On the Capacity for Distributed Index Coding
Yucheng Liu, Parastoo Sadeghi
Research School of Engineering
Australian National University
{yucheng.liu, parastoo.sadeghi}@anu.edu.au
Fatemeh Arbabjolfaei, Young-Han Kim
Department of Electrical and Computer Engineering
University of California, San Diego
{farbabjo, yhk}@ucsd.edu
Abstract
The distributed index coding problem is studied, whereby multiple messages are stored at different servers to be broadcast to receivers with side information. First, the existing composite coding scheme is enhanced for the centralized (single-server) index coding problem,
which is then merged with fractional partitioning of servers to yield a new coding scheme for distributed index coding.
New outer bounds on the capacity region are also established. For 213 out of 218 non-isomorphic distributed index coding problems with four messages the achievable sum-rate of the proposed distributed composite coding scheme matches the outer bound, thus establishing the sum-capacity for these problems.
I Introduction
Introduced by Birk and Kol [1], the index coding problem studies the optimal broadcast rate from a server to multiple receivers with some side information about the messages.
This paper considers the distributed index coding problem in which, unlike the aforementioned single-server index coding problem, the messages are distributed over multiple servers.
The distributed index coding problem was first studied by Ong, Ho, and Lim [2], where lower and upper bounds on the (optimal) broadcast rate were derived in the special case in which each receiver has a distinct message as side information and it is shown that the bounds match if no two servers have any messages in common.
Thapa, Ong, and Johnson [3] considered the distributed index coding problem with two servers each having an arbitrary subset of messages and extended some of the existing schemes for the centralized index coding to the two-server distributed case.
The main objective of this paper is to study a general distributed index coding problem and to establish new inner and outer bounds on the capacity region.
For the inner bounds, we propose distributed composite coding schemes that extend those in [4] through an enhanced version of the centralized composite coding scheme.
The enhancement is interesting on its own and strictly improves upon the original composite coding scheme in [5].
For the outer bounds, we establish a set of new inequalities to add to the existing polymatroidal outer bound derived in [4]. The inner and outer bounds, when applied to the sum-rate, match in 213 out of 218 non-isomorphic distributed index coding problems with four messages, thus establishing their sum-capacity. Note that in [4], the capacity region for all three-message distributed index coding problems was established.
Throughout the paper, [n] denotes the set {1,2,…,n} and
N≐{J⊆[n]:J=∅} denotes the set of all nonempty subsets of [n].
Given a tuple (x1,…,xn) and A⊆[n], x(A) denotes the subtuple (xi\mathchar58i∈A).
II System Model and Problem Setup
Consider the general distributed index coding problem in which there are n messages x1,x2,…,xn, where xi∈{0,1}ti, i∈[n].
As shown in Fig. 1, there are 2n−1 servers, where server J∈N has access to messages x(J).
There are n receivers, where receiver i∈[n] wishes to obtain message xi and knows x(Ai) as side information for some Ai⊆[n]∖{i}.
Server J is connected to all receivers via a noiseless broadcast link of finite capacity CJ.
This is a fairly general model that allows for all possible message availabilities on different servers.
If CJ=1 only for J=[n] and is zero everywhere else, we recover the centralized index coding problem.
The question is to find the maximum amount of information that can be communicated to the receivers and the optimal coding scheme that achieves this maximum.
To answer this question formally, we define
a (t,r)=((ti,i∈[n]),(rJ,J∈N)) distributed index code by
2n−1 encoders, one for each server J∈N, such that ϕJ\mathchar58∏j∈J{0,1}tj→{0,1}rJ maps the messages in server J, x(J), to an rJ-bit sequence yJ, and
n decoders ψi\mathchar58∏J∈N{0,1}rJ×∏k∈Ai{0,1}tk→{0,1}ti that maps the received sequences ϕJ(xj,j∈J) and the side information x(Ai) to
x^i for i∈[n].
Let Xi and X^i be the random variables representing message xi and message estimate x^i, respectively.
Assume that X1,…,Xn are uniformly distributed and independent of each other.
We say that a rate–capacity tuple (R,C)=((Ri,i∈[n]),(CJ,J∈N)) is achievable if for every ϵ>0, there exist a (t,r) code and r such that
[TABLE]
and the probability of error
[TABLE]
For a given C=(CJ,J∈N), the capacity region C of this index coding problem is the closure of the set of all R=(R1,⋯,Rn) such that (R,C) is achievable.
Although the capacity region of the centralized index coding problem is known to be equal to its zero-error capacity region [6], it is not known whether these two capacity regions are equal for the distributed case.
Throughout the paper, we will compactly represent a distributed index coding instance (for a given C) by a sequence (i∣j∈Ai), i∈[n]. For example, for A1=∅, A2={3}, and A3={2}, we write
(1∣−),(2∣3),(3∣2).
III Composite Coding for the Centralized Case
We present a new composite coding scheme for the centralized index coding problem, which is an extension of the original composite coding scheme proposed in [5].
III-A Existing Centralized Composite Coding Scheme
First, we briefly review the scheme of [5].
Our slightly modified presentation here will lead to better understanding of both centralized and distributed composite coding schemes that are developed in this paper.
There is a single server containing all messages in [n], which is connected to the receivers via a noiseless broadcast channel of capacity C.
To each non-empty subset K⊆[n] (or K∈N) of the messages, we associate a virtual encoder with composite coding rate SK.
