Novel Algorithms for Sampling Abstract Simplicial Complexes
John Lombard

TL;DR
This paper introduces dual algorithms for sampling abstract simplicial complexes, including a generative sampler and a local ergodic random walk, with formulas for exact probabilities and empirical validation.
Contribution
It presents novel sampling algorithms for abstract simplicial complexes, including a heuristic-based generative sampler and a local ergodic random walk with known transition probabilities.
Findings
The generative sampler balances combinatorial multiplicities effectively.
The local ergodic random walk has well-characterized autocorrelation.
Numerical tests demonstrate the efficacy of the proposed methods.
Abstract
We provide dual algorithms for sampling the space of abstract simplicial complexes on a fixed number of vertices. We develop a generative and descriptive sampler designed with heuristics to help balance the combinatorial multiplicities of the states and more widely sample across the space of nonisomorphic complexes. We provide a formula for the exact probabilities with which this algorithm will produce a requested labeled state, and compare with an existing benchmark. We also design a highly conductive local ergodic random walk with known transition probabilities. We characterize the autocorrelation of the walk, and numerically test it against our sampler to illustrate its efficacy.
Click any figure to enlarge with its caption.
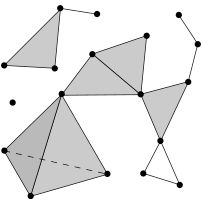 Figure 1
Figure 1 Figure 2
Figure 2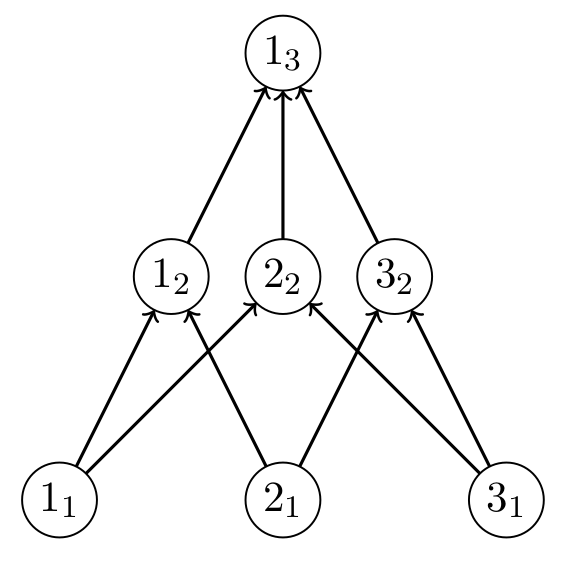 Figure 2
Figure 2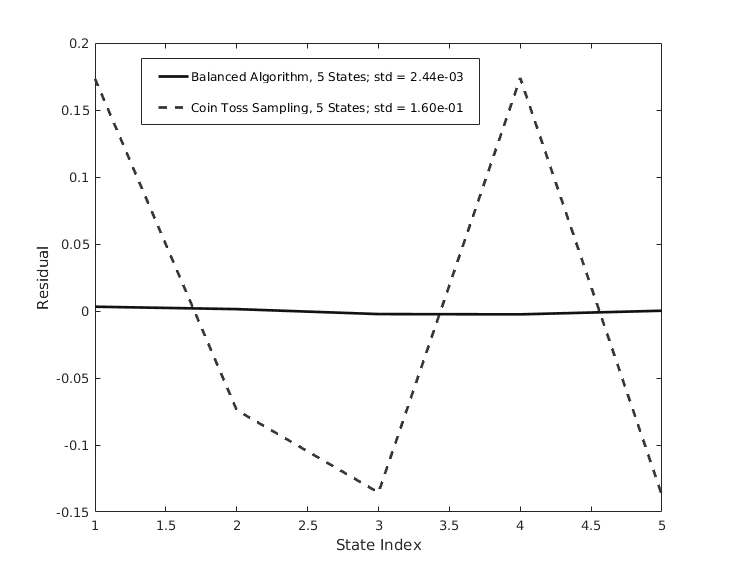 Figure 3
Figure 3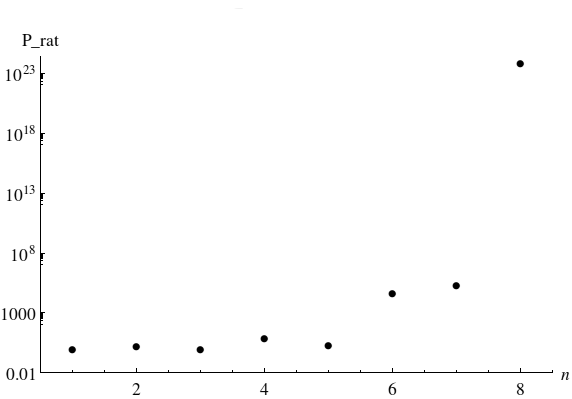 Figure 4
Figure 4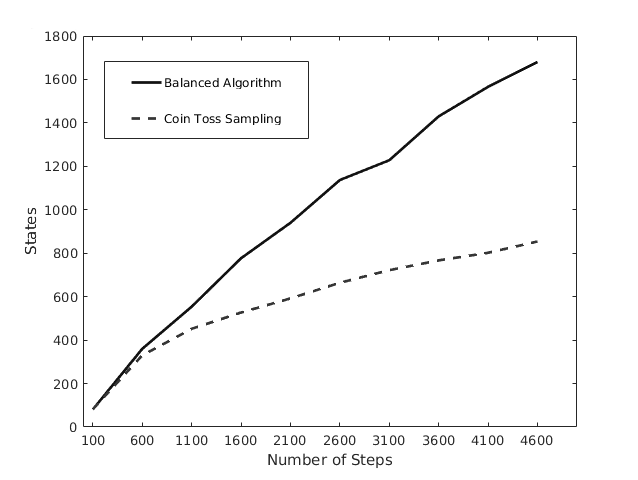 Figure 5
Figure 5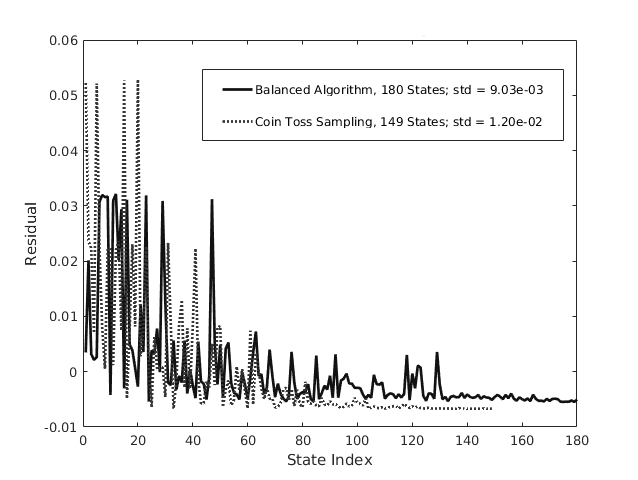 Figure 6
Figure 6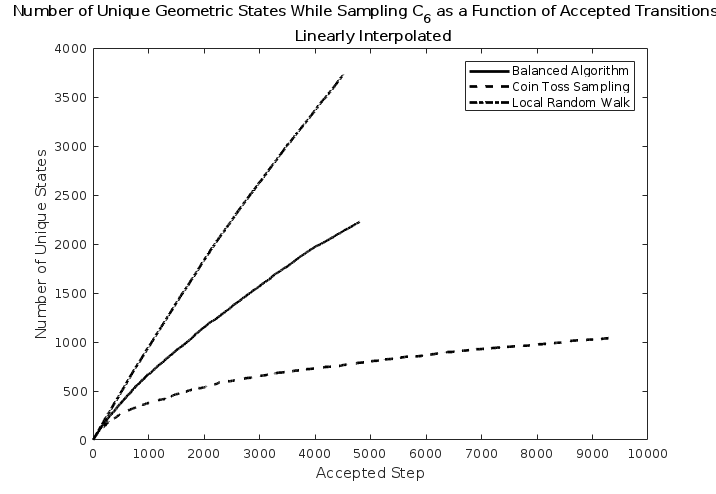 Figure 8
Figure 8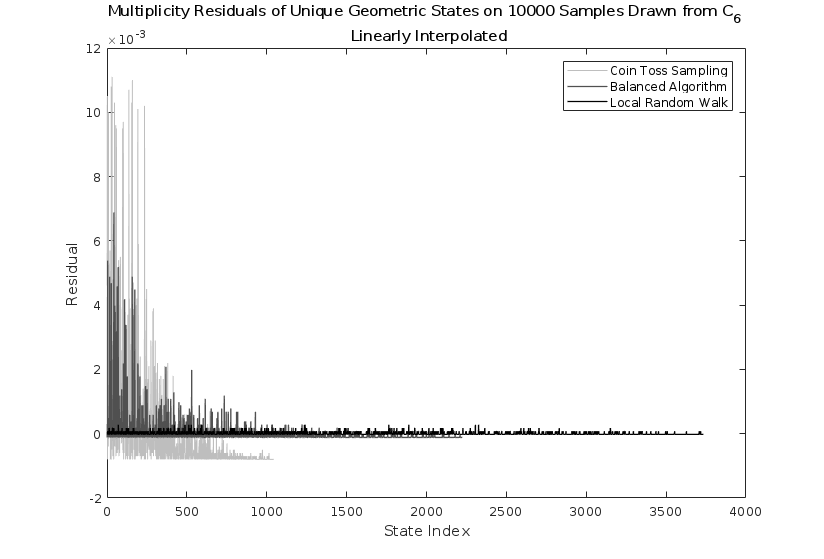 Figure 9
Figure 9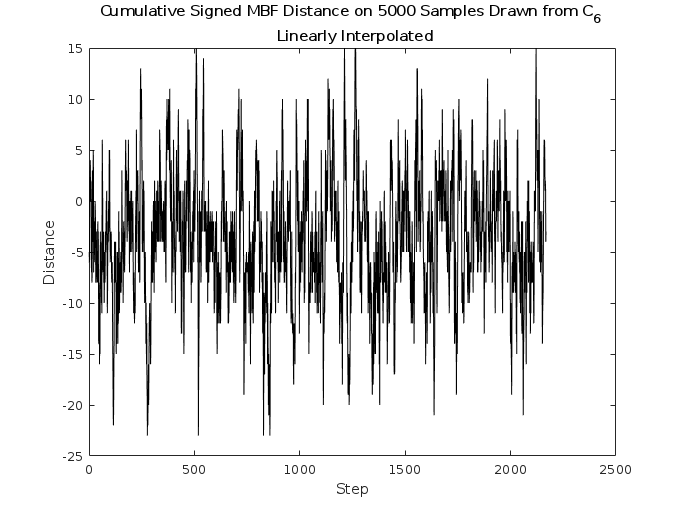 Figure 10
Figure 10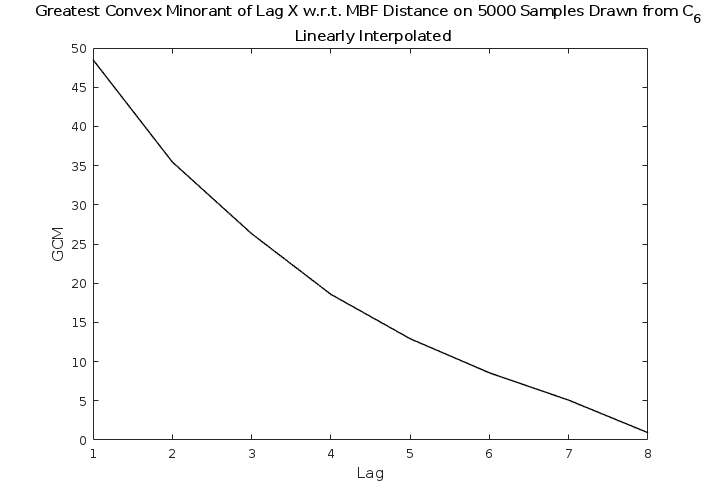 Figure 11
