Building Usage Profiles Using Deep Neural Nets
Domenic Curro, Konstantinos G. Derpanis, Andriy V. Miranskyy

TL;DR
This paper presents a method using deep convolutional neural networks to automatically recognize user actions in tutorial videos, enabling the construction of software usage profiles for testing and quality improvement.
Contribution
It introduces an automatic approach leveraging DCNNs to extract user actions from instructional videos, a novel application in software usage profiling.
Findings
Achieved a mean average precision of 94.42% in classifying user actions.
Demonstrated the effectiveness of DCNNs in extracting software usage information from videos.
Validated the approach on 236 publicly available tutorial videos.
Abstract
To improve software quality, one needs to build test scenarios resembling the usage of a software product in the field. This task is rendered challenging when a product's customer base is large and diverse. In this scenario, existing profiling approaches, such as operational profiling, are difficult to apply. In this work, we consider publicly available video tutorials of a product to profile usage. Our goal is to construct an automatic approach to extract information about user actions from instructional videos. To achieve this goal, we use a Deep Convolutional Neural Network (DCNN) to recognize user actions. Our pilot study shows that a DCNN trained to recognize user actions in video can classify five different actions in a collection of 236 publicly available Microsoft Word tutorial videos (published on YouTube). In our empirical evaluation we report a mean average precision of…
Click any figure to enlarge with its caption.
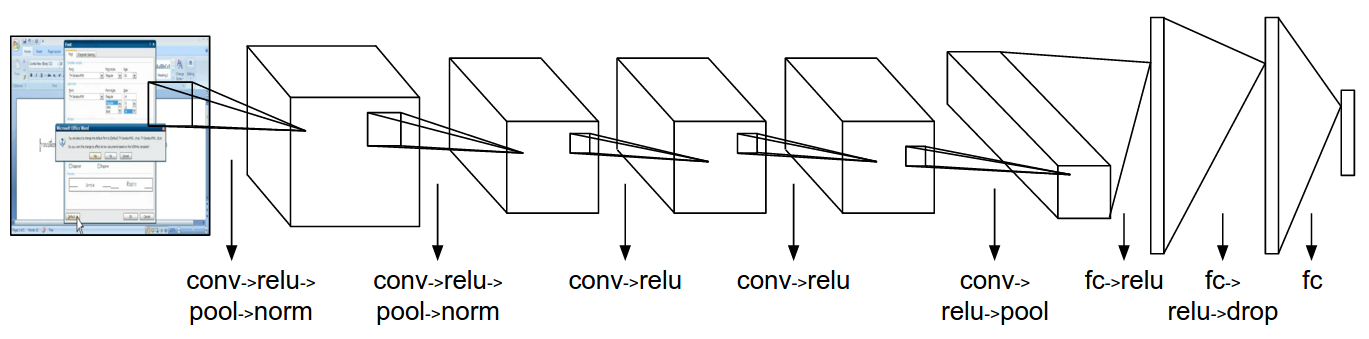 Figure 1
Figure 1 Figure 2
Figure 2| %recall | |||||||
| 38852 | 49 | 25 | 210 | 170 | 198 | 98.35 | |
| 27 | 86 | 2 | 0 | 3 | 0 | 72.88 | |
| 8 | 4 | 33 | 0 | 1 | 0 | 71.74 | |
| 34 | 0 | 0 | 347 | 0 | 0 | 91.08 | |
| 93 | 0 | 1 | 2 | 300 | 0 | 75.76 | |
| 39 | 0 | 0 | 0 | 1 | 253 | 86.35 | |
| 99.49 | 61.87 | 54.10 | 62.08 | 63.16 | 56.10 | %precision | |
| 98.91 | 66.93 | 61.68 | 73.83 | 68.89 | 68.01 | %F1-score |
| %recall | ||||||
| 4 | 1 | 1 | 0 | 0 | 66.67 | |
| 2 | 15 | 0 | 0 | 0 | 88.24 | |
| 1 | 0 | 75 | 2 | 2 | 93.75 | |
| 0 | 0 | 4 | 54 | 0 | 93.10 | |
| 0 | 0 | 1 | 0 | 74 | 98.67 | |
| 57.14 | 93.75 | 92.59 | 96.43 | 97.37 | %precision | |
| 61.54 | 90.91 | 93.17 | 94.74 | 98.01 | %F1-score | |
| 80.16 | 95.1 | 97.25 | 99.82 | 99.79 | % |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
MethodsDiffusion-Convolutional Neural Networks
Building Usage Profiles Using Deep Neural Nets
Domenic Curro, Konstantinos G. Derpanis, Andriy V. Miranskyy
Department of Computer Science, Ryerson University, Toronto, Canada
{d2curro, kosta, avm}@ryerson.ca
Abstract
To improve software quality, one needs to build test scenarios resembling the usage of a software product in the field. This task is rendered challenging when a product’s customer base is large and diverse. In this scenario, existing profiling approaches, such as operational profiling, are difficult to apply. In this work, we consider publicly available video tutorials of a product to profile usage. Our goal is to construct an automatic approach to extract information about user actions from instructional videos. To achieve this goal, we use a Deep Convolutional Neural Network (DCNN) to recognize user actions. Our pilot study shows that a DCNN trained to recognize user actions in video can classify five different actions in a collection of 236 publicly available Microsoft Word tutorial videos (published on YouTube). In our empirical evaluation we report a mean average precision of 94.42% across all actions. This study demonstrates the efficacy of DCNN-based methods for extracting software usage information from videos. Moreover, this approach may aid in other software engineering activities that require information about customer usage of a product.
I Motivation
