Remote Parameter Estimation in a Quantum Spin Chain Enhanced by Local Control
Jukka Kiukas, Kazuya Yuasa, Daniel Burgarth

TL;DR
This paper investigates how local control on a qubit probe can significantly enhance parameter estimation in a quantum spin chain, revealing connections to quantum state transfer.
Contribution
It demonstrates that local control on a probe qubit improves estimation accuracy and uncovers links to quantum state transfer in spin chains.
Findings
Control improves estimation performance
Connections to quantum state transfer are identified
Potential for enhanced quantum sensing applications
Abstract
We study the interplay of control and parameter estimation on a quantum spin chain. A single qubit probe is attached to one end of the chain, while we wish to estimate a parameter on the other end. We find that control on the probe qubit can substantially improve the estimation performance and discover some interesting connections to quantum state transfer.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1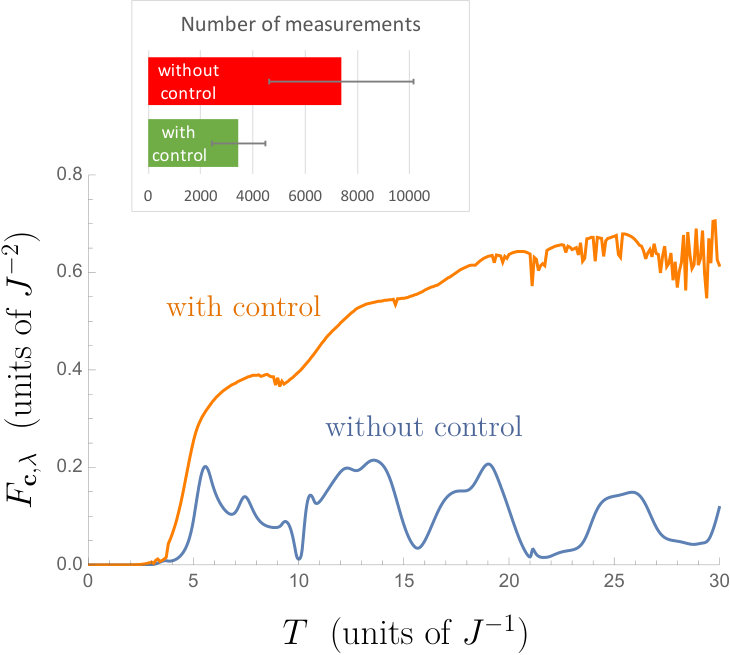 Figure 2
Figure 2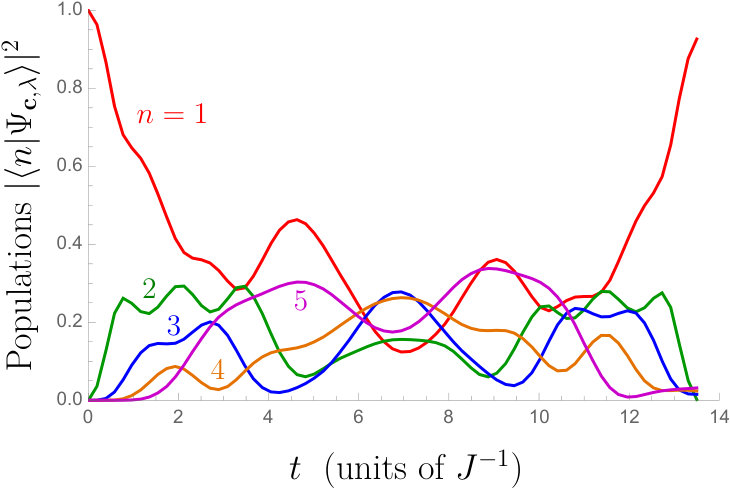 Figure 3
Figure 3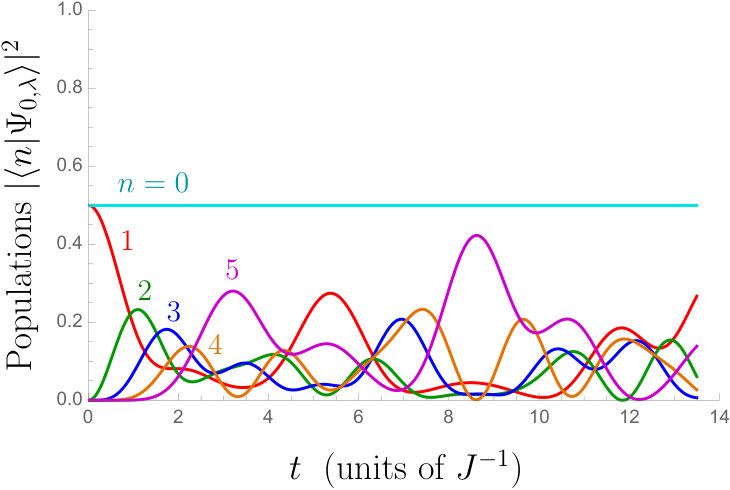 Figure 3
Figure 3Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Remote Parameter Estimation in a Quantum Spin Chain Enhanced by Local Control
Jukka Kiukas
Department of Mathematics, Aberystwyth University, Aberystwyth SY23 3BZ, UK
Kazuya Yuasa
Department of Physics, Waseda University, Tokyo 169-8555, Japan
Daniel Burgarth
Department of Mathematics, Aberystwyth University, Aberystwyth SY23 3BZ, UK
Department of Mathematics, Aberystwyth University, Aberystwyth SY23 3BZ, UK
Department of Physics, Waseda University, Tokyo 169-8555, Japan
Department of Mathematics, Aberystwyth University, Aberystwyth SY23 3BZ, UK
Abstract
We study the interplay of control and parameter estimation on a quantum spin chain. A single qubit probe is attached to one end of the chain, while we wish to estimate a parameter on the other end. We find that control on the probe qubit can substantially improve the estimation performance and discover some interesting connections to quantum state transfer.
*Introduction.—*Control and estimation are two sides of the same coin. Without control, estimation cannot be performed; without estimation, the parameters required for control are unknown. On one side, the statistical inference of parameters specifying partially unknown quantum systems is currently an active research topic ref:MetrologyScience ; ref:HayashiAsymptoticTheory ; parisqest ; ref:MetrologyNaturePhoto ; ref:DowlingReview . In such problems, the control resources for the estimation are usually neglected. On the other side, in the active