. (6), each one corresponding to the logical “dit” . Bob discriminates unambiguously (confidence 1) among the possible states with the optimal success probability given by Eq. (29). Then, over a public classical channel, he tells Alice whether the discrimination succeeded or not. If it has succeeded, they keep the dit; if it has failed, they discard it. After many repetitions of this procedure, Alice and Bob will share a sequence of ’s which will be used as a key.
Now, assume that an eavesdropper (Eve) intercepts the quantum system before it arrives to Bob. As the states are not orthogonal, she cannot determine perfectly which one Alice has prepared. What she can do is to apply a given discrimination strategy to infer the state in the best possible way. Then, she keeps the inferred dit, prepares a new state identical to the inferred one, and send it to Bob. Obviously, this procedure will introduce errors in the protocol since Eve will, sometimes, send the wrong dit to Bob. To detect these errors, Alice and Bob compare some of their dits in a public channel. If there are no errors, there is no eavesdropper and the remaining dits will be kept to form the key. Otherwise, if there are errors within a given range, the presence of the eavesdropper will be very likely and, in this case, they will discard all the dits and repeat the process.
The error rate introduced by Eve in this procedure as well as how much she learns about the key will depend on the discrimination strategy she adopts. In order to remain undetected (or, at least, hard to be detected), she must introduce as few errors as possible. In this scenario, let us analyze, qualitatively, the advantages and shortcomings of the strategies studied here. First, we consider the two extreme cases where Eve applies either ME or MC strategy:
- (i)
If Eve chooses to apply the ME strategy (Sect. 3), she will not get a perfect key. However, she introduce the least amount of errors. If these errors are below the unavoidable errors from other sources (e.g., imperfect communication channel and detection), she will remain undetected.
- (ii)
If Eve chooses to apply MC strategy (Sect. 4 for ), she will learn the key with much more confidence. However, since the overall probability of identifying the states incorrectly is always larger than in the ME strategy, she will introduce a higher error rate. Thus, she could be detected more easily.
How the discrimination strategies studied in Sects. 4 and 5 would fit in this problem? First of all, since both are probabilistic, the errors in identifying the states are always larger than in the deterministic ME strategy [23]. Accordingly, the error rate introduced by Eve would always be higher than in (i) should she applies any of those strategies. However, there may still be advantages in using them:
- (iii)
If Eve chooses to apply the state separation (Sect. 4 for ) followed by a ME measurement, she can trade-off (by setting the distinguishability parameter ) between the level of confidence in learning the key and the error rate introduced in the protocol. The former would be larger than in (i) and the latter, lower than in (ii).
- (iv)
If Eve chooses to apply the multistage decoding (Sect. 5), she will have the chance of learning the key with as much confidence as in (ii) and, at the same time, to introduce a lower error rate. This is because the overall error probability in identifying the states is reduced in comparison with a single-stage MC measurement.
Therefore, for high-dimensional QKD—considering the B92 protocol using symmetric states—Alice and Bob must be aware of these many discrimination strategies which Eve can implement to get the key. With this knowledge, they will be able to establish the range of errors introduced by a possible eavesdropper adopting any of these strategies and hence, to detect his/her presence.
7 Conclusion
In summary, we revisited the problem of dense coding with non-maximally entangled states for protocols adopting the standard encoding method. Using the recent advances in the field of quantum-state discrimination, we proposed optimal probabilistic decoding schemes which generalized and improved over previous approaches. Firstly, we demonstrated that by applying quantum-state separation onto the information carriers, one can controllably increase the distinguishability of the messages, with an optimal success probability. This scheme was shown to include those of Refs. [5, 6] and [8, 12] as special cases and continuously interpolate between them, enabling the decoder to trade-off between the level of confidence desired to identify the received messages and the success probability for doing so. After that we introduced the concept of multistage decoding, based on successive attempts of state discrimination when there is a failure in the current attempt. We showed that this scheme applies only for dense coding with qudits and is advantageous over previous reports [12, 15] as it increases the mutual information between the sender and receiver. Finally, we discussed, qualitatively, the application of these decoding schemes in a high-dimensional QKD protocol. Further, quantitative studies on this subject may bring advances in this field.
Acknowledgements This work was supported by the Brazilian agencies CNPq through Grant No. 485401/2013-4 and FAPEMIG through Grant No. APQ-00240-15.
Appendix
In this appendix we show that the mutual information between Alice and Bob in the dense coding protocol described in Sect. 2 is given by Eqs. (11) and (12). For a pair of random variables and , the mutual information is defined as [32]
[TABLE]
where and are the Shannon and conditional entropies, respectively. In the present context, the random variable is associated with the set of possible messages encoded by Alice in the quantum state [see Eq. (10)] with a probability . Thus, the Shannon entropy will be given by
[TABLE]
On the other hand, the random variable is associated with the set of Bob’s measurement results in his decoding process. The index () is connected with the result of a measurement on system 1 (2), and the number of values it assumes, (), will be explained later. With these definitions, the conditional entropy will be written as
[TABLE]
Using Bayes’ rule
[TABLE]
we can rewrite (38) as
[TABLE]
where is the overall probability of obtaining the outcome , which, from the symmetry of the problem [23], is given by
[TABLE]
is the conditional probability of obtaining the outcome given that the prepared state was . As we showed in Sect. 2, the state of system 2 is perfectly discriminated by a projective measurement onto the computational basis . However, for discriminating the states of system 1, we need, in general, to implement an -outcome generalized measurement , with , where stands for the strategy to be adopted. Therefore, we obtain
[TABLE]
Replacing these results in Eq. (40), the conditional entropy will be given by
[TABLE]
where is the conditional entropy associated with the encoding/decoding process for the part of the message encoded in system 1. Using the results of Eqs. (37) and (43) in Eq. (36), we obtain the mutual information of Eq. (11), which ends the proof.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Barnett, S.M.: Quantum Information. Oxford University Press, Oxford (2009)
- 2[2] Bennett, C.H., Brassard, G., Crépeau, C., Jozsa, R., Peres A., Wootters, W. K.: Teleporting an unknown quantum state via dual classical and Einstein-Podolsky-Rosen channels. Phys. Rev. Lett. 70 , 1895 (1993)
- 3[3] Ekert, A.K.: Quantum cryptography based on Bell’s theorem. Phys. Rev. Lett. 67 , 661 (1991)
- 4[4] Bennett, C.H., Wiesner, S.J.: Communication via one- and two-particle operators on Einstein-Podolsky-Rosen states. Phys. Rev. Lett. 69 , 2881 (1992)
- 5[5] Barenco, A., Ekert, A.K.: Dense coding based on quantum entanglement. J. Mod. Opt. 42 , 1253 (1995)
- 6[6] Hausladen, P., Jozsa, R., Schumacher, B., Westmoreland, M., Wootters, W.K.: Classical information capacity of a quantum channel. Phys. Rev. A 54 , 1869 (1996)
- 7[7] Bose, S., Plenio, M.B., Vedral, V.: Mixed state dense coding and its relation to entanglement measures. J. Mod. Opt. 47 , 291 (2000)
- 8[8] Hao, J.-C., Li, C.-F., Guo, G.-C.: Probabilistic dense coding and teleportation. Phys. Lett. A 278 , 113 (2000)