Adaptive Matching for Expert Systems with Uncertain Task Types
Virag Shah, Lennart Gulikers, Laurent Massoulie, Milan Vojnovic

TL;DR
This paper introduces an adaptive matching model for expert systems with uncertain task types, optimizing task-expert assignments by considering feedback and externalities to improve throughput in online platforms.
Contribution
It develops a novel backpressure algorithm that accounts for task externalities and feedback, outperforming greedy approaches in expert resource allocation.
Findings
The proposed algorithm achieves maximum throughput in the model.
Greedy matching approaches are suboptimal due to externalities.
Simulation results validate the theoretical throughput gains.
Abstract
A matching in a two-sided market often incurs an externality: a matched resource may become unavailable to the other side of the market, at least for a while. This is especially an issue in online platforms involving human experts as the expert resources are often scarce. The efficient utilization of experts in these platforms is made challenging by the fact that the information available about the parties involved is usually limited. To address this challenge, we develop a model of a task-expert matching system where a task is matched to an expert using not only the prior information about the task but also the feedback obtained from the past matches. In our model the tasks arrive online while the experts are fixed and constrained by a finite service capacity. For this model, we characterize the maximum task resolution throughput a platform can achieve. We show that the natural…
Click any figure to enlarge with its caption.
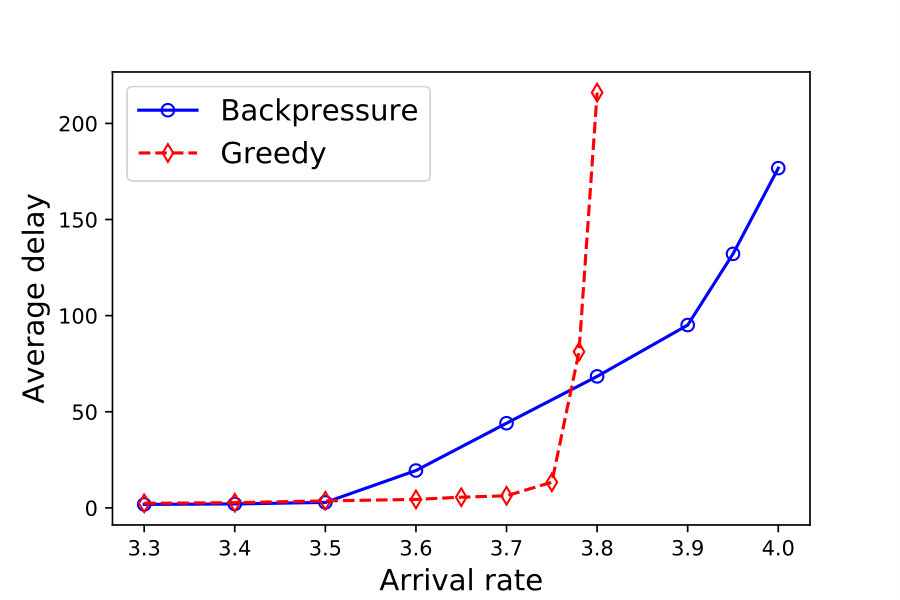 Figure 1
Figure 1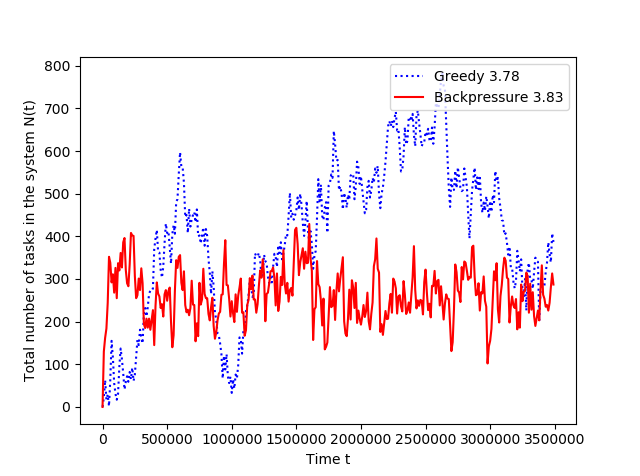 Figure 2
Figure 2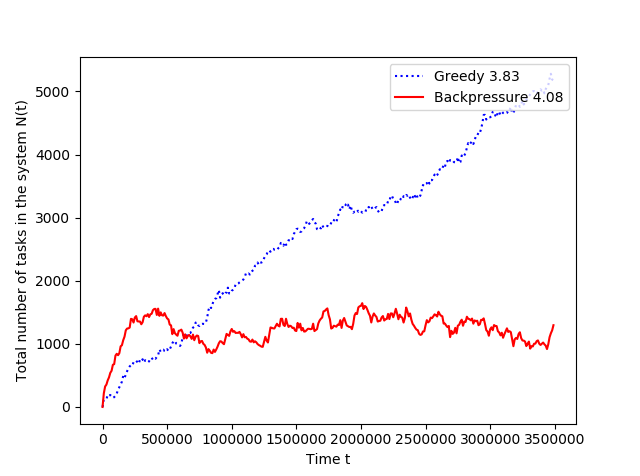 Figure 3
Figure 3| Expert Clusters | ||||||||||
| Tags | ||||||||||
| calculus | .32 | .39 | .30 | .35 | .37 | .47 | .28 | .16 | .26 | .41 |
| real-analysis | .17 | .41 | .25 | .32 | .23 | .49 | .40 | .10 | .10 | .44 |
| linear-algebra | .46 | .29 | .05 | .36 | .14 | .48 | .26 | .31 | .07 | .43 |
| probability | .07 | .49 | .02 | .33 | .02 | .50 | .06 | .02 | .46 | .04 |
| abstract-algebra | .02 | .05 | .03 | .32 | .02 | .38 | .23 | .50 | .01 | .27 |
| integration | .09 | .43 | .05 | .19 | .44 | .45 | .03 | .01 | .06 | .37 |
| sequences-and-series | .05 | .32 | .16 | .31 | .20 | .45 | .09 | .04 | .06 | .33 |
| general-topology | .02 | .10 | .03 | .16 | .02 | .43 | .50 | .07 | .02 | .31 |
| combinatorics | .03 | .14 | .06 | .43 | .04 | .37 | .02 | .06 | .19 | .05 |
| matrices | .27 | .15 | .02 | .31 | .02 | .44 | .06 | .11 | .02 | .34 |
| complex-analysis | .02 | .19 | .08 | .16 | .14 | .50 | .09 | .05 | .01 | .44 |
| Size | 165 | 188 | 313 | 200 | 179 | 183 | 231 | 187 | 178 | 176 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Adaptive Matching for Expert Systems with Uncertain Task Types
Virag Shah
Stanford University
Lennart Gulikers
Microsoft Research-INRIA Joint Centre
Laurent Massoulié
Microsoft Research-INRIA Joint Centre
Milan Vojnović
London School of Economics
Abstract
A matching in a two-sided market often incurs an externality: a matched resource may become unavailable to the other side of the market, at least for a while. This is especially an issue in online platforms involving human experts as the expert resources are often scarce. The efficient utilization of experts in these platforms is made challenging by the fact that the information available about the parties involved is usually limited.
