TL;DR
This paper extends Piecewise Deterministic Monte Carlo algorithms to handle parameters constrained to restricted domains, enabling scalable Bayesian inference with sub-sampling.
Contribution
It introduces a novel implementation of PDMC methods suitable for restricted parameter spaces, broadening their applicability.
Findings
Effective handling of constrained parameters in PDMC algorithms
Maintains scalability with sub-sampling in restricted domains
Potential for improved Bayesian inference in constrained settings
Abstract
Piecewise Deterministic Monte Carlo algorithms enable simulation from a posterior distribution, whilst only needing to access a sub-sample of data at each iteration. We show how they can be implemented in settings where the parameters live on a restricted domain.
Click any figure to enlarge with its caption.
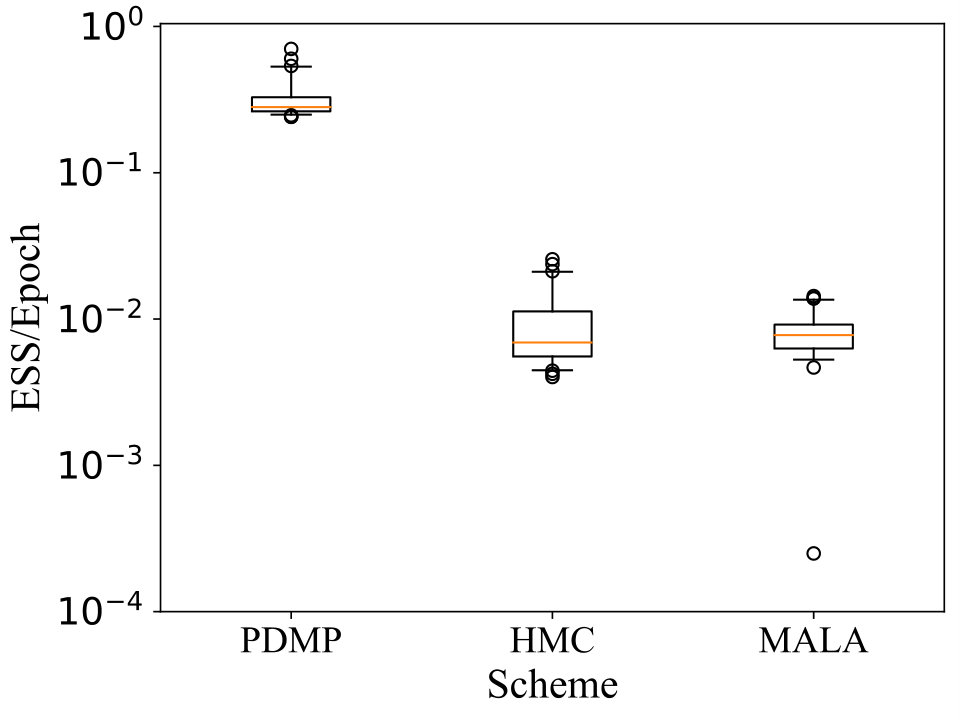 Figure 1
Figure 1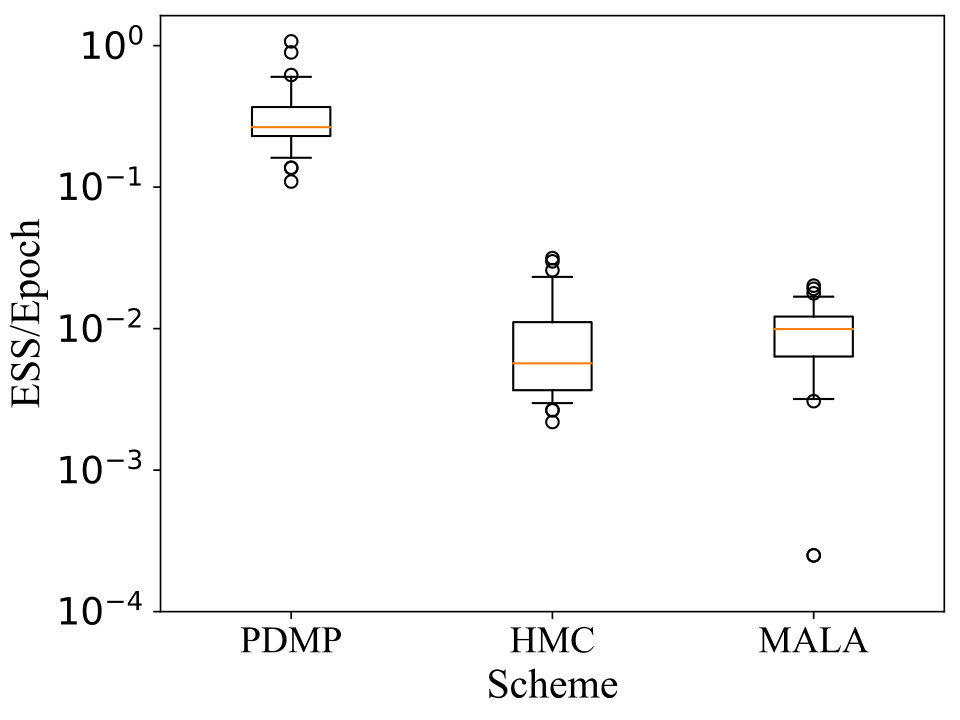 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Piecewise Deterministic Markov Processes for Scalable Monte Carlo on Restricted Domains
Joris Bierkens [email protected]; Corresponding Author Delft Institute of Applied Mathematics, TU Delft, Netherlands
Alexandre Bouchard-Côté
Department of Statistics, University of British Columbia, Canada
Arnaud Doucet
Department of Statistics, University of Oxford, UK
Andrew B. Duncan
School of Mathematical and Physical Sciences, University of Sussex, UK
Paul Fearnhead
Department of Mathematics and Statistics, Lancaster University, UK
Thibaut Lienart
Department of Statistics, University of Oxford, UK
Gareth Roberts
Department of Statistics, University of Warwick, UK
Sebastian J. Vollmer
Department of Statistics, University of Warwick, UK
Abstract
Piecewise Deterministic Monte Carlo algorithms enable simulation from a posterior distribution, whilst only needing to access a sub-sample of data at each iteration. We show how they can be implemented in settings where the parameters live on a restricted domain.
1 Introduction
Markov chain Monte Carlo (MCMC) methods have been central to the wide-spread use of Bayesian methods. However their applicability to some modern applications has been limited due to their high computational cost, particularly in big-data, high-dimensional settings. This has led to interest in new MCMC methods, particularly non-reversible methods which can mix better than standard reversible MCMC [9, 23], and variants of MCMC that require accessing only small subsets of the data at each iteration [25].