In the first step of composite coding, the virtual encoder K maps x(K) into a single composite index wK, which is generated randomly and independently as a Bern(1/2) sequence of length rSK bits.
In the second step, the server uses flat coding [5] to encode the composite indices (wK,K∈N) into a single sequence y∈{0,1}r.
As with the encoding, decoding also takes place in two steps.
Each receiver first uses its side information to recover all composite indices (wK,K∈N).
This is successful with vanishing probability of error (for t,r, and r sufficiently large) if
[TABLE]
As the second step of decoding, each receiver recovers the desired message (together with a subset of other messages) from the composite
indices and the side information.
Let Di be the set of the messages that receiver i recovers (due to index coding requirements i∈Di) and Δ=D1×⋯×Dn be the set of all possible decoding set tuples across all receivers, where Di={Di∣Di⊆[n]∖Ai\mathchar58i∈Di} is the set of all possible decoding sets for receiver i.
Assume D∈Δ is the chosen decoding set tuple.
Then, receiver i can successfully recover messages in Di with vanishing probability of error if
[TABLE]
for all L⊆Di.
Now let (R(D),S) be the set of index coding rate tuples and composite rate tuples that satisfy (1) and (2) for a given decoding choice D∈Δ, where R(D)=(Ri,i∈[n]) and S=(SK,K∈N).
The overall achievable rate region RCC can be written as
[TABLE]
where “co” denotes the convex hull and
“Proj”
denotes projecting (R,S) into R coordinates.
It can be shown that RCC can equivalently be computed as
[TABLE]
III-B Enhanced Composite Coding
The main idea behind this new method is to allow the composite coding rates SK to
depend on the decoding choices of the receivers.
Effectively, composite coding rates can be individually tailored to different decoding choices, as long as they collectively satisfy the conditions of (1).
Splitting the rate of each message, we represent the message xi by independent parts xi(D) at rate Ri(D).
Thus,
[TABLE]
To send (xi(D),i∈[n]), we generate composite messages wK(D) at composite coding rate SK(D), K∈N.
Each receiver first recovers all composite
indices (wK(D),K∈N,D∈Δ).
This is successful with vanishing probability of error if
[TABLE]
For a given D∈Δ,
receiver i can successfully recover messages in Di
with vanishing probability of error if
[TABLE]
for all L⊆Di.
The enhanced achievable rate region RCC(e) is obtained by projecting out (SK(D),K∈N,D∈Δ) and (Ri(D),i∈[n],D∈Δ) through Fourier-Motzkin elimination [7, Appendix D].
The enhanced composite coding inner bound is no smaller than the original composite coding inner bound due to a larger degrees of freedom in choosing the composite rates for different decoding choices D.
The enhanced inner bound can also be strictly larger than the original one, as illustrated in the following.
Example 1
For index coding problem
[TABLE]
the largest symmetric rate in RCC is 0.2963, while the largest symmetric rate in RCC(e) is 0.2987, and thus RCC⊊RCC(e).
A possible disadvantage of this method is its computational complexity due to the increase in the number of composite coding rate variables and the necessity to perform a single Fourier-Motzkin elimination operation on all (SK(D)) and (Ri(D)).
To overcome this, one can either apply the technique to a subset of decoding choices in Δ (possibly at the expense of some reduction in the rate region) or use linear programming (LP) to solve for a desired weighted sum-rate or equal rates subject to (5)-(7).
IV Composite Coding for the Distributed Case
In this section, we present new composite coding schemes for the distributed index coding problem.
First, we apply the enhanced composite coding to all servers as a single group, which is an extension of [4, Section IV-B].
Next, we apply the enhanced composite coding to fractional partitions of the servers, which is an extension of the partitioned distributed composite coding [4, Section IV-C].
IV-A All-server Distributed Composite Coding
Using rate splitting, similar to the centralized case, we have
[TABLE]
For each non-empty subset K⊆J at server J∈N and each decoding choice D∈Δ, there is a virtual encoder at server J.
In the first step of composite coding, virtual encoder K at server J maps (xi(D),i∈K) into a composite index wK,J(D) with rate SK,J(D), which is generated randomly and independently as a Bern(1/2) sequence of length rJSK,J(D) bits.
In the second step, server J uses flat coding to encode the composite indices (wK,J(D),K⊆J,D∈Δ) into yJ∈{0,1}rJ.
Each receiver first recovers all composite indices (wK,J(D)), which is successful with vanishing probability of error if
[TABLE]
As the second step of decoding, for each decoding choice D∈Δ, receiver i∈[n] recovers (xj(D),j∈Di) (which includes the desired message xi(D)) using the composite indices and its side information.
This is successful with vanishing probability of error if
[TABLE]
for all L⊆Di.
The second summation on the right hand side of the above ensures that all servers that contain the message subset K are taken into account.
The computational complexity of the enhanced composite coding for distributed index coding is even higher than its centralized counterpart, since the number of composite coding rates rapidly grows with the number of servers.
For each decoding set tuple D∈Δ, there are ∑k=1n(kn)(2k−1) composite coding rates SK,J(D) and n message rates Ri(D).
Hence, even for n=4 and ∣Δ∣=2, the number of variables to eliminate is 2×(65+4).
However, an LP can be solved subject to (8)-(10).
Note that in the scheme proposed in [4, Section IV-B], the rates of the composite messages SK,J,K⊆J,J∈N did not depend on the choice of the decoding set tuple D.
