The Storage vs Repair-Bandwidth Trade-off for Clustered Storage Systems
N. Prakash, Vitaly Abdrashitov, Muriel Medard

TL;DR
This paper explores the fundamental trade-offs in clustered storage systems between storage efficiency and repair bandwidth, proposing optimal codes and bounds for both functional and exact repairs, considering intra- and inter-cluster communication costs.
Contribution
It introduces a generalized model for clustered storage, derives the optimal trade-off between storage and repair bandwidth, and provides new code constructions and bounds for intra- and inter-cluster repairs.
Findings
Optimal trade-off between storage and inter-cluster repair bandwidth identified.
New exact-repair code constructions outperform space-sharing solutions.
Bounds on intra-cluster repair bandwidth reveal increased helper nodes impact.
Abstract
We study a generalization of the setting of regenerating codes, motivated by applications to storage systems consisting of clusters of storage nodes. There are clusters in total, with nodes per cluster. A data file is coded and stored across the nodes, with each node storing symbols. For availability of data, we require that the file be retrievable by downloading the entire content from any subset of clusters. Nodes represent entities that can fail. We distinguish between intra-cluster and inter-cluster bandwidth (BW) costs during node repair. Node-repair in a cluster is accomplished by downloading symbols each from any set of other clusters, dubbed remote helper clusters, and also up to symbols each from any set of surviving nodes, dubbed local helper nodes, in the host cluster. We first identify the optimal trade-off between…
Click any figure to enlarge with its caption.
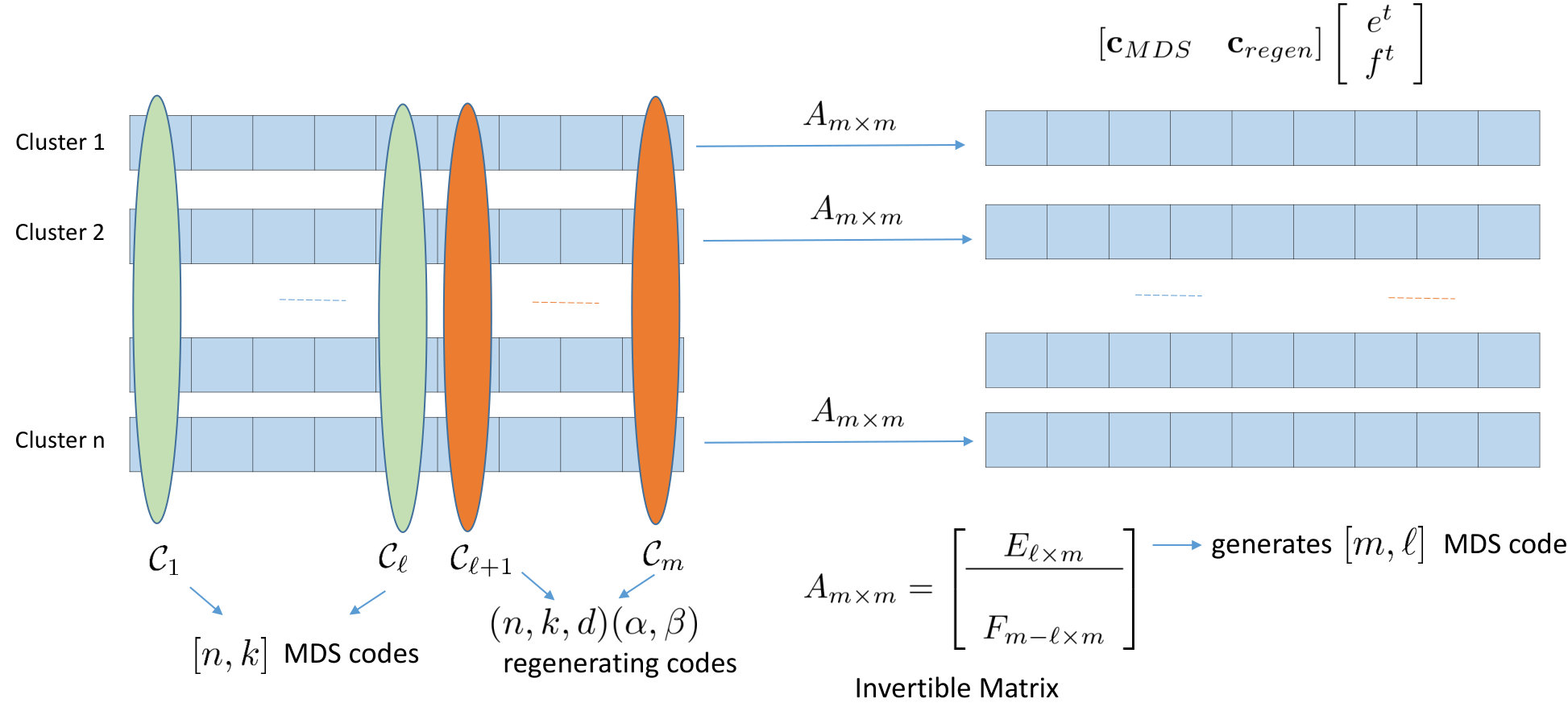 Figure 1
Figure 1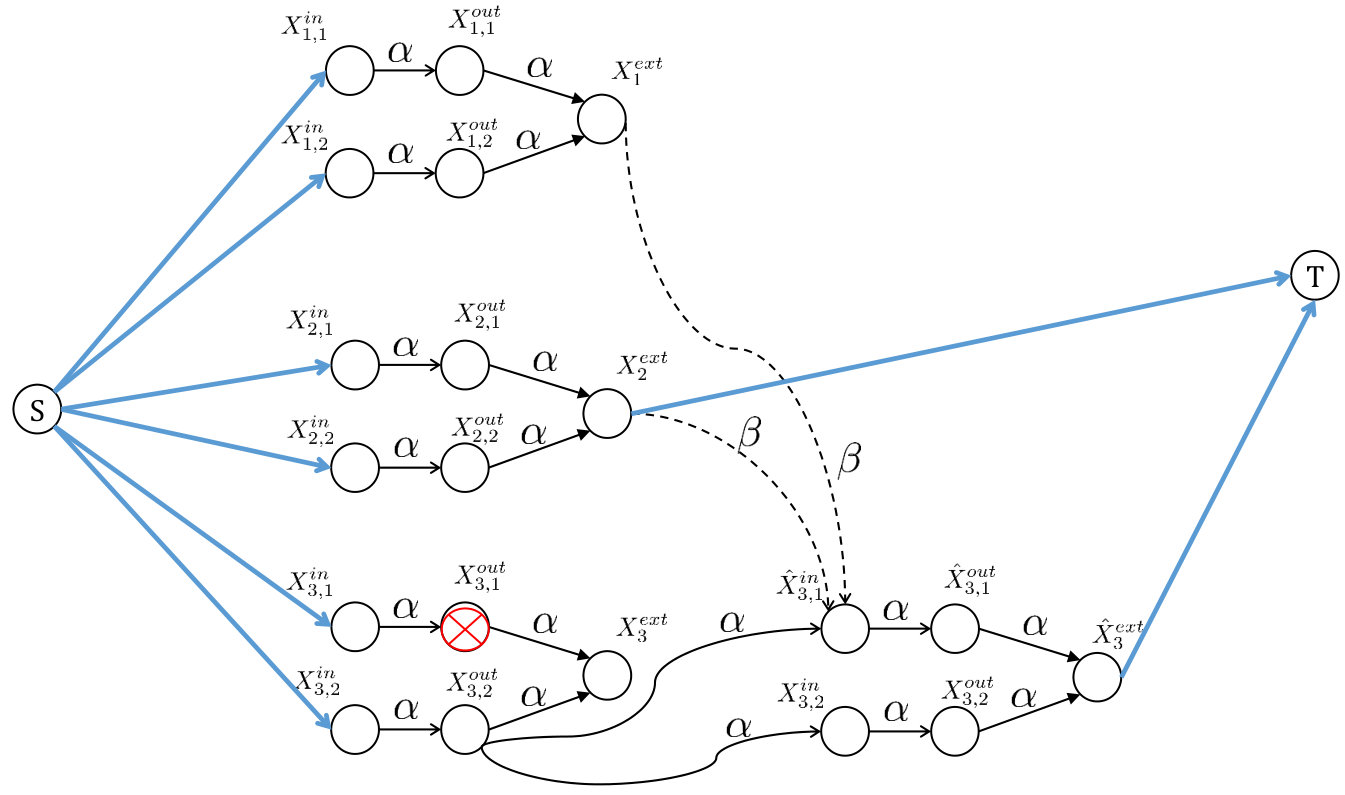 Figure 2
Figure 2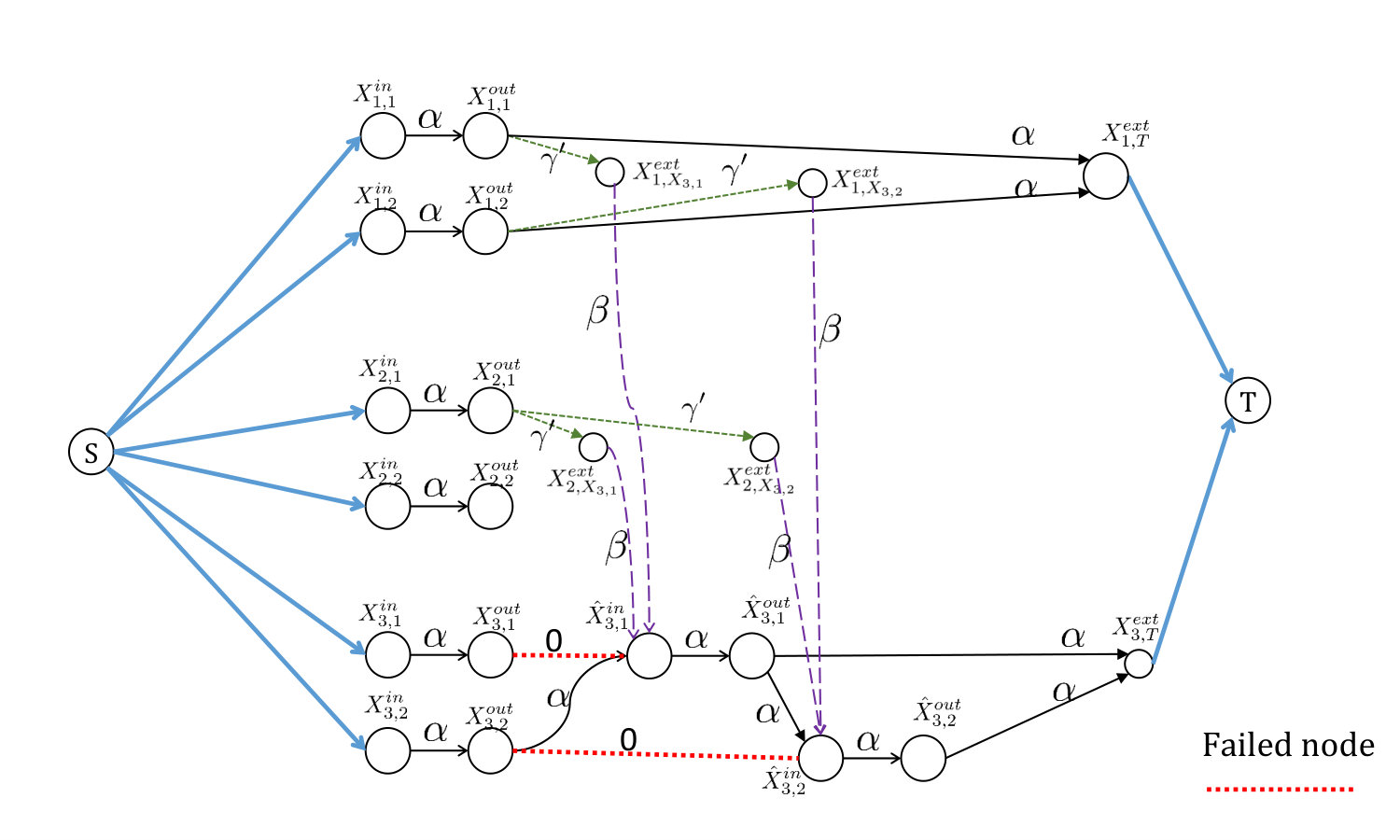 Figure 3
Figure 3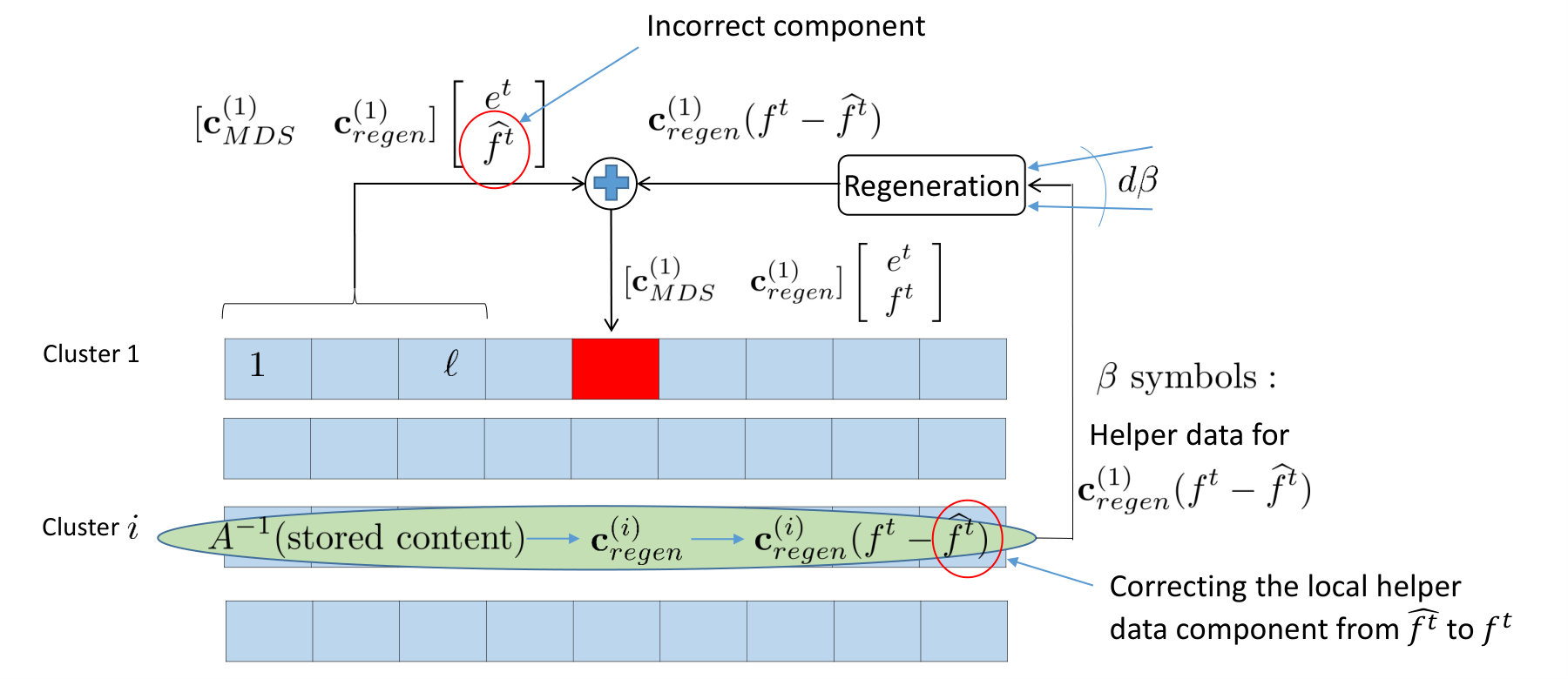 Figure 4
Figure 4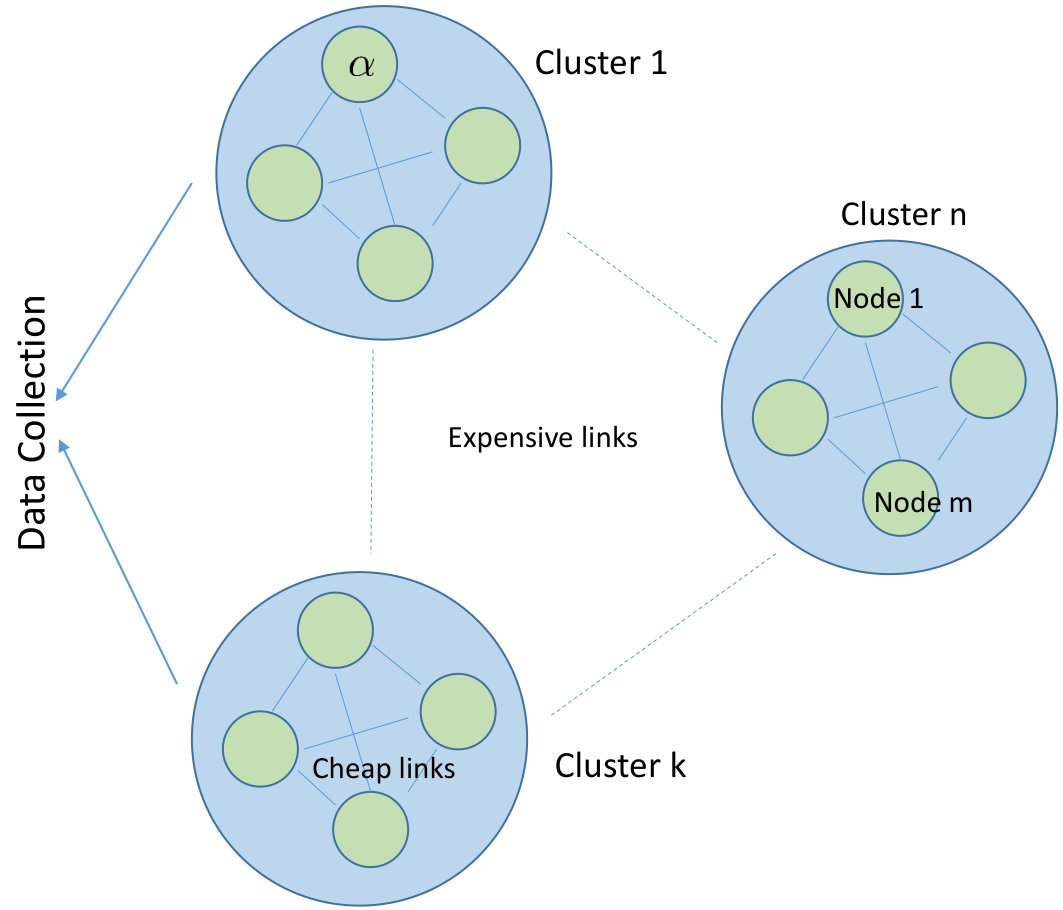 Figure 5
Figure 5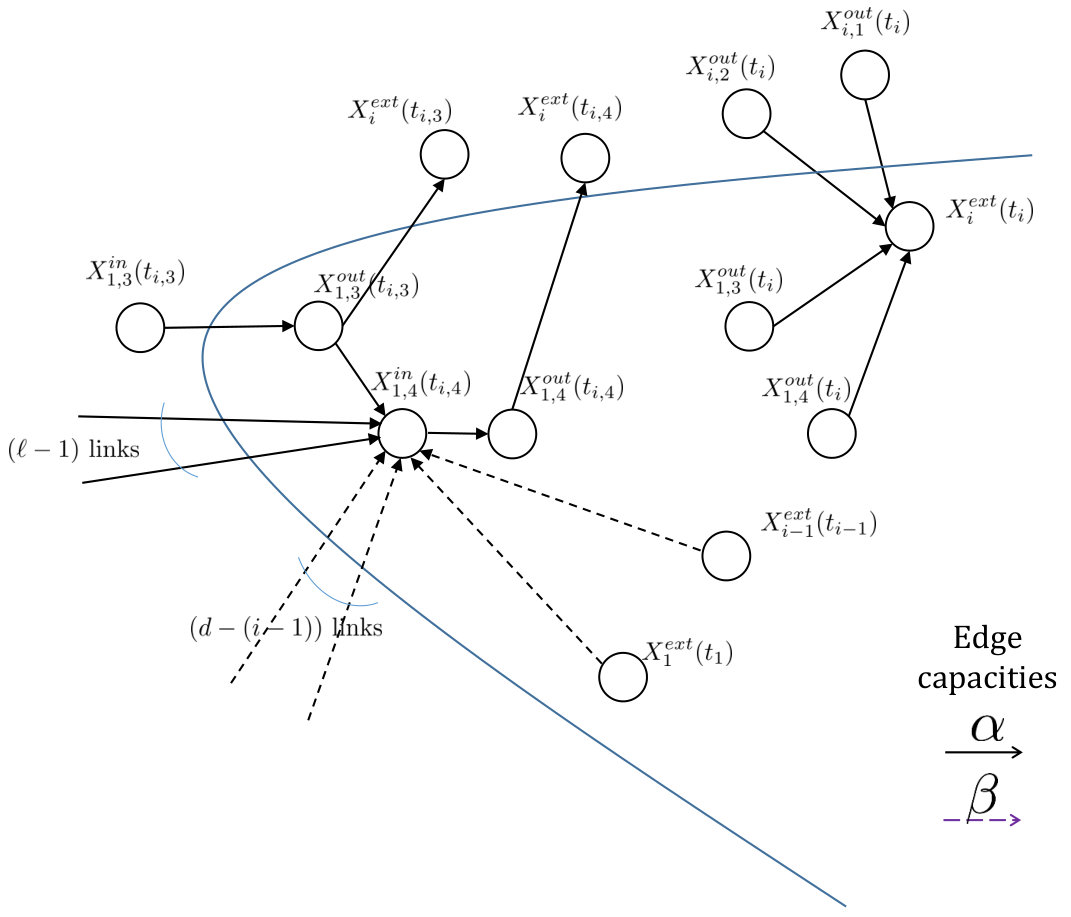 Figure 6
Figure 6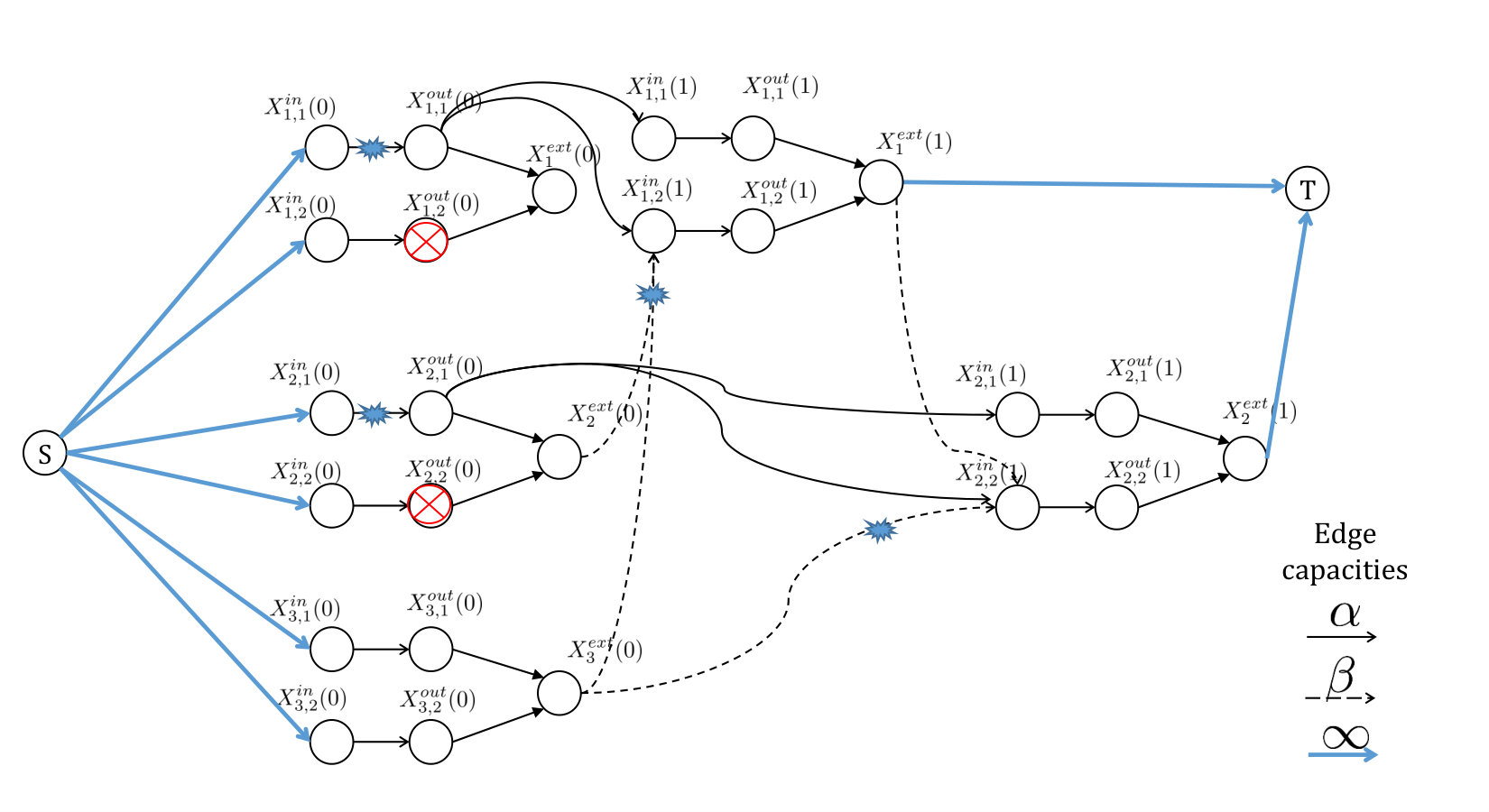 Figure 7
Figure 7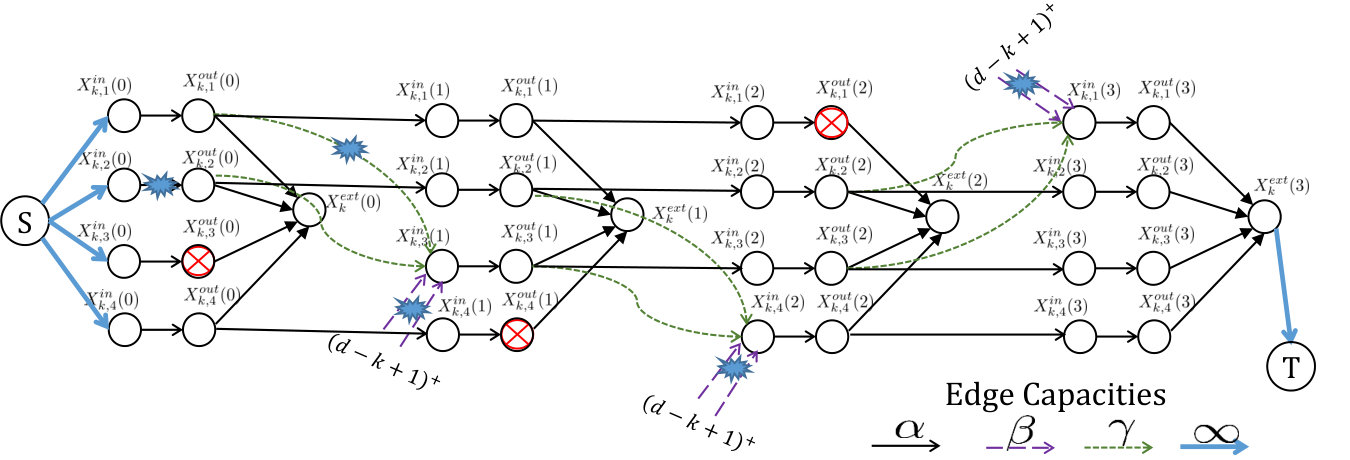 Figure 8
Figure 8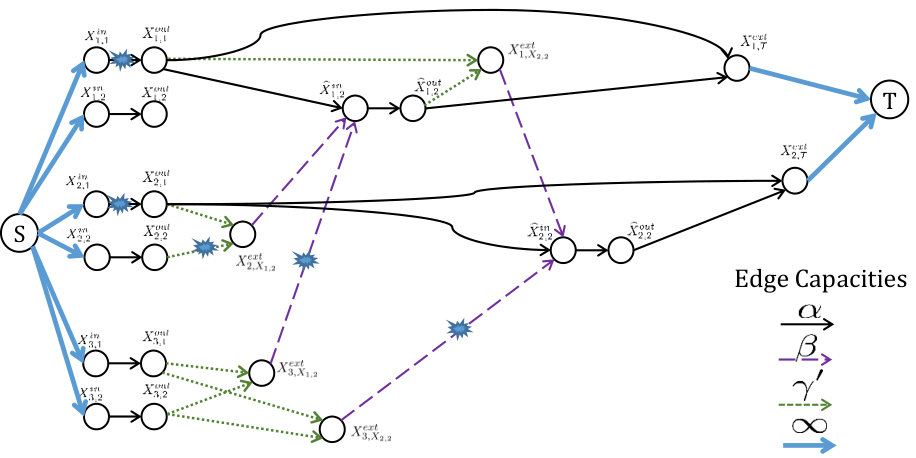 Figure 9
Figure 9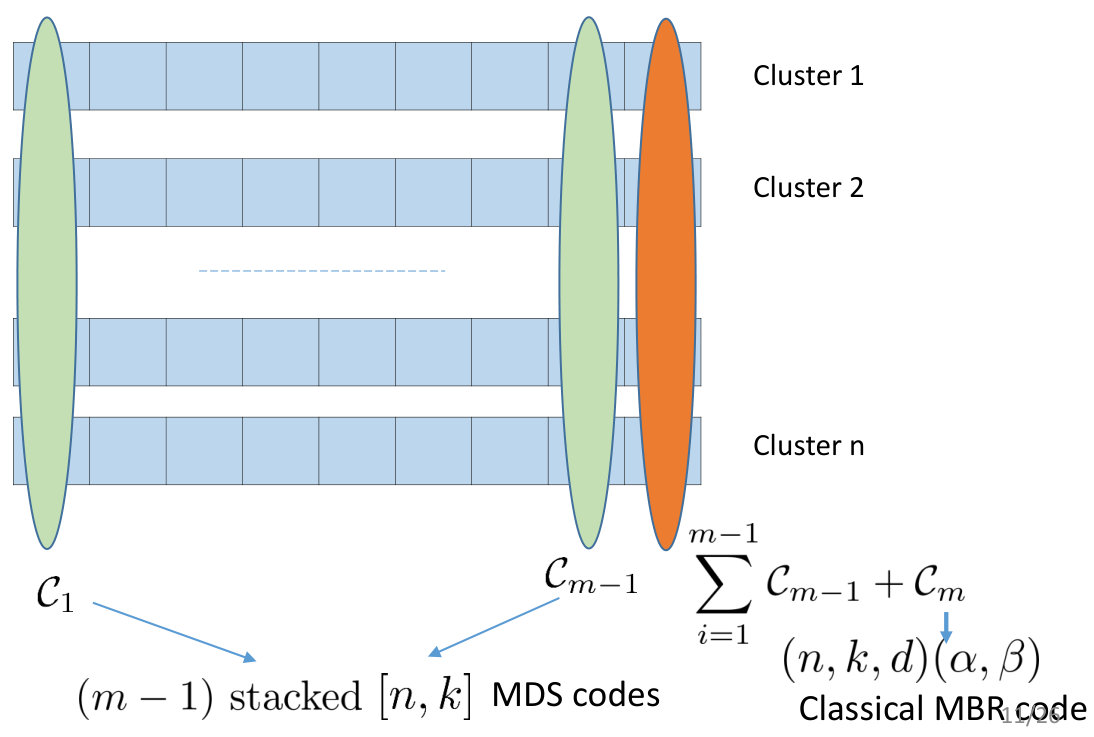 Figure 10
Figure 10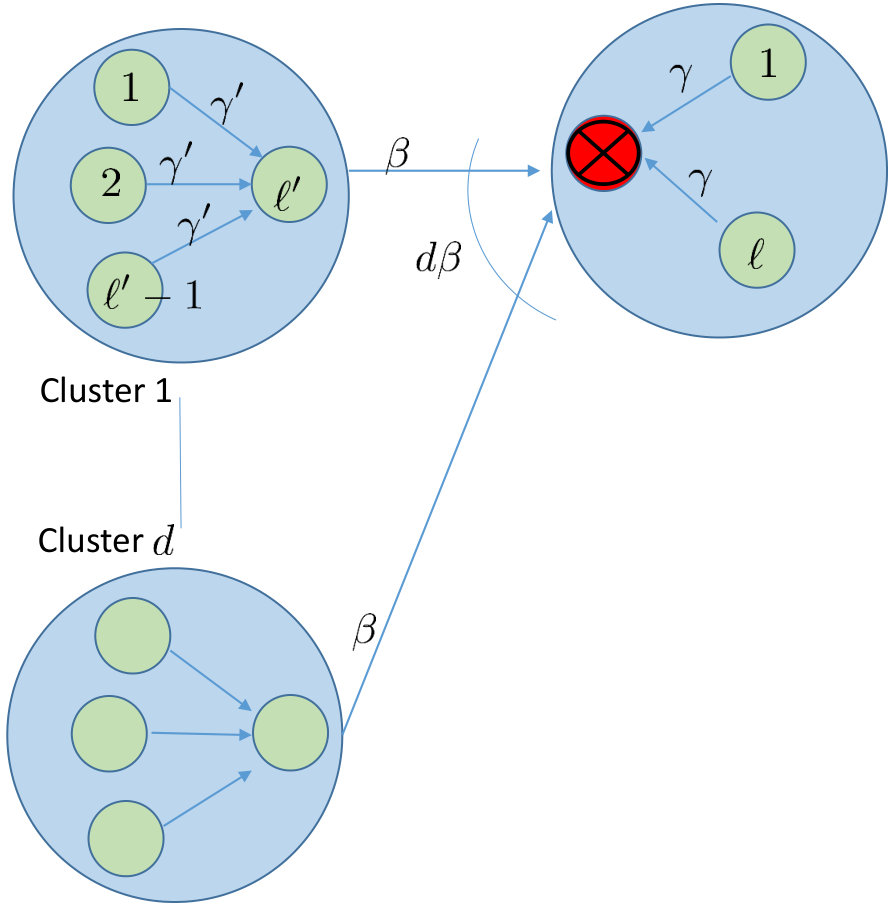 Figure 11
Figure 11 Figure 12
Figure 12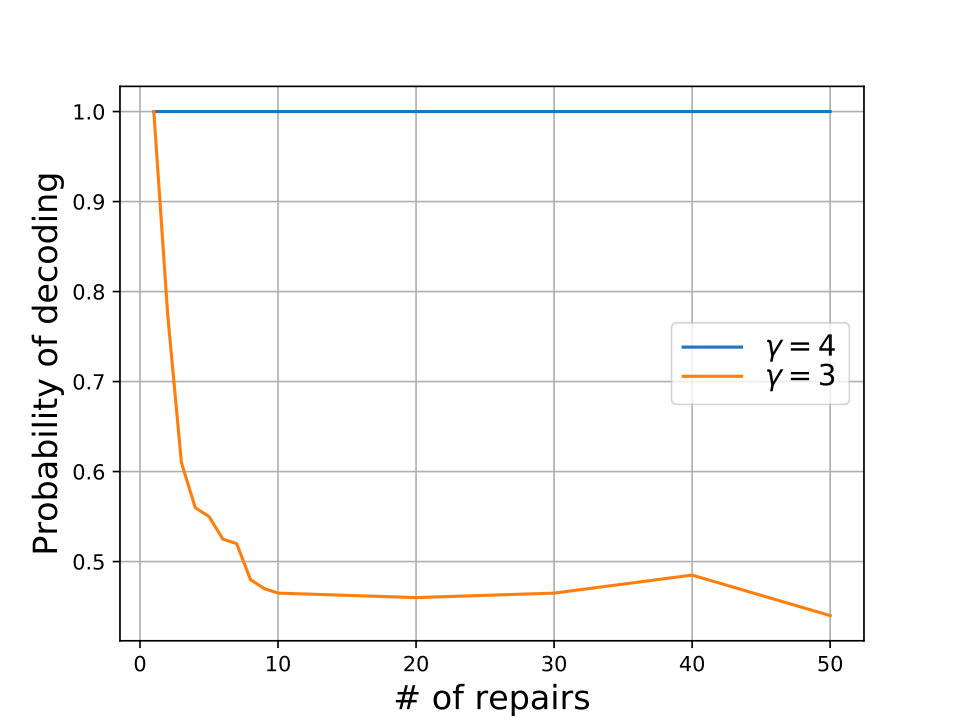 Figure 13
Figure 13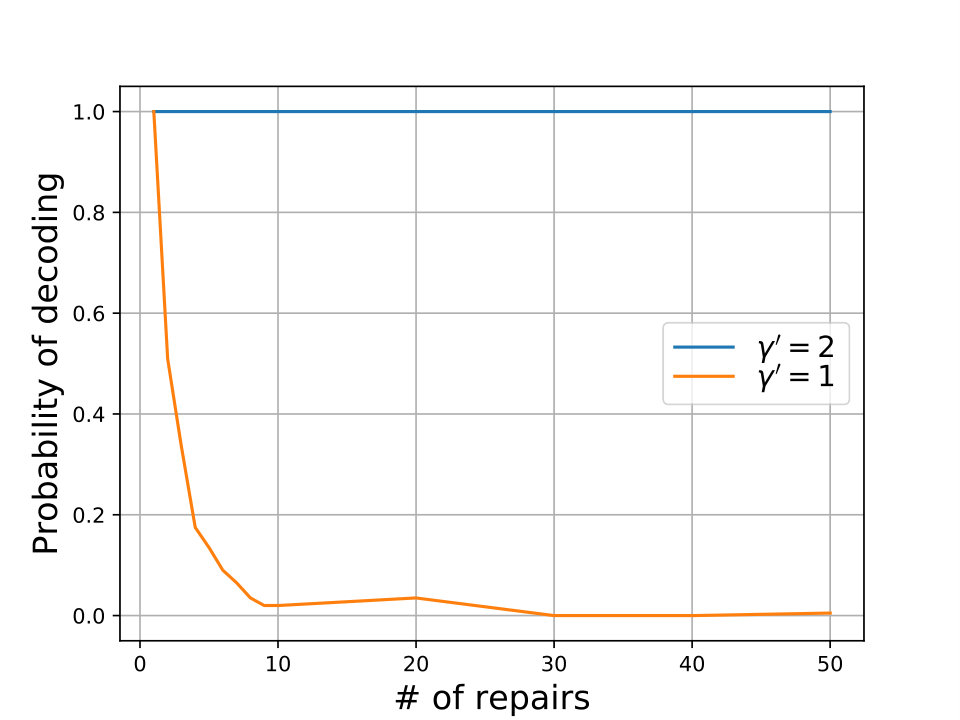 Figure 14
Figure 14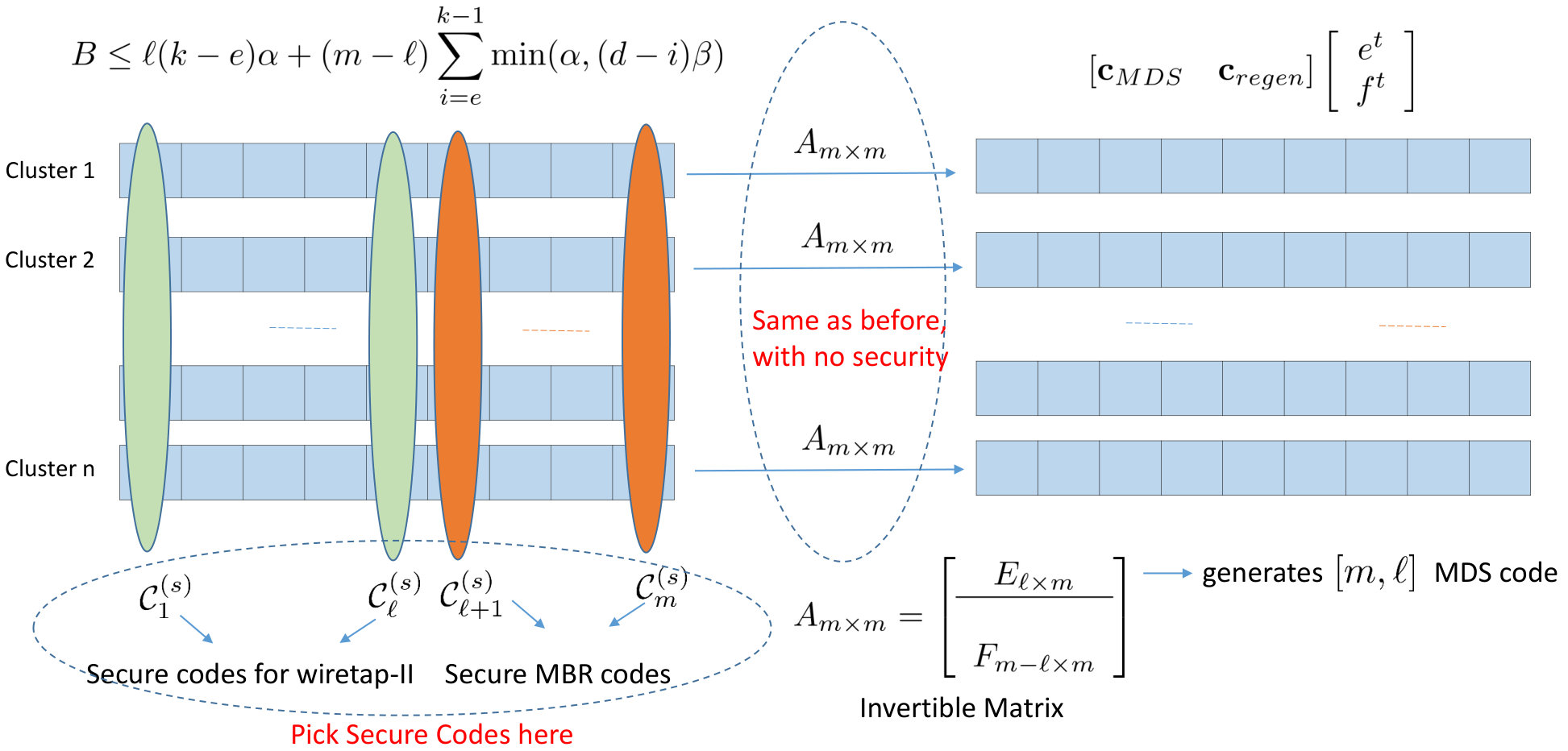 Figure 15
Figure 15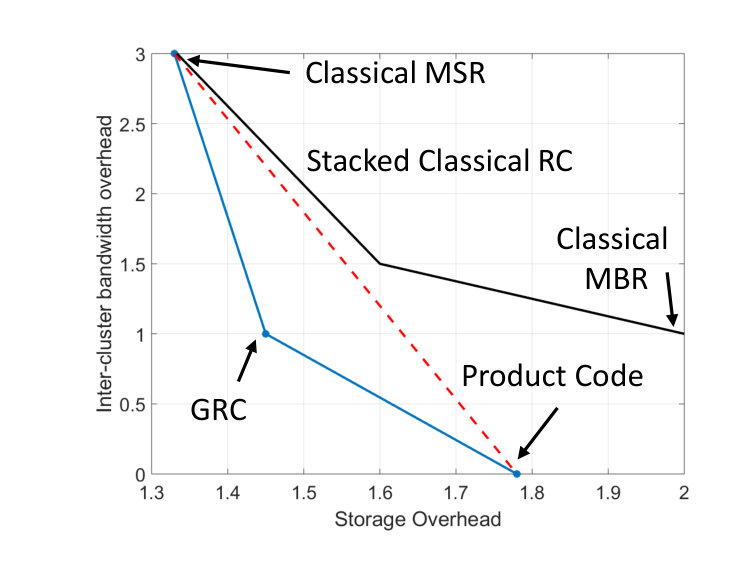 Figure 16
Figure 16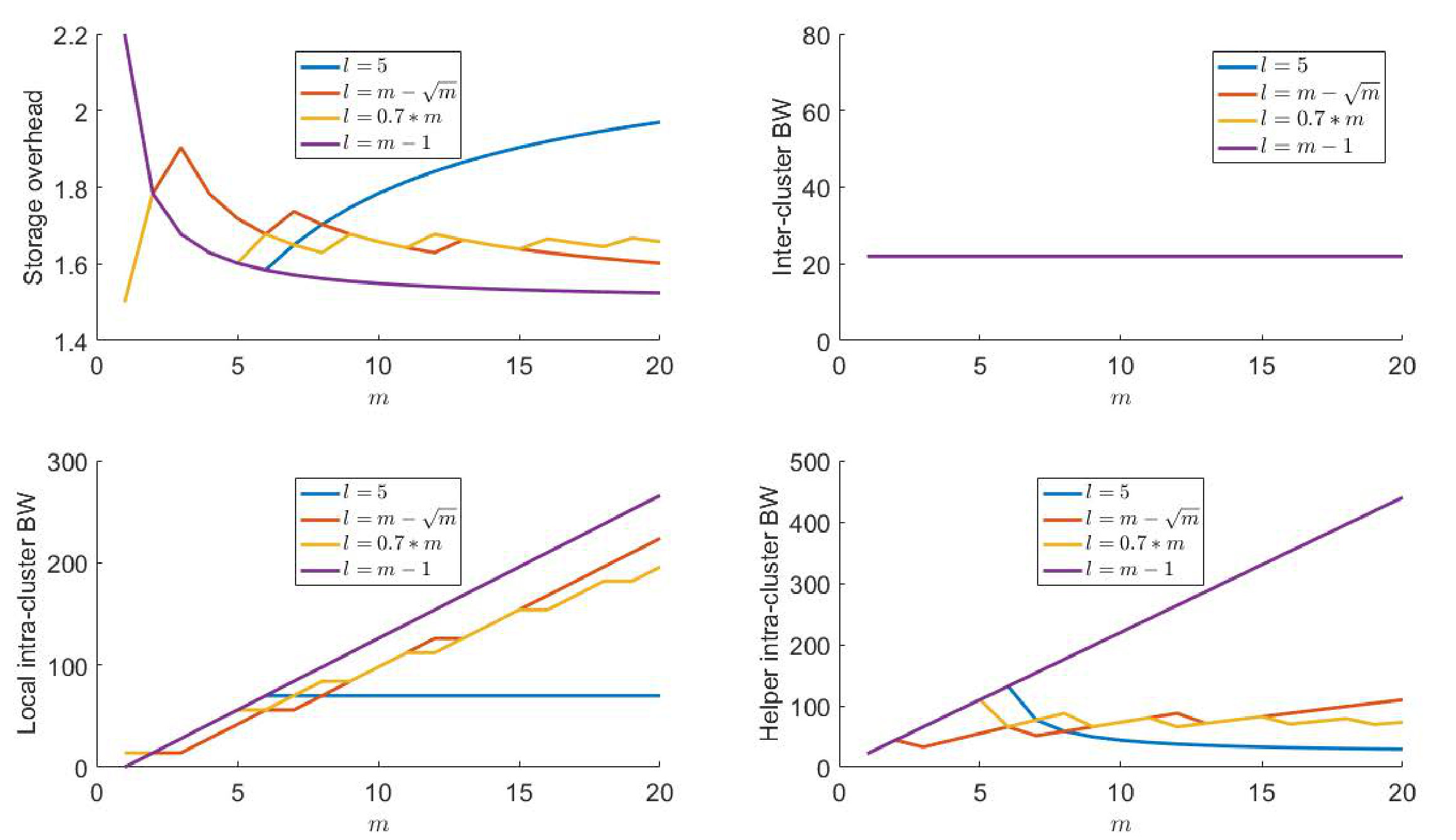 Figure 17
Figure 17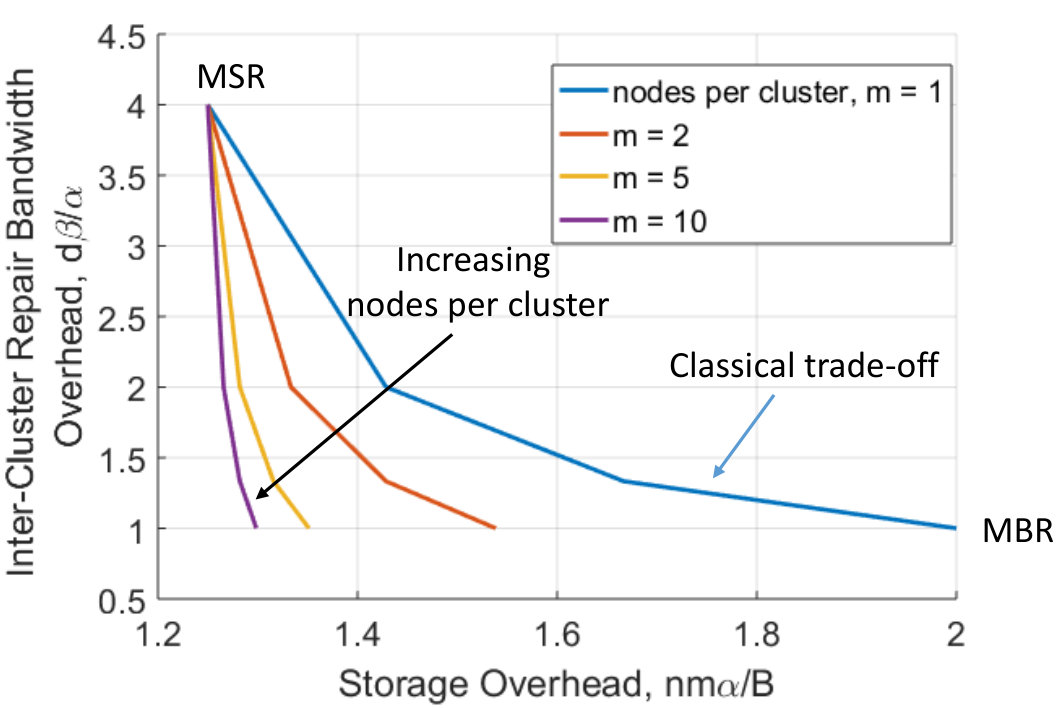 Figure 18
Figure 18| Symbol | Definition |
|---|---|
| total number of clusters in the system | |
| number of storage nodes in each cluster | |
| number of clusters required for data collection | |