One of the main technical challenges associated with likelihood-based inference for big data is the fact that likelihood calculation is computationally expensive (typically for data sets of size ). MCMC methods built from piecewise deterministic Markov processes (PDMPs) offer considerable promise for reducing this burden, due to their ability to use sub-sampling techniques, whilst still being guaranteed to target the true posterior distribution [5, 7, 11, 12, 18]. Furthermore, factor graph decompositions of the target distribution can be leveraged to perform sparse updates of the variables [7, 17, 21].
PDMPs explore the state space according to constant velocity dynamics, but where the velocity changes at random event times. The rate of these event times, and the change in velocity at each event, are chosen so that the position of the resulting process has the posterior distribution as its invariant distribution. We will refer to this family of sampling methods as Piecewise Deterministic Monte Carlo methods (PDMC).
Existing PDMC algorithms can only be used to sample from posteriors where the parameters can take any value in . In this paper (Section 2) we show how to extend PDMC methodology to deal with constraints on the parameters. Such models are ubiquitous in machine learning and statistics. For example, many popular models used for binary, ordinal and polychotomous response data are multivariate real-valued latent variable models where the response is given by a deterministic function of the latent variables [1, 10, 22]. Under the posterior distribution, the domain of the latent variables is then constrained based on the values of the responses. Additional examples arise in regression where prior knowledge restricts the signs of marginal effects of explanatory variables such as in econometrics [13], image processing and spectral analysis [3], [14] and non-negative matrix factorization [15]. A few methods for dealing with restricted domains are available but these either target an approximation of the correct distribution [20] or are limited in scope [19].
2 Piecewise Deterministic Monte Carlo on Restricted Domains
Here we present the general PDMC algorithm in a restricted domain. Specific implementations of PDMC algorithms can be derived as continuous-time limits of familiar discrete-time MCMC algorithms [6, 21], and these derivations convey much of the intuition behind why the algorithms have the correct stationary distribution. Our presentation of these methods is different, and more general. We first define a simple class of PDMPs and show how these can be simulated. We then give simple recipes for how to choose the dynamics of the PDMP so that it will have the correct stationary distribution.
