Guaranteed Parameter Estimation for Discrete Energy Minimization
Mengtian Li, Daniel Huber

TL;DR
This paper introduces a method for guaranteed parameter estimation in discrete energy minimization, transforming intractable inference into polynomial time solvable problems, enabling exact solutions with bounded error.
Contribution
It proposes a novel approach that exploits the joint inference and learning problem to achieve tractable exact inference for complex models.
Findings
Runs significantly faster than previous methods
Achieves exact inference with bounded error
Effective on 3D scene parsing datasets
Abstract
Structural learning, a method to estimate the parameters for discrete energy minimization, has been proven to be effective in solving computer vision problems, especially in 3D scene parsing. As the complexity of the models increases, structural learning algorithms turn to approximate inference to retain tractability. Unfortunately, such methods often fail because the approximation can be arbitrarily poor. In this work, we propose a method to overcome this limitation through exploiting the properties of the joint problem of training time inference and learning. With the help of the learning framework, we transform the inapproximable inference problem into a polynomial time solvable one, thereby enabling tractable exact inference while still allowing an arbitrary graph structure and full potential interactions. Our learning algorithm is guaranteed to return a solution with a bounded…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1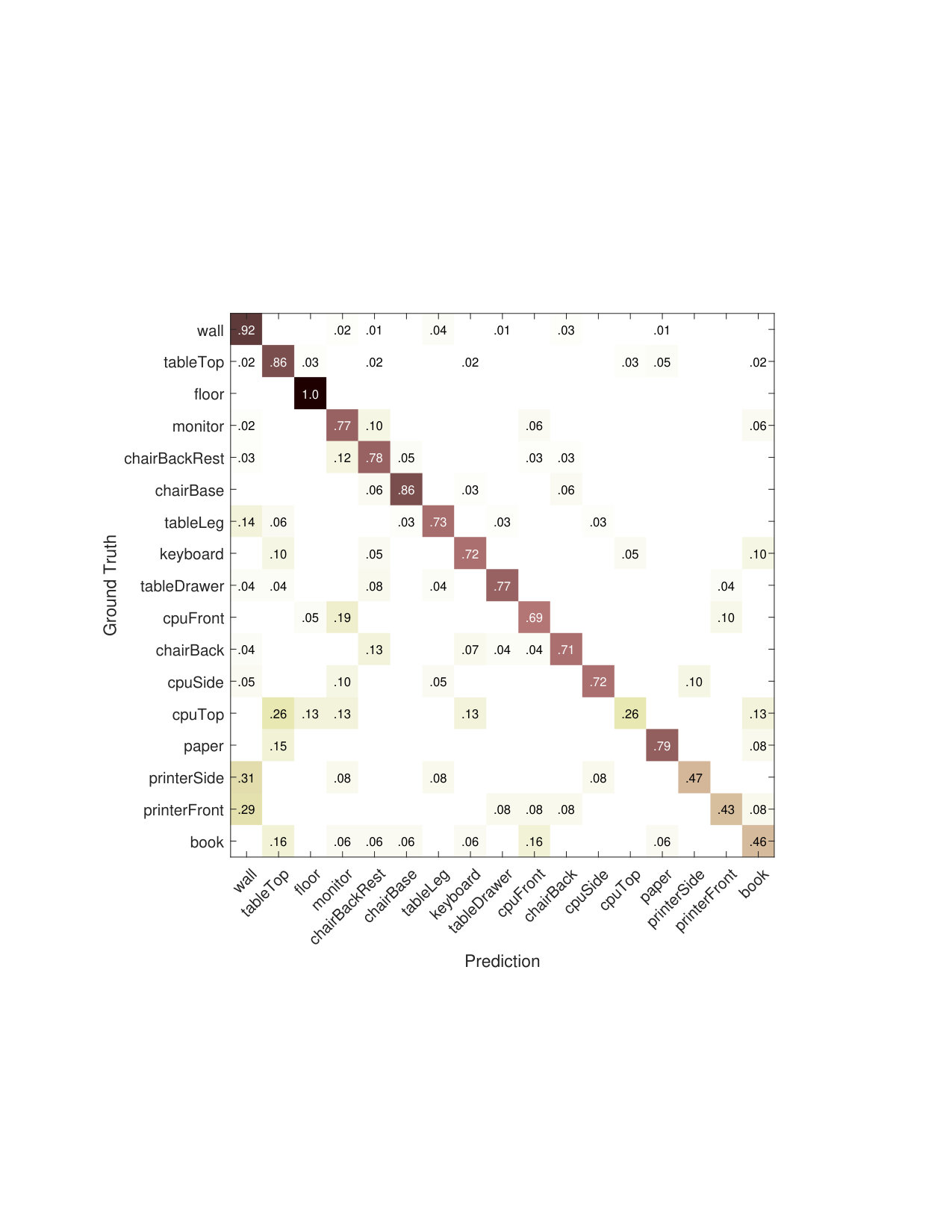 Figure 2
Figure 2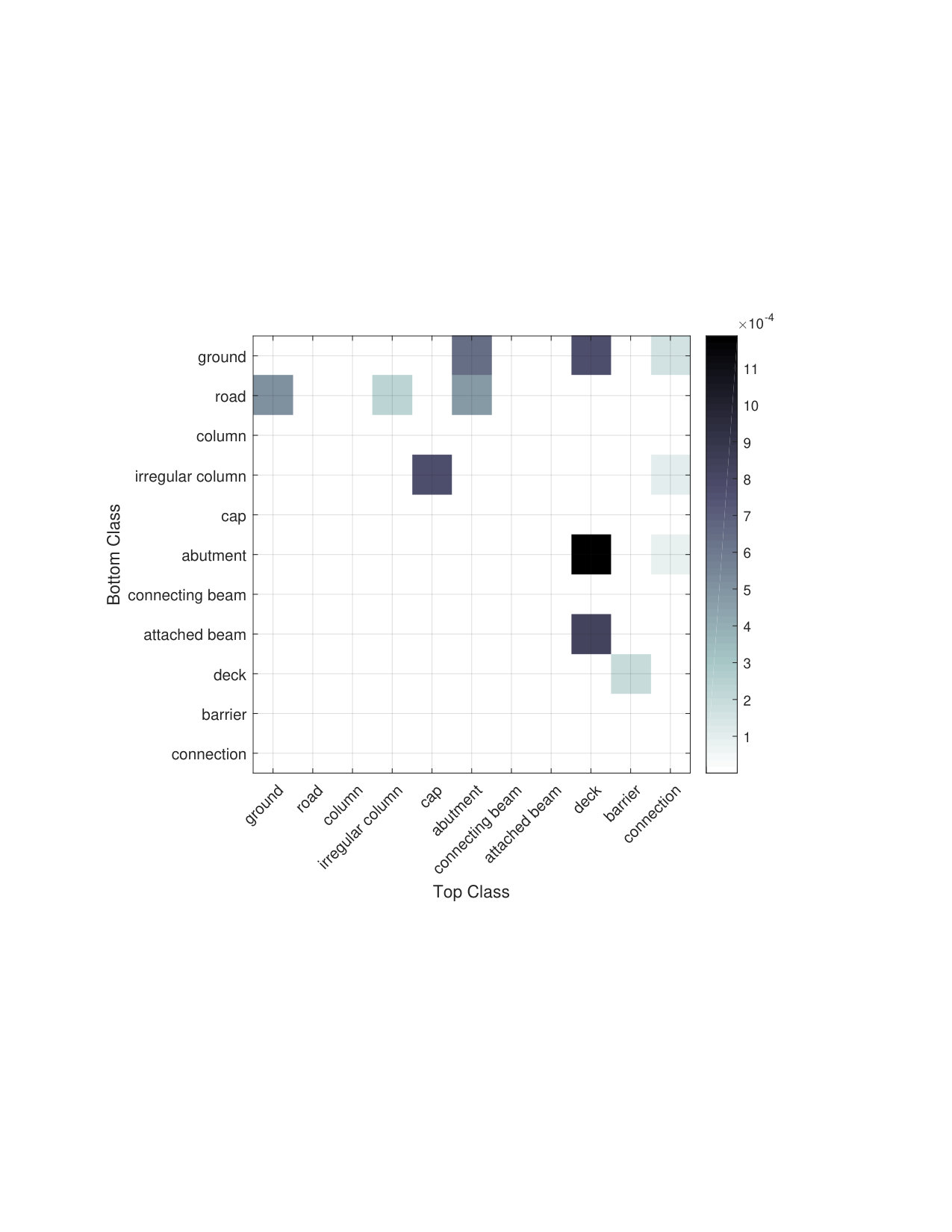 Figure 3
Figure 3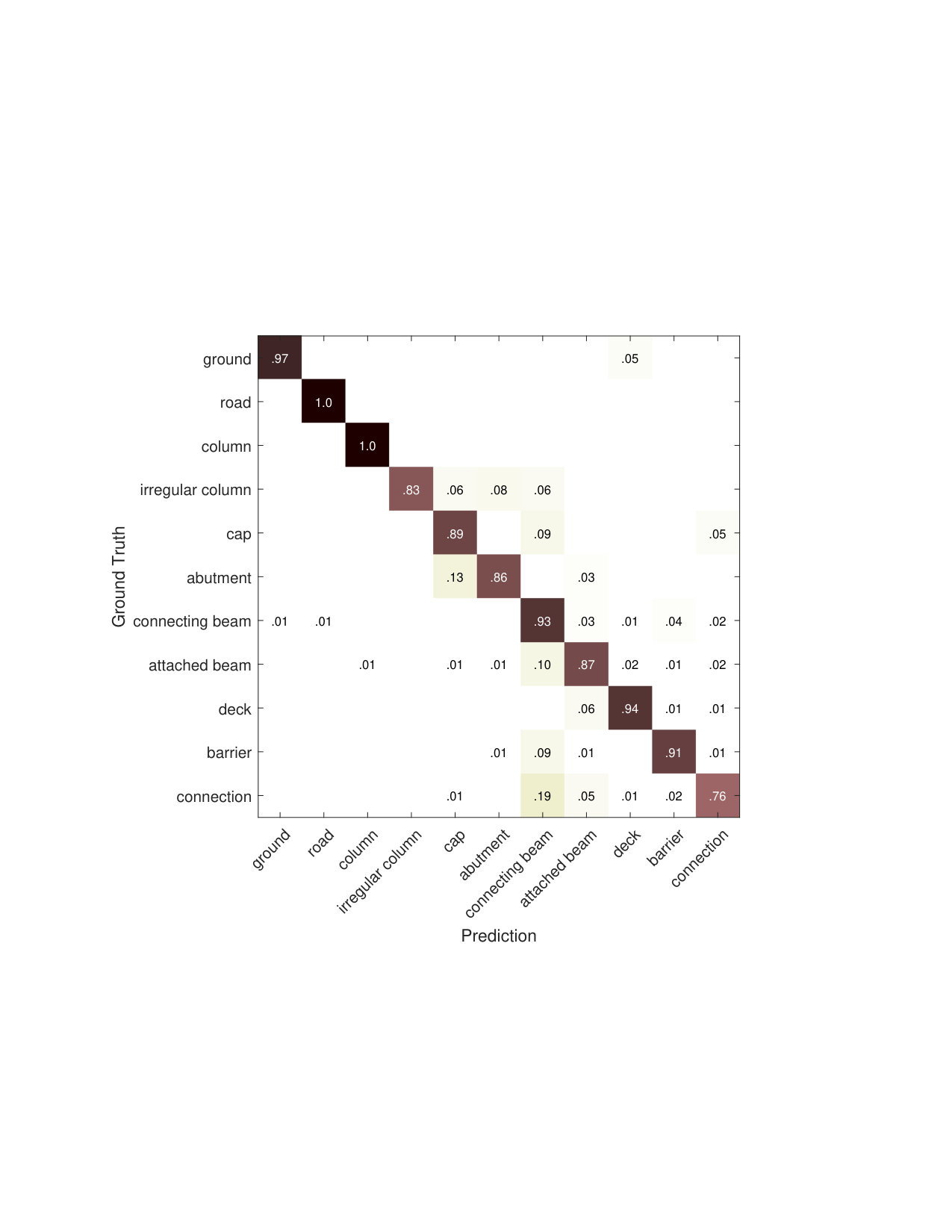 Figure 4
Figure 4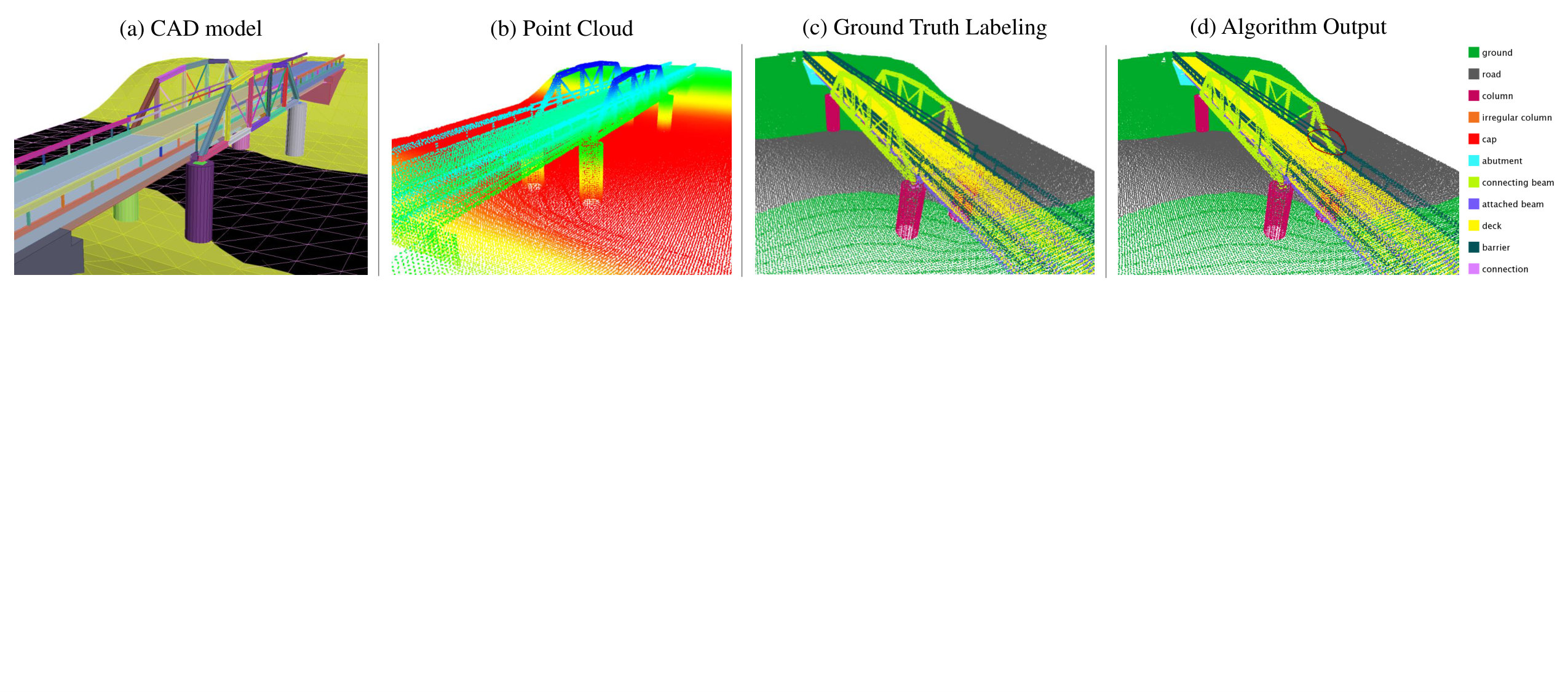 Figure 5
Figure 5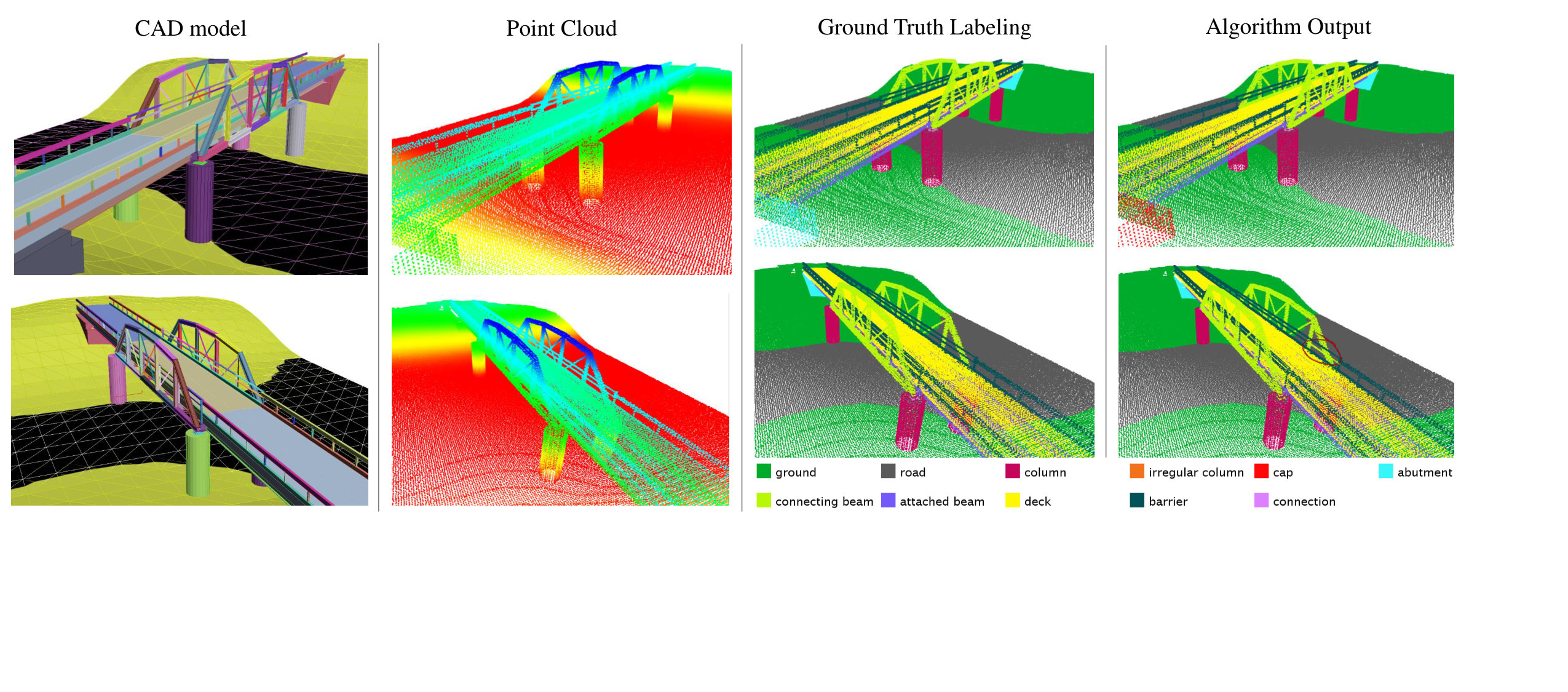 Figure 6