| number of remote helper clusters providing helper data during node repair | |
| number of local helper nodes providing helper data during node repair | |
| finite field size for data symbols | |
| number of symbols each storage node holds for one coded file | |
| size of helper data downloaded from each remote helper cluster during node repair, in symbols | |
| \hdashline | size of helper data downloaded from each local helper during node repair, in symbols |
| number of nodes in a remote helper cluster that contribute toward computing the helper symbols of the cluster | |
| size of the data provided by each of nodes at remote helper cluster to compute the cluster helper data, in symbols |
| Reference | Focus |
| RCs in clustered topologies | |
| Hu et al. [15], Sohn et al. [17], Gastón et al. [18] | Rack-based topology with cluster-based repair, allow use of cheaper local-rack helper data. [15] and [17] permit pooling of intra-rack helper data to decrease inter-rack bandwidth. Unlike GRC, the works assume node-based data collection with no notion of clustering for data collection |
| Pernas et al. [19] | Similar to Gastón et al. [18] with 2 racks with different per-node storage |
| Calis and Koyluoglu [20] | Two-layered storage with nodes grouped in blocks, block failure model, repair and data collection from fixed number of nodes from surviving blocks. All links have same costs |
| Rashmi et al. [21] | Two sets of nodes, repair from nodes of the other set, data collection from nodes of any single set. All links have same costs |
| RCs in heterogeneous systems | |
| Shah et al. [22] | Non-uniform amount of data downloaded from nodes during repair or data collection, without any notion of clustering |
| Yu et al. [23], Ernvall et al. [24] | Non-uniform storage sizes and repair BW costs |
| Akhlaghi et al. [25] | Repair BW cost can take two different values, depending on the helper node used, this is different from clustering |
| Li et al. [26], Wang et al. [27] | Aim to transmit the repair helper data in shortest amount of time by finding the optimal path from helper nodes to replacement nodes through a network with non-uniform link capacities |
| Gopalan et al. [14] | Inherent notion of clustering for node repair, and single node is performed locally with the help of other nodes in the clusters. Thus unlike GRC, LRCs assume dependency among nodes in a cluster for single node repair. Further, there is no notion of clustering for data collection. |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
The Storage vs Repair-Bandwidth Trade-off for Clustered Storage Systems