field of quantum control quaint , the knowledge of the parameters of a given system is often assumed. Given the current world-wide initiatives to build high-performance quantum devices, it is no surprise that the interplay between quantum control and estimation is regaining attention QSI ; Yan ; metrologyctrl ; QFIctrl . Only by considering both one has the chance to find an optimal performance. We consider this problem in the context where a large many-body quantum system is observed via a single qubit probe, to estimate an unknown parameter specifying a part of the Hamiltonian localised far away from the probe carlo ; daniel ; SoneCappellaro . Such a setting is natural in scenarios where a large system is only partially accessible to experimentalists due to limitations forced by the implementation taminiau . We show that control can substantially improve estimation and reveal some interesting connections with quantum state transfer on spin chains bose ; dbreview .
*Parameter estimation enhanced by control.—*Suppose that we wish to estimate a parameter of a large quantum system through a single probe spin in contact with the former. We are allowed to control and measure the probe, while we have no direct access to the target system. Our Hamiltonian reads . The target parameter is contained in , while represents a local control on the probe, which is tuned by the control pulse . More generally, we could have more control Hamiltonians; however in this paper we only need to consider one. We then let the system evolve from a certain initial state , e.g., the probe prepared in while the target system is initialised in its ground state. We are given a probing time , during which we control the probe, and we measure the probe in the final state to gain some information on . We optimise the control field to enhance the precision of the estimation of . See Fig. 1 for a paradigmatic setup with a spin chain.
As we can only measure the probe, the precision of the estimation is ruled by the reduced density operator of the probe, where are the Pauli operators and is the Bloch vector depending on the target parameter and the control field . The quantum Fisher information (QFI) parisqest ; ref:MetrologyNaturePhoto for the estimation of is then qubitfisher
[TABLE]
The optimal quantum estimator is given by parisqest , where the symmetric logarithmic derivative has an explicit form given in the Supplemental Material Suppl . It satisfies and , showing that the expectation value of coincides with the target parameter , and the variance saturates the Cramér-Rao lower bound on the estimation error parisqest ; ref:MetrologyNaturePhoto . Our basic idea is to tune to maximise , using a tailored optimal control software.
