Logical Randomized Benchmarking
Joshua Combes, Christopher Granade, Christopher Ferrie, and Steven T., Flammia

TL;DR
Logical randomized benchmarking is a new method that directly measures the performance of quantum error correction at the logical level, providing more accurate assessments than traditional physical error rate extrapolations.
Contribution
It introduces a logical benchmarking procedure that reduces to physical randomized benchmarking, enabling direct and reliable evaluation of logical error correction performance.
Findings
Reliable reporting of logical performance
Estimation of correctable and uncorrectable error probabilities
Reduces assumptions compared to traditional methods
Abstract
Extrapolating physical error rates to logical error rates requires many assumptions and thus can radically under- or overestimate the performance of an error correction implementation. We introduce logical randomized benchmarking, a characterization procedure that directly assesses the performance of a quantum error correction implementation at the logical level, and is motivated by a reduction to the well-studied case of physical randomized benchmarking. We show that our method reliably reports logical performance and can estimate the average probability of correctable and uncorrectable errors for a given code and physical channel.
Click any figure to enlarge with its caption.
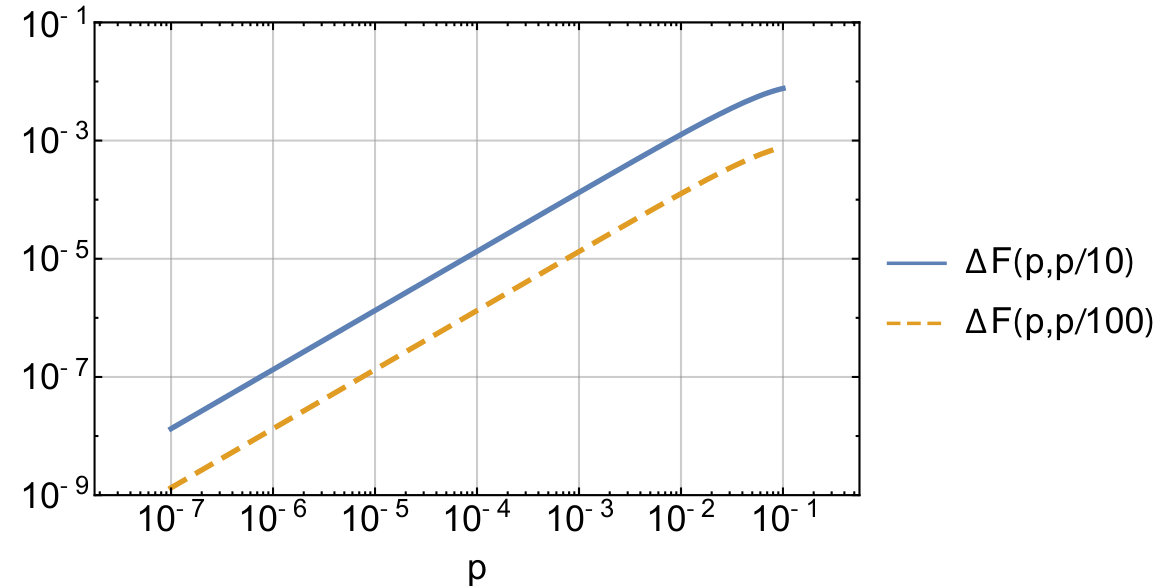 Figure 3
Figure 3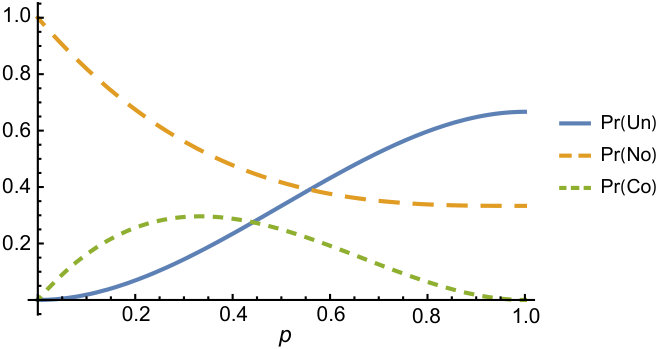 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.