Interplay between Quantumness, Randomness, and Selftesting
Xiao Yuan

TL;DR
This paper explores how quantum properties like superposition and entanglement enable tasks such as randomness generation and selftesting, highlighting their interplay and demonstrating quantum advantages through theory and experiments.
Contribution
It introduces new methods for quantifying quantumness via randomness, demonstrates quantum advantage in Bernoulli factory problems, and proposes measurement-independent entanglement witnessing and randomness-independent selftesting schemes.
Findings
Quantum coherence can generate true randomness.
Quantum advantage demonstrated in Bernoulli factory tasks.
Measurement-independent entanglement witness and randomness-independent selftesting proposed.
Abstract
Quantum information processing shows advantages in many tasks, including quantum communication and computation, comparing to its classical counterpart. The essence of quantum processing lies on the fundamental difference between classical and quantum states. For a physical system, the coherent superposition on a computational basis is different from the statistical mixture of states in the same basis. Such coherent superposition endows the possibility of generating true random numbers, realizing parallel computing, and other classically impossible tasks such as quantum Bernoulli factory. Considering a system that consists of multiple parts, the coherent superposition that exists nonlocally on different systems is called entanglement. By properly manipulating entanglement, it is possible to realize computation and simulation tasks that are intractable with classical means. Investigating…
Click any figure to enlarge with its caption.
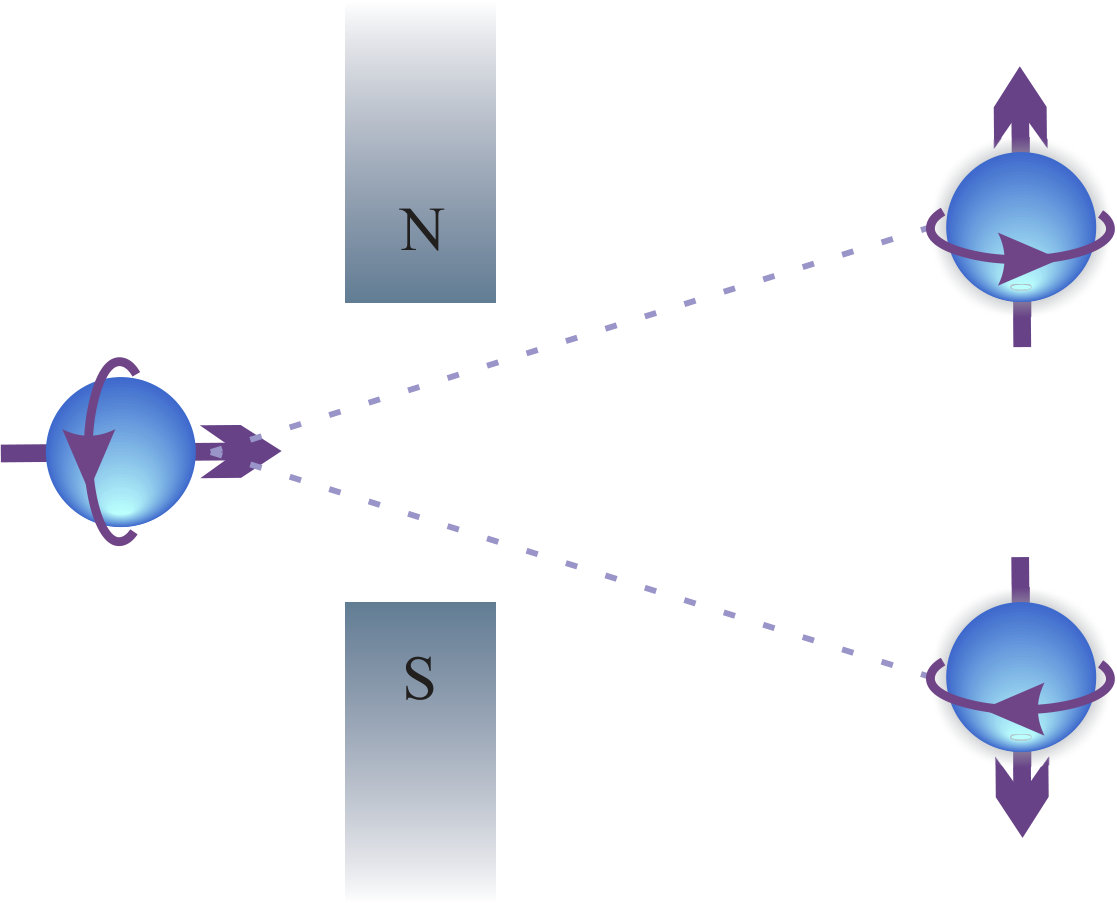 Figure 1
Figure 1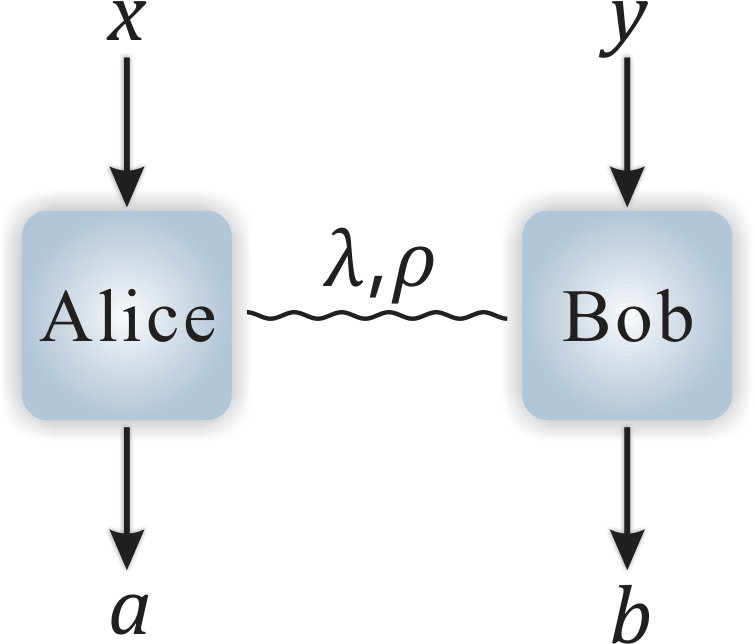 Figure 2
Figure 2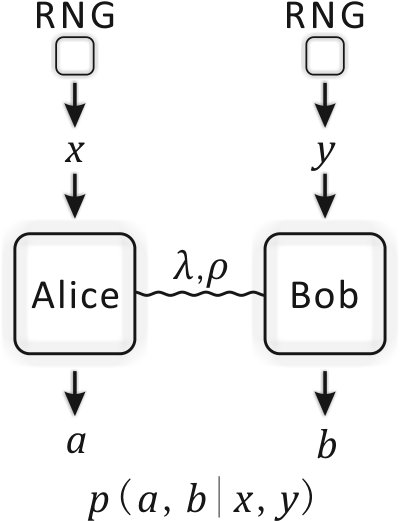 Figure 3
Figure 3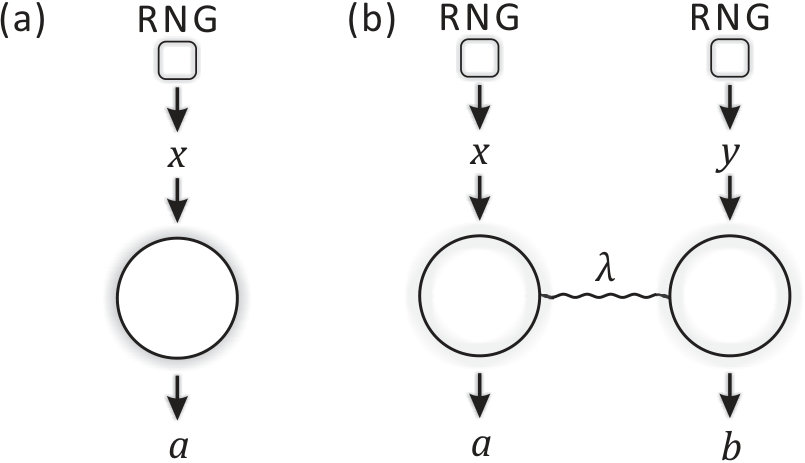 Figure 4
Figure 4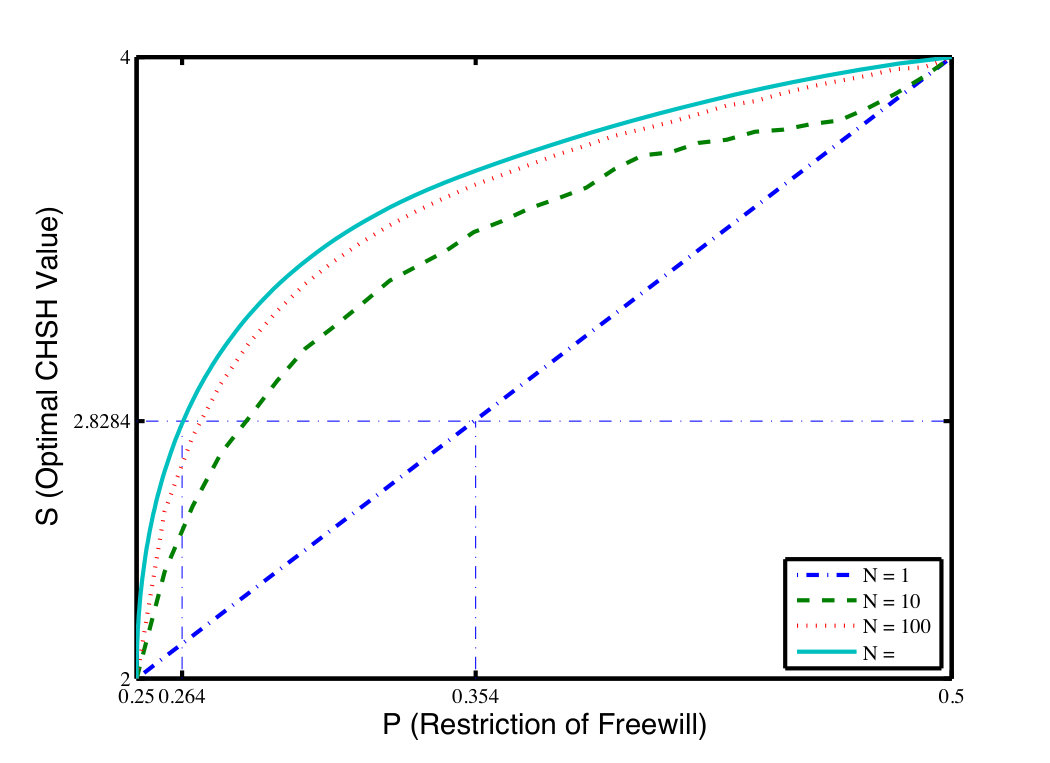 Figure 5
Figure 5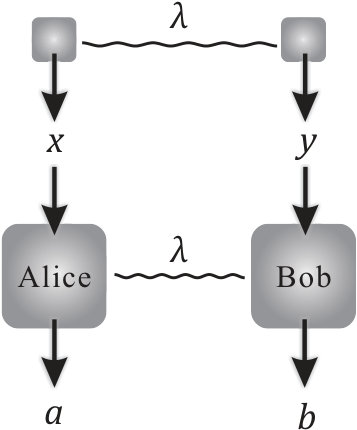 Figure 6
Figure 6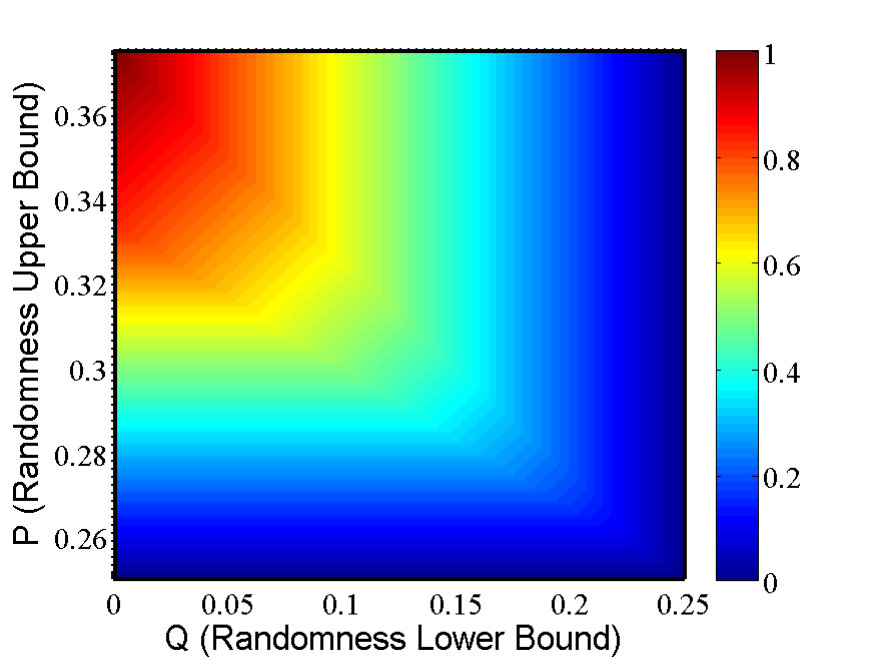 Figure 7
Figure 7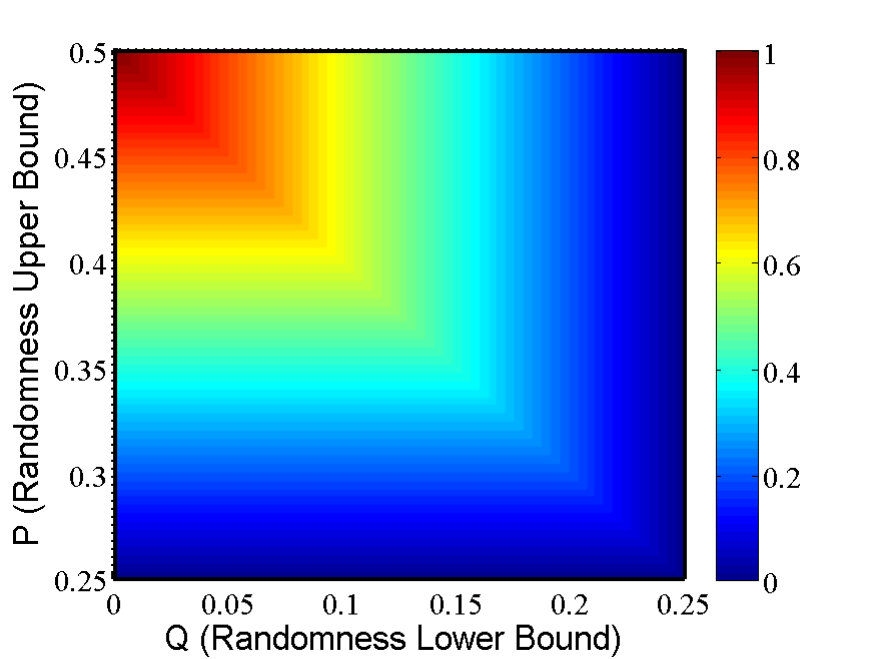 Figure 8
Figure 8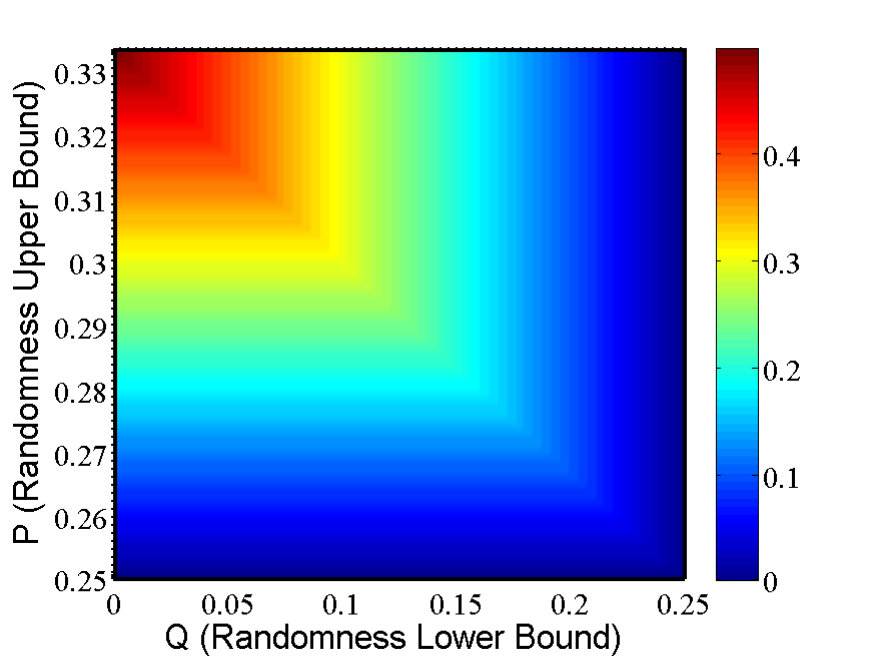 Figure 9
Figure 9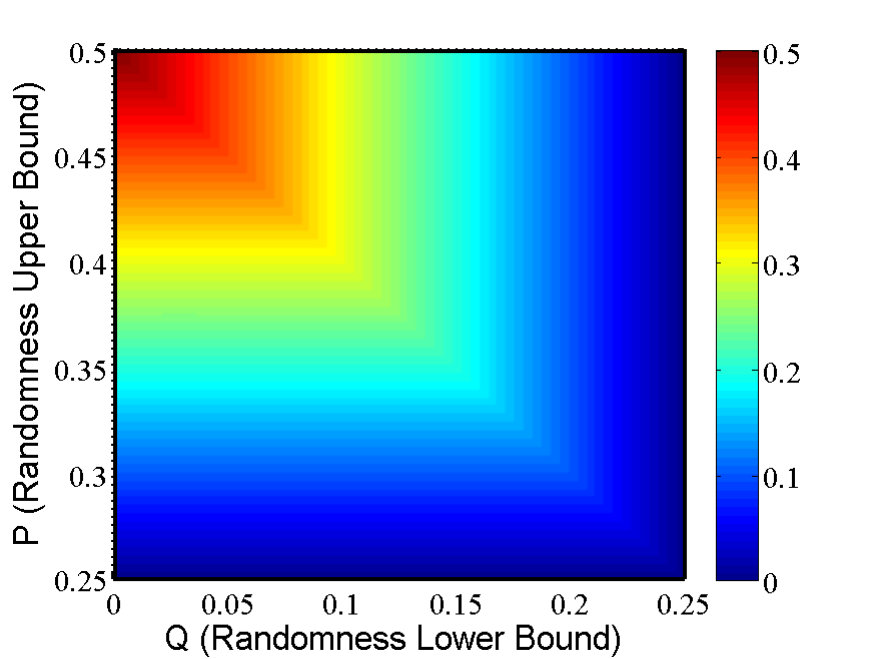 Figure 10
Figure 10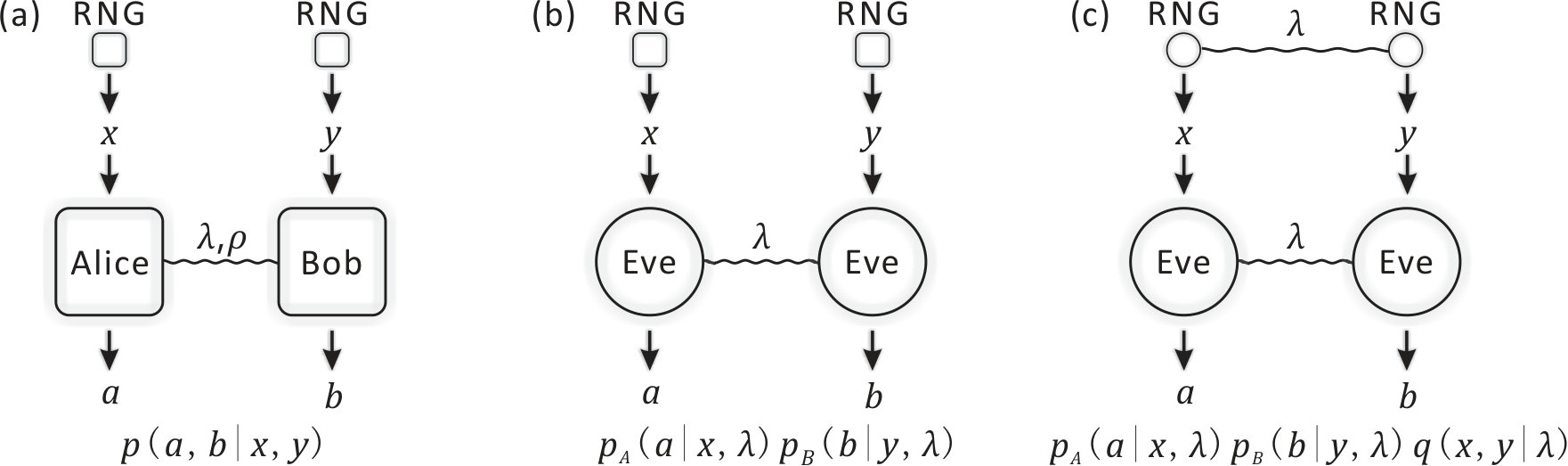 Figure 11
Figure 11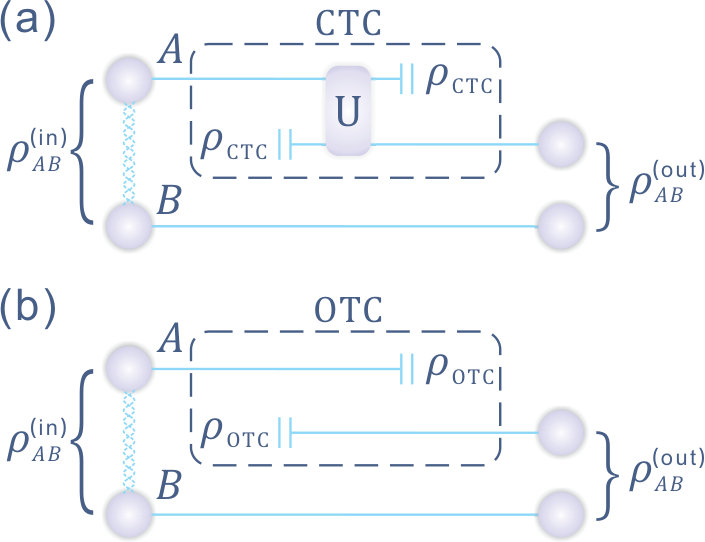 Figure 12
Figure 12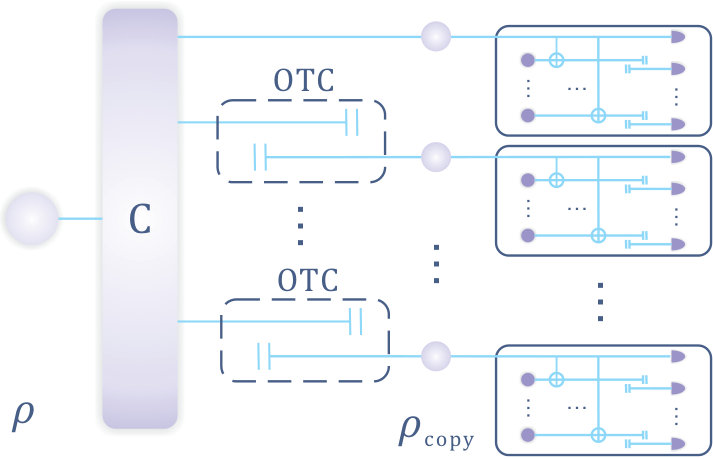 Figure 13
Figure 13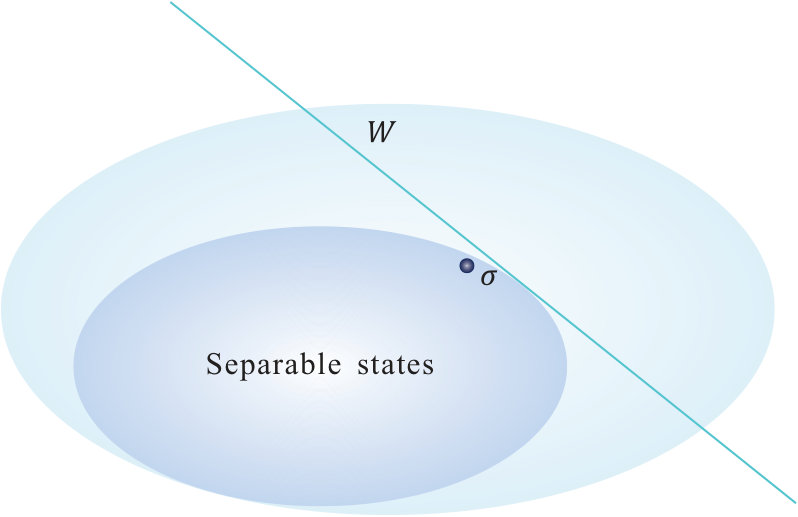 Figure 14
Figure 14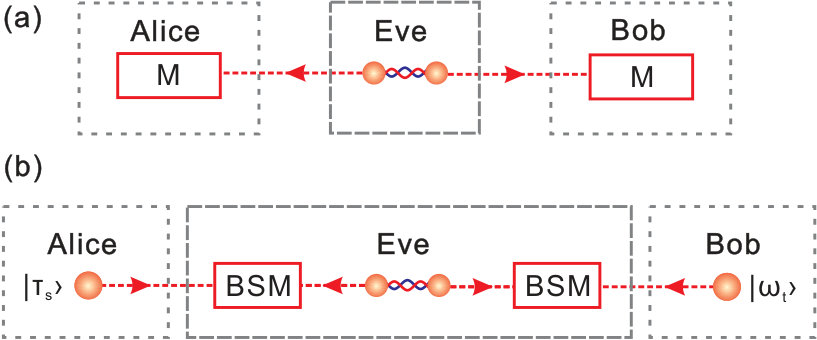 Figure 15
Figure 15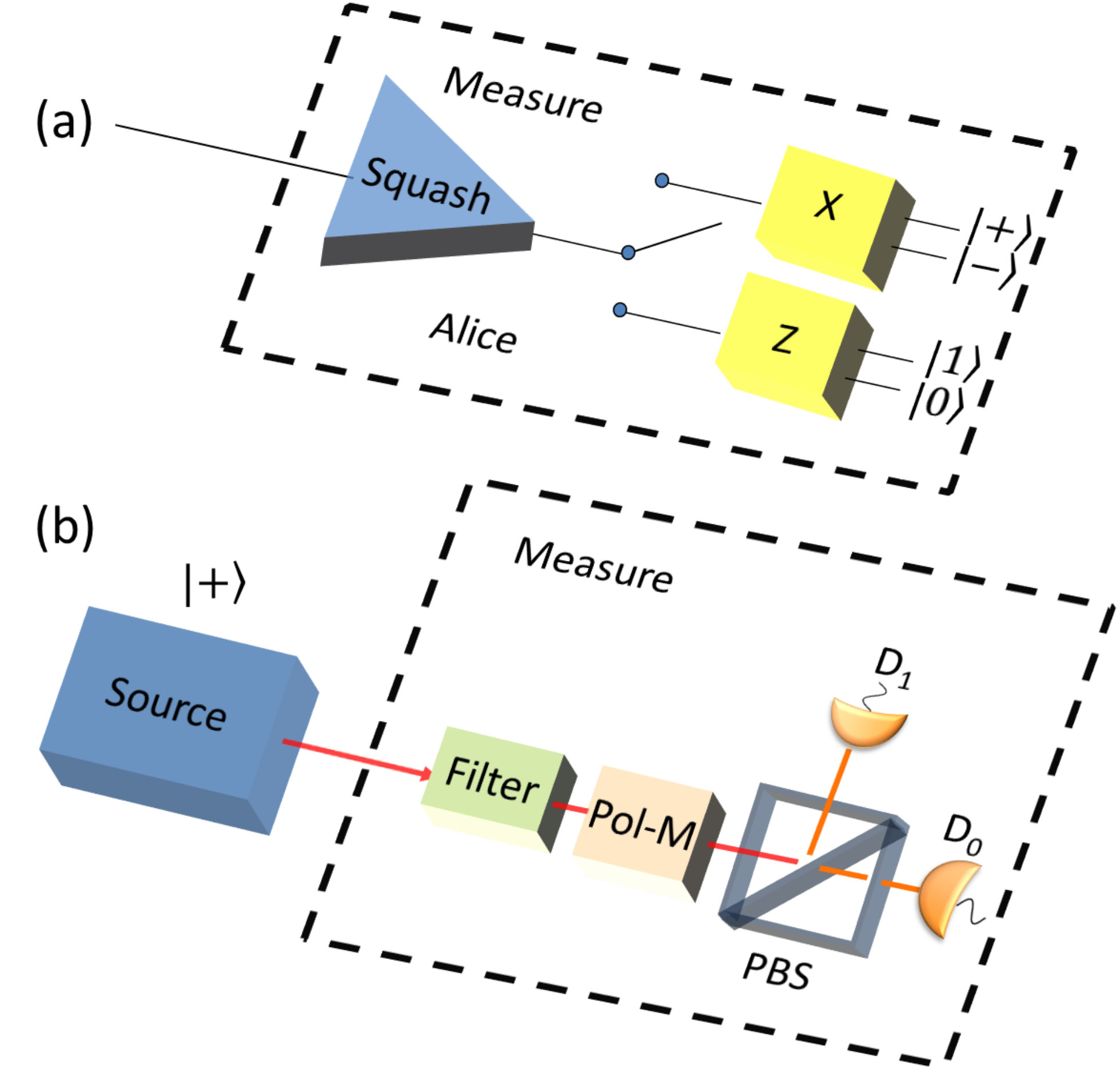 Figure 4
Figure 4 Figure 17
Figure 17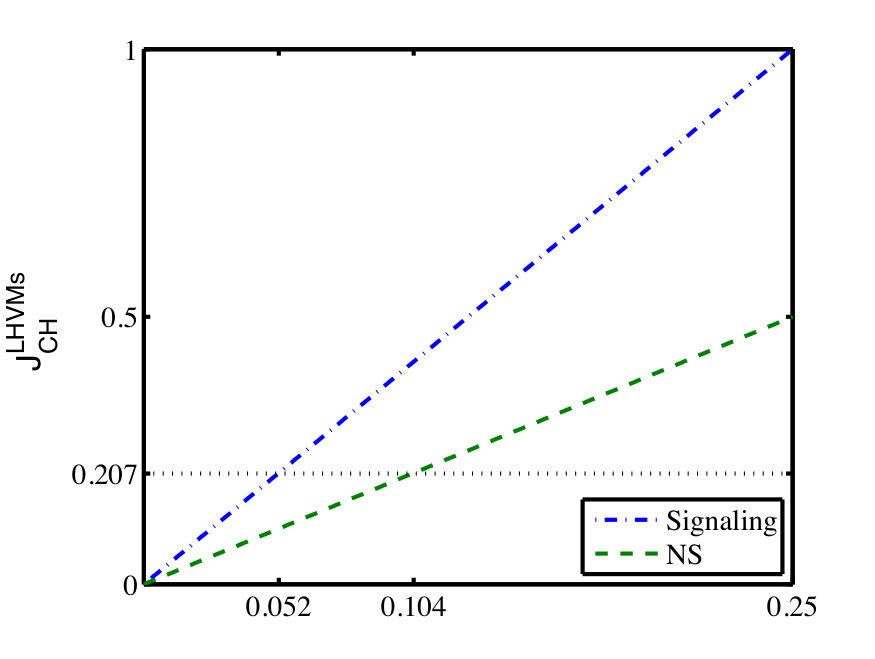 Figure 18
Figure 18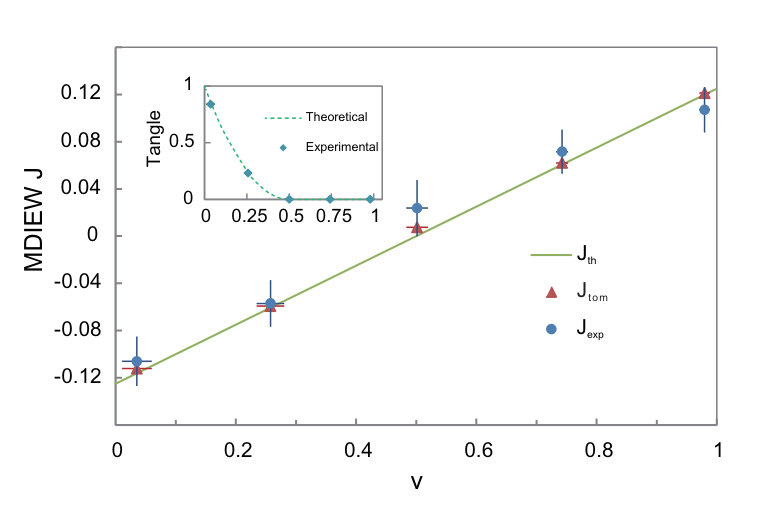 Figure 19
Figure 19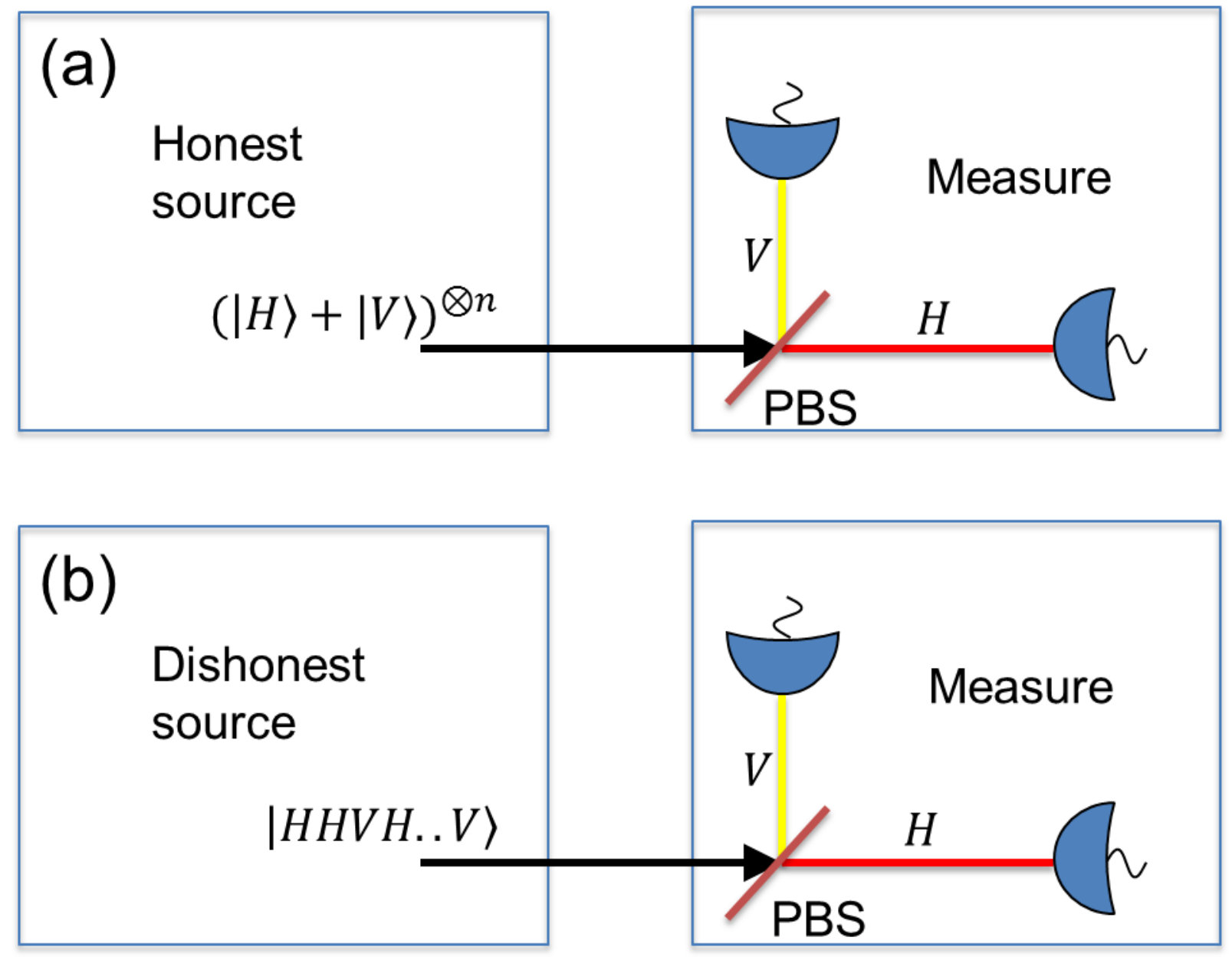 Figure 2
Figure 2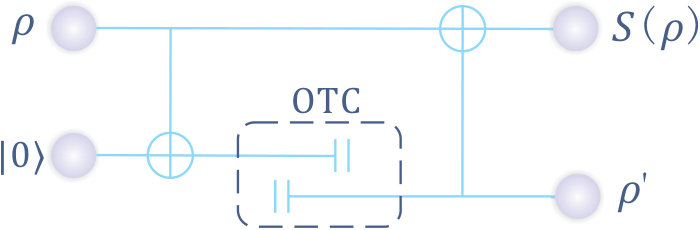 Figure 21
Figure 21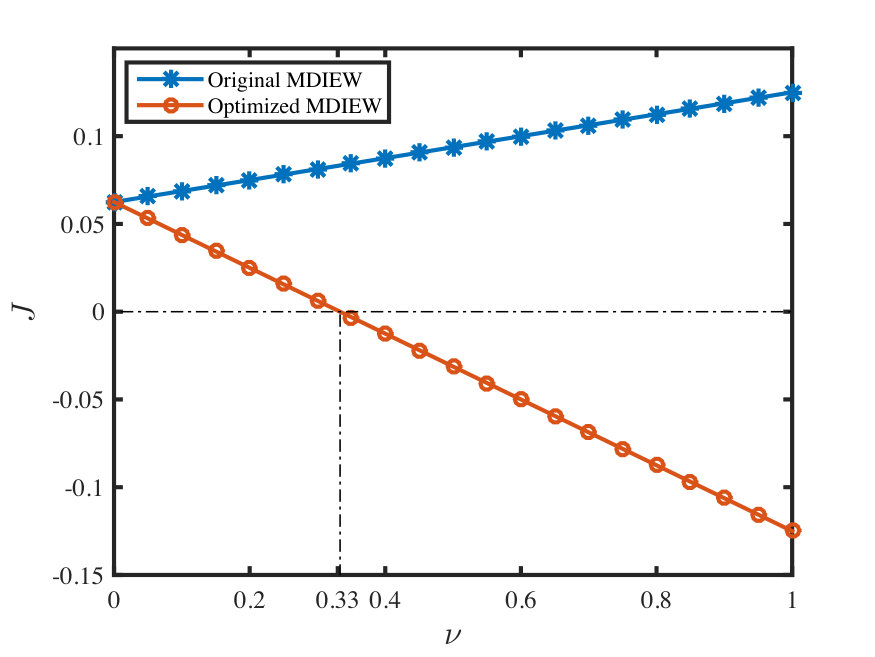 Figure 22
Figure 22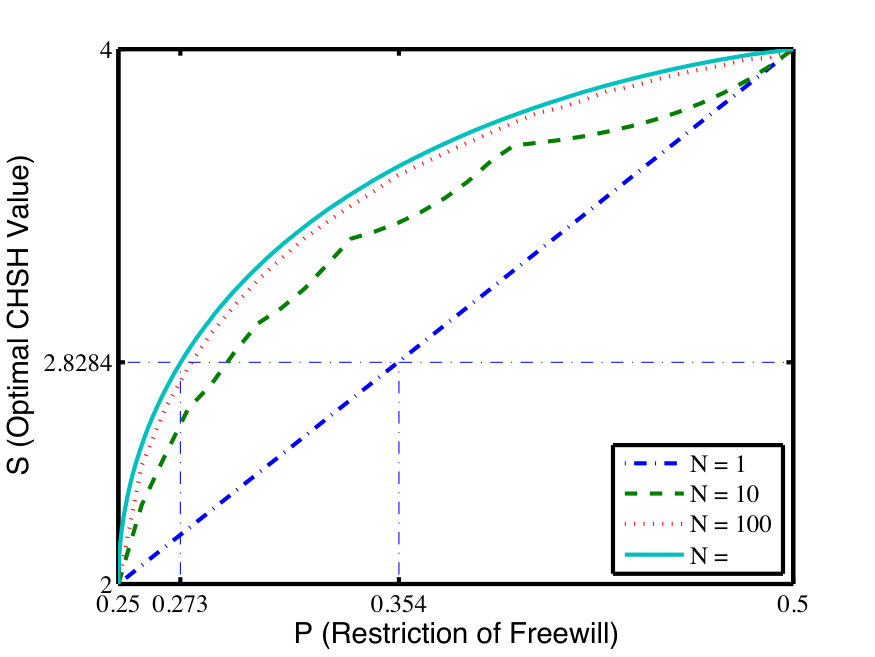 Figure 23
Figure 23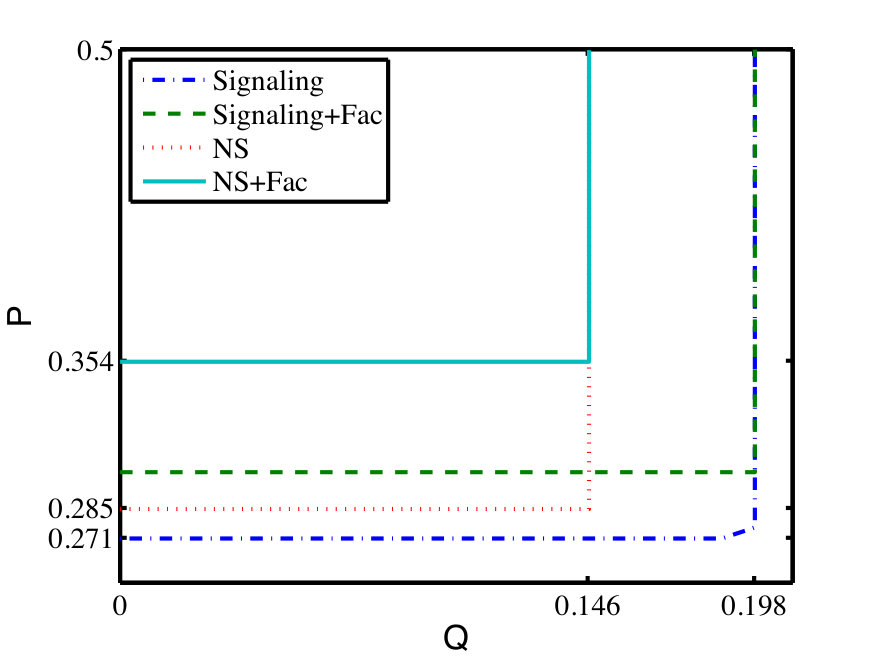 Figure 24
Figure 24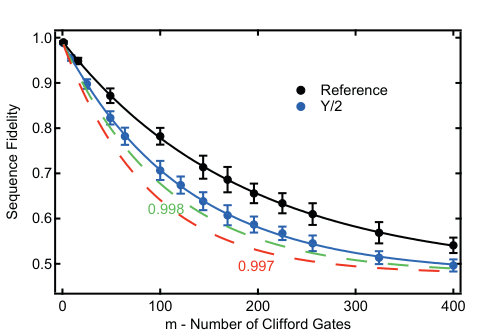 Figure 25
Figure 25 Figure 26
Figure 26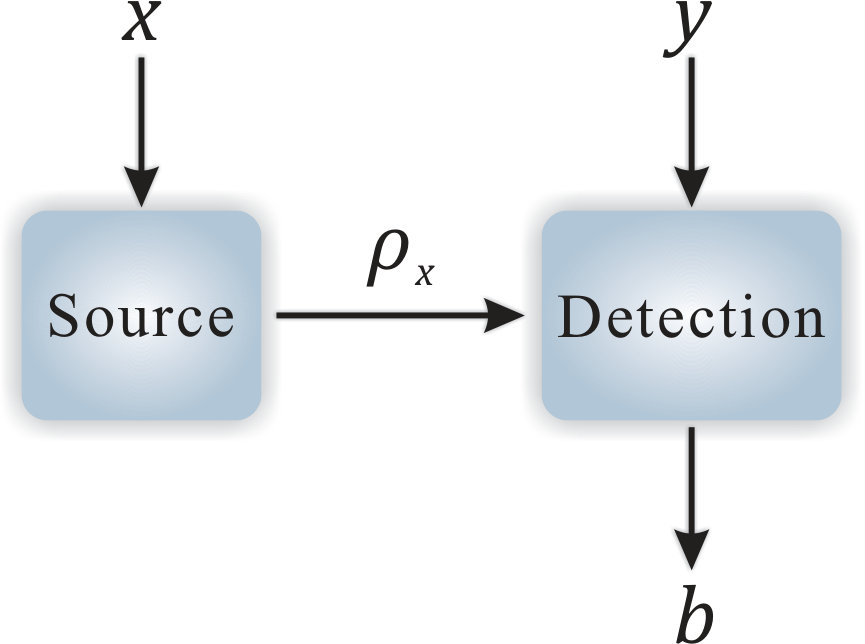 Figure 27
Figure 27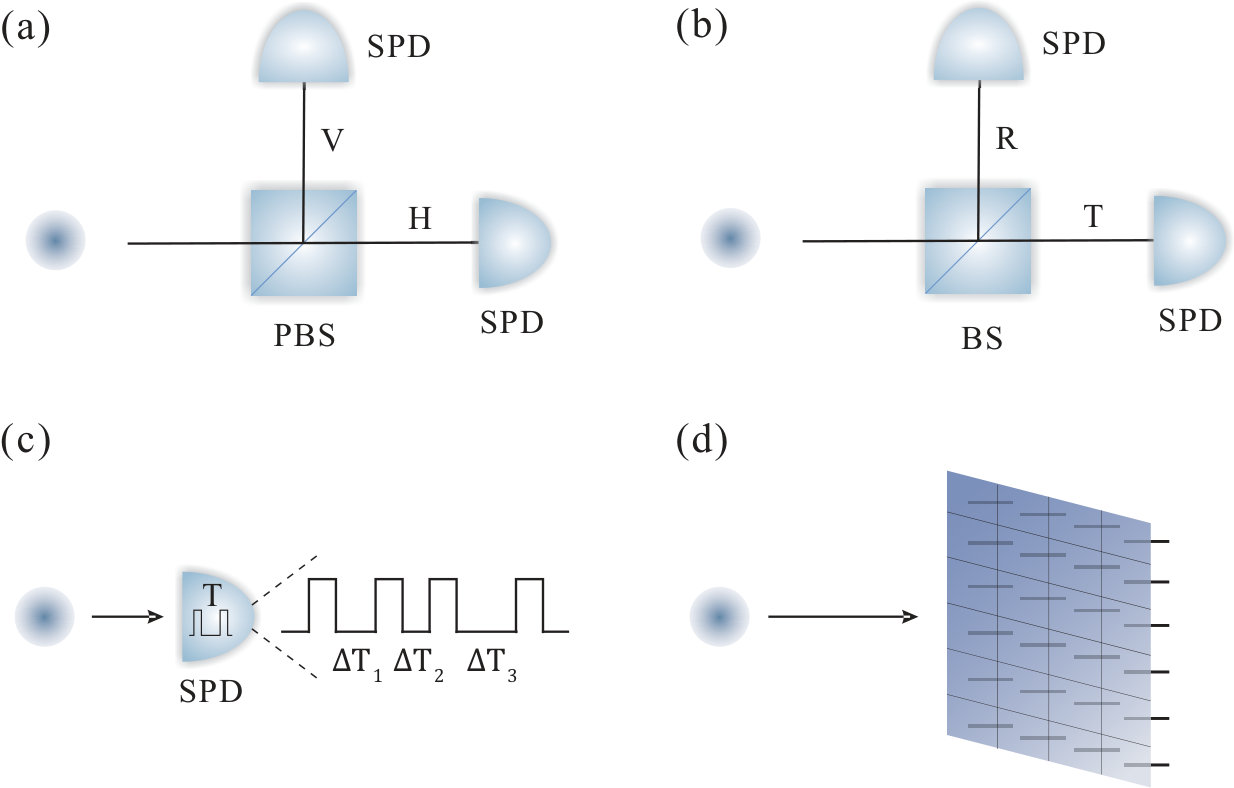 Figure 28
Figure 28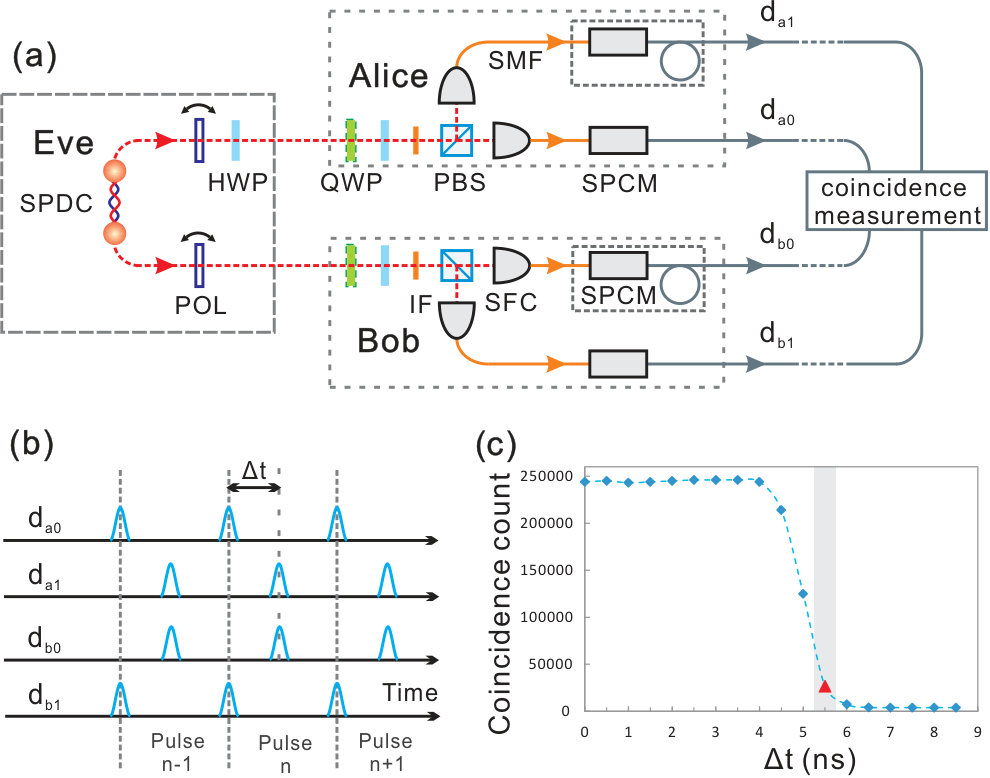 Figure 29
Figure 29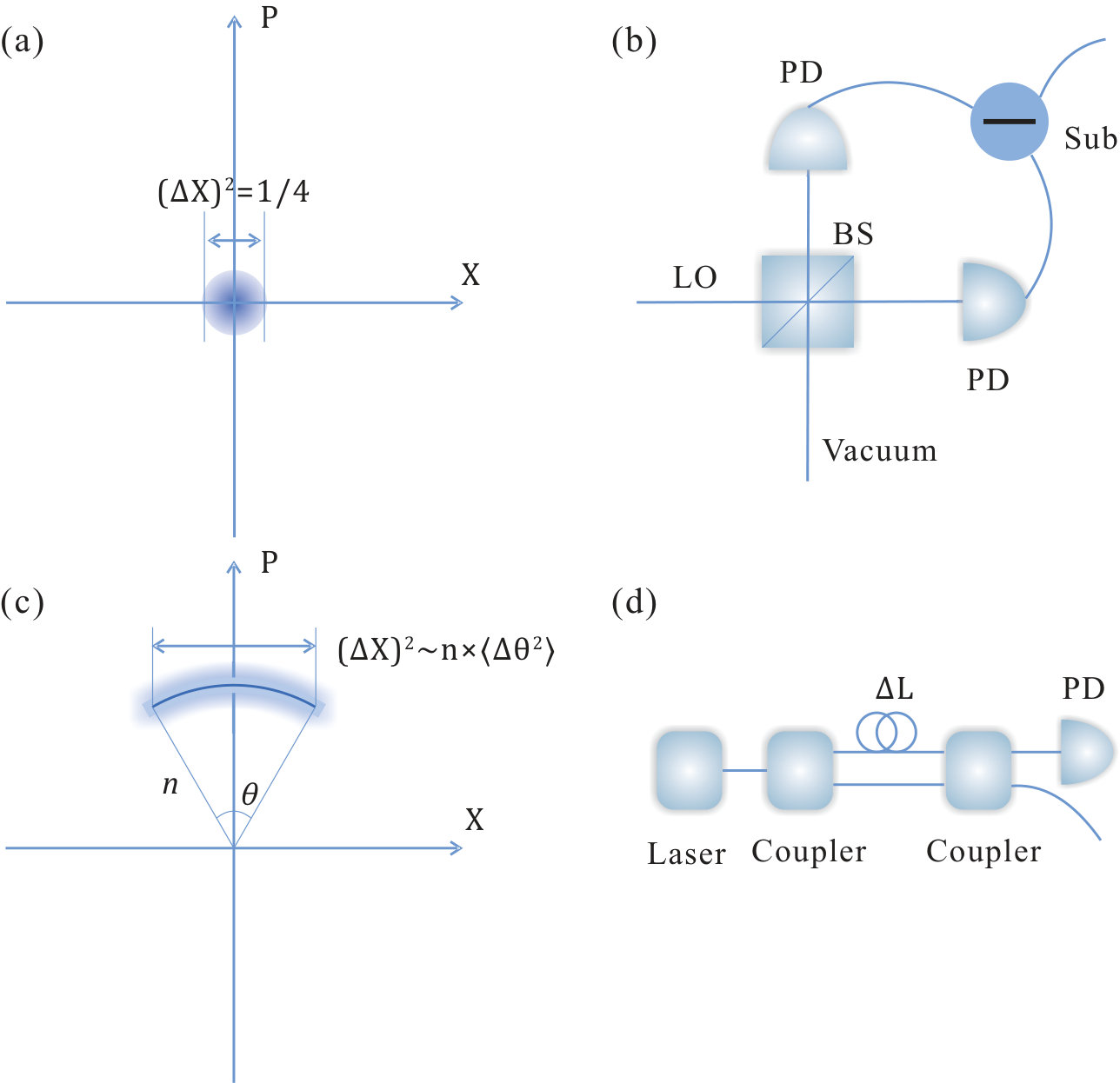 Figure 30
Figure 30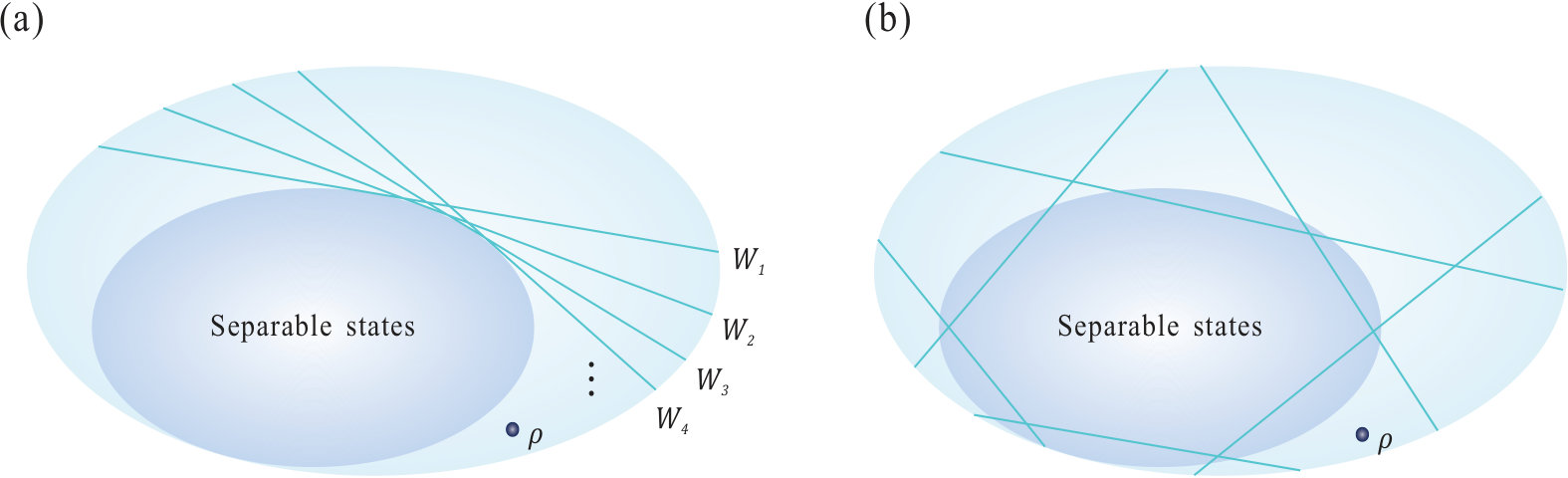 Figure 31
Figure 31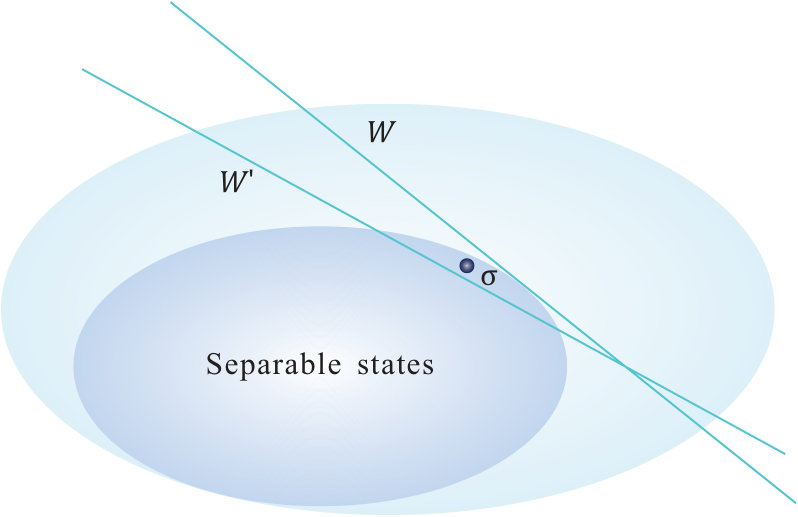 Figure 32
Figure 32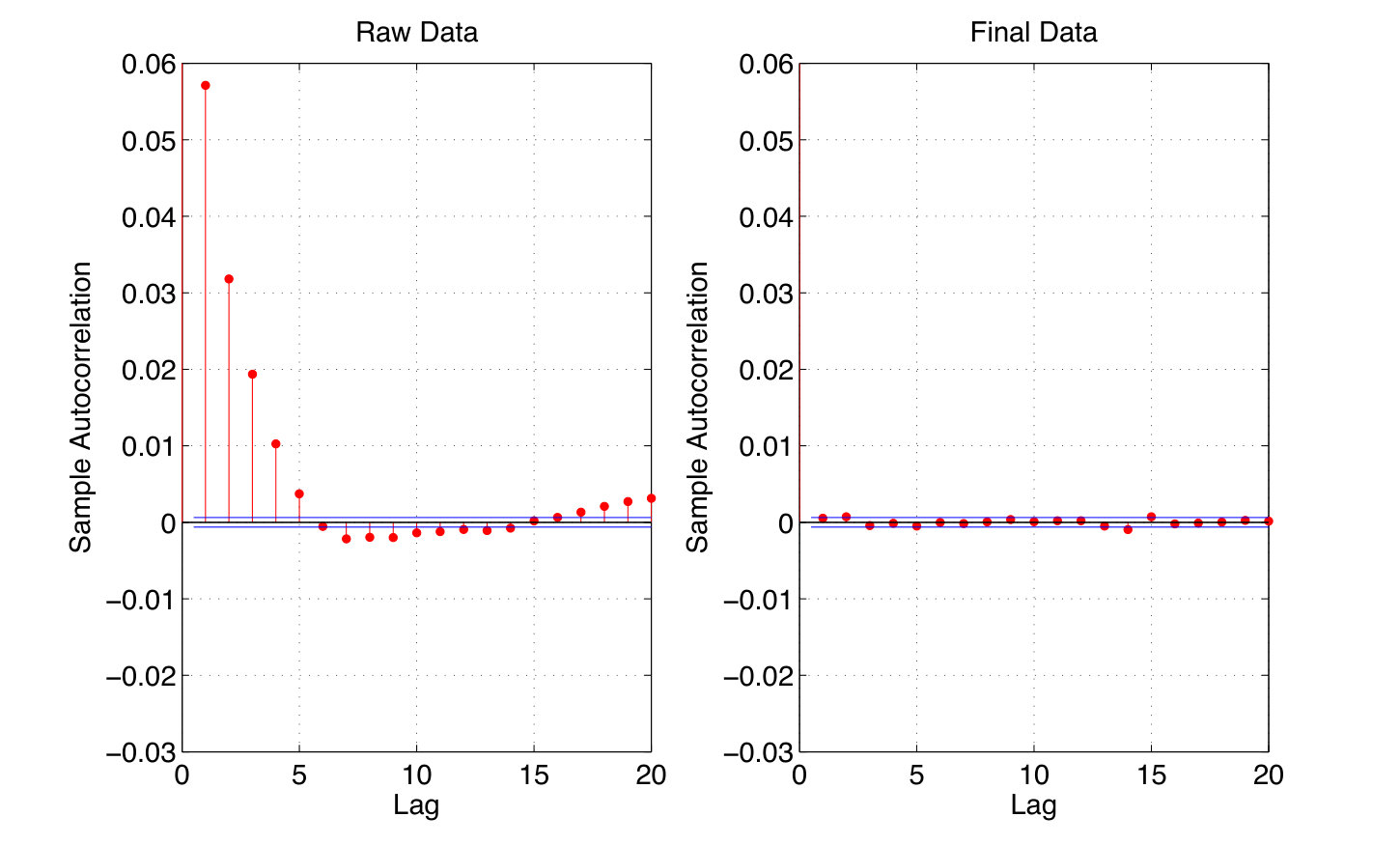 Figure 33
Figure 33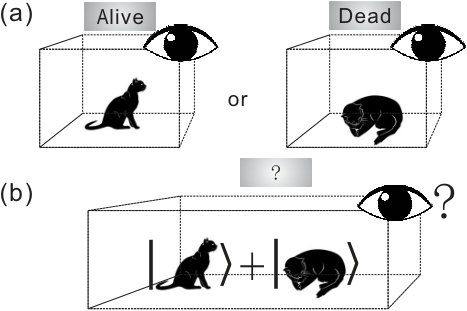 Figure 34
Figure 34 Figure 35
Figure 35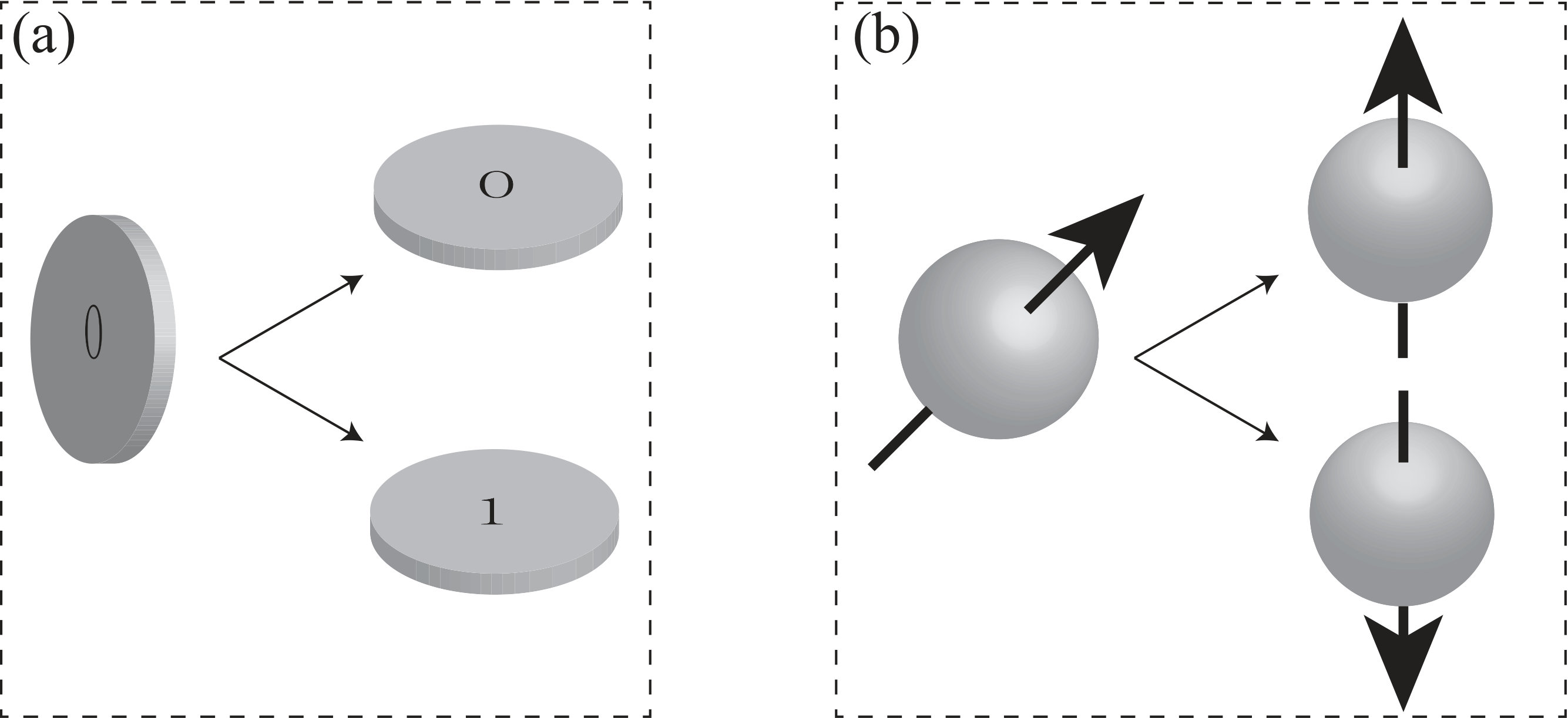 Figure 36
Figure 36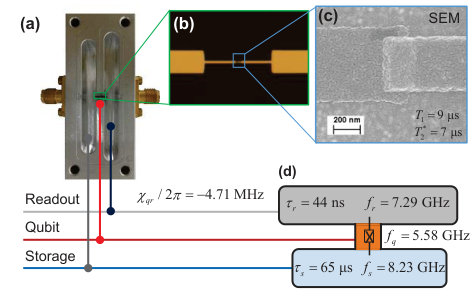 Figure 37
Figure 37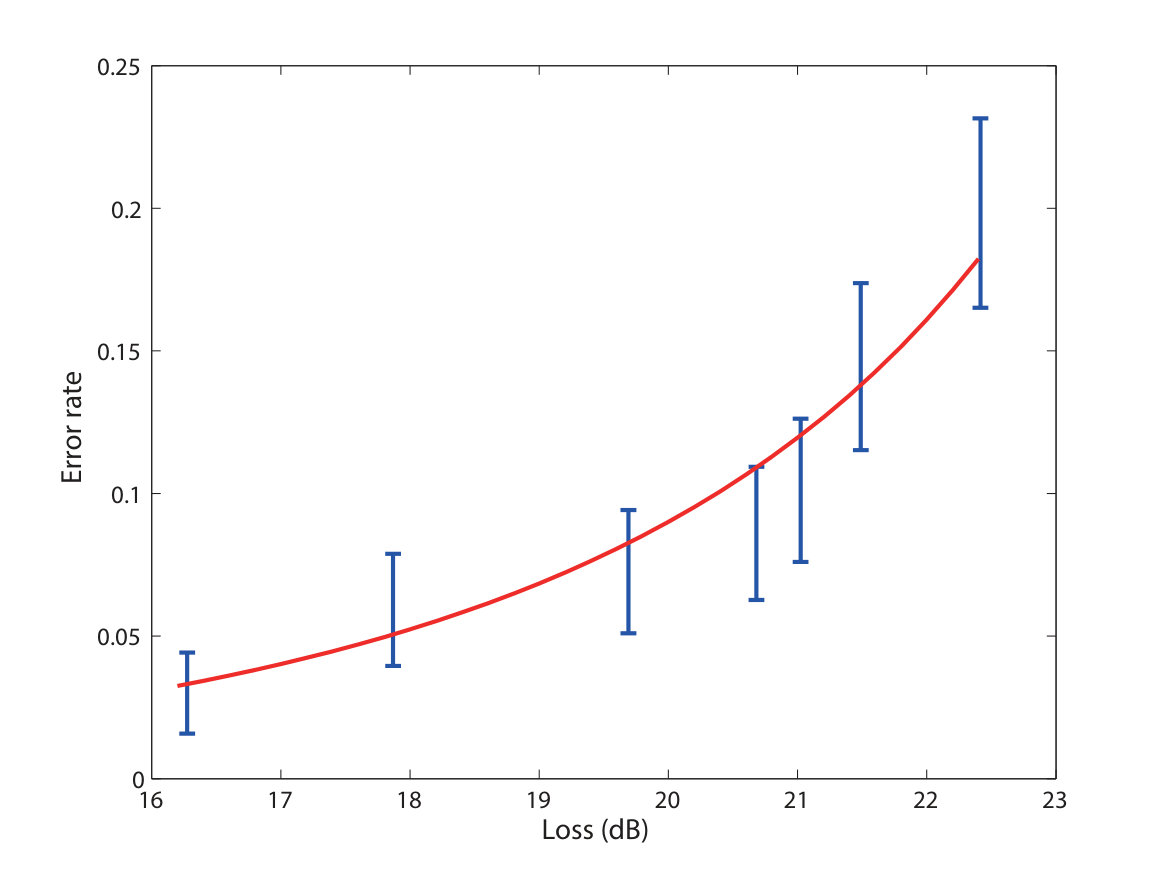 Figure 38
Figure 38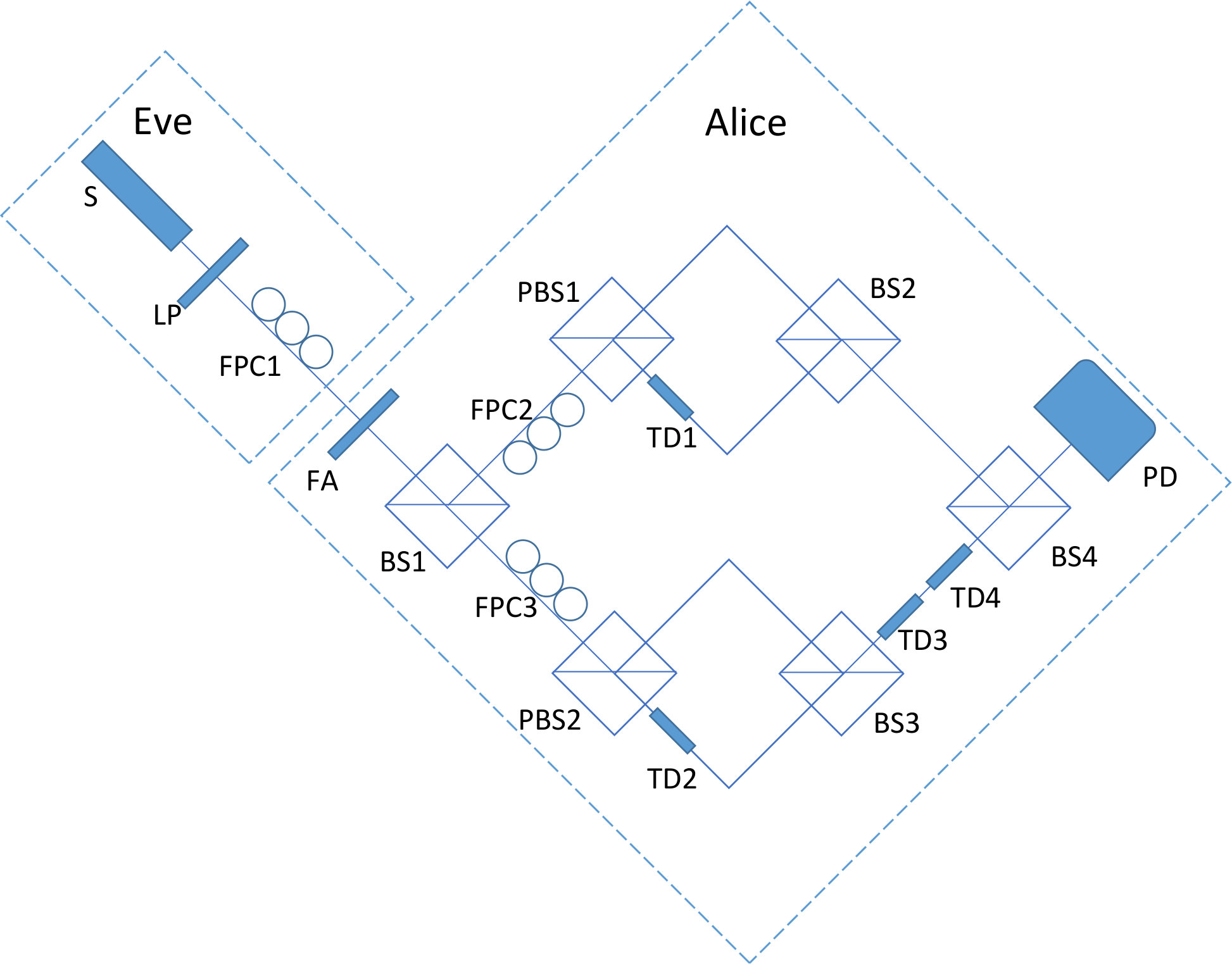 Figure 39
Figure 39 Figure 40
Figure 40| Year | Entropy source | Detection | Raw | Refined | Acquisition |
|---|---|---|---|---|---|
| 2000 | Spatial mode [93] | SPD | 1 Mbps | dedicated | |
| 2000 | Spatial mode [94] | SPD | 100 Kbps | dedicated | |
| 2014 | Spatial mode [95] | MCP-PCID | 8 Mbps | dedicated | |
| 2008 | Temporal mode [96] | SPD | 4.01 Mbps | dedicated | |
| 2009 | Temporal mode [97] | SPD | 55 Mbps | 40 Mbps | dedicated |
| 2011 | Temporal mode [98] | SPD | 180 Mbps | 152 Mbps | dedicated |
| 2014 | Temporal mode [99] | SPD | 109 Mbps | 96 Mbps | dedicated |
| 2010 | Photon number [100] | PNRD | 50 Mbps | dedicated | |
| 2011 | Photon number [101] | PNRD | 2.4 Mbps | dedicated | |
| 2015 | Photon number [102] | PNRD | 143 Mbps | oscilloscope | |
| 2010 | Vacuum noise [103] | Homodyne | 10 Mbps | 6.5 Mbps | dedicated |
| 2010 | Vacuum noise [104] | Homodyne | 12 Mbps | dedicated | |
| 2011 | Vacuum noise [105] | Homodyne | 3 Gbps | 2 Gbps | dedicated |
| 2010 | ASE-intensity noise [106] | Photo detector | 12.5 Gbps | dedicated | |
| 2011 | ASE-intensity noise [107] | Photo detector | 20 Gbps | ||
| 2010 | ASE-phase noise [108] | Self-heterodyne | 1 Gbps | 500 Mbps | oscilloscope |
| 2011 | ASE-phase noise [109] | Self-heterodyne | 1.2 Gbps | 1.11 Gbps | oscilloscope |
| 2012 | ASE-phase noise [110] | Self-heterodyne | 8 Gbps | 6 Gbps | oscilloscope |
| 2014 | ASE-phase noise [111] | Self-heterodyne | 80 Gbps | oscilloscope | |
| 2014 | ASE-phase noise [112] | Self-heterodyne | 82 Gbps | 43 Gbps | oscilloscope |
| 2015 | ASE-phase noise [113] | Self-heterodyne | 80 Gbps | 68 Gbps | oscilloscope |
| Properties | Coherence | Entanglement |
| Classical operation | Inherent operation [14] | LOCC [15] |
| Classical state | Incoherent state, Eq. (3.1) | Separable state |
| Distance measure | , Eq. (3.3) | Relative entropy distance [16] |
| Convex roof measure | , Eq. (4.6) | EOF [15, 176, 170] |
| Distillation | Coherence distillation (Methods) | Entanglement distillation [177, 17] |
| Formation (cost) | Coherence formation | Entanglement cost [174, 17] |
| Foundation tests | Further research direction | Nonlocality tests [19, 1] |
| Interconvertibility | [178, 179] | Deterministic [180], stochastic [181] |
| Catalysis effect | Further research direction | Entanglement catalysis [182, 183] |
| Witness | Further research direction | Entanglement witness (EW) |
| DI applications | Further research direction | DIQKD [55, 184], DIQRNG [64] |
| MDI applications | Further research direction | MDIQKD [185, 186], MDIEW [29, 30] |
| 0 | - | ||||
| 0 | - | ||||
| 0 | - | ||||
| 0 | - |
| 45 | 0 | 0.0196 | 0.0228 | 0.0064 | 0.0258 | 0.0290 | 0.0207 | 0.0039 | 0.0087 |
| 30 | 0.25 | 0.2580 | 0.2538 | 0.2426 | 0.2686 | 0.2644 | 0.2575 | 0.0045 | 0.0101 |
| 22.5 | 0.5 | 0.4944 | 0.4820 | 0.4824 | 0.5230 | 0.5108 | 0.4985 | 0.0081 | 0.0180 |
| 15 | 0.75 | 0.7298 | 0.7198 | 0.7280 | 0.7718 | 0.7620 | 0.7423 | 0.0103 | 0.0231 |
| 0 | 1 | 0.9680 | 0.9818 | 0.9222 | 0.9684 | 0.9822 | 0.9645 | 0.0110 | 0.0246 |
| tangle() | |||||