As a software product’s codebase grows, the number of execution paths grows exponentially [9]. This makes it impossible to test all conceivable execution paths, especially at the system-test level or above, where a tester must simulate how a client uses the product as a whole in practice [9, 13]. Therefore, the tester needs to focus on the paths that users execute in the field. This requires the tester to identify the paths clients actually use, as well as the popularity of those paths [14]. To create a representative test scenario (i.e., workload covering execution paths traversed by the users in the field), the tester needs to know the action sequences that users perform along with their respective popularity among users. In this paper, usage profile denotes the sequences of user actions and popularity of these sequences among users.
A classic solution to this problem is operational profiling [14]. To create a profile one needs to log information about execution paths covered by users (typically, actions can be extracted from the paths). Once the data are gathered, the popularity of a given path can be estimated based on its execution frequency. In practice, this approach is difficult to apply to every client. For instance, customers are reluctant to enable logging infrastructure on production systems, as it may lead to performance degradation, instability, and privacy breaches [12]. Moreover, reaching every client (if the customer base is large) can be economically infeasible [13].
Another approach to identifying execution paths is by analyzing defects that users encounter and the sequences of actions/events needed to reproduce the defect [13]. The popularity of a given execution path can be estimated by the number of encounters of this defect that users report to support personnel. A drawback of this approach is that it is biased towards problematic execution paths (as the paths target defect reproduction). Moreover, not every defect encounter gets reported, e.g., because a user found a simple workaround or because the defect gets “patched” in the production codebase before a user executes a path containing a defect.
II Goal and Potential
In this work, we consider non-traditional data sources to construct representative client usage profiles. In particular, we use readily-available software product tutorials posted on video-sharing websites, such as YouTube. The tutorials allow an analyst to reconstruct the sequence of user actions to achieve their goal. The analyst can then assess the popularity of this sequence by looking at the number of views of a given video, as well as its rating (the views and rating data are publicly available). One can assume that the higher the number of views and rating of a video, the higher the probability that a given sequence will be used by clients in the field. Thus, the analyst can obtain two pieces of data needed to construct a usage profile: a sequence of actions and its popularity.
Information about the number of views and rating of the videos can be easily obtained using YouTube’s API. In contrast, manually obtaining the action sequences described in the videos is prohibitively expensive due the larger number of videos and their significant lengths. For example, at the time of writing, there were approximately videos (based on the number of videos found on youtube.com for the search keywords “microsoft word tutorial”). This motivates the need for automatic means to extract information about actions and their sequences from videos.
III Method
Deep Convolutional Neural Networks (DCNNs) [8, 11] have emerged as the standard approach for image understanding tasks, e.g., object recognition [1]. Recent work has demonstrated that the features learned in a DCNN are transferable to other related tasks [15, 7]. As a result, this reduces the amount of data required to train a network. In particular, rather than train a network from scratch, one begins with a pretrained network and fine-tunes the network’s parameters based on their (possibly limited) training data for the task at hand. Leveraging these advancements, we demonstrate that videos posted on websites, such as YouTube, are a rich source of untapped user-profiling data.