IV-B Fractional Distributed Composite Coding
In the previous scheme, all servers participated in a single group to perform composite coding. However, it is also possible that servers form different groups and participate in group-based composite coding. For each group, they allocate a fraction of their server capacity, hence the name “fractional”.
Let Π be the collection of non-empty subsets of N.
For each P∈Π, let I(P)={i∣∃J∈P\mathchar58i∈J}⊆[n] be the union of all messages held by at least one server in P.
For every i∈I(P), let Ai(P)=Ai∩I(P),
Di(P)={Di(P)∣Di(P)⊆I(P)∖Ai(P)\mathchar58i∈Di(P)},
and Δ(P)=D1(P)×⋯×Dn(P).
Essentially, we now apply the all-server distributed composite coding methodology to each server group.
Then, each receiver is able to decode its desired message with vanishing probability of error if the following sets of inequalities are satisfied.
For all P∈Π and J∈P
[TABLE]
For all P∈Π, i∈I(P) and a given D∈Δ(P), (10) is modified as
[TABLE]
for all L⊆Di.
Finally, we have the following conditions on message rates and server capacities
[TABLE]
The achievable rate region is characterized by eliminating the variables (CJ(P),P∈Π,J∈P), (Ri(P,D),P∈Π,i∈I(P),D∈Δ(P)), and (SK,J(P,D),P∈Π,J∈P,K⊆J,D∈Δ(P)).
A possible advantage of this technique is that each receiver only recovers composite indices of the groups that hold its desired message.
Consider the index coding problem
[TABLE]
Without server grouping, for receiver i=4 and server J={1,2} we have
[TABLE]
With partitioning, let us consider the server group P={{1,2},{2,3}}. Since i=4 does not belong to this group, we do not have the above constraint for that group.
A disadvantage of this technique is its computational complexity.
For n messages, the number of possible non-empty server subsets is ∣Π∣=22n−1−1, which is doubly exponential in n. As a result, Fourier-Motzkin elimination is not practical. Linear programs can be solved by excluding some servers from the problem (for example through dealing with trivial singleton servers, ∣J∣=1, in N separately), by considering only a subset of Π (at the possible expense of some reduction in the rate region), or when max∣Δ∣ is not very large.
Clearly the fractional distributed composite coding scheme reduces to the all-server scheme of Section IV-A when all the servers are put into a single group. At this point, however, we do not know any example for which the inner bound corresponding to the fractional distributed composite coding is strictly larger.
V Outer Bounds
In this section, we use the shorthand notation X[n] to represent all messages (Xi,i∈[n]) and YN to represent all server outputs (YJ,J∈N). For any set U, we use U to represent the complimentary set of U (when no confusion about the ground set will arise), and for any two sets U and V, we use UV to represent U∪V. Note that due to source independence, H(XU∣XV)=H(XU) for any two disjoint sets U,V⊆[n]. Also, the exact decoding condition at receiver i stipulates H(Xi∣YN,X(Ai))=0. We note that an ϵ-error probability can be handled in a standard manner through converse techniques that use Fano’s inequality. Finally, note that sever outputs only depend on the messages they contain. For example, H(YN∣X[n])=0.
We now briefly review an outer bound on the capacity region from [4], which is based on the polymatroidal axioms.
Theorem 1
Let Bi be the set of interfering messages at receiver i, i.e., Bi=[n]\(Ai∪{i}). If (R,C) is achievable, then for every T∈N and every i∈T,
[TABLE]
for some fT(S),S⊆T satisfying the polymatroidal axioms.
The above theorem does not result in tight outer bounds in general, as we will show through numerical examples later. Now we introduce a new outer bound on the sum-rate based on Shannon inequalities, which can be strictly tighter. For simplicity of exposition, we focus on ∑i=1nRi, but a subset of rates can also be considered in the sum. The following two disjoint sets U,V will prove useful.
Definition 1
Given a distributed index coding problem, U is the largest set such that U⊆[n] and H(XU∣YN)=0.
Definition 2
Given a distributed index coding problem and its corresponding set U from Definition 1, set V is the smallest set that satisfies V⊆[n]\U and H(XUV∣YN,XUV)=0.
Note that set U is unique and can be found through exhaustive search. However, for some index coding problems, there can be multiple sets V.
Example 1
Consider the problem (1∣−); (2∣1,4); (3∣1,2); (4∣1,2,3). Using H(Xi∣YN,X(Ai))=0,i∈[n], we find that U={1} and V={2} or V={4}.
Lemma 1 below comes directly from Definitions 1 and 2.
Lemma 1
Given an index coding problem and sets U and V defined in Definitions 1 and 2, we always have
[TABLE]
Now we consider the following condition that is used to establish a new outer bound on the sum-rate.
Condition 1
For any set V⊆[n], if H(XV∣YN,XV)=0, then we say that set V satisfies Condition 1.
Theorem 2
Given a distributed index coding problem, if set V from Definition 2 satisfies Condition 1, then we have the following outer bound on the sum-rate:
[TABLE]
Proof:
Consider H(XV) and I(XV;YJ\mathchar58J∩V=∅∣XU):
[TABLE]
where (22) is due to the fact that set V satisfies Condition 1.
[TABLE]
Since H(XV)=H(YJ\mathchar58J∩V=∅∣XV)≤H(YJ\mathchar58J∩V=∅∣XU) and H(XV∣YN,XU)≤H(XV∣YJ\mathchar58J∩V=∅,XU), by comparing (24) and (25), we have
[TABLE]
Therefore, we have
[TABLE]
where the equality in (27) follows from Lemma 1.