Figure 6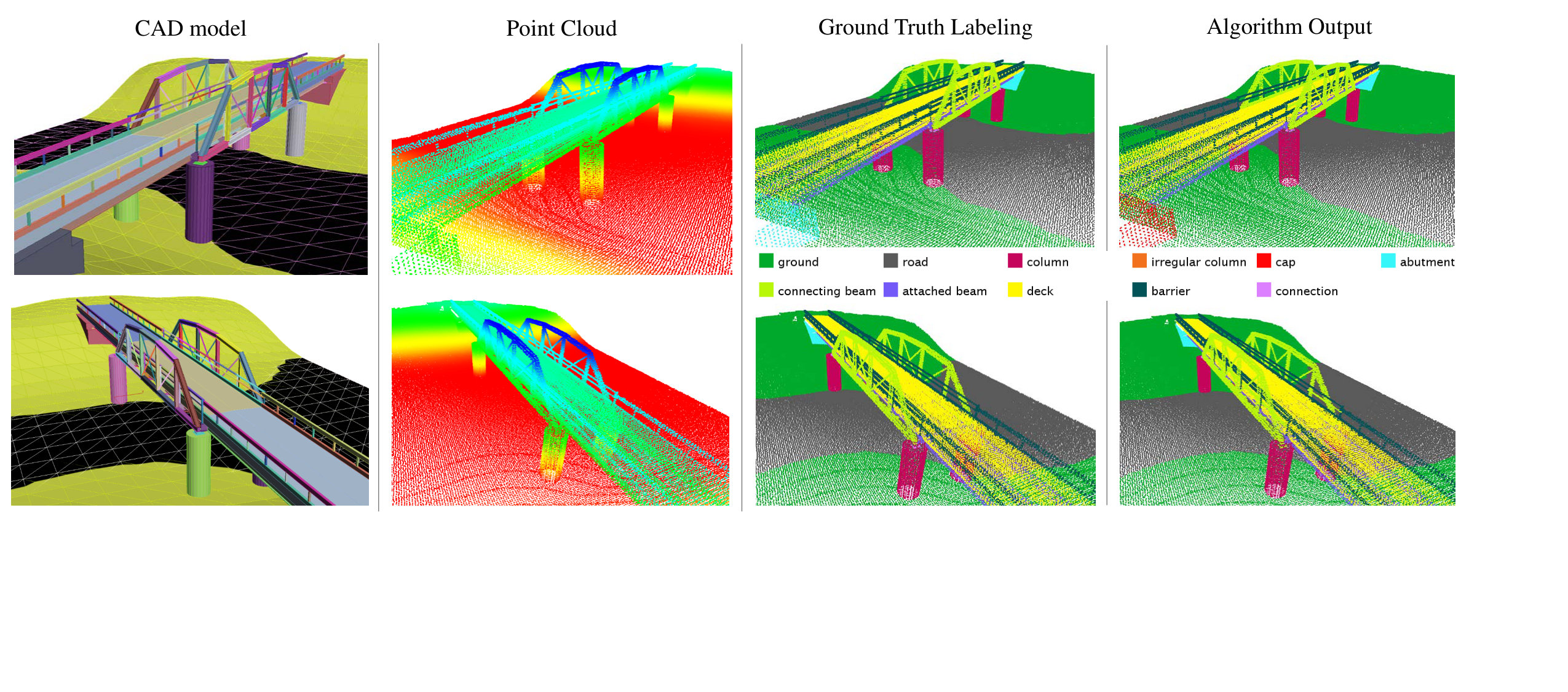 Figure 7
Figure 7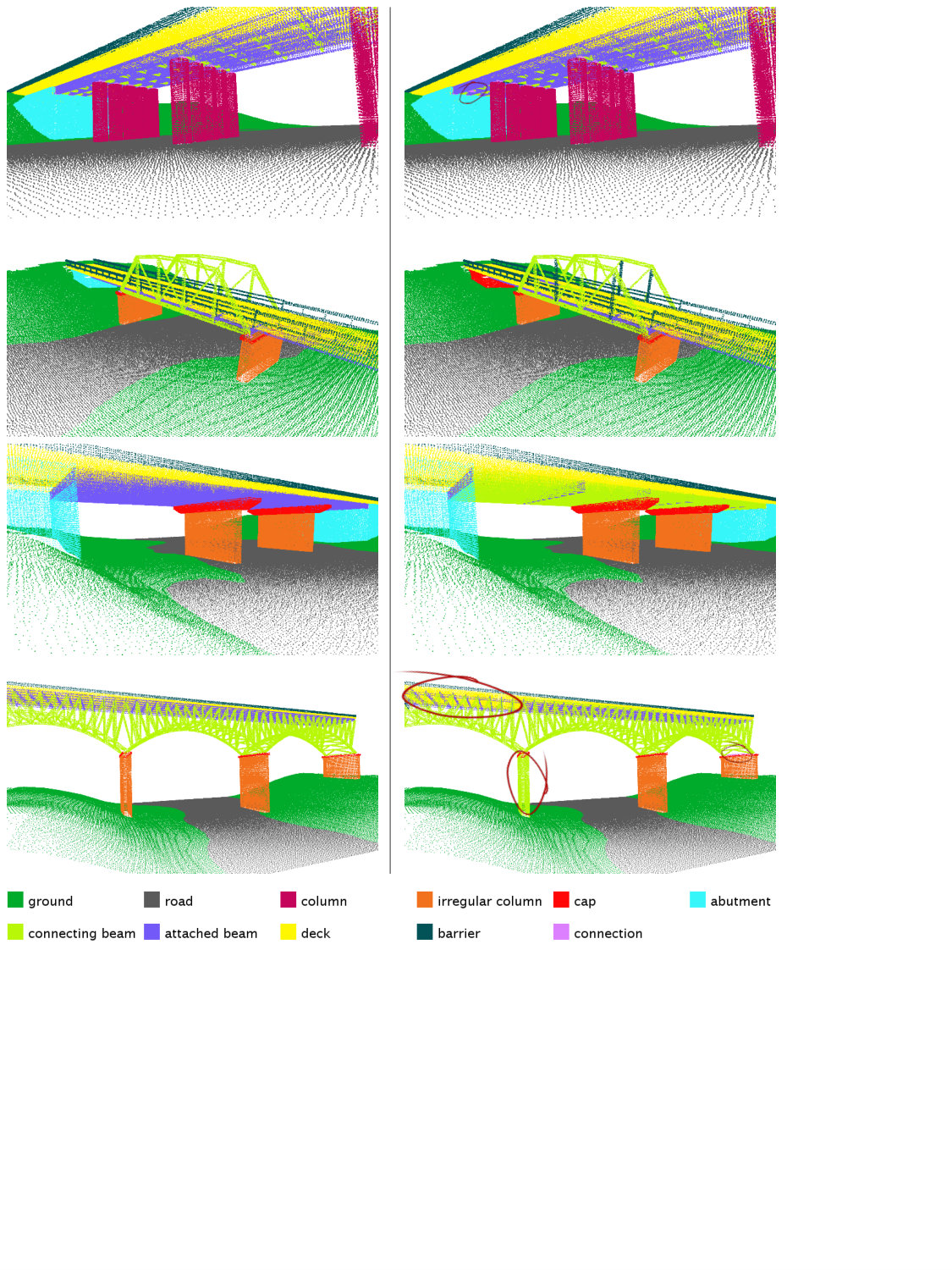 Figure 8
Figure 8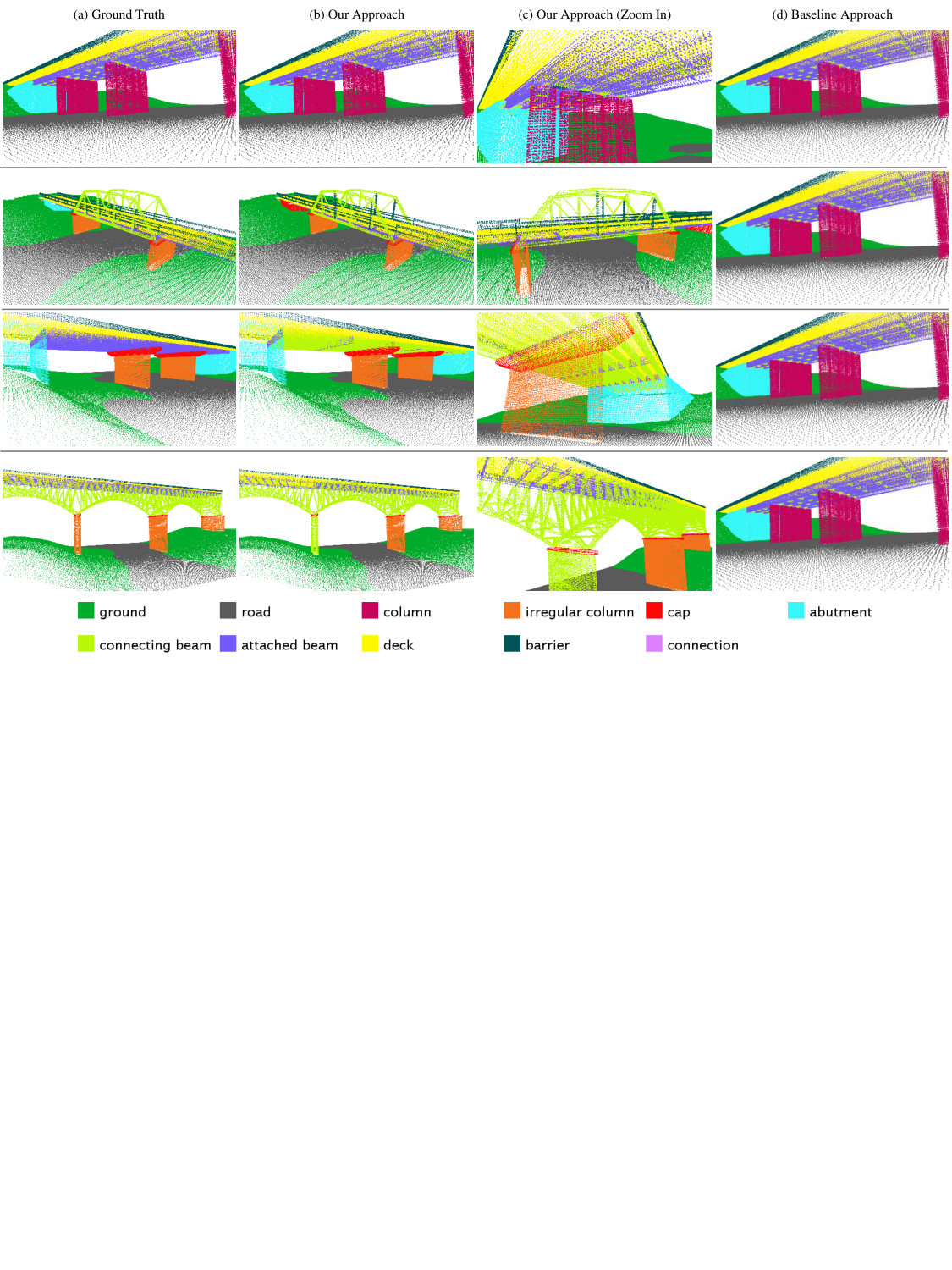 Figure 9
Figure 9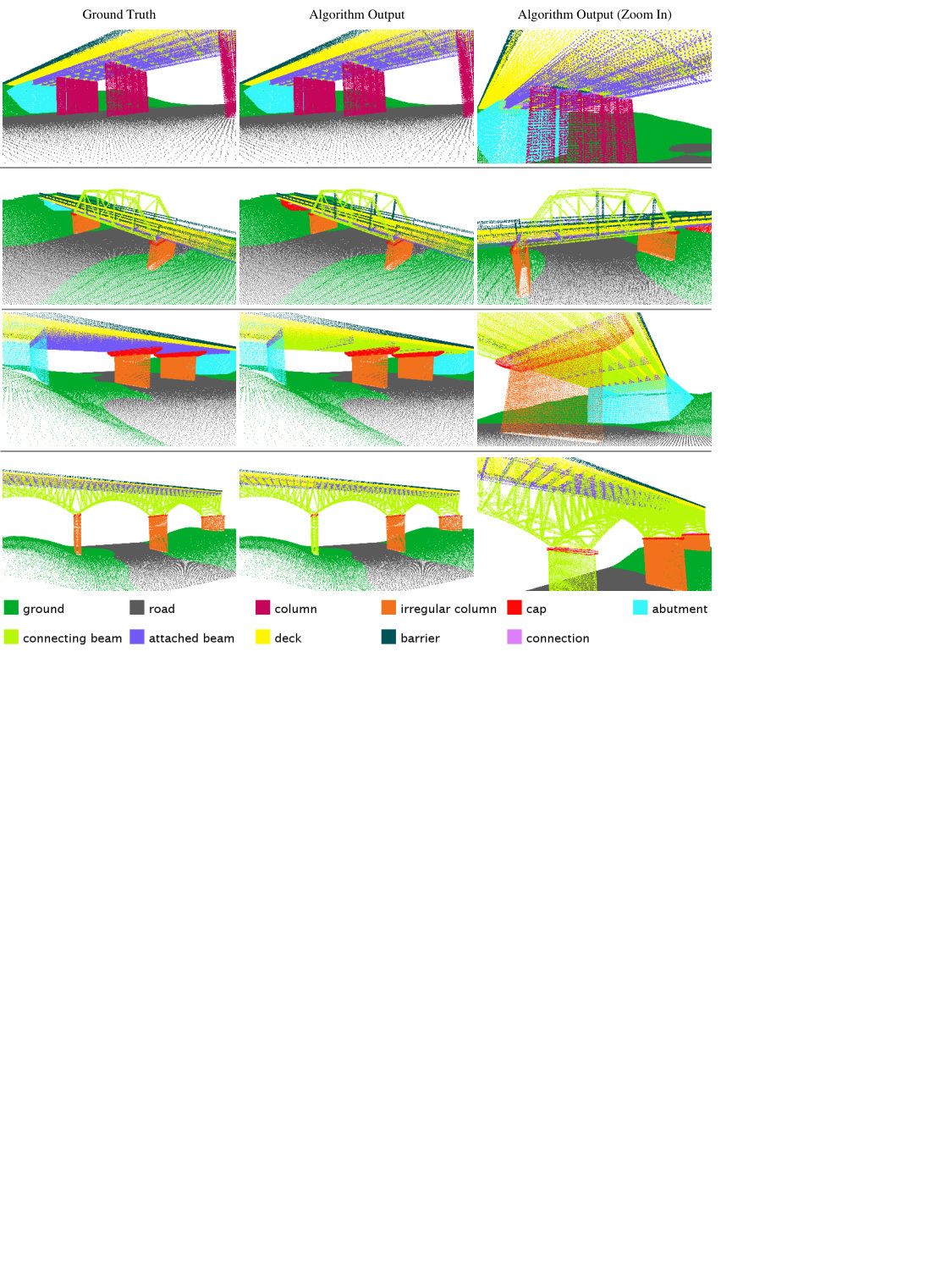 Figure 10
Figure 10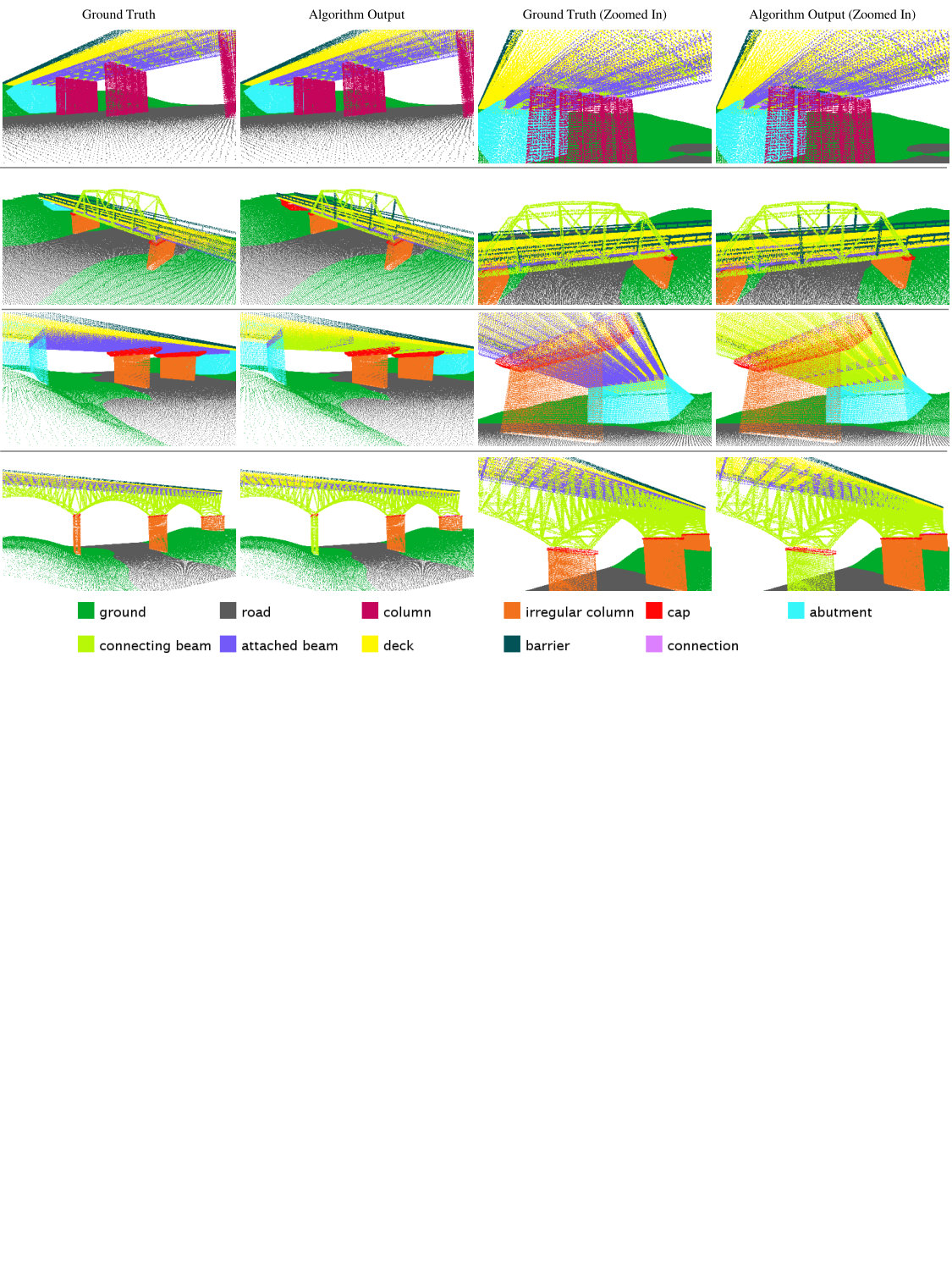 Figure 11
Figure 11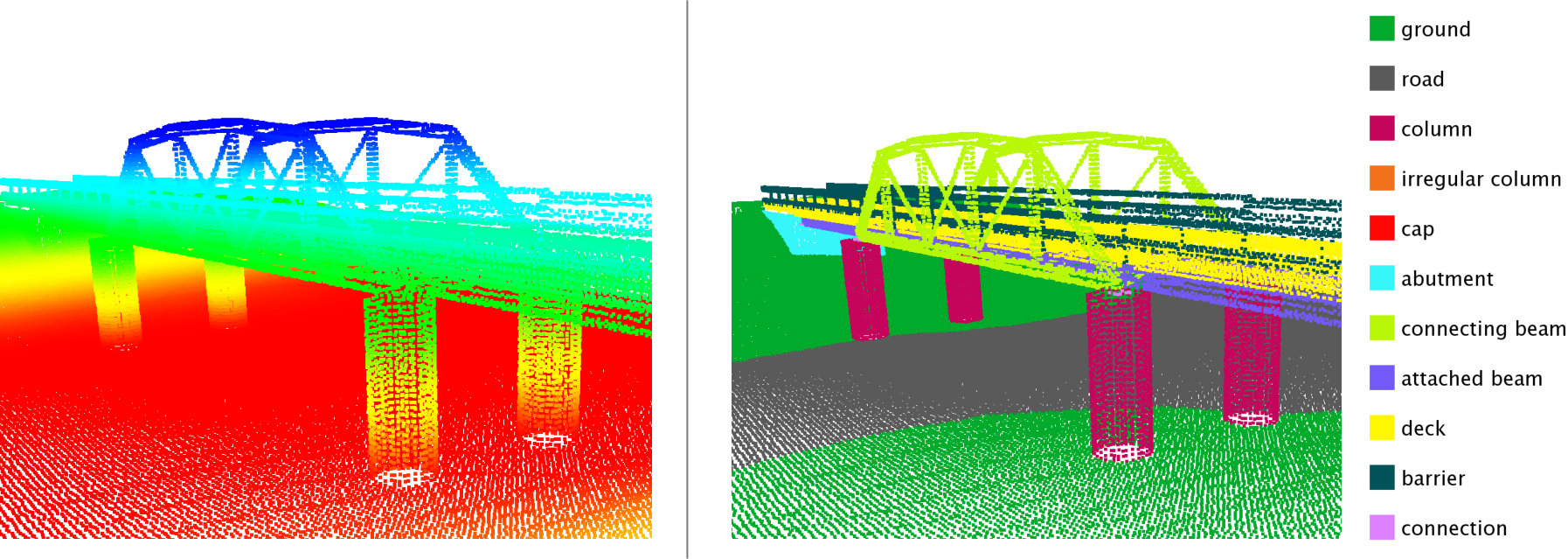 Figure 12
Figure 12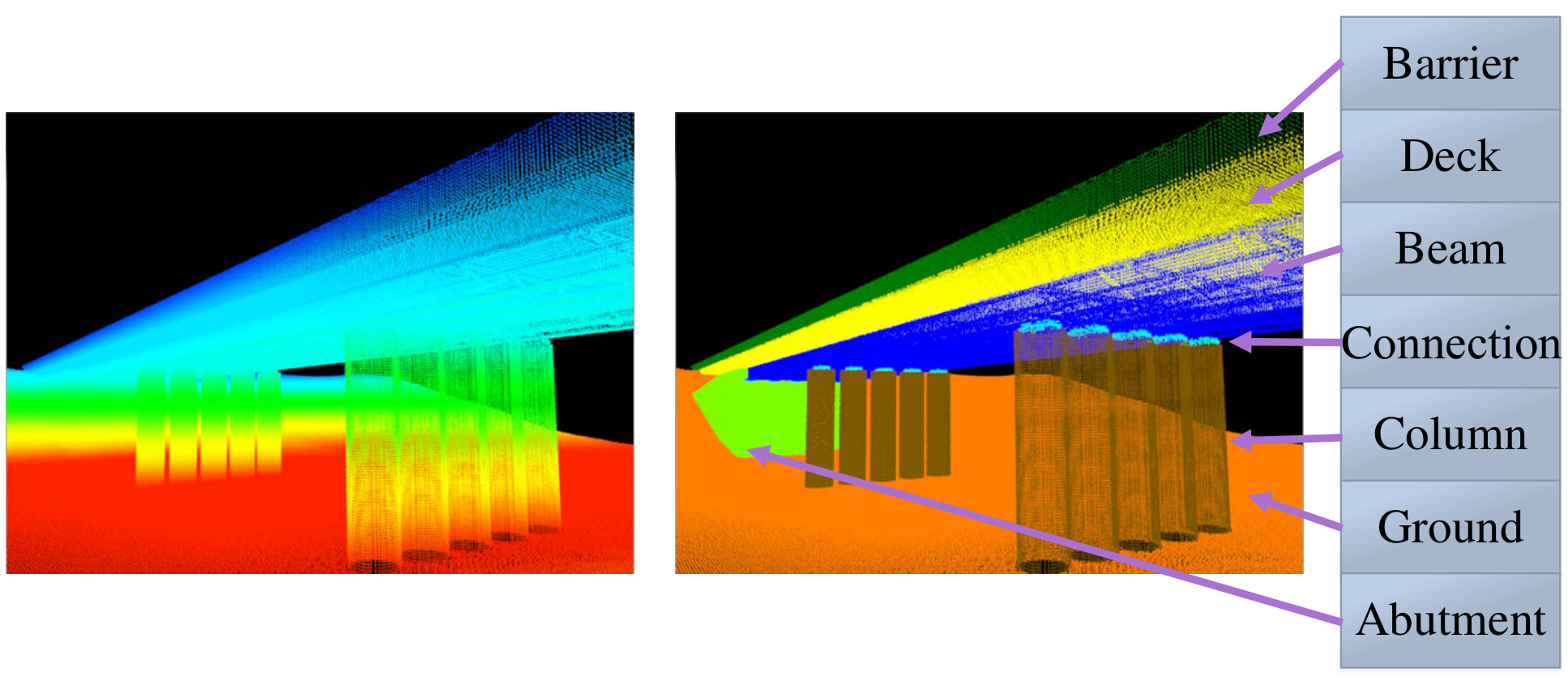 Figure 13
Figure 13 Figure 14
Figure 14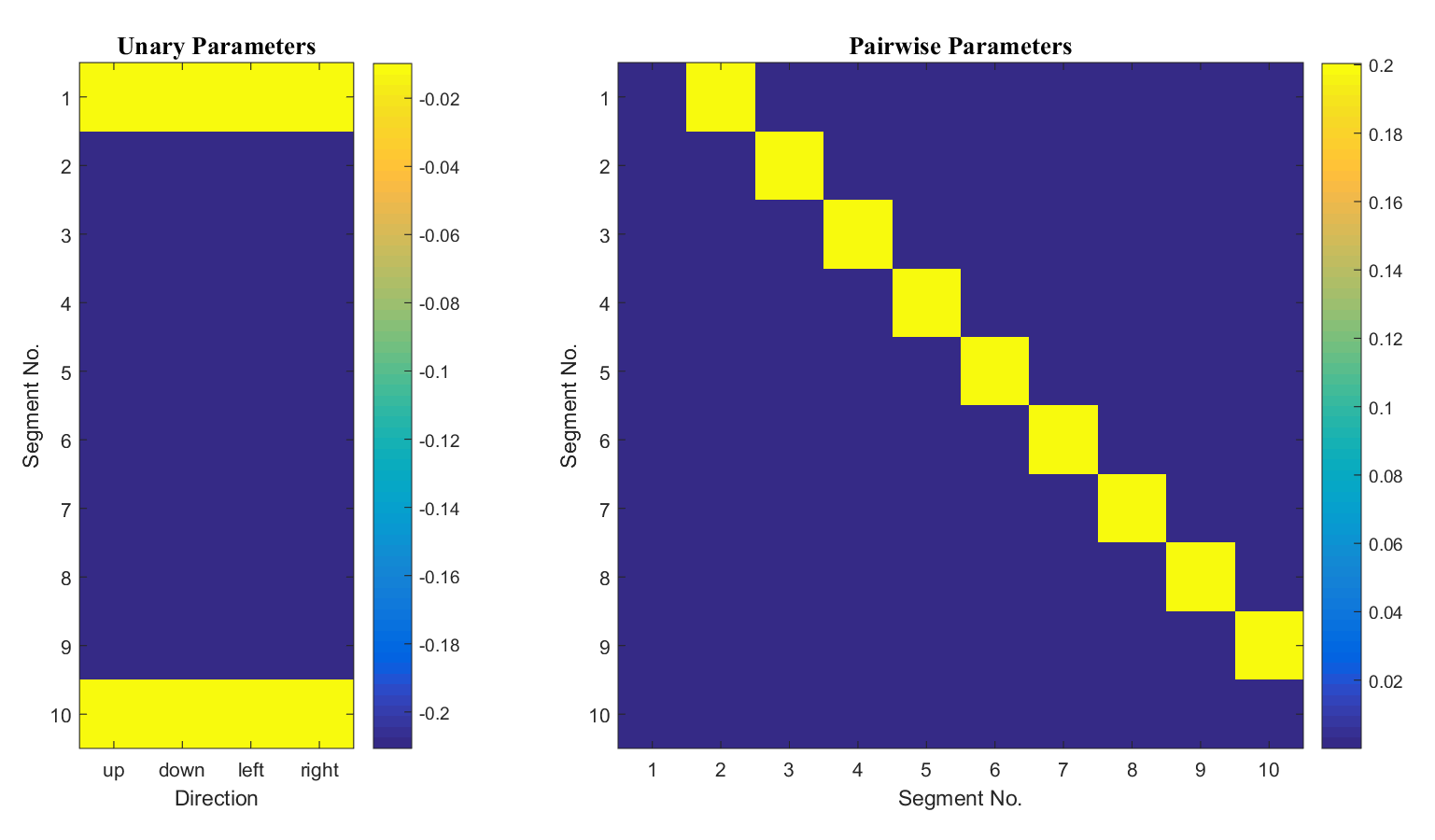 Figure 15
Figure 15 Figure 16
Figure 16| Accu | macro P | macro R | Time | Speedup | |
|---|---|---|---|---|---|
| [1] | 81.45 | 76.79 | 70.07 | 4.11h | 1.00 |
| Ours | 80.72 | 73.42 | 69.74 | 1.34h | 3.06 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Neural Network Applications · 3D Shape Modeling and Analysis · Medical Image Segmentation Techniques
\newaliascnt
corollarytheorem\aliascntresetthecorollary
\newaliascntdefinitiontheorem\aliascntresetthedefinition
\newaliascntstatementtheorem\aliascntresetthestatement
\newaliascntlemmatheorem\aliascntresetthelemma
\newaliascntexampletheorem\aliascntresettheexample
\newaliascntremarktheorem\aliascntresettheremark
\newaliascntpropositiontheorem\aliascntresettheproposition
\newaliascntpropertytheorem\aliascntresettheproperty
\newaliascntproblemtheorem\aliascntresettheproblem
Guaranteed Parameter Estimation for Discrete Energy Minimization
Mengtian Li
Carnegie Mellon University
Daniel Huber
Carnegie Mellon University
Abstract
Structural learning, a method to estimate the parameters for discrete energy minimization, has been proven to be effective in solving computer vision problems, especially in 3D scene parsing. As the complexity of the models increases, structural learning algorithms turn to approximate inference to retain tractability. Unfortunately, such methods often fail because