|---|---|---|---|---|---|
| 0 | 0.021 | 0.009 | 0.840 | 0.001 | |
| 0.25 | 0.257 | 0.010 | 0.233 | 0.001 | |
| 0.5 | 0.499 | 0.018 | 0.000 | 0 | |
| 0.75 | 0.742 | 0.023 | 0.000 | 0 | |
| 1 | 0.965 | 0.025 | 0.000 | 0 |
| (0,1,1,0) | |
|---|---|
| (0,1,1,1) | |
| (1,0,0,1) | |
| (1,0,1,1) | |
| (1,1,0,1) | |
| (1,1,1,0) | |
| (1,1,1,1) |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsQuantum Information and Cryptography · Quantum Mechanics and Applications · Quantum Computing Algorithms and Architecture
\department
Institute for Interdisciplinary Information Sciences
\major
Physics
\degree
Doctor of Philosophy
\degreemonth
December \degreeyear2016
\thesisdate
December 20, 2016
\supervisor
Xiongfeng MaAssistant Professor
Interplay between Quantumness, Randomness, and Selftesting
Xiao Yuan
{abstractpage}
Quantum information processing shows advantages in many tasks, including quantum communication and computation, comparing to its classical counterpart. The essence of quantum processing lies on the fundamental difference between classical and quantum states. For a physical system, the coherent superposition on a computational basis is different from the statistical mixture of states in the same basis. Such coherent superposition endows the possibility of generating true random numbers, realizing parallel computing, and other classically impossible tasks such as quantum Bernoulli factory. Considering a system that consists of multiple parts, the coherent superposition that exists nonlocally on different systems is called entanglement. By properly manipulating entanglement, it is possible to realize computation and simulation tasks that are intractable with classical means.
Investigating quantumness, coherent superposition, and entanglement can shed light on the original of quantum advantages and lead to the design of new quantum protocols. This thesis mainly focuses on the interplay between quantumness and two information tasks, randomness generation and selftesting quantum information processing. We discuss how quantumness can be used to generate randomness and show that randomness can in turn be used to quantify quantumness. In addition, we introduce the Bernoulli factory problem and present the quantum advantage with only coherence in both theory and experiment. Furthermore, we show a method to witness entanglement that is independent of the realization of the measurement. We also investigate randomness requirements in selftesting tasks and propose a random number generation scheme that is independent of the randomness source.
By investigating the interplay between quantumness and the two information tasks, we have investigated the essence of quantumness and its fundamental role in quantum information processing. Apart from the theoretical significance, the results can be experimentally tested and applied in practice.
Key words: Coherence; entanglement; randomness; selftesting; quantum cryptography
Acknowledgements
The research presented in this Doctor of Philosophy thesis is carried out under the the supervision of Professor Xiongfeng Ma at the Institute for Interdisciplinary Information Sciences at Tsinghua University, China. Being a wonderful mentor in research and an intimate friend in life, it is Xiongfeng who, for the first time, makes me feel the pleasure of doing research. I acknowledge him for the inspiring instruction, discussion, and encouragement and for sharing his extensive knowledge. In the mean time, I would like to thank Professor Giulio Chiribella for his guidance during the first year of my Ph.D. study. With his altruistic help, I learned the basics of quantum information and completed my first few researches. In addition, I acknowledge Professor Mile Gu for sharing his insightful thoughts in quantum correlation and relativistic quantum information. Under his guidance, I broadened my knowledge of quantum science and completed an interesting work of quantum information in the presence of time-traveling.
During my Ph.D. study, I am lucky to have many chances to visit several wonderful academic institutes. My special thanks go to the hosts for their kindly help and valuable discussions. In chronological order of the visiting places, the hosts include Professor Yu-Ao Chen and Jian-Wei Pan at the University of Science and Technology of China, Professor Hoi Fung Chau at the University of Hong Kong, Professor Peter Zoller at Austria University of Innsbruck, Professor Anton Zeilinger at the University of Vienna, Professor Renato Renner at ETH, Professor Nicolas Gisin at the Université de Genève, Professor Romain Alléaume at Telecom ParisTech, Professor Qiang Zhang at the University of Science and Technology of China, Dr. Graeme Smith, Dr. John Smolin and Dr. Charles H. Bennett at IBM’s Thomas J. Watson Research Center, Dr. Qingyu Cai at the Chinese Academy of Sciences Wuhan Physics and Mathematics Institute, and Professor Yeong-Cherng Liang at the National Cheng Kung University, Tainan. Especially, I would like to thank Dr. Charles H. Bennett for enthusiastically showing his ‘antique’ of the first quantum key distribution experiment instrument and introducing the quantum side channel.
My works have been guided by many brilliant minds, including Assad, Syed M; Chen, Luo-Kan; Chen, Tengyun; Cao, Zhu; Fan, Jinyun; Girolami, Davide; Haw, Jing Yan; Huang, Miao; Jiang, Xiao; Lam, Ping Koy; Li, Li; Liu, Ke; Li, Wei; Li, Zheng-Da; Liu, Nai-Le; Liu, Yang; Lu, Chao-Yang; Lu, He; Lutkenhaus Norbert; Ma, Yuwei; Mei, Quanxin; Pan, Jian-Wei; Peng, Cheng-Zhi; Qi, Bing; Ralph, Timothy C; Thompson, Jayne; Vijay, R; Vedral, Vlatko; Weedbrook, Christian; Wang, Weiting; Yan, Zhaopeng; Yao, Xing-Can; Xu, Yuan; Xu, Ping; Zhang, Fang; Zhang, Yan-Bao; Zhang, Zhen; Zhou, Hongyi; Zhou, Shan. I acknowledge my collaborators for sharing their knowledge and offering their help.
Last but not least, I want to sincerely thank my parents for their selfless love and thoughtful care in every details of my life. I am also very grateful to the students and professors in our institute. I would like to thank my friends for bring pleasures in my life.
Contents
-
2.1 Quantum mechanics formalism—pure states and projective measurements
-
8 Randomness Requirement on CHSH Bell Test in the Multiple Run Scenario
-
12.1.2 Informational principles and their translation in the Hilbert space language
-
12.2 Measurement sharpness trims nonlocality and contextualize in every physical theory
-
B.1 Calculation of the number of effective -basis measurements
-
B.2 Proof of the random sampling property for a type of QRNG input after loss
List of Figures
- 1.1 An illustration of Schrödinger’s cat gedanken experiment.
- 1.2 Device independent processing of one (a) and two (b) parties.
- 3.1 Witnessing entanglement via entanglement witness operators.
- 3.2 Bipartite Bell inequality. The inputs and of Alice and Bob are determined by perfect random number generators (RNGs), which produce uniformly distributed random numbers.
