Real-Time Energy Disaggregation of a Distribution Feeder's Demand Using Online Learning
Gregory S. Ledva, Laura Balzano, Johanna L. Mathieu

TL;DR
This paper presents an online learning approach to disaggregate distribution feeder demand into specific components using existing sensors, improving real-time understanding of energy consumption without additional infrastructure.
Contribution
It introduces the Dynamic Fixed Share (DFS) algorithm for real-time demand disaggregation using historical data and real-time measurements, demonstrating its effectiveness with real case studies.
Findings
DFS effectively disaggregates demand in real-time.
Model choice impacts disaggregation accuracy.
Performance comparable to Kalman filter sets.
Abstract
Though distribution system operators have been adding more sensors to their networks, they still often lack an accurate real-time picture of the behavior of distributed energy resources such as demand responsive electric loads and residential solar generation. Such information could improve system reliability, economic efficiency, and environmental impact. Rather than installing additional, costly sensing and communication infrastructure to obtain additional real-time information, it may be possible to use existing sensing capabilities and leverage knowledge about the system to reduce the need for new infrastructure. In this paper, we disaggregate a distribution feeder's demand measurements into: 1) the demand of a population of air conditioners, and 2) the demand of the remaining loads connected to the feeder. We use an online learning algorithm, Dynamic Fixed Share (DFS), that uses…
Click any figure to enlarge with its caption.
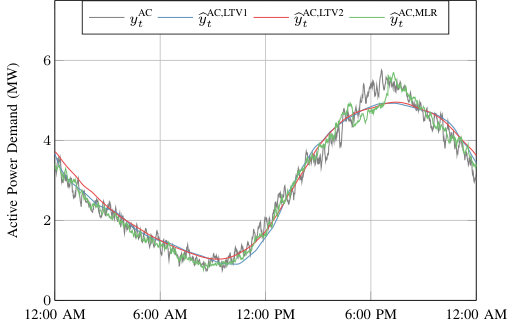 Figure 1
Figure 1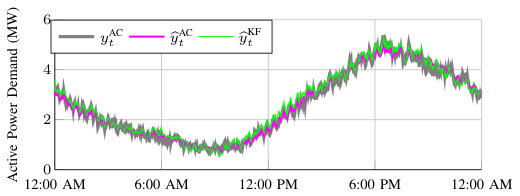 Figure 2
Figure 2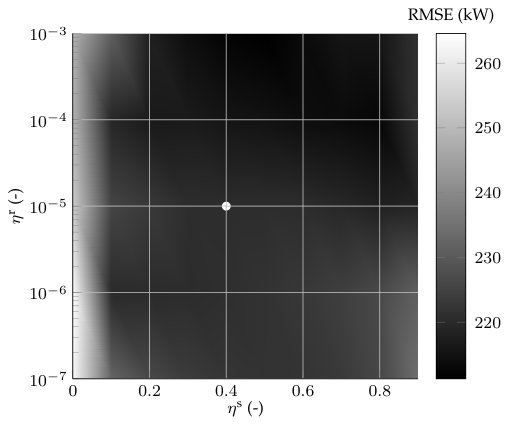 Figure 3
Figure 3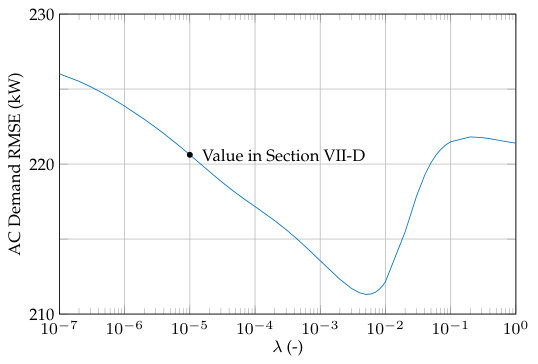 Figure 4
Figure 4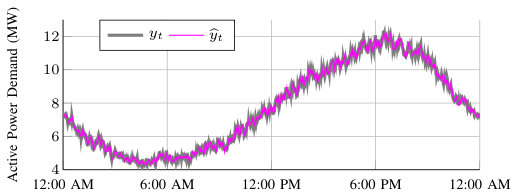 Figure 5
Figure 5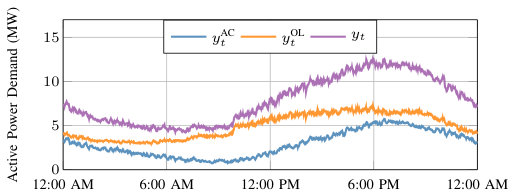 Figure 6
Figure 6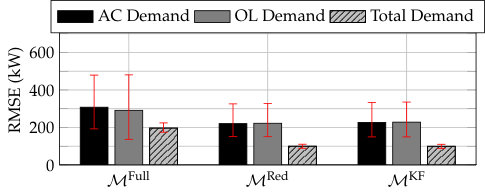 Figure 7
Figure 7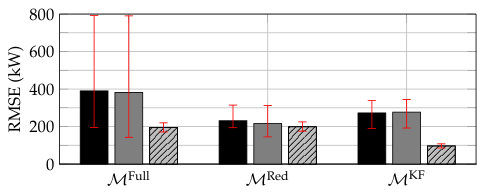 Figure 8
Figure 8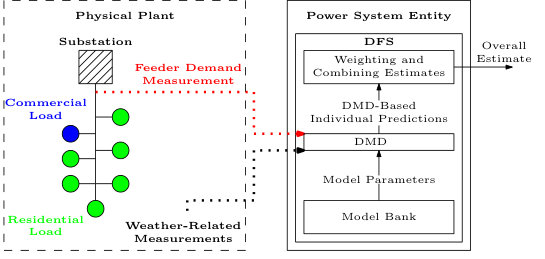 Figure 9
Figure 9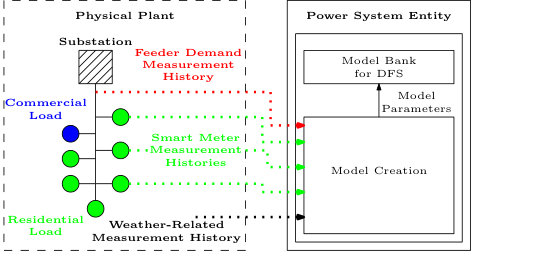 Figure 10
Figure 10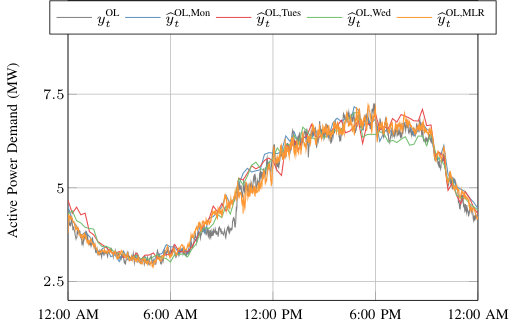 Figure 11
Figure 11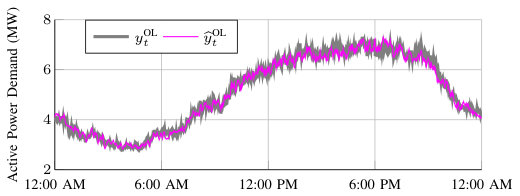 Figure 12
Figure 12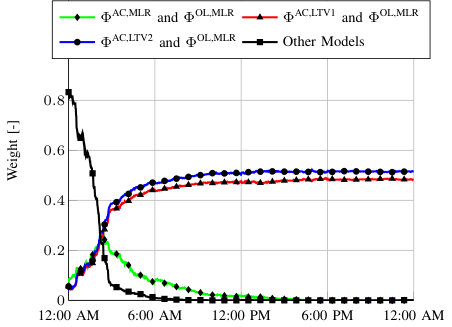 Figure 13
Figure 13| Model Set | ||||||
|---|---|---|---|---|---|---|
| Update Method | 1 | 2 | 1 | 2 | 1 | 2 |
| 0.013 | 0.015 | 0.4 | 0.013 | 0.4 | 0.5 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
\DeclareCaptionLabelSeparator
periodspace.
Real-Time Energy Disaggregation of a Distribution Feeder’s Demand Using Online Learning
Gregory S. Ledva, Laura Balzano, and Johanna L. Mathieu The authors are with the Department of Electrical Engineering & Computer Science, University of Michigan, Ann Arbor, MI 48109 USA (e-mail: [email protected]; [email protected]; [email protected]). This research was funded by NSF Grant #ECCS-1508943.IEEE owns the copyright [1]
Abstract
Though distribution system operators have been adding more sensors to their networks, they still often lack an accurate real-time picture of the behavior of distributed energy resources such as demand responsive electric loads and residential solar generation. Such information could improve system reliability, economic efficiency, and environmental impact. Rather than installing additional, costly sensing and communication infrastructure to obtain additional real-time information, it may be possible to use existing sensing capabilities and leverage knowledge about the system to reduce