Our objective is to compute expectations with respect to a probability distribution on which is assumed to have a smooth density, also denoted , with respect to the Lebesgue measure on . With this objective in mind, we will construct a continuous-time Markov process taking values in the domain , where and are subsets of , such that is open, pathwise connected and with Lipschitz boundary . In particular, if then . The dynamics of are easy to describe if one views as position and as velocity. The position process moves deterministically, with constant velocity between a discrete set of switching times which are simulated according to inhomogeneous Poisson processes, with respective intensity functions , , depending on the current state of the system. At each switching time the position stays the same, but the velocity is updated according to a specified transition kernel. More specifically, suppose the next switching event occurs from the Poisson process, then the velocity immediately after the switch is sampled randomly from the probability distribution given the current position and velocity . The switching times are random, and designed in conjunction with the kernels so that the invariant distribution of the process coincides with the target distribution .
To ensure that remains confined within the velocity of the process is updated whenever hits so that the process moves back into . We shall refer to such updates as reflections even though they need not be specular reflections.
The resulting stochastic process is a Piecewise Deterministic Markov Process (PDMP, [8]). For it to be useful as the basis of a Piecewise Deterministic Monte Carlo (PDMC) algorithm we need to (i) be able to easily simulate this process; and (ii) have simple recipes for choosing the intensities, , and transition kernels, , such that the resulting process has as its marginal stationary distribution. We will tackle each of these problems in turn.
2.1 Simulation
The key challenge in simulating our PDMP is simulating the event times. The intensity of events is a function of the state of the process. But as the dynamics between event times are deterministic, we can easily represent the intensity for the next event as a deterministic function of time. Suppose that the PDMP is driven by a single inhomogeneous Poisson process with intensity function
[TABLE]
We can simulate the first event time directly if we have an explicit expression for the inverse function of the monotonically increasing function
[TABLE]
In this case the time until the next event is obtained by (i) simulating a realization, say, of an exponential random variable with rate ; and (ii) setting the time until the next event as the value that solves .
Inverting (1) is often not practical. In such cases simulation can be carried out via thinning [16]. This requires finding a tractable upper bound on the rate, for all . Such an upper bound will typically take the form of a piecewise linear function or a step function. Note that the upper bound is only required to be valid along the trajectory in . Therefore the upper bound may depend on the starting point of the line segment we are currently simulating. We then propose potential events by simulating events from an inhomogenous Poisson process with rate , and accept an event at time with probability . The time of the first accepted event will be the time until the next event in our PDMP.
To handle boundary reflections, at every given time , we also keep track of the next reflection event in the absence of a switching event, i.e. we compute
[TABLE]
If the boundary can be represented as a finite set of hyper-planes in , then the cost of computing is . When generating the switching event times and positions for we determine whether a boundary reflection will occur before the next potential switching event. If so, then we induce a switching event at time where and sample a new velocity from the transition kernel , i.e. .
Although theoretically we may choose a new velocity pointing outwards and have an immediate second jump, we will for algorithmic purposes assume that the probability measure for is concentrated on those directions for which , where is the outward normal at .
For a PDMP driven by inhomogeneous Poisson processes with intensities the previous steps lead to the following algorithm for simulating the next event of our PDMP. This algorithm can be iterated to simulate the PDMP for a chosen number of events or a pre-specified time-interval.
- (0)
Initialize: Set to the current time and to the current position and velocity.
- (1)
Determine bound: For each , find a convenient function satisfying for all , depending on the initial point from which we are departing.
- (2)
Propose event: For simulate the first event times of a Poisson process with rate function . Compute the next boundary reflection time .
- (3)
Let and .
- (4)
Accept/Reject event:
- (4.1)
If then set ; set ; sample a new velocity .
- (4.2)
Otherwise with probability
[TABLE]
accept the event at time .
- (4.2.1)
Upon acceptance: set ; sample a new velocity .
- (4.2.2)
Upon rejection: set and set .
- (5)
Update: Record the time and state .
2.2 Output of PDMC algorithms
The output of these algorithms will be a sequence of event times and associated states , . To obtain the value of the process at times , we can linearly interpolate the continuous path of the process between event times, i.e. . Time integrals of a function of the process can often be computed analytically from the output of the above algorithm. If not they can be approximated by numerically integrating the one dimensional integral along the piecewise linear trajectory of the PDMP. Alternatively we can sample the PDMP at a set of evenly spaced time points along the trajectory and use this collection as an approximate sample from our target distribution.