N. Prakash, Vitaly Abdrashitov and Muriel Médard N. Prakash, Vitaly Abdrashitov and Muriel Médard are with the Research Laboratory of Electronics, Massachusetts Institute of Technology, USA (email: {prakashn, vit, medard}@mit.edu). A part of the results in the paper were presented as part of an invited talk at the 54th Annual Allerton Conference on Communication, Control, and Computing, 2016, Allerton Park and Retreat Center, Monticello, IL, USA. This work is in part supported by the Air Force Office of Scientific Research (AFOSR) under award No FA9550-14-1-043, and in part supported by the National Science Foundation (NSF) under Grant No. CCF-1527270.
Abstract
We study a generalization of the setting of regenerating codes, motivated by applications to storage systems consisting of clusters of storage nodes. There are clusters in total, with nodes per cluster. A data file is coded and stored across the nodes, with each node storing symbols. For availability of data, we require that the file be retrievable by downloading the entire content from any subset of clusters. Nodes represent entities that can fail. We distinguish between intra-cluster and inter-cluster bandwidth (BW) costs during node repair. Node-repair in a cluster is accomplished by downloading symbols each from any set of other clusters, dubbed remote helper clusters, and also up to symbols each from any set of surviving nodes, dubbed local helper nodes, in the host cluster. We first identify the optimal trade-off between storage-overhead and inter-cluster repair-bandwidth under functional repair, and also present optimal exact-repair code constructions for a class of parameters. The new trade-off is strictly better than what is achievable via space-sharing existing coding solutions, whenever . We then obtain sharp lower bounds on the necessary intra-cluster repair BW to achieve optimal trade-off. Under functional repair, random linear network codes (RLNCs) simultaneously optimize usage of both inter- and intra-cluster repair BW; simulation results based on RLNCs suggest optimality of the bounds on intra-cluster repair-bandwidth. Our bounds reveal the interesting fact that, while it is beneficial to increase the number of local helper nodes in order to improve the storage-vs-inter-cluster-repair-BW trade-off, increasing not only increases intra-cluster BW in the host-cluster, but also increases the intra-cluster BW in the remote helper clusters. We also analyze resilience of the clustered storage system against passive eavesdropping by providing file-size bounds and optimal code constructions.
I Introduction
We consider the problem of designing efficient erasure codes for fault-tolerant data storage in a clustered network of storage nodes. Nodes within a cluster are connected to each other via one network, while a second network provides connectivity between clusters. In clustered networks, there is often a differentiation between intra- and inter-cluster bandwidth costs, and this occurs because of factors like physical distance between the clusters or some other differentiating characteristic in the communications within and between clusters. Typically, intra-cluster bandwidth cost is much less than