We constructed our dataset (available at [5]) by extracting the salient video frames. Frames were deemed salient when they were distinct enough from their neighbouring frames by a simple image difference approach. This ensures a wide variety in image appearances. The images were resized to pixels, and labelled based on the apparent user action.
The DCNN model was trained with Caffe [10], a popular open source deep learning framework. There are a variety of DCNN architectures used for image understanding. In this work, we used the AlexNet architecture [11], a standard DCNN baseline, summarized in Figure 1, which is a formulation of a Neural Network that is designed for image processing. It consists of five convolutional layers, which perform a discrete sliding window style image filtering with each element of the filter being a learnable weight; three max-pooling layers, which perform downsampling; three fully-connected layers, which compute the inner products of the learnable weights and the input feature vector; one dropout layer which deactivates 50 percent of the units randomly, adding a form of regularization; and a softmax loss layer, which performs a normalized multinomial logistic function of the output of the final fully-connected layer, producing class probability confidences. Each convolutional and fully-connected layer, except the final two, are followed by a non-linear rectified linear unit (ReLU) layer.
We leveraged knowledge transfer (in the spirit of [15, 7], as discussed above) by initializing the convolutional layers with the parameters learned by AlexNet for the ImageNet challenge [1]: a large scale natural image classification challenge consisting of 1000 classes [1] ranging from different species of dogs, to buildings and structures. The model was trained for three epochs111An epoch is the number of iterations to process the entire training set., using Stochastic Gradient Descent with a momentum of 0.9, weight decay of 0.0005, and a batch size of 128 images. The learning rate was initialized to 0.001 and was annealed by a factor of 0.1 every epoch. The network’s training error is computed with a multinomial logistic loss [11]. The input images are zero centered by subtracting the pre-calculated mean image from the ImageNet dataset. During training, we performed small random translations and randomly crop each image to pixels. This step artificially increases the training set, allowing for some spatial invariance [17, 4]. At test time, only the center pixels of the image are evaluated.
To profile user behaviour, each video was manually labelled with the class of the sequence of actions occurring in the video. When a video contains more than one class, it was split up into video clips, with one class per clip (standard practice within the action recognition community [2]).
Profiling is achieved by first classifying each frame of our test video to generate a time series of softmax-confidence class scores. Essentially, given frames in a video, we get a sequence of characters, , where represents the class of the -th frame. Regular expressions are used to localize the desired user action, within the sequence. (More sophisticated approaches to reasoning about action sequences are possible and reserved for future work.) The expression that returns the highest confidence score is considered the predicted execution path. In the case that no expressions matched [3], the frame with the highest confidence is mapped to its highest related execution path.
Performance is measured by analyzing a confusion matrix222Each row and column sums to the image count per class, and predictions per class, respectively. , precision, recall, and F1-score333The weighted average of the precision and recall.. To obtain overall model performance for classification of the video clips, we compute the Average Precision , a standard measure of model performance in computer vision444 is more sensitive than the Area Under the Curve measure [6, Sec. 4.2].: , where is the measured precision at recall ; see [6, Sec. 4.2] for details. All measures range between 0 and 1; the higher the value – the better the performance.
IV Pilot Study
IV-A Data Preparation
We manually assembled a dataset consisting of 236 Microsoft Word video clips, downloaded from YouTube. The dataset contains tutorial videos of users explaining how to achieve the following three goals: (i) change the default font, (ii) choose the number of columns in the document, and (iii) add page numbers to the document, for Word 2007, 2010, and 2013.
The resolutions of the videos range between and . The videos contain variety of user interface (UI) changes, screen-capturing software artifacts, intro and outro segments, screen tones and colors, user themes, tutorial artifacts, mouse occlusions, and varying system fonts. Example frames from the dataset are shown in Figure 2.
Individual actions Our dataset consists of a subset of frames from the original videos. Each frame was individually labelled based on its dominant class: , Font window; , Default Font window; , Column dropdown; , Column window; , Page Number; and , Background. There are 118 , 46 , 381 , 396 , 293 , and 39,504 frames.