Under the assumption that the resulting PDMP is ergodic (for sufficient conditions see e.g. [5, 7]) and that the marginal density on of the stationary distribution of is equal to , we have the following version of the law of large numbers for the PDMP : For all we have that, with probability one,
[TABLE]
It is this formula which allows us to use PDMPs for Monte Carlo purposes.
2.3 Choosing the intensity and transition kernels
Assume, as most existing PDMC methods do [5, 7, 21], that the target density, is differentiable. Under this condition we can provide criteria on the switching intensities and transition kernels and which must hold for a given probability distribution to be a stationary distribution of . We shall consider stationary distributions for which and are independent, i.e. distributions of the form on . Furthermore we assume that where is continuously differentiable.
We impose the condition that
[TABLE]
A sufficient condition for (2) is that each is reversible with respect to , i.e. for every and , we have that .
Moreover, we shall require the following condition which relates the probability flow with the switching intensities :
[TABLE]
Finally, the boundary transition kernel should satisfy
[TABLE]
and
[TABLE]
where for , we denote by the outward unit normal of .
Proposition 1**.**
Consider the process on where is an open, pathwise connected subset of with Lipschitz boundary . Suppose that conditions (2),(3), (4) and (5) are satisfied. Then is an invariant distribution for the process .
The proof of this result relies on verifying that where denotes the generator of our PDMP and is deferred to the supplementary material, Section 1.
In practice we only have to satisfy (4) and (5) on the exit region . For example if and , then . The specification of on is irrelevant as these points are never reached by . On this irrelevant set, we may choose as desired to satisfy (5).
2.4 Example: The Bouncy Particle Sampler
Current PDMC algorithms differ in terms of how the and are chosen such that the above equation holds for some simple distribution for the velocity. Here we discuss how the Bouncy Particle Sampler (BPS), introduced in [21] and explored in [7], is an example of the framework introduced here. In the supplementary material, Section 1.1, the Zig-Zag sampler is described as a second example. In the following example denotes the Dirac-measure centered in .
The Bouncy Particle Sampler is obtained setting and on or , i.e. the uniform distribution on the unit sphere. The single switching rate is chosen to be , with corresponding switching kernel which reflects with respect to the orthogonal complement of with probability 1:
[TABLE]
where denotes orthogonal projection along the one dimensional subspace spanned by .
As noted in [7] this algorithm suffers from reducibility issues. These can be overcome by refreshing the velocity by drawing a new velocity independently from . In the simplest case the refreshment times come from an independent Poisson process with constant rate . This also fits in the framework above by choosing and
[TABLE]
As boundary transition kernel it is natural to choose
[TABLE]
for , so that the process reflects specularly at the boundary (i.e. angle of incidence equals angle of reflection of process with respect to the boundary normal). It is straightforward to check that condition (2) holds at the boundary and that (5) is satisfied.
As a generalization of the BPS, one can consider a preconditioned version, which is obtained by introducing a constant positive definite symmetric matrix to rescale the velocity process. The choice of plays a very similar role to the mass matrix in HMC, and careful tuning can give rise to dramatic increases in performance [12, 18].
3 Subsampling
When using PDMC to sample from a posterior, we can use sub-samples of data at each iteration of the algorithm, as described in [5, 7], which reduces the computational complexity of the algorithm from to , where is the size of the data, without affecting the theoretical validity of the algorithm. In the following we will assume that we can write the posterior as for some function . For example this would be the likelihood for a single IID data point times the th power of the prior.
The idea of using sub-sampling, within say the Bouncy Particle Sampler (BPS), is that at each iteration of our PDMC algorithm we can replace by an unbiased estimator in step (3). We need to use the same estimate both when calculating the actual event rate in the accept/reject step and, if we accept, when simulating the new velocity. The only further alteration we need to the algorithm is to choose an upper bound that holds for all realizations of . A more comprehensive explanation of this argument can be found in [5, 11] in the context of the Zig-Zag sampler, and in [7, 12] for the bouncy particle sampler.
We first present a way for estimating unbiasedly using control variates [2, 5]. For any we note that . We can then introduce the estimator of by
[TABLE]
where is drawn uniformly from .
It is straightforward to show that the resulting BPS algorithm uses an event rate that is , and that this rate and the resulting transition probability at events satisfies Proposition 1. Hence this algorithm still targets , but only requires access to one data point at each accept-reject decision.
Note that this gain in computational efficiency does not come for free, as it follows from Jensen’s inequality that the overall rate of events will be higher. This makes mixing of the PDMC process slower. It is also immediate that the bound, , we will have to use will be higher. However [5] show that if our estimator of has sufficiently small variance, then we can still gain substantially in terms of efficiency. In particular they give an example where the CPU cost effective sample size does not grow with – by comparison all standard MCMC algorithms would have a cost that is at least linear in .