Figure 11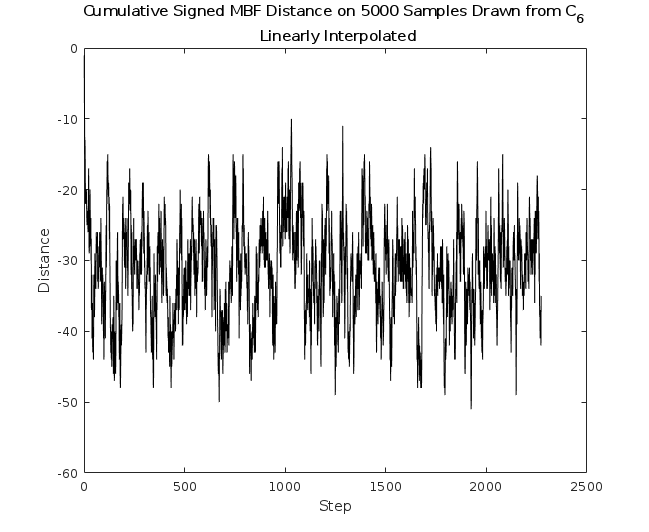 Figure 12
Figure 12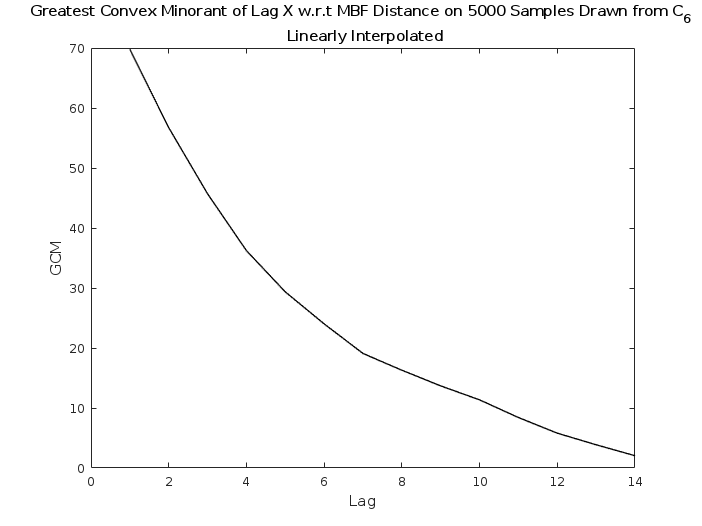 Figure 13
Figure 13Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsTopological and Geometric Data Analysis · Complex Network Analysis Techniques · Markov Chains and Monte Carlo Methods
Novel Algorithms for Sampling Abstract Simplicial Complexes
Abstract
We provide dual algorithms for sampling the space of abstract simplicial complexes on a fixed number of vertices. We develop a generative and descriptive sampler designed with heuristics to help balance the combinatorial multiplicities of the states and more widely sample across the space of nonisomorphic complexes. We provide a formula for the exact probabilities with which this algorithm will produce a requested labeled state, and compare with an existing benchmark. We also design a highly conductive local ergodic random walk with known transition probabilities. We characterize the autocorrelation of the walk, and numerically test it against our sampler to illustrate its efficacy.