inter-cluster bandwidth cost. A user file is erasure coded and stored across the nodes in the various clusters. From an availability perspective, it is of interest to encode and store a data file such that access to a subset of clusters allows reconstruction of the entire uncoded file. We consider nodes as failure domains, and require efficient repair of failed nodes in any cluster. Repair of a failed node in a cluster is performed by downloading helper data from other clusters, and also a subset of surviving nodes in the host-cluster. We permit the possibility that a cluster that aids in the repair of a failed node gathers and processes helper-data from its various nodes, before sending it to the target-node, in order to decrease inter-cluster repair-bandwidth costs. A good erasure-code solution allows a desirable trade-off between storage-overhead and the inter- and intra-cluster repair BW costs for a given availability requirement.
The model described above is motivated by applications to cloud storage settings, where user data is spread across distinct data-centers. For instance, the clusters could represent geographically separated data centers of a cloud-service provider or a content-delivery network. All major cloud service providers like Amazon [1], Microsoft Azure [2] and Akamai [3] provide options for geo-replicating user data in multiple data centers. Geo-replication across data centers improves both availability and durability of user data. Data-center unavailability occurs owing to network or power outages, software bugs and even security vulnerabilities. Note that in the event of unavailability, data is never lost and thus does not necessitate data-center wide rebuild. While the three systems mentioned above do not mention erasure coding across data centers, other practical systems indeed consider this possibility. For example, Facebook’s F blob storage system [4] considers storing the xored content of two data centers in a third data-center. Similarly, the authors of the Hitachi white-paper [5] suggest using Reed-Solomon like codes across data centers for private clouds consisting of a small number of data-centers. Microsoft Giza [6], a geo-distributed storage system considers erasure coding data across as many as data centers spread over continents. Giza employs MDS codes like Reed-Solomon codes across data centers to handle availability requirement during data collection; i.e., a user connects to the nearest available data centers (assuming an MDS code is used) during data collection to download the data. The paper notes that (we quote) “cross-DC erasure coding only becomes economically attractive if 1) there are workloads that consume very large storage capacity while incurring very little cross-DC traffic; 2) there are enough cross-DC network bandwidth at very low cost”. The paper provides justification for both these aspects; we refer to [6] for details.