To obtain such a low-variance estimator requires a good choice of , so that with high probability will be closer to . This involves a preprocessing step to find a value close to the posterior mode, a preprocessing step to then calculate is also needed.
We now illustrate how to find an upper bound on the event rate. Following [5], if we assume is a uniform (in space and ) upper bound on the largest eigenvalue of the Hessian of , and if :
[TABLE]
Thus the upper bound on the intensity is of the form with . In this case the first arrival time can be simulated as follows
[TABLE]
An alternative and complementary approach to improve the efficiency of this subsampling procedure is to use an estimator of the gradient (6) where is drawn according to a distribution dependent on the observations [7, 12].
4 Software and Numerical Experiments
A open-source Julia package PDMP.jl has been developed to provide efficient implementations of various recently developed piecewise deterministic Monte Carlo methods for sampling in (possibly restricted) continuous spaces. A variety of algorithms are implemented including the Zig-Zag sampler and the Bouncy Particle Sampler with full and local refreshment along with control variate based sub-sampling for these methods. The package has been specifically designed with extensibility in mind, permitting rapid implementation of new PDMP based methods. The library along with code and documentation is available at github.com/alan-turing-institute/PDSampler.jl.
We use Bayesian binary logistic regression as a testbed for our newly proposed methodology and perform a simulation study. The data is modelled by
[TABLE]
where are fixed covariates and . We will assume that we wish to fit this model under some monotonicity constraints – so that the probability of is known to either increase or decrease with certain covariates. This is modeled through the constraint and respectively. An example where such restrictions occur naturally is in logistic regression for questionnaires, see [24]. In following we consider the case for along with the additional linear constraint where .
For simplicity we use a flat prior over the space of parameters values consistent with our constraints. By Bayes’ rule the posterior satisfies
[TABLE]
where is the space of parameter values consistent with our constraints. We implement the BPS with subsampling. As explained in the introduction, subsampling is a key benefit of using piecewise deterministic sampling methods; see Section 3. We use reflection at the boundary i.e. for . We can bound the switching intensity by a linear function of time, even when we use the subsampling estimator for the switching rate. See the supplementary material, Section 2, for details on the application of subsampling in this example. We use and and generate artificial data based on and whose components are a realization i.i.d. of uniformly distributed random variables satisfying the imposed constraints.
We compare the performance of BPS to standard MALA and HMC schemes, in terms of effective sample size (ESS) per epoch of data evaluation. For each scheme we obtain the distribution of ESS based on independent realisations of each chain. In Figure 1(a) we plot for each scheme, the distribution of ESS per epoch with respect to the function . Similarly, In Figure 1(b) we plot the ESS per epoch for each chain with respect to the function . The performance of MALA and HMC appears commensurate and the BPS demonstrates a clear advantage over both in terms of ESS per epoch.
The HMC and MALA schemes were tuned by minimising the ESS with respect to the step-size, calculated from exploratory runs. For HMC we use leap-frog steps. We find that we must tune both HMC and MALA to have a small step size due to proposals being rejected at the boundary. The ESS is estimated based on asymptotic variance using the batch means method; see [4, 5] for details.
For specific types of constraints more efficient implementations of HMC and MALA are possible, either by introducing an appropriate transformation of the restricted state space, or by reflecting the posterior distribution along the constraint boundaries. Moreover, we note that there exists a version of HMC which can sample from truncated Gaussian distributions [19]. However, to our knowledge there is no efficient HMC or MALA scheme able to handle generally restricted domains.
The Bouncy Particle Sampler for this model was implemented using PDSampler.jl while the corresponding HMC and MALA samplers implemented with Klara.jl. The code for this numerical experiment along with results are carefully presented in github.com/tlienart/ConstrainedPDMP/.
5 Discussion
This work provides a framework for describing a general class of PDMC methods which are ergodic with respect to a given target probability distribution. Open questions remain on how the choice of intensity function, velocity transition kernel as well as other parameters of the system influence the overall performance of the scheme. The problem of understanding the true computational cost of such PDMC schemes is more subtle than for classical discrete time MCMC schemes: often one needs to find a balance between fast mixing of the continuous time Markov process and having a switching rate that is relatively cheap to simulate. For example, when using subsampling the mixing of the Markov process is slower than without subsampling, but the computational cost per simulated switch is significantly smaller. Further investigation is required to understand this delicate balance.