∎
Example 2
Revisiting Example 1 and directly applying Theorem 2, for V={2} we will have
[TABLE]
And for V={4} we will have
[TABLE]
If CJ=1,∀J, then both sets V={2} and V={4} give the same outer bound of 21 on the sum-rate. However, in general one needs to evaluate all bounds due to different sets V and take the minimum. Note that with CJ=1,∀J, Theorem 1 gives i∈[n]∑Ri≤22, which is strictly looser.
VI Numerical Results
We numerically evaluated inner and outer bounds on the sum-rate of all 218 non-isomorphic distributed index coding problems with n=4 messages. The receiver side information of these problems are listed in the next section. For instance, the side information in Examples 1 and 2 is labelled as problem number 140. The inner bound is computed by applying LP on the composite coding scheme of Section IV-A and compares with the outer bound on the sum-rate as follows.
For 145 out of 218 problems, the outer bound on the sum-rate due to Theorem 1 and the inner bound matched. These cases are shown normally in Table I.
For 53 out of the remaining 73 cases, the outer bound of Theorem 2 gave a tighter result than Theorem 1 and matched the inner bound. These cases are shown in bold font in Table I. For the final 20 cases, the outer bounds of Theorems 1 or 2 did not match the inner bound.
For 4 of these final 20 cases, there did not exist a single set V that satisfied Condition 1. However, we partitioned V into several disjoint subsets such that each part satisfied Condition 1. Then we used a method similar to Theorem 2 and obtained a tighter outer bound that matched the inner bound. These cases are shown as underlined in Table I.
For 6 of the final 20 cases, we had to use non-trivial extensions of Theorem 2, not presented in this paper due to space limitations. The obtained tighter outer bound matched the inner bound. These cases are shown as doubly underlined in Table I.
For 5 of the remaining problems, we had to use f-d separation methods based on [8, 9] to obtain a tighter outer bound that matched the inner bound. The details are not presented in this paper due to space limitations. These cases are shown as overlined in Table I. The sum-capacity of five problems 81, 112, 115, 119, and 148 remains open. The tightest outer bound on the sum-rate that we have achieved is 2332, which we conjecture can be further tightened to 23.5.
