The cumulative Kolmogorov filter for model-free screening in ultrahigh dimensional data
Arlene K. H. Kim, Seung Jun Shin

TL;DR
This paper introduces a cumulative Kolmogorov filter that enhances model-free screening in ultrahigh-dimensional data by improving theoretical properties and demonstrating better finite sample performance.
Contribution
It develops a new cumulative Kolmogorov filter that extends the fused Kolmogorov filter with cumulative slicing, offering improved asymptotic results and practical performance.
Findings
Enhanced finite sample performance demonstrated numerically
Improved asymptotic results under relaxed assumptions
Extension of the fused Kolmogorov filter with cumulative slicing
Abstract
We propose a cumulative Kolmogorov filter to improve the fused Kolmogorov filter proposed by Zou (2015) via cumulative slicing. We establish an improved asymptotic result under relaxed assumptions and numerically demonstrate its enhanced finite sample performance.
Click any figure to enlarge with its caption.
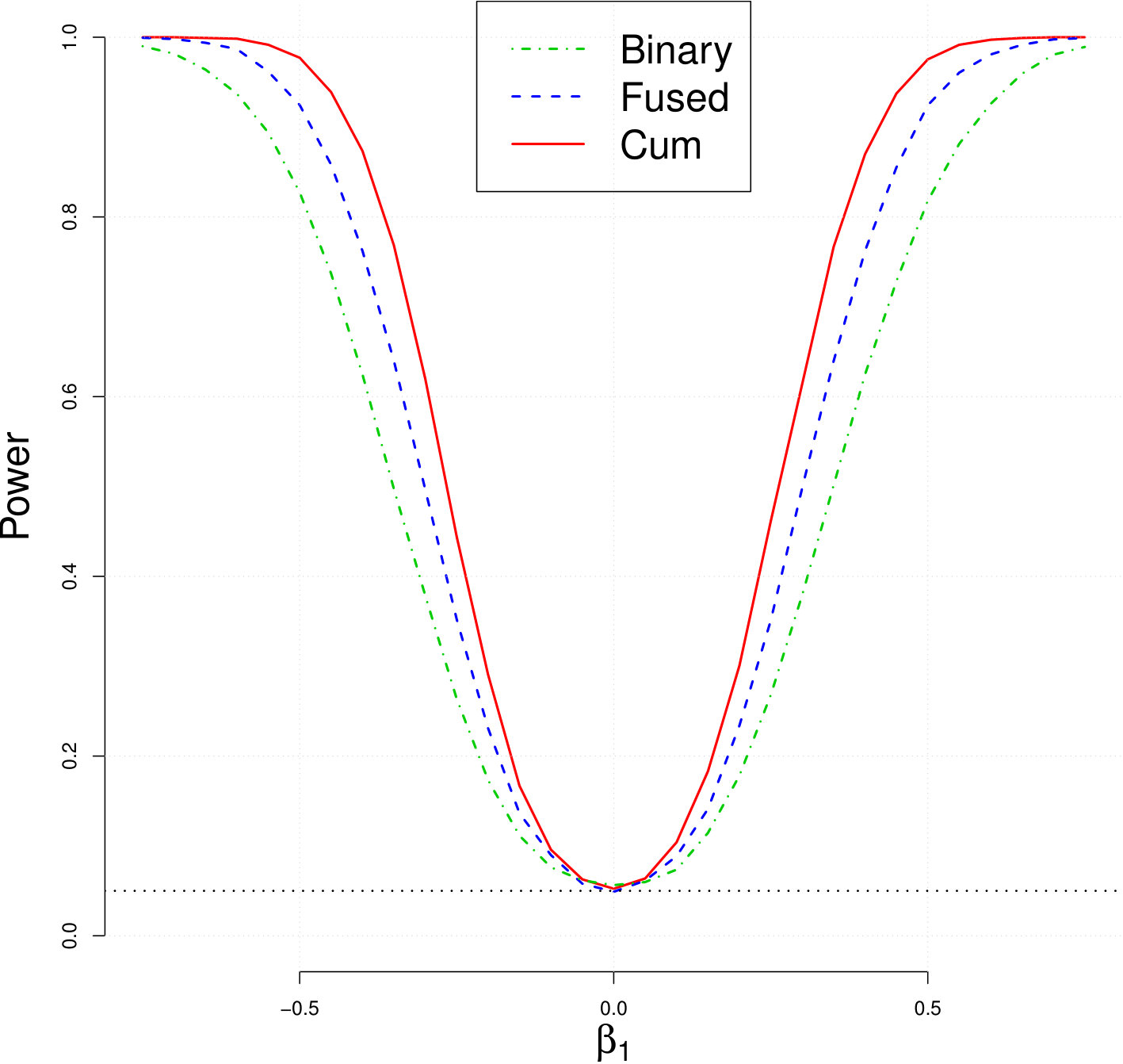 Figure 1
Figure 1| Model | SIS | DCS | FKF | CKF | |||||
| 1 | 2 | 2.00 | (0.00) | 2.00 | (0.00) | 3.79 | (6.28) | 2.00 | (0.00) |
| 2 | 2 | 2038.12 | (1348.05) | 1985.10 | (1460.82) | 4.62 | (9.14) | 2.00 | (0.00) |
| 3 | 2 | 891.22 | (1071.58) | 350.88 | (794.67) | 3.88 | (6.96) | 2.00 | (0.00) |
| 4 | 10 | 10.04 | (0.20) | 10.04 | (0.20) | 10.26 | (1.09) | 10.06 | (0.24) |
| 5 | 10 | 150.10 | (351.46) | 12.50 | (10.42) | 10.23 | (0.49) | 10.11 | (0.35) |
| 6 | 10 | 1618.50 | (1423.11) | 927.16 | (916.20) | 10.81 | (4.27) | 10.03 | (0.17) |
| 7 | 2 | 1051.14 | (1473.43) | 682.47 | (965.43) | 2.00 | (0.00) | 2.00 | (0.00) |
| 8 | 3 | 2980.23 | (1494.26) | 277.43 | (606.47) | 9.05 | (18.69) | 6.66 | (11.27) |
| 9 | 8 | 3562.30 | (1252.76) | 231.63 | (526.51) | 60.84 | (126.12) | 38.59 | (52.58) |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