the approximation can be arbitrarily poor. In this work, we propose a method to overcome this limitation through exploiting the properties of the joint problem of training time inference and learning. With the help of the learning framework, we transform the inapproximable inference problem into a polynomial time solvable one, thereby enabling tractable exact inference while still allowing an arbitrary graph structure and full potential interactions. Our learning algorithm is guaranteed to return a solution with a bounded error to the global optimal within the feasible parameter space. We demonstrate the effectiveness of this method on two point cloud scene parsing datasets. Our approach runs much faster and solves a problem that is intractable for previous, well-known approaches.
1 Introduction
With the increased accessibility of 3D sensing, demand is increasing for efficient methods to transform 3D data into higher level, semantically relevant representations. Many of the most popular and successful 3D scene parsing algorithms can be reduced to some form of discrete energy minimization (or energy minimization for short) [1, 3, 9, 20, 25, 27, 28, 36]. One of the benefits of energy minimization methods is that they are able to capture contextual information or to encode prior knowledge. These capabilities are particularly important in complex 3D scene parsing, where local cues may be insufficient. For example, in the task of bridge component recognition (Figure 1), attached beams have similar appearance to connecting beams. The difference is that attached beams are usually beneath the deck and on top of connections, whereas connecting beams are not. Therefore, to tell these two classes apart, the scene parsing algorithms need to incorporate knowledge of how a bridge is typically built, which governs the spatial