Sequences of actions Each individual video clip was labelled to indicate the apparent user execution path. A video clip contains one the following five sequences of user actions: , opening the Font window, followed by opening the Default Font window; , opening the Font window, but not opening the Default Font window; , opening the Column Dropdown menu, selecting More Columns, opening the Columns Window; , opening the Column Dropdown menu, but not selecting More Columns; , selecting the Page Number Dropdown. There are 6 , 17 , 80 , 58 , and 75 clips. Note that and , and and represent mutually exclusive execution paths dedicated to fulfilling the same goal: setting the font and setting the number of columns, respectively. This shows that there can be multiple execution paths used to achieve a relatively simple goal.
IV-B Classifying Individual Images / Actions
We used 10-fold cross validation to train and evaluate our approach. The images were split into 10 subsets, where each fold contains a unique permutation of eight subsets as the training set, one as the validation set, and one as the test set.
We trained one model per fold, monitoring its performance on the respective validation subset. When the validation loss plateaued, training was manually stopped. Visualizing a loss (lower is better) over iteration curve, candidate iterations were chosen and their F1-scores and confusion matrices were produced. The best iterations ranged between 2133 and 4085 (with 3270 iterations on average), indicating that the best model is not always found at the final iteration of training. The average logistic loss for the best model of each fold ranged between 0.069 to 0.478 (0.168 averaged over all of the folds), suggesting that some models perform better than others.
Evaluating our models, we classify the images in each fold’s test set. The performance of our approach is summarized in Table I, which depicts an amalgamated confusion matrix of all ten folds (covering 40,738 images), as well as the precision, recall, and F1-scores. The background class, having the most examples, scored the highest on the F1-score at 98.91%. The remaining F1-scores range between 73.83% to 61.68%.
IV-C Classifying Videos / Sequences of Actions
Each frame of a video clip is associate with one or more user actions. Classifying the sequence of frames of a video, we generate a sequence of actions, allowing us to profile the customer’s use of the product (discussed in Section II).
First, the trained DCNN model555Models only predict video clips that were used to compose their test set. is used to predict the class of each frame of a test set video. This generates a sequence of class prediction softmax-confidence scores, as discussed in Section III. The sequences are then average-smoothed using a one second wide kernel (sliding window style smoothing). We also tried using a Gaussian kernel, but average-smoothing provided the best results. Then, to determine the user behaviour (also discussed in Section III), we applied regular expressions to these sequences of characters as follows.
Discovering if the user:
) sets their font via the Font window, we search for the font menu appearing for at least one second: f{r,}666In regular expression notation x{a,b} represents x occurring a to b times; x{a,} – x occurring a or more times., where r is the frame rate of the video, which acts as one second of video time in this context.
) sets their default font, we search for the Font window appearing, followed by the Default Font window appearing: f{r,}F{r,}f{0,r}. When the default font prompt is closed, for a short while, the font menu may remain open.
) sets the number of columns in the document via the Column dropdown menu, we search for the Column dropdown menu opening: c{r,}.
) sets the number of columns in the document via the Column window, we search for the Column dropdown opening, followed by the Column window appearing: c{r,}[^cC]{0,r}C{r,}. We allow time between the column drop down menu closing, and for the columns pop-up window finally appearing, accounting for noisy intermediate predictions of neither C nor c.
) sets the page number, we search for the Page Number dropdown menu opening: p{r,}.
Mandating that one second of a desired classification occurs eliminates one-off random false positive predictions, caused by the individual frame classification process.
When a regular expression is matched, that region of the sequence is removed to prevent any related regular expression from considering it. Thus, the user setting her default font via the Default Font window () must be searched for and removed prior to the user setting her font via the Font window (). Similarly, () should be searched for before ().
Results are summarized in Table II. Overall, the sequence classifier achieves a mean Average Precision of 94.42% (computed using Pascal VOC challenge toolbox); the ranges between 80.16% and 99.82%.
V Discussion and limitations
Training was performed using an nVidia Titan X Pascal GPU card. Training takes approximately thirty minutes. Validation speed was approximately 530 images per second. Thus, one hour of GPU time could potentially process 6.8 hours of YouTube video (assuming that we sample 1 frame per second), making it applicable for practical applications. Since the videos are independent of each other, processing can be easily parallelized on multiple GPU cards.
