Achieving Privacy in the Adversarial Multi-Armed Bandit
Aristide C. Y. Tossou, Christos Dimitrakakis

TL;DR
This paper presents a novel approach combining differential privacy mechanisms with the EXP3 algorithm to achieve improved privacy guarantees and regret bounds in adversarial multi-armed bandit problems, supported by empirical validation.
Contribution
It introduces a new method that enhances privacy in adversarial bandits by integrating Laplace and exponential mechanisms with EXP3, improving regret bounds and privacy levels.
Findings
Achieves $ ilde{O}( rac{ oot{2} ext{T} ext{ln T}}{ ext{ε}})$ regret bound with differential privacy.
Improves privacy from linear leakage to $ ilde{O}( oot{ln T})$-DP in EXP3.
Demonstrates empirical results aligning with theoretical improvements.
Abstract
In this paper, we improve the previously best known regret bound to achieve -differential privacy in oblivious adversarial bandits from to . This is achieved by combining a Laplace Mechanism with EXP3. We show that though EXP3 is already differentially private, it leaks a linear amount of information in . However, we can improve this privacy by relying on its intrinsic exponential mechanism for selecting actions. This allows us to reach -DP, with a regret of that holds against an adaptive adversary, an improvement from the best known of . This is done by using an algorithm that run EXP3 in a mini-batch loop. Finally, we run experiments that clearly demonstrate the validity of our theoretical analysis.