relationships of the components. For another example, in 3D indoor scene parsing [36], coplanarity of two planes fitted on point clouds is a strong cue for them to be labeled as “wall.” In contrast, the same coplanarity might not be useful if one of them is labeled as clutter. So the existence of certain features on a pair of nodes in the graph encourages certain joint labeling of the two nodes. These relationships can depend on the feature, the label configuration, and the particular edge. In order to encode the interactions, we need a parametrized energy function with a large parameter space 111Note that the simple and popular smoothing prior model of energy minimization [5] is unable to capture such sophisticated interactions.. An immediate question with such formulation is how to estimate these parameters autonomously.
Parameter estimation for energy minimization, also called structural learning, fails when the input data becomes large and complex, due to the intractable inference subroutine. Such intractability arises, for example, in 3D scene parsing of complex structures, where a scene can be composed of hundreds or thousands of objects with arbitrary connectivity. For these problems, it might not be possible to solve the inference subroutine exactly or even to approximate to a certain precision. However, the inference subroutine, or the separation oracle to be precise, plays the important role of finding the subgradients of the objective in a structural learning framework. Using unbounded approximation for the separation oracle generates imperfect gradients, causing the learning algorithm to fail, since the quality can be arbitrarily poor [7]. Commonly, in structural learning, the inference subroutine is treated as a modular “black box,” but that approach leads to an intractable formulation.
