Risk Estimators for Choosing Regularization Parameters in Ill-Posed Problems - Properties and Limitations
Felix Lucka, Katharina Proksch, Christoph Brune, Nicolai Bissantz,, Martin Burger, Holger Dette, Frank W\"ubbeling

TL;DR
This paper analyzes the effectiveness of risk estimators like SURE and GSURE for selecting regularization parameters in ill-posed problems, revealing limitations especially as ill-posedness increases, and shows they can lead to unreliable regularization choices.
Contribution
The paper provides a theoretical and numerical study of risk estimators' properties in ill-posed problems, highlighting their limitations and potential failures in high ill-posedness scenarios.
Findings
GSURE risk estimator deteriorates asymptotically for ill-posed problems
Risk estimators often suggest overly small regularization parameters
Unbiased risk estimation may not be reliable for ill-posed inverse problems
Abstract
This paper discusses the properties of certain risk estimators recently proposed to choose regularization parameters in ill-posed problems. A simple approach is Stein's unbiased risk estimator (SURE), which estimates the risk in the data space, while a recent modification (GSURE) estimates the risk in the space of the unknown variable. It seems intuitive that the latter is more appropriate for ill-posed problems, since the properties in the data space do not tell much about the quality of the reconstruction. We provide theoretical studies of both estimators for linear Tikhonov regularization in a finite dimensional setting and estimate the quality of the risk estimators, which also leads to asymptotic convergence results as the dimension of the problem tends to infinity. Unlike previous papers, who studied image processing problems with a very low degree of ill-posedness, we are…
Click any figure to enlarge with its caption.
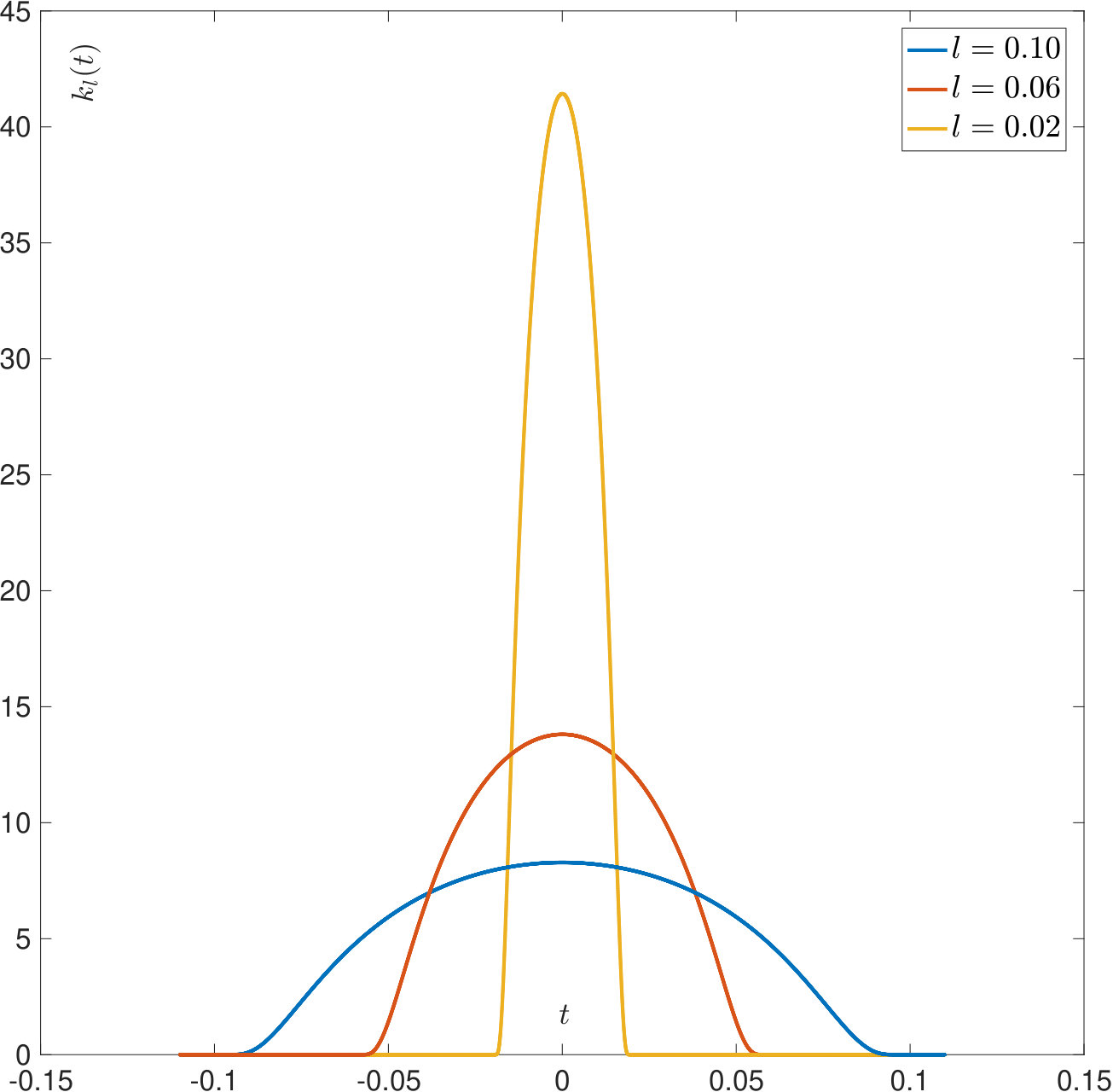 Figure 1
Figure 1 Figure 2
Figure 2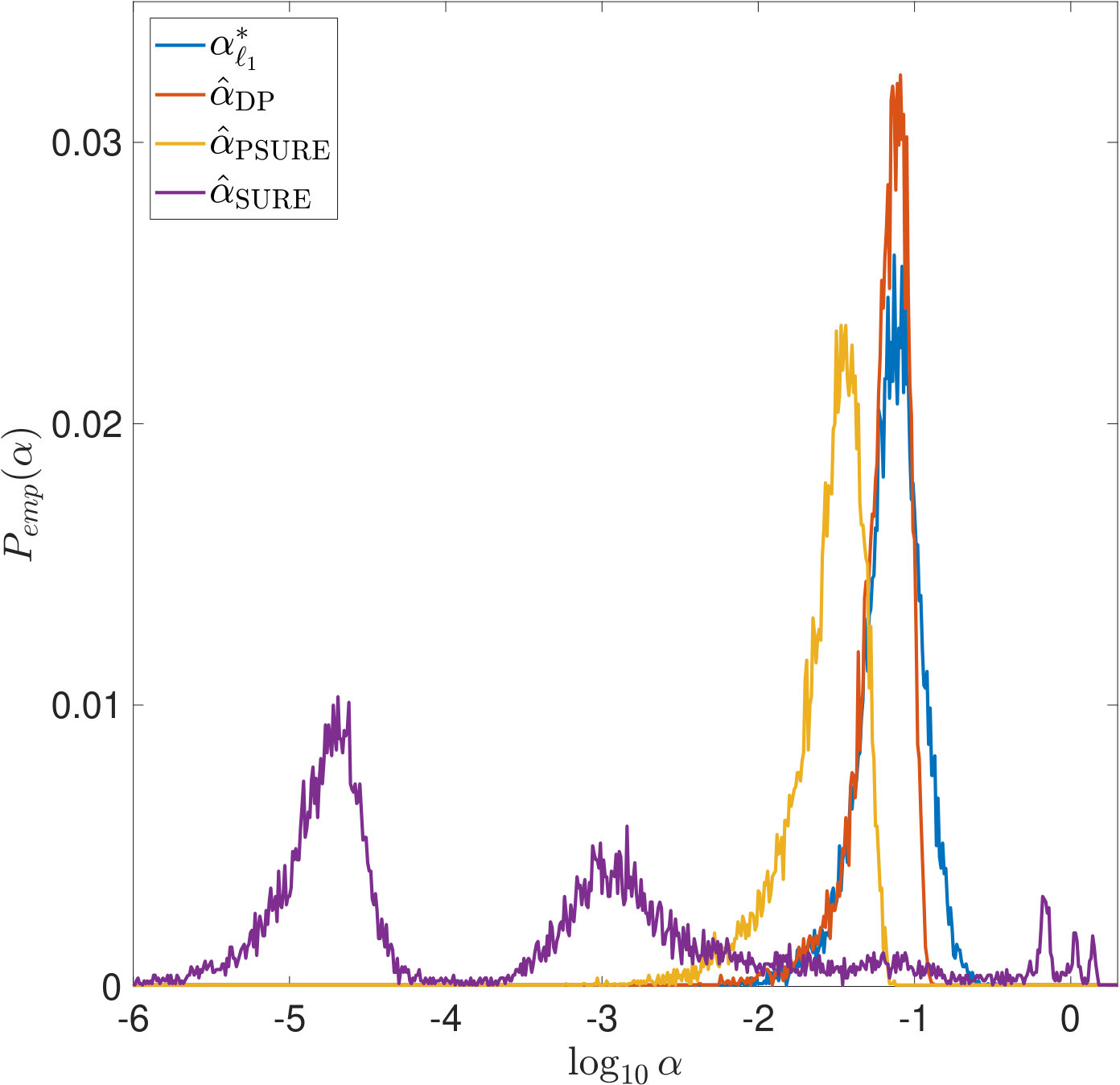 Figure 3
Figure 3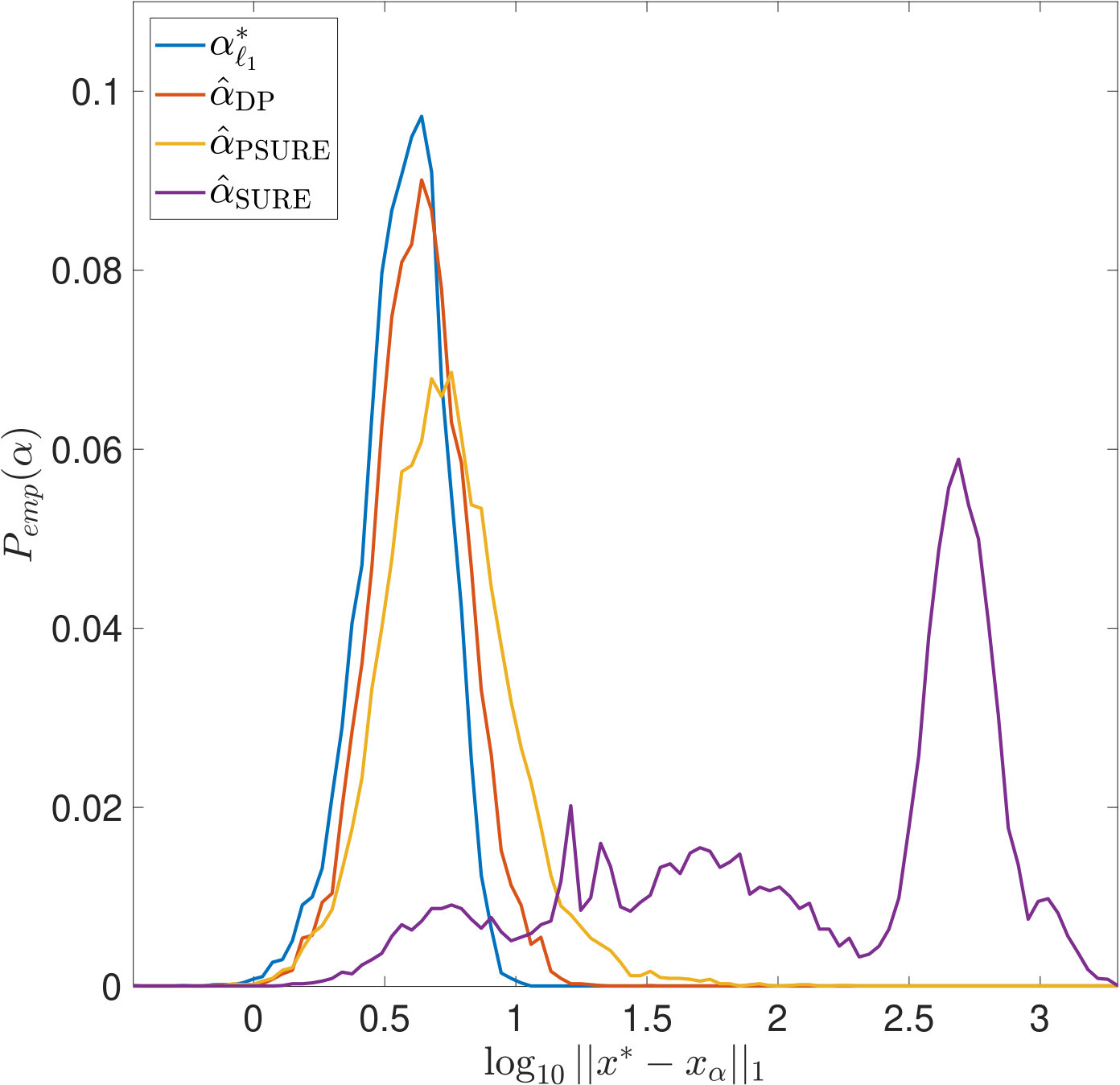 Figure 4
Figure 4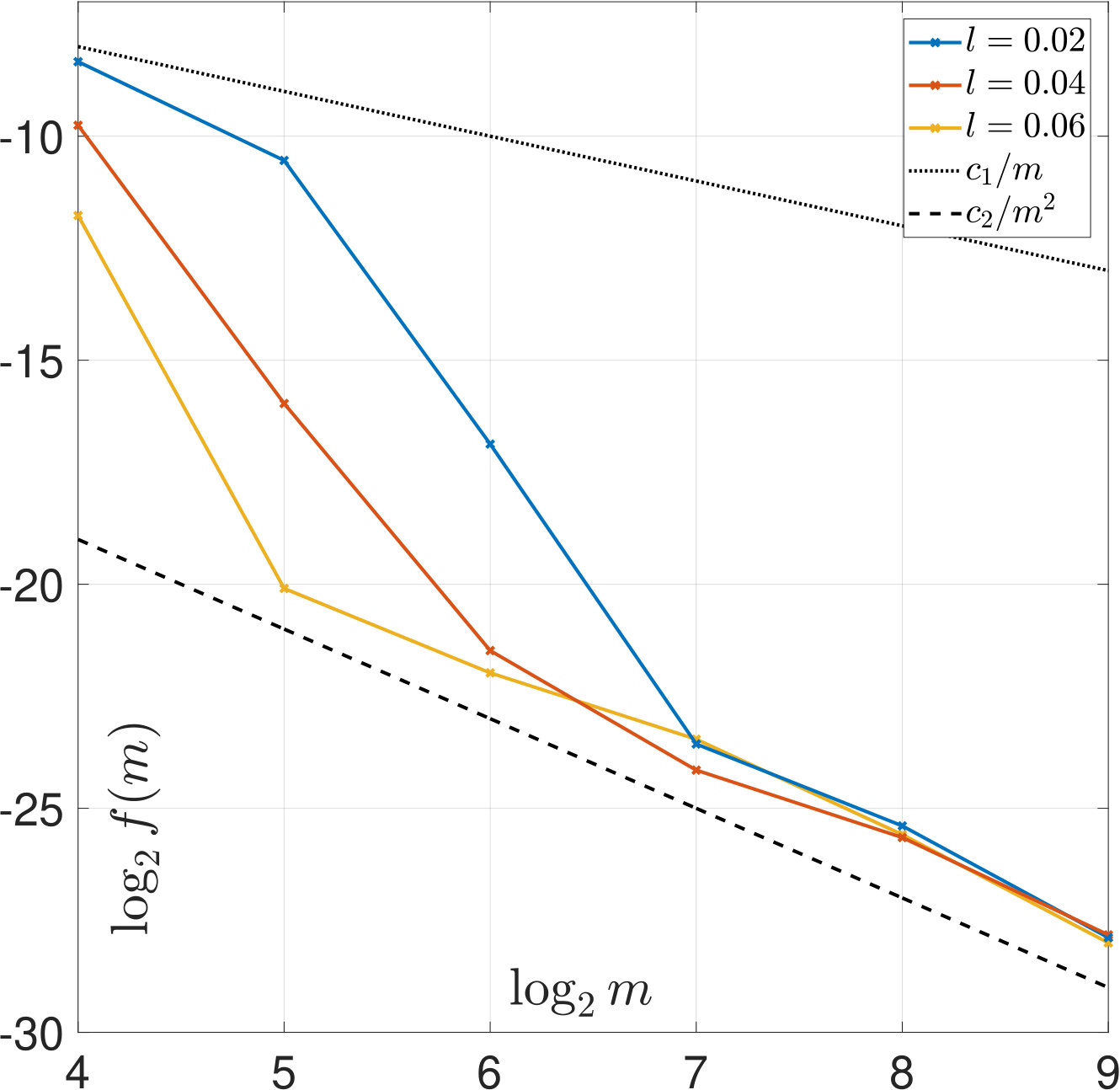 Figure 5
Figure 5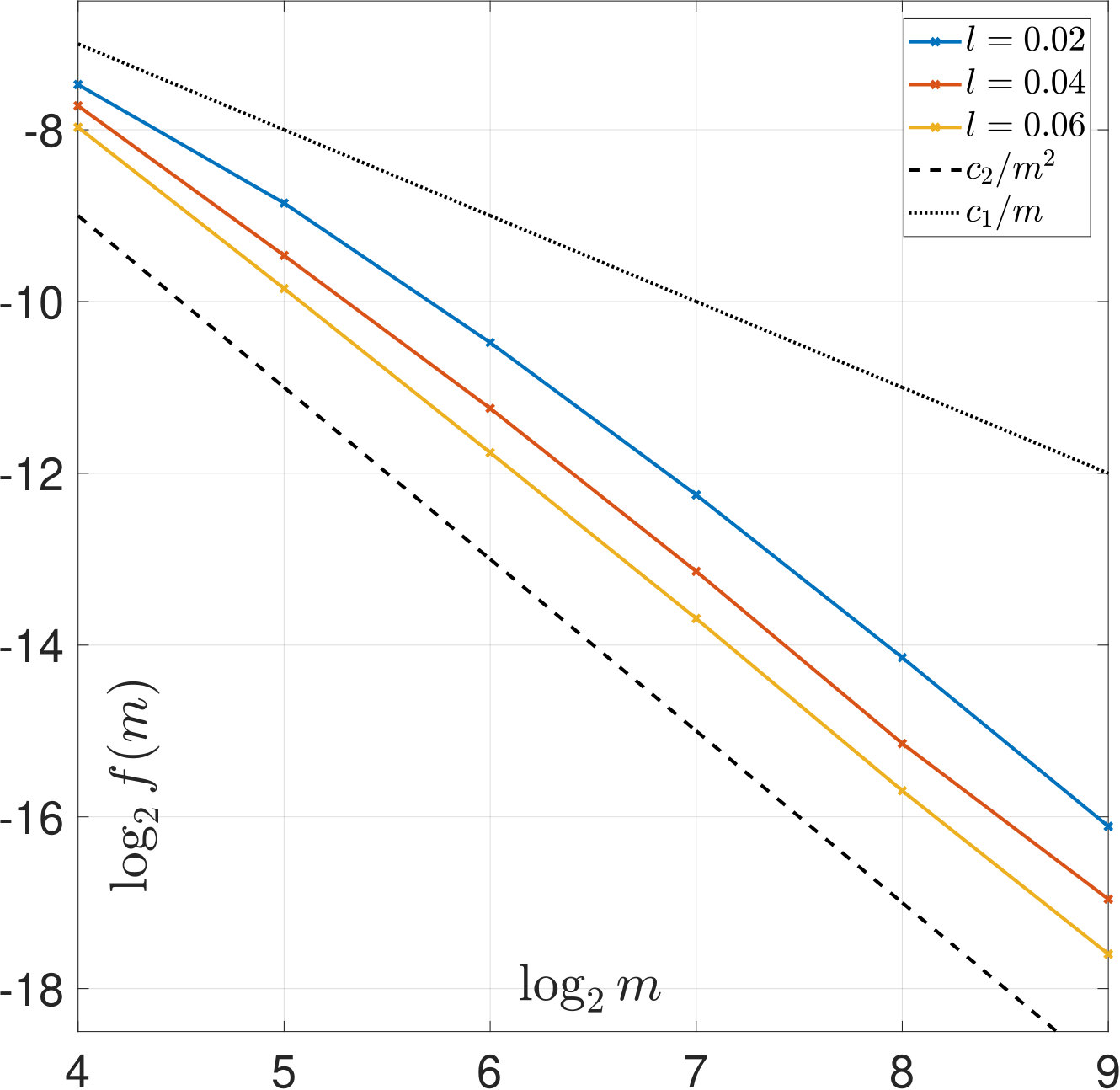 Figure 6
Figure 6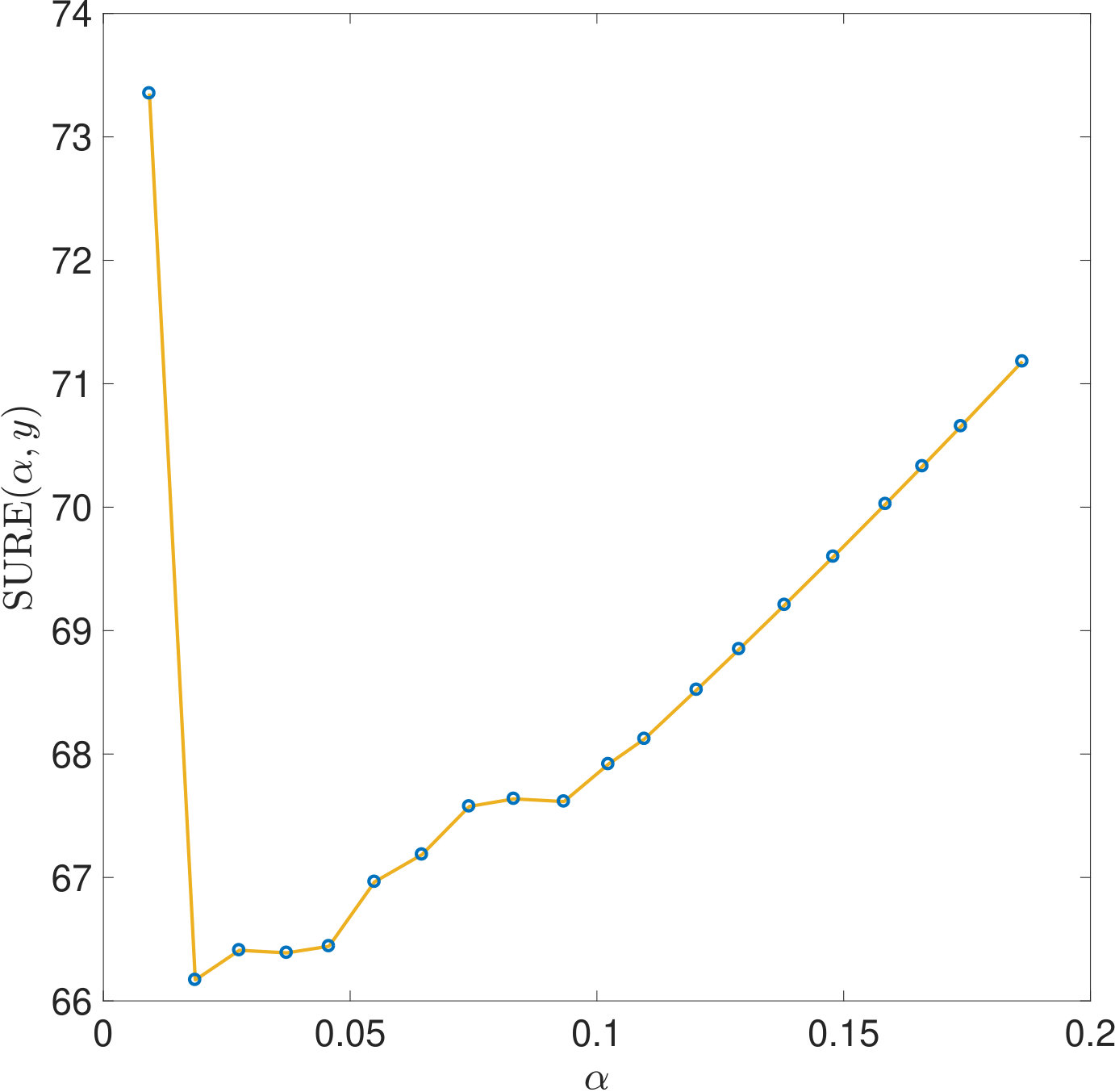 Figure 7
Figure 7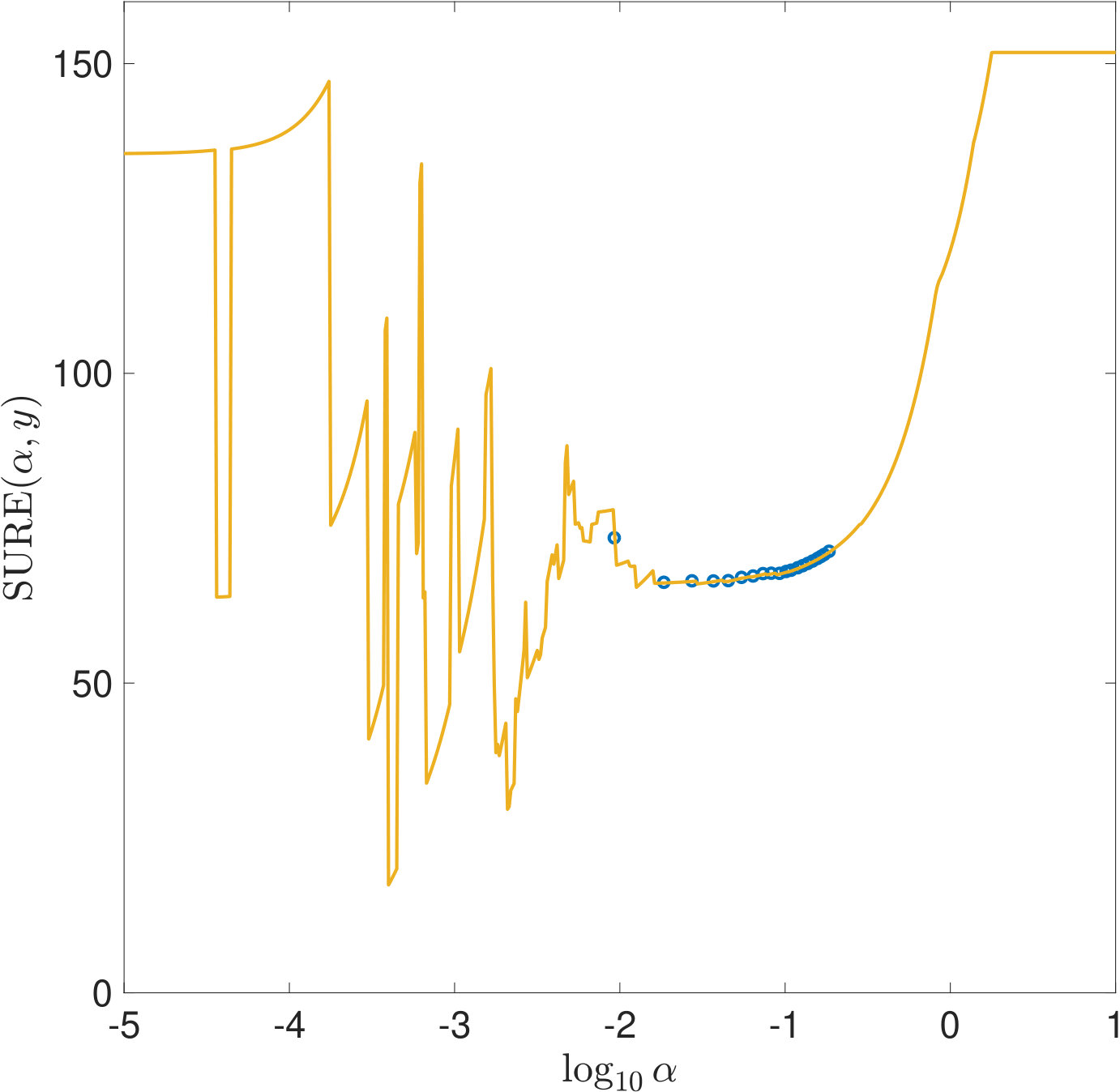 Figure 8
Figure 8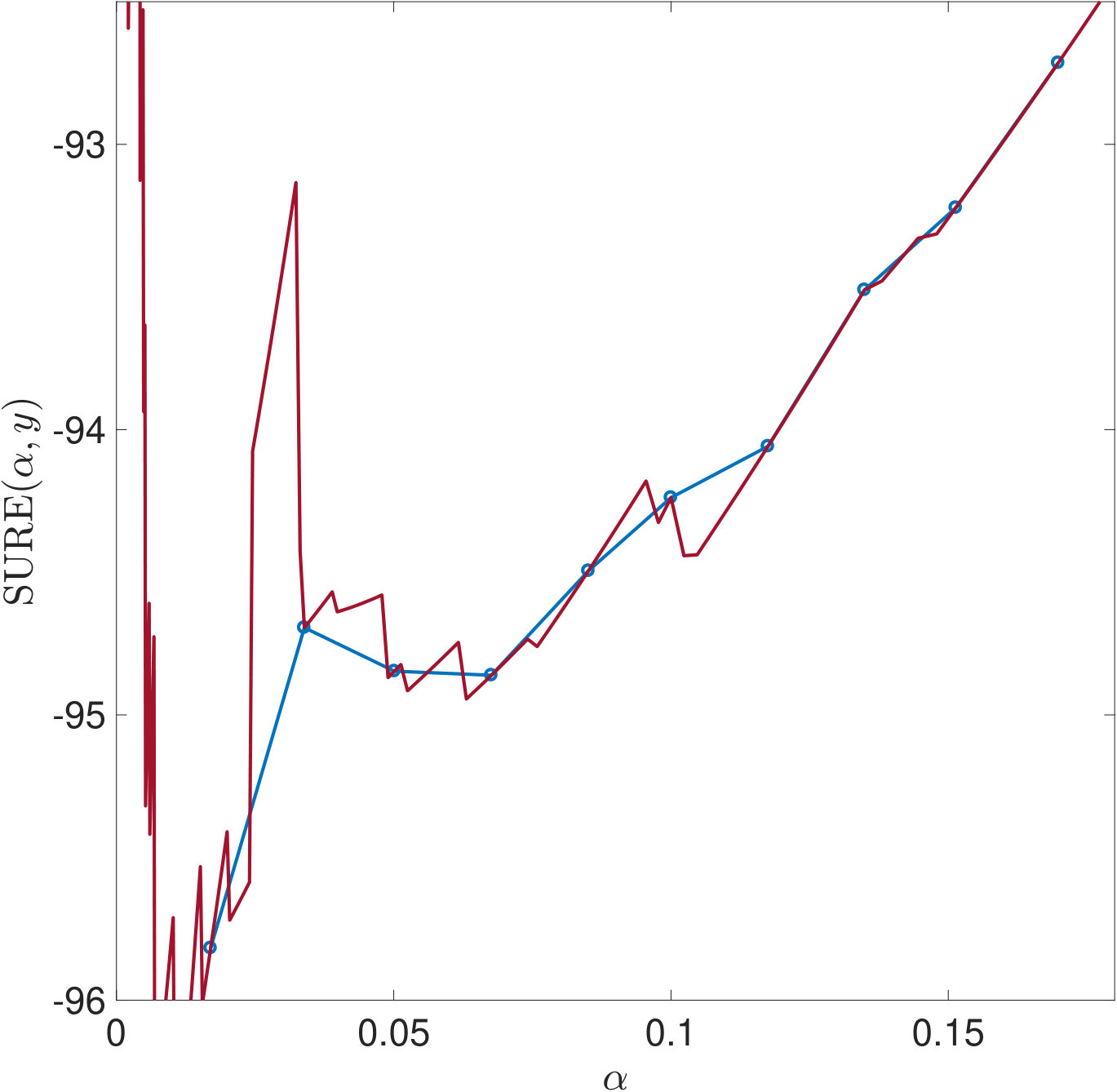 Figure 9
Figure 9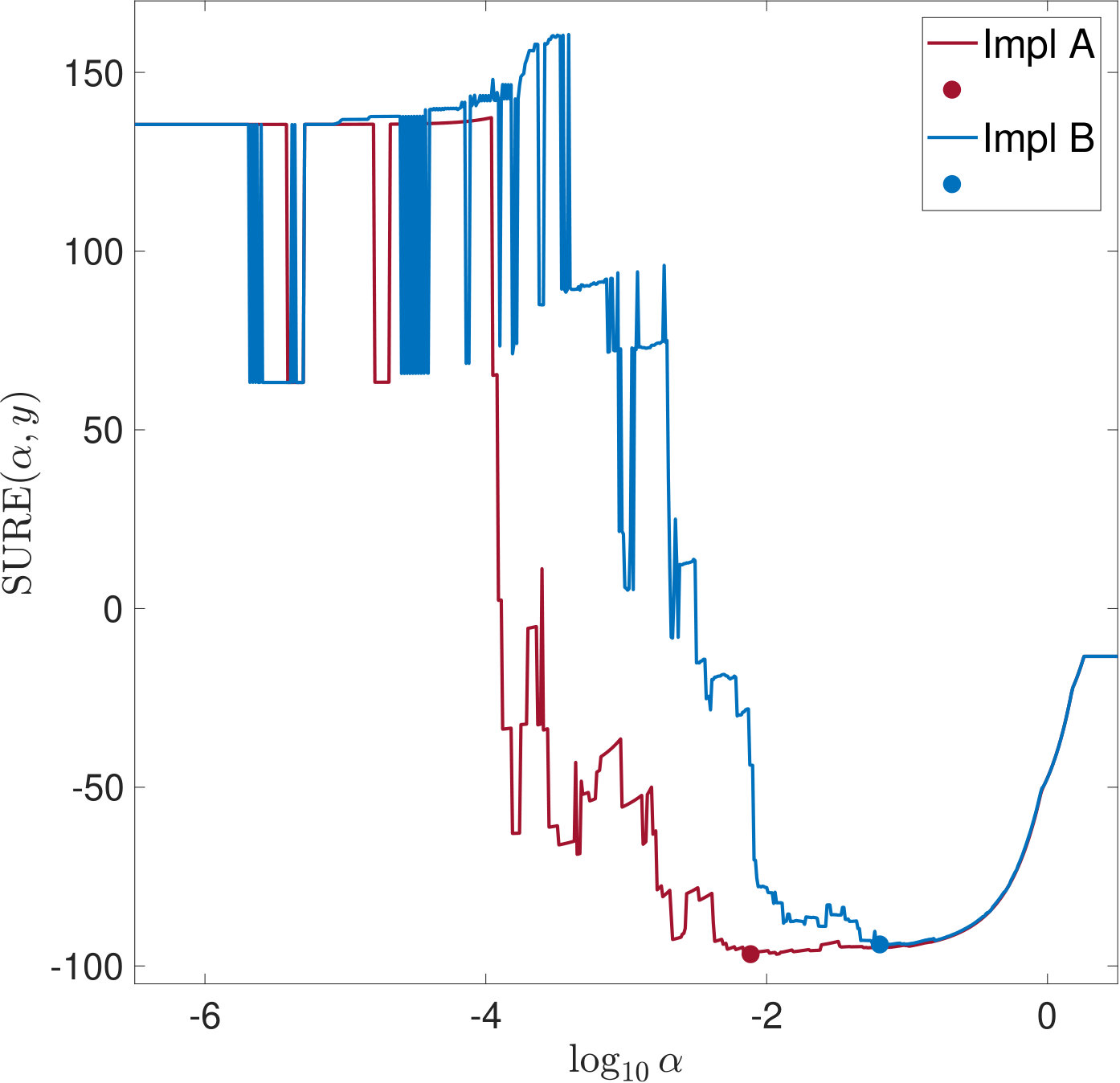 Figure 10
Figure 10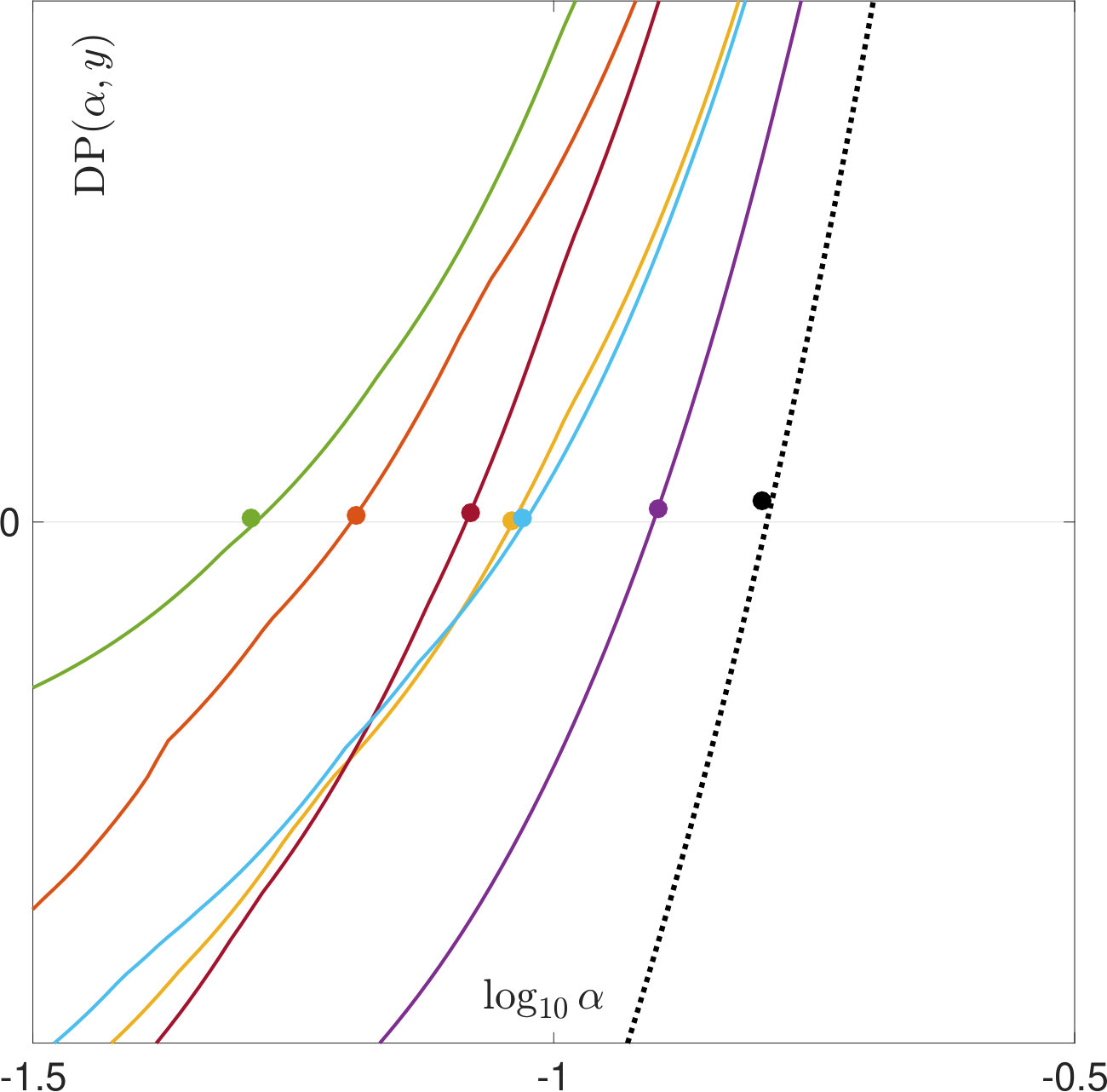 Figure 11
Figure 11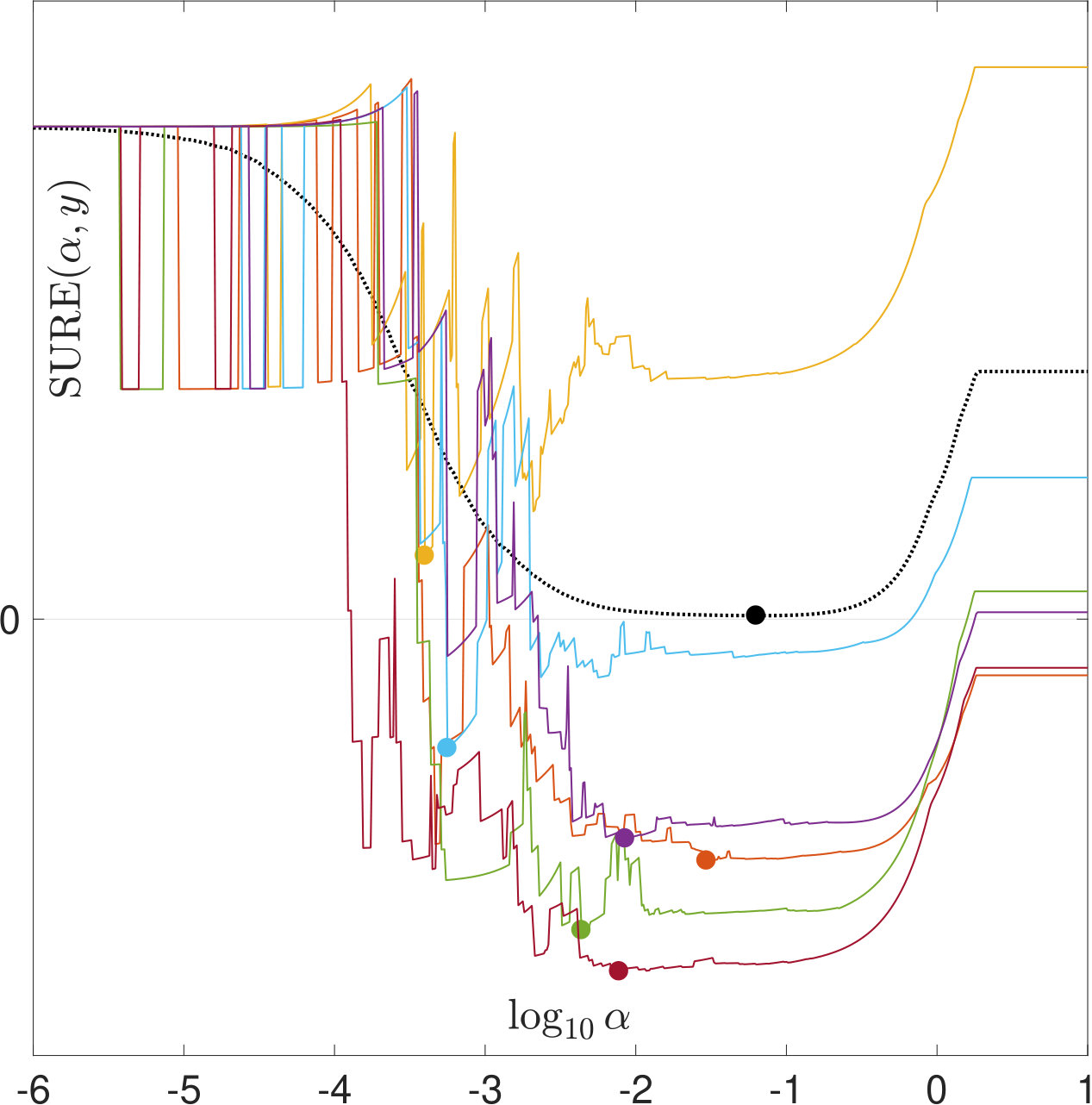 Figure 12
Figure 12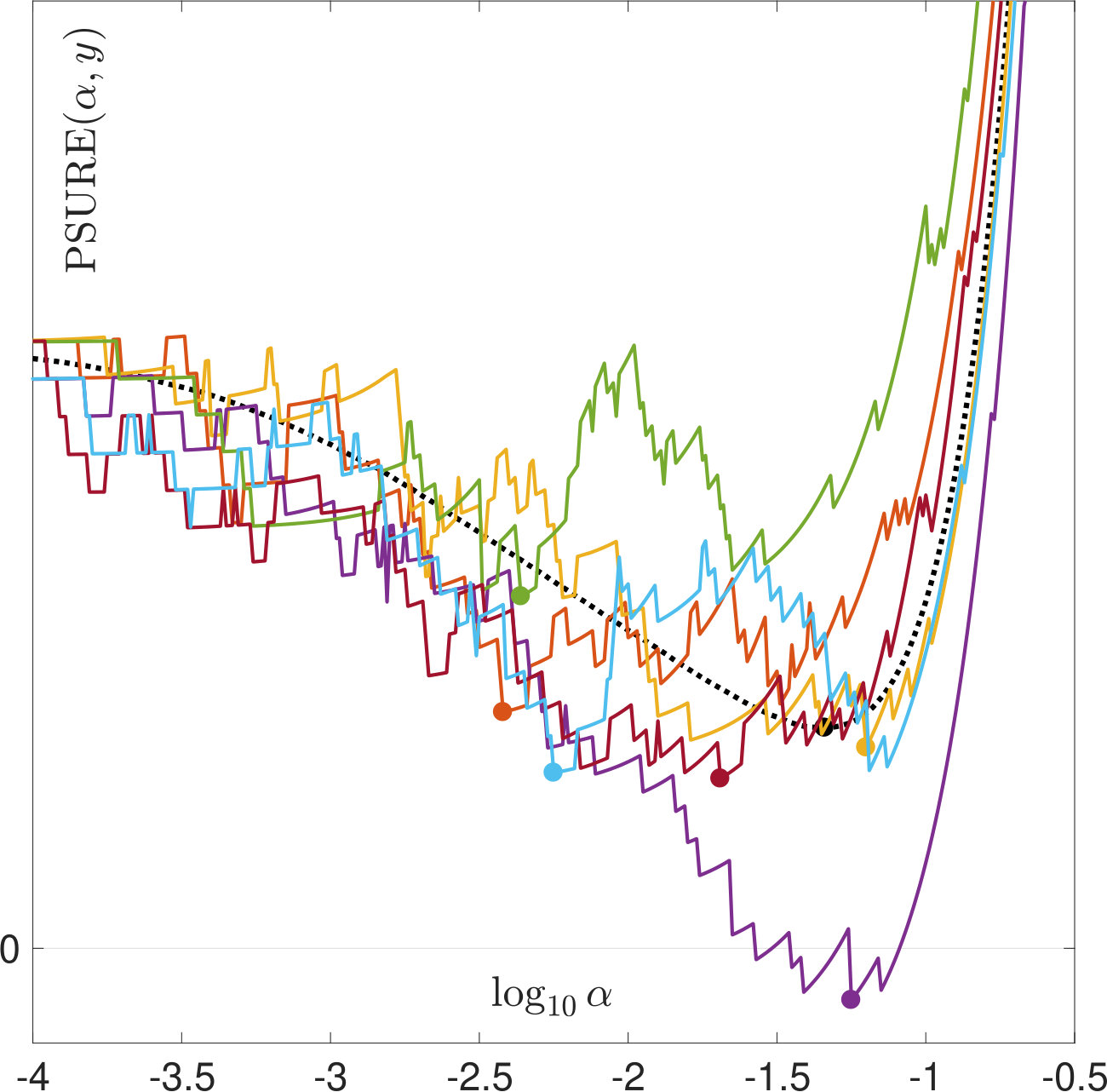 Figure 13
Figure 13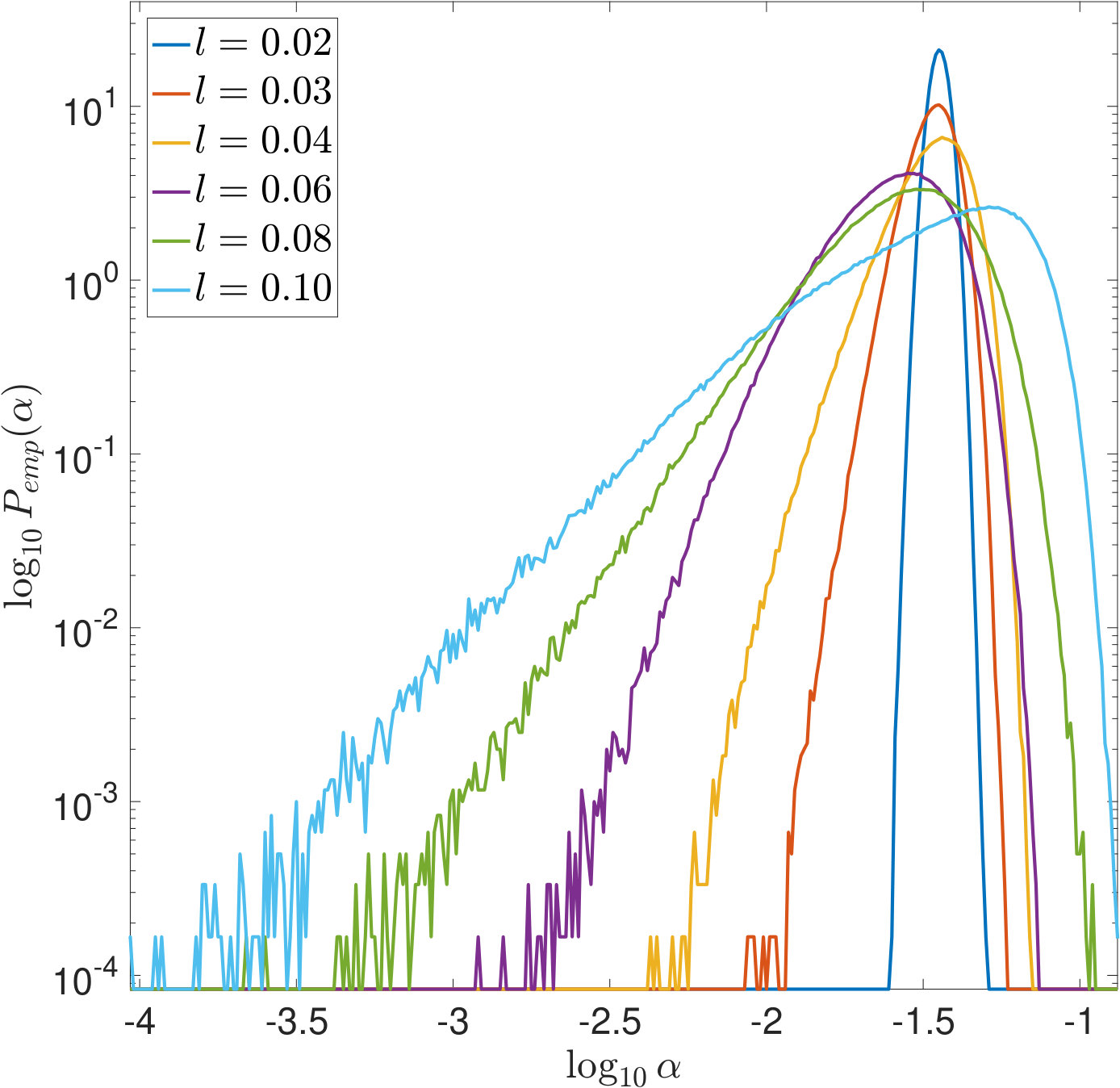 Figure 14
Figure 14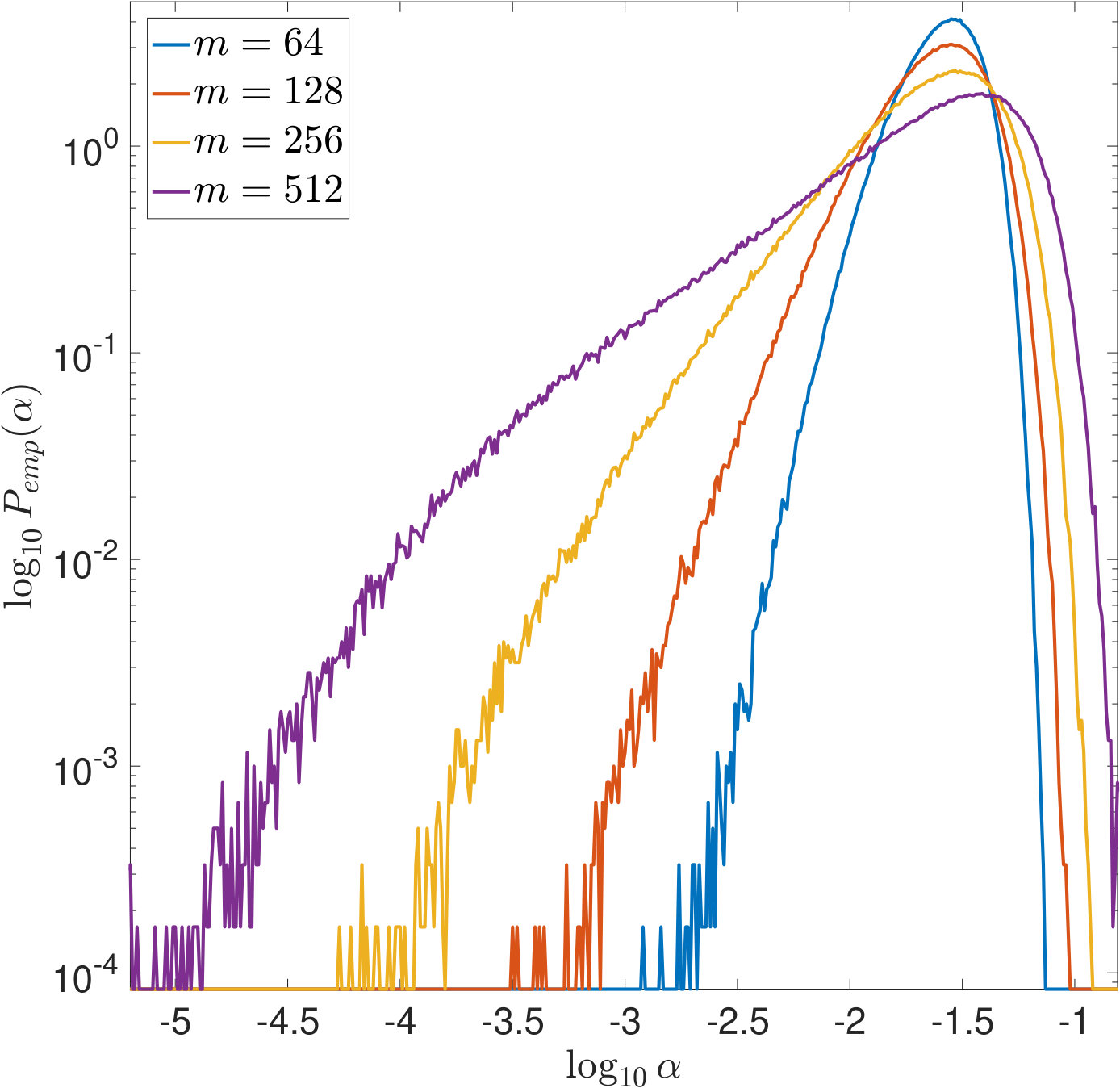 Figure 15
Figure 15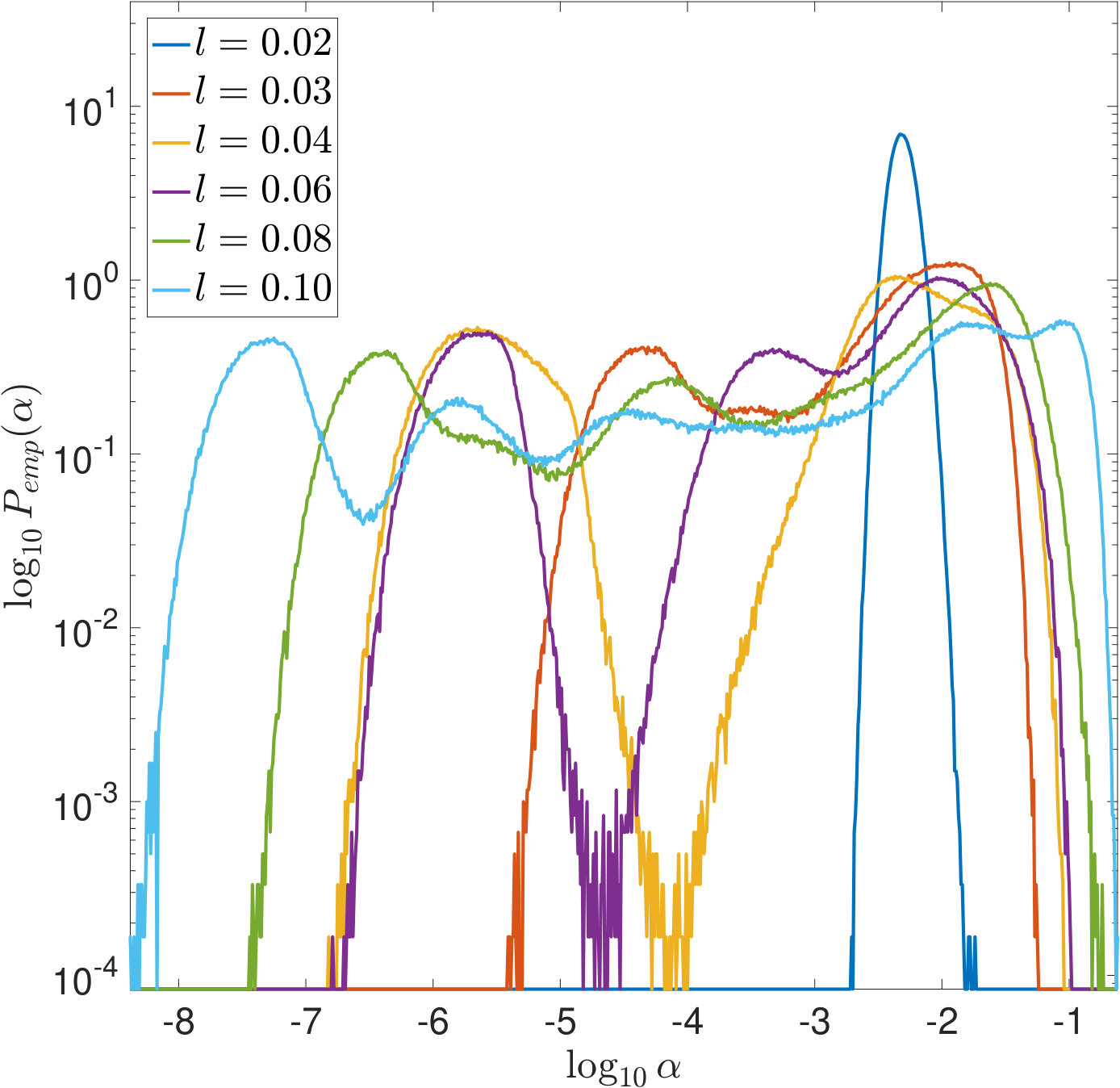 Figure 16
Figure 16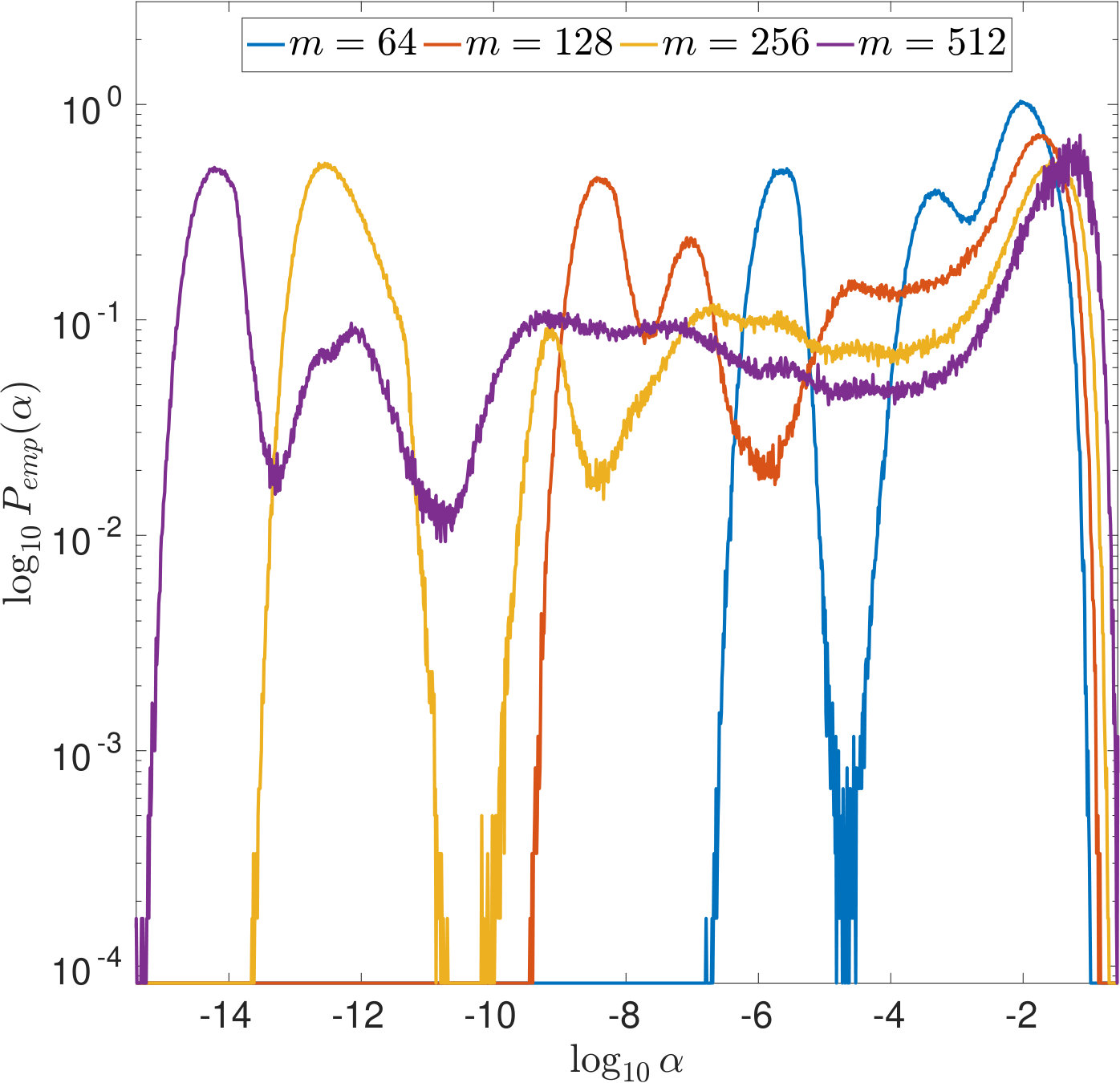 Figure 17
Figure 17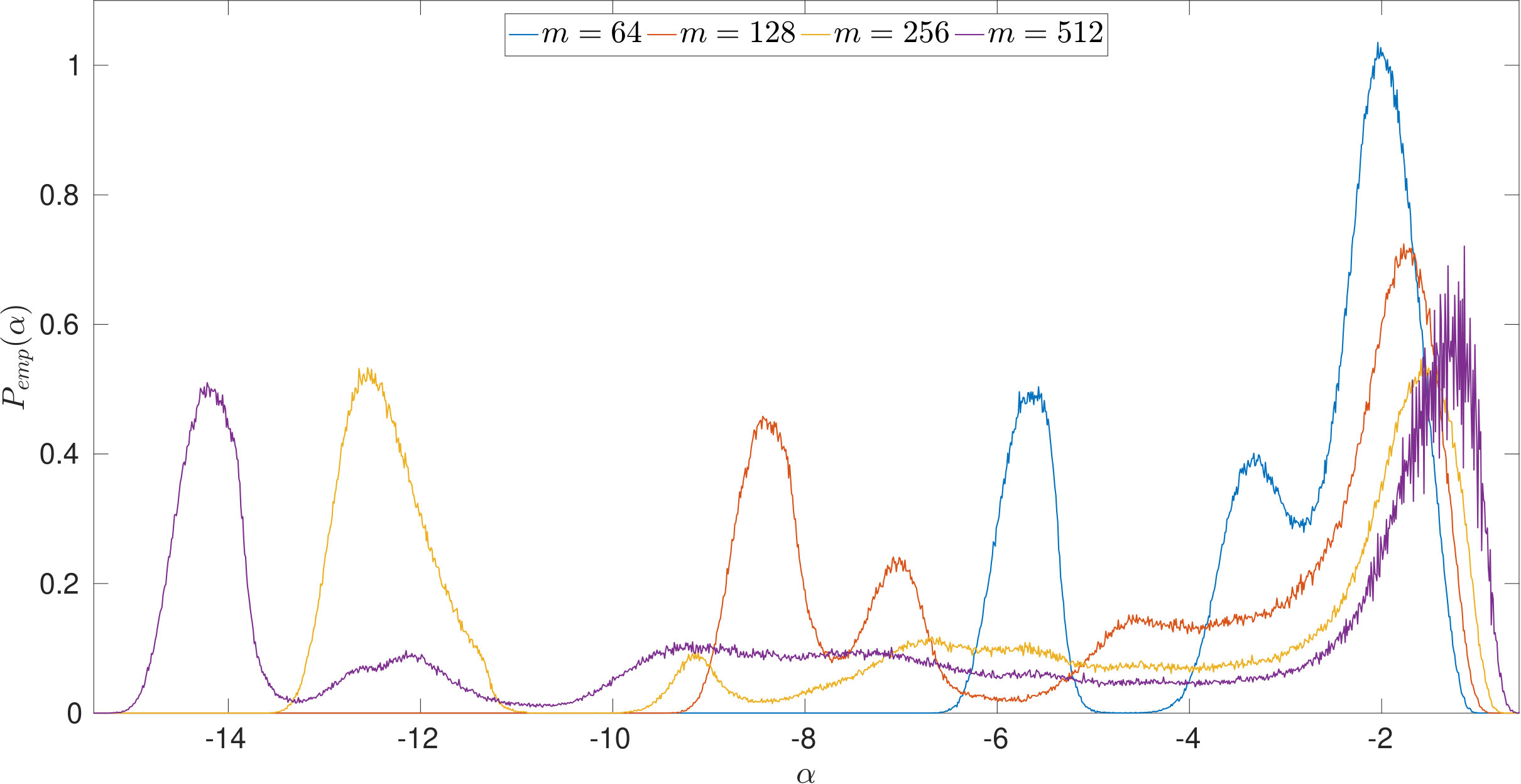 Figure 18
Figure 18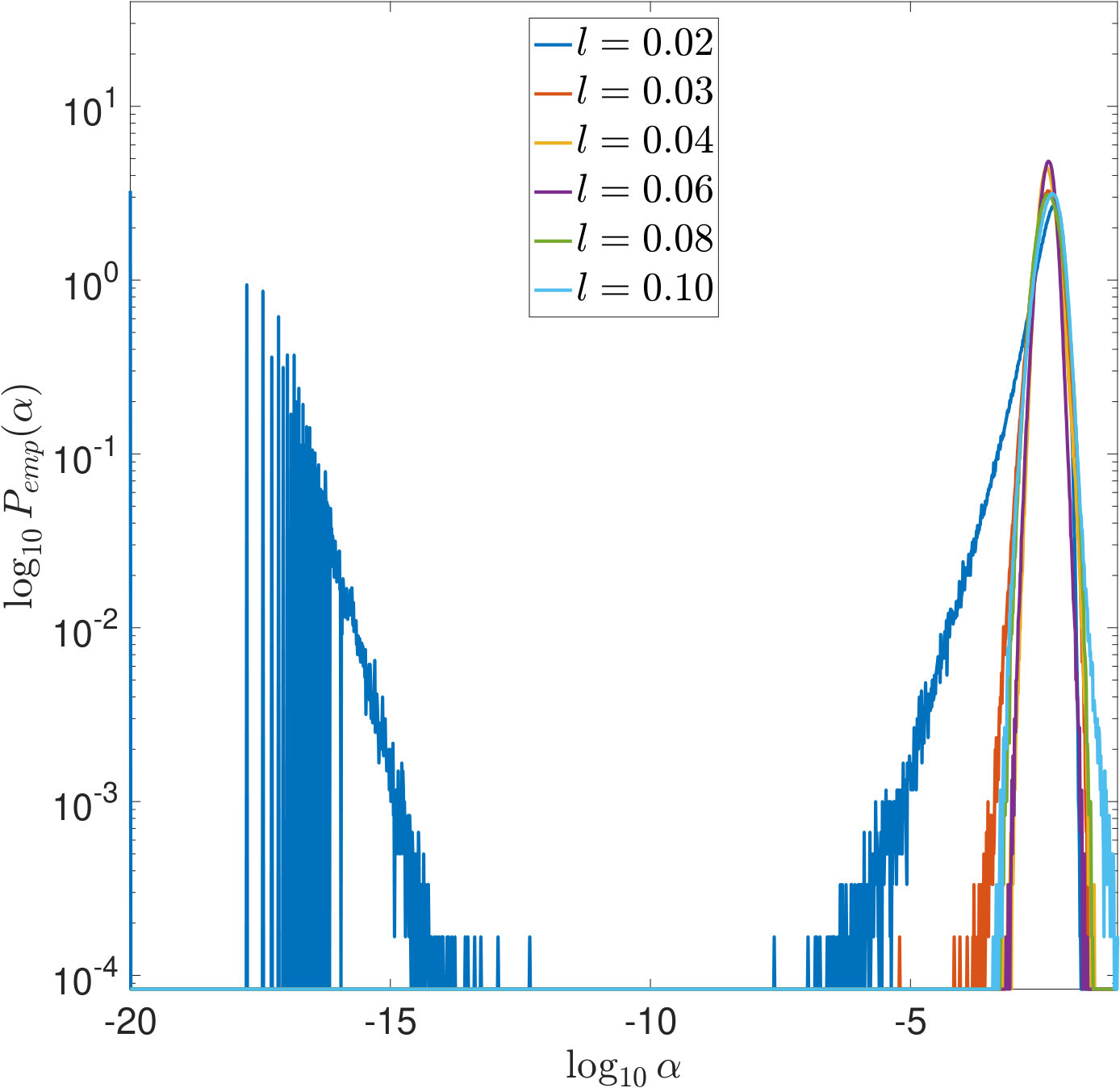 Figure 19
Figure 19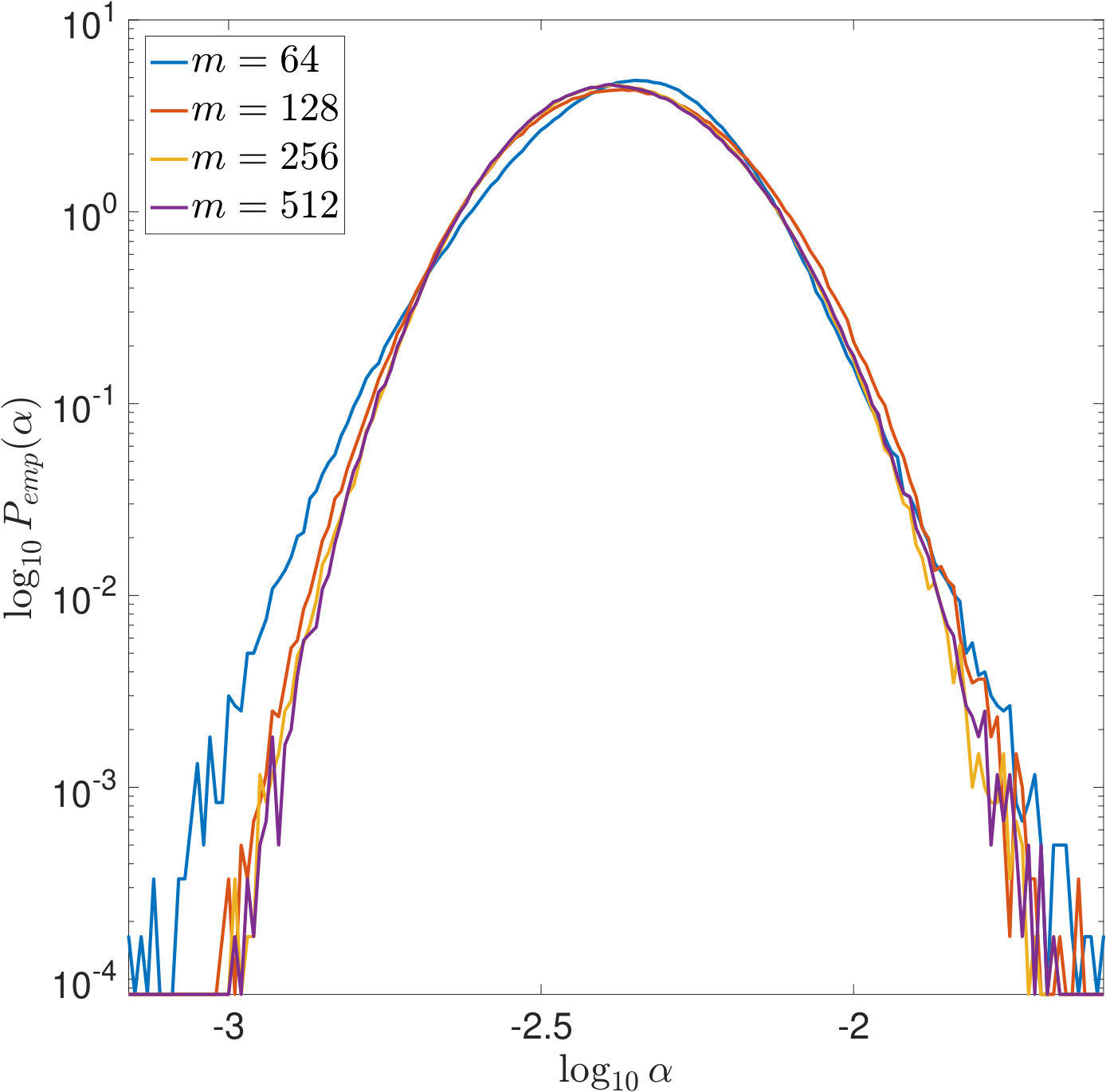 Figure 20
Figure 20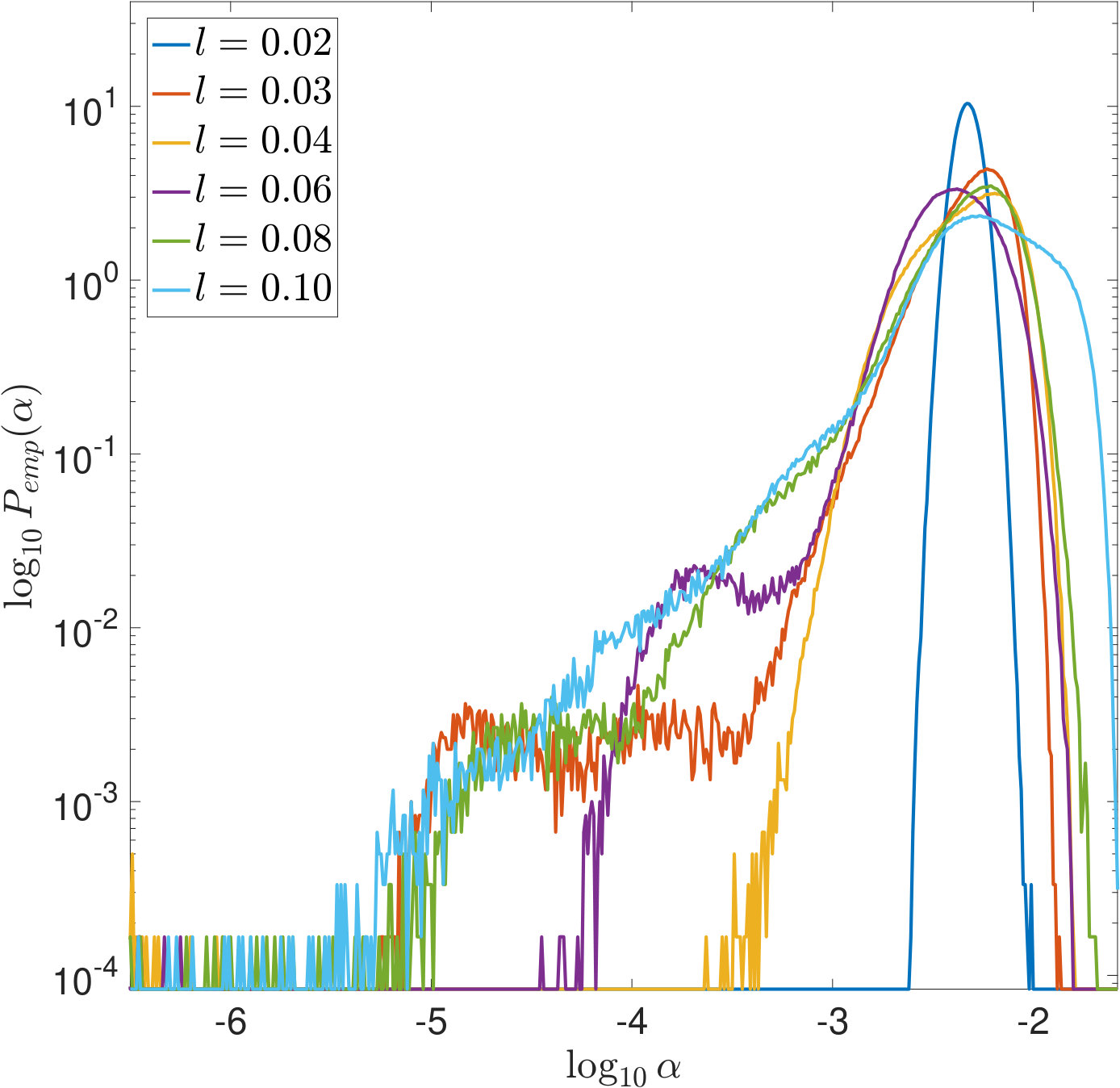 Figure 21
Figure 21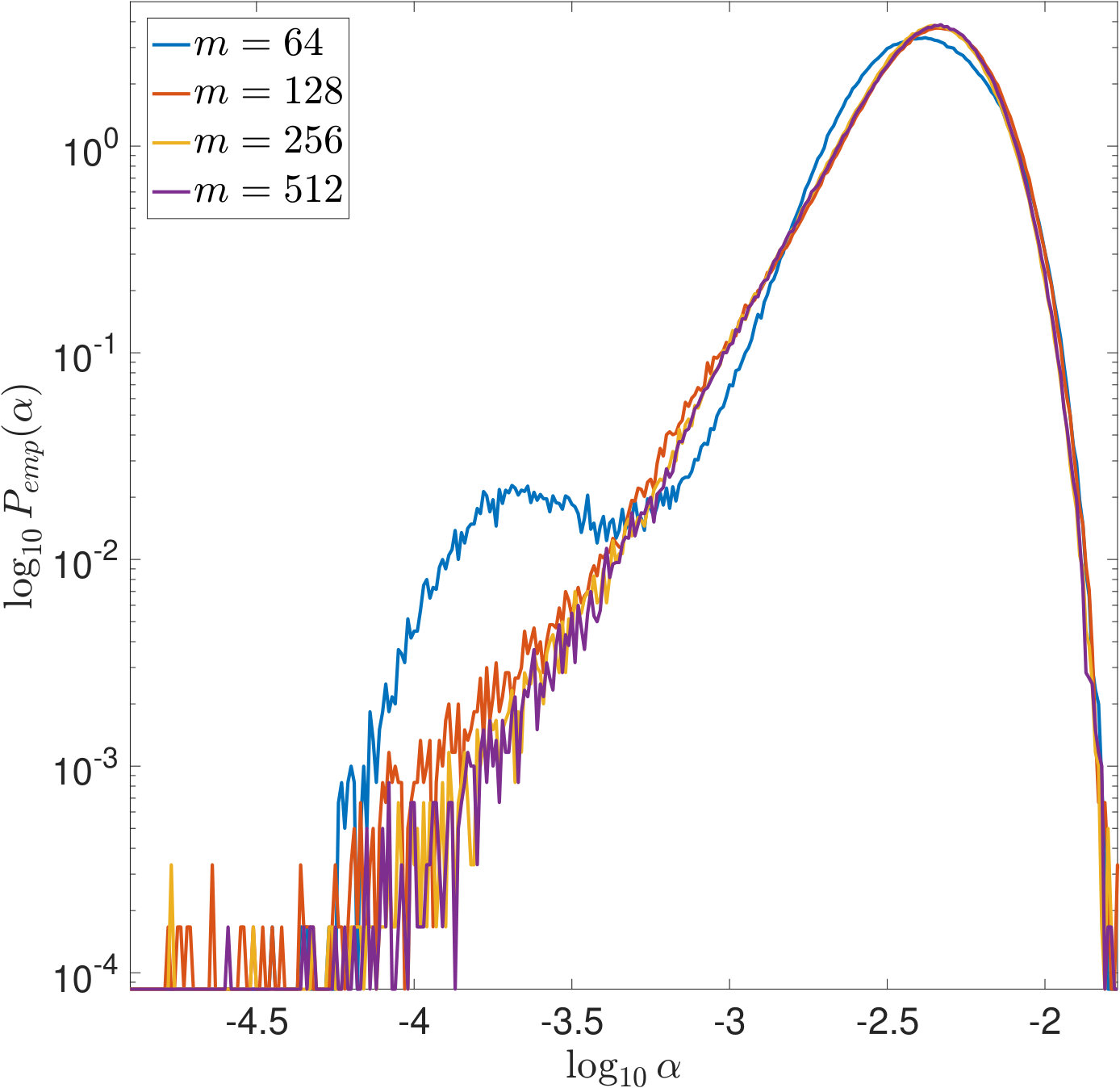 Figure 22
