An Efficient Decomposition Framework for Discriminative Segmentation with Supermodular Losses
Jiaqian Yu, Matthew B. Blaschko

TL;DR
This paper introduces an ADMM-based decomposition framework for discriminative image segmentation that enables efficient training with supermodular loss functions, improving accuracy and computational performance.
Contribution
It presents a novel ADMM decomposition method for loss-augmented inference in structured SVMs, allowing practical use of supermodular losses in image segmentation.
Findings
Improved segmentation accuracy on Grabcut and brain data.
Enhanced computational efficiency over existing algorithms.
Validated effectiveness of supermodular losses during training.
Abstract
Several supermodular losses have been shown to improve the perceptual quality of image segmentation in a discriminative framework such as a structured output support vector machine (SVM). These loss functions do not necessarily have the same structure as the one used by the segmentation inference algorithm, and in general, we may have to resort to generic submodular minimization algorithms for loss augmented inference. Although these come with polynomial time guarantees, they are not practical to apply to image scale data. Many supermodular losses come with strong optimization guarantees, but are not readily incorporated in a loss augmented graph cuts procedure. This motivates our strategy of employing the alternating direction method of multipliers (ADMM) decomposition for loss augmented inference. In doing so, we create a new API for the structured SVM that separates the maximum a…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4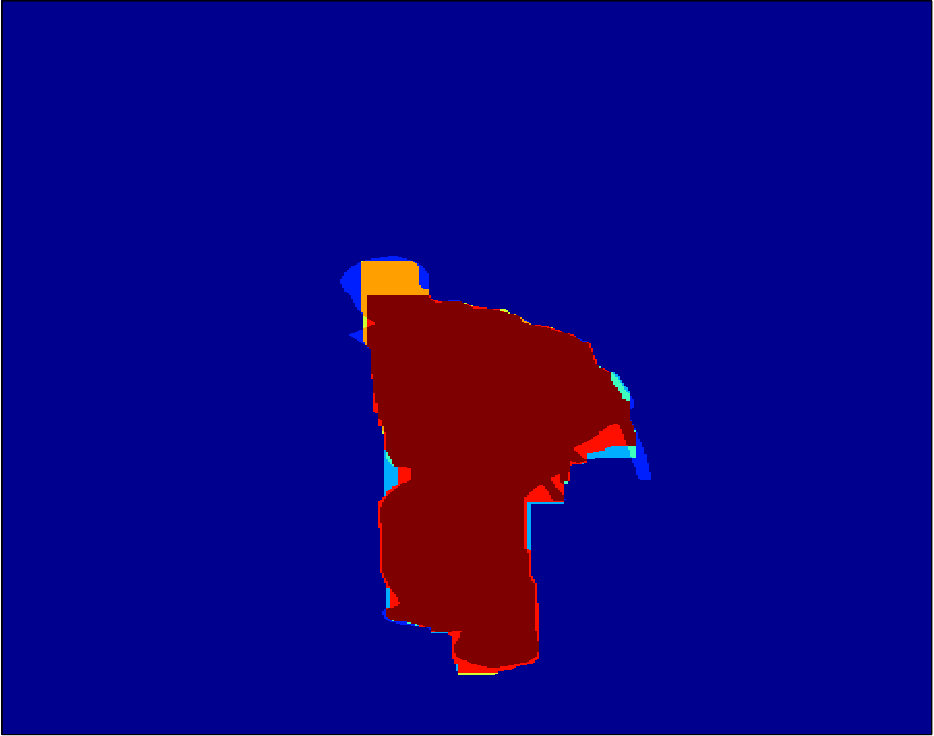 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7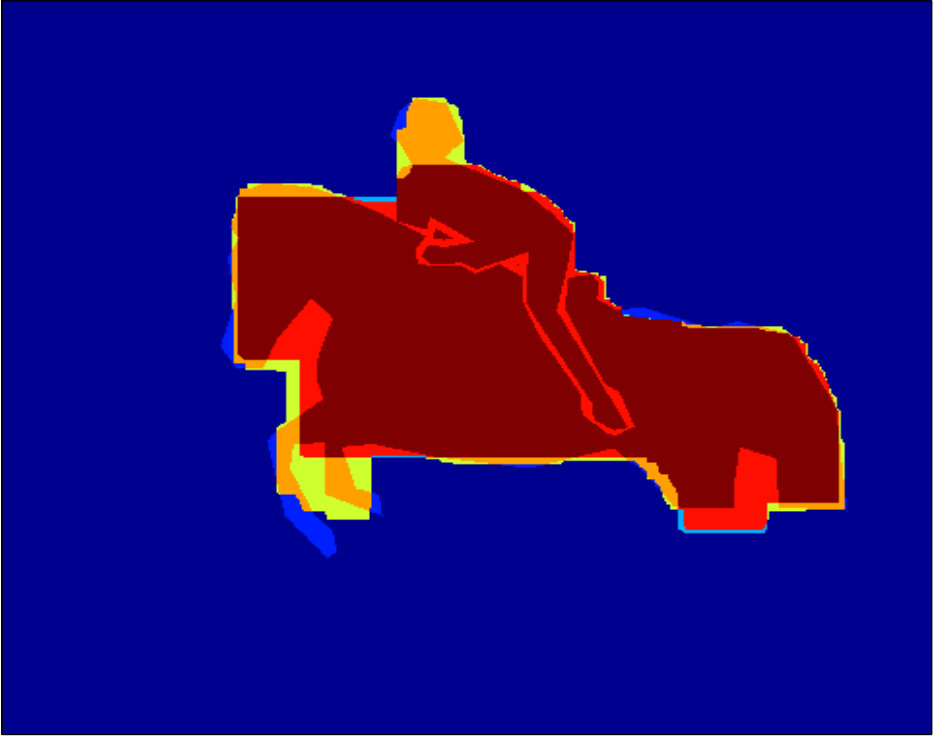 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16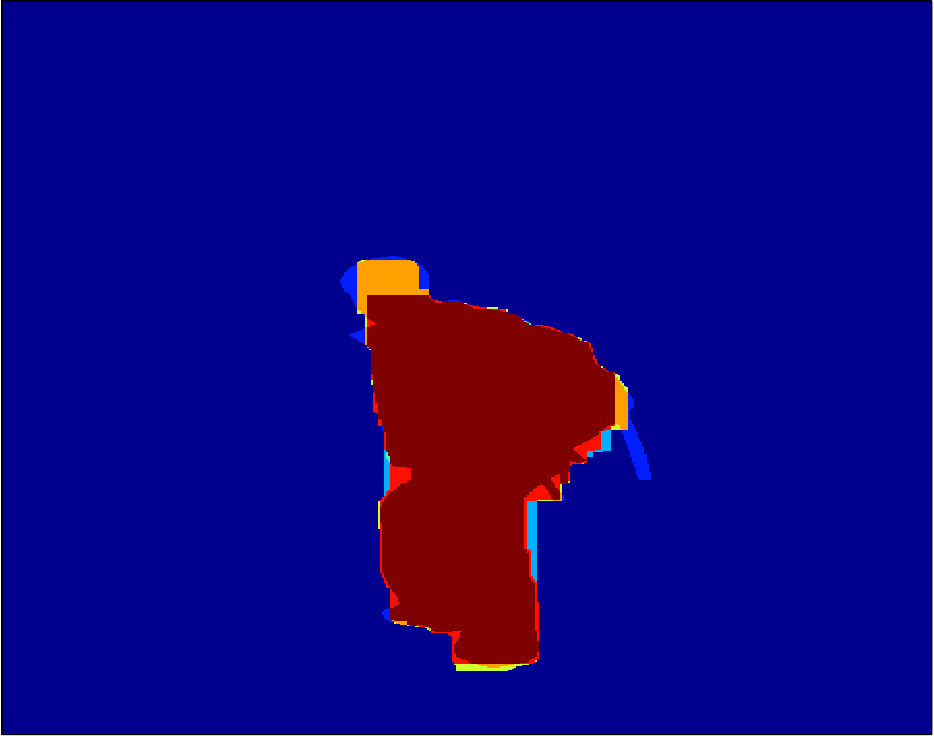 Figure 17