the need for new infrastructure. In this paper, we disaggregate a distribution feeder’s demand measurements into: 1) the demand of a population of air conditioners, and 2) the demand of the remaining loads connected to the feeder. We use an online learning algorithm, Dynamic Fixed Share (DFS), that uses the real-time distribution feeder measurements as well as models generated from historical building- and device-level data. We develop two implementations of the algorithm and conduct case studies using real demand data from households and commercial buildings to investigate the effectiveness of the algorithm. The case studies demonstrate that DFS can effectively perform online disaggregation and the choice and construction of models included in the algorithm affects its accuracy, which is comparable to that of a set of Kalman filters.
Index Terms:
Online learning, machine learning, energy disaggregation, output feedback, real-time filtering
I Introduction
Distributed energy resources (DERs) such as demand responsive electric loads and residential solar generation are becoming more common within electricity distribution networks [2, 3]. Sensing infrastructure, such as household smart meters, are also becoming more common [4]. However, distribution system operators still often lack an accurate real-time picture of overall DER characteristics such as i) the total power consumption of the air conditioners connected to a distribution feeder, or ii) the total power production of all solar panels installed on a distribution feeder.
Perfect real-time knowledge of DER characteristics requires a sensor at each of the large number (e.g., thousands) of spatially distributed devices and a communication infrastructure capable of reliably transmitting the data at the necessary frequency (e.g., every few seconds). Rather than installing additional, costly metering and communication infrastructure, in this paper, we show that it is possible to estimate real-time DER characteristics using existing sensing capabilities and some knowledge of the underlying system. Specifically, we show how to separate measurements of the net demand served by a distribution feeder into its components in real-time, using knowledge of the physical processes driving load/generation. We refer to this task as feeder-level energy disaggregation.
Real-time, feeder-level energy disaggregation can help system operators, utilities, and demand response providers improve power system reliability, economic efficiency, and environmental impact. For example, a system operator can 1) estimate the real-time balancing reserve requirement from its estimate of the production of distributed generation resources; 2) estimate the real-time potential for fault induced delayed voltage recovery (FIDVR) caused by stalling in small motor loads [5] from its estimate of the motor load consumption; and 3) optimize conservation voltage recovery (CVR) strategies using its estimate of the mix of constant impedance, constant power, and constant current loads [6]. A utility can 4) better plan demand response actions by knowing the weather forecast and the real-time portion of weather-dependent loads (e.g., air conditioners, heaters, dehumidifiers). A demand response provider can 5) optimize capacity bids into ancillary services markets using its estimate of the real-time, aggregate, demand-responsive load; and 6) use its estimate of the real-time, aggregate, demand-responsive loads as a feedback signal in load coordination algorithms, e.g., [7, 8]. Note that the consumption of demand-responsive loads often needs to be measured for auditing purposes, but the consumption data need not be communicated in real-time.
