Phase Transitions of Spectral Initialization for High-Dimensional Nonconvex Estimation
Yue M. Lu, Gen Li

TL;DR
This paper analyzes the phase transition behavior of spectral initialization in high-dimensional nonconvex estimation, revealing thresholds for when the method provides meaningful signal estimates.
Contribution
It offers a precise asymptotic characterization of spectral initialization performance across generalized linear models, extending beyond phase retrieval.
Findings
Performance sharply transitions at specific sample-to-dimension ratios.
Below threshold, estimates are no better than random.
Above threshold, estimates align with the true signal.
Abstract
We study a spectral initialization method that serves a key role in recent work on estimating signals in nonconvex settings. Previous analysis of this method focuses on the phase retrieval problem and provides only performance bounds. In this paper, we consider arbitrary generalized linear sensing models and present a precise asymptotic characterization of the performance of the method in the high-dimensional limit. Our analysis also reveals a phase transition phenomenon that depends on the ratio between the number of samples and the signal dimension. When the ratio is below a minimum threshold, the estimates given by the spectral method are no better than random guesses drawn from a uniform distribution on the hypersphere, thus carrying no information; above a maximum threshold, the estimates become increasingly aligned with the target signal. The computational complexity of the…
Click any figure to enlarge with its caption.
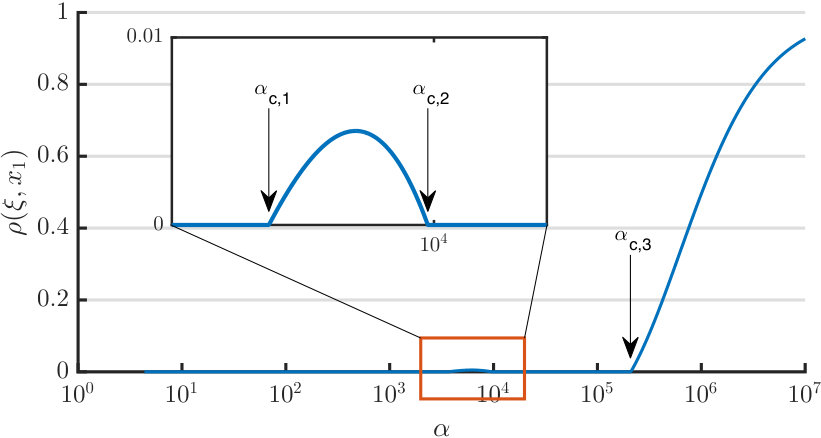 Figure 1
Figure 1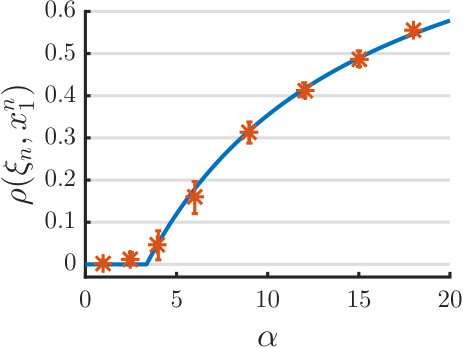 Figure 2
Figure 2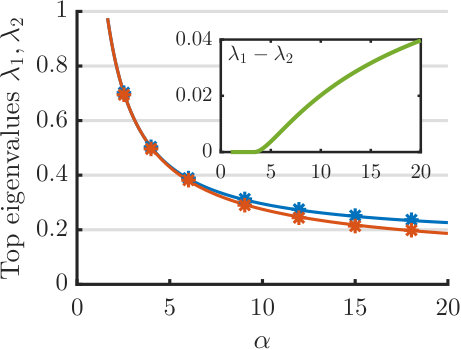 Figure 3
Figure 3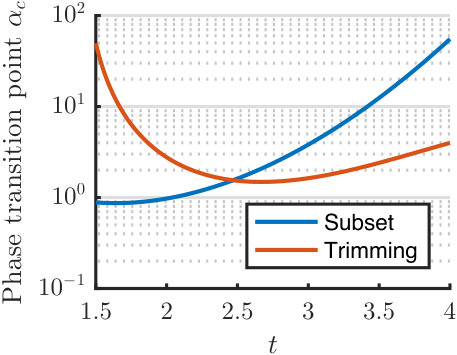 Figure 4
Figure 4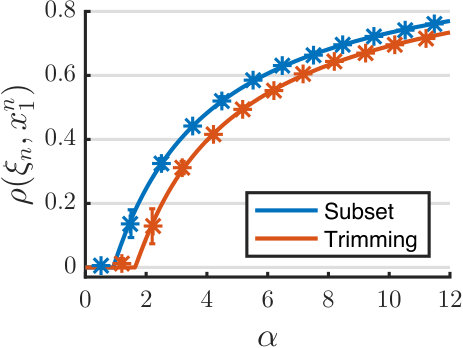 Figure 5
Figure 5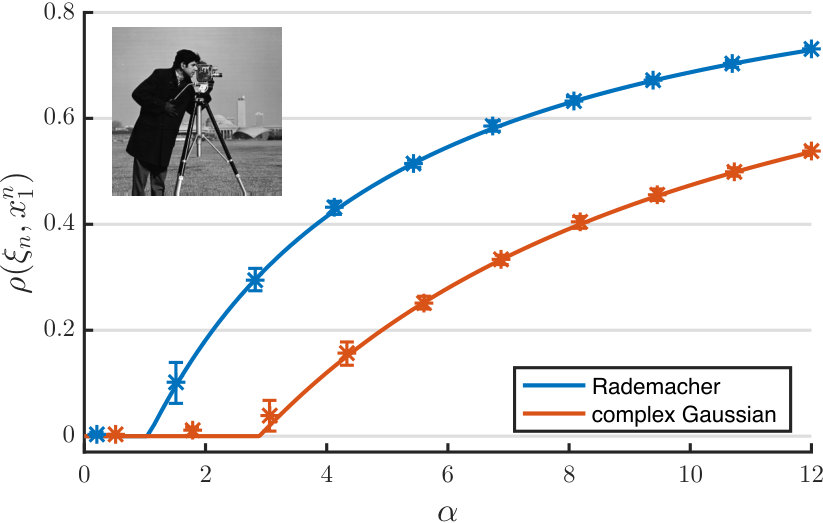 Figure 6
Figure 6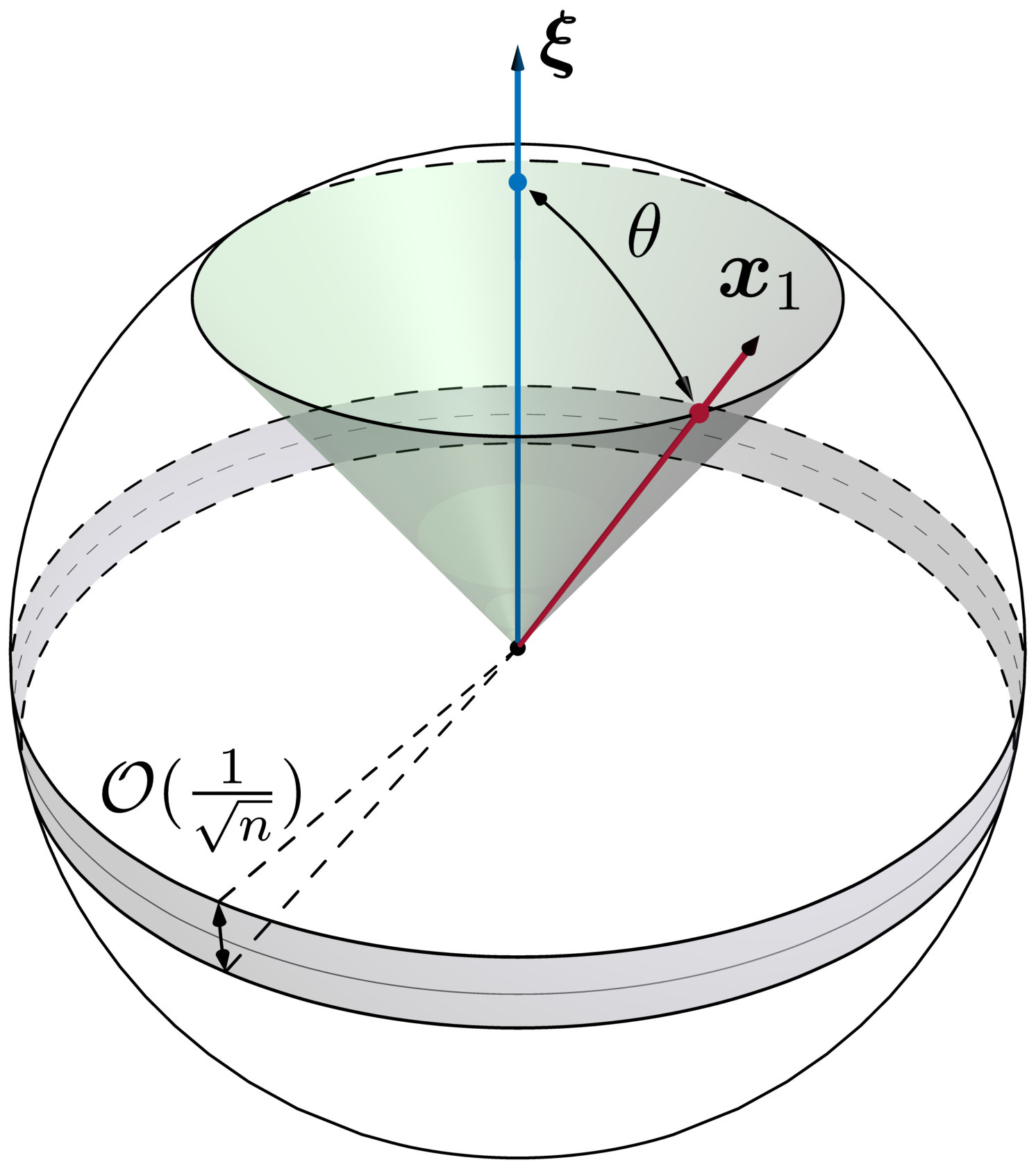 Figure 7
Figure 7Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Phase Transitions of Spectral Initialization for High-Dimensional Nonconvex Estimation
Yue M. Lu and Gen Li Y. M. Lu is with the John A. Paulson School of Engineering and Applied Sciences, Harvard University, Cambridge, MA 02138, USA (e-mail: [email protected]). Part of this work was done during his visit to the Information Initiative at Duke (iiD) in Spring 2016. He thanks members of this interdisciplinary program for their hospitality.G. Li is with the Department of Electronic Engineering, Tsinghua University, Beijing 100084, China (e-mail: [email protected]). He was a summer visiting undergraduate student at the John A. Paulson School of Engineering and Applied Sciences, Harvard University.This work was supported in part by the ARO under contract W911NF-16-1-0265 and by the US National Science Foundation under grants CCF-1319140 and CCF-1718698. Preliminary version of this work was presented at the IEEE International Symposium on Information Theory (ISIT) in 2017.
Abstract
We study a spectral initialization method that serves a key role in recent work on estimating signals in nonconvex settings. Previous analysis of this method focuses on the phase retrieval problem and provides only performance bounds. In this paper, we consider arbitrary generalized linear sensing models and present a precise asymptotic characterization of the performance of the method in the high-dimensional limit. Our analysis also reveals a phase transition phenomenon that depends on the ratio between the number of samples and the signal dimension. When the ratio is below a minimum threshold, the estimates given by the spectral method are no better than random guesses drawn from a uniform distribution on the hypersphere, thus carrying no information; above a maximum threshold, the estimates become increasingly aligned with the target signal. The computational complexity of the method, as measured by the spectral gap, is also markedly different in the two phases. Worked examples and numerical results are provided to illustrate and verify the analytical predictions. In particular, simulations show that our asymptotic formulas provide accurate predictions for the actual performance of the spectral method even at moderate signal dimensions.
Index Terms:
Spectral initialization, signal estimation, nonconvex optimization, spiked covariance model, phase transition
I Introduction
We consider the problem of estimating an -dimensional vector from a number of generalized linear measurements. Let be a set of sensing vectors in . Given , the measurements are drawn independently from
[TABLE]
where is a conditional density function modeling the acquisition process. This model arises in many problems in signal processing and statistical learning. Examples include photon-limited imaging [1, 2], phase retrieval [3], signal recovery from quantized measurements [4], and various single-index and generalized linear regression problems [5, 6].
The standard method for recovering is to use the estimator
[TABLE]
where is some loss function (e.g., the negative log-likelihood of the observation model as used in maximum likelihood estimation). In many applications, however, the natural loss function is not convex with respect to . There is often no effective way to convexify (2). In those cases for which convex relaxations do exist, the resulting algorithms can be computationally expensive. The problem of phase retrieval, where for some noise terms , is an example in the latter scenario. Convex relaxation schemes such as those based on lifting and semidefinite programming (e.g., [7, 8, 9, 10]) have been successfully developed for solving the phase retrieval problem, but the challenges facing these schemes lie in their actual implementation. In practice, the computational complexity and memory requirement associated with these convex-relaxation methods are prohibitive for signal dimensions that are encountered in real-word applications such as imaging.
In light of these issues, there is strong recent interest in developing and analyzing efficient iterative methods that directly solve nonconvex forms of (2). Examples include the alternating minimization scheme for phase retrieval [11], the Wirtinger Flow algorithm and its variants [12, 13, 14, 15, 16], iterative projection methods [17, 18], and recent schemes for phase retrieval using linear programming [19, 20, 21, 22]. A common ingredient that contributes to the success of these algorithms for nonconvex estimation is that they all use some carefully-designed spectral method as an initialization step, which is then followed by further (iterative) refinement. Beyond the signal estimation problem considered in this paper, related spectral methods have also been successfully applied to initialize algorithms for solving other nonconvex problems such as matrix completion [23], low-rank matrix recovery [24], blind deconvolution [25, 26], sparse coding [27], and joint alignment from pairwise differences [28].
In this paper, we present an exact high-dimensional analysis of a widely-used spectral method [11, 12, 13] for estimating . The method consists of only two steps: First, construct a data matrix from the sensing vectors and measurements as
[TABLE]
where is a preprocessing function (e.g., a trimming or truncation step). Second, compute a normalized eigenvector, denoted by , that corresponds to the largest eigenvalue of . The vector is then our estimate of (up to an unknown scalar). It is notable that this method is model-free in that the algorithm does not require the knowledge of the exact acquisition process [i.e., the conditional density in (1)].
The idea of this spectral method can be traced back to the early work of Li [29], under the name of Principal Hessian Directions for general multi-index models. Similar spectral techniques were also proposed in [23, 24], for initializing algorithms for matrix completion. In [11], Netrapalli, Jain, and Sanghavi used this method to address the problem of phase retrieval. Under the assumption that the sensing vectors consist of i.i.d. Gaussian random variables, these authors show that the leading eigenvector is aligned with the target vector in direction when there are sufficiently many measurements. More specifically, they show that the squared cosine similarity
[TABLE]
which measures the degree of the alignment between the two vectors, approaches with high probability, when the number of samples . This sufficient condition on sample complexity was later improved to in [7], and further improved to in [13] with an additional trimming step on the measurements. In these expressions, stand for some unspecified numerical constants.