Figure 17 Figure 18
Figure 18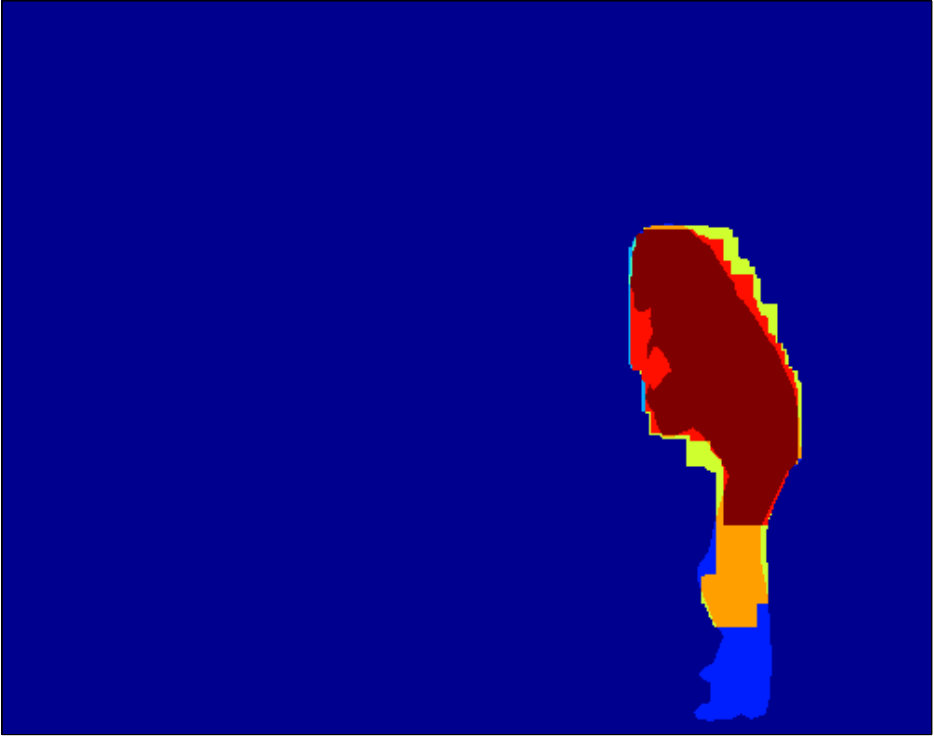 Figure 19
Figure 19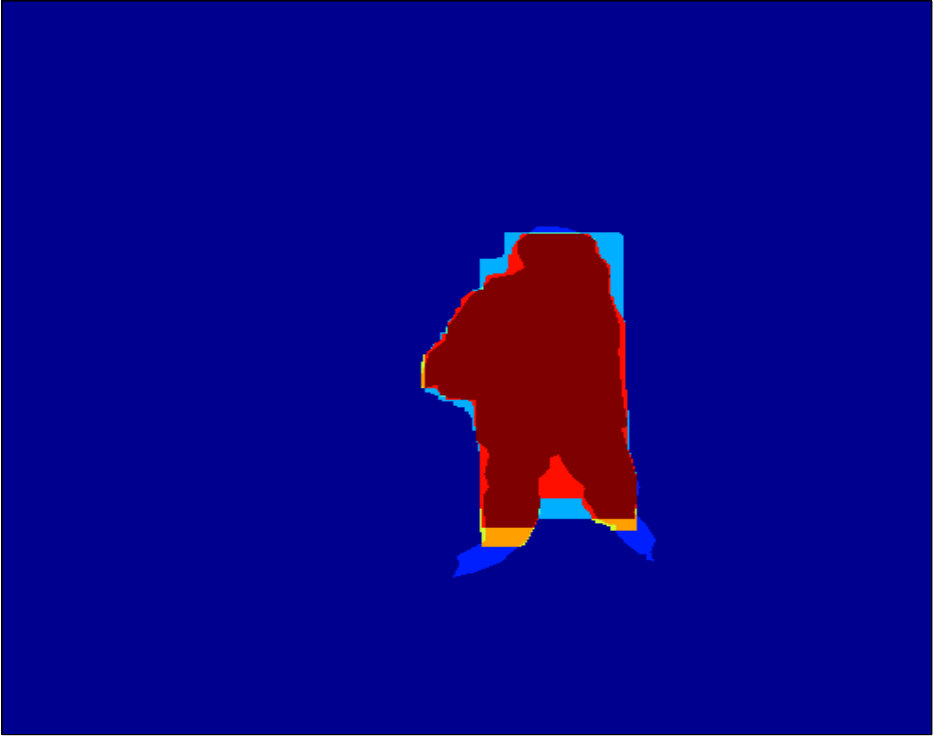 Figure 20
Figure 20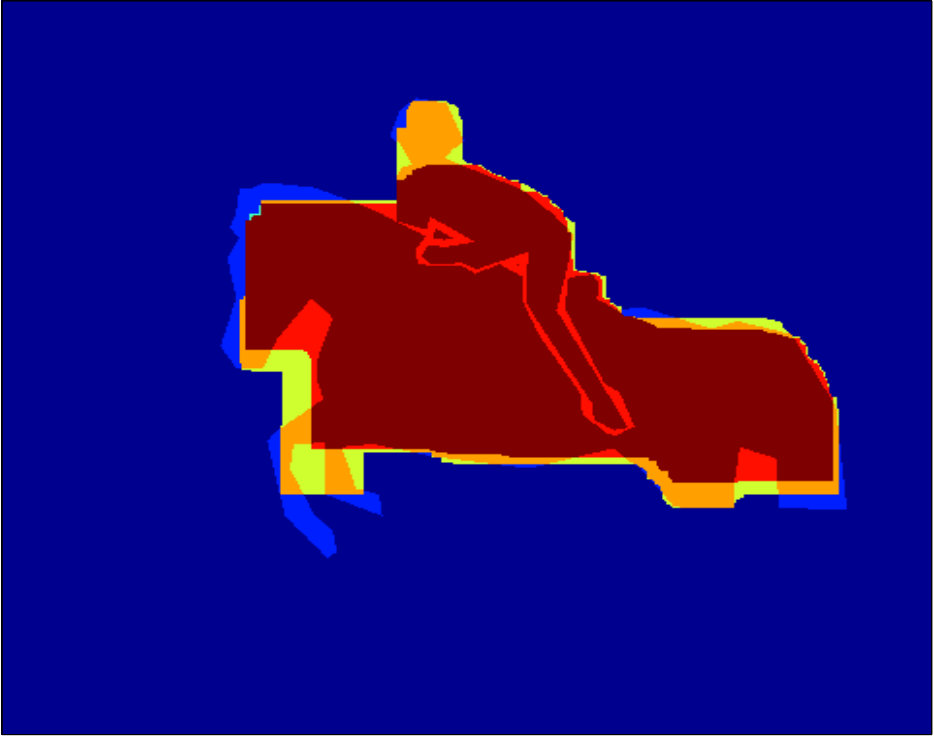 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32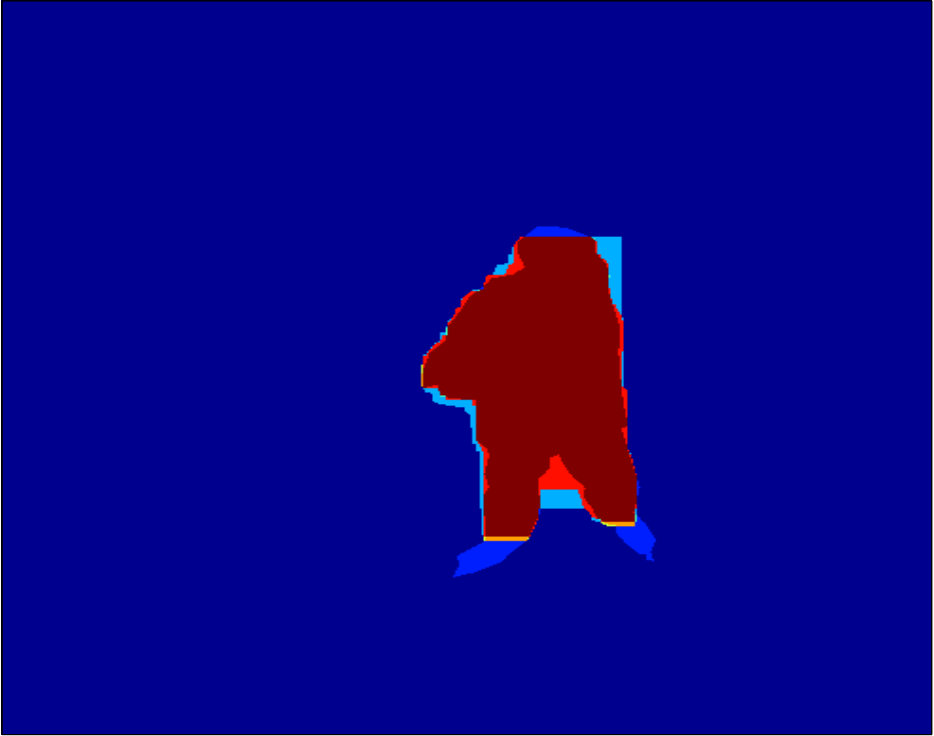 Figure 33
Figure 33 Figure 34
Figure 34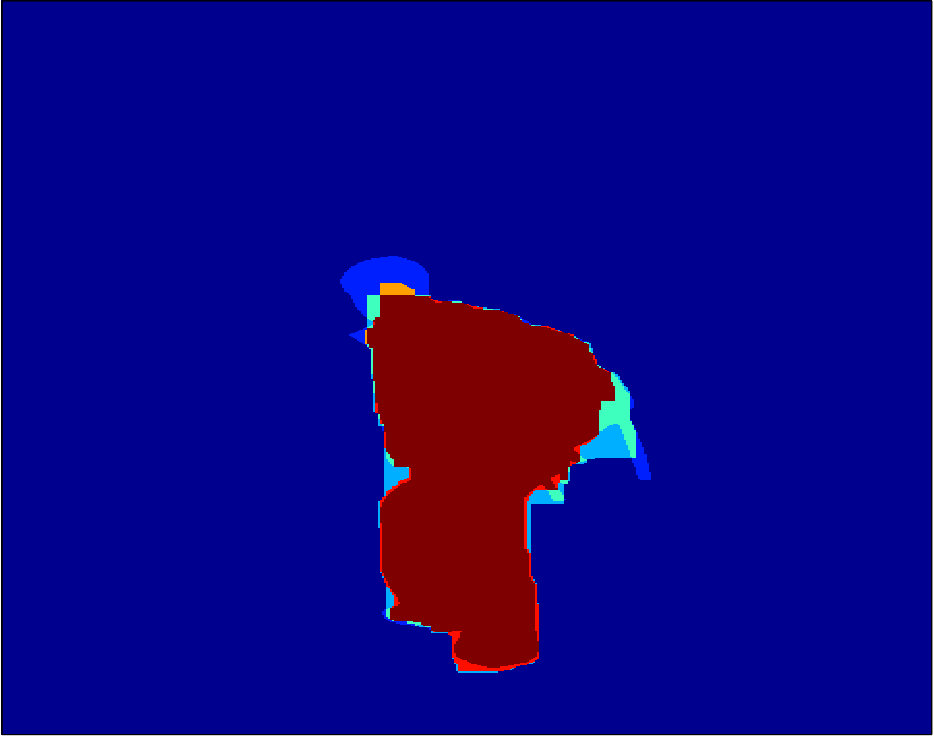 Figure 35
Figure 35 Figure 36
Figure 36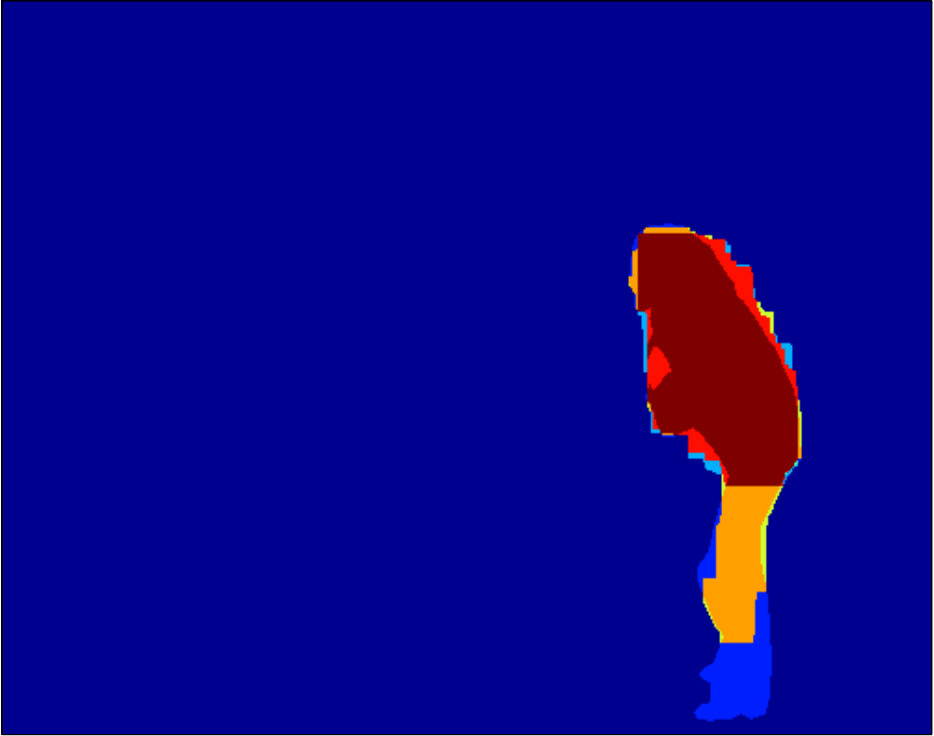 Figure 37
Figure 37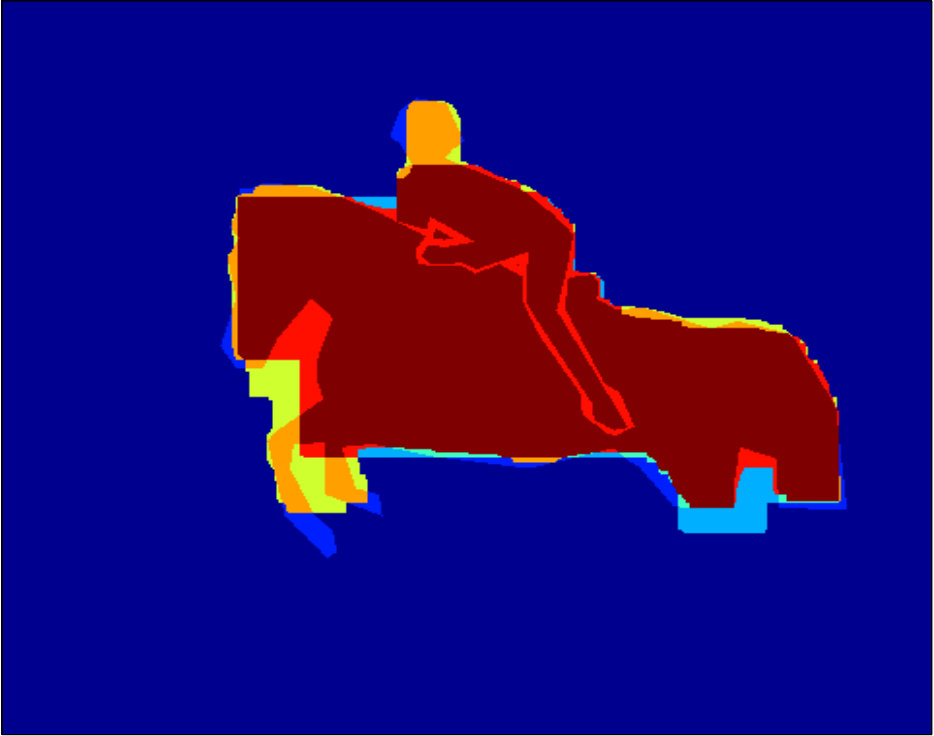 Figure 38
Figure 38 Figure 39
Figure 39 Figure 40
Figure 40| Eval. | ||||
|---|---|---|---|---|
| 0-1(1e3) | (1e3) | IoU | ||
| Train. | 0-1 | |||
| Eval. | |||
|---|---|---|---|
| 0-1 | IoU | ||
| vs 0-1 | |||
| vs 0-1 | |||
| vs 0-1 | |||
| vs 0-1 | |||
| Eval. | ||||
|---|---|---|---|---|
| (1e3) | 0-1(1e3) | IoU | ||
| Train. | ||||
| 0-1 | ||||
| Eval. | |||||
|---|---|---|---|---|---|
| 0-1(1e3) | Square loss(1e3) | Biconvex loss | IoU loss | ||
| Train. | 0-1 | ||||
| size | size | size | ||
|---|---|---|---|---|
| ADMM | ||||
| LP |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Neural Network Applications · Medical Image Segmentation Techniques · Sparse and Compressive Sensing Techniques
MethodsSupport Vector Machine · Alternating Direction Method of Multipliers
An Efficient Decomposition Framework for Discriminative Segmentation with Supermodular Losses
Jiaqian Yu [email protected] Center for Visual Computing, CentraleSupélec & Inria, Université Paris-Saclay
Matthew B. Blaschko [email protected] Center for Processing Speech and Images, Dept. Elektrotechniek, KU Leuven
Abstract