To conclude, we report that for 28 out of these 218 problems, the composite coding scheme of [4, Section IV-B] gives a looser inner bound on the sum-rate than the enhanced method of Section IV-A in this paper. For example, for problem number 155: (1∣4);(2∣3,4);(3∣1,2);(4∣2,3), [4, Section IV-B] gives ∑i∈[n]Ri≤23, whereas the sum-capacity 24 is achievable through the method of Section IV-A. In effect, server partitioning of [4, Section IV-C] is not necessary to achieve the sum-capacity of problem no 155. It remains unclear whether and when the fractional method of Section IV-B offers strict improvement over the all-server method of Section IV-A. This is our ongoing research.
VII List of all Non-isomorphic Index Coding Problems with n=4 Messages
Problem No 1: (1∣−),(2∣−),(3∣−),(4∣−)
Problem No 2: (1∣2),(2∣−),(3∣−),(4∣−)
Problem No 3: (1∣2,3),(2∣−),(3∣−),(4∣−)
Problem No 4: (1∣−),(2∣−),(3∣4),(4∣3)
Problem No 5: (1∣−),(2∣−),(3∣4),(4∣2)
Problem No 6: (1∣−),(2∣−),(3∣2),(4∣2)
Problem No 7: (1∣−),(2∣−),(3∣2),(4∣1)
Problem No 8: (1∣2,3,4),(2∣−),(3∣−),(4∣−)
Problem No 9: (1∣−),(2∣−),(3∣4),(4∣2,3)
Problem No 10: (1∣−),(2∣−),(3∣4),(4∣1,2)
Problem No 11: (1∣−),(2∣−),(3∣2),(4∣2,3)
Problem No 12: (1∣−),(2∣−),(3∣2),(4∣1,3)
Problem No 13: (1∣−),(2∣−),(3∣2),(4∣1,2)
Problem No 14: (1∣−),(2∣4),(3∣4),(4∣3)
Problem No 15: (1∣−),(2∣4),(3∣4),(4∣1)
Problem No 16: (1∣−),(2∣4),(3∣2),(4∣3)
Problem No 17: (1∣−),(2∣4),(3∣2),(4∣1)
Problem No 18: (1∣−),(2∣4),(3∣1),(4∣2)
Problem No 19: (1∣−),(2∣4),(3∣1),(4∣1)
Problem No 20: (1∣−),(2∣1),(3∣1),(4∣1)
Problem No 21: (1∣2,3,4),(2∣1),(3∣−),(4∣−)
Problem No 22: (1∣−),(2∣−),(3∣2),(4∣1,2,3)
Problem No 23: (1∣−),(2∣−),(3∣2,4),(4∣2,3)
Problem No 24: (1∣−),(2∣−),(3∣2,4),(4∣1,3)
Problem No 25: (1∣−),(2∣−),(3∣2,4),(4∣1,2)
Problem No 26: (1∣−),(2∣−),(3∣1,2),(4∣1,2)
Problem No 27: (1∣−),(2∣4),(3∣4),(4∣2,3)
Problem No 28: (1∣−),(2∣4),(3∣4),(4∣1,3)
Problem No 29: (1∣−),(2∣4),(3∣2),(4∣2,3)
Problem No 30: (1∣−),(2∣4),(3∣2),(4∣1,3)
Problem No 31: (1∣−),(2∣4),(3∣2),(4∣1,2)
Problem No 32: (1∣−),(2∣4),(3∣2,4),(4∣2)
Problem No 33: (1∣−),(2∣4),(3∣2,4),(4∣1)
Problem No 34: (1∣−),(2∣4),(3∣1),(4∣2,3)
Problem No 35: (1∣−),(2∣4),(3∣1),(4∣1,3)
Problem No 36: (1∣−),(2∣4),(3∣1),(4∣1,2)
Problem No 37: (1∣−),(2∣4),(3∣1,4),(4∣2)
Problem No 38: (1∣−),(2∣4),(3∣1,4),(4∣1)
Problem No 39: (1∣−),(2∣4),(3∣1,2),(4∣1)
Problem No 40: (1∣−),(2∣3,4),(3∣1),(4∣1)
Problem No 41: (1∣−),(2∣1),(3∣1),(4∣1,3)
Problem No 42: (1∣4),(2∣4),(3∣4),(4∣3)
Problem No 43: (1∣4),(2∣4),(3∣2),(4∣3)
Problem No 44: (1∣4),(2∣4),(3∣2),(4∣2)
Problem No 45: (1∣4),(2∣4),(3∣2),(4∣1)
Problem No 46: (1∣4),(2∣3),(3∣2),(4∣1)
Problem No 47: (1∣4),(2∣3),(3∣1),(4∣2)
Problem No 48: (1∣2,3,4),(2∣1,3),(3∣−),(4∣−)
Problem No 49: (1∣−),(2∣−),(3∣1,2),(4∣1,2,3)
Problem No 50: (1∣−),(2∣4),(3∣4),(4∣1,2,3)
