TL;DR
This paper introduces DYNAMIC, a C++ library of dynamic compressed data structures for string processing, demonstrating their theoretical efficiency and practical advantages in space savings over traditional methods.
Contribution
It presents a comprehensive framework of dynamic compressed data structures, with theoretical bounds and empirical validation, and applies them to improve string compression algorithms.
Findings
Dynamic structures are up to 1000 times more space-efficient.
Theoretical bounds closely match empirical results.
Applications show significant space savings in compression algorithms.
Abstract
In this paper we present DYNAMIC, an open-source C++ library implementing dynamic compressed data structures for string manipulation. Our framework includes useful tools such as searchable partial sums, succinct/gap-encoded bitvectors, and entropy/run-length compressed strings and FM-indexes. We prove close-to-optimal theoretical bounds for the resources used by our structures, and show that our theoretical predictions are empirically tightly verified in practice. To conclude, we turn our attention to applications. We compare the performance of four recently-published compression algorithms implemented using DYNAMIC with those of state-of-the-art tools performing the same task. Our experiments show that algorithms making use of dynamic compressed data structures can be up to three orders of magnitude more space-efficient (albeit slower) than classical ones performing the same tasks.
Click any figure to enlarge with its caption.
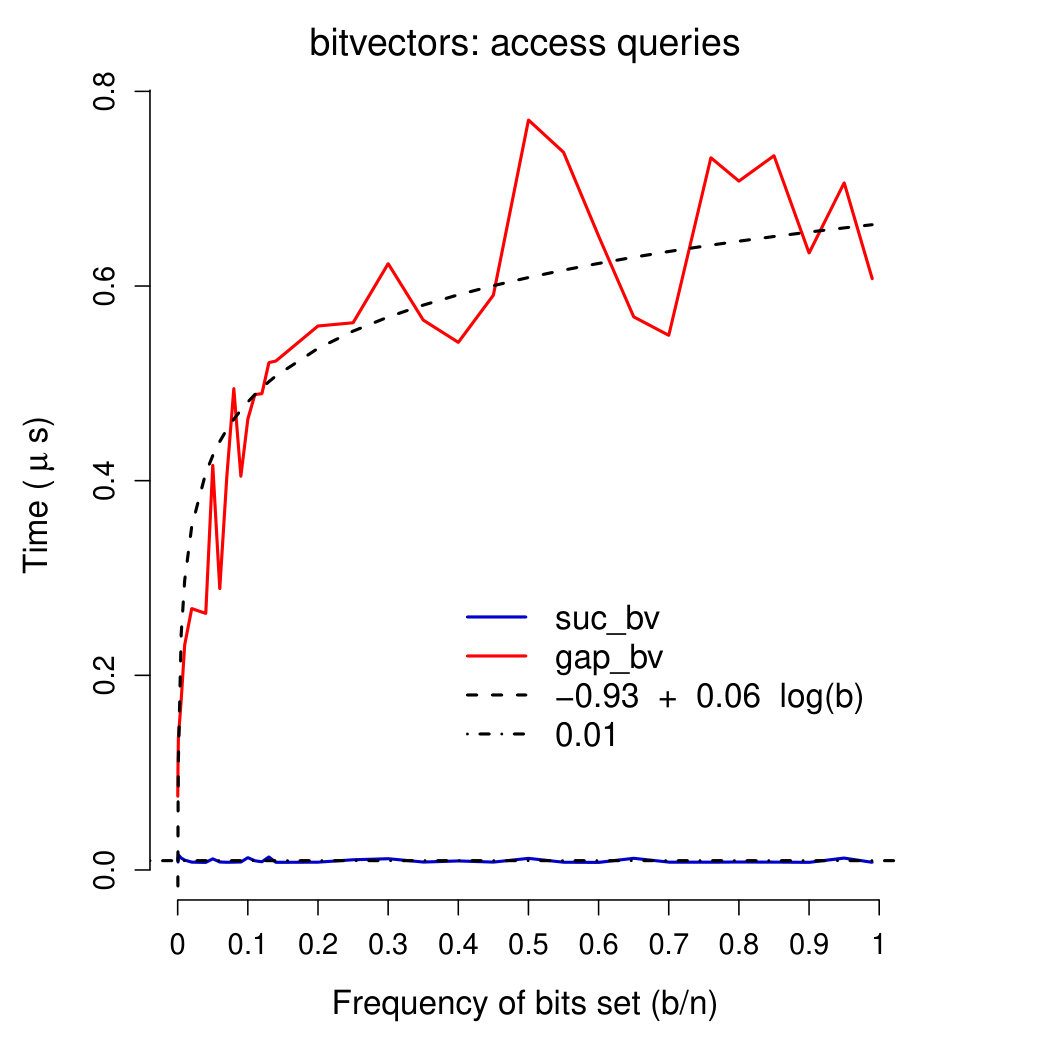 Figure 1
Figure 1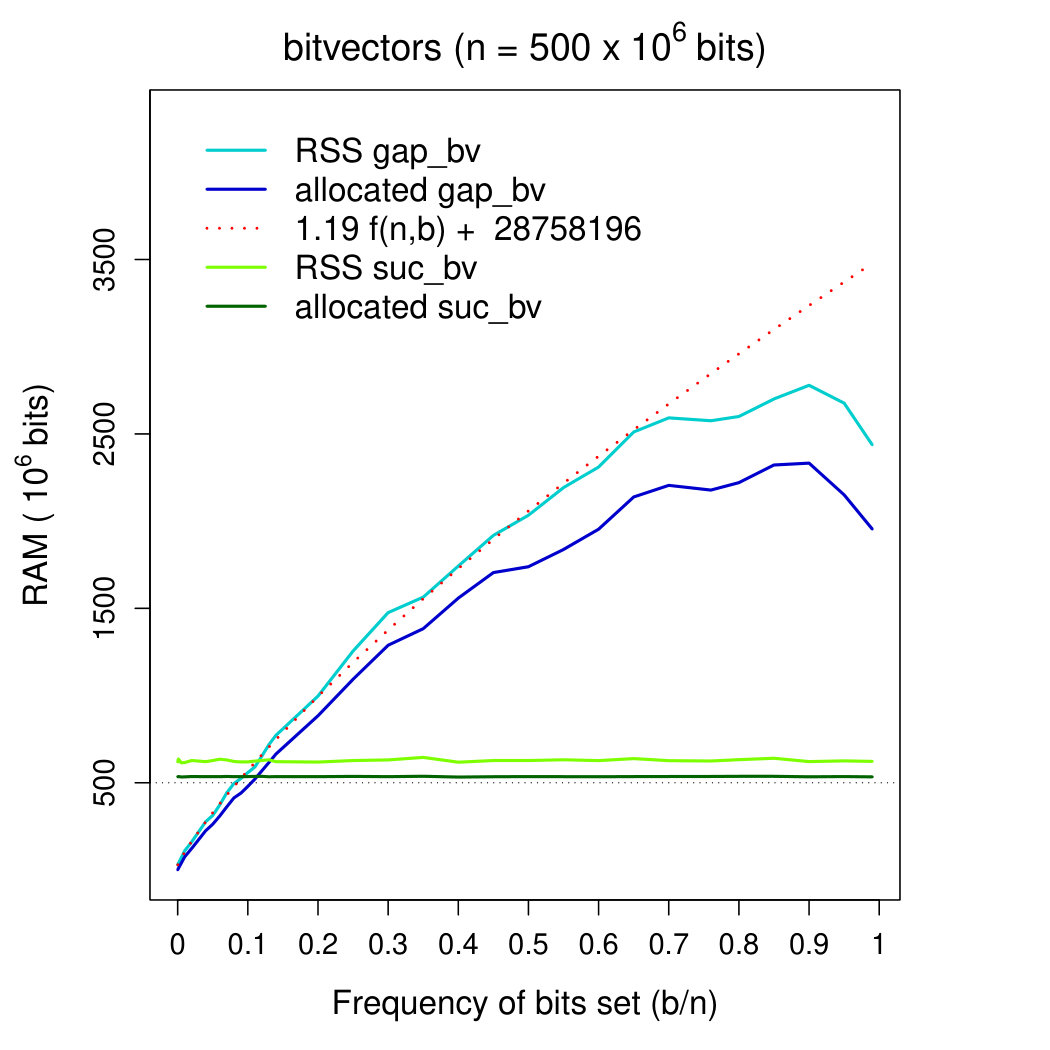 Figure 2
Figure 2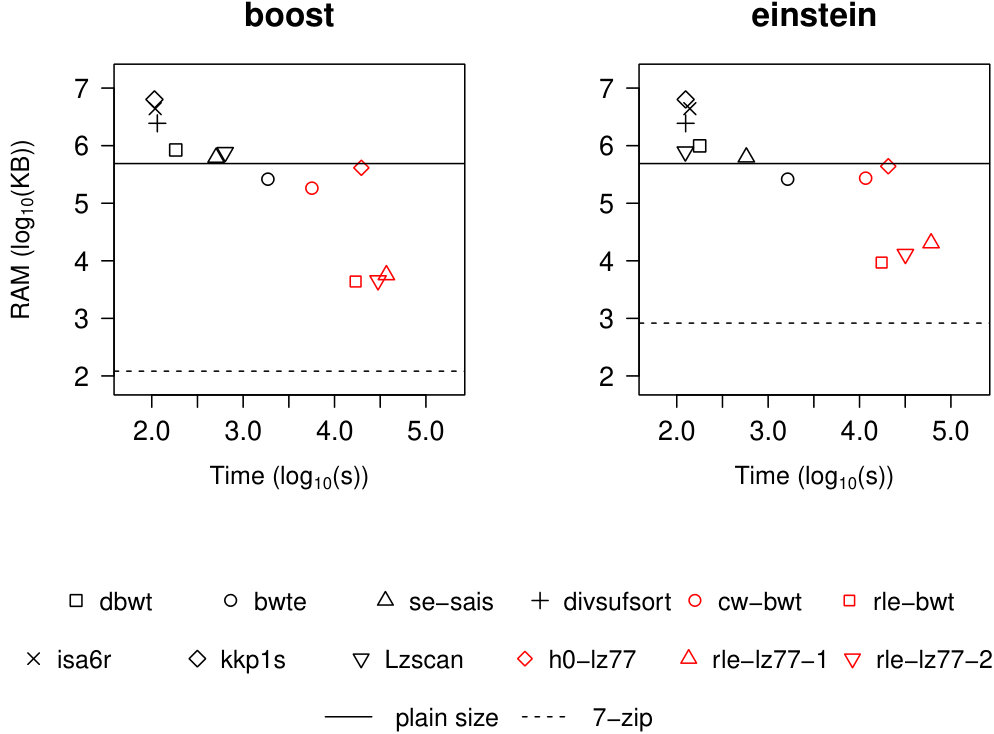 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5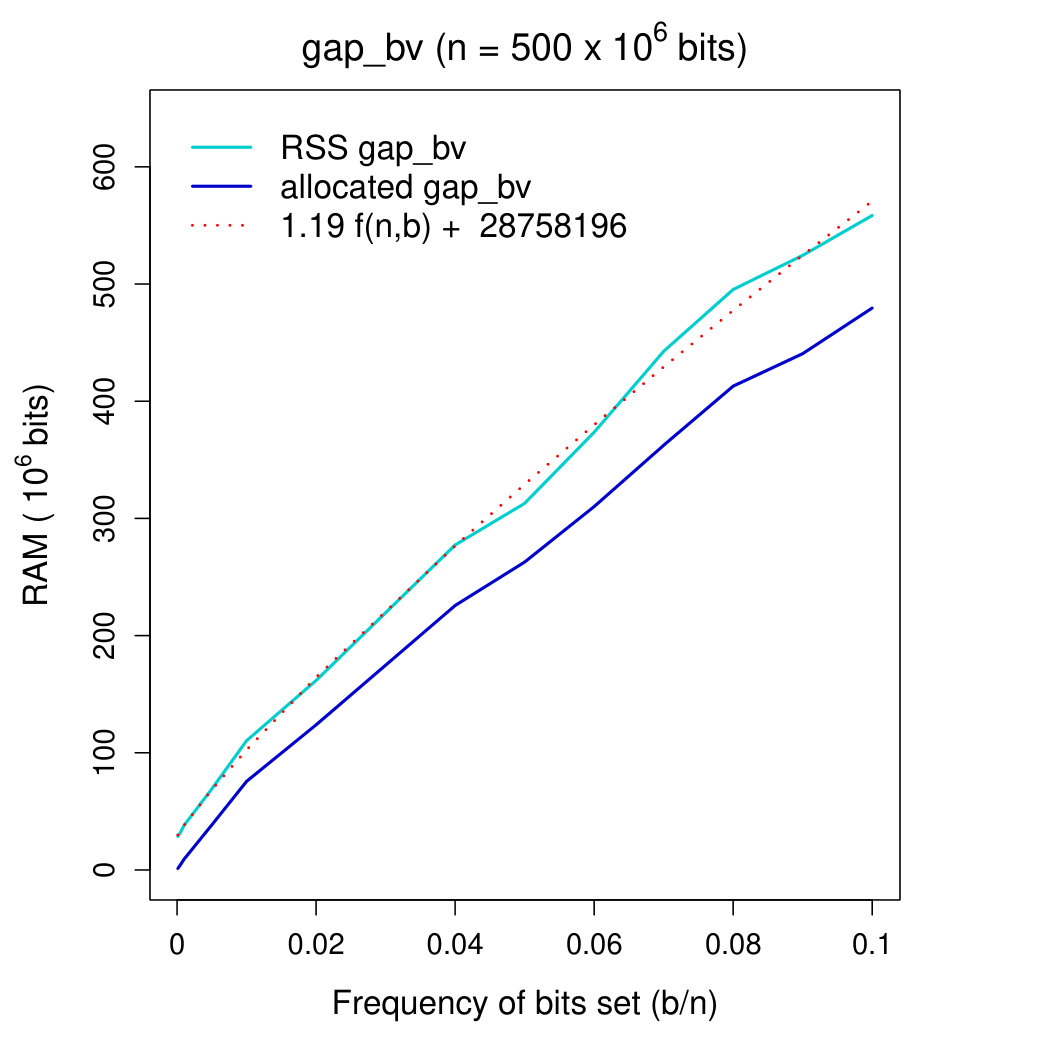 Figure 6
Figure 6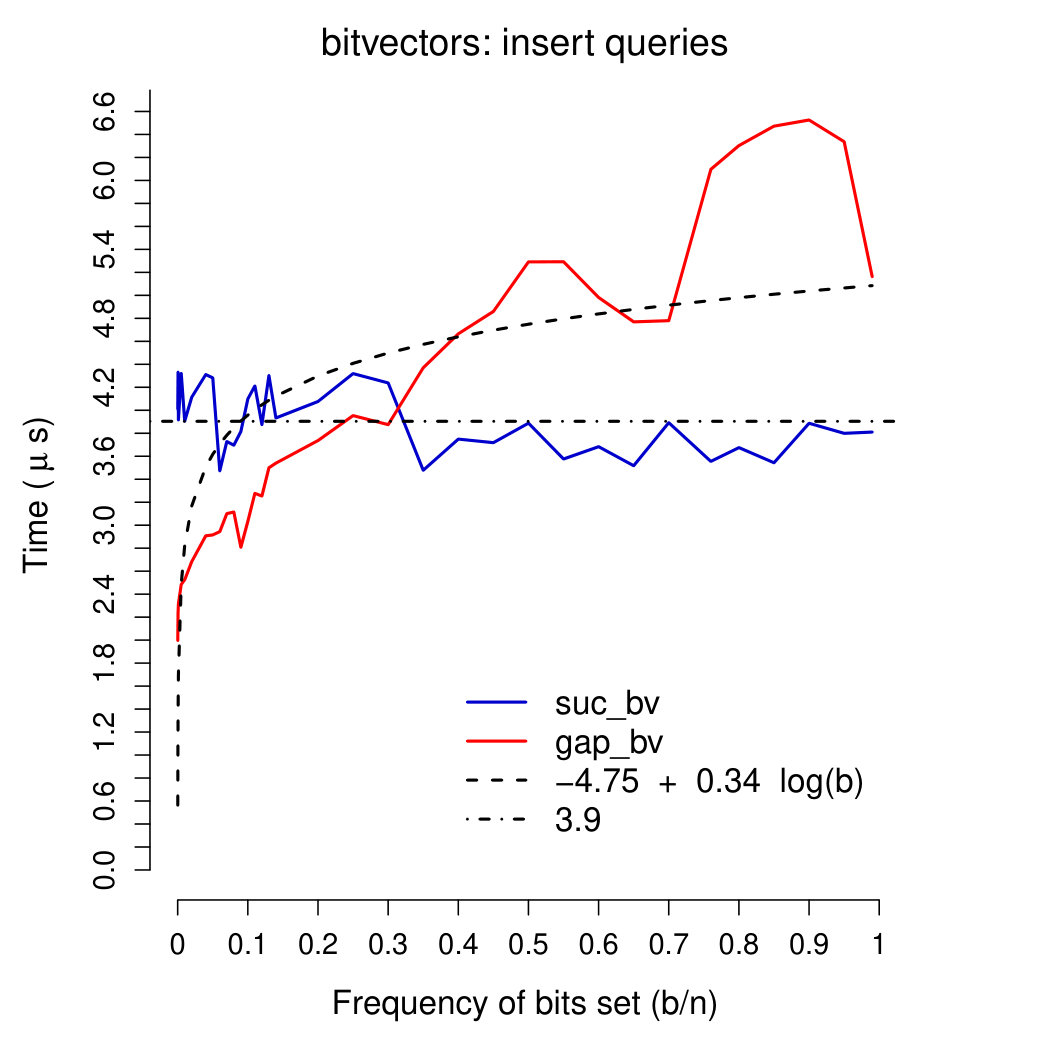 Figure 7
Figure 7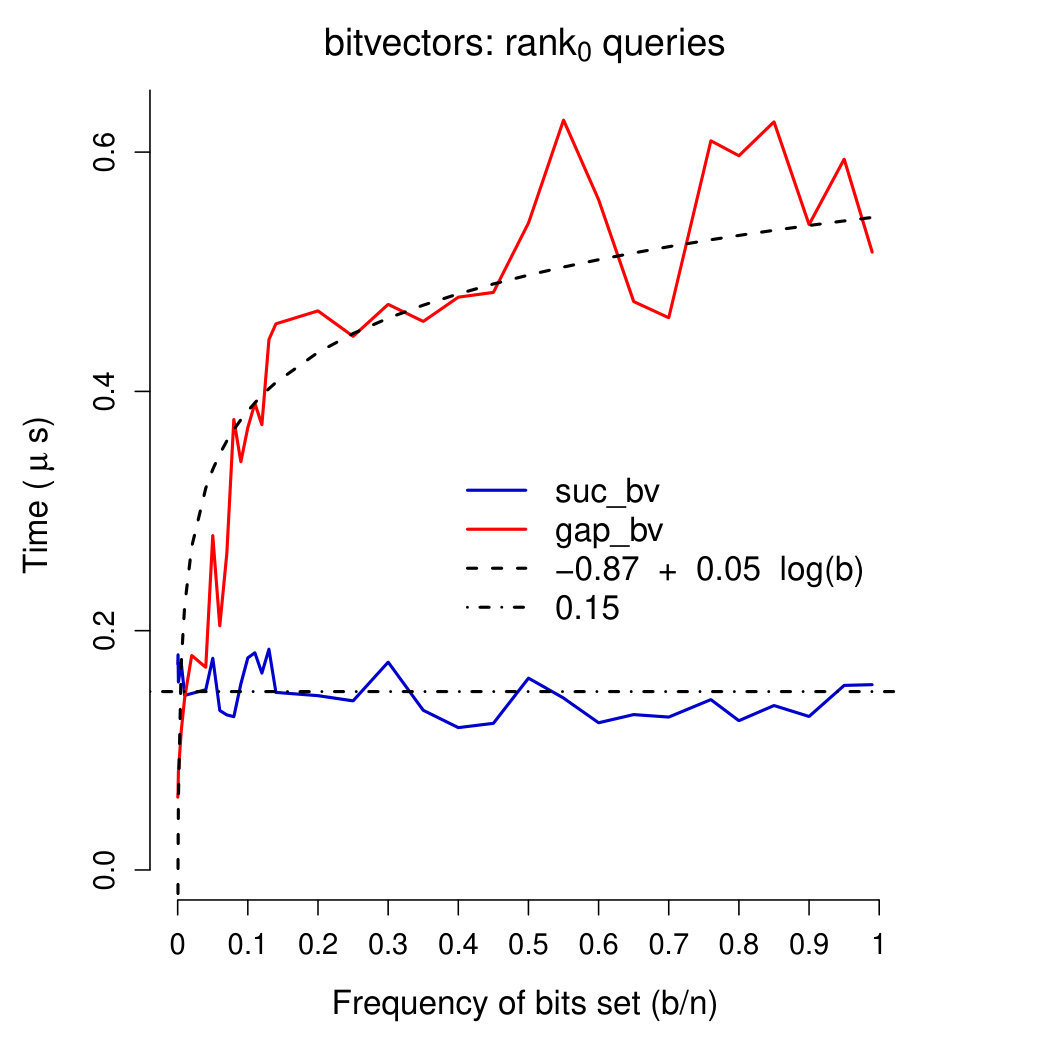 Figure 9
Figure 9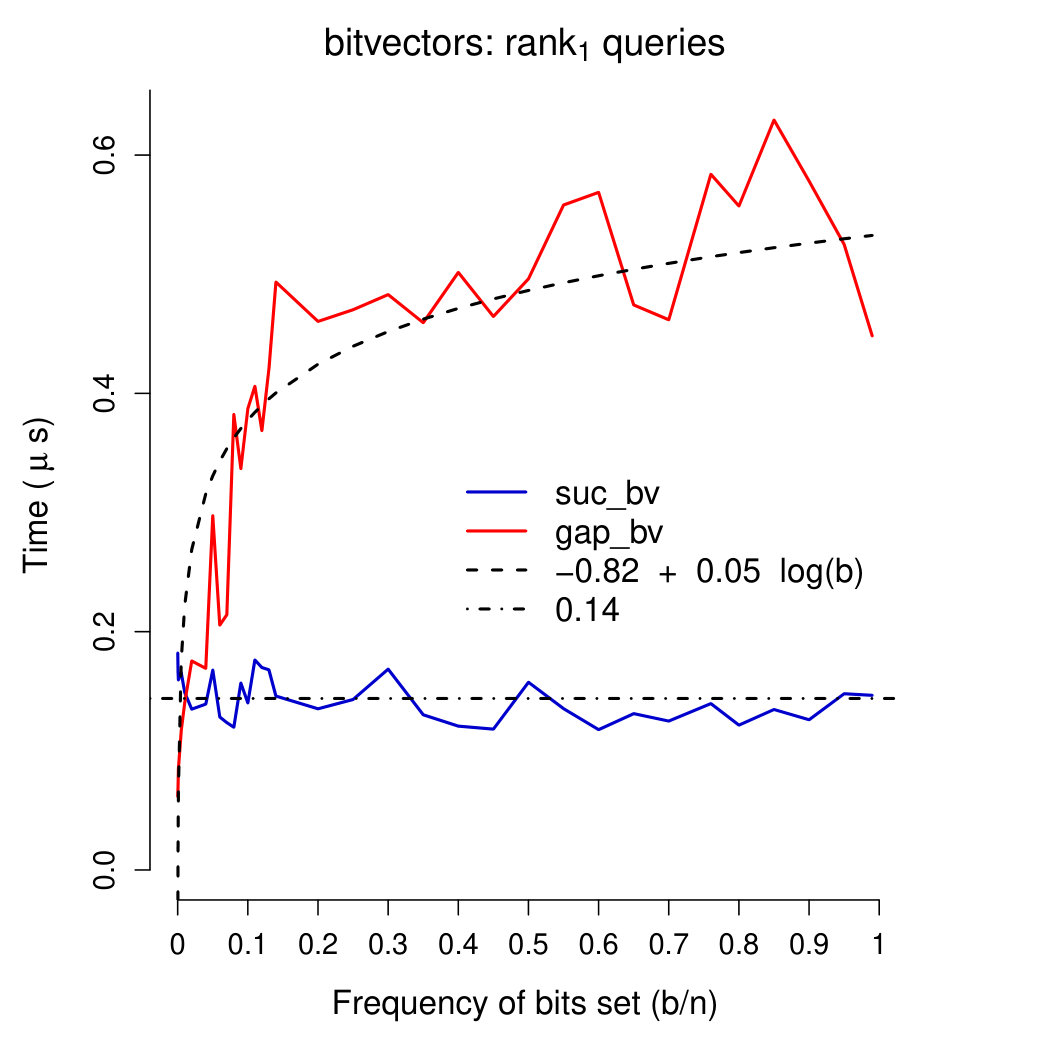 Figure 10
Figure 10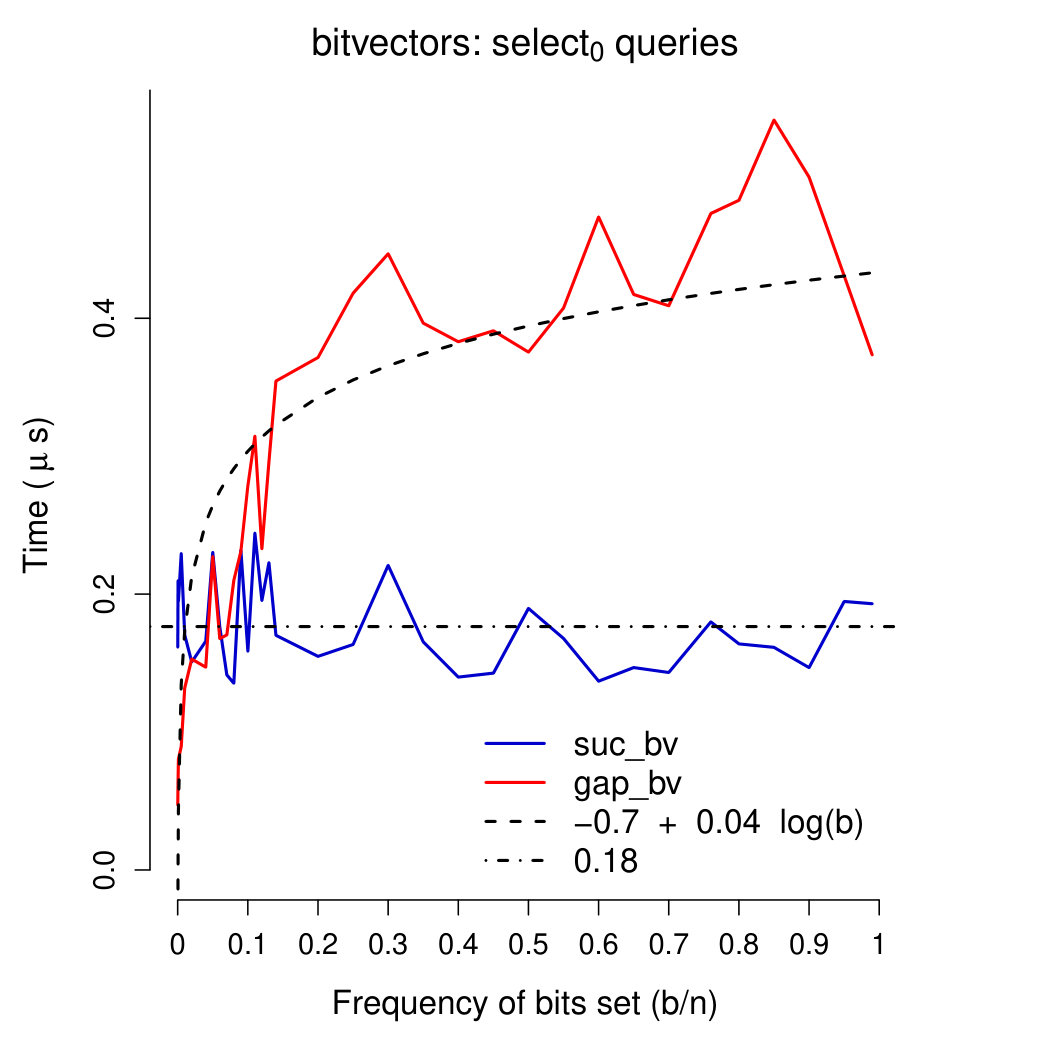 Figure 11
Figure 11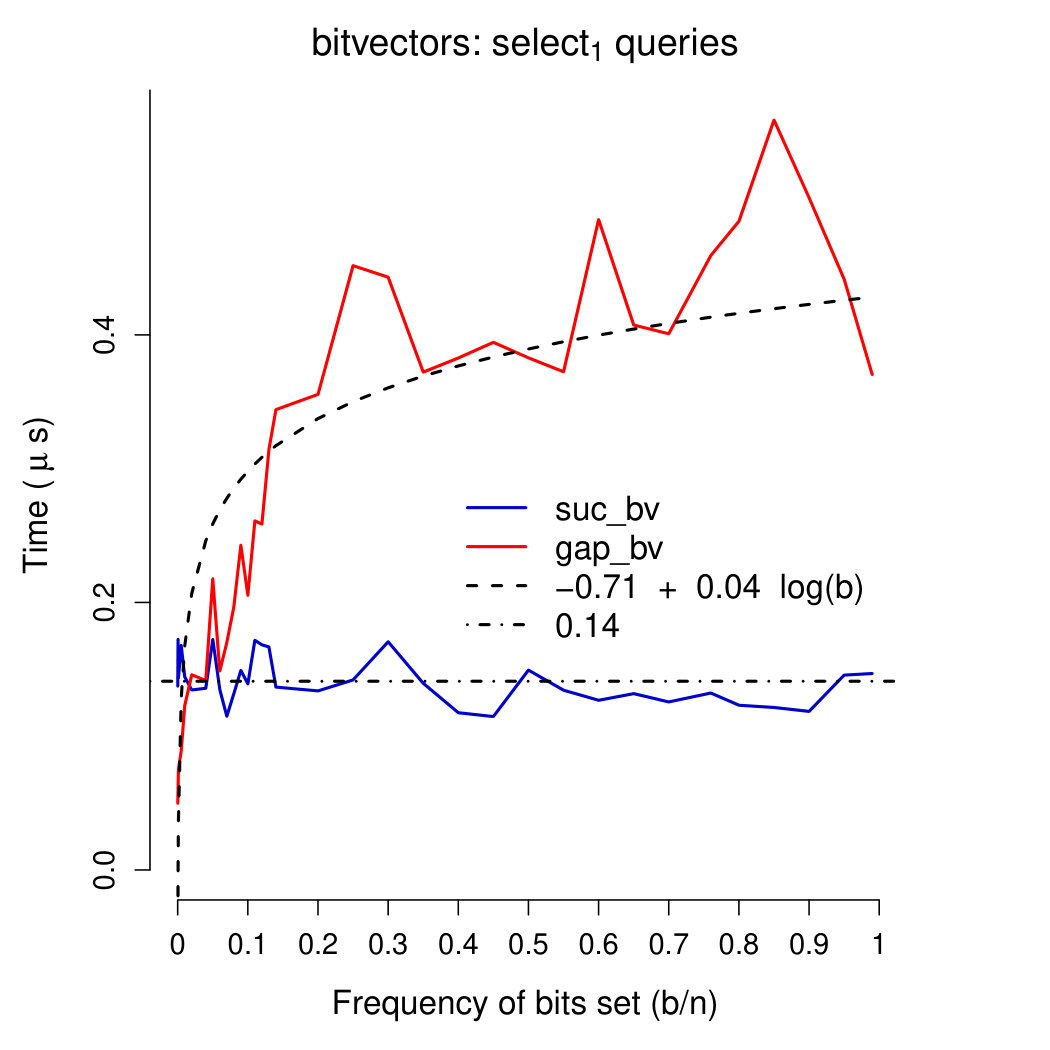 Figure 12
Figure 12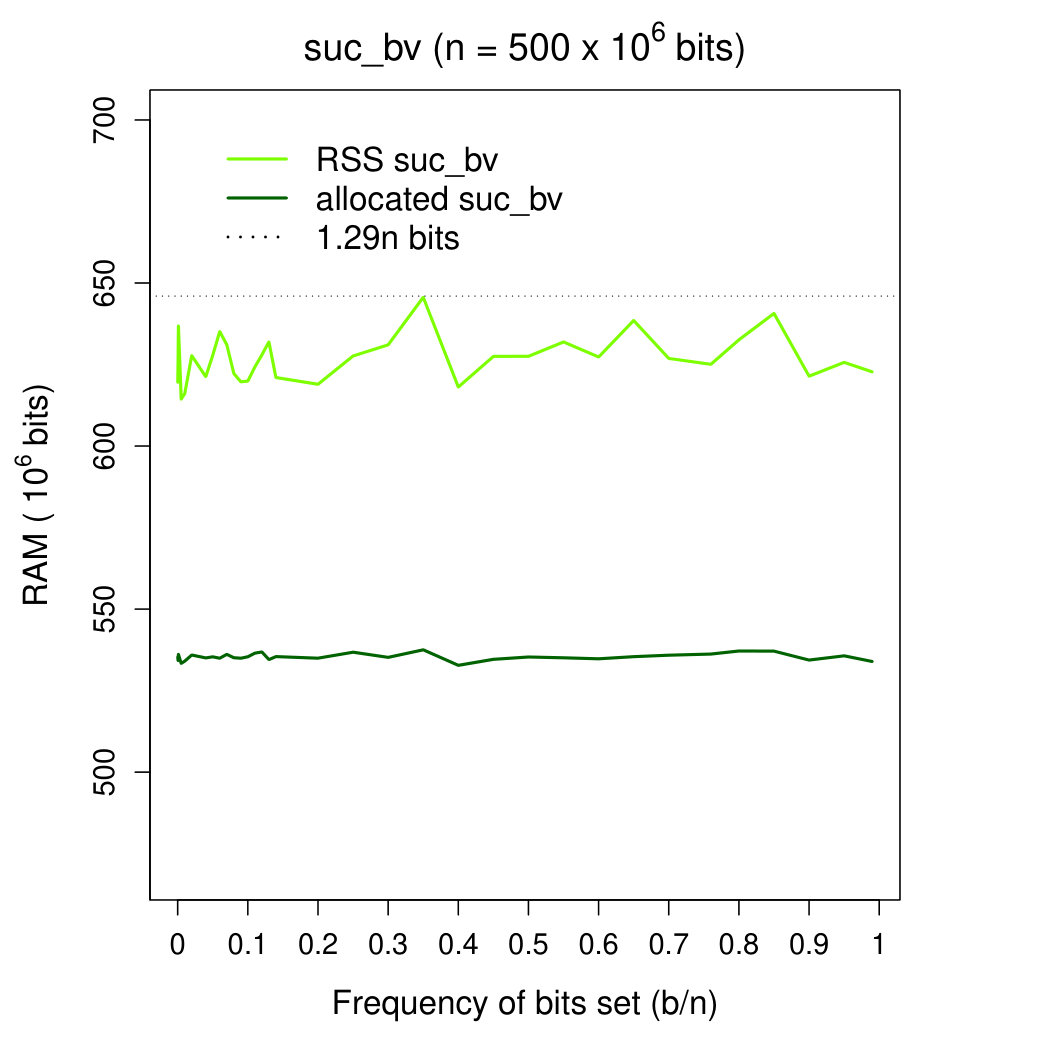 Figure 13
Figure 13Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
\Copyright