Several supermodular losses have been shown to improve the perceptual quality of image segmentation in a discriminative framework such as a structured output support vector machine (SVM). These loss functions do not necessarily have the same structure as the one used by the segmentation inference algorithm, and in general, we may have to resort to generic submodular minimization algorithms for loss augmented inference. Although these come with polynomial time guarantees [18, 13, 14], they are not practical to apply to image scale data. Many supermodular losses come with strong optimization guarantees, but are not readily incorporated in a loss augmented graph cuts procedure. This motivates our strategy of employing the alternating direction method of multipliers (ADMM) decomposition for loss augmented inference. In doing so, we create a new API for the structured SVM that separates the maximum a posteriori (MAP) inference of the model from the loss augmentation during training. In this way, we gain computational efficiency, making new choices of loss functions practical for the first time, while simultaneously making the inference algorithm employed during training closer to the test time procedure. We show improvement both in accuracy and computational performance on the Microsoft Research Grabcut database and a brain structure segmentation task, empirically validating the use of several supermodular loss functions during training, and the improved computational properties of the proposed ADMM approach over the Fujishige-Wolfe minimum norm point algorithm.
1 Introduction
Discriminative structured prediction is a valuable tool in computer vision that has been applied to a wide range of application areas, and in particular object detection and segmentation [2, 6, 29, 31, 32, 39]. It is frequently applied using variants of the structured output support vector machine (SVM) [42, 43] in which a domain specific discrete loss function is upper bounded by a piecewise linear surrogate. In the case of