In this paper, we show that considering together the joint problem of the overarching training and the inference subroutine enables us to exploit properties that would not be possible otherwise. Specifically, we make the following contributions. First, we propose a theoretically sound structural learning algorithm without the limitation of intractable inference. We review and exploit the properties of the joint problem of training time inference and learning. By modifying the training procedure, we can perform a training time inference corresponding to a binary submodular problem that is much easier than the original one while keeping the testing time inference problem almost the same. This method can be extended to learn higher order potentials as well. Second, while making no assumptions on the structure of the graph or on the potential type, we prove that our algorithm returns a solution within a given absolute error relative to the global optimal within the feasible parameter space. In addition, we demonstrate our algorithm’s performance on two 3D scene parsing datasets. On one dataset, our algorithm runs three times faster than the competing method [1] and achieves the same level of accuracy. Our algorithm finds a solution efficiently on the second, more complex problem, which is intractable for competing methods. Also, we show that what is learned by the model captures domain knowledge and is easily interpretable.
2 Related Work
Most existing literature on structural learning is based on the max-margin formulation proposed by Taskar et al. [23]. Directly minimizing the negative log-likelihood is NP-hard for many problems, and approximation must be used. The max-margin formulation uses a convex surrogate loss, removing the need for computing the partition function. Joachims et al. [12, 33] generalized this max-margin formulation