Click any figure to enlarge with its caption.
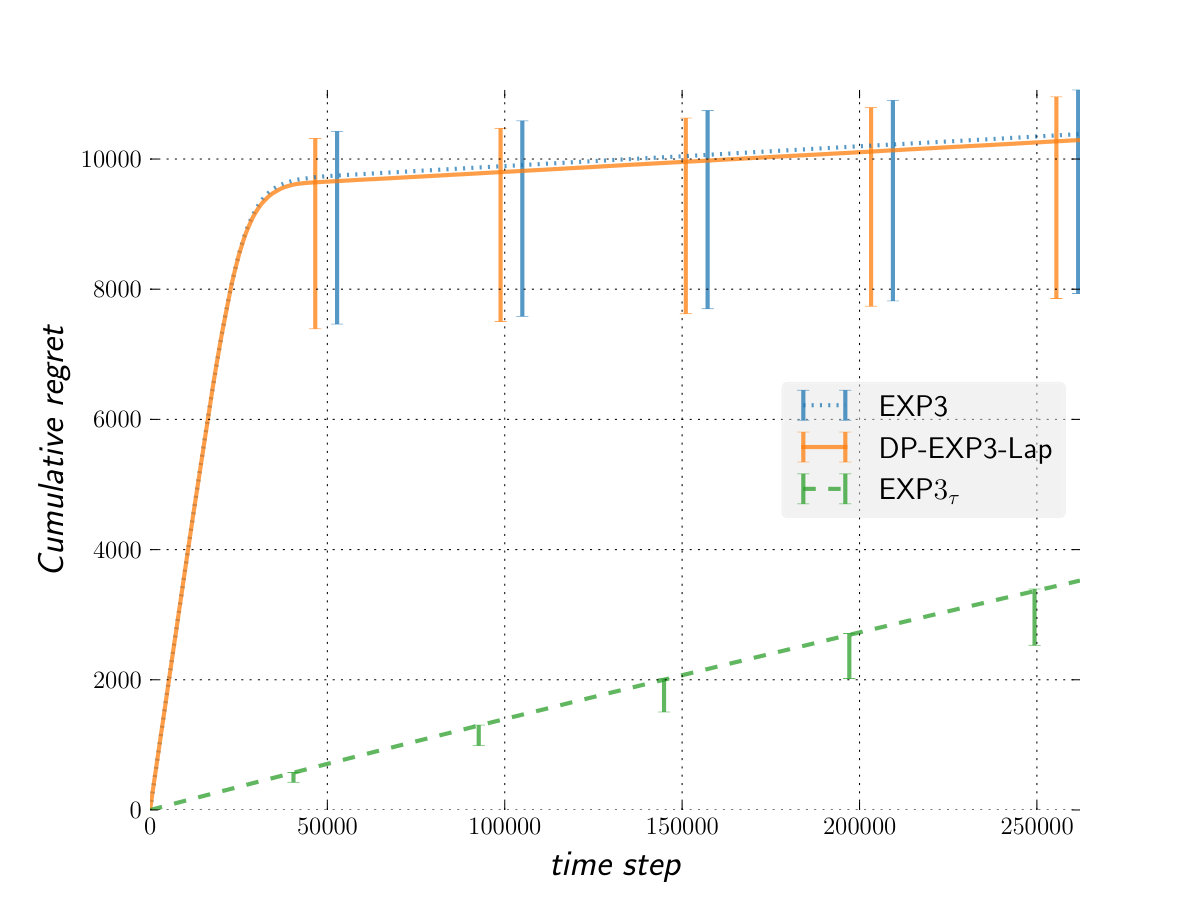 Figure 1
Figure 1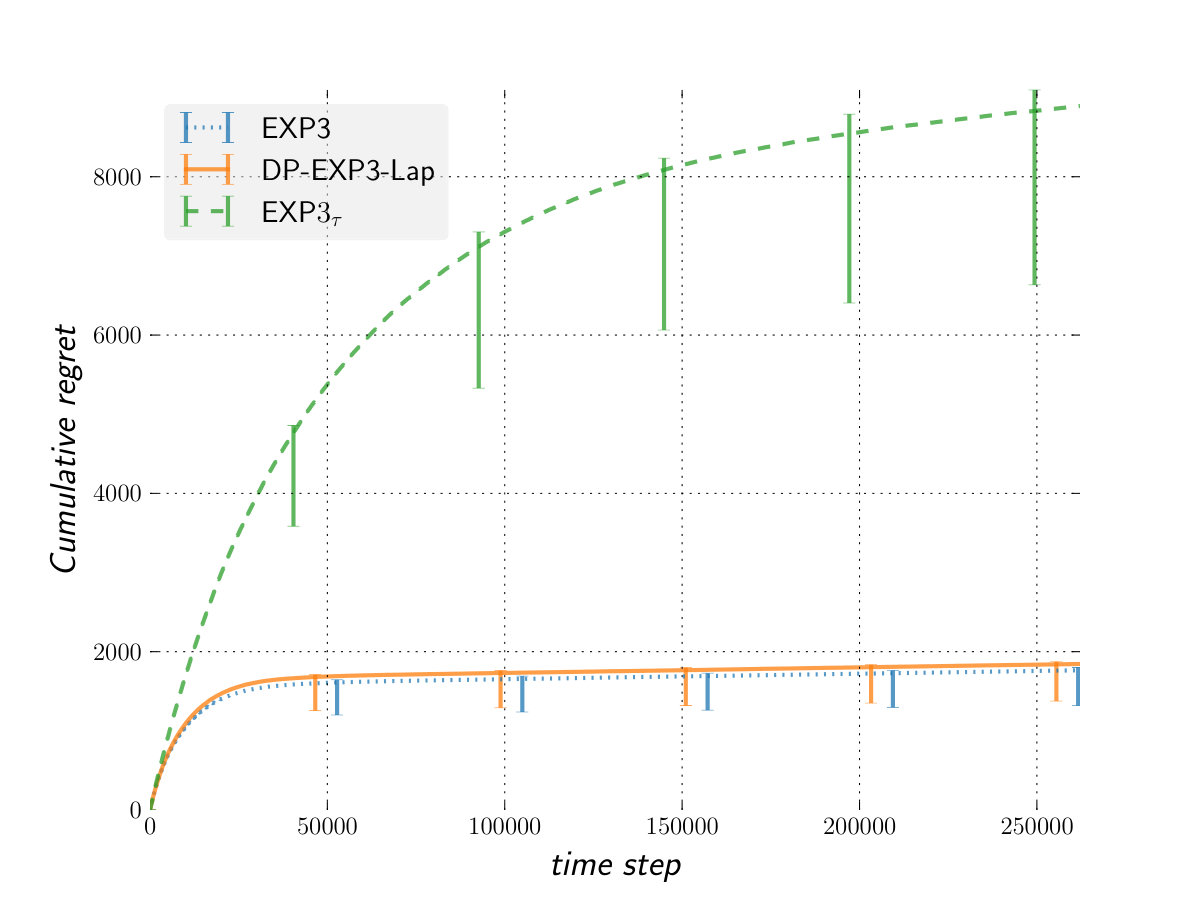 Figure 2
Figure 2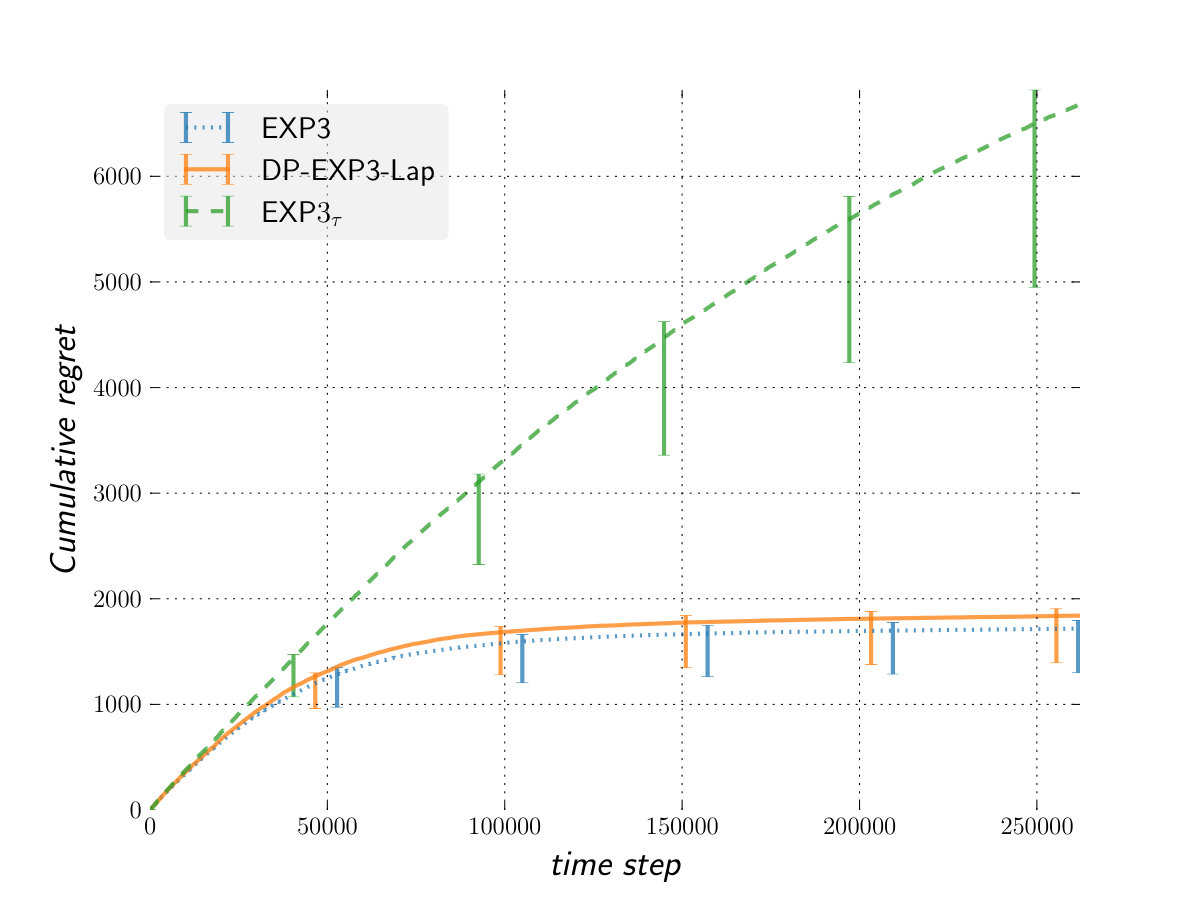 Figure 3
Figure 3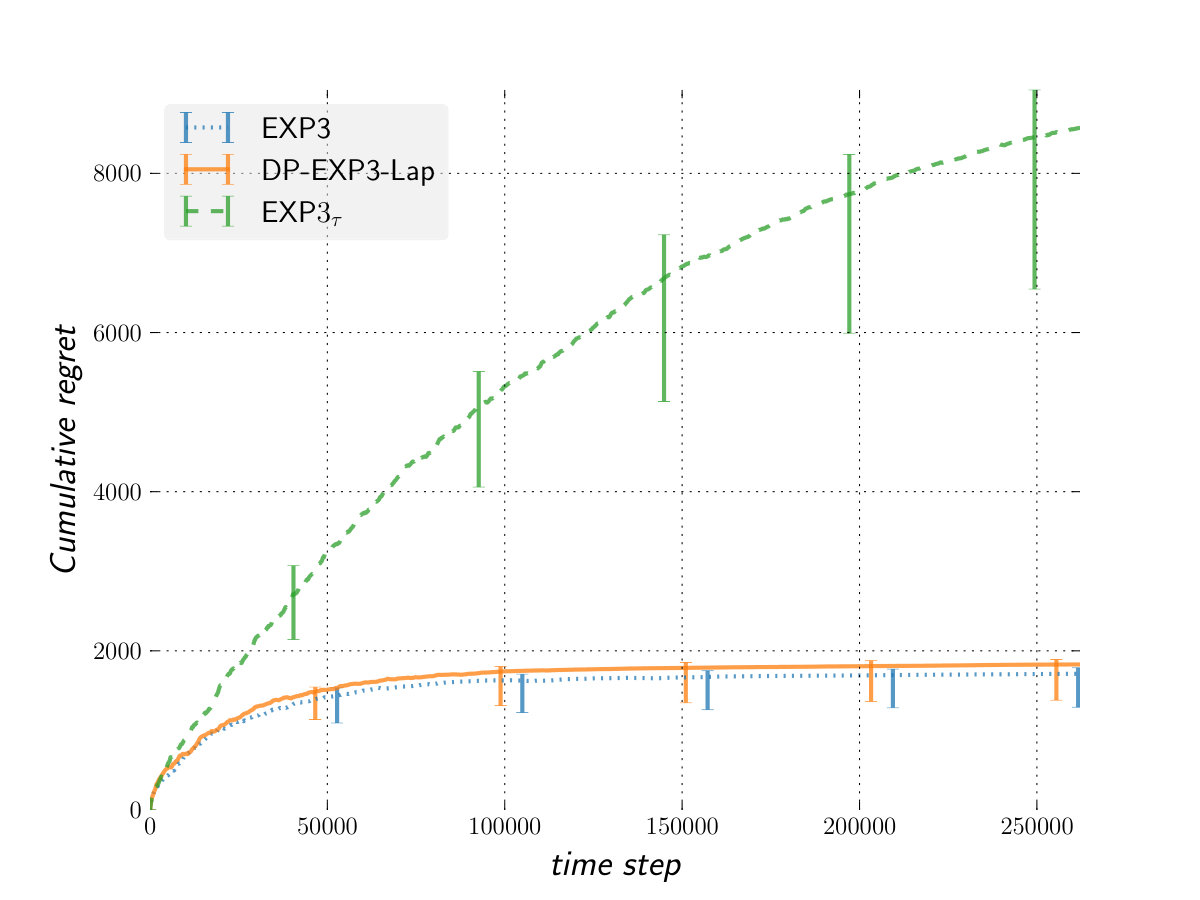 Figure 4
Figure 4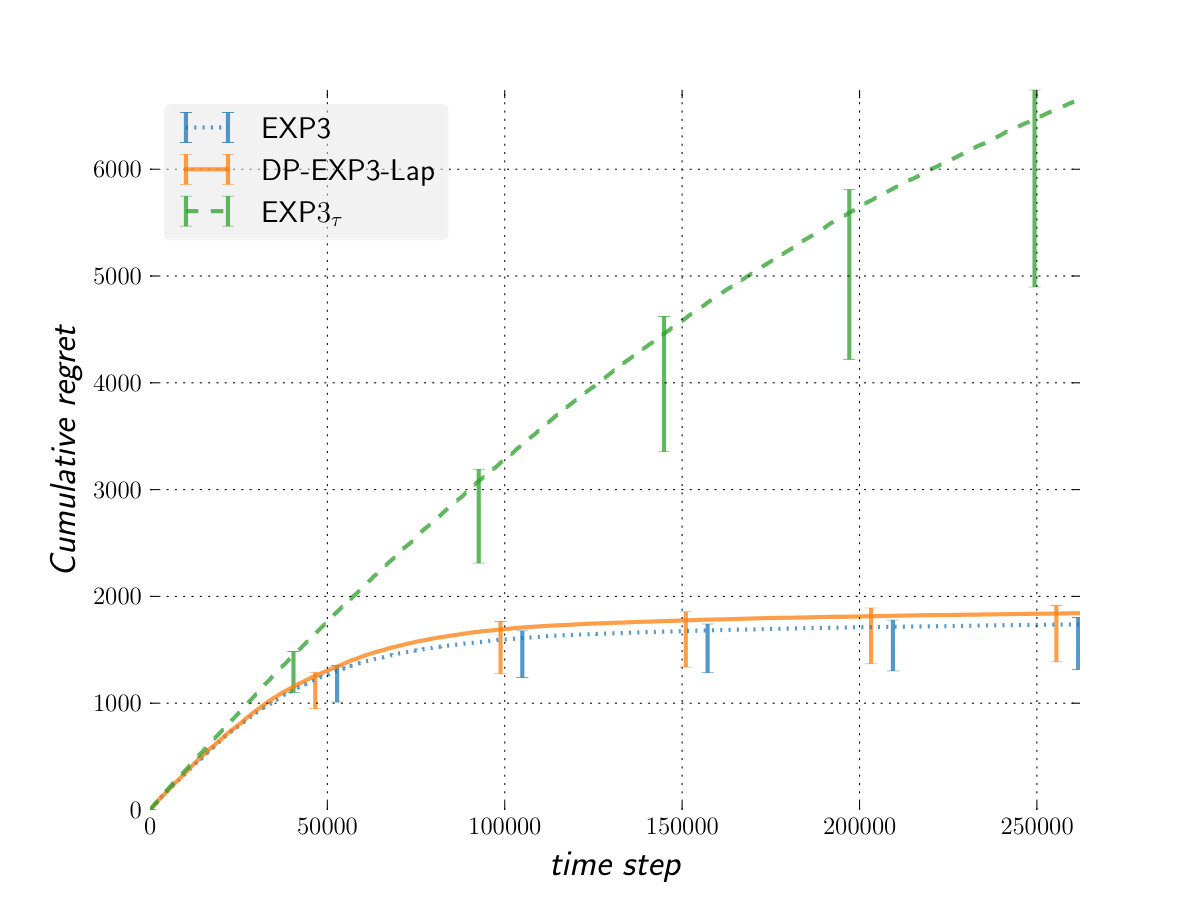 Figure 5
Figure 5Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Achieving Privacy in the Adversarial Multi-Armed Bandit
Aristide C. Y. Tossou
Chalmers University of Technology
Gothenburg, Sweden
[email protected] &Christos Dimitrakakis
University of Lille, France
Chalmers University of Technology, Sweden
Harvard University, USA
Abstract
In this paper, we improve the previously best known regret bound to achieve -differential privacy in oblivious adversarial bandits from to . This is achieved by combining a Laplace Mechanism with EXP3. We show that though EXP3 is already differentially private, it leaks a linear amount of information in . However, we can improve this privacy by relying on its intrinsic exponential mechanism for selecting actions. This allows us to reach -DP, with a regret of that holds against an adaptive adversary, an improvement from the best known of . This is done by using an algorithm that run EXP3 in a mini-batch loop. Finally, we run experiments that clearly demonstrate the validity of our theoretical analysis.