In this paper, we provide a precise asymptotic characterization of the performance of the spectral method under Gaussian measurements. Our analysis considers general acquisition models under arbitrary conditional distributions , of which the phase retrieval problem is a special case. Unlike previous work, which only provides bounds for , we derive the exact high-dimensional limit of this value. In particular, we show that, as and both tend to infinity with the sampling ratio kept fixed, the squared cosine similarity converges in probability to a limit value . Explicit formulas are provided for computing .
Geometrically, the squared cosine similarity as defined in (4) specifies the angle between and . The values of vary from [math] to : means perfect alignment, i.e., or ; and is the opposite case, meaning is orthogonal to (i.e. uncorrelated with) . That the spectral method can yield an estimate with a positive in high dimensional settings is a nontrivial property. To see this, assume that is pointing towards the “north pole” in the unit -sphere , as illustrated in Figure 1. If we choose uniformly at random from , then with high probability, the resulting correlation will be of order . In other words, for large , most of the uniform measure on is concentrated within a very thin band of width near the “equator” of the sphere (see Figure 1).
Our analysis reveals a phase transition phenomenon that occurs at certain critical values of the sampling ratio. In particular, there exist a lower and an upper threshold, denoted by and , respectively, that mark the transitions between two very different phases.
(a) An uncorrelated phase takes place when the sampling ratio . Within this phase, the limiting value , meaning that the estimate from the spectral method is asymptotically uncorrelated with the target vector . In this case, the spectral method is not effective, as its estimate is no better than a random guess drawn uniformly from the hypersphere .
(b) A correlated phase takes place when , with being the upper threshold. Within this phase, the limiting value . Geometrically, the estimate (or its negative version ) will be concentrated on the surface of a right-circular cone (see Figure 1) whose generating lines make an angle \theta=\arccos\big{(}\sqrt{\rho(\alpha)}\big{)} to the target vector . Moreover, tends to 1 as .
In many signal estimation models that we have studied so far, the two thresholds coincide, i.e. , meaning that the phase transition happens at a single critical value of the sampling ratio. However, it is indeed possible that , in which case a finite number of correlated and uncorrelated phases alternative when varies within the interval . A concrete example demonstrating this more complicated situation can be found in Section IV-C.
The above phase transition phenomenon also has implications in terms of the computational complexity of the spectral method. In a correlated phase, there is a nonzero gap between the largest and the second largest eigenvalues of . As a result, the leading eigenvector can be efficiently computed by using power iterations on . In contrast, within an uncorrelated phase, the gap of the eigenvalues converges to zero, making power iterations inefficient.
The rest of the paper is organized as follows. After precisely laying out the various technical assumptions, we present in Section II the main results of this work, stated as Theorem 1 and Proposition 1. Examples and numerical simulations are also provided there to demonstrate and verify these analytical results. In particular, as a worked example, we derive a universal closed-form expression for the limiting values for all acquisition models that generate one-bit measurements. We prove Theorem 1 in Section III. Key to our proof is a deterministic, fixed-point characterization of the squared cosine similarity , which is valid for any finite dimension and for any deterministic sensing vectors . When specialized to Gaussian measurements, this fixed-point characterization allows us to connect our problem to a generalized version of the spiked population model (see, e.g., [30, 31, 32]) studied in random matrix theory. In Section IV, we look more closely at the phase transition phenomenon predicted by our asymptotic results and prove Proposition 1. Section V concludes the paper with discussions on possible generalizations and improvements of our results as well as their connections to related work in the literature.
Notations: To study the high-dimensional limit of the spectral initialization method, we shall consider a sequence of problem instances, indexed by the ambient dimension . For each , we seek to estimate an underlying signal denoted by . Formally, we should use to denote the data matrix, where is the number of measurements as a function of the dimension . However, to lighten the notation, we will simply write it as , keeping the dependence of on implicit. stands for a leading eigenvector of . We use and to denote convergence in probability and almost sure convergence, respectively. Let be a symmetric matrix. Its eigenvalues in descending order are written as . In particular, , sometimes also written as , denotes the largest eigenvalue of . Throughout the paper, stands for the principal square root of a positive semi-definite symmetric matrix . For any , we write as . Finally, stands for the indicator function of a set .
II Main Results
II-A Technical Assumptions
In what follows, we first state the basic assumptions under which our results are proved.
- (A.1)
The sensing vectors are independent Gaussian random vectors. Specifically, let , for , be a doubly infinite array of i.i.d. standard normal random variables. Then the th sensing vector . 2. (A.2)
with as . 3. (A.3)
. 4. (A.4)
Let and be three random variables such that
[TABLE]
where is the conditional density function (1) associated with the observation model, and is the preprocessing step used in the construction of in (3). We shall assume that the probability measure of the random variable is supported within a finite interval . Throughout the paper, we always take to be the tightest such upper bound. 5. (A.5)
As approaches from the right,
[TABLE] 6. (A.6)
The random variables and are positively correlated: , which is equivalent to
[TABLE]
The last three assumptions require some explanations. First, we note that assumption (A.4) requires that should take values within a finite interval on the positive axis. This can be enforced by choosing a suitable function . For example, in the problem of phase retrieval, the measurement model () leads to unbounded . We can set
[TABLE]
where is some parameter and denotes the indicator function for the condition . This is indeed the trimming strategy proposed in [13]. As shown there, this boundedness condition on the support of is an essential ingredient in achieving linear sample complexities. The assumption that be nonnegative is largely made to simplify our analysis, but this restriction can be removed. In a recent work [33], Mondelli and Montanari extended our results by showing that the same asymptotic predictions presented in this paper still hold under cases where can take negative values. See also Remark 2 in Section II-B.
In assumption (A.5), the expressions in (6) essentially require that the random variable should have sufficient probability mass near the upper bound . Let . We show in Appendix -A that (6) holds when there exist some positive constants and such that the probability density function of and the conditional moment are both bounded below by for all . The model in (8) represents one such case. Another sufficient condition for (6) to hold is when the law of has a point mass at . The acquisition models described in (27) and (28) in later sections are examples for which this condition is applicable.
The inequality in (A.6) is also a natural requirement. To see this, we note that the data matrix in (3) is the sample average of i.i.d. random rank-one matrices . When the number of samples is large, this sample average should be “close” to the statistical expectation, i.e.,
[TABLE]
where . To compute the above expectation, it will be convenient to assume that the underlying signal , where is the first vector of the canonical basis of . (This assumption can be made without loss of generality, due to the rotational invariance of the multivariate normal distribution.) Correspondingly, we can partition each sensing vector into two parts, as
[TABLE]
so that and the conditional density of given is . Since and are all independent of ,
[TABLE]
where is the identity matrix of size . If the inequality , as required in (A.6), indeed holds, the leading eigenvector of the expected matrix will be , which is perfectly aligned with the target vector . Now since the data matrix is an approximation of the expectation, the sample eigenvector should also be an approximation of .
The above argument provides an intuitive but nonrigorous explanation for why the spectral initialization method would work. The approximation in (9) can be made exact if the signal dimension is kept fixed and the number of measurement goes to infinity. However, we consider the case when and both tend to infinity, at a constant ratio bounded away from [math] and . In this regime, the approximation in (9) will not become an equality even if . As we will show, the correlation between the target vector and the sample eigenvector will converge to a deterministic value that depends on the sampling ratio .
