Is a Data-Driven Approach still Better than Random Choice with Naive Bayes classifiers?
Piotr Szyma\'nski, Tomasz Kajdanowicz

TL;DR
This study compares data-driven, a priori, and random label space partitioning methods for multi-label classification using Gaussian Naive Bayes, showing data-driven methods generally outperform random approaches on benchmark datasets.
Contribution
It provides an empirical comparison of label partitioning strategies for Naive Bayes classifiers, highlighting the conditions under which data-driven methods outperform others.
Findings
Data-driven methods outperform random baselines on average.
Data-driven approaches are more likely to outperform random methods in F1 and Subset Accuracy.
A method exists that always beats a priori approaches in the worst case.
Abstract
We study the performance of data-driven, a priori and random approaches to label space partitioning for multi-label classification with a Gaussian Naive Bayes classifier. Experiments were performed on 12 benchmark data sets and evaluated on 5 established measures of classification quality: micro and macro averaged F1 score, Subset Accuracy and Hamming loss. Data-driven methods are significantly better than an average run of the random baseline. In case of F1 scores and Subset Accuracy - data driven approaches were more likely to perform better than random approaches than otherwise in the worst case. There always exists a method that performs better than a priori methods in the worst case. The advantage of data-driven methods against a priori methods with a weak classifier is lesser than when tree classifiers are used.
Click any figure to enlarge with its caption.
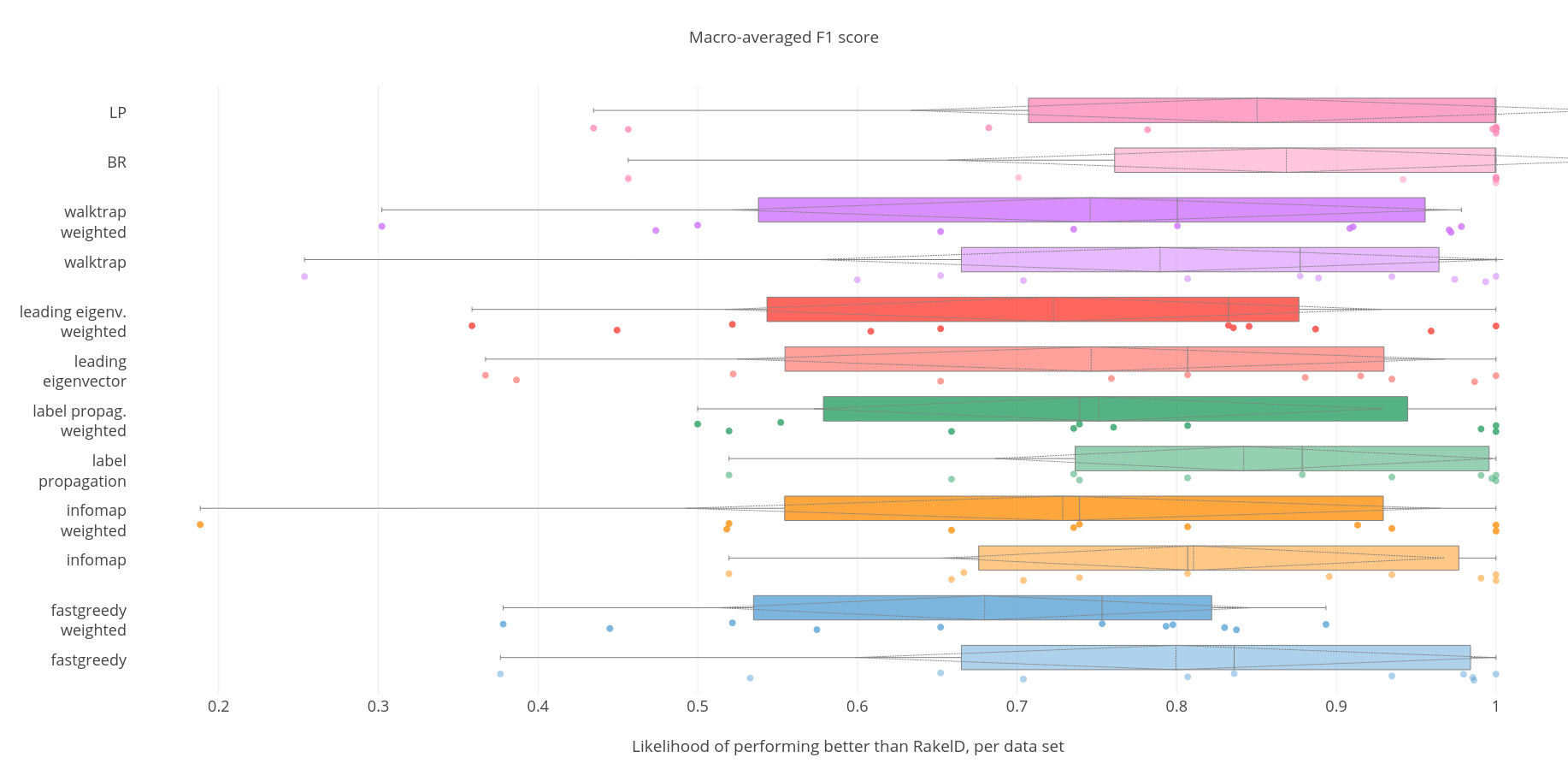 Figure 1