keywords:
Abstract Simplicial Complexes ; Sampling Algorithms; MCMC; Random Walk
\authornames
John Lombard
\authorone
[University of Washington]John Lombard \addressoneDepartment of Physics, University of Washington, Seattle, Washington, 98195, USA. Email Address: [email protected]
\ams
05C8568Q87; 65C99
1 Introduction to the Space and Use of Abstract Simplicial Complexes
Whether used to model information theoretic phenomena like social networks or to study the combinatorial properties of fundamental structures in understanding emergent geometry, abstract simplicial complexes have a rich history of applications and are increasingly used in physics as powerful tools with extensive mathematical structures [6]. Unlike 1-dimensional graphs that only convey connectivity data between nodes, abstract simplicial complexes (ASCs) are generalizations that can allow representations of data through higher-dimensional geometric structures, such as surfaces and volumes in the form of combinatorial triangles and tetrahedra (and their higher dimensional equivalents). Informally, an ASC is the combinatorial abstraction of a geometric simplicial complex encoding the downward closure property. Unlike a geometric simplicial complex where the intersections of any two simplicies in the complex must also be a simplex in the complex that is in the union of the boundaries of the intersecting simplicies, ASCs only require that any boundary of a simplex is also a simplex in the complex. For example, the clique complex of a graph—the set of all complete subgraphs—is an abstract simplicial complex on the vertices. For a graphical picture of the differences of an ASC with a geometric simplicial complex when embedded into an ambient space, see Fig. 1.
This structure allows one to model more complex association data that may not be captured by the limited degrees of freedom in a traditional graph or directed graph. Many models that involve these structures are generative, that is to say that one has a well defined way of prescribing a constructive growth paradigm and studying the complex emergent properties of the resulting states [8]. However, statistical physics models on the space of simplicial complexes and ASCs with certain structures are becoming more popular [1]. Although work continues to formally understand the topological properties of this space, finding descriptive algorithms with known probability distributions still requires concentrated effort—especially for models that would be computational feasible [2].
2 Challenges and Solutions in Sampling Abstract Complexes
Our goal is to introduce a new sampling algorithm that is both generative and descriptive on the ASC space with a fixed number of nodes that can then be used for sampling within algorithms that require random walks on this space, such as the oft used Metropolis Algorithms within Markov Chain Monte-Carlo methods employed throughout computational physics. Due to the combinatorial explosion, the cardinality of this space becomes very large very quickly with increasing . Richard Dedekind in 1897 was the first to count the number of such configurations, as labeled ASCs are related to monotone boolean functions [3]. Dedekind numbers, which count the number of ASCs with elements, are only known for ; however, asymptotic formulas are also known for large . For the purposes of sampling the unique (nonisomorphic) configurations in the space, we need to remove the labeling that introduces equivalence classes of states under label automorphisms. The inequivalent state cardinalities (and their asymptotic forms) are known only for , and grow to be on the order of by [7]. We note that these numbers provide an upper bound on , as they also include nodal removal. Nevertheless, efficiently sampling such a high dimensional space, especially given the equivalence classes, is a challenge. Since there is not yet a general way to know the cardinalities of the isomorphism classes of simplicial complexes on nodes, we can do little to tune our algorithm to accommodate this directly. Furthermore, designing either a reversible walk or a sampler with known transition probabilities on such a constrained space is an additional challenge that we face.
In the sections to follow, we introduce two new algorithms for sampling on . We design some basic guiding principles that we show analytically yield a non-local uncorrelated fully ergodic sampler that exhibits extremely strong sampling properties. We numerically illustrate its fast and wide sampling capabilities in comparison to a benchmark model. We also design a local ergodic random walk with known transition probabilities that, at the cost of autocorrelation, samples even more efficiently. Lastly, we characterize the autocorrelation of the walk, and numerically test it against our sampler.
3 Notation and State Visualization
As there are a variety of ways to encode the data of a state , we take the opportunity to clarify for the reader the representation we will work with.
Definition 3.1** **(Digraph Representation G)
A state is expressed in a leveled digraph representation if each node in the digraph at level represents a -simplex in , with as a member of the indexing set on level , . Defining the set to the be ‘roots’ of the graph with no incoming edges, the directed adjacency structure is constrained such that the following conditions are satisfied:
Directed edges exist only between levels 2. 2.
The number of parents of node must be 3. 3.
The number of roots corresponding to the union of the heads of all dipaths leading to must be
The last condition guarantees simplicial closure, such that for each simplex, its boundary set are also nodes in the graph state with the proper completeness. There can be at most nodes in a level, corresponding to the ASC that is the d-skeleton of the complete clique complex on nodes. Similarly, the maximum level is .
This graph representation encodes an ASC uniquely up to labeling. We denote the geometric state as one in which the labeling has been removed. For an example of a labeled state with a canonical ordering, we illustrate in Fig. 2 the complete state on 3 roots corresponding to a 2-simplex.
The convenience of this representation allows us to repackage the boundary closure constraints into the adjacency structure of this digraph, with the directed nature proving useful for easily identifying branching subgraphs affected by said closure.
Definition 3.2** **(Boolean Map)
Let the complete state on nodes be denoted . A boolean representation of is given by an ALL-TRUE vector with length , where the elements of the vector correspond to a level-canonical ordering of nodes in : indicating existence of node and indicating non-existence.
Define as a boolean function that assigns to each such that the conditions in Def. 3.1 are satisfied.
It is trivial to see that the space of all such functions covers . provides an arbitrary labeled ASC in the boolean representation that can be again visualized through the graph representation and can be thought of as a mask on . Isomorphic states are related by boolean functions equivalent up to subset permutations preserving the constraints.
On for example, the masks and correspond to the same geometric state and can be shown to be equivalent through the allowed subset permutation on the elements corresponding to level .