A notable exception to (7) is when
[TABLE]
is an odd function plus some arbitrary constant . In this case, and and thus (7) does not hold. In practice, this means that the spectral method will not be effective for acquisition models such as . We will revisit this point in Section V where we describe an alternative initialization scheme that can handle such cases.
A final remark before we present our main results: Since the eigenvector is always normalized, the spectral method cannot provide any information about the norm of . However, in many cases where the sensing vectors are drawn from certain random ensembles, there are simple methods to accurately estimate . We provide some discussions on how to do this in Appendix -B.
II-B Main Results: Asymptotic Characterizations
In this section, we summarize the main results of our work on an asymptotic characterization of the spectral method with Gaussian measurements. To state our results, we first need to introduce several helper functions. Let be the random variables defined in (5). We consider two functions
[TABLE]
and
[TABLE]
both defined on the open interval , where is the bound in assumption (A.4). Within their domains, it is easy to check that both functions are convex. In particular, achieves its minimum at a unique point denoted by
[TABLE]
Finally, let
[TABLE]
be a modification of . This new function is again defined for .
Theorem 1
Under (A.1) – (A.6), the following hold:
There is a unique solution, denoted by , to the equation
[TABLE] 2. 2.
As ,
[TABLE]
where and denote the derivatives of the two functions. 3. 3.
Let be the top two eigenvalues of .
[TABLE]
as . Moreover, , with the inequality becoming strict if and only if .
Remark 1
The above theorem, whose proof is given in Section III, provides a complete asymptotic characterization of the performance of the spectral method. In particular, the theorem shows that the squared cosine similarity converges in probability to a deterministic value in the high-dimensional limit. Moreover, there exists a generic phase transition phenomenon: depending on the sign of the derivative at , the limiting value can be either zero (i.e., the uncorrelated phase) or strictly positive (i.e., the correlated phase). The computational complexity of the spectral method is also very different in the two phases. Within the uncorrelated phase, the gap between the top two leading eigenvalues, and , diminishes to zero, making iterative algorithms such as power iterations increasingly difficult to converge. In contrast, within the correlated phase, the spectral gap converges to a positive value.
Remark 2
The results of this work were first reported in [34, 35]. When this paper was under review, the results given in Theorem 1 were further extended by Mondelli and Montanari in [33]. In particular, these authors extended our asymptotic predictions from the real-valued case to the complex-valued case, and more importantly, they showed that the same predictions still hold under cases where the variable defined in assumption (A.4) can take negative values. See [33, Lemma 2] for details.
It will be more convenient to characterize the phase transitions predicted by Theorem 1 in terms of the sampling ratio . To do so, we first introduce a set , containing all the zero-crossings of the function on the open interval . We can show that is always nonempty and that it contains a finite number of points (see Lemma 2 in Section IV-A). Let
[TABLE]
denote the smallest and the largest elements in , respectively.
Proposition 1
[TABLE]
where
[TABLE]
and is a function with the following parametric representation in terms of a parameter :
[TABLE]
for all . Moreover, as .
Remark 3
In many of the signal acquisition models we have studied, the set contains exactly one element. In this case, and hence . Consequently, the phase transition of the spectral method takes place at a single threshold value , which separates the uncorrelated phase from the correlated one. However, it is indeed possible to find cases for which . This leads to a more complicated scenario, where a finite number of correlated and uncorrelated phases can alternatively take place within the interval . One such example is given in Section IV-C.
II-C Worked-Example: Binary Models
To illustrate the results presented above, we consider here a special case where takes only binary values . This situation naturally appears in problems such as logistic regression and one-bit quantized sensing, where the measurements and we can set . For cases where the measurements are not necessarily binary, this type of one-bit model is still relevant whenever the preprocessing function generates binary outputs. The simplicity of this setting allows us to obtain closed-form expressions for the various quantities in Theorem 1 and Proposition 1.
To proceed, we first explicitly compute the functions and defined in Section II-B as
[TABLE]
where
[TABLE]
and both functions are defined on the interval . The minimum of is achieved as , and thus
[TABLE]
Solving equation (17) and using (18), we get
[TABLE]
where . (Note that this result can also be obtained by invoking the parametric characterization of given in Proposition 1.) Finally, the asymptotic predictions (19) for the top two eigenvalues can be computed as
[TABLE]
and
[TABLE]
for all .
Remark 4
It is interesting to note that the asymptotic characterizations given in (24), (25) and (26) are universal, in the sense that they only depend on the two constants and defined in (23) but not on the exact details of the joint probability distributions of and . Thus, for one-bit models, it suffices to compute the constants in (23), which then completely determine the asymptotic performance of the spectral method.
II-D Numerical Simulations
Example 1** (Logistic regression)**
Consider the case where are binary random variables generated according to the following conditional distribution:
[TABLE]
where is some constant. Let . Since , we just need to compute the constants and in (23), after which we can use the closed-form expressions (24), (25) and (26) to obtain the asymptotic predictions. In Figure 2(a) we compare the analytical prediction (24) of the squared cosine similarity with results of numerical simulations. In our experiment, we set the signal dimension to . The norm of is , and . The sample averages and error bars (corresponding to one standard deviation) shown in the figure are calculated over 16 independent trials. We can see that the analytical predictions match numerical results very well. Figure 2(b) shows the top two eigenvalues. When , the two eigenvalues are asymptotically equal, but they start to diverge as becomes larger than . To clearly illustrate this phenomenon, we plot in the insert the eigengap as a function of .
Example 2** (Phase retrieval)**
In the second example, we consider the problem of phase retrieval, where
[TABLE]
Here, and is the standard deviation of the noise. In [13], the authors show that it is important to omit large values of , and they propose to use the scheme in (8) when constructing the data matrix . A different strategy can be found in [15], where the authors propose to use
[TABLE]
In what follows, we shall refer to (8) and (28) as the trimming algorithm and the subset algorithm, respectively. Figure 3(a) shows the asymptotic performance of these two algorithms and compare them with numerical results ( and 16 independent trials). The performance of the subset algorithm (for which we choose the parameter ) can be characterized by the closed-form formula (24). The trimming algorithm (for which we use ) is more complicated as is no longer binary. We use the parametric characterization in Proposition 1 to obtain its asymptotic performance. Again, our analytical predictions match numerical results. The performance of both algorithms clearly depends on the choice of the thresholding parameter . To show this, we plot in Figure 3(b) the critical phase transition points of both algorithms as functions of , at two different noise levels: and . This points to the possibility of using our analytical prediction to optimally tune the algorithmic parameters and, more generally, to optimize the functional form of the preprocessing function . Indeed, the optimal design of was obtained in a recent work [36], which leverages the asymptotic characterizations given here. Interestingly, under a mild technical condition, it is shown that there exists a simple fixed design that is uniformly optimal over all sampling ratios; see [36, Theorem 1].
III Proof of the Main Results
In this section, we prove Theorem 1, which provides an exact characterization of the asymptotic performance of the spectral method for signal estimation.
III-A Overview
We first rewrite the data matrix in (3) as
[TABLE]
where is an matrix of i.i.d. normal random variables and
[TABLE]
is a diagonal matrix with entries . Our goal boils down to studying the largest eigenvalue of and the associated eigenvector . To simplify notation, we shall first assume that , with being the first vector in the canonical basis.
Remark 5
The non-null eigenvalues of are equal to those of a companion matrix
[TABLE]
which bears strong resemblance to a sample covariance matrix. Limiting spectral distributions (LSDs) of sample covariance matrices have been extensively studied in random matrix theory; see for instance [37] and the references given there. As a special case, when is the identity matrix, the LSD of is given by the classical Marčenko-Pastur law [38]. Results for more general diagonal matrices are also available [39]. However, in these studies, and need to be independent. A challenge in our problem is that and are correlated. To see this, we partition each sensing vector into two parts as in (10). We can then write
[TABLE]
where is an -dimensional Gaussian random vector, and is an matrix consisting of i.i.d. standard normal random variables. Since , the diagonal elements of are independent of but they do depend on through . Consequently, we cannot apply existing results on the LSD of sample covariance matrices to our case.