Figure 1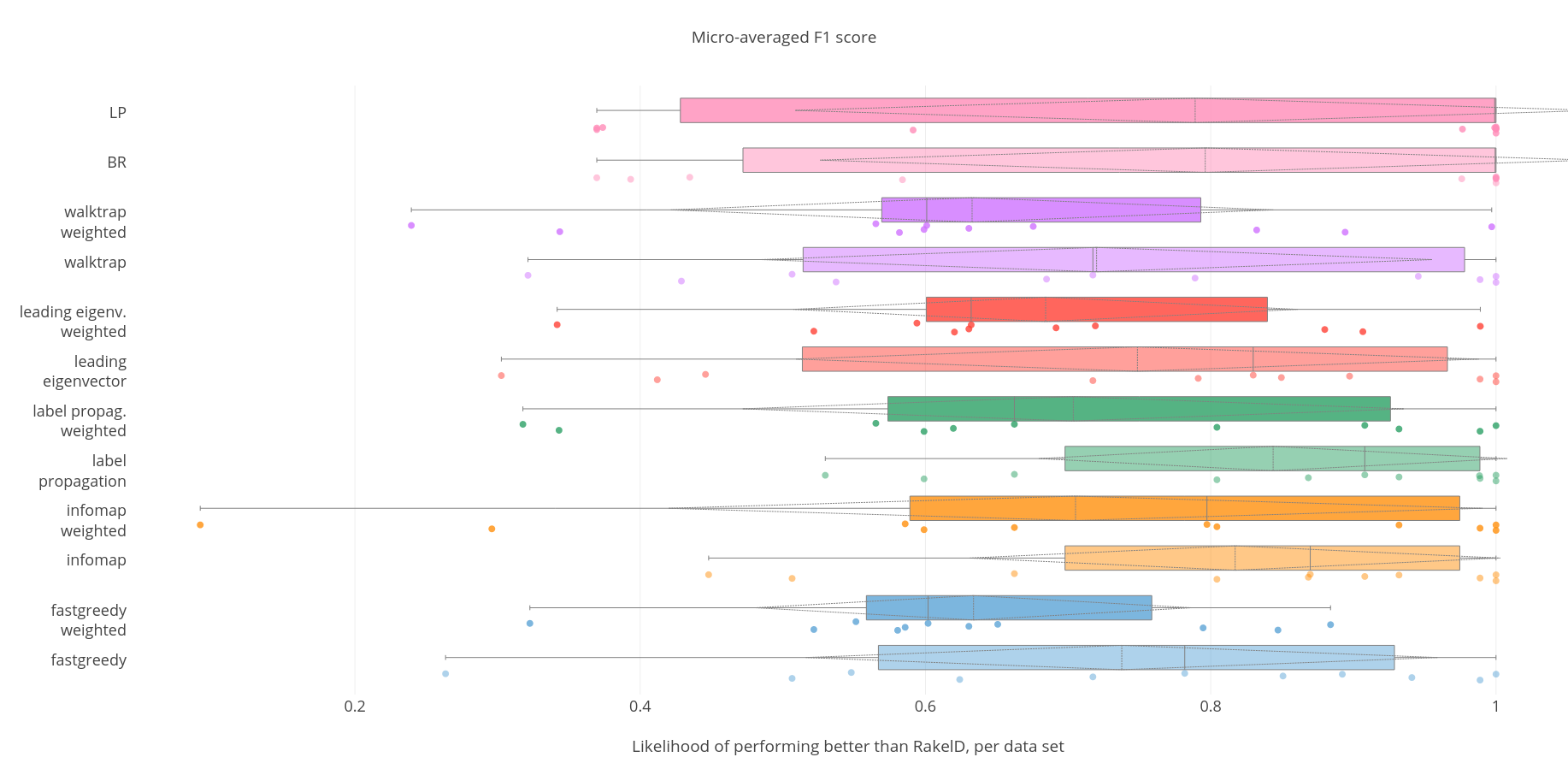 Figure 2
Figure 2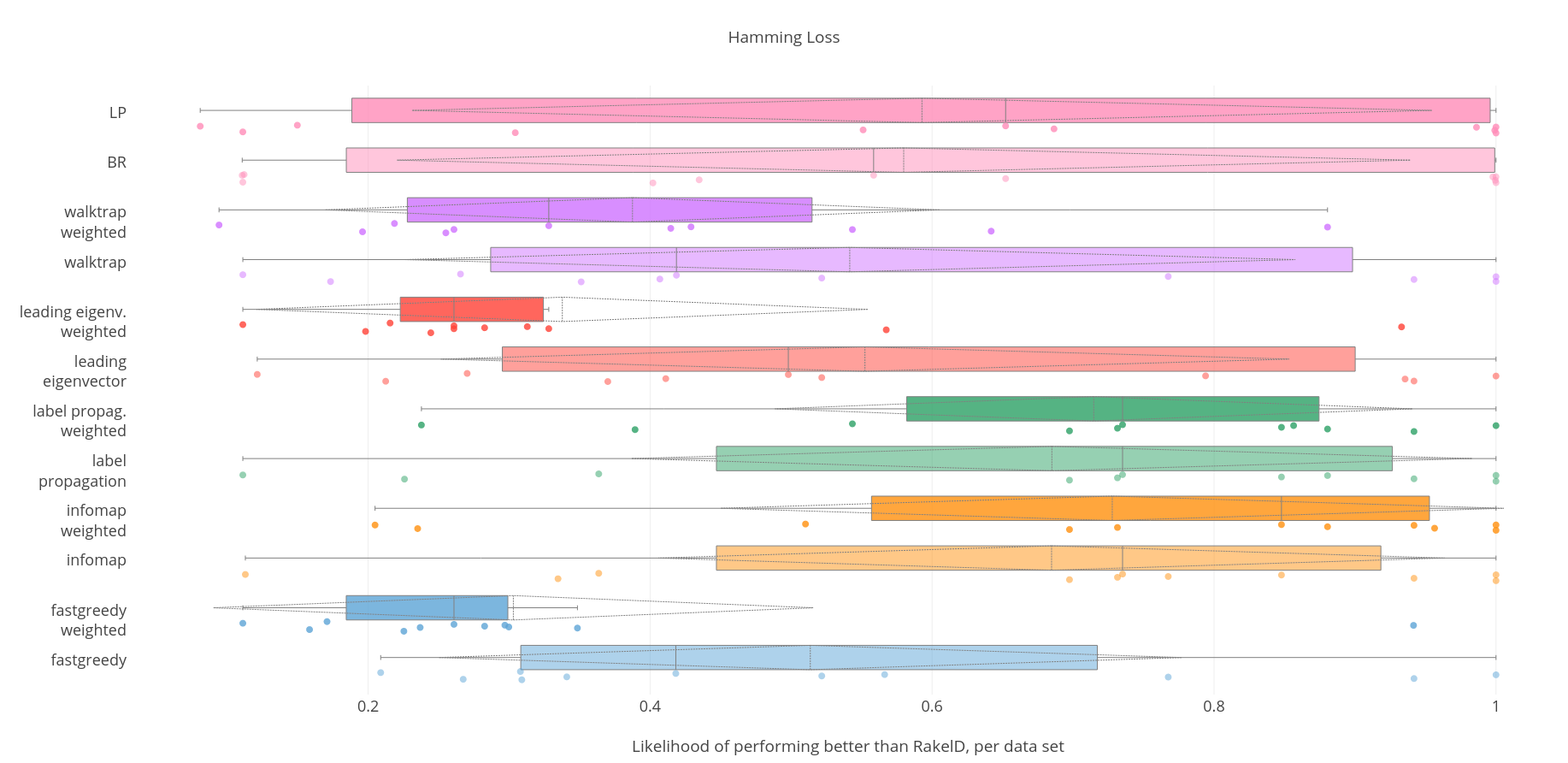 Figure 3
Figure 3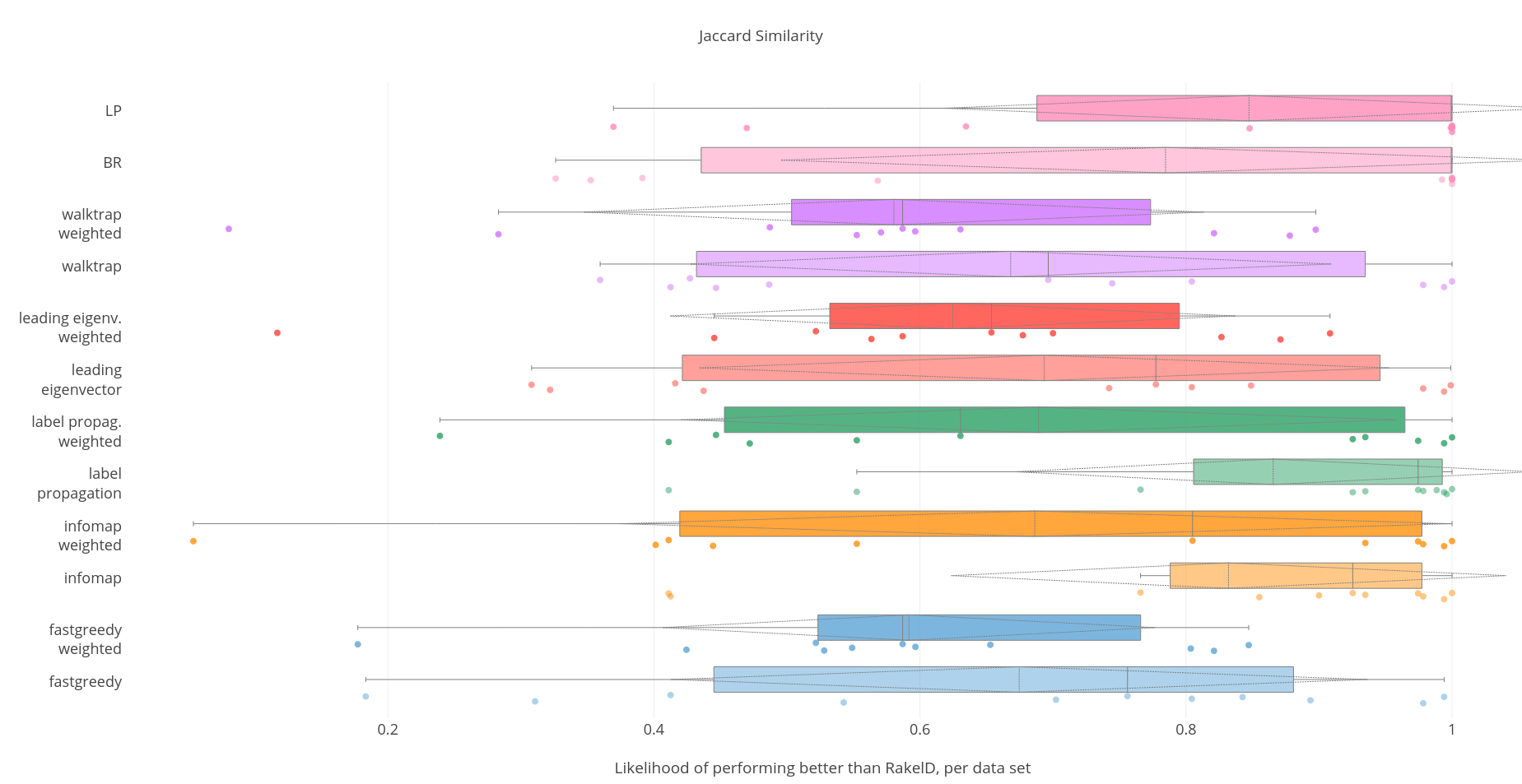 Figure 4
Figure 4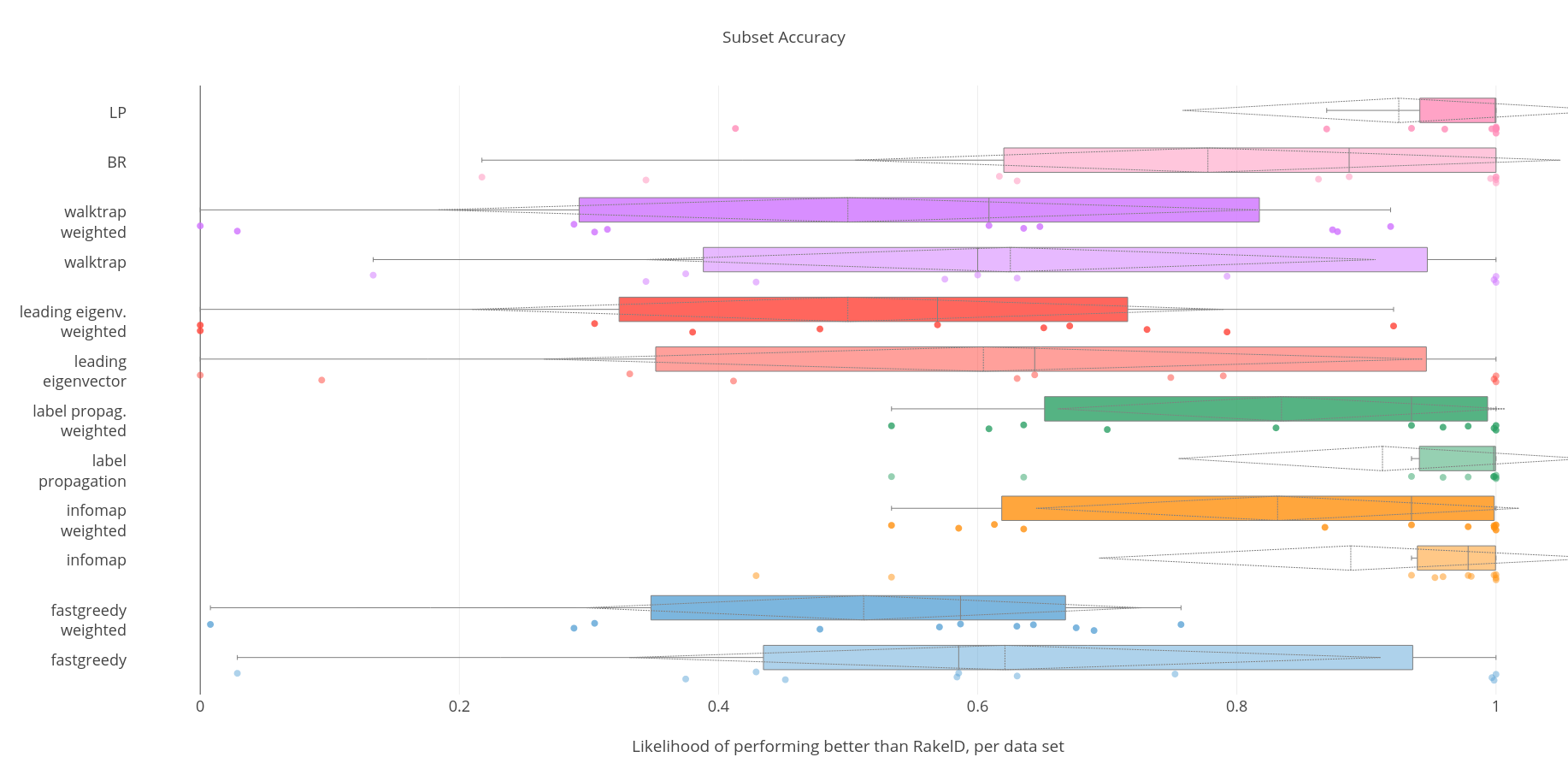 Figure 5
Figure 5| FG | FGW | LE | LEW | WTW | |
|---|---|---|---|---|---|
| Macro-averaged F1 | 0.068 | 0.37 | 0.054 | 0.37 | 0.37 |
| Micro-averaged F1 | 0.011 | 0.071 | 0.003 | 0.011 | 0.043 |
| Jaccard Score | 0.026 | 0.07 | 0.008 | 0.026 | 0.070 |
| Micro-averaged F1 | Macro-averaged F1 | Subset Accuracy | Jaccard Similarity | Hamming Loss | |
|---|---|---|---|---|---|
| RH1 | Yes | Yes | Yes | Yes | Yes |
| RH2 | Undecided | No | No | Undecided | Yes |
| RH3 | Yes | Yes | Yes | Yes | Yes |
| RH4 | Yes | Yes | Yes | No | No |