In this paper, we develop the feeder-level energy disaggregation problem framework and apply an online learning algorithm to separate the active power demand served by a feeder into the active power demand of a population of residential air conditioners and the active power demand of all other loads connected to the feeder. The algorithm [9] incorporates dynamical system models of arbitrary forms, blending aspects of machine learning and state estimation. Building upon our preliminary work [10], the contributions of this paper are to i) frame the feeder-level energy disaggregation problem, ii) adapt the machine learning algorithm in [9] to the feeder-level energy disaggregation problem, iii) develop a variation of the machine learning algorithm that allows it to include models with different underlying states, iv) demonstrate the performance of the online learning algorithm via a realistic data-driven case study, and v) compare the performance of the algorithm to that of a set of Kalman filters. Beyond [10], this paper develops a modified version of the algorithm, compares this modified implementation to a direct implementation of the algorithm, uses only real data (rather than models) to construct the feeder active power signal, uses real data to identify all load models, and compares algorithm performance to that of an aggressive benchmark as opposed to a simple prediction model.
Section II compares our problem and approach to related problems/work. Section III defines the problem framework. Section IV describes the data used to construct the underlying system, and Section V describes the models used within the algorithm. Section VI summarizes the online learning algorithm and our implementations for the feeder-level energy disaggregation problem. Section VII constructs case studies and summarizes their results. Finally, Section VIII presents the conclusions.
II Comparison to related problems and work
The feeder-level energy disaggregation problem combines aspects of building-level energy disaggregation and load forecasting. Building-level energy disaggregation, also referred to as nonintrusive load monitoring[11], separates building-level demand measurements into estimates of the demand of individual or small groups of devices [12]. Disaggregation algorithms use data sampled at frequencies ranging from over 1 MHz to 0.3 mHz (i.e., hourly interval data) where higher-frequency data allows separation of more devices [12]. The problem is not usually solved online because the goal is long-term energy efficiency decisions such as identification and replacement of faulty appliances and/or load research. Both unsupervised and supervised learning approaches have been proposed, with the latter often using models developed with submetering data.
Load forecasting predicts the total future demand within a given area over time horizons ranging from hours to years [13]. Whereas energy disaggregation typically deals with small load aggregations, load forecasting typically deals with large aggregations, e.g., thousands to millions of loads. For example, forecasting the load served by a distribution transformer is considered a “small” forecasting problem [13]. Very short term load forecasting, corresponding to intraday forecasts, generally uses 15 min to one hour interval data [13, 14]. Smart meter data enables offline development of detailed load models [15], which may be used online for operational decisions [16], e.g., for predicting the curtailable load [15]. However, load forecasting is typically done offline and is typically used for planning.
In contrast to building-level energy disaggregation, feeder-level energy disaggregation involves disaggregating the demand of a large number of loads, e.g., thousands, into a small number of source signals, e.g., two. In contrast to load forecasting, feeder-level energy disaggregation estimates portions of the total demand and assumes real-time demand measurements, e.g., taken by SCADA systems at distribution substations, are available on timescales of seconds to minutes. This corresponds to relatively fast sampling for load forecasting and relatively slow sampling for building-level energy disaggregation. In contrast to both building-level energy disaggregation and load forecasting, feeder-level energy disaggregation is done online. However, much like load forecasting and some building-level energy disaggregation approaches, we assume detailed historical load data are available and used offline to construct models.
Machine learning algorithms have been proposed to address a number of problems in power systems including security assessment, forecasting, and optimal operation [17]. A variety of machine learning techniques have been used to forecast load, renewable generation, and prices[18, 19, 20, 21, 22]. References [23, 24, 25, 26, 27] apply learning approaches to demand response. However, to the best of our knowledge, this is the first paper to pose and solve the feeder-level energy disaggregation problem, or to apply the approach in [9] to a power systems problem.
III Problem Framework
We assume that a power system entity (e.g., a system operator, utility, or third-party company) has access to real-time measurements of the electricity demand served by a distribution feeder. The power system entity is interested in separating these measurements into two components in real-time, i.e., at each time-step. The first component is the power demand of a population of residential air conditioners served by the feeder, referred to as the “AC demand.” Air conditioners generally draw power periodically to maintain a building’s indoor temperature within a range centered at a user-defined temperature set-point. The AC demand varies in time due to each air conditioner’s power cycling, weather-related influences, and building occupant influences. The second component is the power demand of the other loads on the feeder, referred to as the “OL demand,” which we assume includes both residential and commercial loads. Figure 1 displays example time series for the measured total demand , the AC demand , and the OL demand over a day. We measure at each time-step and try to estimate and at each time-step as each measurement arrives.
The power system entity has two distinct modes of operation. The first is the real-time estimation mode depicted in Fig. 2a. The second is the offline model generation mode, depicted in Fig. 2b. During real-time operation, we assume that the power system entity has access to active power measurements corresponding to the demand served by the distribution feeder as well as weather-related measurements. The power measurements are time-averaged active power demands over one min intervals, and they are the sum of the AC and OL demand. The weather-related measurements could include, for example, temperature and humidity, and can be obtained from existing weather sensors; load-specific weather monitoring is not required.
Model generation occurs offline using historical smart meter, feeder, and weather data. To apply DFS to feeder-level energy disaggregation we assume real-time measurements of the demand components are unavailable, but models of the components are available. These models could be created using a variety of techniques (e.g., via system identification using historical measurements obtained from the same system or a different system, or using analytical methods and parameters from the literature). In this work, we assume that smart meters are installed at all houses, and they enable the collection of household-level demand measurements at one minute intervals. The smart meters’ communication limitations [12] make real-time communication of this information infeasible, and so we assume that it is only available offline for prior days. Because we do not need real-time, device-level demand measurements, we assume that historical device-level demand estimates can be obtained offline from the historical household-level measurements either by applying non-intrusive load monitoring (NILM) algorithms or by using information from communicating or advanced thermostats, which are becoming more common within residences. These thermostats can measure and record the on/off mode of a residence’s AC unit and measurement histories can be used to estimate the power draw of these devices. The resulting device-level demand estimates may not be exact, but they are accurate enough to be used within the computation of model parameters. As a result, we use historical, device-level measurements to construct the AC demand models. We also assume that the power system entity has access to historical feeder and weather data. Once the models are formed, they are used along with the real-time measurements to estimate the AC and OL demand.