Our proof of Theorem 1 consists of two main ingredients. First, we will show in Proposition 2 that and can be obtained from a fixed-point equation involving a function , to be defined in (36), where is an auxiliary variable. The main benefit of introducing the variable and the function is that, for each , the above-mentioned correlation between and can be effectively decoupled. This then allows us to obtain the second ingredient of our proof: using results from random matrix theory [40, 32], we show in Section III-C that , under the assumption of Gaussian sensing vectors, will converge almost surely to a deterministic limit function as the dimension (see Proposition 4).
III-B A Fixed-Point Characterization
By substituting (31) into (29), we can write in a more compact block-partitioned form as
[TABLE]
where
[TABLE]
is a scalar that converges to as ,
[TABLE]
is a symmetric matrix, and
[TABLE]
Next, we consider a parametric family of matrices , and let denote their largest eigenvalues, i.e.,
[TABLE]
In what follows, we show how to compute and via a fixed-point equation involving . Since we assume that and that the leading eigenvector is normalized, the quantity is equal to , the squared magnitude of the first element of the eigenvector.
Our discussions below are general and they apply to any block-partitioned matrix in the form
[TABLE]
Its components , and can be arbitrarily chosen, not necessarily defined as in (33), (34) and (35). Our only requirements are that is a symmetric matrix and that .
Let be the set of eigenvalues of , and let be a corresponding set of orthonormal eigenvectors. Consider a function
[TABLE]
which has poles on those eigenvalues for which . In what follows, we restrict the domain of to
[TABLE]
Within this open interval, is a well-defined smooth function. It increases monotonically from to [math], and thus it admits a functional inverse, denoted by , for all . Similar to (36), we define
[TABLE]
for all .
Lemma 1
Let be a symmetric matrix and a nonzero vector. Then, for each ,
[TABLE]
Moreover, is a nondecreasing convex function with . It is differentiable everywhere on except at (up to) one point.
Proof:
Since is diagonalizable by an orthonormal matrix, we can assume without loss of generality that is a diagonal matrix. In this case, we can simply write , and this function is defined on the open interval .
Using the matrix determinant lemma [41], we can compute the characteristic polynomial of as
[TABLE]
In (40), stands for the adjugate of a matrix. To reach (41), we have used the fact that, for any diagonal matrix , .
Partition the set into two subsets:
[TABLE]
We observe that the characteristic polynomial can be factored into , where and
[TABLE]
It is possible that the second subset is empty, in which case is understood to be equal to , but is never empty, since . Next, we study the largest root of the polynomial . For any , we can write
[TABLE]
Recall that is the function defined in (38) and is its functional inverse. It follows from (43) that is the only root of in the interval , and therefore it is also the largest root. Due to the factorization , we have
[TABLE]
Finally, since , we reach the formula in (39).
By construction, is strictly increasing and . It is also differentiable everywhere on . It follows that is nondecreasing with , and that the function is differentiable everywhere except for at most one point , which, if it exists, must satisfy the identity . Finally, the convexity of follows from the fact that it is the maximum of a set of linear functions, as . ∎
Given a block-partitioned matrix , the following proposition shows that its leading eigenvalue and the squared cosine similarity can be obtained from the function .
Proposition 2
Let be the unique solution to the fixed-point equation
[TABLE]
Then, and
[TABLE]
where and denote the left and right derivatives of , respectively. In particular, if is differentiable at , then
[TABLE]
Remark 6
We prove this result in Appendix -C. Note that (44) is equivalent to
[TABLE]
Since is nondecreasing with whereas decreases monotonically from to [math], the equation (47), and thus (44), always admits one and only one solution. Moreover, by Lemma 1, is a convex function, and therefore its left and right derivatives always exist.
III-C Asymptotic Limit of
The characterization given in Proposition 2 is valid for any block-partitioned matrix in the form of (37). When applied to the specific case of our data matrix in (32), with its components , and defined as in (33), (34) and (35), this result provides a very general deterministic characterization of the performance of the spectral method that is valid for any finite dimension and for any sensing vectors.
Next, we specialize to the case of i.i.d. Gaussian sensing vectors and show that converges almost surely to a deterministic function as . To that end, we note that is the leading eigenvalue of
[TABLE]
where
[TABLE]
is a rank-one perturbation of the diagonal matrix given in (30). Since and are independent, we first study the spectrum of .
Let be the set of eigenvalues of in descending order. Let
[TABLE]
be the empirical spectral measure of the last eigenvalues.
Proposition 3
Fix . As , the empirical spectral measure converges almost surely to the probability law of the random variable . Meanwhile,
[TABLE]
where is the functional inverse of the function
[TABLE]
The domain of is the open interval , with being the upper bound of the support of the probability law of .
Remark 7
By construction, is a continuous and strictly decreasing function with . Assumption (A.5) further guarantees that . Thus, admits a functional inverse and that is well-defined for all .
According to assumption (A.4) stated in Section II-A, the law of is supported within the interval . The above proposition, whose proof can be found in Appendix -D, shows that the spectrum of consists of two parts: a “bulk spectrum” of eigenvalues supported within and a single spiked eigenvalue well separated from the bulk. This setting is a generalization of the classical spiked population model [30]. Adapting the results given in [32] (see also [40] for related results under more general settings), we thus reach the second important ingredient of our proof of Theorem 1, characterizing the asymptotic limit of .
Proposition 4
For each fixed ,
[TABLE]
where is the function defined in (16) and is the limit value in (50).
Proof:
Recall from (48) that is the leading eigenvalue of . Since and are independent, and since is a Gaussian random matrix with a rotationally invariant distribution, we can equivalently study the leading eigenvalue of the following matrix
[TABLE]
Proposition 3 shows that form a bulk spectrum, which converges to the law of as , whereas converges to a “spike” , which is separated from the bulk.
The asymptotic limits of extreme sample eigenvalues of matrices in the form of (53) have been studied in [40, 32]. In our proof, we use the asymptotic characterization given in [32]. Key to this asymptotic analysis is the function defined111We have adapted the original definition of in [32, eq. (3.2)] because our matrix in (53) has a slightly different scaling from the one considered in [32]. in (14). The asymptotic behaviors of the leading sample eigenvalue turn out to depend on the sign of at the point :
In particular, applying [32, Theorem 4.1], we have
[TABLE]
The case when is covered in [32, Theorem 4.2]. Adapting that result to our specific setting, we have
[TABLE]
As an equivalent form, we can write . From this, we can easily check that is a convex function and that it admits a unique minimum within its domain . It follows that the two separate cases in (54) and (55) can be more compactly written as , where is the modified function defined in (16). ∎
III-D Proof of Theorem 1
We are now ready to prove our asymptotic characterizations given in Theorem 1. Since the sensing vectors are drawn from the rotationally invariant multivariate normal distribution, the quantity for a general vector (with ) and for the special case have exactly the same probability distribution. In what follows, we will carry out the proof by assuming that the target vector . By showing that converges to the right-hand side of (18) almost surely, the convergence to the same limit in probability for a general then follows as an immediate consequence.