Figure 22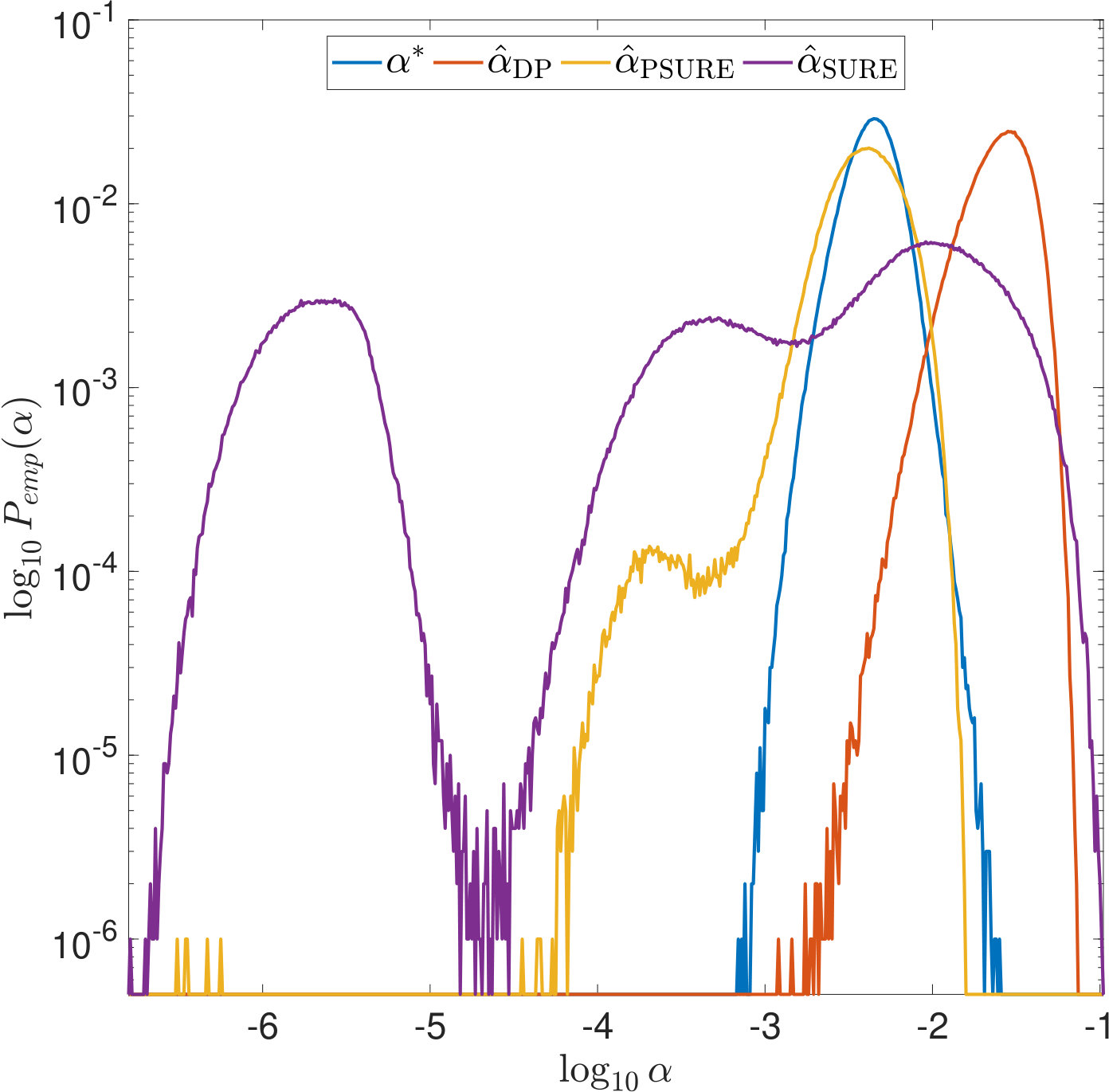 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25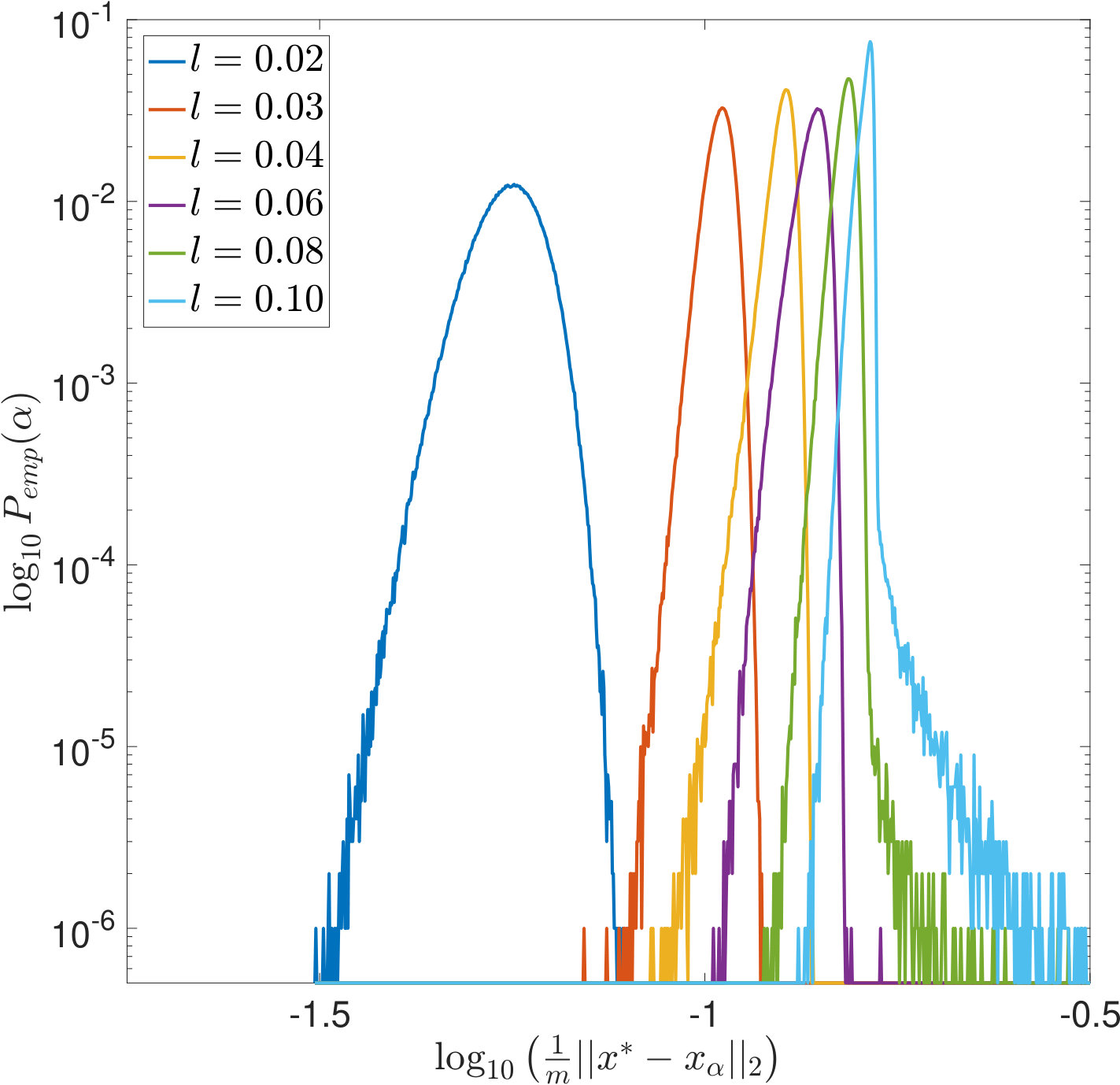 Figure 26
Figure 26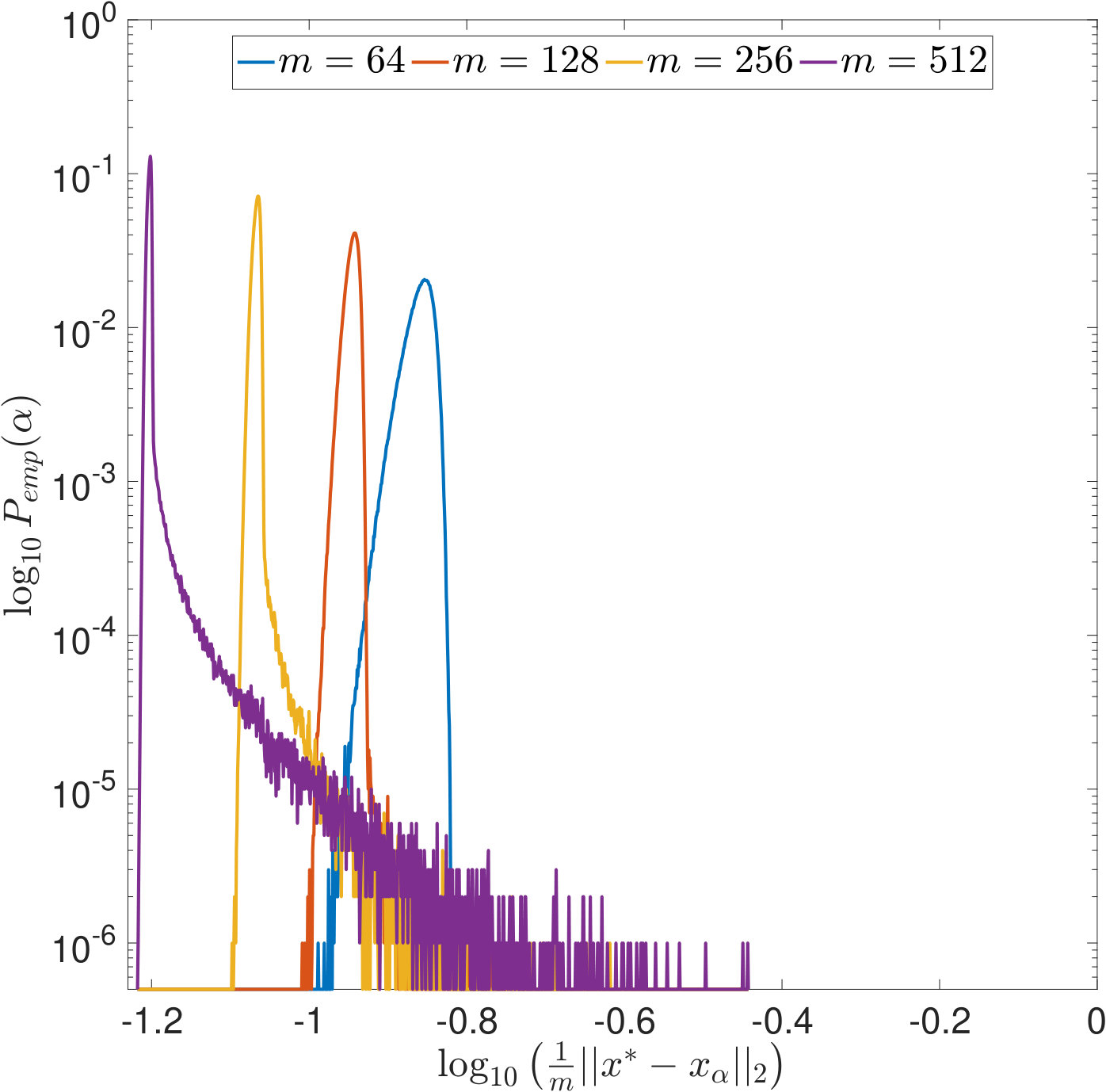 Figure 27
Figure 27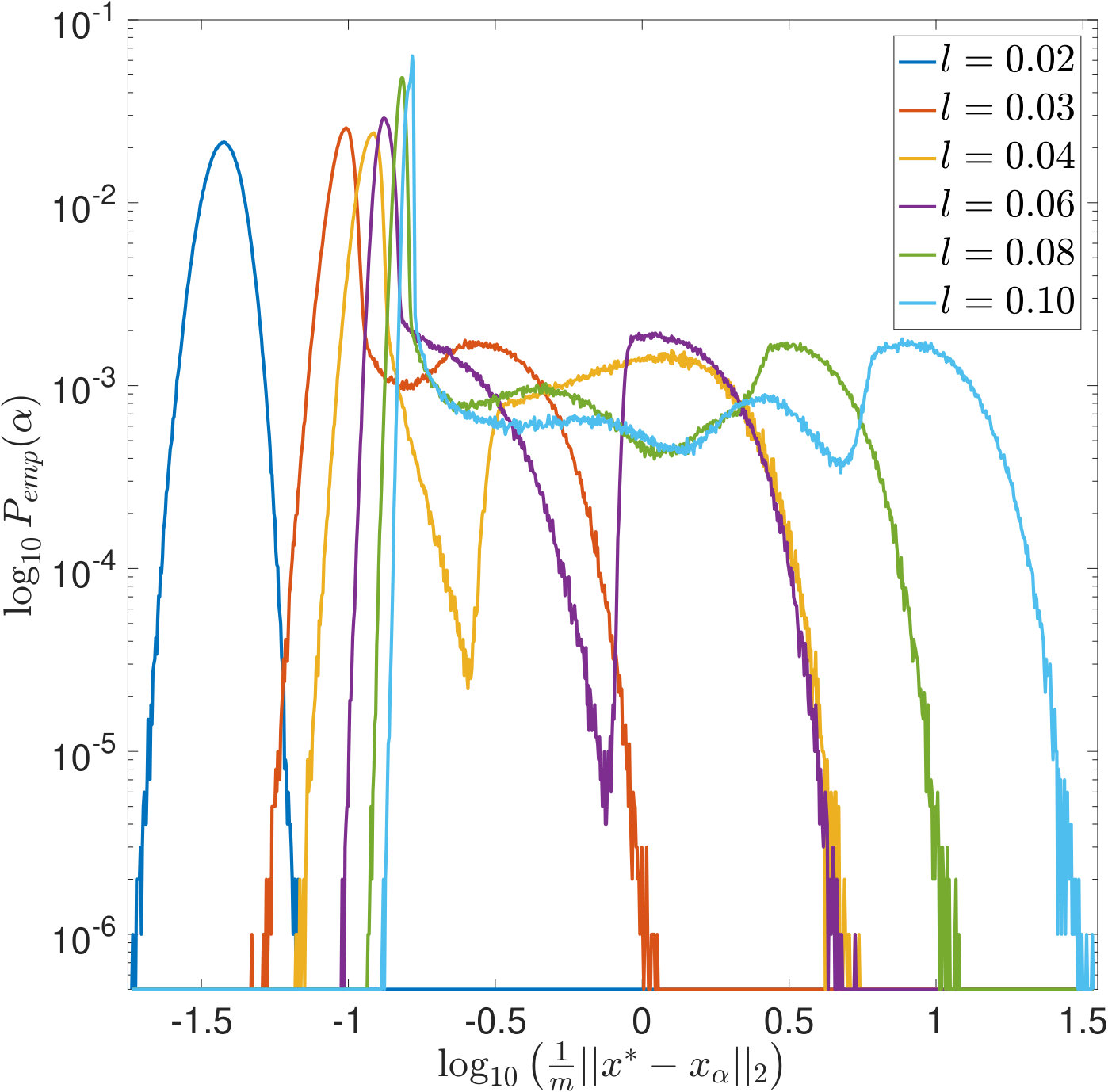 Figure 28
Figure 28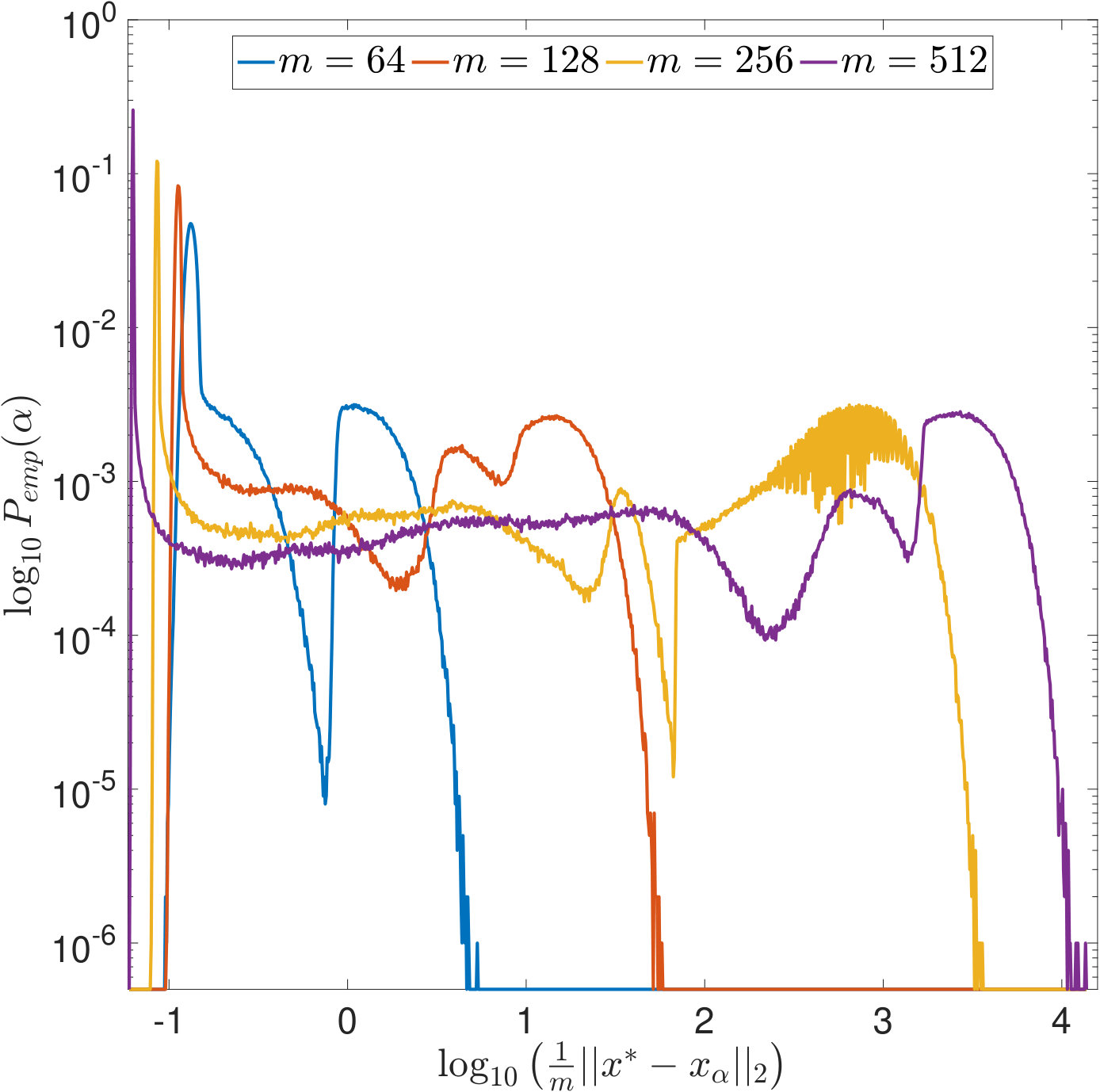 Figure 29
Figure 29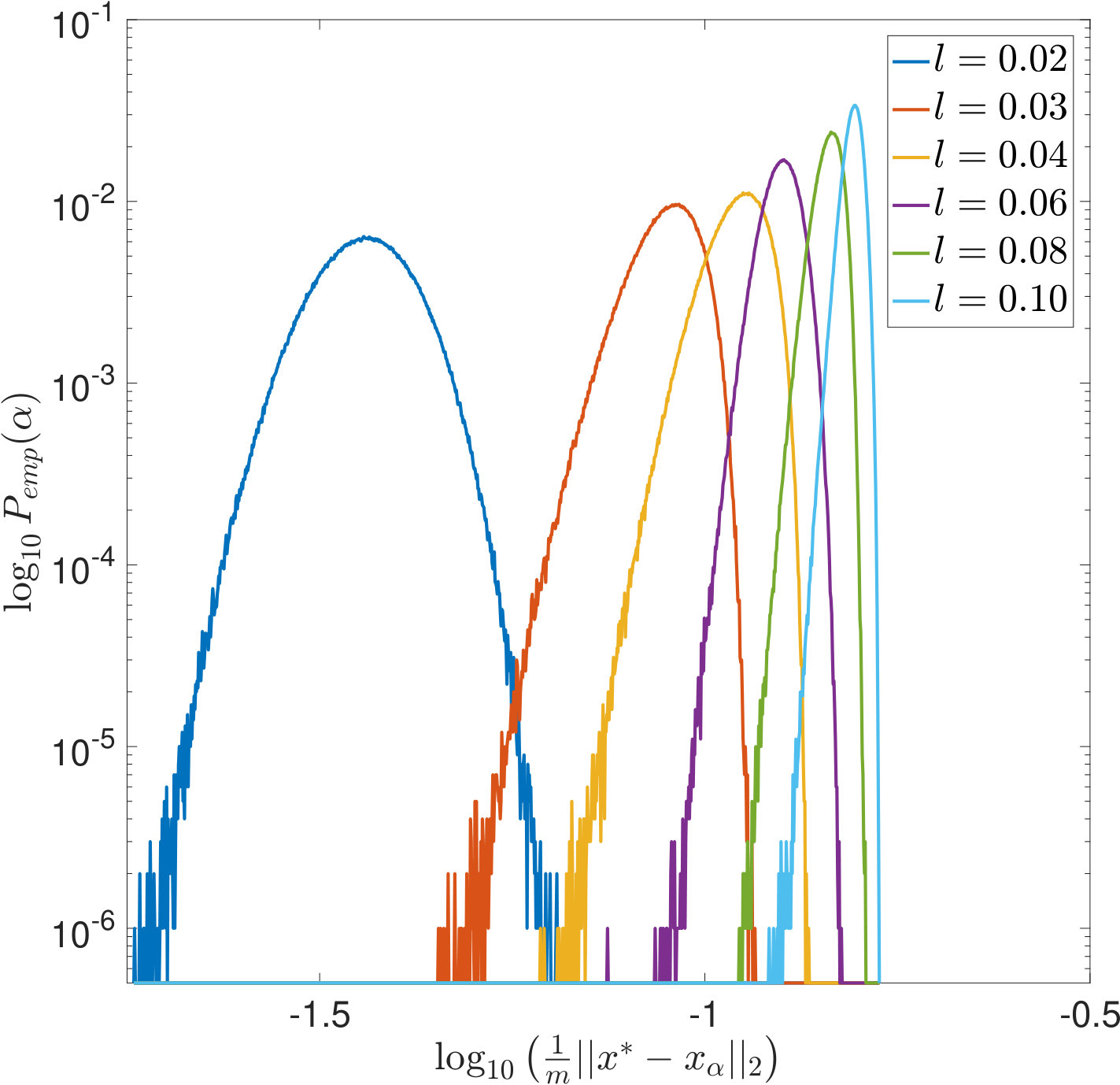 Figure 30
Figure 30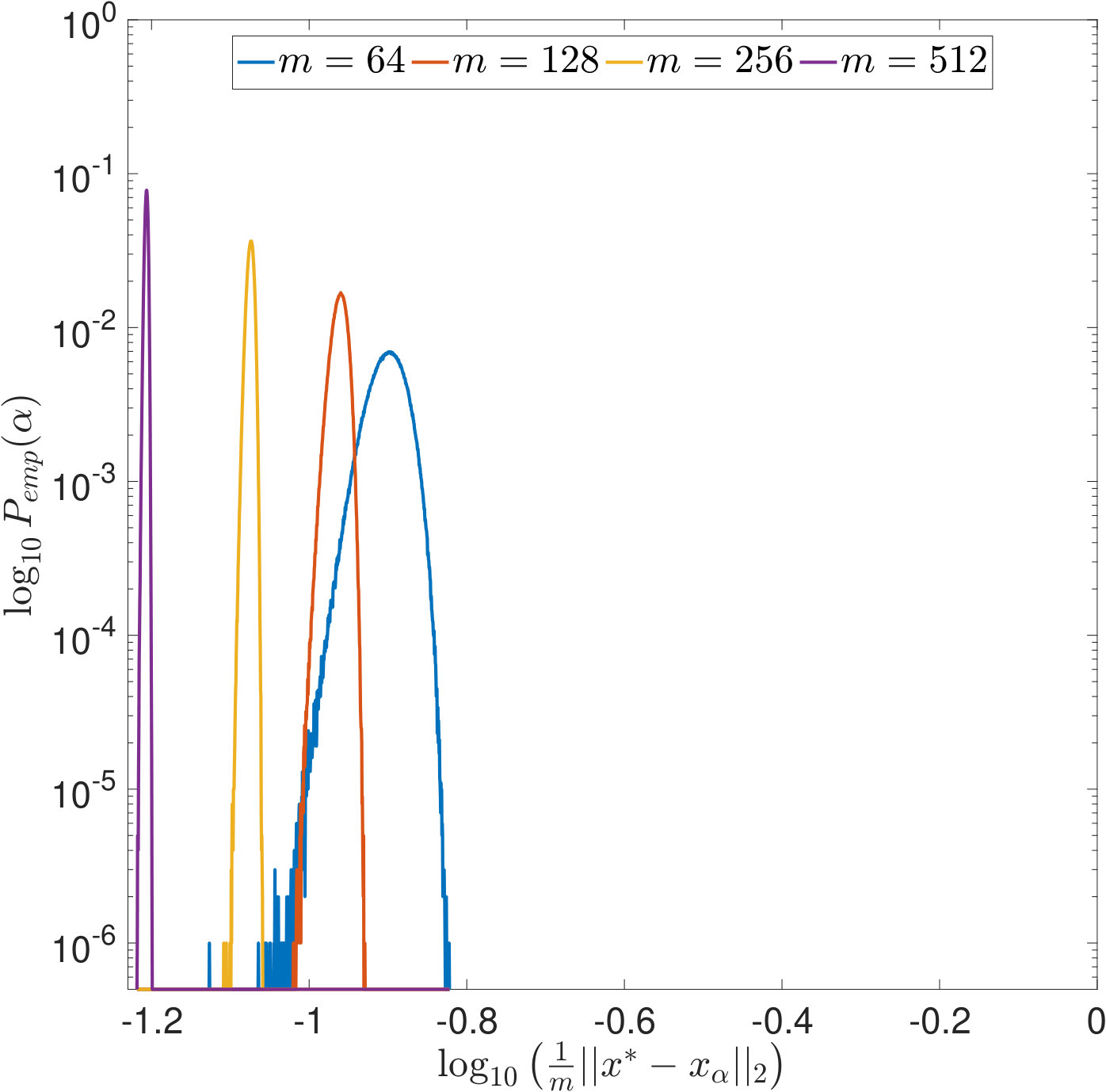 Figure 31
Figure 31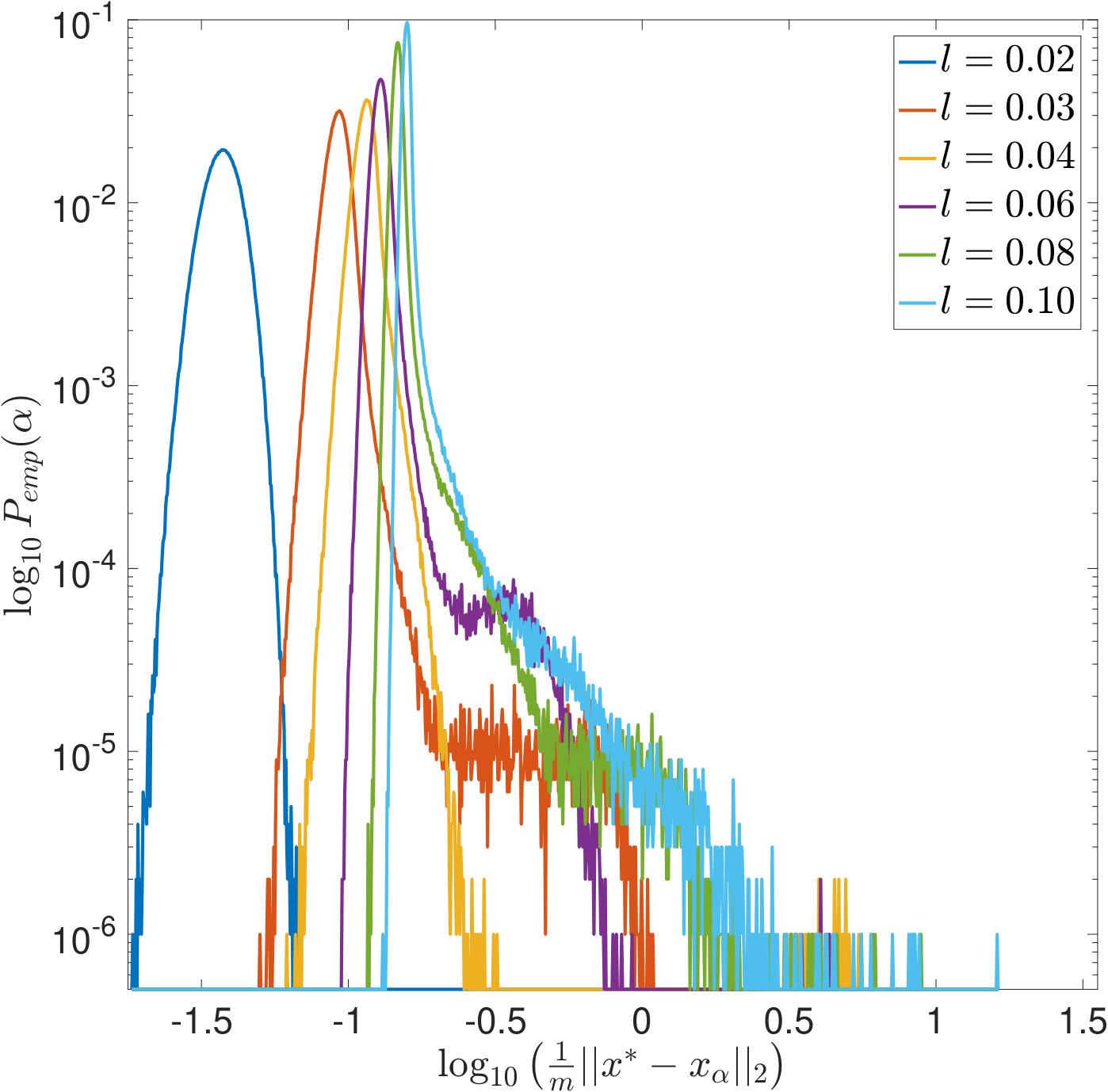 Figure 32
Figure 32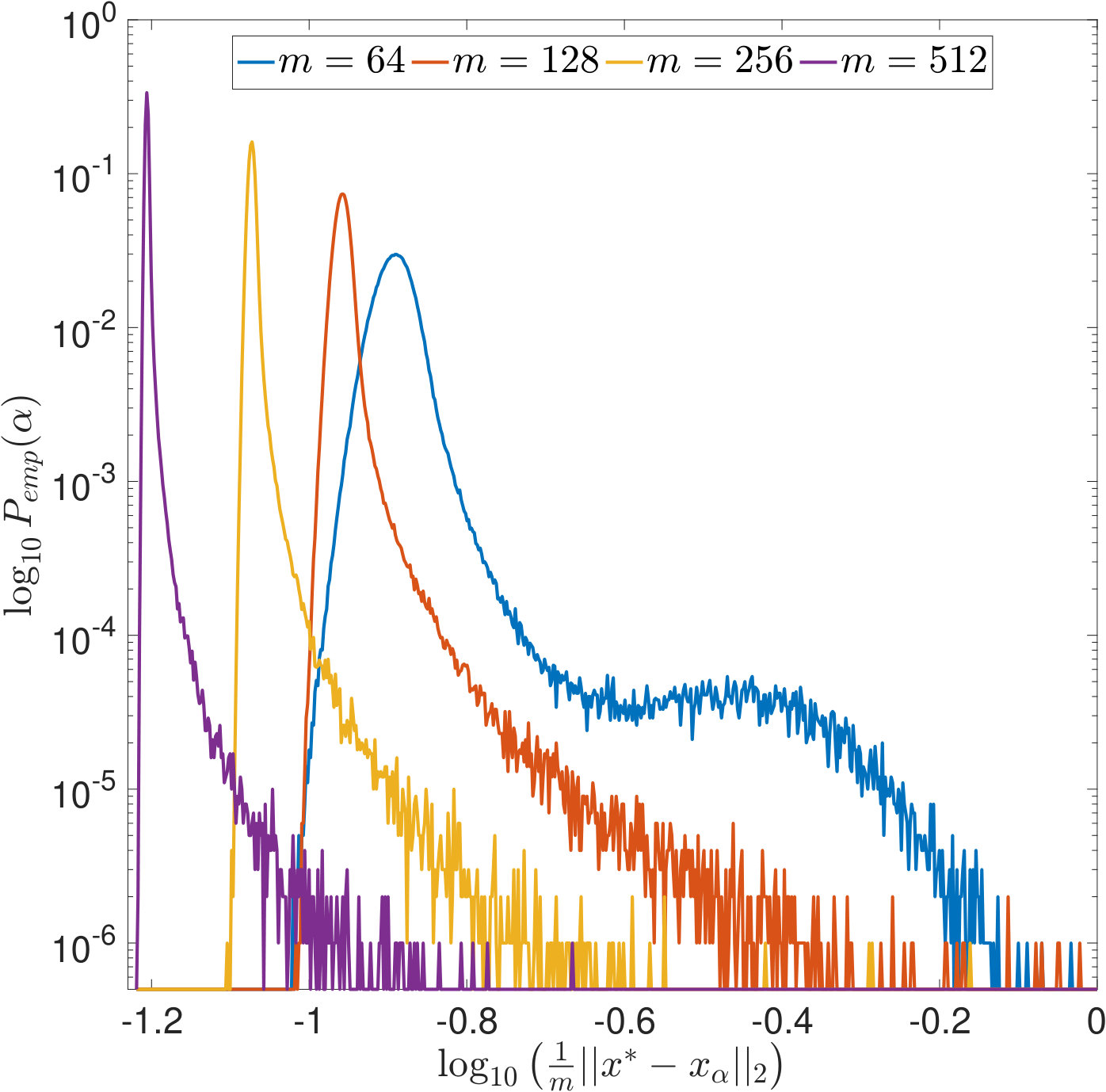 Figure 33
Figure 33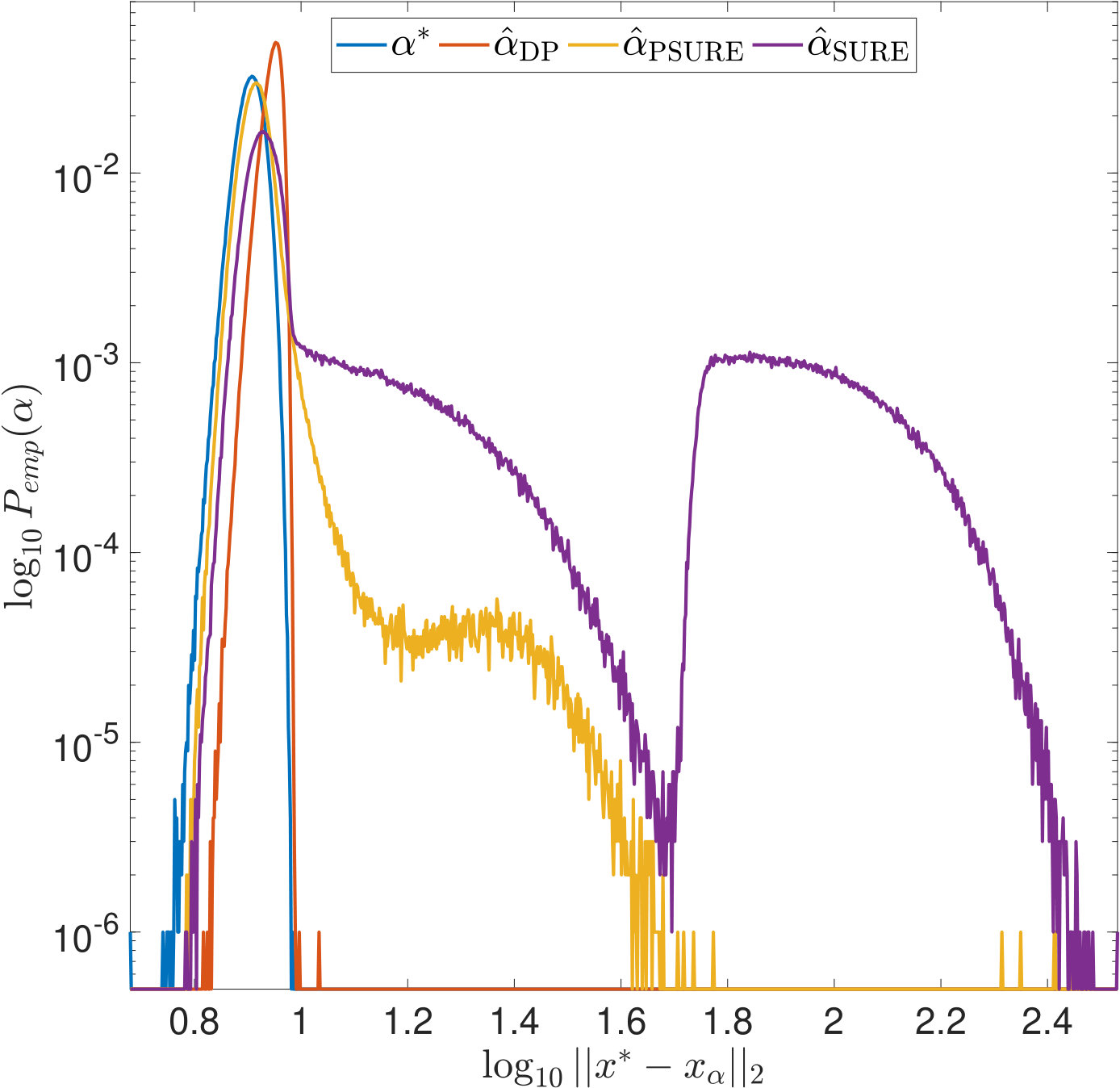 Figure 34
Figure 34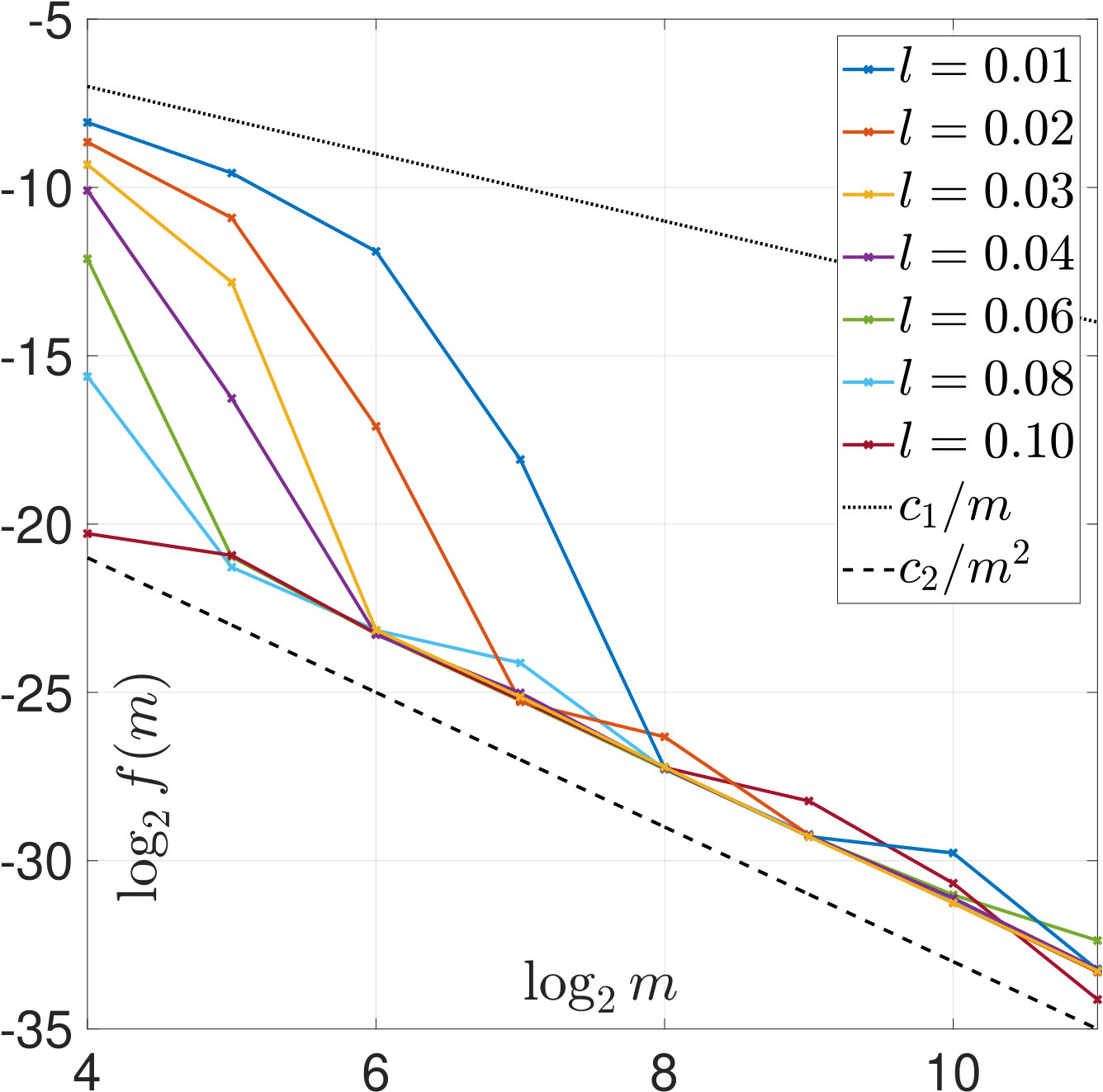 Figure 35
Figure 35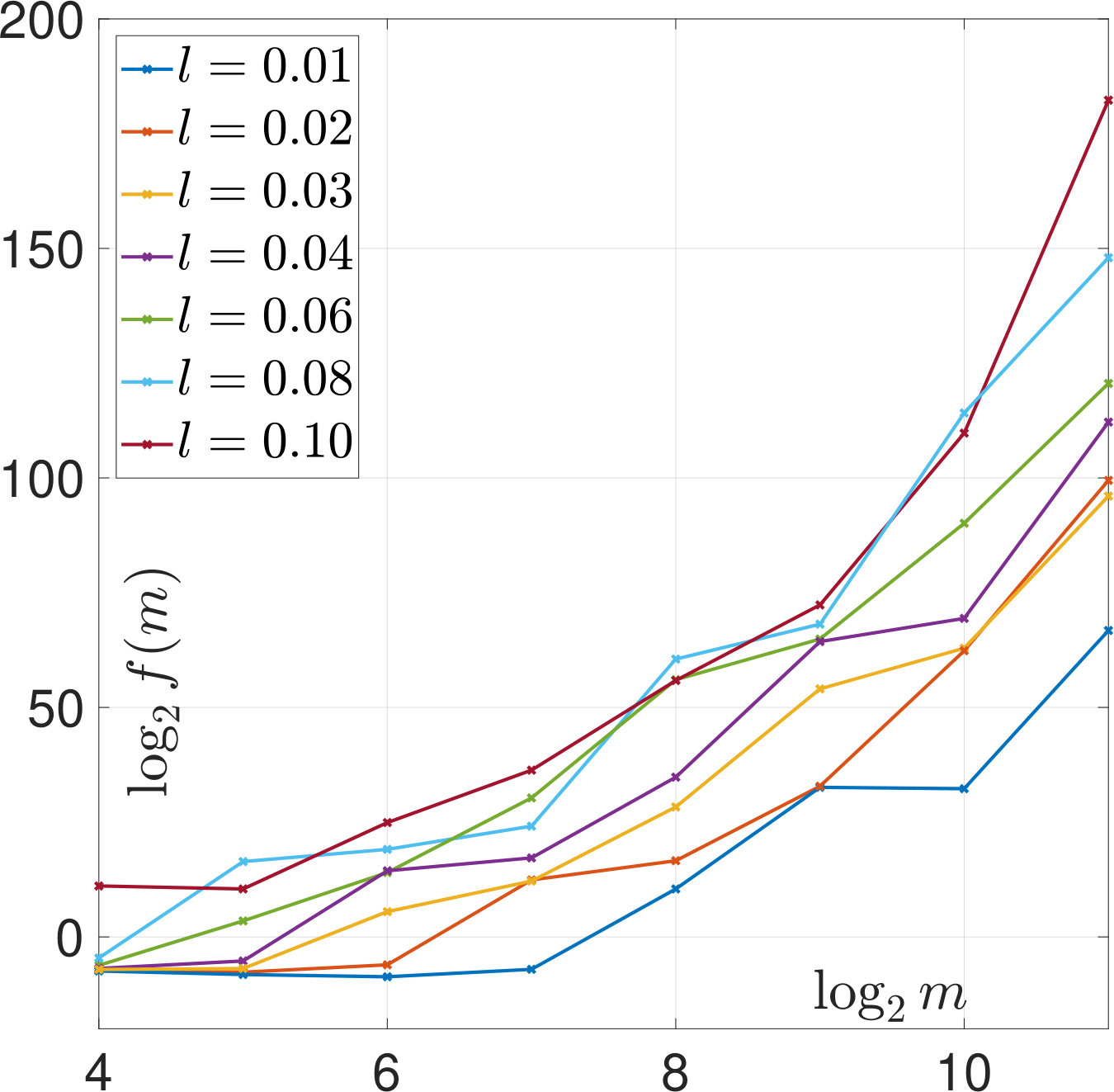 Figure 36
Figure 36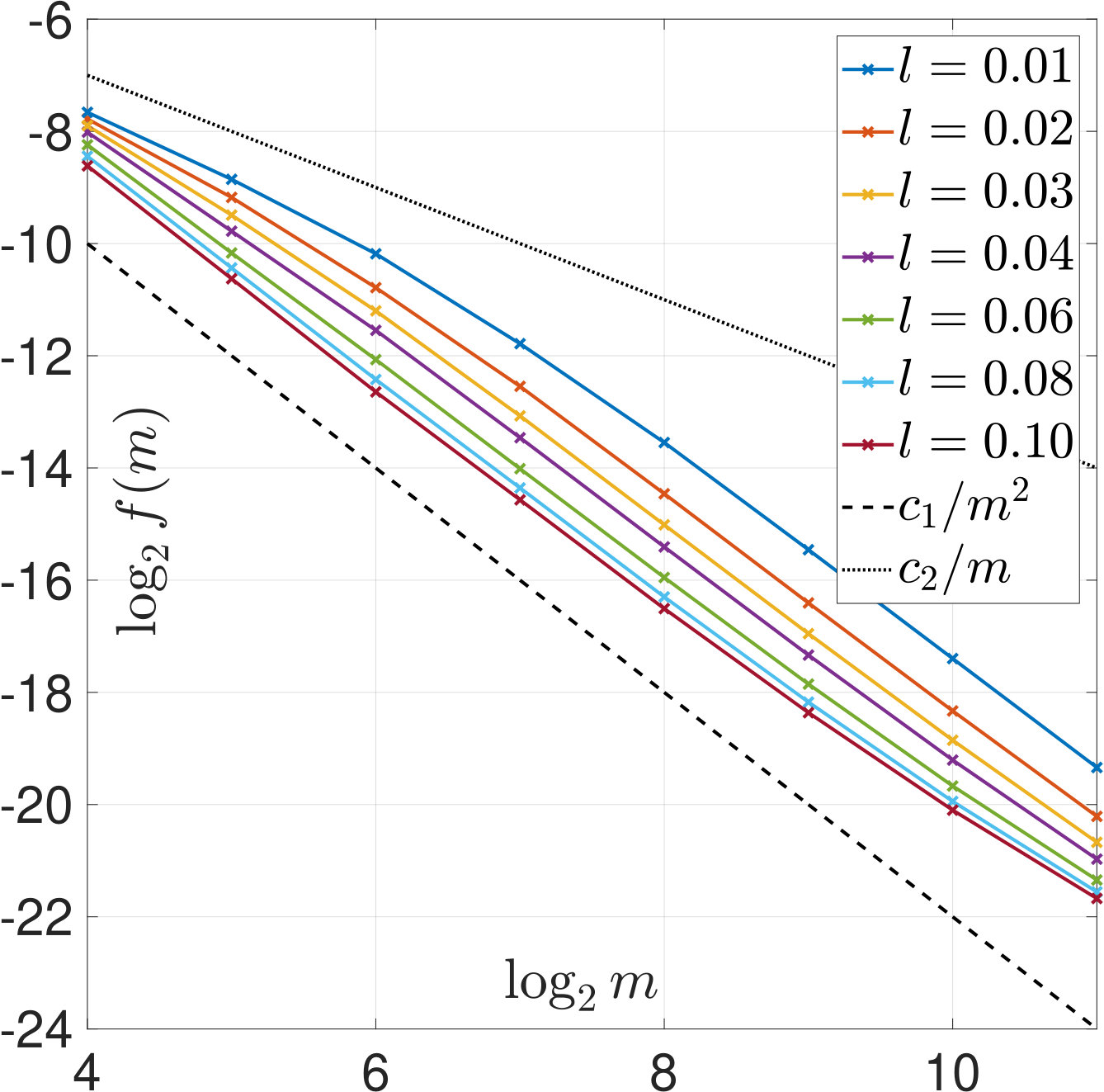 Figure 37
Figure 37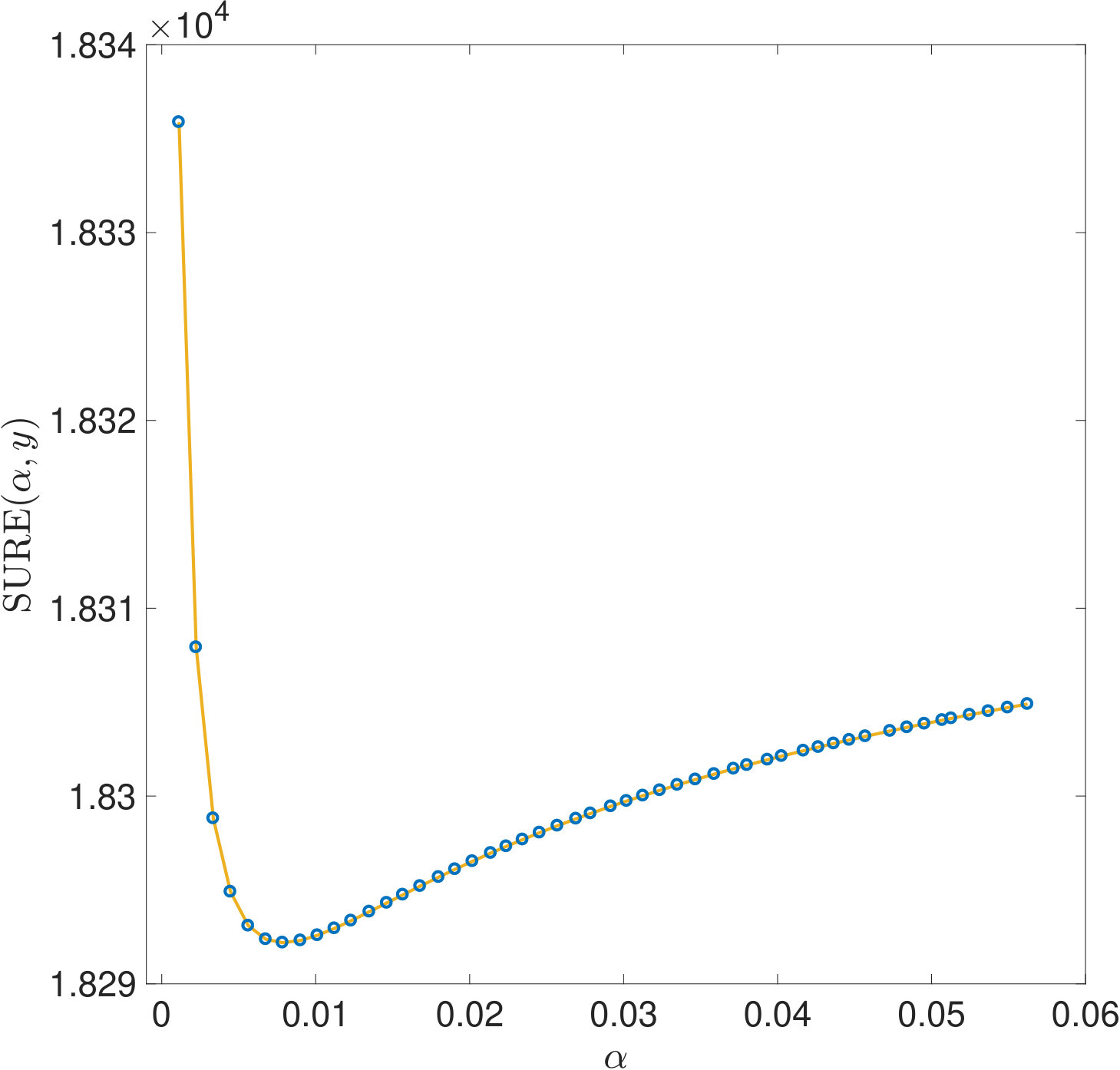 Figure 38
Figure 38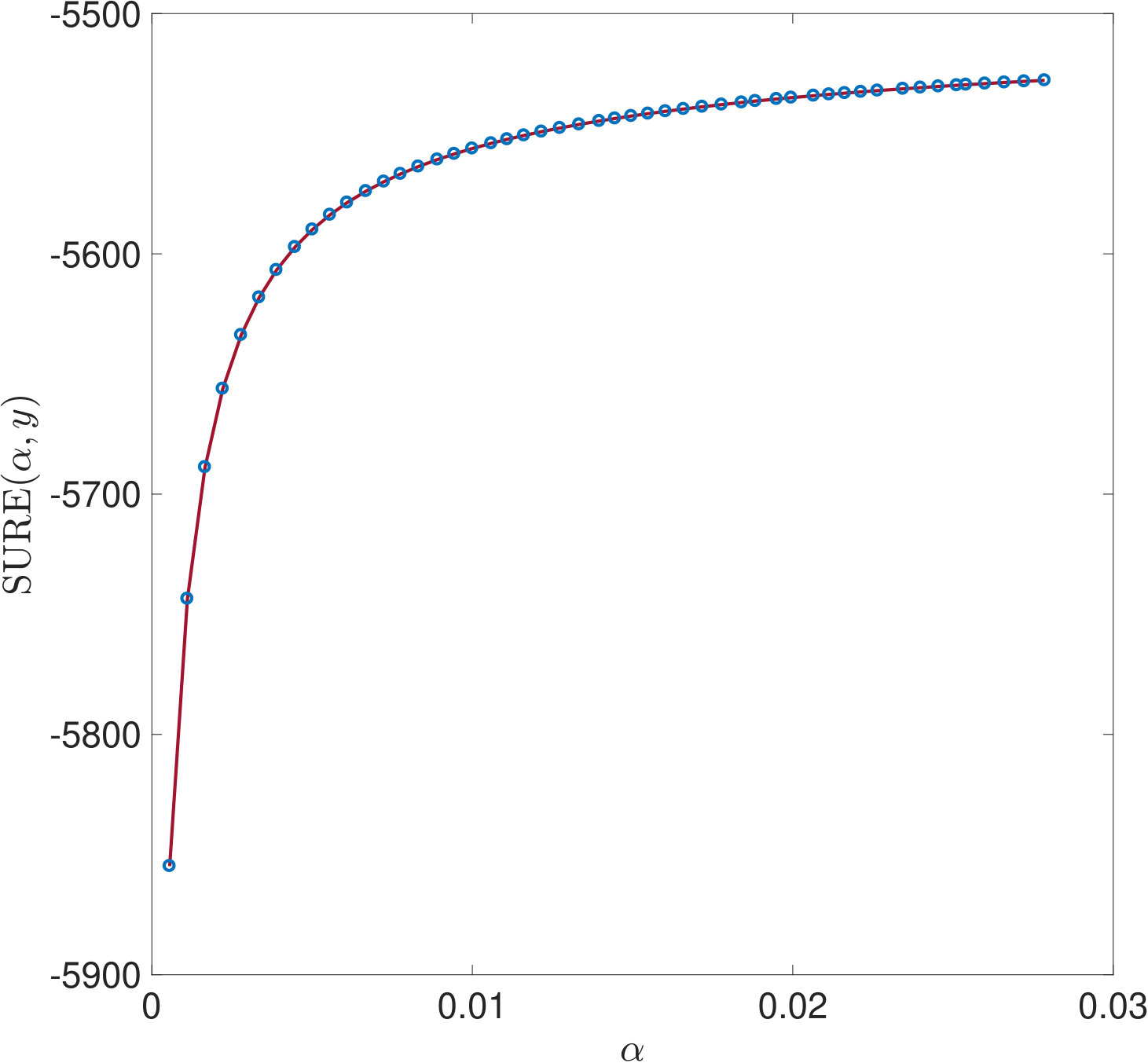 Figure 39
Figure 39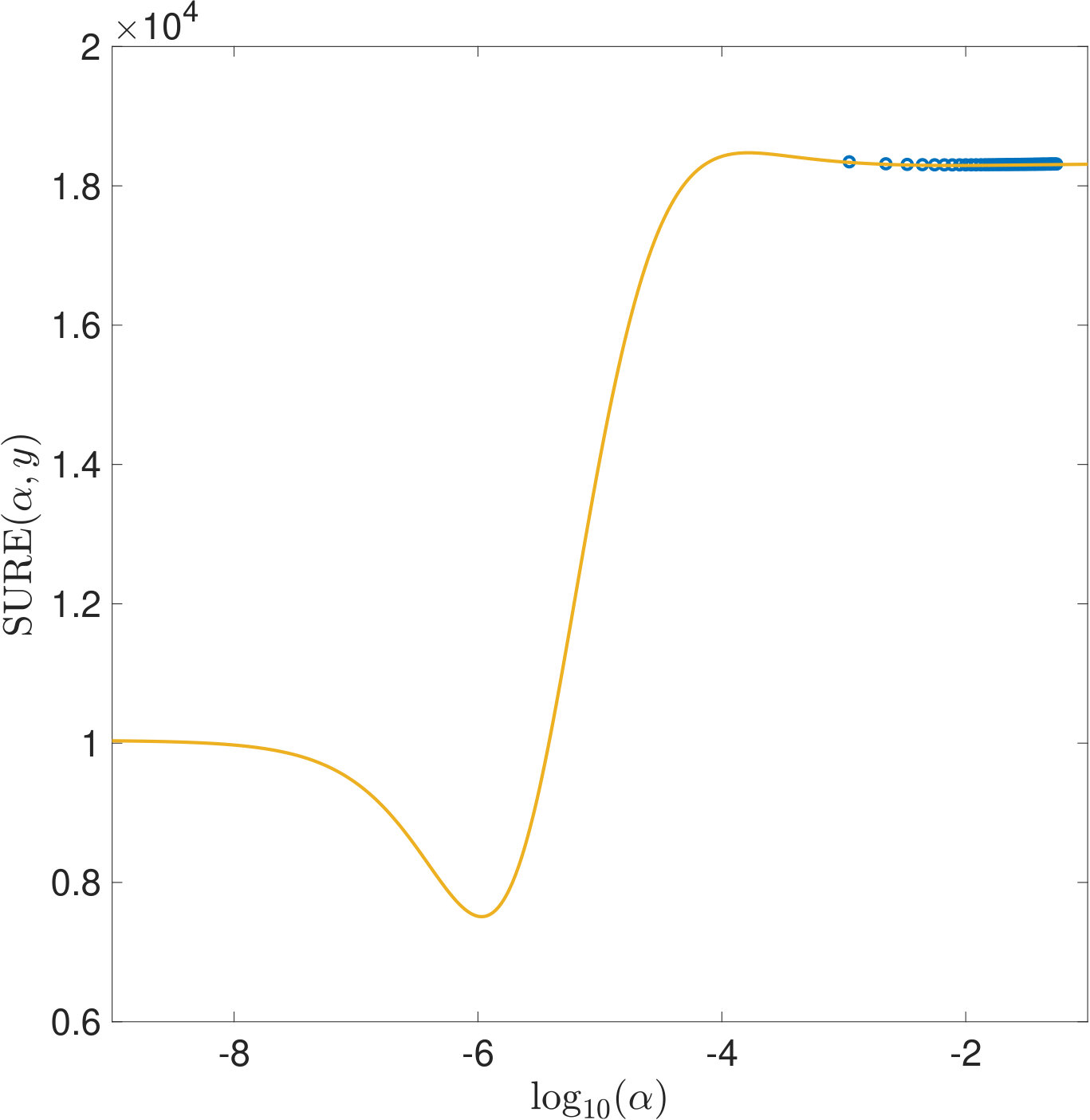 Figure 40
Figure 40| 1.27e+0 | 1.75e+0 | 2.79e+0 | 6.77e+0 | 2.31e+2 | |
| 1.75e+0 | 6.77e+0 | 6.94e+1 | 6.88e+2 | 2.30e+2 | |
| 6.77e+0 | 6.88e+2 | 6.42e+2 | 1.51e+3 | 4.22e+3 | |
| 6.88e+2 | 1.51e+3 | 1.51e+4 | 4.29e+3 | 4.29e+4 | |
| 1.70e+3 | 4.70e+4 | 1.87e+6 | 4.07e+6 | 1.79e+6 | |
| 4.70e+4 | 1.11e+7 | 1.22e+7 | 2.12e+7 | 3.70e+7 |
| min | max | mean | median | std | |
|---|---|---|---|---|---|
| optimal | 4.78 | 9.63 | 8.04 | 8.05 | 0.43 |
| DP | 6.57 | 10.81 | 8.82 | 8.87 | 0.34 |
| PSURE | 6.10 | 277.24 | 8.38 | 8.23 | 1.53 |
| SURE | 6.08 | 339.80 | 27.71 | 8.95 | 37.26 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Risk Estimators for Choosing Regularization Parameters in Ill-Posed Problems - Properties and Limitations
Felix Lucka Centre for Medical Image Computing, University College London, WC1E 6BT London, UK email: [email protected]
Katharina Proksch Institut für Mathematische Stochastik, Georg-August-Universität Göttingen, Goldschmidtstrasse 7, 37077 Göttingen, Germany, e-mail: [email protected]
Christoph Brune Department of Applied Mathematics, University of Twente, P.O. Box 217, 7500 AE Enschede, The Netherlands, e-mail:[email protected]
Nicolai Bissantz Fakultät für Mathematik, Ruhr-Universität Bochum, 44780 Bochum, Germany, e-mail: [email protected]
Martin Burger Institut für Numerische und Angewandte Mathematik, Westfälische Wilhelms-Universität (WWU) Münster. Einsteinstr. 62, D 48149 Münster, Germany. e-mail: [email protected]
Holger Dette Fakultät für Mathematik, Ruhr-Universität Bochum, 44780 Bochum, Germany, e-mail: [email protected]
Frank Wübbeling Institut für Numerische und Angewandte Mathematik, Westfälische Wilhelms-Universität (WWU) Münster. Einsteinstr. 62, D 48149 Münster, Germany. e-mail: [email protected]
Abstract