4 Kahle’s Inductive Construction
Kahle recently introduced a construction for generating random ASCs [5]. We describe some of its properties here, using our above notation for consistency.
Definition 4.1** **(Kahle’s Model)
Kahle’s multi-parameter model builds an ASC inductively, starting at the edge set with . For every , include the simplex with probability provided it satisfies the boundary conditions in Def. 3.1.
The full state is built level by level, with constraints on the allowable set of nodes one can include at a given level due to the boundary existence requirements induced by the lower levels.
Let indicate the number of included simplicies at level and indicate the number of possible simplicies given the structure:
[TABLE]
A labeled state is generated with probability given by the following:
[TABLE]
As shown by Zuev et al., Kahle’s model is an Exponential Random Simplicial Complex, implying that it generates a maximum entropy ensemble for an expected number of simplicies in the skeletal structures (directly constrained by the probability parameters) [9].
We note that the probability of achieving a particular state decreases as a binomial power in the number of total nodes in . Even under a nonuniform probability weighting of the levels, it can be easily seen that the combinatorial multiplicities of nodes in each level create a sampling that is highly peaked around states with a given maximum level for large —either one that terminates early at the lower levels leaving no higher structures, one that does the opposite, or one that samples toward the ‘half-graph’ state with levels in the case when we take the probabilities to be coin flips. Precise fine tuning would be needed to allow for sampling across a stretch of widely differing geometries, and the power behavior for finding a particular state will still not be mitigated. Additionally, the isomorphism classes of geometric states will be sampled from with additional probability factors based on their sizes. As the number density of labeled states concentrates toward those that terminate at the central level, we will take the model to benchmark against. Such an algorithm has a probability lower bound at the complete state as follows:
[TABLE]
We note Kahle’s construction was never claimed to be a fast and broad sampler on . However, from the class of both descriptive and generative algorithms, and as a producer of a maximum entropy ensemble, it is an incredibly simple and natural inductive construction that we feel would serve as a reasonable baseline to compare against our random sampler on this space with the goal of rounding small probability sets in mind.
5 The Balanced Algorithm
Our goal is to sample across geometrically inequivalent states with better mixing than the model. To this end, we define three key properties that we wish our model to satisfy as heuristics that we intuitively suggest would promote more rapid and broad sampling.
Any isolated node such that should be given a probability of appearance of . At this level in the induction, there are only two possible states that can be selected as the rest of the structure is already fixed. Each state should be given equal probability, as from the vantage of the current step in the algorithm, there is no differentiating property of either state that would induce a bias in the probability. For example, the highest dimension simplex should always have . 2. 2.
The power law behavior of binomials in the probabilities should be avoided for individual states, which may also aid the associated issue in over-selecting multiple isomorphic states. 3. 3.
The completely disconnected state on nodes, , should have the same probability of occurrence as . This heuristic aims to re-balance the combinatorial effects of the intimate coupling between nodes at different levels due to simplicial closure, since not including any nodes at generates , while in a construction like , all nodes in must be independently kept to generate , regardless of what probabilities are assigned to each level or even each individual simplex.
To accomplish this, we first note that we will work inversely from Kahle’s inductive constructive model and instead consider an equivalent inductive destructive model. Instead of starting from , we start from and remove nodes starting at and work upwards in level. This is equivalent to sampling on the space , inductively building the boolean mask starting from the all-ones vector. This is computationally easier, as instead of checking the complicated closure conditions at each node we would like to place, we only have to solve for the complete graph state once (which involves finding all complete subgraphs on nodes, the NP-complete clique problem), save this state to disk, and reference it at will. To retain the simpliciality, upon removing node , one simply removes the unique directed tree associated with as a starting node, which is a linear-time computation. In practice, this amounts to inductively applying a logical AND between the active masking function and the logical vector for the removed head node.
Theorem 5.1
Let be a probability vector such that with denoting the probability that nodes are chosen uniformly at random and removed from level , and indicating the number of nodes already removed from level due to directed tree pruning from lower level removals.
[TABLE]
satisfies all properties of conditions 1, 2 and 3.
Proof 5.2
We first note that , as the total node set is positive, finite, and the maximum is achieved in condition 1 as proven below. Additionally, is defined such that . We need to show that to conclude that this is a valid probability vector element.
We only seek to show that , as we already know this quantity is strictly positive due to above arguments. It should be clear that is inversely proportional to the total number of nodes left in the state at step in the inductive construction (). The combinatorial prefactor is simply the total number of nodes remaining on level , which must be less than or equal to the total number of nodes in the state. Hence, our claim is justified.
Lastly, we can safely conclude that by our construction of .
To show that this distribution satisfies the condition 1, it can be seen from the definitions that
[TABLE]
Hence,
[TABLE]
Condition 2 is satisfied by algorithmic construction. In choosing groups of nodes uniformly at random to remove from level , we trade the power-binomial behavior in the probabilities that grow with the number of total nodes in for a polynomial-binomial behavior that grows with the number of levels instead. Additionally, the model will always pick out a specific labeled insensitive to the number of isomorphic reachable graphs. In the balanced model, we select from a class of graphs with a certain number of simplicial elements. Although there can also be many such graphs that are not isomorphic but have the same number of elements of given dimensions, we sample the number of elements per level uniformly instead of with product probabilities, giving a key advantage in sets of small probability measure as will be seen exactly in the case of shown in Section 6.