image segmentation, this discrete loss function has frequently been taken to be the Hamming loss, which simply counts the number of incorrect pixels [2, 39]. Following the principle of empirical risk minimization, one might expect that minimization of the desired loss at training time would lead to the best performing loss at test time. However, it has recently been shown that in the finite sample regime, minimizing a different loss can lead to better performance even when measured using Hamming loss [31]. In that work, a supermodular loss function was employed, and a custom graph cuts solution was found to the loss augmented inference problem necessary for computation of a subgradient or cutting plane of the learning objective [19].
Several non-modular loss functions have been considered in the context of image segmentation, e.g. the intersection over union loss in the context of a Bayesian framework [28], an area/volume based label-count loss that enforces high-order statistics [32], or a layout-aware loss function that takes into account the topology/structure of the object [31]. A message passing based optimization scheme is proposed for optimizing several families of structured loss functions [40, 41], which assumes the loss function is constructed by a grammar for which the productions specify function composition [40]. By contrast, we provide a generic framework for decomposing the loss function from model inference that assumes a custom solver for the loss, but that does not assume the loss belongs to a specific compositional grammar. We concern ourselves primarily with supermodular loss functions in this work as they lead to provable polynomial time loss augmented inference problems (an essential step in training structured output SVMs), while non-supermodular loss functions lead to NP-hard optimization in general.