Our model is perhaps even more applicable to the setting of “cloud of clouds”, where user data is spread across data centers corresponding to multiple cloud service providers. Implementation studies that show the advantages of using Reed-Solomon-like erasure codes to store data in user-defined cloud-of-clouds appear in [7, 8, 9, 10]. Several reasons motivate a cloud-of-cloud setting, instead of a single cloud setting. The first is the need for high availability in a local geographic zone [8] - individual cloud service providers might be limited in their number of geographic zone specific data centers. Another motivation for a cloud-of-cloud setting is the flexibility to avoid vendor lock-in [7, 8]. With an ever increasing number of new cloud providers offering competitive pricing and features, it might be of interest to migrate from an existing cloud provider to a new one. However, individual cloud providers charge the users differently for in-network (intra-cluster in our model) and out-of-network (inter-cluster) data movement. In this scenario, to decrease the cost of migration, it is beneficial to spread data across several providers, so that the user only needs to migrate data in the less competitive providers to the new provider. Finally, a reason for providing user-defined cloud-of-clouds is that of privacy concerns [9, 10, 11], where security compromise of any one cloud provider does not compromise user data.
In this work, we model an entire data-center as a cluster. We restrict ourselves to the storage of a single user file; the solution provided here can be applied independently to any of the user files. For storage of a single coded file, we assume an equal number of storage nodes in any of the clusters. While performing data collection, we assume a cluster to be either completely available or completely unavailable. Such an assumption is sensible in a multi-data-center cloud setting [5]. In our model, we restrict ourselves to recovery from single node failure. If there are multiple node failures in the system, it is assumed that the recovery process happens sequentially, one node at a time. While catastrophic failure of an entire data-center is rare, correlated failures of nodes in a data center are an important issue reported in practice [12]. In this scenario, in our model, we parametrize the number of nodes, named local helper nodes, in the host-cluster that can aid in the repair of a node in the host-cluster. Further, to keep the model simple, we ignore any hierarchical topologies that may be present inside a data-center (cluster), and simply assume equal cost connectivity between any two nodes inside a cluster. We also assume direct connectivity between any two clusters in the network.
A straightforward solution that guarantees availability of data, and minimizes inter-cluster repair-bandwidth costs is simply to use a product code consisting of two Maximum Distance Separable (MDS) codes - one across the clusters, and another within a cluster. While the solution entirely eliminates any inter-cluster bandwidth cost, it suffers from poor storage-overhead owing to the need to have redundancy in every cluster. At the other extreme, it is also possible to achieve highly optimized storage cost, at the expense of inter-cluster repair-bandwidth, by using minimum storage regenerating (MSR) codes [13] across the clusters. For instance, if we assume there are clusters in total, then MSR codes across the clusters ensure that data is retrievable by accessing (entire) content of any clusters. However, the solution suffers from high inter-cluster repair-bandwidth cost. Our goal in this work, at a high level, is to explore alternate solutions which can smoothly trade-off storage-overhead against inter-cluster repair-bandwidth for given availability requirements. We show that it is indeed possible to achieve (see Fig. 6) operating points which are strictly better than those obtained by space-sharing between product MDS codes and MSR codes. We also characterize the amount of intra-cluster repair-bandwidth needed for achieving the optimal trade-off between storage-overhead and inter-cluster repair bandwidth.
For the rest of the introduction, we first provide an abstract description of the system model used in this work. This is followed by a discussion of other related system models in the literature, a summary of our results, and also an example of the proposed erasure-coding solution.
I-A System Model
We propose a natural generalization of the setting of regenerating codes (RC) [13] for clustered storage networks. The network consists of clusters, with nodes in each cluster. The network is fully connected such that any two nodes within a cluster are connected via an intra-cluster link, and any two clusters are connected via an inter-cluster link. A node in one cluster that needs to communicate with another node in a second cluster does so via the corresponding inter-cluster link. A data file of size symbols is encoded into symbols, and stored across the nodes such that each node stores symbols. The symbols are assumed to come from a finite field of elements. For data collection we have an availability constraint such that the entire content of any clusters be sufficient to recover the original data file (Fig. 1). As mentioned before, nodes represent failure domains, and we restrict ourselves to the case of efficient recovery from single node failure. Node repair is parametrized by three parameters and . We assume that the replacement of a failed node is in the same cluster as the failed node. The replacement node downloads symbols each from any set of other clusters, dubbed remote helper clusters. The symbols from any of the remote helper clusters are possibly a function of the symbols present in the cluster - we assume that any one of the nodes in the cluster takes responsibility for computing these symbols before passing them outside the cluster111One could also assume the presence of a dedicated compute unit to compute the helper data. Such an assumption allows us to enforce a symmetric demand on the usage of intra-cluster bandwidth for all the nodes in the remote helper cluster. We will rely on the presence of such dedicated compute units in the information flow graphs (see Section III) used to derive file-size upper bounds.. Further, we also permit the replaced node to download (entire) content from any set of other nodes, dubbed local helper nodes, in the host cluster, during the repair process. The quantity represents the inter-cluster repair-bandwidth. We refer to the overall code as the generalized regenerating code (GRC) with parameters .
The model reduces to the setup of RCs in [13], when (in which case, automatically). We shall refer to the setup in [13] as the classical setup or classical regenerating codes. Our generalization has two additional parameters and when compared with the classical setup. As in the classical setup we consider both the notions of functional and exact repair. Under exact repair, the content of the repaired node is identical to that of the failed node; while in functional repair, the repair content permits data collection and repair of additional failed nodes. The first goal of the paper is to obtain a trade-off between storage-overhead and inter-cluster repair-bandwidth for an GRC. We further note that, unlike the classical setup, the generalized setup permits . In our model, whenever , we assume that the encoding function does not introduce any local dependence among the content of the various nodes of a cluster222Under linear encoding, the coded content of cluster can be written as , where is the message vector of length , and is a matrix. In this case, when we say that the encoding not introduce local dependence, we mean that the matrix has full column-rank; for example, the model excludes the possibility of a local parity node within a cluster, which would hold the component-wise sum in of the other nodes’ data. As we shall show, the case is a special one where local dependence is necessary.
The model described above does not consider intra-cluster bandwidth incurred during repair. Intra-cluster bandwidth is needed, firstly, to compute the symbols in any remote helper cluster, and, secondly, to download content from local helper nodes in the host cluster. In order to characterize the amount of intra-cluster bandwidth that is needed to establish optimal trade-off between storage-overhead and inter-cluster repair-bandwidth, we consider the repair model shown in Fig. 1(b). In this model, the replacement node downloads at most symbols from each of the local helper nodes from the host-cluster. With regard to a remote helper cluster, we assume that the symbols contributed by it are only a function of at most nodes of the cluster. We make the assumption that any set of nodes can be used to compute the symbols. Further, we limit the amount of data that each of these nodes can contribute to at most symbols. A second goal of this paper is to identify necessary requirements on the parameters that are needed to guarantee optimal trade-off between storage-overhead and inter-cluster repair-bandwidth.
A summary of the various parameters used in the description of the system model appears in Table I.
I-B Related Work
Regenerating codes were originally introduced in [13] for simultaneously optimizing storage overhead and repair bandwidth for flat storage systems. By a flat storage system, it is meant that every node in the storage system is connected to every other storage node via some logical link, where all logical links incur the same bandwidth cost for communication per bit. Further, the data collector also connects to any of the storage nodes via links of similar cost. There has since then been significant progress in the area of classical RCs in terms of code constructions, finding optimal trade-offs under exact repair, and practical implementation. Below, we review variations of RCs that have been proposed for non-flat topologies, and see how our model relates to these existing variations. We shall also comment on how the model of locally repairable codes [14] relates to our model.
I-B1 Regenerating Code Variations for Clustered Topologies
Regenerating code variations for data-center like topologies consisting of racks and nodes are considered in [15, 16, 17, 18, 19, 20]. In [15], [17] and [18], the authors distinguish between inter-rack (inter-cluster) and intra-rack (intra-cluster) bandwidth costs. Further, the works [15] and [17] permit pooling of intra-rack helper data to decrease inter-rack bandwidth. Also, all three works allow taking help from host-rack nodes during repair. Unlike our model, for data collection all three works simply require file retrievability from any set of nodes irrespective of the racks (clusters) to which they belong. In other words, the notion of clustering applies only to repair, and not data collection, and this is a major difference with respect to our model. Thus while these variations are suitable for modeling the node-rack topologies present within a data center, they do not model situation of erasure coding across data centers with the availability requirement as considered in this work. The work [16] applies the theoretical results of [15] for the practical setting of Hadoop file system. The work in [19] is a variation of that in [18] for a two-rack model, where the per-node storage capacity of the two racks differ. In [20], the authors consider a two-layer storage setting like ours, consisting of several blocks (analogous to clusters as considered in this work) of storage nodes. A different clustering approach is followed for both data collection and node repair. For data collection, one accesses nodes each from any of blocks. Though [20] focuses on node repair, the model assumes possible unavailability of the whole block where the failed node resides, and as such uses only nodes from other blocks for repair. Further, unlike our model in this work, the authors do not differentiate between inter-block and intra-block bandwidth costs. The framework of twin-codes introduced in [21] is also related to our model and implicitly contains the notion of clustering. In [21] nodes are divided into two sets. For data collection, one connects to any nodes in the same set. Recovery of a failed node in one set is accomplished by connecting to nodes in the other set. However, there is no distinction between intra-set and inter-set bandwidth costs, and this becomes the main difference with our model.
I-B2 Regenerating Code Variations for Heterogeneous Systems
Several works [22, 23, 24, 25, 26, 27] study variations of RCs in varied settings, with different combinations of node capacities, link costs, and amount of data-download-per-node. The main difference between our model and these works is that none of them explicitly considers clustering of nodes while performing data collection. In [22], the authors introduce flexible regenerating codes for a flat topology of storage nodes, where uniformity of download is enforced neither during data collection, nor during node-repair. References [23], [24] consider systems where the storage and repair-download costs are non-uniform across the various nodes. The authors of [23], as in [22], allow a replacement node to download an arbitrary amount of data from each helper node. In [25], nodes are divided into two sets, based on the cost incurred while these nodes aid during repair. As noted in [19], the repair model of [25] is different from a clustered network, where the repair cost incurred by a specific helper node depends on which cluster the replacement node belongs to. The works of [26] and [27] focus on minimizing regeneration time rather regeneration bandwidth in systems with non-uniform point-to-point link capacities. Essentially, each helper node is expected to find the optimal path, perhaps via other intermediate nodes, to the replacement node such that the various link capacities are used in a way to transfer all the helper data needed for repair in the shortest possible time. It is interesting to note both of these works permit pooling of data at an intermediate node, which gathers and processes any relayed data with its own helper data. Recall that our model (and the one in [15]) also considers pooling of data within a remote helper cluster, before passing on to the target cluster.
I-B3 Locally Repairable Codes
Locally repairable codes (LRCs), introduced in [14], are motivated by the need to carry out efficient node repair in hierarchical storage systems, such as data centers. The subject of LRCs, like regenerating codes, has attained significant attention both in theory and practice, since its introduction. Recovery of a node failure within a cluster is first attempted locally, in order to minimize cross-cluster bandwidth; if too many nodes in the cluster are unavailable, global parity nodes, spread across various clusters, aid in recovery. However, LRCs do not model clustering of nodes while carrying out data collection, and this is once again a major difference with our model. To draw further similarities with LRCs, we note that in our model, during the repair of a node, the helper data from the nodes from the same cluster can be considered as local-helper data. However if , unlike in LRCs, local-helper data alone is not sufficient for single-node-repair, since in this work we assume the encoding function of the generalized regenerating code to introduce no dependency among the content of the nodes in any cluster. For , lack of dependencies within each cluster reduces storage overhead when compared to LRCs; at the same time, local-helper data allows us to achieve a trade-off between storage-overhead and the inter-cluster-repair-bandwidth better than that of a system with stacked classical RCs, in which the set of -th nodes in all clusters stores the data encoded with -th RC. The case corresponds to one having no remote helper clusters, so that the repair is carried out entirely locally. The difference in this case of with model of LRCs is notion of clustering of nodes, while performing data collection.
A tabular summary of related works appears in Table II.
I-C Our Results
I-C1 Upper Bound on File Size
Under the setting of functional repair, the file-size is shown to be upper bounded by
[TABLE]
where we use the notation to mean , for any integer . The bound is shown by considering the information-flow graph (see Section III) under functional-repair, and calculating the minimum cut. For any finite information-flow graph, the achievability of (1) follows from results in network coding [28]. This establishes the optimality of (1) when we know an upper bound on the number of node failures that occur during the life-time of the system. In practice, random linear network codes (RLNCs) [29] can be used to achieve near-optimal operating points.
For fixed values of , (1) gives a normalized trade-off (see Fig. 2) between storage-overhead and inter-cluster-repair-bandwidth-overhead (see Section IV-A as to why we refer to as repair-bandwidth-overhead). For any , when , the trade-off is exactly same as that of the classical regenerating codes [13]. When (implies ), the trade-off is strictly better than that of the classical setup.
I-C2 Optimal Code Constructions
We present optimal codes for the minimum storage-overhead and the minimum inter-cluster repair-bandwidth-overhead operating points of the trade-off, for a class of parameters and under the setting of exact repair. These two operating points corresponding to MSR and MBR codes, respectively. The operating points of the MSR and MBR codes are characterized by relations and respectively. The construction works by suitably combining vector MDS codes over and classical exact-repair MSR (MBR) codes. We also present an optimal code construction for functional-repair, which tolerates an arbitrary number of failures333The network-coding based achievability works only if there is a known upper bound on the number of repairs that occur over the duration of operation of the system., for the case . The code is constructed by combining vector MDS codes over , and an functional-repair code from [30] for the classical setting. The code construction in [30] is an instance of a functional-repair code for the classical setting, which tolerates an arbitrary number of failures and repairs for the duration of operation of the system.
I-C3 Lower bound on Intra-Cluster Bandwidth Related Parameters
We calculate lower bounds on the intra-cluster-bandwidth related parameters , shown in Fig. 1, under assumption that (1) is achieved with equality. While studying the impact of any one of these parameters, we ignore the effects of the other two; for example, the lower bound on is obtained under the assumption that and , etc.