An online learning algorithm, Dynamic Mirror Descent (DMD) [9], uses a single model to generate predictions of the total demand, a loss function to penalize errors between the predicted and measured total demand, and a convex optimization formulation to adjust this prediction based on the measured total demand. Dynamic Fixed Share (DFS) [9], uses DMD within the Fixed Share Algorithm [28] to include predictions from a bank of models. Specifically, DFS applies DMD separately to each model and uses a weighting algorithm to associate a weight with each model’s adjusted prediction before combining the predictions into an overall estimate. In DFS, these models are weighted based on their prediction accuracy – better prediction-measurement matching leads to larger weighting and more influence in the overall prediction.
Rather than predicting the AC demand using a single load forecast, the proposed approach has two main advantages. First, in DMD, the AC and OL demand predictions are adjusted in real-time based on the real-time, realized feeder demand. This feedback improves future predictions; in contrast, load forecasting is open-loop. It is necessary to predict both the AC and OL demand since only the total demand is measured. If only the AC demand is predicted, the prediction cannot be adjusted in real-time because measurements of the realized AC demand are not available in real-time. Second, the DFS algorithm can incorporate a number of AC demand predictions into an overall AC demand prediction. Predictions associated with prediction methods that have performed well recently are weighted more heavily and the weights evolve over time so different predictors will be preferred at different times. The algorithm is described in detail in Section VI, but first we describe the construction of the underlying physical system, i.e., the plant, used within the case studies and the models used within the algorithm.
IV Construction of Plant
In this section, we detail the methods used to form the AC and OL demand time series and the associated weather time series over one day. These time series incorporate data from real households, the devices within those households, commercial buildings, and nearby weather stations. The data for individual, residential air conditioners are summed to form the AC demand, the data for household non-AC devices are summed to form the residential OL demand, and the data for commercial building demand signals are summed and scaled to form the commercial, OL demand signal. Lastly, the outdoor temperature data consists of real data from nearby weather stations, and the data is interpolated to make it applicable on the time-steps used within the problem scenario. These time series are then used as the plant, i.e., the underlying physical system or the ground-truth signals. The time series for a day consist of one-minute time-steps with at 12:00 AM. Because we were unable to find sufficient data from a single location/day, we use demand and weather data from a variety of sources.
We use feeder model R5-25.00-1 from GridLAB-D’s feeder taxonomy [29] to set the average residential and commercial demand on the feeder to MW and MW, respectively. Ignoring network losses (which, if included, would be treated as part of the OL demand), the total feeder demand measurements are the sum of the AC and OL demand, i.e., , where is the sum of the other residential demand and the commercial demand .
Both and are constructed using residential data from the Pecan Street Dataport [30]. The data consists of historical one min interval household- and device-level demand measurements for a set of single family homes in Texas. Daily household demand signals were randomly drawn with replacement and added together until the total residential signal’s mean matched that of the feeder model, resulting in total houses. To construct the AC demand signal, we summed the demand of each household’s primary air conditioner and air blower unit. Note that some houses have no/multiple air conditioner and air blower units. We assume that only one unit per household contributes to the AC demand, resulting in units. The remaining demand is the residential OL demand.
The commercial data consists of 4 second interval whole-building demand measurements from two buildings in California, a municipal building and a big box retail store. We summed the demand of the two buildings, and then scaled the sum by 2.61 to match the average commercial demand of the feeder model. We also down-sampled the data to one min intervals by averaging the values over each minute.
The plant’s weather data is constructed from data obtained from the Pecan Street Dataport [30] and the National Climatic Data Center [31]. The Pecan Street weather data corresponds to the residential demand. It consists of the outdoor air temperature for Austin, TX, and it is sampled at one hour intervals. We linearly interpolate the data down to one min intervals. The NOAA weather data corresponds to the commercial demand. It consists of outdoor temperature data from the Concord, CA weather station, sampled at one hour intervals. Again, we linearly interpolate the data down to one min intervals. All weather data was taken from the same day as the demand data.
V System Models
In this section, we describe the models used to generate predictions of the AC and OL demands. These models are generated offline, using historical data, and then used within the online learning algorithm detailed in Section VI. The historical demand signals were constructed in the same manner as described in Section IV, using the same combination of houses as used to construct the plant signals. The OL demand is modeled using two different linear regression methods as detailed in Section V-A, and the AC demand is modeled using several linear dynamic systems as well as a linear regression method as detailed in Section V-B. Note that other models may prove to be more accurate on average than the models that are used within this work. However, the intended objective within this work is to use an array of models (including some that are known to be overly simple or less accurate) to investigate the performance of DFS on the feeder-level energy disaggregation problem.
V-A OL Demand Models
We use two types of regression models to predict the OL demand: time-of-day (TOD) regression models and a multiple linear regression (MLR) model. Figure 3 displays for a simulated day, several TOD regression model predictions, e.g., , and the MLR model prediction . We next describe the construction of these models.
V-A1 TOD Regression Models
The TOD regression model is a lookup table where an OL demand prediction is generated for each minute of the day based on the OL demand of a single day in the past
[TABLE]
Whereas indexes overall time-steps, indexes the time of day in minutes, i.e., for 12:00 AM and for 1:00 AM. The scalar corresponds to the predicted OL demand value for time-of-day , is a row vector containing all values, and is a column vector that selects the appropriate based on the corresponding time of day for . We generate by smoothing the OL demand signal of a previous day using a piecewise linear and continuous, least-squares fit. Each linear segment corresponds to a 15 min interval of the historical data. We generate one TOD regression model for each weekday, and the models are denoted , , , , and . Their corresponding predictions are , , , , and , respectively.