In general, it is a time consuming process to develop custom loss-augmented solvers for different combinations of loss functions and inference procedures. We show in this work a direct combination of two submodular graph cuts procedures may in fact lead to a non-submodular minimization problem, and reparametrizations or novel graph constructions may be necessary. Furthermore, if we attempt to solve a non-submodular minimization problem approximately, this may lead to poor convergence of the learning procedure and catastrophic failure of the learning algorithm [12].
An alternative approach is to resort to generic submodular optimization algorithms, such as that of Iwata [18] which has complexity , or Orlin [30] with complexity , where is the time for a single function evaluation and is an upper bound on the absolute value of the function. Although these optimization algorithms are polynomial, the exponent is sufficiently large as to render them infeasible for images of even less than one megapixel. In practice, the Fujishige-Wolfe minimum norm algorithm [13, 14] is empirically faster [10]. However, we will show that even this state of the art optimization strategy is infeasible for relatively small consumer images.
Specific subclasses of submodular functions come with lower complexity optimization algorithms, and we should be able to exploit these known classes in a general learning framework. Examples include decomposable submodular functions [38, 27], several notions of symmetry [21, 33], and graph partition problems [22, 11]. A problem with the current API for loss augmented inference is that it is assumed that the loss function will decompose with a structure compatible to that of the inference problem. We address the case that this assumption does not hold and that separate efficient optimization procedures are available for the loss and for inference.
We propose to use Lagrangian splitting techniques to separate loss maximization from the inference problem. Strategies such as dual decomposition have become popular in Markov Random Field (MRF) inference [23], while later developments such as the alternating direction method of multipliers (ADMM) [4, 7] have improved convergence guarantees. Other strategies involving a quadratic penalty term have also been proposed in the literature, although still with the assumption that the loss decomposes as the inference [26]. We make use of ADMM to separate these inference problems and apply them to several supermodular loss functions that cannot be straightforwardly incorporated in a submodular graph partition problem for loss augmented inference. Instead we allow separate optimization strategies for the loss maximization and inference procedures yielding substantially improved computational performance, while making feasible the application of a wide range of supermodular loss functions by changing a single line of code.
This article is an extended version of [47] with additional theoretical contributions and experimental results. Specifically, we have added:
Section 2.2: a supermodular loss function, the square loss function; 2. 2.
Section 2.3: a new section on supermodular loss functions through biconvexity, with the definition of biconvexity, a proposition that biconvexity characterizes supermodularity for an important class of loss functions, and its proof; 3. 3.
Section 2.4: a novel supermodular loss function from biconvexity; 4. 4.
Section 2.6: a new section on ADMM convergence theorems; 5. 5.
Section 2.7: a new section on the optimization algorithm related to the novel supermodular loss functions in Sections 2.2 and 2.4; 6. 6.
Tables 1 and 2: additional results with more parameter values; 7. 7.
Section 3.2: new experimental results with the supermodular loss functions introduced in Sections 2.2 and 2.4; 8. 8.
Figures 8 to 10: additional qualitative segmentation results.
2 Methods
We discriminatively train a graph cuts based segmentation system using a structured SVM [43]. We first construct a supermodular loss function that is solvable with graph cuts, but that when incorporated in a joint loss-augmented inference leads to non-submodular potentials, which causes graph cuts based optimization to fail. We therefore use an ADMM based decomposition strategy to perform loss augmented inference. This strategy consists of alternatingly optimizing the loss function and performing maximum a posteriori (MAP) inference, with each process augmented by a quadratic term enforcing the labeling determined by each to converge to the optimum of the sum.
The structured output SVM is a discriminative learning framework that has been applied in diverse computer vision applications [2, 6, 29, 31, 32, 39]. Given a training set of labeled images , where for a binary segmentation problem with pixels, it optimizes a regularized convex upper bound to a structured loss function, . measures the mismatch between a ground truth labeling and a hypothesized labeling. With provided as an input, the structured SVM with margin rescaling minimizes [43]:
[TABLE]
In the case of image segmentation, we may interpret as a function that is monotonic in the log probability of the joint configuration of observed and unobserved variables as determined by a CRF [25]. Under this interpretation, a standard definition of is
[TABLE]
where determines a vector of features, a linear combination of which form the unary potentials of the CRF, and determines the pairwise potentials over a model specific edge set . In this work, we have set to map to an indicator vector of three cases: (i) , (ii) , or (iii) , and have placed hard constraints on the corresponding entries of in the optimization of the structured SVM to ensure that the pairwise potentials in the energy minimization problem remain submodular [48].
During training of the structured SVM, we must perform loss augmented inference in order to compute a subgradient of the loss. In the case of margin rescaling, this consists of computing
[TABLE]
If is isomorphic to for some , will be isomorphic to a set function where is the power set of a base set with . This allows us to discuss the properties of such loss functions in terms of the language of set functions as occurs in real analysis [20] and discrete optimization [37]. In particular, we are interested in corresponding to a supermodular set function [37, 44]:
Definition 1** (Supermodular set function [14]).**
A supermodular set function is a set function which satisfies: for every with and every we have that
[TABLE]
A function is submodular if its negative is supermodular. Given the definition of supermodularity, we may now define when a loss function is supermodular.
Definition 2** (Supermodular loss function [44]).**
A loss function is called supermodular if, for every , the unique set function such that is supermodular.
We note that in Definition 2 the mapping to the set function has an explicit dependency on the ground truth labeling and varies per training image.
Necessary to the sequel of the article, we introduce also the definition of a symmetric set function:
Definition 3** (Symmetry).**
A set function is symmetric if for some function . ( is the set of integers and is the set of non-negative integers.)
Theorem 1** (Cardinality-based set function [3]).**
If and there exist a function such that , where is the cardinality of . Then is supermodular if and only if is convex.
As we have guaranteed that maximization of with respect to corresponds to a submodular minimization problem, the loss augmented inference as in Equation (4) remains a submodular minimization when is supermodular and can be aligned with the inference, and therefore polynomial time solvable. By contrast, non-supermodular result in NP-hard optimization problems in general.
Modular loss functions, such as Hamming loss, can be incorporated into the unary potentials in a graph cuts optimization framework for loss augmented inference. However, the formulation of loss augmented inference with supermodular losses as a graph cuts problem is not straightforward, despite previous work (in which a custom graph cuts formulation was derived for a specific family of supermodular losses) that indicated a supermodular loss can lead to improved segmentation quality [31]. Moreover, while supermodular loss functions guarantee polynomial time solvability, they do not do so with low order polynomial guarantees in general. We have observed that the Fujishige-Wolfe algorithm is infeasible to apply even in the case of sub-megapixel images, and scales poorly for useful supermodular loss functions. Consequently, we develop a general framework for decomposing loss augmented inference based on ADMM. This framework solely relies on a loss function being able to be efficiently optimized in isolation using a specialized solver specific to the loss function.