The cumulative Kolmogorov filter for model-free screening in ultrahigh dimensional data
Arlene K. H. Kim and Seung Jun Shin
University of Cambridge and Korea University
Abstract
We propose a cumulative Kolmogorov filter to improve the fused Kolmogorov filter proposed by Mai and Zou (2015) via cumulative slicing. We establish an improved asymptotic result under relaxed assumptions and numerically demonstrate its enhanced finite sample performance.
Keyword: cumulative slicing; Kolmogorov filter; model-free marginal screening
1 Introduction
Since Fan and Lv (2008), a marginal feature screening has been regarded as one canonical tool in ultrahigh-dimensional data analysis. Let be a univariate response and be a -dimensional covariate. We assume that only a small subset of covariates are informative to explain . In particular, we assume where
[TABLE]
with being the conditional distribution function of . Such assumption is reasonable since including large number of variables with weak signals often deteriorates the model performance due to accumulated estimation errors.
Since the introduction of Fan and Lv (2008), numerous marginal screening methods have been developed (see Section 1 of Mai and Zou (2015) for a comprehensive summary). Among these methods, model-free screening (Zhu et al., 2011; Li et al., 2012; Mai and Zou, 2015) is desirable since the screening is a pre-processing procedure followed by a main statistical analysis.
For feature selection in binary classification, Kolmogorov filter (KF) is proposed by Mai and Zou (2012). For each , KF computes
[TABLE]
and selects variables with large ’s among all . A sample version of is obtained by replacing the probability measure with its empirical counterpart, leading to the well-known Kolmogorov–Smirnov statistic where its name came from. KF shows impressive performance in binary classification.