- 3.3 Electron spin detection in the Stern-Gerlach experiment. Assume that the spin takes two directions along the vertical axis, denoted by and . If the electron is initially in a superposition of the two spin directions, , detecting the location of the electron would breaks the coherence and the outcome ( or ) is intrinsically random.
- 3.4 Practical QRNGs based on single photon measurement. (a) A photon is originally prepared in a superposition of horizontal (H) and vertical (V) polarizations, described by . A polarising beam splitter (PBS) transmits the horizontal and reflects the vertical polarization. For random bit generation, the photon is measured by two single photon detectors (SPDs). (b) After passing through a symmetric beam splitter (BS), a photon exists in a superposition of transmitted (T) and reflected (R) paths, . A random bit can be generated by measuring the path information of the photon. (c) QRNG based on measurement of photon arrival time. Random bits can be generated, for example, by measuring the time interval, , between two detection events. (d) QRNG based on measurements of photon spatial mode. The generated random number depends on spatial position of the detected photon, which can be read out by an SPD array.
- 3.5 QRNGs using macroscopic photodetector. (a) Phase-space representation of the vacuum state. The variance of the -quadrature is 1/4. (b) QRNG based on vacuum noise measurements. The system comprises a strong local oscillator (LO), a symmetric beam splitter (BS), a pair of photon detector (PD), and an electrical subtracter (Sub). (c) Phase-space representation of a partially phase-randomised coherent state. The variance of the -quadrature is in the order of , where is the average photon number and is the phase noise variance. (d) QRNGs based on measurements of laser phase noise. The first coupler splits the original laser beam into two beams, which propagate through two optical fibres of different lengths, thereafter interfering at the second coupler. The output signal is recorded by a photon detector. The extra length in one fibre introduces a time delay between the two paths, which in turn determines the variance of the output signal.
- 3.6 Illustration of a bipartite Bell test. Alice and Bob are two spacelikely separated parties, that output and from random inputs and , respectively. A Bell inequality is defined as a linear combination of the probabilities . For instance, the Clauser-Horne-Shimony-Holt (CHSH) inequality [1] is defined by , where all of the inputs and outputs are bit values, and is the classical bound for all local hidden-variable models. With quantum settings, that is, performing measurements on quantum state , , the CHSH inequality can be violated up to . Quantum features (such as intrinsic randomness) manifest as violations of the CHSH inequality.
- 3.7 A semi-self-testing QRNG. Conditional on the input setting , the source emits a quantum state . Conditional on the input , the detection device measures and outputs .
- 4.1 Quantum randomness. In a bipartite Alice-Eve system described by a pure state , the quantum randomenss of a measurement performed by Alice on the system in the mixed state is given by the amount of uncertainty Eve has on the measurement outcome. Such quantum uncertainty is quantified by the relative entropy of coherence .
- 4.2 Alternative definition of Quantum randomness. In a bipartite Alice-Eve system described by a pure state , the quantum randomness of a measurement performed by Alice on the system in the mixed state is given by the minimum amount of uncertainty Eve has on the measurement outcome after performing a measurement on her own systems. Such quantum uncertainty is quantified by the convex roof measure .
- 4.3 Comparison of the measures of quantum randomness (red dotted line) and (blue dot-dashed line) in the qubit state versus the mixing parameter .
- 4.4 Random number extraction and coherence distillation. The randomness extraction process can be replicated by first distilling the coherence of the quantum state. Measurement outcomes will directly produce uniformly random bits.
- 5.1 Classical and quantum coin. For a given value, (a) classical and (b) quantum -coin corresponds to two different ways of encoding , see Eqs. (5.1) and (5.2), respectively. The key difference lies in whether there is coherence in the computational basis.
- 5.2 Experimental setup. (a) Optical image of a transmon qubit located in a trench, which dispersively couples to two 3D Al cavities. (b) Optical image of the single-junction transmon qubit. (c) Scanning electron microscope image of the Josephson junction. (d) Schematic of the device with the main parameters. In our experiment, the higher frequency cavity is not used and always remains in vacuum, which can be used as another -quoin in future experiments [2]. Note that the highlighted boxes in (a) and (b) are not to scale and are intended for illustrative purposes only.
- 5.3 Readout properties of the qubit. The phase between the JPA readout signal and the pump has been adjusted such that and states can be distinguished with optimal contrast. a) Bimodal and well-separated histogram of the qubit readout. A threshold has been chosen to digitize the readout signal. Solid line is for an initial measurement showing about 8.5% state, while dashed line is for a second measurement after initially selecting state. The disappearance of state demonstrates both a high purification and high quantum non-demolition measurement of the qubit. b) Basic qubit readout matrix. The loss of fidelity predominantly comes from the process during both the waiting time after the initialization measurement and the qubit readout time.
- 5.4 Experimental pulse sequences for the preparation of quoins and the measurements in the (a) and (b) bases. An initial measurement M1 is firstly performed to purify the qubit to the ground state . The rotation of the qubit is realized by applying an on-resonance microwave pulse with various amplitudes. The measurement is always performed in the -basis. The measurement in the -basis is realized by performing an extra pre-rotation. The phase of this extra pre-rotation is chosen to minimize the effect from qubit decoherence during the measurement for the case of , which is most sensitive to the final qubit readout accuracy.
- 5.5 Theoretical and experimental results for the (a) -coin and (b) -coin. Here, the number of experiment data for the -quoins is in the order of and the number for the -coin is in the order of . On average, we need about 20 -quoins to construct a -coin. The standard deviations of , , and are in the order of , thus are not plotted in the figure.
- 5.6 Randomized benchmarking measurement for gate fidelity. The reference curve is measured after applying sequences of random Clifford gates, while the curve is realized after applying sequences that interleave with random Clifford gates. Each sequence is followed by a recovery Clifford gate in the end right before the final measurement. The number of random sequences of length in our experiment is . Both curves are fitted to with different sequence decay . The data point is the average of the sequence fidelities of the sample sequences, and the error bar shows the standard deviation of the sample. The average single-qubit gate error , and the gate error . The dashed lines indicate a gate fidelity of 0.998 and 0.997 respectively.
- 6.1 (a) Conventional EW setup, where Alice and Bob perform local measurements separately and collect information to decide whether the input state is entangled or not. (b) Measurement-device-independent (MDI) EW setup, where Alice and Bob each prepares an ancillary state and a third party Eve performs Bell state measurements (BSMs) on the ancillary states and the to-be-witnessed bipartite state. Based on the choices of Alice and Bob’s ancillary states and the BSM results, they can judge whether the input state is entangled or not.
- 6.2 Time shift attack to the conventional EW. (a) Experimental setup of the time-shift attack. Photon pairs are generated by SPDC using a femtosecond pump laser with a central wavelength of 390 nm and a repetition frequency of 80 MHz. POL: polarizer, HWP: half-wave plate, QWP: quarter-wave plate, IF: interference filter with 780 nm central wavelength, PBS: polarizing beam splitter, SFC: single-mode fiber coupler, SMF: single-mode fiber, SPCM: single-photon-counting module, some with extra internal delay lines. (b) Synchronization between SPCMs. Build-in delay lines enable Eve to shift the output signals and by . (c) Coincidence count versus time delay, where the time window is set to 4 ns. All data points are measured for 2 seconds, and time-shift attack is implemented with ns, which corresponds to the grey area.
- 6.3 Experimental setup for the MDIEW. The photon pairs are generated by type-II SPDC in 2-mm -barium-borate (BBO) crystals. The pulsed pump laser has a central wavelength of 390 nm and a repetition rate of 76 MHz. To prepare the desired state (6.2), two 2-mm decoherer BBOs (D BBO) on each side with fast axis setting at (up) and (down) to reduce the spatial walk-off effect. By changing the angle of the selector HWP (S HWP), the desired state (6.2) is prepared with . Heralded photons 2 and 5 are triggered by the detections of photon 1 and 6, respectively. Waveplates are used to rotate the polarizations to encode photons 2 and 5 to the desired states, and . The BSM module is composed of three PBSs and two HWPs at . All photons are filtered by narrow-band filters (with = 2.8 nm for BSM I and = 8.0 nm for BSM II) and then coupled into single-mode fibers which connect to SPCMs.
- 6.4 MDIEW values are compared for three cases. The theoretical results (, solid line) are calculated for the states with different values of in Eq. (6.2). The tomography results (, triangle points) are evaluated for the states after performing tomography on the to-be-witnessed bipartite state. Each point of the experimental results (, circular points) is measured from a 16-hour experiment. Vertical error bars indicate one standard deviation and horizontal error bars of the fitting values from state tomography are described in Supplemental Materials. The inset shows theoretical and experimental values of tangle for input states .
- 6.5 Tomography of the bipartite state . Density matrices are constructed through tomography and over 250,000 coincidence detection events are obtained for each plot. Depending on the angle of the state selector defined in Eq. (6.22), various states are prepared. (a) Real part of the density matrices . (b) Imaginary part of the density matrices .
- 7.1 Entanglement witness and the reliability problem.
- 7.2 Optimization of entanglement witnesses. (a) To get the optimal witness of an unknown entangled state , one has to run over all possible witnesses. Intuitively, this is done by scanning over all witnesses that are tangent to the set of separable states. (b) The optimization can be efficiently done if certain failure probability can be tolerated.
- 7.3 Bipartite nonlocal game with classical and quantum inputs. (a) Nonlocal game with classical inputs. Based on the classical inputs and , Alice and Bob perform local measurement on the pre-shared entangled state , and get classical outputs and , respectively. A linear combination of the probability distribution defines a Bell inequality as shown in Eq. (9.1). (b) Nonlocal game with quantum inputs. The quantum inputs of Alice and Bob are respectively and . It is shown [3] that any entangled quantum states can be witnessed with a certain nonlocal game with quantum inputs. Equivalently, if we consider that Alice and Bob each prepares an ancillary state and a third party Eve performs the measurement, this setup also corresponds to the case of MDIEW.
- 7.4 Simulation results of the original and optimized MDIEW protocol. The to be witness state is the two-qubit Werner state defined in Eq. (7.22). Here, we consider that Alice projects onto and Bob projects onto . In this case, the original MDIEW cannot detect entanglement, while the optimized MDIEW protocol detects all entangle Werner states.
- 8.1 Bell tests in the bipartite scenario. (a) The inputs of Alice and Bob, and , are decided by perfect random number generators (RNGs), which produce uniformly distributed random numbers; (b) The measurement devices are controlled by an adversary Eve through local hidden variables ; (c) The input random numbers are also controlled by the same local hidden variable , which is accessible to Eve.
- 8.2 (Color online) Optimal values of the CHSH test for different randomness with various rounds based on only Alice’s inputs biased when conditioned on the hidden variable . The solid line is the optimal strategy for , which upper bounds all finite rounds. Note that the curve is not smooth for finite runs because the optimal strategy defined in Eq. (8.27) jumps on . With grows larger, the curve tends to be smoother.
- 8.3 (Color online) Possible optimal values of the CHSH test for different randomness with various rounds based on uncorrelated inputs of Alice and Bob. The solid line corresponds the strategy for , which upper bounds all finite cases. The curves are not smooth for finite as for similar reasons like in the one party biased case, and it tends to be smooth with .
- 9.1 Bell tests in a bipartite scenario. In general, the inputs depend on some local hidden variable . The local hidden variables that control the inputs and the devices may be different. While, we can still denote these two local hidden variables with a single one denoted as .
- 9.2 (Color online) The CH value as a function of and , according to Eq. (9.18).
- 9.3 (Color online) The CH value as a function of and with the factorizable condition Eq. (9.7).
- 9.4 (Color online) The CH value as a function of and under NS condition Eq. (9.22).
- 9.5 (Color online) The CH value as a function of and under factorizable Eq. (9.7) and NS Eq. (9.22) conditions.
- 9.6 The critical value of and such that the CH value equals the maximal quantum value .
- 9.7 The CH value under different conditions.
- 10.1 Illustration of a generic QRNG setup in which we take photon polarization as the example. and refer to horizontal and vertical polarizations, respectively. PBS refers to a polarizing beam splitter. (a) The source functions normally (or trusted) and sends superpositions of and polarizations, which offers quantum randomness. (b) The source malfunctions (or untrusted) and sends and polarizations in a predetermined order, which should output no genuine randomness. From the measurement result viewpoint, one cannot distinguish these two cases.
- 10.2 (a) Measurement model for SIQRNG. The quantum state first passes through a squasher and is projected as either a qubit or a vacuum. Then, the output qubit is measured in the or basis chosen by an active switch. There are two outcomes for each basis measurement, corresponding to the two eigenstates of the basis. (b) An optical implementation of the SIQRNG in (a), as discussed in Section . Here Pol-M refers to a polarization modulator, PBS refers to a polarizing beam splitter, and and are the threshold detectors.
- 10.3 Source-independent QRNG with the finite data size effect. The results are proven in Section 10.2.2.
- 10.4 An equivalent protocol of source-independent QRNG.
- 10.5 Experiment setup of SIQRNG. S: laser source; LP: linear polarizer; FPC: fiber polarization controller; FA: fiber attenuator; BS: beam splitter; PBS: polarizing beam splitter; TD: time delay implemented with a 12 m fiber; PD: photon detector.
- 10.6 Relation between the phase error rate and the loss. The big error bars are caused by a very conservative estimation of statistical fluctuations and also partially by the fluctuation of experimental parameters for different losses.
- 10.7 Dependency of randomness generation rate on the loss. The data points on the figure are taken to be the lower bound of the rate, evaluated by random sampling. The security parameter is
- 10.8 The autocorrelation function of the raw data and the final data. The x-axis is the lag between the sampled data and , while the y-axis is the autocorrelation defined in Eq. (10.7). Data sizes of both the raw data and the final data are in the order of . The autocorrelation of the final data is significantly smaller than the raw data in absolute value. Due to finite-key-size effect, the autocorrelation cannot be zero even for perfectly random strings.
- 10.9 The P-value of the statistical tests. The x-axis lists the names of statistical tests in the NIST test suite. The final data size is 91 Mbit, which is extracted from 115 Mbit raw data. To pass each test, the P-value should be at least 0.01 and the proportion of sequences that satisfy should be at least 96%. It can be seen in the figure that the P-values of all tests are greater than .
- 11.1 Deutschian timelike curves. (a) depicts a physical visualization of a CTC, where an object entering one mouth of a wormhole at some point may jump to a prior time (with respect to an chronology respecting observer) and interact with its past self via some unitary . (b) In the special case where no interaction occurs, we obtain an open timelike curve. This naturally occurs, for example, in instances where the wormhole mouths are spatially separated.
- 11.2 CTCs and OTCs in presence of ancilla. represents the system to be sent through the space-time wormhole, and some chronology respecting system initially correlated with . (a) In general CTCs, temporal self-consistency demands that satisfies . (b) In the case of OTCs, this implies that system has state after application of the protocol.
- 11.3 Quantum circuit of OTC enhanced measurement. The protocol first introduces ancilla qudits, all of which are initialized in the state , where is an eigenstate of . A sequence of gates then perfectly correlates each ancilla with with respect to basis. The erasure of these correlations via OTCs, followed by measurements on each individual qudit, allows determination of to a standard error that scales inversely with .
- 11.4 Solving NP-complete problems with OTCs. The key non-linear gate , that takes to , can be implemented via open timelike curves. This is achieved by the use of a single OTC, applied between two successive gates.
- 11.5 OTC Assisted Cloning. An arbitrary qudit can be cloned to any desired fidelity. The process involves (i) application of a standard quantum cloner to generate imperfect copies, and (ii) use of OTC enhanced measurements to measure different observables on each imperfect copy. We can choose to be informationally complete, and OTCs ensure that we can determine to any desired precision. Thus this protocol can yield (to any fixed precision) the classical description of .
- 12.1 The structure of sharp measurements. (a) Every non-sharp measurement (round diagram on the l.h.s.) is equivalent to a sharp measurement (triangular diagram on the r.h.s.) performed on the system along with an environment. (b) Coarse-graining a sharp measurement yields a new sharp measurement . (c) When two sharp measurements and are performed in parallel, they yield a new sharp measurement .
- 12.2 Winning graphs for examples of nonlocal games. The vertices are coloured so that two connected vertices have distinct colours, using the minimum number of colours. (a) Winning graph for the CHSH game. The player win if and 0 otherwise. The graph is not perfect, because the largest clique in the graph has 3 vertices while the number of colours in the graph is 4. Here classical strategies are not optimal among the strategies that satisfy LO. (b) Winning graph for Guess Your Neighbor’s Input [4] in the case of parties. The players win if for every . The graph is a disjoint union of disconnected cliques and therefore classical strategies are optimal among all strategies satisfying LO. (c) Winning graph for the game “Guess the Product” in the case of parties. The players win if for every and 0 otherwise. The graph is perfect and therefore the classical strategy is optimal [5]. (d) Winning graph for the game “Guess the Parity” in the case of parties. The players win + 1 if for every and 0 otherwise. The graph is not perfect, because it contains odd cycles with more than 3 vertices. Still, classical strategies are optimal for this game, as shown in Supplementary Note 2 for arbitrary number of players.
List of Tables
- 3.1 Properties that a coherence measure should satisfy.
- 3.2 Properties that an entanglement measure should satisfy.
- 3.3 A brief summary of trusted-device QRNG demonstrations. Detailed description of these schemes can be found in Section and . Note that the quality/security of random numbers in different demonstrations may be different. Raw: reported raw generation rate, Refined: reported refined rate, Acquisition: data acquisition by dedicated hardware or commercial oscilloscope, SPD: single photon detector, BS: beam splitter, MCP-PCID: micro-channel-plate-based photon counting imaging detector, PNRD: photon-number-resolving detector, CMOS: complementary metal-oxide-semiconductor, : no related information found.
- 3.4 A summary of self-testing and semi-self-testing QRNG demonstrations. MDI: measurement device independent, SI: source independent, CV: continuous variable.
- 4.1 Comparing the frameworks of coherence and entanglement. DI: device-independent; MDI: measurement-device-independent; QKD: quantum key distribution; QRNG: quantum random number generation.
- 5.1 Experiment results. is the angle of the quoin state; is the total number of -quoins prepared. About half of the prepared -coins are measured in the basis to prepare the -coin. is the theoretically estimated value based on the estimation of ; is the experimentally estimated value from the obtained -coins; is the theoretically estimated value from the estimation of ; is the experimentally estimated value from the obtained -coins; is the number of -coins obtained.
- 6.1 Decomposition of based on different measurement outcomes.
- 6.2 Coefficients and probabilities for MDIEW with outcomes and . Note that when , the corresponding probability is irrelevant.
- 6.3 Coefficients and probabilities for MDIEW with outcomes and . Note that when , the corresponding probability is irrelevant.
- 6.4 Our MDIEW in the form of Eq. (6.21) for the bipartite states defined in Eq. (6.8).
- 6.5 Error estimation of density matrix, real non-zero parts
- 6.6 The tangle values of the input states by tomography.
- 8.1 The lower bound for randomness parameter defined in Eq (9.2) that allows the CHSH value , defined in Eq. (9.5), to reach the quantum bound by LHVMs in the CHSH test under different conditions.
- 9.1 The value of with deterministic strategy.
- 9.2 Possible strategies for letting be positive.
- 9.3 The coefficient of in the expression of of the CH inequality.
- 9.4 The coefficient of in the expression of of the CHSH inequality.
- C.1 The coefficient of in the expression of J.
- C.2 The coefficient of in the expression of J.
Part I Introduction and Preliminaries
Chapter 1 Introduction
Manipulation of quantum information empowers many tasks such as communication [6, 7, 8], computation [9, 10], and simulation [11, 12]. In a communication task, the quantum key distribution protocol by Charles Bennett and Gilles Brassard in 1984 (BB84)[6] makes it possible to extend secret keys between two remote parties by transmitting quantum signals. Such a task has been proven impossible by classical methods. In quantum computing, the Shor algorithm named after its inventor Peter Shor [9] factorizes integers 111given an integer , find its prime factors at exponentially faster speeds than any existing classical methods. In quantum simulation [13], one can efficiently simulate quantum systems that requires exponential resources with a classical computer.
To investigate the origin of the quantum information processing power, we need to find the major difference between the manipulation of quantum and classical information. Focusing on states of physical systems, the major distinction derives from the quantum features or quantumness. In different scenarios, the quantumness manifests differently. For instance, considering the whole system, coherent superpositions on a computational basis inherently differ from classical (stochastic) mixtures of the basis states. Named quantum coherence, such coherent superpositions underlies the quantumness of a single quantum system [14]. In bipartite systems, the quantumness can also be defined as the nonlocal correlation between the two systems. Considering local operation and classical communication (LOCC) as free or classical operations, quantum entanglement is the major quantumness in bipartite states [15, 16, 17].
One important research direction is the quantumness of states, which aims to analyze quantumness in a systematic way. Quantum coherence and entanglement can be quantified by resource frameworks. In general, a quantumness resource framework relies on identifying classical states and classical operations. The corresponding quantumness of an operational task emerges when a quantum behavior cannot be explained by classical means. A state is called classical when it exhibits no quantum behavior. Denote the set of classical states by , then a state that does not belong to is called quantum. Based on classical states, classical operations are physically realizable operations that cannot generate quantum states from any classical state. With classical states and operations, a resource framework of quantumness is completed by defining measures, which is a real-valued functions of states. Generally, a quantumness measure should satisfy the monotonicity requirement: that is, classical operations cannot increase the quantumness of a system.
From a mathematical viewpoint, finding legitimate quantumness measures is important for completing the quantumness resource framework. Moreover, these quantities should have meaningful interpretation in detailed operational tasks. For instance, the entanglement of formation measures the amount of maximally entangled states on average that are required to prepare the target state in the asymptotical scenario; the distillable entanglement measures the amount of maximally entangled states on average that can be obtained via LOCC operations on the target states in the asymptotical scenario.
This thesis focuses on the operational interpretation of quantumness measures. We consider two operational tasks: randomness processing and selftesting quantum information processing and investigate the key roles of quantumness in both tasks. We also probe the interplay between randomness and selftesting quantum information tasks.
Quantumness and randomness
In classical theory, all physical processes are deterministic due to basic Newton’s laws. In contrast, Born’s rule [18] endows the quantum world with true randomness. Such is the counter-intuitiveness of the result that Einstein was quoted as saying ‘God is not playing at dice’. Nevertheless, the intrinsically random nature of measurement outcomes is now considered a key characteristic that distinguishes quantum mechanics from classical theory [19].
In measurement theory, decoherence, breaking coherence or superposition, in a specific (classical) computational basis results in random outcomes [20]. Intuitively, from the resource perspective, the randomness can be generated by consuming coherence of a quantum state. In order to quantitatively establish this connection, one needs to find a proper way to assess the randomness of measurement, which normally contains quantum and classical processes. The superficially random outcomes in classical processes are generally not truly random, although they might appear so if information is ignored. Thus, such classical part of randomness should be precluded when quantifying a quantum feature — coherence. A quantum process, on the other hand, can generate genuine unpredictable randomness, which we call intrinsic (quantum) randomness. Observing such intrinsic random outcomes of measurements would indicate non-classical (quantum) features of objects.
As an example, we can consider the famous Schrödinger’s cat gedanken experiment as shown in Fig. 1.1. In a classical world, a cat might be either alive or dead before observation, which can be described by the density matrix for the case of being alive and dead equally likely, see Fig. 1.1 (a). The observation result of whether the cat is alive or dead looks random, which is due to the lack of knowledge of the cat system. After considering some hidden variables or an ancillary system that purifies , , we can simply observe the system to infer whether the cat is alive or dead. In quantum mechanics, the cat can be in a coherent superposition of the states of alive and dead, , where , see Fig. 1.1 (b). The observation outcome would be intrinsically random according to Born’s rule. That is, without directly accessing the system of the cat and breaking the coherence, we can never predict whether the cat is alive or dead better than blindly guessing. Therefore, the existence of intrinsic randomness can be regarded as a witness for quantum coherence.
This thesis investigates the relation between intrinsic randomness and quantum coherence [21, 22]. We show that the amount of intrinsic randomness arising from state measurements in a basis indicates the amount of coherence in the same basis. Therefore, we can naturally regard coherence as the resource for generating randomness. In addition, we examine a simple yet interesting randomness processing task, called the Bernoulli factory [23, 24] and investigate how coherence can be used to beat classical method. In the discussed randomness tasks, we reveal that coherence is an important resource for both randomness generation and processing.
Quantumness and selftesting
The concept of selftesting is unique in quantum information processing. A selftesting or device independent protocol can maintain its property even with untrusted devices that do not assume the physical implementations [25, 26, 27]. Considering the process in Fig. 1.2(a), a general picture for a single party process involves classical or quantum random input and output . Without assuming the physical implementation of the box that transforms inputs into outputs, what we observe in practice is the probability distribution of . Then, a selftesting protocol is to ensure its property only based on the probability distribution of . In the bipartite scenario, Fig. 1.2(b), we can further impose other requirements on the two parties. For instance, in the Bell test, we generally assume no-signaling between the two parties. Given the inputs , outputs , and the probability distribution , the Bell test has proven remarkable power in many tasks.
Here, we take randomness generation as an example. True random numbers can be generated when measuring a coherent state on its basis. Such randomness, however, assumes physical implementation (i.e., the state and its measurement). We instead consider whether random numbers can be generated without the physical implementations. The single device in Fig. 1.2(a) cannot be used to device independently generate randomness because one can always choose a predetermined sequence that satisfies the probability distribution . As the sequence is predetermined, no randomness is generated, thus, it appears that randomness cannot be generated in a selftesting way.
Now, we consider the two-devices case in Fig. 1.2(b). Following a similar argument, both parties can produce predetermined probability distributions and to simulate the observed probability distribution . Although the two parties cannot communicate, they can still share a predetermined strategy that is independent of the inputs. The probability distribution of a given is . On average, the probability distribution the two parties can simulate with predetermined strategy is
[TABLE]
where is the probability distribution of . Such a strategy is called local hidden variable models [28]. We then question whether the probability distribution Eq. (1.1) covers all possible probability distributions . If the answer is yes, then the observed probability distribution cannot certify randomness; if no, the process generates true random numbers. Remarkably, there exist probability distributions that emerge from measuring entangled states cannot be simulated as Eq. (1.1). In practice, when observing a probability distribution that cannot be simulated, the randomness in the output is assured without assuming any physical realizations.
Although a selftesting protocol does not assume physical realizations, the quantumness remains the crucial ingredient for demonstrating quantum advantages. If there is no quantumness, the process becomes classical and cannot be verified device independently. Conversely, quantumness can be witnessed by selftesting protocols. For instance, entanglement is revealed by violations of Bell inequalities. This thesis investigates the relation between quantumness and selftesting [29, 30, 31, 32]. Specifically, we investigate the witnessing of general multipartite entanglement via a selftesting protocols with quantum states as inputs.
Randomness and selftesting
A selftesting protocol requires genuine random input. If the input is also predetermined, the device can always simulate any probability distribution by a predetermined strategy. The randomness (freewill) loophole refers to the underlying assumption in Bell tests that different measurement settings can be chosen randomly (freely). Generally, a Bell test requires the input of each party to be fully random in order to avoid information leakage between different parties. If there is a local hidden variable that shares information about the random inputs, where in the worst scenario, the inputs are all predetermined such that each party knows exactly the input of the other party, it is possible to violate Bell inequalities just with local hidden variable model (LHVM) strategies [28]. Since one can always argue that there might exist a powerful creator who determines everything including all the Bell test experiments, this loophole is widely believed to be impossible to close perfectly. In this case, as we cannot prove or disprove the existence of true randomness, the assumption of freewill is indispensable in general Bell tests.
Yet, it is still meaningful to discuss the randomness requirement222The imperfect input randomness requirement is sometimes called measurement dependence in literature. of Bell tests in a practical scenario. In this thesis, we suppose that the randomness generation devices are partially controlled by an adversary Eve, who thus possesses certain knowledge of the inputs of Alice and Bob [33, 34]. Then Eve can make use of the information about the inputs to fake violations of Bell’s inequalities [35] and hence lead to the device independent tasks insecure. Therefore, it is interesting to see how much of randomness needed for a Bell test in order to ensure the correctness of the conclusion. This is especially meaningful when considering a loophole free Bell test [36, 37] and its applications to practical tasks in the presence of an eavesdropper.
In summary, this thesis investigates three main topics— quantumness, randomness, and selftesting, and the interplays among these features. Following a brief introduction to quantum information theory, we discuss these three features and their interplays from different perspectives. We also investigate two studies on quantum information in general relativity and axioms and discuss the basic principles of quantum information theory and their extension to a general physical theory.
Chapter 2 Basics of quantum mechanics
This chapter briefly covers the basics of quantum mechanics. We focus on the formalism of quantum information formalism, which involves the density matrix and the positive observable valued measures (POVMs). Due to the length limit, we only present the results that are used in this thesis. For a more detailed introduction of quantum information, please see Ref. [38, 39, 40].
2.1 Quantum mechanics formalism—pure states and projective measurements
In this part, we review the Dirac notation of quantum mechanics and its equivalent form of vectors.
Pure states
Unlike classical mechanics, quantum states can be expressed as a superposition of different bases. Following the Dirac bra ket representation, a pure quantum state can be denoted as
[TABLE]
where the set of represents a state basis, such as the polarization of the photon or the energy levels of an atom. Suppose the dimension of the basis is , then we can regard the state space as a -dimensional Hilbert space and quantum states as vectors. Suppose forms an orthogonal basis, then quantum states can be equivalently denoted as
[TABLE]
Measurements
In the Dirac representation, a projective measurement can be denoted in bra form as,
[TABLE]
The measurement probability is given by
[TABLE]
Suppose forms an orthogonal basis, then the probability is given by
[TABLE]
Similar to the vector representation, a projective measurement can be denoted as a dual vector as
[TABLE]
and the probability of measuring is given by the square of the inner product
[TABLE]
Observables
In quantum mechanics, an observable is a Hermitian operator that satisfies for two arbitrary states and . Here is the complex conjugate of . Therefore, the average of for state is given by the real value
[TABLE]
When is denoted as a vector and as a dual vector, can be denoted as a Hermitian matrix . In this case, the average value can be given by matrix multiplication .
Any Hermitian operator has a spectral decomposition,
[TABLE]
where forms an orthogonal basis, so the average value of can also be regarded as a projective measurement on the basis. The probability of the th outcome is and the average is
[TABLE]
Evolution
In quantum mechanics, the evolution of a quantum state is determined by the Schrdinger equation. Given the Hamiltonian of the system, we have
[TABLE]
Considering a closed system where energy is conserved, the Hamiltonian is independent of time and the state can be determined by
[TABLE]
where gives the evolution of the state and is the state at time .
In quantum mechanics, the Hamiltonian is Hermitian. In the vector representation, corresponds to a Hermitian matrix that satisfies . Here denotes the hermitian conjugate of . Because
[TABLE]
the matrix representation of is given by . In this case, the evolution operator can be regarded as a unitary operator that satisfies
[TABLE]
where .
To summary, when considering a -dimensional system, pure quantum states, projective measurements, observables and state evolution can be represented as vectors, dual vectors, Hermitian operators, and unitary operators, respectively. Because the vector representation is equivalent to the Dirac bra ket representation, we use them interchangeably.
2.2 Composite systems and subsystems
Composite system
We now consider two systems and that are defined in Hilbert space and , respectively. Similarly, a pure quantum state on system can be represented as
[TABLE]
where and forms orthogonal bases for systems and , respectively. Equivalently, in vector form, we have
[TABLE]
Projective measurements, observables and evolution can be similarly defined. Next, we move to the density matrix description of states for subsystems. Before, we first redefine the pure state formalism with states and measurement denoted as matrices.
Subsystems
In the Dirac notation, quantum states and measurements are given by and and the measurement probability is given by , respectively. Equivalently, we can denote quantum state as and a measurement as . Then the measurement probability is
[TABLE]
where is the trace operation. Thus, quantum states and measurements can also be denoted as matrices.
Consider now a projective measurement on system of and the probability of the measurement. Because systems and are correlated, we cannot directly calculate the probability of solely measuring system from the state. In this case, we consider that a projective measurement on the basis is also applied on system . The probability of projecting onto and is calculated by
[TABLE]
and the probability of projecting system onto is
[TABLE]
where
[TABLE]
with being the trace over system only.
Therefore, when measuring a subsystem, one can equivalently describe the state with a density matrix by tracing out the other systems. In general, it is easy to verify that a density matrix should have the following properties:
- •
is a Hermitian operator.
- •
is nonnegative. That is, its spectral values are nonnegative.
- •
.
Qubit systems
A two-level system is referred to as a quantum bit or qubit system. Its density matrix is a Hermitian matrix. The Pauli matrices
[TABLE]
together with the identity matrix form a basis for Hermitian matrices. That is, given , , , , and the inner product to be the inner product of matrices, we can verify that
[TABLE]
For any single qubit state , its Bloch sphere representation is
[TABLE]
Here, are real values and . It is easy to verify that
[TABLE]
Two qubit states can also be decomposed in the Pauli matrices basis,
[TABLE]
Here, the coefficients are determined by the average value
[TABLE]
Purification and Schmidt decomposition
For any state with a spectral decomposition of , one can always find its purification. That is, we can find a pure bipartite state such that
[TABLE]
such that .
For any pure state of a bipartite system, orthonormal bases and exist such that:
[TABLE]
The subsystems and have the same eigenvalues, s and the number of s is called the Schmidt number of . The pure state is an entangled state when the Schmidt number is greater than one. It is easy to see that the Bell states are entangled states.
Positive observable valued measures
When performing local measurements on a joint state, the state can be denoted as a density matric to simplify the calculation. We now consider performing a joint measurement and want to know the measurement probability of a local system. Suppose a joint measurement is performed on , then the probability distribution is
[TABLE]
Here, we first trace out system to get
[TABLE]
In this case, when focusing only on system , the effective measurement performed on system is . Therefore, general measurements are defined by positive observable valued measures (PVOMs). That is, and .
Entropy of quantum states
For any quantum state , the definition of function acting on is given by acting on its spectral decomposition:
[TABLE]
where and forms an orthogonal basis.
The entropy of quantum state is defined as
[TABLE]
or equivalently
[TABLE]
Here, .
The relative entropy of quantum state is
[TABLE]
We also know that , where the equality holds if and only if .
For a bipartite quantum state , the conditional entropy and mutual information is defined by
[TABLE]
When , we also have
[TABLE]
where .
Chapter 3 Quantumness, selftesting, and randomness
This chapter introduces the basic concepts of quantumness, selftesting, and randomness. In Sec. 3.1, I introduce the quantumness of states, including the coherence of a single quantum system and the entanglement of multipartite systems. Sec. 3.2 introduces the Bell nonlocality test, which is the basic tool for selftesting protocols. Finally, Sec. 3.3 reviews the development of quantum random number generation.
3.1 Quantumness
This section introduces the basics of quantumness of states. For a single quantum system, we focus on its coherence on the computational basis. We refer to Ref. [41, 42] for recent reviews on this subject. For multipartite systems, we mainly focus on entanglement correlations. Nice reviews on this subject are available in Ref. [43, 17, 44].
3.1.1 Quantum coherence
As a key feature of quantum mechanics, coherence measures the superposition power on the computational basis and is often considered as a basic ingredient for quantum technologies [45, 46]. Considerable effort has been undertaken to theoretically formulate the quantum coherence [47, 48, 49, 50, 51, 14, 52, 53]. Recently, a comprehensive framework of coherence quantification has been established [14], by which coherence is considered to be a resource that can be characterized, quantified and manipulated in a manner similar to that of another important feature— quantum entanglement [15, 16, 43, 17]. Here, we focus on the resource framework of coherence.
In a general -dimensional Hilbert space and a computational basis , coherence measures its superposition power on the basis. Note that, any state that can be represented by a diagonal state of , that is,
[TABLE]
has no superposition. Thus, such state is called incoherent (classical) state and the set of such state is denoted by . Conversely, a maximally coherent state is given by the maximal superposition state
[TABLE]
up to arbitrary relative phases between the components .
When considering coherence as a resource, incoherent states are thus “useless” or “free” states. If we make an analogy with the theory of thermodynamics, incoherent state would be similar to thermal states from which no energy can be extracted. In thermodynamics, thermal operations are generally considered as free operations. Applying a thermal operations on thermal state results in a thermal state. In the same spirit, one can define a “free” or incoherent operation to be the operation that transforms incoherent state only to incoherent state. That is, incoherent operations are defined by incoherent completely positive trace preserving (ICPTP) maps , where the Kraus operators satisfy and . In the case, where post-selections are enabled, the output state corresponding to the th Kraus operation is given by , where is the probability of obtaining the outcome .
Given the definition of incoherent states and incoherent operations, we can measure the amount of coherence. Generally, a measure of coherence is a map from quantum state to a real non-negative number that satisfies the properties listed in Table 3.1.
There are various measures for coherence. Considering the distance measure of two quantum states, the measure of coherence may be defined as the minimum distance from to all incoherent states in . Two examples [14] are now presented.
Relative entropy: Here the relative entropy is used as the distance measure.
[TABLE]
where only contains diagonal elements of .
norm: Another distance measure is a function of the off-diagonal elements of the quantum state. The simplest form is the norm, which is given by
[TABLE]
Besides the distance measures, coherence can be defined in other ways.
Convex roof: According to [21], the intrinsic randomness is also a measure of coherence, therefore we have
[TABLE]
where and , and the minimization runs over all possible decompositions.
3.1.2 Quantum entanglement
Entanglement framework
Quantum entanglement describes the nonlocal correlation between different systems. For instance, considering in the bipartite scenario, any product state
[TABLE]
has no nonclassical correlation. In addition, a mixture of classical states should also be classical state. Thus, we say that a state is separable when it can be written as
[TABLE]
where .
Similar to the framework of coherence, we also need to define classical operations for entanglement. In the same spirit of incoherent operations that do not create coherence from incoherent states, a separable operation is defined such that no entangled state can be generated from separable state. In practice, the operation of local operation and classical communication (LOCC) draws more attention because it has operational meanings. In this case, as a strict subset of separable operations, LOCC are generally referred as the “free” operation for entanglement.
Given the definitions of separable states and LOCC operations, we propose measures for entanglement that have the following properties.
Two widely adopted measures are the relative entropy of entanglement and the entanglement of formation.
1. Relative entropy of entanglement:
[TABLE]
where the minimization runs over all separable states .
2. Entanglement of formation:
[TABLE]
where the minimization runs over all possible decomposition of and with being the density matrix of system .
Entanglement witness
Quantum entanglement plays an important role in the nonclassical phenomena of quantum mechanics. Being the key resource for many tasks in quantum information processing, such as quantum computation [54], quantum teleportation [7] and quantum cryptography [6, 8], entanglement needs to be verified in many scenarios. There are several proposals to witness entanglement and we refer to Ref. [44] for a detailed review.
A conventional way to detect entanglement, entanglement witness (EW), gives one of two outcomes: ‘Yes’ or ‘No’, corresponding to conclusive result that the state is entangled or fail to draw a conclusion, respectively. Mathematically, for a given entangled quantum state , an Hermitian operator is called a witness, if (output of ‘Yes’) and (output of ‘No’) for any separable state . Note that there could also exist entangled state such that (output of ‘No’). The EW method is shown schematically in Fig. 3.1.
In an experimental verification, one can realize the conventional EW with only local measurements by decomposing into a linear combination of product Hermitian observables [44]. For example, we can consider a Werner state and the EW
[TABLE]
with and and being the identity matrix. The state is entangled if , which can be witnessed by the EW,
[TABLE]
and its result, . When considering local measurements of Pauli operators, it is easy to verify that
[TABLE]
In experiment, one simply measures local observables of , , , and take the average to get the estimation of .
3.2 Selftesting: Bell nonlocality test
The basic idea of selftesting quantum information processing is to guarantee the quantum advantage with only the observed statistics instead of the implementation device. The key ingredient for fully selftesting is based on the violation of Bell inequalities. Bell test [19] is motivated to rule out local hidden variable models (LHVMs) [28]. The faithful violation of a Bell inequality assures that the underlying physical process cannot be explained with LHVMs. In quantum information processing, violations of Bell’s inequalities are powerful tools that enable device independent tasks, such as quantum key distribution [55, 26, 56, 57], randomness amplification [58, 59, 60] and generation [61, 62, 63, 64], entanglement quantification [65], and dimension witness [66]. In this section, we introduce the background of Bell nonlocality test and leave its application to randomness generation in next section. We also leave the discussion of semi-selftesting quantum information in Part III.
3.2.1 Clauser-Horne-Shimony-Holt inequality
One of the best-known Bell inequalities is the Clauser-Horne-Shimony-Holt (CHSH) inequality [1], which may be expressed in many ways. We study it from a quantum game point of view.
As shown in Fig. 9.1, two space-like separated parties, Alice and Bob, choose input bit settings and at random and output bits and based on their inputs and pre-shared quantum () and classical () resources, respectively. The probability distribution , obtaining outputs and conditioned on inputs and , is determined by specific strategies of Alice and Bob. By assuming that the input settings and are chosen fully randomly and equally likely, the CHSH inequality is defined by a linear combination of the probability distribution according to
[TABLE]
where the plus operation is modulo 2, is numerical multiplication, and is the (classical) bound of the Bell value for all LHVMs.
An achievable bound for the quantum theory is [67]. In this case, a violation of the classical bound indicates the need for alternative theories other than LHVMs, such as quantum theory. For general no signalling (NS) theories [68], we denote the corresponding upper bound as . It is straightforward to see that .
Different strategies impose different constraints on the probability distribution.
- •
Classical:
- •
Quantum:
- •
No-signaling:
3.2.2 Practical loopholes
In practice, the conclusion of the violation of a Bell test depends on several assumptions. Experimental demonstrations suffer from three major loopholes; a faithful Bell test should close all such loopholes.
Locality loophole: The measurement events of Alice and Bob should be space-like separated. If this condition is not satisfied, Bell’s inequality can be violated by signaling even with LHVMs. This loophole can be closed by separating Alice and Bob sufficiently far apart such that the measurement events become space-like separated. In experiment, this loophole is closed in optical systems [69] and appears nearly closed in atomic systems [70].
Efficiency loophole: The detection efficiency must be greater than a threshold to ensure violation of Bell inequalities without assuming fair sampling. The famous Clauser-Horne (CH) or Eberhard [71] test show that the efficiency should be at least 2/3 for each party, which is also proven to be a tight bound [72, 73] for all bipartite Bell tests with two inputs. The efficiency loophole has been closed in different realizations [74, 75, 76].