Problem No 51: (1∣−),(2∣4),(3∣2),(4∣1,2,3)
Problem No 52: (1∣−),(2∣4),(3∣2,4),(4∣2,3)
Problem No 53: (1∣−),(2∣4),(3∣2,4),(4∣1,3)
Problem No 54: (1∣−),(2∣4),(3∣2,4),(4∣1,2)
Problem No 55: (1∣−),(2∣4),(3∣1),(4∣1,2,3)
Problem No 56: (1∣−),(2∣4),(3∣1,4),(4∣2,3)
Problem No 57: (1∣−),(2∣4),(3∣1,4),(4∣1,3)
Problem No 58: (1∣−),(2∣4),(3∣1,4),(4∣1,2)
Problem No 59: (1∣−),(2∣4),(3∣1,2),(4∣2,3)
Problem No 60: (1∣−),(2∣4),(3∣1,2),(4∣1,3)
Problem No 61: (1∣−),(2∣4),(3∣1,2),(4∣1,2)
Problem No 62: (1∣−),(2∣4),(3∣1,2,4),(4∣2)
Problem No 63: (1∣−),(2∣4),(3∣1,2,4),(4∣1)
Problem No 64: (1∣−),(2∣3,4),(3∣2,4),(4∣1)
Problem No 65: (1∣−),(2∣3,4),(3∣1),(4∣1,3)
Problem No 66: (1∣−),(2∣3,4),(3∣1),(4∣1,2)
Problem No 67: (1∣−),(2∣1),(3∣1),(4∣1,2,3)
Problem No 68: (1∣−),(2∣1),(3∣1,4),(4∣1,3)
Problem No 69: (1∣−),(2∣1),(3∣1,4),(4∣1,2)
Problem No 70: (1∣−),(2∣1),(3∣1,2),(4∣1,2)
Problem No 71: (1∣4),(2∣4),(3∣4),(4∣2,3)
Problem No 72: (1∣4),(2∣4),(3∣2),(4∣2,3)
Problem No 73: (1∣4),(2∣4),(3∣2),(4∣1,3)
Problem No 74: (1∣4),(2∣4),(3∣2),(4∣1,2)
Problem No 75: (1∣4),(2∣4),(3∣2,4),(4∣3)
Problem No 76: (1∣4),(2∣4),(3∣2,4),(4∣2)
Problem No 77: (1∣4),(2∣4),(3∣2,4),(4∣1)
Problem No 78: (1∣4),(2∣4),(3∣1,2),(4∣3)
Problem No 79: (1∣4),(2∣4),(3∣1,2),(4∣2)
Problem No 80: (1∣4),(2∣3),(3∣2),(4∣2,3)
Problem No 81: (1∣4),(2∣3),(3∣2),(4∣1,3)
Problem No 82: (1∣4),(2∣3),(3∣2,4),(4∣2)
Problem No 83: (1∣4),(2∣3),(3∣1),(4∣2,3)
Problem No 84: (1∣4),(2∣3),(3∣1),(4∣1,2)
Problem No 85: (1∣4),(2∣3,4),(3∣1),(4∣3)
Problem No 86: (1∣2,3,4),(2∣1,3,4),(3∣−),(4∣−)
Problem No 87: (1∣−),(2∣4),(3∣2,4),(4∣1,2,3)
Problem No 88: (1∣−),(2∣4),(3∣1,4),(4∣1,2,3)
Problem No 89: (1∣−),(2∣4),(3∣1,2),(4∣1,2,3)
Problem No 90: (1∣−),(2∣4),(3∣1,2,4),(4∣2,3)
Problem No 91: (1∣−),(2∣4),(3∣1,2,4),(4∣1,3)
Problem No 92: (1∣−),(2∣4),(3∣1,2,4),(4∣1,2)
Problem No 93: (1∣−),(2∣3,4),(3∣2,4),(4∣2,3)
Problem No 94: (1∣−),(2∣3,4),(3∣2,4),(4∣1,3)
Problem No 95: (1∣−),(2∣3,4),(3∣1),(4∣1,2,3)
Problem No 96: (1∣−),(2∣3,4),(3∣1,4),(4∣1,3)
Problem No 97: (1∣−),(2∣3,4),(3∣1,4),(4∣1,2)
Problem No 98: (1∣−),(2∣3,4),(3∣1,2),(4∣1,2)
Problem No 99: (1∣−),(2∣1),(3∣1,4),(4∣1,2,3)
Problem No 100: (1∣−),(2∣1),(3∣1,2),(4∣1,2,3)
Problem No 101: (1∣−),(2∣1,4),(3∣1,4),(4∣1,3)
Problem No 102: (1∣−),(2∣1,4),(3∣1,2),(4∣1,3)
Problem No 103: (1∣4),(2∣4),(3∣4),(4∣1,2,3)
Problem No 104: (1∣4),(2∣4),(3∣2),(4∣1,2,3)
Problem No 105: (1∣4),(2∣4),(3∣2,4),(4∣2,3)
Problem No 106: (1∣4),(2∣4),(3∣2,4),(4∣1,3)
Problem No 107: (1∣4),(2∣4),(3∣2,4),(4∣1,2)
Problem No 108: (1∣4),(2∣4),(3∣1,2),(4∣2,3)
Problem No 109: (1∣4),(2∣4),(3∣1,2),(4∣1,2)
Problem No 110: (1∣4),(2∣4),(3∣1,2,4),(4∣3)