| Recommended data-driven approach | Unweighted label propagation | Unweighted label propagation | Unweighted label propagation | Unweighted label propagation | Weighted infomap |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMachine Learning and Data Classification · Advanced Statistical Methods and Models
11institutetext: Department of Computational Intelligence, Wrocław University of Technology, Wybrzeże Stanisława Wyspiańskiego 27, 50-370 Wrocław, Poland
Is a Data-Driven Approach still Better than Random Choice with Naive Bayes classifiers?
Piotr Szymański
Tomasz Kajdanowicz
Abstract
We study the performance of data-driven, a priori and random approaches to label space partitioning for multi-label classification with a Gaussian Naive Bayes classifier. Experiments were performed on 12 benchmark data sets and evaluated on 5 established measures of classification quality: micro and macro averaged F1 score, subset accuracy and Hamming loss. Data-driven methods are significantly better than an average run of the random baseline. In case of F1 scores and Subset Accuracy - data driven approaches were more likely to perform better than random approaches than otherwise in the worst case. There always exists a method that performs better than a priori methods in the worst case. The advantage of data-driven methods against a priori methods with a weak classifier is lesser than when tree classifiers are used.
Keywords:
multi-label classification, label space clustering, data-driven classification
1 Introduction
In our recent work [11] we proposed a data-driven community detection approach to partition the label space for the multi-label classification as an alternative to random partitioning into equal subsets as performed by the random -label sets method proposed by Tsoumakas et. al. [13]. The data-driven approach works as follows: we construct a label co-occurrence graph (both weighted and unweighted versions) based on training data and perform community detection to partition the label set. Then, each partition constitutes a label space for separate multi-label classification sub-problems. As a result, we obtain an ensemble of multi-label classifiers that jointly covers the whole label space. We consider a variety of approaches: modularity-maximizing techniques approximated by fast greedy and leading eigenvector methods, infomap, walktrap and label propagation algorithms. For comparison purposes we evaluate the binary relevance (BR) and label powerset (LP) - which we call a priori methods, as they a priori assume a total partitioning of the label space into singletons (BR) and lack of any partitioning (LP).