To start, we use the deterministic characterization given in Proposition 2. For each , let be the unique fixed-point of (44). Equivalently, satisfies the identity
[TABLE]
By Proposition 4, for every fixed ,
[TABLE]
as . Since and are nondecreasing, the two functions on both sides of (56) are strictly increasing. This condition, together with the fact that , allows us to apply Lemma 3 in Appendix -E to conclude , where is the unique point such that
[TABLE]
To determine the asymptotic behavior of the leading eigenvector , we use the characterization given in (45). Since are convex functions, we apply Lemma 4 in Appendix -E. In particular, if is differentiable at , that lemma gives us
[TABLE]
and similarly
[TABLE]
Substituting these limits into (45), we get
[TABLE]
To simplify the above expression, we introduce a change of variable, writing . In particular, . Using the characterization (57) and recalling the definition of in (51), we get
[TABLE]
where is defined in (13). By their constructions, it is easily checked that is a nondecreasing continuous function on whereas is a strictly decreasing continuous function. Moreover, by assumption (A.5), . Thus, the existence of satisfying (59) and its uniqueness are guaranteed. Substituting into (58) gives us
[TABLE]
where we have also used the fact that . To reach the characterization (18) given in the theorem, we just need to note that, by its definition in (16), if and if .
Next, we characterize the first two eigenvalues and . By Proposition 2, the leading eigenvalue . Since , applying Lemma 3 stated in Appendix -E leads to
[TABLE]
Recall from (32) that is a principal submatrix of obtained by deleting the first row and column of . It follows from the standard Cauchy interlacing theorem (see, e.g., [42, Theorem 4.3.8]) that
[TABLE]
Applying [32, Lemma 3.1] (which is due to [43]), the upper edge of the support of the limiting spectral density of is given by
[TABLE]
where is the minimizing point defined in (15). It follows that and , and thus
[TABLE]
by the interlacing inequalities in (60). Finally, by the constructions of and , we have if and only if , and the proof is complete.
IV Sampling Ratios and Phase Transitions
In this section, we study the phase transition phenomena characterized in Theorem 1 in more detail. In particular, we prove Proposition 1 (as stated in Section II-B), which specifies the phase transitions and the asymptotic limits of the cosine similarities in terms of the sampling ratio .
IV-A Critical Sampling Ratios
By Theorem 1, whether the leading eigenvector is asymptotically correlated or uncorrelated with the target vector depends on the sign of the derivative evaluated at a point . And this point is uniquely defined through the equation . Let , defined in (15), be the point at which the strictly convex function achieves its minimum. Calculating the derivative of and setting it to zero, we get
[TABLE]
By the construction of the function in (16) and by the monotonicity of , we can conclude that if and only if
[TABLE]
Substituting (61) into (14) gives us . Thus, transitions between the correlated and uncorrelated phases take place exactly at the zero-crossings of the function
[TABLE]
where is obtained by removing a common factor from the difference and by writing simply as . Let be the set consisting of all the zero-crossings of within the open interval . Using (61), we can then establish a one-to-one mapping between points in and a set of critical values of the sampling ratios.
Lemma 2
The set is nonempty. It contains a finite number of points, denoted by for some . Moreover,
[TABLE]
Proof:
We first show that is nonempty. For , applying the Cauchy-Schwartz inequality gives us
[TABLE]
By assumption (A.5), as approaches from the right. Thus, we have
[TABLE]
To study the function as , we note that
[TABLE]
By assumption (A.6), . We can then conclude from inequality (65) that
[TABLE]
Since is a continuous function, (64) and (65) imply that there must exist at least one zero-crossing.
Next, we show the upper bound given in (63). For any , we have from (62) that
[TABLE]
By assumption (A.4), is bounded within . It follows that
[TABLE]
Substituting the above inequalities into (67) gives us , which, after some simple manipulations, leads to the upper bound given in (63).
Finally, to show that is a finite set, we extend in (62) to the complex domain . Since is analytic and it is not zero everywhere, by the principle of permanence, it has at most a finite number of zeros in the bounded domain . ∎
IV-B Proof of Proposition 1
Write and . The corresponding critical sampling ratios and , as defined in (20), are obtained through the one-to-one mapping given in (61).
Fix . By the monotonicity of the mapping (61), the corresponding is strictly less than the smallest zero-crossing point . From the proof of Lemma 2, we conclude that , and thus and intersects at a point . This implies that and thus Theorem 1 gives us
[TABLE]
Now fix , in which case . Since , we must have and thus . To derive the parametric form of given in the statement of the proposition, we note that
[TABLE]
Thus, the equation becomes . Using the explicit definitions of these functions given in (13) and (14), we get
[TABLE]
We can also explicitly compute
[TABLE]
Similarly, we can write
[TABLE]
Substituting (70) and (71) into the asymptotic characterization (18) gives us (22), which, together with (68), provides a parametric representation of the function .
Finally, we show that as . From (68) and after some simple manipulations, we have
[TABLE]
Since as , the above formula gives us
[TABLE]
where the leading coefficient is positive by assumption (A.6). By the boundedness of ,
[TABLE]
and thus . It follows from (69) that . Similarly, we conclude from (71) that . Substituting these limiting expressions into (18) then gives us , and this completes the proof.
Remark 8
When the set consists of a single element, which is the case for many signal acquisition models we have studied, and thus . There then exists a single critical sampling ratio separating the uncorrelated phase from the correlated one. For , the estimates from the spectral method is asymptotically orthogonal to ; for , the estimates will be concentrated on the surface of a right-circular cone whose generating lines make an angle to the target vector . The situation is more complicated when contains multiple zero-crossings, in which case a finite number of correlated and uncorrelated phases can alternatively take place between and . A concrete example demonstrating this situation is shown in the next subsection.
IV-C Multiple Phase Transitions: an Example
Consider the following model:
[TABLE]
where , and are two nonoverlapping intervals on the positive real axis. We also set , and thus has the same distribution as a standard normal random variable, denoted by . Define
[TABLE]
where is the indicator function of , for . As takes only different values, we can explicitly compute in (62) as
[TABLE]
Choose , , and . We then have , , and . In this case, turns out to have three zero-crossings:
[TABLE]
By the mapping in (61), they correspond to three critical sampling ratios:
[TABLE]
Using the characterization given in Theorem 1, we obtain the limiting values of the squared cosine similarity as a function of the sampling ratio . Figure 4 illustrates this function . We can see that, when , the estimates given by the spectral method are asymptotically uncorrelated with . When is in the interval , however, the function has a small “bump” (see the insert for a zoomed-in view), meaning that the estimates become asymptotically correlated with . However, the correlation returns to zero as moves past the second phase transition point . Finally, when , the estimates become correlated with again, and tends to one as .
Remark 9
It would be desirable to obtain a deeper understanding of the above phenomenon involving multiple phase transitions. The example provided here is purely theoretical, as its phase transitions take place at very large values of . It will be interesting to explore other possible examples of multiple phase transitions with more practical values of . Moreover, as most signal acquisition models we have studied seem to involve only a single phase transition point, it will be interesting to seek easy-to-verify conditions for the function defined in (62) to have only one zero-crossing. We leave these as interesting open questions.
V Discussion
In this paper, we have presented a precise asymptotic characterization of the performance of a spectral method for estimating signals from generalized linear measurements with Gaussian sensing vectors. Our analysis also reveals a phase transition phenomenon that takes place at certain critical sampling ratios. Below a minimum threshold, estimates given by the methods are nearly orthogonal to the true signal , thus carrying no information; above a maximum threshold, the estimates become increasingly aligned with . The computational complexity of the spectral method is also markedly different in the two phases. Within the uncorrelated phase, the gap between the top two leading eigenvalues diminishes to zero. In contrast, a nonzero spectral gap emerges within the correlated phase. In this section, we close the paper by discussing some possible directions for extending and improving our results as well as their connections to related work in the literature.