Problem No 111: (1∣4),(2∣4),(3∣1,2,4),(4∣2)
Problem No 112: (1∣4),(2∣3),(3∣2),(4∣1,2,3)
Problem No 113: (1∣4),(2∣3),(3∣2,4),(4∣2,3)
Problem No 114: (1∣4),(2∣3),(3∣2,4),(4∣1,3)
Problem No 115: (1∣4),(2∣3),(3∣2,4),(4∣1,2)
Problem No 116: (1∣4),(2∣3),(3∣1),(4∣1,2,3)
Problem No 117: (1∣4),(2∣3),(3∣1,4),(4∣2,3)
Problem No 118: (1∣4),(2∣3),(3∣1,4),(4∣1,2)
Problem No 119: (1∣4),(2∣3),(3∣1,2),(4∣1,2)
Problem No 120: (1∣4),(2∣3,4),(3∣2,4),(4∣3)
Problem No 121: (1∣4),(2∣3,4),(3∣2,4),(4∣1)
Problem No 122: (1∣4),(2∣3,4),(3∣1),(4∣2,3)
Problem No 123: (1∣4),(2∣3,4),(3∣1),(4∣1,3)
Problem No 124: (1∣4),(2∣3,4),(3∣1),(4∣1,2)
Problem No 125: (1∣4),(2∣3,4),(3∣1,4),(4∣3)
Problem No 126: (1∣4),(2∣3,4),(3∣1,4),(4∣2)
Problem No 127: (1∣4),(2∣3,4),(3∣1,4),(4∣1)
Problem No 128: (1∣4),(2∣3,4),(3∣1,2),(4∣3)
Problem No 129: (1∣4),(2∣3,4),(3∣1,2),(4∣1)
Problem No 130: (1∣4),(2∣1),(3∣1,2),(4∣2,3)
Problem No 131: (1∣4),(2∣1),(3∣1,2),(4∣1,2)
Problem No 132: (1∣4),(2∣1),(3∣1,2,4),(4∣2)
Problem No 133: (1∣4),(2∣1,4),(3∣1,4),(4∣1)
Problem No 134: (1∣2,3,4),(2∣1,3,4),(3∣1),(4∣−)
Problem No 135: (1∣−),(2∣3,4),(3∣2,4),(4∣1,2,3)
Problem No 136: (1∣−),(2∣3,4),(3∣1,4),(4∣1,2,3)
Problem No 137: (1∣−),(2∣3,4),(3∣1,2),(4∣1,2,3)
Problem No 138: (1∣−),(2∣1),(3∣1,2,4),(4∣1,2,3)
Problem No 139: (1∣−),(2∣1,4),(3∣1,4),(4∣1,2,3)
Problem No 140: (1∣−),(2∣1,4),(3∣1,2),(4∣1,2,3)
Problem No 141: (1∣−),(2∣1,4),(3∣1,2,4),(4∣1,2)
Problem No 142: (1∣4),(2∣4),(3∣2,4),(4∣1,2,3)
Problem No 143: (1∣4),(2∣4),(3∣1,2),(4∣1,2,3)
Problem No 144: (1∣4),(2∣4),(3∣1,2,4),(4∣2,3)
Problem No 145: (1∣4),(2∣4),(3∣1,2,4),(4∣1,2)
Problem No 146: (1∣4),(2∣3),(3∣2,4),(4∣1,2,3)
Problem No 147: (1∣4),(2∣3),(3∣1,4),(4∣1,2,3)
Problem No 148: (1∣4),(2∣3),(3∣1,2),(4∣1,2,3)
Problem No 149: (1∣4),(2∣3,4),(3∣2,4),(4∣2,3)
Problem No 150: (1∣4),(2∣3,4),(3∣2,4),(4∣1,3)
Problem No 151: (1∣4),(2∣3,4),(3∣1),(4∣1,2,3)
Problem No 152: (1∣4),(2∣3,4),(3∣1,4),(4∣2,3)
Problem No 153: (1∣4),(2∣3,4),(3∣1,4),(4∣1,3)
Problem No 154: (1∣4),(2∣3,4),(3∣1,4),(4∣1,2)
Problem No 155: (1∣4),(2∣3,4),(3∣1,2),(4∣2,3)
Problem No 156: (1∣4),(2∣3,4),(3∣1,2),(4∣1,3)
Problem No 157: (1∣4),(2∣3,4),(3∣1,2),(4∣1,2)
Problem No 158: (1∣4),(2∣3,4),(3∣1,2,4),(4∣3)
Problem No 159: (1∣4),(2∣3,4),(3∣1,2,4),(4∣2)
Problem No 160: (1∣4),(2∣3,4),(3∣1,2,4),(4∣1)
Problem No 161: (1∣4),(2∣1),(3∣1,2),(4∣1,2,3)
Problem No 162: (1∣4),(2∣1),(3∣1,2,4),(4∣2,3)
Problem No 163: (1∣4),(2∣1),(3∣1,2,4),(4∣1,2)
Problem No 164: (1∣4),(2∣1,4),(3∣1,4),(4∣2,3)
Problem No 165: (1∣4),(2∣1,4),(3∣1,4),(4∣1,3)
Problem No 166: (1∣4),(2∣1,4),(3∣1,2),(4∣2,3)
Problem No 167: (1∣4),(2∣1,4),(3∣1,2),(4∣1,3)