Nicola Prezza\EventEditorsJohn Q. Open and Joan R. Acces \EventNoEds2 \EventLongTitle42nd Conference on Very Important Topics (CVIT 2016) \EventShortTitleCVIT 2016 \EventAcronymCVIT \EventYear2016 \EventDateDecember 24–27, 2016 \EventLocationLittle Whinging, United Kingdom \EventLogo \SeriesVolume42 \ArticleNo23
A Framework of Dynamic Data Structures for String Processing
Nicola Prezza Part of this work was done while the author was a PhD student at the University of Udine, Italy. Work supported by the Danish Research Council (DFF-4005-00267) Technical University of Denmark, DTU Compute
Abstract.
In this paper we present DYNAMIC, an open-source C++ library implementing dynamic compressed data structures for string manipulation. Our framework includes useful tools such as searchable partial sums, succinct/gap-encoded bitvectors, and entropy/run-length compressed strings and FM-indexes. We prove close-to-optimal theoretical bounds for the resources used by our structures, and show that our theoretical predictions are empirically tightly verified in practice. To conclude, we turn our attention to applications. We compare the performance of four recently-published compression algorithms implemented using DYNAMIC with those of state-of-the-art tools performing the same task. Our experiments show that algorithms making use of dynamic compressed data structures can be up to three orders of magnitude more space-efficient (albeit slower) than classical ones performing the same tasks.