Under functional repair with , the per-node intra-cluster bandwidth needed from the host-cluster is lower bounded by
[TABLE]
When , the bound gives , i.e. the entire content of the local helper nodes must be used. For , at the MBR point characterized by , the bound gives , and at the MSR point characterized by , the bound gives . The trivial bound at the MSR point is indeed optimal, since optimal (achieving equality in (1)) codes at the MSR point can be achieved by simply stacking classical MSR codes. In this case, no local help is needed for repair, and hence is indeed optimal at the MSR point. In fact, under functional repair, the bound in (2) is optimum not just at the MSR point; we prove the converse statement that, as long as , it is indeed possible to achieve the optimal file-size in for any set of parameters, as long as there is a known upper bound on the number of repairs in the system.
We provide bounds for the parameters and which characterize intra-cluster bandwidth from remote helper cluster under the assumption 444The values of in the range corresponds to the region in the trade-off between the minimum-storage operating point and the next corner point. The bound in (3) does not apply when is in this range. that , and . Specifically we show the parameter is no less than , i.e., , and
[TABLE]
Under functional repair, RLNCs simultaneously optimize usage of both inter-cluster and intra-cluster bandwidths. Our simulations based on RLNCs indicate the tightness (achievability) of the bound in (3), under functional repair (see Fig. 3). We do not have an analytical converse for this bound.
The bounds on and highlight the necessary trade-off between the system capacity and the remote helper intra-cluster bandwidth555We note that we quantify the remote helper intra-cluster bandwidth as though from Fig. 1, one gets the impression that this is . This discrepancy arises because, in our IFG analysis (see Section III), we assume the presence of a dedicated external compute node which connects to all the helper nodes and generates the helper data. Such an assumption makes the IFG modeling symmetric with respect to the helper nodes. The choice of instead of as the amount of helper bandwidth is purely matter of convenience. The nature of results do not change even if one assumed as the amount of helper bandwidth. , via parameter , the key parameter that distinguishes our model from the classical model. Our bounds reveal the interesting fact that, while it is beneficial to increase the number of local helper nodes in order to improve the storage-vs-inter-cluster-repair-bandwidth trade-off, increasing not only increases intra-cluster repair-bandwidth in the host-cluster, but also increases the intra-cluster repair-bandwidth in the remote helper clusters. For example, if we consider MBR codes (having minimum inter-cluster-repair-bandwidth), we see that their storage-overhead approaches that of MSR codes for large as gets close to . However, a high value of also increases the remote helper cluster bandwidth; indeed, surges as approaches ; see Fig. 4 for an illustration.
I-C4 Security under Passive Eavesdropping - Bounds and Codes
We study resilience of the clustered storage system against passive eavesdropping. An eavesdropper (say, Eve) gains access to the entire content of any subset of clusters, where . Eve also gets to observe all the helper data downloaded for repair of nodes in these clusters. The properties of data collection and disk repair remain same as in the case of no eavesdropper. The setting is along the lines of that considered in [31], where authors study security under the classical RC framework. The maximum file size that can be securely stored such that Eve does not gain any information about the file is shown to be upper bounded by
[TABLE]
We also present explicit optimal secure codes for the MBR point under the setting of exact repair. Like in the case of no security, an optimal secure code is constructed by suitably precoding a combination of component codes, but this time the component codes themselves are secure codes. A code at the MBR point is constructed by combining secure MDS codes for the wiretap-II channel [32][33], and classical exact-repair secure MBR codes [31][34]. Our security results are straightforward extensions of the security results for classical RCs, given our own results for the no-security case.
I-D An Example
Consider a system consisting of clusters, with nodes/cluster, where we have the availability requirement that content from any set of clusters suffice for data collection. Let us consider three coding options, which permit single node repair: A product code consisting of two simple parity check codes, one across the clusters, and another within a cluster. In this case, repair happens entirely within a cluster, and there is no inter-cluster bandwidth. Note that this corresponds to the case of in our framework. Stacking classical RCs - by this we mean that corresponding nodes from the clusters employ the classical RCs. This corresponds to the case of in our framework. A GRC, which is constructed as follows (see Fig. 5): We stack simple parity check codes (over the vector alphabet ) to populate coded data in all but the last nodes of all the clusters. In the last column (corresponding to the last node of all clusters), we place the sum of the three previous codes plus a classical MBR code. Constructions of classical MBR codes appear in [35]. Data collection property of the code is straightforward. For repair of any node, the last node of each of the remote helper clusters (with the help of the remaining nodes) first extracts the MBR code, and passes the helper data for the MBR code to the replacement node. The latter regenerates the MBR code content first, and uses the helper data from the local nodes to finally recover the original stored content. The storage-overhead vs inter-cluster-repair-bandwidth trade-off achieved by these three options is shown in Fig. 6. We see that the framework of GRCs introduced here, offers operating points which are strictly better than those that can be achieved by space sharing the first two options.
We note that in the above example, the product-code solution carries the extra advantage of handling node-availability during data collection. In other words, when using the product code, one can chose to download content from any nodes from any of the clusters. This is sometimes beneficial when the node is temporarily unavailable. No such feature is present in the GRC. In the current paper, since we deal with the case of recovery from single node failure, enforcing availability (local dependence within a cluster) essentially implies restricting oneself to using product codes, and nothing else. A key insight that we wish to convey from Fig. 6. is the fact that while dealing with single node repair, it is potentially beneficial to sacrifice availability (of nodes during data collection, offered by product codes) in order to achieve operating points that are strictly better than those obtained by space sharing the two schemes.
The rest of the document is organized as follows. In Section II, we present simple proof of the file-size bound in (1) for the special cases and . As mentioned before, the general case of the file-size bound is based on the notion of information-flow graph (IFG) models; these IFG models are developed in III, followed by the derivation of the file-size bound under functional repair for general set of parameters in Section IV. The exact-repair and functional-repair code constructions appear in Section V. Bounds on parameters relating to intra-cluster bandwidth under functional repair, are discussed in Section VI. Section VII considers security under passive eaves-dropping. Finally, our conclusions and directions for future work appear in Section VIII.
II File size bound for Special Cases
In this section, we consider certain special cases of the setting of generalized regenerating codes, and identify the corresponding storage vs inter-cluster-repair-bandwidth trade-offs. The following cases are considered , which corresponds to the case when repair of a node is carried out entirely with the help of other local helper nodes in the cluster. , which corresponds to the case when repair of a node is carried out solely with the help of remote clusters, without taking any help from local nodes in the host-cluster.
II-A Case : No Inter-Cluster Help for Repair
When , node repair is accomplished by contacting any set of other nodes in the host cluster. Since any set of clusters should be sufficient to decode the whole file, it follows that the file-size is upper bounded by
[TABLE]
The achievability of the above bound follows by using an product code, with both component codes being MDS codes over . In fact, the parameter is redundant for this case; one may choose in practice. It is clear that there is no storage vs inter-cluster-repair-bandwidth trade-off offered by this case.
II-B Case : No local helper data
We next consider the special case when repair is performed without any help from nodes in the host-cluster. Let denote a GRC of file-size with parameters . Let denote that maximum possible file-size for any GRC having parameters . We note that the code denotes a classical RC, and under functional-repair, we know that [13]
[TABLE]
Theorem II.1
The optimal file size under the setting of functional-repair GRCs, for the case of no local helper nodes, is given by
[TABLE]
Proof:
The achievability part of the proof is straightforward; the optimal code is constructed by simply stacking classical codes each of which achieves the bound in (6). By stacking, we mean that the code is deployed across the corresponding nodes from all clusters. In this case, note that during node-repair, there is no pooling of content from various nodes of a remote helper cluster; repair happens as though there is only one code in the system.
For showing the upper bound on the file size, we note that given a code with file-size having parameters , one can construct a functional-repair classical regenerating code , also with file-size , and having parameters , where . For this, we simply assume the contents of all nodes of any cluster of , to be the contents of node of . Clearly retains the data collection property. For node repair in , we perform individual repairs of each of the nodes, but with the same set of remote helper clusters. In this case, we know that
[TABLE]
∎
Theorem II.1 implies that, under functional repair, the normalized trade-off between storage-overhead and inter-cluster-repair-bandwidth-overhead for an GRC is identical for any ; specifically, it is identical to the trade-off of an functional-repair classical RC.
III Information Flow Graph Model
In this section, we describe the information flow graph (IFG) models used to derive the various bounds in this work. The models are generalizations of the one used in [13] for the case of classical regenerating codes. Under functional repair, the problem is one of multicasting the source file to an arbitrary number of data collectors over the IFG. The IFG characterizes the data flows from the source to a data collector, and also reflects the sequence of failures and repairs in the storage system. Two models of IFGs will be used; the first one will be used in two scenarios: to derive the trade-off between storage-overhead and inter-cluster repair-bandwidth overhead. While obtaining this trade-off, we ignore the effects of intra-cluster bandwidth, to find the optimal local helper node intra-cluster bandwidth , which is needed to establish the optimal trade-off between storage-overhead and inter-cluster repair-bandwidth overhead. We wish to note that while obtaining the bound on , we do not impose any limitations on , i.e, we assume that and . A second related model will be used while deriving the lower bounds on the parameters , which relate to the intra-cluster repair bandwidth needed in the remote helper clusters. In this second model, we shall assume that , i.e., we ignore the effects of limited local helper-node intra-cluster bandwidth, while calculating bounds on remote helper-node intra-cluster bandwidth. We describe the two models next.
III-A IFG Model for Storage vs Inter-Cluster Repair Bandwidth Trade-off
Let denote the physical node in cluster , . Recall that capacity of any node is . In the IFG, the physical node is represented by the pair of nodes and , with an edge of capacity going from to . The nodes and will be respectively referred to as the in-node and out-node corresponding to the physical node . We will write to denote that there is an edge from going from to . With a slight abuse of notation, we will let to also denote the pair of the graph nodes. Cluster also has an additional external node, denoted as . Each out-node is connected to via an edge of capacity . The external node is used to transfer data outside the cluster, and thus serves two purposes: it represents a single point of contact to the cluster, for a data collector which connects to this cluster, and it represents the compute unit which generates the symbols for repair of any node in a different cluster.
The source node represents the original placement of the encoded source file into the storage nodes. connects to the in-nodes of all physical storage nodes in their original state , via links of infinite capacity. The sink node represents a data collector, it connects to the external nodes of an arbitrary subset of clusters also via links of infinite capacity.
Each cluster at any moment has active nodes. When a physical node fails, it becomes inactive, and its replacement node, say , becomes active instead (see Fig. 7 for an illustration). The replacement node is regenerated by downloading symbols from any nodes in the set . The replacement node also connects to any subset of nodes in the set . The capacity of the links depend on whether we use the model for finding the inter-cluster-bandwidth vs storage trade-off, or we use it for finding bounds on local helper bandwidth . These links have capacity and in the former and latter cases, respectively.
In our model, recall that we focus on one repair at a time. In this scenario, along with the replacement of with , we will also copy all the remaining nodes, as they are, in the cluster , and represent them with new identical pair of nodes . We shall also a have a new external node for the cluster, which connects to the new out-nodes. Thus, in the IFG modeling, we say that the entire old cluster (where the failed node resides) becomes inactive, and gets replaced by a new active cluster. For either data collection or repair, we connect to external nodes of the active clusters. Note that, at any point in time, a physical cluster contains only one active cluster in the IFG, and inactive clusters in the IFG, where denotes the total number of failures and repairs experienced by the various nodes in the cluster. We shall use the notation to denote the cluster that appears in IFG after the repair associated with cluster . The clusters are inactive, while is active, after repairs. The nodes of will be denoted by . With a slight abuse of notation, we will let to also denote the collection of all nodes in this cluster. We write to denote the pair ; again, with a slight abuse of notation, we shall use to also denote the node in cluster after the repair (in cluster ). We further use notation to denote the union of all nodes in all inactive clusters, and the active cluster, corresponding to the physical cluster after repairs in cluster , i.e., . We have avoided indexing with the parameter as well, to keep the notation simple. The value of in our usage of the notation will be clear from the context.
III-B IFG Model for Finding Bounds on Intra-Cluster Repair Bandwidth
We now describe the model used to obtain lower bounds on the parameters . Unlike in the case of bounds for file-size and local helper node intra-cluster bandwidth , where we also show converses, for and we do not provide converses to the lower bounds. When only dealing with lower bounds, we can significantly simplify the model described above. In addition to making these simplifications, we also add some structure to the model to enable usage of and . We describe these changes next.
In the second model, each physical node is again represented by the pair of nodes , such that the edge has capacity . In this model, an external node(s) is(are) added dynamically to a cluster whenever it aids in either data collection or repair of another node. Each instance of an external node is used exactly once, either for a repair or a data collection operation. Whenever a physical node fails, we say that it becomes inactive, and its replacement node, say , becomes active in the same cluster. The remaining nodes are not replicated, as in the previous model. Thus, in the second model, there is only a single graph cluster corresponding to a physical cluster. On the graph representation, the replacement node is visually linked to the replaced failed node with a red dotted line (see Fig. 8 for an example).
We explain the repair and data collection operation in the IFG in more detail next. During repair, the replacement node connects to any subset of active nodes in the same cluster via links of capacity . It also downloads symbols each from remote helper clusters via their external nodes. If replacement node downloads helper data from cluster , an external node, , is added to the IFG, such that the edge has capacity . External node also connects locally to a subset of active out-nodes of cluster via links of capacity . Note how we index the external node of cluster that aids in the repair of . Every time cluster acts as a remote helper cluster toward the repair of any node, we add a new external node in a manner similar to . Finally, a data collector, , connects to cluster via the external node , which in turn connects to all active out-nodes in the cluster via links of capacity . We index the external node also with since the active nodes that form part of the cluster evolves over time.
In comparison with previous model, we do not time-index the sequence of failures in the current model. This is because, in our proof of bounds for and , we only consider system evolutions in which each node fails at most once. In this case, we find it convenient simply to denote the replacement node of as .
IV File size bound for General Parameters
In this section, we derive the file-size bound in (1) under the setting of functional repair, for arbitrary set of code parameters. We further use this bound to characterize the storage-overhead vs inter-cluster-repair-bandwidth-overhead trade-off. Intra-cluster bandwidth is ignored in this section. Thus, for the repair of any node, the entire content of local helper nodes can be used; similarly, the entire content ( symbols) of each remote helper cluster is used to generate its helper symbols.
Theorem IV.1
The file size of a functional repair generalized regenerating code having parameters is upper bounded by
[TABLE]
Further, if there is a known upper bound on the number of repairs that occur for the duration of operation of the system, the above bound is sharp, i.e., gives the functional repair storage capacity of the system.