To address this challenge, we develop a model of a task-expert matching system where a task is matched to an expert using not only the prior information about the task but also the feedback obtained from the past matches. In our model the tasks arrive online while the experts are fixed and constrained by a finite service capacity. For this model, we characterize the maximum task resolution throughput a platform can achieve. We show that the natural greedy approaches where each expert is assigned a task most suitable to her skill is suboptimal, as it does not internalize the above externality. We develop a throughput optimal backpressure algorithm which does so by accounting for the ‘congestion’ among different task types. Finally, we validate our model and confirm our theoretical findings with data-driven simulations via logs of Math.StackExchange, a StackOverflow forum dedicated to mathematics.
1 Introduction
Online platforms that enable matches between trading partners in two-sided markets have recently blossomed in many areas: LinkedIn and Upwork facilitate matches between employers and employees; Uber allows matches between passengers and car drivers; Airbnb and Booking.com connect travelers and housing facilities; Quora and Stack Exchange facilitate matches between questions and either answers, or experts able to provide them.
These platforms often propose matches based on imperfect knowledge of the characteristics of the two parties to be matched. Such uncertainty may result into inferior matches and may incur negative externalities of the following kind: If a constrained resource is matched sub-optimally then it becomes unavailable to a more suitable match for a while. For example, in online labour platforms and Q&A platforms if an expert is matched to a task which does not meet her expertise then the tasks which meet her expertise may suffer. Similarly, in hospitality platforms an economical accommodation becomes unavailable to a financially constrained customer if it is matched to a flexible customer.
This naturally leads to the following questions:
- •
How to quantify the loss in efficiency resulting from such uncertainty?
- •
Which matching recommendation algorithms can lead to the most efficient platform operation in presence of such uncertainty?
A natural measure of efficiency is the throughput that the platform achieves, i.e. the rate of successful matches it allows.
In this paper, we progress towards answering these questions as follows. In what follows, we will anchor our discussion to task-expert systems but the insights developed are more generally applicable.
First, we propose a simple model of such platforms, which features a static collection of servers, or experts on the one hand, and a continuous stream of arrivals of tasks, or jobs, on the other hand. In our model, the platform’s operation consists of servers iteratively attempting to solve tasks. After being processed by some server, a task leaves the system if solved; otherwise it remains till successfully treated by some server. To model uncertainty about task types, we assume that for each incoming task we are given the prior distribution of this task’s “true type”. Servers’ abilities are then represented via the probability that each server has to solve a task of given type after one attempt at it.
In a Q&A platform scenario, tasks are questions, and servers are experts; a server processing a task corresponds to an expert providing an answer to a question. A task being solved corresponds to an answer being accepted. In an online labour platform, tasks could be job offers, and a server may be a pool of workers with similar abilities. A server processing a task then corresponds to a worker being interviewed for a job, and the task is solved if the interview leads to a hire. We could also consider the dual interpretation when the labour market is constrained by workers rather than job offers. Then a task is a worker seeking work, while a server is a pool of employers looking for hires.
An important feature of our model consists in the fact that when a task’s processing does not lead to success, it does however affect uncertainty about the task’s type. Indeed, the a posteriori distribution of the task’s type after a failed attempt on it by some server differs from its prior distribution. For instance in a Q&A scenario, a question which an expert in Calculus failed to answer either is not about Calculus, or is very hard. Further, the feedback from the expert may reveal some information about the task’s type.
For our model, we then determine necessary and sufficient conditions for an incoming stream of task arrivals to be manageable by the servers, or in other words, determine achievable throughputs of the system. In the process we introduce candidate policies, in particular the greedy policy according to which a server choses to serve tasks for which its chance of success is highest. This scheduling strategy is both easy to implement and is based on a natural motivation. Surprisingly perhaps, we show that it is not optimal in the throughput it can handle. In contrast, we introduce a so-called backpressure policy inspired from the wireless networking literature [42], which we prove to be throughput-optimal.
We summarize contributions of this paper as follows:
- •
We propose a new model of a generic task-expert system that allows for uncertainty of task types, heterogeneity of skills, and recurring attempts of experts in solving tasks.
- •
We provide a full characterization of the stability region, or sustainable throughputs, of the task-expert system under consideration. We establish that a particular backpressure policy is throughput-optimal, in the sense that it supports maximum task arrival rate under which the system is stable.
- •
We show that there exist instances of task-expert systems under which simple matching policies such as a natural greedy policy and a random policy can only support a much smaller maximum task arrival rate, than the backpressure policy.
- •
We report the results of empirical analysis of the popular Math.StackExchange Q&A platform which establish heterogeneity of skills of experts, with experts knowledgeable across different types of tasks and others specialized in particular types of tasks. We also show numerical evaluation results that confirm the benefits of the backpressure policy on greedy and random matchmaking policies.
The remainder of the paper is structured as follows. In Section 2 we present our system model. In Section 3 we present the throughput optimal algorithm as well as the characterization of task arrival rates that can be supported by the system. In Section 4, we present a case study where we compare performance of our algorithm with other baseline algorithms. In Section 5, we present our experimental results. In Section 6 we generalize our results to arbitrary feedback structure. Related work is discussed in Section 7. We conclude in Section 8. Proofs of the results are provided in Section 9.
2 Problem Setting
Let be the set of task types. Each task in the system is of a particular type in . Let be the set of servers (or experts) present in the system. When a server attempts to resolve a task of type , the outcome is (a success) with probability and it is [math] (a failure) with probability . Upon success we say that the task is resolved. In the context of online hiring platform, this is equivalent to successful hiring of an employee for a job. In the context of Q&A platform, this is equivalent to an answer by an expert being accepted by the asker of the question.
We consider a Bayesian setting where we have a prior distribution for a task’s type, where is the set of all distributions. Note, different tasks may have different prior distributions. Clearly, if server processes a task with prior distribution then the probability that it fails is given by
[TABLE]
Further, upon failure, the posterior distribution of task’s type is given by
[TABLE]
Note that the posterior distribution of a task’s type upon failure by a subset of servers does not depend on the sequence in which these servers resolve the task, i.e., for each we have . At any point in time a task is associated with a ‘mixed-type’ which is defined as the posterior distribution of its type given the past attempts.
We allow a task to be attempted sequentially by multiple servers until it is resolved. We would like to resolve the tasks as quickly as possible. The matching algorithm may use the past feedback from the servers. In the setting described above the feedback is binary, namely, in the form of success and failure. More generally, the servers may provide a more detailed feedback. Although in several cases such a feedback is not reliable and often biased, e.g., see [13]. For now, we will stick with the binary feedback structure. We will generalize our results to an arbitrary feedback structure in Section 6.
2.1 Single Task Scenario
Before considering the setting of online task arrivals, for ease of exposition we first consider a toy scenario with single task for which greedy algorithms are known to be approximately optimal. Suppose that time is discrete. A task arrives at time . Let the prior distribution of its type upon arrival (equivalently, its mixed-type at time ) be . At a time, only one server attempts to resolve a task. Consider the problem of designing a sequence of servers such that the probability that the task is resolved within a fixed time is maximized. Let , and for each let , i.e., is the mixed-type of the task at time given that it was not resolved upon previous attempts. Then the probability that the task is resolved by time is given as g\big{(}(s(t):0\leq t\leq\tau)\big{)}=1-\prod_{t=0}^{\tau}\psi_{s(t)}(z(t)).
Contrast this with the Bayesian active learning setting in [18, 21] where the goal is to reduce uncertainty in true hypothesis via outcome from several experiments. Using a diminishing returns property called adaptive submodularity the authors in [18] obtain a policy which is competitive with the optimal. In our setting, is a submodular function. Thus a greedy policy where for each is chosen to be from is -competitive, see [36].