Randomness loophole: The inputs and should be random and thus cannot be predetermined. Also, we require and to be uncorrelated with each other and also come from different runs [77, 78]. In experiment, this loophole cannot be closed perfectly, as we can never unconditionally certify the randomness without a faithful Bell test, which in turn requires faithful randomness. Thus, we have to assume the existence of a true random seed. In practice, we can use independent RNGs, such as causally disconnected cosmic photons [79]. Conversely, if we can well characterize the randomness, we can also check whether the input randomness satisfies the requirement [35, 77, 77, 78, 21, 34] that guarantees the conclusion even with imperfectly randomness input.
In experiment, the conclusion of a Bell test is not faithful unless these three major loopholes are closed. In addition, we must address several technical issues that may also invalidate the Bell test conclusion or make a violation impossible.
Coincidence-time problem: If the local detection time depends on the measurement settings, a coincidence time loophole [80] may exist. This loophole can be solved by distinguishing each coincidence detection event such that it does not depend on the measurement settings.
Imperfect devices: The experiment devices cannot be perfect, which will affect the result of a Bell test.
- •
Source: The input photon source will differ from the desired source due to practical imperfections. For instance, the photon source may contain multiple photon pairs, which will affect the fidelity of the prepared state.
- •
Dark count: The measurement of the state will be affected by dark counts from environment. A Bell violation will be observed only if the dark count is below a certain threshold.
- •
Misalignment error: In experiment, the measurement may contain misalignment errors that output opposite result. Misalignment error should also be below a certain threshold to guarantee a Bell violation.
Finite statistics, memory problem: In the most general scenario, the measurement devices of Alice and Bob contain a memory such that the outputs of the current run can be conditioned on the inputs and outputs of previous runs [81]. In this case, we cannot directly obtain the probability distribution. This loophole can only be closed by considering statistics test of a Bell inequality with correlated strategy. Most previous experiments [75, 76] consider asymptotic condition and assume the data to be independent and identically distributed (i.i.d.).
Nonuniform random inputs: Nonuniform random inputs do not affect the CH inequality, which is defined by a linear combination of probability distributions. However, Eberhard’s inequality, which is used in practice, should be normalized when the input random bits are not uniform. In this case, we have to consider finite statistics with nonuniform random inputs.
3.3 Randomness generation and quantification
In this section, we review the developments of quantum random number generators [82].
3.3.1 Randomness generation
Random numbers play essential roles in many fields, such as, cryptography [83], scientific simulations [84], lotteries, and fundamental physics tests [85]. These tasks rely on the unpredictability of random numbers, which generally cannot be guaranteed in classical processes. In computer science, random number generators (RNGs) are based on pseudo-random number generation algorithms [86], which deterministically expand a random seed. Although the output sequences are usually perfectly balanced between 0s and 1s, a strong long-range correlation exists, which can undermine cryptographic security, cause unexpected errors in scientific simulations, or open loopholes in fundamental physics tests [87, 35, 33].
Many researchers have attempted to certify randomness solely based on the observed random sequences. In the 1950s, Kolmogorov developed the Kolmogorov complexity concept to quantify the randomness in a certain string [88]. A RNG output sequence appears random if it has a high Kolmogorov complexity. Later, many other statistical tests [89, 90, 91] were developed to examine randomness in the RNG outputs. However, testing a RNG from its outputs can never prevent a malicious RNG from outputting a predetermined string that passes all of these statistical tests. Therefore, true randomness can only be obtained via processes involving inherent randomness.
In quantum mechanics, a system can be prepared in a superposition of the (measurement) basis states, as shown in Fig. 3.3. According to Born’s rule, the measurement outcome of a quantum state can be intrinsically random, i.e. it can never be predicted better than blindly guessing. Therefore, the nature of inherent randomness in quantum measurements can be exploited for generating true random numbers. Within a resource framework, coherence [14] can be measured similarly to entanglement [15]. By breaking the coherence or superposition of the measurement basis, it is shown that the obtained intrinsic randomness comes from the consumption of coherence. In turn, quantum coherence can be quantified from intrinsic randomness [21].
A practical QRNG can be developed using the simple process as shown in Fig. 3.3. Based on the different implementations, there exists a variety of practical QRNGs. Generally, these QRNGs are featured for their high generation speed and a relatively low cost. In reality, quantum effects are always mixed with classical noises, which can be subtracted from the quantum randomness after properly modelling the underlying quantum process [92].
The randomness in the practical QRNGs usually suffices for real applications if the model fits the implementation adequately. However, such QRNGs can generate randomness with information-theoretical security only when the model assumptions are fulfilled. In the case that the devices are manipulated by adversaries, the output may not be genuinely random. For example, when a QRNG is wholly supplied by a malicious manufacturer, who copies a very long random string to a large hard drive and only outputs the numbers from the hard drive in sequence, the manufacturer can always predict the output of the QRNG device.
On the other hand, a QRNG can be designed in a such way that its output randomness does not rely on any physical implementations. True randomness can be generated in a self-testing way even without perfectly characterizing the realisation instruments. The essence of a self-testing QRNG is based on device-independently witnessing quantum entanglement or nonlocality by observing a violation of the Bell inequality [85]. Even if the output randomness is mixed with uncharacterised classical noise, we can still get a lower bound on the amount of genuine randomness based on the amount of nonlocality observed. The advantage of this type of QRNG is the self-testing property of the randomness. However, because the self-testing QRNG must demonstrate nonlocality, its generation speed is usually very low. As the Bell tests require random inputs, it is crucial to start with a short random seed. Therefore, such a randomness generation process is also called randomness expansion.
In general, a QRNG comprises a source of randomness and a readout system. In realistic implementations, some parts may be well characterised while others are not. This motivates the development of an intermediate type of QRNG, between practical and fully self-testing QRNGs, which is called semi-self-testing. Under several reasonable assumptions, randomness can be generated without fully characterising the devices. For instance, faithful randomness can be generated with a trusted readout system and an arbitrary untrusted randomness resource. A semi-self-testing QRNG provides a trade off between practical QRNGs (high performance and low cost) and self-testing QRNGs (high security of certified randomness).
In the last two decades, there have been tremendous development for all the three types of QRNG, trusted-device, self-testing, and semi-self-testing. In fact, there are commercial QRNG products available in the market. A brief summary of representative practical QRNG demonstrations that highlights the broad variety of optical QRNG is presented in Table 3.3. These QRNG schemes will be discussed further in Section 3.3.1 and 3.3.1. A summary of self-testing and semi-self-testing QRNG demonstrations is presented in Table 3.4, which will be reviewed in details in Section 3.3.1 and 3.3.1.
Trusted-device QRNG I: single-photon detector
True randomness can be generated from any quantum process that breaks coherent superposition of states. Due to the availability of high quality optical components and the potential of chip-size integration, most of today’s practical QRNGs are implemented in photonic systems. In this survey, we focus on various implementations of optical QRNGs.
A typical QRNG includes an entropy source for generating well-defined quantum states and a corresponding detection system. The inherent quantum randomness in the output is generally mixed with classical noises. Ideally, the extractable quantum randomness should be well quantified and be the dominant source of the randomness. By applying randomness extraction, genuine randomness can be extracted from the mixture of quantum and classical noise. The extraction procedure is detailed in Methods.
Qubit state
Random bits can be generated naturally by measuring a qubit111A qubit is a two-level quantum-mechanical system, which, similar to a bit in classical information theory, is the fundamental unit of quantum information. in the basis, where and are the eigenstates of the measurement . For example, Fig. 3.4 (a) shows a polarization based QRNG, where and denote horizontal and vertical polarization, respectively, and denotes polarization. Fig. 3.4 (b) presents a path based QRNG, where and denote the photon traveling via path and , respectively.
The most appealing property of this type of QRNGs lies on their simplicity in theory that the generated randomness has a clear quantum origin. This scheme was widely adopted in the early development of QRNGs [118, 94, 93]. Since at most one random bit can be generated from each detected photon, the random number generation rate is limited by the detector’s performance, such as dead time and efficiency. For example, the dead time of a typical silicon SPD based on an avalanche diode is tens of ns [119]. Therefore, the random number generation rate is limited to tens of Mbps, which is too low for certain applications such as high-speed quantum key distribution (QKD), which can be operated at GHz clock rates [120, 121]. Various schemes have been developed to improve the performance of QRNG based on SPD.
Temporal mode
One way to increase the random number generation rate is to perform measurement on a high-dimensional quantum space, such as measuring the temporal or spatial mode of a photon. Temporal QRNGs measure the arrival time of a photon, as shown in Fig. 3.4 (c). In this example, the output of a continuous-wave laser is detected by a time-resolving SPD. The laser intensity can be carefully controlled such that within a chosen time period , there is roughly one detection event. The detection time is randomly distributed within the time period and digitized with a time resolution of . The time of each detection event is recorded as raw data. Thus for each detection, the QRNG generates about bits of raw random numbers. Essentially, is limited by the time jitter of the detector (typically in the order of 100 ps), which is normally much smaller than the detector deadtime (typically in the order of 100 ns) [119].
One important advantage of temporal QRNGs is that more than one bit of random number can be extracted from a single-photon detection, thus improving the random number generation rate. The time period is normally set to be comparable to the detector deadtime. Comparing to the qubit QRNG, the temporal-mode QRNG alleviates the impact of detection deadtime. For example, if the time resolution and the dead time of an SPD are 100 ps and 100 ns respectively, the generation rate of temporal QRNG is around 10 Mbps, which is higher than that of the qubit scheme (limited to 10 Mbps). The temporal QRNGs have been well studied recently [122, 96, 97, 98, 99].
Spatial mode
Similar to the case of temporal QRNG, multiple random bits can be generated by measuring the spatial mode of a photon with a space-resolving detection system. One illustrative example is to send a photon through a beam splitter and to detect the position of the output photon. Spatial QRNG has been experimentally demonstrated by using a multi-pixel single-photon detector array [95], as shown in Fig. 3.4 (d). The distribution of the random numbers depends on both the spatial distribution of light intensity and the efficiency uniformity of the SPD arrays.
The spatial QRNG offers similar properties as the temporal QRNG, but requires multiple detectors. Also, correlation may be introduced between the random bits because of cross talk between different pixels in the closely-packed detector array.
Multiple photon number states
Randomness can be generated not only from measuring a single photon, but also from quantum states containing multiple photons. For instance, a coherent state
[TABLE]
is a superposition of different photon-number (Fock) states , where is the photon number and is the mean photon number of the coherent state. Thus, by measuring the photon number of a coherent laser pulse with a photon-number resolving SPD, we can obtain random numbers that follow a Poisson distribution. QRNGs based on measuring photon number have been successfully demonstrated in experiments [100, 101, 102]. Interestingly, random numbers can be generated by resolving photon number distribution of a light-emitting diode (LED) with a consumer-grade camera inside a mobile phone, as shown in a recent study [123].
Note that, the above scheme is sensitive to both the photon number distribution of the source and the detection efficiency of the detector. In the case of a coherent state source, if the loss can be modeled as a beam splitter, the low detection efficiency of the detector can be easily compensated by using a relatively strong laser pulse.
Trusted-device QRNG II: macroscopic photodetector
The performance of an optical QRNG largely depends on the employed detection device. Beside SPD, high-performance macroscopic photodetectors have also been applied in various QRNG schemes. This is similar to the case of QKD, where protocols based on optical homodyne detection [124] have been developed, with the hope to achieve a higher key rate over a low-loss channel. In the following discussion, we review two examples of QRNG implemented with macroscopic photodetector.
Vacuum noise
In quantum optics, the amplitude and phase quadratures of the vacuum state are represented by a pair of non-commuting operators ( and with ), which cannot be determined simultaneously with an arbitrarily high precision [125], i.e. , with defined by and denoting the average of . This can be easily visualised in the phase space, where the vacuum state is represented by a two-dimensional Gaussian distribution centered at the origin with an uncertainty of (the shot-noise variance) along any directions, as shown in Fig. 3.5 (a). In principle, Gaussian distributed random numbers can be generated by measuring any field quadrature repeatedly. This scheme has been implemented by sending a strong laser pulse through a symmetric beam splitter and detecting the differential signal of the two output beams with a balanced receiver [103, 104, 105].
Given that the local oscillator (LO) is a single-mode coherent state and the detector is shot-noise limited, the random numbers generated in this scheme follow a Gaussian distribution, which is on demand in certain applications, such as Gaussian-Modulated Coherent States (GMCS) QKD [124]. There are several distinct advantages of this approach. First, the resource of quantum randomness, the vacuum state, can be easily prepared with a high fidelity. Second, the performance of the QRNG is insensitive to detector loss, which can be simply compensated by increasing the LO power. Third, the field quadrature of vacuum is a continuous variable, suggesting that more than one random bit can be generated from one measurement. For example, 3.25 bits of random numbers are generated from each measurement [103].
In practice, an optical homodyne detector itself contributes additional technical noise, which may be observed or even controlled by a potential adversary. A randomness extractor is commonly required to generate secure random numbers. To extract quantum randomness effectively, the detector should be operated in the shot-noise limited region, in which the overall observed noise is dominated by vacuum noise. We remark that building a broadband shot-noise limited homodyne detector operating above a few hundred MHz is technically challenging [126, 127, 128]. This may in turn limit the ultimate operating speed of this type of QRNG.
Amplified spontaneous emission
To overcome the bandwidth limitation of shot-noise limited homodyne detection, researchers have developed QRNGs based on measuring phase [108, 109, 110, 112, 111, 113] or intensity noise [106, 107] of amplified spontaneous emission(ASE), which is quantum mechanical by nature [129, 92, 130].
In the phase-noise based QRNG scheme, random numbers are generated by measuring a field quadrature of phase-randomized weak coherent states (signal states). Figure 3.5 (c) shows the phase-space representation of a signal state with an average photon number of and a phase variance of . If the average phase of the signal state is around , the uncertainty of the -quadrature is of the order of . When is large, this uncertainty can be significantly larger than the vacuum noise. Therefore, phase noise based QRNG is more robust against detector noise. In fact, this scheme can be implemented with commercial photo-detectors operated above GHz rates.
QRNG based on laser phase noise was first developed using a cw laser source and a delayed self-heterodyning detection system [108], as shown in Fig. 3.5 (d). Random numbers are generated by measuring the phase difference of a single-mode laser at times and . Intuitively, if the time delay is much larger than the coherence time of the laser, the two laser beams interfering at the second beam splitter can be treated as generated by independent laser sources. In this case, the phase difference is a random variable uniformly distributed in , regardless of the classical phase noise introduced by the unbalanced interferometer itself. This suggests that a robust QRNG can be implemented without phase-stabilizing the interferometer. On the other hand, by phase-stabilizing the interferometer, the time delay can be made much shorter than the coherent time of the laser [108], enabling a much higher sampling rate. This phase stabilization scheme has been adopted in a Gbps QRNG [110] and a 68 Gbps QRNG demonstration [113].
Phase noise based QRNG has also been implemented using pulsed laser source, where the phase difference between adjacent pulses is automatically randomized [109, 112, 111]. A speed of 80 Gbps (raw rate as shown in Table1) has been demonstrated [111]. It also played a crucial role in a recent loophole-free Bell experiment [131]. Here, we want to emphasize that strictly speaking, none of these generation speeds are real-time, due to the speed limitation of the randomness extraction [92]. Although such limitation is rather technical, in practice, it is important to develop extraction schemes and hardware that can match the fast random bit generation speed in the future.
Self-testing QRNG
Realistic devices inevitably introduce classical noise that affects the output randomness, thus causing the generated random numbers depending on certain classical variables, which might open up security issues. To remove this bias, one must properly model the devices and quantify their contributions. In the QRNG schemes described in Section 3.3.1 and Section 3.3.1, the output randomness relies on the device models [92, 130]. When the implementation devices deviate from the theoretical models, the randomness can be compromised. In this section, we discuss self-testing QRNGs, whose output randomness is certified independent of device implementations.
Self-testing randomness expansion
In QKD, secure keys can be generated even when the experimental devices are not fully trusted or characterised [55, 26]. Such self-testing processing of quantum information also occur in randomness generation (expansion). The output randomness can be certified by observing violations of the Bell inequalities [85], see Fig. 3.6. Under the no-signalling condition [68] in the Bell tests, it is impossible to violate Bell inequalities if the output is not random, or, predetermined by local hidden variables.
Since Colbeck [132, 61] suggested that randomness can be expanded by untrusted devices, several protocols based on different assumptions have been proposed. For instance, in a non-malicious device scenario, we can consider that the devices are honestly designed but get easily corrupt by unexpected classical noises. In this case, instead of a powerful adversary that may entangle with the experiment devices, we can consider a classical adversary who possesses only classical knowledge of the quantum system and analyzes the average randomness output conditioned by the classical information. Based on the Clauser-Horne-Shimony-Holt (CHSH) inequality [1], Fehr et al. [62] and Pironio et al. [63] proposed self-testing randomness expansion protocols against classical adversaries. The protocols quadratically expands the input seed, implying that the length of the input seed is , where denotes the experimental iteration number.
A more sophisticated exponential randomness expansion protocol based on the CHSH inequality was proposed by Vidick and Vazirani [64], in which the lengths of the input seed is . In the same work, they also presented an exponential expansion protocol against quantum adversaries, where quantum memories in the devices may entangle with the adversary. The Vidick-Vazirani protocol against quantum adversaries places strict requirements on the experimental realisation. Miller and Shi [133] partially solved this problem by introducing a more robust protocol. Combined with the work by Chung, Shi, and Wu [134], they also presented an unbounded randomness expansion scheme. By adopting a more general security proof, Miller and Shi [135] recently showed that genuinely randomness can be obtained as long as the CHSH inequality is violated. Their protocol greatly improves the noise tolerance, indicating that an experimental realisation of a fully self-testing randomness expansion protocol is feasible.
The self-testing randomness expansion protocol relies on a faithful realisation of Bell test excluding the experimental loopholes, such as locality and efficiency loopholes. The randomness expansion protocol against classical adversaries is firstly experimentally demonstrated by Pironio et al. [114] in an ion-trap system, which closes the efficiency loophole but not the locality loophole. To experimentally close the locality loophole, a photonic system is more preferable when quantum memories are unavailable. As the CHSH inequality is minimally violated in an optically realised system [76, 75], the randomness output is also very small (with min-entropy of in each run), and the randomness generation rate is bits/s. To maximise the output randomness, the implementation settings are designed to maximally violate the CHSH inequality. Due to experimental imperfections, the chosen Bell inequality might be sub-optimal for the observed data. In this case, the output randomness can be optimised over all possible Bell inequalities [136, 137].
Although nonlocality or entanglement certifies the randomness, the three quantities, nonlocality, entanglement, and randomness are not equivalent [138]. Maximum randomness generation does not require maximum nonlocal correlation or a maximum entangled state. In the protocols based on the CHSH inequality, maximal violation (nonlocality and entanglement) generates 1.23 bits of randomness. It is shown that 2 bits of randomness can be certified with little involvement of nonlocality and entanglement [138]. Furthermore, as discussed in a more generic scenario involving nonlocality and randomness, it is shown that maximally nonlocal theories cannot be maximally random [139].
Randomness amplification
In self-testing QRNG protocols based on the assumption of perfectly random inputs, the output randomness is guaranteed by the violations of Bell tests. Conversely, when all the inputs are predetermined, any Bell inequality can be violated to an arbitrary feasible value without invoking a quantum resource. Under these conditions, all self-testing QRNG protocols cease to work any more. Nevertheless, randomness generation in the presence of partial randomness is still an interesting problem. Here, an adversary can use the additional knowledge of the inputs to fake violations of Bell inequalities. The task of generating arbitrarily free randomness from partially free randomness is also called randomness amplification, which is impossible to achieve in classical processes.
The first randomness amplification protocol was proposed by Colbeck and Renner [58]. Using a two-party chained Bell inequality [140, 141], they showed that any Santha-Vazirani weak sources [142] (defined in next section), with , can be amplified into arbitrarily free random bits in a self-testing way by requiring only no-signaling. A basic question of randomness amplification is whether free random bits can be obtained from arbitrary weak randomness. This question was answered by Gallego et al. [59], who demonstrated that perfectly random bits can be generated using a five-party Mermin inequality [143] with arbitrarily imperfect random bits under the no-signaling assumption.
Randomness amplification is related to the freewill assumption [87, 35, 144, 77, 78, 145, 33] in Bell tests. In experiments, the freewill assumption requires the inputs to be random enough such that violations of Bell inequalities are induced from quantum effects rather than predetermined classical processes. This is extremely meaningful in fundamental Bell tests, which aim to rule out local realism. Such fundamental tests are the foundations of self-testing tasks, such as device-independent QKD and self-testing QRNG. Interestingly, self-testing tasks require a faithful violation of a Bell inequality, in which intrinsic random numbers are needed. However, to generate faithful random numbers, we in turn need to witness nonlocality which requires additional true randomness. Therefore, the realisations of genuine loophole-free Bell tests and, hence, fully self-testing tasks are impossible. Self-testing protocols with securities independent of the untrusted part can be designed only by placing reasonable assumptions on the trusted part.
Semi-self-testing QRNGs
Traditional QRNGs based on specific models pose security risks in fast random number generation. On the other hand, the randomness generated by self-testing QRNGs is information-theoretically secure even without characterising the devices, but the processes are impractically slow. As a compromise, intermediate QRNGs might offer a good tradeoff between trusted and self-testing schemes — realising both reasonably fast and secure random number generation.
As shown in Fig. 3.7, a typical QRNG comprises two main modules, a source that emits quantum states and a measurement device that detects the states and outputs random bits. In trusted-device QRNGs, both source and measurement devices [92, 130] must be modeled properly; while the output randomness in the fully self-testing QRNGs does not depend on the implementation devices.
In practice, there exist scenarios that the source (respectively, measurement device) is well characterised, while the measurement device (respectively, source) not. Here, we review the semi-self-testing QRNGs, where parts of the devices are trusted.
Source-independent QRNG
In source-independent QRNG, the randomness source is assumed to be untrusted, while the measurement devices are trusted. The essential idea for this type of scheme is to use the measurement to monitor the source in real time. In this case, normally one needs to randomly switch among different (typically, complement) measurement settings, so that the source (assumed to be under control of an adversary) cannot predict the measurement ahead. Thus, a short seed is required for the measurement choices.
In the illustration of semi-self-testing QRNG, Fig. 3.7, the source-independent scheme is represented by a unique (corresponding to a state ) and multiple choices of the measurement settings . In Section 3.3.1, we present that randomness can be obtained by measuring in the basis. However, in a source-independent scenario, we cannot assume that the source emits the state . In fact, we cannot even assume the dimension of the state . This is the major challenge facing for this type of scheme.
In order to faithfully quantify the randomness in the basis measurement, first a squashing model is applied so that the to-be-measured state is equivalent to a qubit [146]. Note that this squashing model puts a strong restriction on measurement devices. Then, the measurement device should occasionally project the input state onto the basis states, and , and check whether the input is [115]. The technique used in the protocol shares strong similarity with the one used in QKD [147]. The basis measurement can be understood as the phase error estimation, from which we can estimate the amount of classical noise. Similar to privacy amplification, randomness extraction is performed to subtract the classical noise and output true random values.
The source-independent QRNG is advantageous when the source is complicated, such as in the aforementioned QRNG schemes based on measuring single photon sources [94, 93, 118], LED lights [123], and phase fluctuation of lasers [110]. In these cases, the sources are quantified by complicated or hypothetical physical models. Without a well-characterized source, randomness can still be generated. The disadvantage of this kind of QRNGs compared to fully self-testing QRNGs is that they need a good characterization of the measurement devices. For example, the upper and the lower bounds on the detector efficiencies need to be known to avoid potential attacks induced from detector efficiency mismatch. Also the intensity of light inputs into the measurement device needs to be carefully controlled to avoid attacks on the detectors.
Recently, a continuous-variable version of the source-independent QRNG is experimentally demonstrated [116] and achieves a randomness generation rate over 1 Gbps. Moreover, with state-of-the-art devices, it can potentially reach the speed in the order of tens of Gbps, which is similar to the trusted-device QRNGs. Hence, semi-self-testing QRNG is approaching practical regime.
Measurement-device-independent QRNGs
Alternatively, we can consider the scenario that the input source is well characterised while the measurement device is untrusted. In Fig. 3.7, different inputs (hence multiple ) are needed to calibrate the measurement device with a unique setting . Similar to the source-independent scenario, the randomness is originated by measuring the input state in the basis. The difference is that here the trusted source sends occasionally auxiliary quantum states , such as , to check whether the measurement is in the basis [148]. The analysis combines measurement tomography with randomness quantification of positive-operator valued measure, and does not assume to know the dimension of the measurement device, i.e., the auxiliary ancilla may have an arbitrary dimension.
The advantage of such QRNGs is that they remove all detector side channels, but the disadvantage is that they may be subject to imperfections in the modeling of the source. This kind of QRNG is complementary to the source-independent QRNG, and one should choose the proper QRNG protocol based on the experimental devices.
We now turn to two variations of measurement-device-independent QRNGs. First, the measurement tomography step may be replaced by a certain witness, which could simplify the scheme at the expense of a slightly worse performance. Second, similar to the source-independent case, a continuous-variable version of measurement-device-independent QRNG might significantly increase the bit rate. The challenge lies on continuous-variable entanglement witness and measurement tomography.
Other semi-self-testing QRNGs
Apart from the above two types of QRNGs, there are also some other QRNGs that achieve self-testing except under some mild assumptions. For example, the source and measurement devices can be assumed to occupy independent two-dimensional quantum subspaces [117]. In this scenario, the QRNG should use both different input states and different measurement settings. The randomness can be estimated by adopting a dimension witness [149]. A positive value of this dimension witness could certify randomness in this scenario, similar to the fact that a violation of the Bell inequality could certify randomness of self-testing QRNG in Section 3.3.1.
Outlook
The needs of “perfect” random numbers in quantum communication and fundamental physics experiments have stimulated the development of various QRNG schemes, from highly efficient systems based on trusted devices, to the more theoretically interesting self-testing protocols. On the practical side, the ultimate goal is to achieve fast random number generation at low cost, while maintaining high-level of randomness. With the recent development on waveguide fabrication technique [150], we expect that chip-size, high-performance QRNGs could be available in the near future. In order to guarantee the output randomness, the underlying physical models for these QRNGs need to be accurate and both the quantum noise and classical noise should be well quantified. Meanwhile, by developing a semi-self-testing protocol, a QRNG becomes more robust against classical noises and device imperfections. In the future, it is interesting to investigate the potential technologies required to make the self-testing QRNG practical. With the new development on single-photon detection, the readout part of the self-testing QRNG can be ready for practical application in the near future. The entanglement source, on the other hand, is still away from the practical regime (Gbps).
On the theoretical side, the study of self-testing QRNG has not only provided means of generating robust randomness, but also greatly enriched our understanding on the fundamental questions in physics. In fact, even in the most recent loophole-free Bell experiment [151, 152, 153, 154] where high-speed QRNG has played a crucial role, it is still arguable whether it is appropriate to use randomness generated based on quantum theory to test quantum physics itself. Other random resources have also been proposed for loophole-free Bell’s inequality tests, such as independent comic photons [79]. It is an open question whether we can go beyond QRNG and generate randomness from a more general theory.
3.3.2 Randomness quantification
Here, we breifly review the quantification of randomness.
Min-entropy source
Given the underlying probability distribution, the randomness of a random sequence on can be quantified by its min-entropy
[TABLE]
For example, for a uniform random sequence on , when , the min-entropy is given . As another example, we consider the same random sequence except that and . Although the two sequences looks very similar, the min-entropy for the latter example is much more smaller, .
Santha-Vazirani weak sources [142]
We assume that random bit numbers are produced in the time sequence . Then, for , the source is called -free if
[TABLE]
for all values of . Here represents all classical variables generated outside the future light-cone of the Santha-Vazirani weak sources.
Randomness extractor
A RNG typically consists of two components, an entropy source and a randomness extractor [150]. In a QRNG, the entropy source could be a physical device whose output is fundamentally unpredictable, while the randomness extractor could be an algorithm that generates nearly perfect random numbers from the output of the above preceding entropy source, which can be imperfectly random. The two components of QRNG are connected by quantifying the randomness with min-entropy. The min-entropy of the entropy source is first estimated and then fed into the randomness extractor as an input parameter.
The imperfect randomness of the entropy source can already be seen in the SPD based schemes, such as the photon number detection scheme. By denoting as the discrimination upper bound of a photon number resolving detector, at most raw random bits can be generated per detection event. However, as the photon numbers of a coherent state source follows a Poisson distribution, the raw random bits follow a non-uniform distribution; consequently, we cannot obtain bits of random numbers. To extract perfectly random numbers, we require a postprocessing procedure (i.e. randomness extractor).
In the coherent detection based QRNG, the quantum randomness is inevitably mixed with classical noises introduced by the detector and other system imperfections. Moreover, any measurement system has a finite bandwidth, implying unavoidable correlations between adjacent samples. Once quantified, these unwanted side-effects can be eliminated through an appropriate randomness extractor [92].
The composable extractor was first introduced in classical cryptography [155, 156], and was later extended to quantum cryptography [157, 158]. To generate information-theoretically provable random numbers, two typical extractor, the Trevisan’s extractor or the Toeplitz-hashing extractor, are generally employed in practice.
Trevisan’s extractor [159, 160] has been proven secure against quantum adversaries [161]. Moreover, it is a strong extractor (its seed can be reused) and its seed length is polylogarithmic function of the input. Tevisan’s extractor comprises two main parts, a one-bit extractor and a combinatorial design. The Toeplitz-hashing extractor was well developed in the privacy amplification procedure of the QKD system [162]. This kind of extractor is also a strong extractor [163]. By applying the fast Fourier transformation technique, the runtime of the Toeplitz-hashing extractor can be improved to .
On account of their strong extractor property, both of these extractors generate random numbers even when the random seed is longer than the output length of each run. Both extractors have been implemented [92] and the speed of both extractors have been increased in follow-up studies [164, 165], but remain far below the operating speed of the QRNG based on laser-phase fluctuation (68 Gbps [113]). Therefore, the speed of the extractor is the main limitation of a practical QRNG.
Part II Quantumness and randomness
Chapter 4 Coherence and randomness
This chapter introduces the basic quantification and witness methods for quantum coherence. We relate coherence measures with the quantum randomness measured on the computational basis. We refer to Ref. [21, 22] for references of this chapter.
4.1 Quantifying quantum randomness
4.1.1 Quantum randomness against quantum information
Let us consider a -dimensional Hilbert space and a reference basis . Suppose a projective measurement is performed on a given quantum state accessed by an experimentalist Alice. The measurement outcome has a probability distribution . In quantum information theory, a practical quantifier of the total randomness associated to the measurement is given by the Shannon entropy . However, the randomness of the measurement is intrinsically twofold: a classical uncertainty due to Alice’s ignorance about the system state; and a quantum one due to the coherence of the state in the reference basis. For a mixture of incoherent states the measurement randomness is given by the state mixedness, i.e., a classical source of uncertainty, quantified by the state von Neumann entropy: . On the other hand, for pure states, , the randomness is due to the genuinely quantum overlap between the state and the basis elements: . Here we present an operational characterization of the quantum randomness for arbitrary coherent mixed states. To be a good measure of quantum uncertainty, a quantity should satisfy the following properties:
Being nonnegative; 2. 2.
Vanishing if and only if the measurement uncertainty is only due to the state mixedness; 3. 3.
Representing the total uncertainty for pure states; 4. 4.
Being convex [49, 166, 167, 168, 14].
We consider the worse case scenario depicted in Fig.4.1, where Alice and Eve share a bipartite system in state . Alice makes a measurement and obtains outcomes following a probability distribution . The total randomness associated to the measurement is . The uncertainty of Eve about Alice’s measurement outcome is quantified by the conditional entropy .
After the Alice’s measurement, define the global state by and Alice’s resulted state becomes . Hence, in the best case scenario for Eve, her uncertainty is given by the von Neumann conditional entropy
[TABLE]
where the optimization runs over all the possible Eve’s states such that , and the conditional entropy is given by . It is not hard to see that the best case scenario for Eve is to hold a purification of Alice, . In fact, one can always extend Eve’s part to hold a purification of a mixed state , which will not increase her uncertainty about Alice’s measurement outcome.
When is a pure state, then and hence are both product states. It is easy to verify that Eve’s uncertainty corresponds to the total randomness of Alice’s measurement:
[TABLE]
When is not a pure state, after Alice’s measurement, the state is changed to , where . In fact, is a pure state. The conditional entropy of the post measurement state is given by . Using the equality , the conditional entropy is then . Since , , and we have
[TABLE]
It is immediate to observe that the Eve’s uncertainty is equal to the relative entropy of coherence
[TABLE]
thus satisfying all the requirements for a consistent measure of quantum randomness as well as being a measure of BCP coherence [14].
Note that, when considering a tripartite pure state and a projective measurement on system , it is shown [169] that the quantum randomness of the measurement outcome conditioned on system corresponds the distance between state and state after the measurement. Furthermore, by regarding system as a trivial system, the analysis in Ref. [169] also applies to our scenario.
4.1.2 Quantum randomness against classical information
In the last part, we showed that the quantum randomness of a local measurement can be quantified by the best case uncertainty of a correlated party Eve. Such uncertainty has been quantified by the quantum conditional entropy. We compare the result with an alternative measure of quantum randomness reported in Ref. [21]. The setting is for the sake of clarity depicted in Fig. 4.2. The difference is that Eve performs a measurement with probability distribution on her own system to predict Alice’s measurement outcome. The best case uncertainty is then given by the classical conditional entropy:
[TABLE]
where the minimization runs over all the possible Eve’s states and measurements. When Alice’s system is in a pure state , the probability distributions of and are uncorrelated as the the global system is in a tensor product state. Hence, we have for any Eve’s strategy. The quantity corresponds to the total randomness as expected. For an arbitrary mixed state , it turns out that the Eve’s uncertainty on Alice’s measurement is given by
[TABLE]
where the minimization is over all possible decompositions of . We briefly review the proof here. Given the spectral decomposition , then a purification of is . Here is an orthogonal basis of Eve’s system. Eve performs a projective measurement on her local system, then based on her measurement outcome , the Alice’s state is
[TABLE]
where . As the state of Alice is pure for each outcome of Eve, the averaged quantum randomness is . On the other hand, Eve can choose an arbitrary measurement basis, which determines a decomposition of , to maximize his prediction success probability. Therefore, the quantum randomness measure should be optimized over all the possible decompositions of . When Eve performs a general measurement (POVM), we can always enlarge the system of Eve and consider a projective measurement, then the proof follows accordingly q.e.d.
The quantum randomness measure obtained by convex roof extension of the pure state randomness is a measure of BCP coherence as well [21].
Verifying the properties of .
Now we show that the intrinsic randomness , defined in Eq. (4.6), satisfies the properties of coherence measures listed in Table. 3.1. That is, the requirements of the measures for quantum coherence and intrinsic randomness are equivalent.
Proof of (C1)
In the language of generating randomness, the requirement (C1) in Table. 3.1 can be interpreted as that classical states generate no randomness. This is because that an incoherent state , defined in Eq. (3.1), can be understood as a statistical mixture of classical states. We can easily verify that , since from Eq. (3.1) and by definition. The stronger requirement (C1’) implies that any non-classical states, which cannot be represented in the form of Eq. (3.1), could always be used to generate intrinsic randomness. Thus, this result answers why nonzero intrinsic randomness always indicates ‘quantumness’ as discussed above. To prove that satisfies (C1’), consider a state that has . From the definition of , there exists a decomposition such that for all . As any pure state with zero randomness is in the basis , we have , and , which belongs to the set , which is a contradiction. We can also show that the upper bound of its intrinsic randomness is given by . The maximally coherent state , defined in Eq. (3.2), has the largest intrinsic randomness.
Proof of (C2)
The requirement (C2) implies a monotonicity property of incoherent operations. In the corresponding randomness picture, incoherent operations can be understood as classical operations that map one zero intrinsic randomness (classical) state to another one. An interpretation of (C2a) is that such classical operations should not increase the randomness of a given state. While (C2b) requires that the randomness cannot increase on average when probabilistic strategies are considered. Let us quickly check why (C2b) is true for the pure state case. For a pure state , the randomness measure equals the relative entropy of coherence , whose monotonicity has been proved [14]. That is, we have
[TABLE]
where , and . This is because for a pure state , the intrinsic randomness equals the relative entropy coherence measure [14], whose monotonicity has already been proved.
For a general mixed state , suppose that the optimal decomposition that achieves the minimum in Eq. (4.6) is given by . Then, we have
[TABLE]
Now suppose that the incoherent operation defined in the main text is acted on . What we need to prove is that
[TABLE]
where and . As , we have
[TABLE]
where, we denote , , and we have . Then, we can finish the proof
[TABLE]
where the first inequality is based on the conclusion for pure states in Eq. (4.8) and the last inequality is due to the convexity of .
Proof of (C3)
The convexity property (C3) can be understood as a requirement on the randomness generation process. In other words, the randomness cannot increase on average by statistically mixing several states. With the convex roof definition of , given in Eq. (4.6), we can easily verify the convexity property (C3). The proof follows directly by considering a specific decomposition of in (C3). Note that, the property (C2a) can be derived when (C2b) and (C3) are fulfilled, thus we also prove (C2a) for .
In summary, we prove that the intrinsic randomness indeed measures the strength of coherence. A state with stronger coherence would therefore indicate larger randomness in measurement outcomes, and vice versa.
4.1.3 Qubit example
Here, we derive the intrinsic randomness formula of qubit state. We denote the Pauli matrices by . When measured in the basis, the intrinsic randomness for pure a qubit state is given by
[TABLE]
where . If we define and , then it is easy to check that
[TABLE]
For a general mixed state , we can follow the method for deriving the entanglement of formation [170]. In this case, we need to first define , and the coherent concurrence by
[TABLE]
Then it is easy to check that
[TABLE]
The randomness can be obtained according to Eq. (4.16) by first calculating the coherent concurrence. Follow the method of deriving the entanglement of formation, the value can be obtained by , where and are the eigenvalues of the matrix . In the Bloch sphere representation, the value of of a quantum state can be calculated by
[TABLE]
Compared to the norm coherence measure [14], which is defined by the sum of the off-diagonal elements
[TABLE]
one can easily check that equals the concurrence for the qubit case. This is because
[TABLE]
We conjecture that the coherence concurrence can be generalized to an arbitrary high dimensional space by following a similar method to that used for the entanglement concurrence [171, 172, 173].
4.1.4 Comparison between the two randomness measures
Let us compare the two quantities in a simple example about a qubit system. In the Bloch sphere representation, , where and are the Pauli matrices. Supposing that the measurement basis is the eigenbasis, which is denoted by , then we obtain
[TABLE]
where and is the binary entropy. Specifically, for the state , where , we have
[TABLE]
In Fig. 4.3, we plot the quantum randomness versus the mixing parameter . As expected, the quantum randomness measure obtained through the a fully quantum picture is smaller than , which is derived by the measurement-based method, while they both vanish when the state is incoherent, and are equal to the Shannon entropy in the pure state case.
4.2 Coherence or randomness distillation
When Alice performs a projective measurement on identical pure states , she will obtain i.i.d. random variables . For the state that is not maximally coherent, the randomness of the measurement outcomes is biased. Then, as shown in Fig. 4.4(a), Alice can perform a randomness extraction process to transform the biased random numbers to almost uniformly distributed random bits.
We show in Fig. 4.4(b) that the extraction can be equivalently performed before measurement. Now, the extraction becomes a quantum procedure, which we call quantum extraction. Considering the equivalence between intrinsic randomness and quantum coherence, quantum extraction can be regarded as a procedure of coherence distillation. This concept resembles the distillation procedure of another (more popular) quantumness measure—entanglement [15].
With quantum extraction, we can first distil the input state into the maximally coherent state . Then, we can directly obtain uniformly distributed random bits by measuring the maximally coherent state. For copies of , it is shown in Supplementary Materials that we can asymptotically obtain copies of , where and satisfy the following condition,
[TABLE]
Taking a pure qubit input state as an example, the distillation procedure is summarized as follows.
Prepare copies of qubit state , which can be binomially expanded on the computational basis. There are distinct coefficients, , corresponding to different subspaces that have the same number of or . 2. 2.
Perform a projection measurement to distinguish between those subspaces. For the th subspace, which has coefficient , the measurement probability is given by . The resulting quantum state of the th outcome corresponds to a maximally coherent state of dimension . 3. 3.
Suppose that , then we can directly project onto the subspace and convert to copies of as desired.
To see why equals the randomness of on average, we only need to take account of the operations that cause a loss of coherence. As shown in Supplementary Materials, the only two projection measurements lose negligible amount of coherence, thus we asymptotically have .
In Appendix A, we further extend the definition of distillable coherence to mixed quantum states. Compared to the definition of the regulated entanglement of formation [174], we also define coherence of formation and conjecture that it equals the regulated intrinsic randomness measure,
[TABLE]
4.2.1 Comparison with entanglement
As shown in Table 4.1, there exist strong similarities between the frameworks of coherence and entanglement (see also Ref. [175]), our study can be regarded as an extension of the convex roof measure from entanglement to coherence. Similar to the case of EOF, as a convex roof measure for coherence, we expect our proposed measure to play an important role in the research of coherence.
For further research directions, it is interesting to extend the framework of entanglement to coherence. An incomplete list of comparison between the two are shown in Table 4.1. For instance, it is interesting to see whether and are the unique lower and upper bounds of all coherence measures after regularization, and whether they can coincide. Another interesting and related question is that of quantifying the coherence for an unknown quantum state, similar to the task of using an entanglement witness for quantification. The coherence measure given in Eq. (4.6) ensures the true randomness when measuring a state in the basis. Such a technique can be utilized to construct a semi self-testing quantum random number generator. A straightforward way to do this is to first perform tomography on the to-be-measured state and then estimate the randomness of the basis measurement outcomes according to Eq. (4.6). As the coherence measure quantifies the output randomness in a measurement, our result can also be applied in other randomness generation scenarios [187, 103, 110, 64].