This paper discusses the properties of certain risk estimators that recently regained popularity for choosing regularization parameters in ill-posed problems, in particular for sparsity regularization. They apply Stein’s unbiased risk estimator (SURE) to estimate the risk in either the space of the unknown variables or in the data space, which we call PSURE in order to distinguish the two different risk functions. It seems intuitive that SURE is more appropriate for ill-posed problems, since the properties in the data space do not tell much about the quality of the reconstruction. We provide theoretical studies of both approaches for linear Tikhonov regularization in a finite dimensional setting and estimate the quality of the risk estimators, which also leads to asymptotic convergence results as the dimension of the problem tends to infinity. Unlike previous works which studied single realizations of image processing problems with a very low degree of ill-posedness, we are interested in the statistical behaviour of the risk estimators for increasing ill-posedness. Interestingly, our theoretical results indicate that the quality of the SURE risk can deteriorate asymptotically for ill-posed problems, which is confirmed by an extensive numerical study. The latter shows that in many cases the SURE estimator leads to extremely small regularization parameters, which obviously cannot stabilize the reconstruction. Similar but less severe issues with respect to robustness also appear for the PSURE estimator, which in comparison to the rather conservative discrepancy principle leads to the conclusion that regularization parameter choice based on unbiased risk estimation is not a reliable procedure for ill-posed problems. A similar numerical study for sparsity regularization demonstrates that the same issue appears in non-linear variational regularization approaches.
**Keywords: ** Ill-posed problems, regularization parameter choice, risk estimators, Stein’s method, discrepancy principle.
1 Introduction
Choosing suitable regularization parameters is a problem as old as regularization theory, which has seen a variety of approaches both from deterministic (e.g. L-curve criteria, [23, 22]) or statistical perspectives (e.g. Lepskij principles, [3, 26]), respectively in between (e.g. discrepancy principles motivated by deterministic bounds or noise variance, cf. [38, 4]). While the particular class of statistical parameter choice rules based on unbiased risk estimation (URE) was used for linear inverse reconstruction techniques early on [35, 37, 17], there is a renewed interest in these approaches for iterative, non-linear inverse reconstruction techniques, in particular in the context of sparsity constraints, see e.g., [33, 15, 42, 19, 30, 43, 12, 13, 14, 40, 44, 11, 39]). These works are based on extending Stein’s general construction of an unbiased risk estimator [36] to the inverse problems setting. Compared to approaches that measure the risk in the data space, the classical SURE and a generalized version (GSURE, [15, 19, 13, 40]) measure the risk in the space of the unknown which seems more appropriate for ill-posed problems. Previous investigations show that the performance of such parameter choice rules is reasonable in many different settings (cf. [21, 45, 9, 2, 34, 31, 15]). However, most of the problems considered in these works are very mildly ill-posed (which we will define more precisely below), the interplay between ill-posedness and the performance of the risk estimators is not studied explicitly and the inherent statistical nature of the selected regularization parameter is ignored as only single realizations of noise are typically considered.