Recently, Mai and Zou (2015) have extended the idea of KF beyond the binary response by slicing data into pieces depending on the value of . In particular, a pseudo response taking if for , is defined for given knots . Following the spirit of KF, one can select a set of variables with large values of
[TABLE]
However, information loss is inevitable due to the lower resolution of pseudo variable compared to regardless of the choice of . To tackle this, Mai and Zou (2015) proposed fused Kolmogorov filter (FKF) that combinies for different sets of knots and selects variables with large values of , for . The source of improvement in FKF is clear, however, it cannot perfectly overcome the information-loss problem caused by slicing. In addition, it is subtle to decide how to slice data in a finite sample case. To this end, we propose the cumulative Kolmogorov filter (CKF). CKF minimizes information loss from the slicing step and is free from choice of slices. As a consequence, it enhances the FKF.
2 Cumulative Kolmogorov filter
We let denote the conditional distribution function of given . Given such that , define
[TABLE]
We remark that (3) is identical to (2) with except that the sliced variable in (3) is instead of . The choice of a slicing variable between and is not crucial, however, it would be more natural to slice independent variable in regression set up whose target is . Now,
[TABLE]
which immediately yields for all satisfying if and only if and are independent. In fact, indicates the level of dependence as shown in the following lemma.
Lemma 2.1
If has a bivariate Gaussian copula distribution such that is jointly normal with correlations after transformation via two monotone funcitons , and and are marginally standard normal. Then
* if and if .* 2. 2.
Denoting y^{*}=x\big{(}\frac{1-\sqrt{1-\rho_{j}^{2}}}{\rho_{j}}\big{)},
[TABLE] 3. 3.
For each , is a strictly increasing function of .
Nonetheless, (3) loses lots of information from the dichotomization of . To overcome this, we define
[TABLE]
where denotes an independent copy of . In the population level, (4) is fusing infinitely many KFs with all possible dichotomized ’s. By doing this, we can not only minimize efficiency loss but also be free from the choice of knot sets. Similar idea has been firstly proposed by Zhu et al. (2010) in the context of sufficient dimension reduction where the slicing scheme has been regarded as a canonical approach.
Given where , a sample version of (3) is where and is similarly defined. Following the convention, we regard . Now, an estimator of (4) is given by
[TABLE]
Finally, for , we propose CKF to select the following set
[TABLE]
3 The Sure Screening Property
We assume a regularity condition.
Assumption 3.1
There exists a nondegenerate set such that and
[TABLE]
Assumption 3.1 is similar to the regularity condition (C1) for KFK (Mai and Zou, 2015). In fact, FKF requires one additional condition that guarantees that the estimated slices are not very different from oracle slices based on population quantiles of , which is not necessary for CKF since it is free from the slice choice. KF with a binary response requires only one assumption similar to Assumption 3.1.
Theorem 3.2
Under Assumption 3.1, when and ,
[TABLE]
where
[TABLE]
This probability tends to 1 when .
The sure screening probability converges to one when .
4 A simulation study
4.1 A toy example
Consider a simple regression model where and are from independent . In this regard, (5) can be thought as a statistic for testing . To demonstrate the performance of CKF, we compare its power to i) and ii) with four equally-spaced knot sets whose sizes are 3,4,5, and 6 as suggested by Mai and Zou (2015). Figure 1 depicts numerically computed power functions of three methods under significance level . As expected, CKF (5) performs best while the simplest does worst, which echoes the fact that screening performance can be improved by minimizing information loss entailed in the slicing step and CKF indeed achieves it.
4.2 Comparison to other screening methods
We consider the following nine models with and independent of :
, where , with . is a compound symmetry correlation matrix with the correlation coefficient of . Let , . 2. 2.
and other settings are the same as Model 1. 3. 3.
and other settings are the same as Model 1. 4. 4.
, where , with . is an autoregressive correlation matrix with the autoregressive correlation coefficient of . Let , . 5. 5.
and and other settings are the same as Model 4. 6. 6.
and other settings are the same as Model 4. 7. 7.
, where . 8. 8.
, where independently. 9. 9.
, where with .
To avoid a cutoff selection problem, we report the average number of minimum variables needed to recover all informative ones over 100 independent repetitions. Hence, a smaller value implies a better performance. Table 1 contains the comparison results against correlation learning (CS, Fan and Lv, 2008) and distance correlation learning (DCS, Li et al., 2012) as well as FKF. The results clearly show that the proposed CKF has improved performance compared to others including FKF.