The definition of coherence and intrinsic randomness is based on a specific computational basis. In this perspective, the quantum feature can be quantified by the superposition strength on the measurement basis. Alternatively, we can define similar quantumness as the ability of measurements. For an arbitrary pure quantum state, if we can choose the measurement basis that is complementary to the state, quantum feature similar to coherence can also be maximally revealed. The definitions of coherence based on the property of quantum state with a given measurement basis and the property of measurement is similar to the relationship between the pictures of Schrodinger and Heisenberg. The current definition of coherence thus follows from the routine of the Schrodinger¡¯s picture.
We also investigate intrinsic randomness without specifying a measurement basis. In this case, we consider the scenario that an optimal measurement basis is chosen to maximize the output randomness. Here, we do not assume that the choice of measurement basis is secret from Eve¡¯s point of view. Thus, we still have to consider the minimization of intrinsic randomness on the chosen measurement basis. In this case, this basis-independent intrinsic randomness can be defined as . In the qubit example, we show that the basis-independent intrinsic randomness is related to the purity of a quantum state. We thus demonstrate that intrinsic randomness can be used to quantify other quantum features.
4.3 Basis independent randomness and coherence
Here, we quantify the intrinsic randomness under a different scenario. When the measurement basis has not been specified, we can still consider the intrinsic randomness. In this case, Alice can choose an optimal measurement basis to maximize the output randomness. Here, we do not assume that the choice of measurement basis is secret from Eve¡¯s point of view. Thus, we still have to consider the minimization of intrinsic randomness on the chosen measurement basis. In this case, this basis-independent intrinsic randomness can be defined as
[TABLE]
Here, the maximization is over all possible projective measurement basis and the randomness measure could be either or . We do not consider general POVM measurement for Alice as for it generally requires ancillary quantum states which might introduce coherence and hence randomness. The new definition still represents the existence of quantum effects. That is, nonzero will always indicate the existence of quantumness, although does not quantify the coherence of quantum states in this instance, since the coherence is defined on a specific basis.
As an example, we consider the basis independent randomness with randomness measure for qubit state . In this example, we also give a direct expression of for a qubit state . As the randomness measure is a function of according to Eq. (4.16), we can thus similarly define . In the following, we will focus on calculating and the basis independent randomness is a direct function of it.
An arbitrary measurement basis can be considered as a unitary transformation of the measurement basis on the original basis. Equivalently, we can suppose that the measurement basis is unchanged, while a unitary transformation acts upon the to-be-measured quantum state. Suppose that the original state has a spectral decomposition given by
[TABLE]
Thus, a unitary transformation on the state would only transform the eigenstates and to another basis and leave the eigenvalues and unchanged. In this case, we can still work on the basis, and obtain
[TABLE]
Now, the maximization over all possible measurement basis is equivalently achieved over all possible eigenstates and with given eigenvalues and .
We assume that and , where the normalized coefficients are complex numbers yielding and and are eigenstates of . Then a general density matrix can be represented by
[TABLE]
To get , we need to calculate , which can be written as
[TABLE]
By denoting
[TABLE]
The matrix can be denoted by
[TABLE]
And and will be the two roots of the equation
[TABLE]
Now we can calculate the square of by
[TABLE]
Here we notice that , hence
[TABLE]
where , thus
[TABLE]
Notice that, the equal sign is taken for a measurement basis complementary to the eigenbasis of . For , we have that and , where . Therefore, we have
[TABLE]
Thus this value can be physically related to the degree of how mixed the state is.
Chapter 5 Quantum Bernoulli Factory
Bernoulli factory [23, 24] is a simple yet interesting task in classical randomness processing. This chapter discusses quantum Bernoulli factory [188] and show its fundamental difference from classical Bernoulli factory. The key difference lie on the coherent superposition of states. To demonstrate this difference, we also present a theoretical protocol and an experiment verification with superconducting qubits [189].
5.1 Theoretical protocol
Coherent superposition of different states, coherence, is a peculiar feature of quantum mechanics that distinguishes itself from Newtonian theory. In different scenarios, coherence exhibits as various quantum resources, such as entanglement [17], discord [190], and single-party coherence [14]. In many quantum information tasks, the common resource leading to quantum advantage is multipartite quantum correlations. For instance, entanglement plays a crucial role in quantum key distribution [6, 8], teleportation [191], and computation [9, 10]. While the essence of multipartite correlation originates from coherent superposition, it is natural to expect the essence of quantum advantage to also originate from coherence. This raises a fundamental question: Can quantum advantage be obtained without using multipartite correlations?
In randomness generation, it has been shown that coherence is the essential resource for generating true random numbers [21]. It is thus natural to expect coherence to be a resource for displaying quantum advantages in certain randomness related tasks. Remarkably, in a recent work by Dale et al., a rather simple task of randomness processing is proposed to show that coherence yields a provable quantum advantage over classical stochastic physics [188]. In this randomness processing task, a classical coin, see Fig. 5.1(a), corresponds to a classical machine that produces independent and identically distributed random variables where each one has the binary values, head (0) and tail (1). A coin is called -coin if the probability of producing a head is , where . Given an unknown -coin, an interesting question is whether one can construct an -coin, where is a function of and . Such construction processing is called a Bernoulli factory [23, 24].
Let us take for example, which was solved by von Neumann with a rather simple but heuristic strategy [192]. Flip the -coin () twice. If the outcomes are the same start over; otherwise, output the second coin value as the -coin output. Therefore, the function of can be constructed from an arbitrary unknown -coin. As a generalization, a natural question involves which kind of function can be constructed from an unknown -coin. This classical Bernoulli factory problem was solved by Keane and O’Brien [193]. Generally speaking, a necessary condition for being constructible is that or when . The function satisfies this condition, while there are many other examples that violate it. For instance, surprisingly, the simple “probability amplification” function 111A complete definition is: when and when . does not satisfy the constructible condition, where we have . Therefore, there is no classical method to construct an -coin.
In the language of quantum mechanics, a -coin corresponds to a machine that outputs identically mixed qubit states,
[TABLE]
where , and is the computational basis denoting head and tail, respectively. As is generally unknown, we can regard as a classical way of encoding an unknown parameter . A measurement in the basis would output a head or a tail with a probability according to and , respectively. On the other hand, a quantum way of encoding , see Fig. 5.1(b), can be a coherent superposition of and , i.e., with
[TABLE]
Following the nomenclature in Ref. [188], we call such a quantum coin a quoin. It is straightforward to see that a -coin can always be constructed from a -quoin by measuring it in the (computational) basis. Thus, classically constructible (via coins) functions are also quantum mechanically constructible (via quoins), while a really interesting question is whether the set of quantum constructible functions (via quantum a Bernoulli factory) is strictly larger than the classical set.
In Ref. [188], Dale et al. have theoretically proved the necessary and sufficient conditions for being quantum constructible. Specifically, they show that there are functions, for instance , which are impossible to construct classically, but can be efficiently realized in the presence of -quoins. Therefore, they provide a positive answer to this problem where quantum resources are strictly superior to classical ones. The protocol for generating the function relies on Bell state measurement on two quoins, which essentially establish entanglement between the two quoins.
Now, we are interested in seeing whether such a quantum advantage persists even when multipartite correlations, such as entanglement, are absent. Thus, we only allow single qubit operations. Without two-qubit operations, it turns out that constructing the function will require many copies of qubits defined in Eq. (5.2) and the convergence could be poor. In this chapter, we propose another function that is impossible with classical means but feasible with only limited number of single-qubit operations.
The protocol for quantum Bernoulli factory
Here, we analyze a classically impossible function defined by
[TABLE]
For , we have which means that this function is classically unachievable. On the other hand, it is straightforward to check that the -function satisfies the requirements for beign quantum constructible [188]. Given a -quoin, we explicitly present an efficient protocol for generating an -coin as follows.
- Step 1
Generate a -coin:
When measuring a -quoin, as given by Eq. (5.2), in the basis, the probabilities of obtaining [math] and are and , respectively. 2. Step 2
Generate a -coin, where :
When measuring a -quoin in the basis, the probabilities of obtaining and are and , respectively. 3. Step 3
Construct an -coin from a -coin, where : toss the -coin twice, output head if the two tosses are different and tail otherwise.
The probability of output two different tossing result is
[TABLE]
Similarly, one can construct an -coin from a -coin, where . 4. Step 4
Construct an -coin from an -coin, where : toss the -coin twice, if the first toss is tail then output tail; otherwise if the second toss is tail, output head; otherwise, repeat this step.
Denote the probability of outputting head and tail by and , respectively, then,
[TABLE]
Solving this equation, we have
[TABLE]
Similarly, one can construct a -coin from an -coin, where . 5. Step 5
Construct an -coin: first toss the -coin and then the -coin. If the first toss is head and the second toss is tail, then output head; if the first toss is tail and the second toss is head, then output tail; otherwise repeat this step.
Denote the probability of outputting head and tail by and , respectively, then,
[TABLE]
Solving this equation, we have
[TABLE]
In our protocol, generating the -coin, where
[TABLE]
is an essential nonclassical step. In fact, the only additionally required coin for constructing all quantum constructible -coins is the -coin,
[TABLE]
which can be obtained by measuring the quoin in the basis. In our case, we set . Here, one can see that entanglement is not necessary to quantum Bernoulli factory.
In the protocol, the first two steps involve quantum devices, where quoins are measured in the and bases, respectively, to obtain the - and -coins. The following steps (step 3-5) are classical processing of the - and -coins. The rigourous derivation of the classical steps can be found in the Appendix. Comparing to the function, our protocol converges much faster, which results in a higher fidelity for the realization.
In practice, owing to experimental imperfections, we cannot realize perfect -quoins and perform ideal measurements to get perfect - and -coins. Thus, in reality, we cannot realize exact -coins, especially, we cannot get when . Following previous studies [194, 195, 196], we employ a truncated function
[TABLE]
with describing the imperfections. When is nonzero, the truncated function of falls in the classical Bernoulli factory and hence can be constructed via -coins. However, the number of classical coins required to construct scales poorly with , see Appendix for more details. In the experiment, we need to implement high fidelity state preparation and measurement to reduce as small as possible in order to faithfully demonstrate the quantum advantage.
In the following, we focus on the preparation and measurement of the -quoin, and how to construct an coin via necessary classical processing. Here, we emphasize that the quantum circuit to realize the operations should be independent of . In demonstration, we fix the measurement setting and prepare -quoins for various values.
5.2 Experimental realization
We choose a superconducting qubit system to prepare -quoins. Superconducting quantum systems have made tremendous progress in the last decade, including realizing long coherence times, showing great stability with fast and precise qubit manipulations, and demonstrating high fidelity quantum non-demolition (QND) qubit measurement. Thus, it makes a perfect candidate for our test.
5.2.1 Experiment setup
In our experiment, we employ the so-called ‘circuit quantum electrodynamics architecture’ [197]. A superconducting transmon qubit (our quoin) is located in a waveguide trench and dispersively couples to two 3D cavities [198, 199, 200] as shown in Fig. 5.2. The transmon qubit has a transition frequency of GHz, an anharmonicity MHz, an energy relaxation time s, and a Ramsey time s. The larger cavity has a resonant frequency of GHz and a decay rate of MHz, which provides a fast way of reading out the qubit state through their strong dispersive interaction with a dispersive shift MHz. As we focus on exhibiting quantum advantage solely with a single quantum system, the smaller cavity with a higher resonant frequency is not used and remains in a vacuum state. This higher frequency cavity can potentially be used as another -quoin in future experiments [2]. In this case, joint measurement can be performed on two -quoins, which may save the resource. For now, we focus on single-qubit operations.
The output of the readout cavity is connected to a Josephson parametric amplifier (JPA) [201, 202], operating in a double-pumped mode [203, 204] as the first stage of amplification between the readout cavity, at a base temperature of 10 mK, and the high electron mobility transistor, at 4 K. To minimize pump leakage into the readout cavity and achieve a longer dephasing time, we operate the JPA in a pulsed mode. The readout pulse width has been optimized to 180 ns with a few photons in order to have a high signal-to-noise ratio. This JPA allows a high-fidelity single-shot readout of the qubit state. The overall readout fidelity of the qubit measured for the ground state when initially prepared at by a post-selection is 0.996, demonstrating the high QND nature of the readout, while the fidelity for the excited state is slightly lower, 0.943 (see Appendix). The loss of both fidelities is predominantly limited due to the process during both the waiting time of the initialization measurement (300 ns) and the qubit readout time (180 ns).
Due to stray infrared photons and other background noise, our qubit has an excited state population of about in the steady state. The high QND qubit measurement allows us to eliminate these imperfections by performing an initialization measurement to purify the qubit by only selecting the ground state for the following experiments [205]. The measurement pulse sequences for preparing quoins can be found in the Appendix. It is worth mentioning that our superconducting system always yields a detection result once the measurement is performed, which is very challenging for other implementations, such as lossy photonic systems.
We apply an on-resonant microwave pulse to rotate the qubit to an arbitrary angle along the -axis, , where is the Pauli matrix, for a preparation of any -quoins. We choose a gaussian envelope pulse truncated to ns for the rotation operations. We also use the so-called “derivative removal by adiabatic gate” [206] technique to minimize qubit leakage to higher levels outside the computational space. A randomized benchmark calibration [207, 208, 209, 210] shows that the gate fidelity itself is about 0.998, mainly limited by the qubit decoherence. The final measurement for the quoins is along either the -axis or the -axis. The measurement along the -axis is realized by applying an extra rotation (Hadamard transformation) followed by a -basis measurement.
The readout property of the qubit is first characterized as shown in Fig. 5.3. The smaller cavity has a resonant frequency of GHz and remains in vacuum all the time. Because we always purify our qubit initial state to the ground state and use pulses with DRAG [206] to minimize the leakage to levels higher than the first excited state , we do not distinguish the levels higher than in the readout. We thus adjust the phase between the JPA readout signal and the pump such that and states can be distinguished with optimal contrast. Figure 5.3a shows the histogram of the qubit readout. The histogram is clearly bimodal and well-separated. A threshold is chosen to digitize the readout signal.
Due to stray infrared photons or other background noises, our qubit has an excited state population of about in the steady state (solid histogram in Fig. 5.3a). In order to eliminate these excited states for the quoin experiments, a high quantum non-demolition qubit measurement M1 is performed to allow a qubit purification by only selecting state (see Fig. 5.4) [205]. We wait 300 ns for the readout photons to leak out before the preparation of the qubit to arbitrary superposition states through an on-resonant microwave pulse with various amplitudes. After a purification to state, the following measurement gives a probability of 0.996 of state (dashed histogram in Fig. 5.3a), demonstrating the high quantum non-demolition nature of the qubit measurement. Figure 5.3b shows the basic qubit readout properties. The readout fidelity of the qubit measured at state while initially prepared at state by a measurement is 0.943. The loss of both fidelities is predominantly limited due to the process during both the waiting time of the initialization measurement (300 ns) and the qubit readout time (180 ns).
5.2.2 Results
The experimental pulse sequences for the quoins with state preparations are shown in Fig. 5.4. The measurement is always performed in the basis. The -basis measurement is realized by performing an extra rotation before the Z-basis measurement. The phase of this extra pre-rotation is chosen to minimize the effect from qubit decoherence during the measurement. In our experiment, the -coins as defined in Eq. (5.9) are implemented, which are also classically impossible 222The function is defined in Eq. (5.9). It is straightforward to check to see that , indicating that it is classically impossible when regarded as a function of . The -coin corresponds to the qubits of . For different , our experiment results are listed in Table 5.1.
We also plot the experiment result of the -coins in Fig. 5.5(a) and the result of the -coins by following the protocol in Fig. 5.5(b). The experimentally realized values of and are sampled from the observed coins, which match well with the theoretical predictions. By implementing state preparation, operation and measurement with high fidelities, we are able to achieve and , which can be well modeled by the truncated function defined in Eq. (5.12) with and , respectively.
A randomized benchmarking experiment [207, 208, 209, 210] is performed to determine the fidelity of the gate around the axis, , which is the most critical gate for the quoin measurement. The randomized gates used in this experiment are chosen from the single-qubit Clifford group. This group contains 24 rotation gates which are composed from rotations around the and axes using the generators: . The reference curve is measured after applying sequences of random Clifford gates, while the curve is realized after applying sequences that interleave with random Clifford gates. Each sequence is followed by a recovery Clifford gate in the end right before the final measurement. The number of random sequences of length in our experiment is chosen to be . Both curves are fitted to with different sequence decay . The reference decay indicates the average error of the single-qubit gates, while the ratio of the interleaved and reference decay gives the specific gate fidelity. The experiment results are displayed in Fig. 5.6. The data point is the average of the sequence fidelities of the sample sequences, and the error bar shows the standard deviation of the sample. Each random sequence is measured over 10,000 times to get the sequence fidelity whose error could be neglected. As a result, the average single-qubit gate error , and the gate error . The dashed lines indicate a gate fidelity of 0.998 and 0.997 respectively. Therefore, the gate fidelity in our experiment is greater than 0.998, and the uncertainty in the gate fidelity is typically 7e-5, determined by bootstrapping.
5.3 Simulation of Experiment data
5.3.1 The truncated function
Here, we show how to construct the truncated function
[TABLE]
from -coin by classical means. The protocol works as follows.
- (i)
Toss the -coin twice, if the outputs are different, then output head otherwise output tail. This achieves -coin with two -coins. 2. (ii)
Apply Theorem 1 in Ref. [194], which gives , and perform the composition . Let , the desired function is obtained.
Now, we calculate the number of -coins needed in step (ii). By Theorem 1 in Ref. [194], the probability that more than -coins are needed is bounded by
[TABLE]
With large and small , we can approximate Eq. (5.13) by
[TABLE]
This bound is nontrivial only if the right hand side is less and equal to 1, that is,
[TABLE]
Thus combining (i) and (ii), the number of -coins needed to simulate the function is more than . Note that, Eq. (5.13) provides only an upper bound to the probability distribution, there may exists more efficient protocols that requires less number usages of -coins.
5.3.2 Simulation of the -coin
Here, we show how to simulate the truncated function of coin,
[TABLE]
with . To do so, we first construct the truncated coin defined in Eq. (5.12). Then we can simulate with the -coin by applying the following protocol,
Apply a square root function of , which gives a -coin. 2. 2.
Toss the 1/2-coin and the -coin, output tail if both tosses are tail.
Then, it is straightforward to check that the following coin is prepared
[TABLE]
which coincides with the -coin if we let
[TABLE]
In this case, we have . To simulate the -coin, we can follow the protocol in Sec. 5.3.1, which costs more than number of -coins on average for each -coin. The square root function of can be constructed by following the method from Ref. [195] or the one presented in Ref. [188]. On average, more than coins are needed for constructing the square root function. Therefore, more than number of -coins are necessary for the construction of the truncated function .
The classical Bernoulli factory cannot produce exact - and -coins with finite number of usages of -coins. In practice, the implemented function may deviate from the desired one due to device imperfections. In this case, the practically realized coins may be constructible with classical means, though the number of classical coins required may increase drastically with decreasing deviation. Focusing on the truncated function defined in Eq. (5.12), we present a classical protocol for simulating the experiment data with . It is shown that, on average, more than classical -coins are required for constructing the truncated function, which is much larger than the average number of quoins (about ) used in our protocol 333Strictly speaking, the quantum advantage demonstrated here is a weaker version of the one mentioned in the beginning of the Letter, where the function is classically impossible to construct.. For the -coin, as the deviation is smaller, the classical simulation is even harder. In the Appendix, we show that more than classical coins are needed for the truncated function, while our quantum protocol only requires one quoin.
From the experimental perspective, the small deviation from unity in the ideal case is dominated by qubit decoherence. With better qubit coherence times of s achieved recently [211], we expect the deviation of from to be an order of magnitude lower. In future, a more accurate quantum Bernoulli factory can be realized and the classical simulation will eventually become intractable.
It is noteworthy that entanglement can be exploited to save resource in the quantum Bernoulli factory, which provides an extra advantage for randomness processing [188]. Extending our implementation to multi-qubit systems can verify this extra quantum advantage. When considering practical imperfections, multiple qubit operation generally has a lower fidelity of measurement. Balancing between the saving of resource and decoherence due to multiple-qubit interactions, it is interesting to see whether multipartite correlation can have extra advantage in practice. As we are focusing on proving the advantage only with coherence, we leave such extension and discussion to future works.
Part III Quantumness and selftesting
Chapter 6 Measurement-device-independent entanglement witness
A conventional way to detect entanglement is via entanglement witness (EW). Practical imperfections can affect the correctness of the witness conclusion. This chapter introduces the measurement device independent entanglement witness (MDIEW) method [29]. We show a time-shift attack to conventional EW and how the MDIEW scheme be immune to such attacks. We also show an experimental realization of the MDIEW scheme [30].
6.1 Time-shift attack
In this section, we show the time-shift attack to conventional entanglement witness. By controlling the arriving time of the photon, we show that the measurement efficiencies mismatches can be exploited to attack conventional EW.
6.1.1 EW and device imperfections
Mathematically, for a given entangled quantum state , an Hermitian operator is called a witness, if (output of ‘Yes’) and (output of ‘No’) for any separable state . Focusing on the bipartite scenario, a general illustration of the conventional EW is shown in Fig. 6.1(a), where two parties, Alice and Bob, each receives one component of a bipartite state from an untrusted third party Eve. They want to verify whether is entangled or not, by performing local operations and measurements on and . The correctness of such witness relies on implementation details of . An unfaithful implementation of , say, due to device imperfections, would render the witness results unreliable. For example, the measurement devices used by Alice and Bob might possibly be manufactured by another untrusted party, who could collaborate with Eve and deliberately fabricate devices to make the real implementation be deviated from , such that is not a witness any more,
[TABLE]
That is, with the deviated witness , a separable state could be identified as an entangled one, which is more likely to happen when is near zero.
There is a strong similarity between EW and quantum key distribution (QKD) where an entanglement-breaking channel would cause insecurity [212]. Roughly speaking, it is crucial for Alice and Bob to prove that entanglement can be preserved in a secure QKD channel. From this point of view, there exists correlation between the security of QKD and the success of EW. For the varieties of attacks in QKD, such as time-shift attack [213] and fake-state attack [214], one may also find similar detection loopholes in the conventional EW process. Originated from this analogy, we construct a time-shift attack that manipulates the efficiency mismatch between detectors used in an EW process. Under this attack, any state could be witnessed to be entangled, even if the input state is separable. By this example, we demonstrate that there do exist loopholes in the conventional EW procedure.
6.1.2 Time-shift attack
Originated from quantum cryptography [213], takes advantage of efficiency mismatch of the measurement devices. As shown in Fig. 6.2(a), typically two detectors are used on each side of Alice and Bob. By controlling the single-photon-counting modules (SPCMs) and coincidence gate, Eve is able to enlarge the efficiency mismatch and hence manipulate the EW result.
To implement this attack, we choose a conventional witness,
[TABLE]
for bipartite states in the form of
[TABLE]
where H (V) denotes the horizontal (vertical) polarization of the single photons and is a Bell state. By decomposing into a linear combination of product Pauli matrices,
[TABLE]
the EW can be realized by local measurements, we can decompose to
[TABLE]
That is, to identify the entanglement, Alice and Bob just have to each analyze the qubit state in three bases separately. When the bipartite state is projected to the positive (negative) eigenstates of , , and , it will contribute positively (negatively) to the witness result . For example, when measuring , Alice and Bob will both project the input state to the eigenstates of , or , with corresponded eigenvalues of or , respectively, and obtain probabilities . Then the value of is defined as . From Eve’s point of view, she wants to convince Alice and Bob that the bipartite state is entangled, that is, . Thus, her objective is to suppress the positive contributions of , such as and for measurement, by manipulating the coincidence rate between SPCMs, equivalently enlarging the detector efficiency mismatch. In this case, from Alice and Bob’s point of view, the real implemented witness is deviated from the desired one , and satisfies Eq. (6.1).
To realize the attack, we exploit the time mismatch of the two single-photon-counting modules (SPCMs) such that one detector is more efficient than the other. In this case, the real implementation () is deviated from the original design witness . In the attack Eve can suppress the positive contributes of the witness result to let the witness result be negative by adjusting the time mismatch. For example, when measuring , Alice and Bob will project the input state to the eigenstates of , that is and , corresponding to positive and negative eigenvalue respectively, and obtain probabilities . Then the value of is defined as
[TABLE]
The probabilities is measured from coincidence counts of detectors, that is
[TABLE]
If the positive coincidence counts are all suppressed, that is , then the outcome of is
[TABLE]
Similarly, the all the other local measurements and become by suppressing positive coincidence counts, which gives a witness result of
[TABLE]
for any state .
In our experiment demonstration, we only suppress the positive coincidence counts to instead of neglecting all of them to make a wrong witness result of a separable state to be entangled.
In our experiment, as shown in Fig. 6.2(a), by encoding qubits in the polarization of photons, the bipartite state is generated via spontaneous parametric down conversion (SPDC). Two adjustable POLs are used to disentangle the initial state and project it to and with equal probabilities, corresponding to the separable state with in Eq. (6.2). After a HWP, the to-be-witnessed two-qubit system is prepared in the state of . Then Alice and Bob each performs polarization analysis on a qubit from the bipartite state using waveplates, PBSs and SPCMs, and guides the electronic signals from the SPCMs into a coincidence gate.
As shown in Fig. 6.2b, in the time-shift attack, Eve controls the delay lines in the detection systems and the time window of the coincidence gate, and hence manipulates the time-dependent coincidence counting rates between detectors and , and . Hence, she can suppress the positive contributions of measurements and . In our demonstration, by setting proper parameters, we let the positive contributions drop to 10.9(1) of their original values. Since this attack would not affect the negative contributions of , the experimental outcomes for and become negative as expected. Finally, Alice and Bob obtain a witness of be , although the input state is, in fact, separable. By changing the to a larger value, one can even obtain a fake result as that from a maximal entangled state. Thus, a separable bipartite state could be wrongly witnessed to be entangled when Eve is able to manipulate the detection system. It is not hard to see that for any state , Eve can perform a similar attack and trick Alice and Bob that it is entangled.
6.2 The MDIEW scheme
Recently, Lo et al. [185] proposed an measurement-device-independent (MDI) QKD method, which is immune to all hacking strategies on detection. Due to the similarity between QKD and EW, one would also expect that there exist EW schemes without detection loopholes. Meanwhile, a nonlocal game is proposed to distinguish any entangled state from all separable states [3]. Inspired by this game, Branciard et al. [29] proposed an MDIEW method, where they proved that there always exists an MDIEW for any entangled state with untrusted measurement apparatuses.
As shown in Fig. 6.1(b), Alice and Bob want to identify whether a given bipartite state, prepared by an untrusted party Eve, is entangled or not without trusting measurement devices. To do so, Alice (Bob) prepares an ancillary state () and sends it along with the to-be-witnessed bipartite state to a willing participant, who can be assumed to be Eve again in the worst case scenario. Eve performs two Bell-state measurements (BSMs) on the two ancillary states and the bipartite state. Then, she announces to Alice and Bob the BSMs results, based on which they will witness the entanglement of the bipartite state. In MDIEW, it is guaranteed that a separable state will never be wrongly identified as an entangled one, even if Eve maliciously makes wrong measurements and/or announces unfaithful information.
Measurement-device-independent entanglement witness (MDIEW) provides means to witness entanglement of a quantum state without trusting measurement devices [29]. The idea of MDIEW is inspired from the MDI quantum key distribution (MDIQKD) [185]. As proved in Ref. [29], there always exists an MDIEW for any quantum state , as one can always construct MDIEW based on the conventional witness which exists for any quantum state (we refer to [44] for details of conventional entanglement witness). In the following, we will design a MDIEW scheme and apply it to a type of bipartite quantum states in the form of
[TABLE]
with and . The state is entangled if , which can be witnessed by a conventional EW,
[TABLE]
and its result, .
Practically, the conventional EW can be realized with only local measurements by decomposing into a linear combination of product Hermitian observables. In the bipartite scenario of Alice and Bob, they only need to perform local measurements to decide the entanglement of quantum states. In contrast, MDIEW requires Alice (Bob) to prepare another ancillary state () and perform Bell-state measurements (BSMs) on the to be witnessed state and the ancillary state. Based on the choice of the ancillary states, labeled by and , and the measurement outcomes, labeled by and , MDIEW is defined as
[TABLE]
That is, is entangled while and for any separable state , we have . Here the probabilities are obtained from performing two BSMs on the to be witnessed state and the ancillary states and . That is,
[TABLE]
where and represent BSMs performed by Alice and Bob with outcome and , respectively. In Eq. (6.10), the coefficient is determined by the choice of ancillary states, measurement outcomes and the conventional witness . In the experiment, as only two and out of four BSM outcomes are recorded, we consider the outcomes of and to be and , which refer to and , respectively. There are four kind of , depending on different values of and . In the following, we will design for our MDIEW.
The case of and is considered in Ref. [29]. Decompose a conventional EW as a linear combination of product Hermitian operators, },
[TABLE]
where the superscript means matrix transpose. In the corresponding MDIEW, Alice and Bob prepare their ancillary states into and , respectively. According to Eq. (6.11), is obtained by projecting the joint states and to the maximally entangled states and , respectively. Then it is easy to show that the relation between MDIEW and the conventional EW is
[TABLE]
which equals using Eq. (6.8) and (6.9).
MDIEW with two measurement outcomes
In our work, we also consider other BSM outcomes. For example, if Alice and Bob get outcomes and , then is calculated similarly as Eq. (6.12) by decomposing ,
[TABLE]
where and . By redefining the basis that is decomposed, , the ancillary states prepared by Alice and Bob are still and . In this case, is obtained by projecting the joint states and to the maximally entangled states and , respectively.
With a similar manner, one can also decompose for the cases of and , and . All the four cases of and are summarized in Table 6.1.
Next, we need to calculate the coefficients and the corresponding probabilities for given ancillary quantum states and . Define and to be the Pauli matrices. Then let and both be the eigenstates of with eigenvalues of 1. That is, , for . By decomposing into and , we find that the coefficients and the probabilities of the two cases and are the same, and those of and are the same.
In the cases of and , the coefficients are given by
[TABLE]
with corresponding probabilities of
[TABLE]
There are ten nonzero terms in the coefficient matrix, so ten different ancillary inputs () are required. In practice, it is possible to reduce the number of inputs by introducing two other states and . In this case, we have another decomposition of with coefficients of
[TABLE]
In this setting, only six ancillary sets are required (comparing to ten in the original construction). As a result, we derive the coefficients and probabilities in Eq. (6.10) for outcomes and , as shown in Table 6.2.
Similarly, for the other two cases of outcomes and , the coefficients are
[TABLE]
with corresponding probabilities of
[TABLE]
when using the ancillary states , for . Similarly, we can define so that another decomposition of is derived,
[TABLE]
Again, in this setting, only six measurements are required. The coefficients and probabilities of outcomes and are shown in Table 6.3.
Although each of the four cases above defines an MDIEW, we can combine four of them as one to enhance the successful probability of MDIEW,
[TABLE]
By doing this, we improve the efficiency of experiments by four times comparing to the original proposal [29].
To witness entanglement for the bipartite states defined in Eq. (6.8) with MDIEW defined in Eq. (6.21), in total eight different ancillary state pairs should be prepared, and the results are summarized in Table 6.4.
6.3 Experimental realization
6.3.1 Experiment setup
Our experimental setup for MDIEW is shown in Fig. 6.3, where a six-photon interferometry is utilized. The to-be-witnessed bipartite state , defined in Eq. (6.2), is encoded in the photon pair 3 and 4. Photon pairs 1, 2 and 5, 6 are used to prepare the ancillary input states and , respectively. In our work, various bipartite states , from maximally entangled to separable, are prepared and tested with the MDIEW. The bipartite state is firstly prepared in the Bell state via a Bell-state synthesizer [215]. As the coherence length of photons is limited by the interference filtering, two 2-mm BBO crystals in each arm result in a relative phase delay between horizontal and vertical polarization components and cause polarization decoherence. Different can be selected by the “state selector” [216]. They satisfy the relation of
[TABLE]
where is the angle of the fast axis of the selector HWP.
In the experiment, eight ancillary state pairs are prepared. The states are encoded by tunable waveplates (one HWP sandwiched by two QWPs), which can realize arbitrary single-qubit unitary transformation. Different from directly polarization measurement in the conventional EW, the analysis of MDIEW is completed by BSMs on and , with two, , out of four outcomes been collected.
As defined in Eq. (6.21), we obtain the experimental results as shown in Fig. 6.4. In comparison, we also plot for all values of . Recall that in the aforementioned time-shift attack demonstration, the conclusion from the conventional witness is entangled for , whereas here we show that our MDIEW result is 0.107 0.019 and does not conclude an entangled state. One can see that our MDIEW is immune to this attack.
Furthermore, we perform tomography on the to-be-witnessed bipartite states . The results of the density matrices are shown in Fig. 6.5. The corresponding are set by the angle of the selector HWP given in Eq. (6.22), which is consistent with our fitting values as shown in Supplemental Materials. We evaluate the MDIEW results, Eq. (6.21), from the results of the state tomography as shown in Fig. 6.4. Meanwhile, to quantify the entanglement of the bipartite states , we adopt the measure of tangle [170], which can be directly calculated from tomography results. When the tangle goes to zero, the bipartite state becomes a separable state. As shown in the insert of Fig. 6.4, no entanglement exists when grows beyond . Such phenomenon is related to the “sudden death of entanglement” [217].
6.3.2 Experiment result
Tomography
In the experiment, we prepare the to-be-witnessed bipartite states in the form of Eq. (6.8) with different values . To verify whether the prepared states is close to the desired ones , their density matrices are reconstructed via quantum tomography with controlled by the angle of the selector HWP, as shown in Eq. (4) in Main Text. Then we fit the value by the measured density matrixes to the desired states . As shown in Eq. (6.8), contains only real numbers, we can infer from the real part of , and the imaginary parts are supposed to be near zero.
The parameter can be derived from the real-part of matrix . For each matrix elements of , , and ( is identical to ), one can estimate , as shown in Table 6.5. Accordingly, the average value of and its error bar are evaluated. As one can see that the experimental results agree the theoretical results well.
Tangle
To quantify the entanglement of quantum states, we adopt the measure of tangle [170]. For a 2-qubit state, , one can evaluate its tangle by the following steps.
Define a non-Hermitian matrix
[TABLE]
where is the transpose of , and the “spin flip matrix ” is defined as
[TABLE] 2. 2.
Calculate the eigenvalues of , and arrange them in decreasing order, ; 3. 3.
The concurrence of is defined as
[TABLE] 4. 4.
The tangle is defined as
[TABLE]
The tangle of a bipartite state is a measure of entanglement. If the tangle is zero, then the bipartite state must be a separable state. For states defined in Eq. (6.8), we can calculate the corresponding tangle. By following the aforementioned steps, we first calculate the four eigenvalues, . For , we have and hence . For , we have and hence . Therefore, for and for ,
[TABLE]
The fitting value of from state tomography and the tangles are shown in Table 6.6.
Chapter 7 Reliable and robust entanglement witness
This chapter introduces the reliable and robust problem in entanglement witness. The reliable problem can be overcome by the MDIEW scheme. While we show in this chapter how the robust problem can also be resolved [31].
7.1 Reliable and robust problem in EW
In reality, EW implementation may suffer from two problems. The first one is reliability. That is, one might conclude unreliable results due to imperfect experimental devices. In this case, the validity of the EW result depends on how faithful one can implement the measurements according to the witness . If the realization devices are not well calibrated, the practically implemented observable may deviate from the original theoretical design , see Fig. 7.1 as an example, which can even be not a witness. That is, there may exist some separable states , such that . Practically, by exploiting device imperfections, an attack has been experimentally implemented for an entanglement witness procedure [30]. In cryptographic applications, such problem is regarded as a loophole, where one mistakes separable states to be entangled ones. For instance, in QKD, this would indicate that an adversary successfully convinces the users Alice and Bob to share keys which they think are secure but are eavesdropped. Such problem is solved by the measurement-device-independent QKD scheme [185], inspired by the time-reversed entanglement-based scheme [218, 219, 186]. Branciard et al. applied a similar idea to EW and proposed the measurement-device-independent entanglement witness (MDIEW) scheme [29], in which entanglement can be witnessed without assuming the realization devices. The MDIEW scheme is based on an important discovery that any entangled state can be witnessed in a nonlocal game with quantum inputs [3]. In the MDIEW scheme, it is shown that an arbitrary conventional EW can be converted to be an MDIEW, which has been experimentally tested [30].
The second problem lies on the robustness of EW implementation. Since each (linear) EW can only identify certain regime of entangled states, a given EW is likely to be ineffective to detect entanglement existing in an unknown quantum state. While a failure of detecting entanglement is theoretically acceptable, in practice, such failure may cause experiment to be highly inefficient. In fact, a conventional EW can only be designed optimal when the quantum state has been well calibrated, which, on the other hand, generally requires to run quantum state tomography. Practically, when the prepared state can be well modeled, one can indeed choose the optimal EW to detect its entanglement. Since a full tomography requires exponential resources regarding to the number of parties, EW plays as an important role for detecting well modeled entanglement, which would generally fail for an arbitrary unknown state. In a way, this problem becomes more serious in the MDIEW scenario, where the measurement devices are assumed to be uncharacterized and even untrusted. In this case, the implemented witness, which may although be designed optimal at the first place, can become a bad one which merely detects no entanglement. However, the observed experimental data may still have enough information for detecting entanglement. Therefore, the key problem we are facing here is that given a set of observed experimental data, what is the best entanglement detection capability one can achieve.
In detecting quantum nonlocality, a similar problem is to find the optimal Bell inequality for the observed correlation, which can be solved efficiently with linear programming [220]. Regarding to our problem, we essentially need to optimize over all entanglement witness to draw the best conclusion of entanglement with the same experiment data, as shown in Fig. 7.2(a). As the set of separable states is not a polytope, this problem cannot be solved by linear programming. Generally speaking, it is proved that the problem of accurately finding such an optimal witness is NP-hard [221]. However, if certain failure probability is tolerable, we show in this work that this problem can be efficiently solved. That is, if we admit a probability less than to detect a separable state to be entangled, we show that the optimal entanglement witness can be efficiently found. As the optimization step can be effectively conducted as post-processing, our scheme does not pose extra burdens to experiments compared to the original MDIEW scheme. In this case, our result can be directly applied in practice.
7.2 Reliable entanglement witness
The reliability problem can be overcome by the MDIEW scheme. For self-consistency, we will breifly review the MDIEW scheme.
7.2.1 Nonlocal game
Before, we first discuss about nonlocal games with classical and quantum inputs as shown in Fig. 7.3. In a classical nonlocal game, classical random inputs and are given to two spacelikely separated users Alice and Bob, who perform measurement on pre-shared entangled state and output and , respectively. According to the probability distribution , a Bell inequality can be defined by
[TABLE]
where is a bound for all separable state . A violation of the inequality can be considered as a witness for entanglement. As the Bell test does not assume measurement detail, witnessing entanglement by Bell test is device independent. However, as the conclusion is so strong such that the implementation is self-testing, not all entangled states can be witnessed in such a way [222, 81]. Furthermore, the requirement of a faithful Bell test is very high, which makes such a witnesses impractical. For instance, the minimum efficiency required is for all Bell tests with binary inputs and outputs [72, 73]. On the other hand, if we can trust the measurement, a Bell test essentially becomes an EW. Although such method is able to detect all entangled state and is easy to realize, this scheme is not measurement-device-imperfection-tolerant.
In the seminal work [3], Buscemi introduces the concepts of nonlocal games with quantum inputs. Denote the inputs of Alice and Bob by and , then an inequality similar to Bell inequality can be defined by
[TABLE]
where is also the bound for all separable state . As the quantum inputs can be indistinguishable, it is proved that all entangled states can violate a certain inequality [3]. If we consider the input states are faithfully prepared by Alice and Bob, then such nonlocal game with quantum inputs can be considered as an MDIEW [29]. Moreover, as shown below, there is no detection efficiency limit for such a test.
7.2.2 MDIEW
The nonlocal game presented in Ref. [3] can be considered as a reliable entanglement witness method, which does not witness separable state as entangled with arbitrary implemented measurement. This nonlocal game is thus an MDIEW, i.e., for all separable states and can be negative if Alice and Bob share entangled state. Furthermore, the statement that for all separable states is independent of the implementation of the measurement. In Ref. [29], the authors put this statement into more concrete and practical framework. They show that, for an arbitrary conventional EW, there is a corresponded MDIEW. Below, we will quickly show how to derive MDIEWs from conventional EWs.
Focus on the bipartite scenario with Hilbert space , with dimensions and . For a bipartite entangled state defined on , we can always find a conventional entanglement witness such that and for any separable state . Suppose and to be two bases for Hermitian operators on and , respectively. Thus, we can decompose on the basis by
[TABLE]
where are real coefficients and the transpose is for later convenience. Notice that, owing to the completeness of the set of density matrices, we further require and to be density matrices. In addition, the decomposition of Hermitian operators is not unique which varies with different and .
With a conventional EW decomposed in Eq. (7.3), an MDIEW can be obtained by
[TABLE]
where and is the probability of outputting with input states . In the MDIEW design, Alice (Bob) performs Bell state measurement on () and (). The probability distribution is thus obtained by the probability of projecting onto the maximally entangled state and .
As shown in Ref. [29], is linearly proportional to the conventional witness with ideal measurement,
[TABLE]
Thus, defined in Eq. (7.4) witnesses entanglement. Furthermore, it can be proved that such a witness is independent of the measurement devices. That is, even if the measurement devices are imperfect, is always non-negative for all separable states and hence no separable state will be mistakenly witnessed to be entangled. We refer to Ref. [29] for a rigorous proof.
Theoretically, the MDIEW scheme prevents identifying separable states to be entangled. Such a reliable MDIEW has been experimentally demonstrated lately [30]. In practice, however, such a scheme can be inefficient, meaning that it witnesses very few entangled states despite that the observed data could actually provide more information. This is because, in the MDIEW procedure, one first chooses a conventional EW and realize in an MDI way. The conventional EW is chosen based on an empirical estimation of the to-be-witnessed state, thus it may not be able to witness the state for an ill estimation. Furthermore, even if the conventional EW is optimal at the first place, the measurement imperfection will make it sub-optimal in practice. Especially, when the input states is complete, a specific witness may not be able to detect entanglement. With complete information, a natural question is whether we can obtain maximal information about entanglement, i.e., get the optimal estimation of MDIEW.