Further, in this paper we add an extra dimension to the problem which was not considered in the [18, 21], namely, we consider the setting of online task arrivals where tasks of different mixed-types may compete for the servers resources before they leave upon being resolved. We design throughput optimal policies under such a setting.
2.2 Online Task Arrivals
We consider a continuous time setting, i.e., . Tasks arrive at a rate of per time unit on average. The mixed types of incoming tasks upon arrival are assumed i.i.d., taking values in a countable subset of . For each , let denote the probability that a new arrival is of mixed type . Finally, the time for server to complete an attempt on a task takes on average time units, and such attempt durations are i.i.d.. All involved sources of randomness are independent.
We assume that is closed under , i.e., for each , . This loses no generality, as the closure of a countable set with respect to a finite number of maps remains countable.
We assume that a given task may be inspected several times by a given server and assume that the outcomes success / failure are independent at each inspection. This can be justified if a label in fact represents a collection of experts with similar abilities, in which case multiple processings by correspond to processing by distinct individual experts.
For such a setting we would like to minimize the expected sojourn time of a typical task, i.e., the expected time between the arrival and the resolving of a typical task. Recall that the success probabilities are assumed to be arbitrary. Under such a heterogeneous setting minimizing expected sojourn time is a hard problem. In fact, this is true even when there is no uncertainty in task types. As a proxy to sojourn time optimal policies, we will strive for throughput optimal policies. In particular, we will characterize the arrival rates for which the system can be stabilized, i.e. for which there exists a scheduling policy which induces a time-stationary regime of the system’s behavior. Indeed for a stable system the long term task resolution rate coincides with the task arrival rate , and thus throughput-optimal policies must make the system stable whenever this is possible. Note that for an unstable system the number of outstanding tasks accumulate over time and the expected sojourn time tends to infinity.
Finally, for simplicity we assume more specifically that the tasks arrive at the instants of a Poisson process with intensity , and that the time for server to complete an attempt at a task follows an Exponential distribution with parameter . These are continuous time analog of i.i.d. arrivals and independent departures per time slot in discrete time setting. These assumptions will imply that the system state at any given time can be represented as a Markov process, which simplifies throughput analysis. The system throughput is often insensitive to such statistical assumptions on arrival and service times, e.g., see [44].
We close the section with some additional assumptions and notations which will aid our analysis.
For each time let represent the number of tasks of mixed-type present in the system and . We also let denote the mixed type of the task that server works on at time . For strategies such that the servers select which task to handle based uniquely on the vector , the process forms a continuous-time Markov chain (CTMC) ([7, 27]). The policies considered in this paper are studied by analyzing the associated CTMC.
We allow a task to be assigned to multiple experts at a given time. Further, we allow both preemptive as well as non-preemptive policies. Recall, in a preemptive policy an expert may drop a task under service if a task of a new mixed-type becomes available, whereas in a non-preemptive policy an expert must wait for his task to be serviced before taking up a new one.
3 Optimal Stability
Main goal of this section is to provide necessary and sufficient conditions for stability of the system, and to provide explicit policies which stabilize the system when the sufficient conditions are satisfied.
We obtain stability conditions via capacity constraints and flow conservation constraints which capture the flow of tasks from one type to another upon service by an expert. For instance, if represents the flow of tasks of mixed-type served by expert , a fraction of it leaves the system due to success while the rest gets converted into a flow of type . The total arrival rate of flow of mixed-type , i.e., , must match the total service rate, i.e., . Further, the total flow service rate expert , i.e., , must be less than its service capacity . The following is the main result of this section.
Theorem 1**.**
Suppose there exists such that . If there exist non-negative real numbers for each and each , and positive real numbers for each such that the following hold:
[TABLE]
then there exists a policy under which the system is stable. If there does not exist non-negative real numbers , for , and non-negative real numbers for such that the above constraints hold, then the system cannot be stable.
We use the condition of existence of an expert such that only for a technical reason to simplify our proof. We believe that the result holds even when this condition is not true.
One may envisage obtaining a throughput optimal static randomized policy from a solution to (3) and (4) which, for example, maximizes the minimum . It is not clear if this policy would result into a stable solution. Consider the following plausible scenario. While the total slack available at each server is finite, the total number of queues is infinite since we have one queue for each mixed-type. Depending on the system parameters, the optimal solution may assign a positive slack to each queue. Then, the infimum over the slacks at different queues would be zero. This would make the system unstable.
To avoid this pitfall, we find a finite set of mixed-types such that the overall arrival rate into queues corresponding to mixed-types is sufficiently small. We then group the infinite number of queues corresponding to into a virtual queue. We thus obtain a system with finite number of queues which consists of the virtual queue and the queues corresponding to the mixed-types in . For this system we use a dynamic policy, provided below, which is motivated by the literature on backpressure policies for constrained queueing systems, e.g., see [42, 16].
One may also envisage a static randomized policy obtained via a solution to a modified version of the constraints (3) and (4) which would stabilize the above finite queueing system. Indeed, such a policy exists and we use its existence to show throughput optimality of our backpressure policy. Such a static policy, however, suffers from a severe practical limitation. By randomly selecting a queue for each server, the policy splits its capacity across several queues In contrast, in our policy each server serves only one queue with a high backlog. It is well known that pooling of a server’s capacity, as against fragmenting its capacity across several queues, achieves better performance due to gains from statistical multiplexing. In fact, the performance improvement scales with the number of queues.
Further, an agile backlog based dynamic policy may offer several practical advantages over solving a high-dimensional optimization problem in real systems where the parameters used may change over time. Thus, we believe it is natural to consider a backpressure approach over a static approach.
We now describe the our dynamic policy which achieves optimal stability. We need some more notation to describe the policy. Consider a set . Let be the number of tasks in the system at time which have mixed-type or have had a mixed-type in the past. Further, for each let be the number of tasks with mixed-type which have had a mixed-type in in the past. Also, for convenience, for each , let be the number of tasks with mixed-type , i.e., for each . Thus, we have .
Finally, for each let be the number of tasks of mixed-type which have not had a mixed-type in in the past. Thus, for each we have . For the rest of this section we suppress the dependence on for brevity in notation.
Our policy operates in two modes, Random mode and Backpressure mode. During Random mode, each server is assigned a task from at random. During Backpressure mode, a server is assigned a task of a mixed type in with the highest ‘expected backlog’, where the expected backlog at mixed-type accounts for the congestion at as well as at . Further, it also accounts for the fact that with probability the task may get resolved and leave the system without seeing the congestion at . The decision regarding which mode to operate in is based on the relative congestions at and .
Definition 1** (Backpressure() policy).**
For a given , let and be as defined above. For each let
[TABLE]
For a given , let
[TABLE]
If
[TABLE]
then each expert is assigned a task in where with ties broken arbitrarily. Else, each expert serves a task in chosen uniformly at random.
Note that, under Backpressure() policy, is a CTMC. The following theorem establishes throughput optimality of the Backpressure() policy.
Theorem 2**.**
Suppose there exists a server such that . If the sufficient conditions for stability as given in the statement of Theorem 1 are satisfied, then there exists a finite subset of such that the policy Backpressure() stabilizes the system.
In particular, the Backpressure() policy is optimally stable for Asymmetric() system as defined in Definition 3.