The variant of RAEL evaluated in this paper is an approach in which the label space is either partitioned into equal-sized subsets of labels. This approach is called RAEL - RAEL distinct as the label sets are non-overlapping. RAEL takes one parameter - the number of label sets to partition into . We assumed that all partitions are equally probable and that the remainder of the label set smaller than becomes the last element of the otherwise equally sized partition family.
In [11] we compared community detection methods to label space divisions against RAEL and a priori methods on 12 benchmark datasets (bibtex [6], delicious [14], tmc2007 [14], enron ([7]), medical [9], scene [1], birds [2], Corel5k [4], Mediamill [10], emotions [12], yeast [5], genbase [3]) over five evaluation measures with Classifier and Regression Trees (CART) as base classifiers. We discovered that data-driven approaches are more efficient and more likely to outperform RAEL than binary relevance or label powerset is, in every evaluated measure. For all measures, apart from Hamming loss, data-driven approaches are significantly better than RAkELd ( ), and at least one data-driven approach is more likely to outperform RAkELd than a priori methods in the case of RAkELd’s best performance. This has been the largest RAkELd evaluation published to date with 250 samplings per value for 10 values of RAkELd parameter k on 12 datasets published to date.
In this paper we extend our result and evaluate whether the same results hold if instead of using tree-based methods, we employ a weak and Gaussian Naive Bayesian classifier from the scikit-learn python package [8]. The experimental setup remains identical to the one presented in tree-based scheme, except for the change of base classifier. Bayesian classifiers remain of interest in many applications due to their low computational requirements.
We thus repeat the research questions we have asked in the case of tree-based classifiers, this time for Naive Bayes based classifiers:
- RH1: Data-driven approach is significantly better than random ( = 0.05)
- RH2: Data-driven approach is more likely to outperform RAkELd than a priori methods
- RH3: Data-driven approach is more likely to outperform RAkELd than a priori methods in the worst case
- RH4: Data-driven approach is more likely to perform better than RAkELd in the worst case, than otherwise
2 Results
Micro-averaged F1 score.
While a priori methods such as Binary Relevance and Label Powerset exhibit a higher median likelihood of outperforming RAEL - we note that the highest mean likelihood is obtained by label propagation data-driven label space division on an unweighted label co-occurrence graph. Unweighted label propagation is also most likely to outperform RAEL in the worst case. Thus we reject RH2 and accept RH3 and RH4. The best performing and recommended community detection method for micro-averaged F1 score - unweighted label propagation - is better than average performance of RAEL with statistical significance, we thus accept RH1.
Macro-averaged F1 score.
In case of macro averaged F1 score Label Powerset is the most likely to outperform RAEL both in median and mean cases, while underperforms in the worst case. Label propagation data-driven label space division on an unweighted label co-occurrence graph is the most likely data-driven approach to outperform RAEL - although other approaches also yield good results. Unweighted label propagation is also most likely to outperform RAEL in the worst case. It is also better than an average run of RAEL with statistical significance. Thus we accept RH1, reject RH2 and accept RH3 and RH4.
Subset Accuracy.
In case of Subset Accuracy label propagation performed on an unweighted graph approach to dividing the labels space is the most resilient approach both in the worst case and in the average (mean/median) likelihood. The weighted version performers equally well in the worst case, so does unweighted infomap. As the worst case performance of three data-driven methods is greater than we accept RH4 for Subset Accuracy. While Label Powerset performs better than label propagation in case of the median/mean likelihood of being better than RAEL - it performs worse by 12 pp. in the worst case. Thus while rejecting RH2 and accepting RH3 we still recommend using data-driven label propagation approach instead of Label Powerset. Label propagation performs better than RAEL with statistical significance - we accept RH1.
Jaccard score.
Among data-driven methods the label propagation performed on an unweighted graph approach to dividing the labels space is the most resilient approach both in the worst case and in the average (mean/median) likelihood. It is followed by infomap. While a priori methods are perform better in case of the median likelihood by 3 pp., they perform worse than data-driven methods in the mean and worst case. We thus confirm RH2 and RH3. The worst case likelihood of data-driven methods outperforming RAEL is not grater than we thus reject RH4. Unweighted infomap performs better than the average run of RAEL with statistical significance - we thus accept RH1.