5 Discussions
We employ a cumulative slicing technique to extend a screening tool for binary response to contiuous one. The idea is quite general and can be applied to t-test-based screening (Fan and Fan, 2008; Fan and Lv, 2008) as well as logistic-regression-based screening (Fan and Song, 2010). In addition, it is possible to extend the idea of CKF to the censored response by replacing the empirical distribution function with the Kaplan-Meier estimator.
Appendix A Proof of Lemma 2.1
Because is invariant under monotone transformation, it suffices to consider the case where , , and thus and are jointly normal. If , then is independent of and . On the other hand, if , . Let
[TABLE]
Then we have
[TABLE]
Note that \frac{\partial G}{\partial y}=\Phi(x)\phi(y)-\Phi\Big{(}\frac{x-\rho_{j}y}{\sqrt{1-\rho_{j}^{2}}}\Big{)}\phi(y)=\phi(y)\left(\Phi(x)-\Phi\Big{(}\frac{x-\rho_{j}y}{\sqrt{1-\rho_{j}^{2}}}\Big{)}\right), which gives \frac{\partial G}{\partial y}\Big{|}_{y=y^{*}}=0. where y^{*}=x\big{(}\frac{1-\sqrt{1-\rho_{j}^{2}}}{\rho_{j}}\big{)}. When then Thus when then attains its supremum at . Similarly, when then attains its supremum at . It follows that
[TABLE]
When , then When , then
Now we show that is an increasing function of by taking derivative with respect to . After some tedious calculations,
[TABLE]
where . Thus, is increasing in since is symmetric.
Appendix B Proof of Theorem 3.2
Under the event that , we know that
[TABLE]
Hence, for any , we have , which implies . On the other hand, by the following Lemma B.1, we have for any ,
[TABLE]
It follows that when , the probability tends to 1.
Lemma B.1 Consider in (4) and in (5). Then for any ,
[TABLE]
Proof of Lemma B.1 Without loss of generality, we only need to consider since otherwise, the probability in the left side is trivially 0. Also we assume that all are distinct for convenience. First, we use a simple triangle inequality to bound
[TABLE]
Then we treat the second term . By the Bernstein’s inequality(e.g. Lemma 2.2.9 in Van Der Vaart and Wellner (1996)), and using the fact that each for is independent and has the same distribution as the distribution of , we have
[TABLE]
where the first inequality follows by bounding the variance of each by 1 from the fact that for any .
Now we consider the first term in (6). First note that for any . We use this trivial bound for where is the maximum of . Let and . Using we have by the union bound that
[TABLE]
where corresponds to the rank of .
We bound (7) by above using similar ideas in Lemma A1 of Mai and Zou (2012). Using the Dvoretzky–Kiefer–Wolfowitz inequality, for any in the support of ,
[TABLE]
where and . Thus by replacing by followed by taking the expectation, we have
[TABLE]
It follows by symmetry
[TABLE]
where the last inequality holds since . The proof is complete.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1)
- 2Fan and Fan (2008) Fan, J. and Fan, Y. (2008). High dimensional classification using features annealed independence rules, The Annals of statistics 36 (6): 2605.
- 3Fan and Lv (2008) Fan, J. and Lv, J. (2008). Sure independence screening for ultrahigh dimensional feature space, Journal of the Royal Statistical Society: Series B 70 (5): 849–911.
- 4Fan and Song (2010) Fan, J. and Song, R. (2010). Sure independence screening in generalized linear models with np-dimensionality, The Annals of Statistics 38 (6): 3567–3604.
- 5Li et al. (2012) Li, R., Zhong, W. and Zhu, L. (2012). Feature screening via distance correlation learning, Journal of the American Statistical Association 107 (499): 1129–1139.
- 6Mai and Zou (2012) Mai, Q. and Zou, H. (2012). The kolmogorov filter for variable screening in high-dimensional binary classification, Biometrika 100 : 229–234.
- 7Mai and Zou (2015) Mai, Q. and Zou, H. (2015). The fused Kolmogorov filter: A nonparametric model-free screening method, The Annals of Statistics 43 (4): 1471–1497.
- 8Van Der Vaart and Wellner (1996) Van Der Vaart, A. W. and Wellner, J. A. (1996). Weak Convergence , Springer, New York.