to arbitrary structural outputs, a method known as structural SVM. The concept of max-margin structural learning has been successfully applied to many problems in computer vision. These works usually have limiting assumptions: tree-like or special structure output [18, 25, 37], small structural space [9, 36], or restricted potential type [2, 19, 31, 30]. Under these assumptions, exact inference is possible. However, we don’t make these assumptions, yet we can still apply exact inference during training. Other works adopt approximate inference for the separation oracle [1]. These methods have no guarantee of the solution quality. Notably, a common approximation scheme is convex programming relaxation [11]. Our early experiments show that methods based on this type of relaxation produce results with undesirably low accuracy.
The most similar work to our approach is [7], in which they point out the problem of training structural SVMs when exact inference is not possible and proposed two workarounds. The first one is to assume a constant factor approximation of the inference procedure. However, it was shown in [17] that such an assumption is not reasonable, as the problem cannot be approximated with any meaningful guarantee. The second workaround is to use the persistency property of binary MRFs, yet there is no quality guarantee of the learned parameters. In addition, we find the approach often fails in practice. Many works [16, 22, 26] focus on improving the performance of structural SVM itself, but still they face the problem of an imperfect separation oracle.
Similar to previous works, our algorithm is based on the max-margin formulation [23]. We adopt non-negative constraints to restrict the parameter space [30, 31], but in combination with a different loss and a different separation oracle for tractability.