In practice the estimator must be constructed with a guessed value of , improved iteratively if necessary. While the general idea of enhancing the QFI by control has appeared recently in different variations (see e.g. Yan ; metrologyctrl ; QFIctrl ), we have not found an explicit implementation of a feedback-based estimation algorithm. Hence we now proceed to describe a simple one. With the probing time fixed, the protocol begins with an initial guess , followed by the control step, where a pulse maximising is found. In the next step, is measured on copies of the true state , and the estimate is updated to (the average of the outcomes). The process is then iterated to get successive estimates , and terminated upon reaching a predetermined accuracy , in the sense of . One can also use subsampling to obtain the standard error, which should tend to zero as the estimates converge, providing a better termination condition. The total number of measurements needed for the convergence then serves as a measure of the estimation resources; by comparing with the one obtained by running the protocol without the control step, we can judge the effect of the control on the performance of the estimation.
We use this method, together with simulated measurements (Bernoulli trials) to numerically illustrate the advantage of control in the setting introduced below, where the control turns out to provide a significant reduction of estimation resources for a specific nontrivial model.
*Parameter estimation across a Heisenberg chain.—*We consider a 1D chain of spins with a Hamiltonian
[TABLE]
where are the Pauli matrices for the th spin, is a fixed coupling constant, is a control field on the first (probe) spin (magnetic field at the first site), and is the unknown target parameter (magnetic field at the last site); see Fig. 1. This setting has been shown to provide full controllability over the whole chain fullcont , and its state transport properties have been studied in bose without control. For quantum estimation in spin systems see e.g. daniel ; loschmidt ; fisherspinchain .
For each spin, the eigenstates of are denoted by and . The first spin () is the probe, and we initialise it in , with all the other spins in . Since commutes with the component of the total spin , the system remains in the subspace spanned by , where all the spins are in , and , where only the th spin () is flipped to . The initial state of the chain is therefore . We fix a total probing time , and discretise it into time slots, each of which having a different constant control. Hence the pulse is given by the vector determining the final state . We reduce this total state to the state of the probe spin, to which our general estimation procedure can be applied.
*Analytical study for the two-spin case.—*Before going to numerics, let us first look at the two-spin case () to understand how the control helps the estimation; this is already a nontrivial indirect estimation problem.
By recalling the Trotter formula, the unitary transformation induced by in (2) for a generic is basically composed of the single-spin rotations on the last spin by with the unitary transformations by the other parts of inserted in between. As discussed in vittorio , the QFI for the estimation of embedded by such sequential transformations is upper bounded by the optimal QFI for the estimation of embedded solely by with direct initialisation and measurement on the last spin permitted. That is, the QFI for our problem is upper bounded by .
If we are allowed to access all the spins, initialising and measuring them at will, this upper bound is actually achievable, by initialising and measuring the so-called NOON state , with no control required during the probing. In our problem, however, only the probe spin is accessible, and it is not clear whether this upper bound is reachable. In particular, this puts a strong constraint on the maximal achievable QFI in the uncontrolled case. For the two-spin case, it is easy to compute the QFI in (1) for the probe spin in the absence of the control, and to perform the optimisation of and in the initial state . We find the asymptotic scaling of the optimised QFI for large given by for and otherwise. This is the best we can attain for the two-spin case without control. This QFI is upper bounded by , and is smaller than the above upper bound at least by a factor of .
The control on the probe can improve the estimation; we can even get close to the upper bound if is not large. Indeed, we provide a naive protocol consisting of three steps, and show that it is asymptotically optimal for the two-spin case. The first step is to use the control to remotely prepare a good state for sensing. The second step is to use the control to let the system evolve so as to acquire the parameter as much as possible. The final step is to remotely measure the state, by mapping the state into one that is measurable locally at the probe.
In the first step, we start with the initial state , and keep the control field at for time . This prepares up to a global phase. In the second step, we apply a very strong field to suppress the exchange interaction between the two spins for time benjamin . Up to a global phase, the system evolves into , acquiring the relative phase depending on the target parameter . In the final step, we apply a strong pulse to induce an instantaneous rotation on the probe spin around the axis to cancel the relative phase , let the system evolve with for time , and measure of the probe. This effectively amounts to measuring in the state after the second step, which is an optimal measurement to estimate the relative phase. Note that the final state just before the measurement is . This does not appear to depend on , but the value of taken in the first and last steps is just a guess and can be different from the true value. If the guess is not perfect, the probe fails to become the pure state . This failure can be detected by the measurement of , which helps us learn about the parameter . The QFI by the above procedure is calculated to be . Since the time spent for the first and last steps is finite, it becomes negligible for large , and the QFI asymptotically approaches the ultimate bound . In this way, the control can enhance the estimation significantly.