Key words and phrases:
C++, dynamic, compression, data structure, bitvector, string
1991 Mathematics Subject Classification:
E.1 DATA STRUCTURES
1. Introduction
Dynamism is an extremely useful feature in the field of data structures for string manipulation, and has been the subject of study in many recent works [3, 14, 20, 25, 17, 10]. These results showed that—in theory—it is possible to match information-theoretic spatial upper and lower bounds of many problems related to dynamic data structures while still supporting queries in provably optimal time. From the practical point of view however, many of these results are based on too complicated structures which prevent them to be competitive in practice. This is due to several factors that in practice play an important role but in theory are often poorly modeled: cache locality, branch prediction, disk accesses, context switches, memory fragmentation. Good implementations must take into account all these factors in order to be practical. Dynamic data structures are based on components that are often cache-inefficient and memory-consuming (e.g. self-balancing trees) and therefore easily run into the above-mentioned problems; this is the main reason why little work in this field has been done on the experimental side. An interesting and promising (but still under development) step in this direction is represented by Memoria [18], a C++14 framework providing general purpose dynamic data structures. Other libraries are also still under development (ds-vector [5]) or have been published but the code is not available [3, 14]. To the best of our knowledge, the only working implementation of a dynamic succinct bitvector is [8]. This situation changes dramatically if the requirement of dynamism is dropped. In recent years, several excellent libraries implementing static data structures have been proposed: sdsl [9] (probably the most comprehensive, used, and tested), pizza&chili [21] (compressed indexes), sux [28], succinct [27], libcds [15]. These libraries proved that static succinct data structures can be very practical in addition to being theoretically appealing.
In view of this gap between theoretical and practical advances in the field, in this paper we present DYNAMIC: a C++11 library providing practical implementations of some basic succinct and compressed dynamic data structures for string manipulation: searchable partial sums, succinct/gap-encoded bitvectors, and entropy/run-length compressed strings and FM-indexes. Our library has been extensively profiled and tested, and offers structures whose performance are provably close to the theoretical lower bounds (in particular, they approach succinctness and logarithmic queries). DYNAMIC is an open-source project and is available at [6].
We conclude by discussing the performance of four recently-published BWT/LZ77 compression algorithms [24, 23, 22] implemented with our library. On highly compressible datasets, our algorithms turn out to be up to three orders of magnitude more space-efficient than classical algorithms performing the same tasks.
2. The DYNAMIC library
The core of our library is a searchable partial sum with inserts data structure (SPSI in what follows). We start by formally defining the SPSI problem and showing how we solve it in DYNAMIC. We then proceed by describing how we use the SPSI structure as building block to obtain the dynamic structures implemented in our library.
2.1. The Core: Searchable Partial Sums with Inserts
The Searchable Partial Sums With Inserts (SPSI) problem asks for a data structure maintaining a sequence of non-negative -bits integers and supporting the following operations on it:
- •
;
- •
is the smallest such that ;
- •
: update to . can be negative as long as ;
- •
: insert [math] between and (if , insert in first position).
As discussed later, a consequence of the fact that our SPSI does not support delete operations is that also the structures we derive from it do not support delete; we plan to add this feature in our library in the future.
DYNAMIC’s SPSI is a B-tree storing integers in its leaves and subtree size/partial sum counters in internal nodes. SPSI’s operations are implemented by traversing the tree from the root to a target leaf and accessing internal nodes’ counters to obtain the information needed for tree traversal. The choice of employing B-trees is motivated by the fact that a big node fanout translates to smaller tree height (w.r.t. a binary tree) and nodes that can fully fit in a cache line (i.e. higher cache efficiency). We use a leaf size (i.e. number of integers stored in each leaf) always bounded by
[TABLE]
and a node fanout . has to be chosen accordingly with the cache line size; a bigger value for reduces cache misses and tree height but increases the asymptotic cost of handling single nodes. See Section 2.2 for a discussion on the maximum leaf size and values used in practice in our implementation. Letting being the size of a particular leaf, we call the coefficient the leaf load.
In order to improve space usage even further while still guaranteeing very fast operations, integers in the leaves are packed contiguously in word arrays and, inside each leaf , we assign to each integer the bit-size of the largest integer stored in . Whenever an integer overflows the maximum size associated to its leaf (after an update operation), we re-allocate space for all integers in the leaf. This operation takes time, so it does not asymptotically increase the cost of update operations. Crucially, in each leaf we allocate space only for the integers actually stored inside it, and re-allocate space for the whole leaf whenever we insert a new integer or we split the leaf. With this strategy, we do not waste space for half-full leaves111in practice, to speed up operations we allow a small fraction of the leaf to be empty. Note moreover that, since the size of each leaf is bounded by , re-allocating space for the whole leaf at each insertion does not asymptotically slow down insert operations.
2.1.1. Theoretical Guarantees
Let us denote with the total number of leaves, with , , the -th leaf of the B-tree (using any leaf order), and with an integer belonging to the -th leaf. The total number of bits stored in the leaves of the tree is
[TABLE]
where is the bit-size of the largest , and is the number of bits required to write number in binary. The above quantity is equal to
[TABLE]
where is the -th leaf load. Since leaves’ loads are always upper-bounded by , the above quantity is upper-bounded by
[TABLE]
which, in turn, is upper-bounded by
[TABLE]
In the above inequality, we use the upper-bound to deal with the case . Let be the sum of all integers stored in the structure plus . From the concavity of and from , it can be derived that the above quantity is upper-bounded by
[TABLE]
To conclude, we store pointers/counters of bits each per leaf and internal node. We obtain:
Theorem 2.1**.**
Let be a sequence of non-negative integers and . The partial sum data structure implemented in DYNAMIC takes at most
[TABLE]
bits of space and supports sum, search, update, and insert operations on the sequence in time.
In our experiments we observed that—even taking into account memory fragmentation—the bit-size of our dynamic partial sum structure is well approximated by function . See the experimental section for full details.
2.2. Plug and Play with Dynamic Structures
The SPSI structure described in the previous section is used as building block to obtain all dynamic structures of our library. In DYNAMIC, the SPSI structure’s type name is spsi and is parametrized on 3 template arguments: the leaf type (here, the type packed_vector is always used222packed_vector is simply a packed vector of -bits integers supporting all SPSI operations in linear time), the leaf size and the node fanout. DYNAMIC defines two SPSI types with two different combinations of these parameters:
typedef spsi<packed_vector,256,16> packed_spsi;
typedef spsi<packed_vector,8192,16> succinct_spsi;
The reasons for the particular values chosen for the leaf size and node fanout will be discussed later. We use these two types as basic components in the definition our structures.
2.2.1. Gap-Encoded Bitvectors
DYNAMIC implements gap-encoded bitvectors using a SPSI to encode gap lengths: bitvector () is encoded with a partial sum on the sequence . For space reasons, we do not describe how to reduce the gap-encoded bitvector problem to the SPSI problem; the main idea is to reduce bitvector’s access and rank to SPSI’s search, bitvector’s select to SPSI’s sum, bitvector’s insert1 to SPSI’s insert, and bitvector’s insert0/delete0 to SPSI’s update.
DYNAMIC’s name for the dynamic gap-encoded bitvector class is gap_bitvector. The class is a template on the SPSI type. We plug packed_spsi in gap_bitvector as follows:
typedef gap_bitvector<packed_spsi> gap_bv;
and obtain:
Theorem 2.2**.**
Let be a bit-sequence with bits set. The dynamic gap-encoded bitvector gap_bv implemented in DYNAMIC takes at most
[TABLE]
bits of space and supports rank, select, access, insert, and delete0 operations on in time.