1 Introduction
We consider multi-armed bandit problems in the adversarial setting whereby an agent selects one from a number of alternatives (called arms) at each round and receives a gain that depends on its choice. The agent’s goal is to maximize its total gain over time. There are two main settings for the bandit problem. In the stochastic one, the gains of each arm are generated i.i.d by some unknown probability law. In the adversarial setting, which is the focus of this paper, the gains are generated adversarially. We are interested in finding algorithms with a total gain over rounds not much smaller than that of an oracle with additional knowledge about the problem. In both settings, algorithms that achieve the optimal (problem-independent) regret bound of are known (?; ?; ?; ?; ?; ?; ?).
This problem is a model for many applications where there is a need for trading-off exploration and exploitation. This is so because, whenever we make a choice, we only observe the gain generated by that choice, and not the gains that we could have obtained otherwise. An example is clinical trials, where arms correspond to different treatments or tests, and the goal is to maximize the number of cured patients over time while being uncertain about the effects of treatments. Other problems, such as search engine advertisement and movie recommendations can be formalized similarly (?).
Privacy can be a serious issue in the bandit setting (c.f. (?; ?; ?; ?)). For example, in clinical trials, we may want to detect and publish results about the best drug without leaking sensitive information, such as the patient’s health condition and genome. Differential privacy (?) formally bounds the amount of information that a third party can learn no matter their power or side information.
Differential privacy has been used before in the stochastic setting (?; ?; ?) where the authors obtain optimal algorithms up to logarithmic factors. In the adversarial setting, (?) adapts an algorithm called Follow The Approximate Leader to make it private and obtain a regret bound of . In this work, we show that a number of simple algorithms can satisfy privacy guarantees, while achieving nearly optimal regret (up to logarithmic factors) that scales naturally with the level of privacy desired.
Our work is also of independent interest for non-private multi-armed bandit algorithms, as there are competitive with the current state of the art against switching-cost adversaries (where we recover the optimal bound). Finally, we provide rigorous empirical results against a variety of adversaries.
The following section gives the main background and notations. Section 3.1 describes meta-algorithms that perturb the gain sequence to achieve privacy, while Section 3.2 explains how to leverage the privacy inherent in the EXP3 algorithm by modifying the way gains are used. Section 4 compares our algorithms with EXP3 in a variety of settings. The full proofs of all our main results are in the full version.
2 Preliminaries
2.1 The Multi-Armed Bandit problem
Formally, a bandit game is defined between an adversary and an agent as follows: there is a set of arms , and at each round , the agent plays an arm . Given the choice , the adversary grants the agent a gain . The agent only observes the gain of arm , and not that of any other arms. The goal of this agent is to maximize its total gain after rounds, . A randomized bandit algorithm maps every arm-gain history to a distribution over the next arm to take.
The nature of the adversary, and specifically, how the gains are generated, determines the nature of the game. For the stochastic adversary (?; ?), the gain obtained at round is generated i.i.d from a distribution . The more general fully oblivious adversary (?) generates the gains independently at round but not necessarily identically from a distribution . Finally, we have the oblivious adversary (?) whose only constraint is to generate the gain as a function of the current action only, i.e. ignoring previous actions and gains.
While focusing on oblivious adversaries, we discovered that by targeting differential privacy we can also compete against the stronger -bounded memory adaptive adversary (?; ?; ?) who can use up to the last gains. The oblivious adversary is a special case with . Another special case of this adversary is the one with switching costs, who penalises the agent whenever he switches arms, by giving the lowest possible gain of 0 (here ).
Regret.
Relying on the cumulative gain of an agent to evaluate its performance can be misleading. Indeed, consider the case where an adversary gives a zero gain for all arms at every round. The cumulative gain of the agent would look bad but no other agents could have done better. This is why one compares the gap between the agent’s cumulative gain and the one obtained by some hypothetical agent, called oracle, with additional information or computational power. This gap is called the regret.
There are also variants of the oracle that are considered in the literature. The most common variant is the fixed oracle, which always plays the best fixed arm in hindsight. The regret against this oracle is :
[TABLE]
In practice, we either prove a high probability bound on or an expected value \mathop{\mbox{\mathbb{E}}}\nolimits\mathcal{R} with:
[TABLE]
where the expectation is taken with respect to the random choices of both the agent and adversary. There are other oracles like the shifting oracle but those are out of scope of this paper.
EXP3.
The Exponential-weight for Exploration and Exploitation (EXP3 (?)) algorithm achieves the optimal bound (up to logarithmic factors) of for the weak regret (i.e. the expected regret compared to the fixed oracle) against an oblivious adversary. EXP3 simply maintains an estimate for the cumulative gain of arm up to round with where
[TABLE]
with a well defined constant.
Finally, EXP3 plays one action randomly according to the probability distribution with as defined above.