The rate of convergence and more refined analysis. The performance of the spectral method was first studied in [11] for the problem of phase retrieval. In that paper, it is shown that, for each , there is a constant such that with high probability when
[TABLE]
This estimate of the sample complexity was improved to in [7] and to in [13]. The key technical tools underlying these previous estimates are matrix concentration inequalities (see, e.g., [44]), which guarantee that the spectral norm of the difference between the data matrix and its expectation will be small when the sampling ratio is sufficiently large. The closeness of the corresponding leading eigenvectors of and then follow from standard perturbation arguments. (See also our discussions towards the end of Section II-A.) Our work differs from and complements these finite-sample bounds in that we obtain sharp asymptotics to characterize the exact performance of the spectral method in the high-dimensional regime. A (theoretical) limitation of our analysis is that it is asymptotic in nature, requiring both . Although numerical simulations shown in Section II-D indicate that the asymptotic predictions are accurate even for moderate signal dimensions, it will be useful to quantify the rate of convergence towards the asymptotic limits in future work.
Another possible direction to further refine our analysis is to consider second-order asymptotics at the level of central limit theorems (CLTs). See for instance [45] for a related CLT analysis for the extreme eigenvalues of spiked covariance models.
Alternative initialization schemes. The spectral method considered in this paper is certainly not the only choice for initialization purposes. For example, an interesting alternative is the simple linear estimator studied in [46]:
[TABLE]
By using the moment calculations in [46, Proposition 1.1] and bounding high-order moments, one can easily obtain that
[TABLE]
where and are the random variables defined in (5).
Recall the function introduced in (12) and our discussions thereafter, where we point out that the spectral method is not suitable for acquisition models for which is an odd function plus a constant. Such cases will pose no problem for the linear estimator in (72). However, it is interesting to note that the linear estimator will be ineffective when is an even function, as is the case in phase retrieval. To see this, we note that when is even. It then follows from (73) that the linear estimator will be asymptotically uncorrelated with the target signal .
For cases where the function is neither odd nor even, the choice between the spectral method and the linear estimator is not as clear-cut. The spectral method exhibits phase transition behaviors with its estimates in the uncorrelated phase at small values of . In contrast, as shown in (73), the performance of the linear estimator increases as a monotonic function of . As a result, in the regime of very small , the linear estimator will be preferable. For (moderately) larger values of , the comparison between the spectral method and the linear estimator cannot be easily made, as their performance also depends on the preprocessing function used in (3) and (72).
The incorporation of priors. In this work, we assume that the target signal is an arbitrary unknown (deterministic) signal. In many applications, the underlying signals satisfy additional constraints (such as sparsity). In [46], the authors considered a two-step scheme, where the initial linear estimate given in (72) is further projected onto a set which encapsulates one’s prior knowledge about . It will be interesting to consider and analyze similar projection schemes for the estimates obtained by the spectral method.
Universality and more realistic sensing vectors. Our asymptotic analysis assumes that the sensing vectors are real-valued i.i.d. Gaussian random vectors. Numerical simulations seem to suggest that the theoretical predictions given in Theorem 1 remain valid for more general random measurement ensembles and for complex-valued sensing vectors. To demonstrate this, we show in Figure 5 the results of applying the spectral method to estimate a cameraman image from phaseless measurements under Poisson noise:
[TABLE]
where the bound is set to 5 and is normalized to 1 in our simulations. Two measurement ensembles are considered: real-valued sensing vectors whose elements are independent Rademacher () random variables, and complex-valued sensing vectors with elements drawn from the complex Gaussian distribution . We see from the figure that the theoretical predictions (the solid lines) have excellent agreement with simulation results for this moderately-sized problem, even though the sensing vectors can be non-Gaussian. Rigorously establishing the validity of our asymptotic predictions without the Gaussian assumption will be an important future work. Thanks to the deterministic characterization given in Proposition 2, this task boils down to showing that the result of Proposition 4 still holds when the sensing matrix consists of i.i.d. entries drawn from more general distributions. A related but more ambitious line of work will be to characterize the performance of the spectral method for structured and more practical sensing ensembles such as the coded diffraction scheme for phase retrieval with random modulation patterns.
Low-rank matrix recovery. The spectral method studied in this paper belongs to a more general theme. Let be a rank- matrix and a collection of sensing matrices of the same size as . To recover from linear measurements of the form , we can consider the following rank-constrained least squares problem
[TABLE]
and try to solve it via projected gradient descent
[TABLE]
where denotes projection onto the set of rank- matrices, and is the step size. As pointed out in [47], the spectral method studied in this paper can be viewed as the very first iteration of (75), if we start the algorithm from and consider the special case of recovering a symmetric rank-one matrix (i.e., , ) with . Thus, an interesting line of future research is to extend the results of this work, notably the key characterization given in Proposition 2, to more general settings with and and to other sensing matrices. Such extensions will be useful in applications such as low-rank matrix recovery, covariance estimation, and blind deconvolution.
-A Sufficient Conditions for Assumption (A.5) to Hold
In this appendix, we provide two sufficient conditions for Assumption (A.5) to hold.
Case 1: Suppose that the probability law of the random variable contains a point mass at its upper boundary , where is some positive constant. This applies to the logistic regression model in Example 1, the subset algorithm (28) in Example 2, the noisy phase retrieval model in (74), and the quantization model described in Section IV-C.
In this case,
[TABLE]
as . To verify the second expression in (6), let . Since , we must have . Thus,
[TABLE]
which tends to as approaches from the right.
Case 2: Suppose that there exist some positive constants and such that the probability density function of and the conditional moment are both bounded below by for all . The model in (8) represents one such case. Under this setting,
[TABLE]
Similarly, we can verify that as .
-B Norm Estimation
The spectral initialization method estimates the orientation of the vector but it provides no information about its norm, as the eigenvector is always normalized. In many cases where the sensing vectors come from certain random ensembles, the norm can be accurately estimated from the measurements.
As a simple illustrative example, we can consider the (noiseless) phase retrieval problem: , where is a deterministic unknown vector with , and the sensing vectors are i.i.d. standard normal random vectors. Since , the measurement can be represented as
[TABLE]
where (for ) are i.i.d. standard normal random variables. A simple estimator of the norm is then
[TABLE]
which is asymptotically consistent as .
More generally, consider an observation model , where is a conditional probability density function and . Again, writing for i.i.d. normal random variables , we can represent the probability distributions of the measurements as
[TABLE]
Let . If is monotonic on the positive real line, the method of moments gives an estimator
[TABLE]
We note that the estimator in (76) is a special case of (77). More generally, one could also estimate by using maximum likelihood
[TABLE]
whose asymptotic consistency can be established under standard conditions [48] on the parametric density function .
-C Proof of Proposition 2
By a suitable choice of a transformation matrix
[TABLE]
where is an orthogonal matrix involving the last rows and columns only, we can get a matrix
[TABLE]
where are the two sets of indices defined in (42) and is a vector consisting of all the nonzero elements of . Let and be the largest eigenvalue of and an associated unit-norm eigenvector, respectively. Clearly, and . Thus, we just need to consider in our proof.
Due to its block-diagonal form, the eigenvalues of is the union of those of its top-left submatrix
[TABLE]
and those of its bottom-right submatrix . In particular,
[TABLE]
The eigenvectors associated with are easy to characterize. Clearly, each is an eigenvalue of , and it corresponds to an eigenvector , where is the row index of in .