Satisfying condition 3 requires that the removal of all nodes at the edge level have the same probability as removing no nodes at any level:
[TABLE]
On the left-hand side,
[TABLE]
On the right-hand side,
[TABLE]
Comparing Eq. 5.2 and 5.2 demonstrates equality.
We mention that the existence of such a solution to these constraints is very nontrivial. For example, the balancing condition 3 can be shown to have no solution for the construction for as equal probability of removal and acceptance would clearly require a solution to an equation of the form
[TABLE]
Since doesn’t admit more than one probability level (equivalently let ), the conditions admit the trivial solution .
For any constant probability model on roots enforcing the balancing condition 3 and condition 1 requires the probabilities to be roots of polynomials of the form
[TABLE]
The computer algebra package Mathematica suggests that this equation does not have any rational solutions for with , indicating that there is likely no natural combinatorial factor that can be attributed to the probability weighting for this model, and relaxing condition 1 does not help.
For a generic model, our constraints require parameters that satisfy the following equation:
[TABLE]
In the generic case with independent level probabilities, rational solutions only appear to exist if we remove condition 1; however, this may lead to an large imbalance in the state probabilities for states that are otherwise inductively identical—taking us further from our goal of uniformly sampling the geometric states. It is clear that although possible in theory to balance this algorithm, it requires finding numerical roots at each order and tuning the probabilities to best counteract the power behavior in the sampling, unlike the version we have presented that has closed-form analytic balancing and naturally handles the power structure.
We conclude this section with the probability of finding a given labeled state using this algorithm. As mentioned, this algorithm samples from classes of complexes with certain numbers of objects per skeletal level. In order to relate these probabilities to a specific geometric state, one must know how these classes decompose into nonisomorphic graphs, as well as the relative sizes of the equivalence classes, introducing an additional combinatorial factor.
Let the set of all graph isomorphisms between representations of a geometric state be denoted such that the cardinality of this set gives the number of equivalent ways of representing under Def. 3.1.
At each inductive step, let nodes be removed from level out of the total number of available nodes.
The fraction given by the number of labeled ways the selection can be made, weighted by the number of equivalent states at that level, yields the leveled combinatorial factor. Multiplying these factors over the full induction yields the resulting combinatorial factor for achieving a particular geometric state:
[TABLE]
However, since is not known in advance, we can only compute probabilities analytically for labeled states as this breaks the symmetry factor. Thus, the combinatorial factor becomes
[TABLE]
It is this quantity that we will use in our comparisons to the model, as they both consider specific labeled states. In practice, the geometric probabilities are larger, with the labeled probabilities providing a lower bound.
Let be a boolean sequence representing whether any nodes were masked from , with as an indicator that no nodes were removed from level . In terms of our boolean function , the elements correspond to a operation over the level subsets . The probability of finding a labeled state is given by the following expression:
[TABLE]
where is the Kronecker delta.
6 Properties of the Balanced Algorithm and Simulation Results
This algorithm samples across a weighted space of paths for inductively building a given state, as opposed to building a specific state itself. In the case where each such path yields a unique state up to relabeling, this algorithm will produce the uniform distribution on the space of complexes. Such a condition is only true for where , and is illustrated in a direct comparison with the benchmark in Fig. 3. This graph bins the multiplicities for which each geometric state was sampled, subtracted by the mean multiplicity to give residuals, and normalized by the total number of samples. The bins themselves do not match to the same geometric state between the two algorithms, but map to the first encountered representative of a given state. One can clearly see the uniform sampling from the balanced algorithm, although given the number of total samples, both algorithms find all geometric states. All simulations were performed using MATLAB.
However, for and higher, there exist nonisomorphic graphs with the same number of simplicial elements in each skeleton. This introduces a nonuniform combinatorial factor that is not possible to account for at the time of writing due to the fact that there is no analytic algorithm for predicting the number of such inequivalent graphs and their combinatorial multiplicities. Of course, since we can explicitly compute the probabilities for generating a labeled state, we mention that this sampler can be equipped with a Metropolis filter to re-weight the probabilities to produce a uniform sampling on labeled states.
We now examine the raw probabilities for sampling a unique labeled state. Directly comparing the minimal probability in the model with the equivalent complete state in the balanced model indicates that this state has a much greater probability of occurrence:
[TABLE]
To indicate whether the new algorithm has balanced the probabilities at large and removed sets of extremely suppressed measure would require looking at the minimal probability bound for this algorithm and comparing it to as generated from . Here, we must use the labeled combinatorial factor for adequate comparison. Due to the balancing, the probabilities are minimized toward the half-graph state, as this maximizes the binomial coefficients at each level with many combinatorial possibilities equivalent to the removal of certain numbers of nodes. As we would like a lower bound, we set . Even though we are removing approximately half of the nodes at each level, to maximize the binomial contribution, maintaining the full combinatorial degree of each level will further decrease the probabilities.
In total, this gives an estimate for a lower bound of the following form:
With
[TABLE]
[TABLE]
Numerical analysis confirms that for reasonable values of before they become numerically unstable due to the combinatorial explosion, as illustrated in Fig. 4. It is immediately apparent that this algorithm has a much stronger probability behavior and actively works against the suppression found in a product model.