2.2 Differential Privacy
The following definition (from (?)) specifies what is meant when we called a bandit algorithm differentially private at a single round :
Definition 2.1** (Single round (-differentially private bandit algorithm).**
A randomized bandit algorithm is -differentially private at round , if for all sequence and that differs in at most one round, we have for any action subset :
[TABLE]
where \mathop{\mbox{\mathbb{P}}}\nolimits_{\Lambda} denotes the probability distribution specified by the algorithm and with the gains of all arms at round . When , the algorithm is said to be -differential private.
The and parameters quantify the amount of privacy loss. Lower (,) indicate higher privacy and consequently we will also refer to (,) as the privacy loss. Definition 2.1 means that the output of the bandit algorithm at round is almost insensible to any single change in the gains sequence. This implies that whether or not we remove a single round, replace the gains, the bandit algorithm will still play almost the same action. Assuming the gains at round are linked to a user private data (for example his cancer status or the advertisement he clicked), the definition preserves the privacy of that user against any third parties looking at the output. This is the case because the choices or the participation of that user would not almost affect the output. Equation (2.2) specifies how much the output is affected by a single user.
We would like Definition 2.1 to hold for all rounds, so as to protect the privacy of all users. If it does for some , then we say the algorithm has per-round or instantaneous privacy loss . Such an algorithm also has a cumulative privacy loss of at most with and after steps. Our goal is to design bandit algorithm such that their cumulative privacy loss are as low as possible while achieving simultaneously a very low regret. In practice, we would like and the regret to be sub-linear while should be a very small quantity. Definition 2.2 formalizes clearly the meaning of this cumulative privacy loss and for ease of presentation, we will ignore the term ”cumulative” when referring to it.
Definition 2.2** ((-differentially private bandit algorithm).**
A randomized bandit algorithm is -differentially private up to round , if for all and that differs in at most one round, we have for any action subset :
[TABLE]
where \mathop{\mbox{\mathbb{P}}}\nolimits_{\Lambda} and are as defined in Definition 2.1.
Most of the time, we will refer to Definition 2.2 and whenever we need to use Definition 2.1, this will be made explicit.
The simplest mechanism to achieve differential privacy for a function is to add Laplace noise of scale proportional to its sensitivity. The sensitivity is the maximum amount by which the value of the function can change if we change a single element in the inputs sequence. For example, if the input is a stream of numbers in and the function their sum, we can add Laplace noise of scale to each number and achieve -differential privacy with an error of in the sum. However, (?) introduced Hybrid Mechanism, which achieves -differential privacy with only poly-logarithmic error (with respect to the true sum). The idea is to group the stream of numbers in a binary tree and only add a Laplace noise at the nodes of the tree.
As demonstrated above, the main challenge with differential privacy is thus to trade-off optimally privacy and utility.
Notation.
In this paper, will be used as an index for an arbitrary arm in , while will be used to indicate an optimal arm and is the arm played by an agent at round . We use to indicate the gain of the -th arm at round . is the regret of the algorithm after rounds. The index and are dropped when it is clear from the context. Unless otherwise specified, the regret is defined for oblivious adversaries against the fixed oracle. We use ”” to denote that is generated from distribution . is used to denote the Laplace distribution with scale while denotes the Bernoulli distribution with parameter .
3 Algorithms and Analysis
3.1 : Differential privacy through additional noise
We start by showing that the obvious technique to achieve a given -differential privacy in adversarial bandits already beat the state-of-the art. The main idea is to use any base bandit algorithm as input and add a Laplace noise of scale to each gain before observes it. This technique gives -DP differential privacy as the gains are bounded in and the noises are added i.i.d at each round.
However, bandits algorithms require bounded gains while the noisy gains are not. The trick is to ignore rounds where the noisy gains fall outside an interval of the form . We pick the threshold such that, with high probability, the noisy gains will be inside the interval . More precisely, can be chosen such that with high probability, the number of rounds ignored is lower than the upper bound on the regret of . Given that in the standard bandit problem, the gains are bounded in , the gains at accepted rounds are rescaled back to .
Theorem 3.2 shows that all these operations still preserve -DP while Theorem 3.1 demonstrates that the upper bound on the expected regret of adds some small additional terms to . To illustrate how small those additional terms are, we instantiate with the EXP3 algorithm. This leads to a mechanism called DP-EXP3-Lap described in Algorithm 1. With a carefully chosen threshold , corollary 3.1 implies that the additional terms are such that the expected regret of DP-EXP3-Lap is which is optimal in up to some logarithmic factors. This result is a significant improvement over the best known bound so far of from (?) and solves simultaneously the challenge (whether or not one can get -DP mechanism with optimal regret) posed by the authors.
Theorem 3.1**.**
If is run with input a base bandit algorithm , the noisy reward of the true reward set to with , the acceptance interval set to with the scaling of the rewards outside done using ; then the regret of satisfies:
[TABLE]
where is the upper bound on the regret of when the rewards are scaled from to
Proof Sketch.