7.3 Robust MDIEW
Now, we present a method to optimize the MDIEW given a fixed observed experiment data . Before digging into the details, we compare the problem to a similar one in nonlocality. In the nonlocality scenario, a Bell inequality is used as a witness for quantumness, see Eq. (9.1). In practice, the Bell inequality may not be optimal for the observed probability distribution . As the probability distribution of classical correlation forms a polytope, one can run a linear programming to get an optimal Bell inequality for . While, in our case, the probability distribution with separable states is only a convex set but no-longer a polytope. Thus, our problem cannot be solved directly with linear programming.
7.3.1 Problem formulation
Let us start with formulating the optimization problem. Informally, our problem can be described as follows,
Problem (informal): find an optimal witness for the observed probability distribution .
According to Eq.(7.4), the witness value is defined by a linear combination of with coefficient . To witness entanglement, the coefficient must lead to a witness as defined in Eq. (7.3). In addition, as we can always assign to double a violation, we require a trace normalization of the witness by
[TABLE]
Under this normalization, the optimal entanglement witness [223] for a given state is defined by the solution to the minimization
[TABLE]
Generally speaking, the minimum value, i.e., maximum violation, of the entanglement witness makes the result more robust to experimental errors and statistical fluctuations. Furthermore, a larger violation of entanglement witness can also help for a larger estimation of entanglement measures [224].
Therefore, the problem can be expressed as
Problem (formal): For a given probability distribution , minimize
[TABLE]
over all satisfying
[TABLE]
for any separable state and
[TABLE]
Contrary to the optimization of Bell inequality, we can see that this problem is much more complex. When the measurements are implemented faithfully, it is easy to verify that , where is the state measured. Therefore, finding the optimal is equivalent to find the optimal entanglement witness for state . A possible solution to this problem is to try all entanglement witnesses to find the optimal one, see Fig. 7.2. However, it is proved that the problem of accurately finding such an optimal witness is NP-hard [221]. Thus, our problem is also intractable for the most general case.
7.3.2 -level optimal EW
The key for the problem being intractable is that there is no efficient way to characterize an arbitrary entanglement witness. In the bipartite case, an operator is an witness if and only if
[TABLE]
for any separable state . As can always be decomposed as a convex combination of separable states as , the condition can be equivalently expressed as
[TABLE]
for any pure states and . The constraints for a witness are very difficult to describe in the most general case, which makes our problem hard.
While, this problem can be resolved if we allow certain failure errors. A Hermitian operator is defined as an -level entanglement witness, when
[TABLE]
where is the set of separable states. That is, the operator has a probability less than to detect a randomly selected separable quantum state to be entangled. Intuitively, can be regarded as a failure error probability. We refer to Ref. [225] for a rigorous definition. It is shown that the -level optimal EW can be found efficiently for any given entangled state . In particular, constrained on and to be an -level EW, one can run a semi-definite programming (SDP) to minimize .
7.3.3 Solution
Following the method proposed in Ref. [225], we can solve the minimization problem given in Eq. (7.8) by allowing a certain failure probability . First, we relax the constraint given in Eq. (7.9). Instead of requiring being non-negative for all separable states, we randomly generate separable states and require that
[TABLE]
where . Then the problem can be expressed as
Problem (-level): given a probability distribution , minimize
[TABLE]
over all satisfying
[TABLE]
for randomly generated separable states and
[TABLE]
This problem can be converted to an SDP solvable problem when we re-express the inequality of numbers in Eq. (7.16) by an inequality of matrices. To do so, we only need to notice that Eq. (7.12) is equivalent to require that
[TABLE]
where indicates that has non-negative eigenvalues. Therefore, we only need to generate states , for , and the problem is
Problem (-level, SDP): given a probability distribution , minimize
[TABLE]
over all satisfying
[TABLE]
for randomly generated states and
[TABLE]
In practice, we can run an SDP to solve this problem. According to Ref. [225, 226], to get the -level witness with probability at least , the number of random states should be at least . Here is the number of optimization variables, i.e., coefficients , and can be understood as the failure probability of the minimization program. It is worth to remark that the problem can be similarly solved in the multipartite case.
7.3.4 Example
In this section, we show explicit examples about how the witness becomes non-optimal in the MDI scenario and how this problem can be resolved by running the optimizing program.
Suppose the to-be-witnessed state is a two-qubit Werner state [222]:
[TABLE]
where and is the identity matrix. The designed entanglement witness for the Werner states is
[TABLE]
As , is entangled for and separable otherwise.
As shown in Ref. [29], we can choose the input set by
[TABLE]
where , is the Pauli matrices, and . According to Eq. (7.3), the witness can be decomposed on the basis of with coefficient given by
[TABLE]
And the MDIEW value is given by
[TABLE]
In the ideal case, the probability distribution is obtained by projecting onto maximally entangled states, that is,
[TABLE]
where and . While, in practice, there may exist imperfection in measurement. For instance, we consider that Alice’s measurement is perfect while Bob’s measurement is instead
[TABLE]
where . In the case of quantum key distribution, projecting onto can be regarded as a phase error.
As shown in Fig. 7.4, we plot the MDIEW and the optimized MDIEW results. For the original MDIEW result, as Bob’s measurement is incorrect, no Werner state given in Eq. (7.22) can be witnessed to be entangled. Although, by optimizing over all possible entanglement witness, we show that is entangled as long as . In this case, the optimized MDIEW can detect all entangled Werner states. In our program, we set and we can see from Fig. 7.4 that no separable state is falsely identified as entangled.
The optimization program finds the optimal -level optimal EW , which as its name indicates, has a probability less than to detect an separable state to be entangled. To get a smaller , one can use a larger number of random states. In this case, the can be regarded as the statistical fluctuation which is inversely related to the number of trials . On the one hand, to efficiently get the optimal witness , one has to introduce a nonzero failure error ; On the other hand, we can always add an extra term to the EW to eliminate , i.e.,
[TABLE]
where is chosen to be the minimum value such that is an entanglement witness. To efficiently find , one can make use of the technique similar to Ref. [227], in which, EW can be systematically constructed.
Part IV Randomness and selftesting
Chapter 8 Randomness Requirement on CHSH Bell Test in the Multiple Run Scenario
This chapter investigates the randomness assumption in Bell test. Specifically, we discuss the randomness requirement such that quantum mechanics can have a violation of the Clauser-Horne-Shimony-Holt (CHSH) inequality [228].
8.1 Randomness Requirement
8.1.1 Randomness loophole
Historically, Bell tests [19] are proposed for distinguishing quantum theory from local hidden variable models (LHVMs) [28]. In a general picture, a Bell test involves multiple parties who randomly choose inputs and generate outputs with pre-shared physical resources. Based on the probability distributions of inputs and outputs, an inequality, called Bell’s inequality, is defined. A Bell test is meaningful when all LHVMs satisfy the Bell’s inequality; while in quantum mechanics, such inequality can be violated via certain quantum settings. Experimentally observing a violation of any Bell’s inequality would show that LHVMs are not sufficient to describe the world, and other theories, such as the quantum mechanics, are demanded.
Here, we focus on the bipartite scenario and investigate one of the most well-known Bell tests, the CHSH inequality [1]. As shown in Fig. 9.1(a), two space-like separated parties, Alice and Bob, randomly choose input bit settings and and generate outputs bits and based on their inputs and pre-shared quantum () and classical () resources, respectively. The probability distribution , obtaining outputs and conditioned on inputs and , are determined by specific strategies of Alice and Bob. By assuming that the input settings and are chosen fully randomly and equally likely, the CHSH inequality is defined by a linear combination of the probability distribution according to
[TABLE]
where the plus operation is modulo 2, is numerical multiplication, and is the (classical) bound of Bell value for all LHVMs. Similarly, there is an achievable bound for the quantum theory [67]. In this case, a violation of the classical bound indicates the need for alternative theories other than LHVMs, such as quantum theory. For general no signalling (NS) theories [68], denote the corresponded upper bound as . It is straightforward to see that .
The violation of Bell’s inequality not only acts as a test for fundamental laws of physics, but has varieties of applications in modern quantum information tasks. For instance, observing violations of Bell’s inequalities can be applied in device independent tasks, such as quantum key distribution [55, 26, 56, 57], randomness amplification [58, 59, 60] and generation [61, 62, 63, 64], entanglement quantification [65], and dimension witness [66]. Security proofs of these tasks are generally independent of the realization devices or correctness of quantum theory, but relies on violating a Bell’s inequality. For instance, consider the devices of Alice and Bob as black boxes. In this case, assume, in the worse scenario, that an adversary Eve, instead of Alice and Bob, performs measurements as shown in Fig. 9.1(b). Because the two parties are space-like separated, the probability distribution generated in this way is always within the scope of LHVMs, that is, , where is a hidden variable that is controlled by Eve. Therefore, Eve cannot fake a violation of any Bell tests, which intuitively explains the security of the device independent tasks.
Since the first experiment in the early 1980s [229], lots of lab demonstrations of the CHSH inequality have been presented. These experiment results show explicit violations of the LHVMs bound , and meanwhile, suffer from a few technical and inherent loopholes, which might invalidate the conclusions. Two well-known technical obstacles are due to the locality loophole and the detection efficiency loophole, which can be closed with more delicately designed experiments and developed instruments in varieties of experiment systems, including optic systems [75, 76], superconducting systems [230], ionic systems [74], and atomic systems [70]. In contrast to the technical loopholes, there also exists an inherent loophole that cannot be closed completely in any Bell test — the input settings may not be chosen randomly. In the worst case, the inputs can be all predetermined, which makes it possible to violate the Bell inequalities even with LHVMs. In this case, witnessing a violation of a Bell’s inequality does not imply the demand for non-LHVM theories and such Bell test cannot be used for the device independent tasks either. On the other hand, without the quantum theory or violation of Bell’s inequalities, one cannot get provable randomness. Therefore, the assumption of true input randomness are indispensable in Bell tests because one cannot prove or disprove its existence.
Practically, the case of not fully random input settings corresponds to the scenario where the input settings are partially controlled by an adversary Eve, who wants to convince Alice and Bob a violation of Bell’s inequality with classical settings. In this case, Eve is able to simultaneously control the input settings and measurement devices, as shown in Fig. 9.1(c). We model the imperfect randomness by assuming that the input settings and are chosen according to some probability distribution , conditioned on the same local variable which is available to the adversary Eve. Now, the probability distribution of LHVMs are defined by
[TABLE]
where is the prior probability distribution of , and is the observed average probability of the input settings and . Notice that is normalized by restricting . Now, the CHSH value under the classical strategy given in Fig. 9.1(c) can be rewritten according to
[TABLE]
where we additionally require the observed probability of choosing and to be uniform, that is, .
Notice that, in the extreme (deterministic) case where or for all , , the local hidden variable deterministically controls the input settings. Then Eve is able to violate Bell tests to an arbitrary value with LHVMs. On the other hand, if Eve has no control of the input settings where for all , , she cannot fake a violation at all. Therefore, a meaningful question to ask is how one can assure that a violation of the CHSH inequality is not caused by Eve’s attack on imperfect input randomness. That is, we want to know what the requirement of the input randomness is to guarantee that an observed violation truly stems from quantum effects.
8.1.2 Randomness requirement in Bell test
Let us start with quantifying the input randomness. Here, we make use of the randomness parameter adopted in Ref. [77] to fulfill such an attempt, other tools such as the Santha-Vazirani source [142] may work similarly. The parameter is defined to be the maximum probability of choosing the inputs conditioned on the hidden variable ,
[TABLE]
With this definition, the larger is, the less input randomness, the more information about the inputs Eve has, and the easier for her to fake a quantum violation with LHVMs. In the CHSH test, takes values in the regime of . When , it represents the case that Eve has whole information of Alice and Bob’s inputs, that is, Eve can always correctly infer the values of and by accessing the local hidden variable . When , it corresponds to the case of complete randomness, where the adversary have no additional information on the inputs compared to naive guess. Note that the definition of essentially follows the min-entropy, which is widely used to quantify randomness of a random variable in information theory, .
Intuitively, given complete randomness where , the value with LHVMs are bounded by as shown in Eq. (9.1); while given the most dependent (on ) randomness where , the value with LHVMs could reach the mathematical maximum, in the CHSH test. Then it is interesting to check the maximal value for with LHVMs. In this work, we are interested in when the adversary can fake a quantum violation given certain randomness . We thus exam the lower bound of such that the Bell test result can reach the quantum bound with an optimal LHVM. This lower bound puts a minimal randomness requirement in a Bell test experiment. Only if the freedom of choosing inputs satisfies , can one claim that the Bell test is free of the randomness loophole.
Recently, lots of efforts have been spent on investigating such requirement of randomness needed to guarantee the correctness of Bell tests [35, 144, 231, 77, 78, 232, 145]. These works analyze under different conditions. One condition is about whether the input settings of the same party are dependent or not in different runs. We call it single run, referring to the case that the input settings of Alice (Bob) are correlated for different runs, and multiple run referring to otherwise. The other condition is about whether the random inputs of Alice and Bob are correlated or not. Conditioned on these different assumptions of the input randomness, the lower bound that allows LHVMs to saturate the quantum bound in the CHSH Bell test is summarized in Table 8.1.
In the single run scenario, the optimal strategies for Eve reach and in the case that Alice’s and Bob’s input settings are correlated and uncorrelated, respectively [35, 77]. To achieve the maximum quantum violation , the critical randomness requirement is shown in Table 8.1. It is worth mentioning that if one has randomness and for the case of correlated and uncorrelated inputs, respectively, Eve is able to recover arbitrary NS correlations.
In a more realistic scenario, the multiple run case, the input settings of Alice (Bob) are dependent in different runs. Now, suppose the inputs may correlate for each sequent runs, where stands for the single run case, and for the multiple run case. For each unit of runs, denote () and () to be the input and output of Alice (Bob) for the th run, where , respectively. In the multiple run scenario, correlations of the inputs of each runs can be represented by
[TABLE]
Therefore, similar to the definition of Eq. (9.5), the value with LHVMs in the multiple run case can be defined by
[TABLE]
where the index denotes the th run, and , . Notice that we only consider the correlations of inputs in the unit of runs, which is not the total number of runs in experiment. To get an accurate estimation of the value defined in Eq. (8.6), one also need to perform the runs multiple times similar to the single run case.
In the multiple run scenario, as an extension of Eq. (9.2), the input randomness parameter is defined according to
[TABLE]
It is quite straightforward that the adversary is easier to fake a violation of a Bell test with LHVMs with increasing number of correlation of the inputs. This is because the adversary can take advantage of additional dependence of the inputs in different runs. It has been shown that with randomness , Eve is able to fake the maximum quantum violation [78] with the number of input correlation goes to infinity. This result [78] lower bounds for all finite , and thus puts a very strict requirement on the input randomness to guarantee a faithful CHSH test.
A meaningful remaining question is thus to consider the multiple run but uncorrelated scenario. As all Bell experiments must run many times to sample the probability distribution, it is reasonable and also practical to consider a joint attack by Eve. On the other hand, the uncorrelated assumption is also reasonable when the inputs of Alice and Bob are independent even conditioned on , that is, and . Equivalently, the probability of the inputs are required to be factorizable,
[TABLE]
This factorizable (uncorrelated) condition constrains the power of Eve in controlling or inferring the inputs of Alice and Bob. A general distribution requires Eve to jointly control the instruments that Alice and Bob use to generate random inputs. In the case when the experiment instruments of Alice and Bob are manufactured independently or the inputs are determined by sources causally disconnected from each other, such as cosmic photons [79], the inputs and can be assumed to be independent to each other conditioned on the hidden variable . That is, Eve can only control each of the input settings independently according to Eq. (9.7).
In the multiple run and uncorrelated scenario, the value with LHVMs is defined by
[TABLE]
Our purpose is to investigate the optimal attack of CHSH test with restricted randomness input . Therefore we want to maximize Eq. (8.9) with the constraint of Eq. (8.7). In particular, we are interested to see when this maximal value can reach .
8.2 Single run case
We first review the optimal strategy in the single run scenario [77] to get an intuition behind the optimal attack of the adversary. Hereafter, we mainly focus on the scenario that Alice and Bob’s inputs are uncorrrelated as defined in Eq. (9.7). Thus, what we want is to maximize the value,
[TABLE]
where
[TABLE]
with restricted randomness , given in Eq. (9.2).
Since any probabilistic LHVM, that is, , could be realized by a convex combination of deterministic ones [233], it is therefore sufficient to only consider deterministic LHVMs. Due to the symmetric definition of the CHSH inequality, we only need to consider a specific strategy of , and for some given , and all the other ones works similarly. By substituting the special strategy into Eq. (8.11), we get
[TABLE]
Suppose , , and hence , can be maximized to
[TABLE]
Given , is upper bounded by
[TABLE]
where the equality holds when and . Thus, the optimal strategy with LHVMs is . Note that, when the input settings are fully random, , the optimal strategy of LHVMs is , which recovers the original LHVMs bound . It is easy to see that, to saturate the quantum bound , the randomness should be at least , as shown in Table 8.1.
In the single run case, we only need to consider one specific deterministic strategy of due to the symmetric definition of the CHSH inequality. We also take advantage of this property in the derivation of the multiple run case. In addition, we can see that the optimal strategy of LHVMs is to choose or fully randomly and the other one as biased as possible. This biased optimal strategy is counter-intuitive since the adversary do not need to control the inputs of both parties, but only those of one party. We show that this counter-intuitive feature does not hold in the optimal strategy in the multiple run case.
8.3 Multiple run case
Now we consider the multiple run scenario with uncorrelated input randomness. That is, optimizing Eve’s LHVM strategy Eq. (8.9) with constraints defined in Eq. (8.7). Similar to the single run case, from the symmetric argument, we can also solely consider one specific deterministic strategy, that is, , and . Given the probabilities of Alice’s and Bob’s inputs, , , the value, defined in Eq. (8.9), for this specific strategy labeled with is given by
[TABLE]
where is vector inner product. Our attempt is therefore to maximize Eq. (8.15) with constraints
[TABLE]
for all and .
Since in the single run scenario, the optimal strategy requires only one party with biased conditional probability, we first analyze the case with only Alice’s inputs biased and Bob’s inputs uniformly distributed. Then we investigate the case where the inputs of both parties are biased. We can see that the one party biased strategy is not optimal in the multiple run case, even when .
8.3.1 One party Biased
In the case when Eve only (partially) controls one of the inputs, say Alice’s, the probability of Alice’s input string is biased and Bob’s input string is uniformly distributed, that is,
[TABLE]
The randomness is characterized by Eq. (8.7), after substituting Eq. (8.17),
[TABLE]
where is defined by . Then, the value, defined in Eq. (8.15), becomes
[TABLE]
Denote the number of bit in an string as . Given the number of bit in , , we can sum over ,
[TABLE]
and group the summation of according to ,
[TABLE]
One only need to consider the LHVMs whose probabilities of with the same are the same. Otherwise, we can always take an average of with the same without increasing the randomness parameter . Thus we can rewrite as
[TABLE]
with normalization requirement
[TABLE]
and constraints defined in Eq. (8.16).
The optimization of Eq. (8.22) can be solved efficiently via linear programming. Intuitively, to maximize with given defined in Eq. (8.18), we can simply assign that has large be 0 and that has small be . Suppose there exists an integer such that can be written as
[TABLE]
then, Eq. (8.22) can be rewritten as
[TABLE]
For a general case where an integer cannot be found satisfying Eq. (8.24), we can first find an integer such that,
[TABLE]
Then we can assign to be
[TABLE]
For finite , one can numerically solve the problem according to Eq. (8.27). As shown in Fig. 8.2, the optimal strategy for are calculated. With increasing , the optimal value increases and hence a valid Bell test requires a smaller (more randomness).
In the case of , we can derive an analytic bound for all finite strategies. By following the technique used in Ref. [78], we first estimate defined in Eq. (8.26) with the limit of by,
[TABLE]
where , and similarly by,
[TABLE]
Then we can substitute Eq. (8.29) into Eq. (8.28), and get a relation between optimized value and the corresponding randomness parameter ,
[TABLE]
By substituting the quantum bound into Eq. (8.30), we can get the critical randomness requirement to be . Note that, although Eve only control Alice’s input settings, she can still fake a quantum violation with sufficiently low randomness, which is lower than the single run case even when Alice’s and Bob’s inputs are correlated. Thus we show that the randomness is more demanded for the conditions of multiple/single run compared to the correlation between Alice and Bob.
8.3.2 Both parties biased
Now we consider a general attack, where Eve controls both inputs of Alice and Bob. In this case, we need to optimize Eq. (8.15) with constraints defined in Eq. (8.16). Similarly, we group the summation of and according to the corresponded number of bit , and ,
[TABLE]
Now, if we assume that () has the same value for equal (), we can sum over and for given and ,
[TABLE]
We can then get the value,
[TABLE]
with the constraints of and ,
[TABLE]
It is worth mentioning that the assumption that () takes the same value for equal () is not obviously equivalent to the original optimization problem defined in Eq. (8.31). We thus take this step as an additional assumption, and conjecture it to be true for certain cases.
The problem defined in Eq. (8.33) with constraints of Eq. (8.3.2) cannot be solved by linear programming directly, as for the nonlinear terms . However, we can still optimize it with similar methods used in the previous section. Define the maximum randomness on each side
[TABLE]
To maximize , we can first optimize Alice’s side, , and then Bob’s side . By doing so, it is not hard to see that is maximized by assigning that has small number of to be and that has large number of to be 0, and similarly for . Thus we need to first find and for Alice and Bob, such that,
[TABLE]
Then we can assign and to be
[TABLE]
to optimize defined in Eq. (8.33).
For finite , we can also numerically solve the optimization problem defined in Eq. (8.33). As shown in Fig. 8.3. The value increases with the number of runs , thus the strategy with infinite rounds puts a bound on the strategy with finite rounds.
In the case of , we can also find analytical relation between optimized and the corresponded . Similarly, we first estimate and defined in Eq. (8.3.2) with the limit of by
[TABLE]
where and , and according to
[TABLE]
As we still have to optimize over all possible and that satisfies , we cannot get a direct analytic formula like in Eq. (8.30), while we can still numerically solve and plot it in Fig. 8.3. To reach a maximum quantum violation with a LHVM, the randomness is required to be , which is larger than the case where Eve only control’s Alice’s input.
8.3.3 Discussion
We take an additional assumption in the derivation of the both parties biased case, thus the obtained bound is still an upper bound of a general optimal attack for the case of goes to infinity. As we already know, the randomness requirement for the worst case, that is, multiple run with Alice and Bob’s inputs correlated, is strictly bounded by [78]. Thus, we know that the tight for the case of multiple run but Alice and Bob uncorrelated should lie in the interval of .
To gain intuition why we take the additional assumption, first notice that what we want is to minimize the average contribution of in Eq. (8.31). In our case, where is near 1/4, and can be regarded as an approximately flat distribution. On average, the () contains less number of 1s will contribute more to , which means we should assign the corresponded probability () bigger in order to maximize . As () is upper bounded by (), an intuitive optimal strategy is then to let () be () for () contains less number of 1s, and be 0 for the ones contains more number of 1s. As () should also satisfy the normalization condition (Eq. (8.3.2)), we can simply follow the strategy defined in Eq. (8.40) to realize the intuition, which on the other hand satisfies the assumption we take. Follow the above intuition, we conjecture the assumption to be true for certain cases of . That is, for finite , we conjecture it to be true when equalities are taken in Eq. (8.3.2) for both and .
On the other hand, we want to emphasize that for a finite , the assumption will not generally hold in the optimal strategy if the equalities in Eq. (8.3.2) are not fulfilled. For example, if the probability of and in Eq. (8.40) is not 0 but very small, we should not take all and equally as and , especially for the case of and , respectively. In fact, there do exists a cleverer assignment of and such that only and that gives small get probability instead of all of and that and . However, with increasing runs , this kind of clever attack stops working as for the equalities can be more approximately satisfied with larger . Therefore, we also conjecture the assumption to be true for all possible with goes to infinity.
As we can see, our obtained is already very close to the worst case value that is , we can therefore conclude that the multiple run correlation is already a strong resource for the adversary, no matter whether the inputs of Alice and Bob are correlated or not. In addition, as we know that the bound for the most loose case, that is, single run and Alice Bob uncorrelated, is given to be [77], we also suggest that the key loophole of the input randomness is the correlation between multiple runs instead of correlation of Alice and Bob.
Considering that Eve controls only Alice’s input but leaves Bob’s input uniformly distributed, we found the least randomness Eve need to control to fake a quantum violation is . And the least randomness required when controlling both Alice and Bob is . By comparing the results to the ones listed in Table. 8.1, we conclude that the key randomness loophole is due to the correlation between multiple runs. As the randomness requirement which considers multiple run attack is not easy to fulfill in real experiments, we thus suggest the experiments to rule correlations of the input settings from different runs. To guarantee the securities of the device independent tasks, we also suggest that one should check whether there are correlations between random inputs from different runs.
For further research, we are interested to know whether there exists Bell inequalities that suffers less from the randomness loophole. By assuming different kinds of assumptions, the randomness requirement behaves different. For example, it is interesting to investigate the scenario where the input settings are uncorrelated with the measurement devices by assuming the manufactures are different. That is, there are two uncorrelated hidden variables in Fig. 9.1(c), controlling the input settings and measurement devices independently. Moreover, recently, by considering a nonzero lower bound for the input random probability , et al. show a Bell inequality which suffers from very little randomness loophole [145]. That is, no adversary can fake a quantum violation as long as the lower bound of is nonzero regardless of its upper bound defined in Eq. (9.2). Therefore, it is interesting to investigate the multiple run randomness requirement of the CHSH inequality with additional assumptions.
Chapter 9 Clauser-Horne Bell test with imperfect random inputs
This chapter investigates general randomness requirement for the Clauser-Horne (CH) inequality [34]. We consider for different conditions. In addition, our method applies for general Bell inequalities.
9.1 General randomness requirement
In the bipartite scenario, a general Bell test involves two remotely separated parties, Alice and Bob, who receive random inputs and and produce outputs and , respectively. Based on the probability distribution of the outputs conditioned on the inputs, Bell’s inequality can be defined by a linear combination of according to
[TABLE]
where is a bound for all local hidden variable models (LHVMs), meaning that, any LHVM cannot violate any Bell’s inequality. Now, we consider the case that the inputs are not fully random. That is, the inputs and depend on some local hidden variable, denoted as , as shown in Fig. 9.1.
The input randomness can be quantified by the dependence of the inputs conditioned on . Suppose the inputs and are chosen according to a priori probability , the input randomness can be measured by its upper and lower bounds,
[TABLE]
As an example, for the CH test, where the inputs are binary, the upper and lower bounds are in the range of and , respectively. Focusing on the upper bound , when it equals , it represent the case that the local hidden variable deterministically decides at least one input. When , this corresponds to the case that the inputs are fully random. Similarly, we can see how the lower bound characterizes the input randomness. In many of previous works [35, 231, 77, 78, 232, 228], only the upper bound is considered. It is recently noted in Ref. [145] that the lower bound also plays an important role in analysis. We thus consider both the upper and lower bounds as quantifications of the input randomness.
With binary inputs, we can consider a symmetric case where and . In other words, we can quantify the input randomness by its deviation from a unform distribution, quantified by ,
[TABLE]
Note that all our following results apply for asymmetric cases (with arbitrary and ) as well.
When the input settings are determined by , the observed probability of outputs conditioned on inputs is given by
[TABLE]
where is the priori probability of , is the averaged probability of choosing and , and is the strategy of Alice and Bob conditioned on . Then, the Bell’s inequality defined in Eq. (9.1) should be rephrased by
[TABLE]
In this work, we are interested in how LHVMs can fake a violation of Bell’s inequality with imperfect input randomness. Thus, we can also set the strategy of deciding the outputs based on the inputs by , and the Bell value with a LHVM is given by
[TABLE]
Here, for simplicity, we assume that is independent of and . What we are interested is to maximize with LHVMs. From another point of view, we want to establish the Bell’s inequality when imperfectly random inputs are considered. Any breach of these bounds (using quantum settings) would rule out LHVMs and in favor of quantum mechanics. Suppose the quantum bound to Eq. (9.5) is denoted by , then we are especially interested to see the condition of and such that . In experiment, such condition is the necessary condition for a valid Bell test. For a specific observed violation and input randomness characteristics and , it witnesses non-local feature only if the Bell value satisfies .
In varieties of previous works [35, 144, 231, 77, 78, 232, 228], randomness requirements for the CHSH inequality are analyzed. In this work, we focus on another inequality — the CH inequality and consider in general scenarios. For instance, many previous work [35, 231, 77, 78, 228] assumes the underlying probability distribution to satisfy the no-signaling (NS) [68] condition. However, in real experiment, the probability distribution may behave signaling due to statistical fluctuation, devices imperfection, or other possible interventions by the adversary Eve. We thus also consider the general case where can be signaling 111It is worth to remark that even if can be signaling, we still assume that the locality loophole is closed. The possibility of signaling comes from the fact that partial knowledge of the inputs are known. In practice, Alice and Bob cannot transmit signal with such signaling probability distribution.. In addition, we consider the case that the random inputs of Alice and Bob are factorizable. In this case, the input randomness can be written as
[TABLE]
This factorizable assumption is reasonable in some practical scenarios, where the experiment devices that determine the input settings are from independent manufactures or the randomness generation events are also spacelikely separated. For example, if the inputs are determined by cosmic photons that are causally disconnected from each other [79], the input randomness can be reasonably assumed to be factorizable.
9.2 CH inequality
In this section, we will investigate the randomness requirement of the CH inequality under different conditions, including whether is signaling or NS, and whether the factorizable condition is satisfied or not.
9.2.1 CH inequality with LHVMs
The CH inequality is defined in the bipartite scenario, where the input settings and and the outputs and are all bits. Based on the probability distribution that obtains a specific measurement outcome, for instance , the CH inequality is defined according to
[TABLE]
where we omit the outputs and and define () to be the probability of detecting [math] with input setting () by Alice (Bob), and the probability of coincidence detection for both sides with input settings and for Alice and Bob, respectively. To satisfy the general definition of a Bell inequality as shown in Eq. (9.1), the single party probabilities and need to be properly defined by coincidence detection probabilities. For instance, we can either define by the detection probabilities with input , or , or a convex mixture. This arbitrary definition vanishes when the NS condition is satisfied.
In experiment realization, one has to run the CH test multiple times, for instance, , to determine the probabilities in Eq. (9.8). Denote the coincidence counts by and single counts by , we can then write
[TABLE]
Here, denotes the total number of trials with input setting and , and the number of trials with input setting () of Alice (Bob).
When the input settings are chosen truly randomly, the CH Bell value with LHVM is always non-positive. While quantum theory could maximally violate it to be . If the measurement settings , are additionally determined by some hidden variable by probability distribution , we show in the following that the CH inequality could be violated even with LHVMs.
With a general LHVM strategy defined in Eq. (9.6), each term in the CH value in Eq. (9.9) can be described by
[TABLE]
Here, we adopt a specific realization of the single counts by taking an average of the observed value. For instance, the single detection probability is defined to be a mean of the single detection probabilities with input and .
Besides, in order to convince Alice and Bob that the input settings and are chosen freely, Eve has to impose that the averaged probability distributions of the input settings are uniformly random. Then, we can assume to be ,
[TABLE]
In real experiments, the input probability can be arbitrary, where our result can still apply with certain modifications on normalization. With the normalization condition Eq. (9.11), the CH value with LHVMs strategies is given by
[TABLE]
with defined by
[TABLE]
With the randomness parameter defined in Eq. (9.2), our target is to maximize defined in Eq. (9.12) for given randomness input and under constraints in Eq. (9.11).
9.2.2 General strategy (attack)
In this part, we consider a general strategy (attack) where no additional assumption is imposed. It is worth mentioning that with the following method, we can essentially convert the optimization problem over all LHVMs into a clearly defined mathematical problem. In the CH example, we show an explicit solution to this mathematical problem. A general solution to this type of mathematical problems will provide a general solution to the problem of imperfect randomness in Bell test.
Note that the optimization of Eq. (9.12) requires to optimize over the strategy of Alice and Bob, and , and also the strategy of deciding the inputs, , which also satisfies the constraints defined in Eq. (9.11). Here, we first analyze how to optimize the strategy of Alice and Bob.
Because all probabilistic LHVM strategies can be realized with a convex combination of deterministic strategies, it is sufficient to just consider deterministic strategies, i.e., for the optimization. Conditioned on different values of and , 16 possible values of are listed in Table 9.1, where we omit the for simple notation hereafter.
Note that, for given , we should choose the optimal strategy of and that maximize . Thus we here only consider the possible optimal strategies as listed in Table 9.2. We refer to Appendix C.1 for rigorous proof of why we only consider the possible optimal strategies.
As the strategies of and are always better than the strategies of and , respectively, we can always replace the later strategies with the former ones without affecting but achieving a larger . For simple notation, we denote by hereafter, thus the possible deterministic strategies for are in the following set
[TABLE]
Because there are only five possible strategies of Alice and Bob, we can also consider that there are only five different strategies of choosing the input settings. The intuition is that, for the input settings that using the same strategies of Alice and Bob, for instance, , we can always take an average of the different strategies of without decreasing . We refer to Appendix C.1 for a rigorous proof. Therefore, we label to be the th strategy of choosing the input settings and can be rewritten in the following way,
[TABLE]
The constraints of and are given by
[TABLE]
Furthermore, we can denote the coefficient of by as shown in Table 9.3. Then can be expressed by
[TABLE]
The solution to this optimization problem is shown in Appendix C.2.1. Based on the value of and , we give the optimal CH value with LHVMs by
[TABLE]
and plot it in Fig. 9.2. Note that when is greater than , the value of is independent of . Hence, we only plot the situation where is less than 3/8.
In addition, we can also investigate the optimal CH value with input randomness quantified as in Eq. (9.3). It is easy to check that , and the optimal CH value is thus
[TABLE]
9.2.3 Result
factorizable condition
Here, we consider the optimal LHVMs strategy in the case where the probability of the input settings are factorizable, as defined in Eq. (9.7).
Following a similar derivation, we show in the Appendix C.2.2 that the optimal CH value with LHVMs under factorizable condition is
[TABLE]
We show the optimal value of in Fig. 9.3.
When we quantify and by and , the fomular can be rewritten by
[TABLE]
It is interesting to note that the factorizable condition does not affect the optimal CH value when the input randomness is quantified as in Eq. (9.3). The quantum bound is given by , thus we can see that should at least be less than for all CH experiment realizations.
NS condition
In addition, we consider the scenario where the probability distribution defined in Eq. (9.4) satisfies the NS condition, which adds a constraint on . That is, the probability of output () only relies on the input () independently of the input from the other party. To be more specific, NS requires to satisfy
[TABLE]
We can follow the above derivation by imposing an additional NS constraint, which makes the problem even more complex.
Instead, we note that the CHSH inequality and the CH inequality are equivalent under NS, that is,
[TABLE]
which we refer to Appendix C.3.1 for a rigorous proof. As the CHSH inequality is defined with strong symmetry, we solve the optimization problem with the CHSH inequality. We should note that we essentially take the NS condition into account when deriving the equivalence between the CH and CHSH inequality.
Based on the general definition of Bell’s inequalities in Eq. (9.1), the coefficients of the CHSH inequality is defined by
[TABLE]
that is,
[TABLE]
When considering LHVMs strategies with imperfect input randomness, the CHSH value can be written by
[TABLE]
where
[TABLE]
Following a similar method described above, we first consider deterministic strategies, i.e., for the reason that any probabilistic LHVM could be realized with convex combination of deterministic ones. Denote as , it is easy to show that the possible optimal deterministic strategies for are
[TABLE]
and the constraints can also be described by Eq. (9.16). Following a similar argument, we only need to consider four different types strategies of choosing the input settings. Thus can be given by
[TABLE]
With a symbolic notation in Eq. (9.17), we can also present the coefficient in a matrix, as shown in Table 9.4.
We solve the optimization problem in Appendix C.3.2. Based on the value of and , we give the optimal CHSH value with LHVMs by
[TABLE]
Then the optimal CH value with LHVMs under NS is
[TABLE]
We show the optimal value of in Fig. 9.4.
If we quantify the input randomness by its deviation from uniform distribution as defined in Eq. (9.3), the optimal CH value is given by
[TABLE]
The quantum bound for the CH inequality is , thus should be less than for all experiment realizations.
NS condition and factorizable
At last, we consider the probability distribution to be NS and the input randomness is factorizable. The optimization of the CHSH inequality is solved in Appendix C.3.3, and the result is,
[TABLE]
Then the optimal CH value with LHVMs under NS and factorizable condition is
[TABLE]
We show the optimal value of in Fig. 9.5.
When the input randomness is quantified as in Eq. (9.3), where and , we have
[TABLE]
Again, it is interesting to note that the factorizable condition does not affect the optimal CH value when the input randomness is quantified as in Eq. (9.3).
Comparison
Let us compare the results of the CH values under different conditions. For the maximal quantum violation , we calculate the critical values of and such that and plot them in Fig. 9.6. When is small, the optimal CH value depends only on . In this case, the critical values of for the signaling, signaling+fac, NS, and NS+fac are 0.207, 0.302, 0.285, 0.354, respectively. Thus, we can see that the factorizable condition puts a stronger requirement for compared to the NS condition. On the other hand, when is large, the optimal CH value depends only on instead. In this case, the critical values of for the signaling and NS condition are 0.198 and 0.146, respectively. It is interesting to note that when both and is large, the optimal CH value is independent on the factorizable condition.
Besides, if we make use of the quantification method defined in Eq. (9.3), we have already noticed that the optimal CH value is independent on the factorizable condition. Here, we compare between the signaling and NS condition as shown in Fig. 9.7. For the maximal quantum violation , we calculate the critical values of for the signaling and NS condition to be 0.052 and 0.104, respectively.
When we quantify the input randomness as Eq. (9.3), we found that the optimal CH value is independent of the factorizable condition, Eq. (9.7). Thus with the quantification method in Eq. (9.3), one may not need to consider the factorizable condition.
For further works, it is interesting to consider joint strategies of LHVMs of the CH inequality, where the inputs of different runs are correlated. It is already shown that joint attacks to the CHSH inequality puts a very high requirement of the input randomness no matter the factorizable condition is satisfied or not [228]. In addition, we can investigate the case where the input randomness is restricted by both lower and upper bounds, and . Due to the asymmetric definition of the CH inequality, the analysis may become extremely complicated with increasing number of correlated runs. Similar cases may also happen for other asymmetric Bell inequalities.
Furthermore, it is interesting to see whether there exist Bell’s inequalities such that the randomness requirement is very low. To do so, we have to solve the problem of optimizing the Bell value with all LHVM strategies. We expect that our derivation method could provide a general way to solve this problem.
Chapter 10 Source-independent quantum random number generation
In general, a physical generator contains two parts¡ªa randomness source and its readout. The source is essential to the quality of the resulting random numbers; hence, it needs to be carefully calibrated and modeled to achieve information-theoretical provable randomness. In this chapter, we discuss quantum random number generation without trusting its randomness source [115] hence semi-selftesting. We show in this chapter that randomness can be obtained even without characterizing its source.
10.1 The prepare and measure model
A typical QRNG can be described by the prepare and measure model that can be decomposed into two modules: a randomness source (quantum state preparation) and its readout (measurement), as shown in Fig. 10.1. In general, the source emits quantum states that are superpositions of the measurement basis. The output (raw) random numbers are the measurement results. In many QRNGs, a short random seed is required to assist state preparation or measurement.
As an example, consider a simple QRNG that projects the quantum state emitted from a single photon source on the horizontal and vertical polarization basis . This QRNG can be divided into two modules, as shown in Fig. 10.1(a). Randomness is guaranteed by the intrinsically probabilistic nature of quantum physics. Hereafter, we denote , (, ) as the -basis (-basis) eigenstates.
Existing practical QRNGs suffer from security loopholes if the devices are not perfect. In the source readout model, the measurement device can normally be trusted due to its simple structure. For instance, in the previous example, the measurement is a simple demolition measurement on the polarization basis. In contrast, the randomness contained in a source, such as a laser or an atomic assemble, is normally difficult to characterize completely. If the source malfunctions and emits classical signals instead of quantum ones, the outputs may not be truly random. Consider the worst-case scenario in which the devices are designed or controlled by an adversary Eve. Eve can employ a pseudo-RNG to output a fixed (from Eve’s viewpoint) string that still appears random to Alice. More concretely, in the example of the previous paragraph, when a dishonest source emits -basis instead of -basis eigenstates for the -basis measurement, the output will just be a fixed string, as shown in Fig. 10.1(b). From this perspective, with given measurement devices, justifying the randomness in a source is crucial to generating randomness.
Most existing QRNGs use complicated physical models [234, 110] to quantify their sources. For example, the dimension of the source is sometimes assumed to be a fixed known number [235]. The underlying models implicitly assume the existence of randomness in the first place, but this assumption cannot be verified experimentally. Therefore, to achieve truly reliable randomness, there is a strong motivation to avoid the use of such models. Note that removing the dimension assumption is the key challenge to the analysis for device-independent scenarios.
Thus, a QRNG without trusting the source (source-independent) is both theoretically and practically meaningful and greatly in need. A device-independent QRNG [64] can generate randomness without having to trust the devices. This type of QRNG requires a short seed for device testing, which is the reason why they are also called randomness expansions [236, 133, 135]. By observing the violation of a certain Bell’s inequality, such as the Clauser–Horne–Shimony–Holt inequality [1], one can guarantee the presence of randomness without any assumptions about the source or the measurement device. The main drawback of device-independent QRNGs is that they are not loss-tolerant, which typically imposes very severe requirements on experimental devices. Furthermore, this type of QRNG generates random numbers at rates that are very low for practical applications. The highest speed of this type of QRNG has, so far, been reported to be 0.4 bps [75].
In this chapter, we will introduce a source-independent QRNG (SIQRNG) scheme based on the uncertainty relation that is loss-tolerant and hence highly practical. In particular, our scheme allows the source to have arbitrary and unknown dimensions. The loss-tolerance property enables potential high-loss implementations of our scheme, such as in integrated optic chips or with inefficient but cheap single photon detectors. We analyze the randomness of the scheme based on complementary uncertainty relations. Our analysis takes account of several practical issues, including finite-key-size effects, multi-photon components in the source, initial seed length, and losses. The analysis combines several ingredients from the security proof of quantum key distribution (QKD), a rich subject that has developed over the last two decades. These ingredients include phase error correction [237], random sampling [238], and the squashing model [146]. Since the squashing model shows the equivalence between threshold detectors and qubit detectors [146], our scheme allows the source to have an unfixed finite dimension as well as an infinite dimension. For simplicity, in the rest of this chapter, we assume a two-level (bit) output system. All our techniques can be directly applied to cases with more outputs.