Proof:
The proof technique is similar to the proof of the bound under functional repair for the setting of classical regenerating codes [13]. The problem of functional repair is one of multicasting, and thus for finding the desired upper bound on the file-size, it is enough if we exhibit a cut in an IFG, for a specific sequence of failures and repairs, which separates the source from the sink, such that the value of the cut is the desired upper bound. We shall then show that, for any valid IFG, independent of the specific sequence of failures and repairs, is indeed a lower bound on the minimum possible value of any cut. The achievability result, when there is known upper bound on the number of failures and repairs, will then follow from results in network coding [28].
We begin with the proof of the upper bound. We consider a sequence of failures and repairs, as follows: Physical nodes fail in this order in cluster , then in cluster , and so on, until cluster . In the IFG, (see Section III-A), this corresponds to the sequence of failures of nodes , in the respective order. The replacement node for draws local helper data from , and remote helper data from the clusters and from some set of other active clusters in the IFG. An example is shown in Fig. 9 for a set of system parameters that is same as those used in Fig. 7.
Let data collector connect to clusters . Consider the cut consisting of the following edges of the IFG:
- •
. Total capacity of these edges is .
- •
For each , either the set of edges remote helper cluster indices for the replacement node , or the edge . Between the two possibilities, we pick the one which has smaller capacity. In this case, the total capacity of this part of the cut is given by .
The value of the cut is given by , which proves our upper bound. In the example on Fig. 9 for , first, node fails in cluster and downloads helper data from clusters , second, a node fails in cluster and downloads helper data from clusters . The data collector connects to clusters . A minimal cut for is shown on the figure, and has value .
We next show that for any valid IFG (independent of the specific sequence of failures and repairs), is indeed a lower bound on the minimum possible value of any cut. Consider any cut, and let IFGS and IFGT denote the two resultant disconnected parts of the IFG corresponding to the nodes and , respectively. Since node connects to external nodes via links of infinite capacity, we only consider cuts such that IFGT has at least external nodes corresponding to active clusters. Next, we observe that the IFG is a directed acyclic graph, and hence there exists a topological sorting of nodes of the graph such that an edge exists between two nodes and of the IFG only if appears before in the sorting. Further, we consider a topological sorting such that all in-, out- and external nodes of the cluster appear together in the sorted order, .
Now, consider the sequence of all the external nodes (which are part of both active and inactive clusters) in IFGT in their sorted order. Let denote the first node in this sequence. Without loss of generality let . Next, consider the subsequence of which is obtained after excluding all the external nodes in from . Let denote the first external node in this subsequence. We continue in this manner until we find the first external nodes in , such that each of the nodes corresponds to a distinct physical cluster. Once again, without loss of generality, we assume that . Let us assume that , for some . Now, consider the out-nodes that connect to . Among these out-nodes, let denote the number of out-nodes that appear in IFGS. Without loss of generality let these be the nodes . Next, corresponding to the out-node , consider its past versions in the IFG, and let , for some denote the first sorted node that appears666It may be noted that even though appears in IFGT, the corresponding external node appears in IFGS. This is due to our assumption that is the first external node, corresponding to physical cluster , that appears in IFGT. in IFGT. Without loss of generality, let us also assume that the nodes are sorted in the order . An illustration is provided in Fig. 10.
To obtain a lower bound on the value of the cut, we make the following observations:
- •
The edges are part of the cut. These contribute a total value of .
- •
For any node , if the corresponding in-node belongs to IFGS, then the edge appears in the cut, and contributes a value of to the cut. Now, consider the case when the in-node belongs to IFGT. In this case, consider the following two sub cases:
- –
The node is not a replacement node: This means that, either the edge appears in the cut, if , or the edge appears in the cut, if . In any case, the contribution to the overall value of the cut is at least .
- –
The node is a replacement node of : We know that local helper nodes and external nodes are involved in repair. It is straightforward to see that out of the local helper nodes, at most belong to IFGT. To see this, note that the potential candidates for the local helper nodes that appear in IFGT correspond to the physical nodes777It may be noted that we count the physical nodes among the possible set of local helpers, although we assume that appears in IFGS. This is because, we cannot discount the possibility that appears in IFGT, for . . The version of the physical node , if it aids in the repair process, appears in IFGS because of our definition of . Next, note that out of the external nodes, at most belong to IFGT. In this case, the contribution to the value of the cut, due to the edges that aid in repair, is lower bounded by .
Based on the observations above, the value of the cut is lower bounded by
[TABLE]
for any . This completes the proof of the converse. ∎
Definition 1** (Optimal Code)**
Code is said to be optimal or capacity achieving, if its file-size , where is as given in Theorem IV.1.
IV-A Minimum Storage and Minimum Inter-Cluster Bandwidth Operating Points
We now define the MSR and MBR operating points based on the bound in Theorem IV.1, whenever . The operating point will be identified with the MBR operating point. An optimal code at the MBR operating point will be referred to as an MBR code. To see the rationale behind the definition of the MBR operating point, we recall our assumption that whenever , the encoding function does not introduce any dependency among the content of the nodes of a cluster. In this case, assuming that symbols of the uncoded file are uniformly distributed over , it is straightforward to see the necessity of the condition for any code .
Towards defining the MSR point, we note that . The MSR code is an optimal code having , and has the lowest possible inter-cluster repair bandwidth. It is clear that the parametrization of the MSR operating point depends on relation between and . For , the optimal file-size of is achievable only if , and thus the operating point will be identified with the MSR operating point. For , note that , and equality is achieved only if . The operating point will be identified with the MSR operating point for the case when .
Based on the definition of the MSR and MBR operating points, we note that for , the range of considered while plotting the trade-off is given by , and when , the range of is given by .
V Code Constructions
In this section, we describe our optimal code constructions. Two constructions are presented; the first one is an instance of an exact repair code, and results in optimal codes at the MSR and MBR points under the setting of generalized regenerating codes; the second construction is a functional-repair regenerating code. Both codes can withstand any number of repairs for the duration of operation of the system. The exact repair code withstands any number of repairs by definition, since after each repair the data on all nodes is the same as at the start of system operation. This logic does not hold for functional repair codes, because the repaired node content is generally different from the original one. Network-coding based achievability proofs for functional-repair work only if there is a known upper bound on the number of repairs that occur over the lifetime of the system. Our functional repair code relies on the construction in [30], which allows our code to operate for arbitrarily many repairs. For both constructions, we rely on existing optimal classical regenerating codes that are linear. By a linear regenerating code, we mean that both encoding and repair are performed via linear combinations of either the input or the coded symbols, respectively. The first construction generates an optimal code for any , whenever an optimal classical exact repair linear regenerating code exists. Our functional repair code construction is limited to the case .
For a linear classical regenerating code that encodes a data file of size symbols, one can associate a generator matrix of size . Without loss of generality, the first columns of generates the content of node , and so on. We say that two classical linear regenerating codes and , having generator matrices and are identical, if . Since we assume that repair is also a linear operation, it follows that the set of linear functions that define repair operations can be taken the same for and that are identical. The following lemma will be used while we prove optimality of the exact-repair construction. The proof of the lemma is straightforward, and is omitted.
Lemma V.1
Let denote identical classical exact repair linear regenerating codes. Let denote a generic codeword of , where the first symbols of are the content of node , and so on. Suppose that we are given such that not every is [math], define a new -length array code over as . Then, the code is an classical exact repair linear regenerating code over , and is identical to .
V-A Exact Repair Code Construction
We begin with a description of the code, and then show its data collection and repair properties. The construction itself is a generalization of the example presented in Section I-D.
Construction V.2
Let denote MDS array codes over . The amount of data that can be encoded with these codes is . Next, let denote classical exact repair linear regenerating codes (also over ), each having a file size . We require that all the codes are identical. For encoding, we first divide the data file of size into stripes, such that first have size , and the last have size . Stripe is encoded by to generate the coded symbols . Next, consider an invertible matrix over such that the first the rows of generate an MDS code . Let matrix be decomposed as
[TABLE]
Thus, the matrix generates an MDS code. The coded data stored in the various clusters is generated as follows:
[TABLE]
The content of node in cluster is given by . This completes the description of the construction. A pictorial overview of the description appears in Fig. 11.
We next prove optimality property of Construction V.2.
Theorem V.3
The code described in Construction V.2 is an optimal exact repair generalized regenerating code, for any . The optimal code can be constructed whenever an optimal exact repair linear regenerating code exists, having a file size .
Proof:
It is clear that the code in Construction V.2 has a file size , where is as given in Theorem IV.1. Further, the data collection property of the code is also straightforward to check, and this essentially follows from the facts that the matrix is invertible, and each of the codes is uniquely decodable given its coded data belonging to any clusters. Towards examining the repair property of the code let us rewrite (20) as follows:
[TABLE]
where and . The matrices and denote rows of and , respectively. Let us also expand the decomposition of matrix in (19) further as follows:
[TABLE]
where and denote the column of the matrices and , respectively. Based on (27) and (35), it can be seen that the content of node in cluster is given by
[TABLE]
Given the notation above, without loss of generality, consider repairing node in cluster with the help of the first local nodes in cluster and clusters . Let us first examine the role of the local nodes in the repair process. Let and denote the first columns of and , respectively. By assumption, generates an MDS code, and hence the submatrix is invertible. In this case, the content from the local nodes can be put together to generate
[TABLE]
where . Thus, the local helper nodes serve to recover the part corresponding to the MDS-codes’ components given by . However, the regenerating-codes’ components differs from the original .
Let us next examine the role of the remote helper clusters. We know that the data stored in cluster is given by . Since matrix is invertible, the vector can be recovered from this. Now, if we define the code , we know from Lemma V.1 that is an classical exact repair linear regenerating code, which is identical to . Thus, cluster generates and passes the helper data ( symbols) toward the repair of the first vector symbol for the code . The replacement node regenerates using the helper data from the remote clusters, and combines it with the local helper data (see (46)) to correct the regenerating-codes’ components, and restore the content of the lost node. A pictorial illustration of the repair process is shown in Fig. 12. ∎
V-B A Functional Repair Code for Arbitrary Number of Failures
In this section, we show the existence of optimal functional repair codes over a finite field that can tolerate an arbitrary number of repairs for the duration of operation of the system. We show the existence for any . The code construction is similar to the one used in the example in Section I-D, and combines MDS array codes with an functional repair code for the classical setting. The code is one that can tolerate an arbitrary number of repairs for the duration of operation of the system. The following lemma is a direct consequence of Theorem and the description in Section of [30], and guarantees the existence of the code that we use here.
Lemma V.4
For any , there exists an optimal deterministic classical functional repair linear regenerating code over that can tolerate an arbitrary number of repairs for the duration of operation of the system, whenever , where is entirely determined by the parameters , and is independent of the number of repairs performed over the lifetime of the code.
In the above lemma, by a deterministic regenerating code, we mean that the regenerated data corresponding to a repair operation of a given physical node is uniquely determined given the content of the helper nodes. As we shall see, the fact the code is deterministic is important to ensure the data collection property of our functional repair construction.
Below, we first describe the code construction, along with the repair procedure, and then show the optimality property of the code. In the following construction, we assume that the characteristic of the finite field is ; i.e., for some . The assumption is made only for the ease of description, the construction can be modified to accommodate finite fields of any characteristic.
Construction V.5
Let denote MDS array codes over . The amount of data that can be encoded with these codes is . Next, let denote an classical functional repair linear regenerating code whose existence is guaranteed by Lemma V.4. The code has a file size . For encoding, we first divide the data file of size into stripes, such that first have size , and the last one has size . Stripe is encoded by to generate the coded symbols . The arrangement of coded data in the various nodes is identical to that in the example in Section I-D. Thus, node in cluster stores the vector . Node in cluster stores the sum of the content of nodes with symbols of the regenerating code , i.e., content of node is given by . This completes the description of the initial layout of the coded data. Since the code is a functional repair code, the code description is not complete unless we specify the procedure for node repair, as well. We do this next.
Node Repair:* Let denote the content of node in cluster , after the repair, anywhere in the system. The quantities denote the initial content present in the system, and are as described above. The repair procedure is such that the vector remains as a valid codeword of the functional repair regenerating code , for every (to be proved in Theorem V.6). Clearly, the above statement is true for . The repair procedure can be described recursively as follows: Let the repair be associated with node in cluster . Each of the remote helper clusters, say , internally computes , and passes the symbols toward the repair of . The replacement node first of all regenerates , as the replacement of , given the helper data from the remote clusters. Next, since , the replacement node gets access to local helper data . The content that is eventually stored in the replacement node is computed as follows:*
[TABLE]
Also, for any , we assume that
[TABLE]
This completes the description of the repair process and the code construction.
In the following theorem, we argue the optimality property of the above construction. Specifically, we show that the code retains the functional repair and data collection properties, after every repair. We assume that the data collector is aware of the entire repair-history of the system. By this we mean that the data collector is aware of the exact sequence of failures and repairs that has happened in the system, and the indices of the remote helper clusters that aided in each of the repairs.
Theorem V.6
The code described in Construction V.5 is an optimal functional repair generalized regenerating code.
Proof:
It is clear that the code in Construction V.5 has a file-size , as given by Theorem IV.1. Toward showing that the code retains functional repair property, it is sufficient if we show that the vector remains as a valid codeword of the functional repair regenerating code , for every . We do this inductively. Clearly, the statement is true for . Let us next assume that the statement is true for , and show its validity for . Assume that the repair is associated with node in cluster . The relation between the content of the various nodes before and after the repair are obtained via (47) and (48). In this case, the quantities are given by
[TABLE]
where follows from our assumption that the finite field has characteristic . Now, recall that is the replacement of , which is regenerated using the helper data generated using elements of the set . Combining with the induction hypothesis for , it follows that the induction statement holds good for as well. This completes the proof of functional repair property of the code.
Let us next see how data collection is accomplished after repairs in the system. Without loss of generality assume that a data collector connects to clusters , and accesses . The data collector as a first step computes the vector , and uses this to decode the data corresponding to the code . Now, recall the fact that the code is deterministic, and also our assumption that the data collector is aware of the entire repair-history of the system. In this case, having decoded , using (47) and (48), the data collector can iteratively recover , for by starting at and proceeding backwards until the content at is recovered (essentially, we are rewinding the system by eliminating the effects of all the repairs, starting from the last one and proceeding backwards in time). Finally, from Construction V.5, we know that the content is the stacked coded data corresponding to the MDS coded , and thus these codes can also be decoded. The completes the proof of data collection, and also the theorem.