To prove Theorem 2, we use Lyapunov-Forster theorem to show stability. We use the following Lyapunov function:
[TABLE]
As such, proving this result requires significantly different approach as compared to stability proofs via quadratic Lyapunov functions of classical constrained queueing networks with finite number of queues. In particular, the flow equations do not directly give a stabilizing static policy. In fact, there does not exist a static policy which stabilizes the system at all feasible loads. To avoid this pitfall, we find a finite set such that the overall arrival rate into is small, and ‘pool’ the slack capacity at the servers to serve the infinite number of queues in .
The stability part of Theorem 1 follows from Theorem 2. For the converse statement in Theorem 1, we use system ergodicity.
We now provide an alternative policy which achieves stability under a more restrictive condition that are bounded away from [math] and , but with the advantage that it does not rely on the precise numbers of jobs sharing the same mixed type , but rather on ‘local averages’. As such it may remain optimally stable even when the distribution of mixed types of incoming jobs is no longer assumed to be discrete.
Definition 2** (Backpressure() policy).**
Partition set into finitely many subsets , , such that each has diameter at most , that is for all we have We then define , and the backpressure with respect to server of a given as
[TABLE]
where and are such that and . Then, each expert is assigned a task with mixed-type in
[TABLE]
with ties broken uniformly at random
We then have the following:
Theorem 3**.**
Suppose that there exists such that for each we have
[TABLE]
Suppose further that the sufficient conditions for stability as given in the statement of Theorem 1 are satisfied. Then, there exists an sufficiently small such that the Backpressure() policy stabilizes the system.
For its proof, we use the Lyapunov function . Again, the proof involves a significantly different approach as compared to stability proofs for standard constrained queuing networks with finite number of queues. In particular, we develop and use new flow equations which account for not only the sets associated with the mixed-types of the tasks but also the lengths of the history of the tasks.
Unlike backpressure policy proposed in [42] under a different setting, which was agnostic to system arrival rates, a set (or the ) such that the policy Backpressure() (or policy Backpressure()) stabilizes the system may depend on the value of . While the policies as stated may be complex to implement, it allows us to develop implementable heuristics which significantly outperform greedy policy. We demonstrate this in Section 5.
4 Asymmetric() Systems: A Case Study
In this section we study a class of task-expert systems, namely Asymmetric() systems, defined below. These systems resemble the -system considered in the literature of queueing systems where the tasks types are assumed to be known, see [19, 5, 43]. In particular, we study the loss in throughput due to uncertainty in task type, and also compare the performance of the optimal algorithm with some baseline policies, namely the Random policy and the Greedy policies.
Definition 3** (Asymmetric() System).**
Fix . In the Asymmetric() system there are two task types and two experts . Each arrival is equally likely to be of both types, i.e., where satisfies for each , and if . Both experts provide responses at unit rate, i.e., for each . Further, for class we have for each , and for class we have , and .
For the Asymmetric() system, if a task of mixed-type receives a failure from either of the experts then its mixed type becomes where and . Thus, it is sufficient to assume that where for each , and , where if is true and [math] otherwise. Further, it is easy to check that , , , and .
4.1 Loss in throughput due to uncertainty in task types
To understand the source of loss in throughput due to uncertainty, we first provide throughput of the Asymmetric() system, and then compare it with an analogous system where true type is known. The following proposition uses the flow equations from Theorem 1. Its detailed proof is provided in the Appendix.
Proposition 1**.**
There exists a policy which stabilizes the Asymmetric() system if we have . Further, if then no policy can stabilize the system.
Now suppose that the true type of each task is revealed upon arrival. Throughput of such systems can be computed using the well-known stability conditions for the flexible-server systems, e.g., see [30]; in particular, the throughput of the Asymmetric() system if true types are known is equal to .
Thus, for there is a loss in efficiency of the system. In particular, for the throughput reduces by . This can be reasoned as follows. For small values of , the main system bottleneck is servicing of tasks of true type by server since this is the only server which can serve such tasks. Since server is not bottlenecked, in case of uncertain task types its extra capacity may be used to identify tasks of true type . However, if the is large, then both the servers are bottlenecked and thus the wasteful use of in servicing tasks of true type results in loss of throughput.
4.2 Throughput under Random Policy:
Let us first define the Random policy and then provide an expression for the throughput.
Definition 4** (Random Policy).**
In the Random policy each expert is assigned a task chosen uniformly at random from the pool of outstanding tasks.
The following proposition provides throughput under Random policy for task expert systems in general, and the Asymmetric() system in particular. Its proof is provided in the Appendix.
Proposition 2**.**
Under Random policy, a task-expert system is stable if and only if it satisfies the following:
[TABLE]
In particular, the Random policy stabilizes the Asymmetric() system if and only if .
As expected, for the Asymmetric() system the throughput under the Random policy is significantly lower than the optimal throughput.
To prove the above result we use fluid limit approach developed in [38, 12, 31]. Let be the number of tasks in the system of pure-type . Let . Roughly, given initial condition , we let , and study . We use the following Lyapunov function:
[TABLE]
where .
4.3 Throughput under Greedy Policies
Following the discussion in Section 2.1, a question arises: does a greedy approach work well even under the online setting? From throughput perspective, a natural greedy approach is one where each expert is assigned a task which best suits its skills.
We will consider two greedy policies, a Preemptive Greedy policy and a Non-Preemptive Greedy policy. As we will see below, both the greedy policies are throughput suboptimal for the Asymmetric() system. Intuitively, the reason for their suboptimality can be explained as follows. Note that for we have for each . Thus, under the greedy policies each expert gives priority to the tasks of mixed-type . However, since only one expert can successfully serve the tasks of mixed-type , servicing of these tasks may become a bottleneck, especially for the small and moderate values of . In such a scenario, a policy in which the expert would prioritize queue , especially when its length is relatively large, as done by the Backpressure policy, would achieve a better throughput.
We first discuss the Preemptive Greedy policy and then the Non-Preemptive Greedy policy.
Definition 5** (Preemptive Greedy Policy).**
In the Preemptive Greedy policy, at each time an expert is assigned an outstanding task which maximizes its success probability, i.e., for each time such that we have
[TABLE]
where ties are broken uniformly at random.
The following proposition provides throughput achieved by the Preemptive Greedy policy for the Asymmetric() system. The main idea behind its throughput derivation can be intuitively explained as follows. Since both the servers give priority to the tasks of mixed-type at each time, the corresponding queue acts as an M/M/1 queue with service rate and arrival rate . Since the fraction of time this queue is empty is , the capacity available at server to server tasks of mixed-type is . Thus, maximum rate of service for tasks of mixed-type is . Similarly, the arrival rate for tasks of mixed type can be shown to be . The stability condition follows by comparing these two. The formal proof of the proposition can be found in the Appendix.
Proposition 3**.**
The Preemptive Greedy policy stabilizes the Asymmetric() system if and only if we have .
A surprising implication of the above theorem is that, for , the Preemptive Greedy policy as well as the Random Policy achieve throughput equal to . The optimal throughput is higher. This shows the importance of designing a matching policy which is cognizant of the system bottlenecks, such as the Backpressure policies designed in Section 3. For the N-systems where the task types are known, it was first observed in [19] that a greedy policy is suboptimal.
In the Preemptive Greedy policy, the process is a CTMC. In particular, the order in which the tasks of a given mixed-type are served does not matter to the evolution of . However, this is not the case in the Non-preemptive Greedy policy. For simplicity, in the Non-preemptive Greedy policy, we will view each mixed-type as queue and assume that the tasks of a given mixed-type are served in the FCFS discipline. In other words, if at time for a given server we have , then it serves the task which became of mixed type the earliest. Note that, in our general model, upon leaving a queue , a task may re-enter the queue at a later point in time. In such a case we consider the arrival time into the queue to be the one corresponding to the latest entry.