2.1 A supermodular loss function for binary image segmentation
As a first example, we propose a loss function that is itself optimizable with graph cuts. The loss simply counts the number of incorrect pixels plus the number of pairs of neighboring pixels that both have incorrect labels
[TABLE]
where is Iverson bracket notation, is a loss specific edge set and is a positive weight. We have used 8-connectivity for the loss function in the experiments (Figure 1(a)), referred to as “8-connected loss” in the sequel. We may identify this function with a set function to which the argument is the set of mispredicted pixels.
Proposition 1**.**
Maximization of the loss function in Equation (6) is equivalent to a supermodular function maximization problem.
Proof sketch.
Equation (6) is isomorphic to a binary random field model for which label is iff a pixel has a different label from the ground truth. Neighboring pixels that both have label contribute a positive amount to the energy, while all other configurations contribute zero. This corresponds to a supermodular function following Definition 1. ∎∎
This loss function emphasizes the importance of correctly predicting adjacent groups of pixels, e.g. those present in thin structures more than one pixel wide. While the pairwise potential in has a tendency to reduce the perimeter of the segment, the loss strongly encourages the correct identification of adjacent pixels. We will observe in the experimental results that the use of this loss function during training improves the test time prediction accuracy, even when measuring in terms of Hamming loss.
It may appear at first glance that the structure of this loss function is aligned with that of the inference, and that we can therefore jointly optimize the loss augmented inference with a single graph cuts procedure. Indeed, the loss function is isomorphic to a supermodular set function, and the inference is isomorphic to a supermodular set function, both of which can be solved by graph cuts. However, the isomorphisms are not the same. The loss function maps to a set function by considering the set of pixels that are incorrectly labeled, while the inference maps to a set function by considering the set of pixels that are labeled as foreground. Shown in Figure 1 is the pairwise potential for an edge with and .
If we apply a single mapping, the inference procedure can be solved by graph cuts when the sum of the diagonal elements of is less than the sum of the off diagonal elements. While it is enforced during optimization that , the presence of in the off diagonal, for which the exact position depends on the value of , removes the guarantee of a resulting submodular minimization problem. We therefore consider a Lagrangian based splitting method to solve the loss augmented inference problem in Section 2.5
2.2 Symmetric supermodular loss function: square loss
As a second example, we consider the following loss which simply takes the square of the number of mis-predictions. This function is not readily incorporated in graph-cuts, as the square induces a pairwise dependency between all pixels.
[TABLE]
where is a scale factor to prevent the value to be too large in an image scale problem. We used in our setting, where is the number of positive labels of . This is a function on the misprediction set which only depends on the size of the input set i.e. . As the square function is a convex function, is a supermodular loss w.r.t. the misprediction set. Then maximizing the loss itself is a supermodular maximization i.e. a submodular minimization problem, following Theorem 1.
2.3 Supermodular Loss Functions Through Biconvexity
In this section, we develop a family of supermodular loss functions based on biconvex functions of the number of false positives and false negatives.
Definition 4** (Biconvexity [16]).**
A function is called a biconvex function if
[TABLE]
is a convex function on for every fixed and
[TABLE]
is a convex function on for every fixed .
- Remark
The usual definition of biconvexity specifies that the function be defined over a biconvex set [16, Definition 1.1], but for the purpose of this section we will restrict ourselves to and being convex sets so that biconvexity of the domain of follows trivially.
Denote by the number of positive labels in the ground truth labeling ,
[TABLE]
Proposition 2** (Biconvexity characterizes supermodularity).**
For a given ground truth labeling and a given prediction , let denote the number of false negatives, and denote the number of false positives:
[TABLE]
where is Iverson bracket notation. The following holds
[TABLE]
is a supermodular loss function iff that is a biconvex function and
[TABLE]
In particular, we may select to be the convex closure of [3, Section 5.1].
Proof.
We first show that supermodularity implies the existence of a corresponding biconvex function. [3, Proposition B.2] indicates that for a function to be supermodular, all contractions of that function must be supermodular, in particular the contractions achieved by fixing a set of false positives and fixing a set of false negatives.
For the contraction obtained by fixing false positives to be supermodular, we have from Theorem 1 that there exists a convex function that specifies the contraction. Similarly for the contraction obtained by fixing false negatives to be supermodular, there exists a (different) convex function that specifies the contraction. Combining all such contractions and convex functions yields the conditions in Definition 4 for integral points. The existence of a function satisfying these conditions for non-integral points is obtained by noting that the convex closure satisfies the required properties.
It now remains to show that a biconvex function yields a supermodular set function. Given a biconvex function of the number of false negatives and the number of false positives, by Definition 4, the function obtained by fixing the number of false positives is convex in the number of false negatives, then we have from Theorem 1 that the set function restricted to the set of foreground pixels is supermodular. A symmetric argument gives that the restriction to the set of background pixels is also supermodular. ∎∎
Several popular loss functions such as Intersection over Union loss [45, Equation (43)] or Sørensen-Dice loss [46, Definition 11] can be specified as functions of the number of false positives and false negatives, but both have been shown to be non-supermodular. In the next section we will develop a novel supermodular loss function by specifying an increasing biconvex function of and .
2.4 A novel loss function from biconvexity
The Intersection over Union loss [6, Equation (7)] has been shown to be non-supermodular [45, Proposition 10]:
[TABLE]
We develop here a novel loss function that is similar in flavor to Equation (15) but we will see that it is supermodular:
[TABLE]
We can verify that , , and .
Given a ground truth labeling , we can consider to be a constant. With the notation in Equation (11) and Equation (12), we can write as a function of and , denoted :
[TABLE]
Proposition 3**.**
There exits a function that is biconvex and
[TABLE]
Proof.
We set
[TABLE]
It is straightforward that it satisfies Equation (14) in Proposition 2. We now prove that this is a biconvex function. We note that with fixed, is linear in and therefore is convex.
Now to show that is convex, we calculate its first and second derivatives with respect to :
[TABLE]
Given the fact that is the number of false negatives and is the number of ground truth positive labels, we have . All parenthesized terms of Equation (21) must therefore be strictly positive. As is twice differentiable everywhere and its second derivative is non-negative, is convex wrt . ∎∎
Following Proposition 2, we then have the following corollary:
Corollary 1**.**
* in Equation (16) is supermodular.*
2.5 ADMM algorithm for loss augmented inference
Several Lagrangian based decomposition frameworks have been proposed, such as dual decomposition and ADMM [7], with the latter having improved convergence guarantees. We have also observed a substantial improvement in performance using ADMM over dual decomposition in our own experiments. Here we consider a splitting method to optimize the minimization of the negative of Equation (4), which is equivalent to finding the most violated constraint in cutting plane optimization:
[TABLE]
and we form the augmented Lagrangian as
[TABLE]
where . (23) can be optimized in an iterative fashion by Algorithm 1 [7].