Therefore, a first motivation of this paper is to further study the properties of SURE in Tikhonov-type regularization methods from a statistical perspective and systematically in dependence of the ill-posedness of the problem. For this purpose we provide a theoretical analysis of the quality of unbiased risk estimators in the case of linear Tikhonov regularization. In addition, we carry out extensive numerical investigations on appropriate model problems. While in very mildly ill-posed settings the performances of the parameter choice rules under consideration are reasonable and comparable, our investigations yield various interesting results and insights in ill-posed settings. For instance, we demonstrate that SURE shows a rather erratic behaviour as the degree of ill-posedness increases. The observed effects are so strong that the meaning of a parameter chosen according to this particular criterion is unclear.
A second motivation of this paper is to study the discrepancy principle as a reference method and as we shall see it can indeed be put in a very similar context and analysed by the same techniques. Although the popularity of the discrepancy principle is decreasing recently in favour of choices using more statistical details, our findings show that it is still more robust for ill-posed problems than risk-based parameter choices. The conservative choice by the discrepancy principle is well-known to rather overestimate the optimal parameter, but on the other hand it avoids to choose too small regularization as risk-based methods often do. In the latter case the reconstruction results are completely deteriorated, while the discrepancy principle yields a reliable, though not optimal, reconstruction.
Formal Introduction
We consider a discrete inverse problem of the form
[TABLE]
where is a vector of observations, is a known matrix, and is a noise vector. We assume that consists of independent and identically distributed (i.i.d.) Gaussian errors, i.e., . The vector denotes the (unknown) exact solution to be reconstructed from the observations. There are two potential difficulties for this: If has a non-trivial kernel, e.g. for , we simply cannot observe certain aspects of and regularization has to interpolate them from the observed features in some way. This, however, typicallyis not the ill-posedness we are interested, in practice we know what we miss and we consider these problems only ”mildly ill-posed”. The second difficulty is more subtle: The singular values of might decay very fast, which means that certain aspects of are barely measurable and even small additional noise can render their recovery unstable. This is the main difficulty we are interested in here, so we will measure the degree of ill-posedness of (1) by the condition of restricted to its co-kernel, i.e. the ratio between largest and smallest non-zero singular value. Note that this definition deviates from the classical definition of ill-posedness for continuous problems by Hadamard [20], which leads to a binary classification of problems as either well- or ill-posed but is not very useful for practical applications. In order to find an estimate of from (1), we apply a variational regularization method:
[TABLE]
where is assumed convex and such that the minimizer is unique for positive regularization parameter . In what follows the dependence of on and the data may be dropped where it is clear without ambiguity that
In practice there are two choices to be made: First, a regularization functional needs to be specified in order to appropriately represent a-priori knowledge about solutions and second, a regularization parameter needs to be chosen in dependence of the data . The ideal parameter choice would minimize a difference between and over all , which obviously cannot be computed and is hence replaced by a parameter choice rule that tries to minimize a worst-case or average error to the unknown solution, which can be referred to as a risk minimization. In the practical case of having a single observation only, the risk based on average error needs to be replaced by an estimate as well, and unbiased risk estimators that will be detailed in the following are a natural choice.
For the sake of a clearer presentation of methods and results we first focus on linear Tikhonov regularization, i.e.,
[TABLE]
leading to the explicit Tikhonov estimator
[TABLE]
In this setting, a natural distance for measuring the error of is given by its -distance to . Thus, we define
[TABLE]
as the optimal, but inaccessible, regularization parameter. Many different rules for the choice of the regularization parameter are discussed in the literature. Here, we focus on strategies that rely on an accurate estimate of the noise variance . A classical example of such a rule is given by the discrepancy principle: The regularization parameter is given as the solution of the equation
[TABLE]
The discrepancy principle is robust and easy-to-implement for many applications (cf. [5, 24, 32]) and is based on the heuristic argument, that should only explain the data up to the noise level.
The broader class of unbiased risk estimators accounts for the stochastic nature of by aiming to choose such that it minimizes certain -errors between and only in expectation: We first define the mean squared prediction error*(MSPE)* as
[TABLE]
and refer to its minimizer as . Since depends on the unknown vector , we have to replace it by an unbiased estimate we will call here and define:
[TABLE]
with
[TABLE]
While the classical SURE estimator would try to estimate the expectation of the simple -error between and like in (4), a generalization [15, 19] is often considered in inverse problems where may have a non-trivial kernel: We define the mean squared estimation error*(MSEE)* here as
[TABLE]
where denotes the orthogonal projector onto the range of ( denotes the Pseudoinverse of ), and refer to the minimizer of as . Again, we replace by an unbiased estimator to obtain
[TABLE]
with
[TABLE]
If is non-singular, as it will be in the theoretical analysis and numerical experiments in this work, the above definition coincides with the classical one considered by Stein [36].