Definition 6** (Non-preemptive Greedy Policy).**
In the Non-preemptive Greedy policy, upon completion of an attempt at a task each expert serving it is assigned an outstanding task such that its success probability is non-zero. If multiple such tasks exists for a server then it is assigned one which maximizes its success probability. In other words, if an attempt on a task with mixed-type is completed at time , then for each such that we set
[TABLE]
where ties are broken uniformly at random. If no such task exists, i.e., if is empty, then the server stays idle till such a task arrives and starts serving it upon arrival. Further, the tasks with a given mixed-type are served in the FCFS discipline as described above.
For the Non-preemptive Greedy policy, owing to the complexity of the underlying Markov chain, we provide below a rather weak condition for instability which is nonetheless sufficient to establish its sub-optimality. See the Appendix for its proof.
Proposition 4**.**
Suppose that the Asymmetric() system is stabilizable, i.e., . Then, under the Non-preemptive Greedy policy, the Asymmetric() system is unstable if we have .
In particular, the above proposition implies that for the throughput of the Asymmetric() system under the Non-preemptive Greedy policy is less than , which is sub-optimal. Recall that the optimal throughput for this value of is .
5 Experimental Results
In this section, we present our empirical results obtained by using data from Math.Stack-Exchange Q&A platform. In this platform, users post tagged questions that are answered by other users. Upon resolution of the question, the asker may reveal which of the submitted answers resolved the question. We will use this data to estimate the success probabilities of experts in answering questions, and use these parameters in simulations to compare the throughputs that can be achieved by greedy, random, and backpressure policies. As we will see, a substantially larger throughput can be achieved by backpressure policy than greedy and random.
Dataset
The dataset consists of around questions and answers. It was retrieved on February 2nd, 2017. The top most common tags are given in Table 1 in decreasing order of popularity. Among these tags, the most common is calculus which covers questions, and the least common is complex analysis which covers questions. In our analysis, we used only questions that are tagged with at least one of the most popular tags, which amounts to a total of questions and answers.
Estimated skill sets
The success probabilities of answering questions are estimated as follows. For a given user-tag pair, the success probability is estimated by the empirical frequency of the accepted answers by this user for questions of given tag, conditional on that the user had at least accepted answers for questions of the given tag, and otherwise we estimate the success probability is set to be equal to zero. These success probabilities are estimated for users with the most accepted answers. Among these users, the user with the most accepted answers had accepted answers, and the user with the least number of accepted answers had accepted answers. There were users which had more than answers accepted. In order to form clusters of users with similar success probabilities for different tags, we ran the k-means clustering algorithm.
The estimated success probabilities are shown in Table 1. The columns correspond to different centroids of the clusters and give average success probabilities for different tags. In the bottom row, we give the sizes of the corresponding clusters. For instance, the persons in cluster have on average of their calculus, and of their linear algebra answers accepted.
There is a pronounced heterogeneity in user expertise. We highlighted in bold the success probabilities with values larger than . A subset of users, namely cluster , have high success probabilities at all topics whereas the users in the other clusters have high success rate at a subsets of topics.
Estimating There is a prevalence of questions with different combinations of tags, that is, mixed types. When a question arrives with multiple tags, we associated with it a mixed-type which is the uniform distribution across the associated tags. We kept only those combinations of tags that occur for at least of the total number of questions. This results in tag combinations among which are singletons and are a combinations of tags. These are the mixed types with positive , we set for all other mixed types. From among the questions with these mixed-types, the fraction of questions which belong the mixed-type is the estimated for . We observed that roughly of the questions are tagged with multiple tags, showing the relevance of our model.
Simulation setup
We assumed that the experts have unit service rates. We make this approximation as we do not have the information about times at which experts begin to respond a question. We examined the system for increasing values of task arrival rates. We simulate our CTMC via a custom discrete event simulator.
We implement the Backpressure() policy where the set consists of all pure types, the most frequently seen mixed types upon arrival as described above, and the mixed types which result from an attempt by an expert exactly once. Note that a task belonging to a pure type can be attempted upon multiple times without changing its type. We thus have . Our choice of is a result of a compromise between performance and complexity. Choosing a larger set of may increase the stability region by a small fraction, but may significantly increase the complexity of the Backpressure() policy.
Further, while serving the tasks in , instead of choosing tasks at random, we choose tasks greedily, i.e., each server is assigned a task in which maximizes its probability of success. Empirically, this improves the performance over random selection of tasks in .
In the following, we will use the short hand ‘greedy policy’ for the Preemptive Greedy policy, and ‘backpressure policy’ for the Backpressure() policy.
Performance comparison of different policies
In the following, we will use the short hand ‘greedy policy’ for the Preemptive Greedy policy, and ‘backpressure policy’ for the Backpressure() policy. In Figure 1 we plot the time-evolution of the total number of active tasks in the system for the greedy policy and the backpressure policy at the respective arrival rates and (Figure 1 left), and also at the arrival rates and (Figure 1 right). In Figure 1 left, both the policies are stable. Yet, the sample path under the backpressure policy is more steady than that under greedy policy, which is an added advantage to its throughput optimality. In Figure 1 right, while the greedy policy is unstable at , the backpressure policy is stable even at and thus significantly outperforms the greedy policy.
In Figure 2 we plot the average delay (sojourn time) of tasks in the system against the task arrival rates. The average delay is computed by first computing the time-averaged number of tasks in the system and then applying Little’s law. We observe that the task arrival rates at which random (not shown in the plot), greedy, and backpressure policies become unstable are approximately equal to , , and , respectively. Thus, the backpressure policy achieves throughput improvement of about over the greedy policy.
The backpressure policies marginally outperforms greedy in terms of average delay at the low loads, and significantly at high loads. However, observe that at the moderate loads the greedy policy outperforms the backpressure policy. The reason for this is as follows. The backpressure policy achieves throughput optimality by building gradients (in the form of weights) at the large loads which guide system operation. At moderate loads the queue lengths are small and the associated gradients are not very meaningful. This is similar in principle to the well known poor performance of backpressure policy at lower loads in multihop wireless networks, see [45]. Designing policies which perform well at all loads is an interesting avenue for future research.
6 General Feedback Structure
The model described in Section 2 allows for only binary feedback, in the form of success and failure. Upon success a task leaves the system, whereas upon failure, the fact of failure is used to reduce uncertainty in the true-type of the task. In this section we generalize the feedback structure as follows. Upon success a task leaves the system, as in the earlier model. However, upon failure, a server may additionally provide a feedback from a countable set of possible feedbacks . Let the be the probability that for a task of true type , server provides a feedback upon failure. Thus, for each and , is a probability mass function. We assume that for each and is known. In practice, it needs to be learned.
In this setting, if an attempt by a server on a task of mixed type results into a failure and if the feedback provided by the server is then the task’s new mixed-type, denoted by , is the resulting posterior distribution, namely,
[TABLE]
where is the probability that the task for mixed type results into failure upon an attempt by server and receives feedback , i.e.,
[TABLE]
We again assume that, for each and , is closed under .