V-A2 MLR Model
The MLR model of the OL demand is denoted , and it uses input features that include calendar-based variables, e.g., the day of the week, as well as weather-based variables, e.g., the outdoor temperature, to generate an OL demand prediction. We split the MLR model into two distinct components: one model for the commercial demand and one model for the residential OL demand since the underlying data corresponds to different geographic areas and time periods. The overall MLR model of the OL demand is then the sum of the predicted residential OL demand and the predicted commercial demand , i.e.,
[TABLE]
where the row vectors and are regression parameters for the residential OL demand and the commercial demand, respectively. The column vectors and are the corresponding input features.
The MLR model for the residential OL demand uses input features where is an indicator vector for the time of week in minutes, is the outdoor temperature for Austin, TX, and is the measured total demand of the previous time-step. The commercial regression model corresponds to “Baseline Method 1” from [32]; it uses input features where is the outdoor temperature for Concord, CA and is a vector that associates the temperature to the corresponding time of week.
V-B AC Demand Models
We use three types of models to predict the AC demand: a MLR model, linear time invariant (LTI) system models, and linear time varying (LTV) system models. Figure 4 displays for a simulated day, several LTV model predictions, e.g., , and the MLR regression model prediction . We next describe the construction of these models.
V-B1 MLR Model
The MLR model of the AC demand, denoted , is similar to the MLR model in Section V-A2 with different input features , where is the temperature in Austin, TX from time-steps ago and is the time lag that maximizes the cross correlation between the historical AC demand signal and temperature signal (119 min for our plant).
V-B2 LTI Models
We construct a set of LTI models , originally developed in [33, 34]. As in [35], each model within the set captures the aggregate behavior of the population of air conditioners at outdoor temperature and has the form
[TABLE]
with . The state vector consists of the portion of the air conditioners within each of discrete states. In this paper, we use one state to represent the portion of air conditioners that are drawing power and another to represent those that are not, i.e., . The state transition matrix, , is a transposed Markov transition matrix. Its entries capture the probabilities that air conditioners maintain their current state or transition to the other state during the time-step. The output matrix estimates the AC demand from the portion of air conditioners that are drawing power, i.e., , where is a parameter approximating of the average power draw of air conditioners drawing power and is the number of air conditioners, which we assume is known.
To identify and for all , we first define a set of evenly spaced temperatures and denote the -th temperature of the set as . The difference between successive temperatures and is . Matrices and are constructed using power demand signals from each air conditioner corresponding to periods when . Some heuristics were used to exclude anomalous high or low power demand measurements. Parameter is set as the average power draw of air conditioners that are drawing power. The four entries of were determined by checking whether an air conditioner 1) started drawing power, 2) stopped drawing power, 3) continued to draw power, or 4) continued to not draw power during each time-step. The occurrences for each case were counted for every air conditioner at every time-step and the totals were placed into their respective entries in , and then each column was normalized so that the sum of the column entries was 1. In our case studies, we construct an LTI model for each integer temperature in the set . If the outdoor temperature lies outside of this range, we use the model corresponding to the closest temperature.
V-B3 LTV Models
We use two LTV models. The first uses the delayed temperature and has the form
[TABLE]
where and are generated by linearly interpolating the matrix entries based on . The second uses a moving average of the past temperature over time-steps to generate the prediction . We chose to be the value that maximizes the cross correlation between the historical moving average temperature and the historical AC demand signal (270 min for our plant). When evaluating either LTV model, if the temperature lies outside of the range used to generate the model, we extrapolate using the difference between the nearest two models.
VI Online Learning Algorithm
In this section, we first summarize the DFS algorithm developed in [9] and then describe two algorithm implementations, one inspired by DFS and one a direct implementation of it. DFS incorporates DMD, also developed in [9], into the Fixed Share algorithm originally developed in [28]. The Fixed Share algorithm combines a set of predictions that are generated by independent experts, e.g., models, into an estimate of the system parameter using the experts’ historical accuracy with respect to observations of the system. DMD extends the traditional online learning framework by incorporating dynamic models, enabling the estimation of time-varying system parameters (or states). DFS uses DMD, applied independently to each of the models, as the experts within the Fixed Share algorithm.
VI-A The DFS Algorithm
The objective of DFS is to form an estimate of the dynamic system parameter at each discrete time-step where is a bounded, closed, convex feasible set. The underlying system produces observations, i.e., measurements, at each time-step after the prediction has been formed, where is the domain of the measurements. From a control systems perspective, this is equivalent to a state estimation problem where is the system state.
DFS uses a set of models defined as to generate the estimate . To do this, DFS applies the DMD algorithm to each model, forming predictions for each . DMD is executed in two steps (similar to a discrete-time Kalman filter): 1) an observation-based update incorporates the new measurement into the parameter prediction, and 2) a model-based update advances the parameter prediction to the next time-step. DFS then uses the Fixed Share algorithm to form the estimate as a weighted combination of the individual model’s DMD-based predictions. A weighting algorithm computes the weights based on each model’s historical accuracy with respect to the observations . Models that perform poorly have less influence on the overall estimate. The DFS algorithm is [9]
[TABLE]
for each , and
[TABLE]
where each term is defined below. DMD is applied to each model in (8) and (9) to form the expert predictions, where (8) is a convex program that constructs the measurement-based update to the previous prediction and (9) is the model-based advancement of the adjusted prediction. The Fixed Share algorithm consists of (10) and (11), where (10) computes the weights and (11) computes the estimate as a weighted combination of the individual experts’ estimates. We note that the Fixed Share algorithm’s updates are independent of the dynamics and only use the experts’ predictions and their resulting losses.
In (8), we minimize over the variable , is a step-size parameter, and is the standard dot product. The value is a subgradient of the convex loss function , which penalizes the error between the predicted and observed values using a known, possibly time-varying, function that maps to an observation, i.e., , to form predictions of the measurements. An example loss function is where the matrix is . In (9), the function applies model to advance the adjusted estimate in time. Each can have arbitrary form and time-varying parameters. In (10), the weight associated with model at time-step is , determines the amount of weight that is shared amongst models, and influences switching speed. The weight for model is based on the loss of each model and the total loss of all models. The term captures the alignment of the variable with the positive gradient of . To minimize this term alone, we would choose to be exactly aligned with the negative gradient direction. The term is a Bregman divergence that penalizes the deviation between the new variable and the old variable . For simplicity, we have excluded regularization within (8), which DMD readily incorporates [9].