The separation oracle in structural learning is frequently solved by energy minimization. Here, we highlight energy minimization algorithms used in this work and refer readers to [13] for a complete overview. Boykov and Kolmologrov (BK) [6] solved MAP inference for binary MRFs with a specially optimized max-flow algorithm. Rother et al. [24] proposed the Quadratic Pseudo-Boolean Optimization (QPBO) algorithm for binary problems of arbitrary potentials. They first created a different auxiliary graph, in which each original node corresponds exactly to two non-terminal nodes in the new graph. Then they ran the BK algorithm on this auxiliary graph. Note that some nodes will remain unlabeled if the corresponding non-terminal node pair has conflicting assignments. For multi-class problems of arbitrary potentials, Kolmologrov [14] built a convergent version of the tree-reweighted max-product message passing algorithm (TRW-S). By creating a proper local polytope, an energy minimization problem can be reduced to an integer linear programming (ILP) problem [34], and the integral constraint can be removed to derive an approximation algorithm (LP).
3 Our Approach
In this paper, we propose a max-margin structural learning algorithm for a pairwise model with a linear discriminant function. Our algorithm enables tractable exact training time inference through our submodular formulation, which leads to a guaranteed solution quality. Submodularity cannot be easily enforced because it requires a binary problem and limits the potential type. As adopted in standard machine learning algorithms, multi-class classification can be solved by training a set of 1-vs-all binary classifiers and post-processing the classifier output to make a final one-hot prediction where only a single class is labeled for each example. We adopt a similar idea. During training, we solve a set of binary classification problems but without resolving the conflicts among the binary classifiers. This setup can still learn the desired parameters, since the loss will encourage the parameters to make one-hot predictions. During testing, we enforce one-hot prediction by adding a hard constraint to the inference problem. Because we are enforcing the submoduarity on the transformed binary problems, the potential type of the original energy is not constrained. The rest of this section introduces the desired theoretical properties of the inference procedure and the learning framework before showing our modifications to exploit these properties to build to our structural learning algorithm.
3.1 Problems and Properties
In this subsection, we first review the energy minimization formulation and the submodular property. Then we introduce our testing and training formulation.
Problem \theproblem.
Discrete Energy Minimization
- •
Given a graph , define the energy function
[TABLE]
where .
- •
Energy minimization assigns to each node a label from a finite label set to minimize the energy
[TABLE]
Definition \thedefinition ([24]).
A binary (two-class) energy minimization problem is submodular if
[TABLE]
It is well-known that if the energy is submodular, the global minimum can be found in polynomial time using graph cut. For multi-class problems, submodularity [21] is hard to exploit due to the order dependency and magnitude constraint. The definition of submodularity requires the label set to be a totally ordered set, e.g., a depth value from 0 to 255. This definition also constrains the relative magnitude of potentials on the same edge as in the binary case. These two conditions are not generally applicable.
Another interesting property, which is exploited by [7], is persistency, or partial optimality. Comparing to submodularity, persistency is an optimality indicator rather than an optimality guarantee. If we run the QPBO algorithm [24] on binary problems with arbitrary potentials, some nodes will be left unlabeled, but labelled nodes are part of the globally optimal solution. Boros et al. [4] showed that in an equivalent linear programming formulation, all variables corresponding to the unlabeled nodes take 0.5 in optimal solution. Let’s assume we accept relaxed ([0, 1] instead of {0, 1}) solutions, then running QPBO and replacing the unlabeled nodes with 0.5 will result in an approximation algorithm, which we denote as QPBO-R.
An immediate question is how good the QPBO-R approximation is. This question is answered from a more general perspective in [17]: assuming P NP, for binary energy minimization in general, there does not exist a constant ratio approximation algorithm or even one with a ratio subexponential in the input size. Unfortunately, the theoretical properties of many structural learning algorithms [7, 16, 26] depend on a separation oracle with at least a constant ratio approximation, and the finding in [17] makes pointless the assumption along with the derived properties for these algorithms when applied to energy minimization in general.
We use full potential structural prediction as our testing time formulation.
Problem \theproblem.
Full Potential Structural Prediction
- •
Given a node feature extractor , an edge feature extractor and a vector of weights , define the unary and pairwise potentials
[TABLE]
- •
Denote the graph as , and define the linear discriminant function (score function)
[TABLE]
- •
is called the joint feature map. Using binary encoding , can be decomposed as follows:
[TABLE]
- •
Then the testing time inference problem is
[TABLE]
- •
By abuse of notation, let be an example from a dataset .
The potentials depend on both the parameters and the features, so given , defines an energy function for an example . An ideal set of parameters should put the ground truth at or close to the place of lowest energy/highest score for each example so that the output of testing time inference is at or close to the ground truth. A linear score function makes the parameter estimation easier than non-linear forms. For some structural learning algorithms, kernel tricks can be applied to capture complicated mappings [12].
Full Potential Interaction Notice here we have a full potential matrix for each edge. This generalizes the well-known Potts model and associative Markov networks [31], where only the diagonal terms are non-zero. The relative magnitude of diagonal terms and off-diagonal terms can be arbitrary. This implies that the model is more expressive as it can be both attractive (modeling a smoothing prior) or repulsive. Moreover, the potential matrix does not need to be symmetric. Thus, such a formulation is able to encode directed relationships like relative positions, e.g., a computer monitor is usually placed above desk.
Next, we present the standard learning framework before presenting our modifications.
Problem \theproblem.
Structural SVM [12]
- [TABLE]
[TABLE]
where and are shorthand for and .
Structural SVMs are an extension to standard SVMs for structural outputs. A structural SVM finds the optimal set of parameters that creates a large margin relative to the loss for each structural example in the dataset. Here is the parameter that controls the relative weighting between regularization and risk minimization, and is a loss function encoding the penalty for a wrong labeling.
Due to the combinatorial nature of the label space () , its size, i.e., the number of constraints (11) is exponential. Joachims et al. [12, 33] proposed the cutting-plane algorithm, which finds the optimal solution by adding only a polynomial number of constraints, given a separation oracle to compute the subgradients.
Definition \thedefinition.
Given a loss function , the loss augmented inference or separation oracle is a procedure that finds
[TABLE]
The loss augmented inference finds the worst violators of the margin. Instead of bounding in the entire structural space , the cutting-plane algorithm bounds the violation of the worst violators. It can be shown that this is equivalent to solving the original problem, but now the algorithm terminates in polynomial time and returns a globally optimal solution.
3.2 The Joint Problem for Parameter Estimation
This subsection describes our modifications to solve the joint problem that is not limited by the intractable separation oracle as in previous approaches. For the loss fuction, we use Hamming loss with the goal of labeling each node in the graph correctly:
[TABLE]
The loss equals to (1 - accuracy) scaled by a factor . The structure of the loss is simple, and the loss can be merged into the unary potentials, making loss augmented problem the same problem as Problem 3.1.
3.2.1 Multi-class to Binary Transformation
For loss augmented inference, we use a binary encoding and remove the sum-up-to-1 constraint () to use the graph-cut algorithm [24]. The loss also needs to be slightly modified to address the removal of the constraint. We adopt the Hamming loss for binary encoding:
[TABLE]
The above modifications are based on the following observations:
- •
With the sum-up-to-1 constraint, and are equivalent;
- •
Without the sum-up-to-1 constraint, let , then is a tight upper bound of in that and if and only if ;
In our approach, the removal of the sum-up-to-1 constraint changes the separation oracle, and the binary labeling might not have a consistent interpretation of the original labeling during training. However, the tightness of the loss function shows that we are effectively learning parameters to minimize the original loss. The sum-up-to-1 constraint is implicitly enforced in a soft manner through the loss minimization during training. Soft labeling () is adopted in [1, 7]. In this case, the loss is defined by replacing with in (14). In contrast to the hard labeling that we use, for soft labeling without the sum-up-to-1 constraint, does not have the same property of being a tight upper bound.
3.2.2 Enforcing Submodularity
As presented in Section 3.1, without any relaxation, the transformed binary problem puts great challenge to the inference subroutine because the problem is NP-hard and not even possible to approximate with a guarantee. Thus, we need to enforce submodularity to enable tractable exact inference.
The transformed binary problem takes the form
[TABLE]
Note that it does not have a full potential matrix, and only can be nonzero. If, for all edges, is non-positive, the whole energy satisfies (3) and is submodular. Since our algorithm depends on only being non-zero, the multi-class-to-binary transformation must also be applied to binary classification problems, which is not necessary in the typical 1-vs-all setup.
One way to satisfy the condition of is to have all edge features and pairwise parameters be non-negative. It is reasonable to assume pairwise features can be always non-negative, since in many applications, the features are normalized to [0, 1] during a pre-processing step. Therefore, we add additional constraints only on the weights (18). We summarize our formulation as follows:
Problem \theproblem.
Partially Non-negative Structural SVM
- [TABLE]
[TABLE]
[TABLE]
where and are short for and . is the set of indices where the parameter should be non-negative, e.g., the pairwise weights.
To solve this problem, we adopt the standard max-margin formulation. Our complete algorithm is shown in Algorithm 1.
3.2.3 Solving the Modified Quadratic Program
Non-negative constraints have been previously employed in structural learning but in a different context. In pose estimation [37, 38], the quadratic spring terms must be non-negative. These works employ a tree-structured model, so exact inference is possible through dynamic programming. It is shown in [22] that for solvers in the primal space, adding non-negative constraints amounts to clipping the parameters during the update step while leaving the rest unchanged. We adopt the dual coordinate descent solver from [22] to solve the minimization problem in Problem 3.2.2. In practice, however, we find that a commercial general purpose QP solver, namely Gurobi [8], is several times faster under the same tolerance setting.