In our experiments, the optimal node fanout for the SPSI stucture employed in this component turned out to be 16, while the optimal leaf size 256 (these values represented a good compromise between query times and space usage). Our benchmarks show (see the experimental section for full details) that the bit-size of our dynamic gap-encoded bitvector is well approximated by function .
2.2.2. Succinct Bitvectors and Entropy-Compressed Strings
Let be the bitvector length. Dynamic succinct bitvectors can be implemented using a SPSI where all stored integers are either 0 or 1. At this point, rank operations on the bitvector correspond to sum on the partial sum structure, and select operations on the bitvector can be implemented with search on the partial sum structure333Actually, search permits to implement only select1. select0 can however be easily simulated with the same solution used for search by replacing each integer with at run time. This solution does not increase space usage.. access and insert operations on the bitvector correspond to exactly the same operations on the partial sum structure. Note that in this case we can accelerate operations in the leaves by a factor of by using constant-time built-in bitwise operations such as popcount, masks and shifts. This allows us to use bigger leaves containing bits, which results in a total number of internal nodes bounded by . The overhead for storing internal nodes is therefore of bits. Moreover, since in the leaves we allocate only the necessary space to store the bitvector’s content (i.e. we do not allow empty space in the leaves), it easily follows that the dynamic bitvector structure implemented in DYNAMIC takes bits of space and supports all operations in time.
In our experiments, the optimal node fanout for the SPSI stucture employed in the succinct bitvector structure turned out to be 16, while the optimal leaf size 8192. DYNAMIC’s name for the dynamic succinct bitvector is succinct_bitvector. The class is a template on the SPSI type. DYNAMIC defines its dynamic succinct bitvector type as:
typedef succinct_bitvector<succinct_spsi> suc_bv;
We obtain:
Theorem 2.3**.**
Let be a bit-sequence. The dynamic succinct bitvector data structure suc_bv implemented in DYNAMIC takes bits of space and supports rank, select, access, and insert operations on in time.
In our experiments (see the experimental section) the size of our dynamic succinct bitvector was always upper-bounded by bits. The overhead on top of the optimal size comes mostly from memory fragmentation (). The remaining comes from succinct structures on top of the bit-sequence.
Dynamic compressed strings are implemented with a wavelet tree built upon dynamic succinct bitvectors. We explicitly store the topology of the tree ( bits) instead of encoding it implicitly in a single bitvector. This choice is space-inefficient for very large alphabets, but reduces the number of rank/select operations on the bitvector(s) with respect of a wavelet tree stored as a single bitvector. DYNAMIC’s compressed strings (wavelet trees) are a template on the bitvector type. DYNAMIC defines its dynamic string type as:
typedef wt_string<suc_bv> wt_str;
The user can choose at construction time whether to use a Huffman, fixed-size, or Gamma encoding for the alphabet. Gamma encoding is useful when the alphabet size is unknown at construction time. When using Huffman topology, the implementation satisfies:
Theorem 2.4**.**
Let be a string with zero-order entropy equal to . The Huffman-compressed dynamic string data structure wt_str implemented in DYNAMIC takes
[TABLE]
bits of space and supports rank, select, access, and insert operations on in average time.
In the case a fixed-size encoding is used (i.e. bits per character), the structure takes bits of space and supports all operations in time.
2.2.3. Run-Length Encoded Strings
To run-length encode a string , we adopt the approach described in [26]. We store one character per run in a string , we mark the end of the runs with a bit set in a bit-vector , and for every we store all -runs lengths consecutively in a bit-vector as follows: every -length -run is represented in as .
Example 2.5**.**
Let . We have: , , , , , and
By encoding with a wavelet tree and gap-compressing all bitvectors, we achieve run-length compression. It can be easily shown that this representation allows supporting rank, select, access, and insert operations on , but for space reasons we do not give these details here. In DYNAMIC, the run-length compressed string type rle_string is a template on the gap-encoded bitvector type (bitvectors and ) and on the dynamic string type (run heads ). We plug the structures of the previous sections in the above representation as follows:
typedef rle_string<gap_bv, wt_str> rle_str;
and obtain:
Theorem 2.6**.**
Let be a string with equal-letter runs. The dynamic run-length encoded string data structure rle_str implemented in DYNAMIC takes
[TABLE]
bits of space and supports rank, select, access, and insert operations on in time.
2.2.4. Dynamic FM-Indexes
We obtain dynamic FM-indexes by combining a dynamic Burrows-Wheeler transform with a sparse dynamic vector storing the suffix array sampling. In DYNAMIC, the BWT is a template class parametrized on the L-column and F-column types. For the F column, a run-length encoded string is always used. DYNAMIC defines two types of dynamic Burrows-Wheeler transform structures (wavelet-tree/run-length encoded):
typedef bwt<wt_str,rle_str> wt_bwt;
typedef bwt<rle_str,rle_str> rle_bwt;
Dynamic sparse vectors are implemented inside the FM index class using a dynamic bitvector marking sampled BWT positions and a dynamic sequence of integers (a SPSI) storing non-null values. We combine a Huffman-compressed BWT with a succinct bitvector and a SPSI:
typedef fm_index<wt_bwt, suc_bv, packed_spsi> wt_fmi;
and obtain:
Theorem 2.7**.**
Let be a string with zero-order entropy equal to , a pattern occurring times in , and the suffix array sampling rate. The dynamic Huffman-compressed FM-index wt_fmi implemented in DYNAMIC takes
[TABLE]
bits of space and supports:
- •
access* to BWT characters in average time*
- •
count* in average time*
- •
locate* in average time*
- •
text left-extension in average time
If a plain alphabet encoding is used, all terms are replaced by and times become worst-case.
If, instead, we combine a run-length compressed BWT with a gap-encoded bitvector and a SPSI as follows:
typedef fm_index<rle_bwt, gap_bv, packed_spsi> rle_fmi;
we obtain:
Theorem 2.8**.**
Let be a string whose BWT has runs, a pattern occurring times in , and the suffix array sampling rate. The dynamic run-length compressed FM-index rle_fmi implemented in DYNAMIC takes
[TABLE]
bits of space and supports:
- •
access* to BWT characters in time*
- •
count* in time*
- •
locate* in time*
- •
text left-extension in time
The suffix array sample rate can be chosen at construction time.
3. Experimental Evaluation
We start by presenting detailed benchmarks of our gap-encoded and succinct bitvectors, standing at the core of all other library’s structures. We then turn our attention to applications: we compare the performance of five recently-published compression algorithms implemented with DYNAMIC against those of state-of-the-art tools performing the same tasks and working in uncompressed space. All experiments were performed on a intel core i7 machine with 12 GB of RAM running Linux Ubuntu 16.04.
3.1. Benchmarks: Succinct and Gap-Encoded Bitvectors
We built 34 gap-encoded (gap_bv) and 34 succinct (suc_bv) bitvectors of length bits, varying the frequency of bits set in the interval . In each experiment, we first built the bitvector by performing insertb queries, being equal to 1 with probability , at uniform random positions. After building the bitvector, we executed rank0, rank1, select0, select1, and access queries at uniform random positions. Running times of each query were averaged over the repetitions. We measured memory usage in two ways: (i) internally by counting the total number of bits allocated by our procedures—this value is denoted as allocated memory in our plots—, and (ii) externally using the tool /usr/bin/time—this value is denoted as RSS in our plots (Resident Set Size).