Along the lines of the development of stability conditions in Section 3, we obtain below the necessary and sufficient conditions for stability. Again, we let represent the flow of tasks of mixed-type served by expert . In developing the new flow conservation constraints we now account for the more general feedback structure. The capacity constraints remain identical.
Theorem 4**.**
Suppose there exists such that . If there exist non-negative real numbers for each and each , and positive real numbers for each such that the following hold:
[TABLE]
then there exists a policy under which the system is stable. If there does not exist non-negative real numbers for , and non-negative real numbers for such that the above constraints hold, then the system cannot be stable.
A stabilizing policy is again obtained by finding a finite set such that the overall arrival rate into is small, and using a backpressure policy policy for congestion control. More formally, recall the definitions of , , and from Section 3. Consider the following policy.
Definition 7** (Modified Backpressure() policy).**
For each let
[TABLE]
For a given , let
[TABLE]
If
[TABLE]
then each expert chooses a task in where with ties broken arbitrarily. Else, each expert serves a task in chosen uniformly at random.
Again, using the Lyapunov function and the arguments identical to the proof of Theorems 1 and 2 in the Appendix but with appropriate changes, it follows that there exists a finite subset of such that the policy Backpressure() stabilizes the system if the necessary conditions are satisfied. Further, the converse statement of the theorem follows from system ergodicity. We omit details for brevity.
7 Related Work
Bayesian Active Learning (see [18, 21, 10, 14]) aims at learning true hypothesis by adaptively selecting sequence of experiments. In [10] labels are obtained for a batch of items at a time. In [14] a stream based budgeted setting is considered where a finite number of items arrive in a random order. In contrast we allow infinite stream of tasks and are interested in maximizing the task resolution throughput under capacity constraints at the servers. The crowdsourcing works such as [24, 39, 46, 15] consider task assignment problems for classification with unknown ground truths, however they consider a static model. In [32] the labeling tasks arrive dynamically and their exit is tied to the expert allocation decisions, in that a task leaves once the probability of error in the label estimate falls below a threshold.
Our work is also broadly related to that of multi-arm bandits, e.g., see [28, 4, 17, 8, 1] and citations therein, in the sense of optimizing the trade-off between exploration, to learn job types, and exploitation, to optimize task performance. It also has some relation with collaborative filtering systems such as those studied in [25, 26, 41], which can be interpreted as expert-task systems where success probabilities admit a low-rank matrix structure. Unlike our work, there good matches are inferred from observed assignments of tasks to experts, which are according to a given statistical model, and there are no resources constraints imposed on the experts.
A related line of work is that on stochastic online matching, e.g., see [33, 34, 20]. The stochastic online matching can be interpreted as a task-expert system where each expert is associated with a budget constraint that allows to solve at most one task. Unlike our work where the task types are uncertain, uncertainty in these models come from the arbitrariness of the future task arrivals and the monotonically decreasing available resource budgets.
Another related literature is that of constrained queueing systems, where arriving tasks are to be served by heterogeneous servers subject to resource constraints, e.g., see [42, 35, 30, 16, 45, 9, 2, 22, 11, 29, 40]. The goal is to efficiently utilize server resources while providing good performance in servicing tasks, e.g., optimizing task delays. Our matching policy is of a flavor similar to the stability-optimal backpressure policy first proposed in [42]. A setting close to ours is the one studied in [40] for routing queries in peer-to-peer networks. Here, the types of the queries are known but the locations of nodes where the queries may by successfully resolved are uncertain. More technically, we associate queues with each prior distribution which may be infinite in number. This makes the stability analysis much more challenging. Another related work is that on scheduling flexible servers, e.g., see [30, 29], which allows for tasks of different types and servers of different skills. It has been established that a so called max-weight policy is optimal in a heavy traffic regime. The main difference from our work is that all these works assume that the task types are known.
In [6], the authors considered a task-expert system where task types are of two difficulty levels (hard or easy) and expert skills are of two levels (senior or junior). Seniors may serve any task, but juniors may only serve easy tasks. The hardness of each task is unknown upon arrival. In comparison, we allow for much more generality with respect to the heterogeneity of skills of experts. In their model, a task upon service can only become progressively harder, which amounts to a feed-forward system, unlike our model.
The work in [23] considers a model where the job types are known but the expert types are unknown. They consider the problem of matching while simultaneously learning the expert types. A key idea is to use a shadow price which simultaneously accounts for resource utilization and type uncertainties. They consider an asymptotic regime where each expert is allowed to work on a large number of tasks, a vanishingly small amount of which could be used to accurately learn the expert types, and the rest can be served optimally. In the limit, the learning aspect is decoupled form the expert utilization, and it is thus different from our work.
8 Conclusion
We studied matching of tasks and experts in a system with uncertain task types. We established a complete characterization of the stability region of the system, i.e. the set of task arrival rates that can be supported by a matching policy such that the expected number of tasks waiting to be served is finite. We showed that any task arrival rate in the stability region can be supported by a back-pressure matching policy. We also compared with two baseline matching polices, and identified instances under which there is a substantial gap between the maximum task arrival rates that can be supported by these policies and that of the optimum back-pressure matching policy.
There are several interesting directions for future research. First, for the case when task types are unknown, it is of interest to consider matching policies that optimize different kinds of performance objectives, such as, for example, minimizing the long-run average of a function of task waiting times. Second, much remains to be said about matching policies for the case when both task types and the skills of experts are unknown.
9 Proofs
9.1 Proof of Theorem 1 and Theorem 2
We first show stability under sufficient conditions provided in the statement of Theorem 1. In the process, we prove Theorem 2.
In constrained queueing systems, e.g., see [42, 16], a standard approach towards proving stability of a backpressure type policy is to design a ‘static’ policy using flow variables and the slacks which provides a fixed service rate to each queue such that its drift is sufficiently negative for each. However, in our setup the total number of queues could be countable, while the total available slack is finite. Thus, it is not possible to design a static policy such that the drift in each individual queue is bounded from above by a negative constant. This is unlike any finite-server queueing system considered in the previous literature.
We thus take a different approach, which can be explained roughly as follows. Since the total exogenous arrival rate , and the total endogenous arrival rate, i.e. arrival into a queue due to failure at another queue, are both finite (they are bounded from above by ), there exists a finite set such that the total arrival rate into is less than . Each task which enters a queue where is instead sent to a virtual queue , and stays there until there is a success. If is ‘large’ compared to the other queues then all the servers focus on . The finite number of remaining queues are operated via a backpressure policy which accounts for the ‘expected backlog’ seen in these queues.
More formally, consider and positive constants as postulated in the theorem. Without loss of generality, assume that there exists a constant such that for each . Let be a finite subset of such that
[TABLE]
Since , such a exists.
Let be the number of tasks in the system which are or have been in past of type . Once a task enters queue it does not leave it until success. There may be tasks in it with mixed-type in . Note, our policy will depend on and thus will not be measurable. In turn, will not be a CTMC. For , let and be the tasks of mixed-type which have and have not had mixed-type in . Also, for convenience for each , let be the tasks of mixed-type , i.e., for each . We now formally define -measurable backpressure policy. Thus, is a CTMC.
We now show stability of the system under this policy for Backpressure() as given in Definition 1. Below we will assume that the ties in selecting from are broken uniformly at random for simplicity of exposition. The proof can be easily extend to any other tie breaking approach. Consider the following Lyapunov function.
[TABLE]
For each , let be the time at which the first event (arrival or completion of a response) occurs after time . Clearly, is a stopping time. Further, let .