Hamming Loss
The data-driven methods that are most likely to outperform RAEL are infomap and label propagation performed on a weighted label co-occurence graph. We recommend using weighted infomap which is also most resilient in the worst case, although much less resilient than the desired likelihood of outperforming RAEL in the worst case. As a result the case of Hamming Loss we confirm RH2 and RH3 but reject RH4. Weighted infomap perform significantly better than an average run of RAEL - we accept RH1.
3 Conclusion and Outlook
We have examined the performance of data-driven, a priori and random approaches to label space partitioning for multi-label classification with a Gaussian Naive Bayes classifier. Experiments were performed on 12 benchmark data sets and evaluated on 5 established measures of classification quality. Table 12 summarizes out findings. Data-driven methods are significantly better than an average RAEL run that had not undergone parameter estimation - i.e. when results are compared against the mean result of all evaluated RAEL paramater values. When compared against the likelihood of outperforming a RAEL in the evaluated parameter space - in case of F1 scores and Subset Accuracy - data driven approaches were more likely to perform better than RAEL than otherwise in the worst case. There always exists a method that performs better than a priori methods in the worst case.
Data driven methods perform better than a priori methods in the mean likelihood but worse in median when it comes to micro-averaged F1 and Subset Accuracy. This can be attributed to differences in how likelihoods per data set distribute - data-driven methods perform better in worst case, but are also less likely to be always better than RAEL as opposed to a priori methods. The advantage of data-driven methods against a priori methods with a weak classifier is lesser than when tree classifiers are used. The authors acknowledge support from the National Science Centre research projects decision no. 2016/21/N/ST6/02382 and 2016/21/D/ST6/02948.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Boutell, M.R., Luo, J., Shen, X., Brown, C.M.: Learning multi-label scene classification. Pattern Recognition 37(9), 1757–1771 (Sep 2004), http://www.sciencedirect.com/science/article/pii/S 0031320304001074
- 2[2] Briggs, F., Lakshminarayanan, B., Neal, L., Fern, X.Z., Raich, R., Hadley, S.J.K., Hadley, A.S., Betts, M.G.: Acoustic classification of multiple simultaneous bird species: A multi-instance multi-label approach. The Journal of the Acoustical Society of America 131(6), 4640–4650 (2012), http://scitation.aip.org/content/asa/journal/jasa/131/6/10.1121/1.4707424
- 3[3] Diplaris, S., Tsoumakas, G., Mitkas, P.A., Vlahavas, I.: Protein Classification with Multiple Algorithms. IEEE Transactions on Pattern Analysis and Machine Intelligence pp. 448–456 (2005), http://www.springerlink.com/index/P 662542 G 78792762.pdf
- 4[4] Duygulu, P., Barnard, K., Freitas, J.F.G.d., Forsyth, D.A.: Object recognition as machine translation: Learning a lexicon for a fixed image vocabulary. In: Proceedings of the 7th European Conference on Computer Vision-Part IV. p. 97–112. ECCV ’02, Springer-Verlag, London, UK, UK (2002), http://dl.acm.org/citation.cfm?id=645318.649254
- 5[5] Elisseeff, A., Weston, J.: A kernel method for multi-labelled classification. In: In Advances in Neural Information Processing Systems 14. pp. 681–687. MIT Press (2001)
- 6[6] Katakis, I., Tsoumakas, G., Vlahavas, I.: Multilabel text classification for automated tag suggestion. In: In: Proceedings of the ECML/PKDD-08 Workshop on Discovery Challenge (2008)
- 7[7] Klimt, B., Yang, Y.: The enron corpus: A new dataset for email classification research. Machine Learning: ECML 2004 pp. 217–226 (2004), http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.61.1645&rep=rep 1&type=pdf
- 8[8] Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., Duchesnay, E.: Scikit-learn: Machine learning in Python. Journal of Machine Learning Research 12, 2825–2830 (2011)