VI-B Algorithm Implementations
We next describe two algorithm implementations to update the expert predictions. First, we describe an implementation that uses the concept of DMD but it is not a direct implementation of DMD. This method treats the models as black boxes and adjusts only their output, i.e., the OL and AC demand predictions, using the measured and predicted total feeder demand. Second, we describe a direct implementation of DMD, which updates the state of the LTI and LTV AC demand models. In the following, the total demand model is where is an AC demand model and is an OL demand model, with predictions and , respectively.
VI-B1 Update Method 1
The models used within this paper have different underlying parameters, dynamic variables, and/or structures, which makes it difficult to define a common across all of the models used. Therefore, we develop a variation of the DMD algorithm that adjusts the demand predictions directly, rather than applying the updates to quantities influencing the demand predictions. This allows us to include a diverse set of models. Specifically, we modify the DMD formulation to
[TABLE]
The AC and OL demand models generate their predictions independently from one another, and so (38) can be rewritten as
[TABLE]
The convex program (12) is now used to update a value that accumulates the deviation between the predicted and actual measurements. The model-based update (29) computes an open-loop prediction {\mathchoice{{\ooalign{\hbox{\raise 7.12962pt\hbox{\scalebox{1.0}[-1.0]{\lower 7.12962pt\hbox{\displaystyle\widehat{\vrule width=0.0pt,height=6.94444pt\vrule height=0.0pt,width=4.69444pt}}}}}\cr\hbox{\displaystyle\theta}}}}{{\ooalign{\hbox{\raise 7.12962pt\hbox{\scalebox{1.0}[-1.0]{\lower 7.12962pt\hbox{\textstyle\widehat{\vrule width=0.0pt,height=6.94444pt\vrule height=0.0pt,width=4.69444pt}}}}}\cr\hbox{\textstyle\theta}}}}{{\ooalign{\hbox{\raise 6.43518pt\hbox{\scalebox{1.0}[-1.0]{\lower 6.43518pt\hbox{\scriptstyle\widehat{\vrule width=0.0pt,height=4.8611pt\vrule height=0.0pt,width=3.2861pt}}}}}\cr\hbox{\scriptstyle\theta}}}}{{\ooalign{\hbox{\raise 5.97221pt\hbox{\scalebox{1.0}[-1.0]{\lower 5.97221pt\hbox{\scriptscriptstyle\widehat{\vrule width=0.0pt,height=3.47221pt\vrule height=0.0pt,width=2.34721pt}}}}}\cr\hbox{\scriptscriptstyle\theta}}}}}_{t+1}, meaning that the measurements do not influence {\mathchoice{{\ooalign{\hbox{\raise 7.12962pt\hbox{\scalebox{1.0}[-1.0]{\lower 7.12962pt\hbox{\displaystyle\widehat{\vrule width=0.0pt,height=6.94444pt\vrule height=0.0pt,width=4.69444pt}}}}}\cr\hbox{\displaystyle\theta}}}}{{\ooalign{\hbox{\raise 7.12962pt\hbox{\scalebox{1.0}[-1.0]{\lower 7.12962pt\hbox{\textstyle\widehat{\vrule width=0.0pt,height=6.94444pt\vrule height=0.0pt,width=4.69444pt}}}}}\cr\hbox{\textstyle\theta}}}}{{\ooalign{\hbox{\raise 6.43518pt\hbox{\scalebox{1.0}[-1.0]{\lower 6.43518pt\hbox{\scriptstyle\widehat{\vrule width=0.0pt,height=4.8611pt\vrule height=0.0pt,width=3.2861pt}}}}}\cr\hbox{\scriptstyle\theta}}}}{{\ooalign{\hbox{\raise 5.97221pt\hbox{\scalebox{1.0}[-1.0]{\lower 5.97221pt\hbox{\scriptscriptstyle\widehat{\vrule width=0.0pt,height=3.47221pt\vrule height=0.0pt,width=2.34721pt}}}}}\cr\hbox{\scriptscriptstyle\theta}}}}}_{t+1}. The measurement-based updates and model-based, open-loop predictions are combined in (38). In contrast, DMD uses a closed-loop model-based update where the convex program adjusts the parameter estimate to , which is used to compute the next parameter estimate .
In this method, we define as the AC and OL demand, i.e., . The mapping from the parameter to the measurement is where the matrix . While the mapping and matrix are time-invariant, they may be time-varying in Section VI-B2, and so we use the more general notation. We choose the loss function as and the divergence as . We can then write (12) in closed form as
[TABLE]
VI-B2 Update Method 2
This method applies only to dynamic system models with dynamic states, i.e., in this paper the LTI or LTV AC demand models, which have dynamic states . We set , where is in (4), in (6), or in an update equation similar to (6). The mapping from the parameter to the measurement is then where is the output matrix of the LTI or LTV AC demand model, i.e., , , or . Defining the system parameter in this way allows us to update the dynamic states of the LTI and LTV AC demand models, rather than just the output as in Update Method 1. The model-based update is then
[TABLE]
where we update the AC demand model using the adjusted parameter estimate, as in DMD. Because the OL demand models do not include dynamic states, we continue to update their estimates according to Update Method 1. We again use (48) as the measurement-based update.
VII Case Studies
In this section, we define the scenarios, describe the benchmark, summarize the parameter settings, and present the results. In [9], performance bounds for DMD and DFS were established in terms of a quantity called regret. Regret is the total (or cumulative) loss of an online learning algorithm’s prediction sequence versus that of a comparator sequence, often a best-in-hindsight offline algorithm. In [9], the DMD regret bound uses a comparator that can take on an arbitrary sequence of values from the feasible domain . The DFS regret bound uses a comparator that chooses the best-in-hindsight possible sequence of models chosen from the same model collection used by DFS, where the number of model switches is a predefined number. In lieu of developing formal performance bounds for the given problem scenario, we benchmark the algorithms’ performance using Kalman filters, which is described in Section VII-B. Future work will investigate regret bounds for our particular problem.