The original AlexNet DCNN was trained on natural images [11] (e.g., pictures of dogs, cats, and buildings), while we deal with a significantly different class of images from the UI domain. Nevertheless, our models have good predictive power, suggesting that at some level of abstraction (e.g., shape and thickness of the lines in the image) the key factors differentiating classes of natural and UI images are similar. Borrowing pretrained features from a network trained in a related domain has been demonstrated to yield better results [15, 7]. Thus, initializing our network with the learned features from a network specialized on UI images would likely yield higher classification power.
Note that the performance of the video clip classifier (discussed in Section IV-C) is higher than that of the classifier of a single image (discussed in Section IV-B). This can be explained by the increase of the amount of information in the sequence of frames in comparison with a single image: e.g., if we misclassify one frame in a sequence of ten frames, we will still be able to use the correct information from the remaining nine frames.
Limitations There are two major drawbacks with the proposed approach. First, DCNNs require a large volume of images for training to achieve high predictive power [11]. As a result, this approach may not be applicable to actions containing a relatively small number of training videos. Second, GPUs outperform CPUs in training and validating DCNNs by one to two orders of magnitude [16]. Thus, specialized hardware is required to speedup computation.
VI Related work
Video recordings are already used in Software Engineering (SE); e.g., in ethnographic studies of development organizations and in user experience research (see [18] for review). To the best of our knowledge, automatic classification of sequences in videos is not utilized.
There also exist tools for automatic user interface testing that search for a specific image on the screen [20]. However, these tools can only match user provided images to areas on the screen. While they do provide a threshold-error to allow near matches, they cannot account for unpredictable variation on the screen. While both approaches can automatically profile user action, only ours remains invariant to scale, color change, and version style change; thus, reducing the amount of manual labour and saving analysts’ time.
It was suggested [19] that DCNNs may be used in source code analysis for “… viz. code suggestion, code summarization, traceability link recovery, and feature location”. To the best of our knowledge, no-one in SE has considered extracting UI-based actions from videos using DCNN.
VII Conclusions and Future Work
In this work, we have studied the applicability of DCNNs to the extraction of user activities from video tutorials, showing that the extraction of information about user activities from video clips can be automated. Moreover, DCNNs are capable of generalizing to multiple versions of the UI. The information about the activities may be utilized in building usage profiles (e.g., to construct representative test scenarios/workloads) or in other software engineering activities that can leverage information about usage of a product. The approach is fast (processing approximately seven hours of video per GPU-hour) and scalable (as it can be easy parallelized on a GPU cluster). The predictive power of the DCNN model is high: the mean average precision is 94.42% on the five action sequences considered in our dataset [5] comprised of 236 Microsoft Word tutorial videos (published on youtube.com).
Going forward, we plan to expand the study to other products and features, explore statistical techniques for classifying sequences of images, and develop custom-built DCNNs tailored for the UI domain.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Image Net large scale visual recognition competition 2012 (ilsvrc 2012), 2012. \url http://image-net.org/challenges/LSVRC/2012/browse-synsets.
- 2[2] The first int. workshop on action recognition with a large number of classes, 2013. \url http://crcv.ucf.edu/ICCV 13-Action-wkshp/.
- 3[3] perlre - perldoc.perl.org, 2016. \url http://perldoc.perl.org/perlre.html.
- 4[4] D. Ciregan, U. Meier, and J. Schmidhuber. Multi-column deep neural networks for image classification. In CVPR , pages 3642–3649, 2012.
- 5[5] D. Curro, K. G. Derpanis, and A. V. Miranskyy. User-profiling dataset, Feb. 2017. \url https://doi.org/10.5281/zenodo.321921.
- 6[6] M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman. The pascal visual object classes (VOC) challenge. IJCV , 88(2):303–338, 2010.
- 7[7] A. W. Harley, A. Ufkes, and K. G. Derpanis. Evaluation of deep convolutional nets for document image classification and retrieval. In ICDAR , pages 991–995, 2015.
- 8[8] K. Jarrett, K. Kavukcuoglu, M. Ranzato, and Y. Le Cun. What is the best multi-stage architecture for object recognition? In ICCV , pages 2146–2153, 2009.