Working space We fitted measured RSS memory with the theoretical predictions of Section 2.1.1 using a linear regression model. Parameters of the model were inferred using the statistical tool R (function lm). In detail, we fitted RSS memory in the range 444For it becomes more convenient—see below—to use our succinct bitvector, so we considered it more useful to fit memory usage in . In any case—see plot 2—the inferred model well fits experimental data in the (more wide) interval . with function , where: is our theoretical prediction (recall that memory occupancy of our gap-encoded bitvector should never exceed ), is a scaling factor accounting for memory fragmentation and average load distribution in the B-tree, and is a constant accounting for the weight of loaded C++ libraries (this component cannot be excluded from the measurements of the tool /usr/bin/time). Function lm provided us with parameters and bits . The value for was consistent with the space measured with close to 0.
Figures 2 and 2 show memory occupancy of DYNAMIC’s bitvectors as a function of the frequency of bits set. In Figure 2 we compare both bitvectors. In Figure 2 we focus on the behavior of our gap-encoded bitvector in the interval . In these plots we moreover show the growth of function . Plot in Figure 2 shows that our theoretical prediction fits almost perfectly the memory usage of our gap-encoded bitvector for . The plot suggests moreover that for it is preferable to use our succinct bitvector rather than the gap-encoded one. As far as the gap-encoded bitvector is concerned, memory fragmentation555we estimated the impact of memory fragmentation by comparing RSS and allocated memory, after subtracting from RSS the estimated weight—approximately MB—of loaded C++ libraries amounts to approximately of the allocated memory for . This fraction increases to for close to 1. We note that RSS memory usage of our succinct bitvector never exceeds bits: the overhead of bits is distributed among (1) rank/select succinct structures ( bits) (2) loaded C++ libraries (a constant amounting to approximately MB, i.e. bits in this case), and memory fragmentation ( bits). Excluding the size of C++ libraries (which is constant), our bitvector’s size never exceeds bits (being bits on average).
Query times Plots in Figures 4-6 show running times of our bitvectors on all except rank0 and select0 queries (which were very close to those of rank1 and select1 queries, respectively). We used a linear regression model (inferred using R’s function lm) to fit query times of our gap-encoded bitvector with function . Query times of our succinct bitvector were interpolated with a constant (being fixed). These plots show interesting results. First of all, our succinct bitvector supports extremely fast ( on average) access queries. rank and select queries are, on average, 15 times slower than access queries. As expected, insert queries are very slow, requiring—on average—390 times the time of access queries and 26 times that of rank/select queries. On all except access queries, running times of our gap-encoded bitvector are faster than (or comparable to) those of our succinct bitvector for . Combined with the results depicted in Plot 2, these considerations confirm that for our gap-encoded bitvector should be preferred to the succinct one. access, rank, and select queries are all supported in comparable times on our gap-encoded bitvector (), and are one order of magnitude faster than insert queries.
3.2. An Application: Space-Efficient Compression Algorithms
We used DYNAMIC to implement five recently-published algorithms [24, 23, 22] computing the Burrows-Wheeler transform [2] (BWT) and the Lempel-Ziv 77 factorization [29] (LZ77) within compressed working space: cw-bwt [22] builds a BWT within bits of working space by breaking it in contexts and encoding each context with a zero-order compressed string; rle-bwt builds the BWT within words of working space using the structure of Theorem 2.6; h0-lz77 [23] computes LZ77 online within bits using a dynamic zero-order compressed FM-index; rle-lz77-1 and rle-lz77-2 [24] build LZ77 within words of space by employing a run-length encoded BWT augmented with a suffix array sampling based on BWT equal-letter runs and LZ77 factors, respectively. Implementations of these algorithms can be found within the DYNAMIC library [6]. We compared running times and working space of our algorithms against those of less space-efficient (but faster) state-of-the-art tools solving the same problems. BWT construction tools: se-sais [1, 9] ( Bytes of working space), divsufsort [19, 9] ( words), bwte [7] (constant user-defined working space; we always used 256 MB), dbwt [4] ( Bytes). LZ77 factorization tools: isa6r [13, 16] ( words), kkp1s [12, 16] ( words), lzscan [11, 16] ( Bytes). We generated two highly repetitive text collections by downloading all versions of the Boost library (github.com/boostorg/boost) and all versions of the English Einstein’s Wikipedia page (en.wikipedia.org/wiki/Albert_Einstein). Both datasets were truncated to Bytes to limit RAM usage of the and computation times of the tested tools. The sizes of the 7-Zip-compressed datasets (www.7-zip.org) were 120 KB (Boost) and 810 KB (Einstein). The datasets can be found within the DYNAMIC library [6] (folder /datasets/). RAM usage and running times of the tools were measured using the executable /usr/bin/time.
In Figure 7 we report our results. Solid and a dashed horizontal lines show the datasets’ sizes before and after compression with 7-Zip, respectively. Our tools are highlighted in red. We can infer some general trends from the plots. Our tools use always less space than the plain text, and from one to three orders of magnitude more space than the 7-Zip-compressed text. h0-lz77 and cw-bwt (entropy compression) use always a working space very close to (and always smaller than) the plain text, with cw-bwt (-th order compression) being more space-efficient than h0-lz77 ([math]-order compression). On the other hand, tools using a run-length compressed BWT—rle-bwt, rle-lz77-1, and rle-lz77-2—are up to two orders of magnitude more space-efficient than h0-lz77 and cw-bwt in most of the cases. This is a consequence of the fact that run-length encoding of the BWT is particularly effective in compressing repetitive datasets. bwte represents a good trade-off in both running times and working space between tools working in compressed and uncompressed working space. kkp1s is the fastest tool, but uses a working space that is one order of magnitude larger than the uncompressed text and three orders of magnitude larger than that of rle-bwt, rle-lz77-1, and rle-lz77-2. As predicted by theory, tools working in compact working space (lzscan, se-sais, dbwt) use always slightly more space than the uncompressed text, and one order of magnitude less space than tools working in words. To conclude, the plots show that the price to pay for using complex dynamic data structures is high running times: our tools are up to three orders of magnitude slower than tools working in words of space. This is mainly due to the large number of insert operations—one per text character—performed by our algorithms to build the dynamic FM indexes.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Timo Beller, Maike Zwerger, Simon Gog, and Enno Ohlebusch. Space-efficient construction of the burrows-wheeler transform. In String Processing and Information Retrieval , pages 5–16. Springer, 2013.
- 2[2] Michael Burrows and David J Wheeler. A block-sorting lossless data compression algorithm, 1994.
- 3[3] Joshimar Cordova and Gonzalo Navarro. Practical dynamic entropy-compressed bitvectors with applications. In International Symposium on Experimental Algorithms , pages 105–117. Springer, 2016.
- 4[4] dbwt: direct construction of the bwt. http://researchmap.jp/muuw 41s 7s-1587/#_1587 . Accessed: 2016-11-17.
- 5[5] ds-vector: C++ library for dynamic succinct vector. https://code.google.com/archive/p/ds-vector/ . Accessed: 2016-11-17.
- 6[6] DYNAMIC: dynamic succinct/compressed data structures library. https://github.com/xxsds/DYNAMIC . Accessed: 2017-01-22.
- 7[7] Paolo Ferragina, Travis Gagie, and Giovanni Manzini. Lightweight data indexing and compression in external memory. Algorithmica , 63(3):707–730, 2012.
- 8[8] bitvector: succinct dynamic bitvector implementation. https://github.com/nicola-gigante/bitvector . Accessed: 2016-11-17.