Let
[TABLE]
is called drift in state . We would like to show that there exists a positive integer and positive constant such that
[TABLE]
Let for each and let
[TABLE]
Then, one can check that
[TABLE]
Further, let
[TABLE]
Then, we have that
[TABLE]
Thus, we get
[TABLE]
Upon arranging terms, we obtain
[TABLE]
The last of the above three terms can be bounded by a constant, say . For each and let and . Further, let and . Then,
[TABLE]
Consider the following lemma. Its proof is given in Section 9.2.
Lemma 1**.**
Recall the as postulated by the theorem. For , where and for each are reals, let
[TABLE]
Then,
[TABLE]
From definition of , we get that the first term in for is equal to [math], and, from (8) we have that the second term in it is less than or equal to 0.
Thus, we have that . From (9) we in turn obtain
[TABLE]
Fix . We now show that there exists a positive integer such that if or if then . Upon rearranging terms, we obtain
[TABLE]
From the definition of the algorithm we get that
[TABLE]
Hence, for any such that , we have .
We also have that
[TABLE]
Thus,
[TABLE]
Now suppose that . Then, if we are able to show that as , then we would have that a positive integer such that . We now show that, under , we have as .
Let . Then we have
[TABLE]
which tends to infinity because
[TABLE]
Thus, there exist positive constants and such that if or if then .
Let . Then, using a variant of Lyapunov-Foster theorem, namely Theorem 8.13 in [37], we obtain that from any state such that , the expected time to return to , i.e., is finite. Further,
[TABLE]
Thus, starting with any state in , we return to in a finite expected time. We will be done if we show that expected time to return to state is also finite. We do this as follows. Fix a constant . Since there exists such that , we have that for any interval of time of size the probability that no arrival happens in this interval and that a task leaves the system is finite.
Suppose that system is in a state at time . Now consider renewal times , where and for each , is defined as follows: is equal to if indeed no arrival happens and a task leaves the system in the interval , else is the first time of return to after . Clearly since as defined above is finite. Further probability that a task leaves system in time is finite, say . Thus, time for system emptying after first reaching can be upper-bounded by sum of geometric random variables with rate . Thus expected time to return to state is finite. Hence, the system is stable.
Now suppose that the system is stable. Then, the necessary conditions can be shown to hold by the ergodicity of the system, and letting for each to be the long-term fraction of times a server attempts a task in . ∎
9.2 Proof of Lemma 1
Upon rearrangement of terms in the expression of we obtain
[TABLE]
By using the definition of weights , we obtain
[TABLE]
Thus,
[TABLE]
Hence, the lemma holds. ∎
9.3 Proof of Theorem 3
Suppose that the sufficient conditions as given in Theorem 1 are satisfied. Then, in the proof of Theorem 1 we showed existence of a policy such that the system is ergodic. In fact, since we have a strict slack for capacity constraint at each server, using proof of Theorem 1 we can design a policy for a system which achieves stability even when the server capacities are modified as , where . Under such a policy, for each , , , let represent the long-term fraction of times a server attempts a task in which has been attempted times in the past. Then, the following hold.
[TABLE]
The inequalities in (10) can be strengthened to achieve positive slack for each server’s capacity, but (10) as mentioned is sufficient for our purposes. Using existence of which solves (10), we now show that, for Backpressure() policy, provided has been chosen small enough, the function is a Lyapunov function in the sense that its drift is negative, bounded away from 0 except for states with for some threshold . This will imply the announced result by the same arguments as in the proof of Theorem 2.
Let be given. For each such that , we pick arbitrarily one point in such that . We then define the projection operator which maps to if . For such that we say that is undefined. We shall also consider for each the operator
[TABLE]
This is defined so long as all the involved projections are defined, i.e. the constructed sequence only visits sets with . We also let denote the application resulting from applications of .
We now define for each the following rates:
[TABLE]
Finally, we define the following rates for all , where and are constants to be specified shortly:
[TABLE]
We extend the definition of the rates for by induction as follows. First, for we let . For server , we let
[TABLE]
and for :
[TABLE]
The functions are all Lipschitz-continuous. Under the assumption (5), it is easily verified that the functions are also Lipschitz-continuous. Let be such that all these functions are -Lipschitz-continuous.
It is readily established by induction on that for all , so long as is defined, one has
[TABLE]
Indeed, one has
[TABLE]
and (16) follows by induction.
We now exploit these properties to show that for suitable choices of , the previously defined rates verify the following inequalities for all such that and thus is defined:
[TABLE]
The first equation in (17) reads, in view of (12), (13):
[TABLE]
which holds with equality by (10) i).
The left-hand side of the second equation in (17) reads for :
[TABLE]
Using the Lipschitz property of , the bound (16) established between and , and letting , this is no larger than
[TABLE]
Indeed, the sum of rates at step is at most . This last expression can be rearranged to give
[TABLE]
In view of (10) ii), the first summation is equal to
[TABLE]
The difference between the right-hand side and the left-hand side of the second equation in (17) is therefore lower-bounded by
[TABLE]
Assuming , , and , this difference is at least
[TABLE]
Letting , we have in fact shown a strengthening of the second equation in (17), namely:
[TABLE]
Consider now . The left-hand side of the second equation in (17) verifies
[TABLE]
by the lower-bound of on the . This implies that the announced inequality also holds for .
We now verify that, provided was chosen small enough, the constructed rates satisfy the capacity constraints of the servers. For , this is easily verified, as by (10) iii),
[TABLE]
Consider now server . We then have
[TABLE]
Thus by (10) iv) this meets the capacity constraint of server provided
[TABLE]
This can clearly be achieved by first choosing such that , and then such that
[TABLE]
It finally remains to prove that the Foster-Lyapunov stability criterion holds for our proposed backpressure policy. Assume that each server dedicates capacity to jobs of type . This does not exceed servers’ capacities as we just showed. Moreover, in view of (17) and (18), under this allocation the drift of any such that reads
[TABLE]
For an arbitrary policy, let denote the service rate it devotes to those in , and denote the overall arrival rate of jobs with type in whether from external arrivals or unsuccessful treatments. The drift for our candidate Lyapunov function then reads
[TABLE]
where we used the fact that the overall arrival rate cannot be larger than the exogeneous arrival rate plus the overall service rate.
Under the allocations we just considered, the summation in the right-hand side is at most . Since the backpressure policy we have introduced minimizes this summation among all feasible policies, it guarantees a drift for the Lyapunov function of at most . We can therefore rely on Foster’s criterion to deduce that the return time to the set has bounded expectation. We will be done if we show that the system empties infinitely often. For this, we use the argument similar to that used in Theorem 2.
Fix a constant . Since , we have that for any interval of time of size the probability that no arrival happens in this interval and that a task leaves the system is finite.
Suppose that system is in a state at time . Now consider renewal times , where and for each , is defined as follows: is equal to if indeed no arrival happens and a task leaves the system in the interval , else is the first time of return to after . Clearly since as defined above is finite. Further probability that a task leaves system in time is finite, say . Thus, time for system emptying after first reaching can be upper-bounded by sum of geometric random variables with rate . Thus expected time to return to state [math] is finite. Hence, the system is stable. ∎
9.4 Proof of Proposition 1
We use Theorem 1 to prove this result. We first establish the sufficient condition and then the necessary condition. For Asymmetric() system we have where for each , and . The flow conservation constraints in Theorem 1 can be given as follows:
[TABLE]
Suppose . There exists an such that . It can be checked that where
[TABLE]
and where for each satisfy sufficient conditions of Theorem 1.