*Numerical simulation for a longer chain.—*Let us now look at longer chains. We implement the crucial control step of the above estimation procedure using the optimal control software QTRL, which is a part of the QuTip control package qutip ; qtrl . In addition to the existing software, we have implemented an exact gradient of the QFI in a way applicable to an arbitrary quantum system probed by a single spin. See the Supplemental Material Suppl for details. We note that this requires the computation of the second derivatives of matrix exponentials, for which we have employed the method given in gradctrl .
In Fig. 2, the QFI normalised by with optimised control is shown as a function of the probing time for the chain of spins, and is compared with the uncontrolled case. The initial state is for the controlled case, while it is optimised to maximise the QFI for each for the uncontrolled case. It is clear from this result that the local control on the probe improve the precision of the estimation. In order to illustrate this explicitly, we display in the inset the results of the full estimation algorithm (described above) for the specific probing time : we observe that the estimation resource, i.e., the number of measurements needed for the convergence, is significantly reduced by control, even when taking into account the considerable random variation in the results.
Longer chains naturally require longer probing times , as ruled by the fundamental Lieb-Robinson bound for the propagation speed of the excitation, which for this specific system has been studied in bose , and found to increase linearly in . From the estimation point of view, the relevant threshold is the time after which we start gaining the information on ; for the case, we observe from Fig. 2 that . Another interesting time would be the one after which the Fisher information rate no longer increases essentially, and the relevant question is how close to the ultimate precision bound we can get. While in the two-spin case we could construct a control sequence asymptotically achieving the bound, it is now more difficult to get close to it. Loosely speaking this is because transferring the excitation to the end of the chain takes a longer time, and keeping it there to acquire the information is more difficult as the control is at the other end of the chain. Furthermore, as we see from Fig. 2, the numerics appears to become unstable for large values of , in that different initial pulses lead to different rates, making it difficult to judge if we have actually found the maximal rate. For the case, we observe from Fig. 2 that after , the rate is roughly . With we found the best rates , respectively (, respectively, in the uncontrolled case). While the QFI drops quickly with increasing the distance between the probe and the target field, the control increases it significantly.
Let us then see how the excitation is transferred across the chain. In Fig. 3, the evolution of the population probability at each site is shown for the probing time . In the controlled case, we start with . As in the two-spin case, we observe roughtly three stages: first the excitation propagates across the chain, reaching the end at around . While the information on is accumulated, the populations remain more or less the same with some fluctuations, and eventually the excitation is brought back to the probe spin. We observed that this behaviour is fairly typical also with other parameters and longer chains. In particular, the system often returns to the initial state by the time the measurement is performed on the probe spin. As we already discussed in the two-spin case, the final state does not explicitly depend on the target parameter ; we learn about by the failure of the return of the excitation.
From the numerics it appears that the initial state gives the best estimation results. In order to understand this, let us exclude a couple of suggestive alternatives: one might think that a superposition state of the probe such as would be good for sensing the phase . Such a final pure state, as a reduced state of the probe spin, is not available for the initial state , since the probe spin is entangled with the rest of the chain when the probe spin is partially populated. It is also understandable that initial states with small are not useful, since the excitation transferred to the target spin is small.
*Discussion and outlook.—*We started with a natural setup for controlled parameter estimation in a quantum many-body system and found that its optimal performance is closely related to achieving perfect state transfer bose . Although the methods developed here were used for a specific system, they are completely general. This means that we can immediately employ the program to study spin networks and experimental setups, paving the way to an optimal interplay of control and estimation in quantum technologies.
Acknowledgements.
We acknowledge fruitful discussions with Rafał Demkowicz-Dobrzański and Ugo Marzolino. This work was supported by the Top Global University Project from the Ministry of Education, Culture, Sports, Science and Technology (MEXT), Japan. DB acknowledges support from the EPSRC Grant No. EP/M01634X/1. KY was supported by the Grant-in-Aid for Scientific Research (C) (No. 26400406) from the Japan Society for the Promotion of Science (JSPS) and by the Waseda University Grant for Special Research Projects (No. 2016K-215).
I Supplemental Material
I.1 Optimal Estimation of a Single Qubit
After tracing out the large system as described in the main text, we are left with the probe qubit with the density matrix
[TABLE]
where is the unknown parameter to be estimated, and is a control pulse to be optimised for optimal QFI. For any parameter value , the optimal measurement is given by
[TABLE]
where the symmetric logarithmic derivative is determined by the coefficients
[TABLE]
It is easy to verify that the Hermitian operator admits a projective measurement with two outcomes
[TABLE]
and projectors .