We observed that is an instance of run with the noisy rewards instead of . This means is an upper bound of the regret on . Then, we derived a lower bound on showing how close it is to . This allows us to conclude. ∎
Corollary 3.1**.**
If is run with EXP3 as its base algorithm and , then its expected regret \mathop{\mbox{\mathbb{E}}}\nolimits R_{{\emph{DP-EXP3-Lap}}} satisfies
[TABLE]
Proof.
The proof comes by combining the regret of EXP3 (?) with Theorem 3.1 ∎
Theorem 3.2**.**
* is -differentially private up to round .*
Proof Sketch.
Combining the privacy of Laplace Mechanism with the parallel composition (?) and post-processing theorems (?) concludes the proof. ∎
3.2 Leveraging the inherent privacy of EXP3
On the differential privacy of EXP3
(?) shows that a variation of EXP3 for the full-information setting (where the agent observes the gain of all arms at any round regardless of what he played) is already differentially private. Their results imply that one can achieve the optimal regret with only a sub-logarithmic privacy loss () after rounds.
We start this section by showing a similar result for EXP3 in Theorem 3.3. Indeed, we show that EXP3 is already differentially private but with a per-round privacy loss of . 111Assuming we want a sub-linear regret. See Theorem 3.3 Our results imply that EXP3 can achieve the optimal regret albeit with a linear privacy loss of -DP after rounds. This is a huge gap compared with the full-information setting and underlines the significance of our result in section 3.1 where we describe a concrete algorithm demonstrating that the optimal regret can be achieved with only a logarithmic privacy loss after rounds.
Theorem 3.3**.**
The EXP3 algorithm is:
[TABLE]
differentially private up to round .
In practice, we also want EXP3 to have a sub-linear regret. This implies that and EXP3 is simply -DP over rounds.
Proof Sketch.
The first two terms in the theorem come from the observation that EXP3 is a combination of two mechanisms: the Exponential Mechanism (?) and a randomized response. The last term comes from the observation that with probability we enjoy a perfect [math]-DP. Then, we use Chernoff to bound with high probability the number of times we suffer a non-zero privacy loss. ∎
We will now show that the privacy of EXP3 itself may be improved without any additional noise, and with only a moderate impact on the regret.
On the privacy of a EXP3 wrapper algorithm
The previous paragraph leads to the conclusion that it is impossible to obtain a sub-linear privacy loss with a sub-linear regret while using the original EXP3. Here, we will prove that an existing technique is already achieving this goal. The algorithm which we called is from (?). It groups the rounds into disjoint intervals of fixed size where the ’th interval starts on round and ends on round . At the beginning of interval , receives an action from EXP3 and plays it for rounds. During that time, EXP3 does not observe any feedback. At the end of the interval, feeds EXP3 with a single gain, the average gain received during the interval.
Theorem 3.4 borrowed from (?) specifies the upper bound on the regret . It is remarkable that this bound holds against the m-memory bounded adaptive adversary. While in theorem 3.5, we show the privacy loss enjoyed by this algorithm, one gets a better intuition of how good those results are from corollary 3.2 and 3.3. Indeed, we can observe that achieves a sub-logarithmic privacy loss of with a regret of against a special case of the m-memory bounded adaptive adversary called the switching costs adversary for which . This is the optimal regret bound (in the sense that there is a matching lower bound (?)). This means that in some sense we are getting privacy for free against this adversary.
Theorem 3.4** (Regret of (?)).**
The expected regret of is upper bounded by:
[TABLE]
against the m-memory bounded adaptive adversary for any .
Theorem 3.5** (Privacy loss of ).**
* is -DP up to round .*
Proof.
The sensitivity of each gain is now as we are using the average. Combined with theorem (3.3), it means the per-round privacy loss is . Given that EXP3 only observes rounds, using the advanced composition theorem (?) (Theorem III.3) concludes the final privacy loss over rounds. ∎
Corollary 3.2**.**
* run with is differentially private up to round with , . Its expected regret against the switching costs adversary is upper bounded by .*
Proof.
The proof is immediate by replacing and in Theorem 3.4 and 3.5 and the fact that for the switching costs adversary, . ∎
Corollary 3.3**.**
* run with is differentially private and its expected regret against the switching costs adversary is upper bounded by: *
4 Experiments
We tested DP-EXP3-Lap, together with the non-private EXP3 against a few different adversaries. The privacy parameter of DP-EXP3-Lap is set as defined in corollary 3.2. This is done so that the regret of DP-EXP3-Lap and are compared with the same privacy level. All the other parameters of DP-EXP3-Lap are taken as defined in corollary 3.1 while the parameters of are taken as defined in corollary 3.2.
For all experiments, the horizon is and the number of arms is . We performed independent trials and reported the median-of-means estimator222Used heavily in the streaming literature (?) of the cumulative regret. It partitions the trials into equal groups and return the median of the sample means of each group. Proposition 4.1 is a well known result (also in (?; ?)) giving the accuracy of this estimator. Its convergence is , with exponential probability tails, even though the random variable may have heavy-tails. In comparison, the empirical mean can not provide such guarantee for any and confidence in (?).