The saddle point of the Lagrangian will correspond to an optimal solution over a convex domain, while we are optimizing w.r.t. binary variables. Strictly speaking, we may therefore consider the linear programming (LP) relaxation of our loss augmented inference problem, followed by a rounding post-processing step. We use a standard stopping criterion as in [7]: the primal and dual residuals must be small with an absolute criterion and a relative criterion . In practice, we have found that discretizing the quadratic terms and incorporating them into the unary potentials of the respective graph cuts problems is more computationally efficient, while yielding results that are nearly identical with exact optimization with a primal-dual gap of 0.01%. We show in the experimental results that this strategy yields results almost identical to those of an LP relaxation.
In general, we simply need task-specific solvers for Line 3 and Line 4 of Algorithm 1. These solvers need not use a single graph cut algorithm, and can therefore exploit any available structure even though it may not be present, or aligned, between the two subproblems. Although we have used this framework for the specific supermodular loss functions described in the previous subsection, we note that this provides an API for the structured output SVM framework alternate to that provided by SVMstruct [43]. We have released our structured prediction toolbox as an open source project, enabling the application of this strategy to diverse structured prediction problems with non-modular loss functions.
2.6 ADMM Convergence
Consider the standard form of the problem solved by ADMM:
[TABLE]
with variables and , where , , and . Following [7], some general convergence results for ADMM are considered in this section.
Assumption 1**.**
The (extended-real-valued) functions and are closed, proper, and convex.
Assumption 2**.**
The unaugmented Lagrangian of the problem has a saddle point.
If Assumption 1 and Assumption 2 hold, the ADMM algorithm guarantees: (1) the residual convergence: as , i.e., the iterates approach feasibility; (2) the objective convergence: as , i.e., the objective function of the iterates approaches the optimal value; (3) and the dual variable convergence: as , where is a dual optimal point. Proofs of the residual and objective convergence results are given in [7].
2.7 Optimization
As shown in Line 4 in Algorithm 1, we need to solve the subproblem that minimizes the negative of the loss function augmented by a term from the ADMM iteration. It is equivalent to maximizing the sum of the loss function and the negative of the ADMM term. Among the three examples of supermodular loss functions we proposed, maximizing the 8-connected loss in Equation (6), augmented by a modular term from the ADMM iteration, can be solved by a modified graph-cut. Maximizing the square loss (Equation (7)) and the biconvex loss (Equation (16)) can also be solved efficiently, as we will show in this section.
Explicitly, we maximize over the sum of a supermodular loss function and a modular function:
[TABLE]
where is an asymmetric modular function wrt the misprediction set for a given and at the current iteration (we discard the supercript for simplicity). We know that any modular function can be written as
[TABLE]
for some coefficient vector . In our case, we have
[TABLE]
Under the assumption that is a symmetric loss function, such as the square loss in Equation (7), Algorithm 2 solves the required optimization efficiently.
By exploiting the symmetry properties of the loss function, all operations in Algorithm 2 are linear except for the first sorting operation.
For biconvex, as in Equation (16), we analyze the problem wrt to false positives and false negatives separately. For a given ground truth labeling , we note that the subset is the set of all possible false negatives. following Equation (10), is the set of all possible false positives, i.e. . We first rewrite the modular function as a coefficient vector of ground truth positive entries and ground truth negative entries separately,
[TABLE]
for two coefficient vectors .
Under the assumption that is a biconvex function, as in Equation (16), Algorithm 3 is an efficient solver for the resulting optimization.
3 Experimental Results
In this section, we consider a foreground/background segmentation task. We compare the prediction using our proposed supermodular loss functions with the prediction using Hamming loss. We show that: (i) our proposed splitting strategy is orders of magnitude faster than the minimum norm point algorithm; (ii) our strategy yields results nearly identical to a LP-relaxation while being much faster in practice; and (iii) training with the same supermodular loss as during test time yields better performance.
Datasets
The dataset provided by [17, 5] contains color images in RGB space, ground truth foreground/background segmentations, and user-labelled seeds (see Figure 2, Figure 2, and Figure 2, respectively). As we are discriminatively training a class specific segmentation system in our experiments, we focus on the images in which the foreground objects are people. We compute in total 18 unary features following [31]. Figure 2 to Figure 2 show examples of the extracted features.
IBSR Dataset
We additionally utilise the Internet Brain Segmentation Repository (IBSR) dataset [34], which consists of T1-weighted MR images. Images and masks have been linearly registered and cropped to . We choose one horizontal slice within each volume and we follow the feature extraction procedure as in [1].
3.1 Training with the 8-connected loss function
We use the ADMM splitting strategy to solve the minimization problem in Equation (22). We use the GCMex - MATLAB wrapper for the Boykov-Kolmogorov graph cuts algorithm [15, 8, 9, 22] to solve the optimization problems on Line 3 for the inference. Results computed with different values of are shown in Table 1 and Table 3. During the training stage, we use for the ADMM step-size parameter. The regularization parameter in Equation (1) is chosen by cross-validation in the range . We additionally train and test with Hamming loss as a comparison.
At test time, we have computed the unnormalized Hamming loss, the intersection over union loss (IoU), and our 8-connected loss for each training scenario. We have performed several random train-test splits in order to compute error bars on the loss estimates. During testing stage, we evaluate one prediction as the average loss value for all images in the testing set. We compare different loss functions during training and during testing and measure the empirical loss values. We randomly split the data into training and testing sets five times to obtain an estimate of the average performance.
Empirical Results
We show in Table 1 and Table 3 the empirical error values by training with the 8-connected supermodular loss compared with training with the Hamming loss (labeled 0-1). In Table 1 we show the results by using different values of for the 8-connected loss. We notice that in all cases, training with the same supermodular loss as used for testing has achieved the best performance, i.e. lower error values. Training with the supermodular loss even outperforms training with Hamming loss when measured by Hamming loss on the test set. Wilcoxon sign rank tests are shown in Table 2, which shows that training with the supermodular loss functions gives significantly better results in nearly all cases.
We have additionally tried training with a joint graph cuts loss augmented inference using the pairwise potentials illustrated in Figure 1. However, due to the non-submodular potentials, the graph cuts procedure does not correctly minimize the energy resulting in incorrect cutting planes that causes optimization to fail after a small number of iterations. The performance of this system was effectively random, and we have not included these values in Table 1.
Qualitative segmentation results are shown in Figure 3. In Figure 6 and 7 we show a pixelwise comparison of the predictions. The 8-connected loss achieves better performance on the foreground/background boundary, as well as on elongated structures of the foreground object, such as the head and legs, especially when the appearance of the foreground is similar to the background.
We also ran a baseline comparing non-submodular loss augmented inference with the QPBO approach [35]. We computed pairwise energies as in Figure 1(a). QPBO found loss augmented energies across the dataset of while ADMM found loss augmented energies of , a substantial improvement.
3.2 Training with the square loss and the biconvex loss
We show in Table 4 the empirical error values by training with the square loss (labeled ), and with the biconvex loss (labled ), compared to training with the Hamming loss (labeled 0-1). We can see that training with the same supermodular loss during test time yields better performance than training with the Hamming loss, which validates the correctness of the ADMM splitting strategy with more loss/inference combinations.