Now suppose . There exists an such that . It can be checked that where
[TABLE]
and where for each satisfies sufficient conditions of Theorem 1.
The sufficient condition then follows from the proof of Theorem 1 by taking as .
We now show the necessary condition. From the necessary conditions in Theorem 1, we have the following:
[TABLE]
From (20) we get:
[TABLE]
By substituting in (21) this the above expression for , we get
[TABLE]
Upon simplifying, we get
[TABLE]
Further, we need to be non-negative. Thus, we need .
Substituting (23) in (19) we get
[TABLE]
Suppose . Then, subject to (22) and , the right hand side of the above is maximized when and . We thus obtain . Similarly, if , then subject to (22) and , the right hand side of the above is maximized when and , from which we obtain . Thus, overall, we have . Hence the result follows. ∎
9.5 Proof of Proposition 2
We show the result for a general a task-expert system. The result for Asymmetric() system then follows immediately.
Note that the system under random policy is equivalent to the one where pure-type of a task is revealed upon arrival, i.e., there is no uncertainty in task types. This is true since the random policy does not use the information of type (pure or mixed). We thus let the pure-type of each task be revealed upon arrival. Let be the number of tasks in the system of pure-type . Let . For each , the arrival rate into queue is equal to
[TABLE]
We first show the if part of the result. Suppose that we have . We use the fluid limit approach developed in [38, 12, 31]. Roughly, given initial condition , the fluid trajectories of the state process can be obtained by scaling initial conditions, speeding time, and then studying the rescaled process; i.e., letting , and studying .
Using arguments similar to those used in [31], the fluid limits for the number of tasks in each class can be shown to satisfy the following at almost all times : for each and we have
[TABLE]
Define a function on as
[TABLE]
where .
Further, by following the arguments similar to [31], if we have that and for all such that under fluid limits then the stability of the original system follows. We show below that both these limits hold.
Using (24) and (25), we obtain
[TABLE]
where . Now, (29) is negative and strictly bounded away from zero. This can be seen as follows. Firstly, all terms in the sum are non-positive. Therefore, it suffices to show that there exists a such that there always exists a for which Since, and, for some fixed , , it follows that there exists such that For this , we thus also have . Consequently,
Let and for each . Since , we have . Let be the Kullback-Leibler divergence between two Bernoulli distributions with parameters and , i.e., . Now, we can write
[TABLE]
which converges to as grows large.
Hence, the if part of the result follows.
We now show that the system is unstable if . We consider the original system instead of the fluid limits. Consider the following function:
[TABLE]
Clearly, as . Define as in (33), but for instead of . Then, we have
[TABLE]
and for , we have
[TABLE]
Thus, the drift is non-negative for all but finite number of states. Further, since is bounded from below, the maximum change in upon an arrival or a departure is also bounded, using Proposition I.5.4 on page 22 in [3], we get the only if part. ∎
9.6 Proof of Proposition 3
We first show the if part. For each let be the time at which the first event (arrival or completion of a response) occurs after time . Let , i.e., given that at time , is the expected time at which the first event occurs after time . For example, for we have .
Now suppose that . Then, it can be checked that . Thus, there exists such . Now, consider the following candidate Lyapunov function: for each , we have
[TABLE]
where is a constant obtained as above.
Let
[TABLE]
Consider the states such that . For these states, we obtain
[TABLE]
Now, consider states such that and . For these states we have
[TABLE]
Since the drift outside of the state is less than or equal to , from the Lyapunov-Foster Theorem we obtain that is positive recurrent if .
We now show the only if part. Suppose that . Then, there exists such . Thus, drift is non-negative for all but finite values of . Further, since is bounded from below, and since the maximum change in upon an arrival or a departure is bounded, using Proposition I.5.4 on page 22 in [3], we establish the only if part.
9.7 Proof of Proposition 4
First, consider the following lemma.
Lemma 2**.**
Under Non-preemptive Greedy policy, the fraction of time server spends in serving tasks of true type is bounded from below by .
Thus, the maximum capacity available to serve tasks of true type is . In turn, the system is unstable if . From this the result follows via some simplifications. We prove the lemma below.
In what follows we assume that queue is saturated, since forcing to be saturated only reduces the time the server spends on queue under Non-preemptive Greedy policy. Further, note that the quantity of interest is twice the fraction of time server spends in serving tasks of true type . To obtain a bound on this quantity, we separately obtain an upper bound on the expected length of a busy-idle cycle at queue and a lower bound bound on the expected time spends in serving queue within a busy-idle cycle, and use the renewal reward theorem.
The expected length of a busy-idle cycle at queue can be bounded from above by that of an alternate system in which server is forced to stay idle while server is serving queue . In this modified system, the idle time for queue is upper bounded by since the inter-arrival times are Exponential() and the time server is forced to stay idle is Exponential(). Further, the number of arrivals into queue in an Exponential() time period is Geometric() distributed. Thus, at the end of idle period, when both the servers start serving the queue, the backlog in the queue is where is Geometric() distributed. In turn, the expected busy period for queue is bounded from above by .
Thus, the expected length of a busy-idle cycle at queue is bounded from above by .
We now provide a lower bound on the expected time server spends on serving queue within its busy-idle cycle. At the beginning of the busy period of queue , with probability the server is serving queue and server is serving queue . The time it takes for one of the servers to complete the current service is Exponential() distributed. Let be the number of arrivals into queue in this period. Then, is Geometric() distributed. With probability half, server is the one who completed first, and the two servers are now working to drain a backlog of . The average duration for this to terminate is . Thus, is a lower bound on the expected time server spends on serving queue within its busy-idle cycle.
Thus, the fraction of time spends in serving queue is . From this the lemma follows upon some simplifications, and thus the proposition follows as well.
Some details of simplifications:
To obtain the fraction of time…
[TABLE]
To obtain stability conditions
[TABLE]
[TABLE]
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Shipra Agrawal and Navin Goyal. Analysis of thompson sampling for the multi-armed bandit problem. In Proceedings of the 25th Conference on Learning Theory , 2012.
- 2[2] M. Alresaini, M. Sathiamoorthy, B. Krishnamachari, and M.J. Neely. Backpressure with adaptive redundancy (bwar). In Proc. IEEE INFOCOM , pages 2300–2308, March 2012.
- 3[3] Søren Asmussen. Applied probability and queues . Springer Science & Business Media, 2nd edition, 2003.
- 4[4] Peter Auer, Nicolò Cesa-Bianchi, and Paul Fischer. Finite-time analysis of the multiarmed bandit problem. Machine Learning , 47(2):235–256, 2002.
- 5[5] S. L. Bell and R. J. Williams. Dynamic scheduling of a system with two parallel servers in heavy traffic with resource pooling: asymptotic optimality of a threshold policy. Ann. Appl. Probab. , 11(3):608–649, 08 2001.
- 6[6] Kostas Bimpikis and Mihalis G Markakis. Learning and hierarchies in service systems. Unpublished manuscript , 2015.
- 7[7] Pierre Brémaud. Markov chains: Gibbs fields, Monte Carlo simulation, and queues , volume 31. Springer Science & Business Media, 2013.
- 8[8] Sébastien Bubeck and Nicolò Cesa-Bianchi. Regret analysis of stochastic and nonstochastic multi-armed bandit problems. Foundations and Trends in Machine Learning , 5(1), 2012.