∎
VI Intra-cluster bandwidth for Optimal Codes
We now turn our attention to calculate the amount of intra-cluster repair bandwidth that is needed for a code to have optimal file-size , given by Theorem IV.1. As discussed in Section I-A, there are two contributors to intra-cluster repair bandwidth: the local helper bandwidth , which is the amount of data that each of the local helper nodes contributes to repair, and the remote helper bandwidth , which is amount of the data that each of the nodes of a remote helper cluster contribute toward computing the symbols of the cluster. In this section, we study individually the minimum requirements on the parameters , and . For obtaining lower bound on , we continue to work with the IFG model in Section III-A, except for the fact that links that connect the local helper out-nodes to the in-node of the replacement node, will have a capacity , instead of . The IFG model in Section III-B will be used when we compute lower bound on and . We also prove the tightness of the bound on via a converse; however, no such converse is known to us regarding the bound on . We note that, while computing the bound on , we ignore the effects of limited and (and vice versa), i.e., we assume that and . Further, the bounds on and (or ) are obtained under the assumptions that and , respectively.
VI-A Bound on Local Helper Node Intra-cluster Repair Bandwidth,
Theorem VI.1
For an optimal functional repair generalized regenerating code with parameters , local helper node bandwidth is lower-bounded by
[TABLE]
Further, if there is a known upper bound on the number of repairs that occur over the life-time of the system, the above bound is sharp; i.e., the functional repair capacity of the system remains as as long as .
Proof:
For the bound, we consider a system evolution similar to that used in proof of Theorem IV.1, and demonstrate a cut-set whose value depends on . The lower bound on follows from the observation that the value of this cut is necessarily lower bounded by for a capacity-achieving code. We shall then prove that, as long as , the min-cut of any valid IFG is necessarily lower bounded by ; in this case, like in the proof of Theorem IV.1, we know that the functional repair capacity remains as , as long as there is a known upper bound on the number of repairs in the system. We start with the proof of the lower bound. Consider the same system evolution as in the proof of the bound in Theorem IV.1, except for the -th cluster accessed by the data collector. Thus, physical nodes fail in this order in cluster , then in cluster , and so on, until cluster . Note that each of the first clusters experiences a total of node failures. For cluster , we consider failure of nodes, corresponding to physical nodes in this respective order. In terms of the notation introduced in III-A, the sequence of failures in the cluster correspond to IFG nodes . For the repair of , the local helper nodes used are . For the repair of any of the remaining nodes , the local helper nodes used are . Also, clusters are included in the set of remote clusters that aid in the repair of the nodes in the cluster. An illustration of the IFG, for the cluster is shown in Fig. 13. Note in this figure that the edges corresponding to local help have capacity .
Let data collector connect to clusters . Consider an - cut in the IFG that partitions the graph nodes in clusters in the same way as in IV.1; however it differs in the way the nodes of cluster are partitioned. The overall set of edges in the cut-set is given as below:
Clusters :
- •
. Total capacity of these edges is .
- •
For each , either the set of edges remote helper cluster indices for the replacement node or the edge . Between the two possibilities, we pick the one which has smaller sum-capacity. In this case, the total capacity of this part of the cut is given by .
Cluster :
- •
of capacity .
- •
. Total capacity of these edges is .
- •
Either the set of edges remote helper cluster indices for the replacement node or the set of edges . Among the two sets, we pick the one which has smaller sum-capacity. In this case, the total capacity of these edges is .
The value (say, ) of the cut is given by
[TABLE]
Since we assume an optimal code, it must be true that , which results in . Finally, note that in the two cases , and . The equivalence for the case follows since we only consider , when (see Section IV-A).
We next prove the converse, where we show that, as long as , the min-cut of any valid IFG is necessarily lower bounded by . Toward this, consider the proof of converse part of Theorem IV.1, where we obtained a lower bound on the min-cut of any valid IFG. One can repeat the sequence of arguments exactly as in the proof of converse part of Theorem IV.1, except with the change that the edges corresponding to local help have capacity (instead of ). In this case, it can be seen that instead of (12), we get the following lower bound on min-cut:
[TABLE]
In the above expression, observe that if , we have
[TABLE]
whenever . In this case, it follows that (52) can be written as (13). It is then clear that is indeed lower bounded by as long as . This completes the proof of the converse, and also the theorem. ∎
VI-B Bounds on
In this section, we provide bounds on the parameters and . We use the second IFG model in Section III-B here. Recall that in our setting, for any of the remote helper clusters, we allow any subset of nodes in the cluster to be used to generate the symbols contributed by the cluster. Also, in this section, we make the assumption that the number of remote helper clusters .
Theorem VI.2
For an optimal functional repair generalized regenerating code with parameters , the remote helper-node repair bandwidth is lower-bounded by
[TABLE]
whenever .
Proof:
We consider data collection from clusters to . Before data collection, the system experiences repairs. Nodes fail and get repaired in cluster in this respective order. This is followed by failure and repair of nodes in cluster , and so on, until we consider failure and repair of nodes in cluster . In terms of physical nodes, it may be noted that this is the same sequence of failures that was considered in the proof of Theorem IV.1; however, in here, we will impose additional restrictions on the choice of the remote helper clusters. In this proof, external help is taken from the set of the first clusters, excluding the cluster where the failed node resides. Thus, for the repair of , the indices of remote helper clusters are . The choice of local helper nodes remain same as in the proof of Theorem IV.1, where we used the first nodes in the cluster. An illustration of the IFG is shown in Figure 14.
It can be seen that the following cut-set separates the source from the data collector:
- •
. Total capacity of these edges is .
- •
For each , the edge set with smaller capacity out of and where
- –
. Total capacity of edges in is . Recall that is simply the replacement node for the failed node , in the second IFG model that is used here.
- –
. Total capacity of edges in is
- –
. Total capacity of edges in is .
The capacity of the cut-set is given by
[TABLE]
Since we consider optimal codes, we have
[TABLE]
In this case, since we assume that , we claim that
[TABLE]
To see why (58) is true, if we suppose on the contrary that , we have
[TABLE]
The above equation implies that
[TABLE]
where (61) follows from the assumption that . Clearly, adding up the two corresponding sides (L.HS. and R.H.S.) of (60) and (61), and comparing them contradicts the fact that . Thus, it must be true that , whenever . ∎
The following theorem establishes the necessary condition on for optimal codes. The proof is along the lines of proof of Theorem VI.2, and is omitted.
Theorem VI.3
For an optimal functional repair GRC with parameters , whenever , each remote helper cluster must necessarily access all the nodes in the cluster while generating the symbols; i.e., whenever , we have for an optimal functional repair GRC.
VII Security Under Passive Eavesdropping
In this section, we analyze resilience of the clustered storage system against passive eavesdropping. Our model of clustered storage systems is in part motivated by the need to provide security against an eavesdropper who may gain access to a subset of the clusters. In this context, we extend result in Theorem IV.1 to settings that require security. Below, we first introduce the model for security, and then present the revised file bound. Optimal code construction for security can be provided along the same lines of Construction V.2.
VII-A Passive Eavesdropper Model
The security model is along the lines of the passive eavesdropper model considered in [31], where the authors study security under the classical regenerating code framework. An eavesdropper (say, Eve) gains access to the entire content of any subset of clusters, where . Eve also gets to observe all the helper data that gets downloaded for repair of any node in these clusters. Eve is passive in the sense that Eve does not change any stored or repair data. The properties of data collection and disk repair remain same as in the case of no eavesdropper (see Section I-A). In this model we ignore the effects of intra-cluster bandwidth, and restrict ourselves to the setting of deterministic exact repair codes. By deterministic exact repair code, we mean that the helper data for the repair of any node is uniquely determined given the indices of the failed node, local helper nodes and remote helper clusters. We avoid the possibility that the same set of helpers can pass two possible sets of helper data for the repair of the same node.
We wish to store a file such that Eve does not gain any information about it, by having eavesdropped into any subset of clusters. To be precise, let denote the random variable corresponding to the data file that gets securely stored. We assume the file to be uniformly distributed over , and thus denotes the file-size. We wish to ensure that the mutual information . Note that the data observed by Eve not only includes the content of the clusters, but also any inter-cluster helper data that is received toward the repair of nodes in these clusters. We shall write to denote a secure generalized regenerating code, and its parameter set will be identified with }.
VII-B File Size Under Exact Repair
In this section, we obtain an upper bound on the file-size of the exact repair secure generalized regenerating code . To derive the bound, we use information theoretic techniques similar to those used in [36], [31]. We begin with some necessary notation. Let denote the content stored in node of cluster . We write to denote . The property of data collection requires that
[TABLE]
where denotes the entropy function computed with respect to . Next, consider the repair of node in cluster . Let , and respectively denote the indices of remote helper clusters and local helper nodes that aid in the repair process. Let denote helper data passed by cluster . Recall our assumption that the exact repair code is deterministic, and thus is uniquely determined as a function of and . The property of exact repair is jointly characterized by the following set of inequalities:
[TABLE]
Next, define to denote the collection of all the inter-cluster helper data ever received toward the repair of nodes in cluster , i.e.,
[TABLE]
The property of being secure against the passive eavesdropper Eve is equivalent to saying that
[TABLE]
The following theorem characterizes the file-size bound under passive eavesdropping.
Theorem VII.1
The file-size of a secure exact-repair deterministic generalized regenerating code having parameters is upper bounded by
[TABLE]
Proof:
Without loss of generality, let us assume that . Using (67), the file-size is given by
[TABLE]
From (62), we further get that
[TABLE]
Combining (69) and (70), we get
[TABLE]
where (76) follows from (63)-(65). This completes the proof of the upper bound. ∎
As before, whenever , we associate the operating point with the minimum repair bandwidth secure regenerating codes. Construction V.2 can be easily adapted to construct optimal secure exact repair codes at the MBR point. In the modified construction, one combines secure MDS codes for the wiretap-II channel [32][33], and classical exact-repair secure MBR codes [31][34]. The construction and proof of optimality are similar to Construction V.2; we avoid a full description here. A pictorial illustration of the secure code construction appears in Fig. 15. Finally, we note that the bound in (77) is weak at the MSR point, since it is known that classical exact-repair secure MSR codes in general cannot achieve file size [37, 38]. It is an interesting question as to whether the analysis like in [37, 38] can be used to provide a tighter bound for secure MSR codes under the framework of GRCs considered in this paper.
VIII Conclusions
To conclude, we study the problem of storage-overhead vs repair-bandwidth overhead in clustered storage systems. The notion of clustering is used in both data collection and node repair. For data collection, we require retrievability using content from any set of clusters. For node repair, we take the help of surviving local nodes in the host cluster, as well as from other remote clusters. We first characterize the optimal file-size that is achievable while ignoring intra-cluster bandwidth costs, and then obtain bounds on intra-cluster bandwidth costs that is needed to achieve this file-size. Our results show that while it is beneficial to increase the number of local helper nodes () during repair in order to simultaneously improve both storage and inter-cluster bandwidth costs, increasing has an adverse effect on intra-cluster repair bandwidth. Our bounds on file-size and intra-cluster bandwidth give guidelines for choosing the desired number of local helper nodes in practice, based on the relative costs of the various metrics. We present constructions of optimal exact and functional repair codes, which enable operating points for clustered systems that are not achievable via previously known coding solutions. We also analyze the resilience of the system against passive eavesdropping.
Two key questions remain at the end of this work. Firstly, our bounds on intra-cluster bandwidth are derived under the assumption of functional repair. It is unclear if these bounds hold under exact repair; specifically at the minimum-inter-cluster bandwidth operating point. The exact repair constructions in this paper, although they have optimal file-size (and inter-cluster bandwidth), incur the maximum possible intra-cluster bandwidth. Secondly, the bound on any one of the intra-cluster bandwidth related parameters (say, ) was derived without limiting the other two other parameters (). It is of special interest to know the simultaneously optimality of the the bounds in (2) and (3). We believe that a first step in this direction would be to prove a converse statement (achievability) to (3). Achievability of (3) is indeed suggested by RLNC-based simulations.
Finally, model extensions of interest include the case of simultaneous recovery from multiple node failures in a given cluster. While studying recovery for multiple node failures, it is of interest to consider presence of local parity relations in each cluster, even when .
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1ama [2016] “AWS storage services overview,” Amazon Web Services Whitepapers , 2016. [Online]. Available: https://d 0.awsstatic.com/whitepapers/Storage/AWS
- 2[2] “Azure storage replication,” Microsoft Azure Documentation . [Online]. Available: https://docs.microsoft.com/en-us/azure/storage/storage-redundancy
- 3[3] “Netstorage,” Akamai Media Delivery Solutions: Product Brief . [Online]. Available: https://www.akamai.com/us/en/multimedia/documents/product-brief/netstorage-product-brief.pdf
- 4Muralidhar et al. [2014] S. Muralidhar, W. Lloyd, S. Roy, C. Hill, E. Lin, W. Liu, S. Pan, S. Shankar, V. Sivakumar, L. Tang et al. , “f 4: Facebook’s warm blob storage system,” in Proceedings of the 11th USENIX conference on Operating Systems Design and Implementation . USENIX Association, 2014, pp. 383–398.
- 5Cook et al. [2014] J. D. Cook, R. Primmer, and A. de Kwant, “Compare cost and performance of replication and erasure coding,” hitachi Review , vol. 63, p. 304, 2014.
- 6Chen et al. [2017] Y. L. Chen, S. Mu, J. Li, C. Huang, J. Li, A. Ogus, and D. Phillips, “Giza: Erasure coding objects across global data centers,” in 2017 USENIX Annual Technical Conference (USENIX ATC 17) . Santa Clara, CA: USENIX Association, 2017, pp. 539–551. [Online]. Available: https://www.usenix.org/conference/atc 17/technical-sessions/presentation/chen-yu-lin
- 7Abu-Libdeh et al. [2010] H. Abu-Libdeh, L. Princehouse, and H. Weatherspoon, “Racs: a case for cloud storage diversity,” in Proceedings of the 1st ACM symposium on Cloud computing . ACM, 2010, pp. 229–240.
- 8Mu et al. [2012] S. Mu, K. Chen, P. Gao, F. Ye, Y. Wu, and W. Zheng, “ μ 𝜇 \mu libcloud: Providing high available and uniform accessing to multiple cloud storages,” in Grid Computing (GRID), 2012 ACM/IEEE 13th International Conference on . IEEE, 2012, pp. 201–208.