10.2 The Protocol
10.2.1 Theoretical protocol
A schematic of our SIQRNG protocol is shown in Fig. 10.2(a). Here, we take an optical implementation as the example, as shown in Fig. 10.2(b). All our results apply similarly to other implementation systems. Quantum signals from the source first go through a modulator that actively chooses between the and bases. Then, a polarizing beam splitter and two threshold detectors perform a projective measurement. Since two detectors are used, there are four possible outcomes: no clicks (losses), two single clicks, and double clicks. This implementation is equivalent to the schematic setup of squashing model as discussed in Section 10.2.2. The details of the protocol are presented in Fig. 10.3.
10.2.2 Analysis
In this part, we analyze the randomness output of the SIQRNG protocol. Strictly speaking, like device-independent QRNGs, our scheme is a randomness expansion scheme, in which a random seed is used to generate extra independent randomness. The procedure of parameter estimation is an analog to the phase error rate estimation in QKD postprocessing [240]. Randomness extraction is mathematically equivalent to privacy amplification in QKD. The difference between the biased measurement used here and the biased-basis choice QKD protocol [241] is that the number of -basis measurements is a constant in our case, whereas in QKD, this number must go to infinity when the data size is infinitely large.
Squashing model
In the SIQRNG scheme, we assume that measurement devices are trusted and well characterized. The key assumption here is that the measurement setup is compatible with the squashing model. That is, a measurement can be treated in two steps. First, the (unknown arbitrary-dimensional) signal state emitted from the source is projected to a qubit or vacuum. The projection is called a squasher, as shown in Fig. 10.2(a). Then, the squashed qubits are post-selected by discarding the vacua and measuring them in the or basis. This assumption can be satisfied when threshold detectors are used with random bit assignments for double clicks [146]. For the protocol described in Section 10.2, the -basis measurement results are used for parameter estimation and are then discarded in postprocessing. Thus, the random assignment can be replaced by adding half of the double-click ratio to the -basis error rate.
In practice, it is a challenge to verify whether a measurement setup is compatible with the squashing model. Much effort has been put into this question [242]. The key point here is to make the two detectors respond equally to (four) different qubits, and hence make the measurement device basis-independent [243]. This can be done by adding a series of filters (including spectrum and temporal filters) before the threshold detectors, to ensure that the input states stay within a proper set of optical modes [244], in which the detectors have the same efficiencies [146, 243]. One can further assume that Alice uses a trusted source to calibrate the measurement devices beforehand; that is, Alice performs a quantum measurement tomography. A similar measurement calibration procedure should be done in most current QKD and QRNG realizations. Here, we emphasize that the verification of the squashing model does not affect the source-independent property of our scheme. Thus, we leave detailed investigation on validating the measurement setting for future works.
Similar to the QKD case [146], we can assume that the squashing operator is held by Eve in the randomness analysis. By this, we mean that Eve can choose a valid operator, so long as the output is a qubit or a vacuum. In the following discussions, we focus on the squashed qubits. We need to determine the min-entropy associated with these qubits in the -basis measurement.
Complementary uncertainty relation
First, we show intuitively why the protocol works. According to quantum mechanics, the outcome of projecting the state on the basis is random. Of course, in reality, due to device imperfections, Alice would never obtain a perfect state of . Now, the key question for Alice becomes how to verify that the source faithfully emits the state . This can be done by borrowing a similar technique from the security analysis of QKD [245, 237, 246] and consider an equivalent virtual protocol depicted in Fig. 10.4, where we replace steps and by and . In steps and of the protocol, Alice occasionally performs the -basis measurement and define the phase error rate to be the ratio of detecting . In the virtual protocol, once Alice knows the phase error rate by random sampling tests, she can perform a phase error correction (step ) before the final -basis measurement (step ). By an smart design of the phase error correction procedure [237], Alice can make it commute with the -basis measurement. Thus, she can perform the -basis measurement (step ) first and then apply randomness extraction (step ). At this stage, all the states have already collapsed to classical results, and the phase error correction procedure becomes randomness extraction (or privacy amplification in QKD) [245, 237, 246]. Besides QKD, the argument here is similar to the one used in Ref. [21], where one can consider the error correction process as distilling coherence or randomness extraction.
It has been proved that the phase error correction (randomness extraction) can be efficiently done with Toeplitz-matrix hashing [239]. Suppose the number of qubits measured in the basis is and the phase error rate is , the number of bits sacrificed in the phase error correction is given by
[TABLE]
and the probability that the phase error correction fails is [240]. Here, is the binary Shannon entropy function, all the is base 2 throughout this chapter, and is the parameter Alice picks up by balancing the failure probability and the final output length. Then, the number of final random bits is given by,
[TABLE]
In practice, Alice needs to prepare a Toeplitz matrix of size for randomness extraction.
We note that the failure probability quantifies fidelity between the state that results from the phase error correction and the ideal state . In the composable security definition [157, 158], a trace-distance measure security parameter should be employed. Its relation to the fidelity measure is given by [238]
[TABLE]
In the following, we shall use the fidelity measure for the failure probability, which, in the end, can be conveniently converted to the trace-distance measure security parameter.
To construct the Toeplitz matrix of size , Alice needs to use random bits. Thanks to the Leftover Hash Lemma [247], the Toeplitz hashing extractor can be proven to be a strong extractor. That is, the output random bits are independent of the random bits used in the construction of the Toeplitz matrix [248]. Thus, the Toeplitz matrix can be reused.
Our result can also be derived via a different but elegant approach by employing a newly developed seminal uncertainty relation [249] and extending the Leftover Hash Lemma [247] to the quantum scenario [250]. Interestingly, the result from that approach yields a security parameter (in trace distance measure) that is of the order of , which is consistent with ours. Such techniques have been successfully applied in some applications, including QRNGs [235].
Finite key analysis
In practice, the QRNG only runs for a finite time; consequently, the sampling tests for the -basis measurements will suffer from statistical fluctuations. In the parameter estimation step, the key parameter in Eq. (10.2) should be estimated (bounded) from the finite data size effect.
In the random sampling test, Alice measures the squashed qubits in the basis and obtains the error rate, . Remember that, as required in the squashing model, this error rate includes half of the double-click ratio. Henceforth, we simply call this error rate as the -basis error rate. Recall that the phase error rate is defined as the error rate if the quantum signals measured in the basis were measured in the basis. When the sampling size is large enough, can be well approximated by .
Before presenting the details of the random sampling analysis, we establish a notation. Suppose Alice receives squashed qubits and randomly chooses of them to be measured in the basis, leaving the remaining qubits in the basis. Let the ratio of -basis measurements be , the number of errors Alice finds in the basis to be , and the total number of errors to be if Alice had measured all qubits in the basis. Then, the number of errors in the qubits measured in the basis is , which is the key parameter we need to determine through random sampling. The quantity determines the randomness extraction rate. Define the lower bound of by,
[TABLE]
where is the deviation due to statistical fluctuations. Following the random sampling results of Fung et al. [238], we can bound the probability when Eq. (10.4) fails,
[TABLE]
where . Note that in the unlikely event that , the failure probability is unbounded, and one should rederive the failure probability or simply replace with a small value, say, .
In practice, the failure probability is normally picked to be a small number depended on applications. In later data postprocessing, we pick up . Once is fixed, there is a trade-off between and for the ratio of the final random bit length over the raw data size. Thus, the number of samples for the -basis measurement should be optimized for the randomness extraction rate.
One key property for the random sampling is that the locations of the -basis measurements are randomly chosen from the total locations, i.e., the cases occur equally likely. Then, Alice needs a random seed with a length of
[TABLE]
The effect of loss on the seed length will be discussed in Section 10.2.2. In Appendix B.1, we show that can remain a constant, given the failure probability, when is large. Then, in the large data size limit, the seed length is exponentially small compared to the length of the output random bit. Therefore, we reach an exponential randomness expansion.
Practical issues
Multi photons: In our protocol, the source is allowed to emit multi photons, since its dimension is assumed to be uncharacterized. In other words, these components would not affect the randomness of the final output. In practice, multi photons may introduce double clicks when threshold detectors are used [146]; these double clicks will directly contribute to the error rate term . Thus, when the multi-photon ratio is very high, the double-click ratio will increase to a point that the upper bound on information leakage increases to oen half; at that point, when no random bits can be extracted according to Eq. (10.2) and Alice simply aborts the protocol.
Loss: The loss tolerance of our protocol is guaranteed by the squashing model in which the measurement is assumed to be basis independent [146]. This assumption can be guaranteed by the fact that the basis is chosen after losses. Alice does not anticipate the positions of losses, so she effectively decides the (random) positions for -basis measurements before losses. The effect of loss only decreases the number of effective measurements, but the positions of effective measurements are still uniformly random in squashed qubits; this fulfills the requirement of random sampling. The detailed proof is shown in Appendix B.2.
Basis-dependent detector efficiency: Our protocol assumes that the efficiencies of the detectors are the same. In practice, efficiency mismatches would cause the measurement to be different for the two bases (basis dependent). A viable way to deal with this imperfection is to recalculate the rate as a function of the ratio between the efficiencies of the two bases, employing the technique used in QKD [243]. As indicated by the result in QKD [243], the random number generation rate will slightly decrease when there is a small mismatch in detector efficiencies. More precisely, denote the ratio between the minimum and maximum efficiencies of the two detectors as , then the key size becomes bits. We leave detailed analysis of this imperfection for future work.
Double clicks: Our analysis takes account of the effect of double clicks by adding half of the double-click ratio to the -basis error rate, as required in the squashing model. This is also essentially why multi-photon states can be used on the source side without affecting final randomness. Note that double clicks should not be discarded freely in the measurement. Otherwise a security loophole will appear, namely, a strong pulse attack [251]. In a strong pulse attack, Eve always sends strong signals (with many photons) in the basis. Suppose she sends a strong state in ; if Alice chooses the -basis measurement, a valid raw random bit will be obtained, but if she chooses the basis, a double click is likely to happen. In our protocol, when Alice chooses the -basis measurement, she should get an error (resulting in ) with a probability of one half. If Alice simply discards all double clicks, Eve’s attack will not be noticed. This attack cannot be explained by a qubit measurement. This is intuitively why the squashing model requires random assignments for double clicks.
Basis choice: When choosing - or -basis measurements, an input random string of length (as a seed) is needed to choose the basis. Suppose the number of -basis measurements to be performed is , then Alice chooses positions out of with equal probability, i.e., with probability . Then, she needs a seed length of . This is similar to Eq. (10.6) with the difference that before the measurement, Alice does not know the positions of losses. More details on how to dilute a short random seed to a longer (partially random) one are provided in Appendix B.3.
Intensity optimization: The intensity of the source should be optimized to maximize the randomness generation rate. With increasing intensity, the detection rate will increase along with an increases in the double-click rate (and hence increases). There exists a trade-off between and , as shown in Eq. (10.2).
10.3 Experiment demonstration
In this section, we perform a proof-of-principle experimental demonstration to show the practicality of SIQRNG scheme. Our experiment setup consists of two parts, the source, owned by an untrusted party Eve, and the measurement device, owned by the user Alice. The schematic diagram is shown in Fig. 10.5.
On Eve’s side, a laser, labeled as , with a wavelength of 850 nm and a repetition rate of 1 MHz is used as a photon source. The power of the laser is adjusted to be one photon number per pulse. Instead of assuming each state to be a qubit system, each pulse that the laser sends is a coherent state of infinite dimensions. The pulse of the laser is then modulated to polarization by a linear polarizer (LP) and a fiber polarization controller (FPC1). Between the source and the measurement device, we put an fiber attenuator (FA) to simulate different losses in the system.
On Alice’s side, first a series of filters need to be applied to ensure the measured optical mode is pure before entering the threshold detectors, as required by the squashing model. For demonstration purpose, we use a single-mode fiber to play the role of a filter. Ideally, frequency and temporal filters should be also added to further purify the optical mode in order to make the photons indistinguishable. For demonstration purpose, a biased beam splitter (BS1) with a ratio of is used to passively choose the or basis. Finally, Alice records when the photon detector (PD) clicks. The detector is time-division-multiplexed by adding four time delays TD1 to TD4 (60 ns each) in the optical paths, so that it can simulate four detectors which detect the outcomes of both bases and each bit values. The gate width and the dead time of the detector are 10 ns and 50 ns, respectively.
The phase error rate, as calculated in Eq. (10.4), is plotted in Fig. 10.6. The related experimental parameters are listed as follows. The raw key sizes is ; the dark count is ; the detector efficiency (without FC adaptor) is ; the misalignment error of the source is 2%; and the failure probability is . The figure shows that the error rate increases as the loss becomes large. This is because the effect of dark counts becomes dominant when the loss is high. Due to statistical fluctuations, the phase error rate increases when the data size shrinks. Note in particular that the phase error rate can go beyond under high losses, which does not yield any key rates in most QKD protocols. Nevertheless, random numbers can still be generated in our SIQRNG scheme.
The relation between the randomness generation rate and the loss is plotted in Fig. 10.7. It can be seen that the randomness generation rate becomes lower with a larger loss, which is consistent with Fig. 10.6. Under practical detector efficiency, the randomness generation rate still achieves a relatively high rate of bit/s. Note that, the intensity of the source is fixed in our experimental demonstration. In practice, the intensity of the source can be increased to compensate the loss, and actually the maximum randomness generation rate in our scheme is mainly limited by the dead time of the detector. For our detector with a dead time of 50 ns, the maximum randomness generation rate is bit ns=20 Mbps, which requires the source to be a single photon source with a repetition rate of 20 Mbps. For practical implementations with coherent-state sources, the randomness generation rate can reach the order of 2 Mbps after taking account of various errors and finite data size effects.
After obtaining the random bits, we apply the Toeplitz-matrix hashing [239] on the raw data to obtain final random numbers. To test the randomness, we further perform two statistical tests on the output of our SIQRNG, autocorrelation test and the NIST test suite 222See http://csrc.nist.gov/groups/ST/toolkit/rng.. The autocorrelation is defined as
[TABLE]
where is the lag between the samples, is the -th sample bit, and are the average and the variance of the sample, and stands for expectation. The result of autocorrelation test of raw data and final data is shown in Fig. 10.8. It can be seen that the autocorrelation is substantially reduced in the final data.
The result of NIST tests on the final data is shown in Fig. 10.9. We can see that all tests are passed.
We have proposed a source-independent and loss-tolerant QRNG scheme and its experimentally demonstration in a passive basis choice realization. From an experimental point of view, the beam splitter itself, as a part of the measurement device, may also be uncharacterized. Thus, it would also be interesting to demonstrate our scheme with an active basis choice in the future. In fact, when the source operates properly, the speed of our protocol is comparable to that of a trusted polarization-based QRNG whose frequency is limited only by single photon detectors—approximately 100 Mbps [252].
Some current realizations of QRNG experiments could be converted to our SIQRNG protocol. For example, an LED could be used as the source, as regular QRNG [123]. Since the polarizations of an LED light are random, it would be convenient to add a polarizer for the direction to make the source polarized light. Since the detector can work in a gated mode, it does not matter whether the light source is continuous or pulsed. This shows why the repetition rate is limited only by single photon detectors. Viewed from another angle, such a setup could also be used to test quantum features of macroscopic sources.
Recently, a continuous-variable version of the source-independent QRNG is experimentally demonstrated[116] and achieves a randomness generation rate over 1 Gbps. Moreover, with state-of-the-art devices, it can potentially reach the speed in the order of tens of Gbps, which is similar to the trusted-device QRNGs. Hence, semi-self-testing QRNG is approaching practical regime.
Apart from the protocol based on uncertainty relation, we can also make use of the coherence on the measurement basis to quantify the randomness output. Note that, the SI-QRNG protocols based on uncertainty relation does not maximally exploits the randomness in the source. For instance, suppose the source emits state , then we have and hence . In this case, although the measurement outcome on the basis is genuinely random, it cannot be revealed by the information on the complementary basis . Instead, the genuine randomness can be extracted if the basis is measured. On the other hand, if the basis is also measured, we can directly calculate the coherence of the state and the randomness output will be maximized.
Part V Other works
Chapter 11 Open timelike curves
In general relativity, closed timelike curves (CTCs) can break causality with remarkable and unsettling consequences. At the classical level, they induce causal paradoxes disturbing enough to motivate conjectures that explicitly prevent their existence. At the quantum level such problems can be resolved through the Deutschian formalism, however this induces radical benefits¡ªfrom cloning unknown quantum states to solving problems intractable to quantum computers. Instinctively, one expects these benefits to vanish if causality is respected. This chapter shows that in harnessing entanglement, we can efficiently solve NP-complete problems and clone arbitrary quantum states¡ªeven when all time-travelling systems are completely isolated from the past [253]. Thus, the many defining benefits of Deutschian closed timelike curves can still be harnessed, even when causality is preserved.
11.1 Open timelike curves
11.1.1 Causality and CTC
Causality aligns with our natural sense of reality. We expect there to be a natural chronology to our reality - two events should not be simultaneous causes for each other. The breaking of causality defies classical logic, resulting in causal paradoxes with no simple solution - the iconic example being the case where a man travels back in time to kill his own grandfather. Thus, physical predictions that break causality face intense scrutiny - often considered to be theoretical artifacts that are likely suppressed once we gain a more complete understanding of reality - motivating various chronology protection conjectures [254].
Nevertheless, causality breaking theories are consistent with current scientific knowledge. Closed timelike curves (CTCs) are valid solutions of Einstein’s equations in general relativity [255, 256, 257]. Meanwhile, Deustch demonstrated that in the quantum regime, the resulting causal paradoxes always have self consistent solutions [258]. This resolution, however, has radical operational consequences. Many foundational constraints of quantum theory break. Non-orthogonal quantum states can be perfectly distinguished, the uncertainty principle can be violated, and arbitrary unknown quantum states can be cloned to any fixed fidelity [259, 260]. In harnessing these effects, many problems thought to be intractable to standard quantum computers now field efficient solutions [261, 262, 263, 264]. Though radical, these effects seem somewhat rationalized in the context of requiring broken causality - the sentiment being that they are curiosities that will vanish once causality is imposed.
What happens, however, if causality is not strictly broken? In this context, Pienaar et.al introduced open timelike curves [265] (OTCs). Consider a particle that travels back in time with respect to a chronology respecting observer, but is completely isolated from anything that can affect its own causal past during the time-traveling process (See Fig. 11.1). While the time-traveling particle has the potential to break causality, its complete isolation ensures that causality never breaks. Nevertheless, such OTCs can violate uncertainty principles between position and momentum. This opens a remarkable possibility - could the many other radical effects of CTCs stand independent from the breaking of causality?
Here, we demonstrate that OTCs are remarkably powerful, and can replicate many defining operational benefits of CTCs. In sending a particle back in time - even when it interacts with nothing in the past - we can clone arbitrary quantum states to any fixed accuracy, and thus violate any uncertainty principle. Meanwhile, they also grant quantum processors additional computational power, allowing efficient solution of NP-complete problems. Our results hint that the remarkable power of Deustchian CTCs may survive the censorship of chronology protection. This drastically improves the potential of harnessing such power via alternative effects - such as certain models of gravitational time dilation [265]. Thus, we open the possibility of testing the many radical protocols that harness CTCs in significantly less controversial settings.
11.1.2 OTC and CTC
In general relativity, causality can be violated due to the presence of spacetime wormholes that facilitate closed timelike curves (see Fig. 11.1). This allows a physical system to travel into its own causal past, and interact with its past self via some unitary . The Deutschian model resolves potential paradoxes by enforcing temporal self-consistency [258, 266], i.e.,
[TABLE]
where denotes the initial state of the system, is the state it evolves to at the point of wormhole traversal and represents tracing over all systems other than . Given a solution for , the final output of the process is given by
[TABLE]
The many radical effects of CTCs rely on using specific self-interactions to break causality in different ways [259, 260, 261, 262, 263].
Note that while the above analysis does not assume is pure, it only applies to mixed inputs if represents one partition of a larger composite system that is pure. In the scenario where an input is prepared with probability , the dynamics of the CTC on each must be analyzed separately [258]. This is due to non-linearity, which implies different unravellings of the density operator yield differing outputs.
In OTCs, causality is preserved. The unitary is the identity - such that the time-travelling system does not interact with its causal past. Any observer in the frame of reference of can assign a valid chronology to all the events they witness. Meanwhile, to any outside observer, all events involving interactions with will respect causality. From an operational standpoint, there is no breaking of causality. If all information were classical, this entire procedure would only have the effect of desynchronizing ’s clock with that of an observer .
Non-trivial effects, however, emerge when we consider quantum ancilla. Suppose we have access to a bipartite system in state , where only one bipartition is sent through the OTC (see Fig. 11.2b). The self-consistency relations imply
[TABLE]
Thus, the OTC acts as a universal decorrelator on - in sending a system though an OTC, we erase all quantum correlations between and the rest of the universe (and in particular, ). The resulting state, fields identical local statistics with respect to the input , but none of its bipartite correlations. While this operation appears similar to trivial decoherence, it is non-linear, and shown to be impossible to synthesize with standard quantum dynamics [267].
This effect is associated with the monogamy of entanglement [266] - a particle and its past self cannot be simultaneously entangled with the same external ancilla. While OTCs produce non-trivial dynamics when the input appears completely classical (e.g., when ), it applies only for mixed inputs if this mixedness is due to entanglement with some other system . If we input and with equiprobability, then the dynamics of each input must be analyzed separately, and the OTC will have no effect.
11.2 Quantum information with OTC
11.2.1 OTC enhanced measurement
We first introduce OTC enhanced measurement, a procedure that harnesses OTCs to measure an arbitrary observable to any fixed precision. Specifically, given an unknown qudit ( dimensional quantum system) in state , we can determine to any desired accuracy with negligible failure probability. This protocol functions as a building block for more sophisticated applications of OTCs, such as the efficient solution of NP-complete problems and cloning of unknown quantum states.
The protocol is illustrated in Fig. 11.3. Let denote a basis that diagonalizes . On this basis, we introduce the two qudit controlled addition operator, , where addition is done modulo . We then
Prepare identical ancillary states in an eigenstates of , say . 2. 2.
Apply the operations times, each controlled on and targeting a fresh ancilla state. This correlates with each of the ancillaries. 3. 3.
Pass each of the ancillaries through an OTC to destroy all correlations in this -partite system.
This results in uncorrelated qudits, each in state , where are the diagonal elements of in the basis. Thus, each qudit exhibits identical statistics to when measured in the basis. In taking the mean of these measurements, we obtain an estimate for . By the central limit theorem, the error of our estimate scales linearly with . In particular, provided the eigenvalues of are bounded, Hoeffding’s bound implies we can estimate to any desired accuracy and error rate using OTCs (see methods for details).
Scaling Analysis
Execution of the OTC enhanced measurement with ancillaries (and therefore uses of the OTC) to estimate gives an output . We define the measurement as being successful if the estimate achieves a desired accuracy of (i.e., ). Application of Hoeffding’s inequality [268] gives failure probability that obeys
[TABLE]
Here, and are the respective maximum and minimum eigenvalues of . Therefore
[TABLE]
OTC applications ensures a failure probability of no more than . Provided is bounded, this scales as .
In OTC assisted cloning, we need to make informationally complete measurements, each to a desired accuracy with negligible failure probability . Recall this is achieved via a universal cloner, whose imperfect copies are to be decorrelated via the use of OTCs (Fig. 11.5). For each of the copies, we apply an OTC enhanced measurement. To ensure this measurement is within accuracy , an extra overhead is required to compensate for the noise within the imperfect copies. The total number of OTCs required is then of order
[TABLE]
where is equal to 1 for members of the information complete basis.
11.2.2 Solving NP-complete problems
We take inspiration from Bacon [262], who devised an efficient algorithm to solve the boolean satisfaction problem - a known NP-complete problem - using CTCs.
Bacon’s protocol
Here we outline explicitly how a non-linear map that takes to allows the efficient solution of NP-complete problems. Specifically we study the satisfaction problem: Given a Boolean function , specified in conjunctive normal form, does there exist a satisfying assignment ? This problem is known to be NP-complete.
Bacon [262] showed that this problem can be efficiently solved if when given an input qubit , we can synthesize a quantum gate such that . Here denotes the Bloch sphere vector, and is a 3 component vector of Pauli matrices. In Fig. 11.4 we demonstrated how this gate can be synthesized using OTCs. With this established, the satisfaction problem is efficiently solved as follows:
Prepare ancillary qubits in the state and a target qubit in state . 2. 2.
Apply the unitary
[TABLE]
on this system (with the last qubit representing the target). Tracing out the ancillary qubits leaves the target in
[TABLE]
where is the number of satisfying . 3. 3.
Apply to the target via the use of OTCs (See Fig. 11.4). Repeat this step times to get
[TABLE]
Notice that, we could easily check the case of . Thus we only need to distinguish between and . With the limit of , the two output states corresponding to the cases of and are and , respectively. By performing measurement in the basis, one can distinguish the two types of output states and , that is, the case of and , with failure probability being . By repeating these steps more times, say, , the failing probability exponentially decays. For finite and that are polynomial in , the probability of failure is given by [262]
[TABLE]
Solving NP-complete problems with OTC
We modify this algorithm to preserve causality - without losing efficiency. In the causality breaking algorithm, the key role of CTCs is to implement the non-linear map that maps an input qubit in state to an output state , where and denotes the Pauli matrix (see methods for details).
This non-linear map can be replicated without breaking causality (See Fig. 11.4). Consider a special case of OTC enhanced measurement, with as the observable of interest and a single ancilla. For the input qubit with matrix elements , application of the enhanced measurement protocol outputs two uncorrelated qubits, each in state . Instead of measuring each in directly, we apply a further gate controlled on the ancilla. After discarding the ancilla, the input qubit is now transformed to as required.
In generating using only OTCs, we can translate Bacon’s algorithm into one that does not break causality. We note that as each call of only takes one OTC, the translation from CTCs to OTCs incurs no overhead on the number of times a particle needs to be sent through a spacetime wormhole. Thus, for the purpose of solving NP-complete problems, an OTC, together with one bit of entanglement, is at least as a powerful as a CTC.
11.2.3 Cloning with OTCs
Given an unknown input , OTCs allow us to generate an unlimited number of clones to arbitrary fidelity. Our approach harnesses OTC enhanced measurements as a subroutine, which allows us to accurately determine , for any observable . First, observe that this remains possible even if we are supplied with
[TABLE]
a very noisy version of . Here is the -dimensional identity matrix, and is some fixed parameter such that .
This observation, together with imperfect quantum cloners, form the basis of OTC enhanced cloning (Fig. 11.5). In conventional quantum theory, an unknown quantum state can be cloned if we are given sufficiently many copies to perform accurate tomography [269]. One way to do this, is to use a set of informationally complete measurements , whose expectation values has a one-to-one correspondence with the classical matrix description of . Given only a single copy of , this option is no longer valid. Recently, Brun et.al demonstrated that close timelike curves circumvent this restriction, and allows the estimation of each to any desired accuracy [260].
OTC enhancement measurements can replicate this effect while preserving causality. We use standard methods to construct imperfect clones in the form of Eq. 11.11, where scales as for an optimal cloner [270]. Each clone is passed through an OTC to remove all entanglement between clones. An OTC enhanced measurement is then performed on each clone with respect to a different . The outcomes of these measurements determine the density matrix of . In methods, we show that by using OTCs, we can ensure that each is obtained to an accuracy of with failure probability .
A Simple Example
We illustrate these ideas by cloning a qubit. Here, the Pauli operators is informationally complete - any is uniquely defined by the expectation values . To determine each , we first apply a universal 1-to-3 quantum cloner to obtain three imperfect clone of , each in state with [271]. These copies can be made independent via OTCs.
An OTC enhanced measurement of is then performed on one such imperfect clone. We initialize ancilla qubits in state , and apply a CNOT gate between each ancilla and the clone (with the clone as the control qubit). In erasing the resulting correlations by sending each clone through an OTC, we obtain qubits, each in the state . Provided is sufficiently large, measurement of these qubits allows to be determined to any desired accuracy with negligible error. Repetition of this process with and on the two remaining imperfect clones then yields complete information about .
Our result highlights the intricate interplay between quantum theory and general relativity. If all physical systems have a well defined local reality, open timelike curves would have no operational effect. Our protocol thus fields no classical explanation. In the quantum regime, however, entanglement exists. While the local properties of a physical system are unaffected by open timelike curves, their correlations with other chronology respecting systems are complete erased. In each of our protocols, this effect played a central role, allowing us to replicate the many defining benefits of close timelike curves. This remarkable success propels us to conjecture whether entanglement assisted open timelikes curves are operationally equivalent to their causality breaking counterparts. Could one, for example, derive a map that takes any quantum circuit with CTCs, and engineer it in a way that does not break causality?
Preserving causality has significant benefits. Breaking causality is likely to be non-trivial, and opportunities to do so are negligible in the foreseeable future. This makes it unlikely for us to directly test the predictions of Deutschian CTCs. The preservation of causality in OTCs, however, suggest that its non-linear effects may be synthesized using alternative means. For instance, from the perspective of a chronology respecting observer, a particle sent through an OTC exhibits nothing more than time delay. Thus, in order to reconcile quantum field theory with non-hyperbolic space-times, gravitational time-dilation has been conjectured to share similar operational effects as OTCs [272]. If true, our protocols suggest the exotic benefits of quantum processing in the general relativistic regime can be tested much sooner than previously expected.
Chapter 12 Quantum theory from axioms
Quantum Information provided a new angle on the foundations of Quantum Mechanics, where the emphasis is placed on operational tasks pertaining information-processing and computation. In this spirit, several authors have proposed that the mathematical structure of Quantum Theory could (and should) be rebuilt from purely information-theoretic principles. This chapter reviews the particular route proposed by D’Ariano, Perinotti, and Chiribella [273, 274, 275] and probes its application in nonlocality and contextuality [276].
12.1 Axiomization of quantum theory
Quantum mechanics has been one of the greatest scientific breakthroughs of the 20th century, and at the beginning of the 21st it still provides the most accurate predictions about the microscopic world and a key to new exciting discoveries. A young branch of quantum mechanics is quantum information science. Over the past three decades, this new field brought to light a wealth of operational consequences of the mathematical structure of quantum theory: no-cloning [277], quantum teleportation [7], dense coding [54], quantum key distribution [6, 8], and quantum algorithms [10, 9] are just a few examples showing that quantum theory entails a powerful and totally new model of information processing.
Which are the conceptual ingredients of this power? What makes the quantum model special with respect to the classical one or to other more exotic models that we can conceive? Stimulating new questions are the best route to answering older, long-standing questions. Inspired by the surprising features of quantum information, many researchers—notably Fuchs [278] and Brassard [279]—suggested that the whole structure of quantum theory, with its dowry of Hilbert spaces and operator algebras, could be reconstructed from a few simple principles of information-theoretic nature. Reconstructing quantum theory means rigorously proving that, once we define a sufficiently general class of possible theories, quantum theory is the only one compatible with the principles. Many proposals of reconstructions of quantum theory have been made, in different frameworks and with emphasis on different features [274, 280, 281, 282, 283, 284, 285, 286], bringing a breeze of fresh air on the long standing problem of a conceptual axiomatization of quantum mechanics. Here we will focus on the reconstruction of Ref. [274], which presented a new set of information-theoretic principles directly inspired by quantum information.
The structure of Ref. [274] is devised to highlight one particular feature as the ingredient that generates the surprising features of quantum theory: the ingredient is the purification principle [274, 273], stating that every physical process can be simulated using only pure states and reversible interactions with an environment. The principle is directly inspired by quantum information, where the applications of purification are countless. In addition to purification, Ref. [274] contains five principles that are influence the outcome probabilities of present experiments. Combining these five, seemingly innocuous requirements with the purification principle, Ref. [274] singled out quantum theory uniquely. This result has been recently presented in a non-technical terms in Ref. [287]. In the following we will introduce the reader to the principles of Ref. [274], providing their translation in the ordinary mathematical language of quantum theory. The principles will be first stated in the non-technical terms of Ref. [287], and then illustrated in the special example of quantum theory.
12.1.1 Operational vs Hilbert space framework
Most works on the reconstruction of quantum theory adopt an operational framework describing the experiments that a physicist can perform in a laboratory. Each device has an input system and an output system, a set of possible outcomes that the experimenter can read out, and a set of random processes occurring in conjunction with the outcomes. As a special case, a device can have trivial input (i.e. no input at all), in which case its action consists in preparing a system in a particular set of states. Likewise, the device can have trivial output, in which case its action consists in a demolition measurement that absorbs the system, producing an outcome with some probability (think for example of the absorption of a photon on a photograhic plate). Quantum theory can be cast in the operational framework as a special example. In the mathematical language of quantum theory, systems are described by Hilbert spaces, and the outcomes of a device correspond to outcomes of an (indirect) measurement. A device that prepares states of a system with Hilbert space corresponds to an ensemble , where each is a density matrix (non-negative operator with unit trace) and are probabilities. Here is the probability that the device outputs the system in the state . A device that performs a demolition measurement will be described by a positive operator valued measure (POVM), namely a collection of non-negative operators satisfying the condition , where is the identity operator on the Hilbert space of the system. When a POVM measurement is performed on a system prepared in the quantum state , one obtains the outcome with probability . The textbook example of POVM measurement is the measurement on an orthonormal basis ( being the dimension of the Hilbert space), corresponding to the POVM with .
General quantum processes (with both non-trivial input and non-trivial output) are described by the theory of open quantum systems [288, 289]. When a system , initially prepared in state , interacts with an environment , initially prepared in state , through a joint unitary evolution , the joint state changes to . If we perform a measurement on the environment, with POVM , the outcome will occur with probability and, for , the state of the system conditionally to outcome will be given by . Here, is the linear map
[TABLE]
denoting the partial trace over the environment. Any such map is completely positive (it transforms positive operators into positive operators even if we apply it only on one part of a composite system) and trace-decreasing ( for every density matrix ). Completely positive trace-decreasing maps are known as quantum operations [290]. A collection of quantum operations as in Eq. (12.1) is known as quantum instrument [291]. A quantum instrument describes the action of a device that couples the system with an environment and performs a measurement on the latter. A quantum operation can be always written in the Kraus form [290]
[TABLE]
where is a set of operators on the system’s Hilbert space. Here we can think of each operator as representing a “quantum jump” that randomly changes the state of the system to .
When there is a single operator in Eq. (12.2), we know exactly which quantum jump has occurred for outcome . In this case, we say that the process is fine-grained, because knowing the outcome gives full information about the jump undergone by the system. On the contrary, a quantum operation with more than one Kraus operator represents a coarse-grained process: in principle, one can devise a finer measurement on the environment with outcomes , inducing the quantum operations . For example, if the environment is a particle with spin, measuring only the position of the particle would result in a coarse-grained process, because the information coming from the spin degree of freedom has been ignored.
Coarse-graining over all possible outcomes , the evolution of the system’s state under the random-process is given by . The linear map is called quantum channel. Due to the normalization of the probabilites, the map is trace-preserving, namely
[TABLE]
as it can be easily checked by taking the sum in Eq. (12.1) and using the normalization .
12.1.2 Informational principles and their translation in the Hilbert space language
At the general operational level, devices can be connected with one another, if the output system of one device coincides with the input system of the next. Note that the notion of input and output of a device singles out in a privileged direction when we compose systems. The first principle in Ref. [274, 287] states that information can only flow from input to output.
Causality: * The probability of an outcome at a certain step does not depend on the choice of experiments performed at later steps.*
Let us illustrate the meaning of the principle in the Hilbert space framework. Suppose that a quantum system, initially prepared in the state , is sent first to the quantum instrument and then to another quantum instrument (for example, the two instruments could be to successive Stern-Gerlach devices). The joint probability of observing the sequence of outcomes will be . In the general operational framework, causality states that the probability of observing outcome , given by should not depend on the choice of the particular quantum instrument (in the example, it should not depend on the orientation of the magnetic field in the second Stern-Gerlach device). This condition is indeed satisfied, thanks to the normalization condition of Eq. (12.3), which gives , independently of the choice of .
In we place our operational theory in a relativistic spacetime, than we have that causality forbids information to travel faster than the speed of light, in the sense that the outcome probabilities for an experiment performed at a spacetime point can not depend on the settings of experiments performed at spacetime points that do not contain in their light cone. As a consequence, causality implies the no signalling principle: when two experiments take place in space-like separated regions, the outcome probabilities for an experiment should not depend on the settings of the other experiment.
The second principle in Ref. [287] pertains the extraction of information from composite systems.
Local tomography: The state of a composite system is determined by the statistics of local measurements on its components.
Let us illustrate the principle in the quantum case: suppose that two density matrices on the Hilbert space give the same statistics for every pair of local POVM measurements and on and , namely for all . Choosing and to be arbitrary rank-one projectors and and using the polarization identity, we then conclude that must be equal to . This means that the probability distributions for local measurements are sufficient to identify the density matrix of the composite system . Note that the property of local tomography, which holds both for classical and quantum theory, fails to hold for the variant of quantum theory on real Hilbert spaces [292].
The following principle states an information-theoretic property of the composition of physical processes.
Fine-Grained Composition: The sequence of two fine-grained processes is a fine-grained process.
As we already noted, a fined-grained process in quantum theory is represented by a quantum operation of the form , so that the information about the outcome is enough to identify the quantum jump . Suppose now that we have two devices in a sequence, and that the two devices produce two outcomes and corresponding to two fine-grained processes and , respectively. The composite process will be given by the quantum operation , which still represents a fine-grained process.
The next principle guarantees that we can encode classical bits using the physical systems available in our operational theory:
Perfect Distinguishability: If a state is not compatible with some preparation, then it is perfectly distinguishable from some other state.
What does it mean that a state is not compatible with some preparation? Consider a mixed quantum state, with density matrix . The state can be interpreted as the average state of the ensemble , where the system is prepared in the pure state with probability . According to this interpretation, the state is compatible with the system being prepared in every pure state . Saying that a density matrix is not compatible with some preparation means that there exists some pure state that cannot appear in any ensemble decomposition of . In formula, this means that the only solution to the equation
[TABLE]
with a density matrix, is and . Technically, if a density matrix is not compatible with some pure state, then cannot be invertible. This means that will have a non-trivial kernel . Hence, every unit vector will be orthogonal to , and, therefore, it will represent a pure state of the system that is perfectly distinguishable from . For example, the state of a three-level system is not compatible with the system being prepared in the pure state . The perfect distinguishability principle then imposes that there must exist a state that is perfectly distinguishable from : in this particular example, . Perfect distinguishability enables us to encode classical bits into quantum states. For instance, we can encode a classical bit into the angular momentum of a nucleous, by encoding the logical 0 in the the spin up state and the logical 1 in the spin down state .
The next principle ensures the possibility of encoding the state of a system in the state of another system of potentially smaller “size”.
Ideal Compression: Information can be compressed in a lossless and maximally efficient fashion.
Let us make mathematically precise the meaning of this principle through an example in quantum theory. Suppose that a three-level system is prepared in the mixed state . This preparation is compatible with the system being in every pure state , with . It is clear that we can encode these states in a two-level system using the encoding channel with and . With this encoding, the state is the “codeword” for the state . The encoding is lossless for the information compatible with , because we can always restore the initial state from . The encoding is also maximally efficient, because we cannot encode without losses the pure states in a system of Hilbert space dimension smaller than 2. In general, the encoding of a mixed state into another physical system is maximally efficient if every pure state of is the codeword for some pure state compatible with . For a density matrix of rank , the ideal compression is obtained by encoding the information in a Hilbert space of dimension .
All the principles discussed so far are satisfied both by classical and quantum theory. The principle that singles out uniquely quantum theory is the following
Purification Principle: Every random process can be simulated in an essentially unique way as a reversible interaction of the system with a pure environment.
Let us illustrate the meaning of the principle in the Hilbert space framework, where random processes are described by quantum channels. One way to simulate a random process is to introduce an environment with Hilbert space . For example, every pure state and every unitary operator satisfying will give
[TABLE]
This means that the random process can be simulated by letting the system interact unitarily with an environment prepared in the pure state . Since unitary interactions are reversible, this is an example of the pure and reversible simulation required by the purification principle. The pure and reversible simulation is not unique, because we are free to choose to be any pure state of the environment and to choose the basis used in the definition of to be any orthonormal basis for . However, the pure and reversible simulation is essentially unique: once we fix the environment there is no remaining freedom except for the choice of bases for Hilbert space .
The ability to purify every random process is a unique feature of quantum theory. The main message of Refs.[274, 287] is that, among all physical theories satisfying the first five reasonable requirements, quantum theory is the only one that enables a pure and reversible simulation of every random process. Such a key feature places quantum theory at the core of the theory of reversible computation. From this angle, the usual picture is turned upside down: instead of regarding quantum theory as “incomplete” [28] because it fails to give deterministic predictions about the outcomes of arbitrary measurements, we are brought to regard classical theory as “incomplete” because it fails to provide a pure and reversible simulation of arbitrary random processes. This type of simulation is essential if we want to reconcile information theory and physics, the former being based on the notions of random variable and noisy channel, and the latter trying to model phenomena in terms of pure states and fundamentally reversible interactions.
12.2 Measurement sharpness trims nonlocality and contextualize in every physical theory
Nonlocality [28, 19] and contextualize [293, 294] are among the most striking features of quantum mechanics, in radical conflict with the worldview of classical physics. Still, quantum mechanics is neither the most nonlocal theory one can imagine, nor the most contextual. For nonlocality, this observation dates back to the seminal work of Popescu and Rohrlich [295], who showed that relativistic no-signalling is compatible with correlations that are much stronger than those allowed by quantum theory. Their work stimulated the question whether other fundamental principles, yet to be discovered, characterize the peculiar set of correlations observed in the quantum world. Up to now, several candidates that partly retrieve the set of quantum correlations have been proposed, including Non-Trivial Communication Complexity [296, 297], No-Advantage in Nonlocal Computation [298], Information Causality [299], Macroscopic Locality [300], and, most recently, Local Orthogonality (LO) [301]. The observation that quantum theory is not maximally contextual is more recent [302, 303] and so is the search for principles that characterize the quantum set of contextual probability distributions. On this front, the only principle put forward so far is Consistent Exclusivity (CE) [304, 305, 5].