Lastly, we advertised that the combinatorial balancing would allow for a broader access of states. Below we provide some simulation results to illustrate this property. Fig. 5 shows the number of unique geometric states encountered while sampling for a variety of sampling lengths. We can see that the balanced algorithm samples states at a faster rate than the benchmark test. This is again demonstrated in Fig. 6, where 50000 samples were drawn on . The balanced algorithm has appeared to converge, while the benchmark has yet to find all of the inequivalent states. Naturally, the states with higher probability of being encountered were among the first to be sampled, explaining the correlation between the large initial fluctuations in the two algorithms given the first-representative binning process. However, the multiplicity fluctuations are much smaller for the balanced algorithm, indicating that the goal of heuristically rounding the space of state probabilities has been preliminarily accomplished by this algorithm.
7 Local Random Walks
The algorithm introduced in Sec. 5 can be naturally used to perform an ergodic walk on the ASC space. We can jump from any state to another without a barrier as there is no dependence on the current state to restrict the space of next available states. This is a desirable feature from the perspective of sampling on the full space, as there are no regions of low conductance in the state space where our ‘walk’ can become trapped. However, when a Metropolis filter is utilized, the fact that this sampler can introduce transitions between arbitrary configurations may be a detriment to the acceptance rate if the filter is not naturally tuned to the intrinsic sampling probabilities of the walk. A local random walk between nearby configurations would be more likely to permit an acceptance with respect to a Metropolis filter, and as a result, may sample the full space faster. We would still like to be able to make this local random walk reversible, however, to ensure the Markov property. However, on the ASC space, the closure constraints make constructing a reversible local random walk very difficult. It is even still difficult to find any local random walk where one can compute forward and backward transition probabilities in order to force the walk to be reversible with respect to an additional Metropolis filter. In the following sections, we illustrate one example of a local random walk in the ASC space, and compare its properties to our global sampler.
8 A Local Random Walk on Abstract Simplicial Complexes
Our goal is to create a local random walk that has more favorable acceptance ratios for a Metropolis filter that is in some way sensitive to the topological structure of the current ASC. To that end, we define ‘local’ with respect to a new metric on the ASC space that is restricted to a unidirectional walk away from a given state.
Definition 8.1** **(Unconstrained Nodes)
Given an ASC in the graph representation , we define an ‘unconstrained node’ u as one that can be freely added or removed without requiring or destroying additional containment structure.
An unconstrained node is ‘removable’ if is has no children and is itself not a root (as the we hold the roots fixed in ).
An unconstrained node is ‘addable’ if it is a member of (the complete graph with the current state excluded) that has all of its parents in .
We work with unconstrained nodes for two reasons. Foremost, we would like to have a walk that admits a range of local movement as opposed to simply a one step nearest-neighbor walk on individual simplices. If we admit moves that can add or remove an arbitrary number of nodes within the state space, one needs to worry about the closure constraints. These constraints will make it very difficult to generate a walk that has computable probabilities for reversibility, as the number of admissible additions or removals would be dynamic with each sub-step within the same transition move, and there can be multiple paths with different probabilities that could lead to the same state. We want to restrict down this capability, but still admit larger jumps through the state space. Hence, we work with the space of unconstrained nodes as pure additions or removals within this space will prevent such issues from arising and admit a walk with computable probabilities. The restriction that nodes are only added or removed in a single step additionally guarantees that we do not have any closed loops within our multi-step walk for a given transition.
Our notion of local distance is therefore the number of added or removed nodes in a given transition step, actioned by a binary flip on the boolean function representing .
The algorithm mimics an exponential ball walk with respect to this distance measure. First, we compute the total number of nodes one could maximally flip on the state space. From this set, we establish a normalized probability function based on an exponential decrease in probability for larger numbers of binary flips. We decide to either add or remove nodes in a given transition. Once this choice is made, we compute all addable/removable nodes for the current configuration. We select a distance to move based on the fixed probability measure. If that distance takes the state outside of the state space or beyond the number of admissible adds/removes, then the algorithm resets until an admissible move is found—this is our rejection sampling step similar to a ball walk on the edge of the state space. Once a good distance is accepted, a uniformly random selection of those unconstrained nodes have their entries flipped in the boolean representation. The forward and backward probabilities are symmetric with respect to the exponential distance weighting, as this is not dependent on the state itself. Therefore, a Metropolis filter would only need to account for the uniform selection step, producing a combinatorial factor of
[TABLE]
9 Computational Results
Since our sampler now has local correlations, it becomes necessary to characterize more carefully the efficiency of the random walk and breadth of sampling. We present two extreme situations for the initial start of the walk: beginning at a corner of the state space, , and beginning at a ‘central’ state consisting of roughly half of the available simplices being activated. We examine both the multiplicity residuals as before, as well as the autocorrelation length.
To characterize the autocorrelation length, we use an initial convex sequence method that involves the greatest common minorant [4]. First, we implement a Metropolis filter utilizing Eq. 4 such that our samples can be expected to be i.i.d. To measure autocorrelation, we compute the signed displacement of a transition between two states and as the difference in the sums of their boolean representations:
[TABLE]
where still corresponds to the number of binary flips between the two, as discussed in the algorithm. We then look at the cumulative sum of the time sequence of values for each step in the walk. This gives some sense of a -dimensional projection of the random walk through the ASC space, making it a natural random variable to compute autocorrelations with.