Note that the main difference between the two risk functions MSPE and MSEE and their corresponding estimators PSURE and SURE is that they measure in image and domain of the ill-conditioned operator , respectively. The second important observation here is that all parameter choice rules depend on the data and hence on the random errors . Therefore, , and are random variables, described in terms of their probability distributions. In the next section, we first investigate these distributions by a numerical simulation study in a simple inverse problem scenario using quadratic Tikhonov regularization. The results point to several problems of the presented parameter choice rules, in particular of SURE, and motivate our further theoretical investigation in Section 3. The theoretical results will be illustrated and supplemented by an exhaustive numerical study in Section 4. Finally we extend the numerical investigation in Section 5 to a sparsity-promoting LASSO-type regularization, for which we find a similar behaviour. Conclusions are given in Section 6.
2 Risk Estimators for Quadratic Regularization
In the following we discuss the setup in the case of the simple quadratic regularization functional , i.e. we recover the well-known linear Tikhonov regularization scheme. The linearity can be used to simplify arguments and gain analytical insight in the next section. While the arguments presented can easily be extended to more general quadratic regularizations, this model already contains all important properties.
2.1 Singular System and Risk Representations
Considering a quadratic regularization allows to analyze in a singular system of in a convenient way. Let , . Let
[TABLE]
denote a singular value decomposition of with
[TABLE]
Defining
[TABLE]
we can rewrite model (1) in its spectral form
[TABLE]
where are still i.i.d. . All quantities considered in the following depend on or . In particular, we have , , , , and . This dependence is made explicit in the statements of the results and technical assumptions for clarity but is dropped in the main text for ease of notation. Increasing corresponds to sampling from an equation such as (1) more finely, whereas an increase in increases the level of discretization of an operator (see section 2.2). In our asymptotic considerations both and tend to infinity.
We will express some more terms in the singular system that are frequently used throughout this paper. In particular, we have for , the regularized solution (dropping the dependence on below for notational simplicity) and its norm
[TABLE]
as well as the residual and distance to the maximum likelihood estimate
[TABLE]
Based on the generalized inverse we compute
[TABLE]
which yields the degrees of freedom and the generalized degrees of freedom
[TABLE]
Next, we derive the spectral representations of the parameter choice rules. For the discrepancy principle, we use (13) to define
[TABLE]
and now, (5) can be restated as . For (7) and (9), we find
[TABLE]
2.2 An Illustrative Example
We consider a simple imaging scenario which exhibits typical properties of inverse problems. The unknown function is mapped to a function by a periodic convolution with a compactly supported kernel of width :