VII-A Scenario Definitions
We define the three sets of models for use within DFS:
, all of the models developed in Section V, i.e., every combination of AC and OL demand models from the AC demand model set and the OL demand model set ; 2. 2.
, a reduced set that excludes the LTI models, which are not accurate over the course of the day; 3. 3.
, a further reduced set that excludes the MLR AC demand model, which can not be used in a Kalman filter;
Since the Update Method 2 is only applicable to the LTI and LTV AC demand models, case studies using Update Method 2 apply the method to all applicable model combinations and otherwise use Update Method 1.
VII-B Kalman filter benchmark
A set of Kalman filters are used to establish a benchmark for the DFS algorithm. A Kalman filter uses measurements, an assumed system model, and known statistics of random variables, which are assumed to be zero-mean and normally distributed, to estimate the value of dynamic system parameters, i.e., the system state, at each time-step. Additional background on Kalman filters can be found in [36].
We use the LTV AC demand models within the Kalman filters. For each LTV model, the covariance of the process noise is computed using a week of historical data, where the true state is generated using the measured AC demand and the LTV model’s matrices. The Kalman filter estimates the state of the AC demand model, i.e., where is or , using output pseudo-measurements of the AC demand . We assume that is noise-free, but is noisy due to OL demand prediction error. The covariance of the measurement errors depends on the OL demand model used, and is computed for each model using a week of historical errors.
We run one Kalman filter for each model pair in the set . We compare the performance of the DFS algorithm to that of the best Kalman filter (BKF), which takes the lowest ex post root mean squared error (RMSE) achieved by a Kalman filter within the set , and the average Kalman filter (AKF), which is the average RMSE across all of the Kalman filters.
VII-C Data
We test the methods on data from Aug 3-5, 10-14, 17, and 18, where the commercial data is from 2009 and the residential data is from 2015. Note that the dates in both years pertain to the same days of the week. The household and commercial demand data for Aug 3 were used to determine the set of houses included on the feeder and construct the plant. To generate the MLR regression models of the AC and OL demand, we use data from June 24 to Aug 2, 2015 and commercial data from June 24 to Aug 2, 2009. The LTI and LTV models of the AC demand were constructed using device-level data from individual air conditioners from May 2 to Aug 2, 2015. The TOD regression models and Kalman filter covariance matrices were generated using data from the week preceding Aug 3. All testing and training data are available at [37].
VII-D Investigation of Algorithm Performance
Table I gives the settings of , and we set across all simulations (with the exception of sensitivity simulations in Sections VII-E and VII-F). Parameter dictates the amount of weight shared amongst the models, where values near 1 force the DFS algorithm to generate estimates that are close to an average of the predictions of all models. By using a value near 0, a single model can dominate the estimate if one model is more accurate than the rest. Parameters and were roughly tuned to achieve qualitative characteristics of fast switching between models without over-fitting. The optimal and for a given day will generally not be optimal across all days, and so tuning to achieve the desired qualitative characteristics is appropriate. In practice, and can be tuned based on recent historical data, and can be tuned based on the historical accuracy of the models within the algorithm. An avenue for future research is to develop methods for online parameter tuning using real-time data.
Figure 5 depicts time series for the Aug 17 simulation with while using Update Method 1. Figure 6 shows the evolution of the dominant model weights. The weights of the remaining models are summed and referred to as “Other Models." In this scenario, the total demand is accurately separated into its AC demand and OL demand components in real-time, where the RMSE of the total demand, AC demand, and OL demand is kW, kW, and kW, respectively. In this scenario, DFS produces a more accurate AC demand estimate than BKF, which has an AC demand RMSE of kW. The RMSE of the AC demand for AKF is kW. The majority of the weight is initially given to the “Other Models," because we initialize all models with the same weight. As the simulation progresses, the weight shifts between different model combinations. Since the combinations and perform best, they eventually earn more weight and dominate the predictions. It is unsurprising that the is the most accurate OL demand model as it captures weather and time variables with the most detail, and it is unsurprising that and are the most accurate AC demand models as they capture the physical phenomenon driving changes in the AC demand as the outdoor temperature changes.
Figure 7 presents the minimum, mean, and maximum RMSE across the full set of testing days for the total demand, the AC demand, and the OL demand for each DFS scenario. For comparison, BKF achieves a minimum RMSE of 148.4 kW, a mean RMSE of 195.3 kW, and a maximum RMSE of 318.9 kW for the AC demand, and AKF achieves a minimum RMSE of 173.1 kW, a mean RMSE of 259.4 kW, and a maximum RMSE of 357.5 kW for the AC demand. The model corresponding to the BKF varies from day to day and so it is not possible to obtain a single Kalman filter that always outperforms DFS.111Choosing BKF on a particular day and applying it to all other days, we find that DFS performs better on approximately half of the days when using . However, the loss function, divergence function, and initial model weights within DFS could be modified based on historical performance, which would improve its performance relative to the Kalman filter.To demonstrate the value of the measurement-based updates, we generated results for the full set of days using the model set and with ; the measurement-based update is irrelevant with this parameter setting. The resulting total demand, AC demand, and OL demand RMSEs were kW, kW, and kW, respectively. These are significant increases over the DFS scenarios using .
The scenarios using have significantly higher AC demand RMSEs than the simulations using as well as the BKF and AKF simulations. Each of the LTI models may be accurate for a portion of the day when the AC demand is near the steady-state demand of the particular model. However, as the AC demand changes due to changes in the outdoor temperature, a given LTI model will become highly inaccurate. The DFS algorithm takes time to shift weight from the inaccurate model that was heavily weighted to the new model, and this results in increased RMSE. Eliminating these “bad models”, by using rather than , eliminates this issue.