Let an estimator for the sample mean on samples be denoted
[TABLE]
A natural estimator for the auto-covariance function at lag is given by the following:
[TABLE]
The greatest convex minorant at lag ,
[TABLE]
is a strictly positive, decreasing, and convex function for a reversible Markov chain. Therefore, examining our estimator for the point at which it becomes nonpositive indicates the lag where we encounter autocorrelation. Due to the dependence on twice the lag, our autocorrelation is related to when .
We can see in Fig. 8 that the local random walk started from a central state, upon re-weighting with the Metropolis filter, produces autocorrelation out to about steps, and the walk has a natural rejection rate on the order of .
Fig. 9, produced starting from a corner state, tells not much of a different story. This indicates that the edges in the state space are not incredibly narrow, and that this random walk is good at working its way out of those corners. We see less than double the autocorrelation, which is not unexpected due to the time spent in the region of small state density. A burn-in process would reduce this down to toward the autocorrelation lengths found in the central case.
We lastly compare the efficiency of all of these algorithms for sampling geometrically unique states. As seen in Figs. 10 and 11, the local random walk performs remarkably better, sampling more states with less accepted steps. This lends credence to the notion that the best sampler on this space would likely be a linear combination of the two Markov chains. Since such a construction still retains its theoretical properties, we can achieve the best of both algorithms by choosing to perform a local walk with some large probability to reap the rewards of the rapid sampling, while occasionally using the balanced sampler to avoid regions of narrow conductance bands and to promote ergodicity and large nonlocal transitions.
10 Discussion on the New Samplers
As is the case with a wide variety of combinatorial spaces, it is often very difficult to develop a sampling procedure with transition probabilities that can a priori sample such that the uniform distribution is the stationary distribution without the use of a Metropolis filter. In the case of abstract simplicial complexes, the unknown isomorphism classes of configurations make this problem seemingly intractable. We have introduced an algorithm that uses three simple principles to attempt to re-balance the sampling such that the algorithm more readily samples inequivalent configurations with a wide breadth across the space. Our analytical results show that this algorithm has a worst case lower-bound on state probabilities that is larger than the equivalent sampling through a uniformly weighted Kahle process, which we used as an unoptimized benchmark. Our simulations confirm that a direct comparison between the two algorithms favors the balanced algorithm when attempting to sample across the geometric space of states.
We have also discussed a local random walk that can be made reversible. The advantage of this walk is to increase the acceptance rates for a Metropolis filter when sampling nearby states as opposed to large jumps in the state space, and we have illustrated through simulation its efficiency in also sampling from a wide range of states in the ASC space. However, in some applications with Metropolis filters, this walk may be sensitive to trapping regions, as it is not able to explore any possible configuration in a single transition step. Thus, a combination of our local walk and the balanced sampler can be used to promote ergodicity and rapid sampling.
Future work toward finding a better generative algorithm for sampling across equivalence classes of large random abstract simplicial complexes while maintaining analytical control is necessary in order to begin to probe the very large space of states. With a variety of applications on the horizon, we anticipate this problem being approached from a broad range of perspectives, and we hope to have provided some insight through some practical, simple algorithms that accomplish the first steps toward this task.
{acks}
This work was supported in part by the University of Washington. We would like to thank Hariharan Narayanan and Stephen Sharpe for their help in revising this manuscript.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Bianconi, G., Rahmede, C. and Wu, Z. (2015). Complex quantum network geometries: Evolution and phase transitions. Phys. Rev. E 92, 022815.
- 2[2] Costa, A. and Farber, M. (2016). Random simplicial complexes. In Configuration Spaces: Geometry, Topology and Representation Theory . ed. F. Callegaro, F. Cohen, C. De Concini, E. M. Feichtner, G. Gaiffi, and M. Salvetti. Springer International Publishing, Cham pp. 129–153.
- 3[3] Dedekind, R. (1897). Uber zerlegungen von zahlen durch ihre grossten gemeinsamen teiler. Festschrift der Technischen Hochschule zu Braunschweig bei Gelegenheit der 69. Versammlung Deutscher Naturforscher und Arzte 1–40.
- 4[4] Geyer, C. (2011). Introduction to mcmc. In Handbook of Markov Chain Monte Carlo . ed. S. Brooks, A. Gelman, G. Jones, and X.-L. Meng. Chapman and Hall ch. Introduction to MCMC.
- 5[5] Kahle, M. (2014). Topology of random simplicial complexes: A survey. AMS Contemp. Math. 620, 201–22.
- 6[6] Maletic, S. and Rajkovic, M. (2009). Complex Networks (Studies in Computational Intelligence Series) vol. 207. Springer-Verlag, Berlin. ch. Simplicial Complex of Opinions on Scale-Free Networks, pp. 127–34.
- 7[7] Stephen, T. and Yusun, T. (2014). Counting inequivalent monotone boolean functions. Discrete Applied Mathematics 167, 15 – 24.
- 8[8] Wu, Z., Menichetti, G., Rahmede, C. and Bianconi, G. (2015). Emergent complex network geometry. Nature Scientific Reports 5, 10073.