Qualitative segmentation results are shown in Figure 8. Pixelwise comparison of the segmentation results using the square loss and the biconvex loss are shown in Figure 9 and Figure 10, respectively.
3.3 Computation Time
In addition, when using the 8-connected loss, we compare the time of one calculation of the loss augmented inference by the ADMM algorithm and by the minimum norm point algorithm [14] (MinNorm). For MinNorm, we use the implementation provided in the SFO toolbox [24]. Although it has been proven that in iterations, the MinNorm returns an -approximate solution [10], the first step of this algorithm is to find a point in the submodular polytope, which alone is computationally intractable even for small pixel images. Therefore, we measure the computation time on downsampled images, showing the growth in computation as a function of image size (Figure 4 and Figure 5). The running times are recorded on a machine with a 3.20GHz CPU. Similarly, a dual-decomposition baseline took orders of magnitude longer computation than the ADMM approach, following known convergence results [7].
We measure the computation time for 120 calculations of the loss augmented inference by ADMM and MinNorm on different sized images. From Figure 4 and Figure 5 we can see that ADMM is always faster than the MinNorm by a substantial margin, and around 100 times faster when the problem size reaches . The computing time for both ADMM and MinNorm vary approximately linearly in log-log scale, while MinNorm has a higher slope, suggesting a worse big- computational complexity. We note that theoretical bounds on MinNorm are currently weak and the exact complexity is unknown [10].
Although it is immediately clear from Figure 5 that ADMM is substantially faster than the minimum norm point algorithm, we have performed Wilcoxon sign rank tests that show this difference is significant with in all settings.
3.4 Comparison to LP-relaxation
We additionally compare ADMM to an LP relaxation procedure for the loss augmented inference to determine the accuracy of our optimization in practice, with using the 8-connected loss function and the Hamming loss (0-1). For the implementation of the LP relaxation, we use the UGM toolbox [36]. We show in Table 5 the comparison between using ADMM and the LP relaxation. The first column represents the energy achieved by the loss augmented inference (Equation (4)). We observe that the (maximal) energy achieved by ADMM is almost the same as the LP relaxation: a difference of . Columns 2–4 show the computing time for one calculation of the loss augmented inference on the downsampled images. Using an LP relaxation, the computation time is orders of magnitude slower, growing as a function of the image size. ADMM provides a more efficient strategy without loss of performance.
4 Discussion and Conclusion
A somewhat surprising result in Table 1 is that training with the supermodular loss results in better performance as measured by Hamming loss. This has been previously observed with a different loss function by [32, 31], and indicates that in the finite sample regime a supermodular likelihood can result in better generalization performance. This holds, although the model space and regularizer were identical in both training settings. We have observed the same effect with the other two supermodular loss functions, and , indicating that this may be a broader property of supermodular loss functions.
Our results in terms of computation time give clear evidence for the superiority of ADMM inference when a specialized optimization procedure is available for the loss function. As shown in Figure 5, the Fujishige-Wolfe minimum norm point algorithm does not scale to typical consumer images (i.e. several megapixels), which indicates that loss functions for which a specialized optimization procedure is not available are likely infeasible for pixel level image segmentation without unprecedented improvements in general submodular minimization. Figure 5 shows that the log-log slope of the runtime for the min-norm point algorithm is higher than for ADMM, suggesting a worse computational compexity. One may wish to employ the result that early termination of the min-norm point algorithm gives a guaranteed approximation of the exact result, but even this is infeasible for images of the size considered here. In addition, Table 5 suggests that ADMM provides a more efficient strategy without lost of performance compared to using an LP-relaxation. Joint graph-cuts optimization for loss augmented inference results in non-submodular pairwise potentials and graph-cuts fails to correctly minimize the joint energy. As a result, a cutting plane optimization of the structured output SVM objective fails catastrophically, and the resulting accuracy is on par with a random weight vector. Consequently, the ADMM technique yielded the only feasible training strategy.
In this work, we propose three novel supermodular loss functions. We have shown that using supermodular loss functions achieves improved performance both in qualitative and quantitative terms on a binary segmentation task. We observe that a key advantage of the proposed supermodular losses over modular losses, e.g. Hamming loss, is an improved ability to find elongated regions such as heads and legs, or thin articulated structures in medical images.
Previous to our work, specialized inference procedures had to be developed for every model/loss pair, a time consuming process. By contrast, we have proposed a Lagrangian splitting technique based on ADMM to perform general loss augmented inference. We demonstrate the feasibility of the ADMM algorithm for loss augmented inference on an interactive foreground/background segmentation task, for which alternate strategies such as the Fujishige-Wolfe minimum norm point algorithm are infeasible. Our proposed ADMM algorithm provides a strategy to solve the loss augmented inference as two separate subproblems. This provides an alternate API for the structured output SVM framework to that of SVMstruct [43]. We envision that this can be of use in a wide range of application settings, and an open source general purpose toolbox for this efficient segmentation framework with supermodular losses is available for download from https://github.com/yjq8812/efficientSegmentation.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Stavros Alchatzidis, Aristeidis Sotiras, and Nikos Paragios. Discrete multi atlas segmentation using agreement constraints. In Michel Valstar, Andrew French, and Tony Pridmore, editors, Proceedings of the British Machine Vision Conference . BMVA Press, 2014.
- 2[2] Dragomir Anguelov, Ben Taskar, Vassil Chatalbashev, Daphne Koller, Dinkar Gupta, Geremy Heitz, and Andrew Ng. Discriminative learning of Markov random fields for segmentation of 3D scan data. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition , volume 2, pages 169–176, 2005.
- 3[3] Francis Bach. Learning with submodular functions: A convex optimization perspective. Foundations and Trends® in Machine Learning , 6(2–3):145–373, 2013.
- 4[4] Dimitri P. Bertsekas. Nonlinear Programming . Athena, 1999.
- 5[5] Andrew Blake, Carsten Rother, M. Brown, Patrick Perez, and Philip Torr. Interactive image segmentation using an adaptive GMMRF model. In Tomás Pajdla and Jiří Matas, editors, Computer Vision – ECCV 2004: 8th European Conference on Computer Vision, Proceedings, Part I , pages 428–441, Berlin, Heidelberg, 2004. Springer.
- 6[6] Matthew B. Blaschko and Christoph H. Lampert. Learning to localize objects with structured output regression. In David Forsyth, Philip Torr, and Andrew Zisserman, editors, Computer Vision – ECCV 2008 , volume 5302 of Lecture Notes in Computer Science , pages 2–15. Springer Berlin Heidelberg, 2008.
- 7[7] Stephen Boyd, Neal Parikh, Eric Chu, Borja Peleato, and Jonathan Eckstein. Distributed optimization and statistical learning via the alternating direction method of multipliers. Foundations and Trends in Machine Learning , 3(1):1–122, 2011.
- 8[8] Yuri Boykov and Vladimir Kolmogorov. An experimental comparison of min-cut/max-flow algorithms for energy minimization in vision. IEEE Transactions on Pattern Analysis and Machine Intelligence , 26(9):1124–1137, September 2004.