In the estimation procedure described in the main text, the measurement of with an optimal control pulse for the th guessed value is performed on the state , which is the true quantum state generated with that pulse. Hence the probabilities for the two outcomes of the measurement of are given by
[TABLE]
By repeating the measurement on copies of the true state, we would estimate the expectation value
[TABLE]
We simulate this experiment by generating random outcomes from a Binomial distribution with sample size and the true (unknown!) probabilities calculated from the above formula. This gives us frequencies which we then use in place of the true probabilities in the above formula to calculate updated estimate described in the main text.
I.2 Computation of the QFI and Its Gradient
The optimal control software QTRL qtrl generally optimises control pulses by minimising a given fidelity, which by default is chosen to be a suitable distance from a target quantum object (either a state or a unitary operator). For the purpose of the present work, we needed to implement a completely different fidelity, namely the negative of the QFI described in the main text. Since the optimisation is based on a gradient search, the implementation requires the computation of both the function
[TABLE]
and its gradient. We now proceed to detail how these are obtained. We note that even though we applied the scheme to the specific Heisenberg spin chain, the composed optimisation program is general, and can in principle be used in any setting involving a large system estimated via an embedded single qubit probe.
First of all, we need to specify how the probe is embedded. This is done simply by defining how the qubit Pauli matrices act on the total system consisting of both the probe and the large system. For instance, if the qubit is a subsystem (i.e., a tensor factor), the action of the th Pauli matrix is just , where the nontrivial action is on the probe system and the identity acts everywhere else. In our case, working in a single excitation sector, it is necessary to consider direct sum instead; hence we allow arbitrary embeddings .
As described in the main text, the final state is determined by a control pulse , through , where the total transformation is a unitary given by the product of unitary propagators of the form . Here the generator depends on the target parameter and a single constant characterising the strength of the applied control. By tracing out everything except the probe qubit, we obtain the Bloch vector of the probe, which gives us the QFI via Eq. (1) of the main text. The control optimisation refers to maximising with respect to the pulse . More generally, the program can handle generators of the form , i.e., with several control pulses, but we present the following with a single pulse so as to avoid cluttering the notation.
In order to compute , we need the components of the Bloch vector of the final probe state, together with their derivatives:
[TABLE]
where and the expectation values on the right-hand side are understood componentwise in the obvious fashion. Using the chain rule we can write the relevant derivative as
[TABLE]
which we get once we have a method of computing and for arbitrary .
We now proceed to look at the gradient. We use the shorthand notation and suppress the parameter dependence for simplicity. By differentiating the formula (1) in the main text, we find
[TABLE]
where . In order to evaluate this function, we need two new quantities
[TABLE]
Since only appears in the th propagator (while is in each one), we have
[TABLE]
Hence, in order to compute both and its gradient, we need the four quantities , , , and . While the first two had already been implemented in QTRL, we needed to construct the -derivatives specific to the estimation context.
Following gradctrl_suppl , we observe that all these derivatives can be conveniently computed simultaneously as follows. We write for each , and successively differentiate the evolution equation to get
[TABLE]
This can be written as the single block matrix equation
[TABLE]
with
[TABLE]
where
[TABLE]
Since , we immediately get
[TABLE]
that is, we can extract all the required derivatives from the first column of the blocks of the matrix . The computation of this matrix exponential therefore completes the calculation of both the QFI and its gradient.
References
- (1)
R. Johansson et al., qutip/qutip: QuTiP-4.0.0 [Data set], Zenodo, 2016, http://doi.org/10.5281/zenodo.220867.
- (2)
S. Machnes, D. J. Tannor, F. K. Wilhelm, and E. Assémat, arXiv:1507.04261 [quant-ph] (2015).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1) V. Giovannetti, S. Lloyd, and L. Maccone, Science 306 , 1330 (2004).
- 2(2) M. Hayashi, Asymptotic Theory of Quantum Statistical Inference: Selected Papers (World Scientific, Singapore, 2005).
- 3(3) M. G. A. Paris, Int. J. Quant. Inf. 7 , 125 (2009).
- 4(4) V. Giovannetti, S. Lloyd, and L. Maccone, Nat. Photon. 5 , 222 (2011).
- 5(5) J. P. Dowling and K. P. Seshadreesan, J. Lightwave Techno. 33 , 2359 (2015).
- 6(6) S. J. Glaser et al. , Eur. Phys. J. D 69 , 279 (2015).
- 7(7) D. Burgarth and K. Yuasa, Phys. Rev. Lett. 108 , 080502 (2012).
- 8(8) H. Yuan and C.-H. F. Fung, Phys. Rev. Lett. 115 , 110401 (2015).