Despite many successes, a complete characterization of the quantum set is still challenging. What makes the problem hard is the fact that—intendedly—the principles considered so far dealt only with input-output probability distributions, without making any hypothesis on how these distributions are generated. On the other hand, a physical theory does not provide only probability distributions, but also specifies rules on how to combine physical systems together, how to measure them, and how to evolve their state in time [306]. Considering that fundamental quantum features like no-cloning and the possibility of universal computation cannot be expressed just in terms of input-output distributions, it is natural to wonder whether also quantum nonlocality and contextualize could better understood in a broader framework of general probabilistic theories (GPTs) [280, 307, 273, 308]. Further motivation to extend the framework comes from the latest principles in the nonlocality and contextualize camps, LO and CE. Both principles refer to a notion of orthogonal events and impose that the sum of the probabilities of a set of mutually orthogonal events shall no not exceed one. This is a powerful requirement, which in the case of LO is even capable to rule out non-quantum correlations that are compatible with every bipartite principle [309]. But why should Nature obey such a requirement? And what does this requirement tell us about the fundamental laws that govern physical processes?
Here we tackle the problem of understanding quantum nonlocality and contextualize from a new angle, which focuses on the fundamental structure of measurements. In an arbitrary physical theory, we introduce a class of ideal measurements, called sharp, that are repeatable and cause the minimal amount of disturbance on future observations. We postulate that all measurements are sharp at the fundamental level and we explain the apparent unsharpness of real life experiments as due to the interaction with the environment. Assuming that sharp measurements remain sharp under elementary operations, such as joining two outcomes together and applying two measurements in parallel, we show that the fundamental sharpness of measurements implies the validity of CE and LO, thus providing a strong constraint on the set of probability distributions. Our result demonstrates that principles formulated in the broader framework of GPTs can offer an extra power in the characterization of the quantum set and identifies the fundamental sharpness of measurements as a candidate principle for future axiomatizations of quantum theory.
12.2.1 Framework
In a general theory, a measurement is described by a collection of events, each event labelled by an outcome. We first consider demolition measurements, which adsorb the measured system. In this case, the measurement events are called effects and the measurement is a collection of effects . For a system prepared in the state , the probability of the outcome is denoted by . In quantum theory this is a notation for the Born rule , where is a density matrix and is a measurement operator. In general theories, however, does not denote a trace of matrices and in fact the actual recipe for computing the probability is irrelevant here. We will often use the notation and for effects and states, respectively. It is understood that two different states give different probabilities for at least one effect, and two different effects take place with different probabilities on at least one state.
When two measurements and are performed in parallel on two systems and , we denote by the measurement event labelled by the pair of outcomes . Similarly, when two states of systems and , say and , are prepared independently, we denote by the corresponding state of the composite system . In quantum theory, this is the ordinary tensor product of operators, but this may not be the case in a general theory and, again, the actual recipe for computing is irrelevant here. What is relevant, instead, is that the notation is consistent with the operational notion of performing independent operations on different systems: If two systems are independently prepared in states and and undergo to independent measurements and , we impose that the probability has the product form .
The most basic operation one can perform on a measurement is to join some outcomes together, thus obtaining a new, less informative measurement. This operation, known as coarse-graining, is achieved by dividing the outcomes of the original measurement into disjoint groups , and by identifying outcomes that belong to the same group. The result of this procedure is a new measurement satisfying the relation for every every and for every possible state . For brevity, we write .
Coarse-graining allows one to express the principle of causality, which states that the settings of future measurements do not influence the outcome probabilities of present experiments [273]. Causality is equivalent to the requirement that for every system there exists an effect , called the unit, such that
[TABLE]
for every measurement on . In quantum theory, is the identity operator on the Hilbert space of the system and Eq. (12.6) expresses the fact that quantum measurements are resolutions of the identity. When there is no ambiguity, we drop the subscript from .
Causality has major consequences. First of all, it implies that the probability distributions generated by local measurements satisfy the no-signalling principle [273]. Moreover, it allows to perform adaptive operations: for example, if is a measurement on system and is a measurement on system for every value of , then causality guarantees that it is possible to choose the measurement on depending on the outcome on system , i. e. that is a legitimate measurement. Finally, causality allows one to describe non-demolition measurements. For a non-demolition measurement , the measurement events are transformations, which turn the initial state of the system, say , into a new unnormalized state . For a system prepared in the state , the probability of the outcome is and, conditionally on outcome , the post-measurement state is . We will often refer to the non-demolition measurements as instruments, in analogy with the usage in quantum theory [310, 311]. Note that, thanks to causality, every instrument is associated to a unique demolition measurement via the relation
[TABLE]
By definition, describes the statistics of the instrument: for every state and for every outcome , one has .
Sharp measurements in arbitrary theories
In textbook quantum mechanics, physical quantities are associated to self-adjoint operators, called observables CITA. The values of a quantity are the eigenvalues of the corresponding operator and the probability that a measurement outputs the value is given by the Born rule , where is the projector on the eigenspace for the eigenvalue and is the density matrix of the system before the measurement. If the measurement gives the outcome , then the state after the measurement is , according to the projection postulate. These canonical measurements, where all the measurement operators are orthogonal projectors, are called sharp [312]. While it is clear that sharp measurements play a key role in quantum theory it is by far less clear how to define them in an arbitrary GPT. Here we propose a simple definition based on the notions of repeatability and minimal disturbance.
Let us start from repeatability. An instrument is repeatable if it gives the same outcome when performed two consecutive times, namely
[TABLE]
where is the measurement of Eq. (12.7). Repeatability poses a fairly weak requirement on : every measurement that discriminates perfectly among a set of states can be realized by a repeatable instrument, which consists in measuring and, if the outcome is , re-preparing the system in state .
The second ingredient entering in our definition of sharp measurements is minimal disturbance. We say that the instrument does not disturb the measurement if the former does not affect the statistics of the latter, namely
[TABLE]
where . Then, we ask which instruments disturb the smallest possible set of measurements. Clearly, if does not disturb , then must be compatible with the measurement , in the sense that and can be measured jointly. Indeed, by measuring after one obtains the probability distribution , whose marginals on and are equal to the probability distributions of and , respectively. Read in the contrapositive, this means that if and are incompatible, the instrument must disturb . This leads us to the following definition: an instrument has minimal disturbance if it disturbs only the measurements that are incompatible with .
We define an instrument to be sharp if it is both repeatable and with minimal disturbance. We say that a measurement is sharp if it describes the statistics of a sharp instrument and we call an effect sharp if it belongs to a sharp measurement. In quantum theory, our definition coincides with the usual one: one can prove that the only sharp instruments are the Lüders instruments [313], of the form where is a collection of orthogonal projectors. Hence, the sharp measurements are projective measurements. In addition, we can prove that when a sharp measurement extracts a coarse-grained information, the experimenter can still retrieve the finer details at a later time. In fact, this is a necessary and sufficient condition for a measurement to be sharp, as proven in the Methods section.
Fundamental sharpness of measurements
Sharp measurements are an ideal standard—they are the measurements that generate outcomes in a repeatable way, while at the same time causing the least disturbance on future observations. Unfortunately though, most measurements in real life appear to be noisy and not repeatable. Hence the natural question: Is noise is fundamental? Or rather it is contingent to the fact that the experimenter has incomplete control on the conditions of the experiment? Here we state that noise is not fundamental and only arises from the fact that the realistic measurements do not extract information only from the system, but also from the surrounding environment:
Axiom 1** (Fundamental Sharpness of Measurements).**
*Every measurement arises from a sharp measurement performed jointly on the system and on the environment. *
Precisely, we require that for every measurement there exists an environment , a state of , and a sharp measurement on the composite system such that, for every state of system , one has for every outcome . In quantum theory, this is the content of the celebrated Naimark’s theorem [314, 315]. This is a deep property, hinting at the idea there exists a fundamental level where all measurements are ideal.
Let us push the idea further. If measurements are sharp at the fundamental level, it is natural to assume that the set of sharp measurements is closed under the basic operation of coarse-graining, which transforms an initial measurement into a new, less informative measurement . Indeed, since provides less information than , one expects that should not be less repeatable, nor create more disturbance, than . This intuition leads to the following requirement:
Axiom 2** (Less Information, More Sharpness).**
If a measurement is less informative than a sharp measurement, then it is sharp.
Suppose now that two experimenters, Alice and Bob, perform two sharp measurements on two systems and in their laboratories. Again, if measurements are sharp at the fundamental level, one expects the result of Alice’s and Bob’s measurements to be a sharp measurement on the composite system . If this were not the case, it would mean that at the fundamental level some measurements require nonlocal interactions, even though at the operational level the they appear to be implemented locally by Alice and Bob. We then postulate the following
Axiom 3** (Locality of Sharp Measurements).**
If two sharp measurements are applied in parallel on systems and , then the result is a sharp measurement on the composite system .
Axioms 1-3 lay down the fundamental structure of sharp measurements, summarized in Fig. 12.1.
They are satisfied by classical theory and by quantum theory, both on complex and real Hilbert spaces. In the following we will show that the fundamental structure of sharp measurements has an enormous impact on the amount of nonlocality and contextualize that can be found in a physical theory.
12.2.2 Derivation of CE
At present, CE is the only principle known to constrain the amount of contextualize of a generic theory. Operationally, the principle can be formulated as follows: Consider a collection of sharp measurements , each measurement having outcomes in a set . Suppose that the possible events have been labelled so that two effects corresponding to the same outcome coincide, i. e. , independently of . Letting be the set of all outcomes, one calls two distinct outcomes exclusive if there exists a measurement setting such that both and belong to . We say that a theory satisfies CE if for every set of mutually exclusive outcomes and for every state the probabilities obey the bound
Our first key result is the derivation of CE. In fact, we prove a stronger result: We define two sharp effects and to be orthogonal if they belong to the same measurement and we prove that mutually orthogonal effects can be combined into a single sharp measurement (see Methods). Clearly, since mutually exclusive outcomes correspond to mutually orthogonal effects, the existence of a joint measurement containing the effects implies the bound . Our result implies that in a theory where measurements are fundamentally sharp the violation of Kochen-Specker inequalities is upper bounded by the value set by CE [303]. What is remarkable here is that a single requirement on measurements influences directly the strength of contextualize in an arbitrary physical theory. This situation contrasts with that of the known axiomatizations of quantum theory [280, 274, 283, 282, 316, 284], where the quantum bounds on contextualize are retrieved only indirectly through the derivation of the Hilbert space framework.
Our axioms do not imply only CE, but also the whole hierarchy of extensions of this principle defined in Ref. [5]. The -th level of the hierarchy can be defined by considering independent measurements on copies of the state . Denoting by the string of all outcomes, one says that two strings and are exclusive if there exists some such that and are exclusive. A physical theory satisfies the -th level of the hierarchy if the probabilities obey the bound for every set of mutually exclusive strings. In the Methods section we show that our axioms on sharp measurements imply that this bound is satisfied for every possible .
12.2.3 Derivation of LO
In the nonlocality camp, LO occupies a special position, being up to now the only known principle that rules out non-quantum correlations that are not detected by any bipartite principle [309]. LO refers to a scenario where parties perform local measurements on systems, initially prepared in some joint state. The -th party can choose among different measurement settings in a set and her measurements give outcomes in another set . Let be the string of all settings, be the string of all outcomes, and be the pair . In this context, the pair is called an event and two events are called locally orthogonal iff there exists a party such that and . Setting to be the conditional probability distribution , one says that theory satisfies local orthogonality if all the probability distributions generated by local measurements obey the bound for every set of pairwise locally orthogonal events.
To derive LO, we specify how the probability distribution is generated: In the most general scenario, the parties share a state and that, for setting , party performs a measurement . Denoting the product effects , the probability distribution of the outcomes is given by . The proof that LO follows from the axioms, provided in Methods, consists of three steps: First, thanks to the Fundamental Sharpness of Measurements, the problem is reduced to proving that LO holds for probability distributions generated in a scenario where all parties perform sharp measurements. Then, we observe that, in the case of sharp measurements, locally orthogonal events correspond to orthogonal effects. Finally, we use the fact that mutually orthogonal effects can coexist in a single measurement. As a corollary, we obtain the bound , establishing the validity of LO for all the probability distributions generated by measurements in our theory.
Like in the case of CE, our axioms imply the whole hierarchy of extensions of LO introduced in [5]. The hierarchy is defined as follows: the probabilities satisfy the -th level of the hierarchy if their product satisfies LO. Now, we can think of the product as being generated by measurements on copies of the state . In this way, we reduce the problem of proving the -th level of the hierarchy to the problem of proving LO for measurements performed on the state . But we already proved the validity of LO for arbitrary measurements and arbitrary states. In conclusion, the structure of sharp measurements implies that LO is satisfied at every possible level. A striking consequence of this argument is that the fundamental sharpness of measurements rules out PR box correlations, as the latter violate the LO hierarchy [301]. In other words, in the world of PR boxes some measurements must be fundamentally noisy. Finally, since our axioms imply LO, in particular they imply all the limitations that LO sets on Bell inequalities and nonlocal games. We will elaborate on this point in the following.
12.2.4 Sharp Bell inequalities
The request that measurements are ideal at the fundamental level exerts a censorship on the amount of nonlocality that can be detected by experiments. To illustrate this fact, we show a number of Bell inequalities where the sharpness of measurements prevents every violation. We call such inequalities sharp.
Consider a game played by non-communicating parties and a referee, who sends to party an input and receives back an output . The referee chooses the input string at random with probability and assigns a payoff to the players, assumed without loss of generality to be nonnegative for every . The expected payoff obtained by the players is given by , where is the probability distribution describing their strategy. For a given game, the maximum payoff that can be achieved by classical strategies—call it —defines a Bell inequality, . The game can be associated with a graph , here called the winning graph, by choosing as vertices the events such that and placing an edge between two events and if they are not locally orthogonal, as illustrated in Figure 12.2.
In this picture, the maximum payoff achieved by classical strategies is
[TABLE]
where is a clique, i. e. a subset of with the property that every two vertices in are connected [301].
A first class of games leading to sharp Bell inequalities is the class of games with a graph that is the disjoint union of mutually disconnected cliques . This class contains the game Guess Your Neighbor’s Input [4] and the maximally difficult Distributed Guessing Problems of Ref. [301]. In addition, it contains other games such as, for even , the “Guess the Parity” game where each player is asked to guess the parity of the input string . For all these games, LO implies that the classical payoff is an upper bound. Indeed, picking for every the event that has maximum probability, the payoff can be bounded as
[TABLE]
and since the events are locally orthogonal by construction, one has and, therefore, . In conclusion, every sharp game defines a Bell inequality, that cannot be violated by any theory satisfying LO, and, in particular, by any theory where measurements are fundamentally repeatable and minimally disturbing. Using a result of Ref. [5], the proof that LO cuts the payoff down to its classical value can be extended to a larger class of games, defined by the property that the winning graph is a perfect graph [317]. For example, one such game is the “Guess the Product” game where the players are win if they guess the product of their inputs. Finally, there are examples of games where the Bell inequality is sharp even if the winning graph is not perfect, such as Guess the Parity when the number of players is odd (see Supplementary Note 1 for the proof that the payoff is upper bounded by the classical value).
Our results are derived in a minimal framework, which avoids some assumptions commonly made in GPTs. In particular, our arguments do not invoke local tomography [280, 318, 307], but only the requirement that sharp measurements are local. This requirement is strictly weaker: for example, it is satisfied by quantum theory on real Hilbert spaces, where local tomography fails. Also, the validity of our results does not require that the states of a given physical system form a convex set. Thanks to this feature, the results apply also to non-convex theories, like Spekkens’ toy theory [319]. Interestingly, probabilities themselves do not play a crucial role in our arguments and it is quite straightforward to extend the results to theories that only specify which outcomes are possible, impossible or certain, without specifying their probabilities, such as Schumacher’s and Westmoreland’s theory [320].
Since sharp measurements play a central role in quantum mechanics, it is not surprising that they have been the object of extensive investigation since the early days [321, 313, 322]. Later, Holevo proposed a purely statistical definition of sharp measurement, which does not refer to post-measurement states [323]. Although in the quantum case Holevo’s definition reduces to that of projective measurement, in general theories it is inequivalent to ours, and it is not clear how one could use it to derive features like LO and CE. Different notions of ideal measurements were put forward by Piron [324, 325] and Beltrametti-Cassinelli [326] in the framework of quantum logic. In general, they differ form our definition in the way the condition of minimal disturbance is defined. Most recently, measurement disturbance came back to play an important role in the search for basic principles principles, as shown e. g. by the No Disturbance Without Information principle of Ref. [327].
Our work joined the insights from two different approaches to the foundations of quantum mechanics: the characterization of quantum correlations [295, 296, 297, 298, 299, 300, 301] and the study of general probabilistic theories [280, 274, 283, 282, 316, 284]. Although these two approaches have developed on separate tracks so far, they share the same fundamental goal: understanding which picture of Nature lies behind the mathematical laws of quantum mechanics and guiding our intuition towards the formulation of new protocols and new physical theories. Our results demonstrate that the interaction between the two approaches can be beneficial for both. Here LO and CE stimulated the search for new principles in the GPT framework, leading to a compelling picture of nature where measurements are repeatable and cause minimal disturbance at the fundamental level. The idea that a noisy physical process can be reduced to an ideal process at the fundamental level reminds immediately of another quantum feature: Purification [273]. Operationally, Purification is the property that every mixed state can be generated from a pure state of a composite system by discarding one component. This principle implies directly entanglement and is at the core of the reconstruction of quantum theory of Ref. [274]. Our result suggests the possibility that purification and sharpness could be sufficient to derive quantum theory. In terms of quantum correlations, this would lead to the tantalizingly simple picture “Purification brings nonlocality in, sharpness cuts it down”. Going even further, it is intriguing wonder whether purification and sharpness can be viewed as two sides of the same medal by imposing that physical theories must satisfy a suitable requirement of time symmetry, similarly to what was done in quantum theory by Aharonov, Bergmann and Lebowitz [328, 329].
12.2.5 Methods
Characterization of sharp instruments. The starting point of our results is the observation that an instrument is sharp if and only if
[TABLE]
for every measurement that refines , i. e. for every . Let us see why Eq. (12.11) is equivalent to sharpness. First, suppose that Eq. (12.11) holds. Clearly, this implies that is repeatable, as one can see by summing over . Moreover, Eq. (12.11) implies that is a minimal disturbance measurement. Indeed, take a generic measurement that is compatible with . By definition, this means that there exists a joint measurement such that for every and for every . We then obtain
[TABLE]
having used Eq. (12.11) in the second equality. Summing over and using the normalization of the measurement we obtain the condition , or, equivalently, for every . Since probabilities are non-negative, this implies that each term in the sum vanishes, leading to the relation for every . Inserting this relation back in Eq. (12.12) we conclude that , that is, the instrument does not disturb . Hence, Eq. (12.11) implies that is a sharp instrument. Conversely, if is a sharp instrument then Eq. (12.11) must be satisfied. By definition, one has
[TABLE]
and using the repeatability condition one obtains . Again, the fact that probabilities are nonnegative implies that each term in the sum must vanish, namely for every . Now, let be a measurement such that . Since the measurement is compatible with , Eq. (12.9) implies with . On the other hand, for the condition implies . Hence, we conclude that for every and . ∎
Joint measurability of orthogonal effects. The characterization of sharp instruments, combined with the Less Information-More Sharpness principle, leads directly to the first key result of our work: a construction showing that mutually orthogonal effects can be measured jointly in a single sharp measurement. Precisely, if is orthogonal to for every , we show that there exists a joint sharp measurement such that .
Let us see how to construct the joint measurement. Let be the sharp measurement that contains the effect . By coarse graining of one obtains the binary measurement , with and . By the Less Information, More Sharpness postulate, is sharp. Let be the corresponding instrument. Now, since and are orthogonal, must be a valid measurement. Since is a coarse-graining of , Eq. (12.11) gives
[TABLE]
Now, consider the following measurement procedure: i) perform the first instrument ii) if the outcome is , then perform the second instrument, iii) for every , if the outcome of the -th instrument is , perform the -th instrument. The resulting instrument, denoted by consists of the transformations
[TABLE]
The measurement associated to the instrument is the desired joint measurement: indeed, and using Eqs. (12.7) and (12.13) we obtain for every . In addition, the measurement is sharp. Indeed, if a measurement is a refinement of , i. e. for all , then is also a refinement of the sharp measurement for every fixed . Hence, one has
[TABLE]
Using this fact and the definition of it is immediate to obtain the relation for every . Thanks to Eq. (12.11), this proves that the instrument is sharp, and so is the corresponding measurement . ∎
The ability to combine orthogonal effects into a single measurement is a powerful asset. As we already observed, it implies CE at its basic level. In the following we show that it can be used also to obtain the whole CE hierarchy.
Orthogonality of product effects. In a causal theory the information available at a given moment of time can be used to make decisions about the settings of future experiments, thus allowing for adaptive measurements where the choice of setting for a system depends on the outcome of a measurement on system . In particular, if is a sharp measurement on and is a sharp measurement for every , then is a legitimate measurement. Now, the Locality of Sharp Measurements implies that is sharp for every fixed . Since if arbitrary, this means that each effect is sharp and that two effects and are orthogonal unless and .
Thanks to this observation, it is easy to see that every level of the CE hierarchy is satisfied. The key is to note that if two strings of outcomes and are exclusive, then the corresponding effects and are orthogonal. This is clear because, by definition, the effects corresponding to two exclusive strings are of the form and where the effects and are orthogonal and the effects and are sharp thanks to the Locality of Sharp Measurements. Using our result about product effects, we then have that and are orthogonal. Now, a set of mutually exclusive strings corresponds to a set of mutually orthogonal effects . Since mutually orthogonal effects can be combined into a joint measurement, the probabilities obey the bound , meaning that the theory satisfies the -th level of the CE hierarchy for arbitrary .
Note that the same argument can be used to prove the validity of LO for the probability distributions generated in a scenario where all parties perform sharp measurements. In this scenario, two locally orthogonal events and correspond to two orthogonal effects and , for exactly the same reason mentioned above. Hence, the joint measurability of orthogonal effect implies the bound for every set of locally orthogonal events. In other words, all the probability distributions generated by sharp measurements obey LO.
Reduction to sharp measurements. While CE applies only to sharp measurements, LO applies to arbitrary measurements. This is because every probability distribution that we can encounter in our theory is a probability distribution generated by sharp measurements. This fact can be seen as follows: combining the Fundamental Sharpness with the Locality of Sharp Measurements, one can show that for every party and every measurement , there exists an ancilla , a state of , call it , and a sharp measurement such that for every and for every (cf. Supplementary Note 2 for the proof). Now, since all measurements that party can perform can be replaced by sharp measurements by adding an ancilla in a fixed state , the input-output distribution generated by arbitrary measurements on the state coincides with the input-output distribution generated by sharp measurements on the state . In other words, at the level of correlations there is no difference between sharp and non-sharp measurements. Thanks to this fact, deriving LO for sharp measurements is equivalent to deriving LO for arbitrary measurements.
Appendix A Coherence Distillation Procedure
A coherence distillation procedure refers to a series of incoherent operations by which a large number of identical partly coherent states can be transformed into a smaller number of maximally coherent states. This chapter introduces a coherence distillation procedure for pure qubit states. With copies of states , we show that we can asymptotically obtain copies of , where and satisfy . The derivation method can be generalized to an arbitrary dimension.
A.1 Coherence distillation: qubit
First we prepare copies of a partially coherent qubit state which will be uniformly divided into groups. The initial state of each group can be expressed according to
[TABLE]
A binomial expansion on the computational basis contains distinct coefficients . Thus we can divide the original -dimensional Hilbert space into subspaces according to the coefficients. For the th coefficient , the corresponding th subspace is a dimensional Hilbert space, whose basis are denoted by
[TABLE]
When considering the computational basis, is an N-qubit basis with s and s.
Next, we perform a projection measurement on to the subspaces. In our case, the projection operator that maps onto the th subspace is given by
[TABLE]
The probability of obtaining the th outcome is
[TABLE]
Note that as the coefficients for the expansion are the same, the post-selection of the th outcome corresponds to a maximally coherent state of dimension .
If , we can directly convert to copies of as desired. Or, we can repeat this process times, and take the tensor product of the post selected state to obtain a maximally coherent state of dimension ,
[TABLE]
where is the outcome of the th measurement, and the total dimension is . The total dimension will lie between and for some power . It can be proved [15] that as increases, will asymptotically approach [math].
Therefore, we can perform a second projection measurement to the -dimensional Hilbert subspace and directly get obtain a final state
[TABLE]
Using the above procedure, copies of a partly coherent qubit state have been distilled into copies of maximally coherent state .
In the following, we will show that all the operations of the distillation protocol are incoherent operations. In addition, we will show that the number of distilled maximally coherent state and the number of initial qubit satisfy the relation .
A.1.1 Incoherent operations
As the only operations are the two projective measurements, we only need to prove the following lemma.
Lemma 1**.**
Suppose an -dimensional Hilbert space has a complete basis . A projection measurement that divides into its complementary subsets are incoherent operations on the basis of .
Proof.
Suppose that the basis is divided into complementary subsets , such that , for all , and . Denote the projector that projects onto the subspace by . Thus, we can show that the projection measurement is a set of Kraus operators that satisfy and . To prove the projection measurement to be an incoherent operation, we additionally need to show that , where is the set of all incoherent states that can be represented by . As the definition of , we have
[TABLE]
where if and otherwise. Thus, we can show that for an arbitrary state , we have
[TABLE]
∎
Therefore, we have proven that the operations in the distillation protocol are incoherent.
A.1.2 Coherence loss
To explain why we have , we only need to consider the coherence loss during the distillation process. The initial state in each group can be rewrite as
[TABLE]
where is a maximally coherent state of dimension . Thus the density matrix of the initial state is
[TABLE]
As the coherence of is defined by its von Neumann entropy of its diagonal terms, we first look at . That is,
[TABLE]
Here, we can see that when , . Therefore Eq. (A.11) can be simplified as
[TABLE]
Here, has the decomposition . Thus, we have
[TABLE]
where is the von Neumann entropy of and is the Shannon entropy. Considering our coherence (intrinsic randomness) definition, Eq. (A.13) is equivalent to
[TABLE]
where is the average initial coherence and is the average coherence left after the first projection measurement. Therefore, the coherence loss in the first operation is
[TABLE]
The coherence loss for the second projection measurement can be easily estimated by . Thus the total coherence loss has an upper bound given by
[TABLE]
which is negligible relative to the initial coherence when and are large.
A.2 General definition
Generally, when considering the intrinsic randomness of multiple copies of , we can define the average intrinsic randomness in a manner similar to the definition of entanglement cost [174, 43, 17] by
[TABLE]
where is a suitable measure of distance, which, for instance, could be the trace norm. In this case, the intrinsic randomness is understood as the average coherence cost in preparing . Compared to the definition of the regulated entanglement of formation [174], we conjecture that equals the regulated intrinsic randomness measure,
[TABLE]
In the other direction, we can apply intrinsic operations to transform non-maximally coherent copies of to maximally coherent state . Similarly, we can define the distillable coherence by the supremum of over all possible distillation protocols [177, 43, 17],
[TABLE]
This distillable coherence can thus be considered as the amount of intrinsic randomness when a quantum extractor is performed before measurement, as shown in the main context. For a general reasonable regularized coherence measure similar to Eq. (A.18), we conjecture that the two measures and are equivalent for all possible distance measures. They serves as two extremal measures, such that, for all regularized . In addition, similar to entanglement measures [330, 331, 332], we show in the next section that the coherence measure for pure states is unique under regularization
A.3 A unique measure for pure states
In this section, we show that the measure of randomness is unique for pure quantum states.
First note that . Otherwise, we could first distill copies of into copies of , and then convert into copies of . For a pure state , we have already give a distillation protocol such that . Now, suppose that is a coherence measure for a single quantum state. By regularization, the coherence measure is given by
[TABLE]
Suppose that , we now prove that for pure state .
Proof.
For a given pure state , suppose that , that is, , where is a finite positive number. After the distillation process, we can convert copies of into approximately copies of . From the main context, we know that the remaining coherence is . For the measure, the coherence after distillation is also , while the initial coherence is given by . As is a finite positive number, the distillation process increases coherence, which leads to a contradiction.
If , we can follow a similar method by considering the transformation copies of into copies of . The contradiction originates from checking the coherence increase with the measure during the incoherent transformation process. ∎
Appendix B SI-QRNG
This chapter discusses finite size effect of the source independent quantum random number generator.
B.1 Calculation of the number of effective -basis measurements
In this appendix, we show that in the asymptotic limit, the number of effective -basis measurements is independent of . Our starting point is Eq. (10.5) and . Notice that normally is smaller than to ease fast post-processing; thus, the term and the other polynomial terms in Eq. (10.5) play a relatively small role in making . In the following, we consider only the exponent in Eq. (10.5).
For ease of notation, let , and . Then the exponent of Eq. (10.5) becomes
[TABLE]
and the inequality is approximately equivalent to
[TABLE]
Since is very small, one can make three approximations:
[TABLE]
[TABLE]
and
[TABLE]
Then, by applying Eqs. (B.2) and (B.3), the inequality (B.1) becomes
[TABLE]
Applying Eq. (B.4) yields
[TABLE]
and rearranging terms, we have
[TABLE]
Substituting the definitions of and , we obtain
[TABLE]
Finally, we substitute and get
[TABLE]
which is independent of .
B.2 Proof of the random sampling property for a type of QRNG input after loss
In this appendix, we first restate the setting. In the idealistic protocol, the measurement device chooses its measurement basis after confirming that the state received from the source is not a vacuum (or equivalently, not lost). In practice, confirming whether a state is a vacuum is usually done by observing whether detectors in the measurement device click or not. Thus, it is desirable for the measurement device to choose its basis before confirming whether loss happens.
We prove that for a specific input that defines the measurement basis choices before the potential loss, the positions of valid -basis measurements (after excluding loss events) are randomly drawn from the positions of the total of valid measurements. This proves that the random sampling technique from Fung et al. can still be applied when the measurement basis is chosen before the loss.
For ease of presentation, we state the input that specifies the measurement choices before the loss as follows. The input is a string of length that contains 0s and 1s. The possibilities for choosing the positions of 1s from the total positions are equally likely. Here, 0 stands for an -basis measurement and 1 stands for a -basis measurement. After loss, the numbers of valid -basis measurements and -basis measurements are denoted by and , respectively, with a total string length of
[TABLE]
We need to show that the output is uniform for the possibilities of choosing the positions of 1s from the total positions.
The proof proceeds through a symmetry argument. The input is symmetric, i.e., if we exchange the indices of two positions, the distribution will not change. Suppose that the initial positions are and the probability of choosing specific positions for 1s from the total positions is
[TABLE]
For ease of presentation, denote the left positions after loss as . Then each possibility with 0s in the left positions has the same probability
[TABLE]
which proves our claim.
As a side remark, we could see that the proof does not depend on whether the loss is basis dependent or independent. Thus, the same property also holds for a more general class of losses that could be useful in other settings. Another remark is that independent and identically distributed input also satisfies the property, as in the work of Fung et al.
B.3 Random seed dilution
The input is either given directly or expanded from a uniformly random seed. Here, we provide a method for performing the expansion. The expansion is straightforward since the input is also uniformly random within its support. We can simply map a uniform seed of length bijectively to the input support, which is the possibilities of choosing the positions of 0s from the string of of length . Then, we have obtained the desired input. Furthermore, note that this construction is deterministic; thus, input randomness is only needed for the uniformly random seed of length .
For the input of our protocol, the ratio of the initial random seed length to the number of runs becomes negligible as goes to infinity because the number of -basis measurements is a constant, as derived in Appendix B.1. More precisely, the min-entropy of the input as well as the length of the uniformly random seed has an upper bound given by
[TABLE]
Note that since the detector completely controls this random seed length, calculating the exact input min-entropy is possible. This is very different from estimating the error rate in the finite-key analysis section, in which we can only estimate the range of the error rate with a high probability of success. Apart from the input specified in the main text, independent and identically distributed bit strings are also a possible choice for the input. Finally, we remark that the reason to include this input seed length analysis is to make our QRNG composable.
Appendix C Proof for randomness requirement for the CH inequality
This chapter is the proof of the randomness requirement for the CH inequality.
C.1 Proof for finite strategies of choosing input settings
As we discussed in Sec. 9.2, there are two levels of strategies. One is the strategy of choosing the input settings and the other is about the outputs conditioned on inputs of Alice and Bob. As there are finite deterministic strategies of Alice and Bob, here, we prove that the strategies of choosing input settings is finite and can be characterized by all the possible optimal strategies of Alice and Bob.
Essentially, even the strategies of Alice and Bob are finite, the strategies of choosing input settings can always be infinite. Here, what want to prove is that any optimal strategy (including both levels) can be realized with finite strategies of choosing input settings.
Suppose there exist an optimal strategy that gives maximal CH value with LHVMs. For this strategy, we suppose there are finite strategies of choosing the input settings (the proof for infinite case follows similarly). Then, it is easy to check that for a given and hence in the optimal strategy, the optimal strategy for the output of Alice and Bob should be from the set Eq. (9.14). This also proves why we only take account of the possibly optimal deterministic strategies of Alice and Bob.
Now, suppose that there exist strategies of of choosing input settings for the first strategy of Alice and Bob, , that is,
[TABLE]
Here the superscript denotes the strategies of and the subscript denotes the strategy for Alice and Bob. It is easy to see that we can always take an average of all the strategies without decreasing the Bell value and violate the constraints. In this case, we can define one to the denote all the , , . That is,
[TABLE]
where
[TABLE]
Thus, we show that the strategies for choosing input settings can be combined into one for any strategy of Alice and Bob. In the following, we prove this argument in more detail.
Proof.
We use label to denote the th strategy of choosing input settings for a given strategy of Alice and Bob, to denote the strategies of Alice and Bob, and to denote the number of inputs meaning the subscript of .
We denote to be the th strategy of choosing input settings when the optimal strategy for Alice and Bob is . The prior probability for and input settings of each strategy are denoted as and , where and , respectively. Denote the Bell value for the th strategy to be , which is linear function of . Thus, the total Bell value is given by
[TABLE]
and the constraints of and are given by,
[TABLE]
Just as mentioned above, we can add up by defining and by
[TABLE]
Take Eq. C.6 into the Eq. C.5, consequently we find the constraints of and are given by
[TABLE]
We should also note that the substitution in Eq. (C.6) will not affect the Bell value,
[TABLE]
where the last equality is because is a linear function.
∎
C.2 Optimal strategy of the CH test
C.2.1 General condition
In this section, we present the optimal strategy in order to maximizing defined in Eq. (9.17) under constraints defined in Eq. (9.16).
For simplicity, we first consider the randomness requirement and set to be 0. That is, the input randomness is upper bounded by ,
[TABLE]
The Bell value with LHVMs is given by
[TABLE]
Hereafter, we denote by for simple notation. Group by the index of the strategies of Alice and Bob , , instead of , then we have
[TABLE]
where
[TABLE]
And the constraints are given by
[TABLE]
In the following, we investigate the optimal strategy based on value of .
(1) when .
With the normalization condition of , we can rewrite as
[TABLE]
In this case, we can write by
[TABLE]
where the coefficient is given in Table C.1.
Note that is upper bounded by , then we have
[TABLE]
Therefore, we have
[TABLE]
In addition, we can see that the equality holds by simply letting to be for and to be for . This special strategy is valid when , we have to consider differently for the other cases.
(2) When .
With the constraints defined in Eq. (C.14), we can also write as follows,
[TABLE]
Then can be similarly expressed by
[TABLE]
with coefficient defined in Table .
The intuition to maximize Eq. (C.19) is to assign smaller values to for smaller corresponding coefficients. Because , we can see that
[TABLE]
Therefore, the Bell value defined in Eq. (C.19) can be upper bounded by
[TABLE]
This equal sign can be achieved by following parameter:
[TABLE]
(3) When .
For this case, we can easily see that maximal Bell value can be achieved to be , which is the algebra maximum of . We show in the following that the Bell value cannot exceed .
From Eq. (C.19), we know that can be expressed by
[TABLE]
where denotes the part contribute negatively,
[TABLE]
Therefore, we show that . The equal sign is satisfied with the following strategy
[TABLE]
In this part, we consider the input randomness quantification of with both and , which are defined in Eq. (9.2). In this case, we have
[TABLE]
Note that, if we we substitute by
[TABLE]
we can show that the constraints on are given by
[TABLE]
Compared to Eq.C.10, if we replace by , we obtain a new Bell value ,
[TABLE]
Because and are related by Eq. (C.27), we can prove that
[TABLE]
Therefore, instead of considering both upper and lower bound of in the original Bell’s inequality, we can equivalently consider the same Bell inequality with , which has upper bound and lower bound [math]. We have our result as follows,
(1) When , that is
[TABLE]
(2) When , that is and
[TABLE]
(3) When , that is
[TABLE]
Therefore, the optimal CH value with LHVMs,
[TABLE]
C.2.2 Factorizable condition
Now, we consider the optimal strategy of the CH test with LHVMs under factorizable condition,
[TABLE]
As we denote by , we have
[TABLE]
Similarly, we consider first the case with . In the following, we show that all the five possible strategies are upper bounded by .
(1) When .
The result is based on the order of , , , and .
(a) and .
This case is equivalent to and . Thus we have . Amongst the five strategies, the biggest one is , which can be upper bounded by
[TABLE]
(b) and .
This case is equivalent to and . Thus we have . Amongst the five strategies, the biggest one is , which can be upper bounded by
[TABLE]
(c) and .
This case is equivalent to and . Thus we have . Amongst the five strategies, the biggest one is , which can be upper bounded by
[TABLE]
(d) and .
This case is equivalent to and . Thus we have . Amongst the five strategies, the biggest one is , which can be upper bounded by
[TABLE]
Therefore, we show that all the strategies are upper bounded by . Then the total Bell value
[TABLE]
and the equal sign holds.
(2) When .
It is easy to see that the maximal Bell value reaches 1 when .
Consequently, we show the optimal Bell value with LHVMs,
[TABLE]
We can follow a similar way in Appendix C.2.1 to take account of nonzero .
(1) When , that is
[TABLE]
(2) When , that is
[TABLE]
Thus, the Bell value with LHVMs under factorizable condition is,
[TABLE]
C.3 Optimal strategy of the CHSH inequality
C.3.1 CH and CHSH inequalities under NS
In this section, we prove that the CH and CHSH inequality are equivalent when NS is assumed. We refer to [333] for detail discussion about the connection between CH and CHSH.
Proof.
According to the inputs, we can divide the CHSH inequality into four parts. When inputs are , define :
[TABLE]
Owing to the NS condition, can be rewritten by probabilities with output [math],
[TABLE]
Therefore, we have
[TABLE]
∎
Hence, under the NS assumption, the value of the CH and the CHSH inequality are linearly related. To analyze the best LHVMs strategy for the CH test, we can therefore consider the CHSH Bell test instead.
C.3.2 General condition
Follwing the similar method described above, we first consider deterministic strategies, i.e., for the reason that any probabilistic LHVM could be realized with convex combination of deterministic ones. Denote as , it is easy to show that the possible optimal deterministic strategies for are
[TABLE]
Here, we also first consider that .
(1) When .
We can show that, all the four strategies are upper bounded by . Take the strategy of as an example,
[TABLE]
In this case, we can see that the CHSH value is upper bounded by .
(2) When .
In this case, LHVMs reaches the maximum Bell value, that is can be 4.
Thus, the Bell value LHVMs is
[TABLE]
For the case that is nonzero, we apply the same transformation as Appendix C.2.1. After the transformation defined in Eq. (C.27), the relation between and is given by
[TABLE]
In this case, the optimal Bell value for the CHSH inequality with LHVMs is
[TABLE]
And the optimal CH value with LHVMs under NS is
[TABLE]
C.3.3 Factorizable condition
In addition, we consider the factorizable condition,
[TABLE]
In this case, we have
[TABLE]
(1) When .
For the case that , are upper bounded by only. As the four strategies are symmetric, suppose that is the smallest one, which is equivalent to and . Thus we can see that is the largest strategy and is also upper bounded by
[TABLE]
Thus, we see that all the strategies are upper bounded by . Then the Bell value is upper bounded by .
(2) When.
We can easily see that LHVMs reaches the maximum Bell value, that is can be 4.
Consequently, the CHSH Bell value with LHVMs with factorizable condition is given by,
[TABLE]
For the case where , we can similarly derive our result. The CHSH Bell value is given by
[TABLE]
And the optimal CH value with LHVMs under NS and factorizable condition is
[TABLE]
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] John F. Clauser, Michael A. Horne, Abner Shimony, and Richard A. Holt. Proposed experiment to test local hidden-variable theories. Phys. Rev. Lett. , 23:880–884, Oct 1969.
- 2[2] Z. Leghtas, G. Kirchmair, B. Vlastakis, R. J. Schoelkopf, M. H. Devoret, and M. Mirrahimi. Hardware-efficient autonomous quantum error correction. Phys. Rev. Lett. , 111:120501, 2013.
- 3[3] Francesco Buscemi. All entangled quantum states are nonlocal. Phys. Rev. Lett. , 108:200401, May 2012.
- 4[4] Mafalda L. Almeida, Jean-Daniel Bancal, Nicolas Brunner, Antonio Acín, Nicolas Gisin, and Stefano Pironio. Guess your neighbor’s input: A multipartite nonlocal game with no quantum advantage. Phys. Rev. Lett. , 104:230404, Jun 2010.
- 5[5] Antonio Acín, Tobias Fritz, Anthony Leverrier, and Ana Belén Sainz. A combinatorial approach to nonlocality and contextuality. ar Xiv:1212.4084 , 2012.
- 6[6] C. H. Bennett and G. Brassard. Quantum Cryptography: Public Key Distribution and Coin Tossing. In Proceedings of the IEEE International Conference on Computers, Systems and Signal Processing , pages 175–179, New York, 1984. IEEE Press.
- 7[7] Charles H. Bennett, Gilles Brassard, Claude Crépeau, Richard Jozsa, Asher Peres, and William K. Wootters. Teleporting an unknown quantum state via dual classical and einstein-podolsky-rosen channels. Phys. Rev. Lett. , 70:1895–1899, Mar 1993.
- 8[8] Artur K. Ekert. Quantum cryptography based on bell’s theorem. Phys. Rev. Lett. , 67:661–663, Aug 1991.