[TABLE]
where the 1-periodic function is defined for by
[TABLE]
and continued periodically for . Examples of are plotted in Figure 1. The normalization ensures that and suitable discretizations thereof have the spectral radius which simplifies our derivations and the corresponding illustrations. The used in the numerical examples is the sum of four delta distributions:
[TABLE]
The locations of the delta distributions approximate by irrational numbers which will simplify the discretization of this continuous problem.
Discretization
For a given number , let
[TABLE]
denote the equidistant partition of and an orthonormal basis (ONB) of piecewise constant functions over that partition. If we use and degrees of freedom to discretize range and domain of , respectively, we arrive at the discrete inverse problem (1) with
[TABLE]
The two dimensional integration in (17) is computed by the trapezoidal rule with equidistant spacing, employing points to partition . Note that we drop the subscript from whenever the dependence on this parameter is not of importance for the argument being carried out.
As the convolution kernel has mass and the discretization was designed to be mass-preserving, we have and the condition number of is given by , where . Figure 2 shows the decay of the singular values for various parameter settings and Table 1 lists the corresponding condition numbers: From this, we can see that the degree of ill-posedness of solving (1) measured in terms of the rate of decay of the singular values and the condition number grows very fast with increasing and . It is easy to show that in the infinite dimensional setting, the rate of decay would be exponentially fast.
Empirical Distributions
Using the above formulas and , , , we computed the empirical distributions of the values selected by the different parameter choice rules by evaluating (14), (15) and (16) on a fine logarithmical -grid, i.e., was increased linearly in between and with a step size of . We draw samples of . The results are displayed in Figures 3 and 4: In both figures, we use a logarithmic scaling of the empirical probabilities wherein empirical probabilities of [math] have been set to . While this presentation complicates the comparison of the distributions as the probability mass is deformed, it facilitates the examination of small values and tails.
First, we observe in Figure 3 that typically overestimates the optimal . However, it performs robustly and does not cause large -errors as can be seen in Figure 3. For and , the latter is not true: While being closer to than most often, and, as can be seen from the joint error histograms in Figure 4, producing smaller -errors more often (87%/56% of the time for PSURE/SURE), both distributions show outliers, i.e., occasionally, very small values of are estimated that cause large -errors. In the case of , we even observe two clearly separated modes in the distributions. Table 2 shows different statistics that summarize the described phenomena. These findings motivate the theoretical examinations carried out in the following section.