3.3 Generalization to Higher Order Potentials
Higher order potentials capture more interactions than the pairwise potentials. For example, a column between a pair of abutments is a \nth3 order interaction. Our generalization is based on the pairwise reduction from arbitrary high order potentials proposed by Ishikawa et al. [10]. Taking the \nth3 order case as an example, the reduction is based on the identity over Boolean variables
[TABLE]
If the \nth3 order potential is non-positive, then the constructed pairwise potentials in the reduction are also non-positive and vice versa. This enables us to enforce submodularity on \nth3 order energy minimization problems. Likewise, we can apply similar constraints for even higher order problems. Details for general higher order can be found in the supplementary material.
4 Analysis
The following theorems prove that our algorithm is both efficient and globally optimal.
Theorem 4.1**.**
Correctness of the algorithm For any training datasets and any , if is the optimal solution of Problem 3.2.2, then Algorithm 1 returns a solution that has a better objective value than , and for which is feasible in Problem 3.2.2.
Proof.
The original proof presented in [12] holds, since it does not depend on any constraints involving only , and in our case, all separation oracles during training are exact. ∎
Theorem 4.2**.**
Convergence of the algorithm Algorithm 1 terminates in polynomial time.
The proof is provided in the supplementary material. Briefly, the separation oracle terminates in polynomial time, and adding negative constraints does not change the nature of the convex optimization in line 5. Note that the actual convergence rate depends on the QP solver used for line 5.
5 Testing Time Inference
While we have a transformed and restricted problem during training, during testing we might still have a full potential matrix for each potential. The only limitation in the expressiveness of the formulation is that all the pairwise potentials are non-positive (in the sense of minimization). We show in our experiments that this restriction has limited effect on the overall accuracy. At testing time, the inference is performed independently on each example, and the error does not accumulate as it does at training time. If the graph is small or sparse, exact inference is possible through ILP. Otherwise, TRW-S [14] provides good approximation in practice for general potentials [13].
6 Experiments
We demonstrate the performance of our algorithm on the standard Cornell RGB-D dataset and a larger scale bridge dataset, which we created. On Cornell’s dataset, our algorithm runs three times faster while keeping the same level of accuracy as the competing method. On the bridge dataset, the competing methods are unable to solve the scene parsing problem due to the intractable seperation oracle. In contrast, our algorithm is able to solve it efficiently and accurately. In addition, we visualize the weights learned by our algorithm to show that our model captures domain knowledge.
6.1 Cornell RGB-D Dataset: Understanding 3D Scenes
The Cornell RGB-D dataset [15, 1] is an indoor point cloud dataset captured by Microsoft Kinect. The point clouds are obtained through merging multiple RGB-D views using the simultaneous localization and mapping (SLAM) algorithm. The point clouds are clustered into multiple segments. This dataset is suitable for testing structural learning prediction algorithms because it is necessary to take into account the neighborhood interaction for each node in order to label the segments correctly.
We compare our approach with [1] (also [7]) and use the same segmentation and features to ensure a fair comparison. The pairwise features cover visual appearance, local shape and geometry, and geometric context. Their algorithm adopts the persistency based approach in [7] (QPBO-R in Section 3.1). Note this method has no guarantee of optimality and an empirical heuristic needs to be adopted as discussed below. A variant of their algorithm makes use of additional class label information to limit the pairwise interactions to a predefined set of classes. The method assumes some labels are parts of an object, and restricts some potentials to be only among these labels. This information is usually not available on other structural datasets, so we do not include it in our comparison. The 4-fold cross-validation results are summarized in Table 1. The first row is taken from their paper. Our confusion matrix is shown in Figure 2. Notice that even with the additional constraints, our algorithm achieves approximately the same accuracy as [1] in 1/3 the time and with the critical advantage of a theoretical guarantee bounding the error.
The competing method’s implementation uses an undocumented heuristic that is vital for the learning procedure. In our algorithm, there is no need for this heuristic, because no relaxation is involved. Recall the rationale for interpreting an unlabeled node as 0.5 in Section 3. To compute the joint feature map , we need to compute in (8). If both are unlabeled, then would be 0.25. In [1], an additional measure is taken when neither side is labeled by QPBO:
- •
is interpreted as 0.5, if the coefficient, i.e., , is positive;
- •
is interpreted as 0, otherwise.
We found that without this rounding heuristic, the learning algorithm in [1] terminates after a dozen or fewer iterations with a newly found violation smaller than the violation of the current working set, which is impossible if the loss augmented inference is exact. Such early termination prevents the structral SVM from learning any meaningful potentials, and the prediction is usually a failure. This effect has been observed using both their implementation and our independent implementation on Cornell’s RGB-D Dataset and the bridge dataset in next subsection.
6.2 Bridge Dataset: Scaling up to Complex Structures
For a second experiment, we tested out our algorithm on a domain-specific dataset to evaluate its performance against a large dataset with complex structures. To this aim, we created a synthetic but realistic bridge dataset (Figure 1) modeling complicated building structure. Such a dataset is useful for developing 3D reverse engineering techniques, which can find their application in as-built Building Information Model (BIM) creation [35] and infrastructure inspection [29]. Unlike color or RGB-D images, full building laser scan datasets are scarce, thus we utilize a realistic synthetic dataset. We constructed CAD models of bridges, and generated the point clouds by placing a virtual laser scanner, complete with a noise model, in the scene as if we are actually conducting actual field scans. Multiple scans are taken per scene and merged into a single point cloud. In total, we have 25 bridge models of five different types. Each model contains 200K to 500K 3D points after down-sampling.
Similar to the Cornell RGB-D dataset, the task is to semantically label the segments, and we define eleven semantic classes for this dataset. We train a random forest classifier on SHOT descriptors [32] to obtain a label class distribution for each point. The descriptor encodes histogram of local surface information. We take the mean class distribution as the node feature for each segment. We use ground truth segmentation for benchmarking the contextual classification algorithms. We build a graph based on the physical adjacency of the segments and use on-top-of, principal direction consistency, and perpendicularity as three edge features. The accuracy is computed at the node level. On average, the bridge scenes contain ten times more segments and nine times more edges than the Cornell RGB-D dataset. We split the dataset into five folds, each containing five bridge models.
The cross-validation result is summarized in Figure 3 and visualized in Figure 5. We obtain 90.07% overall accuracy for semantic labeling the scene with 11 classes. For a single fold, the training takes 1.3 hours, and testing takes 89 seconds for five scenes. We attempted to use [16] and [1] as competing methods. However, the first fails due to the poor separation oracle and the latter could not handle this large scale of data and did not terminate after 7.5 days.
Capturing domain knowledge. Our algorithm is able to encode domain knowledge in the pairwise weights. For instance, we visualize the weights for the on-top-of feature in Figure 4. The feature is a binary indicator, and the product of this feature and the corresponding weight adds towards the overall score. The matrix reveals typical structural relationships seen in bridge architecture, e.g., the abutment and attached beam are usually placed beneath the deck.
7 Conclusion
In this work, we propose a method to overcome the problem caused by using unbounded approximation for the separation oracle in structural learning. We show theoretically that after properly exploiting the properties of the joint problem of optimizing structural SVM and the separation oracle, we can retrieve the theoretical guarantees of structural SVMs that are lost when unbounded approximation is used. The performance on the Cornell RGB-D dataset and our bridge dataset demonstrates the effectiveness and efficiency of this method.
Acknowledgements
This material is based upon work supported by the National Science Foundation under Grant No. IIS-1328930.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] A. Anand, H. S. Koppula, T. Joachims, and A. Saxena. Contextually guided semantic labeling and search for three-dimensional point clouds. The International Journal of Robotics Research , page 0278364912461538, 2012.
- 2[2] D. Anguelov, B. Taskarf, V. Chatalbashev, D. Koller, D. Gupta, G. Heitz, and A. Ng. Discriminative learning of Markov random fields for segmentation of 3D scan data. In Computer Vision and Pattern Recognition, 2005. CVPR 2005. IEEE Computer Society Conference on , volume 2, pages 169–176. IEEE, 2005.
- 3[3] I. Armeni, O. Sener, A. R. Zamir, H. Jiang, I. Brilakis, M. Fischer, and S. Savarese. 3D semantic parsing of large-scale indoor spaces. CVPR, 2016.
- 4[4] E. Boros and P. L. Hammer. Pseudo-boolean optimization. Discrete applied mathematics , 123(1):155–225, 2002.
- 5[5] Y. Boykov and G. Funka-Lea. Graph cuts and efficient ND image segmentation. International journal of computer vision , 70(2):109–131, 2006.
- 6[6] Y. Boykov and V. Kolmogorov. An experimental comparison of min-cut/max-flow algorithms for energy minimization in vision. Pattern Analysis and Machine Intelligence, IEEE Transactions on , 26(9):1124–1137, 2004.
- 7[7] T. Finley and T. Joachims. Training structural SV Ms when exact inference is intractable. In Proceedings of the 25th international conference on Machine learning , pages 304–311. ACM, 2008.
- 8[8] I. Gurobi Optimization. Gurobi optimizer reference manual, 2015.