The eigenvalues and eigenvectors of can also be precisely characterized. Due to its shape, is sometimes referred to in the literature as an arrowhead matrix [49, 50]. It can be shown (see for instance [51][pp. 94 – 97]) that is the unique point within the interval to satisfy the equation
[TABLE]
where is the function defined in (38). (Alternatively, we can use the Laplace expansion to explicitly derive the characteristic polynomial of as
[TABLE]
Then, by following similar arguments as those used in the proof of Lemma 1, we can reach the characterization (80) about .) Furthermore, let be a unit-norm eigenvector of associated with . It is easily checked that
[TABLE]
where and is a row vector of zeroes with being the cardinality of . It follows that
[TABLE]
where denotes the derivative of the function .
To show the claim of the proposition, we consider the following three cases.
Case 1: . We choose , and thus . It follows from Lemma 1 that
[TABLE]
where the second equality is due to the fact that
[TABLE]
and the last equality comes from (79).
Using the identity (80) for , we can also verify that indeed satisfies the equation (44). (Its uniqueness is always guaranteed; see Remark 6 at the end of Section III-B.) The unit-norm leading eigenvector of in this case is the vector defined in (81). Since in a neighborhood of , the function is differentiable at and
[TABLE]
Substituting (84) into (82) leads to (46).
Case 2: , in which case , where the last equality is due to (83). The corresponding leading eigenvector has nonzero elements only in its last entries, where is the cardinality of . Thus,
[TABLE]
We set . (Note that we are guaranteed to have . This can be verified by observing that , where the equality is due to (80) and the last inequality follows from the fact that .) Since is a strictly increasing function, we have
[TABLE]
where the equality comes from (80). It then follows from Lemma 1 that and, moreover, satisfies the equation (44).
To characterize the eigenvector, we note that in a neighborhood of . We then have , which, together with (85), leads to (46).
Case 3: . This is a special case, where the algebraic multiplicity of the leading eigenvalue is greater than one. The leading eigenvectors are not unique, and they can be any vector in the form of
[TABLE]
where is the eigenvector defined in (81) and is an eigenvector associated with , and are two constants satisfying . Since , we have from (82) that
[TABLE]
Same as what we did in Case 2, we set . Following the same arguments there, we can show that and satisfies the equation (44). Moreover, we can see that for and for . The function is not differentiable at , but its right and left derivatives do exist. It is easy to get [see (84)] and . Substituting these quantities into (86), we reach the characterization given in (45).
-D Proof of Proposition 3
To establish the almost-sure convergence of the random measure to the probability law of , we just need to show that, almost surely, the empirical distribution function
[TABLE]
converges to , the cumulative distribution function of z, at all points where is continuous. Since is a rank-one perturbation of the diagonal matrix , standard interlacing theorems (see [42, Theorem 4.3.4]) give us
[TABLE]
for . Let be the empirical distribution function of the eigenvalues of . We can then easily verify from (87) that
[TABLE]
Since is an i.i.d. sample of the random variable , with probability one converges to all all points where is continuous. It then follows from (88) that converges almost surely to the same limit .
To study the leading eigenvalue , we use Lemma 1. To apply that result, we require as defined in (35) to be not equal to the all-zero vector. This condition holds almost surely for all sufficiently large . To see this, we note that , as otherwise assumption (A.6) will not hold. Moreover, with probability one. It follows that the i.i.d. sequence has an infinite number of nonzero elements. Thus, almost surely, the -dimensional vector for sufficiently large .
Applying (39) to our case, we have , where
[TABLE]
with this function defined on . Since , we can further simplify the characterization to
[TABLE]
For every , with being the upper bound of the support of the probability distribution of , it follows from the strong law of large numbers that converges almost surely to
[TABLE]
where is defined in (51). On its domain , the function is strictly increasing and thus it admits a functional inverse . Applying Lemma 3 in Appendix -E, we have
[TABLE]
as .
-E Auxiliary Lemmas
We prove here two auxiliary lemmas that are used in our proofs of Proposition 3 and Theorem 1.
Lemma 3
Let be a family of (random) functions defined on an open interval . Each is continuous and nondecreasing. For each , as , where is a continuous and nondecreasing function. Then, for any sequence with , we have
[TABLE]
If, in addition, the functions and are strictly increasing, we denote by and the corresponding functional inverses. Assume that the domains of and contain a common open interval . Then for any sequence such that , we have
[TABLE]
Proof:
We first show (89). Let for be a sequence that converges to from the left. We choose so that the entire sequence stays within the interval . Similarly, define a sequence , for , that converges to from the right. Denote by the intersection of the event that for all and the event that . Clearly, . Next, we show that (89) holds within this almost sure event.
Fix . As , we have for all sufficiently large . By the monotonicity of ,
[TABLE]
It follows that
[TABLE]
As is arbitrary, we take the limit, which leads to by the continuity of .
The proof of (90) is similar. We establish it under the additional assumption that and are strictly increasing. Construct two sequences and as above, with replaced by . Also define the event similarly. We show that, within the almost sure event , we have .
Fix . Since is strictly increasing, implies that
[TABLE]
As , and , the inequalities
[TABLE]
hold for all sufficiently large . By the strict monotonicity of ,
[TABLE]
for all sufficiently large . It then follows that , for each . As and , we are done. ∎
Lemma 4
Let be a sequence of (random) convex functions defined on an open interval . For each , . Let be a sequence such that for some . If is differentiable at , then
[TABLE]
where and denote the left and right derivatives of , respectively.
Proof:
Similar to the proof of Lemma 3, we construct two sequences: is strictly increasing and converges to from the left, whereas is strictly decreasing and converges to from the right. Denote by the intersection of the event that for all and the event that . It is easily checked that . Next, we establish (91) within this almost sure event.
For any , since and , we must have for all sufficiently large . By the convexity of , its left derivatives always exist and we have
[TABLE]
for all sufficiently large . It follows that
[TABLE]
for all . Since
[TABLE]
we must have
[TABLE]
Working with the sequence and using similar arguments as above, we can show that
[TABLE]
Since , we use (92) and (93) to conclude that exists and that it is equal to . By similar arguments, the same claim also holds for the sequence , and thus the proof is complete. ∎
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] M. Unser and M. Eden, “Maximum likelihood estimation of linear signal parameters for Poisson processes,” IEEE Trans. Acoust., Speech, and Signal Process. , vol. 36, no. 6, pp. 942–945, Jun. 1988.
- 2[2] F. Yang, Y. M. Lu, L. Sbaiz, and M. Vetterli, “Bits from photons: Oversampled image acquisition using binary poisson statistics,” IEEE Trans. Image Process. , vol. 21, no. 4, pp. 1421–1436, 2012.
- 3[3] J. R. Fienup, “Phase retrieval algorithms: a comparison,” Applied Optics , vol. 21, no. 15, pp. 2758–2769, 1982.
- 4[4] S. Rangan and V. K. Goyal, “Recursive consistent estimation with bounded noise,” Information Theory, IEEE Transactions on , vol. 47, no. 1, pp. 457–464, 2001.
- 5[5] A. J. Dobson and A. Barnett, An Introduction to Generalized Linear Models , 3rd ed. Boca Raton: Chapman and Hall/CRC, May 2008.
- 6[6] T. Hastie, R. Tibshirani, and J. Friedman, The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition , 2nd ed. New York, NY: Springer, Apr. 2011.
- 7[7] E. J. Candes, T. Strohmer, and V. Voroninski, “Phaselift: Exact and stable signal recovery from magnitude measurements via convex programming,” Communications on Pure and Applied Mathematics , vol. 66, no. 8, pp. 1241–1274, 2013.
- 8[8] E. J. Candes and X. Li, “Solving quadratic equations via Phase Lift when there are about as many equations as unknowns,” Foundations of Computational Mathematics , vol. 14, no. 5, pp. 1017–1026, 2014.