3 Properties of the Parameter Choice Rules for Quadratic Regularization
In this section we consider the theoretical (risk) properties of PSURE, SURE and the discrepancy principle. To allow for a concise and accessible presentation of the main results, all proofs are shifted to Appendix A. As we are investigating random quantities, convergence rates are given in terms of the stochastic order symbols and , which correspond to Landau’s big and small notation, respectively, when convergence in probability is considered. Let us recall the definition of and using the formulation in [41], Chapter 2.1.
Definition 1** (Stochastic Order Symbols).**
Let a probability space. , be a sequence of random variables, and be a sequence of positive numbers. We say that
[TABLE]
We say that
[TABLE]
Instead of or we may also write or , respectively.
Assumption 1**.**
For the sake of simplicity we only consider in this first analysis. Furthermore, we assume
[TABLE]
Note that all assumptions are fulfilled in the numerical example we described in the previous section.
We mention that we consider here a rather moderate size of the noise, which remains bounded in variances as . A scaling corresponding to white noise in the infinite dimensional limit is rather and an inspection of the estimates below shows that the risk estimate is potentially far from the expected values in such cases additionally.
3.1 PSURE-Risk
We start with an investigation of the PSURE risk estimate. Based on (15) and Stein’s result, the representation for the risk is given as
[TABLE]
Figure 5 illustrates the typical shape of and PSURE estimates thereof. Following [29, 25] who considered the case and [46, 18], who investigated the performance of Stein’s unbiased risk estimate in the different context of hierarchical modeling, we show that, with the definition of the loss by
[TABLE]
is close to for large Note that PSURE is an unbiased estimate of the expectation of
Theorem 1**.**
If Assumption 1 holds, then we have for any sequence of vectors , such that as
[TABLE]
Remark 1**.**
The result of Theorem 1 guarantees stochastic boundedness of the sequence
[TABLE]
It does not entail the existence of a proper weak limit of , which would require stronger assumptions on the sequences and \big{(}(\gamma_{i,m})_{i=1}^{m}\big{)}_{m\in\mathbb{N}}.
The latter result can be used to show that, in an asymptotic sense, if the loss is considered, the estimator does not have a larger risk than any other choice of regularization parameter. This statement is made precise in the following corollary.
Corollary 1**.**
Let be a sequence of positive real numbers such that . Under the assumptions of Theorem 1 the following holds true for any sequence of positive real numbers :
[TABLE]
We finally mention that our estimates are rather conservative, in particular with respect to the quantity in the proof of Theorem 1, since we do not assume particular smoothness of . With an additional source condition, i.e., certain decay speed of the , it is possible to derive improved rates, which are however beyond the scope of our paper. We refer to [10] and [27] for recent results in that direction, where optimality of with respect to the risk under source conditions for spectral cut-off and more general, filter based methods are shown, respectively. We turn our attention to the convergence of the risk estimate as as well as the convergence of the estimated regularization parameters.
Theorem 2**.**
If Assumption 1 holds, then we have for any sequence of vectors , such that as
[TABLE]
and
[TABLE]
Remark 2**.**
It follows from Theorem 2 and Definition 1 that
[TABLE]
whereas is bounded away from zero by the assumptions of Theorem 3. Therefore, asymptotically, minimizing is the same as minimizing
In order to understand the behaviour of the estimated regularization parameters we start with some bounds on , which recover a standard property of deterministic Tikhonov-type regularization methods, namely that does not diverge for suitable parameter choices (cf. [16]).
Lemma 1**.**
A regularization parameter obtained from satisfies
[TABLE]
From a straight-forward estimate of the derivative of on sets where is bounded away from zero, together with the Arzela-Ascoli theorem we obtain the following result:
Proposition 1**.**
The sequence of functions is equicontinuous on sets with and hence has a uniformly convergent subsequence with continuous limit function .
In order to obtain convergence of minimizers it suffices to be able to choose uniform constants and , which is possible if the bounds in Lemma 1 are uniform:
Theorem 3**.**
Let be uniformly bounded in and be uniformly bounded away from zero. Then there exists a subsequence that converges to a minimizer of the asymptotic risk . Moreover converges to to a minimizer of the asymptotic risk in probability.
3.2 Discrepancy Principle
We now turn our attention to the discrepancy principle, which we can formulate in a similar setting as the PSURE approach above. With a slight abuse of notation, in analogy to the other methods, we denote the expectation of by and define as the solution of the equation
[TABLE]
Figure 5 illustrates the typical shape of and its DP estimates. Observing that
[TABLE]
we immediately obtain the following result:
Theorem 4**.**
If Assumption 1 holds, we have for any sequence of vectors , such that
[TABLE]
and
[TABLE]
3.3 SURE-Risk
Now we consider the SURE-risk estimation procedure. Figure 5 illustrates the typical shape of and SURE estimates thereof. Based on (16), if for all , the risk can be written as
[TABLE]
For the PSURE criterion we showed in Theorem 1 that is close to the loss in an asymptotic sense with the standard -rate of convergence. An analogous result can be shown for SURE and the associated loss but with different associated rates of convergence , dependent on the singular values.
Theorem 5**.**
Let Assumption 1 be satisfied and in addition to (20), let for all and . Then we have for any sequence of vectors , such that is uniformly bounded as
[TABLE]
where
[TABLE]
In the same manner as for PSURE, we may use the latter convergence result to show that, in an asymptotic sense, if the loss is considered, the estimator does not have a larger risk than any other choice of regularization parameter. We stress again that this optimality property depends on the loss considered, as it is the case in Corollary 1.
Corollary 2**.**
Let be a sequence of positive reals such that . If the assumptions of Theorem 5 hold, we have for any sequence of positive real numbers :
[TABLE]
Note that , depending on the behaviour of the singular values. If , in Theorem 5 and only sequences such that are permissible in Corollary 2.
We can now proceed to an estimate between and similar to the ones for the PSURE risk, however we observe a main difference due to the appearance of the condition number of the forward matrix :
Theorem 6**.**
Let be a full rank matrix. In addition to Assumption 1, let for all and . Then, we have for any sequence of vectors , such that as
[TABLE]
and
[TABLE]
We finally note that in the best case the convergence of SURE is slower than that of PSURE. However, since for ill-posed problems the condition number of will grow with the typical case is rather divergence of , hence the empirical estimates of the regularization parameters might have a large variation, which will be confirmed by the numerical results below.
4 Numerical Studies for Quadratic Regularization
4.1 Setup
As in the illustrative example in Section 2.1, we computed the empirical distributions of the different parameter choice rules for the same scenario (cf. Section 2.2) for each combination of , and . For , and for , noise realizations were sampled. The computation was, again, based on a logarithmical -grid, i.e., is increased linearly in between -40 and 40 with a step size of . In addition to the distributions of , the expressions
[TABLE]
were computed over the -grid. As in some cases, the supremum is obtained in the limit , and hence, on the boundary of our computational grid, we also evaluated (24) for in these cases.
4.2 Illustration of Theorems
We first illustrate Theorems 2 and 6 by computing (22) and (23) based on our samples. The results are plotted in Figure 6 and show that the asymptotic rates hold. For SURE, the comparison between Figures 6(b) and 6(c) also shows that the dependence on is crucial.
4.3 Dependence on the Ill-Posedness
We then demonstrate how the empirical distributions of and the corresponding -error, , such as those plotted in Figure 3, depend on the ill-posedness of the inverse problem.
Dependence on
In Figures 7 and 8, is increased while the width of the convolution kernel is kept fix. The impact of this on the singular value spectrum is illustrated in Figure 2. Most notably, smaller singular values are added and the condition of increases (cf. Table 1). Figures 7(a) and 8(a) suggest that the distribution of the optimal is Gaussian and converges to a limit for increasing . The distribution of the corresponding -error looks Gaussian as well and seems to concentrate while shifting to larger mean values. For the discrepancy principle, Figures 7(b) and 8(b) show that the distribution of widens for increasing , and the distribution of the corresponding -error develops a tail while shifting to larger mean values. Figures 7(c) and 8(c) show that the distribution of seems to converge to a limit for increasing . The distribution of the corresponding -error also develops a tail while shifting to larger mean values. For SURE, Figures 7(d) and 8(d) reveal that increasing leads to erratic, multimodal distributions: Compared to the other -distributions, the distribution of includes a significant amount of very small values, and the corresponding -error distributions range over very large values.
Dependence on
In Figures 9 and 10, the width of the convolution kernel, , is increased while is kept fix (cf. Figure 2 and Table 1). It is worth noticing that as corresponds to a very well-posed problem, the optimal is often extremely small or even [math], as can be seen from Figure 9(a). The general tendencies are similar to those observed when increasing . For SURE, Figures 9(d) and 10(d) illustrate how the multiple modes of the distributions slowly evolve and shift to smaller vales of (and larger corresponding -errors).
4.4 Linear vs Logarithmical Grids
One reason why the properties of SURE exposed in this work have not been noticed so far is that they only become apparent in very ill-conditioned problems (cf. Section 1). Another reason is the way the risk estimators are typically computed: Firstly, for high dimensional problems, (3) often needs to be solved by an iterative method. For very small , the condition of is very large and the solver will need a lot of iterations to reach a given tolerance. If, instead, a fixed number of iterations is used, an additional regularization of the solution to (1) is introduced which alters the risk function. Secondly, again due to the computational effort, a coarse, linear -grid excluding instead of a fine, logarithmic one is often used for evaluating the risk estimators. For two of the risk estimations plotted in Figure 5, Figure 11 demonstrates that this insufficient coverage of small values by the grid can lead to missing the global minimum and other misinterpretations.
5 Numerical Studies for Non-Quadratic Regularization
In this section, we consider the popular sparsity-inducing as a regularization functional (LASSO penalty) to examine whether our results also apply to non-quadratic regularization functionals. For this, let be the support of and its complement. Let further and be a projector onto and the restriction of to . We have that
[TABLE]
as shown, e.g., in [39, 14, 12], which allows us to compute PSURE (7) and SURE (9). Notice that while is a continuous function of [7], PSURE and SURE are discontinuous at all where the support changes.
To carry out similar numerical studies as those presented the last section, we have to overcome several non-trivial difficulties: While there exist various iterative optimization techniques to solve (2) nowadays (see, e.g., [8]), each method typically only works well for certain ranges of , and tolerance levels to which the problem should be solved. In addition, each method comes with internal parameters that have to be tuned for each problem separately to obtain fast convergence. As a result, it is difficult to compute a consistent series of for a given logarithmical -grid, i.e., that accurately reproduces all the change-points in the support and has a uniform accuracy over the grid. Our solution to this problem is to use an all-at-once implementation of ADMM [6] that solves (2) for the whole -grid simultaneously, i.e., using exactly the same initialization, number of iterations and step sizes. See Appendix B for details. In addition, an extremely small tolerance level () and maximal iterations were used to ensure a high accuracy of the solutions.
Another problem for computing quantities like (24) is that we cannot compute the expectations defining the real risks (7) and (9) anymore: We have to estimate them as the sample mean over PSURE and SURE in a first run of the studies, before we can compute (24) in a second run (wherein and are replaced by the estimates from the first run).
We considered scenarios with each combination of , and . Depending on , noise realizations were examined. The computation was based on a logarithmical -grid where is increased linearly in between -10 and 10 with a step size of .
Risk Plots:
Figure 12 shows the different risk functions and estimates thereof. The jagged form of the PSURE and SURE plots evaluated on this fine -grid indicates that the underlying functions are discontinuous. Also note that while PSURE and SURE for each individual noise realization are discontinuous, and are smooth and continuous, as can be seen already from the empirical means over .
Empirical Distributions:
Figure 13 shows the empirical distributions of the different parameter choice rules for . Here, the optimal is chosen as the one minimizing the -error to the true solution . We can observe similar phenomena as for -regularization. In particular, the distributions for SURE, also have multiple modes at small values of and at large values of -error.
Sup-Theorems:
Due to the lack of explicit formulas for the -regularized solution , carrying out similar analysis as in Section 3 to derive theorems such as Theorems 2 and 6 is very challenging. In this work, we only illustrate that similar results may hold for the case of -regularization by computing the left hand side of (22) and (23) based on our samples. The results are shown in Figure 14 and are remarkably similar to those shown in Figure 6.
Linear Grids and Accurate Optimization
All the issues raised in Section 4.4 about why the properties of SURE revealed in this work are likely to be overlooked when working on high dimensional problems are even more crucial for the case of -regularization: For computational reasons, the risk estimators are often evaluated on a coarse, linear -grid using a small, fixed number of iterations of an iterative method such as ADMM. Figure 15 illustrates that this may obscure important features of the real SURE function, such as the strong discontinuities for small , or even change it significantly.
6 Conclusion
We examined variational regularization methods for ill-posed inverse problems and conducted extensive numerical studies that assessed the statistical properties different parameter choice rules. In particular, we were interested in the influence of the degree of ill-posedness of the problem (measured in terms of the condition of the forward operator) on the probability distributions of the selected regularization parameters and of the corresponding induced errors. This perspective revealed important features that were not discussed or noticed before but are essential to know for practical applications, namely that unbiased risk estimators encounter enormous difficulties: While the discrepancy principle yields a rather unimodal distribution of regularization parameters resembling the optimal one with slightly increased mean value, the PSURE estimates start to develop multimodality, and the additional modes consist of underestimated regularization parameters, which may lead to significant errors in the reconstruction. For the case of SURE, which is based on a presumably more reliable risk, the estimates produce quite wide distributions (at least in logarithmic scaling) for increasing ill-posedness, in particular there are many highly underestimated parameters, which clearly yield bad reconstructions. We expect that this behaviour is rather due to the bad quality of the risk estimators than the quality of the risk. These findings may be explained by Theorem 6, which indicates that the estimated SURE risk might deviate strongly from the true risk function when the condition number of is large, i.e. the problem is asymptotically ill-posed as . Consequently one might expect a strong variation in the minimizers of with varying compared to the ones of . A potential way to cure those issues is to develop novel risk estimates for that are not based on Stein’s method, possibly it might even be useful not to insist on the unbiasedness of the estimators.
We finally mention that for problems like sparsity-promoting regularization, the SURE risk leads to additional issues, since it is based on a Euclidean norm. While the discrepancy principle and the PSURE risk only use the norms appearing naturally in the output space of the inverse problem (or in a more general setting the log-likelihood of the noise), the Euclidean norm in the space of the unknown is rather arbitrary. In particular, it may deviate strongly from the Banach space geometry in or similar spaces in high dimensions. Thus, different constructions of SURE risks are to be considered in such a setting, e.g. based on Bregman distances.
Appendix A Proofs
Proof of Theorem 1.
We find
[TABLE]
where , that is, . Note that
[TABLE]
and recall from (10) that Since , Var. This yields
[TABLE]
We obtain the representation
[TABLE]
where the terms are defined in an obvious manner. Since are independent and identically distributed with expectation we immediately obtain that
[TABLE]
Note that is independent of Next, we consider the term
Due to (20) the values for , are monotonically decreasing (with respect to ). Thus, we find
[TABLE]
It follows from [28], Lemma 7.2:
[TABLE]
and an application of Kolmogorov’s maximal inequality yields
[TABLE]
Hence
[TABLE]
and therefore, by Definition (18),
[TABLE]
where we also used that Var which follows from .
Finally, we estimate
Now, if , then it follows from condition (20) that and
[TABLE]
and a further application of Kolmogorov’s maximal inequality as in (25) yields
[TABLE]
To determine its asymptotic order, we consider the term \bigl{(}Sl_{3}(\alpha),\alpha\in[0,1]\bigr{)} as a (Gaussian) stochastic process in for fixed . Clearly, by the Cauchy-Schwarz inequality
[TABLE]
The first factor is bounded since, by Assumption, and for any , is a random variable (independent of ) and therefore almost surely bounded (w.r.t. ). Hence, the process \bigl{(}Sl_{3}(\alpha),\alpha\in[0,1]\bigr{)} is almost surely bounded (w.r.t. ). Recall that we need to show that , where the stochastic order symbol is defined in (18). Let An application of the Markov inequality yields
[TABLE]
Since and have the same distribution due to symmetry of the standard normal distribution,
[TABLE]
Hence, the desired result follows if we show that
[TABLE]
To do so, we apply the following Gaussian comparison inequality.
Theorem 7** (Sudakov-Fernique inequality (Theorem 2.2.3 in [1])).**
Let and be a.s. bounded Gaussian processes on . If
[TABLE]
for all then
[TABLE]
Let
[TABLE]
Consider the process
[TABLE]
Obviously, is almost surely bounded and
[TABLE]
which yields
[TABLE]
Since for all the assumptions of Theorem 7 are satisfied, which allows us to conclude
[TABLE]
Furthermore,
[TABLE]
where we used that \frac{4}{m}\sum_{i=1}^{m}x_{i}^{*}\tilde{\varepsilon}_{j}\sim\mathcal{N}\big{(}0,16\sigma^{2}/m^{2}\sum_{i=1}^{m}(x_{i}^{*})^{2}\big{)} and that for a random variable the first absolute moment is given by This yields
[TABLE]
since, by Assumption, . By Definition (18) we conclude
∎
Proof of Corollary 1.
By definition . This yields
[TABLE]
It follows from Theorem 1 that for any sequence such that By definition (see (19)),
[TABLE]
Setting above, the claim now follows.
∎
Proof of Theorem 2.
Observing (15) and (3.1) we find
[TABLE]
where . The random variables are independent and centered. Notice that
[TABLE]
since .
Consider the monotonically increasing function (where ) and note that the sequence \big{(}\frac{1}{(\gamma_{i}^{2}+\alpha)^{2}}\big{)}_{i=1}^{m} is increasing. With the same arguments as in the proof of Theorem 1 (see (25)), using Kolmogorov’s maximal inequality, we estimate
[TABLE]
It remains to show the -convergence (22). To this end define the -th partial sum
[TABLE]
and observe that forms a martingale. The -maximal inequality for martingales yields
[TABLE]
as above.
∎
Proof of Lemma 1.
It is straightforward to see the differentiability of and to compute
[TABLE]
Hence, for , the risk is strictly decreasing, which implies the first inequality. Moreover, for we obtain
[TABLE]
and we finally see that is nonnegative if in addition .
∎
Proof of Theorem 3.
From the uniform convergence of the sequence in Proposition 1 we obtain the convergence of the minimizers . Combined with Theorem 2 we obtain an analogous argument for . ∎
Proof of Theorem 5.
For and invertible matrices the projection satisfies and
[TABLE]
where we used (2.1). Recall from (11) that This yields
[TABLE]
Hence,
[TABLE]
Recall from (16) that
[TABLE]
We obtain
[TABLE]
where and are defined in an obvious manner. Obviously,
[TABLE]
by assumption (20). Therefore
[TABLE]
where the last estimate follows from Kolmogorov’s maximal inequality as in (25) . Now, since
[TABLE]
Next we derive a corresponding estimate for the term . Observe that and for any and any by ordering of the singular values. This implies
[TABLE]
by a further application of Kolmogorov’s maximal inequality as in (25). Notice that and Therefore, since
[TABLE]
the claim of the theorem follows. ∎
Proof of Theorem 6.
For full rank matrices we have from (26)
[TABLE]
As in the proof of Theorem 2 we set Recall that the random variables are centered, independent with Var. We find
[TABLE]
With the same arguments as in the proofs of Theorems 1 and 2 we obtain
[TABLE]
Again, an application of Kolmogorov’s maximal inequality yields
[TABLE]
and the first claim of the theorem follows with . Moreover, in a similar manner as in the proofs of the previous theorems, we find
[TABLE]
and by the maximal inequality the second claim now follows as
[TABLE]
∎
Appendix B Consistent LASSO Solver
We want to solve (2) with for a large number of different values of but need to ensure that the results are comparable and consistent. For this, we rely on an implementation of the scaled version of ADMM [6] that carries out the iterations for all simultaneously, with the same penalty parameter for all and a stop criterion based on the maximal primal and dual residuum over all . Online adaptation of is also performed based on primal and dual residua for all . While ensuring the consistency of the results, this leads to sub-optimal performance for individual ’s which has to be countered by using a large number of iterations to obtain high accuracies.
Algorithm 1** (All-At-Once ADMM).**
*Given , (penalty parameter), , (adaptation parameters), (max. iterations) and (stopping tolerance), initialize by [math], and , , where denotes an all-one column vector in . Further, let denote the component-wise multiplication between matrices (Hadamard product).
For do:
[TABLE]
The algorithm returns both and as approximations of the solution to (2) with and of which we use for our purposes as it is exactly sparse due to the soft-thresholding step (z-update). In the computations, we furthermore initialized and used , , and .
Acknowledgements. The work of N. Bissantz, H. Dette and K. Proksch has been supported by the Collaborative Research Center “Statistical modeling of nonlinear dynamic processes” (SFB 823, Projects A1, C1, C4) of the German Research Foundation (DFG).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Robert J. Adler and Jonathan E. Taylor, Random fields and geometry , Springer Monographs in Mathematics, Springer, New York, 2007. MR 2319516
- 2[2] M. S. C. Almeida and M. a T. Figueiredo, Parameter estimation for blind and non-blind deblurring using residual whiteness measures. , IEEE Transactions on Image Processing 22 (2013), no. 7, 2751–63.
- 3[3] F. Bauer and T. Hohage, A Lepskij-type stopping rule for regularized Newton methods , Inverse Problems 21 (2005), no. 6, 1975–1991.
- 4[4] Gilles Blanchard and Peter Mathé, Discrepancy principle for statistical inverse problems with application to conjugate gradient iteration , Inverse problems 28 (2012), no. 11, 115011.
- 5[5] Peter Blomgren and Tony F Chan, Modular solvers for image restoration problems using the discrepancy principle , Numerical linear algebra with applications 9 (2002), no. 5, 347–358.
- 6[6] S. Boyd, N. Parikh, E. Chu, B. Peleato, and J. Eckstein, Distributed optimization and statistical learning via the alternating direction method of multipliers , Foundations and Trends in Machine Learning 3 (2011), no. 1, 1–122.
- 7[7] Björn Bringmann, Daniel Cremers, Felix Krahmer, and Michael Möller, The homotopy method revisited: Computing solution paths of ℓ _ 1 ℓ _ 1 \ell\_1 -regularized problems , ar Xiv preprint ar Xiv:1605.00071 (2016).
- 8[8] M. Burger, A. Sawatzky, and G. Steidl, First Order Algorithms in Variational Image Processing , ar Xiv (2014), no. 1412.4237, 60.