Proposition 4.1*.*
Let be a random variable with mean and variance . Assume that we have independent sample of and let be the median-of-means computed using groups. With probability at least , satisfies .
We set the number of groups to , so that the confidence interval holds w.p. at least .
We also reported the deviation of each algorithm using the Gini’s Mean Difference (GMD hereafter) (?). GMD computes the deviation as with the -th order statistics of the sample (that is ). As shown in (?; ?), the GMD provides a superior approximation of the true deviation than the standard one. To account for the fact that the cumulative regret of our algorithms might not follow a symmetric distribution, we computed the GMD separately for the values above and below the median-of-means.
At round , we computed the cumulative regret against the fixed oracle who plays the best arm assuming that the end of the game is at . The oracle uses the actual sequence of gains to decide his best arm. For a given trial, we make sure that all algorithms are playing the same game by generating the gains for all possible pair of round-arm before the game starts.
Deterministic adversary.
As shown by (?), the expected regret of any agent against an oblivious adversary can not be worse than that against the worst case deterministic adversary. In this experiment, arm is the best and gives for every even round. To trick the players into picking the wrong arms, the first arm always gives whereas the third gives for every round multiple of . The remaining arms always give [math]. As shown by the figure, this simple adversary is already powerful enough to make the algorithms attain their upper bound.
Stochastic adversary
This adversary draws the gains of the first arm i.i.d from whereas all other gains are drawn i.i.d from .
Fully oblivious adversary.
For the best arm , it first draws a number uniformly in and generates the gain . For all other arms, is drawn from . This process is repeated at every round. In our experiments,
An oblivious adversary.
This adversary is identical to the fully oblivious one for every round multiple of . Between two multiples of the last gain of the arm is given.
The Switching costs adversary
This adversary (defined at Figure 1 in (?)) defines a stochastic processes (including simple Gaussian random walk as special case) for generating the gains. It was used to prove that any algorithm against this adversary must incur a regret of .
Discussion
Figure 1 shows our results against a variety of adversaries, with respect to a fixed oracle. Overall, the performance (in term of regret) of DP-EXP3-Lap is very competitive against that of EXP3 while providing a significant better privacy. This means that DP-EXP3-Lap allows us to get privacy for free in the bandit setting against an adversary not more powerful than the oblivious one.
The performance of is worse than that of DP-EXP3-Lap against an oblivious adversary or one less powerful. However, the situation is completely reversed against the more powerful switching cost adversary. In that setting, outperforms both EXP3 and DP-EXP3-Lap confirming the theoretical analysis. We can see as the algorithm providing us privacy for free against switching cost adversary and adaptive m-bounded memory one in general.
5 Conclusion
We have provided the first results on differentially private adversarial multi-armed bandits, which are optimal up to logarithmic factors. One open question is how differential privacy affects regret in the full reinforcement learning problem. At this point in time, the only known results in the MDP setting obtain differentially private algorithms for Monte Carlo policy evaluation (?). While this implies that it is possible to obtain policy iteration algorithms, it is unclear how to extend this to the full online reinforcement learning problem.
Acknowledgements.
This research was supported by the SNSF grants “Adaptive control with approximate Bayesian computation and differential privacy” and “Swiss Sense Synergy”, by the Marie Curie Actions (REA 608743), the Future of Life Institute “Mechanism Design for AI Architectures” and the CNRS Specific Action on Security.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[Agrawal and Goyal 2012] Agrawal, S., and Goyal, N. 2012. Analysis of thompson sampling for the multi-armed bandit problem. In COLT 2012 .
- 2[Alon, Matias, and Szegedy 1996] Alon, N.; Matias, Y.; and Szegedy, M. 1996. The space complexity of approximating the frequency moments. In 28th STOC , 20–29. ACM.
- 3[Audibert and Bubeck 2010] Audibert, J.-Y., and Bubeck, S. 2010. Regret bounds and minimax policies under partial monitoring. J. Mach. Learn. Res. 11:2785–2836.
- 4[Auer et al . 2003] Auer, P.; Cesa-Bianchi, N.; Freund, Y.; and Schapire, R. E. 2003. The nonstochastic multiarmed bandit problem. SIAM J. Comput. 32(1):48–77.
- 5[Auer, Cesa-Bianchi, and Fischer 2002] Auer, P.; Cesa-Bianchi, N.; and Fischer, P. 2002. Finite time analysis of the multiarmed bandit problem. Machine Learning 47(2/3):235–256.
- 6[Auer 2002] Auer, P. 2002. Using confidence bounds for exploitation-exploration trade-offs. Journal of Machine Learning Research 3:397–422.
- 7[Balle, Gomrokchi, and Precup 2016] Balle, B.; Gomrokchi, M.; and Precup, D. 2016. Differentially private policy evaluation. In ICML 2016 .
- 8[Burnetas and Katehakis 1996] Burnetas, A. N., and Katehakis, M. N. 1996. Optimal adaptive policies for sequential allocation problems. Advances in Applied Mathematics 17(2):122–142.