The scenarios using generally do better, in terms of AC demand RMSE, than AKF and worse than BKF. On some simulated days DFS also outperforms BKF, as was shown in Fig. 5. Within this set of simulations, Update Method 2 results in higher AC demand RMSE than Update Method 1. The increased RMSE in Update Method 2 versus Update Method 1 can be explained due to the usage of only two discrete states within the LTV models. Specifically, the states reach their steady-state values rapidly, and so the measurement-based updates to the state do not persist for very long, whereas the measurement-based updates to the output used in Update Method 1 do. Using LTV models with more discrete states may allow Update Method 2 to achieve better RMSE, but this would complicate system identification.
Finally, the scenarios with result in larger AC demand RMSE than those with . The MLR model of the AC demand is often weighted heavily in the simulations, especially for Update Method 2. Given this, it makes sense that excluding this model would result in increased RMSE.
VII-E Sensitivity to the Parameters and
We apply DFS to the full set of days while varying and to investigate the impact of those parameters on the results. We vary from 0.0 to 0.9 using increments of 0.1, and we vary from to , where we increment the order (i.e., , ). We apply DFS using every combination of these parameter values while using Update Method 1, , and as in Section VII-D.
Figure 8 provides the average RMSE of the AC demand across the full set of testing days for each parameter value combination. With near zero the RMSE is relatively large as DFS makes small adjustments to the model predictions based on the realized prediction errors. The RMSE with near zero decreases slightly as increases because this allows for faster transitions in the weighting of the models. However, it should be noted that at larger values (e.g., ), the model weights within DFS become erratic or noisy, and overfitting is possible. The RMSE is also relatively high with large (e.g., 0.9) and small as DFS adjusts the model predictions too aggressively and the model weights change slowly. Alternatively, as increases with large , the RMSE decreases, but again the weights become vulnerable to overfitting. The RMSE using moderate values (e.g., from 0.2-0.7) are similar. The and values used within Section VII-D do not achieve the lowest RMSE, but they achieve low RMSE while ensuring changes in the weights are reasonably fast but not erratic.
VII-F Sensitivity to the Parameter
We apply DFS to the full set of days while varying from to to investigate the impact of on the results. Within DFS, we use Update Method 1 and , and we also set , and as in VII-D.
Figure 9 gives the average RMSE of the estimated AC demand across all days as a function of . The average RMSE of the AC demand decreases as is increased from and reaches a minimum RMSE of 211.3 kW with . As increases from , the RMSE increases until it remains relatively constant from to . While we set in Section VII-D to allow a single model to dominate the DFS estimate if one model proved to be more accurate than the rest, Fig. 9 indicates that tuning on a set days that are similar to the testing days may allow a reduction in the RMSE.
VIII Conclusions
In this paper, we applied an online learning algorithm, DFS, which uses DMD together with the Fixed Share algorithm, to estimate the real-time AC demand on a distribution feeder using feeder demand measurements, weather data, and system models. Two implementations of algorithms based on DMD were developed and compared via case studies. Our results showed that DFS can effectively estimate the real-time AC demand on a feeder. DFS achieved lower AC demand RMSE than the average across a set of Kalman filters. When selecting the most accurate Kalman filter ex post, DFS generally results in larger RMSE. However, DFS learns the most accurate model, or combination of models, in real-time whereas the best Kalman filter can only be chosen after the simulation. The performance of DFS depends heavily on the inclusion of models within its set. Including models that are inaccurate for majority of the day degraded the algorithm performance as did removing models that were frequently weighted heavily.
In this work, we separated the demand into only two components. However, the algorithm is applicable to scenarios with more than two components, assuming that we have at least one model of each demand component. As the number of components increases, it may become more difficult to disaggregate them, but these difficulties could be counteracted by incorporating more real-time measurements, e.g., the reactive power demand. Future work will develop improved AC demand models, investigate the relationship between the DMD and Kalman filter algorithms, and incorporate active control into the problem framework.
Acknowledgments
We thank the Pacific Gas & Electric Company for the commercial building electric load data.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] G. S. Ledva, L. Balzano, and J. L. Mathieu, “Real-time energy disaggregation of a distribution feeder’s demand using online learning,” IEEE Transactions on Power Systems , (In Press), DOI: 10.1109/TPWRS.2018.2800535.
- 2[2] GTM Research/SEIA: U.S. Solar Market Insight, “Solar market insight report 2015 Q 1,” 2015. [Online]. Available: http://www.seia.org/research-resources/solar-market-insight-report-2015-q 1
- 3[3] Navigant Research, “Direct load control and dynamic pricing programs, DR markets, and DR management systems for residential customers: Global market analysis and forecasts,” 2015. [Online]. Available: https://www.navigantresearch.com/research/residential-demand-response#
- 4[4] M. P. Lee, O. Aslam, B. Foster, S. Hou, D. Kathan, C. Pechman, and C. Young, “Assessment of Demand Response & Advanced Metering,” FERC, Staff Report, Dec. 2015, https://www.ferc.gov/legal/staff-reports/2015/demand-response.pdf .
- 5[5] C. Baone, Y. Xu, and J. Kueck, “Local voltage support from distributed energy resources to prevent air conditioner motor stalling,” in Innovative Smart Grid Technologies (ISGT) , 2010.
- 6[6] S. Paul and W. Jewell, “Impact of load type on power consumption and line loss in voltage reduction program,” in North American Power Symposium (NAPS) , Sept 2013.
- 7[7] E. Can Kara, Z. Kolter, M. Berges, B. Krogh, G. Hug, and T. Yuksel, “A moving horizon state estimator in the control of thermostatically controlled loads for demand response,” in Proceedings of Smart Grid Comm , Vancouver, BC, 2013.
- 8[8] S. Esmaeil Zadeh Soudjani and A. Abate, “Aggregation and control of populations of thermostatically controlled loads by formal abstractions,” IEEE Transactions on Control Systems Technology (in press) , 2014.