Acknowledgements
All authors thank the Alan Turing Institute and Lloyds registry foundation for support. S.J.V. gratefully acknowledges funding through EPSRC EP/N000188/1. J.B., P.F. and G.R. gratefully acknowledge EPSRC ilike grant EP/K014463/1. A.B.D. acknowledges grant EP/L020564/1 and A.D. acknowledges grant EP/K000276/1. We kindly acknowledge comments from the editor and anonymous reviewers which have significantly improved the exposition in this paper.
1 Stationary distribution for PDMPs on restricted domains
From [8, Section 5] the process will have infinitesimal generator given by the closure of the operator
[TABLE]
where is the set of functions which are continuously differentiable with respect to on , which is decaying to infinity as and such that
[TABLE]
for all . Based on this identification of the infinitesimal generator we can now provide a formal proof that the conditions of Proposition 1 of the paper are sufficient to ensure invariance of .
Sketch Proof of Proposition 1.
Without loss of generality we take , i.e. the proportionality factor in is assumed to be 1. We shall only provide a formal proof of this result, by demonstrating that
[TABLE]
so that is infinitesimally invariant. A rigorous proof would require establishing that as defined above is a core for the extended generator. This is a technical result which we defer for future work.
For ,
[TABLE]
where the boundary term arises from integration by parts with respect to . Considering the boundary integral, by applying (4) (in the paper) which is assumed to hold on and (S2) (above) we obtain
[TABLE]
so that the boundary term evaluates to zero.
It follows that
[TABLE]
so that is infinitesimally invariant with respect to ∎
Another possible behaviour at the boundary is to generate the new reflected direction independently of the angle of incidence. This will also preserve the invariant distribution provided that is isotropic.
Proposition 2**.**
Consider the process as in the previous proposition, such that conditions (2) and (3) (of the paper) hold and the distribution has mean zero. Then will be an invariant distribution for the process if is independent of for all .
Sketch Proof of Proposition 2.
Let , so that satisfies (S2). By the assumptions on in Proposition 1 (of the paper), this implies that for all . Following the proof of Proposition 1 above, the boundary integral term becomes
[TABLE]
which is zero if has mean zero, as required. ∎
2 The Zig-Zag sampler
The Zig-Zag sampler [5] can be recovered by choosing and picking as velocity space equipped with discrete uniform distribution , defining switching rates . The corresponding switching kernels over new directions are given by
[TABLE]
where denotes the operation of flipping the -th component, i.e. , and for .
3 Derivation of dominating intensity for logistic regression example
A valid choice of can be derived as follows: Notice that and so that we obtain
[TABLE]
Using for
[TABLE]
So Equation (7) (of the paper) holds with
[TABLE]
as defined above.
This is a linear upper bound on the intensity which can be used to sample according to (8) (of the paper) and then used for thinning as introduced in Section 1 of the paper.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] J. H. Albert and S. Chib. Bayesian analysis of binary and polychotomous response data. Journal of the American Statistical Association , 88(422):669–679, 1993.
- 2[2] R. Bardenet, A. Doucet, and C. Holmes. On Markov chain Monte Carlo methods for tall data. Journal of Machine Learning Research , 18(18):1–43, 2017.
- 3[3] S. Bellavia, M. Macconi, and B. Morini. An interior point Newton-like method for non-negative least-squares problems with degenerate solution. Numerical Linear Algebra with Applications , 13(10):825–846, 2006.
- 4[4] J. Bierkens and A. Duncan. Limit theorems for the Zig-Zag process. Advances in Applied Probability , 49(3), jul 2017.
- 5[5] J. Bierkens, P. Fearnhead, and G. Roberts. The Zig-Zag process and super-efficient sampling for Bayesian analysis of big data. ar Xiv preprint ar Xiv:1607.03188 , 2016.
- 6[6] J. Bierkens and G. Roberts. A piecewise deterministic scaling limit of lifted Metropolis-Hastings in the Curie- Weiss model. Annals of Applied Probability , 27(2):846–882, 2017.
- 7[7] A. Bouchard-Côté, S. J. Vollmer, and A. Doucet. The bouncy particle sampler: A non-reversible rejection-free Markov chain Monte Carlo method. ar Xiv preprint ar Xiv:1510.02451 , 2015.
- 8[8] M. H. A. Davis. Piecewise-deterministic Markov processes: A general class of non-diffusion stochastic models. Journal of the Royal Statistical Society. Series B (Methodological) , pages 353–388, 1984.