Problem No 168: (1∣4),(2∣1,4),(3∣1,2),(4∣1,2)
Problem No 169: (1∣4),(2∣1,4),(3∣1,2,4),(4∣1)
Problem No 170: (1∣4),(2∣1,3),(3∣1,2),(4∣2,3)
Problem No 171: (1∣4),(2∣1,3),(3∣1,2),(4∣1,3)
Problem No 172: (1∣2,3,4),(2∣1,3,4),(3∣1,2),(4∣−)
Problem No 173: (1∣−),(2∣1,4),(3∣1,2,4),(4∣1,2,3)
Problem No 174: (1∣4),(2∣4),(3∣1,2,4),(4∣1,2,3)
Problem No 175: (1∣4),(2∣3),(3∣1,2,4),(4∣1,2,3)
Problem No 176: (1∣4),(2∣3,4),(3∣2,4),(4∣1,2,3)
Problem No 177: (1∣4),(2∣3,4),(3∣1,4),(4∣1,2,3)
Problem No 178: (1∣4),(2∣3,4),(3∣1,2),(4∣1,2,3)
Problem No 179: (1∣4),(2∣3,4),(3∣1,2,4),(4∣2,3)
Problem No 180: (1∣4),(2∣3,4),(3∣1,2,4),(4∣1,3)
Problem No 181: (1∣4),(2∣3,4),(3∣1,2,4),(4∣1,2)
Problem No 182: (1∣4),(2∣1),(3∣1,2,4),(4∣1,2,3)
Problem No 183: (1∣4),(2∣1,4),(3∣1,4),(4∣1,2,3)
Problem No 184: (1∣4),(2∣1,4),(3∣1,2),(4∣1,2,3)
Problem No 185: (1∣4),(2∣1,4),(3∣1,2,4),(4∣2,3)
Problem No 186: (1∣4),(2∣1,4),(3∣1,2,4),(4∣1,3)
Problem No 187: (1∣4),(2∣1,4),(3∣1,2,4),(4∣1,2)
Problem No 188: (1∣4),(2∣1,3),(3∣1,2),(4∣1,2,3)
Problem No 189: (1∣4),(2∣1,3),(3∣1,2,4),(4∣2,3)
Problem No 190: (1∣4),(2∣1,3),(3∣1,2,4),(4∣1,3)
Problem No 191: (1∣4),(2∣1,3),(3∣1,2,4),(4∣1,2)
Problem No 192: (1∣4),(2∣1,3,4),(3∣1,2,4),(4∣1)
Problem No 193: (1∣3,4),(2∣3,4),(3∣2,4),(4∣2,3)
Problem No 194: (1∣3,4),(2∣3,4),(3∣2,4),(4∣1,3)
Problem No 195: (1∣3,4),(2∣3,4),(3∣2,4),(4∣1,2)
Problem No 196: (1∣3,4),(2∣3,4),(3∣1,2),(4∣1,2)
Problem No 197: (1∣3,4),(2∣1,4),(3∣2,4),(4∣2,3)
Problem No 198: (1∣3,4),(2∣1,4),(3∣1,2),(4∣2,3)
Problem No 199: (1∣2,3,4),(2∣1,3,4),(3∣1,2,4),(4∣−)
Problem No 200: (1∣4),(2∣3,4),(3∣1,2,4),(4∣1,2,3)
Problem No 201: (1∣4),(2∣1,4),(3∣1,2,4),(4∣1,2,3)
Problem No 202: (1∣4),(2∣1,3),(3∣1,2,4),(4∣1,2,3)
Problem No 203: (1∣4),(2∣1,3,4),(3∣1,2,4),(4∣2,3)
Problem No 204: (1∣4),(2∣1,3,4),(3∣1,2,4),(4∣1,3)
Problem No 205: (1∣3,4),(2∣3,4),(3∣2,4),(4∣1,2,3)
Problem No 206: (1∣3,4),(2∣3,4),(3∣1,2),(4∣1,2,3)
Problem No 207: (1∣3,4),(2∣1,4),(3∣2,4),(4∣1,2,3)
Problem No 208: (1∣3,4),(2∣1,4),(3∣1,2),(4∣1,2,3)
Problem No 209: (1∣3,4),(2∣1,4),(3∣1,2,4),(4∣1,3)
Problem No 210: (1∣3,4),(2∣1,4),(3∣1,2,4),(4∣1,2)
Problem No 211: (1∣3,4),(2∣1,3,4),(3∣1,4),(4∣1,3)
Problem No 212: (1∣2,3,4),(2∣1,3,4),(3∣1,2,4),(4∣1)
Problem No 213: (1∣3,4),(2∣3,4),(3∣1,2,4),(4∣1,2,3)
Problem No 214: (1∣3,4),(2∣1,4),(3∣1,2,4),(4∣1,2,3)
Problem No 215: (1∣3,4),(2∣1,3,4),(3∣1,4),(4∣1,2,3)
Problem No 216: (1∣3,4),(2∣1,3,4),(3∣1,2),(4∣1,2,3)
Problem No 217: (1∣2,3,4),(2∣1,3,4),(3∣1,2,4),(4∣1,2)
Problem No 218: (1∣2,3,4),(2∣1,3,4),(3∣1,2,4),(4∣1,2,3)

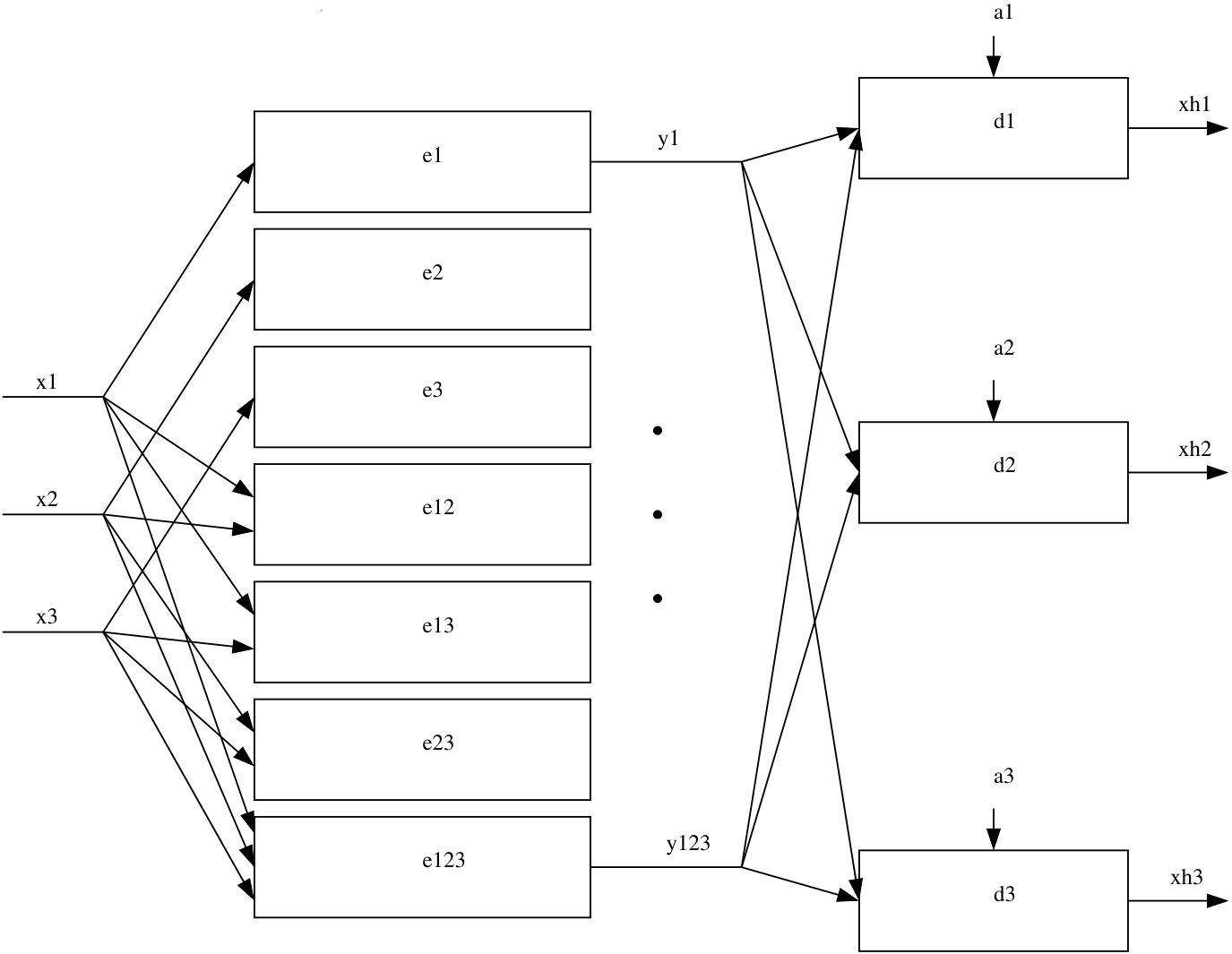 Figure 1
Figure 1